
Near-Infrared Spectroscopy and Machine Learning for Fast Quality Prediction of Bottle Gourd

 and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.1.1. Protein Determination
2.1.2. Free Amino Acids Determination
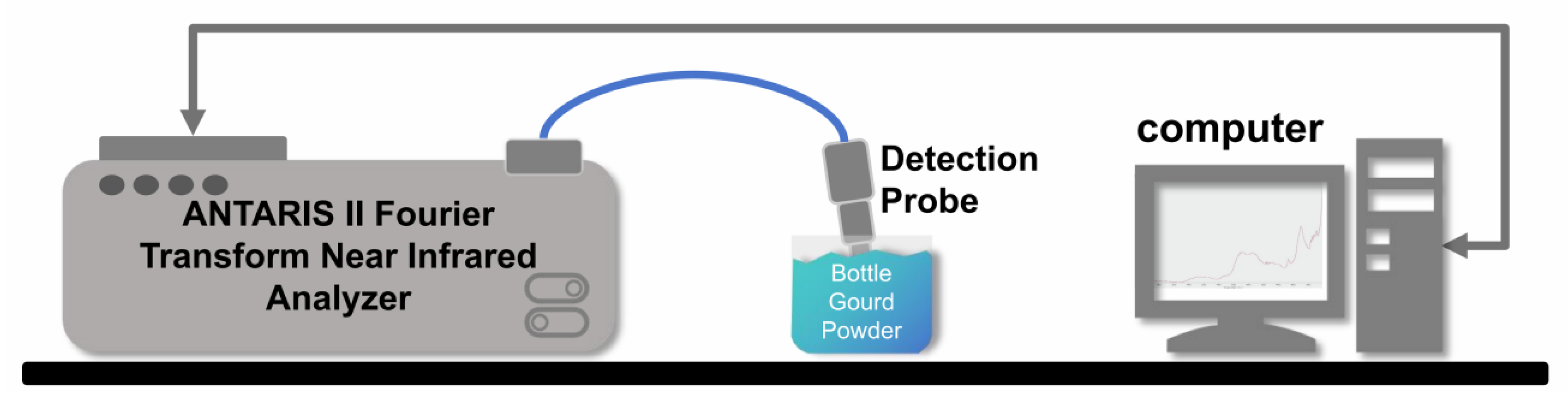
2.1.3. Near-Infrared Spectral Scanning
2.2. Vis–NIR Spectra Acquisition and Preprocessing
2.3. Feature Bands Selection
2.4. Regression Model Based on Ridge Regression
- Dataset Splitting:
- Split the calibration dataset into a modeling set (80%) and a prediction set (20%).
- Monte Carlo Sampling Iterations N setting:
- Define the number of Monte Carlo sampling iterations as N.
- Randomly select a portion of the modeling set for modeling, with the remaining samples reserved for validation.
- Build a PLS model on the selected portion of the modeling set.
- Calculate the absolute values of the regression coefficients for each variable in the PLS model .
- Compute the weight for each variable using the formula , where m is the number of remaining variables.
- Calculate the retention ratio for the wavelength points using an exponential decay function (EDF), as follows:where n is the number of variables.
- Use AWS to select wavelength variables for the next modeling round.
- Construct a PLS model on the selected features and calculate the root mean square error of cross-validation (RMSECV).
2.5. Evaluation Criteria
3. Results
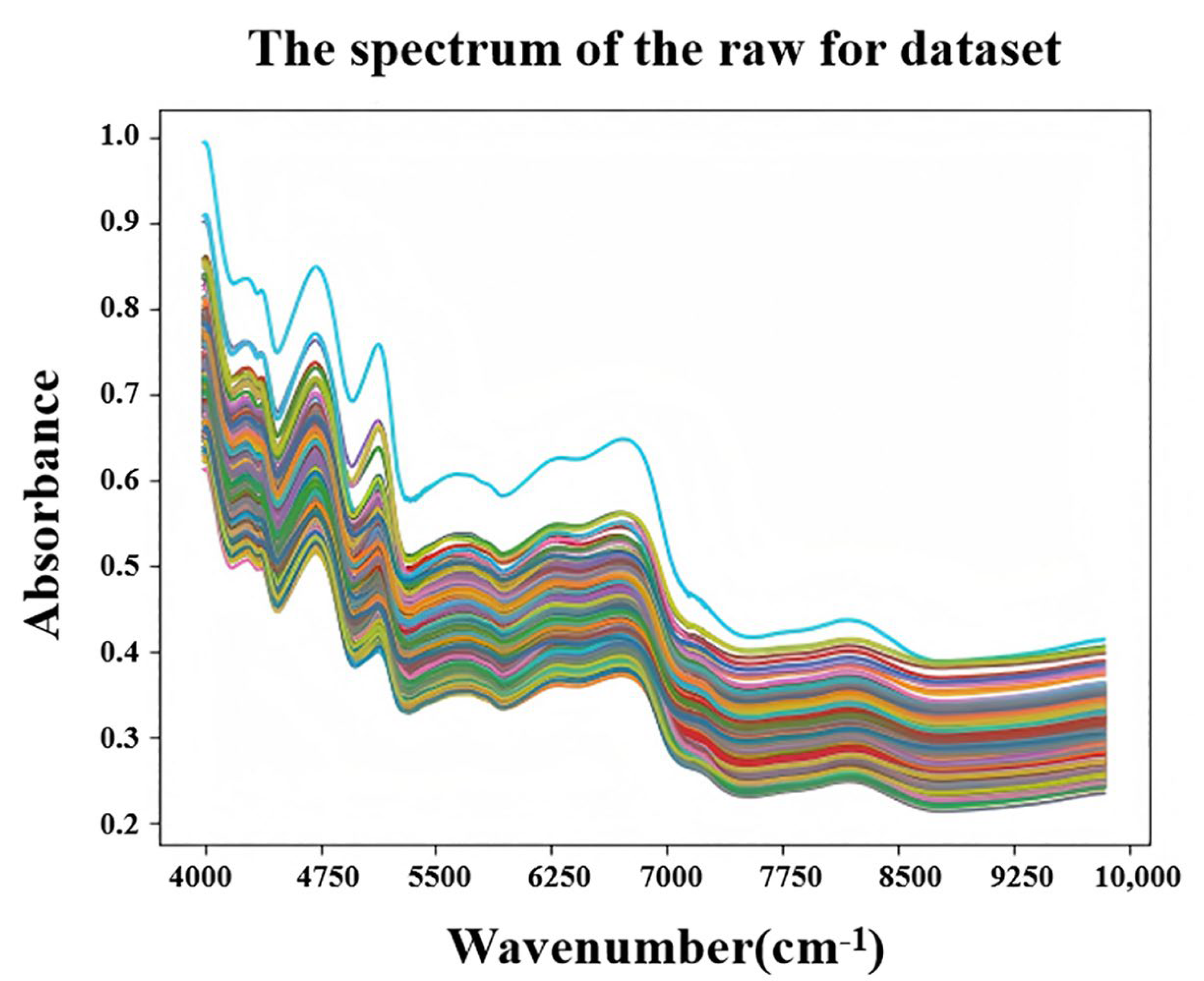
3.1. NIR Spectral Data and Preprocessing Results
3.2. Feature Band Extraction Results
3.3. Predictive Model Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, P.; Xu, S.; Wu, X.; Tao, Y.; Wang, B.; Wang, S.; Qin, D.; Lu, Z.; Li, G. Population genomic analyses from low-coverage RAD-Seq data: A case study on the non-model cucurbit bottle gourd. Plant J. 2014, 77, 430–442. [Google Scholar] [CrossRef]
- Xu, P.; Wang, Y.; Sun, F.; Wu, R.; Du, H.; Wang, Y.; Jiang, L.; Wu, X.; Wu, X.; Yang, L.; et al. Long-read genome assembly and genetic architecture of fruit shape in the bottle gourd. Plant J. 2021, 107, 956–968. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Xu, P.; Wu, X.; Wang, B.; Lu, Z.; Li, G. Genome-wide association analysis of free glutamate content, a key factor conferring umami taste in the bottle gourd [Lagenaria siceraria (Mol.) Standl.]. Sci. Hortic. 2017, 225, 795–801. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, X.; Yu, X.; Li, Y.; Han, S. Research progress on nondestructive testing technology in fruit and vegetable quality. J. Zhejiang Univ. Agric. Life Sci. Ed. 2020, 46, 27–37. [Google Scholar] [CrossRef]
- Kumaravelu, C.; Gopal, A. A review on the applications of near-infrared spectrometer and chemometrics for the agro-food processing industries. In Proceedings of the 2015 IEEE Technological Innovation in ICT for Agriculture and Rural Development (TIAR), Chennai, India, 10–12 July 2015. [Google Scholar]
- Fu, X.; Ying, Y.; Liu, Y.; Lu, H. Detection of Pear Firmness Using Near Infrared Diffuse Reflectance Spectroscopy. Spectrosc. Spectr. Anal. 2006, 26, 1038–1041. [Google Scholar]
- Nordey, T.; Joas, J.; Davrieux, F.; Chillet, M.; Léchaudel, M. Robust NIRS models for non-destructive prediction of mango internal quality. Sci. Hortic. 2017, 216, 51–57. [Google Scholar] [CrossRef]
- Li, X.; Wei, Y.; Xu, J.; Feng, X.; Wu, F.; Zhou, R.; Jin, J.; Xu, K.; Yu, X.; He, Y. Ssc and ph for sweet assessment and maturity classification of harvested cherry fruit based on NIR hyperspectral imaging technology. Postharvest Biol. Technol. 2018, 143, 112–118. [Google Scholar] [CrossRef]
- Oliveira-Folador, G.; Oliveira Bicudo, M.; Andrade, E.; Renard, C.; Bureau, S.; Castilhos, F. Quality traits prediction of the passion fruit pulp using nir and mirspectroscopy. LWT 2018, 95, 172–178. [Google Scholar] [CrossRef]
- Sun, X.; Dong, X.; Cai, L.; Hao, Y.; Ouyang, A.; Liu, Y. Visible-NIR Spectroscopy and Least Square Support Vector Machines Regression for Determination of Vitamin C of Mandarin Fruit. Sens. Lett. 2012, 10, 506–510. [Google Scholar] [CrossRef]
- Chen, B.; Zheng, E.; Guo, T. Application of Various Algorithms for Spectral Variable Selection in NIRS Modeling of Red Ginseng Extraction. Spectrosc. Spectr. Anal. 2021, 41, 2443–2449. [Google Scholar]
- Masithoh, R.E.; Lohumi, S.; Yoon, W.S.; Amanah, H.Z.; Cho, B.K. Development of multi-product calibration models of various root and tuber powders by fourier transform near infra-red (FT-NIR) spectroscopy for the quantification of polysaccharide contents. Heliyon 2020, 6, e05099. [Google Scholar] [CrossRef]
- Agulheiro-Santos, A.C.; Ricardo-Rodrigues, S.; Laranjo, M.; Melgão, C.; Velázquez, R. Nondestructive prediction of total soluble solids in strawberry using near infrared spectroscopy. J. Sci. Food Agric. 2022, 102, 4866–4872. [Google Scholar] [CrossRef] [PubMed]
- Wold, J.P.; Sanden, K.W.; Skaret, J.; Carlehøg, M.; Tjåland, M.; Hansen, A. Non-contact interactance NIR spectroscopy for estimating TSS and sensory sweetness in conveyor-belt transported cherry tomatoes (Lycopersicon esculentum ‘Piccolo’). Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2025, 335, 125962. [Google Scholar] [CrossRef] [PubMed]
- Somton, W.; Pathaveerat, S.; Terdwongworakul, A. Application of near infrared spectroscopy for indirect evaluation of “monthong” durian maturity. Int. J. Food Prop. 2015, 18, 1155–1168. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, R.; Yu, D.; Lv, Y.; Han, Y. Identification of fig maturity based on near-infrared spectroscopy and partial least square-discriminant analysis. Food Mach. 2020, 36, 107–111. [Google Scholar]
- Wang, Y.; Wu, X.; Li, Y.; Feng, Z.; Mu, Z.; Wang, J.; Wu, X.; Wang, B.; Lu, Z.; Li, G. Identification and Validation of a Core Single-Nucleotide Polymorphism Marker Set for Genetic Diversity Assessment, Fingerprinting Identification, and Core Collection Development in Bottle Gourd. Front. Plant Sci. 2021, 12, 747940. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- McDonald, G. Ridge regression. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Singh, B.; Sihag, P.; Singh, K. Modelling of impact of water quality on infiltration rate of soil by random forest regression. Model. Earth Syst. Environ. 2017, 3, 999–1004. [Google Scholar] [CrossRef]
- Allouhi, A.; Choab, N.; Hamrani, A.; Saadeddine, S. Machine learning algorithms to assess the thermal behavior of a Moroccan agriculture greenhouse. Clean. Eng. Technol. 2021, 5, 100346. [Google Scholar] [CrossRef]
- Uzal, L.; Grinblat, G.; Namías, R.; Larese, M.; Bianchi, J.; Morandi, E.; Granitto, P. Seed-per-pod estimation for plant breeding using deep learning. Comput. Electron. Agric. 2018, 150, 196–204. [Google Scholar] [CrossRef]
- Wang, D.; Dowell, F.; Lacey, R. Singlewheat kernel color classification using neural networks. Agric. Food Sci. Comput. Sci. Trans. ASABE 1999, 42, 233–240. [Google Scholar] [CrossRef]
- Delwiche, S.; Massie, D. Classification of Wheat by visible and Near-Infrared Reflectance from Single Kernels. Agric. Food Sci. Cereal Chem. 1996, 73, 399–405. [Google Scholar]
- Fan, C.; Liu, Y.; Cui, T.; Qiao, M.; Yu, Y.; Xie, W.; Huang, Y. Quantitative Prediction of Protein Content in Corn Kernel Based on Near-Infrared Spectroscopy. Foods 2024, 13, 4173. [Google Scholar] [CrossRef]
- Zhu, D.; Wang, K.; Zhang, D.; Huang, W.; Yang, G.; Ma, Z.; Wang, C. Quality assessment of crop seeds by near-infrared hyperspectral imaging. Sens. Lett. 2011, 9, 1144–1150. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Q.; Liu, H.; Liu, L.; Du, Y. Determining the contents of protein and amino acids in peanuts using near-infrared reflectance spectroscopy. J. Sci. Food Agric. 2013, 93, 118–124. [Google Scholar] [CrossRef]
- Guo, Z.; Barimah, A.; Yin, L.; Chen, Q.; Shi, J.; El-Seedi, R.; Zou, X. Intelligent evaluation of taste constituents and polyphenols-to-amino acids ratio in matcha tea powder using near infrared spectroscopy. Food Chem. 2021, 353, 129372. [Google Scholar] [CrossRef]
- Aya, L.F.; Kouassi, K.I.; Koffi, K.K.; Kouakou, K.L.; Baudoin, J.P.; Zoro, B.I.A. Prevalence and variation of viviparous germination with respect to fruit maturation in the bottle gourd Lagenaria siceraria (Molina) Standley (Cucurbitaceae). Heliyon 2019, 5, e02584. [Google Scholar]
- Mkhize, P.; Shimelis, H.; Mashilo, J. Hybrid performance of bottle gourd [Lagenaria siceraria] under drought stress and non-stress conditions. Ecol. Genet. Genom. 2025, 34, 100316. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ridge Regression | Random Forest | Support Vector Machine | FCNN | |
|---|---|---|---|---|
| R2 (CARS) | 0.96 | 0.78 | 0.77 | 0.80 |
| RMSE (CARS) | 0.23 | 0.5 | 0.5 | 0.5 |
| Ridge Regression | Random Forest | Support Vector Machine | FCNN | |
|---|---|---|---|---|
| R2 (CARS) | 0.77 | 0.56 | 0.52 | 0.6 |
| RMSE (CARS) | 0.5 | 0.7 | 0.7 | 0.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Huang, H.; Wang, H.; Cai, C.; Wang, Y.; Wu, X.; Wang, J.; Wang, B.; Zhu, B.; Xiang, Y. Near-Infrared Spectroscopy and Machine Learning for Fast Quality Prediction of Bottle Gourd. Foods 2025, 14, 2503. https://doi.org/10.3390/foods14142503
Guo X, Huang H, Wang H, Cai C, Wang Y, Wu X, Wang J, Wang B, Zhu B, Xiang Y. Near-Infrared Spectroscopy and Machine Learning for Fast Quality Prediction of Bottle Gourd. Foods. 2025; 14(14):2503. https://doi.org/10.3390/foods14142503
Chicago/Turabian StyleGuo, Xiao, Hongyu Huang, Haiyan Wang, Chang Cai, Ying Wang, Xiaohua Wu, Jian Wang, Baogen Wang, Biao Zhu, and Yun Xiang. 2025. "Near-Infrared Spectroscopy and Machine Learning for Fast Quality Prediction of Bottle Gourd" Foods 14, no. 14: 2503. https://doi.org/10.3390/foods14142503
APA StyleGuo, X., Huang, H., Wang, H., Cai, C., Wang, Y., Wu, X., Wang, J., Wang, B., Zhu, B., & Xiang, Y. (2025). Near-Infrared Spectroscopy and Machine Learning for Fast Quality Prediction of Bottle Gourd. Foods, 14(14), 2503. https://doi.org/10.3390/foods14142503