Abstract
The Lomax distribution is arguably one of the most useful lifetime distributions, explaining the developments of its extensions or generalizations through various schemes. The Marshall–Olkin length-biased Lomax distribution is one of these extensions. The associated model has been used in the frameworks of data fitting and reliability tests with success. However, the theory behind this distribution is non-existent and the results obtained on the fit of data were sufficiently encouraging to warrant further exploration, with broader comparisons with existing models. This study contributes in these directions. Our theoretical contributions on the the Marshall–Olkin length-biased Lomax distribution include an original compounding property, various stochastic ordering results, equivalences of the main functions at the boundaries, a new quantile analysis, the expressions of the incomplete moments under the form of a series expansion and the determination of the stress–strength parameter in a particular case. Subsequently, we contribute to the applicability of the Marshall–Olkin length-biased Lomax model. When combined with the maximum likelihood approach, the model is very effective. We confirm this claim through a complete simulation study. Then, four selected real life data sets were analyzed to illustrate the importance and flexibility of the model. Especially, based on well-established standard statistical criteria, we show that it outperforms six strong competitors, including some extended Lomax models, when applied to these data sets. To our knowledge, such comprehensive applied work has never been carried out for this model.
Keywords:
Marshall–Olkin scheme; length-biased Lomax distribution; modeling; asymmetry; simulation; data analysis MSC:
60E05; 62E15; 62F10
1. Introduction
The Lomax distribution introduced by [1] can be described as a simple two-parameter lifetime distribution with a varying polynomial decay. By denoting the shape parameter as and the scale parameter as , it is specified by the following probability density function (pdf):
and for . Basically, the Lomax distribution corresponds to the famous Pareto distribution that has been shifted to the left until its support starts at 0 (see [2], p. 573). It has been widely used for the modeling of various measures in reliability and life testing from heavy tailed data. The literature on the Lomax distribution and its applications is vast, including [3,4,5,6,7,8,9], to name of few.
In order to make the statistical possibilities of the Lomax distribution more flexible and attractive, several multiple-parameter modifications and generalizations have been proposed. Among them, we cite the Marshall–Olkin Lomax distribution by [10], transmuted Lomax distribution by [11], MacDonald Lomax distribution by [12], Poisson Lomax distribution by [13], exponentiated Lomax distribution by [14], exponential Lomax distribution by [15], gamma Lomax distribution by [16], Weibull Lomax distribution by [17], weighted Lomax distribution by [18], power Lomax distribution by [19], length-biased Lomax by [20], half-logistic Lomax distribution by [21], Marshall–Olkin power Lomax by [22] and Marshall–Olkin length-biased Lomax by [23], among others.
In particular, based on the concept of length-biased distribution pioneered by [20,24] introduced the length-biased Lomax (LBLO) distribution with the following pdf:
where denotes the mean of the Lomax distribution. That is, by taking into account that for , the pdf above can be expressed as
for and , and for . One can remark that against . Thus the parameters and only governed the shapes of the pdf independently of the values of the initial value, contrary to the former Lomax distribution, while keeping a similar level of flexibility. In this sense, for some applied problems, the LBLO model is an interesting alternative to the Lomax model, with the same number of parameters. Further detail can be found in [20].
Recently, [23] proposed a new extension of the LBLO distribution called Marshall–Olkin length-biased Lomax (MOLBL) distribution. It consists in modifying the LBLO distribution via the Marshall–Olkin scheme pioneered by [25]. The aim is to add more flexibility to the LBLO distribution through ratio-type definitions of the main functions depending on a tuning parameter. Precisely, the corresponding pdf with the shape parameters and , and scale parameter is
and for . Thus, the parameter modulates the denominator function; the LBLO distribution being recovered by taking . In [23], the parameters of the MOLBL model are estimated by the maximum likelihood estimation method, without convergence evidence. The remission data set by [26] is analyzed, and it is proved that the MOLBL model has a better fit to the former LBLO model by considering the Akaike information criterion (AIC) and Bayesian information criterion (BIC), only. In addition, a reliability test plan is developed to accept or reject a submitted lot of products for inspection whose lifetime is directed to be a MOLBL distribution.
In this study, we complete the study of [23] on several important aspects, making significant theoretical and practical contributions to the MOLBL distribution. For the theoretical findings, (i) we prove that the MOLBL distribution can be derived by a simple compounding argument, (ii) new stochastic ordering properties are established, (iii) asymptotic equivalences are described for the first time with discussion on the role played by the parameters in this regard, (iv) a quantile analysis is performed with a special focus on the case , (v) the incomplete moments are expressed, as well as the ordinary moments, and (vi) the stress–strength parameter is determined for a special configuration on the parameters. For the practical contributions, (a) a complete simulation study guaranties the numerical convergence of the maximum likelihood estimates, (b) four different data sets are considered, and (c), for these data sets, six competitors are used, including some extended Lomax distributions. We show that the MOLBL model is the best based on the following benchmarks: AIC as well as its consistent version (CAIC), BIC, Hannan–Quinn information criterion (HQIC), Anderson–Darling (), Cramer–von Mises (), Kolmogorov–Smirnov (KS) and the p-value of the corresponding KS statistical test. A graphical analysis of the obtained fits is also provided, showing the high quality of the MOLBL model.
2. Theoretical Contributions
This section is devoted to new theoretical facts about the MOLBL distribution.
2.1. Main Functions of the MOLBL Distribution
We now recall the main functions of the MOLBL distribution, as sketched in [23]. First, the cumulative distribution function (cdf) of the MOLBL distribution is given as
and for . The cdf of the LBLO distribution is obtained as a special case; it follows by substituting in Equation (4). Based on Equation (4), the survival function (sf) of the MOLBL distribution can be expressed as
and for . We recall that the pdf of the MOLBL distribution is specified by Equation (3), corresponding to the derivative of with respect to x. From Equations (3) and (5), we can express the hazard rate function (hrf) of the MOLBL distribution by
and for . The above analytical definitions are fundamental to explore the possibilities of the MOLBL model. They are used intensively in the remainder of the paper.
For the purposes of this study, the MOLBL distribution is denoted as MOLBL distribution when the parameters must be communicated.
2.2. Compounding
The following proposition shows that the MOLBL distribution follows from a special compounding distribution involving the classical exponential distribution with parameter .
Proposition 1.
Let X and Y be continuous random variables such that
- the conditional cdf ofis given aswhich is a well-identified cdf specified later,
- Y has the exponential distribution with parameter, that is with the pdf defined byforandfor.
Then X has the MOLBLdistribution.
Proof.
By using the distribution of X conditionally to , the cdf of X is obtained as
This entails the desired result. ☐
As announced, the conditional cdf of expressed in Equation (7) is well identified; it corresponds to the cdf of the Weibull-G family of distributions by [27] defined with the parameters and , and with the LBLO distribution as parental distribution. However, to our knowledge, it has not received a special attention, and can be the object of a future study.
2.3. Stochastic Ordering
The notion of first-order stochastic dominance is the most basic stochastic ordering concept. It consists in giving a mathematical setting to compare several distributions through their cdfs or, equivalently, their sfs. More precisely, we say that a distribution symbolized by A first-order stochastically dominates (FOSD) a distribution symbolized by B if their respective cdfs, say and , satisfy the following inequality: , for all . This concept finds numerous applications in actuarial sciences, econometrics, reliability and biometrics. One may refer to [28,29].
The next result shows several first order stochastic order dominance results for the MOLBL distributions based on all its parameters.
Proposition 2.
The following results hold.
- (i)
- For, the MOLBLdistribution FOSD the MOLBLdistribution.
- (ii)
- For, the MOLBLdistribution FOSD the MOLBLdistribution.
- (iii)
- For, the MOLBLdistribution FOSD the MOLBLdistribution.
Proof.
- (i)
- It is enough to study the monotonicity of in Equation (4) with respect to . After derivatives and standard manipulations, for , we getNow, the following logarithmic inequality is well-known: for . By applying it with and using , we haveTherefore, , implying that is an increasing function with respect to ; For , the MOLBL distribution FOSD the MOLBL distribution.
- (ii)
- Now, let us study the monotonicity of with respect to . After some developments, for , we getSince , this partial derivative is clearly negative. Hence, is a decreasing function with respect to ; For , the MOLBL distribution FOSD the MOLBL distribution.
- (iii)
- The monotonicity of with respect to is now investigated. After some algebraic manipulations, for , we haveSince , the Bernoulli inequality implies thatTherefore, , implying that is a decreasing function with respect to ; for , the MOLBL distribution FOSD the MOLBL distribution.
The proof of Proposition 2 ends. ☐
The next result is about a hazard rate ordering satisfied by the MOLBL distribution. We say that a distribution symbolized by A dominates a distribution symbolized by B in the hazard rate ordering if their respective hrfs, say and , satisfy the following inequality: , for all . This kind of stochastic ordering is a useful concept in reliability and order statistics (see [30]).
Proposition 3.
For, the MOLBLdistribution dominates the MOLBLdistribution in the hazard rate ordering.
Proof.
On the basis of Equation (6), after differentiation and standard operations, we obtain
which is clearly negative. Therefore, is decreasing with respect to , implying that, for , . This ends the proof of Proposition 3. ☐
Note that, by the relation between the first-stochastic order dominance and hazard rate ordering, Proposition 3 implies Proposition 2 (iii).
2.4. Equivalences
The asymptotic behaviors of the main functions of the MOLBL distribution are useful to understand the role of the parameters played in the limit bounds and also, to prove the existence of important probabilistic quantities such as the moments. When x tends to 0, since the following equivalence at the order two holds:
we have
The last result implies that both and tend to 0 with a polynomial rate of degree 1. When x tends to , the following equivalences hold:
and
Therefore, and tend to 0 under all circumstances. This convergence is with a polynomial decay with degree for , and with a polynomial decay with degree 1 for .
As a consequence, by the obtained equivalence: When x tends to , , the Riemann integral criteria ensures that the integral exists for , implying the existence of the moments of the MOLBL distribution for any positive integer s satisfying this condition. Also, with a similar argument, we show that, for all , , meaning that the MOLBL distribution has a heavy (right) tail.
2.5. Quantile Analysis
Quantile analysis provides precise information on the central and dispersion properties of a distribution. In the setting of the MOLBL distribution, the quantile function, say , satisfies the following equation: for any , that is, after a rearrangement,
In full generality, has not a closed-form expression. Only the case is manageable by the analytical approach; In this special case, we have
The median is obtained as . Similarly, the first and third quartiles are specified by substituting and in , respectively. Also, this quantile function can be used for simulated values from the MOLBL distribution.
2.6. Incomplete Moments
The interests of the incomplete moment of a random variable or a distribution are (i) to generalize the notion of ordinary moments, (ii) to be involved in the definitions of important curves, deviation measures and functions, such as the Lorenz curve, mean deviation about the mean and mean residual life function. Discussions and applications on incomplete moments are available in [31,32]. Here, the incomplete moments of the MOLBL distribution are investigated, with discussion on the ordinary moments as well.
First, we need the following general integral result.
Lemma 1.
For any integer , and real numbers , and , let us set
Then, the following sum formula is valid:
This equality is true for provided to , and we have
Proof.
By performing the change of variables , that is, , we obtain
Since a is a positive integer, the classical binomial formula holds and we obtain
For the case , it is enough to notice that, for , we have , implying that tends to 0. The desired result follows. This ends the proof of Lemma 1. ☐
Lemma 1 can be used independently of interest, but will be at the heart for manageable series expression of the incomplete moments.
We are in the position to present the main results of this section, regarding the incomplete moments of the MOLBL distribution. The proposition below proposes a series expansion of any of these incomplete moments in the case .
Proposition 4.
Let s be an integer and X be a random variable having the MOLBL distribution with . Then, for , the incomplete moment of X according to t is given as
where is a random variable having the Bernoulli distribution with parameter , and
Also, provided to , by applying , the ordinary moment of X is given as
where .
Proof.
First, the integral definition of is
Then, since , we have for any , based on the geometric series expansion, we can express in Equation (3) as
Now, by the classical binomial formula, we obtain
Therefore, by multiplication with , integrating over with respect to x and introducing the integral function defined in Equation (8), it comes
The desired result follows from Lemma 1 applied to with , and , after some elementary simplifications. This concludes the proof of Proposition 4. ☐
Based on Proposition 4, the following approximations are acceptable:
where K denotes any large integer. Such finite sums can give precise numerical evaluations of moments, better in terms of error than computational integration procedures.
The next proposition completes Proposition 4 by investigating the case .
Proposition 5.
We adopt the same setting to Proposition 4 but with . Then, for , the incomplete moment of X according to t is given as
where
Also, provided to , by applying , the ordinary moment of X is given as
where .
Proof.
Of course, the integral definition set in Equation (9) still holds. Now, remark that, after some developments, we can write
Then, since , we have for any , the geometric series expansion gives
The classical binomial formula applied two times in a row gives
Through the use of the integral function defined in Equation (8), we obtain
By virtue of Lemma 1 applied to with , and , the stated result follows after some developments. The proof of Proposition 5 is ended. ☐
Thanks to Proposition 5, the following approximations are possible:
where K denotes any large integer. Such finite sums can give precise numerical evaluations of moments, better in terms of error than computational integration techniques.
From the moments of the MOLBL distribution, under some condition on , one can derive standard measures of centrality, dispersion, asymmetry and peakness, such as the mean , variance , moments skewness coefficient and moments kurtosis coefficient , respectively. They are classically defined by
respectively, all existing for .
Table 1 indicates numerical values for mean, variance, skewness and kurtosis of the MOLBL distribution for and some selected values of parameters and .

Table 1.
Numerical values for mean, variance, skewness and kurtosis of the Marshall–Olkin length-biased Lomax (MOLBL) distribution for selected values of the parameters and .
For the considered values, we see that the MOLBL distribution is right skewed. Wide variations for the considered measures are observed.
2.7. Stress-Strength Parameter
The stress–strength parameter of a distribution naturally appears in many random systems and population comparison (see [33,34,35]). Here, we formulate a result on the expression of this parameter in the context of the MOLBL distribution.
Proposition 6.
Let us define the stress–strength parameter by , where X and Y are independent random variables following the MOLBL and MOLBL distributions, respectively. Then, we have
Proof.
We follow the lines of ([36] [Section 2]). Based on the independence of X and Y, and the expressions of their pdf and sf in Equations (3) and (5), respectively, we get the following integral expression:
By performing the change of variables , the above integral is reduced to
We get the desired result. ☐
Proposition 6 is the first step for the statistical treatment of R, as derived in [36], for instance.
3. Applied Contributions
We now focus on the applicability of the MOLBL model in a concrete statistical setting.
3.1. Estimation with Simulation
As developed in [23], the parameters , and of the MOLBL model can be estimated via the maximum likelihood method. That is, based on n data supposed to be drawn from the MOLBL distribution, say , the maximum likelihood estimates (MLEs) of , and , say , and , respectively, are defined by
where is the likelihood function of the model, that is
The log-likelihood function as well as the related score equations can be found in [23]. However, it is worth mentioning that the MLEs , and have no closed-form expressions. For practical purposes, they can be determined numerically by the use of statistical software. Here, we employ the R software with the package named maxLik (see [37]).
As a new contribution, we conduct a simulation study to check the asymptotic behavior of the MLEs of the model using Newton–Raphson method. The algorithm used in this simulation study is as follows.
- Step 1:
- We chose the number of replications denoted by N.
- Step 2:
- We chose the sample size denoted by n, the values of the parameters , , and an initial value denoted by .
- Step 3:
- We generate a value denoted by u from a random variable with the unit uniform distribution.
- Step 4:
- We update by using the Newton formula in the following way:
- Step 5:
- For a small enough tolerance limit denoted by , if , we store as a sample from MOLBL distribution.
- Step 6:
- Otherwise, if then, set and go to Step 3.
- Step 7:
- Repeat Steps 3–6 n times to obtain , respectively.
- Step 8:
- Compute the MLEs of the parameters.
- Step 9:
- Repeat Steps 3–8 N times to generate N MLEs.
The results are obtained from replications. In each replication, a random sample of size , 120, 200, 300 and 800 is generated for different combinations of , and . Here, the considered values of , and are , , , and . Table 2, Table 3, Table 4, Table 5 and Table 6 list the average MLEs, biases and the corresponding mean squared errors (MSEs). We recall that the average MLEs of , and are given by
respectively, the biases of , and are
respectively, and the MSEs of , and are
respectively.
Table 2.
Average maximum likelihood estimates (MLEs), biases and mean squared errors (MSEs) for , and .
Table 3.
Average MLEs, biases and MSEs for , and .
Table 4.
Average MLEs, biases and MSEs for , and .
Table 5.
Average MLEs, biases and MSEs for , and .
Table 6.
Average MLEs biases and MSEs for , and .
The values in Table 2, Table 3, Table 4, Table 5 and Table 6 show that, as the sample size increases, the MSEs of the estimates of the parameters tend to zero and the average estimates of the parameters tend closer to the true parameter values. One can notice that the convergence is slow for the estimation of . This can be explained by the fact that it is taken relatively large in our experiments, i.e., at 5, 8 and 10. The overall numerical convergence can certainly be improved by using modern algorithms, such as the Simulated Annealing (SANN) described in [38]. Indeed, the SANN method guarantees a convergence that does not depend on the initial values, even when several local extrema are present. Further details and applications of this method can be found in [39]. Alternatively, Bayesian estimation can be investigated in a similar manner to the former Lomax distribution, as performed in [8]. However, these methods require additional developments that we leave for future work.
3.2. Applications to Four Data Sets
This section provides new applications to explore the potential of the MOLBL model with other six well known competitive models, namely the power Lomax (POLO) (see [19]), exponentiated Lomax (EXLO) (see [14]), Marshall–Olkin length-biased exponential (MOLBE) (see [40]), length-biased Lomax (LBLO), original Weibull and original Lomax models. The MOLBL, POLO and EXLO models have three parameters, whereas the MOLBE, LBLO, Weibull and Lomax models have two parameters. The pdfs of these competitive models are shown below.
- The pdf of the POLO model isand for .
- The pdf of the EXLO model isand for .
- The pdf of the LBLO model is given as Equation (2), that isand for .
- The pdf of the MOLBE model isand for .
- The pdf of the Weibull model isand for .
- The pdf of the Lomax model is specified by Equation (1), that isand for .
Four data sets were considered and analyzed, chosen for their interests as well as their different statistical natures (right-skewed, left-skewed, high peak, etc.) The model parameters were classically estimated by the maximum likelihood method, as described in Section 3.1 for the MOLBL model. Then, we compared the considered models by taking into account the AIC, CAIC, BIC, HQIC, , , KS and the p-value of the corresponding KS test. The best model is the one with the smallest values for the AIC, CAIC, BIC, HQIC, , , KS and the greatest value for the p-value of the KS test.
Data set 1: The data were extracted from [41]. It represents the survival times of a group of patients suffering from Head and Neck cancer disease and treated using radiotherapy. The data are as follows: 6.53, 7, 10.42, 14.48, 16.10, 22.70, 34, 41.55, 42, 45.28, 49.40, 53.62, 63, 64, 83, 84, 91, 108, 112, 129, 133, 133, 139, 140, 140, 146, 149, 154, 157, 160, 160, 165, 146, 149, 154, 157, 160, 160, 165, 173, 176, 218, 225, 241, 248, 273, 277, 297, 405, 417, 420, 440, 523, 583, 594, 1101, 1146, 1417.
Table 7 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 7.
Estimates and standard errors (in parentheses) of the parameters for Data set 1.
Table 8 indicates the values of the AIC, CAIC, BIC, HQIC, , , KS and p-value of the considered models.
Table 8.
Some criteria and goodness of fit measures for Data set 1.
From Table 8, it is clear the MOLBL model is the best, with the smallest values for the AIC with AIC , CAIC with CAIC , BIC with BIC , with HQIC with HQIC , with , with , KS with KS and the greatest value for the p-value (p).
Data set 2: The data were taken from [42]. They represent the life of fatigue fracture of Kevlar 49/epoxy strands that are subject to a constant pressure at the 90% stress level until the strand failure. The data are as follows: 0.0251, 0.0886, 0.0891, 0.2501, 0.3113, 0.3451, 0.4763, 0.5650, 0.5671, 0.6566, 0.6748, 0.6751, 0.6753, 0.7696, 0.8375, 0.8391, 0.8425, 0.8645, 0.8851, 0.9113, 0.9120, 0.9836, 1.0483, 1.0596, 1.0773, 1.1733, 1.2570, 1.2766, 1.2985, 1.3211, 1.3503, 1.3551, 1.4595, 1.4880, 1.5728, 1.5733, 1.7083, 1.7263, 1.7460, 1.7630, 1.7746, 1.8275, 1.8375, 1.8503, 1.8808, 1.8878, 1.8881, 1.9316, 1.9558, 2.0048, 2.0408, 2.0903, 2.1093, 2.1330, 2.2100, 2.2460, 2.2878, 2.3203, 2.3470, 2.3513, 2.4951, 2.5260, 2.9911, 3.0256, 3.2678, 3.4045, 3.4846, 3.7433, 3.7455, 3.9143, 4.8073, 5.4005, 5.4435, 5.5295, 6.5541, 9.0960.
Table 9 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 9.
Estimates and standard errors (in parentheses) of the parameters for Data set 2.
Table 10 indicates the values of the AIC, CAIC, BIC, HQIC, , , KS and p-value of the considered models.
Table 10.
Some criteria and goodness of fit measures for Data set 2.
From Table 10, the MOLBL model is revealed to be the best, with the smallest values for the AIC with AIC , CAIC with CAIC , BIC with BIC , with HQIC with HQIC , with , with , KS with KS and the greatest value for the p-value (p).
Data set 3: The data were taken from [43]. The data represent the survival times of 72 guinea pigs infected with virulent tubercle bacilli. The data are as follows: 0.1, 0.33, 0.44, 0.56, 0.59, 0.72, 0.74, 0.77, 0.92, 0.93, 0.96, 1, 1, 1.02, 1.05, 1.07, 1.07, 1.08, 1.08, 1.08, 1.09, 1.12, 1.13, 1.15, 1.16, 1.2, 1.21, 1.22, 1.22, 1.24, 1.3, 1.34, 1.36, 1.39, 1.44, 1.46, 1.53, 1.59, 1.6, 1.63, 1.63, 1.68, 1.71, 1.72, 1.76, 1.83, 1.95, 1.96, 1.97, 2.02, 2.13, 2.15, 2.16, 2.22, 2.3, 2.31, 2.4, 2.45, 2.51, 2.53, 2.54, 2.54, 2.78, 2.93, 3.27, 3.42, 3.47, 3.61, 4.02, 4.32, 4.58, 5.55.
Table 11 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 11.
Estimates and standard errors (in parentheses) of the parameters for Data set 3.
Table 12 indicates the values of the AIC, CAIC, BIC, HQIC, , , KS and p-value of the considered models.
Table 12.
Some criteria and goodness of fit measures for Data set 3.
Table 12 confirms that the MOLBL model is more efficient in adaptive capacity, having the smallest values for the AIC with AIC , CAIC with CAIC , BIC with BIC , with HQIC with HQIC , with , with , KS with KS and the greatest value for the p-value (p).
Data set 4: The data were taken from [44]. They represent the survival data on the death times of psychiatric patients admitted to the University of Iowa hospital. The data are as follows: 1, 1, 2, 22, 30, 28, 32, 11, 14, 36, 31, 33, 33, 37, 35, 25, 31, 22, 26, 24, 35, 34, 30, 35, 40, 39.
Table 13 shows the MLEs of the parameters of the considered models, with their standard errors.
Table 13.
Estimates and standard errors (in parentheses) of the parameters for Data set 4.
Table 14 indicates the values of the AIC, CAIC, BIC, HQIC, , , KS and p-value of the considered models.
Table 14.
Some criteria and goodness of fit measures for Data set 4.
Based on Table 14, it is flagrant that the MOLBL model is preferable among all, with the smallest values for the AIC with AIC , CAIC with CAIC , BIC with BIC , with HQIC with HQIC , with , with , KS with KS and the greatest value for the p-value (p).
A graphical analysis is now performed, showing the fitted pdfs and cdfs of all the models. The fitted pdfs are superposed over the corresponding histogram of the data, and the estimated cdfs are superposed over the corresponding empirical cdf of the data. The plots are displayed in Figure 1, Figure 2, Figure 3 and Figure 4, for Data sets 1, 2, 3 and 4, respectively.
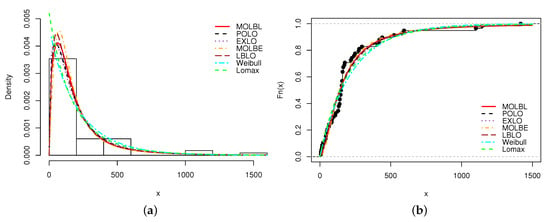
Figure 1.
Plots of (a) estimated probability density function (pdf) and (b) estimated cumulative distribution function (cdf) of the MOLBL model with those of the other competitive models for Data set 1.
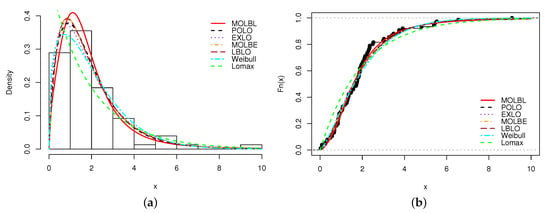
Figure 2.
Plots of (a) estimated pdf and (b) estimated cdf of the MOLBL model with those of the other competitive models for Data set 2.
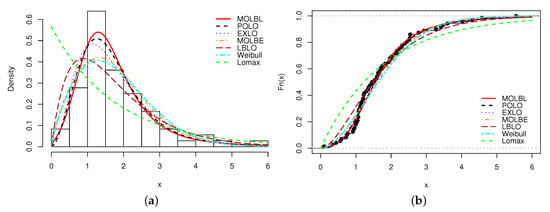
Figure 3.
Plots of (a) estimated pdf and (b) estimated cdf of the MOLBL model with those of the other competitive models for Data set 3.
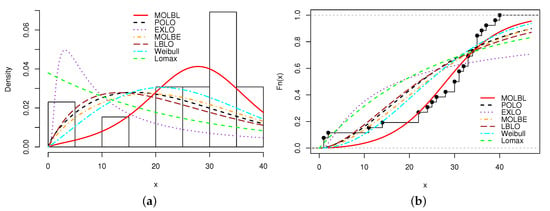
Figure 4.
Plots of (a) estimated pdf and (b) estimated cdf of the MOLBL model with those of the other competitive models for Data set 4.
In all the figures, we see that the MOLBL model better adjusted the empirical objects, making enough pliancy to adapt to the right or left skewness property of the data, as well as versatile peakness.
4. Concluding Remarks
The present study completes the work of [23] about the Marshall–Olkin length-biased Lomax distribution by providing important theoretical and applied contributions. New results on the following subjects are proved: (i) compounding, (ii) stochastic ordering, (iii) asymptotic equivalences of the main functions, (iv) quantile, (v) incomplete and ordinary moments, and (vi) stress–strength parameter. Thanks to a simulation study, the maximum likelihood estimates of the parameters of the Marshall–Olkin length-biased Lomax model are proved to be numerically efficient in the convergence sense. New applications are given, revealing that the Marshall–Olkin length-biased Lomax model is more powerful than expected; it can outperform the famous power Lomax, exponentiated Lomax, Marshall–Olkin length-biased exponential, length-biased Lomax, Weibull and Lomax models. This fact is illustrated by the analysis of four different data sets coming from real-life experiments. Graphic evidence is also provided.
We hope that the present study has revealed the potential of the Marshall–Olkin length-biased Lomax distribution for various probabilistic and statistical purposes, also opening new application horizons.
Author Contributions
Conceptualization, J.M. and C.C.; methodology, J.M. and C.C.; validation, J.M. and C.C.; formal analysis, J.M. and C.C.; investigation, J.M. and C.C.; writing–review and editing, J.M. and C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
We thank the three reviewers for their comprehensive and constructive comments on the document, which helped make it as robust as possible.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lomax, K.S. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Wiley: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Balakrishnan, N.; Ahsanullah, M. Relations for single and product moments of record values from Lomax distribution. Sankhya B 1994, 56, 140–146. [Google Scholar]
- Balkema, A.; de Haan, L. Residual life time at great age. Ann. Probab. 1974, 2, 792–804. [Google Scholar] [CrossRef]
- Bryson, M.C. Heavy-tailed distributions: Properties and tests. Technometrics 1974, 16, 61–68. [Google Scholar] [CrossRef]
- Abdullah, M.A.; Abdullah, H.A. Estimation of Lomax parameters based on generalized probability weighted moment. J. King Abdulaziz Univ. Sci. 2010, 22, 171–184. [Google Scholar]
- Afaq, A.; Ahmad, S.P.; Ahmed, A. Bayesian analysis of shape parameter of Lomax distribution under different loss functions. Int. J. Stat. Math. 2010, 2, 55–65. [Google Scholar]
- Ferreira, P.H.; Ramos, E.; Ramos, P.L.; Gonzales, J.F.B.; Tomazella, V.L.D.; Ehlers, R.S.; Silva, E.B.; Louzada, F. Objective Bayesian Analysis for the Lomax Distribution. Stat. Probab. Lett. 2020, 159, 108677. [Google Scholar] [CrossRef]
- Ahsanullah, M. Record values of Lomax distribution. Stat. Ned. 1991, 41, 21–29. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Awadhi, F.A.; Alkhalfan, L.A. Marshall–Olkin extended Lomax distribution and its application to censored data. Commun. Stat. Theor. Methods 2007, 36, 1855–1866. [Google Scholar] [CrossRef]
- Ashour, S.K.; Eltehiwy, M.A. Transmuted Lomax distribution. Am. J. Appl. Math. Stat. 2013, 1, 121–127. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M. An extended Lomax distribution. J. Theor. Appl. Stat. 2013, 47, 800–816. [Google Scholar] [CrossRef]
- Al-Zahrani, B.; Sagor, H. The Poisson–Lomax distribution. Rev. Colomb. Estad. 2014, 37, 225–245. [Google Scholar] [CrossRef]
- Salem, H.M. The exponentiated Lomax distribution: Different estimation methods. Am. J. Appl. Math. Stat. 2014, 2, 364–368. [Google Scholar] [CrossRef]
- El, A.H.; Abdo, N.F.; Shahen, H.S. Exponential Lomax Distribution. Int. J. Comput. Appl. 2015, 121, 24–29. [Google Scholar]
- Cordeiro, G.M.; Ortega, E.M.M.; Popović, B.V. Gamma–Lomax Distribution. J. Stat. Comput. Simul. 2015, 85, 305–319. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Mansoor, M.; Zubair, M. The Weibull–Lomax distribution: Properties and applications. Hacettepe J. Math. Stat. 2015, 44, 461–480. [Google Scholar] [CrossRef]
- Kilany, N.M. Weighted Lomax distribution. SpringerPlus 2016, 5, 1862. [Google Scholar] [CrossRef]
- Rady, E.H.A.; Hassanein, W.A.; Elhaddad, T.A. The power Lomax distribution with an application to bladder cancer data. SpringerPlus 2016, 5, 1838. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, S.P.; Ahmed, A. Length-biased weighted Lomax distribution: Statistical properties and application. Pak. Stat. Oper. Res. 2016, 12, 245–255. [Google Scholar] [CrossRef]
- Anwar, M.; Zahoor, J. The half-logistic Lomax distribution for lifetime Modeling. J. Probab. Stat. 2018, 2018, 3152807. [Google Scholar] [CrossRef]
- Haq, M.A.U.; Hamedani, G.G.; Elgarhy, M.; Ramos, P.L. Marshall–Olkin Power Lomax distribution: Properties and estimation based on complete and censored samples. Int. J. Stat. Probab. 2020, 9, 1–48. [Google Scholar]
- Mathew, J. Reliability test plan for the Marshall–Olkin length biased Lomax distribution. Reliab. Theory Appl. 2020, 15, 36–49. [Google Scholar]
- Fisher, R.A. The effects of methods of ascertainment upon the estimation of frequencies. Ann. Eugen. 1934, 6, 13–25. [Google Scholar] [CrossRef]
- Marshall, A.W.; Olkin, I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrica 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Lee, E.T.; Wang, J.W. Statistical Methods for Survival Data Analysis, 3rd ed.; John Willey: New York, NY, USA, 2003. [Google Scholar]
- Bourguignon, M.; Silva, R.B.; Cordeiro, G.M. The Weibull-G Family of Probability Distributions. J. Data Sci. 2014, 12, 53–68. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Muller, A.; Stoyan, D. Comparison Methods for Stochastic Models and Risks; Wiley: Chicheste, UK, 2002. [Google Scholar]
- Boland, P.J.; El-Neweihi, E.; Proschan, F. Applications of the hazard rate ordering in reliability and order statistics. J. Appl. Probab. 1994, 31, 180–192. [Google Scholar] [CrossRef]
- Butler, R.J.; McDonald, J.B. Using incomplete moments to measure inequality. J. Econom. 1989, 42, 109–119. [Google Scholar] [CrossRef]
- Arnold, B.C. On Zenga and Bonferroni curves. Metron 2015, 73, 25–30. [Google Scholar] [CrossRef]
- Pepe, M.S. Receiver operating characteristic methodology. J. Am. Stat. Assoc. 2000, 95, 308–311. [Google Scholar] [CrossRef]
- Briggs, W.M.; Zaretzki, R. The skill plot: A graphical technique for evaluating continuous diagnostic tests. Biometrics 2008, 63, 250–261. [Google Scholar] [CrossRef]
- Church, J.D.; Harris, B. The estimation of reliability from stress-strength relationship. Technometrics 1970, 12, 49–54. [Google Scholar] [CrossRef]
- Gupta, R.C.; Ghitany, M.E.; Al-Mutairi, D.K. Estimation of reliability from Marshall–Olkin extended Lomax distributions. J. Stat. Comput. Simul. 2010, 80, 937–947. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Ramos, P.L.; Nascimento, D.C.; Ferreira, P.H.; Weber, K.T.; Santos, T.E.G.; Louzada, F. Modeling traumatic brain injury lifetime data: Improved estimators for the generalized Gamma distribution under small samples. PLOS ONE 2019, 14, e0221332. [Google Scholar] [CrossRef] [PubMed]
- Haq, M.A.U.; Usman, R.M.; Hashmi, S.; Al-Omeri, A.I. The Marshall–Olkin length-biased exponential distribution and its applications. J. King Saud Univ. Sci. 2019, 31, 246–251. [Google Scholar] [CrossRef]
- Shukla, K.K. A comparative study of one parameter lifetime distributions. Biomet. Biostat. Int. J. 2019, 8, 111–123. [Google Scholar] [CrossRef]
- Pobocikova, I.; Sedliackova, Z.; Michalkova, M. Transmuted Weibull distribution and its applications. MATEC Web Conf. 2018, 157, 08007. [Google Scholar] [CrossRef][Green Version]
- Alghamedi, A.; Dey, S.; Kumar, D.; Dobbah, S. A new extension of extended exponential distribution with applications. Ann. Data Sci. 2020, 7, 139–162. [Google Scholar] [CrossRef]
- Klein, J.P.; Moeschberger, M.L. Techniques for Censored and Truncated Data in Survival Analysis; Springer: New York, NY, USA, 1997. [Google Scholar]
Sample Availability: Samples of the compounds ...... are available from the authors. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).