Estimation of Star-Shaped Distributions

1
Department of Engineering and Natural Sciences, University of Applied Sciences Merseburg, 06217 Merseburg, Germany
2
Institute of Mathematics, University of Rostock, Ulmenstraße 69, Haus 3, 18057 Rostock, Germany
*
Author to whom correspondence should be addressed.
Risks 2016, 4(4), 44; https://doi.org/10.3390/risks4040044
Submission received: 2 September 2016
/
Accepted: 18 November 2016
/
Published: 30 November 2016
(This article belongs to the Special Issue Selected Papers from the 10th Tartu Conference on Multivariate Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Scatter plots of multivariate data sets motivate modeling of star-shaped distributions beyond elliptically contoured ones. We study properties of estimators for the density generator function, the star-generalized radius distribution and the density in a star-shaped distribution model. For the generator function and the star-generalized radius density, we consider a non-parametric kernel-type estimator. This estimator is combined with a parametric estimator for the contours which are assumed to follow a parametric model. Therefore, the semiparametric procedure features the flexibility of nonparametric estimators and the simple estimation and interpretation of parametric estimators. Alternatively, we consider pure parametric estimators for the density. For the semiparametric density estimator, we prove rates of uniform, almost sure convergence which coincide with the corresponding rates of one-dimensional kernel density estimators when excluding the center of the distribution. We show that the standardized density estimator is asymptotically normally distributed. Moreover, the almost sure convergence rate of the estimated distribution function of the star-generalized radius is derived. A particular new two-dimensional distribution class is adapted here to agricultural and financial data sets.
Keywords:
star-shaped distributions; antinorm contoured distributions; norm contoured distributions; non-concentric elliptically contoured distributions; kernel density estimatorsAMS Subject Classification:
60E05; 62G07; 62H121. Introduction
The classes of multivariate Gaussian and elliptically contoured distributions have served as the probabilistic basis of many multivariate statistical models over a period of several decades. Accounts of the theory of elliptically contoured distributions may be found in [1,2,3]. The book [4] by Fang and Anderson contains a big chapter about statistical inference of elliptically contoured distributions. The theory of elliptically contoured distributions including applications to portfolio theory is presented in the monograph by [5] Gupta et al. On combining the advantages of several estimators, semiparametric density estimators for elliptical distributions were derived in papers [6,7,8] by Stute and Werner, by Cui and He and by Liebscher. In [9] Battey and Linton considered a density estimator for elliptical distributions based on Gaussian mixture sieves. The performance of their estimators heavily depends on how the density can be approximated by a mixture of normal distributions. Scatter plots of multivariate data sets, however, motivate modeling of star-shaped distributions beyond elliptically contoured ones.
The more flexible star-shaped densities were studied in [10] and later in [11]. The general structure of their normalizing constant given a density generating function was discovered, a geometric measure representation and, based upon it a stochastic representation were derived, and a survey of applications of such densities was given in [12]. Moreover, two-dimensional non-concentric elliptically contoured distributions are introduced there and, based upon two-dimensional star-shaped densities, a universal star-shaped generalization of the univariate von Mises density is derived. These results are further studied in detail in [13] for several particular classes. The big classes of norm and antinorm contoured distributions, being particular cases of star-shaped distributions, are considered in [14,15] for dimension two and for arbitrary finite dimension, respectively. In this paper we study several of those classes of distributions for arbitrary finite dimension and introduce a particular new class of distributions for dimension two. The rather general class of distributions considered in the present paper covers distributions with convex as well as such with non-convex contours.
The main goal of this paper is to develop estimation procedures for fitting multivariate generalized star-shaped distributions. The semiparametric procedure combines the flexibility of nonparametric estimators and the simple estimation and interpretation of parametric estimators. Since we apply nonparametric estimation to a univariate function, we avoid the disadvantages of nonparametric estimators in connection with the curse of dimensionality. The semiparametric approach of this paper is based on that in the earlier paper [7] on elliptical distributions but uses partially weaker assumptions. Alternatively, we consider a pure parametric method. In both cases, a parametric model is assumed for the density contours given by the star body and the Minkowski functional of it. For the semiparametric method, we assume that the contours are smooth, more precisely, that the Minkowski functional is continuously differentiable. The parameters are estimated using a method of moments. The star generalized radius density is estimated nonparametrically by use of a kernel density estimator, or parametrically.
The paper is structured as follows. The class of continuous star-shaped distributions and several of its subclasses are considered in Section 2. Section 3 deals with the estimation of the density and the star-generalized radius distribution. In Section 3, the statements on convergence rates and on the asymptotic normality of the density estimator as well as on the convergence rate of the estimated distribution function of the generalized radius are provided. First the case of a given star body is considered, later the more general case of a parametrized star body is taken into consideration. The particular Section 3.4 surveys on the one hand to a certain extent examples where different subclasses of star-shaped distributions appear in practice and deals on the other hand with applications of the methods developed here to the analysis of two-dimensional agricultural and financial data. The proofs can be found in Section 4.
2. Continuous Star-Shaped Distributions
2.1. The General Distribution Class
Throughout this paper, denotes a star body, i.e., a non-empty star-shaped set that is compact and is equal to the closure of its interior, having the origin as an interior point. The Minkowski functional of K is defined by
The boundary of K is just the set . Further we find a ball which covers K where denotes Euclidean norm. Hence and
The function is assumed to be homogeneous of degree one,
and to satisfy a further assumption.
A countable collection of pairwise disjoint sectors (closed convex cones containing no half-space, with non-empty interior and vertex being the origin ) such that will be called a fan. By we denote the Borel-σ-field in and by S, the boundary of K. We denote and . We shall consider only star bodies K and sets satisfying the following condition.
Assumption 1.
The star body K and the set are chosen such that for every j the set
is well defined and such that for every there is a uniquely determined satisfying .
A star body K satisfying this assumption will be called for short an -star-body.
Let be a nonnegative function which fulfills the condition
Such function is called a density generating function (dgf).
We consider the class of continuous star-shaped distributions of random vectors X taking values in :
where means the interior of K. Suppose that the distribution law has the density
where is a suitable normalizing constant. Moreover, K is called the contour defining star body of .
We consider the random vector X having the density (2) (in symbols ). According to Theorem 8 in [12], this random vector has the representation
where the star-generalized radius variable and the star-generalized uniform basis vector are independent.
Moreover, R has the density
with , and U has a star-generalized uniform probability distribution on the boundary of K, i.e., for . According to [12], means the star-generalized surface measure which is a non-Euclidean one unless for S being the Euclidean sphere, and which is well defined if Assumption 1 is fulfilled. Note that . If is finite, then in view of (4), R takes values in the neighbourhood of zero with a rather small probability. This behaviour is called the volcano effect and is the stronger the higher the dimension is. The density (2) may be written as
Estimating such density may be studied under various assumptions concerning the degree of knowledge on the groups of parameters and , as well as μ. Let and . The next lemma gives helpful information about the mean and the covariances. Here and in what follows denotes the indicator function of an event A.
Lemma 1.
If and K is symmetric w.r.t. the origin, then
Proof.
In view of (3), we have first to show that . Because of the symmetry of K, U has the same distribution as , and with probability 0 for each j. Thus we obtain
Moreover, it follows that
☐
The general approach followed here includes non-convex bodies which can occur in applications. Obviously, and the distribution of the random vector U is concentrated on the set .
2.2. A Class of Two-Dimensional Distributions Whose Contour Defining Star Bodies Are Squared Sine Transformed Euclidean Circles
We define to be the angle in radians between the positive x-axis and the line through the point and the origin: for , for , . The Minkowski functional of any two-dimensional star body K can then be written as
where is a bounded function. In the following examples we consider two-dimensional star bodies with smooth boundaries; i.e., H is differentiable. Here, the following generator function is used
which corresponds to the star-generalized radius density of mixed Erlang type
Example 1.
Here we consider the Minkowski functional
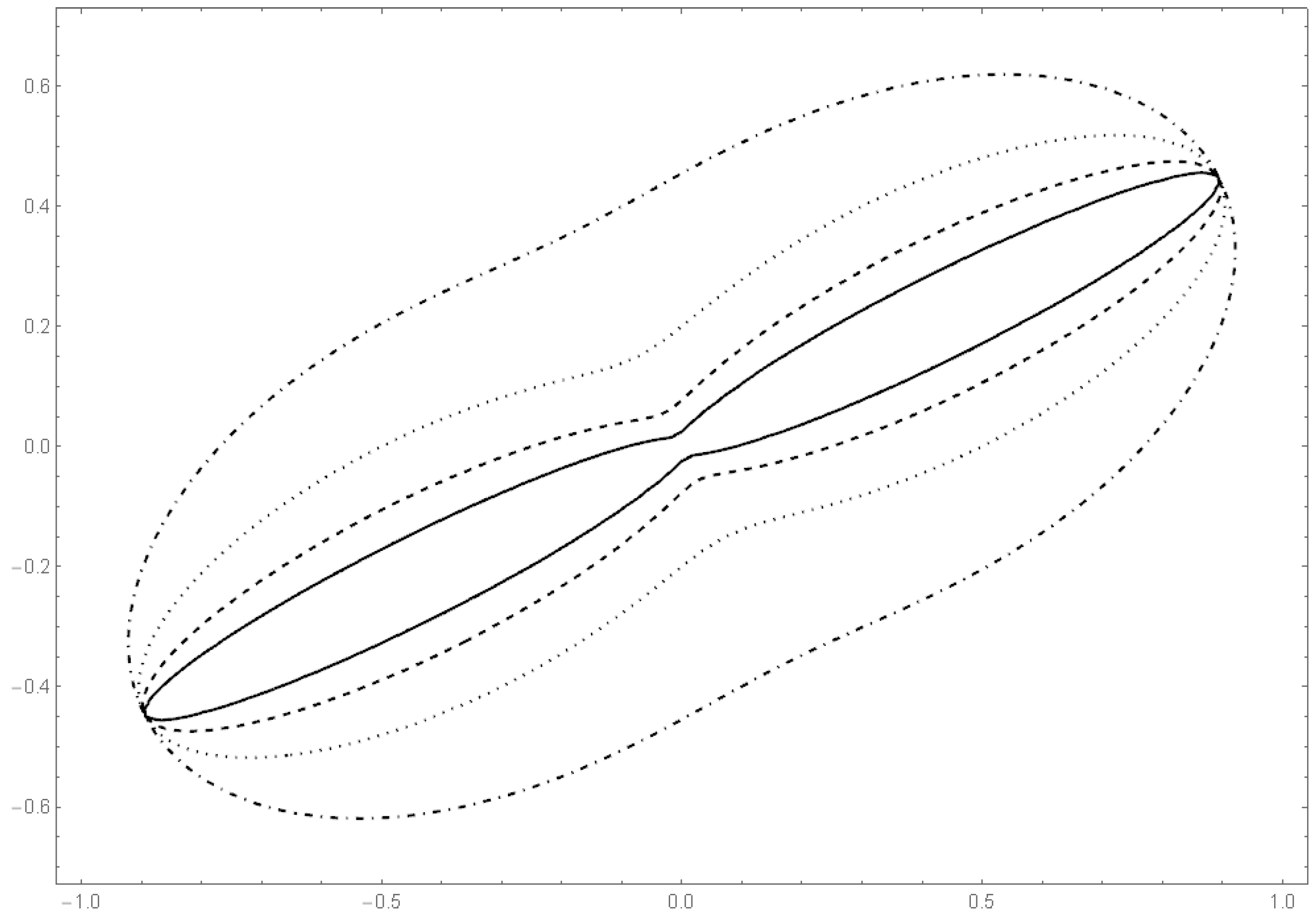
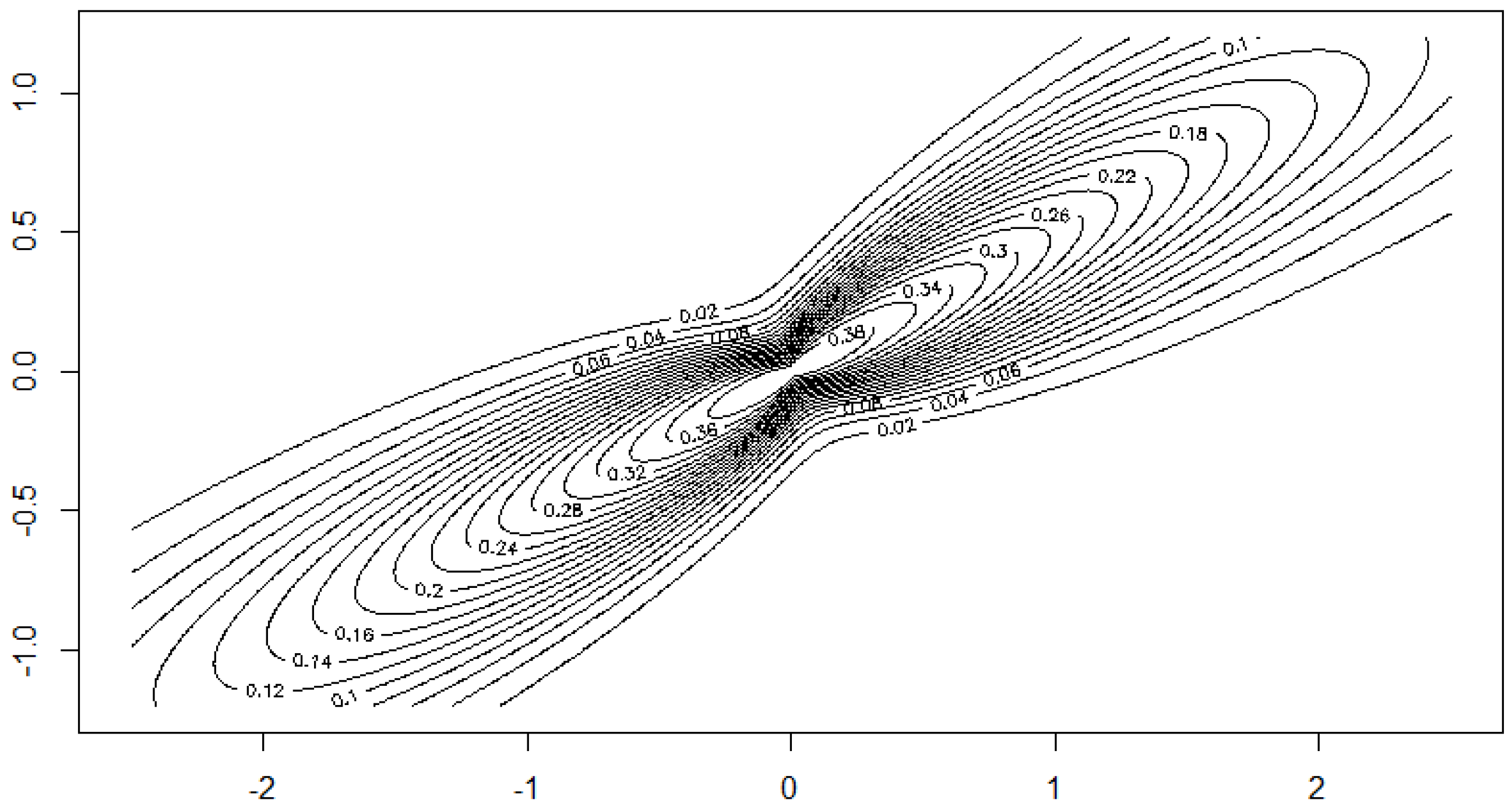
where is a parameter. The Figure 1, Figure 2, Figure 3 and Figure 4 show the contour lines of the boundary of the body for several values of a and the resulting density for one choice of a. These figures show that the distribution class includes densities with convex as well as with non-convex contours.
Example 2.
We consider the star body K with Minkowski functional
where and are parameters such that , and
2.3. Norm-Contoured Distributions
Specific norm-contoured distributions were studied in several papers which are in part surveyed in Richter [14]. A geometric measure representation of arbitrary norm contoured distributions is proved in [15]. The class of all norm-contoured distributions is denoted, according to these papers, by . The class is a subclass of the class StSh of star-shaped distributions. Here, we consider the subclass of continuous norm-contoured distributions CNC.
It is well known that there is a one-to-one correspondence between the class of convex bodies being symmetric w.r.t. the origin, where implies , and the class of norms in . If K is any such symmetric convex body then where is the uniquely determined norm. On the other hand, if is any norm, then is the corresponding convex symmetric body having the origin as interior point, and .
Throughout this section, let be any norm and , and let the density of a norm-contoured distribution be
where O is any orthogonal -matrix. Because any rotated or mirrored norm-ball is again a norm ball we shall restrict our attention to the case O being the unit matrix and will write then . In the present situation, is considered to be the unit sphere in the Minkowski space .
In the following we consider several specific cases of norms and the corresponding norm-contoured distributions.
Example 3.
If K is the Euclidean unit ball then is the Euclidean norm and (2) defines a shifted spherical distribution.
Example 4.
Let be a -matrix satisfying , any norm, and
another norm. If X is -contoured distributed and A is a symmetric and positive definite then we call the distribution of an elliptically generalized -contoured distribution.
Example 5.
Let be a vector with and . If, in Example 4, is the p-norm, then the corresponding norm is
The distribution of X is called an axes aligned p-generalized elliptically contoured distribution.
Example 6.
Assume that data are grouped into k groups, and let and
K may be called then an -generalized axis-aligned ellipsoid and we will say that X follows a grouped -generalized axis-aligned elliptically contoured distribution in .
Example 7.
In the case of two-dimensional observations, let denote the polygon having the n vertices , . The convex body which is circumscribed by will be denoted by K. Then is a norm defined in and a polygonally contoured density which was used implicitly in [13] to construct a corresponding geometric generalization of the von Mises density. For the more general class of multivariate polyhedral star-shaped distributions, see [16].
Example 8.
Given a homogeneous polynomial p of degree k with , the function defines a norm in if it is subadditive. An example for a homogeneous polynomial of degree 3 and is .
2.4. Antinorm-Contoured Distributions
A function which is continuous, positively homogeneous, non-degenerate and superadditive in some fan is called an antinorm in [17]. Thereby, g is called superadditive in a sector C or in the fan if it satisfies the reverse triangle inequality in C or in every sector of the fan , respectively.
Example 9.
If the -functional is defined as in Example 5 but with then it is an antinorm.
2.5. Continuous Non-Concentric Elliptically Contoured Distributions
Let and . If satisfies then is a star body having the origin as an interior point, and
Moreover, for . A Minkowski functional which is homogeneous of degree one will be called a non-concentric elliptically contoured function and a non-concentric elliptically contoured density. If denotes an arbitrary orthogonal transformation then is also a non-concentric elliptically contoured function which is homogeneous of degree one. For the special case of see [12,13].
3. Estimation for Continuous Star-Shaped Distributions
3.1. Parametric Estimators
Let be a sample of independent random vectors, where and . Assume that the star body K is given and Assumption 1 is satisfied. From now on, we suppose that K is symmetric w.r.t. the origin. We consider a model family of continuously differentiable densities for the star-generalized radius R on , see (4). is the parameter space which is assumed to be compact. Suppose that is a continuous function.
Next we give two reasonable model classes for :
- (1)
- Modified exponential model. ,with the expectation
- (2)
- Weibull model. ,with the expectation
Let . In this section the aim is to fit the specific parametric model for the density to the data by estimating the parameters θ and μ where is given according to (5) and (4) with . Therefore, the two models [1] and [2] fulfill the condition which ensures the differentiability of the density at zero.
For the statistical analysis we suppose that the data are given and these data comprise independent random vectors having density . Suppose that θ and μ are interior points of and , respectively. The concentrated log likelihood function (constant addends can be omitted) reads as follows
We introduce the maximum likelihood estimators of θ and μ as joint maximizers of the likelihood function:
Under appropriate assumptions, the maximum-likelihood-estimator are asymptotically normally distributed (cf. Theorem 5.1 in [18], p. 463)
where is the symbol for convergence in distribution and the information matrix is given by with and
3.2. Nonparametric Estimators without Scale Fit
In the present section we deal with nonparametric estimators in the context of star-shaped distributions. This type of estimators is of special interest if no suitable parametric model can be found. The cdf of R will be denoted by .
3.2.1. Estimating μ and
Let be the sample as in Section 3.1. In the following the focus is on the estimation of the parameter μ and the distribution function of the generalized radius R.
First we choose an estimator for μ. For this purpose we assume that . In view of Lemma 1,
is an unbiased estimator for the unknown parameter μ. Define and for . Using this definition, an estimator for the cdf of (cf. (3)) is given by the formula
for . At a first glance, just approximates the empirical distribution function
which is not available from the data because of the unknown μ. We can prove that converges to , in fact at the same rate as every common empirical distribution function converges to the cdf. This is the assertion of the following theorem.
Theorem 1.
Suppose that Assumption 1 is satisfied, is Lipschitz-continuous on , and
If further f is bounded on , then, for ,
Here the condition (9) ensures that which in turn is an assumption for the law of iterated logarithm of .
3.2.2. Density Estimation
In the remainder of Section 3.2, we establish an estimator for the density in the case of a bounded generator function g, and provide statements on convergence properties of the estimator. An estimator for μ is available by Formula (7), the estimation of g is still an open problem. If we want to estimate g, then it is necessary that this function is identifiable. In (2), however, function g is determined up to a constant factor. Therefore, we require to obtain the uniqueness and identifiability. As a consequence, we get, according to [12]
In the following we adopt the approach introduced in Section 2 of [7] to the present much more general situation. This approach combines the advantages of two estimators and avoids their disadvantages. Let be a function having a derivative with for and the property . We introduce the random variable and denote the inverse function of ψ by Ψ. The transformation using ψ is applied to adjust the volcano effect described above. In view of (4), the density χ of is given by
for . This equation implies the following formula for g:
The next step is to establish the estimator for χ. Nonparametric estimators have the advantage that they are flexible and there is no need to assume a specific model. Let us consider the transformed sample with . Further we apply the following kernel density estimator for χ:
where is the bandwidth and k the kernel function. Note that represents the usual kernel density estimator for χ based upon the ’s and including a boundary correction at zero (the second addend in the outer parentheses of (10)). The mirror rule is used as a simple boundary correction. Other more elegant corrections can be applied at the price of a higher technical effort. The properties of are essentially influenced by the bandwidth b. Since the kernel estimator shows reasonable properties only in the case of bounded χ, we have to guarantee by suitable assumptions that in order to get the boundedness of χ (see below). On the basis of , we can establish the following estimator for :
where
This approach has the property that the theory of kernel density estimators applies here (cf. [19]). The kernel estimators are a very popular type of nonparametric density estimators because of their comparatively simple structure. In the literature the reader can find a lot of hints concerning the choice of the bandwidth.
Let us add here some words to the comparison between this paper and [7]. Although the main idea for the construction of estimators is the same, there is a difference in the definition of the generator functions (say g and ). Considering the special case , identity can be established for . This causes some changes in the formulas. For more details in a particular case, see Section 3 in [20].
3.2.3. Assumptions Ensuring Convergence Properties of Estimators
Next we provide the assumptions for the theorems below. Assumption 2 concerns the parameter and the function k of the kernel estimator whereas Assumption 3 is posed on function ψ.
Assumption 2.
(a) We assume that
with constants .
(b) Suppose that the kernel function is continuous and vanishes outside the interval , and has a Lipschitz continuous derivative on . Moreover, assume that holds for ,
for even , where is an integer.
Note that continuity of the derivative at an enclosed boundary point means that the one-sided derivative exists and is the limit of the derivatives in a neighbourhood of this point. Symmetric kernel functions k satisfying (12) are called kernels of order p. Assumption 2 ensures that the bias of the density estimator converges to zero at a certain rate. Under Assumption 2 with and , the estimator is indeed a density. The case is added to complete the presentation and is of minor practical importance unless we have a very large sample size (cf. the discussion in [21]). From the asymptotic theory for density estimators, it is known that the Epanechnikov kernel
is an optimal kernel of order 2 (i.e., in the case in Assumption 2) with respect to the asymptotic mean square error (cf. [19]). This kernel function is simple in structure and leads to fast computations. The consideration of optimal kernels can be extended to higher-order kernels. It turned out that their use is advantageous only in the case of sufficiently large sample sizes (for instance, for a size greater than 1000).
Assumption 3.
The -th order derivative of exists and is continuous on , is positive and bounded on for some integer , and is bounded on . The functions and have bounded derivatives on with some . Moreover,
Notice that in Assumption 3 we require that the right-sided limit of the -th order derivative of is finite at zero. Hence Assumption 3 implies that
and
with a finite constant . On the other hand, it follows from (13) that
with a finite constant . Therefore, χ is bounded under Assumption 3.
Example 10.
Let
with a constant . Then , ,
Hence, Assumption 3 is satisfied for every .
Another condition is required now for .
Assumption 4.
For any bounded subset Q of , the partial derivatives of exist and are bounded on Q, and is Hölder continuous of order on Q for each .
Assumption 5.
For any bounded subset Q of , is Hölder continuous of order .
If Assumption 3 is fulfilled, the function has second order derivatives , and these are bounded on bounded subsets of , then the Assumption 4 is satisfied.
Example 11.
We consider the q-norm/antinorm: ,
Therefore, Assumption 4 is fulfilled in the case , and Assumption 5 is fulfilled in the case .
Examples 1 and 2: (Continued) One can show that exists for , and is bounded. Moreover, is Lipschitz continuous on . Hence, Assumption 4 is satisfied.
3.2.4. Properties of the Density Estimator
First we provide the result on strong convergence of the density estimator.
Theorem 2.
Suppose that the p-th order derivative of g exists and is bounded on for some even integer . Moreover, assume that condition (9) as well as Assumptions 1 to 3 are satisfied for the given p. Let Assumption 4 or Assumption 5 be satisfied. In the first case define , in the latter case . Then, for any compact set D with and ,
For any compact set D with and ,
Theorem 2 applies in particular to the Euclidean case . Since Assumption 2 is weaker than the corresponding assumption on the kernel in [7], Theorem 2 extends Theorem 3.1 in [7] even in the case of . The convergence rate in (15) is the same as that known for one-dimensional kernel density estimators and cannot be improved under the assumptions posed here (cf. [22]).
The next theorem represents the result about the asymptotic normality of the estimator .
Theorem 3.
Suppose that the assumptions of Theorem 2 and Assumption 4 are satisfied. Let such that is continuous at .
- (i)
- DefineThenwhere
- (ii)
- If additionally holds true with a constant , then, for ,
The assertion of Theorem 3 can be used to construct an asymptotic confidence region for . Term describes the asymptotic behaviour of the the bias of the estimator whereas the fluctuations of the estimator are represented by . In view of Theorem 3, converges in distribution to . The mean squared deviation of the leading terms in the asymptotic expansion of is thus given by
The minimization of this function w.r.t. b leads to the asymptotically optimal bandwidth
The bandwidth converges at rate to zero. Under the conditions of Theorem 3(ii), has the convergence rate . This convergence rate of is better than that of a nonparametric density estimator but slower than the usual rate for parametric estimators. In principle, Formula (16) could be used for the optimal choice of the bandwidth. However, one would need then an estimator for and typically, estimators of derivatives of densities do not exhibit a good performance unless n is very large. As a resort, one can consider a bandwidth which makes reference to a specific radius distribution.
3.2.5. Reference Bandwidth
Let us consider an estimator with Epanechnikov kernel, function ψ as in Example 10, and modified exponential radius density in the case . According to (16), the reference bandwidth is then
where
This formula was generated using the computer algebra system Mathematica. The parameter τ can be estimated by utilizing the above Formula (6) for the expectation of the radius.
3.3. Semiparametric Estimators Involving a Scale and a Parameter Fit
In this section we consider the situation where the contour of the body K depends on scale parameters . Suppose that . We introduce the diagonal matrix and a master body , which is symmetric w.r.t. the origin. Define
and . The distribution of is concentrated on the boundary of . We assume that is given such that
Otherwise, is rescaled. Suppose that depends on a further parameter vector where the parameter space is a compact set. Then
The parameter vector θ is able to describe the shape of the boundary of body K, see Examples 1 and 2 (parameters and ). From Lemma 1, we obtain
and
Here we see that (17) results in . The density is given by
In this context, a scaling problem occurs concerning g. Assume that g is a suitably given generator function satisfying . Then is a modified generator for every with . For any , we obtain the same model when g is replaced by and is replaced by for . To get uniqueness, we choose t such that
Let as above. Then represents the variance of the j-th component of X. Based on this property, the sample variances of the components of X can be used as estimators for :
Moreover, we have the sample correlations
In the following we use the notation diag. If θ is unknown, we consider moment estimators based on the correlations. For this we need the following assumptions.
Assumption 6.
Let I be a subset of with cardinality q. There is a vector such that for ,
Assume that has bounded partial derivatives, and θ is an interior point of Θ.
Assumption 7.
For any bounded subset Q of , the partial derivatives , of exist, are bounded for , and , is Hölder continuous of order on for each .
Assumption 8.
For any bounded subset Q of , is Hölder continuous of order .
Examples 1 and 2: (Continued) Similarly as above, it can be proven that Assumption 7 is fulfilled.
Let be the sample version of ρ. Then
is the estimator for θ, . Define . With this definition, is determined according to Formula (8). The following result on the convergence rate of can be proven:
Theorem 4.
Suppose that Assumptions 1 and 6 are satisfied, and
Let be bounded on . Then, for ,
In this section the transformed sample is given by with ψ as in Section 3.2. The estimator for the generator g is calculated using Formulas (10) and (11) from the previous section. The following estimator for the density has thus been established:
The next two theorems show the results concerning strong convergence and asymptotic normality of the density estimator:
Theorem 5.
Suppose that the p-th order derivative of g exists and is bounded on for some even integer . Where needed, with this p, assume further that Assumptions 1, 2, 3, 6, (1) and (18) are satisfied. Let Assumption 7 or Assumption 8 be satisfied, and define in the first case and in the latter case .Then the claim of Theorem 2 holds true for estimator defined in (19).
Theorem 6.
Suppose that the assumptions of Theorem 5 are satisfied. Let such that is continuous at . Assume that holds true with a constant . Then for ,
where is defined in (19),
The remarks following Theorems 2 and 3 are valid similarly.
3.4. Applications
For many decades, statistical applications of multivariate distribution theory were manly based upon Gaussian and elliptically contoured distributions. Studies using non-elliptically contoured star-shaped distributions were basically made during the last two decades and are dealing in most cases with p-generalized normal distributions. Such distributions are convex or radially concave contoured if or respectively, and are also called power exponential distributions. Moreover, common elliptically contoured power exponential (ecpe) distributions build a particular class of the wide class of star-shaped distributions that allows modeling much more flexible contours than elliptically ones.
The class of ecpe distributions is used in a crossover trial on insulin applied to rabbits in [23], in image denoising in [24] and in colour texture retrieval in [25]. Applications of multivariate g-and-h distributions to jointly modeling body mass index and lean body mass are demonstrated in [26] and accompanied by star-shaped contoured density illustrations. The -elliptically contoured distributions build another big class of star-shaped distributions and are used in [27] to explore to which extent orientation selectivity and contrast gain control can be used to model the statistics of natural images. Mixtures of ecpe distributions are considered for bioinformation data sets in [28]. Texture retrieval using the p-generalized Gaussian densities is studied in [29]. A random vector modeling data from quantitative genetics presented in [30] are shown in [31] to be more likely to have a power exponential distribution different from a normal one. The reconstruction of the signal induced by cosmic strings in the cosmic microwave background, from radio-interferometric data, is made in [32] based upon generalized Gaussian distributions. These distributions are also used in [33] for voice detection.
More recently, the considerations in [11] opened a new field of financial applications of more general star-shaped asymptotic distributions, where suitably scaled sample clouds converge onto a deterministic set.
Figure 3 in [34] represents a sample cloud which might be modeled with a density being star-shaped w.r.t. a fan having six cones that include sample points and other cones that do not. Note, however, that Figure 1 d-f in the same paper do not reflect a homogeneous density but might be compared in some sense to the level sets of the characteristic functions of certain polyhedral star-shaped distributions in [16], Figure 5.2.
When modeling Lymphoma data, [35] analyze sample clouds of points, see Figures 2 and 3, which might be interpreted as mixtures of densities having contours in part looking similar like that in [36] where flow cytometric data, Australian Institute of Sport data and Iris data are analyzed, or like that of certain skewed densities as they were (analytically derived and) drawn in [37]. In a similar manner, Figures 2 and 5 in [20] indicate that mixtures of different types of star-shaped distributions might be suitable for modeling residuals of certain stock exchange indices. It could be of interest to closer study in future work more possible connections of all the models behind.
The following numerical examples of the present section are aimed to illustrate the agricultural and financial application of the estimators described in this paper. To this end, we make use of the new particular non-elliptically contoured but star-shaped distribution class introduced in Section 2.2 of the present paper.
Example 12.
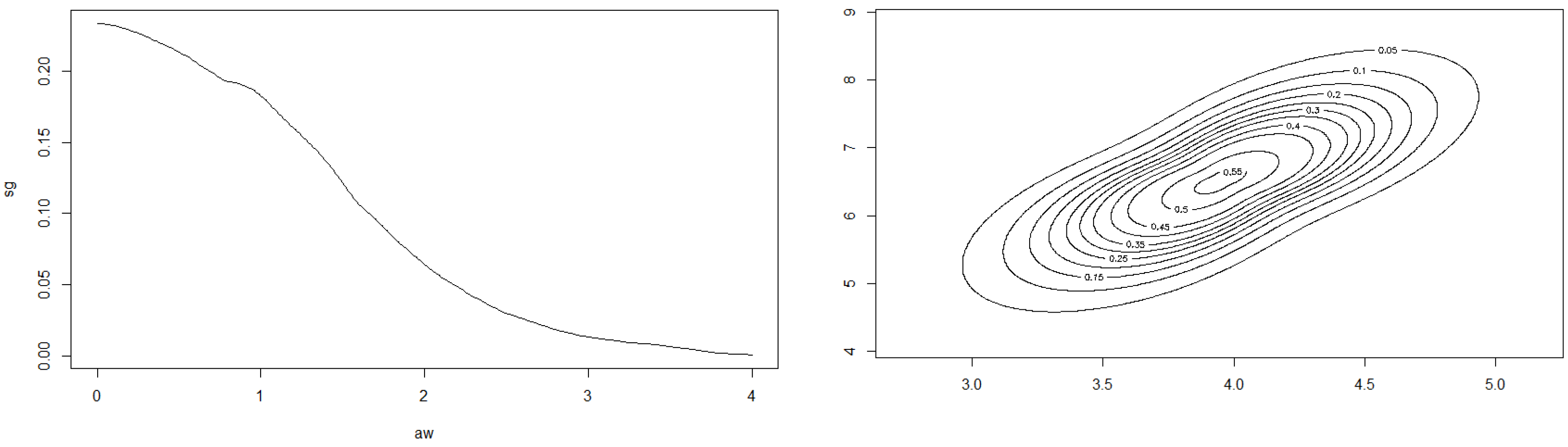
Example 2 of Section 2.2 continued. We consider the class of bodies K of Example 2. Let . Figure 9 shows the dependence of the correlation on the parameter .
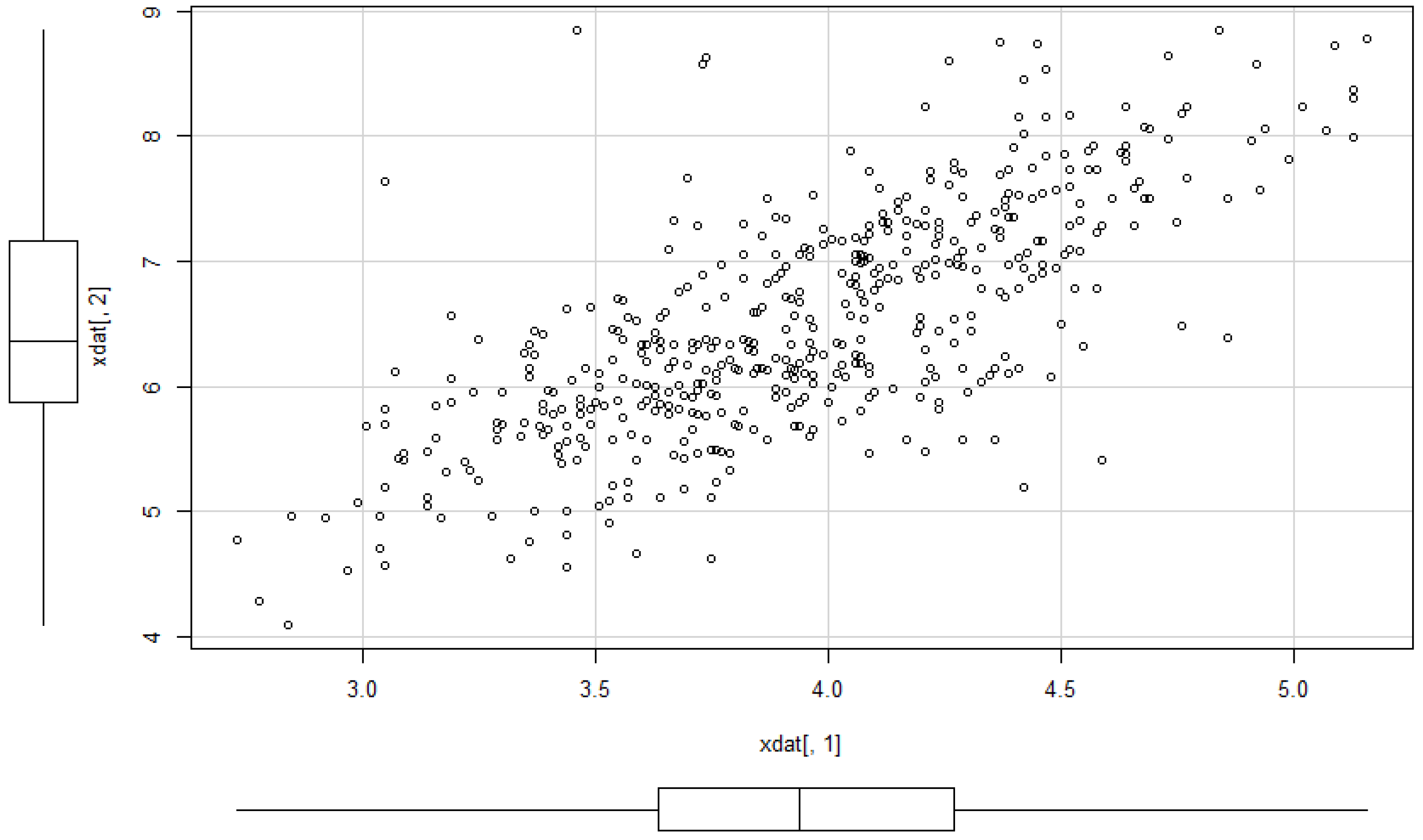
Here we apply the above described methods to the dataset 5 of [38]. The yield of grain and straw are the two variables. The sample correlation is 0.73077. Starting from that value, we can calculate the moment estimator for : . Moreover, we obtain
The data and the shape of the estimated multivariate density are depicted in Figure 10 and Figure 11.
Example 13.
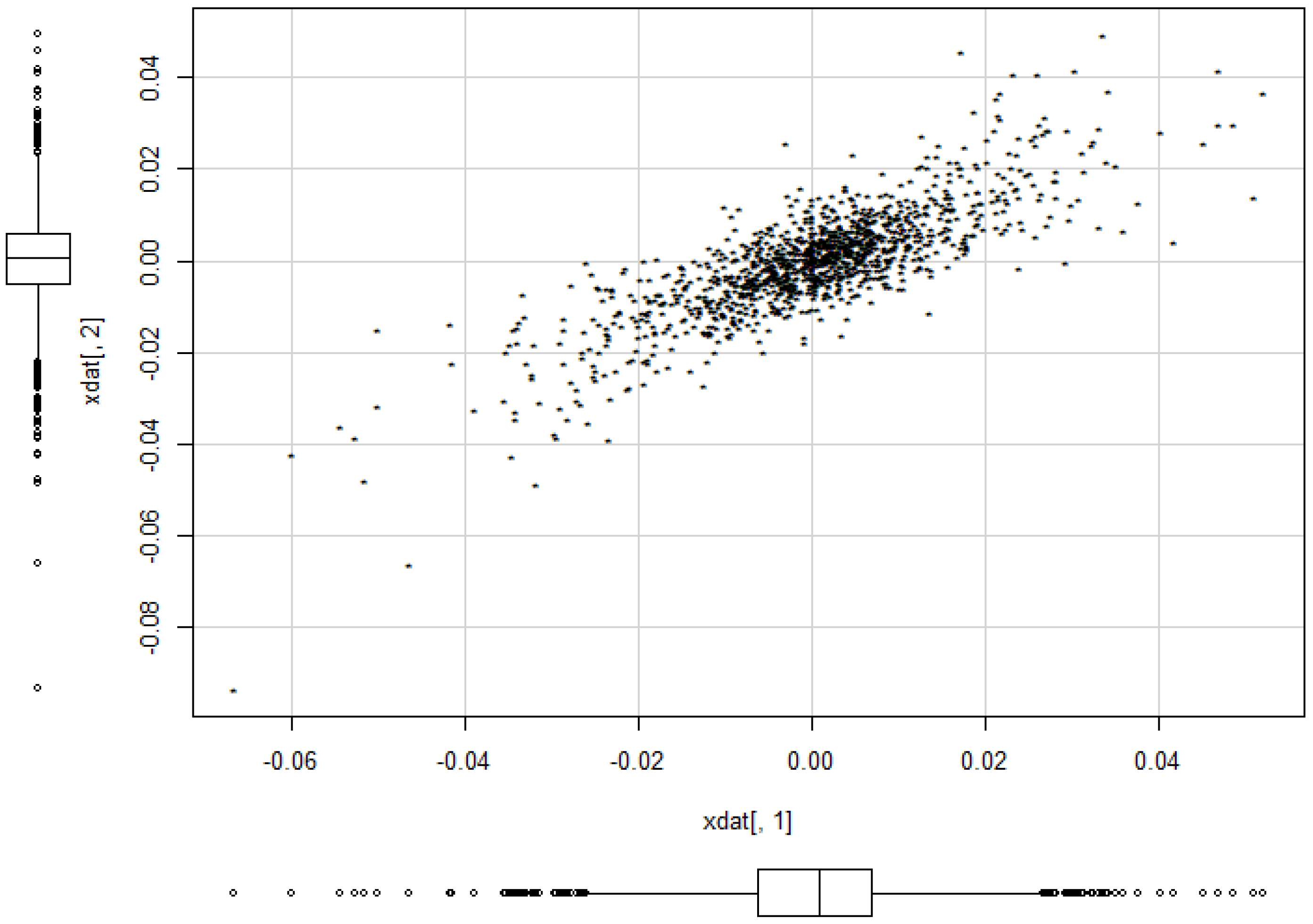
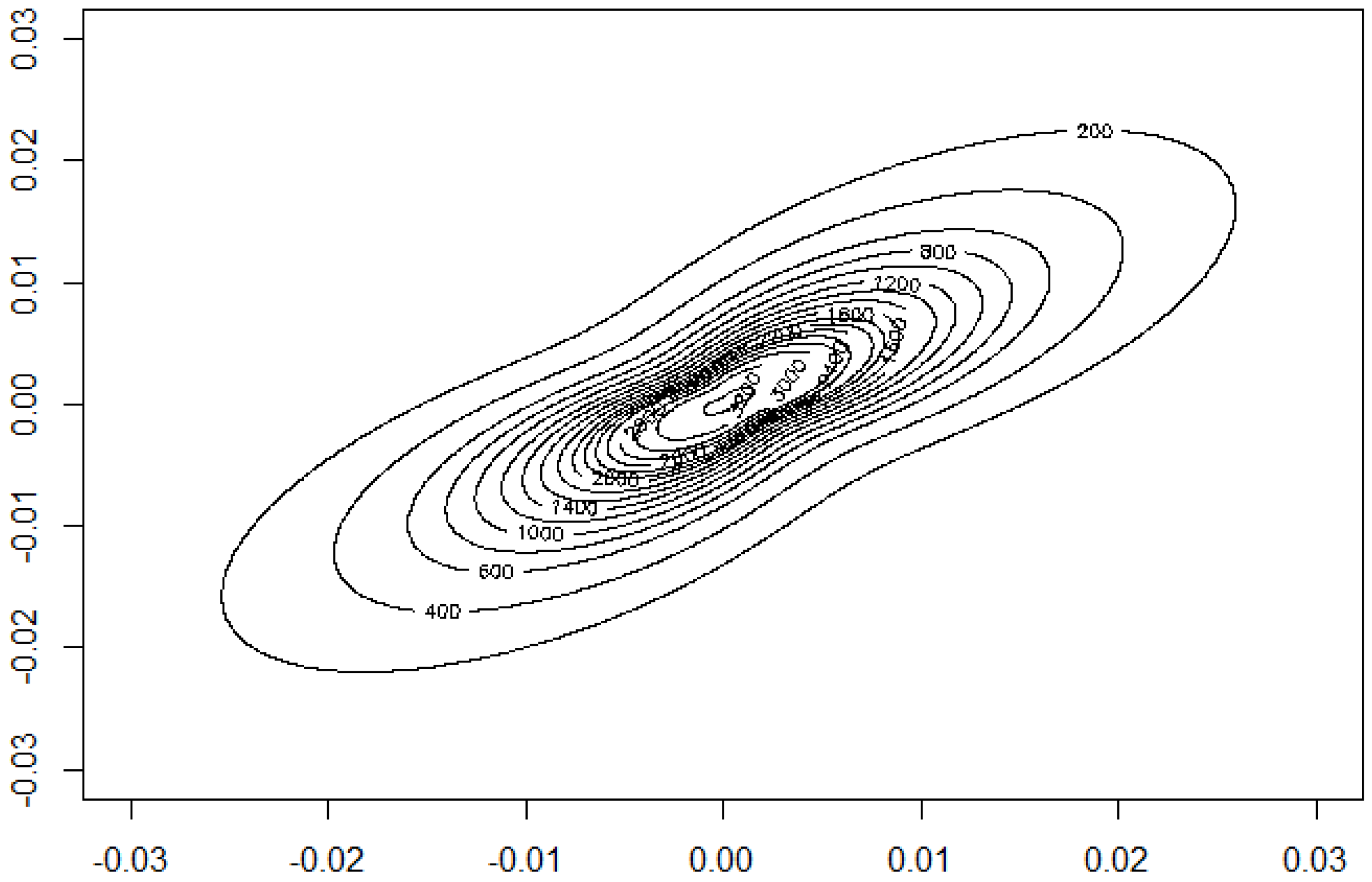
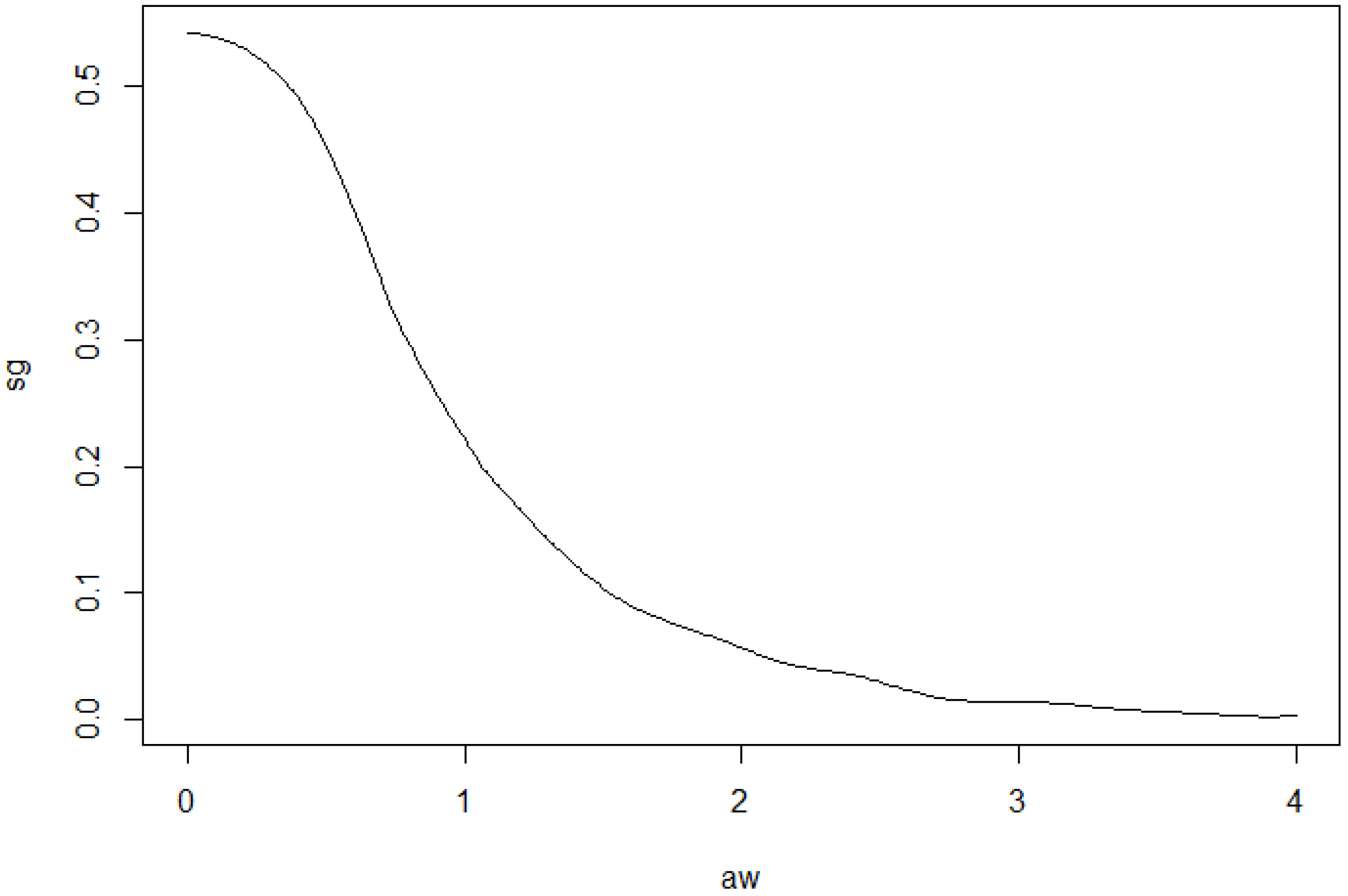
We want to illustrate the potential of our approach for applications to financial data and consider daily index data from Morgan Stanley Capital International of the countries Germany and UK for the period August 2011 to June 2016. The data indicate the continuous daily return values computed as logarithm of the ratio of two subsequent index values. The modelling of MSCI data using elliptical models is considered in [5]. The data are depicted in Figure 12. A visual inspection seems to give some preference for our model from Section 2.2 compared to the elliptically contoured model. Figure 13 and Figure 14 show the estimated model for the data. The basic numerical results are:
Further we proceed with proving the results.
4. Proofs
Throughout the remainder of the paper, suppose that Assumptions 1–3 are satisfied for some integer . First, we prove auxiliary statements which are used in the proof of strong convergence of and later.
4.1. Proof of Auxiliary Statements
The following Lemma 2 clarifies the asymptotic behaviour of χ in the neighbourhood of zero.
Lemma 2.
Suppose that exists and is bounded. Then
for any .
Proof.
Observe that by the Lipschitz continuity of the functions g and in view of Assumption 3,
uniformly for . Here and in the following C is a generic constant which may differ from formula to formula. By assumption, we have
On the other hand,
Hence
In view of (20), the proof is complete. ☐
Proof.
Because of (9), the law of iterated logarithm applies and leads to
Since there is a constant such that for all in view of the norm equivalence property, the first part of the lemma follows from (21). The second part can be shown similarly. ☐
In several places, we will use the following property:
Lemma 4.
Suppose that is a measurable function with . Then
Proof.
Since has the same distribution as , we have
which proves the lemma. ☐
4.2. Proving Convergence of
In this section we prove Theorem 1. The law of the iterated logarithm for the empirical process says (cf. [39], p. 268, for example)
By Lipschitz-continuity of and Lemma 3,
Moreover,
and
Hence, by the boundedness of ,
which leads to the theorem. ☐
4.3. Proving Strong Convergence of the Density Estimator
Next we prove strong convergence rates for and later for . Throughout this section we suppose that Assumptions 1 to 3 and (9) are fulfilled for some even integer . The compact set with arbitrary m and M, can be covered with closed intervals having sides of length and centres such that . The constants m and M will be specified later. Note that
The asymptotic behaviour of the right hand side in (22) as is analyzed term by term in the next lemmas.
Lemma 5.
Assume that the p-th order derivative of χ exists for some even integer and is bounded on every finite closed subinterval of . Let be bounded. Then
where if and if .
The proof of this lemma is omitted since, with minor changes, this lemma can be proven in the same way as Lemma 4.4 in [7]. The following lemma is used later several times in proofs of almost sure convergence rates. We provide it without proof. The proof is almost identical to that of Lemma 4.6 in [7].
Lemma 6.
Assume that χ is bounded. Let be bounded measurable functions with for . Then
- where ,
- ,
- .
We proceed with proving convergence rates of the terms in (22).
Lemma 7.
Suppose that Assumption 4 or 5 is satisfied. Then, as
Proof.
(a) Let Assumption 4 be satisfied. In view of Lemma 3, we obtain
with a suitable constant for . We introduce
Let . Observe that is bounded and Lipschitz continuous on , and are bounded on , functions are bounded, and functions are Hölder continuous of order . We have then by Taylor expansion
where
uniformly w.r.t. . Here we have used Assumption 4 and Lipschitz continuity of k on . This leads to
where
Note that
since the expectation in the last term is zero in view of Lemma 4 ( holds for all ). Applying Lemma 6, it follows that
On the other hand, we obtain
by utilizing Lemma 6 and taking into account. Similarly, it follows that
(b) Let Assumption 5 be satisfied. We obtain
Further, by Lipschitz continuity of k,
uniformly w.r.t. . Hence
☐
Lemma 8.
Suppose that the assumptions of Lemma 5 are satisfied. Then
as in Lemma 5.
Proof.
In view of Lemma 2, we have
Moreover, by the Lipschitz continuity of k, we obtain
which proves assertion (a). Analogously, the validity of assertion (b) can be shown. In view of (22), the lemma follows by Lemma 5 and 7. ☐
We are now in a position to prove the result on strong convergence of .
Proof of Theorem 2:
(i) Case . By Lemma 3, there are such that for , . In view of (11), we obtain
for . Lemma 8 applies to complete the proof of part (i).
(ii) Case . The proof can be done analogously to part (i) taking into account. ☐
4.4. Proving Asymptotic Normality of
Throughout this subsection, assume that Assumptions 1–3 and (9) are fulfilled for some integer . First, an auxiliary result is proven. Define and .
Lemma 9.
Under Assumption 4, we have
Proof.
Let and as in Section 4.3. We can choose such that , for . By Lemmas 7 and 8,
which yields immediately assertion (a). Since
by Lemma 3, we obtain the inequality
by Taylor expansion, where
a.s. Observe that and
Analogously to Lemma 6, we can deduce
since the expectation is zero due to Lemma 4. Analogously to the examination of and in Lemma 7, we obtain
Hence
In view of (27), the proof of part b) is complete. ☐
From kernel density estimation theory, we can take the following lemma, see [40]. Subsequently, we prove asymptotic normality of .
Lemma 10.
Suppose that χ is continuous at y. Then
Proof of Theorem 3.
Note that has a bounded derivative on every finite subinterval of . By Lemmas 3 and 9, we obtain
and hence
where
Using Lemma 10, we have
where . By Taylor expansion, we obtain
and lies between and . This completes the proof. ☐
4.5. Proofs When Additional Scale Fit Is Involved
When proving Theorem 4 we shall make use of the following lemma.
Lemma 11.
Let (18) be satisfied. Then
Proof.
By the law of iterated logarithm and Lemma 3, we obtain
for all . Since the partial derivatives of functions are bounded, it follows that
☐
Proof of Theorem 4.
Let . Note that . By Lipschitz-continuity of , (1) and Lemma 3, we have
We obtain the result as follows:
☐
We proceed with proving Theorem 5. The next two lemmas are used in the proof of this theorem. Here we define and . Notice that has density χ, and Lemmas 5 and 6 hold true for the modified and , too.
Lemma 12.
Let be bounded. Then we have
Proof.
Note that
For , we obtain
Since and are bounded, we can conclude
Further we obtain
by (14). This inequality completes the proof. ☐
Lemma 13.
Suppose that Assumption 7 or Assumption 8 is satisfied. Then
Proof.
We prove the Lemma under Assumption 7, the proof of the other part is analogous to that of Lemma 7(b). As we see later, we need only to involve data vectors with or . This implies by (1), and therefore for with a constant . In view of Lemma 3 and by Assumption 7, we obtain
() with a suitable constant for . We introduce
Let . Observe that is bounded and Lipschitz continuous on , and are bounded on , functions are bounded, and functions are Hölder continuous of order . By Taylor expansion, Assumption 7 and Lipschitz continuity of k on , we have
where, uniformly for ,
This leads to
where are as above, and
Analogously to Lemma 7, we obtain
Observe that , and ( is a homogeneous function). Applying Lemmas 6 and 12, we can derive
() which implies
Further, by Lemma 12,
and
This completes the proof. ☐
Proof of Theorem 5.
We consider only the case , the proof in the other case is similar. By Lemma 3, there are such that for , . In view of (11), we obtain
for . An application of Lemma 8 completes the proof. ☐
In last part of this section, we prove the result on asymptotic normality. Define and .
Lemma 14.
Under Assumption 7, we have
Proof.
Let and as in Section 4.3. We can choose such that for . By Lemmas 7 and 8,
which yields immediately assertion a). Since
by Lemma 3, we obtain the inequality
by Taylor expansion, where
and are as in Section 4.3. Analogously to Lemma 6, we can deduce that
The remainder of the proof is done as in the proof of Lemma 9. ☐
Proof of Theorem 6.
By Lemmas 3 and 14, and analogously to the proof of Theorem 3, we obtain
The remainder of the proof can be done in the same manner as in the proof of Theorem 3. ☐
Acknowledgments
The authors are grateful to the referees who provided valuable suggestions on improving the paper and additional references.
Author Contributions
The authors contributed equally to this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- M. Bilodeau, and D. Brenner. Theory of Multivariate Statistics. New York, NY, USA: Springer, 1999. [Google Scholar]
- K.-T. Fang, S. Kotz, and K. Ng. Symmetric Multivariate and Related Distributions. London, UK: Chapman & Hall, 1990. [Google Scholar]
- K.-T. Fang, and Y. Zhang. Generalized Multivariate Analysis. New York, NY, USA: Springer, 1990. [Google Scholar]
- K.-T. Fang, and T.W. Anderson, eds. Statistical Inference in Elliptically Contoured and Related Distributions. New York, NY, USA: Allerton Press, 1990.
- A.K. Gupta, T. Varga, and T. Bodnar. Elliptically Contoured Models in Statistics and Portfolio Theory. New York, NY, USA: Springer, 2013. [Google Scholar]
- H. Cui, and X. He. “The consistence of semiparametric estimation of elliptic densities.” Acta Math. Sin. Engl. Ser. 11 (1995): 44–58. [Google Scholar]
- E. Liebscher. “A semiparametric density estimator based on elliptical distributions.” J. Multivar. Anal. 92 (2005): 205–225. [Google Scholar] [CrossRef]
- W. Stute, and U. Werner. “Nonparametric estimation of elliptically contoured densities.” In Nonparametric Functional Estimation and Related Topics (Spetses, 1990). NATO Science Series C: Mathematical and Physical Sciences; Dordrecht, The Netherlands: Kluwer Academic Publisher, 1991, pp. 173–190. [Google Scholar]
- H. Battey, and O. Linton. “Nonparametric estimation of multivariate elliptic densities via finite mixture sieves.” J. Multivar. Anal. 123 (2014): 43–67. [Google Scholar] [CrossRef]
- C. Fernandez, J. Osiewalski, and M.F.J. Steel. “Modeling and inference with ν-spherical distributions.” J. Am. Stat. Assoc. 90 (1995): 1331–1340. [Google Scholar] [CrossRef]
- A.A. Balkema, P. Embrechts, and N. Nolde. “Meta densities and the shape of their sample clouds.” J. Multivar. Anal. 101 (2010): 1738–1754. [Google Scholar] [CrossRef]
- W.-D. Richter. “Geometric disintegration and star-shaped distributions.” J. Stat. Distrib. Appl. 1 (2014). [Google Scholar] [CrossRef]
- T. Dietrich, and W.-D. Richter. “Classes of geometrically generalized von Mises distributions.” Sankhya B, 2016. [Google Scholar] [CrossRef]
- W.-D. Richter. “Norm contoured distributions in R2.” Lect. Notes Semin. Interdiscip. Mat. 12 (2015): 179–199. [Google Scholar]
- W.-D. Richter. “Convex and radially concave contoured distributions.” J. Prob. Stat. 2015 (2015): 165468. [Google Scholar] [CrossRef]
- W.-D. Richter, and K. Schicker. “Polyhedral star-shaped distributions. Representations, properties and applications.” J. Prob. Stat., 2016, in press. [Google Scholar]
- M. Moszyńska, and W.-D. Richter. “Reverse triangle inequality. Antinorms and semi-antinorms.” Stud. Sci. Math. Hung. 49 (2012): 120–138. [Google Scholar] [CrossRef]
- E.L. Lehmann, and G. Casella. Theory of Point Estimation, 2nd ed. New York, NY, USA: Springer, 1998. [Google Scholar]
- B.W. Silverman. Density Estimation for Statistics and Data Analysis. London, UK: Chapman & Hall, 1986. [Google Scholar]
- K. Müller, and W.-D. Richter. “Exact distributions of order statistics of dependent random variables from ln,p-symmetric sample distributions.” Depend. Model. 4 (2016). [Google Scholar] [CrossRef]
- J.S. Marron, and M.P. Wand. “Exact mean integrated squared error.” Ann. Stat. 20 (1992): 712–736. [Google Scholar] [CrossRef]
- W. Stute. “A law of the logarithm for kernel density estimators.” Ann. Prob. 10 (1982): 414–422. [Google Scholar] [CrossRef]
- J.K. Lindsey. “Multivariate elliptically contoured distributions for repeated measurements.” Biometrics 55 (1999): 1277–1280. [Google Scholar] [CrossRef] [PubMed]
- D. Cho, and T.D. Bin. “Multivariate statistical modeling for image denoising using wavelet transforms.” Signal Process. Image Commun. 20 (2005): 77–89. [Google Scholar] [CrossRef]
- G. Verdoolaege, S. de Becker, and P. Scheunders. “Multiscale colour texture retrieval using the geodesic distance between multivariate generalized models.” In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 169–172.
- C. Field, and M.C. Genton. “The multivariate g-and h- distribution.” Technometrics 48 (2006): 104–111. [Google Scholar] [CrossRef]
- F. Sinz, and M. Bethge. “The conjoint effect of divisive normalization and orientation selectivity on redundancy reduction.” In Proceedings of the 2008 Conference on Advances in Neural Information Processing Systems 21, Vancouver, BC, Canada, 8–10 December 2008; pp. 1521–1628.
- U.J. Dang, R.P. Browne, and P.D. McNicholas. “Mixtures of multivariate power exponential distributions.” Biometrics 71 (2015): 1081–1089. [Google Scholar] [CrossRef] [PubMed]
- M.N. Do, and M. Vetterli. “Wavelet-based texture retrieval using generalized Gaussian density and Kullback-Leibler Distance.” IEEE Trans. Image Process. 11 (2002): 146–158. [Google Scholar] [CrossRef] [PubMed]
- E. Santiago, J. Albornoz, A. Domínguez, M.A. Toro, and C. López-Fanjul. “The distribution of spontaneous mutations on quantitative traits and fitness in Drosophilamelanogaster.” Genetics 132 (1992): 771–781. [Google Scholar] [PubMed]
- E. Gómez, M.A. Gomez-Viilegas, and J.M. Marín. “A multivariate generalization of the power exponential family of distributions.” Commun. Stat. Theory Methods 27 (1998): 589–600. [Google Scholar] [CrossRef]
- Y. Wiaux, G. Puy, and P. Vandergheynst. “Compressed sensing reconstruction of a string signal from interferometric observations of the cosmic microwave background.” Mon. Not. R. Astron. Soc. 402 (2010): 2626–2636. [Google Scholar] [CrossRef]
- J.-H. Chang, J.W. Shin, and N.S. Kim. “Voice activity detector employing generalized Gaussian distribution.” Electron. Lett. 40 (2004): 24. [Google Scholar] [CrossRef]
- F. Forbes, and D. Wraith. “A new family of multivariate heavy-tailed distributions with variable marginal amounts of tail weight: Application to robust clustering.” Stat. Comput. 24 (2014): 971–984. [Google Scholar] [CrossRef]
- D. Wraith, and F. Forbes. “Location and scale mixtures of Gaussians with flexible tail behaviour: Properties, inference and application to multivariate clustering.” Comput. Stat. Data Anal. 90 (2015): 61–73. [Google Scholar] [CrossRef]
- S.X. Lee, and G.J. McLachlan. “Finite mixtures of canonical fundamental skew t-distributions. The unification of the restricted and unrestricted skew t-mixture models.” Stat. Comput. 26 (2016): 573–589. [Google Scholar] [CrossRef]
- W.-D. Richter, and J. Venz. “Geometric representations of multivariate skewed elliptically contoured distributions.” Chil. J. Stat. 5 (2014): 71–90. [Google Scholar]
- D.F. Andrews, and A.M. Herzberg. Data: A Collection of Problems from Many Fields for the Student and Research Worker. New York, NY, USA: Springer, 1985. [Google Scholar]
- A.W. Van der Vaart. Asymptotic Statistics. Cambridge, UK: Cambridge University Press, 1998. [Google Scholar]
- E. Parzen. “On estimation of a probability density function and mode.” Ann. Math. Stat. 33 (1962): 1065–1076. [Google Scholar] [CrossRef]
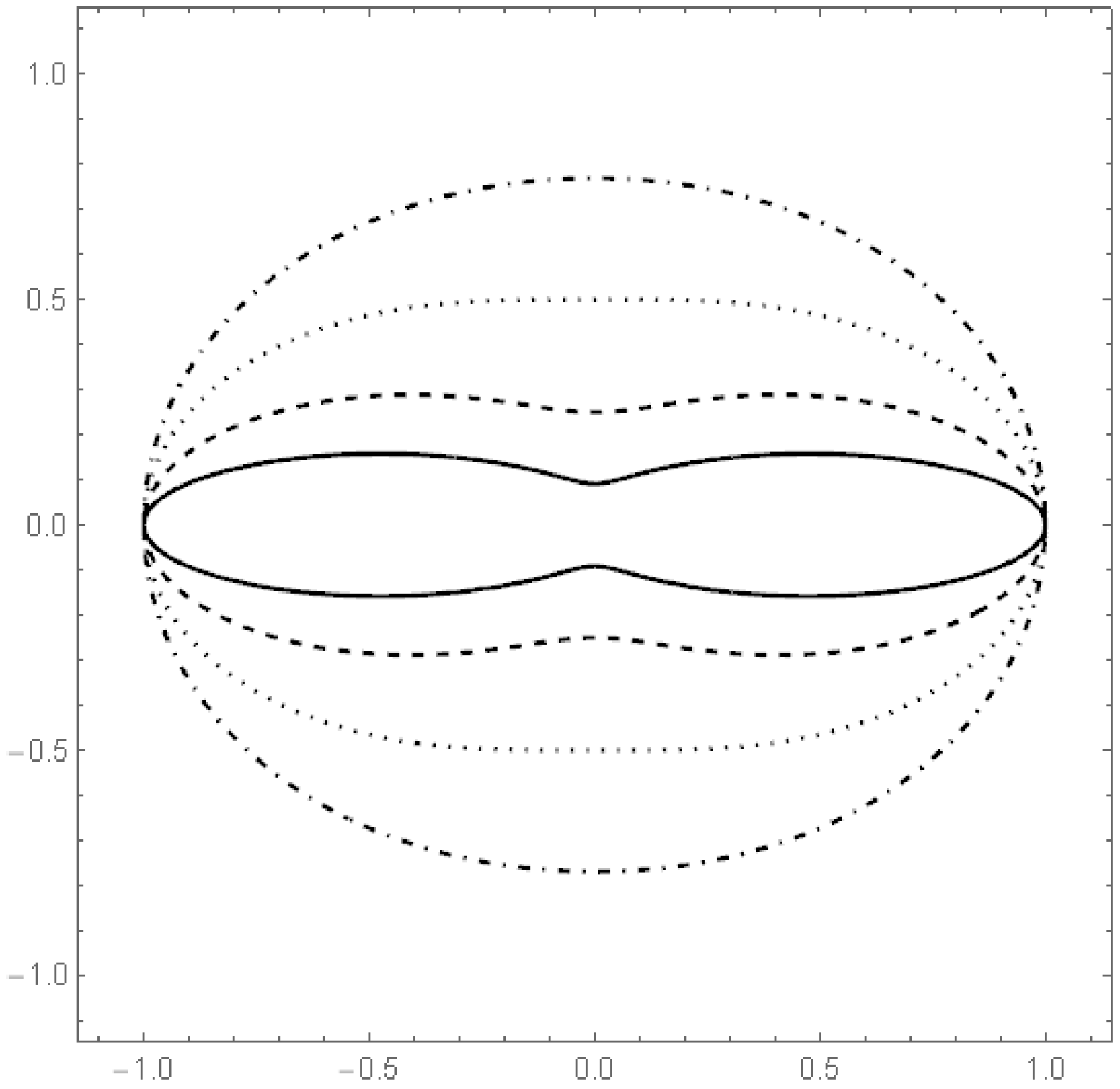
Figure 1.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).
Figure 1.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).
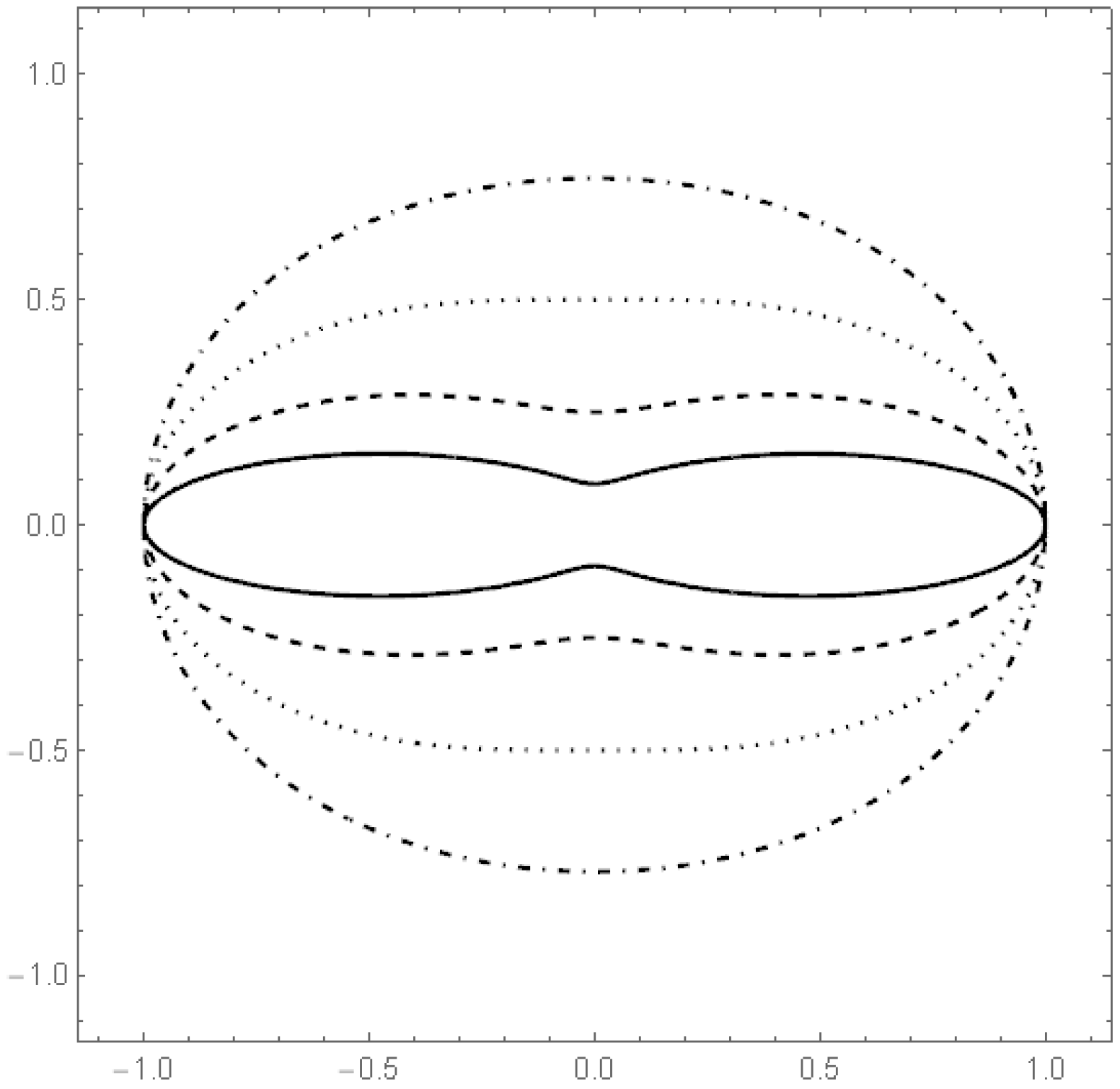
Figure 2.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).
Figure 2.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).
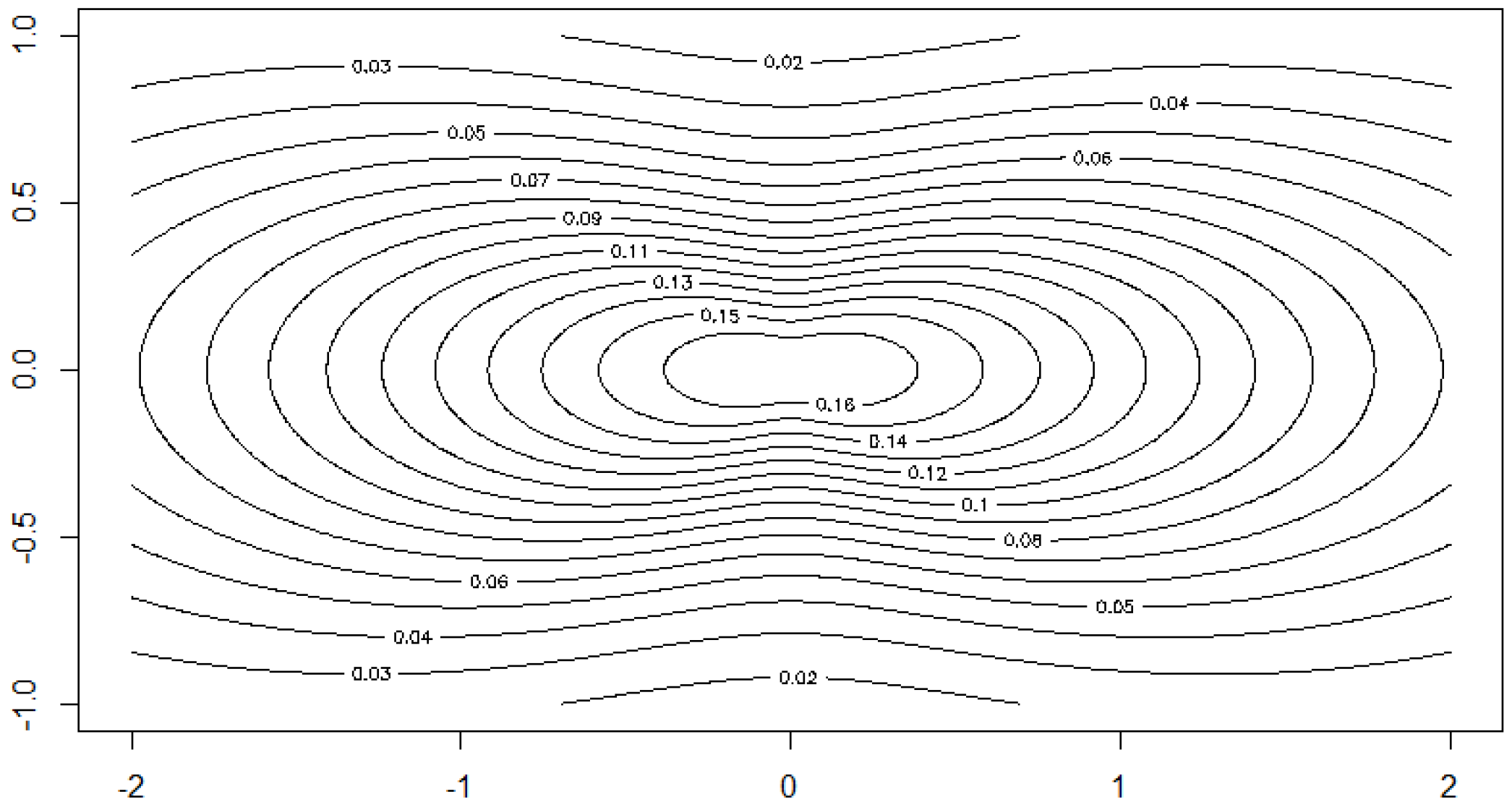
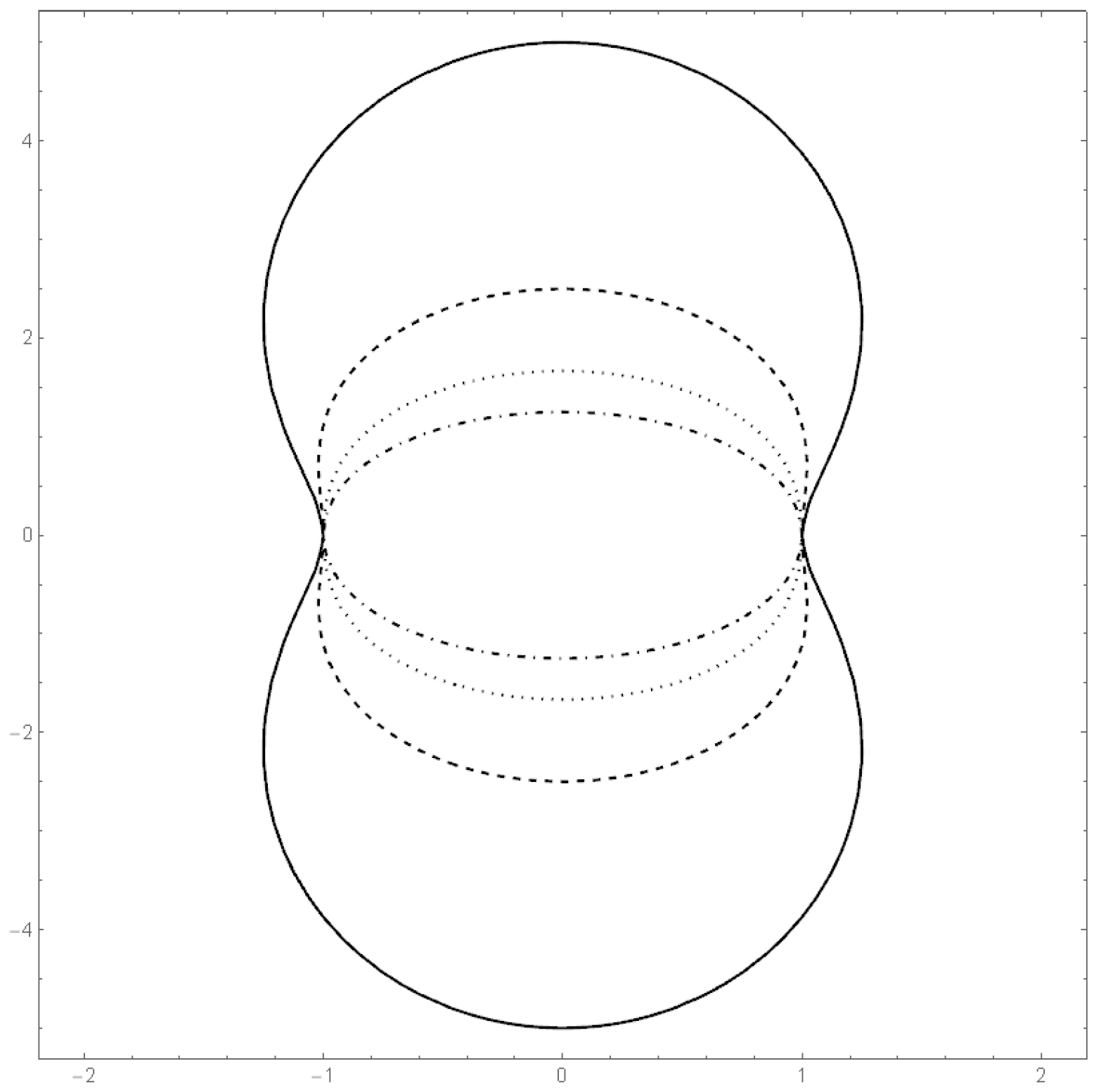
Figure 3.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line), (dashed/dotted line).
Figure 3.
Plot of the boundaries of K in the cases (solid line), (dashed line), (dotted line), (dashed/dotted line).

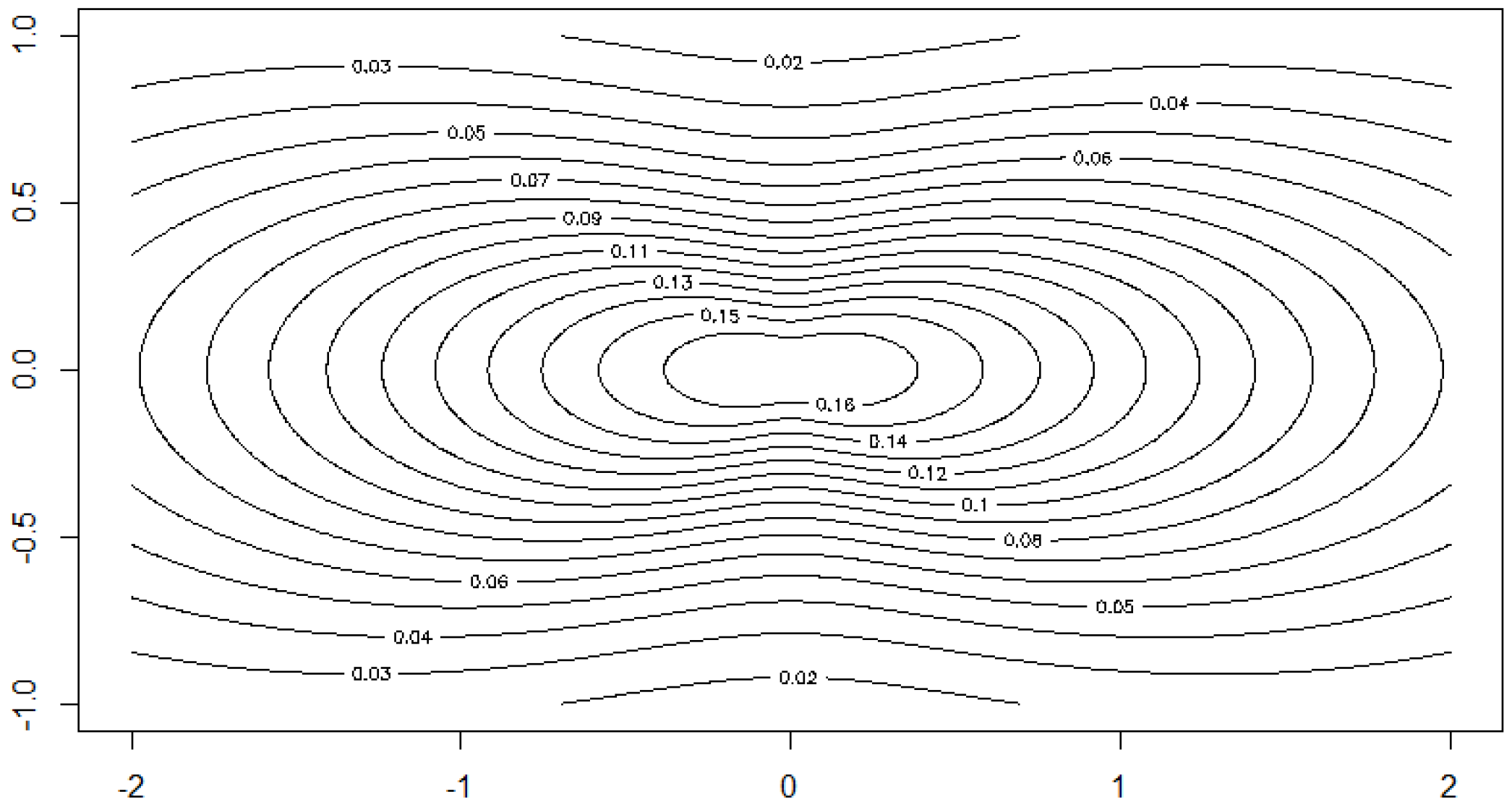
Figure 4.
Contour plot of the density of for and levels .
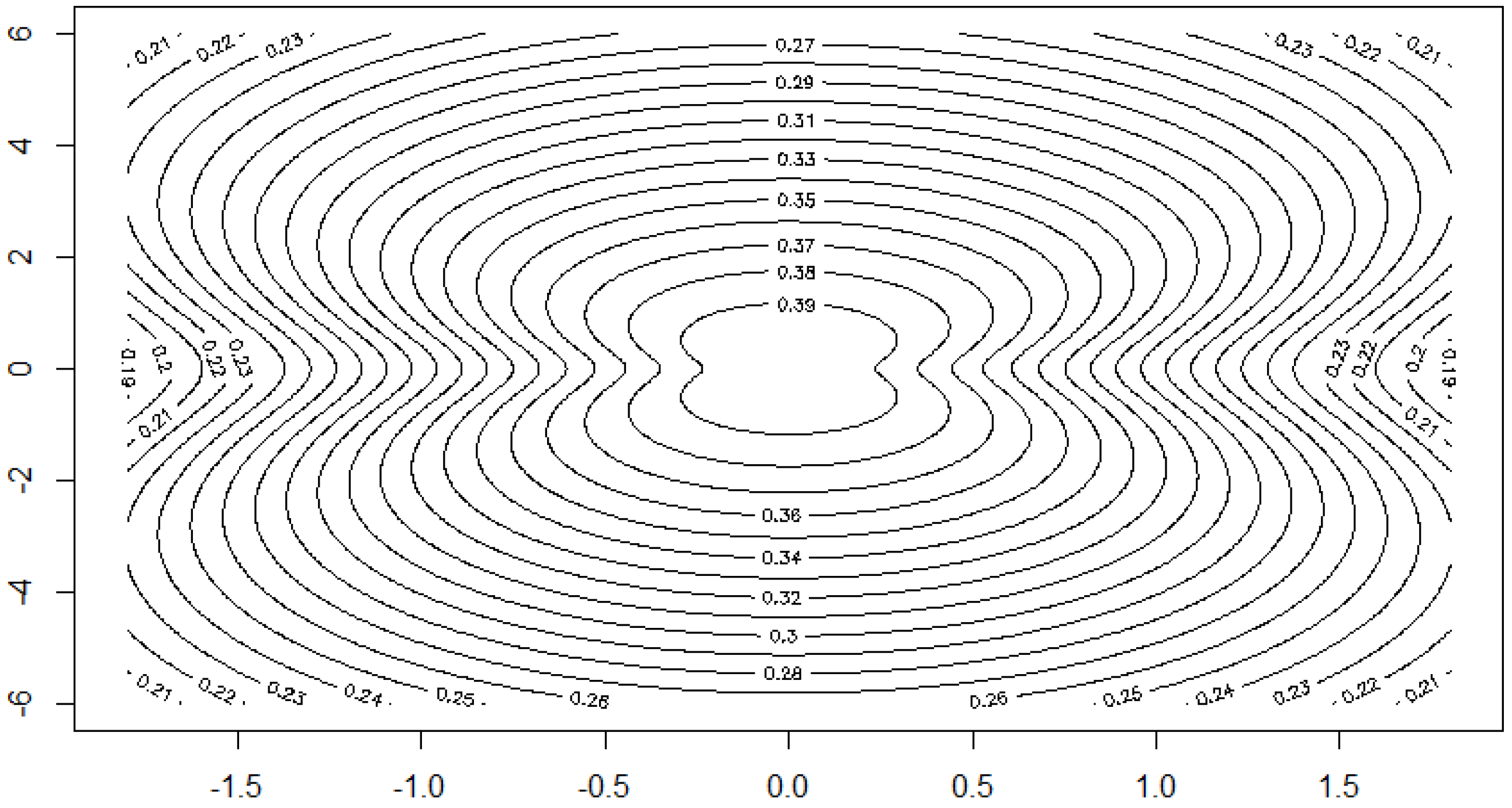
Figure 5.
Plot of the boundaries of K for in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).
Figure 5.
Plot of the boundaries of K for in the cases (solid line), (dashed line), (dotted line) and (dashed/dotted line).

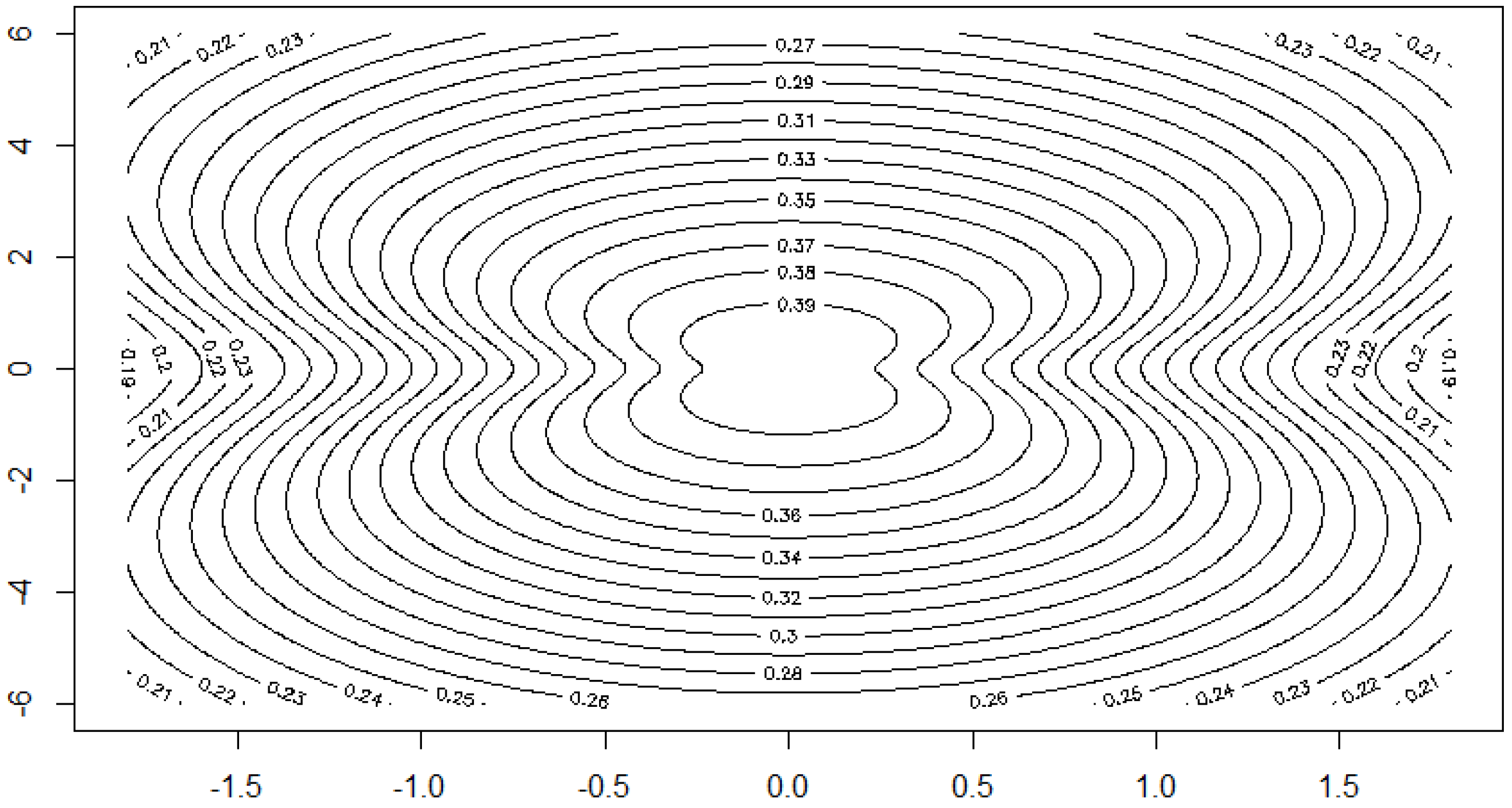
Figure 6.
Contour plot of the density for and levels as in Figure 4.
Figure 6.
Contour plot of the density for and levels as in Figure 4.
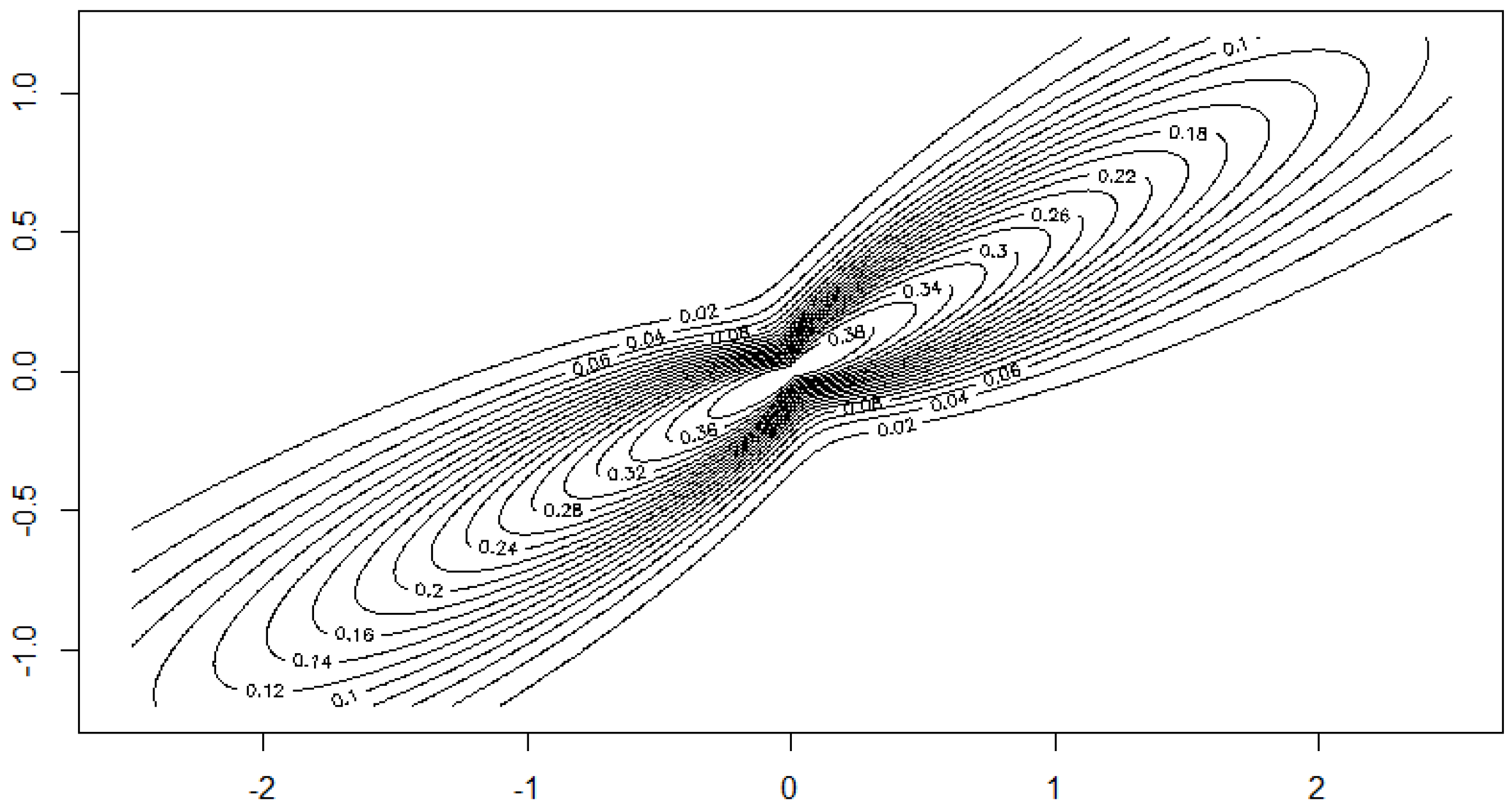
Figure 7.
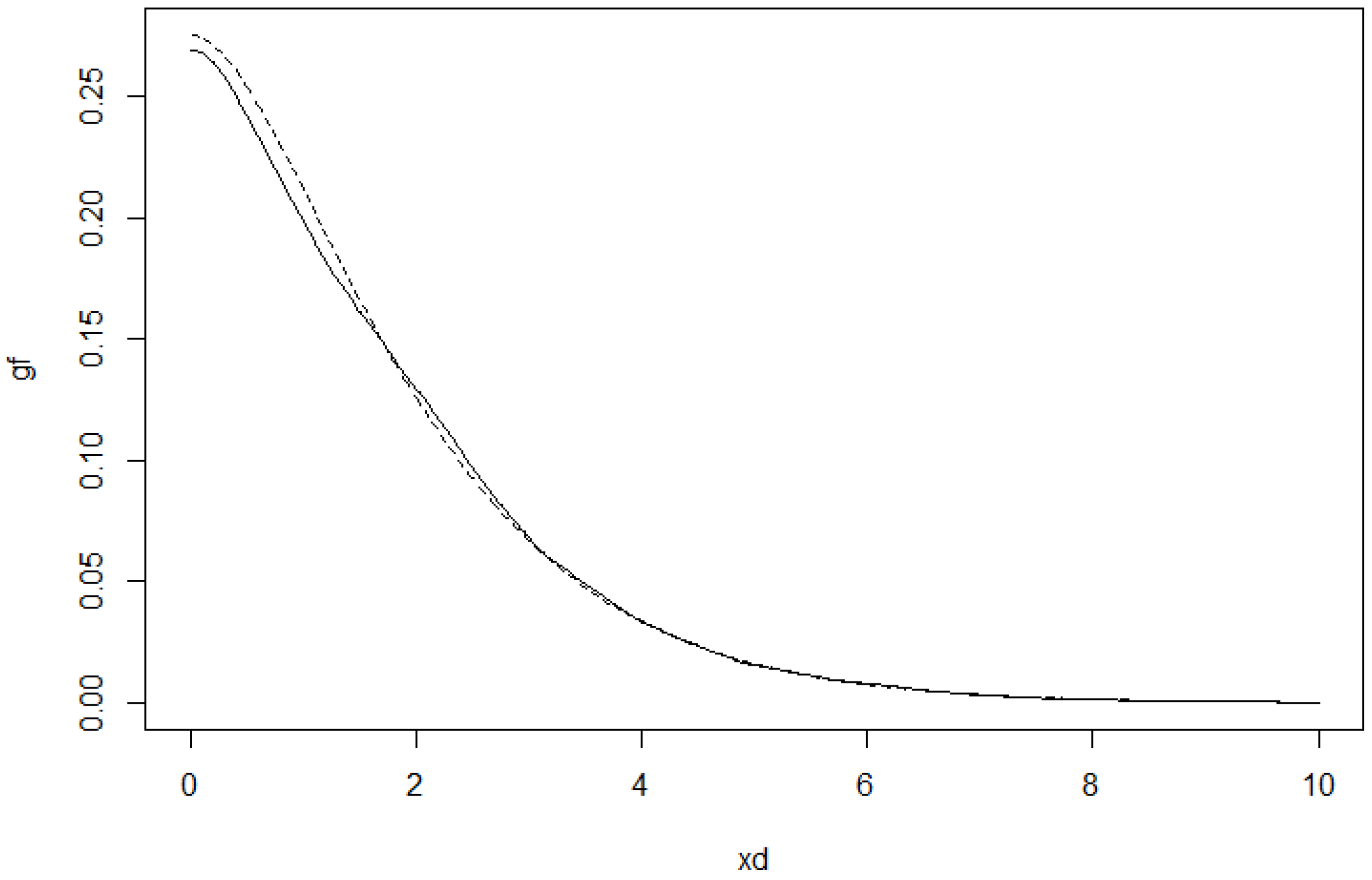
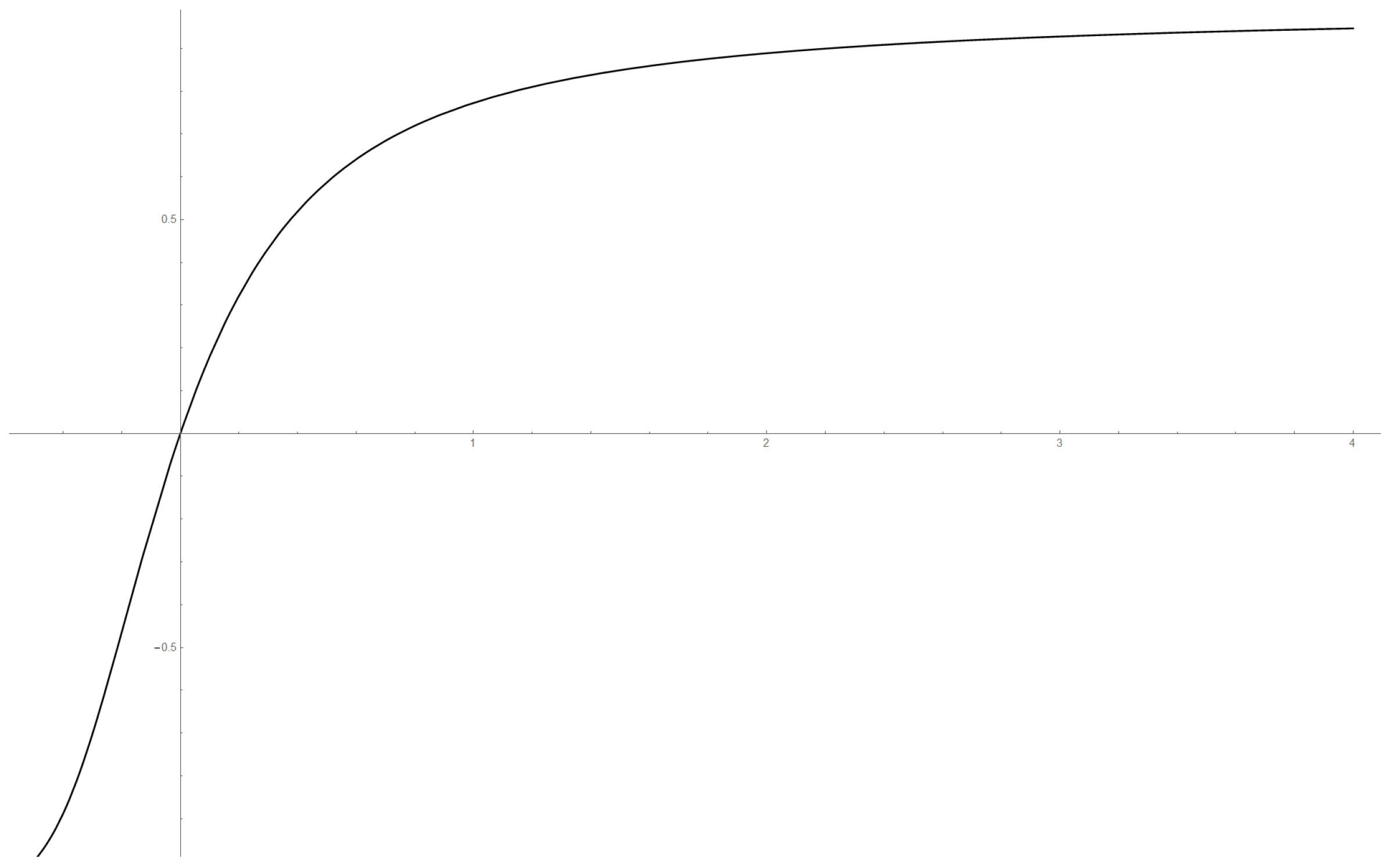
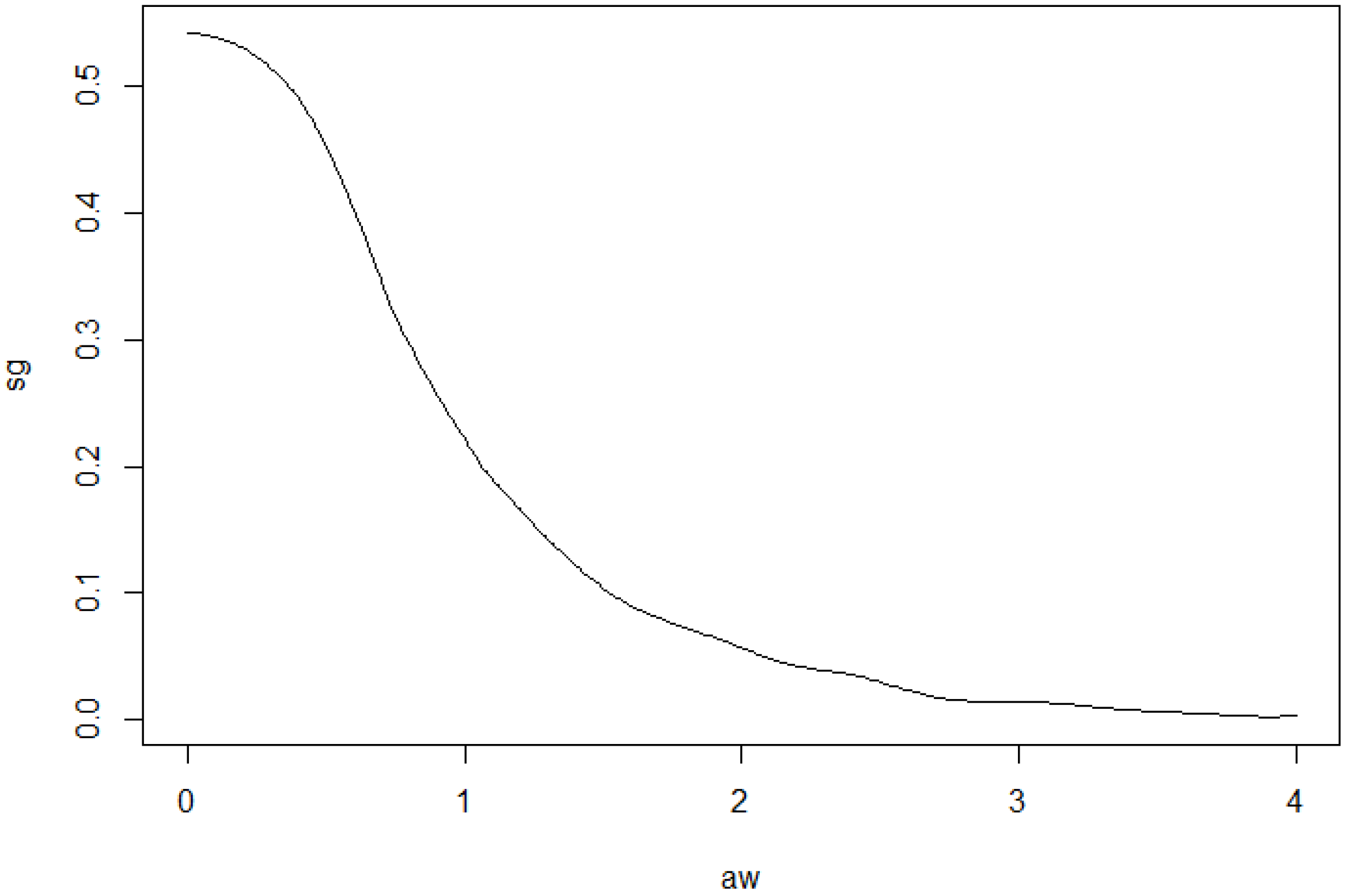
Estimator of g (solid line) and the model function (dashed line) for .

Figure 8.
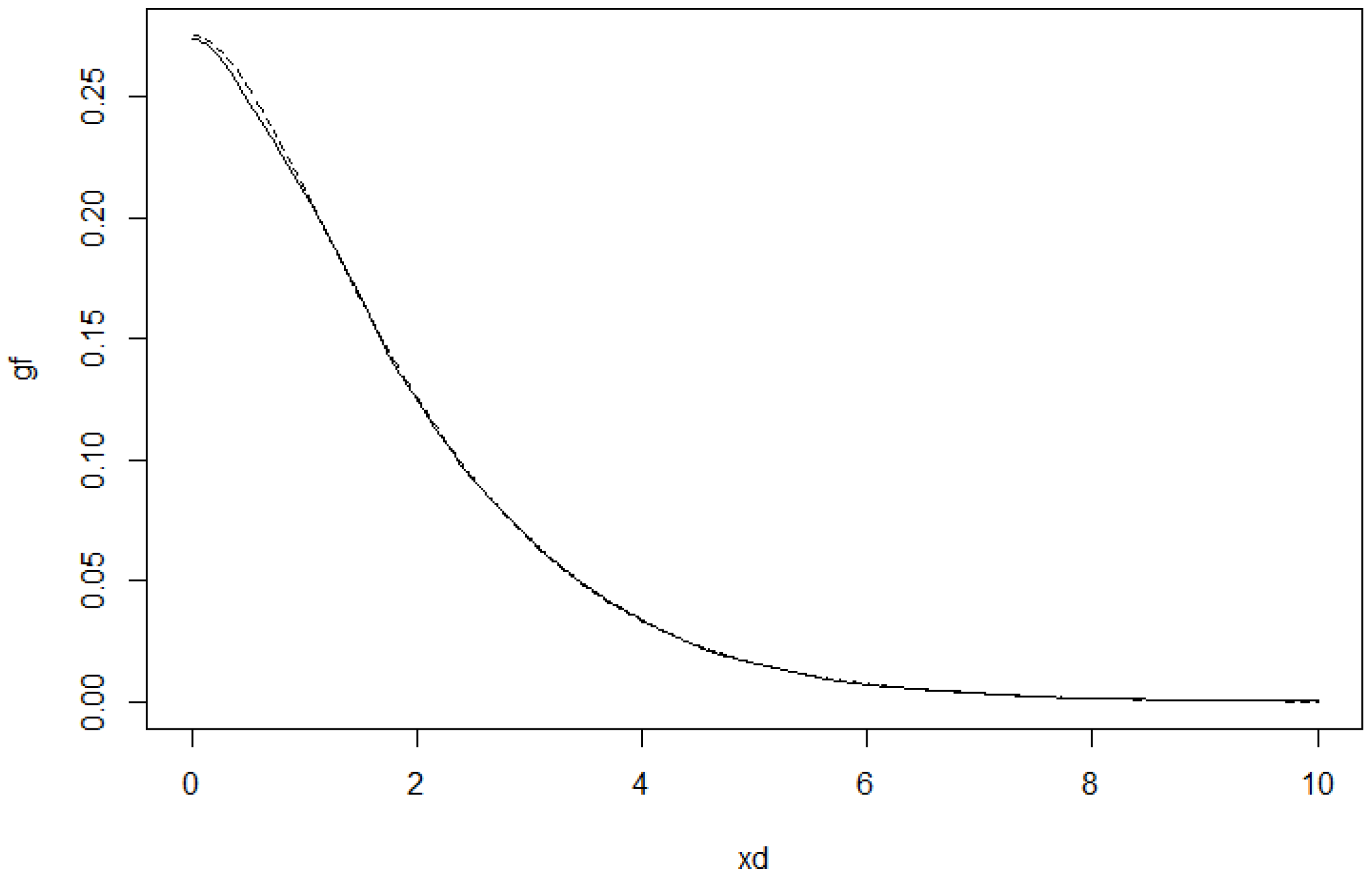
Estimator of g (solid line) and the model function (dashed line) for .
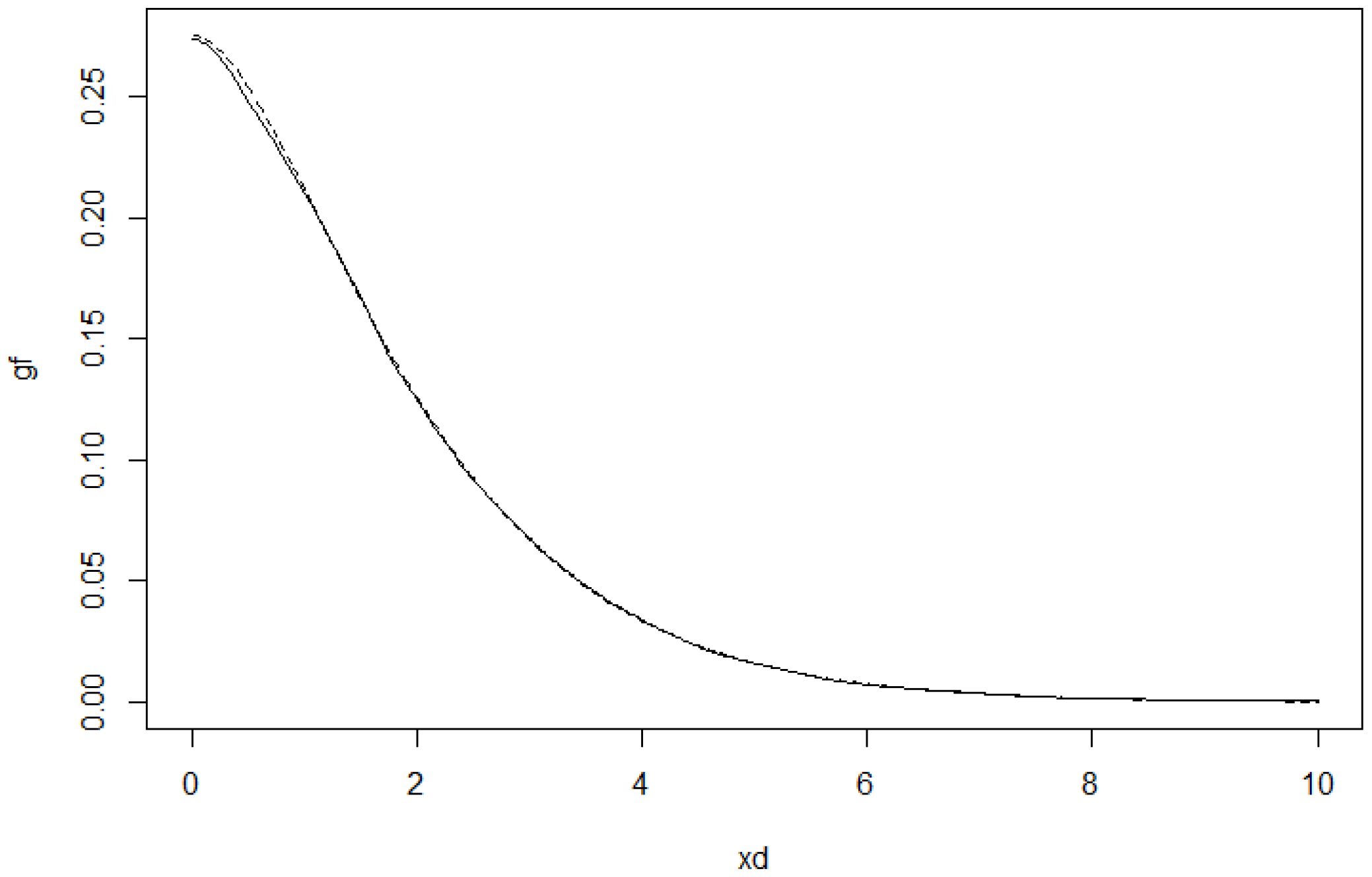
Figure 9.
Function with on the x-axis, ρ on the y-axis; is defined in Assumption 6.
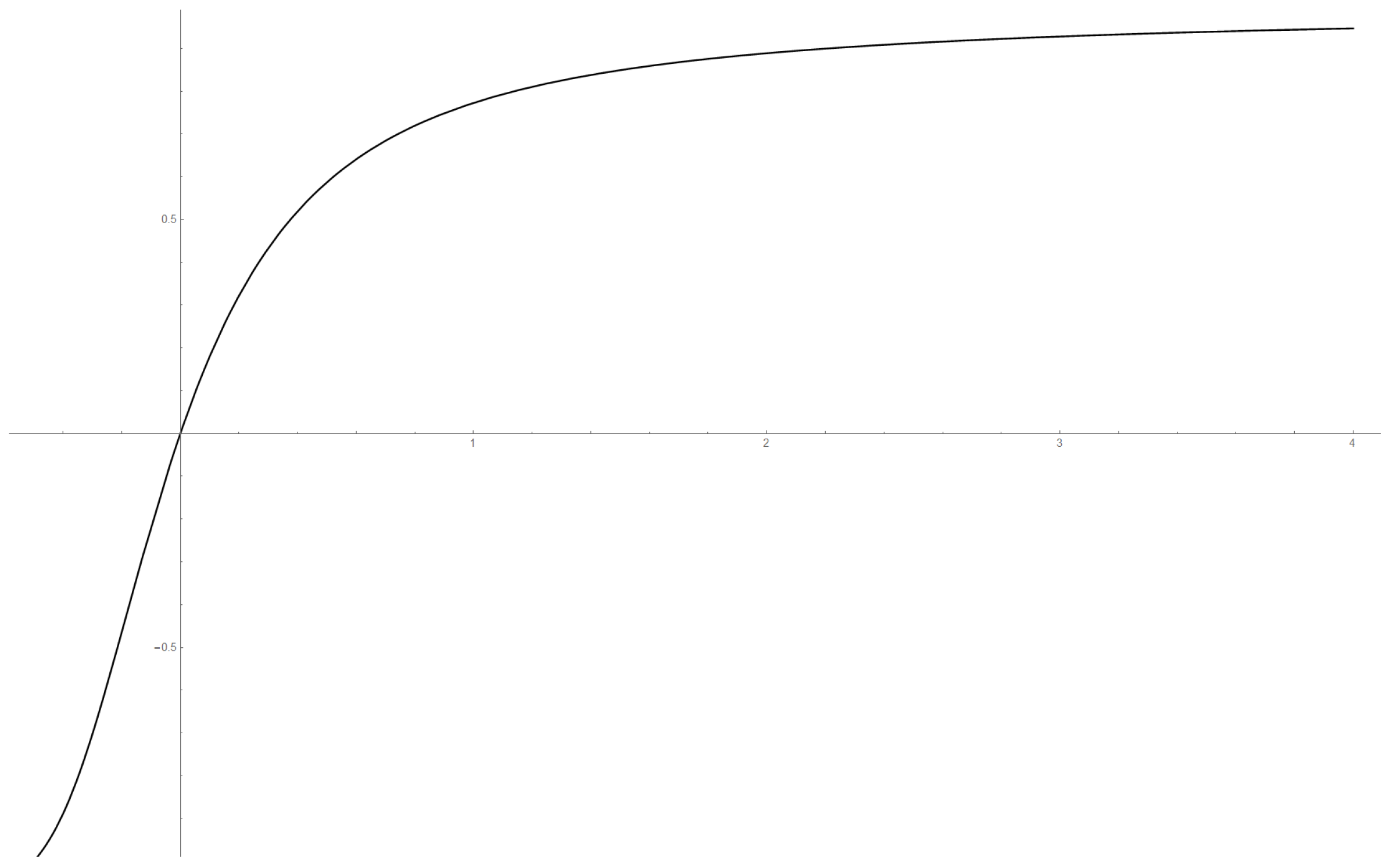
Figure 10.
Scatter plot of the dataset 5 of [38].
Figure 10.
Scatter plot of the dataset 5 of [38].

Figure 11.
Estimated generator function g at left (bandwidth ) and contour plot of at right.

Figure 12.
Scatter plot of the MSCI data.
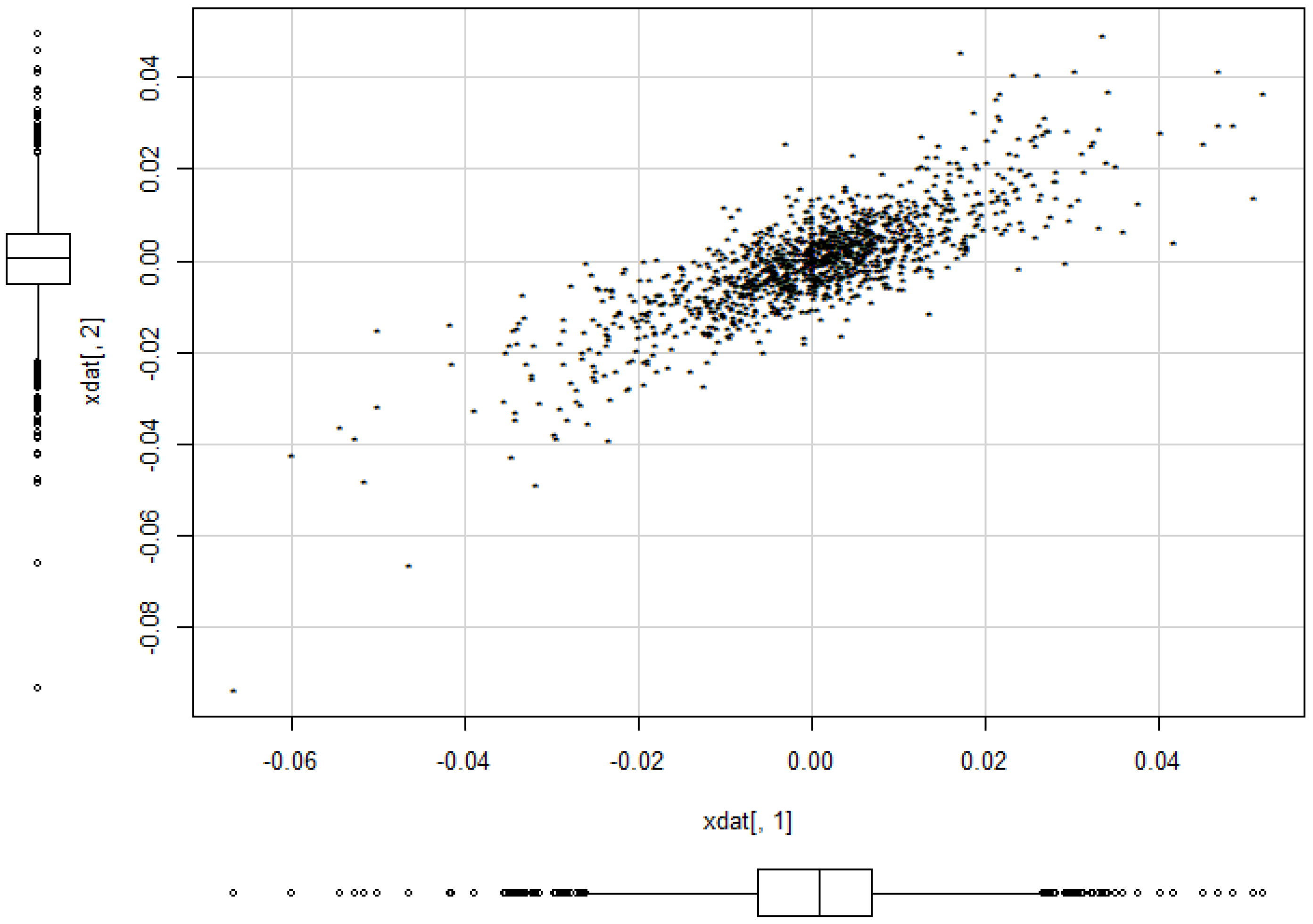
Figure 13.
Contour plot of the estimated density.
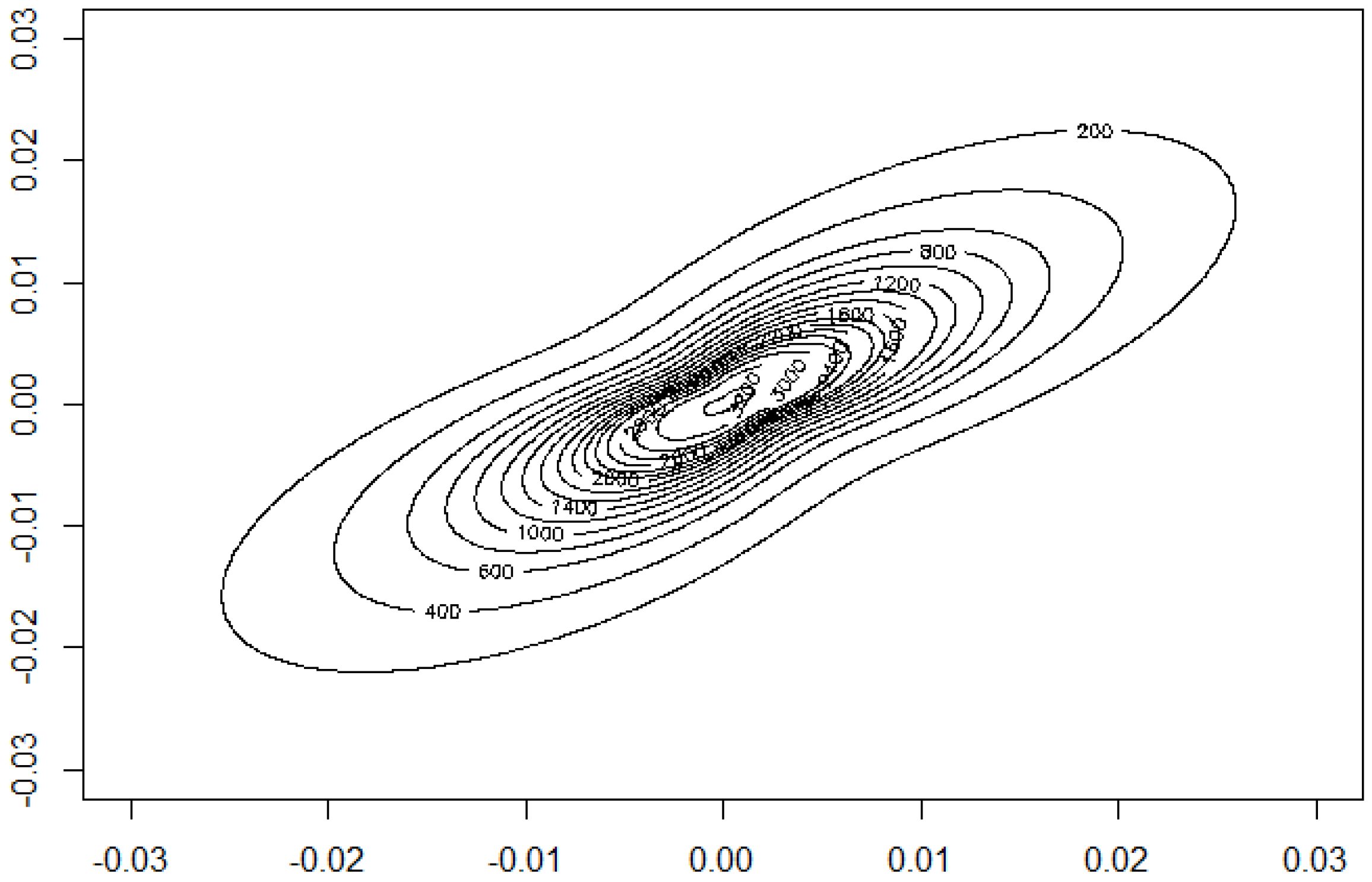
Figure 14.
Estimated generator function g (bandwidth ).
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liebscher, E.; Richter, W.-D. Estimation of Star-Shaped Distributions. Risks 2016, 4, 44. https://doi.org/10.3390/risks4040044
AMA Style
Liebscher E, Richter W-D. Estimation of Star-Shaped Distributions. Risks. 2016; 4(4):44. https://doi.org/10.3390/risks4040044
Chicago/Turabian StyleLiebscher, Eckhard, and Wolf-Dieter Richter. 2016. "Estimation of Star-Shaped Distributions" Risks 4, no. 4: 44. https://doi.org/10.3390/risks4040044
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.