1. Introduction
Not infrequently, variables of interest in economic research are discrete and unordered, as we often find the variables that indicate the behavior or state of economic agents. Some econometric models have been developed to deal with these discrete and unordered outcomes. Above all, parametric models, such as the multinomial logit (MNL) and probit (MNP) models proposed by [
1,
2], respectively, are widely employed, for example, in structural econometric analysis (e.g., the economic models of automobile sales in [
3,
4]) and as part of econometric methods (e.g., selection bias correction of [
5,
6]). However, results obtained by such parametric models may be seriously misleading when the model is misspecified or poorly approximates the true model. Thus, researchers need to examine the validity of parametric assumptions as long as the assumptions are refutable from data alone.
This study proposes a new specification test that is directly applicable to any multinomial choice models with unordered outcome variables. These models set parametric assumptions on response probabilities that an option is chosen from multiple alternatives, and identical assumptions are often set for all response probabilities. Problems occur when these models do not mimic the true models, because the response probabilities and partial effects of some variables on the probabilities cannot be properly predicted. Moreover, the parameter estimation results may be misleading and their interpretation confusing. The specification test proposed here can be utilized to justify the choice of parametric models and to avoid misspecification problems.
The novelty of the test provided in this study is that it allows us to test the specifications of response probabilities jointly for all choice alternatives. Multinomial choice models with unordered outcomes consist of multiple response probabilities, each of which may be parameterized differently. This implies that one needs to test multiple null hypotheses to justify the parametric assumptions of these models. A substantial number of specification tests has been developed to test a single null hypothesis. To our knowledge, however, no joint specification tests have so far been theoretically suggested for multiple null hypotheses.
The test proposed here is based on moment conditions. We show that the test statistic is asymptotically chi-square distributed, consistent against a fixed alternative and able to detect a local alternative approaching the null at the rate of , where q is the number of independent variables.
One eminent feature of our test is that a parametric bootstrap procedure works well to calculate the rejection region for the test statistic. Since the testing method involves nonparametric estimation, a sufficiently large sample size could be required to establish that the chi-squared distribution is a proper approximation for the distribution of the test statistic. Thus, a simple parametric bootstrap procedure to calculate rejection regions is a practical need.
A crucial point that makes parametric bootstrap work is that the orthogonality condition holds with bootstrap sampling under both the null and alternative hypotheses. This is different from the specification test for the regression function that requires the wild bootstrapping procedure to calculate the rejection region proven by [
7]. It is also noteworthy that the parametric nature of the model leads to substantial savings in the computational cost of bootstrapping.
Methodologically, two different approaches have been developed to construct specification tests. One uses an empirical process and the other a smoothing technique. We call the first type empirical process-based tests and the second type smoothing-based tests. Most of the literature on specification tests can be categorized into one of these two types. Empirical process-based tests are proposed by [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], among others. Smoothing-based tests are proposed by [
7,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32], to mention only a few.
These two types of tests are complementary to each other, rather than substitutional, in terms of the power property. For Pitman local alternatives, empirical process-based tests are more powerful than the smoothing-based tests. Empirical process-based tests can detect Pitman local alternatives approaching the null at the parametric rate
, whereas smoothing-based tests can detect them at a rate slower than the parametric rate. Smoothing-based tests are, however, more powerful for a singular local alternative that changes drastically or is of high frequency. Empirical process-based tests can be represented by a kernel-like weight function with a fixed smoothing parameter. Thus, it can be intuitively understood that empirical process-based tests oversmooth the true function and obscure the drastic changes of alternatives. The work in [
33] shows that smoothing-based tests can detect singular local alternatives at a rate faster than
.
The test proposed in this study is most related to [
30], which proposes a smoothing-based test for functional forms of the regression function. Most of the specification tests developed for functional forms of the regression function can be directly applied to test the parametric specifications of ordered choice models, such as the parametric binary choice models, because ordered choice models have only a single response probability that is equal to the conditional expectation of the outcome. For example, [
34] applied several specification tests, originally developed for regression functions, to some ordered discrete choice models for a comparison of their relative merits based on their asymptotic size and power. However, applying them to unordered multinomial choice models, as done in this study, is not a trivial task. Extending empirical process-based tests and rate-optimal tests
1 to unordered multinomial choice models is a task left for future research.
This paper is organized as follows.
Section 2 introduces unordered multinomial choice models and reveals the problems of parametric specification. The new test statistic is proposed in
Section 3. The assumptions and asymptotic behavior are provided in
Section 4.
Section 5 shows how to bootstrap parametrically. We investigate the size and power of the test by conducting Monte Carlo experiments in
Section 6. We conclude with
Section 7. The proofs of the lemmas and propositions are provided in the
Appendix.
2. Unordered Multinomial Choice Models
We have the observations , where is a binary response variable that takes one if individual i chooses alternative j and zero otherwise. Each individual chooses one of J alternatives, which implies for all if . is a vector of independent variables that affect the choice decision made by individual i. Throughout this paper, we assume that is independent and identically distributed for each . With i remaining fixed, however, is not necessarily independent or identical.
Multinomial choice models with unordered response variables are constructed by introducing latent variables
, which may be interpreted as the utility or satisfaction that
i can obtain by choosing alternative
j. We assume each individual chooses an alternative that maximizes personal utility; that is,
if
for all
. Further,
depends on a function
and unobserved error
:
, where
is independent of
and
is a parameter in a subset of a finite dimensional space Θ. Then, the response probability that
i chooses
j can be formulated as follows:
where
is a vector consisting of all independent variables. The dimension
q of
is equal to
when all variables in
are alternative-specific for all
j. This occurs when no variable in
is identical to any of those in
as long as
.
A specification of the functional forms of
and the distributions of ϵ leads to full parameterization of the model in the sense that parameters and response probabilities can be estimated parametrically. For example, if we assume linearity,
, and the Type I extreme-value distribution for
for all
j, we have MNL model in which:
.
2 An alternative model suggested by [
2] is the MNP model, in which
is assumed to be normally distributed. In both cases, the parameters can be inferred by maximum likelihood estimation, and the choice probabilities are obtained by plugging the estimated values into (1).
Specification of the distribution of ϵ in (1) is less restrictive than specifying a distribution of a random variable. This is because specification of ϵ is true if ϵ is in a family of distributions. The strict inequality in (1) holds after any transformations on both sides of the inequality with any strictly increasing functions. For example, the distribution of in (1) could be transformed into a well-known one as the normal or Type I extreme distribution. In these special cases, the distributions of ϵ’s may not be an essential specification issue, provided we can specify the right-hand side of the inequality correctly. In other words, distributional assumptions of error terms that help us simplify the estimation of parametric models could be justified by specifying the functional forms of prudently.
In empirical studies, however, functional forms of
and distributions of
are generally unknown for all
j. Moreover, in unordered multinomial choice models, the functional forms of
and the distributions of
may be nonidentical across
j. Thus, we need joint specification tests that indicate whether parametric specifications provide a good approximation to the true models. The appropriate null and alternative hypotheses are as follows:
where
denotes the true response probabilities and
their parameterized variants.
3. Test Statistic
The test statistic proposed in this study is built on the features of response probabilities, that is the moment conditions that are satisfied when the parametric response probability is true. This implies that we test the specifications of the functional forms of and the distributions of simultaneously for all j. Rejection of the null hypothesis, thus, indicates that at least one of the parametric specifications of and is misspecified.
Before presenting the test statistic, we introduce some notations. Let
be the non-parametric density estimator for a continuous point of
as follows:
where
is a kernel function and
h is a bandwidth depending on
n. In addition, we define
as the two-times convolution product of the kernel and
as that of
.
The test statistic is based on
where
and
is the marginal density of
. Under the null hypothesis,
, since
. Under the alternative hypothesis,
for some positive constant
c, provided that
is bounded away from zero.
The nonparametric estimates of
, denoted as
, can be obtained as follows:
where
and
is the estimate of
. We denote the asymptotic variance of
and the covariance between
and
by
and
, respectively.
We introduce some further notations to provide the test statistic. Note that testing the specification of an arbitrary pair of
response probabilities is a sufficient test for the null hypothesis subject to
for all
i. For notational simplicity, we omit the
J-th response probability from our test statistic. Let
be a
vector and
a
variance-covariance matrix whose
elements are estimates of
. Then, the test statistic is
where
for all
and
.
is the estimated conditional variance of
, where
and
, and
is the estimated covariance between
and
.
Considering the nature of the model,
and
can be easily obtained. Since
is a binary variable taking zero or one,
, where
is an indicator function. The conditional variance of
and the covariance between
and
can then be written straightforwardly as follows:
Thus, consistent parametric estimators of
and
under the null hypothesis are
and
, respectively.
5. Bootstrap Methods
This section presents a bootstrapping method that is useful in approximating the distribution of the test statistic when the sample size is small. Specification tests for the regression function usually require the wild bootstrapping procedure to calculate the rejection region, as proven by [
7]. In our case, however, the wild bootstrap does not work well. The intuitive reason is that it fails to generate a bootstrap sample for the binary response variable.
We show that the parametric bootstrap procedure works well to calculate the rejection region for the test statistic. Intuitively, this is because the binary bootstrap sample for the response variable, say
, can be driven according to the parametrically-generated response probabilities, and there are no specific conditions that should be held by
in multinomial choice models. This is, for example, different from the case of the regression model in which the conditional expectation of the error term should be zero. The proof for the proposition in this section is provided in the
Appendix.
The response probability that person i chooses alternative j can be parametrically estimated under the null hypothesis for all i and j by using the observations . For each person, we randomly choose one of J alternatives (say, alternative ) with individual probabilities equal to the estimated response probabilities. Then, we derive bootstrap observations for each , so that , where and for . We use as the bootstrap observations.
Assumptions 3 and 5 can be rewritten by using the bootstrap observations as follows:
Assumption 3’: and , for all i and j. None of the alternatives is a perfect substitute for any other.
Assumption 5’: There exists a unique value for the θ, defined as . Letting , it satisfies .
where
is the estimate of θ obtained by using the bootstrap observations
.
Since the bootstrap sample is derived in accordance with the parametrically-estimated response probabilities , Assumption 3’ implies that these probabilities do not take the values zero and one; that is, and , for all i and j. Assumption 3’ holds whenever Assumption 3 holds and one applies parametric models whose estimates do not exceed below zero and above one, such as the MNL or MNP model. Assumption 5’ requires that be a consistent estimator of θ. Assumption 5’ is satisfied whenever Assumption 5 holds because the true value of is , which converges to θ in probability.
Bootstrap Methods for
The test statistic is constructed similarly to by using the bootstrap observations . We obtain the quantile by Monte Carlo approximation for the distribution of . The null hypothesis is rejected if . In the following proposition, we show that this parametric bootstrap procedure works: under the null hypothesis, converges to the asymptotic distribution of ; under the alternative hypothesis, converges to the asymptotic distribution of the test statistics under the null hypothesis.
Proposition 4. Let Assumptions 1–6 hold. Then, the test statistic obtained with the bootstrap observation converges to a chi-squared distribution with degrees of freedom:as and .
6. Monte Carlo Experiments
The size and power of the test are examined by Monte Carlo experiments. We consider a simple case in which each individual chooses one of three alternatives. To explore the power properties of the test, we consider three different true models.
The null hypothesis to be tested is the following:
for some
and for all
. The null hypothesis is based on the assumptions that the function
is linear, specifically,
, and that
follows the Type I extreme-value distribution for all
j. For simplicity of calculation,
is assumed to be one-dimensional.
We consider three different true models. Each of these true models has a specific form of , which can be generally written as . By applying specific values in , and , we propose three true models: Model 1: , , and ; Model 2: , , and ; and Model 3: , , and . The true distribution of is a Type I extreme-value distribution for all j.
These true models allow us to investigate the power property of the test in the case of misspecification due to nonlinearity and the choice-specific coefficients. We add nonlinearity to the true function of in all true models by setting and at nonzero values. Choice-specific coefficients are inserted into Model 2 by setting at different values across j. In this experiment, we do not consider the misspecification originating in the distribution of and the omitted variables.
We derive uniformly from [0,1] and randomly from the Type I extreme-value distribution. Then, the latent variable is generated by each true model: . The binary outcome is chosen to be one, if for all , and zero otherwise. Sample sizes are and . The critical value is computed by repetitions of the parametric bootstrap, and all results are based on simulation runs.
To calculate the test statistics, is considered to be specific to each alternative, namely, . The quartic kernel is used for nonparametric estimation. Bandwidths for the kernel estimator are chosen to be .
Table 1 illustrates the size of the test at the
significance level. The first and second rows of the table show the size of the test, where the critical values are obtained by the parametric bootstrap (
) and asymptotic distribution of the test statistic (
), respectively. The first to fourth columns of the table illustrate the results obtained with a sample size of
and bandwidths
h of
,
,
and
, respectively. Similarly, the fifth to eighth columns show the result with
. Overall, the test tends to over-reject the null hypothesis when the critical values are calculated by parametric bootstrap. The probability of rejection is close to its nominal size when
and
. In contrast, the test tends to under-reject the null hypothesis when the critical values are the
quantile of the chi-squared distribution with two degrees of freedom. The probability of rejection is close to its nominal size when
and
.
Table 1.
Monte Carlo estimates of the size.
Table 1.
Monte Carlo estimates of the size.
| Critical Value\h | | |
|---|
| | | | | | | |
|---|
| | | | | | | | |
| | | | | | | | |
In comparing the power performance of the test, it is possible to correct size distortion by using the bandwidths corresponding to the nominal size of the tests. In practice, however, this procedure cannot be employed, because we do not know the true model. Thus, we do not correct the size distortion in this experiment. We rather show the power performance with each bandwidth level, since choosing an appropriate bandwidth in practice is outside the scope of this paper.
Before beginning to show the simulation results of the power performance of the test statistics, we illustrate the discrepancy between the true and parametric null models. The response probabilities in this simulation are mappings of the unit cube to the unit interval. For illustration simplicity, however, we focus on the domain of the response probabilities, being . In this setting, the fitted values for the response probabilities of the parametric model under the null hypothesis are always for all j, because the model does not have any alternative-variant coefficients.
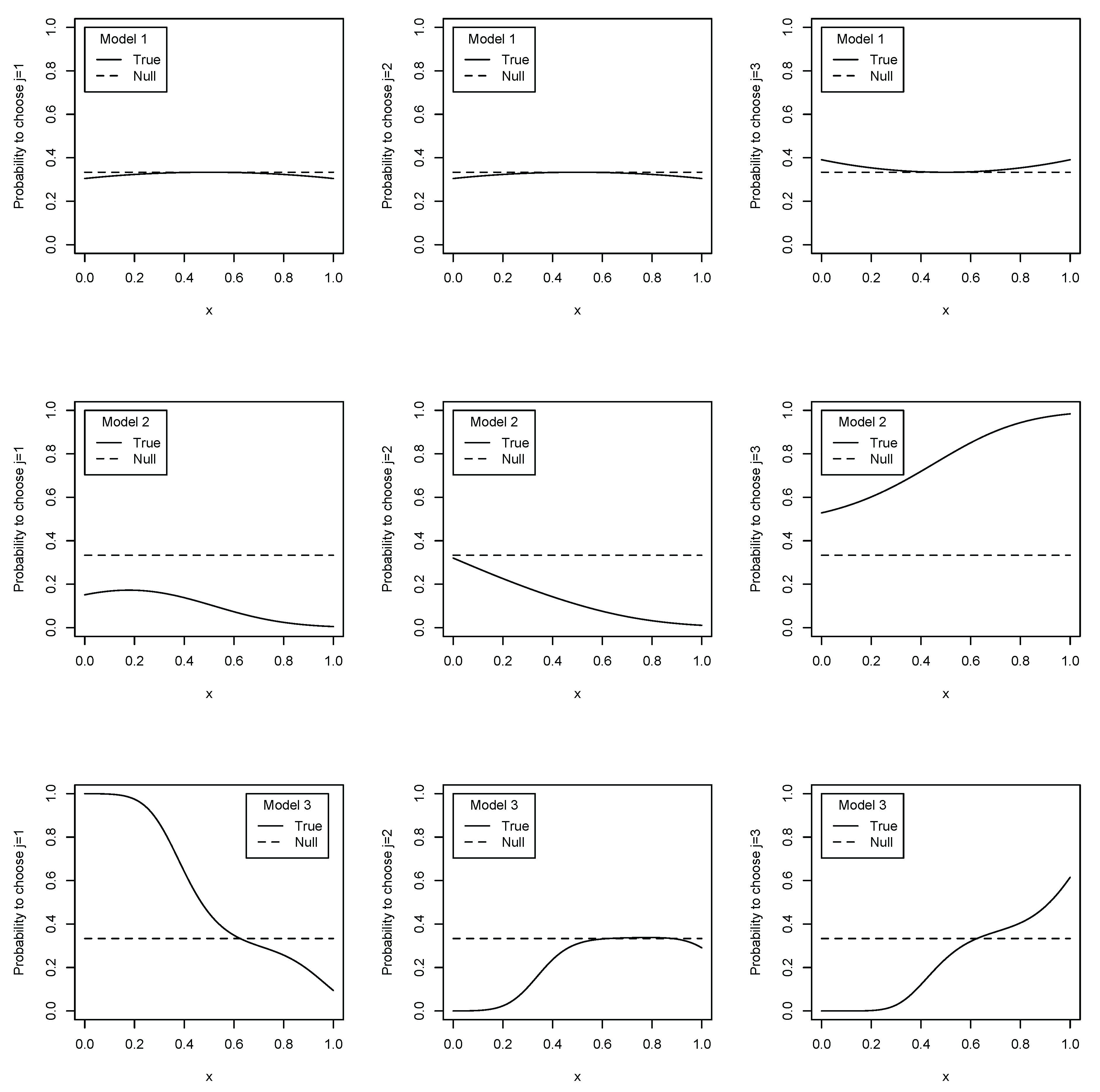
Figure 1 shows how the true and null response probabilities react to the covariates. The larger distance between the true and null models with
x fixed indicates that the parametric null model does not approximate the true model well. The parametric predictions of response probabilities lie closer to the true response probability in Model 1 than in Models 2 and 3 for all
j. For the second and third alternatives, the parametric null response probability appears to lie closer to the true response probability in Model 3 than in Model 2. For the first alternative, however, the distance between the true and null models seems closer in Model 3. In brief, the null model gives the best response probability predictions in Model 1, but the predictions are less accurate in Models 2 and 3. The prediction precision of the null model could reflect the power performance of the test statistics.
Table 2 reports the proportion of rejections of the null hypothesis at the
significance level. The first to third rows of the table show the power of the test when the true models are Model 1, Model 2 and Model 3, respectively, where the critical values are obtained by parametric bootstrap. Similarly, the fourth to sixth rows of the table show the power, where the critical values are obtained by the
quantile of the chi-squared distribution with two degrees of freedom. The first to fourth columns of the table illustrate the power results obtained with a sample size of
and bandwidths
h of
,
,
and
, respectively. Similarly, the fifth to eighth columns show the result with
.
The test does not have a decidedly nontrivial power when Model 1 is true. Non-rejection of the null hypothesis does not imply that the null model is true. However, in fact, as the top three figures in
Figure 1 show, the parametric model under the null hypothesis may provide a proper approximation for the response probabilities of Model 1. Therefore, the low power of the test statistic may be acceptable. In contrast, the test statistic has more nontrivial power when Model 2 or 3 is true. The greater the sample size, the better the power performance, which depends on the choice of bandwidth.
Figure 1.
Discrepancy between true and estimated parametric response probabilities.
Figure 1.
Discrepancy between true and estimated parametric response probabilities.
Table 2.
Proportion of null hypothesis rejections based on Monte Carlo simulation.
Table 2.
Proportion of null hypothesis rejections based on Monte Carlo simulation.
| Critical Value | Model\h | | |
|---|
| | | | | | | |
|---|
| Model 1 | | | | | | | | |
| | Model 2 | | | | | | | | |
| | Model 3 | | | | | | | | |
| Model 1 | | | | | | | | |
| | Model 2 | | | | | | | | |
| | Model 3 | | | | | | | | |
Closer inspection of
Table 2 reveals that the test performs better in terms of power when the critical values are obtained by parametric bootstrap, especially when the sample size is
. Too see this, we compare the results of
when critical values are
with those of
when critical values are
. We compare the results with different bandwidths because the size of the test is close to its nominal size with these bandwidths (
and
, respectively). When the true model is Model 2, the probability of the rejection of the null hypothesis is
for
. The probability of the rejection is
for
. Similarly, when the true model is Model 3, the probability is
for
and
for
. It is surprising that the performance of the test is not unreasonable when critical values are obtained by an asymptotic distribution. However, at least in this setting, the test shows higher power when critical values are obtained by parametric bootstrap when the sample size is small.



{kind=link}