Flash Flood Susceptibility Assessment Based on Geodetector, Certainty Factor, and Logistic Regression Analyses in Fujian Province, China

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
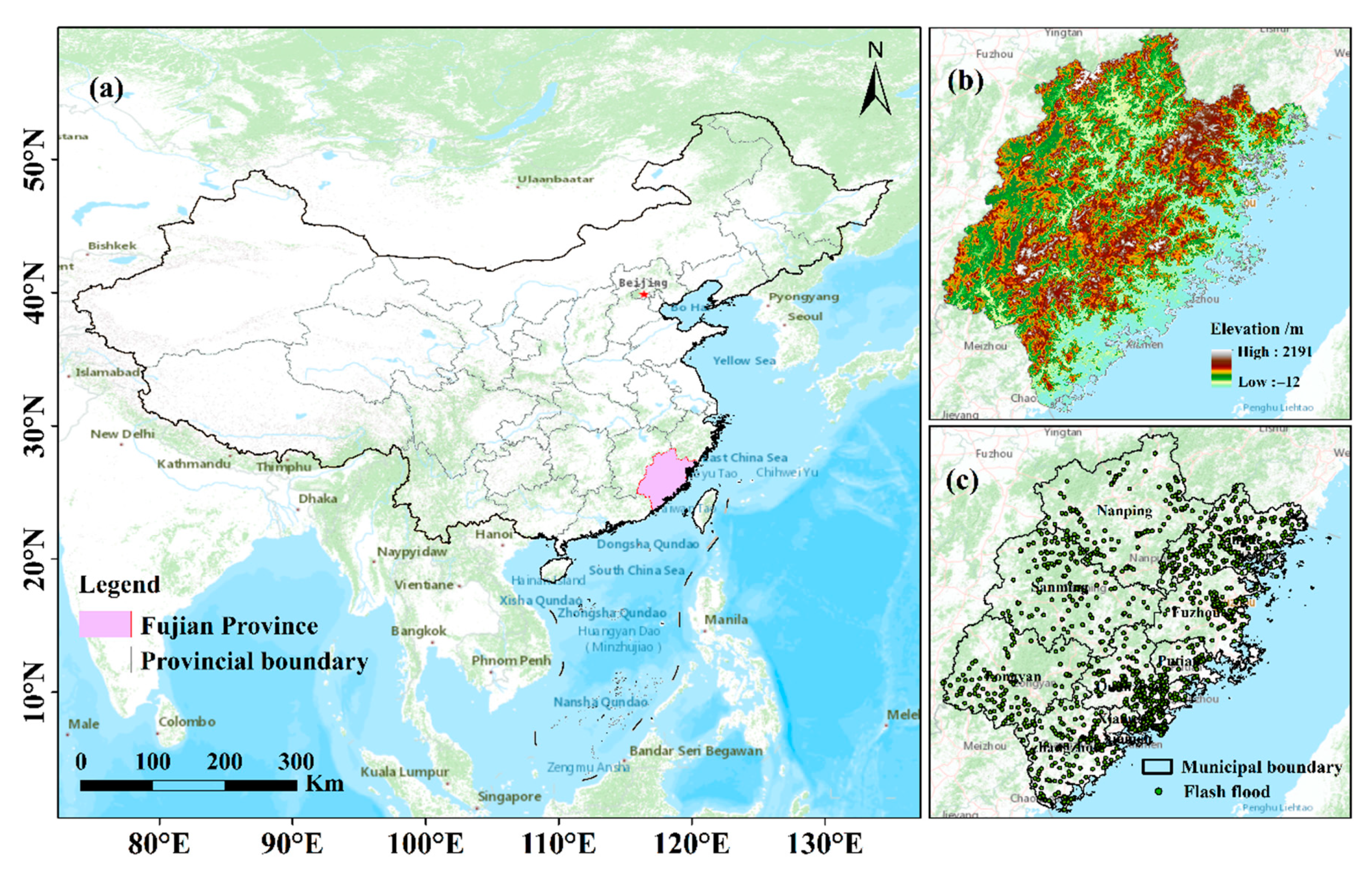
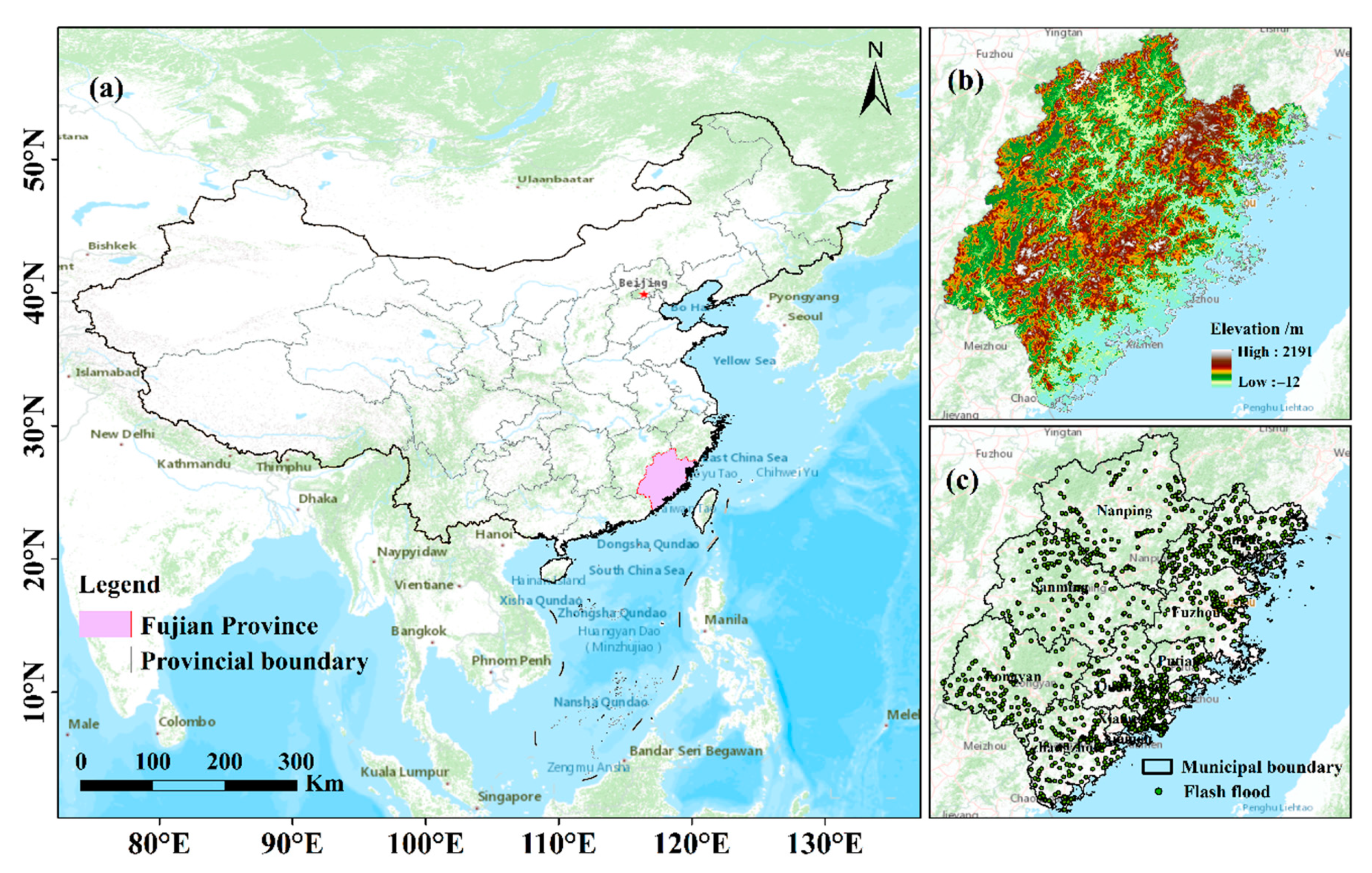
2.1. Study Area
2.2. Materials
2.2.1. Flash Flood Inventory Map
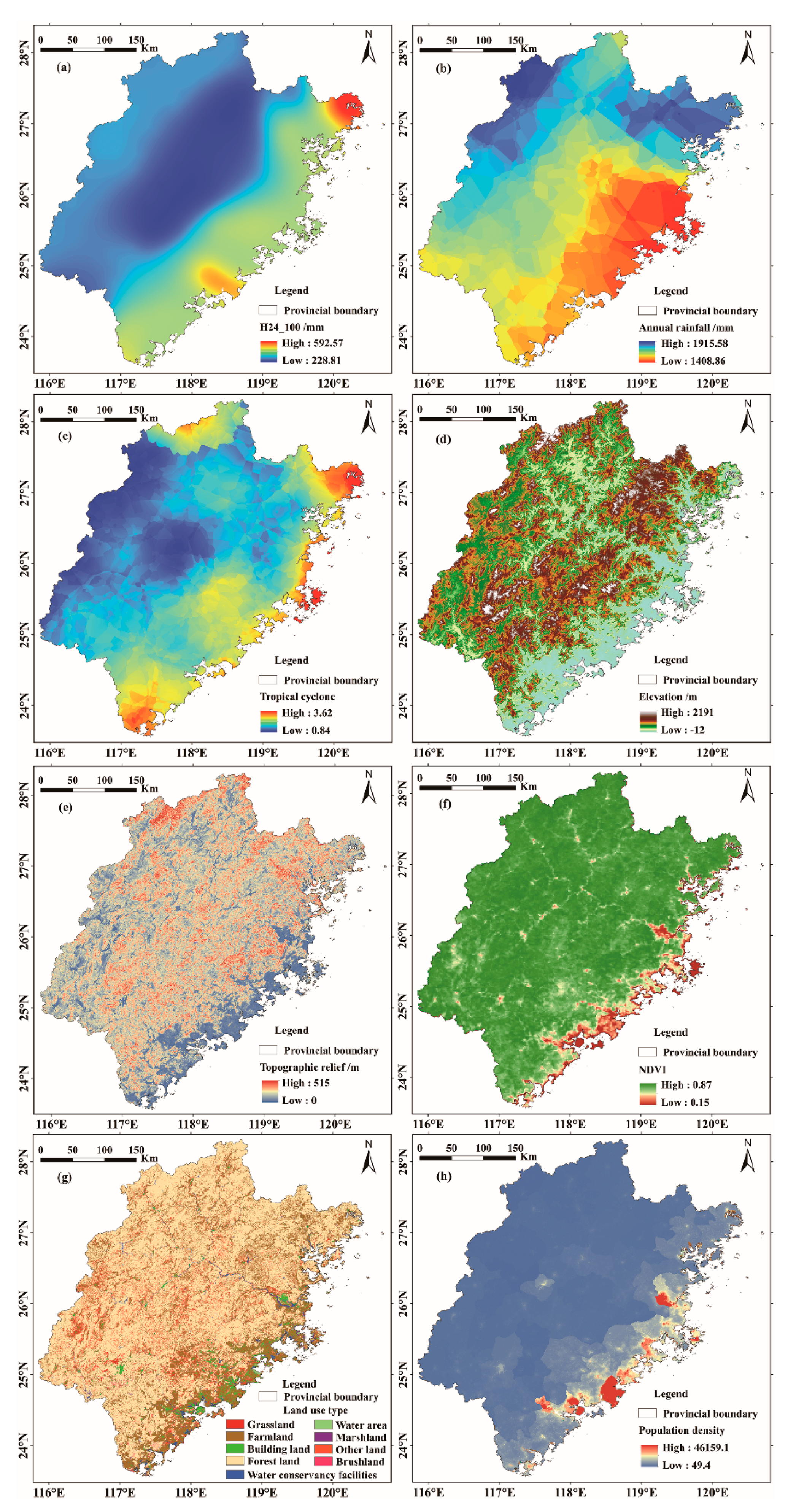
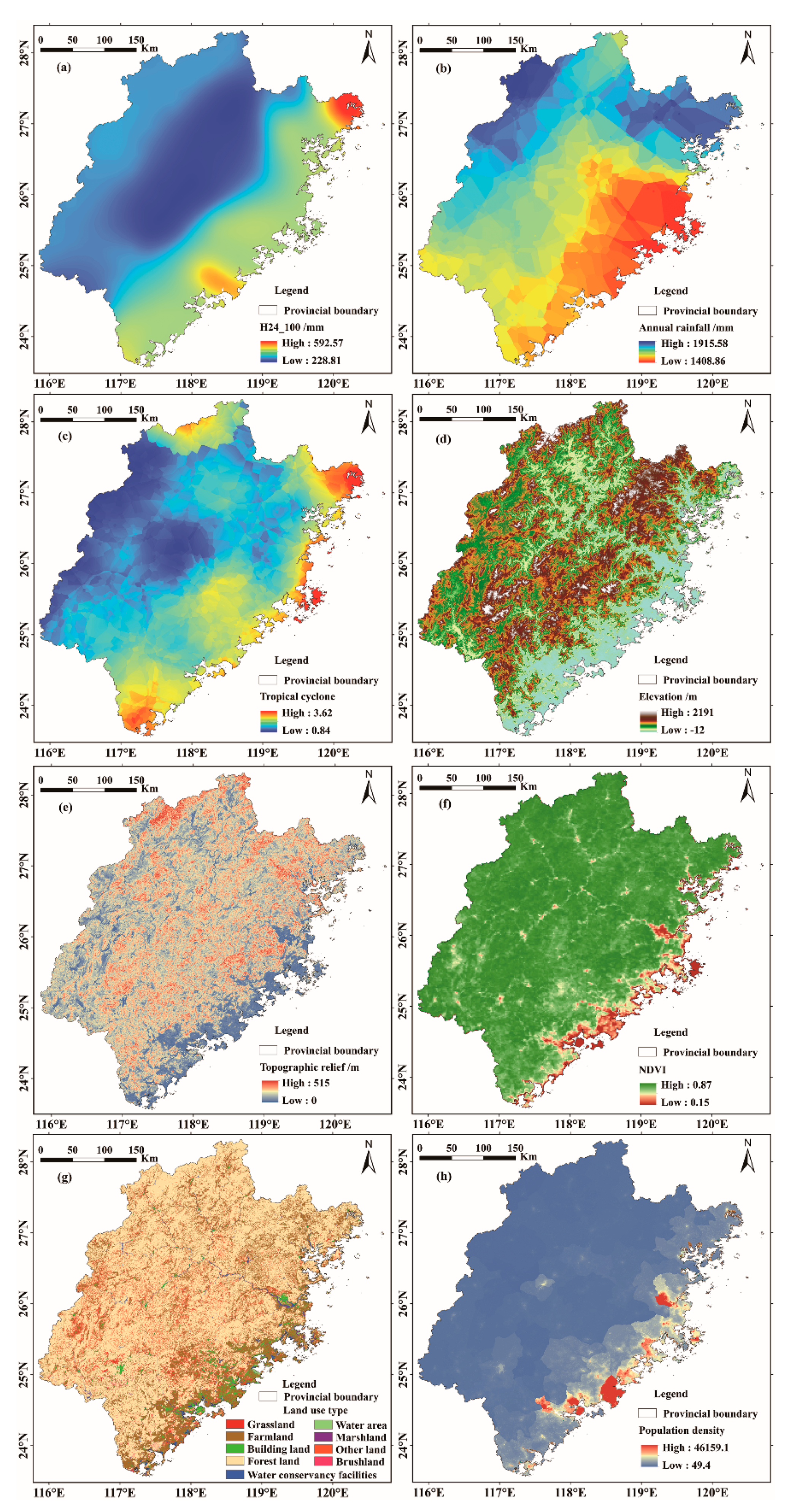
2.2.2. Flash Flood Conditioning Factors
- (1)
- Elevation
- (2)
- Slope
- (3)
- Topographic Relief
- (4)
- NDVI
- (5)
- Land Use Type
- (6)
- Soil Type
- (7)
- Soil Depth
- (8)
- Distance from Rivers
- (9)
- Rainstorm Factors
- (10)
- Annual Rainfall
- (11)
- Tropical Cyclone Index
- (12)
- Population Density
- (13)
- Economic Density
2.3. Methods
2.3.1. Pearson Correlation Coefficient
2.3.2. Geodetector
2.3.3. Certainty Factor
2.3.4. Logistic Regression
3. Results
3.1. Screening of the Assessment Indicators
3.1.1. Correlation Matrix of the Conditioning Factors
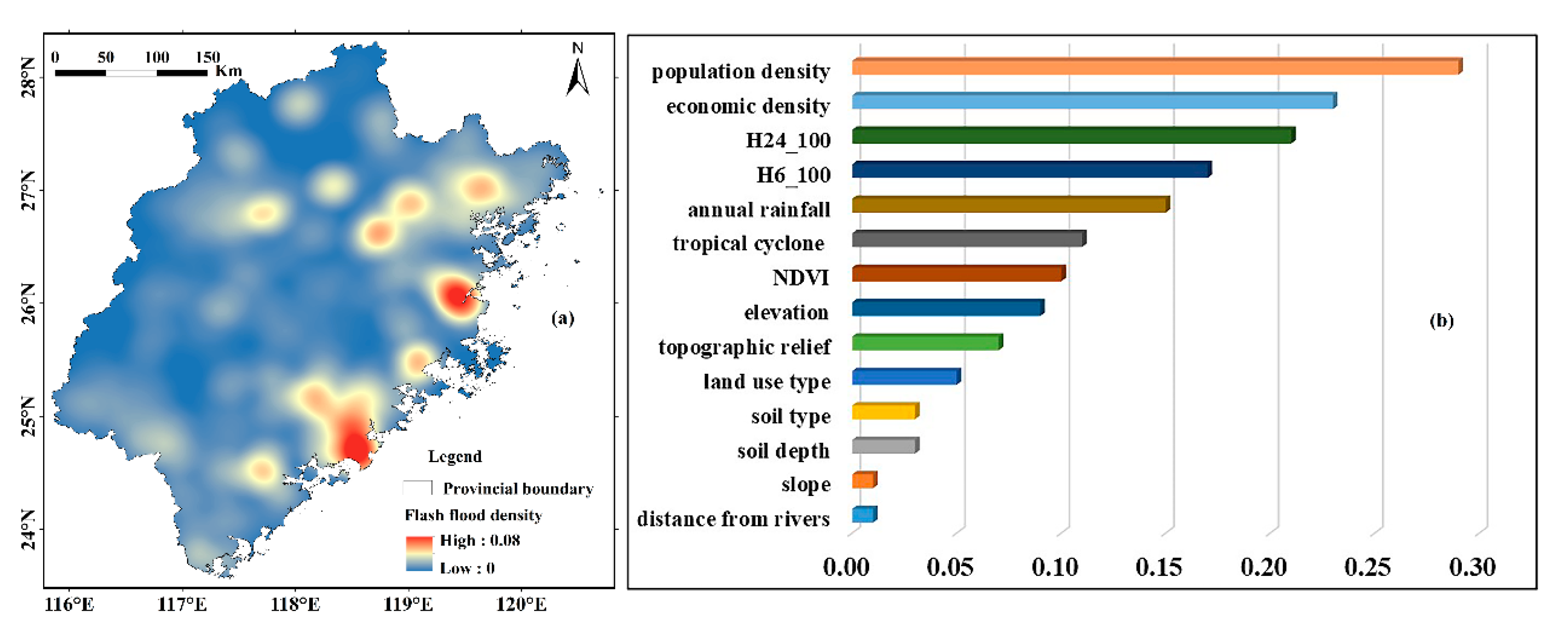
3.1.2. Implementation of Geodetector
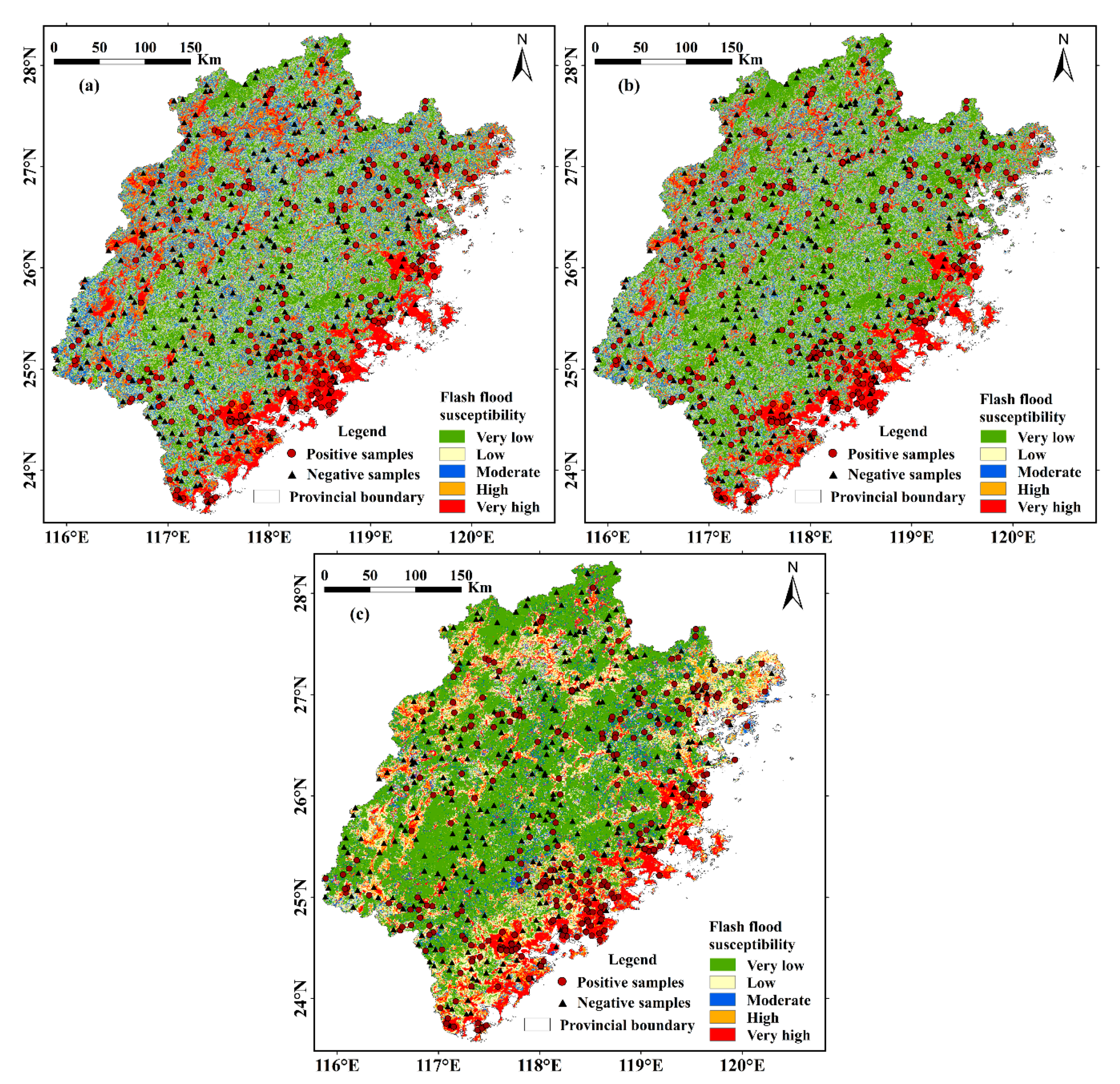
3.2. Susceptibility Assessment and Mapping
3.2.1. Implementation of the Certainty Factor
3.2.2. Implementation of Logistic Regression
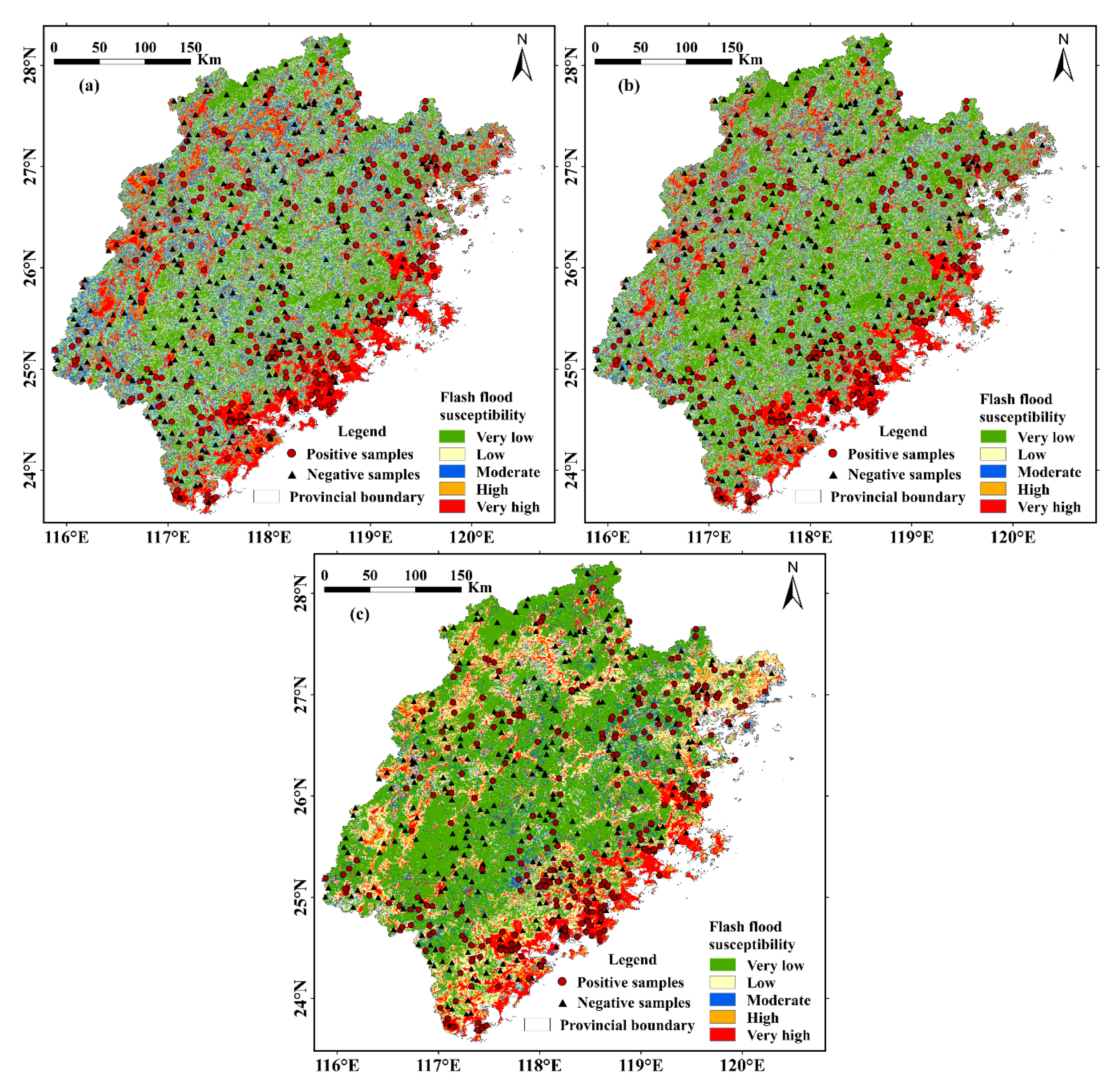
3.2.3. Flash Flood Susceptibility Maps
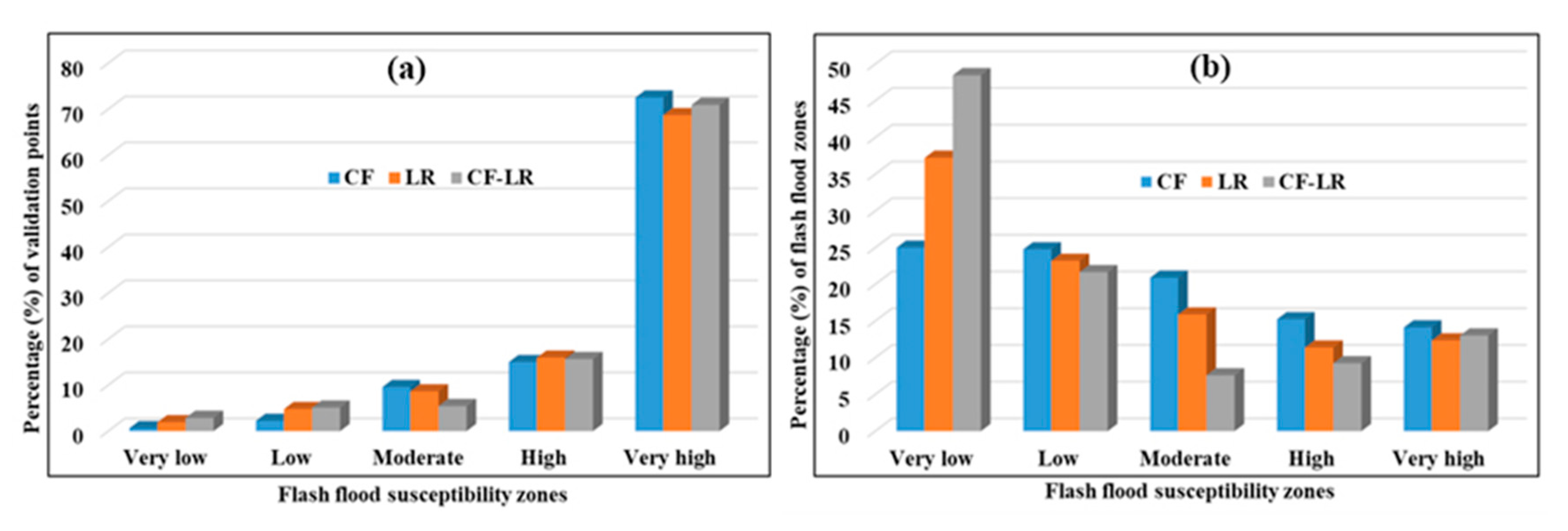
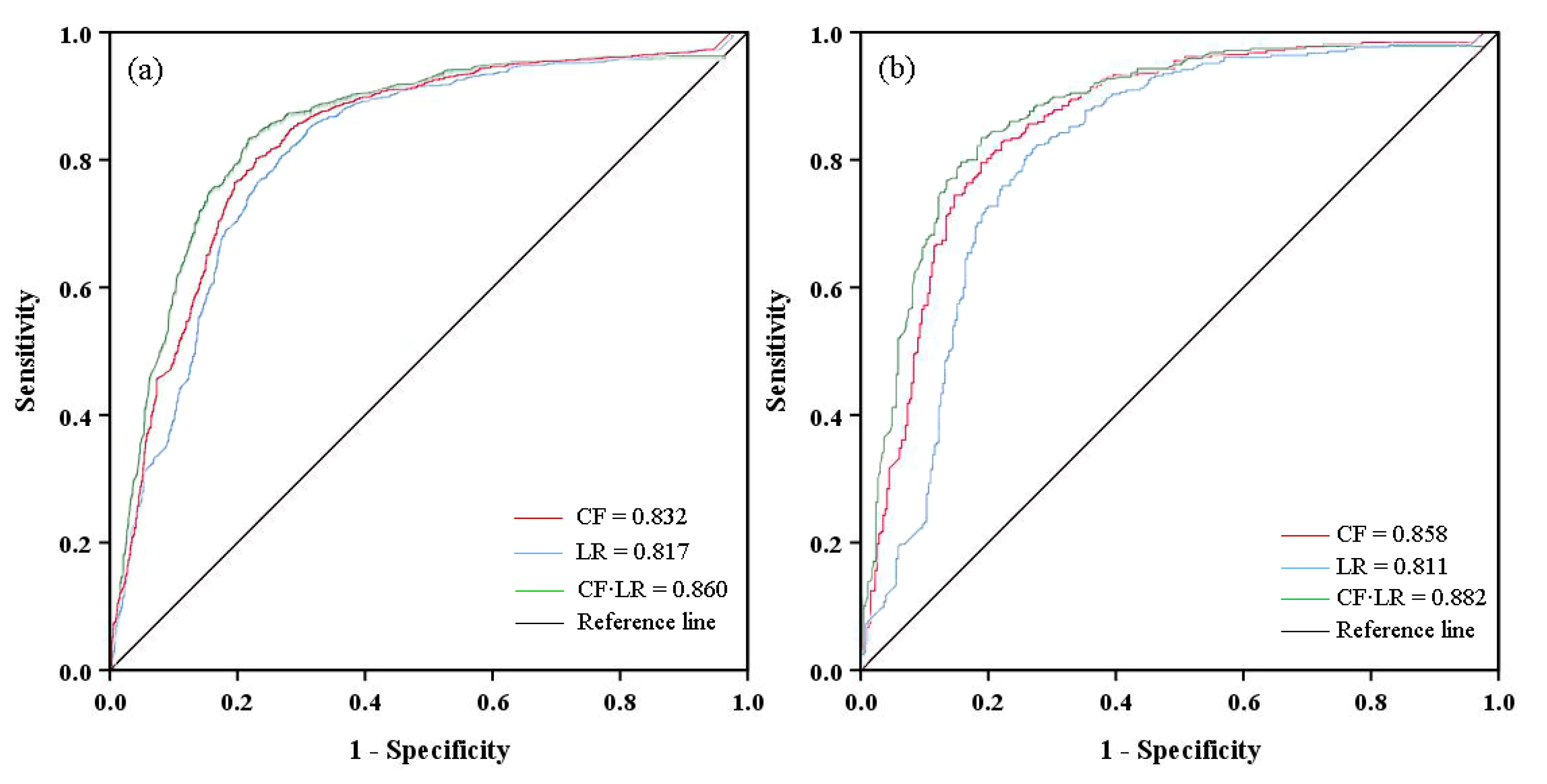
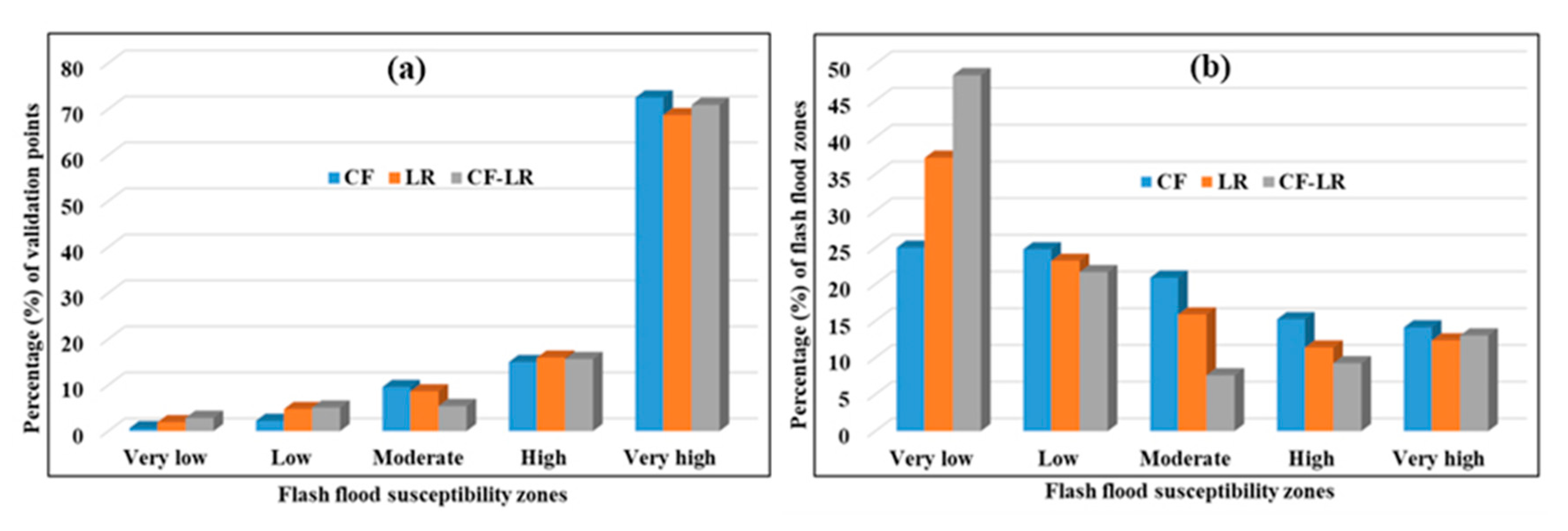
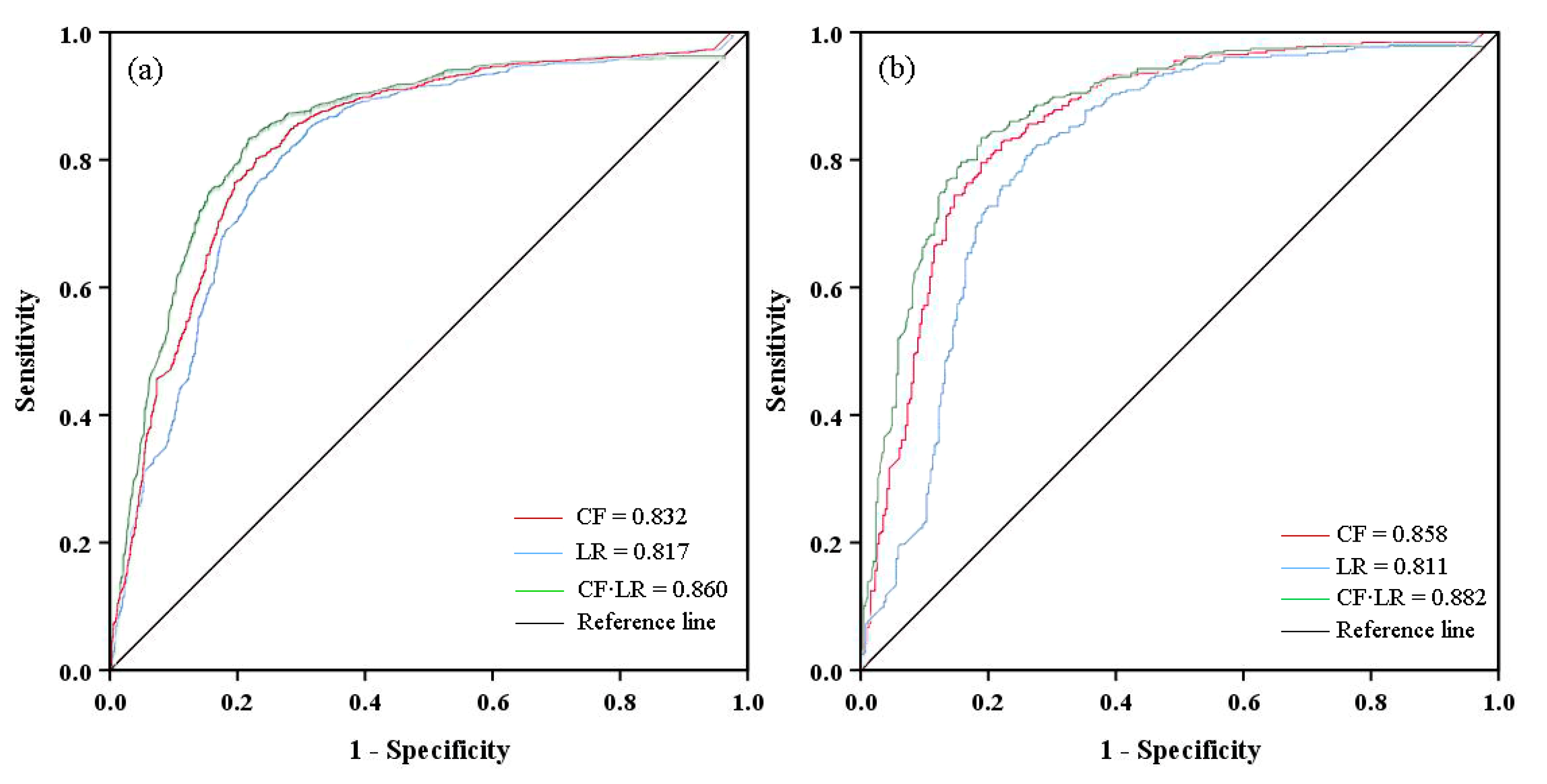
4. Validation of the Susceptibility Assessment Results and Comparison of the Different Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, Z.; Huang, Y.; Liu, C. Spatiotemporal evolution and driving factors of China’s flash flood disasters since 1949. Sci. China Earth Sci. 2018, 61, 1804–1817. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, X.; Guo, L.; Huang, Y.; Zhang, X. Driving Force Analysis of the Temporal and Spatial Distribution of Flash Floods in Sichuan Province. Sustainability 2017, 9, 1527. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Pang, Q.; Fan, C.; Cheng, W.; Ye, C.; Zhao, Y.; He, Y.-R.; Cao, Y. Spatiotemporal Characteristics and Driving Force Analysis of Flash Floods in Fujian Province. ISPRS Int. J. Geo-Inf. 2020, 9, 133. [Google Scholar] [CrossRef] [Green Version]
- Norbiato, D.; Borga, M.; Degli Esposti, S.; Gaume, E.; Anquetin, S. Flash flood warning based on rainfall thresholds and soil moisture conditions: An assessment for gauged and ungauged basins. J. Hydrol. 2008, 362, 274–290. [Google Scholar] [CrossRef]
- Ben Aissia, M.-A.; Chebana, F.; Ouarda, T.; Roy, L.; DesRochers, G.; Chartier, I.; Robichaud, É. Multivariate analysis of flood characteristics in a climate change context of the watershed of the Baskatong reservoir, Province of Québec, Canada. Hydrol. Process. 2012, 26, 130–142. [Google Scholar] [CrossRef] [Green Version]
- Oeurng, C.; Sauvage, S.; Sánchez-Pérez, J.-M. Assessment of hydrology, sediment and particulate organic carbon yield in a large agricultural catchment using the SWAT model. J. Hydrol. 2011, 401, 145–153. [Google Scholar] [CrossRef] [Green Version]
- Bahremand, A.; De Smedt, F.; Corluy, J.; Liu, Y.B.; Poorova, J.; Velcicka, L.; Kunikova, E. WetSpa Model Application for Assessing Reforestation Impacts on Floods in Margecany–Hornad Watershed, Slovakia. Water Resour. Manag. 2007, 21, 1373–1391. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Papaioannou, G.; Vasiliades, L.; Loukas, A. Multi-Criteria Analysis Framework for Potential Flood Prone Areas Mapping. Water Resour. Manag. 2015, 29, 399–418. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Chang, M.-J.; Chang, H.-K.; Chen, Y.-C.; Lin, G.-F.; Chen, P.-A.; Lai, J.-S.; Tan, Y.-C. A Support Vector Machine Forecasting Model for Typhoon Flood Inundation Mapping and Early Flood Warning Systems. Water 2018, 10, 1734. [Google Scholar] [CrossRef] [Green Version]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood hazard risk assessment model based on random forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Bui, D.T.; Khosravi, K.; Shahabi, H.; Daggupati, P.; Adamowski, J.F.; Melesse, A.M.; Pham, B.T.; Pourghasemi, H.R.; Mahmoudi, M.; Bahrami, S.; et al. Flood Spatial Modeling in Northern Iran Using Remote Sensing and GIS: A Comparison between Evidential Belief Functions and Its Ensemble with a Multivariate Logistic Regression Model. Remote Sens. 2019, 11, 1589. [Google Scholar] [CrossRef] [Green Version]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Spatial prediction of flood susceptible areas using rule based decision tree (DT) and a novel ensemble bivariate and multivariate statistical models in GIS. J. Hydrol. 2013, 504, 69–79. [Google Scholar] [CrossRef]
- Yang, J.; Song, C.; Yang, Y.; Xu, C.; Guo, F.; Xie, L. New method for landslide susceptibility mapping supported by spatial logistic regression and GeoDetector: A case study of Duwen Highway Basin, Sichuan Province, China. Geomorphology 2019, 324, 62–71. [Google Scholar] [CrossRef]
- Jebur, M.N.; Pradhan, B.; Tehrany, M.S. Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens. Environ. 2014, 152, 150–165. [Google Scholar] [CrossRef]
- Lee, S.; Talib, J.A. Probabilistic landslide susceptibility and factor effect analysis. Environ. Earth Sci. 2005, 47, 982–990. [Google Scholar] [CrossRef]
- Zeng, F.; Lai, C.; Wang, Z. Flood Risk Assessment Based on Principal Component Analysis for Dongjiang River Basin. In Proceedings of the 2012 2nd International Conference on Remote Sensing, Environment and Transportation Engineering, South China University of Technology, Guangzhou, China, 1–3 June 2012; pp. 1–4. [Google Scholar]
- Shahabi, H.; Bui, D.T.; Yunus, A.P.; Jia, K.; Song, X.; Revhaug, I.; Xia, H.; Zhu, Z. Optimization of Causative Factors for Landslide Susceptibility Evaluation Using Remote Sensing and GIS Data in Parts of Niigata, Japan. PLoS ONE 2015, 10, e0133262. [Google Scholar] [CrossRef] [Green Version]
- Pourghasemi, H.R.; Mohammady, M.; Pradhan, B. Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: Safarood Basin, Iran. Catena 2012, 97, 71–84. [Google Scholar] [CrossRef]
- Luo, W.; Liu, C.-C. Innovative landslide susceptibility mapping supported by geomorphon and geographical detector methods. Landslides 2018, 15, 465–474. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C. Geodetector: Principle and prospective. Acta Geogr. Sin. 2017, 72, 116–134. [Google Scholar]
- Zhu, L.; Meng, J.; Zhu, L. Applying Geodetector to disentangle the contributions of natural and anthropogenic factors to NDVI variations in the middle reaches of the Heihe River Basin. Ecol. Indic. 2020, 117, 106545. [Google Scholar] [CrossRef]
- Wang, X.F.; Zhang, Y.W.; Ma, J.J. Factors influencing the incidence of bacterial dysentery in parts of southwest China, using data from the geodetector. Chin. J. Epidemiol. 2019, 40, 953–959. [Google Scholar]
- China Statistical Yearbook. 2018. Available online: http://tjj.fujian.gov.cn/tongjinianjian/dz2018/index-cn.htm (accessed on 30 November 2020).
- Zhang, K.; Hong, W.; Wu, C.; Ding, X. Study on the Spatial Pattern of Rainfall Erosivity Based on Geostatistics and GIS of Fujian Province. J. Mt. Sci. 2009, 27, 5344–5385. [Google Scholar]
- Fujian Bureau of Geology and Mineral Resources. Regional Geology of Fujian Province; Geological Publishing House: Beijing, China, 1985. [Google Scholar]
- Wang, D.; Zhou, X. Volcanic Petrology; Science Press: Beijing, China, 1982. [Google Scholar]
- Nandi, A.; Mandal, A.; Wilson, M.; Smith, D. Flood hazard mapping in Jamaica using principal component analysis and logistic regression. Environ. Earth Sci. 2016, 75, 1–16. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Shabani, F.; Jebur, M.N.; Hong, H.; Chen, W.; Xie, X. GIS-based spatial prediction of flood prone areas using standalone frequency ratio, logistic regression, weight of evidence and their ensemble techniques. Geomat. Nat. Hazards Risk 2017, 8, 1538–1561. [Google Scholar] [CrossRef]
- Xiong, J.; Ye, C.; Cheng, W.; Guo, L.; Zhou, C.; Zhang, X. The Spatiotemporal Distribution of Flash Floods and Analysis of Partition Driving Forces in Yunnan Province. Sustainability 2019, 11, 2926. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Liu, Y.; Huang, Y.; Tian, F. An approach to quality validation of large-scale data from the Chinese Flash Flood Survey and Evaluation (CFFSE). Nat. Hazards 2017, 89, 693–704. [Google Scholar] [CrossRef]
- Su, C.; Tian, Q.; Liu, B.; Yang, G.; Huang, K.; Huang, F. Regional Landslide Susceptibility Assessment for Longnan County in Jiangxi Province. Sci. Technol. Eng. 2019, 19, 919. [Google Scholar]
- Tehrany, M.S.; Kumar, L. The application of a Dempster–Shafer-based evidential belief function in flood susceptibility mapping and comparison with frequency ratio and logistic regression methods. Environ. Earth Sci. 2018, 77, 490. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pradhan, B.; Hassan, A.M. Flash flood risk estimation along the St. Katherine road, southern Sinai, Egypt using GIS based morphometry and satellite imagery. Environ. Earth Sci. 2011, 62, 611–623. [Google Scholar] [CrossRef]
- Xiong, J.; Li, J.; Cheng, W.; Zhou, C.; Guo, L.; Zhang, X.; Wang, N.; Li, W. Spatial-temporal distribution and the influencing factors of mountain flood disaster in southwest China. Acta Geogr. Sin. 2019, 74, 1374–1391. [Google Scholar]
- Slater, L.J.; Singer, M.B.; Kirchner, J.W. Hydrologic versus geomorphic drivers of trends in flood hazard. Geophys. Res. Lett. 2015, 42, 370–376. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Pradhan, B.; Nampak, H.; Bui, Q.-T.; Tran, Q.-A.; Nguyen, Q.-P. Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibilitgy modeling in a high-frequency tropical cyclone area using GIS. J. Hydrol. 2016, 540, 317–330. [Google Scholar] [CrossRef]
- Meraj, G.; Romshoo, S.A.; Yousuf, A.R.; Altaf, S.; Altaf, F. Assessing the influence of watershed characteristics on the flood vulnerability of Jhelum basin in Kashmir Himalaya. Nat. Hazards 2015, 77, 1531–1575. [Google Scholar] [CrossRef]
- Cai, D.; Xiao, X.; Sun, J. Assessment of the Difficulty of Warning Mountain Torrent Disasters: Case Study of the Yangtze River. J. Yangtze River Sci. Res. Inst. 2015, 32, 848. [Google Scholar]
- Toosi, A.S.; Calbimonte, G.H.; Nouri, H.; Alaghmand, S. River basin-scale flood hazard assessment using a modified multi-criteria decision analysis approach: A case study. J. Hydrol. 2019, 574, 660–671. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Shangguan, W.Y.; Dai, B.; Liu, A.; Zhu, Q.; Duan, L.; Wu, D.; Ji, A.; Ye, H.; Yuan, Q.; Zhang, D.; et al. A China Dataset of Soil Properties for Land Surface Modeling. J. Adv. Model. Earth Syst. 2013, 5, 212–224. [Google Scholar] [CrossRef]
- Vojtek, M.; Vojteková, J. Flood Susceptibility Mapping on a National Scale in Slovakia Using the Analytical Hierarchy Process. Water 2019, 11, 364. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wan, Q. Study on Rainfall Index Selection for Hazard Analysis of Mountain Torrents Disaster of Small Watersheds. J. Geo-Inf. Sci. 2017, 19, 425–435. [Google Scholar]
- Ding, M.; Heiser, M.; Hübl, J.; Fuchs, S. Regional vulnerability assessment for debris flows in China—A CWS approach. Landslides 2016, 13, 537–550. [Google Scholar] [CrossRef]
- Luo, W.; Jasiewicz, J.; Stepinski, T.F.; Wang, J.; Xu, C.; Cang, X. Spatial association between dissection density and environmental factors over the entire conterminous United States. Geophys. Res. Lett. 2016, 43, 692–700. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Li, W.; Cheng, W.; Fan, C.; Li, J.; Zhao, Y. Spatial variability and influencing factors of LST in plateau area: Exemplified by Sangzhuzi District. Remote Sens. Land Resour. 2019, 31, 1641–1671. [Google Scholar]
- Wang, J.-F.; Zhang, T.-L.; Fu, B. A measure of spatial stratified heterogeneity. Ecol. Indic. 2016, 67, 250–256. [Google Scholar] [CrossRef]
- Chen, Z.; Liang, S.; Ke, Y.; Yang, Z.; Zhao, H. Landslide susceptibility assessment using evidential belief function, certainty factor and frequency ratio model at Baxie River basin, NW China. Geocarto Int. 2017, 34, 348–367. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K. Gully erosion zonation mapping using integrated geographically weighted regression with certainty factor and random forest models in GIS. J. Environ. Manag. 2019, 232, 928–942. [Google Scholar] [CrossRef]
- Chen, W.; Li, W.; Chai, H.; Hou, E.; Li, X.; Ding, X. GIS-based landslide susceptibility mapping using analytical hierarchy process (AHP) and certainty factor (CF) models for the Baozhong region of Baoji City, China. Environ. Earth Sci. 2015, 75, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Chen, H.; You, Y.; Chen, X.; Liu, J. Weights-of-evidence method based on GIS for assessing susceptibility to debris flows in Kangding County, Sichuan Province, China. Environ. Earth Sci. 2016, 75, 1–16. [Google Scholar] [CrossRef]
- Lim, J.; Lee, K.-S. Flood Mapping Using Multi-Source Remotely Sensed Data and Logistic Regression in the Heterogeneous Mountainous Regions in North Korea. Remote Sens. 2018, 10, 1036. [Google Scholar] [CrossRef] [Green Version]
- Trigila, A.; Iadanza, C.; Esposito, C.; Mugnozza, G.S. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Chauhan, S.; Sharma, M.; Arora, M. Landslide susceptibility zonation of the Chamoli region, Garhwal Himalayas, using logistic regression model. Landslides 2010, 7, 411–423. [Google Scholar] [CrossRef]
- Khosravi, K.; Khosravi, K.; Pham, B.T.; Adamowski, J.; Dou, J.; Pradhan, B.; Shahabi, H.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.M.; Nassar, A.M.; Al-Juaidi, O.E.M. Evaluation of flood susceptibility mapping using logistic regression and GIS conditioning factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.T.; Han, L.; Chai, H.; Ma, J.; et al. Landslide Susceptibility Modeling Based on GIS and Novel Bagging-Based Kernel Logistic Regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Liu, J.; Zhu, A.-X.; Shahabi, H.; Pham, B.T.; Chen, W.; Pradhan, B.; Bui, D.T. A novel hybrid integration model using support vector machines and random subspace for weather-triggered landslide susceptibility assessment in the Wuning area (China). Environ. Earth Sci. 2017, 76, 652. [Google Scholar] [CrossRef]
- Liuzzo, L.; Sammartano, V.; Freni, G. Comparison between Different Distributed Methods for Flood Susceptibility Mapping. Water Resour. Manag. 2019, 33, 3155–3173. [Google Scholar] [CrossRef]
- Adiat, K.; Nawawi, M.; Abdullah, K. Assessing the accuracy of GIS-based elementary multi criteria decision analysis as a spatial prediction tool–A case of predicting potential zones of sustainable groundwater resources. J. Hydrol. 2012, 440, 75–89. [Google Scholar] [CrossRef]
- Mind’Je, R.; Li, L.; Amanambu, A.C.; Nahayo, L.; Nsengiyumva, J.B.; Gasirabo, A.; Mindje, M. Flood susceptibility modeling and hazard perception in Rwanda. Int. J. Disaster Risk Reduct. 2019, 38, 101211. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Kumar, L.; Jebur, M.N.; Shabani, F. Evaluating the application of the statistical index method in flood susceptibility mapping and its comparison with frequency ratio and logistic regression methods. Geomat. Nat. Hazards Risk 2018, 10, 79–101. [Google Scholar] [CrossRef]
- Huang, Y.; Duan, Y.; Yu, H. A Study of the Impact of Terrain on the Precipitation of “KROSA”. Meteorol. Mon. 2009, 9, 2. [Google Scholar]
- Pang, M.; Si, G. Influence of The Regional Scale Topography on the Climatalogical Distribution of Precipitatio Over Southeastern China. J. Trop. Meteorol. 1993, 9, 370–374. [Google Scholar]
- Xue, D.; Lu, J.; Leung, L.R.; Zhang, Y. Response of the Hydrological Cycle in Asian Monsoon Systems to Global Warming Through the Lens of Water Vapor Wave Activity Analysis. Geophys. Res. Lett. 2018, 45, 11904. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, J.; Xiong, J. Spatial-Temporal Patterns and Controls of Evapotranspiration across the Tibetan Plateau (2000–2012). Adv. Meteorol. 2017, 2017, 7082606. [Google Scholar] [CrossRef] [Green Version]
- King, A.D.; Donat, M.G.; Fischer, E.M.; Hawkins, E.; Alexander, L.V.; Karoly, D.J.; Dittus, A.J.; Lewis, S.C.E.; Perkins, S. The timing of anthropogenic emergence in simulated climate extremes. Environ. Res. Lett. 2015, 10, 094015. [Google Scholar] [CrossRef]
- Yue, Q.; Zhang, L.; Liu, C.; Zhang, H. GIS-based Risk Zoning of Flood Disasters in Upstream of the Minjiang River. J. Environ. Eng. Technol. 2015, 5, 2932–2998. [Google Scholar]
- Keesstra, S.; Nunes, J.P.; Saco, P.M.; Parsons, A.J.; Poeppl, R.; Masselink, R.; Cerdà, A. The way forward: Can connectivity be useful to design better measuring and modelling schemes for water and sediment dynamics? Sci. Total Environ. 2018, 644, 1557–1572. [Google Scholar] [CrossRef]
- Ramesh, V.; Iqbal, S.S. Urban flood susceptibility zonation mapping using evidential belief function, frequency ratio and fuzzy gamma operator models in GIS: A case study of Greater Mumbai, Maharashtra, India. Geocarto Int. 2020, 1–26. [Google Scholar] [CrossRef]
- Mahmood, S.; Rahman, A.-U. Flash flood susceptibility modeling using geo-morphometric and hydrological approaches in Panjkora Basin, Eastern Hindu Kush, Pakistan. Environ. Earth Sci. 2019, 78, 43. [Google Scholar] [CrossRef]
- Kundzewicz, Z.; Su, B.; Wang, Y.; Xia, J.; Huang, J.; Jiang, T. Flood risk and its reduction in China. Adv. Water Resour. 2019, 130, 37–45. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Subfactors | Source, Resolution, and Type |
|---|---|---|
| Flash flood inventory map | Historical flash flood points | Flash Flood Investigation and Evaluation Dataset of China (FFIEDC), 1:50,000, vector data |
| Precipitation | H6_100 | FFIEDC, vector data |
| H24_100 | FFIEDC, vector data | |
| Annual rainfall | National Meteorological Information Center. (http://data.cma.cn/), table data | |
| Tropical cyclone | Tropical cyclone index | An overview of the China Meteorological Administration’s tropical cyclone database (tcdata.typhoon.org.cn), text data |
| Digital elevation model | Elevation | Geospatial Data Cloud (www.gscloud.cn), 30 m × 30 m, raster data |
| Slope | ||
| Topographic relief | ||
| Soil | Soil type | FFIEDC, vector data |
| Soil depth | A China Dataset of Soil Properties for Land Surface Modeling, 1 km × 1 km, raster data | |
| Land use | Land use type | FFIEDC, vector data |
| Vegetations | NDVI | National Earth System Science Data Center (http://www.geodata.cn/), 1 km × 1 km, raster data |
| River system | Distance from rivers | FFIEDC, vector data |
| Human activities | Population density | Resource and Environment Data Center (RESDC), Chinese Academy of Sciences (http://www.resdc.cn/), 1 km × 1 km, raster data |
| Economic density |
| Value of PCC (R) | Correlation Levels |
|---|---|
| |R| = 0 | No correlation |
| 0 < |R| < 0.2 | Very weak correlation |
| 0.2 < |R| < 0.4 | Weak correlation |
| 0.4 < |R| < 0.6 | Intermediate correlation |
| 0.6 < |R| < 0.8 | Strong correlation |
| 0.8 < |R| < 1 | Very strong correlation |
| |R| = 1 | Perfect correlation |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | X13 | X14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X1 | 1 | |||||||||||||
| X2 | −0.65 | 1 | ||||||||||||
| X3 | 0.81 | −0.63 | 1 | |||||||||||
| X4 | −0.42 | 0.35 | −0.38 | 1 | ||||||||||
| X5 | −0.32 | 0.47 | −0.32 | 0.26 | 1 | |||||||||
| X6 | −0.18 | 0.31 | −0.17 | 0.13 | 0.3 | 1 | ||||||||
| X7 | −0.22 | 0.41 | −0.2 | 0.11 | 0.45 | 0.68 | 1 | |||||||
| X8 | 0.27 | −0.28 | 0.29 | −0.38 | −0.23 | −0.1 | −0.04 | 1 | ||||||
| X9 | −0.02 | 0.11 | −0.05 | 0.02 | 0.25 | 0.06 | 0.07 | −0.05 | 1 | |||||
| X10 | −0.19 | 0.25 | −0.11 | 0.12 | 0.22 | 0.26 | 0.34 | −0.05 | 0.04 | 1 | ||||
| X11 | −0.1 | 0.17 | −0.07 | 0.02 | −0.07 | 0.04 | 0.05 | −0.03 | 0.01 | 0.06 | 1 | |||
| X12 | 0.3 | −0.39 | 0.28 | −0.23 | −0.37 | −0.21 | −0.28 | 0.19 | −0.05 | −0.16 | −0.28 | 1 | ||
| X13 | 0.43 | −0.38 | 0.42 | −0.23 | −0.31 | −0.15 | −0.14 | 0.64 | −0.05 | −0.13 | −0.11 | 0.3 | 1 | |
| X14 | 0.42 | −0.36 | 0.41 | −0.31 | −0.29 | −0.12 | −0.09 | 0.7 | −0.04 | −0.12 | −0.08 | 0.26 | 0.92 | 1 |
| Factor | Class | Flash Flood | CF | Factor | Class | Flash Flood | CF |
|---|---|---|---|---|---|---|---|
| Tropical cyclone index | <1.4 | 180 | −0.49 | Topographic relief (m) | <50 | 1240 | 0.76 |
| 1.4–2 | 662 | −0.13 | 50–100 | 246 | −0.54 | ||
| 2–2.6 | 615 | 0.41 | 100–150 | 61 | −0.87 | ||
| 2.6–3.2 | 108 | 0.31 | 150–200 | 17 | −0.92 | ||
| >3.2 | 1 | −0.88 | 200–300 | 2 | −0.97 | ||
| Annual rainfall (mm) | <1581.7 | 465 | 0.53 | >300 | 0 | −1 | |
| 1581.7–1649.3 | 366 | 0.07 | Land use type | Grassland | 58 | −0.52 | |
| 1649.3–1712.8 | 221 | −0.4 | Farmland | 731 | 0.57 | ||
| 1712.9–1778.4 | 237 | −0.3 | Building land | 502 | 0.93 | ||
| >1778.4 | 277 | −0.08 | Forest land | 186 | −0.82 | ||
| H24_100 (mm) | <250 | 125 | −0.42 | Brushland | 2 | −0.57 | |
| 250–350 | 561 | −0.34 | Water conservancy facilities | 74 | 0.75 | ||
| 350–450 | 710 | 0.37 | Water area | 3 | −0.34 | ||
| 450–550 | 157 | 0.74 | Marshland | 5 | 0.62 | ||
| >550 | 13 | 0.11 | Other land | 5 | 0.65 | ||
| Elevation (m) | <500 | 1344 | 0.36 | Population density (people/km2) | <410.9 | 930 | −0.3 |
| 500–1000 | 212 | −0.65 | 411–2219.2 | 513 | 0.58 | ||
| 1000–1500 | 10 | −0.89 | 2219.3–7463 | 123 | 0.86 | ||
| 1500–2000 | 0 | −1 | 7463.1–14,515.1 | 0 | −1 | ||
| >2000 | 0 | −1 | >14,515.1 | 0 | −1 | ||
| NDVI | <0.5 | 189 | 0.84 | ||||
| 0.5–0.64 | 308 | 0.78 | |||||
| 0.64–0.74 | 370 | 0.59 | |||||
| 0.74–0.8 | 493 | −0.01 | |||||
| >0.8 | 206 | −0.75 | |||||
| Factor | Beta | Wald | Sig | Exp(B) |
|---|---|---|---|---|
| Tropical cyclone index | −0.116 | 0.267 | 0.015 | 0.891 |
| Annual rainfall | −0.275 | 5.054 | 0.025 | 0.759 |
| H24_100 | 0.535 | 5.68 | 0.017 | 1.707 |
| Elevation | 0.42 | 10.461 | 0.001 | 1.521 |
| Topographic relief | 1.087 | 156.835 | 0 | 2.965 |
| Land use type | 1.107 | 186.566 | 0 | 3.024 |
| NDVI | 0.489 | 15.904 | 0 | 1.631 |
| Population density | −0.349 | 3.232 | 0.002 | 0.705 |
| B | −0.144 | 6.092 | 0.014 | 0.866 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Jia, H.; Xiong, J.; Cheng, W.; Li, K.; Pang, Q.; Yong, Z. Flash Flood Susceptibility Assessment Based on Geodetector, Certainty Factor, and Logistic Regression Analyses in Fujian Province, China. ISPRS Int. J. Geo-Inf. 2020, 9, 748. https://doi.org/10.3390/ijgi9120748
Cao Y, Jia H, Xiong J, Cheng W, Li K, Pang Q, Yong Z. Flash Flood Susceptibility Assessment Based on Geodetector, Certainty Factor, and Logistic Regression Analyses in Fujian Province, China. ISPRS International Journal of Geo-Information. 2020; 9(12):748. https://doi.org/10.3390/ijgi9120748
Chicago/Turabian StyleCao, Yifan, Hongliang Jia, Junnan Xiong, Weiming Cheng, Kun Li, Quan Pang, and Zhiwei Yong. 2020. "Flash Flood Susceptibility Assessment Based on Geodetector, Certainty Factor, and Logistic Regression Analyses in Fujian Province, China" ISPRS International Journal of Geo-Information 9, no. 12: 748. https://doi.org/10.3390/ijgi9120748