1. Introduction
The provision of high-quality education is a cornerstone of the success of our civilization and today aims to meet the growing demand for highly skilled professionals, particularly in the fields of science, technology, engineering, art, and mathematics (STEAM). Moreover, high-quality education has been defined as one of the sustainable development goals by the United Nations [
1], thereby encouraging researchers, practitioners, and businesses to develop new methods, approaches, and tools to achieve this goal. The need for high-quality education spans from early childhood to adulthood and further to older ages. Consequently, the importance of lifelong learning has been globally and officially recognized by governments and policy-makers, including the European Union and the Republic of Korea [
2,
3].
In contrast to the formal education offered at schools, lifelong learning often occurs in informal contexts, such as workplaces, community centers, outdoor environments, and homes [
4,
5,
6]. This is even more topical today given the pedagogical consequences of the COVID-19 pandemic [
7,
8,
9]; for example, in many European countries formal classroom-based education was transformed to distance education and people were told to self-isolate at home. Although the COVID-19 pandemic has subsided, the importance of distance education has not diminished [
10].
The pandemic accelerated the growth of homeschooling, with the percentage of homeschooling households more than doubling from 5.4 percent in spring 2020 to 11.1 percent by fall 2020 [
11]. This increase was driven by health concerns, safety, and dissatisfaction with traditional school curricula. Even before the pandemic, homeschooling was on the rise, as indicated by the steady increase in homeschooled students in the U.S. from 1999 to 2007 [
12].
These trends underscore the expanding need for educational systems that support personalized learning tailored to individual needs, regardless of the educational context. Whether in formal schooling, distance learning, or homeschooling, personalized learning strategies can enhance educational outcomes by addressing diverse learning preferences and circumstances. To achieve this, lifelong learning services should be designed using a distributed and flexible architecture that enables on-demand delivery of learning experiences in both formal and informal settings.
The diversity of learners, their needs, and contexts poses a significant challenge to learning environment developers striving to deliver high-quality education to all users. One-size-fits-all services that offer uniform content to learners are insufficient in addressing this challenge. Furthermore, with the incorporation of artificial intelligence (AI) technologies, including machine learning algorithms and natural language processing systems, the landscape of educational platforms has evolved. In addition to the diverse learning contexts associated with informal learning, learners may exhibit distinct learning styles [
13,
14,
15,
16]. Thus, adaptive and context-aware learning environments (ACALE), empowered by AI, have emerged to provide meaningful educational services tailored to learners’ unique personalities, requirements, and learning contexts [
17,
18,
19,
20,
21,
22]. ACALEs leverage AI to analyze and interpret learners’ context data, enhancing learning experiences and outcomes by personalizing educational content and activities. ACALEs aim to enhance learning experiences and outcomes by personalizing educational content and activities, through the analysis and interpretation of learners’ context data [
23,
24,
25,
26,
27].
We previously conducted a systematic literature review on 53 ACALEs [
17]. Notable contributions of our analysis of the 53 ACALEs included common taxonomies to identify different aspects of adaptive learning experiences, the establishment of the core features of context awareness and adaptation, and the laying of a foundation for future conceptualization and implementation of ACALEs. Since our 2019 review, several more recent literature reviews have emerged [
28,
29,
30,
31,
32]. These newer reviews either did not address the specific arguments and points we make in this paper or their findings align with and reinforce our proposal. The current study builds upon the foundation laid in our previous work and incorporates the findings from these recent literature reviews, further advancing conceptual and practical frameworks for ACALEs.
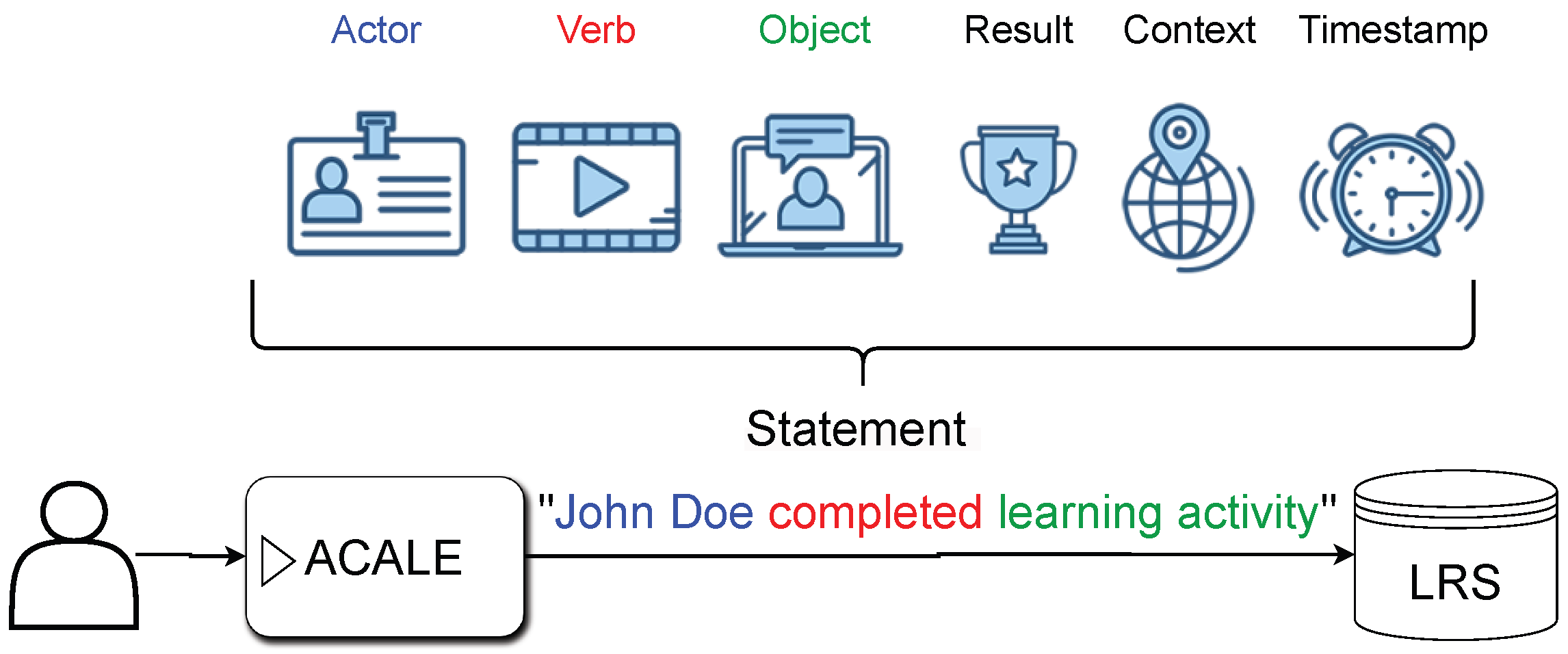
Despite the high number of ACALEs developed in previous research, the majority of them have adaptation engines tightly integrated into the application logic [
17]. An important consequence of this architectural design decision is that it is difficult to reuse the adaptation engine in other ACALE projects. Another consequential shortcoming of a tightly coupled adaptation engine is that it is challenging to extend the adaptation engine’s capabilities, thus limiting future adaptive learning scenarios. Moreover, our analysis of the 53 ACALEs indicated that the majority of their implementations did not follow any standards established in the domain of learning technologies [
17]. There were two exceptions that used technologies such as learning objects and learning object repositories [
33,
34]; however, these technologies are somewhat outdated and have been replaced by the more recent Experience API (xAPI) standard and with its storage technology called learning record store (LRS). Finally, previous studies used diverse expressions and terms to explain the central concepts related to ACALEs, thus indicating a need for establishing a common vocabulary for the field.
There have been several attempts to ease the work of developers of context-aware systems by decoupling the application logic from adaptation decisions. For instance, the GRAPPLE framework [
35] provided an adaptation engine integrated with multiple LMSs, but it was limited to adaptive hypermedia. The Adaptive e-Learning Framework (AeLF) [
36] aimed to support lifelong learning with a distributed user model and xAPI standard but offered limited adaptation types and extensibility. The Adaptive Learning Open Source Initiative (ALOSI) [
37,
38] proposed an ecosystem of decoupled adaptation engines focusing on adaptive assessments. The Generalized Intelligent Framework for Tutoring (GIFT) [
39] provided a service-oriented framework for intelligent tutoring systems but lacked comprehensive extensibility and interoperability.
In this paper, we aim to overcome the aforementioned shortcomings of previous research by proposing Lightlore, an adaptation framework for designing and developing ACALEs. Lightlore aims to make educational context-aware applications easier to develop by providing a reference architecture with a decoupled adaptation engine and adopting state-of-the-art and standardized learning technologies: xAPI for the representation and communication of trackable learning experiences, and LRS for the storage of these experiences. This comprehensive framework enhances the extensibility and interoperability of adaptive learning environments, facilitating seamless integration and communication between various adaptive learning systems.
First, we conducted a follow-up literature review for use in the scenario-based design (SBD) [
40] software design process, resulting in a conceptual model of Lightlore. This was followed by the design of a reference architecture and a proof-of-concept implementation in the form of an adaptive hypermedia system (AHS) that leverages the proposed framework. Through this research, we provide the following contributions to the field of adaptive learning: (I) a conceptual model and reference architecture for Lightlore, (II) a decoupled adaptation engine, (III) interoperability and extensibility through a proposed xAPI profile, (IV) enhanced personalization capabilities, and (V) a proof-of-concept implementation. These contributions aim to advance the field by offering practical solutions and a strong basis for ongoing innovation in adaptive learning technologies.
The remainder of this paper is organized as follows:
Section 2 provides background information for the research conducted, and
Section 3 states our research objectives, and evaluates and describes research methodologies in order to address those research objectives.
Section 4 introduces Lightlore—the proposed framework. Details of Lightlore, including its development process, conceptual model, and reference architecture, are presented in
Section 4.1,
Section 4.2 and
Section 4.3, respectively.
Section 5 presents the implemented proof-of-concept and results. In more detail, related work is laid out in
Section 6. Finally, we discuss some issues related to the design of Lightlore and give conclusions in
Section 7 and
Section 8, respectively.
4. Lightlore: An Adaptation Framework
In this section, we provide the details of the proposed adaptation framework called Lightlore, including a summary of the results of the SBD process, a description of the conceptual model of the framework and its key components, and a detailed account of the reference architecture based on the conceptual model.
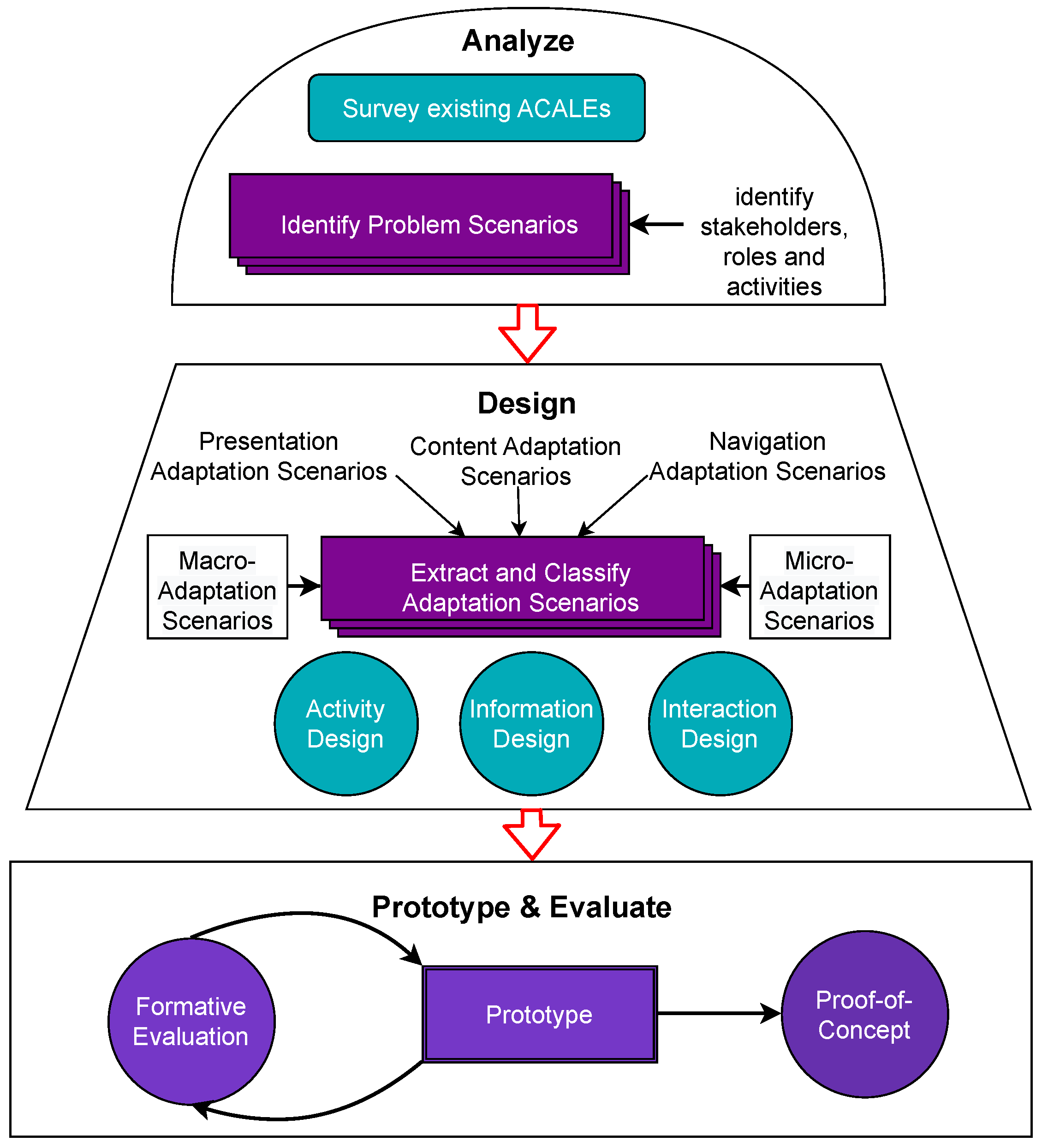
4.1. Scenario-Based Development Process
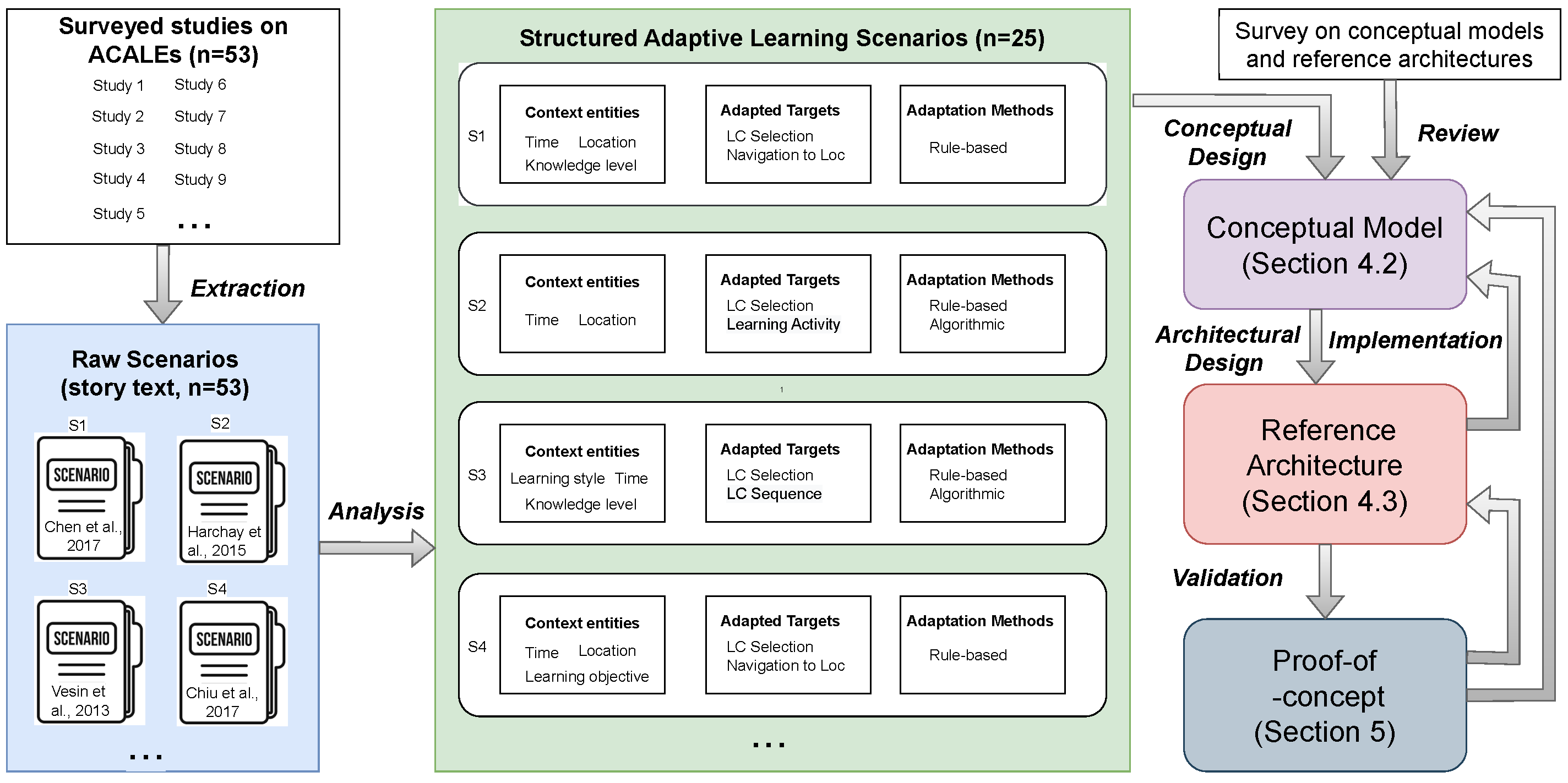
The design of the conceptual model and reference architecture and the subsequent implementation of the proof-of-concept were driven by an in-depth analysis of existing ACALEs and related scenarios. As depicted in
Figure 3, we re-analyzed 53 ACALE studies that had been identified in a previous literature review [
17] and recent studies (
n = 14) discovered during the current study. In the analysis, we extracted raw scenarios in the form of stories that were descriptive of the adaptation processes. We then distilled and synthesized these unstructured scenarios, thus resulting in structured adaptive learning scenarios that had a common structure and explicit manifestation of how the adaptation was made in each case. The concepts and terminology used for the structuring were based on the results of Hasanov et al. [
17]. We removed 28 raw scenarios because they were a poor fit to the structured format, due to a lack of details in the articles. In the end, we were left with 25 distinct structured adaptive learning scenarios, based on which we designed a conceptual model of Lightlore and derived a reference architecture design from this. The final logical step was to instantiate the reference architecture as a proof-of-concept, to evaluate the feasibility of the framework as well as validate it. The process of creating the conceptual model, reference architecture, and proof-of-concept was iterative, as the output of each sub-process often prompted changes in the other sub-processes. Moreover, it is important to note that our review of existing reference models and architectures also played a role in this development. For a more detailed comparison between our results and related work, please refer to
Section 6.
4.2. Conceptual Model
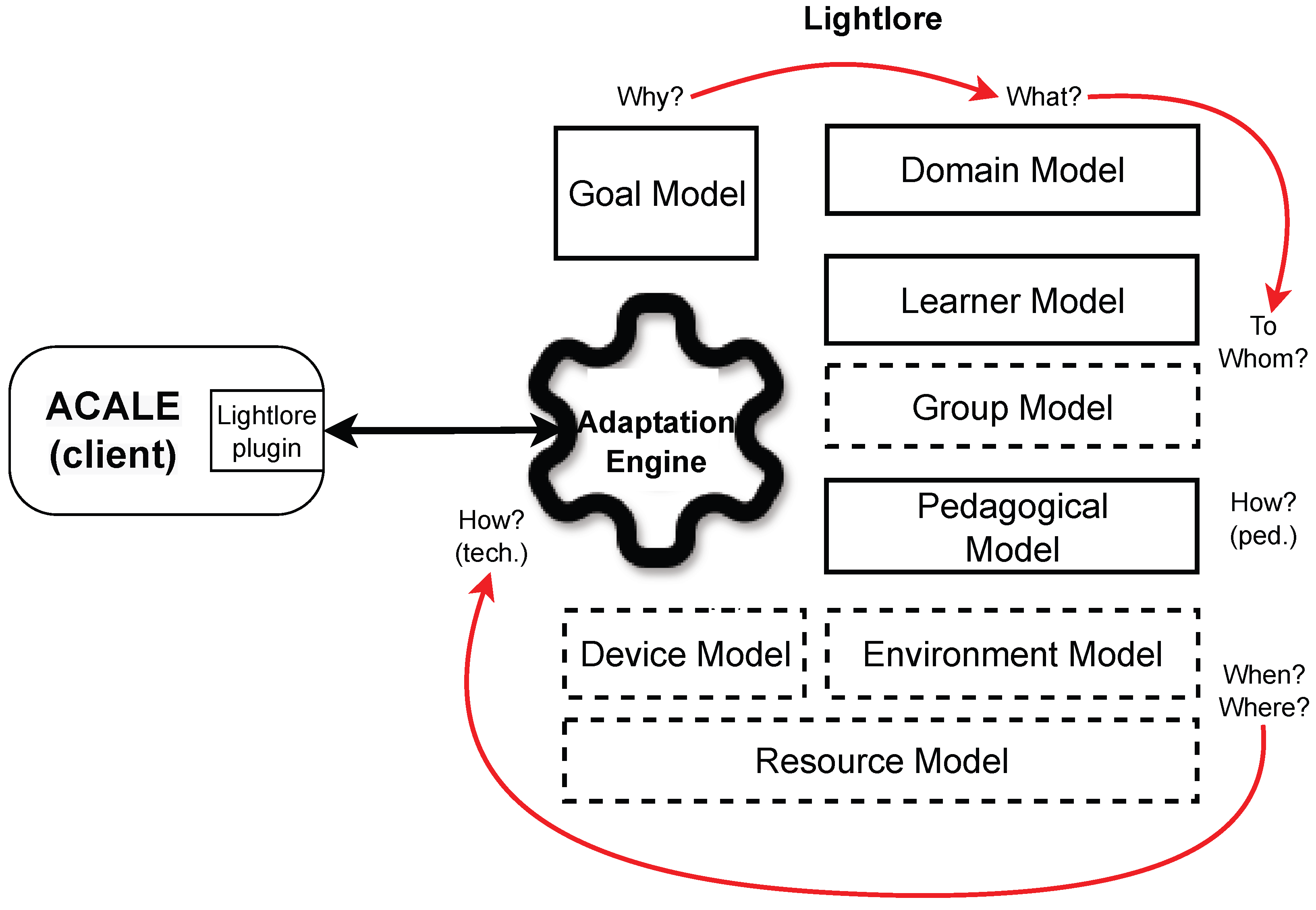
The purpose of the conceptual model of the Lightlore framework is to provide a common theoretical basis and vocabulary for ACALE developers to design their ACALEs. The conceptual model of Lightlore, depicted in
Figure 4, describes both the essential (solid outline) and optional (dotted outline) building blocks, which were identified based on the analysis of the scenarios described in the previous section. The figure shows the conceptual process of adaptation, which provides answers to several key questions related to learning experience adaptation, and their relations to various data models involved in the process.
In the conceptual model, Lightlore demonstrates versatility in support of a spectrum of ACALEs, encompassing adaptive hypermedia systems, intelligent tutoring systems, educational games, and so forth. Acting as a pivotal intermediary, the Lightlore plugin establishes connectivity between Lightlore and any ACALE, wherein the latter functions as the client soliciting adaptation services from the Lightlore server. Facilitating seamless integration, an ACALE developer can leverage the plugin to streamline communication with Lightlore, thereby alleviating the intricacies inherent in development. As an illustrative instance, the plugin assumes the role of abstracting the Experience API (xAPI) service, furnishing a simplified interface for accessing the learning scenario data stored within the xAPI service. Variants of the plugin can be tailored to distinct environments, such as integration with a game engine or incorporation into an adaptive hypermedia platform, thereby enhancing the adaptability and interoperability across diverse learning ecosystems.
Based on the results of our scenario analysis, we identified four essential building blocks—goal model, domain model, pedagogical model, and learner model—that form the minimum required configuration for completing an adaptation process. The goal model answers the adaptation question “Why?”. This might be a domain concept, representing either a new goal to follow or a sequence of concepts to learn. The goal model can also refer to the pedagogical model through pedagogical goals. The domain model answers the adaptation question “What?”. It describes how the conceptual representation of an application domain is structured. Here, the concepts of the domain and their relationships are modeled. The pedagogical model states the relevant pedagogical knowledge, including the pedagogical strategies and rules that provide the pedagogical basis for certain adaptation methods and techniques. The pedagogical model answers the adaptation question “How (pedagogical)?”. The learner model answers to the adaptation question “To whom?”. It represents the learner’s knowledge, interests, preferences, goals and objectives, action history, type, style, and other relevant properties that might be useful for the adaptation. We avoided using the term “user model” here because an adaptation system may also have other users apart from learners, such as teachers and researchers, whose roles are detailed further in
Section 7.7.
Of the optional building blocks, the group model is conceptually related to the user model, and it refers to maintaining a collaborative profile of groups of learners or stereotyping search results by learner attributes, such as location, age group, or gender, which later can be used to rank and recommend results. The environment model and the device model answer the adaptation questions “When?” and “Where?”, respectively, and they refer to the contextual information surrounding the learner (e.g., location, noise level, time, luminosity) or technical information (e.g., the type of the learner’s device, network properties). The underlying resource model maintains the resource data and defines resource retrieval by other models using URIs or querying information when there is not any particular resource linked to a particular element of other models. Finally, the adaptation engine answers the adaptation question “How (technical)?”. It represents the techniques and methods for providing adaptation based on the models and defines the fundamental adaptation functionality. It can perform content adaptation, presentation adaptation, navigation adaptation, and so forth.
4.3. Reference Architecture
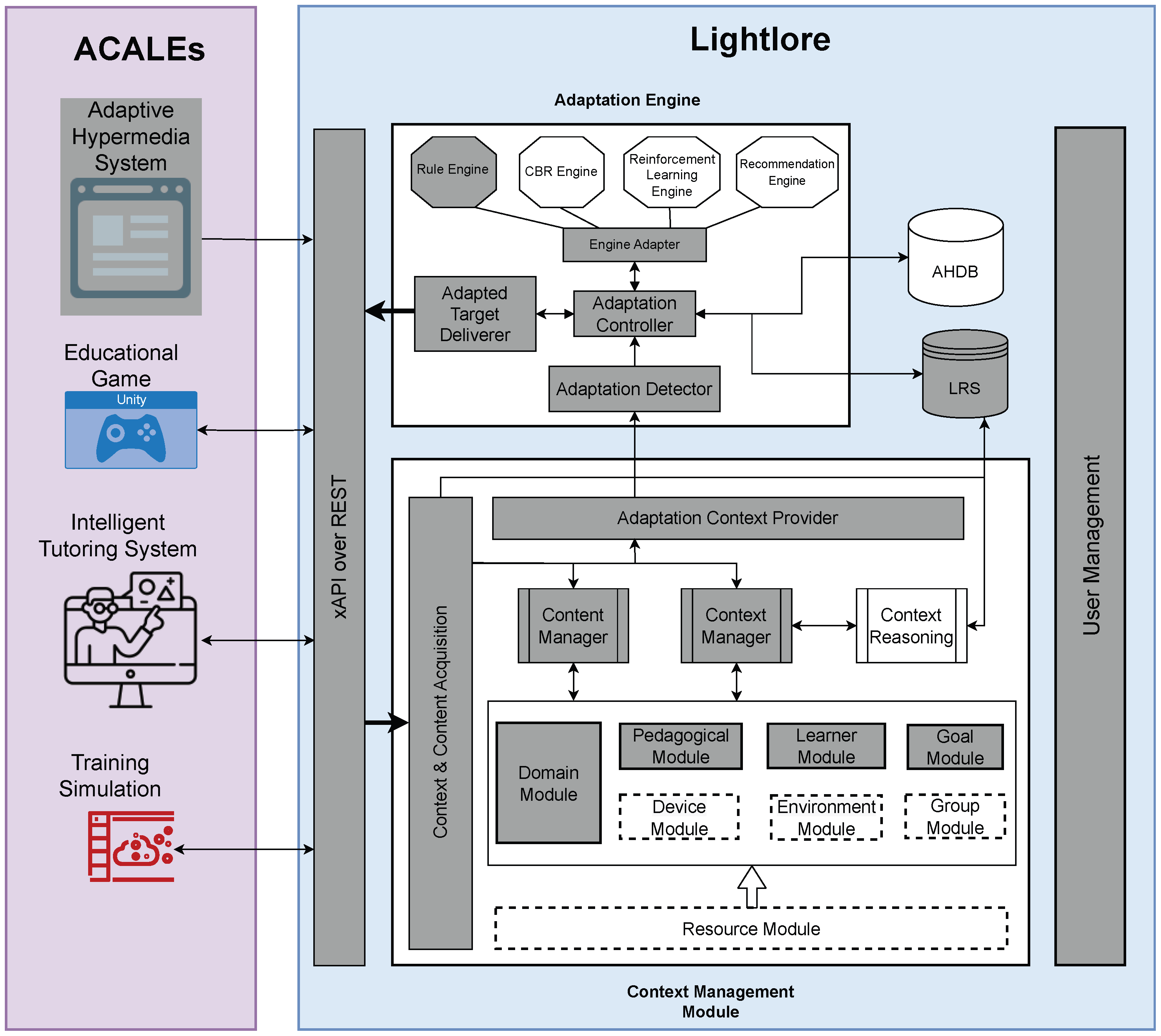
Figure 5 shows the reference architecture, with the highlighted components those that we implemented in the proof-of-concept, which is described in detail in
Section 5. Let us first consider the high-level process of adaptation and the main units involved in the process. An ACALE represents the client in the communication process, which consumes adaptation services provided by Lightlore. We selected xAPI over REST as the communicating protocol between the ACALE and Lightlore because it is an emerging standard in the context of online learning environments. ACALEs can be of various kinds, such as an adaptive hypermedia system, an educational game, an intelligent tutoring system, or a training simulation. The high-level adaptation process involves the ACALE’s interaction with the adaptation engine and context management module. An ACALE is responsible for collecting any context updates and sending them to the context and content acquisition module in Lightlore. Context and content updates can contain anything that reflects a change in the learner’s context, such as data from wearable sensors, a change in the learner’s location, a click of a link on the user interface, or a timer reaching a certain value. When Lightlore receives a context update, its context management module stores it in the respective module and calls for the adaptation engine to conditionally perform adaptation based on the updated information. For example, a location change of the learner may not trigger adaptation if the learner does not enter the vicinity of a predefined point of interest. Because of this conditional nature of the update–adaptation process, the adaptation target deliverer uses asynchronous communication to deliver the adaptation result to the ACALE; a callback method of the ACALE is invoked by the adaptation target deliverer when newly adapted content is available.
4.3.1. Context Management Module
As its name suggests, the context and content acquisition component receives contextual data and learning content from an ACALE. When the ACALE connects to the Lightlore for the first time, it initializes the data models by sending current information about the content and context to the context and content acquisition component. This module delegates the managing functionality for each type of data to the context and content managers accordingly.
The content manager manages learning content by identifying suitable (default) content or content prescribed by domain experts’ representation technology and allows the realization of static and dynamic domain data (it can differentiate them, direct changes to either of them, etc.). Static domain data are data of learning content.
The context manager handles contextual data that are in the original raw form and processes them, since there is a diversity of types of data. Contextual data can include, for example, information about the learner, a group of learners, and technical details of the used device and surrounding environment, which include the physical and temporal aspects. The context manager can utilize a separate context reasoning service to request processing of raw contextual data and receive back higher-level meanings. A number of different context reasoning approaches have been proposed over the years, including those based on ontology, objects, logic/rules, key–value pairs, markup schemes, and graphical representations [
53]. While these approaches all have certain merits, research has shown that ontologies are particularly useful for modeling context data and for performing reasoning on the data [
17]. Nevertheless, rather than fixing a certain context reasoning technique to the reference architecture, we proposed that different techniques could co-exist in Lightlore, and they could be activated on a need basis by the developer. Thus, although we recommend utilizing an ontology-based context modeling approach and ontology-based reasoning to derive new knowledge about the learner’s context, it is ultimately up to the ACALE developer which approach they wish to adopt.
The domain module, pedagogical module, learner module, group module, device module, environment module, goal module, and resource module are the components that comprise the respective data models (see
Figure 4) and operations to store, alter, and query the data models. Thus, their objective is to provide the necessary data for the content manager and context manager, as well as the means for ACALEs to update and query these data. The resource module is separated from the other modules because it acquires and handles data originating from external sources. It is used when there is a need for data that are not directly received from the ACALE or cannot be provided by other users of Lightlore, such as pedagogues or domain experts, through the administration interface. Examples of such resources include weather APIs and other web APIs.
Context reasoning analyzes the collected context information to derive meaningful insights. It uses inference mechanisms and machine learning techniques to understand and predict the learner’s needs, preferences, and potential issues. For example, ontology-based reasoning can be employed to derive new context information. Suppose the context data reveal that
Using ontology-based reasoning, the context reasoner can infer new contexts:
These newly derived contexts are then stored back in the learning record store (LRS) according to the appropriate context module, ensuring that the latest context information is available for future adaptations and analyses.
The adaptation context provider sends the latest changes in the context of adaption to the adaptation engine. It gathers and provides relevant information about the system’s context, including its current state, environmental conditions, user preferences, and other contextual factors. This component ensures the building of a comprehensive understanding of the system’s operating environment and that only relevant and impactful context updates are communicated to the adaptation engine, optimizing the adaptation process.
4.3.2. Adaptation Engine
The main role of the adaptation detector is to monitor incoming contextual data and detect when an adaptation is needed. It receives the latest updates about the learner’s environment and decides whether or not to proceed with the adaptation process. This decision-making can be implemented in different ways, such as using predefined rules and algorithms to identify significant changes or triggers that warrant an adaptation, or employing a threshold-based detector where the developer can configure threshold values. Once a need for adaptation has been detected, the adaptation controller acts as the coordinator of the adaptation process. It first assesses the detected needs, then orchestrates the necessary components to implement the adaptation, ensuring the learning environment is dynamically adjusted to meet the learner’s current context and requirements.
The adaptation history database (AHDB) is responsible for storing information about completed adaptations (e.g., input, parameters, or output). The purpose of this is three-fold: (i) to enable improvement of the adaptation process (e.g., rules) through the analysis of historical adaptation data (e.g., by machine learning); (ii) to enable caching, whereby the main controller can retrieve and return the results of a previously completed adaptation if the same adaptation request is repeated; and (iii) to provide vital information for system monitoring and debugging. This database is essential for tracking the effectiveness of different adaptation strategies and making data-driven improvements to the adaptation process over time.
Lightlore can support a number of different adaptation engines through the engine adapter. This adapter acts as an interface that translates the adaptation controller’s directives into specific actions performed by the respective engines. Examples of possible engines include, but are not limited to, (i) rule-based engines that work with a set of rules that define how the adaptation targets should be changed based on context data values; (ii) case-based reasoning (CBR) engines that leverage past experiences and cases to solve new problems by finding similar situations and adapting their solutions to the current context; (iii) recommendation engines that use algorithms to suggest the most appropriate learning resources and activities for the learner based on their preferences, past interactions, and contextual information; and (iv) reinforcement learning engines that use trial-and-error methods and feedback loops to optimize learning strategies by continuously improving the system’s performance through interaction with the environment. Additionally, the engine adapter allows for the extension of more diverse AI/ML-based adaptation engines, enabling the framework to integrate emerging technologies that further enhance adaptability in educational settings. Each engine represents a unique approach to leveraging AI within e-learning, demonstrating the framework’s capability to integrate diverse AI techniques for adaptive educational experiences. This adaptive architecture exemplifies the synergy between AI and e-learning, fostering more intelligent, responsive, and effective educational environments.
Finally, the main controller acts as the central decision-making unit of the adaptation engine. It processes signals from the adaptation detector and determines the appropriate adaptation strategy. It coordinates with other components to implement the chosen adaptation and passes the adapted target to the adapted target deliverer. The adapted target deliverer ensures that the adapted content and instructions are optimally delivered to the learner. It takes into account the context and adaptation directives to present the learning materials appropriately.
User management is responsible for managing user identities, roles, and permissions within the adaptive learning environment. Its main purpose is to authenticate users, including learners, educators, content experts, researchers, and developers; assign appropriate roles; and control access to system resources and functionalities based on their roles and permissions. User management ensures that each user has the necessary privileges to perform their tasks, while maintaining security and privacy. Additionally, user management handles user profile management, including storing and updating user information, preferences, and activity history.
4.4. xAPI Profile
To develop an xAPI profile, a systematic approach was applied. First, we conducted a thorough analysis of the adaptation framework’s requirements and functionalities, followed by a review of existing xAPI profiles [
54] relevant to adaptive learning, so as to ensure compatibility and interoperability with other xAPI-compliant systems. We identified gaps between existing profiles and framework requirements, guiding the definition of new concepts or extensions. We then validated these with domain experts and educators, refined them based on the feedback, and implemented them within the framework’s data model. Rigorous testing ensured functionality and interoperability, culminating in comprehensive documentation and publication for community review and adoption. This iterative methodology ensured the profile aligns with best practices and effectively supports adaptive learning environments. As a result of this process, the proposed xAPI profile incorporated five existing external vocabulary records and twenty-three internally devised concepts. The detailed xAPI profile can be found in
Table 1.
The goal of achieving interoperability should transcend basic syntactical compatibility between systems exchanging data and must include true semantic interoperability [
55,
56]. This requires systems to not only adhere to standardized data formats but also possess a shared understanding of the data’s meaning within the broader learning ecosystem. Our work in this paper advances this objective by leveraging existing xAPI profile vocabularies and introducing new ones to address existing gaps. This methodology not only utilizes well-established standards but also targets deficiencies in current vocabularies, thereby enhancing the semantic interoperability of adaptive learning systems.
5. Proof-of-Concept
We have implemented a first proof-of-concept of Lightlore, the proposed adaptation framework, which comprises the shaded areas of the reference architecture presented in
Figure 5. To substantiate the applicability and intended purpose of Lightlore, we first developed an educational hypermedia system for learning data structures without any adaptation features. Then, the system was transformed into an adaptive hypermedia system through loosely coupled integration with the Lightlore proof-of-concept.
5.1. Implementation without Adaptation
Data structures were chosen as the target subject of the educational hypermedia system because, based on our experience, they are challenging for many undergraduate students. Moreover, there exists an abundance of learning content on data structures in various modalities (e.g., text, illustrations, videos, interactive hands-on exercises), thus reducing the time needed for learning material preparation. Moreover, we used the Bootstrap library to enable a responsive user interface across mobile and desktop platforms. It is noteworthy that the process of adapting the presentation of the content to different client device profiles was often handled by adaptive hypermedia systems in the past [
57], whereas now it can be easily done by the application developer using libraries like Bootstrap.
5.2. Adaptation to Learning Style
To implement adaptation in the proof-of-concept, we selected learning style as the adaptation context, and presentation and navigation as the adaptation targets. There are various ways to identify the learning style of a learner, such as Honey and Mumford’s Learning Style Questionnaire (LSQ) [
16], Kolb’s Learning Style Inventory (LSI) [
14], and Felder and Silverman’s Learning Style Model (FSLSM) [
15]. These have been utilized in several previous adaptive learning environments [
26,
58,
59]. Among these models, we chose FSLSM for the proof-of-concept for several reasons: (i) it has previously been applied to several adaptive learning environments [
60]; (ii) it was developed for engineering education [
15]; (iii) it has been shown to be well measurable in the context of e-learning [
61]; and (vi) it does not only cover learning styles but also teaching styles. The underlying notion of FSLSM is that learners have preferences regarding how they receive and process information. Based on this notion, FSLSM establishes five dimensions of learning styles:
Information processing: active and reflective learners.
Information perception: sensory and intuitive learners.
Information reception: visual and verbal learners.
Information understanding: sequential and global learners.
Information organization: inductive and deductive learners.
Among these dimensions, we chose information reception and information understanding because they are suitable for web-based learning content. For example, the information perception dimension would be challenging to properly support in a web-based environment. Moreover, the two selected dimensions could clearly demonstrate the differences between adapted learning contents. Teaching styles were not considered in the first version of the proof-of-concept, as we focused solely on the learner.
The information reception dimension concerns different modalities of information presentation. The preferred way for visual learners to receive information is by seeing the information; they remember best if the information is presented in the form of pictures, graphs, diagrams, animations, and other visualization techniques. In contrast, verbal learners prefer verbal explanations to visual perception. Providing them with recorded online lectures about each specific topic can be helpful for them.
The information understanding dimension concerns how the learner progresses toward understanding information. Sequential learners prefer to explore information in an ordered, step-wise manner. To improve learning efficiency, the information should be presented in small units that follow one another. Conversely, global learners prefer to see the big picture of the learning content (e.g., an overview of the module) and think in terms of systems. They may wade through information in a seemingly chaotic manner, and then synthesize it to form an understanding. Giving a global learner the freedom to access all lecture contents and letting them devise their own method of going through the contents is likely to lead to efficient learning.
To measure the learner’s learning style, we utilized the index of learning styles questionnaire [
62] (ILS), which was developed and validated to measure four of the five dimensions of FSLSM. We only adopted questions related to the information reception and information understanding dimensions, making the number of questions 22 out of 44, following the similar questionnaire-shortening experience of a past study [
63].
To implement adaptation according to the Information Reception and Information Understanding dimensions of FSLSM, specific strategies were designed for presentation and navigation within the educational hypermedia system.
For the visual/verbal dimension, we focused on adapting the presentation of learning content. For visual learners, the content was enriched with various visual elements such as pictures, graphs, diagrams, animations, and other visualization techniques. These elements were designed to make the information more accessible and engaging for visual learners, who remember best when information is presented in a visual format. In contrast, for verbal learners, the default level of visuals was maintained, emphasizing textual and verbal explanations. Recorded online lectures and detailed written descriptions were provided to cater to their preference for verbal communication.
For the global/sequential dimension, we adapted the navigation within the web application, as depicted in
Figure 6. For global learners, a navigation bar was made visible on the left side of the interface, allowing them to see the big picture of the entire learning course and navigate freely. Additionally, a short overview was provided at the beginning of each learning module to help them holistically synthesize the content. Conversely, for sequential learners, the navigation bar was hidden, to minimize distractions and guide them through the content step-by-step. Instead, sequential navigation was only facilitated through ”Previous” and ”Next” buttons, which were displayed at the bottom of each learning content page. This was designed to help sequential learners follow the information in a logical, ordered manner by directing them through the material one step at a time. Labeled as “Sequential Navigation Cues” in the figure, at the end of each learning content page, connecting words and phrases were added to encourage sequential learners to follow the information in a logical, ordered manner.
5.3. Proof-of-Concept Operation
The activity diagram in
Figure 7 illustrates the proof-of-concept from the learner’s perspective. The ILS questionnaire is presented after the learner signs up to create a personal profile. Afterward, the learner model, which is stored in LRS, is updated accordingly on the Lightlore side. The questionnaire results are used as the learner’s context for later adaptation. Upon completion of the learner model update, the main page is presented with an opportunity for the learner to state their desired learning goal for the current session. AHS interprets the goal by identifying the name of the chosen course with necessary metadata and requests that Lightlore update the respective goal model. According to the stated goal of the learner, appropriate domain concepts and relationships are retrieved and, along with an updated learner model, further pedagogical functions are performed in the pedagogical module of Lightlore. These pedagogical decisions are translated into the technical language of rules and algorithms during the process of adaptation methods and techniques acquisition. When the necessary inputs such as up-to-date learner’s context and methods and techniques for the adaptation are ready, Lightlore generates an adaptation target and delivers this to the AHS for presentation to the learner. The learner experiences adaptive and personalized learning, with the possibility to start a new course, complete current learning, or continue to the next page, which will trigger updates to the necessary models in Lightlore and request a new adaptation iteration.
5.4. Integration of xAPI
Lightlore utilizes xAPI as a standard for data model and communication and stores learning records in a self-managed open source LRS called LearningLocker [
64,
65] This ensures that data are collected and shared in a consistent and interoperable manner, facilitating the development of adaptive educational systems that can be easily integrated with other tools and platforms.
Figure 8 exemplifies an xAPI statement capturing the completion of the ILS Questionnaire. The ”result” section employs extensions to document the learner’s answers across the four dimensions defined by Felder and Silverman’s Learning Style Model: information processing, information perception, information reception, and information understanding. Each extension encapsulates specific key–value pairs for the questionnaire items, ensuring that all responses are meticulously recorded.
6. Related Work
There have been several attempts to ease the work of the developers of context-aware systems, in terms of decoupling the application logic from the adaptation decisions. As early as 2011, the GRAPPLE Framework [
35] provided an adaptation engine called the Generic Adaptive Learning Environment (GALE) and integrated it with five different LMSs to serve adaptive courses. However, it only uses learning materials in adaptive hypermedia form, thus being unsuitable for other types of learning content. In 2015, the Adaptive e-Learning Framework (AeLF) [
36] was proposed, and it aims to support lifelong learning by providing an architecture that enables different LMSs to interact with a distributed user model, known as the AeLF User Model (AUM). The AUM is utilized by the AeLF Adaptation Engine (AAE) as an additional source of user information to inform adaptations. The AeLF experience learner tracker (AELT) captures all interactions between the learner and LMS, leveraging the xAPI standard. However, the AAE is limited to only two types of adaptation: content adaptation and navigation adaptation. Additionally, there is no interface to allow the extensibility of the AAE. An ecosystem of decoupled adaptation engines with popular LMSs, content source components, and a bridge between them was proposed by the Adaptive Learning Open Source Initiative (ALOSI) in 2018 [
37,
38]. This approach focused on providing recommended activities based on the learner’s activity. The bridge for adaptivity and the ALOSI adaptive engine were designed to integrate with multiple system components, including LMSs and content sources, to deliver adaptive learning experiences. While robust in facilitating adaptive learning, they exhibited a significant limitation by design, due to a primary focus on adaptive assessments. Finally, the generalized intelligent framework for tutoring (GIFT) [
39] is an open-source architecture designed for authoring, managing, and evaluating ITSs and adaptive instruction. In GIFT, computer-based intelligent agents guide learners according to their learning needs, preferences, and progress toward learning objectives. It provides a service-oriented framework of tools, methods, and standards to make an intelligent tutoring system as efficient as possible.
Despite these adaptive learning engines and frameworks demonstrating promising developments in the past, they are missing a strong sense of extensibility and interoperability and the ability to encompass diverse types of ACALEs. Therefore, we proposed the Lightlore adaptation framework through the presentation of a conceptual model, reference architecture, and a proof-of-concept implementation. Lightlore adopts modern educational standards for data modeling and communication (xAPI) and incorporates a meticulously devised xAPI profile. This comprehensive framework aims to enhance the extensibility and interoperability of adaptive learning environments, facilitating seamless integration and communication between various adaptive learning systems.
7. Discussion
The goal of this study was to create an adaptation framework for the development of ACALEs. Based on an in-depth analysis of previously proposed ACALEs, we developed a conceptual model and reference architecture for our adaptation framework called Lightlore using a scenario-based design method. We then developed a proof-of-concept AHS that validated the conceptual model and demonstrated the feasibility of Lightlore for delivering educational content on data structures. The results of this study highlight the importance of separating the adaptation framework from the remaining application logic, to facilitate the reuse of the adaptation framework in future ACALEs.
7.1. Answer to Research Question 1
We answered the first research question—what are the essential system components of an adaptive learning environment and how are the components connected to each other?—by proposing the conceptual model and reference architecture of Lightlore. This contribution provides a comprehensive account of the necessary components and their interrelationships, which can guide the development of future ACALEs. The proposed framework and reference architecture offer a solid foundation for further research and development in the field and can be utilized by developers as a guideline and technical foundation to create ACALEs.
One of the key aspects of the proposed framework is the separation of the adaptation engine from the application logic, which provides numerous benefits for developers. This separation can make the integration of the engine into educational systems more efficient and cost-effective, as developers no longer need to spend time and resources developing their own adaptation engines. Similarly, existing adaptation engines can be reused for different ACALEs. Therefore, the separation of the adaptation engine from the application logic makes the engine easier to use for developers, as they can integrate it into their systems without needing to understand the underlying adaptation algorithms. This can result in a more streamlined development process and increased productivity; however, these aspects need to be confirmed in a follow-up study.
7.2. Answer to Research Question 2
The second research question—what are the common terms and expressions to describe an ACALE and adaptation process?—was addressed by the development of a common vocabulary and set of terms used to describe ACALEs and the adaptation process. This result was achieved by a systematic analysis of previous literature on ACALEs [
17] and recent articles analyzed for this study. This process helped to identify common terms and expressions used to describe ACALEs and ensure that the terminology used in Lightlore was consistent with existing standards and best practices in the field. The resulting vocabulary provides a foundation for future research and development in the field and helps ensure consistency and interoperability between different systems. However, this vocabulary is not intended to be final. As new technologies are adopted and new ways of using existing technology emerge, the vocabulary will need to evolve. The foundational nature of the vocabulary means that it can serve as a starting point for ongoing discussions and refinements in the field.
7.3. Answer to Research Question 3
The use of xAPI for client–system communication is another important aspect of our research that helped address the third research question—how can the adaptation framework be interoperable and conform to existing standards? xAPI allows the adaptation engine to gather data from the learning environment and learners in a standardized manner in real time, as well as to adjust the learning content based on the learner’s context and other data. This results in more personalized and thus potentially more effective learning experiences. This is because xAPI allows for the collection of a wide range of learning data beyond the traditional tracking of completion and scores, such as the types of activities learners engage in, their preferences, their interactions with learning content, and their performance over time. The collected data can then be used to provide adaptive feedback and recommendations to learners, which can lead to a more personalized learning experience that better meets their individual needs. However, it is important to note that the use of xAPI alone does not guarantee successful adaptive learning experiences; it requires careful design and implementation of adaptation strategies based on the collected data and chosen pedagogical approach.
Another advantage of xAPI is that it enables interoperability between different learning systems, which can lead to increased innovation and progress in the field. For example, a developed ACALE can be merged with an existing LMS using xAPI. The xAPI specification allows for capturing learning data from a variety of learning experiences and utilizing them for personalized learning services. The standardization of xAPI makes it possible to integrate Lightlore with existing LMSs, without requiring significant changes to the LMS itself. The possibility of integrating Lightlore with existing LMSs is an important aspect to consider when evaluating the potential impact of the framework on the field of ACALEs.
Despite such potential benefits, adaptive system developers may face challenges in utilizing xAPI in their systems. One such challenge is the need for a deep understanding of xAPI and its implementation. This may require additional training and expertise in xAPI development, which can be a barrier for some developers. Additionally, ensuring interoperability with other xAPI-enabled systems can be a challenge, as there may be differences in the implementation of xAPI between different systems. Finally, ensuring data privacy and security can be a challenge when using xAPI, as it requires the collection and sharing of sensitive data. Developers must therefore take measures to ensure that user data are protected and handled securely.
7.4. Implications
With the development of new and improved adaptation algorithms, Lightlore can become even more versatile and powerful, enabling more effective and personalized learning experiences for students.
Lightlore was designed to be extensible and interoperable, which has important implications for the future of adaptive context-aware learning environments. The potential for future expansion and integration with other systems provides an exciting opportunity for innovation and progress in the field. This may lead to the development of more advanced and effective adaptive context-aware learning environments, which can benefit different stakeholders in addition to developers. Learners can benefit from the adaptability and personalization features of ACALEs developed using Lightlore. Lightlore can provide a more engaging and effective learning experience that better meets the needs of each learner compared to traditional one-size-fits-all learning. This is also beneficial for educators, as they can better support each learner, monitor their progress, and provide individual support to struggling students. Moreover, the data collected and managed by the system can be a useful source for researchers to conduct various studies on the process and implications of adaptive learning scenarios.
7.5. Future Directions of Adaptive Context-Aware Learning
The future incorporation of cmi5 [
66] into Lightlore would bring significant benefits to the framework and provide even greater interoperability and flexibility. Cmi5 is a recent standard for learning technology data exchange that builds on xAPI [
67]. It provides a comprehensive and flexible framework for the management of learning experiences and provides greater interoperability between learning systems and the management of learner data.
The adoption of cmi5 in Lightlore would likely involve the creation of a new layer within the framework that integrates with the existing xAPI layer. This new layer would be responsible for managing the exchange of data between the learning environment and the cmi5 server on the Lightlore side, and would provide a more flexible and extensible approach to data management and exchange. We plan to explore this direction as a future development of the framework.
7.6. Context-Aware Learning in the Post-COVID-19 Era
Lightlore is particularly relevant during the post-COVID-19 era, due to its potential impact on personalized education delivery at distance. The pandemic accelerated the need for flexible and adaptive learning environments that can support remote, hybrid, and mobile learning, and this is what Lightlore is designed to provide. The ability of the engine to adapt learning experiences to the context of the learner, including their previous knowledge, preferences, location, device, and network connectivity, enables it to provide an optimized learning experience, even in challenging and unpredictable mobile environments. With the ability to provide a flexible and adaptive learning environment that is accessible from anywhere and at any time, Lightlore is well-positioned to support the rapidly evolving needs of education in the post-pandemic era.
7.7. Ecosystem, Roles, and Potential Use Cases
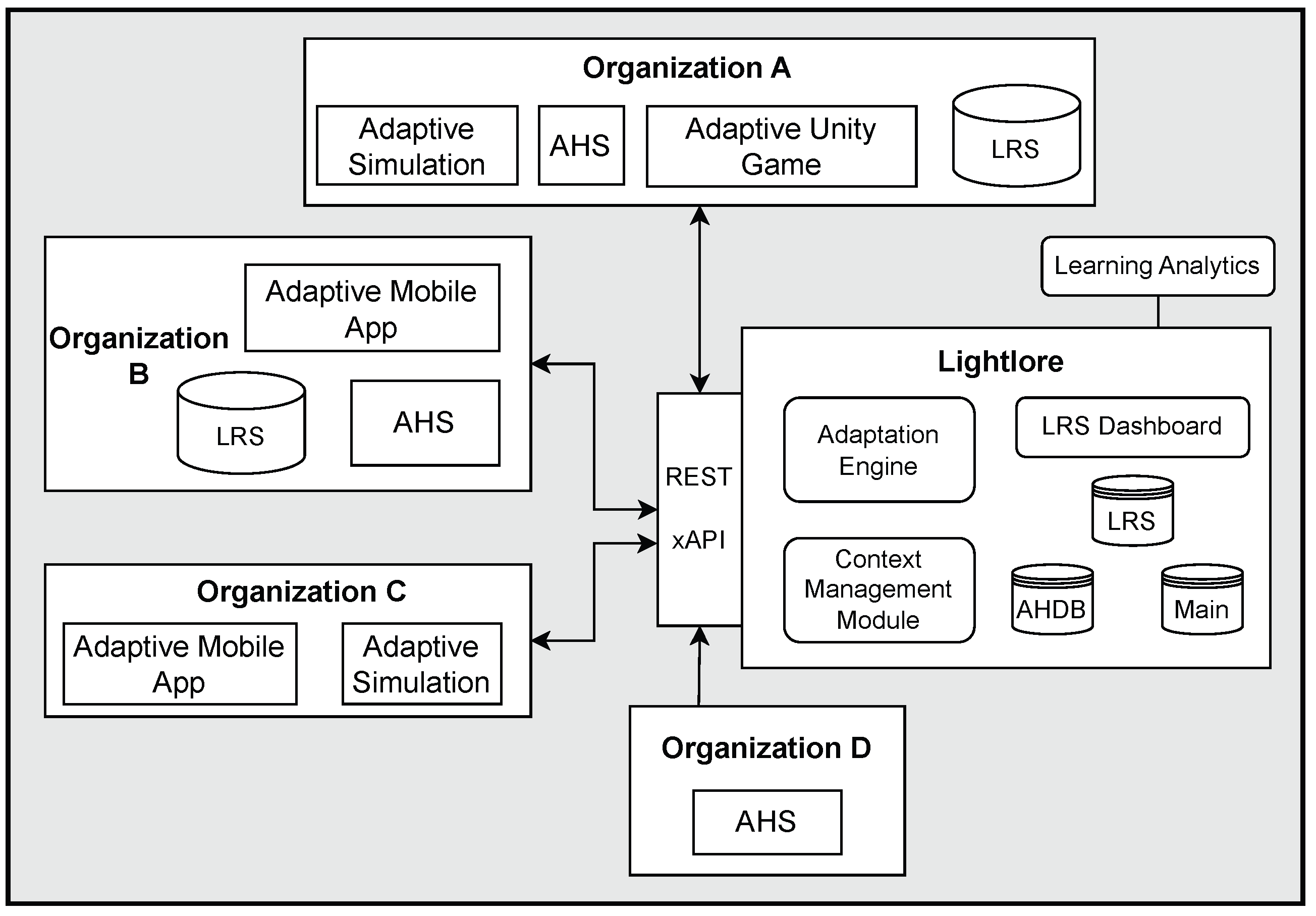
In our vision, Lightlore implementation could provide adaptation services to a number of ACALEs in one or more organizations, thus forming an ecosystem of different adaptive educational systems (
Figure 9). All connected ACALEs exchange information with Lightlore using the xAPI. Lightlore maintains LRS and AHDB instances for each organization, where all data relevant to the organization’s adaptive applications are stored. An organization can also choose to maintain a local LRS instance and allow Lightlore to access it. Moreover, an organization can replicate its LRS instance to its local server if needed. The Lightlore service and its data can be connected to other services, such as learning analytic tools and learning management, through the xAPI or another method.
A systematic literature review investigating stakeholders’ roles in the development of adaptive learning systems highlighted significant opportunities for future research involving key stakeholders [
68]. The review identified a notable gap in educator involvement in the initial design of these systems and emphasized the need for further exploration into whether increased stakeholder inclusion at different stages would improve the effectiveness and user experience of adaptive learning systems. This underscores the importance of considering stakeholder engagement in the development of frameworks like Lightlore, to ensure comprehensive and effective adaptive learning environments.
Although the primary users of an ACALE ecosystem are learners, we also acknowledge the importance of other roles that can contribute to and benefit from the ecosystem.
Figure 10 depicts the different roles that we have envisioned for the ecosystem.
Developers can benefit from the separation of the adaptation engine from the application logic, which increases flexibility and makes it easier to integrate different components and systems. By leveraging xAPI as a standard for communication, developers can also more easily track and analyze learning data, leading to the more effective and efficient development of adaptive educational systems.
Educators can benefit from the ability of Lightlore to provide more personalized and adaptive learning experiences for their students. With Lightlore, educators can more easily monitor student progress and identify areas where individual students may be struggling, allowing them to provide more targeted support and intervention.
Researchers can benefit from the extensive data collection and analysis capabilities of Lightlore. By leveraging the power of xAPI, researchers can more easily gather and analyze large amounts of data on student learning and behavior, leading to new insights and opportunities for research. They could explore the use of learning analytics in adaptive learning systems and investigate how data-driven insights can be utilized to personalize learning pathways and support educators in making informed decisions. One study indicated that data mining analysis utilizing xAPI data achieved higher prediction accuracy compared to traditional online learning data [
69].
Domain experts can utilize Lightlore to seamlessly integrate domain-specific knowledge and content into the learning ecosystem using the domain ontology editor. They can create and incorporate specialized content and assessments more effectively, resulting in a richer and more comprehensive learning experience for students.
7.8. Limitations
Our study has several limitations that should be considered when interpreting the results, and future research should address these limitations to further validate and build upon the findings of this study. First, this study excluded user testing, which is a crucial component of evaluating the pedagogical effectiveness of ACALEs. We plan to conduct user testing in a future study to determine the impact of Lightlore on learning outcomes. Second, our work did not address the potential scaling issues that may arise when implementing the framework on a larger scale. Further research is needed to assess the scalability of Lightlore, to determine the impact of the framework on large-scale learning environments. Third, while the conceptual model of Lightlore supports the coexistence of multiple adaptation techniques, the current proof-of-concept only demonstrated adaptation to two of the four learning style dimensions of the Felder–Silverman learning style model. More research is needed to investigate the feasibility of other adaptation techniques and how they can be integrated into Lightlore. Finally, Lightlore was evaluated through the implementation of an AHS system that focused on a single subject, data structures. Future research should explore the applicability of the framework to other domains and types of educational systems, such as intelligent tutoring systems and educational games, as well as how it can be customized to meet the needs of specific educational contexts. Better integration with other educational technologies and systems could enable a more seamless and efficient implementation of Lightlore in various educational settings.
Despite the advantages of the software of the framework, there are still some areas that need to be improved. For example, it is still at a proof-of-concept level and needs to be more robust/mature to be used in more complex real-life systems. This could be achieved through performing more extensive tests (such as unit tests). Different kinds of case studies may also help to prove the suitability of the framework.
8. Conclusions and Future Work
This study presented Lightlore, an adaptation framework for developing xAPI-conformant ACALEs. The findings comprise a conceptual model of the framework including the key concepts and terms, a reference architecture based on the conceptual model, and a proof-of-concept system implemented as an AHS. Our goal in the study was to provide a conceptual model and reference architecture that improve the flexibility of developing adaptive educational systems, thus making it easier for developers to create personalized learning experiences for a range of users and use cases. By separating the adaptation engine from the application logic and using xAPI as a standard for communication, Lightlore provides technical benefits for developers with a more extensible and interoperable adaptation engine. Despite the acknowledged limitations of this study, the results provide a foundation for future research and development in the field of ACALEs and highlight the potential of Lightlore as a valuable tool for developers and educators.
The conceptual model of Lightlore provides an abstract schema for contextual interpretation and adaptation decision-making, facilitating a conceptual understanding of the adaptive learning process. Complementing this, the reference architecture offers a technical blueprint, consisting of distinct modules such as the context management module and the adaptation engine. These modules orchestrate the adaptation processes within the educational ecosystem, ensuring seamless integration and efficient operation. Furthermore, the framework accommodates diverse user roles, enabling different stakeholders to engage with and contribute to the adaptive learning environment. Leveraging the xAPI as the data model and communication protocol, this framework caters to various types of ACALEs, fostering interoperability and scalability.
A proof-of-concept system based on the conceptual model was implemented as an AHS for teaching data structures, using the Felder–Silverman learning style model for adaptation. The web application was designed to connect to the adaptation engine on the server to update the learning model and goal model, as well as retrieve the adaptation target generated by the engine. Our prototype demonstrated the technical benefits of the Lightlore framework, including its ability to separate the adaptation engine from the application logic and the use of xAPI as a standard for communication. It could potentially provide learners with personalized learning experiences based on their individual learning styles, while developers could benefit from a more extensible and interoperable architecture. The proof-of-concept demonstrated the feasibility of the Lightlore framework to support the development of context-aware learning environments.
The results of this study contribute to the field of adaptive learning by providing a conceptual model of an adaptation framework for building context-aware learning environments, along with a reference architecture and a proof-of-concept implementation. By separating the adaptation engine from the application logic and leveraging xAPI, Lightlore offers an extensible and interoperable approach to developing adaptive educational systems. This framework has the potential to benefit learners, educators, developers, researchers, and domain experts by providing flexible and personalized learning experiences. The proof-of-concept presented in this paper demonstrates the feasibility of Lightlore in an adaptive hypermedia system for learning data structures.
The findings and resolutions outlined in this paper can pave the way for future investigations into ontology implementation and the semantic enrichment of complex concepts, offering diverse functionalities. Exploring the integration of social networks and fostering services for enhanced social interaction has emerged as a promising avenue to bolster student motivation and augment learning outcomes. Additionally, leveraging data mining techniques to discern behavioral patterns for storage within student profiles stands as another avenue for enhancing the Lightlore platform.
Moving forward, concrete and actionable future work includes integrating cmi5 standards into the Lightlore framework, and enabling seamless interoperability with cmi5-compliant learning management systems. Additionally, implementing a reinforcement learning engine within the adaptation engine architecture will allow for dynamic adaptation strategies, enhancing the platform’s responsiveness to diverse and evolving learner needs. Rigorous user experiments will be conducted to evaluate Lightlore’s impact on learning outcomes and learner satisfaction across various educational settings. Furthermore, scalability assessments will be undertaken to validate the framework’s effectiveness in accommodating larger user bases and educational contexts. Further research into data collection methodologies and evaluation techniques will be crucial for refining the platform’s adaptive capabilities and ensuring optimal learning experiences. These endeavors promise to advance the Lightlore framework, fostering continuous improvement and innovation in adaptive context-aware learning environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}