Analysis of the Impact of Residential Property and Equipment on Building Energy Efficiency and Consumption—A Data Mining Approach


Abstract
:1. Introduction
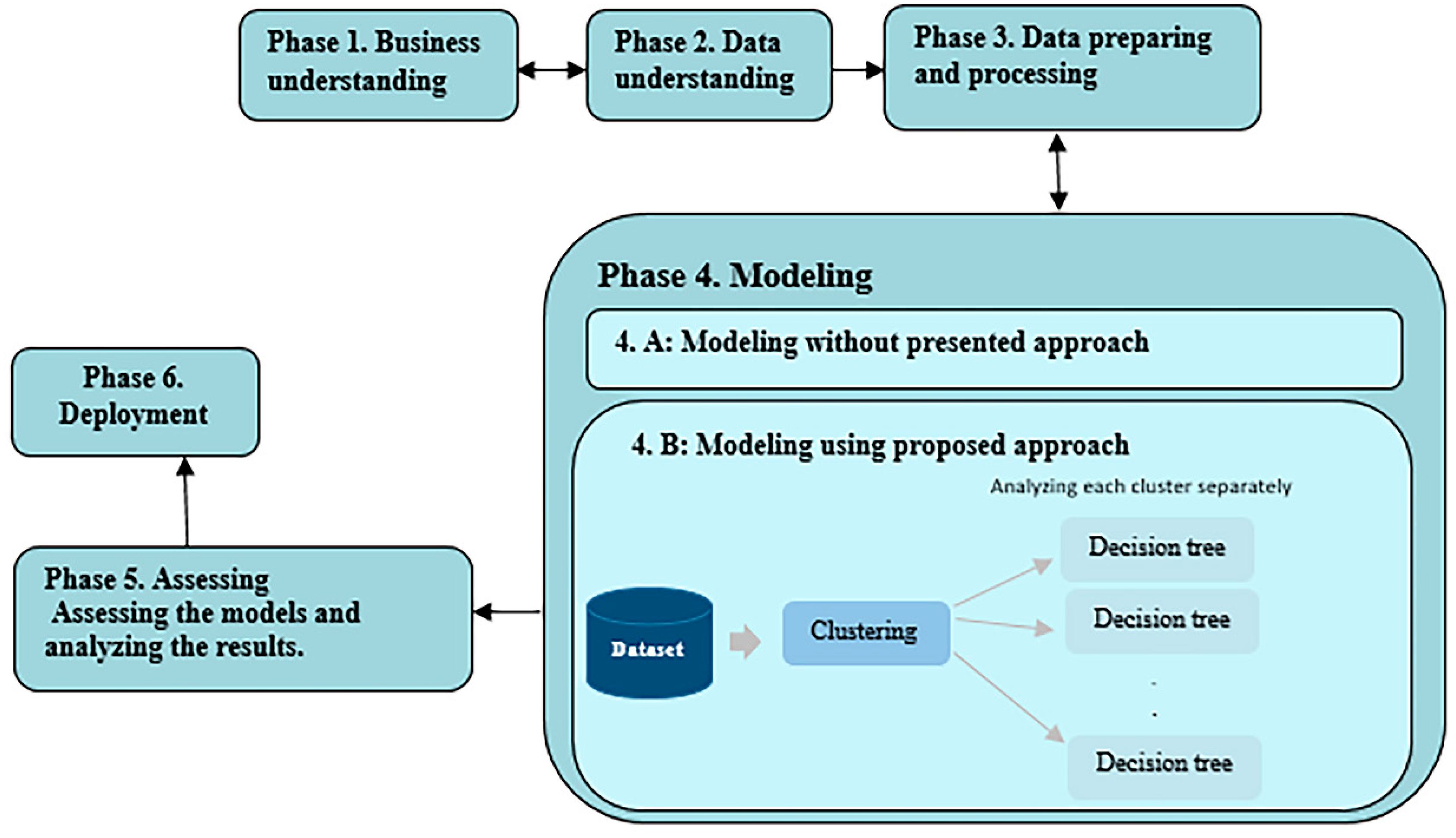
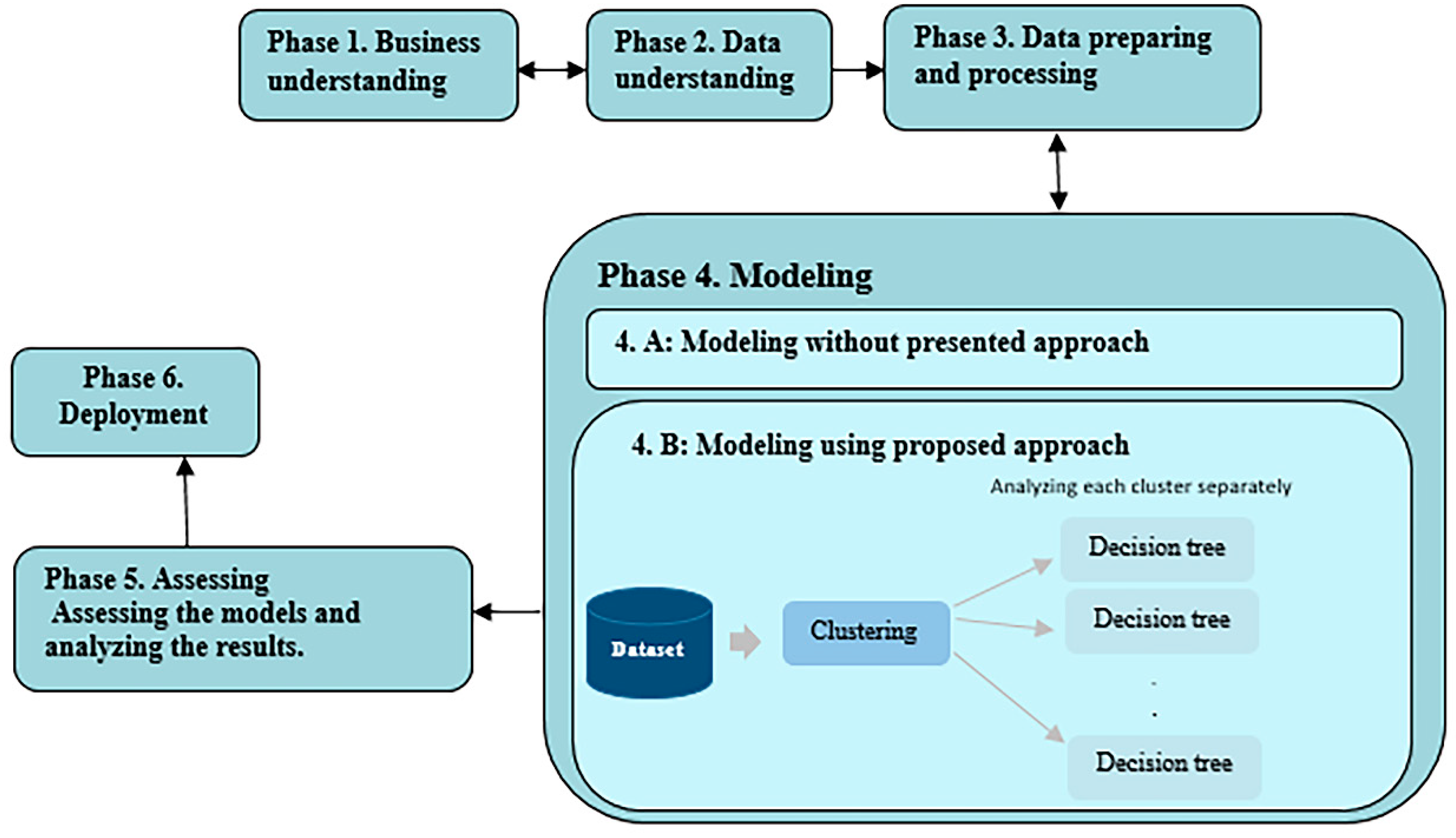
2. Methodology and Approach Presented
2.1. Methodology
2.2. The Proposed Approach
3. Modeling and Analyzing the Energy Efficiency without the Proposed Approach
- Ptrgt: Percentage of records that have the characteristics of the relevant rule and are also in the target energy efficiency group.
- Prule: Percentage of records that have the characteristics of the relevant rule.
- Carefully scrutinizing the rules of rows 2 to 5, it is concluded that installing a boiler will result in better energy efficiency. Dwelling which install boilers in 2009 are in better energy efficiency group. They are followed by the boilers installed in 2005 and 2012. The homes whose boiler was installed in 2010 have not a good Energy Efficiency.
- A comparison of rules 8 and 9 indicates that in area 1, tariffs do not yield an improved energy efficiency. Of course, this was seen among other households, but was not provided due to the low support value.
- In the rules of rows 1, 11 and 13, the household energy efficiency group is very bad. The issue is their built year (built before 1930). Obviously, in old houses, the thermal performance and energy consumption of equipment are weak compared to new ones. In general, only 0.35% of the old homes of datasets have energy efficiency groups A and B, while nearly 52% of them are in weak energy efficiency groups (E, F, and G). But in newly-built houses (after 1996), these percentages reach 13.8% for the energy efficiency groups A and B, and only 2% for poor energy efficiency groups.
- Rules 1, 10 and 11 refer to similar old houses that are located in different regions. Among these rules, the homes of Wales are in better condition in terms of energy efficiency.
- Data set records are in different climate zones (Table 1) and same energy efficiency rating is not obtained with similar conditions in a cold climate zone or a warm climate zone. Region 7 has the most A, B rating (3.84%) and region 5 the least (1.99%). This difference should be referring to the buildings structure, different equipment, and surely the family lifestyle.
- It is obvious that installing insulation on the ceiling and walls leads to a reduction of energy dissipation. Rules 12 and 13 show that an improvement in energy efficiency is achieved by installing insulation in the roof of residential buildings. Also, rules 6 and 7 state that the structure of the cavity wall is better than other structures. Policies to install new insulators in homes that do not have the proper equipment, especially among older homes, can lead to significant improvements in energy efficiency.
4. Modeling and Analyzing the Energy Efficiency Using the Proposed Approach
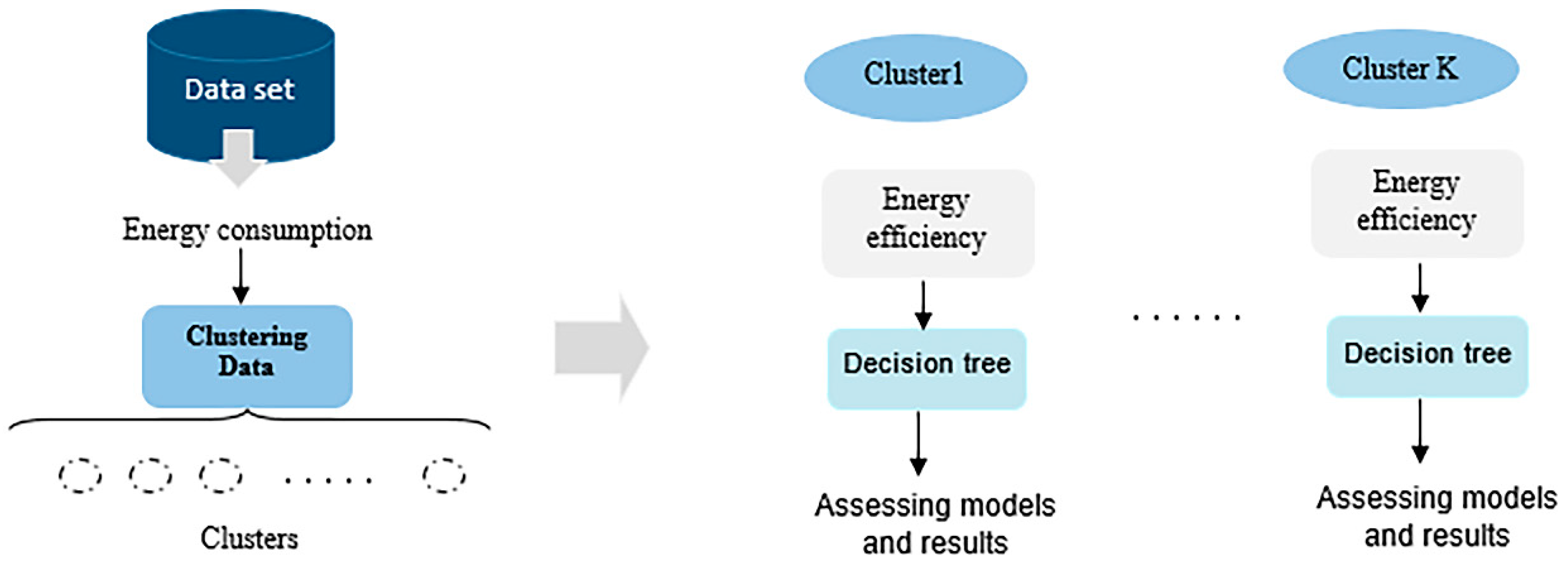
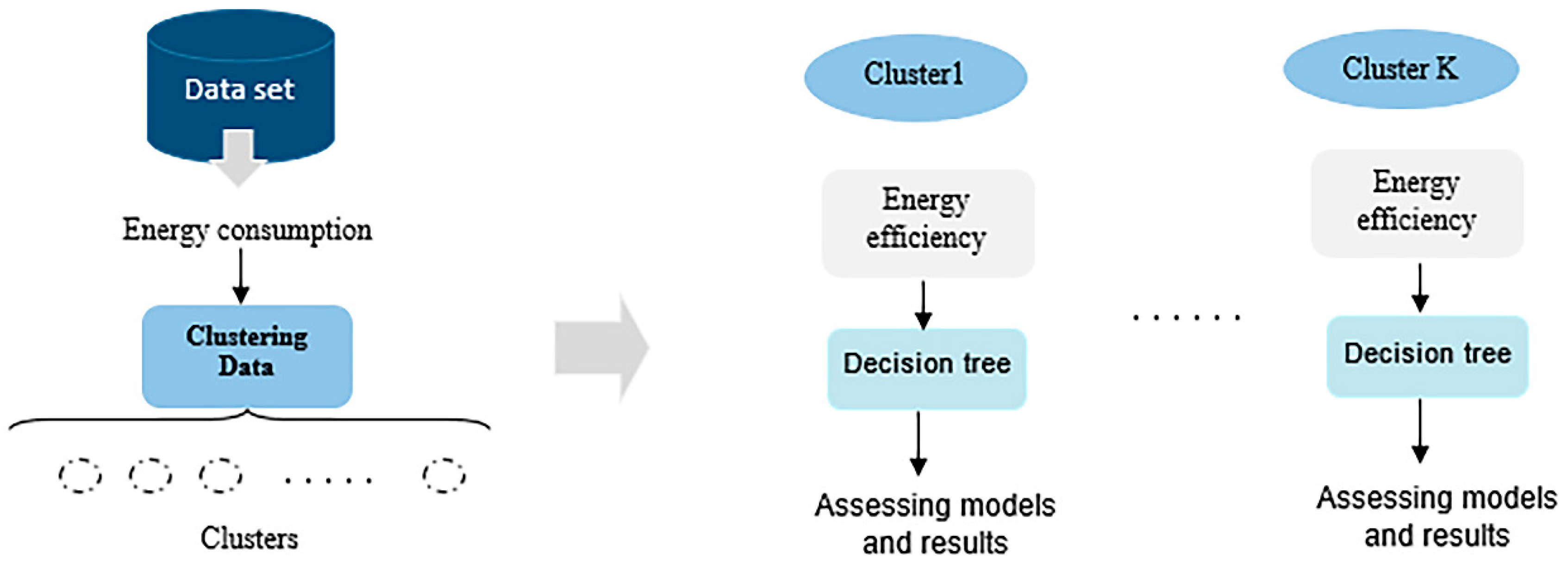
4.1. Clustering Data
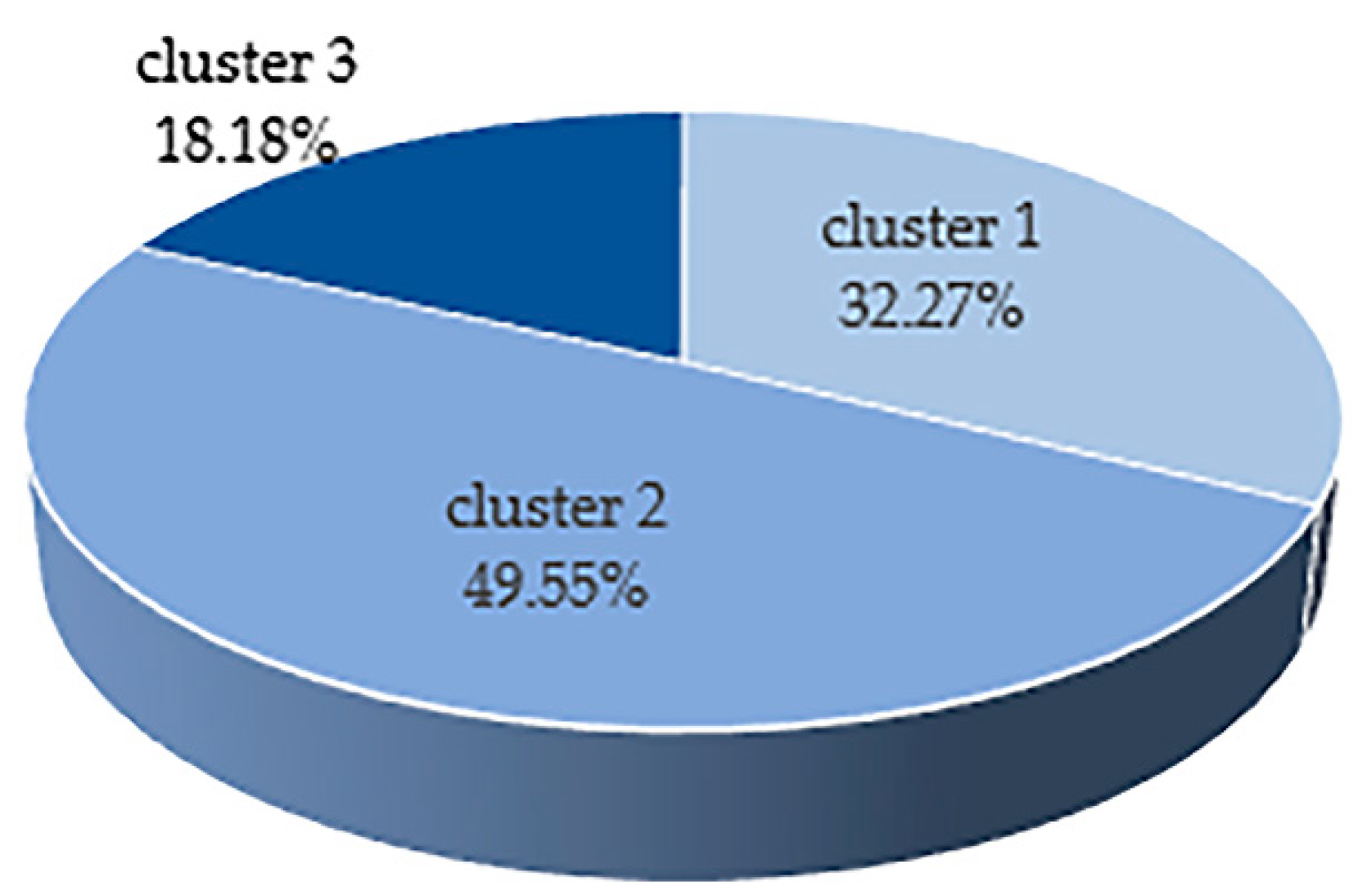
- Cluster 1: This cluster’s homes are old (almost 68% built before 1930). Most of the households have a D label in the energy efficiency group and half of them have houses with an area of 51 m2 to 100 m2.
- Cluster 2: 27.5% of the homes were built between 1968 and 1982. Most of the households have a D label in the energy efficiency group and 58.6% of them have houses with an area of 51 m2 to 100 m2. The households of this cluster have more energy consumption than those of the other clusters.
- Cluster 3: Most of the households have a C label in the energy efficiency group. The cluster homes are small (59% of homes have an area less than 51 m2). In comparison to other clusters, this cluster contains more newly-built houses and these also have the lowest energy consumption.
4.2. Modeling the Energy Efficiency in Each Cluster
- Economic tariff 7 Electricity in this cluster has also shown its impact. More than 34% of the homes that have this tariff have the D label, while more than 46% of the homes which do not use this tariff are labeled C. By comparing rules 2 and 3, it can also be concluded that the use of this tariff in small houses has a greater impact on poor energy efficiency.
- Survey households in this cluster also state that a greater percentage of homes that do not use this electricity tariff 7 are better in energy efficiency than those using tariff 7. This different percentage in the small houses of this cluster (area less than 51 m2) is shown in Table 5.
- Rules 4 and 5 stated that newly built houses are in good condition in terms of energy efficiency and old ones have a poor energy efficiency. The survey reveals that 36.9% of households living in newly built houses have an A or B label, and 3.28% of the old ones have a G label.
- Rules 6 and 8 stated that, firstly, large old houses have not a good energy efficiency. Also, they state that among these homes, the ones which use electricity tariff 7 are better off.
- Rules 9 and 10 refer to the role of house structures in energy efficiency. So, in newly- constructed houses with a flat structure the energy efficiency groups are A and B, and other house structures have a C label.
- In Wales, houses which have a detached structure, are old (built before 1930) and which have installed boilers have an energy efficiency group C (rule 7).
- The good performance of boiler installation in the residential houses of this cluster is evident. In the 12th, 16th and 17th rules, the homes are not newly-built, but are located in the energy efficiency group C. The existence of a boiler in these houses, structured as mid-terrace and end-terrace, has diminished the role of the built-year.
- A comparison of rules 11, 15 and, 18 shows that similar homes in different areas have different energy efficiencies. The study of climatic conditions shows that the groups of areas that are located in one rule are not similar in terms of temperature and have different climates. Thus, it cannot be said that just the similarity or the difference in weather has led to different energy efficiencies. However, in this cluster, households living in Wales have generally a better energy efficiency.
- In the rules 13 and 14, newly-built houses are noted in good energy efficiency groups. It is important to say that newly-built flats have the best efficiency. In fact, the type of house structure is not ineffective in the energy performance.
5. Assessment and Deployment
5.1. Assessment
5.2. Deployment and Discussion
- In general, the installation of boilers will lead to an improved energy efficiency. Dwelling which installed boilers in 2009 have better energy efficiency than others and ones which install boiler in 2010 have the weakest performance, which is seen as an urgent need to replace or modify these boilers.
- Most old homes suffer from unfavorable energy efficiency. This is also reflected in the proposed approach. Homes in the high-consumption cluster are older than those in the low-consumption cluster. In old houses, the appliances and structures have a poor energy efficiency performance. Therefore, planning for structural improvements, installing proper insulation and switching equipment, especially in high-consumption cluster houses, is a constructive way to improve energy efficiency.
- Not using electricity tariffs 7 yields better energy efficiency group in most homes.
- In homes with similar attributes, not using this tariff has resulted in a better energy efficiency group. However, the electricity tariff 7 has different effects in each cluster. An analysis of the approach presented shows that in the low-consumption cluster, the energy efficiency is poor, particularly in small (less than 51 m2) and old houses which do not use this tariff.
- The building structure influences different effects in the proposed approach. In the medium-consumption cluster, flats have a more favorable energy efficiency group than other structures, even among the newly built ones. Also, old homes which are structured as detached have a good energy efficiency group in this cluster. On the other hand, it has been seen before that old houses do not have a good energy efficiency.
- In the high-consumption cluster, homes in Wales have better energy efficiency than homes with similar attributes but which are in different areas.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Han, J.; Pei, J.; Kamber, M. Data Mining Concepts and Techniques, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J.C. A survey on data mining techniques applied to energy time series forecasting. Energies 2015, 8, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Read, B.J. Data mining and science? Knowledge discovery in science as opposed to business. In Proceedings of the 12th ERCIM Workshop on Database Research, Amsterdam, The Netherlands, 2–3 November 1999. [Google Scholar]
- Yu, Z.; Fung, B.C.; Haghighat, F. Extracting knowledge from building-related data—A data mining framework. In Building Simulation; Tsinghua Press: Beijing, China, 2013; Volume 6, pp. 207–222. [Google Scholar]
- Watts, C.; Jentsch, M.F.; James, P.A. ‘Evaluation of domestic Energy Performance Certificates in use’. Build. Serv. Eng. Res. Technol. 2011, 32, 361–376. [Google Scholar] [CrossRef]
- Watson, P. An introduction to UK Energy Performance Certificates (EPCs). J. Build. Apprais. 2010, 5, 241–250. [Google Scholar] [CrossRef]
- Di Corso, E.; Cerquitelli, T.; Piscitelli, M.S.; Capozzoli, A. Exploring Energy Certificates of Buildings through Unsupervised Data Mining Techniques. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 991–998. [Google Scholar]
- Pasichnyi, O.; Wallin, J.; Levihn, F.; Shahrokni, H.; Kordas, O. Energy performance certificates — New opportunities for data-enabled urban energy policy instruments? Energy Policy 2019, 127, 486–499. [Google Scholar] [CrossRef]
- Koo, C.; Hong, T. Development of a dynamic operational rating system in energy performance certificates for existing buildings: Geostatistical approach and data-mining technique. Appl. Energy 2015, 154, 254–270. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Li, G.; Chen, H.; Shen, L.; Xing, L. Evaluation of the energy performance of variable refrigerant flow systems using dynamic energy benchmarks based on data mining techniques. Appl. Energy 2017, 208, 522–539. [Google Scholar] [CrossRef]
- IEEE Industry Applications Society. Power Systems Engineering Committee. IEEE Recommended Practice for Electric Power Systems in Commercial Buildings; American National Standards Institute: New York, NY, USA, 1991. [Google Scholar]
- Danish, M.S.S.; Senjyu, T.; Ibrahimi, A.M.; Ahmadi, M.; Howlader, A.M. A managed framework for energy-efficient building. J. Build. Eng. 2019, 21, 120–128. [Google Scholar] [CrossRef]
- Yu, Z.J.; Haghighat, F.; Fung, B.C. Advances and challenges in building engineering and data mining applications for energy-efficient communities. Sustain. Cities Soc. 2016, 25, 33–38. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.L. Influence of psychological, family and contextual factors on residential energy use behavior: An empirical study of China. Energy Procedia 2011, 5, 910–915. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; MacGill, I.F.; Sproul, A.B. Statistical analysis of driving factors of residential energy demand in the greater Sydney region, Australia. Energy Build. 2015, 105, 9–25. [Google Scholar] [CrossRef]
- Naji, S.S. Application of adaptive neuro-fuzzy methodology for estimating building energy consumption. Renew. Sustain. Energy Rev. 2016, 53, 1520–1528. [Google Scholar] [CrossRef]
- Pérez-Chacón, R.; Luna, J.M.; Troncoso, A.; Martínez-Álvarez, F.; Riquelme, J.C. Big data analytics for discovering electricity consumption patterns in smart cities. Energies 2018, 11, 683. [Google Scholar] [CrossRef] [Green Version]
- Kao, Y.T.; Zahara, E.; Kao, I.W. A hybridized approach to data clustering. Expert Syst. Appl. 2008, 34, 1754–1762. [Google Scholar] [CrossRef]
- Niknam, T.; Amiri, B.; Olamaei, J.; Arefi, A. An efficient hybrid evolutionary optimization algorithm based on PSO and SA for clustering. J. Zhejiang Univ. A 2009, 10, 512–519. [Google Scholar] [CrossRef]
- Fathian, M.; Amiri, B. A honey-bee mating approach on clustering. Int. J. Adv. Manuf. Technol. 2007, 38, 809–821. [Google Scholar] [CrossRef]
- Laszlo, M.; Mukherjee, S. A genetic algorithm that exchanges neighboring centers for k-means clustering. Pattern Recognit. Lett. 2007, 28, 2359–2366. [Google Scholar] [CrossRef]
- Capozzoli, A.G. Discovering knowledge from a residential building stock through data mining analysis for engineering sustainability. Energy Procedia 2015, 83, 370–379. [Google Scholar] [CrossRef] [Green Version]
- Heidarinejad, M.D. Cluster analysis of simulated energy use for LEED certified U.S. office buildings. Energy Build. 2014, 85, 86–97. [Google Scholar] [CrossRef] [Green Version]
- Capozzoli, A.; Serale, G.; Piscitelli, M.S.; Grassi, D. Data Mining for Energy Analysis of a Large Data Set of Flats; Thomas Telford Ltd.: London, UK, 2017. [Google Scholar]
- Raatikainena, M.S.-P. Intelligent analysis of energy consumption in school buildings. Appl. Energy 2016, 165, 416–429. [Google Scholar] [CrossRef]
- Jalali Sepehr, M.; Haeri, A.; Ghousi, R. A cross-country evaluation of energy efficiency from the sustainable development perspective. Int. J. Energy Sector Manag. 2019, 13, 991–1019. [Google Scholar] [CrossRef]
- Bienvenido-Huertas, D.; Oliveira, M.; Rubio-Bellido, C.; Marín, D. A Comparative Analysis of the International Regulation of Thermal Properties in Building Envelope. Sustainability 2019, 11, 5574. [Google Scholar] [CrossRef] [Green Version]
- Haeri, A.; Rezaie, K. An approach to evaluate resource utilization in energy management systems. Energy Sources Part B 2016, 11, 855–860. [Google Scholar] [CrossRef]
- Haeri, A. Proposing a quantitative approach to measure the success of energy management systems in accordance with ISO 50001: 2011 using an analytical hierarchy process (AHP). Energy Equip. Syst. 2017, 5, 349–355. [Google Scholar] [CrossRef]
- Haeri, A.; Jafari, M.; Danesh Asgari, S. A new approach for performance evaluation of energy-related enterprises. Energy Equip. Syst. 2018, 6, 16–26. [Google Scholar] [CrossRef]
- Santamouris, M.; Mihalakakou, G.; Patargias, P.; Gaitani, N.; Sfakianaki, K.; Papaglastra, M.; Pavlou, C.; Doukas, P.; Primikiri, E.; Geros, V. Using intelligent clustering techniques to classify the energy performance of school building. Energy Build. 2007, 39, 45–51. [Google Scholar] [CrossRef]
- Haeri, A. Identification and assessment of training needs for employees of wind farms’. Energy Equip. Syst. 2017, 5, 189–196. [Google Scholar] [CrossRef]
- Huang, M.-J.; Sung, H.-S.; Hsieh, T.-J.; Wu, M.-C.; Chung, S.-H. Applying data-mining techniques for discovering association rules. Soft Comput. 2019, 24, 8069–8075. [Google Scholar] [CrossRef]
- Zhang, C.; Xue, X.; Zhao, Y.; Zhang, X.; Li, T. An improved association rule mining-based method for revealing operational problems of building heating, ventilation and air conditioning (HVAC) systems. Appl. Energy 2019, 253, 113492. [Google Scholar] [CrossRef]
- Li, G.; Hu, Y.; Chen, H.; Li, H.; Hu, M.; Guo, Y.; Liu, J.; Sun, S.; Sun, M. Data partitioning and association mining for identifying VRF energy consumption patterns under various part loads and refrigerant charge conditions. Appl. Energy 2017, 185, 846–861. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F. Mining Gradual Patterns in Big Building Operational Data for Building Energy Efficiency Enhancement. Energy Procedia 2017, 143, 119–124. [Google Scholar] [CrossRef]
- Yu, Z.; Jerry, H.F. A novel methodology for knowledge discovery through mining associations between building operational data. Energy Build. 2012, 47, 430–440. [Google Scholar] [CrossRef]
- Rathod, R.R.; Garg, R.D. Regional electricity consumption analysis for consumers using data mining techniques and consumer meter reading data. Electr. Power Energy Syst. 2016, 78, 368–374. [Google Scholar] [CrossRef]
- Li, J.; Panchabikesan, K.; Yu, Z.; Haghighat, F.; Mankibi, M.; Corgier, D. Systematic data mining-based framework to discover potential energy waste patterns in residential buildings. Energy Build. 2019, 199, 562–578. [Google Scholar] [CrossRef]
- Moslehi, F.; Haeri, A. A Genetic Algorithm based framework for mining quantitative association rules without specifying minimum support and minimum confidence. Sci. Iran. 2019. [Google Scholar] [CrossRef] [Green Version]
- Moslehi, F.; Haeri, A.; Martínez-Álvarez, F. A novel hybrid GA–PSO framework for mining quantitative association rules. Soft Comput. 2019, 24, 4645–4666. [Google Scholar] [CrossRef]
- Shafique, U.; Qaiser, H. A comparative study of data mining process models (KDD, CRISP-DM and SEMMA). Int. J. Innov. Sci. Res. 2014, 12, 217–222. [Google Scholar]
- Wirth, R.; Hipp, J. CRISP-DM: Towards a standard process model for data mining. In Proceedings of the 4th International Conference on the Practical Applications of Knowledge Discovery and Data Mining, Manchester, UK, 11–13 April 2000. [Google Scholar]
- IBM SPSS Modeler-Data Mining, Text Mining, Predictive Analysis. Available online: http://www.spss.com.hk/software/modeler/ (accessed on 22 March 2020).
- SPSS Predictive Analytics. Announcing IBM SPSS Modeler 18 - SPSS Predictive Analytics. 2016. Available online: https://developer.ibm.com/predictiveanalytics/2016/03/15/announcing-ibm-spss-modeler-18/ (accessed on 18 May 2020).
- National Energy Efficiency Data-Framework (NEED): Anonymised Data 2014. Available online: https://www.gov.uk/government/statistics/national-energy-efficiency-data-framework-need-anonymised-data-2014 (accessed on 18 May 2020).
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Pandya, R.; Pandya, J. C5.0 algorithm to improved decision tree with feature selection and reduced error pruning. Int. J. Comput. Appl. 2015, 117, 18–21. [Google Scholar]
- Moslehi, F.; Haeri, A.; Gholamian, M. A novel selective clustering framework for appropriate labeling of the clusters based on K-means algorithm. Sci. Iran. 2019. [Google Scholar] [CrossRef] [Green Version]
- Gaitani, C.L. Using principal component and cluster analysis in the heating evaluation of the school building sector. Appl. Energy 2010, 87, 2079–2086. [Google Scholar] [CrossRef]
- Hsu, D. Characterizing Energy Use in New York City Commercial and Multifamily Buildings; ACEEE Summer Study on Energy Efficient in Buildings: Pacific Grove, CA, USA, 2012. [Google Scholar]
- Xiao, Q.W.H. The reality and statistical distribution of energy consumption in office buildings in China. Energy Build. 2012, 50, 259–265. [Google Scholar] [CrossRef]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters; Taylor & Francis: Abingdon, UK, 1973. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
| Variable | Value | Description |
|---|---|---|
| HH_ID | 1 to 49815 | Household identifier. |
| REGION | (E12000001) North-East (E12000002) North-West (E12000003) Yorkshire and the Humber (E12000004) Mid-East (E12000005) Mid-West (E12000006) East England (E12000007) London (E12000008) South-East (E12000009) South-West (W999999999) Wales | Former Government Office Regions (GORs) in England, and Wales. |
| IMD_ENG | 1 to 5 | Index of multiple deprivations 2010 for England. Households are allocated to five groups. (1) The least deprived and (5) the most deprived. |
| IMD_WALES | 1 to 5 | Welsh Index of multiple deprivations 2011. This has five groups. (1) The most deprived and (5) the least deprived. |
| GconsYEAR | Annual gas consumption based on kWh. | |
| GconsYEARValid | Flag of households’ gas consumption. Valid gas consumption (V), households off the gas network (O) and invalid consumption. | |
| EconsYEAR | Annual electricity consumption based on kWh. | |
| EconsYEARValid | Flag indicating households with a valid electricity consumption. | |
| E7Flag2012 | (1) Households with Economy 7 electricity meters in 2012. (0) Households without Economy 7 electricity meters in 2012. | Economy 7 electricity meters. |
| MAIN_HEAT_FUEL | (1) gas (2) other | Main heating fuel. |
| PROP_AGE | (1) before 1930 (2) 1930 to 1949 (3) 1950 to 1966 (4) 1967 to 1982 (5) 1983 to 1995 (6) after 1996 | Age of property construction. |
| PROP_TYPE | (1) detached (2) semi-detached (3) end-terrace (4) mid-terrace (5) bungalow (6) flat | Type of property. |
| FLOOR_AREA_BAND | (1) less than 50 m2 (2) 51 m2 to 100 m2 (3) 101 m2 to 150 m2 (4) more than 150 m2 | Floor area band. |
| EE_BAND | (1) A and B (2) C (3) D (4) E (5) F (6) G | Energy Efficiency Band. (Six groups: A and B grouped). |
| LOFT_DEPTH | (1) less than 150 mm (2) 150 mm or more | Loft insulation depth. |
| WALL_CONS | (1) other (2) cavity wall | Wall construction. |
| CWI | (0) no (1) yes | Cavity wall insulation installed or not. |
| CWI_YEAR | Year of installation of cavity wall insulation. | |
| LI | (0) no (1) yes | Loft insulation installed or not. |
| LI_YEAR | Year of installation of loft insulation | |
| BOILER | (0) no (1) yes | Boiler installed in property or not. |
| BOILER_YEAR | Year of installation of the boiler. |
| Row | Rule | Result (Energy Efficiency) | Percentage |
|---|---|---|---|
| 1 | The built year is before 1930 and the home structure is semi-detached, has cavity walls, an insulation depth less than 150 mm and uses economy 7 electricity meters. | G | 75% |
| 2 | The home area is 51 m2 to 100 m2 and has a mid-terrace structure. The built year is 1966 and 1982, the home has cavity walls and its boiler was installed in 2009. | C | 100% |
| 3 | The home area is 51 m2 to 100 m2 and has a mid-terrace structure. The built-year is 1966 and 1982, the home has cavity walls and its boiler was installed in 2010. | F | 100% |
| 4 | The home area is 51 m2 to 100 m2 and has a mid-terrace structure. The built-year is 1966 and 1982, the home has cavity walls and its boiler was installed in 2006 or 2011. | D | 80% |
| 5 | The home area is 51 m2 to 100 m2 and has a mid-terrace structure. The built year is 1966 and 1982, the home has cavity walls and its boiler was installed in 2005 or 2012. | E | 71.50% |
| 6 | The region is 4 and the built year is 1930 to 1949, the home structure is a flat and which has cavity walls. | C | 100% |
| 7 | The region is 4 and the built year is 1930 to 1949, the home structure is a flat and it does not have cavity walls. | D | 66.70% |
| 8 | The region is 1 and the home structure is semi-detached, and the built year is after 1966. The homes have not installed wall insulation, and they use economy 7 electricity meters. | D | 100% |
| 9 | The region is 1 and the home structure is semi-detached, and the built year is after 1966. The homes have not installed wall insulation, and they do not use economy 7 electricity meters. | C | 66.80% |
| 10 | The houses are in Wales and their built-year is before 1930, the home structure is semi-detached and does not have cavity walls, their insulation depth is less than 150 mm, and a boiler has been installed. | C | 100% |
| 11 | The region is 1 and the built year is before 1930, the home structure is semi-detached, and does not have cavity walls, and a boiler has been installed and their insulation depth is less than 150 mm | F | 100% |
| 12 | The region is 3 and the built-year is before 1930, the home structure is semi-detached, and does not have cavity walls, the home’s boiler was installed in 2009 and loft insulation was used. | D | 100% |
| 13 | The region is 3 and the built-year is before 1930, the home structure is semi-detached, and does not have cavity walls, the home’s boiler was installed in 2009 and loft insulation was not used. | E | 66.80% |
| Number of Clusters | Silhouette Index Value |
|---|---|
| 2 | 0.243 |
| 3 | 0.239 |
| 4 | 0.189 |
| 5 | 0.195 |
| 6 | 0.155 |
| 7 | 0.155 |
| 8 | 0.166 |
| 9 | 0.158 |
| 10 | 0.179 |
| Cluster Label | Row | Rule | Result (Energy Efficiency) | Percentage |
|---|---|---|---|---|
| Low-consumption cluster | 1 | The home structure is a bungalow and uses economy 7 electricity meters and has installed a boiler. | D | 80% |
| 2 | The home structure is mid-terrace and the built-year is between 1950 and 1966, the floor area is less than 51 m2 and it uses economy 7 electricity meters. | F | 75% | |
| 3 | The home is in region 2 and the floor area is between 51 m2 and 100 m2, the built-year is between 1950 and 1966 and it uses economy 7 electricity meters. | D | 71.50% | |
| 4 | The home structure is detached houses built before 1930. | G | 66.70% | |
| 5 | Homes built after 1996, having cavity walls, and whose floor area is between 51 m2 to 100 m2 and which do not use economy 7 electricity meters. | A and B | 54.90% | |
| Medium-consumption cluster | 6 | The home structure is detached and was built before 1930, does not have a cavity wall, and the floor area is more than 151 m2, it uses economy 7 electricity meters. | E | 100% |
| 7 | The region is Wales, and the home structure is semi-detached and built before 1930 and has a boiler installed. | C | 100% | |
| 8 | The home structure is detached and built before 1930 and does not have a cavity wall, the floor area is more than 151 m2 and it does not use economy 7 electricity meters. | F | 80% | |
| 9 | The home structure is a flat built after 1996, does not have a cavity wall and does not use economy 7 electricity meters. | A and B | 67.90% | |
| 10 | The home structure is detached, semi-detached, mid-terrace, and end-terrace, built after 1996, does not have a cavity wall and does not use economy 7 electricity meters. | C | 65.70% | |
| High-consumption cluster | 11 | The home structure is detached and the region is Wales and it was built between 1983 and 1995, a boiler was installed in 2010 and the home does not use economy 7 electricity meters. | A and B | 100% |
| 12 | The home structure is detached and the region is Wales and it was built between 1983 and 1995, a boiler was installed in 2010 and the home uses economy 7 electricity meters. | D | 100% | |
| 13 | The home structure is a flat, built after 1996 and the floor area is between 51 m2 and 100 m2. | A and B | 100% | |
| 14 | Houses built after 1996, and the structure is mid-terrace. | C | 81.40% | |
| 15 | The home structure is detached and the region is 4, 5 and 9, it was built in 1983 to1995, a boiler was installed in 2010 and it does not use economy 7 electricity meters. | C | 80% | |
| 16 | The home structure is mid-terrace, it was built between 1983 and 1995 and has a boiler installed. | C | 78.80% | |
| 17 | Houses built after 1996; the structure is semi-detached. | C | 72.50% | |
| 18 | The home structure is mid-terrace, it was built between 1966 and 1982 and has boilers installed. | C | 72.20% |
| Household Characteristic | Energy Efficiency Group | |||||
|---|---|---|---|---|---|---|
| A, B | C | D | E | F | G | |
| The small homes which have tariff 7 | 6.92% | 40.34% | 32.54% | 13.51% | 5.47% | 1.50% |
| The small homes which do not have tariff 7 | 12.74% | 51.23% | 26.51% | 6.73% | 2.23% | 0.68% |
| Input Data | The C5.0 Accuracy |
|---|---|
| All the data | 54.4% |
| Cluster 1 (medium-consumption) | 51.5% |
| Cluster 2 (high-consumption) | 57.83% |
| Cluster 3 (low-consumption) | 69.3% |
| Evaluated Data | Findings and Results | |||
|---|---|---|---|---|
| All Data (without using the approach) | Installing boilers lead to better performance. | Old homes (built before 1930) suffer from unfavorable energy efficiency. Old homes in Wales have better energy efficiency. | Not using tariff 7 leads to better energy efficiency. | Improving energy efficiency is achieved by installing insulation in the roof of residential buildings. |
| Low-consumption cluster | Not using tariff 7 leads to better energy efficiency. Using the tariff leads to poor energy efficiency in small and old houses (less than 51 m2). (new finding) | |||
| Medium-consumption cluster | Flats have a more favorable energy efficiency; even newly-built flats. (new finding) Old homes in Wales which have a detached structure, and have installed boilers have a good energy efficiency. (new finding) | Using this tariff leads to a better energy efficiency in big (over 151 m2) and old houses. (new finding) | ||
| High-consumption cluster | Installing boilers leads to a better energy efficiency. In mid-terrace and end-terrace structures, boilers lead to better energy efficiency. (new finding) | The newly constructed flats have the best efficiency. (new finding) | Households living in Wales have better energy efficiency. (new finding) | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazeriye, M.; Haeri, A.; Martínez-Álvarez, F. Analysis of the Impact of Residential Property and Equipment on Building Energy Efficiency and Consumption—A Data Mining Approach. Appl. Sci. 2020, 10, 3589. https://doi.org/10.3390/app10103589
Nazeriye M, Haeri A, Martínez-Álvarez F. Analysis of the Impact of Residential Property and Equipment on Building Energy Efficiency and Consumption—A Data Mining Approach. Applied Sciences. 2020; 10(10):3589. https://doi.org/10.3390/app10103589
Chicago/Turabian StyleNazeriye, Mahsa, Abdorrahman Haeri, and Francisco Martínez-Álvarez. 2020. "Analysis of the Impact of Residential Property and Equipment on Building Energy Efficiency and Consumption—A Data Mining Approach" Applied Sciences 10, no. 10: 3589. https://doi.org/10.3390/app10103589