
A Novel Patient Similarity Network (PSN) Framework Based on Multi-Model Deep Learning for Precision Medicine

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
2.1. Existing Techniques for Building PSNs
2.2. Combination PSN Models
2.3. PSN Application in Various Health Domains
2.4. Performance Evaluation of the Existing PSNs
2.5. Challenges of the Existing Works
3. A Multidimensional Data Fusion Model based on Deep Learning and PSN
3.1. Data Collection, Preparation, and Preprocessing
3.2. Architecture: Component Description
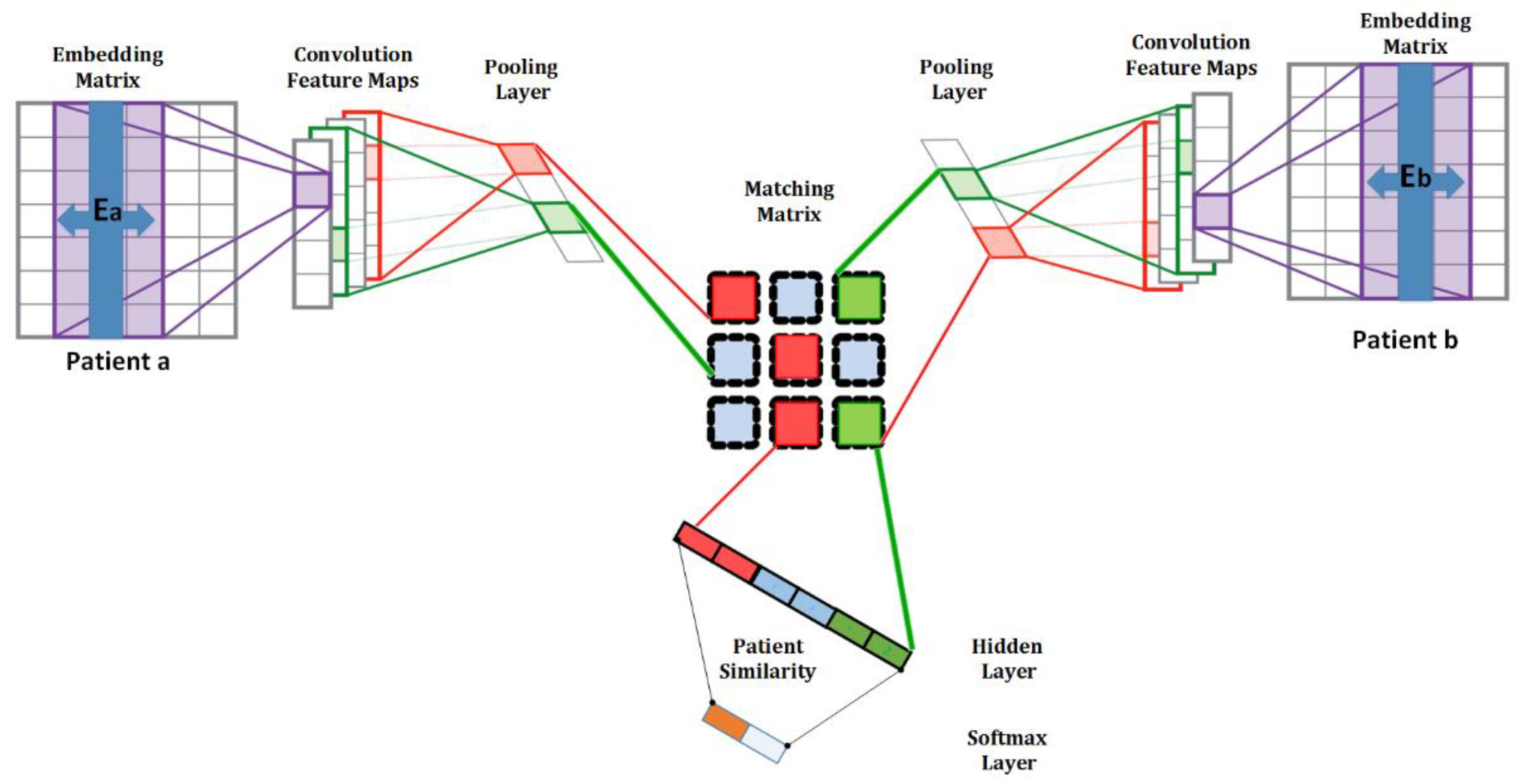
3.2.1. Deep Learning Algorithm Selection
3.2.2. Model Development, Training, Prediction, and Evaluation
3.2.3. Prediction and Visualization
3.3. Architecture: Technologies, DL Platforms, and Tools
4. Model Formulation
4.1. Static Data Modeling
4.1.1. Feature Similarity for Age
4.1.2. Feature Similarity for Gender
4.1.3. Feature Similarity for Other Static Features
4.1.4. Global Static Patient Similarity
4.2. Dynamic Data Modeling
4.2.1. Long Short-Term Memory (LSTM)
4.2.2. Patient Visit Matrix Embedding (Data Dimension Reduction)
4.3. Similarity Network Fusion
5. PSN Construction Algorithms
| Algorithm 1. Static data similarity evaluation algorithm | |
| Input: | |
| PList, | ▷ List of Patients |
| SFList, | ▷ List of selected features |
| SUList, | ▷ List of similarity utility for each feature |
| weights | ▷ List of weight for each feature |
| Output: | |
| SSM | ▷ Static similarity matrix for all patients |
| 1: procedure STATICSIMILARITYMATRIX(PList, SFList, SUList, weights) 2: SSM ← initilizeToEmpty() 3: for si ← 1,N do ▷ each patient i 4: for sj ← si + 1,N do ▷ each patient j 5: for fk ← 1,K do ▷ each selected feature (col) 6: FSscore[si,sj] ← getSimilarityScore(si,sj,SUList[fk]) 7: SSM[si,sj] ← SSM[si,sj]+FSscore[si,sj]∗weights[fk] 8: end for 9: end for 10: end for 11: return SSM 12: end procedure = 0 | |
| Algorithm 2. Dynamic data similarity evaluation algorithm | |
| Input: | |
| DPList, | ▷ List of Patients with dynamic data |
| ACTF, | ▷ Activation function |
| NF, | ▷ Number of features |
| NEMB | ▷ Embedding dimension |
| Output: | |
| DSM | ▷ Dynamic similarity matrix for all patients |
| 1: procedure DYNAMICSIMILARITYMATRIX(DPList, ACTF, NF, NEMB) 2: preprocess(DPList) 3: EB ← deepLearningAutoencoder(DPList,ACTF,NF,NEMB) 4: for si ← 1,N do ▷ each patient i 5: for sj ← si +1,N do ▷ each patient j 6: DSM[si,sj] ← getSimilarityScore(EB[si],EB[sj]) ▷Euclidean 7: end for 8: end for 9: return DSM 10: end procedure=0 | |
| Algorithm 3. Similarity network fusion algorithm | |
| Input: | |
| STM, | ▷ Static similarity matrix |
| DM, | ▷ Dynamic similarity matrix |
| T, | ▷ Number of iterations to complete fusion |
| K, | ▷ Number of nearest neighbors |
| wts, | ▷ Weight for Static similarity matrix |
| wtd | ▷ Weight for Dynamic similarity matrix |
| Output: | |
| FPSM | ▷ Fused patient similarity matrix |
| 1: procedure SIMILARITYNETWORKFUSION(STM,DM,T,K) 2: M1prev ← STM | |
| 3: M2prev ← DM | |
| 4: normalize(STM,DM) | |
| 5: symmetrize(STM,DM) | |
| 6: for si ∈ STM do ▷ calculate local similarity for STM | |
| 7: neighborList←nearestKNeihbors(si,k,STM,DM) | |
| 8: for sj ∈ neighborList do | |
| 9: | |
| 10: end for | |
| 11: end for | |
| 12: for si ∈ DM do ▷ calculate local similarity for DM | |
| 13: neighborList ← nearestKNeihbors(si,k,STM,DM) | |
| 14: for sj ∈ neighborList do | |
| 15: | |
| 16: end for | |
| 17: end for | |
| 18: for ti ← 1, T do | |
| 19: | |
| 20: | |
| 21: | |
| 22: | |
| 23: end for | |
| 24: FPSM ← FM = (M1 +M2)/2 | |
| 25: return FPSM 26: end procedure = 0 | |
6. Experimentation and Result Discussion
6.1. Experimental Setup
6.2. Dataset
6.3. Evaluation Criteria
6.4. Experimental Scenarios
- Scenario 1 evaluated the PSN model, where the data exhibited static features with a mixture of numerical and textual data.
- ICU admission prediction for COVID-19 patients based on Dataset-1.
- Evaluate the accuracy of the patient similarity matrix while using NLP models, BERT, and one-hot-encoding. These models were adopted to better capture the semantics of the clinical textual data and find the most similar patient.
- Identify the best similarity distance measurement approach among the Euclidean, Manhattan, cosine, Chebyshev, and weighted Manhattan approaches.
- Determine the optimal weight distribution among features when using the weighted distance evaluation approach. This approach improves accuracy when giving more significance to certain features than others.
- Evaluating the PSN model performance when applying the local similarity approach for the similarity matrix can limit data conflicts and improve accuracy.
- Scenario 2 evaluated the overall performance of our proposed multidimensional model, where the dataset involved a combination of dynamic and static features.
- Predict a CVD event in the future based on Dataset-2.
- Build a static PSN matrix for the static portion of the data and evaluate the performance of the STPS matrix according to the evaluation criteria mentioned in this study.
- Evaluate the performance of the autoencoder used for the dynamic portion of the patient data for data reduction, thereby compacting the input patient information into a lower-dimensional space.
- Build and evaluate the performance of the dynamic similarity matrix.
- Evaluate the performance of the fused similarity matrix based on our proposed SNF algorithm and confirm that our model can represent the large, heterogeneous, and dynamic contents of a dataset.
6.4.1. Scenario 1. PSN Evaluation on Static Data having Numerical and Textual Data
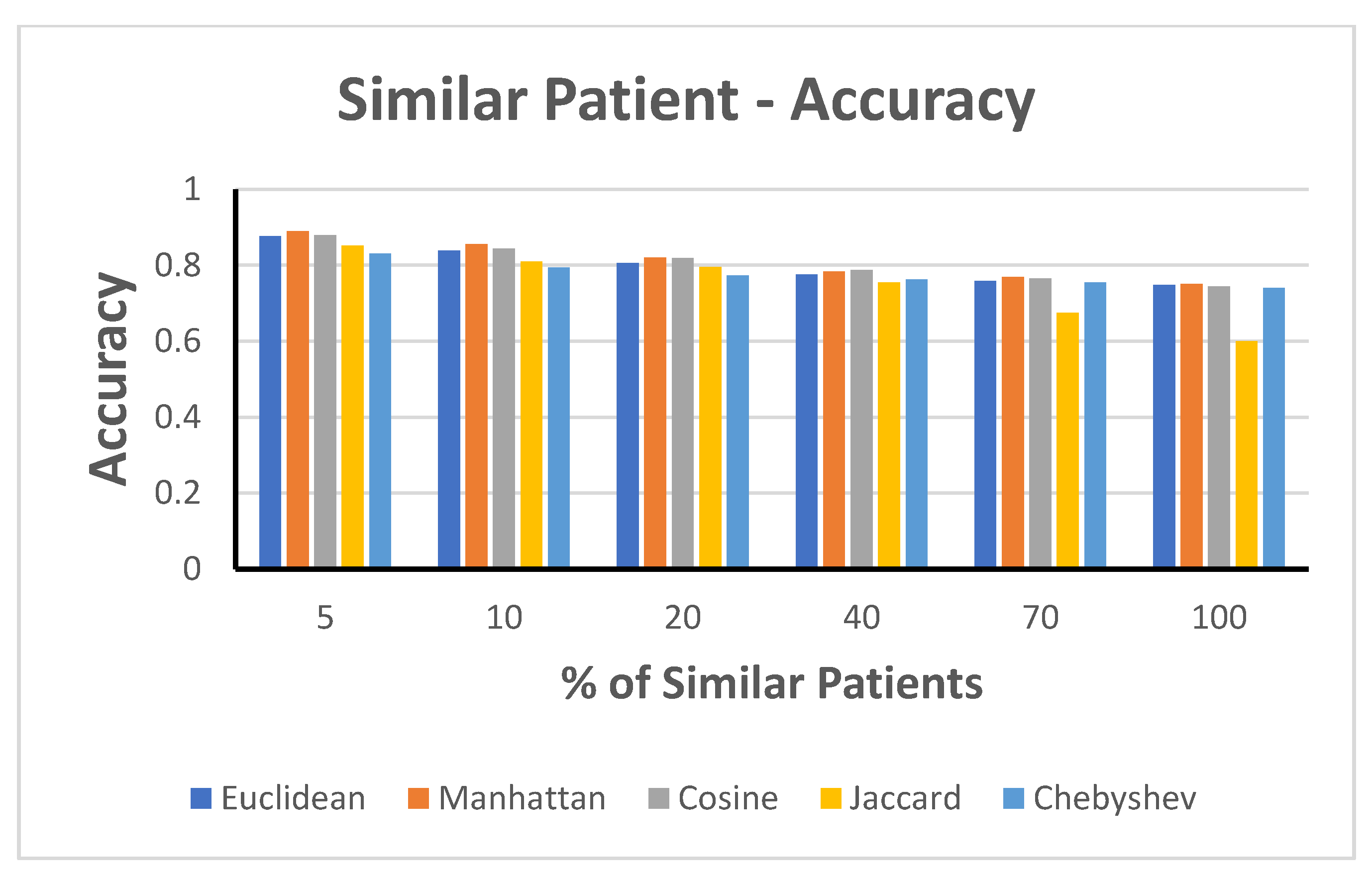
- Accuracy measure of patient similarity
- 2.
- Weighted-Distance Accuracy Measure against Similar Patients
- To boost the score contribution, we set the weight to higher than 1.
- To maintain the score contribution, we set the weight to 1.
- 3.
- Accuracy Measure against the Selected Percentage of Similar Patients
6.4.2. Scenario 2. Hybrid PSN Model Evaluation Data with Static and Dynamic Features
- Static PSN Evaluation
- 2.
- Dynamic PSN Evaluation (Autoencoder)
- 3.
- Fusion PSN Evaluation
6.4.3. Scenario 3. Benchmark to Other Classification Algorithms
- Naïve Bayes: {var_smoothing = 1e-09}
- SVM: {‘SVMType’: C-SVC, ‘KernelType’: 2, ‘Degree’: 3, ‘nu’: 0.5, ‘cachesize’: 40, ‘cost’: 1, ‘eps’: 0.001, ‘loss’:0.1}
- ZeroR: {‘batchsize’: 100, ‘useKernelEstimator’: False, ‘useSupervisedDiscretization’: False}
- CNN: {‘layer’: 5, ‘Out’: 2, ‘gradNormThreshold’: 1.0-minimize, ‘algorithm’: STOCHASTIC_GRADIENT_DESCENT, ‘updater’: Adam, ‘biasUpdater’: Sgd, ‘weightInit’: XAVIER, ‘learningRate’: 0.001, ‘numEpochs’: 10 “}
- Logistic Regression: {‘C’: 1.0, ‘dual’: False, ‘fit_intercept’: True, ‘intercept_scaling’: 1, ‘max_iter’: 100, ‘multi_class’: ‘auto’, ‘penalty’: ‘l2′, ‘solver’: ‘lbfgs’, ‘tol’: 0.0001, ‘warm_start’: False}
- RandomTree: {‘KValue’:0, ‘minNum’: 1, ‘minVarianceProp’:0.001, ‘seed’: 1}
- Decision Tree: {‘ccp_alpha’: 0.0, ‘criterion’: ‘gini’, ‘min_samples_leaf’: 1, ‘min_samples_split’: 2, ‘splitter’: ‘best’}
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Terry, S.F. Obama’s Precision Medicine Initiative. Genet. Test. Mol. Biomark. 2015, 19, 113–114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Du, F.; Plaisant, C.; Spring, N.; Shneiderman, B. Finding Similar People to Guide Life Choices. J. Mol. Biol. 2017, 15, 5498–5544. [Google Scholar] [CrossRef]
- PatientsLikeMe. Available online: https://www.patientslikeme.com/ (accessed on 9 December 2021).
- Allam, A.; Dittberner, M.; Sintsova, A.; Brodbeck, D.; Krauthammer, M. Patient Similarity Analysis with Longitudinal Health Data. Available online: http://arxiv.org/abs/2005.06630 (accessed on 2 April 2022).
- Pai, S.; Bader, G.D. Patient Similarity Networks for Precision Medicine. J. Mol. Biol. 2018, 430, 2924–2938. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Z.F.; Cui, P.; Pei, J.; Song, Y. Recent Advances on Graph Analytics and Its Applications in Healthcare. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 23–27 August 2020; pp. 3545–3546. [Google Scholar]
- Pai, S.; Hui, S.; Isserlin, R.; Shah, M.A.; Kaka, H.; Bader, G.D. netDx: Interpretable patient classification using integrated patient similarity networks. Mol. Syst. Biol. 2019, 15, 8497. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, C.; Qian, B.; Cheng, Y.; Wei, J.; Wang, F. Measuring patient similarities via a deep architecture with medical concept embedding. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 749–758. [Google Scholar] [CrossRef] [Green Version]
- Gupta, V.; Sachdeva, S.; Bhalla, S. A Novel Deep Similarity Learning Approach to Electronic Health Records Data. IEEE Access 2020, 8, 209278–209295. [Google Scholar] [CrossRef]
- Suo, Q.; Ma, F.; Yuan, Y.; Huai, M.; Zhong, W.; Zhang, A.; Gao, J. Personalized disease prediction using a CNN-based similarity learning method. Proceedings of IEEE International Conference of Bioinformacy Biomedicine BIBM, Kansas City, MO, USA, 13–16 November 2017; pp. 811–816. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to Diagnose with LSTM Recurrent Neural Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016 -Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Suo, O.; Ma, F.; Yuan, Y.; Huai, M.; Zhong, W.; Zhang, A.; Gao, J. Deep patient similarity learning for personalized healthcare. IEEE Trans. Nanobiosci. 2018, 17, 219–227. [Google Scholar] [CrossRef]
- Hamet, P.; Tremblay, J. Querying Clinical Workflows by Temporal Similarity. Metabolism 2017, 69, S36–S40. [Google Scholar] [CrossRef]
- Brown, S.A. Patient Similarity: Emerging Concepts in Systems and Precision Medicine. Front. Physiol. 2016, 7, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Gottlieb, A.; Stein, G.Y.; Ruppin, E.; Altman, R.B.; Sharan, R. A method for inferring medical diagnoses from patient similarities. BMC Med. 2013, 11, 2013. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Maslove, D.M.; Dubin, J.A. Personalized mortality prediction driven by electronic medical data and a patient similarity metric. PLoS ONE 2015, 10, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 6, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Mezlini, M.A.; Demir, F.; Fiume, M.; Tu, Z.; Brudno, M.; Haibe-Kains, B.; Goldenberg, A. Similarity network fusion for aggregating data types on a genomic scale. Nat. Methods 2014, 11, 333–337. [Google Scholar] [CrossRef] [PubMed]
- Ng, K.; Sun, J.; Hu, J.; Wang, F. Personalized Predictive Modeling and Risk Factor Identification using Patient Similarity. AMIA Jt. Summits Transl. Sci. 2015, 2015, 132–138. [Google Scholar]
- Chawla, N.V.; Davis, D.A. Bringing big data to personalized healthcare: A patient-centered framework. J. Gen. Intern. Med. 2013, 28, 660–665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, I.; Marsh, N.V. Anonymous indexing of health conditions for a similarity measure. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 737–744. [Google Scholar] [CrossRef]
- Chan, T. Machine Learning of Patient Similarity: A case study on predicting survival in cancer patient after locoregional chemotherapy. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW), Hong Kong, 18 December 2010; pp. 467–470. [Google Scholar] [CrossRef] [Green Version]
- Girardi, D.; Wartner, S.; Halmerbauer, G.; Ehrenmüller, M.; Kosorus, H.; Dreiseitl, S. Using concept hierarchies to improve calculation of patient similarity. J. Biomed. Inform. 2016, 63, 66–73. [Google Scholar] [CrossRef]
- Panahiazar, M.; Taslimitehrani, V.; Pereira, N.L.; D, M.; Pathak, J. Using EHRs for Heart Failure Therapy Recommendation Using Multidimensional Patient Similarity Analytics. Stud. Health Technol. Inform. 2015, 210, 369–373. [Google Scholar] [CrossRef] [Green Version]
- Heckerman, D. Probabilistic similarity networks. Networks 1990, 20, 607–636. [Google Scholar] [CrossRef] [Green Version]
- Heckerman, D.E.; Horvitz, E.J.; Nathwani, B.N. Update on the Pathfinder Project. Annu. Symp. Comput. Appl. Med. Care 1989, 754, 203–207. [Google Scholar]
- Wang, Y.; Tian, Y.; Tian, L.L.; Qian, Y.M.; Li, J.S. An Electronic Medical Record System with Treatment Recommendations Based on Patient Similarity. J. Med. Syst. 2015, 5, 237. [Google Scholar] [CrossRef]
- Roque, F.S.; Jensen, P.B.; Schmock, H.; Dalgaard, M.; Andreatta, M.; Hansen, T.; Søeby, K.; Bredkjær, S.; Juul, A.; Werge, T.; et al. Using electronic patient records to discover disease correlations and stratify patient cohorts. PLoS Comput. Biol. 2011, 7, 2141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lage, K.; Karlberg, E.O.; Størling, Z.M.; Olason, P.I.; Pedersen, A.G.; Rigina, O.; Hinsby, A.M.; Tümer, Z.; Pociot, F.; Tommerup, N. A human phenome-interactome network of protein complexes implicated in genetic disorders. Nat. Biotechnol. 2007, 25, 309–316. [Google Scholar] [CrossRef]
- Seligson, D.N.; Warner, L.J.; Dalton, S.W.; Martin, D.; Miller, S.R.; Patt, D.; Kehl, L.K.; Palchuk, B.M.; Alterovitz, G.; Wiley, K.L. Recommendations for patient similarity classes: Results of the AMIA 2019 workshop on defining patient similarity. J. Am. Med. Inform. Assoc. 2020, 10, 1–5. [Google Scholar] [CrossRef]
- Tashkandi, A.; Wiese, I.; Wiese, L. Efficient In-Database Patient Similarity Analysis for Personalized Medical Decision Support Systems. Big Data Res. 2018, 13, 52–64. [Google Scholar] [CrossRef]
- Perlman, L.; Gottlieb, A.; Atias, N.; Ruppin, E.; Sharan, R. Combining Drug and Gene Similarity Measures for Drug-Target Elucidation. J. Comput. Biol. 2011, 18, 133–145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Köhler, S.; Schulz, M.H.; Krawitz, P.; Bauer, S.; Dölken, S.; Ott, C.E.; Mundlos, C.; Horn, D.; Mundlos, S.; Robinson, P.N. Clinical Diagnostics in Human Genetics with Semantic Similarity Searches in Ontologies. Am. J. Hum. Genet. 2009, 85, 457–464. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Sun, J.; Wang, F.; Wang, S.; Jun, C.-H.; Jiang, X. Privacy-Preserving Patient Similarity Learning in a Federated Environment: Development and Analysis. JMIR Med. Inform. 2018, 6, 7744. [Google Scholar] [CrossRef]
- Koks, S.; Williams, R.W.; Quinn, J.; Farzaneh, F.; Conran, N.; Tsai, S.J.; Awandare, G.; Goodman, S.R. Highlight article: COVID-19: Time for precision epidemiology. Exp. Biol. Med. 2020, 245, 677–679. [Google Scholar] [CrossRef]
- Hartono, P. Similarity maps and pairwise predictions for transmission dynamics of COVID-19 with neural networks. Inform. Med. Unlocked 2020, 20, 100386. [Google Scholar] [CrossRef]
- Gao, J.; Xiao, C.; Glass, L.M.; Sun, J. COMPOSE: Cross-Modal Pseudo-Siamese Network for Patient Trial Matching. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 803–812. [Google Scholar] [CrossRef]
- Shahri, M.P.; Lyon, K.; Schearer, J.; Kahanda, I. DeepPPPred: An Ensemble of BERT, CNN, and RNN for Classifying Co-mentions of Proteins and Phenotypes. bioRxiv 2020. [Google Scholar] [CrossRef]
- Xiong, Y.; Chen, S.; Qin, H.; Cao, H.; Shen, Y.; Wang, X.; Chen, Q.; Yan, J.; Tang, B. Distributed representation and one-hot representation fusion with gated network for clinical semantic textual similarity. BMC Med. Inform. Decis. Mak. 2020, 20, 1–7. [Google Scholar] [CrossRef]
- Žitnik, M.; Zupan, B. Data fusion by matrix factorization. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 41–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhalla, S.; Melnekoff, D.T.; Aleman, A.; Leshchenko, V.; Restrepo, P.; Keats, J.; Onel, K.; Sawyer, J.R.; Madduri, D.; Richter, J.; et al. Patient similarity network of newly diagnosed multiple myeloma identifies patient subgroups with distinct genetic features and clinical implications. Sci. Adv. 2021, 7, 47. [Google Scholar] [CrossRef] [PubMed]
- Ni, J.; Liu, J.; Zhang, C.; Ye, D.; Ma, Z. Fine-grained Patient Similarity Measuring using Deep Metric Learning. Comput. Sci. 2017, 47, 1189–1198. [Google Scholar] [CrossRef]
- Chan, L.W.; Liu, Y.; Chan, T.; Law, H.K.W.; Wong, S.C.; Yeung, A.P.; Lo, K.F.; Yeung, S.W.; Kwok, K.Y.; Chan, W.Y.L.; et al. PubMed-supported clinical term weighting approach for improving inter-patient similarity measure in diagnosis prediction. BMC Med. Inform. Decis. Mak. 2015, 15, 1–8. [Google Scholar] [CrossRef]
- Barkhordari, M.; Niamanesh, M. ScaDiPaSi: An Effective Scalable and Distributable MapReduce-Based Method to Find Patient Similarity on Huge Healthcare Networks. Big Data Res. 2015, 2, 19–27. [Google Scholar] [CrossRef]
- Sun, J.; Wang, F.; Hu, J.; Edabollahi, S. Supervised patient similarity measure of heterogeneous patient records. ACM Explor. Newsl. 2012, 14, 16. [Google Scholar] [CrossRef]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.-H.; Jin, D.; Naumann, T.; McDermott, M.B.A. Publicly Available Clinical BERT Embeddings. arXiv 2019. [Google Scholar] [CrossRef]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBert: Modeling Clinical Notes and Predicting Hospital Readmission. arXiv 2019. [Google Scholar] [CrossRef]
- Lee, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthcare 2020, 3, 1–23. [Google Scholar] [CrossRef]
- Peng, Y.; Yan, S.; Lu, Z. Transfer learning in biomedical natural language processing: An evaluation of BERT and ELMo on ten benchmarking datasets. BioNLP 2019, 56, 58–65. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019. [Google Scholar] [CrossRef]
- Naseem, U.; Khushi, M.; Reddy, V.; Rajendran, S.; Razzak, I.; Kim, J. BioALBERT: A Simple and Effective Pre-trained Language Model for Biomedical Named Entity Recognition. Proc. Int. Jt. Conf. Neural Netw. 2021, 2021, 3884. [Google Scholar] [CrossRef]
- Dai, Z.; Li, Z.; Han, L. BoneBert: A BERT-based Automated Information Extraction System of Radiology Reports for Bone Fracture Detection and Diagnosis. Lect. Notes Comput. Sci. 2021, 12695, 263–274. [Google Scholar] [CrossRef]
- Isah, H.; Abughofa, T.; Mahfuz, S.; Ajerla, D.; Zulkernine, F.; Khan, S. A survey of distributed data stream processing frameworks. IEEE Access 2019, 7, 154300–154316. [Google Scholar] [CrossRef]
- Wang, N. Measurement and application of patient similarity in personalized predictive modeling based on electronic medical records. Biomed. Eng. Online 2019, 18, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735. [Google Scholar] [CrossRef]
- Cheng, H.; Tan, P.N.; Gao, J.; Scripps, J. Multistep-ahead time series prediction. Pac. Asia Conf. Knowl. Discov. Data Min. 2006, 14, 765–774. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Isele, R.; Bizer, C. Learning linkage rules using genetic programming. In Proceedings of the 6th International Conference on Ontology Matching; ACM Digital Library: Bonn, Germany, 2011; Volume 814, pp. 13–24. [Google Scholar]
- Xu, B.; Gutierrez, B.; Mekaru, S.; Sewalk, K.; Goodwin, L.; Loskill, A.; Cohn, E.L.; Hswen, Y.; Hill, S.C.; Cobo, M.M.; et al. Epidemiological data from the COVID-19 outbreak, real-time case information. Sci. Data 2020, 7, 448. [Google Scholar] [CrossRef] [PubMed]
- Framingham Heart Study. Available online: https://framinghamheartstudy.org/participants/participant-cohorts/ (accessed on 2 April 2022).
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Wong, T.T.; Yeh, P.Y. Reliable Accuracy Estimates from k-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
- Weighted Scoring Definition and Overview. Available online: https://www.productplan.com/glossary/weighted-scoring/ (accessed on 5 May 2021).
- Dimensionality Reduction with Autoencoders versus PCA by Andrea Castiglioni towards Data Science. Available online: https://towardsdatascience.com/dimensionality-reduction-with-autoencoders-versus-pca-f47666f80743 (accessed on 5 May 2021).
- Song, Z. Performance of Autoencoder with Bi-Directional Long-Short Term Memory Network in Gestures Unit Segmentation. Aust. Nat. Univ. 2018, 1, 1–6. [Google Scholar]
- Chen, J. The effect of an auto-encoder on the accuracy of a convolutional neural network classification task. Res. Sch. Comput. Sci, Aust. Nat. Univ. 2018, 1–8. Available online: https://users.cecs.anu.edu.au/~Tom.Gedeon/conf/ABCs2018/paper/ABCs2018_paper_166.pdf (accessed on 2 April 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters/Factors | Applications |
|---|---|---|
| Deep learning | ICD9 | Unsupervised/supervised patient similarity (CNN) [8] Diagnosis with LSTM recurrent neural networks [11] Personalized disease prediction (CNN) [10] |
| Triplet-loss metric learning | Longitudinal EHRs | Personalized prediction [12] |
| Temporal similarity | Temporal sequences | Clinical (workflow) case similarity [13] |
| Clustering | Variety of components of patient data | Patient similarity analytics loop [14] |
| Similarity measure construction | ICD code, Empirical co-occurrence frequency, Medical history, Blood test, ECG, Age, Gender | Predict individual discharge diagnoses [15] Predict ICU mortality [16] |
| Deep patient representation (three-layer stacked denoising autoencoders) | ICD9 | Future disease prediction [17] |
| Similarity network fusion (SNF) | Nodes represent patients, and patients’ pairwise similarities are represented by edges | Network-based survival risk prediction Identifying cancer subtypes [18] |
| Locally supervised metric learning (LSML) | Longitudinal patient data | Personalized predictive models and generation of personalized risk factor profiles [19] |
| Collaborative filtering methodology | ICD data | Creates a personalized disease risk profile and a disease management plan for the patient [20] |
| Anonymous indexing of health conditions for a similarity measure | Text similarity | Recommend two other patients for each patient based on a keyword [21] |
| SimSVM | 14 similarity measures from relevant clinical and imaging data | Predicting the survival of patients suffering from hepatocellular carcinoma (HCC) [22] |
| Concept hierarchy | Hierarchical distance measure | Detecting correlations in medical records by comparing the hierarchy of terms considering the distance between non-similar records in a hierarchy [23] |
| Dataset-1 | Dataset-2 | |
|---|---|---|
| Dataset Based On | COVID-19 | CVD |
| Type | Static | Static and Dynamic |
| Size | Small (200) | Big (20,000) |
| Fields | Static: ID, age, gender, date_onset_symptoms, date_admission_hospital, date_confirmation, symptoms, additional_information, chronic_disease_binary, chronic_disease, outcome | Static: PID, exam_age, gender, smoke, diab, hypermed, age_baseline, smoke_baseline, gender_baseline, diab_baseline, hypermed_baseline, time_long_years, time_to_event_years Dynamic: Bmi, sbp, dbp, chol, hdl, ldl, trig non_hdl, chol_hdl_ratio, time_long_years, time_to_event_years, time_long_scal, time_to_event_scal |
| One-Hot Encoding | BERT | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy Std. Dev. | Precision | F1-Score | Accuracy | Accuracy Std. Dev. | Precision | F1-Score | |
| Euclidean | 71.86 | 4.78 | 72.10 | 83.35 | 72.37 | 4.77 | 99.73 | 83.73 |
| Manhattan | 70.78 | 5.63 | 71.01 | 82.62 | 72.28 | 5.52 | 99.89 | 83.70 |
| Cosine | 71.00 | 5.24 | 71.24 | 82.68 | 84.60 | 5.51 | 97.64 | 89.97 |
| Chebyshev | 69.58 | 5.70 | 71.90 | 80.98 | 72.12 | 5.61 | 99.66 | 83.59 |
| Weighted | 71.79 | 5.40 | 72.33 | 82.82 | 71.83 | 4.99 | 96.93 | 83.04 |
| Age | Sex | Symptoms | Addnl_Info | Chronic_Disease_Binary | Chronic_Disease | Score | Rank | |
|---|---|---|---|---|---|---|---|---|
| Weight | 0.1 | 0.15 | 0.2 | 0.15 | 0.2 | 0.2 | ||
| Option1 | 1 | 1 | 3 | 3 | 3 | 1 | 2.1 | 4 |
| Option2 | 1 | 1 | 3 | 2 | 3 | 3 | 2.35 | 2 |
| Option3 | 1 | 1 | 4 | 3 | 2 | 2 | 2.3 | 3 |
| Option4 | 1 | 1 | 3 | 3 | 3 | 3 | 2.5 | 1 |
| Option5 | 1 | 1 | 3 | 1 | 1 | 1 | 1.4 | 5 |
| Option6 | 2 | 1 | 1 | 2 | 1 | 1 | 1.25 | 9 |
| Option7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| Option8 | 1 | 2 | 2 | 1 | 1 | 1 | 1.35 | 6 |
| Option9 | 1 | 1 | 1 | 2 | 1 | 2 | 1.35 | 7 |
| Option10 | 1 | 1 | 1 | 2 | 2 | 1 | 1.35 | 8 |
| Dataset | Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|
| PSN | Naïve Bayes | SVM | ZeroR | CNN | Logistic Regression | Random Tree | Decision Tree | |
| CVD Dataset 2 | 96% | 80.67% | 87.20 | 87.03% | 91.2% | 87.10% | 87.32% | 87.03% |
| COVID-19 Dataset 1 | 89% | 84.80% | 88.45 | 83.20% | 85.84% | 83.20% | 88.80% | 86.40% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navaz, A.N.; T. El-Kassabi, H.; Serhani, M.A.; Oulhaj, A.; Khalil, K. A Novel Patient Similarity Network (PSN) Framework Based on Multi-Model Deep Learning for Precision Medicine. J. Pers. Med. 2022, 12, 768. https://doi.org/10.3390/jpm12050768
Navaz AN, T. El-Kassabi H, Serhani MA, Oulhaj A, Khalil K. A Novel Patient Similarity Network (PSN) Framework Based on Multi-Model Deep Learning for Precision Medicine. Journal of Personalized Medicine. 2022; 12(5):768. https://doi.org/10.3390/jpm12050768
Chicago/Turabian StyleNavaz, Alramzana Nujum, Hadeel T. El-Kassabi, Mohamed Adel Serhani, Abderrahim Oulhaj, and Khaled Khalil. 2022. "A Novel Patient Similarity Network (PSN) Framework Based on Multi-Model Deep Learning for Precision Medicine" Journal of Personalized Medicine 12, no. 5: 768. https://doi.org/10.3390/jpm12050768
APA StyleNavaz, A. N., T. El-Kassabi, H., Serhani, M. A., Oulhaj, A., & Khalil, K. (2022). A Novel Patient Similarity Network (PSN) Framework Based on Multi-Model Deep Learning for Precision Medicine. Journal of Personalized Medicine, 12(5), 768. https://doi.org/10.3390/jpm12050768