
Splitting and Length of Years for Improving Tree-Based Models to Predict Reference Crop Evapotranspiration in the Humid Regions of China

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
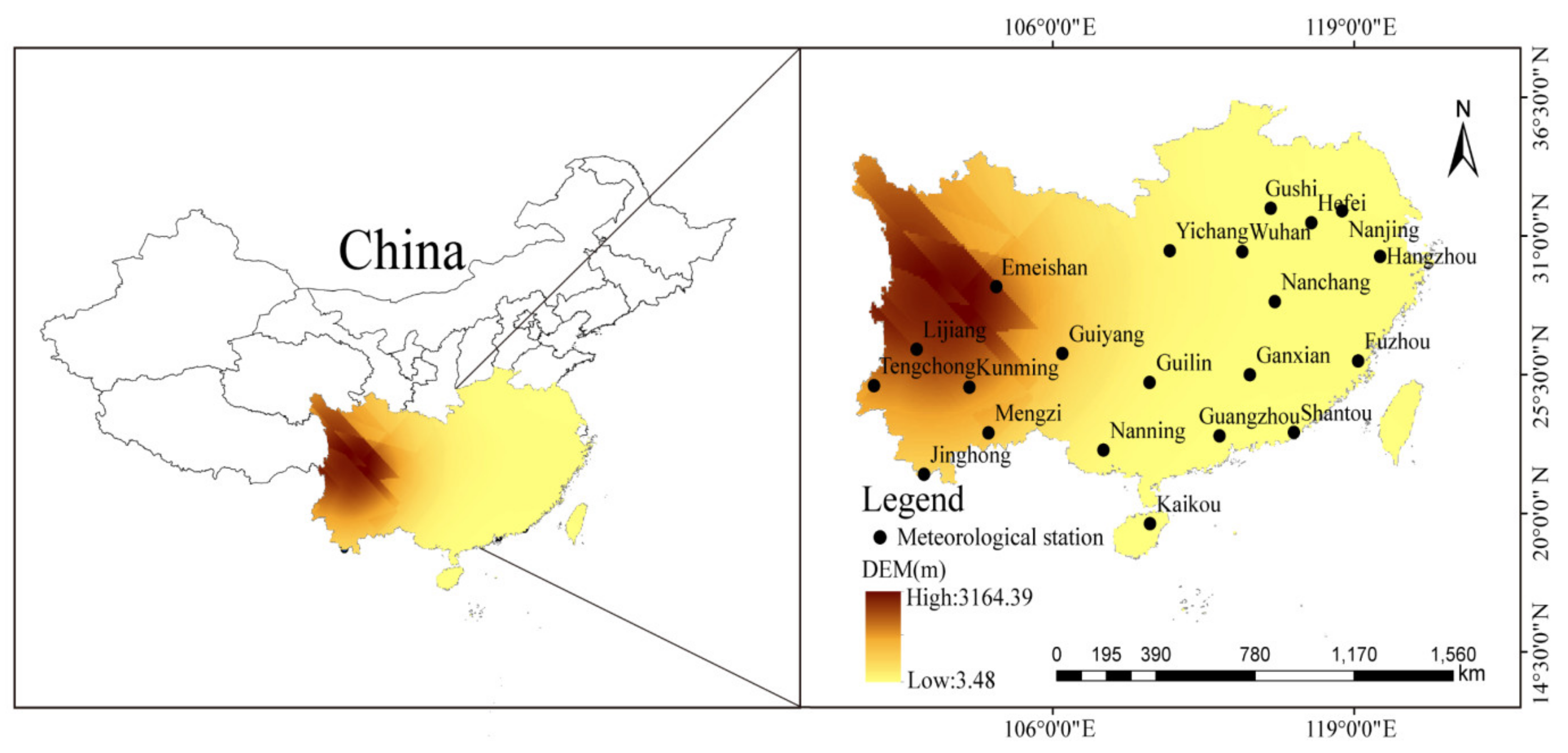
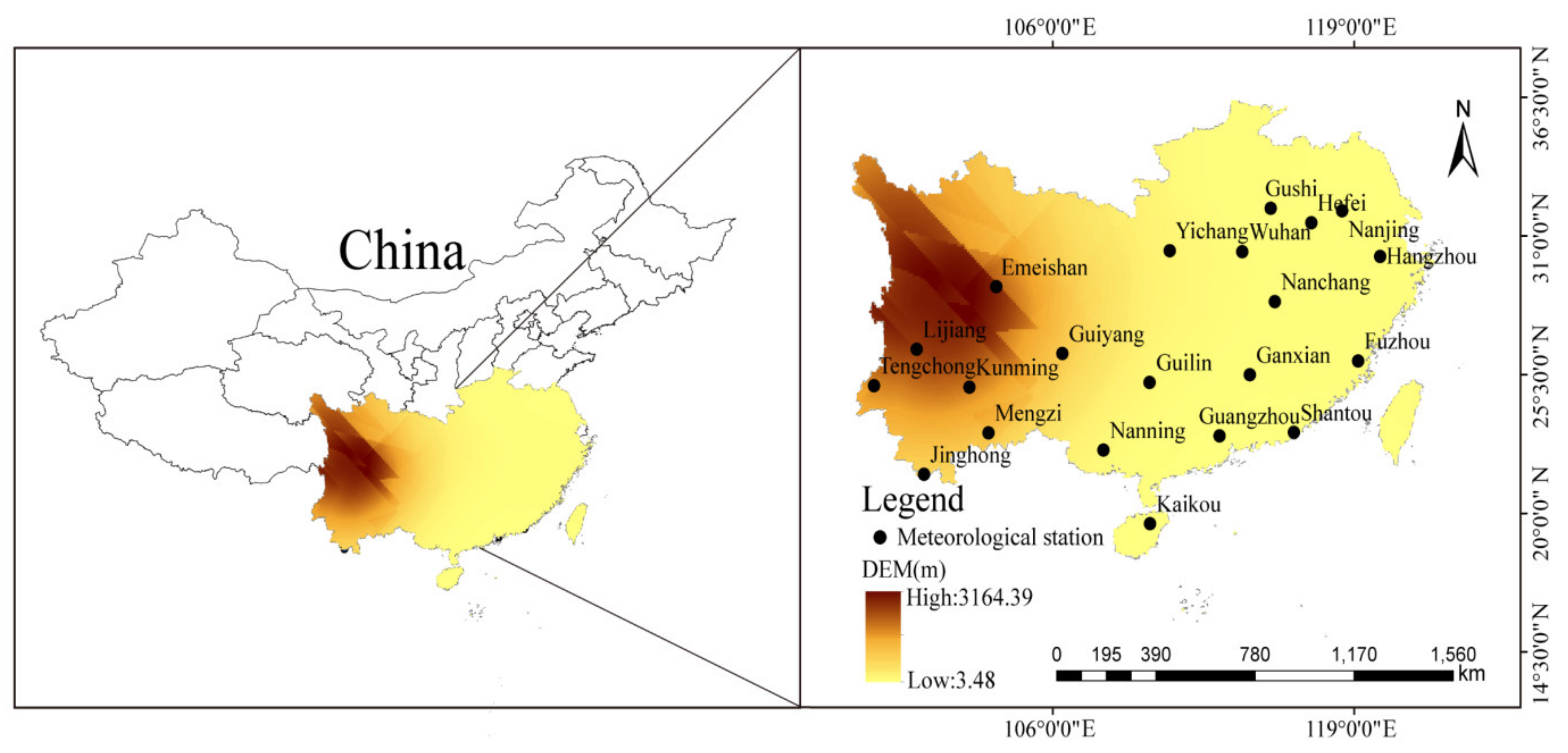
2.1. Study Areas
2.2. Used Temperature Data
2.3. Estimation of Reference Evapotranspiration Using the FAO-56 Penman–Monteith Equation
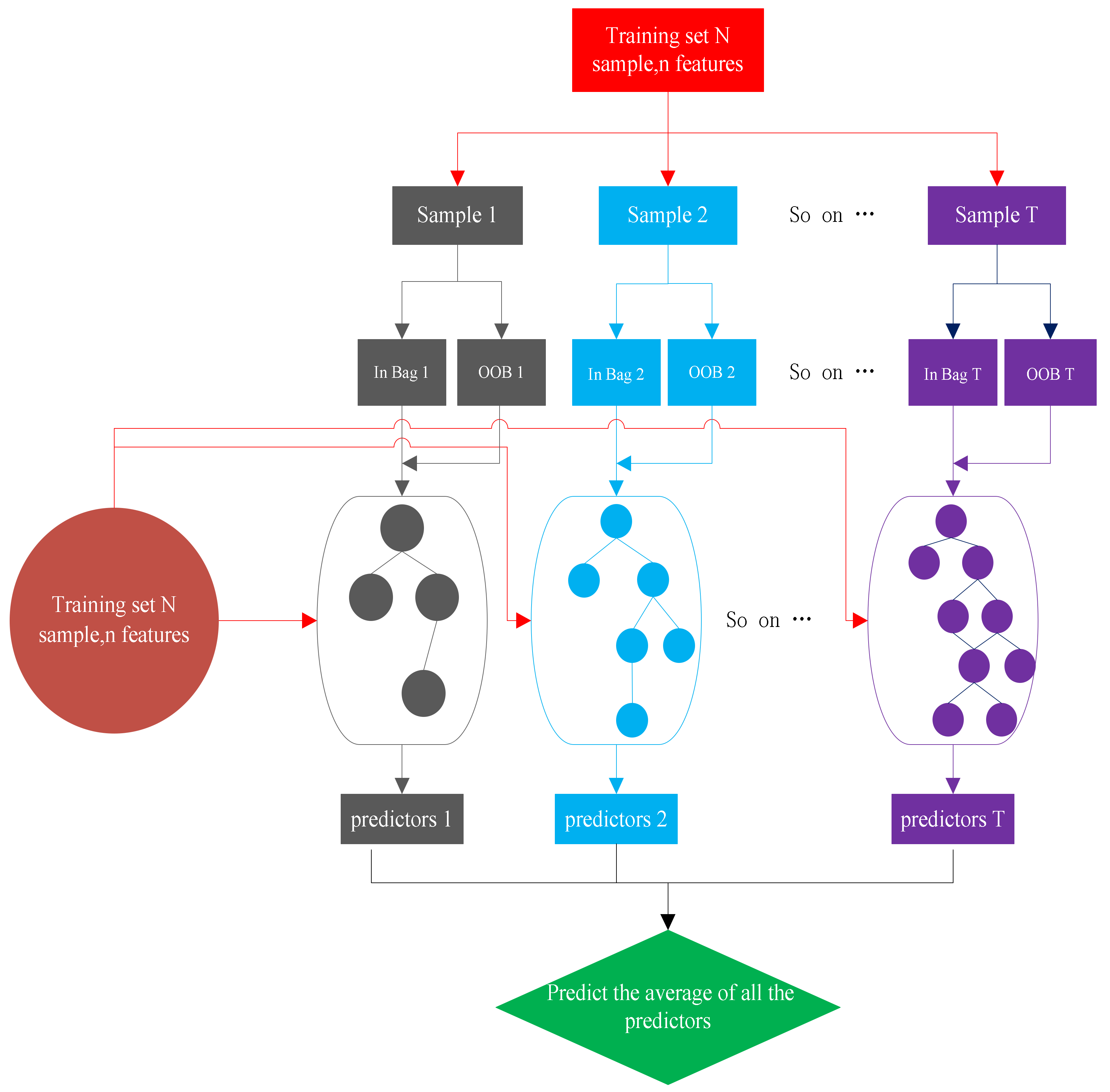
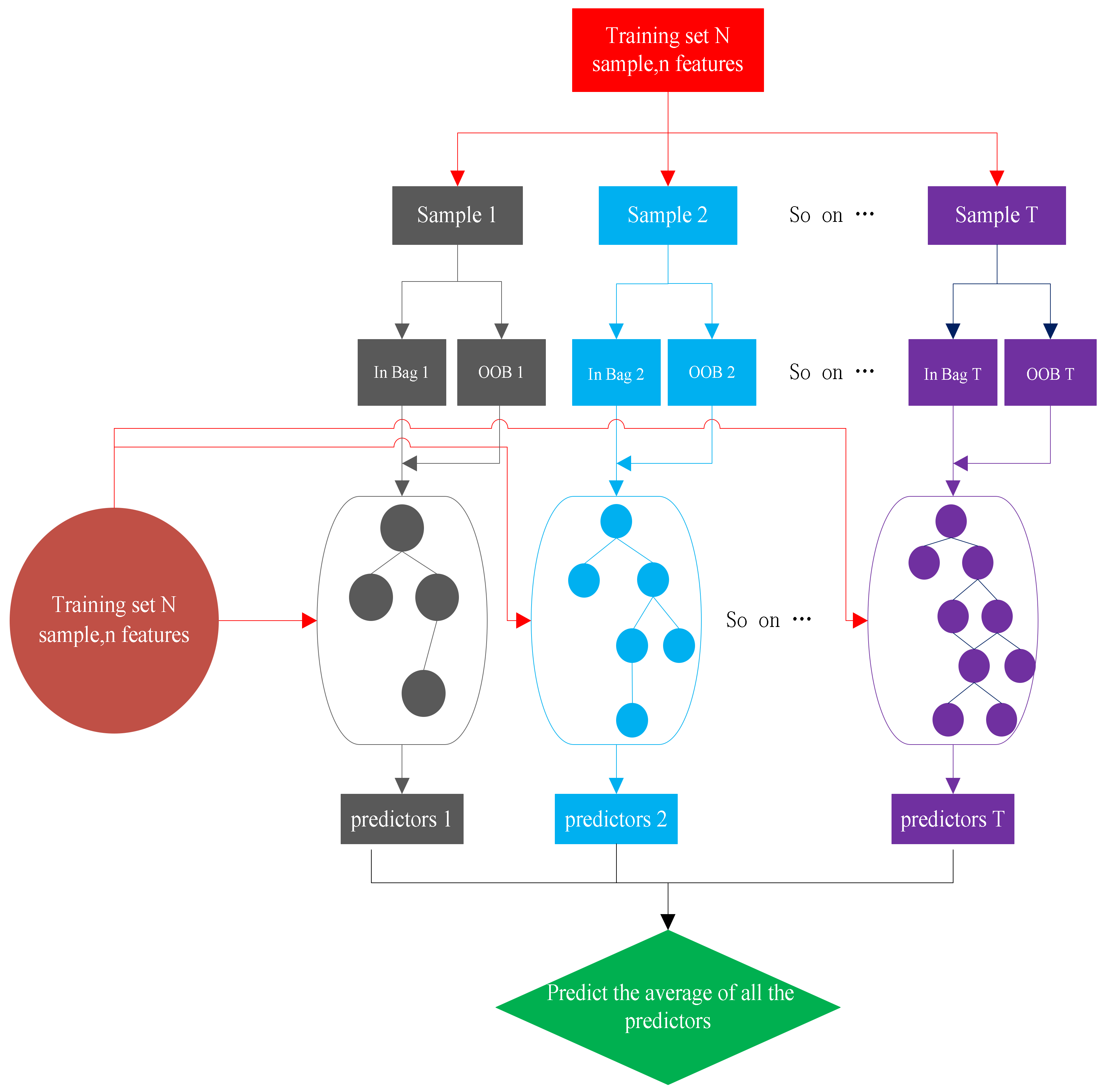
2.4. Random Forest (RF)
2.5. Extreme Gradient Boosting
2.6. Input Combinations
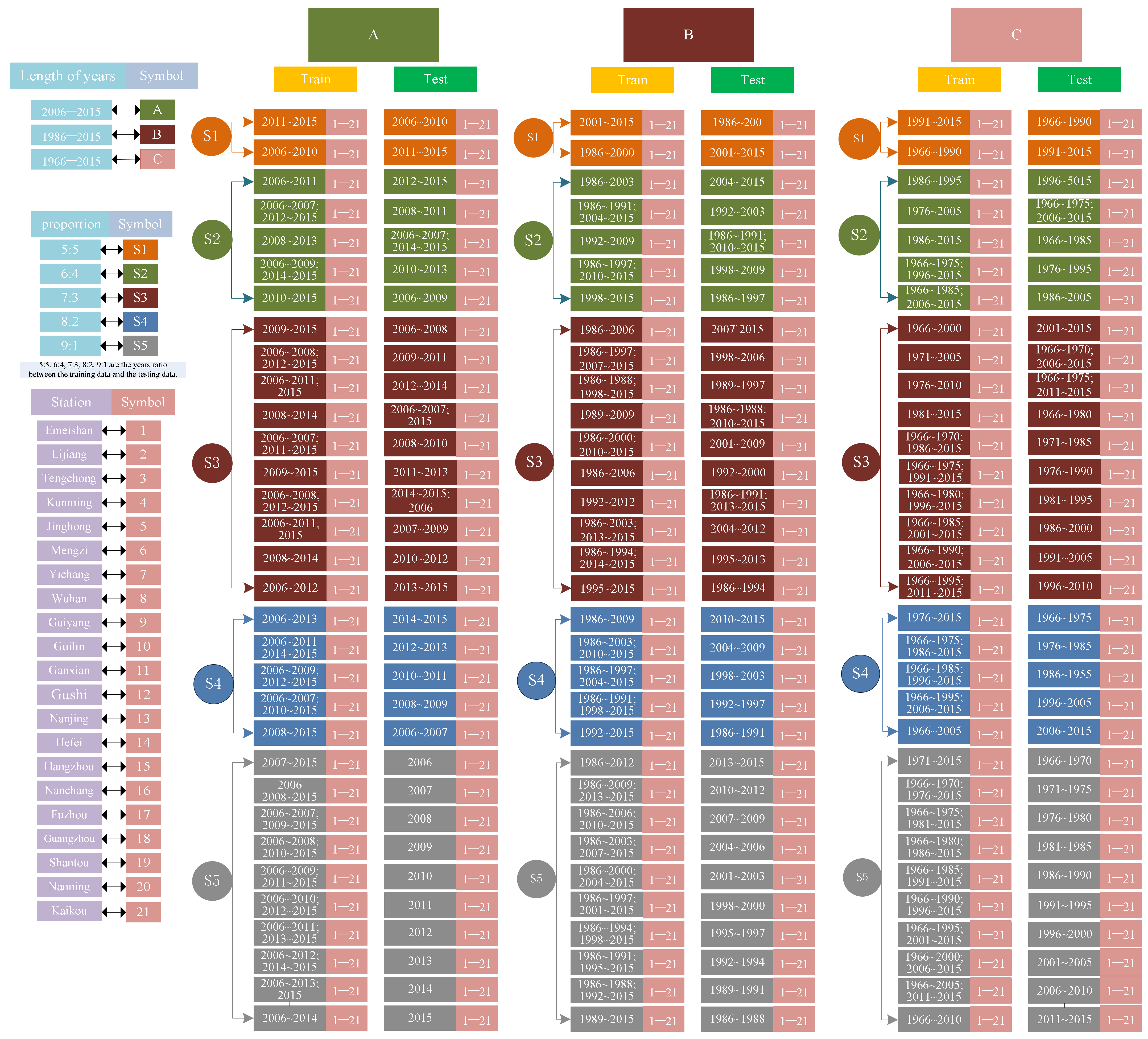
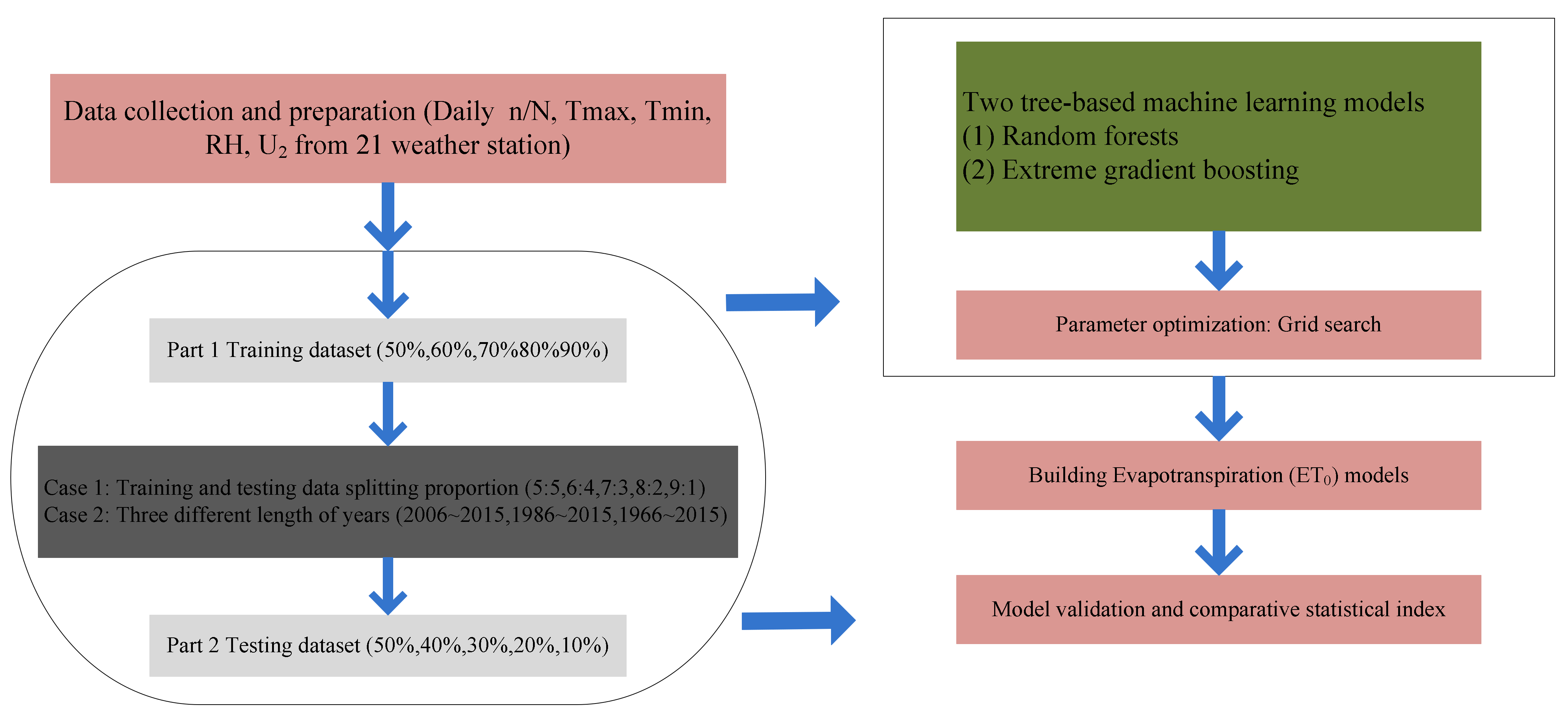
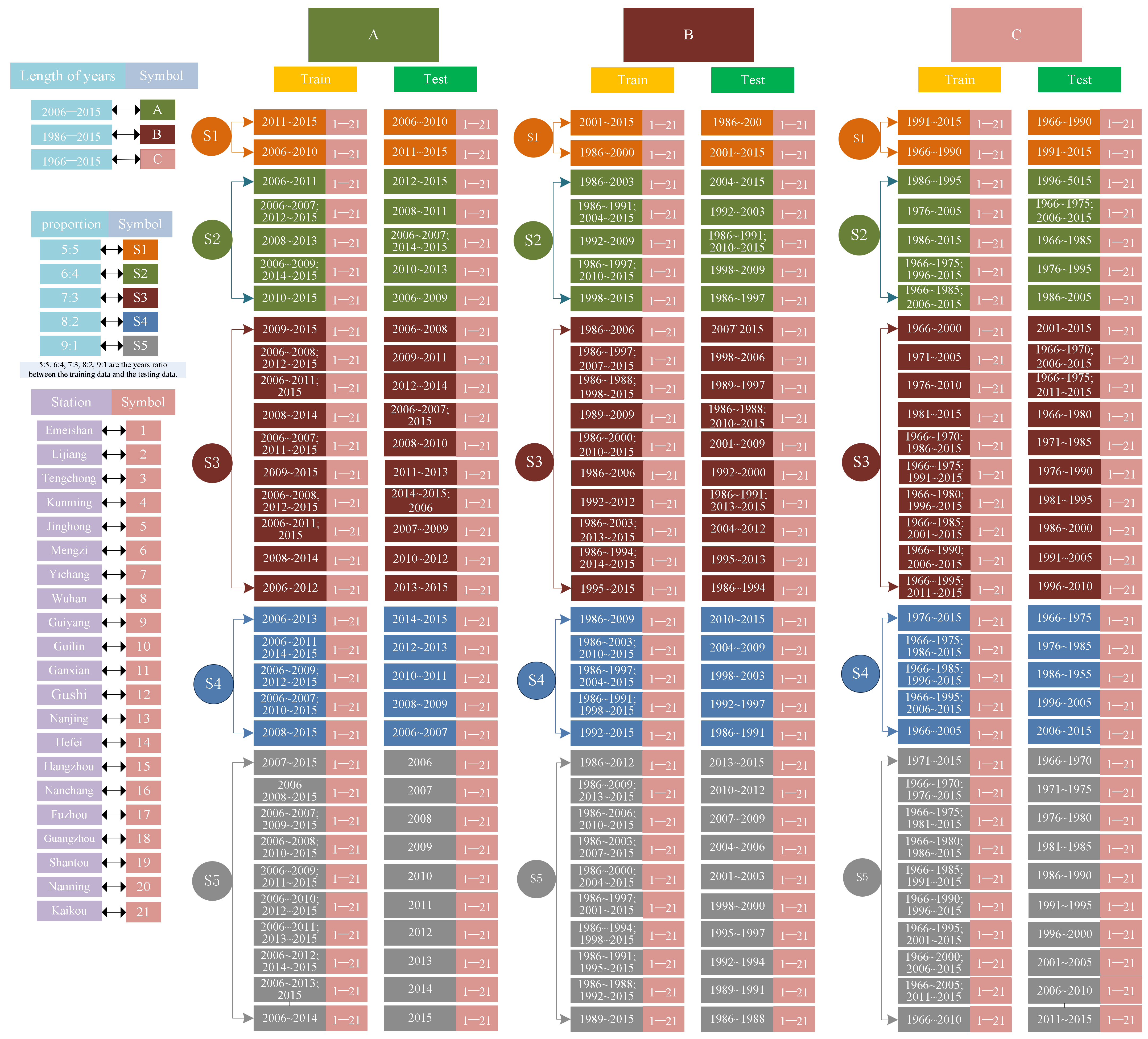
2.7. Data Splitting Strategies and Time Lengths of Input Data
2.8. Statistical Performance Analysis
3. Results
3.1. Comparisons of XGB and RF Predicting Daily ET0 with Various Input Combinations
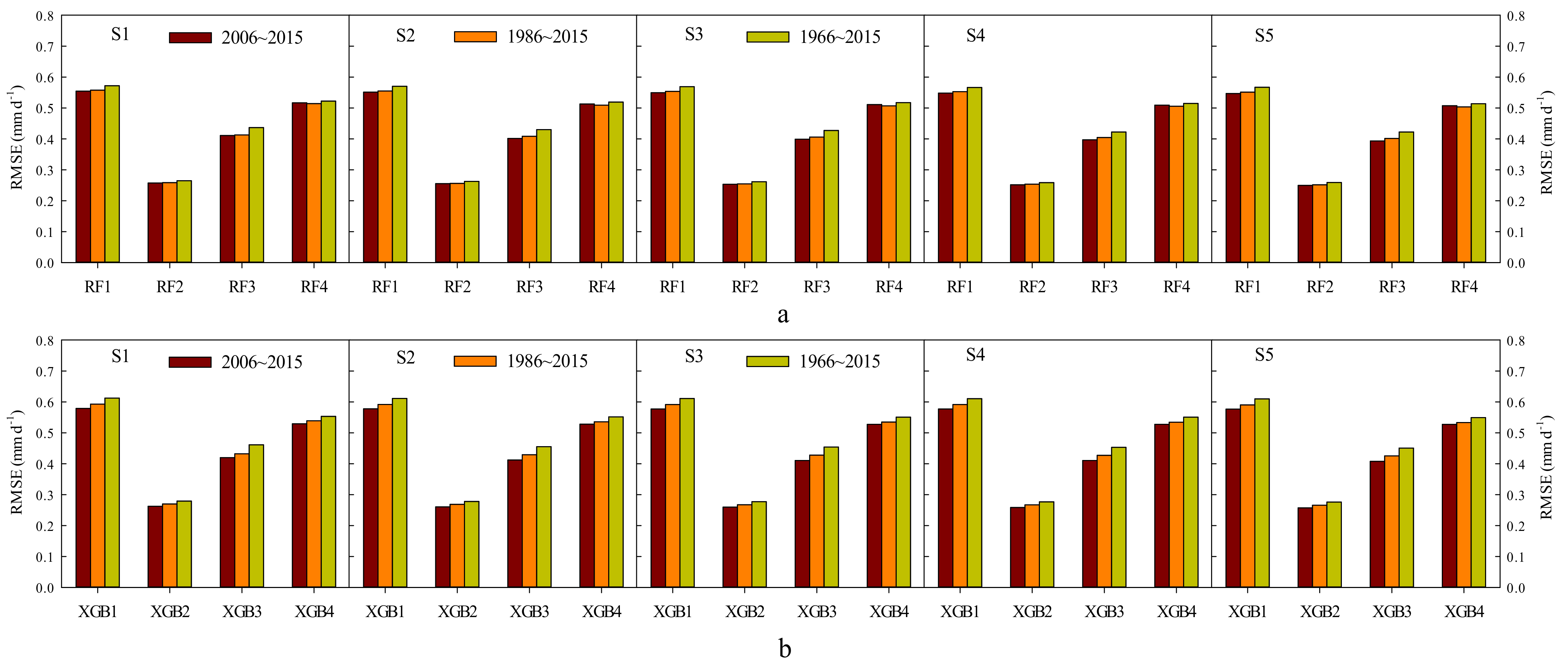
3.2. Comparisons of XGB and RF Predicting Daily ET0 with Data Splitting Proportions
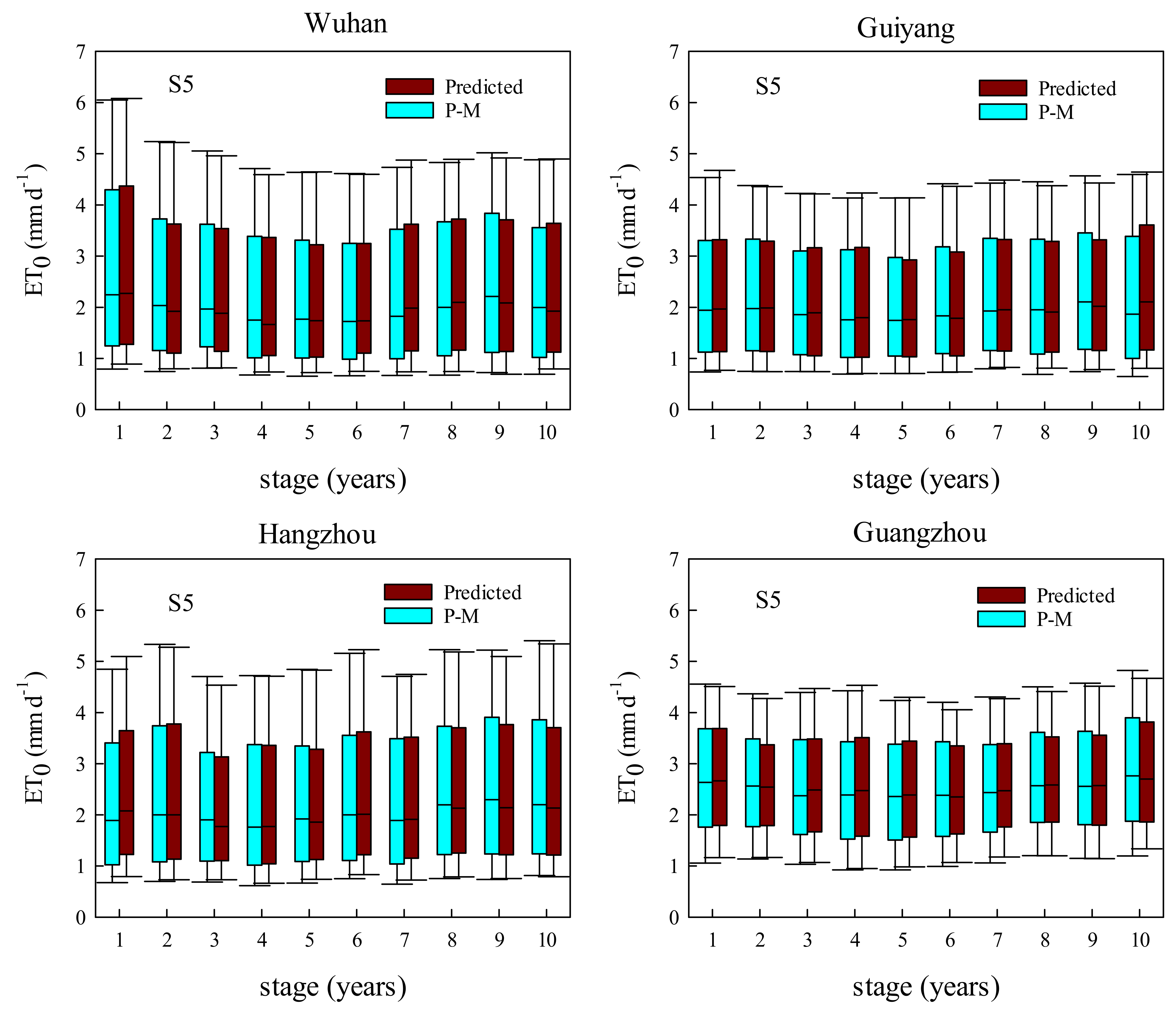
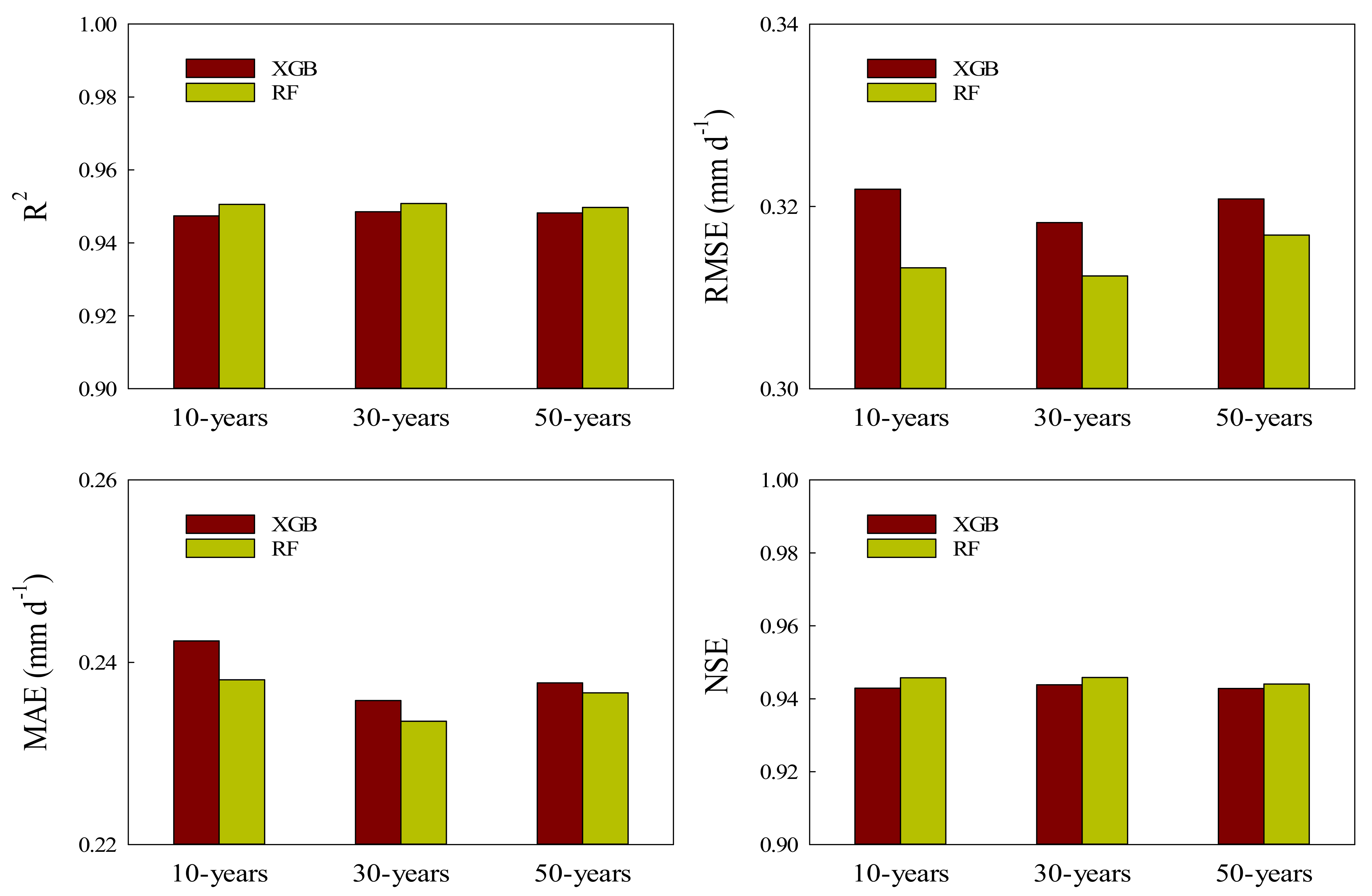
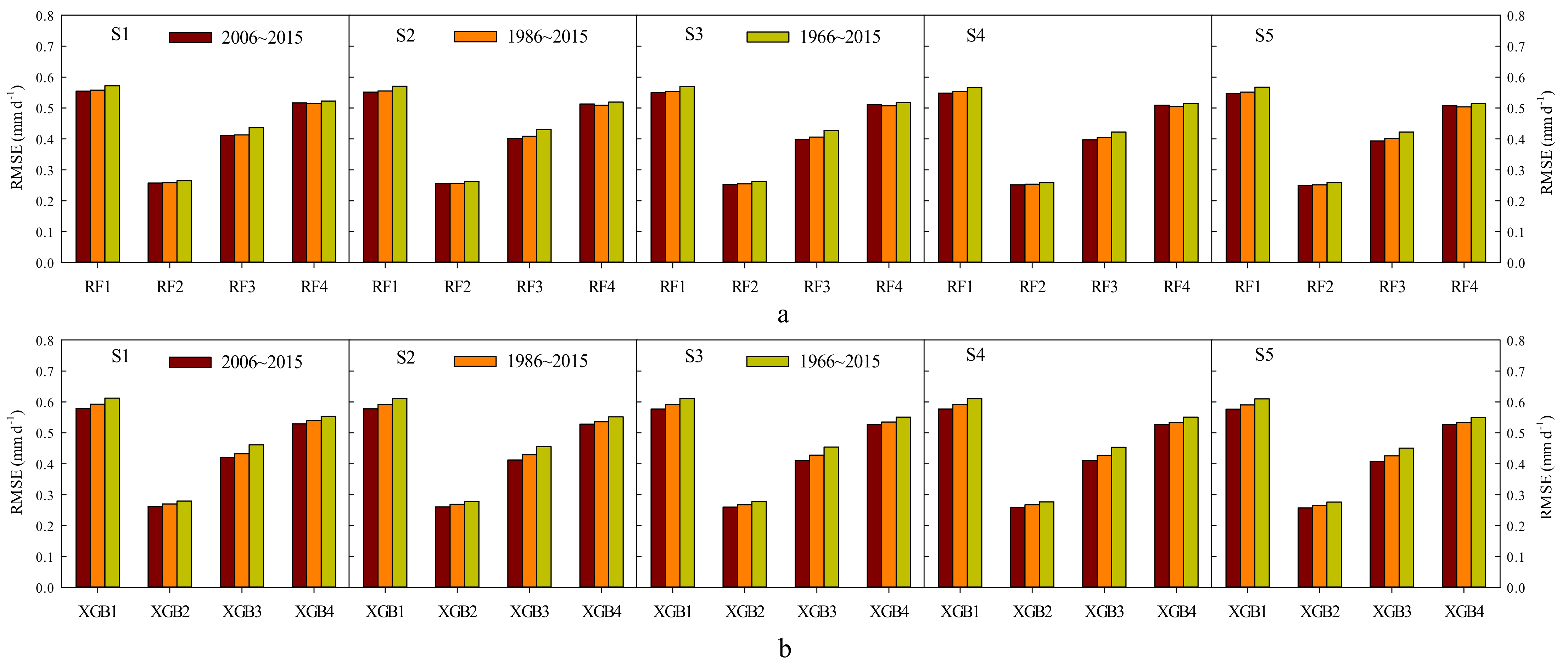
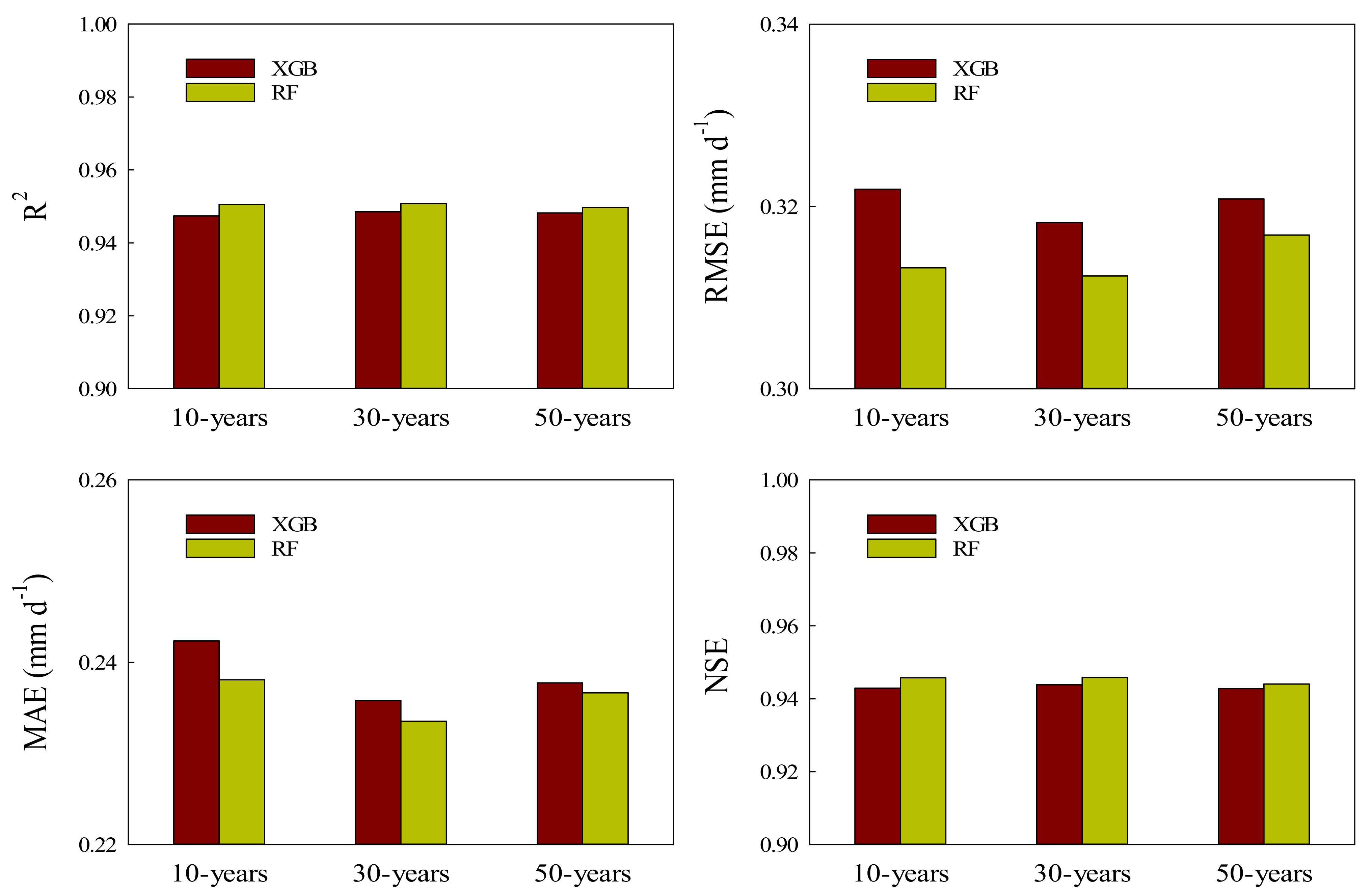
3.3. Comparisons of XGB and RF Predicting Daily ET0 with Various Time Lengths of Input Data
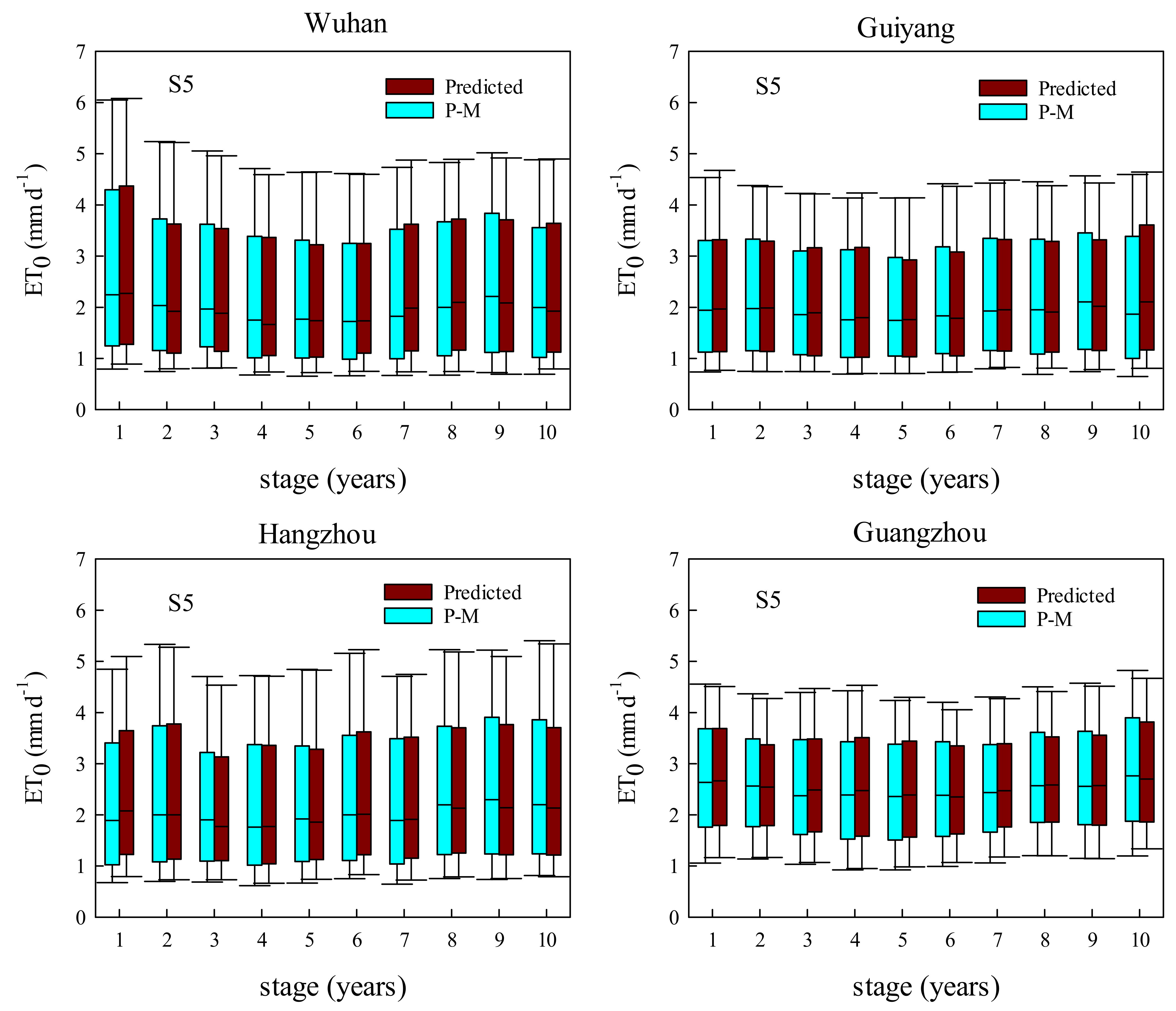
3.4. Comparisons of XGB and RF Predicting Daily ET0 with a Fixed Testing Dataset
4. Discussion
4.1. Effects of Input Combination Strategy on Daily ET0 Estimation
4.2. Effects of Data Splitting Proportions on Daily ET0 Estimation
4.3. Effects of Available Length of Years on Daily ET0 Estimation
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdullah, S.S.A.; Malek, M.A.; Abdullah, N.S.; Kisi, O.; Yap, K.S. Extreme learning machines: A new approach for prediction of reference evapotranspiration. J. Hydrol. 2015, 527, 184–195. [Google Scholar] [CrossRef]
- Fan, J.; Oestergaard, K.T.; Guyot, A.; Lockington, D.A. Estimating groundwater recharge and evapotranspiration from water table fluctuations under three vegetation covers in a coastal sandy aquifer of subtropical Australia. J. Hydrol. 2014, 519, 1120–1129. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Peng, Y.; Cui, N.; Gong, D.; Zhang, K. Modeling reference evapotranspiration using extreme learning machine and generalized regression neural network only with temperature data. Comput. Electron. Agric. 2017, 136, 71–78. [Google Scholar] [CrossRef]
- Traore, S.; Luo, Y.; Fipps, G. Deployment of artificial neural network for short-term forecasting of evapotranspiration using public weather forecast restricted messages. Agric. Water Manag. 2016, 163, 363–379. [Google Scholar] [CrossRef]
- Karimi, S.; Shiri, J.; Mart, P. Supplanting missing climatic inputs in classical and random forest models for estimating reference evapotranspiration in humid coastal areas of Iran. Comput. Electron. Agric. 2020, 176, 105633. [Google Scholar] [CrossRef]
- Priestley, C.H.B.; Taylor, R.J. On the assessment of surface heat flux and evaporation using large-scale parameters. Mon. Weather Rev. 1972, 100, 81–92. [Google Scholar] [CrossRef]
- Djaman, K.; Tabari, H.; Balde, A.B.; Diop, L.; Futakuchi, K.; Irmak, K. Analyses, calibration and validation of evapotranspiration models to predict grass-reference evapotranspiration in the Senegal river delta. J. Hydrol. Reg. Stud. 2016, 8, 82–94. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Cui, N.; Zhao, L.; Hu, X.; Gong, D. Comparison of ELM, GANN, WNN and empirical models for estimating reference evapotranspiration in humid region of Southwest China. J. Hydrol. 2016, 536, 376–383. [Google Scholar] [CrossRef]
- Karimi, S.; Kisi, O.; Kim, S.; Kim, S.; Nazemi, A.; Shiri, J. Modelling daily reference evapotranspiration in humid locations of South Korea using local and cross-station data management scenarios. Int. J. Climatol. 2017, 37, 3238–3246. [Google Scholar] [CrossRef]
- Yan, S.; Wu, Y.; Fan, J.; Zhang, F.; Qiang, S.; Zheng, J.; Xiang, Y.; Guo, J.; Zou, H. Effects of water and fertilizer management on grain filling characteristics, grain weight and productivity of drip-fertigated winter wheat. Agric. Water Manage. 2019, 213, 983–995. [Google Scholar] [CrossRef]
- Guitjens, J.C. Models of Alfalfa yield and evapotranspiration. J. Irrig. Drain. Div. Proc. Am. Soc. Civ. Eng. 1982, 108, 212–222. [Google Scholar] [CrossRef]
- Harbeck, G.E., Jr. A Practical Field Technique for Measuring Reservoir Evaporation Utilizing Mass-Transfer Theory; Paper 272-E; US Government Printing Office: Washington, DC, USA, 1962; pp. 101–105.
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop Evapotranspirationguidelines for Computing Crop Water requirements-FAO Irrigation and Drainage Paper 56. Fao Rome 1998, 300, D05109. [Google Scholar]
- Doorenbos, J.; Pruitt, W.O. Guidelines for predicting crop water requirements. In FAO Irrigation and Drainage Paper 24; FAO: Rome, Italy, 1977. [Google Scholar]
- Monteith, J.L. Evaporation and environment. In Symposia of the Society for Experimental Biology; Society for Experimental Biology: London, UK, 1965; Volume 19, pp. 205–234. [Google Scholar]
- Penman, H.L. Natural evaporation from open water, hare soil and grass. Proc. R. Soc. Lond. 1948, 193, 120–145. [Google Scholar]
- Fan, J.; Wang, X.; Wu, L. New combined models for estimating daily global solar radiation based on sunshine duration in humid regions: A case study in South China. Energy Convers. Manage. 2018, 156, 618–625. [Google Scholar] [CrossRef]
- Fan, J.; Chen, B.; Wu, L. Evaluation and development of temperature-based empirical models for estimating daily global solar radiation in humid regions. Energy 2018, 144, 903–914. [Google Scholar] [CrossRef]
- Shiri, J.; Nazemi, A.H.; Sadraddini, A.A.; Landeras, G.; Kisi, O.; Fard, A.F.; Marti, P. Comparison of heuristic and empirical approaches for estimating reference evapotranspiration from limited inputs in Iran. Comput. Electron. Agric. 2014, 108, 230–241. [Google Scholar] [CrossRef]
- Feng, Y.; Jia, Y.; Cui, N.; Zhao, L.; Li, C.; Gong, D. Calibration of Hargreaves model for reference evapotranspiration estimation in Sichuan basin of south-west China. Agric. Water Manage. 2017, 181, 1–9. [Google Scholar] [CrossRef]
- Jensen, D.T.; Hargreaves, G.H.; Temesgen, B.; Allen, R.G. Computation of ET0 under non ideal conditions. J. Irrig. Drain. Eng. 1997, 123, 394–400. [Google Scholar] [CrossRef]
- Martí, P.; Zarzo, M.; Vanderlinden, K.; Girona, J. Parametric expressions for the adjusted Hargreaves coefficient in Eastern Spain. J. Hydrol. 2015, 529, 1713–1724. [Google Scholar] [CrossRef]
- Mendicino, G.; Senatore, A. Regionalization of the Hargreaves coefficient for the assessment of distributed reference evapotranspiration in Southern Italy. J. Irrig. Drain Eng. 2013, 139, 349–362. [Google Scholar] [CrossRef]
- Barzkar, A.; Najafzadeh, M.; Homaei, F. Evaluation of drought events in various climatic conditions using data-driven models and a reliability-based probabilistic model. Nat. Hazards 2021, 1–22. [Google Scholar] [CrossRef]
- Dong, J.; Wu, L.; Liu, X.; Li, Z.; Gao, Y.; Zhang, Y.; Yang, Q. Estimation of daily dew point temperature by using bat algorithm optimization based extreme learning machine. Appl. Therm. Eng. 2020, 165, 114569. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L. Comparison of support vector machine and extreme gradient boostinging for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manage. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zhang, F. Evaluating the effect of air pollution on global and diffuse solar radiation prediction using support vector machine modeling based on sunshine duration and air temperature. Renew. Sustain. Energy Rev. 2018, 94, 732–747. [Google Scholar] [CrossRef]
- Kaba, K.; Sarıgül, M.; Avcı, M.; Kandırmaz, H.M. Estimation of daily global solar radiation using deep learning model. Energy 2018, 162, 126–135. [Google Scholar] [CrossRef]
- Keshtegar, B.; Mert, C.; Kisi, O. Comparison of four heuristic regression techniques in solar radiation modeling: Kriging method vs RSM, MARS and M5 model tree. Renew. Sustain. Energy Rev. 2018, 81, 330–341. [Google Scholar] [CrossRef]
- Kim, S.; Singh, V.; Lee, C.; Seo, Y. Modeling the physical dynamics of daily dew point temperature using soft computing techniques. KSCE J. Civ. Eng. 2015, 19, 1930–1940. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Behmanesh, J.; Khalili, K. Application of gene expression programming to predict daily dew point temperature, Appl. Therm. Eng. 2017, 112, 1097–1107. [Google Scholar] [CrossRef]
- Movahed, S.F.; Najafzadeh, M.; Mehrpooya, A. Receiving More Accurate Predictions for Longitudinal Dispersion Coefficients in Water Pipelines: Training Group Method of Data Handling Using Extreme Learning Machine Conceptions. Water Resour. Manag. 2020, 34, 529–561. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Niazmardi, S. A Novel Multiple-Kernel Support Vector Regression Algorithm for Estimation of Water Quality Parameters. Nat. Resour. Res. 2021, 5, 3761–3775. [Google Scholar] [CrossRef]
- Singh, K.P.; Basant, N.; Gupta, S. Support vector machines in water quality management. Anal. Chim. Acta 2011, 703, 152–162. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Li, Y.; Wang, Q. A unified model for remotely estimating chlorophyll a in Lake Taihu, China, based on SVM and in situ hyperspectral data. IEEE Trans. Geosci. Rem. Sens. 2009, 47, 2957–2965. [Google Scholar]
- Wang, L.; Niu, Z.; Kisi, O.; Kisi, O.; Li, C.; Yu, D. Pan evaporation modeling using four different heuristic approaches. Comput. Electron. Agric. 2017, 140, 203–213. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Hu, B.; Bilal, M.; Kermani, M.; Li, H. Evaporation modelling using different machine learning techniques. Int. J. Climatol. 2017, 37, 1076–1092. [Google Scholar] [CrossRef]
- Wu, L.; Huang, G.; Fan, J.; Zhang, F.; Wang, X.; Zeng, W. Potential of kernel-based nonlinear extension of Arps decline model and gradient boostinging with categorical features support for predicting daily global solar radiation in humid regions. Energy Convers. Manage. 2019, 183, 280–295. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Awadh, S.M.; Sharafati, A.; Shahid, S. Complementary data-intelligence model for river flow simulation. J. Hydrol. 2018, 567, 180–190. [Google Scholar] [CrossRef]
- Ahmadi, F.; Mehdizadeh, S.; Mohammadi, B.; Pham, Q.B.; DOAN, T.N.C.; Vo, N.D. Application of an artificial intelligence technique enhanced with intelligent water drops for monthly reference evapotranspiration estimation. Agric. Water Manage. 2021, 244, 106622. [Google Scholar] [CrossRef]
- Pandey, P.; Pandey, V. Development of reference evapotranspiration equations using an artificial intelligence-based function discovery method under the humid climate of Northeast India. Comput. Electron. Agric. 2020, 179, 105838. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H.S. Neural networks and genetic algorithm approach for nonlinear evaporation and evapotranspiration modeling. J. Hydrol. 2008, 351, 299–317. [Google Scholar] [CrossRef]
- Kisi, O.; Alizamir, M. Modelling reference evapotranspiration using a new wavelet conjunction heuristic method: Wavelet extreme learning machine vs wavelet neural networks. Agric. For. Meteorol. 2018, 263, 41–48. [Google Scholar] [CrossRef]
- Kumar, M.; Raghuwanshi, N.S.; Singh, R.; Wallender, W.W.; Pruitt, W.O. Estimating evapotranspiration using artificial neural network. J. Irrig. Drain. Eng. 2002, 128, 224–233. [Google Scholar] [CrossRef]
- Chia, M.; Huang, Y.; Koo, C. Swarm-based optimization as stochastic training strategy for estimation of reference evapotranspiration using extreme learning machine. Agric. Water Manage. 2021, 243, 106447. [Google Scholar] [CrossRef]
- Wu, L.; Peng, Y.; Fan, J.; Wang, Y.; Huang, G. A novel kernel extreme learning machine model coupled with K-means clustering and firefly algorithm for estimating monthly reference evapotranspiration in parallel computation. Agric. Water Manage. 2020, 245, 106624. [Google Scholar] [CrossRef]
- Zhu, B.; Feng, Y.; Gong, D.; Jiang, S.; Zhao, L.; Cui, N. Hybrid particle swarm optimization with extreme learning machine for daily reference evapotranspiration prediction from limited climatic data. Comput. Electron. Agric. 2020, 173, 105430. [Google Scholar] [CrossRef]
- Chia, M.; Huang, Y.; Koo, C. Support vector machine enhanced empirical reference evapotranspiration estimation with limited meteorological parameters. Comput. Electron. Agric. 2020, 175, 105577. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F.; de Oliveira, R.A.; Fernandes Filho, E.I. Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM—A new approach. J. Hydrol. 2019, 572, 556–570. [Google Scholar] [CrossRef]
- Moazenzadeh, R.; Mohammadi, B.; Shamshirband, S.; Chau, K.-W. Coupling a firefly algorithm with support vector regression to predict evaporation in northern Iran. Eng. Appl. Comput. Fluid Mech. 2018, 12, 584–597. [Google Scholar] [CrossRef] [Green Version]
- Kiafar, H.; Babazadeh, H.; Marti, P.; Kisi, O.; Landeras, G.; Karimi, S.; Shiri, J. Evaluating the generalizability of GEP models for estimating reference evapotranspiration in distant humid and arid locations. Theor. Appl. Climatol. 2017, 130, 377–389. [Google Scholar] [CrossRef]
- Mattar, M. Using gene expression programming in monthly reference evapotranspiration modeling: A case study in Egypt. Agric. Water Manage. 2018, 198, 28–38. [Google Scholar] [CrossRef]
- Shiri, J. Evaluation of FAO56-PM, empirical, semi-empirical and gene expression programming approaches for estimating daily reference evapotranspiration in hyper-arid regions of Iran. Agric. Water Manage. 2017, 188, 101–114. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of Catboosting method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Z.; Zheng, J. Catboosting: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Fan, J.; Ma, X.; Wu, L.; Zhang, F.; Yu, X.; Zeng, W. Light Gradient boostinging Machine: An efficient soft computing model for estimating daily reference evapotranspiration with local and external meteorological data. Agric. Water Manage. 2019, 225, 105758. [Google Scholar] [CrossRef]
- Kisi, O.; Kilic, Y. An investigation on generalization ability of artificial neural networks and M5 model tree in modeling reference evapotranspiration. Theor. Appl. Climatol. 2016, 126, 413–425. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, Z.; Jiang, H.; Sun, S. Estimating daily reference evapotranspiration based on limited meteorological data using deep learning and classical machine learning methods. J. Hydrol. 2020, 591, 125286. [Google Scholar] [CrossRef]
- Ferreira, L.; Cunha, F. Multi-step ahead forecasting of daily reference evapotranspiration using deep learning. Comput. Electron. Agric. 2020, 178, 105728. [Google Scholar] [CrossRef]
- Ferreira, L.; Cunha, F. New approach to estimate daily reference evapotranspiration based on hourly temperature and relative humidity using machine learning and deep learning. Agric. Water Manage. 2020, 234, 106113. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Gong, N.; Zhang, Q.; Zhao, L. Evaluation of random forests and generalized regression neural networks for daily reference evapotranspiration modelling. Agric. Water Manag. 2017, 193, 163–173. [Google Scholar] [CrossRef]
- Júnior, J.; Medeiros, V.; Garrozi, C.; Montenegro, A.; Gonalves, G. Random forest techniques for spatial interpolation of evapotranspiration data from Brazilian’s Northeast. Comput. Electron. Agric. 2019, 166, 105017. [Google Scholar] [CrossRef]
- Wang, S.; Lian, J.; Peng, Y.; Hu, B.; Chen, H. Generalized reference evapotranspiration models with limited climatic data based on random forest and gene expression programming in Guangxi, China. Agric. Water Manag. 2019, 221, 220–230. [Google Scholar] [CrossRef]
- Avand, M.; Janizadeh, S.; Bui, D.T.; Pham, V.H.; Ngo, P.T.T.; Nhu, V. A tree-based intelligence ensemble approach for spatial prediction of potential groundwater. Int. J. Digit. Earth 2020, 13, 1408–1429. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naïve Bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Avand, M.; Janizadeh, S.; Bui, D.T. Using machine learning models, remote sensing, and GIS to investigate the effects of changing climates and land uses on flood probability. J. Hydrol. 2021, 595, 125663. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Homaei, F.; Farhadi, H. Reliability assessment of water quality index based on guidelines of national sanitation foundation in natural streams: Integration of remote sensing and data-driven models. Artif. Intell. Rev. 2021, 54, 4619–4651. [Google Scholar] [CrossRef]
- Wang, F.; Wang, Y.; Zhang, K.; Gamane, D.; Kisi, O. Spatial heterogeneity modeling of water quality based on random forest regression and model interpretation. Environ. Res. 2021, 202, 111660. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboosting: A scalable tree boostinging system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Fan, J.; Zheng, J.; Wu, L.; Zhang, F. Estimation of daily maize transpiration using support vector machines, extreme gradient boosting, artificial and deep neural networks models. Agric. Water Manag. 2021, 244, 106547. [Google Scholar] [CrossRef]
- Ni, L.; Wang, D.; Wu, J.; Wang, Y.; Tao, Y.; Zhang, J.; Liu, J. Streamflow forecasting using extreme gradient boosting model coupled with Gaussian mixture model. J. Hydrol. 2020, 586, 124901. [Google Scholar] [CrossRef]
- Yu, S.; Chen, Z.; Yu, B.; Wang, L.; Wu, B.; Wu, J.; Zhao, F. Exploring the relationship between 2D/3D landscape pattern and land surface temperature based on explainable extreme Gradient Boosting tree: A case study of Shanghai, China. Sci. Total Environ. 2020, 725, 138229. [Google Scholar] [CrossRef]
- Wu, L.; Peng, Y.; Fan, J.; Wang, Y. Machine learning models for the estimation of monthly mean daily reference evapotranspiration based on cross-station and synthetic data. Hydrol. Res. 2019, 50, 1730–1750. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zheng, J.; Zhang, F. Medium-range forecasting of daily reference evapotranspiration across China using numerical weather prediction outputs downscaled by extreme gradient boosting. J. Hydrol. 2021, 601, 126664. [Google Scholar] [CrossRef]
- Han, Y.; Wu, J.; Zhai, B.; Pan, Y.; Zeng, W. Coupling a bat algorithm with xgboost to estimate reference evapotranspiration in the arid and semiarid regions of china. Adv. Meteorol. 2019, 2019, 9575782. [Google Scholar] [CrossRef]
- Lu, X.; Fan, J.; Wu, L.; Dong, J. Forecasting Multi-Step Ahead Monthly Reference Evapotranspiration Using Hybrid Extreme Gradient boostinging with Grey Wolf Optimization Algorithm. Comp. Model. Eng. 2020, 125, 699–723. [Google Scholar]
- Yan, S.; Wu, L.; Fan, J.; Zhang, F.; Zou, Y.; Wu, Y. A novel hybrid WOA-XGB model for estimating daily reference evapotranspiration using local and external meteorological data: Applications in arid and humid regions of China. Agric. Water Manag. 2021, 244, 106594. [Google Scholar] [CrossRef]
- Shiri, J. Improving the performance of the mass transfer-based reference evapotranspiration estimation approaches through a coupled wavelet-random forest methodology. J. Hydrol. 2018, 561, 737–750. [Google Scholar] [CrossRef]
- Huo, Z.; Dai, X.; Feng, S.; Kang, S.; Huang, G. Effect of climate change on reference evapotranspiration and aridity index in arid region of China. J. Hydrol. 2013, 492, 24–34. [Google Scholar] [CrossRef]
- Li, Y.; Yao, N.; Chau, H.W. Influences of removing linear and nonlinear trends from climatic variables on temporal variations of annual reference crop evapotranspiration in Xinjiang, China. Sci. Total. Environ. 2017, 592, 680–692. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Traore, S.; Lyu, X.; Wang, W.; Wang, Y. Medium range daily reference evapotranspiration forecasting by using ANN and public weather forecasts. Water Resour. Manag. 2015, 29, 3863–3876. [Google Scholar] [CrossRef]
- Luo, Y.; Chang, X.; Peng, S.; Khan, S.; Wang, W.; Zheng, Q.; Cai, X. Short-term forecasting of daily reference evapotranspiration using the Hargreaves—Samani model and temperature forecasts. Agric. Water Manag. 2014, 136, 42–51. [Google Scholar] [CrossRef]
- Tikhamarine, Y.; Malik, A.; Kumar, A.; Souag-Gamane, D.; Kisi, O. Estimation of monthly reference evapotranspiration using novel hybrid machine learning approaches. Hydrol. Sci. J. Des. Sci. Hydrol. 2019, 64, 1824–1842. [Google Scholar] [CrossRef]
- Yassen, A.N.; Nam, W.H.; Hong, E.M. Impact of climate change on reference evapotranspiration in Egypt. Catena 2020, 194, 104711. [Google Scholar] [CrossRef]
- Ning, T.; Zhou, S.; Chang, F.; Shen, H.; Li, Z.; Liu, W. Interaction of vegetation, climate and topography on evapotranspiration modelling at different time scales within the Budyko framework. Agric. For. Meteorol. 2019, 275, 59–68. [Google Scholar] [CrossRef]
- Tabari, H.; Marofi, S.; Aeini, A.; Talaee, P.H.; Mohammadi, K. Trend analysis of reference evapotranspiration in the western half of Iran. Agric. For. Meteorol. 2011, 151, 128–136. [Google Scholar] [CrossRef]
- Espadafor, M.; Lorite, I.; Gavilán, P.; Berengena, J. An analysis of the tendency of reference evapotranspiration estimates and other climate variables during the last 45 years in southern Spain. Agric. Water Manag. 2011, 98, 1045–1061. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, Z. Quantitative estimation of the impact of climate change on actual evapotranspiration in the Yellow River Basin, China. J. Hydrol. 2010, 395, 226–234. [Google Scholar] [CrossRef]
- Tang, B.; Tong, L.; Kang, S.; Zhang, L. Impacts of climate variability on reference evapotranspiration over 58 years in the Haihe river basin of north China. Agric. Water Manag. 2011, 98, 1660–1670. [Google Scholar] [CrossRef]
- Lu, X.; Ju, Y.; Wu, L.; Fan, J.; Zhang, F.; Li, Z. Daily pan evaporation modeling from local and cross-station data using three tree-basedmachine learning models. J. Hydrol. 2018, 566, 668–684. [Google Scholar] [CrossRef]
- Saggi, M.K.; Jain, S. Application of fuzzy-genetic and regularization random forest (FG-RRF): Estimation of crop evapotranspiration (ETc) for maize and wheat crops—ScienceDirect. Agric. Water Manage. 2020, 229, 105907. [Google Scholar] [CrossRef]
- Karimi, S.; Shiri, J.; Kisi, P.; Xu, T. Forecasting daily streamflow values: Assessing heuristic models. Hydrol. Res. 2018, 49, 658–669. [Google Scholar] [CrossRef]
- Song, R.; Chen, S.; Deng, B.; Li, L. Extreme Gradient boostinging for Identifying Individual Users Across Different Digital Devices. In International Conference on Web-Age Information Management; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Najafzadeh, M.; Oliveto, G. More reliable predictions of clear-water scour depth at pile groupsby robust artificial intelligence techniques while preserving physical consistency. Soft Comput. 2021, 25, 5723–5746. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Despotovic, M.; Nedic, V.; Despotovic, D.; Cvetanovic, S. Review and statistical analysis of different global solar radiation sunshine models. Renew. Sustain. Energy Rev. 2015, 52, 1869–1880. [Google Scholar] [CrossRef]
- Antonopoulos, V.Z.; Antonopoulos, A.V. Daily reference evapotranspiration estimates by artificial neural networks technique and empirical equations using limited input climate variables. Comput. Electron. Agric. 2017, 132, 86–96. [Google Scholar] [CrossRef]
- Tabari, H.; Kisi, O.; Ezani, A.; Talaee, P.H. SVM, ANFIS, regression and climate based models for reference evapotranspiration modeling using limited climatic data in a semi-arid highland environment. J. Hydrol. 2012, 444, 78–89. [Google Scholar] [CrossRef]
- Sanikhani, H.; Kisi, O.; Maroufpoor, E.; Yaseen, Z.M. Temperature-based modeling of reference evapotranspiration using several artificial intelligence models: Application of different modeling scenarios. Theor. Appl. Climatol. 2019, 135, 449–462. [Google Scholar] [CrossRef]
- Rezaabad, Z.; Salajegheh, M. ANFIS Modeling with ICA, BBO, TLBO, and IWO Optimization Algorithms and Sensitivity Analysis for Predicting Daily Reference Evapotranspiration. J. Hydol. Eng. 2020, 25, 4020038. [Google Scholar] [CrossRef]
- Shiri, J.; Marti, P.; Landeras, G. Data splitting strategies for improving data driven models for reference evapotranspiration estimation among similar stations. Comput. Electron. Agric. 2019, 162, 70–81. [Google Scholar] [CrossRef]
- Pandey, B.K.; Khare, D. Identification of trend in long term precipitation and reference evapotranspiration over Narmada river basin (India). Global Planet. Change. 2018, 161, 172–182. [Google Scholar] [CrossRef]
- Mutasa, S.; Sun, S.; Ha, R. Understanding artificial intelligence based radiology studies: What is overfitting? Clin. Imaging 2020, 65, 96–99. [Google Scholar] [CrossRef]
- Laaboudi, A.; Mouhouche, B.; Draoui, B. Conceptual reference evapotranspiration models for different time steps. J. Pet. Environ. Biotechnol. 2012, 3, 1000123. [Google Scholar]
- Yin, J.; Deng, Z.; Amor, V.; Wu, J.; Rasu, E. Forecast of short-term daily reference evapotranspiration under limited meteorological variables using a hybrid bi-directional long short-term memory model (Bi-LSTM). Agric. Water Manag. 2020, 242, 106386. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Name | Altitude (m) | Latitude (° N) | Longitude (° E) | Rs (MJ·m−2·d−1) | Tmax (°C) | Tmin (°C) | RH (%) | U2 (m·s−1) | ET0 (mm·d−1) |
|---|---|---|---|---|---|---|---|---|---|
| Emeishan | 3048.6 | 29.31 | 103.21 | 12.60 (0.59) | 7.75 (0.93) | 0.55 (12.95) | 85.51 (0.20) | 2.27(0.57) | 1.72 (0.66) |
| Lijiang | 2394.40 | 26.51 | 100.13 | 16.94 (0.36) | 19.52 (0.23) | 8.07 (0.72) | 62.43 (0.30) | 2.37(0.49) | 3.36 (0.40) |
| Tengchong | 1648.70 | 25.07 | 98.29 | 15.22 (0.38) | 21.61 (0.17) | 10.73 (0.57) | 77.14 (0.16) | 1.24(0.42) | 2.68 (0.38) |
| Kunming | 1896.80 | 25.01 | 102.41 | 14.95 (0.45) | 21.16 (0.22) | 10.77 (0.53) | 71.20 (0.19) | 1.62(0.49) | 2.92 (0.45) |
| Jinghong | 553.60 | 21.55 | 100.45 | 15.60 (0.34) | 29.75 (0.13) | 18.05 (0.25) | 79.28 (0.13) | 0.49(0.77) | 3.12 (0.37) |
| Mengzi | 1301.70 | 23.20 | 103.23 | 15.55 (0.41) | 24.70 (0.20) | 15.07 (0.33) | 70.45 (0.17) | 2.21(0.53) | 3.44 (0.42) |
| Yichang | 134.30 | 30.42 | 111.05 | 10.79 (0.70) | 21.56 (0.43) | 13.59 (0.61) | 75.04 (0.16) | 0.98 (0.51) | 2.28 (0.68) |
| Wuhan | 27.00 | 30.38 | 114.17 | 12.05 (0.65) | 21.41 (0.45) | 13.28 (0.71) | 76.66 (0.15) | 1.38 (0.63) | 2.45 (0.68) |
| Guiyang | 1074.30 | 26.34 | 106.42 | 10.15 (0.70) | 19.58 (0.42) | 12.07 (0.59) | 77.40 (0.14) | 1.67 (0.45) | 2.26 (0.62) |
| Guilin | 166.20 | 25.20 | 110.18 | 11.21 (0.65) | 23.29 (0.37) | 16.06 (0.47) | 74.82 (0.18) | 1.79 (0.70) | 2.66 (0.56) |
| Ganxian | 124.70 | 25.50 | 114.50 | 12.26 (0.60) | 24.20 (0.37) | 16.26 (0.49) | 74.86 (0.15) | 1.18 (0.57) | 2.71 (0.60) |
| Gushi | 57.90 | 32.10 | 115.4 | 12.86 (0.61) | 20.31 (0.48) | 11.89 (0.79) | 76.01 (0.18) | 2.00 (0.47) | 2.57 (0.66) |
| Nanjing | 12.50 | 32.00 | 118.48 | 12.48 (0.59) | 20.54 (0.47) | 11.93 (0.81) | 74.92 (0.16) | 1.86 (0.55) | 2.51 (0.64) |
| Hefei | 36.50 | 31.53 | 117.15 | 12.04 (0.62) | 20.63(0.47) | 12.47 (0.76) | 75.20 (0.17) | 1.96 (0.47) | 2.52 (0.65) |
| Hangzhou | 43.20 | 30.19 | 120.12 | 11.69 (0.67) | 21.22 (0.45) | 13.47 (0.66) | 75.84 (0.18) | 1.66 (0.50) | 2.48 (0.68) |
| Nanchang | 45.70 | 28.40 | 115.58 | 12.11 (0.65) | 21.84 (0.43) | 14.88 (0.59) | 75.95 (0.17) | 1.77 (0.65) | 2.63 (0.64) |
| Fuzhou | 85.40 | 26.05 | 119.17 | 12.11 (0.62) | 24.66 (0.31) | 17.05 (0.40) | 75.13 (0.16) | 1.92 (0.43) | 2.90 (0.55) |
| Guangzhou | 4.20 | 23.08 | 113.19 | 11.62 (0.53) | 26.56 (0.24) | 19.01 (0.33) | 76.70 (0.17) | 1.32 (0.61) | 2.65 (0.47) |
| Shantou | 7.30 | 23.21 | 116.40 | 13.71 (0.48) | 25.57 (0.23) | 19.01 (0.32) | 79.25 (0.12) | 1.81 (0.50) | 2.96 (0.45) |
| Nanning | 73.70 | 22.51 | 108.19 | 12.50 (0.56) | 26.34 (0.27) | 18.56 (0.35) | 79.24 (0.12) | 1.07 (0.62) | 2.73 (0.52) |
| Kaikou | 18.00 | 19.59 | 110.20 | 13.89 (0.52) | 28.14 (0.19) | 21.65 (0.20) | 83.06 (0.10) | 1.97 (0.50) | 3.16 (0.47) |
| maximum value | 3048.60 | 32.10 | 120.12 | 16.94 | 29.75 | 21.65 | 85.51 | 2.37 | 3.44 |
| minimum value | 4.20 | 19.59 | 98.29 | 10.15 | 7.75 | 0.55 | 62.43 | 0.49 | 1.72 |
| average value | 485.31 | 26.39 | 110.38 | 12.97 | 22.40 | 14.02 | 76.00 | 1.64 | 2.70 |
| Input Combination | Models | Meteorological Variables | |
|---|---|---|---|
| RF | XGB | ||
| 1 | RF1 | XGB1 | TmaxTmin Ra |
| 2 | RF2 | XGB2 | TmaxTmin Rs |
| 3 | RF3 | XGB3 | Tmax Tmin Ra RH |
| 4 | RF4 | XGB4 | Tmax Tmin Ra U2 |
| Length of Years/Input Combination | Meteorological Variables | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | ||
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | ||||||
| 10-span | |||||||||
| 1 | Tmax Tmin Ra | 0.792 | 0.673 | 0.494 | 0.783 | 0.801 | 0.657 | 0.484 | 0.792 |
| 2 | Tmax Tmin Rs | 0.951 | 0.320 | 0.231 | 0.948 | 0.954 | 0.311 | 0.225 | 0.951 |
| 3 | TmaxTmin Ra RH | 0.889 | 0.502 | 0.360 | 0.876 | 0.896 | 0.485 | 0.350 | 0.884 |
| 4 | Tmax Tmin Ra U2 | 0.843 | 0.587 | 0.424 | 0.836 | 0.853 | 0.567 | 0.412 | 0.847 |
| 30-span | |||||||||
| 1 | Tmax Tmin Ra | 0.786 | 0.672 | 0.495 | 0.777 | 0.789 | 0.666 | 0.492 | 0.780 |
| 2 | Tmax Tmin Rs | 0.950 | 0.323 | 0.232 | 0.947 | 0.952 | 0.314 | 0.227 | 0.949 |
| 3 | TmaxTmin Ra RH | 0.882 | 0.503 | 0.362 | 0.873 | 0.888 | 0.491 | 0.355 | 0.879 |
| 4 | Tmax Tmin Ra U2 | 0.832 | 0.597 | 0.431 | 0.825 | 0.840 | 0.583 | 0.423 | 0.833 |
| 50-span | |||||||||
| 1 | Tmax Tmin Ra | 0.777 | 0.689 | 0.509 | 0.768 | 0.776 | 0.688 | 0.509 | 0.768 |
| 2 | Tmax Tmin Rs | 0.947 | 0.328 | 0.234 | 0.945 | 0.948 | 0.324 | 0.232 | 0.946 |
| 3 | TmaxTmin Ra RH | 0.875 | 0.526 | 0.379 | 0.862 | 0.880 | 0.516 | 0.372 | 0.868 |
| 4 | Tmax Tmin Ra U2 | 0.820 | 0.620 | 0.448 | 0.812 | 0.827 | 0.607 | 0.440 | 0.819 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.784 | 0.688 | 0.506 | 0.776 | 0.795 | 0.669 | 0.493 | 0.788 |
| S2 | 0.788 | 0.680 | 0.499 | 0.781 | 0.798 | 0.662 | 0.487 | 0.792 |
| S3 | 0.790 | 0.675 | 0.495 | 0.783 | 0.800 | 0.658 | 0.484 | 0.794 |
| S4 | 0.794 | 0.670 | 0.492 | 0.784 | 0.802 | 0.656 | 0.482 | 0.794 |
| S5 | 0.798 | 0.665 | 0.489 | 0.784 | 0.805 | 0.652 | 0.480 | 0.792 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.948 | 0.332 | 0.241 | 0.945 | 0.951 | 0.322 | 0.233 | 0.949 |
| S2 | 0.950 | 0.326 | 0.236 | 0.947 | 0.952 | 0.317 | 0.230 | 0.950 |
| S3 | 0.950 | 0.322 | 0.232 | 0.948 | 0.953 | 0.313 | 0.226 | 0.951 |
| S4 | 0.952 | 0.318 | 0.230 | 0.949 | 0.954 | 0.310 | 0.224 | 0.951 |
| S5 | 0.953 | 0.313 | 0.227 | 0.949 | 0.955 | 0.305 | 0.221 | 0.951 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.882 | 0.533 | 0.385 | 0.860 | 0.890 | 0.514 | 0.375 | 0.869 |
| S2 | 0.884 | 0.511 | 0.366 | 0.874 | 0.892 | 0.493 | 0.356 | 0.882 |
| S3 | 0.887 | 0.504 | 0.361 | 0.877 | 0.894 | 0.487 | 0.351 | 0.885 |
| S4 | 0.889 | 0.500 | 0.358 | 0.878 | 0.897 | 0.482 | 0.348 | 0.886 |
| S5 | 0.894 | 0.490 | 0.352 | 0.880 | 0.901 | 0.473 | 0.343 | 0.887 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.835 | 0.604 | 0.438 | 0.828 | 0.845 | 0.583 | 0.426 | 0.840 |
| S2 | 0.839 | 0.595 | 0.430 | 0.833 | 0.850 | 0.574 | 0.417 | 0.845 |
| S3 | 0.842 | 0.590 | 0.425 | 0.836 | 0.852 | 0.569 | 0.413 | 0.847 |
| S4 | 0.845 | 0.584 | 0.421 | 0.838 | 0.854 | 0.564 | 0.410 | 0.848 |
| S5 | 0.848 | 0.578 | 0.418 | 0.837 | 0.858 | 0.558 | 0.406 | 0.848 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.776 | 0.689 | 0.508 | 0.766 | 0.782 | 0.679 | 0.501 | 0.773 |
| S2 | 0.781 | 0.679 | 0.501 | 0.774 | 0.785 | 0.671 | 0.496 | 0.779 |
| S3 | 0.784 | 0.673 | 0.497 | 0.777 | 0.787 | 0.668 | 0.493 | 0.781 |
| S4 | 0.787 | 0.670 | 0.494 | 0.778 | 0.790 | 0.665 | 0.491 | 0.781 |
| S5 | 0.791 | 0.664 | 0.489 | 0.781 | 0.793 | 0.661 | 0.488 | 0.782 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.946 | 0.333 | 0.240 | 0.942 | 0.949 | 0.326 | 0.236 | 0.945 |
| S2 | 0.948 | 0.326 | 0.234 | 0.945 | 0.950 | 0.320 | 0.231 | 0.947 |
| S3 | 0.950 | 0.321 | 0.231 | 0.947 | 0.951 | 0.315 | 0.228 | 0.948 |
| S4 | 0.950 | 0.318 | 0.229 | 0.947 | 0.952 | 0.313 | 0.226 | 0.949 |
| S5 | 0.952 | 0.312 | 0.225 | 0.949 | 0.953 | 0.308 | 0.222 | 0.950 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.874 | 0.523 | 0.376 | 0.864 | 0.881 | 0.508 | 0.367 | 0.871 |
| S2 | 0.878 | 0.512 | 0.369 | 0.870 | 0.884 | 0.498 | 0.360 | 0.876 |
| S3 | 0.880 | 0.506 | 0.364 | 0.872 | 0.886 | 0.493 | 0.356 | 0.879 |
| S4 | 0.884 | 0.501 | 0.361 | 0.874 | 0.889 | 0.489 | 0.354 | 0.879 |
| S5 | 0.887 | 0.493 | 0.355 | 0.876 | 0.892 | 0.482 | 0.348 | 0.882 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.822 | 0.621 | 0.450 | 0.811 | 0.831 | 0.603 | 0.439 | 0.822 |
| S2 | 0.827 | 0.608 | 0.439 | 0.820 | 0.836 | 0.591 | 0.429 | 0.830 |
| S3 | 0.830 | 0.599 | 0.432 | 0.825 | 0.838 | 0.584 | 0.424 | 0.833 |
| S4 | 0.834 | 0.594 | 0.429 | 0.826 | 0.841 | 0.581 | 0.421 | 0.834 |
| S5 | 0.837 | 0.587 | 0.423 | 0.829 | 0.844 | 0.575 | 0.416 | 0.836 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.766 | 0.705 | 0.522 | 0.758 | 0.769 | 0.701 | 0.519 | 0.761 |
| S2 | 0.772 | 0.697 | 0.514 | 0.764 | 0.773 | 0.694 | 0.513 | 0.765 |
| S3 | 0.775 | 0.691 | 0.510 | 0.767 | 0.775 | 0.691 | 0.510 | 0.767 |
| S4 | 0.778 | 0.687 | 0.507 | 0.769 | 0.776 | 0.682 | 0.504 | 0.769 |
| S5 | 0.782 | 0.681 | 0.503 | 0.772 | 0.780 | 0.683 | 0.505 | 0.770 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.943 | 0.341 | 0.243 | 0.941 | 0.945 | 0.335 | 0.240 | 0.943 |
| S2 | 0.945 | 0.334 | 0.237 | 0.943 | 0.947 | 0.329 | 0.235 | 0.945 |
| S3 | 0.946 | 0.330 | 0.234 | 0.944 | 0.948 | 0.326 | 0.233 | 0.946 |
| S4 | 0.948 | 0.327 | 0.233 | 0.945 | 0.949 | 0.318 | 0.229 | 0.947 |
| S5 | 0.949 | 0.322 | 0.229 | 0.946 | 0.950 | 0.319 | 0.229 | 0.947 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.866 | 0.554 | 0.400 | 0.849 | 0.872 | 0.542 | 0.392 | 0.856 |
| S2 | 0.870 | 0.536 | 0.386 | 0.858 | 0.875 | 0.525 | 0.379 | 0.864 |
| S3 | 0.873 | 0.529 | 0.381 | 0.862 | 0.878 | 0.519 | 0.375 | 0.867 |
| S4 | 0.876 | 0.524 | 0.377 | 0.864 | 0.881 | 0.507 | 0.366 | 0.870 |
| S5 | 0.880 | 0.515 | 0.371 | 0.867 | 0.884 | 0.506 | 0.365 | 0.872 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.809 | 0.643 | 0.468 | 0.798 | 0.818 | 0.626 | 0.457 | 0.809 |
| S2 | 0.815 | 0.630 | 0.456 | 0.807 | 0.823 | 0.616 | 0.447 | 0.816 |
| S3 | 0.819 | 0.622 | 0.450 | 0.811 | 0.826 | 0.609 | 0.442 | 0.819 |
| S4 | 0.822 | 0.617 | 0.446 | 0.814 | 0.827 | 0.601 | 0.435 | 0.821 |
| S5 | 0.826 | 0.609 | 0.439 | 0.818 | 0.831 | 0.599 | 0.434 | 0.823 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.762 | 0.727 | 0.536 | 0.718 | 0.774 | 0.707 | 0.523 | 0.732 |
| S2 | 0.766 | 0.721 | 0.531 | 0.722 | 0.777 | 0.702 | 0.519 | 0.736 |
| S3 | 0.767 | 0.718 | 0.529 | 0.724 | 0.777 | 0.700 | 0.517 | 0.737 |
| S4 | 0.770 | 0.714 | 0.526 | 0.727 | 0.779 | 0.699 | 0.515 | 0.738 |
| S5 | 0.771 | 0.713 | 0.524 | 0.728 | 0.780 | 0.697 | 0.514 | 0.739 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.945 | 0.332 | 0.250 | 0.939 | 0.949 | 0.320 | 0.243 | 0.944 |
| S2 | 0.945 | 0.328 | 0.247 | 0.941 | 0.950 | 0.317 | 0.242 | 0.944 |
| S3 | 0.946 | 0.326 | 0.246 | 0.941 | 0.950 | 0.316 | 0.240 | 0.945 |
| S4 | 0.947 | 0.323 | 0.243 | 0.942 | 0.950 | 0.314 | 0.239 | 0.945 |
| S5 | 0.947 | 0.322 | 0.242 | 0.943 | 0.951 | 0.313 | 0.238 | 0.946 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.870 | 0.536 | 0.383 | 0.844 | 0.878 | 0.517 | 0.370 | 0.854 |
| S2 | 0.871 | 0.528 | 0.377 | 0.849 | 0.880 | 0.508 | 0.363 | 0.860 |
| S3 | 0.872 | 0.526 | 0.375 | 0.851 | 0.881 | 0.505 | 0.361 | 0.861 |
| S4 | 0.873 | 0.522 | 0.372 | 0.852 | 0.881 | 0.502 | 0.358 | 0.863 |
| S5 | 0.873 | 0.520 | 0.370 | 0.854 | 0.882 | 0.501 | 0.357 | 0.864 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.798 | 0.763 | 0.570 | 0.676 | 0.810 | 0.722 | 0.542 | 0.711 |
| S2 | 0.801 | 0.758 | 0.564 | 0.681 | 0.814 | 0.719 | 0.538 | 0.714 |
| S3 | 0.804 | 0.757 | 0.563 | 0.682 | 0.815 | 0.718 | 0.537 | 0.714 |
| S4 | 0.805 | 0.755 | 0.561 | 0.684 | 0.817 | 0.718 | 0.536 | 0.714 |
| S5 | 0.807 | 0.754 | 0.559 | 0.684 | 0.819 | 0.718 | 0.535 | 0.714 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.770 | 0.706 | 0.522 | 0.733 | 0.776 | 0.696 | 0.515 | 0.740 |
| S2 | 0.773 | 0.700 | 0.517 | 0.737 | 0.777 | 0.693 | 0.513 | 0.743 |
| S3 | 0.775 | 0.697 | 0.514 | 0.740 | 0.778 | 0.690 | 0.511 | 0.744 |
| S4 | 0.776 | 0.695 | 0.513 | 0.742 | 0.779 | 0.689 | 0.510 | 0.745 |
| S5 | 0.777 | 0.693 | 0.511 | 0.743 | 0.779 | 0.688 | 0.509 | 0.746 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.946 | 0.326 | 0.242 | 0.941 | 0.950 | 0.317 | 0.238 | 0.944 |
| S2 | 0.947 | 0.323 | 0.239 | 0.942 | 0.950 | 0.315 | 0.236 | 0.945 |
| S3 | 0.948 | 0.321 | 0.238 | 0.943 | 0.950 | 0.314 | 0.235 | 0.945 |
| S4 | 0.948 | 0.319 | 0.237 | 0.943 | 0.951 | 0.313 | 0.234 | 0.946 |
| S5 | 0.949 | 0.318 | 0.236 | 0.944 | 0.951 | 0.312 | 0.234 | 0.946 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.871 | 0.536 | 0.384 | 0.844 | 0.877 | 0.520 | 0.374 | 0.853 |
| S2 | 0.872 | 0.530 | 0.380 | 0.848 | 0.879 | 0.515 | 0.369 | 0.856 |
| S3 | 0.873 | 0.526 | 0.377 | 0.850 | 0.879 | 0.512 | 0.367 | 0.857 |
| S4 | 0.874 | 0.523 | 0.374 | 0.851 | 0.880 | 0.510 | 0.366 | 0.858 |
| S5 | 0.875 | 0.521 | 0.372 | 0.853 | 0.881 | 0.508 | 0.364 | 0.859 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.808 | 0.711 | 0.525 | 0.723 | 0.816 | 0.684 | 0.506 | 0.744 |
| S2 | 0.810 | 0.710 | 0.523 | 0.726 | 0.819 | 0.680 | 0.503 | 0.748 |
| S3 | 0.812 | 0.709 | 0.522 | 0.726 | 0.821 | 0.679 | 0.501 | 0.749 |
| S4 | 0.813 | 0.707 | 0.521 | 0.727 | 0.822 | 0.678 | 0.500 | 0.750 |
| S5 | 0.814 | 0.706 | 0.520 | 0.728 | 0.823 | 0.677 | 0.499 | 0.750 |
| Input/Proportions | XGB | RF | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | NSE | R2 | RMSE | MAE | NSE | |
| (mm·d−1) | (mm·d−1) | (mm·d−1) | (mm·d−1) | |||||
| Tmax, Tmin, Ra | ||||||||
| S1 | 0.771 | 0.710 | 0.526 | 0.867 | 0.774 | 0.703 | 0.522 | 0.735 |
| S2 | 0.773 | 0.706 | 0.523 | 0.866 | 0.774 | 0.702 | 0.521 | 0.736 |
| S3 | 0.774 | 0.704 | 0.521 | 0.865 | 0.775 | 0.700 | 0.519 | 0.738 |
| S4 | 0.776 | 0.701 | 0.519 | 0.867 | 0.776 | 0.699 | 0.517 | 0.739 |
| S5 | 0.777 | 0.699 | 0.517 | 0.867 | 0.776 | 0.699 | 0.518 | 0.739 |
| Tmax, Tmin, Rs | ||||||||
| S1 | 0.945 | 0.328 | 0.243 | 0.986 | 0.948 | 0.320 | 0.239 | 0.943 |
| S2 | 0.947 | 0.325 | 0.241 | 0.987 | 0.949 | 0.319 | 0.238 | 0.943 |
| S3 | 0.947 | 0.324 | 0.240 | 0.987 | 0.949 | 0.318 | 0.238 | 0.944 |
| S4 | 0.948 | 0.322 | 0.239 | 0.987 | 0.950 | 0.317 | 0.237 | 0.944 |
| S5 | 0.948 | 0.321 | 0.238 | 0.987 | 0.950 | 0.317 | 0.237 | 0.944 |
| Tmax, Tmin, Ra RH | ||||||||
| S1 | 0.868 | 0.563 | 0.407 | 0.925 | 0.874 | 0.547 | 0.396 | 0.838 |
| S2 | 0.869 | 0.554 | 0.399 | 0.927 | 0.875 | 0.541 | 0.390 | 0.842 |
| S3 | 0.870 | 0.550 | 0.395 | 0.925 | 0.875 | 0.537 | 0.387 | 0.844 |
| S4 | 0.871 | 0.547 | 0.393 | 0.925 | 0.876 | 0.533 | 0.383 | 0.847 |
| S5 | 0.872 | 0.544 | 0.391 | 0.924 | 0.876 | 0.534 | 0.384 | 0.847 |
| Tmax, Tmin, Ra U2 | ||||||||
| S1 | 0.811 | 0.700 | 0.515 | 0.864 | 0.819 | 0.674 | 0.496 | 0.753 |
| S2 | 0.812 | 0.699 | 0.514 | 0.865 | 0.820 | 0.673 | 0.495 | 0.754 |
| S3 | 0.814 | 0.699 | 0.513 | 0.868 | 0.821 | 0.673 | 0.494 | 0.754 |
| S4 | 0.815 | 0.698 | 0.513 | 0.866 | 0.824 | 0.673 | 0.494 | 0.754 |
| S5 | 0.816 | 0.698 | 0.513 | 0.868 | 0.823 | 0.672 | 0.493 | 0.755 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wu, L.; Zhang, F.; Huang, G.; Yan, F.; Bai, W. Splitting and Length of Years for Improving Tree-Based Models to Predict Reference Crop Evapotranspiration in the Humid Regions of China. Water 2021, 13, 3478. https://doi.org/10.3390/w13233478
Liu X, Wu L, Zhang F, Huang G, Yan F, Bai W. Splitting and Length of Years for Improving Tree-Based Models to Predict Reference Crop Evapotranspiration in the Humid Regions of China. Water. 2021; 13(23):3478. https://doi.org/10.3390/w13233478
Chicago/Turabian StyleLiu, Xiaoqiang, Lifeng Wu, Fucang Zhang, Guomin Huang, Fulai Yan, and Wenqiang Bai. 2021. "Splitting and Length of Years for Improving Tree-Based Models to Predict Reference Crop Evapotranspiration in the Humid Regions of China" Water 13, no. 23: 3478. https://doi.org/10.3390/w13233478