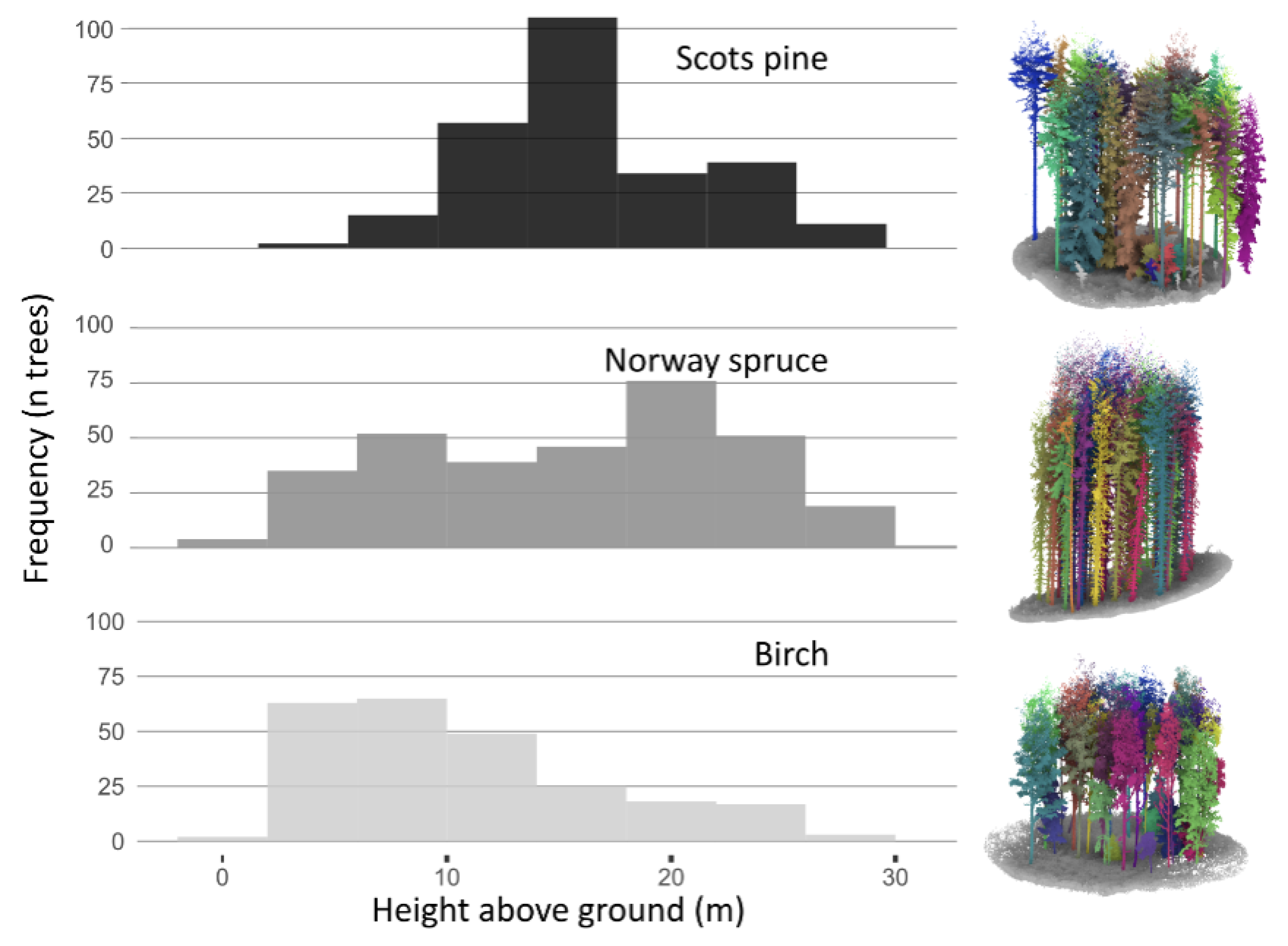
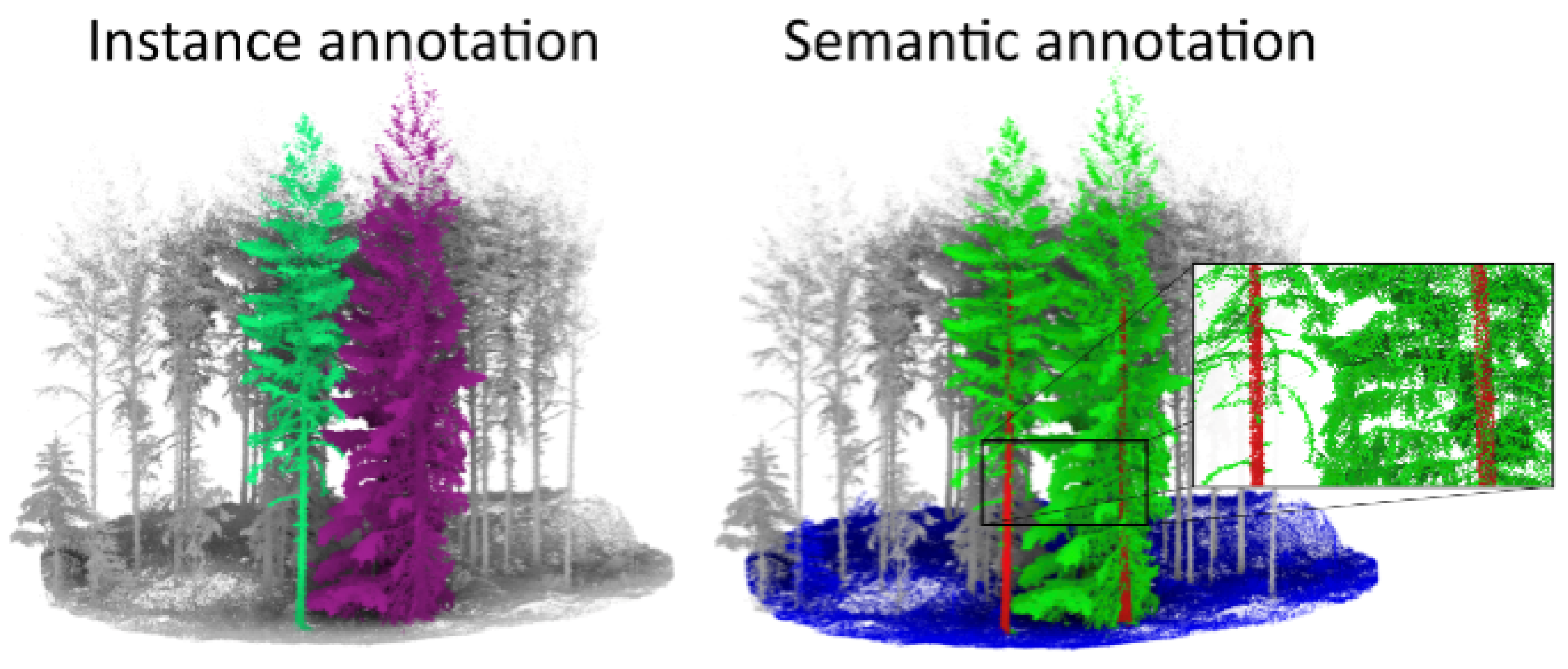
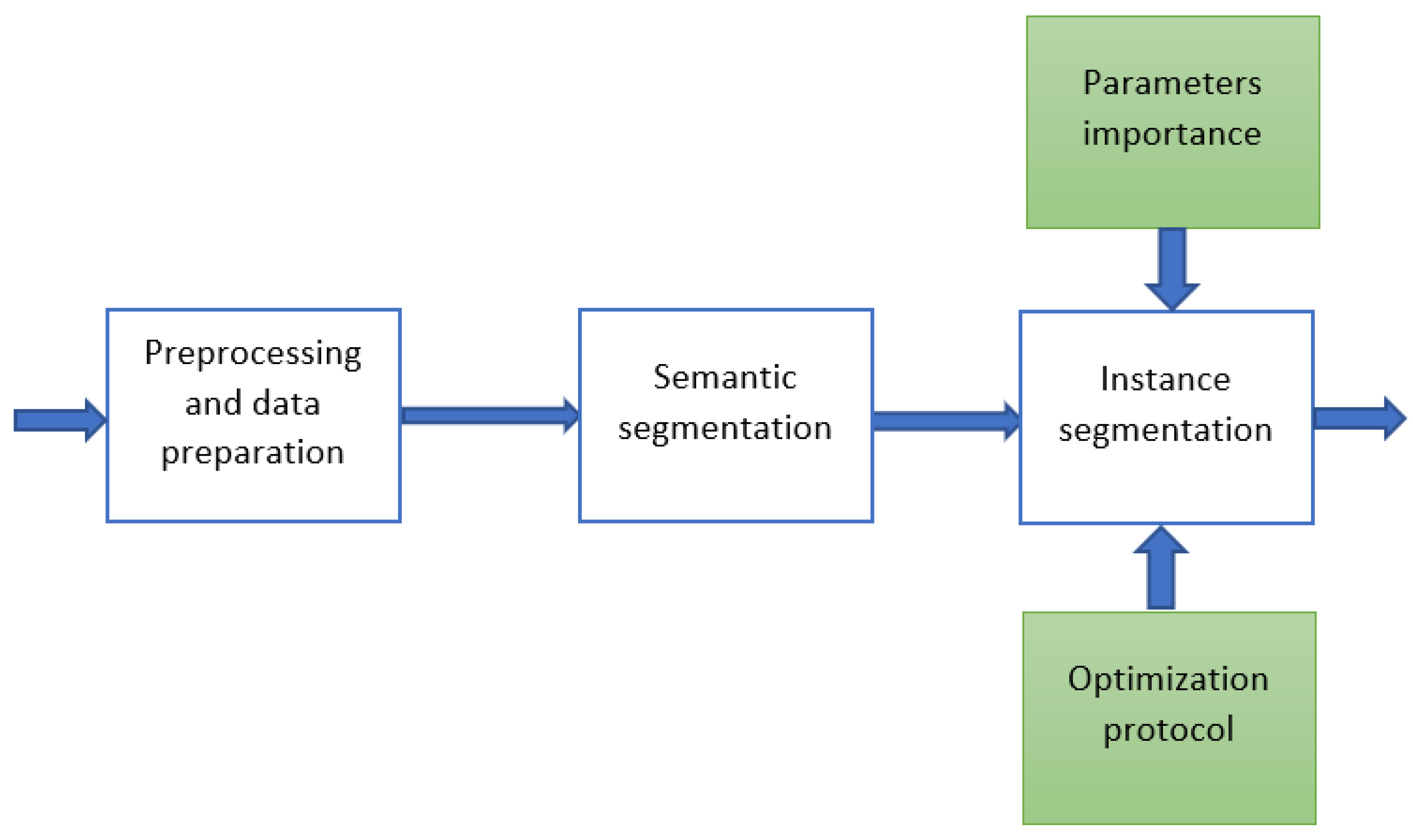
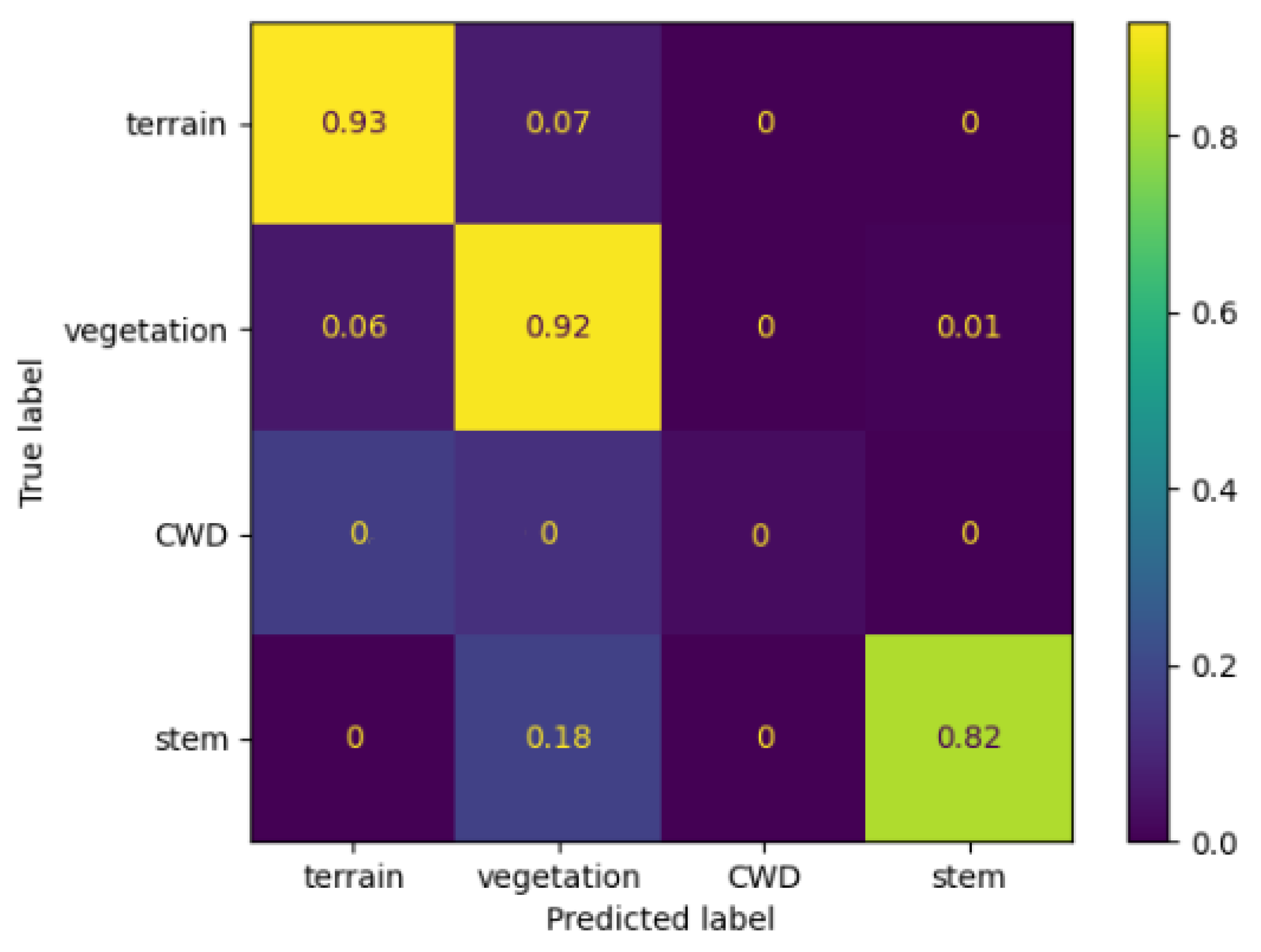
1. Introduction
The use of high-resolution 3D point clouds from terrestrial laser scanning (TLS), personalized laser scanning (PLS), and drone or helicopter-based laser scanning data has long been an area of intensive research for the characterization of forest ecosystems. In addition to measuring traditional variables such as stem volume, diameter, and height [
1] or tree species (e.g., [
2]), these very high-detail 3D forest structural data can allow new insights into single tree properties such as biomass (e.g., [
3,
4]), stem curves (e.g., [
5]), tree height growth (e.g., [
6]), wood quality (e.g., [
7]), key ecological indicators [
8], and phenotyping [
9,
10].
The emergence of improved sensor technology and the implementation of Simultaneous Localization And Mapping (SLAM) algorithms have greatly improved the availability and reduced the cost of dense point clouds from mobile laser scanning (MLS) platforms. The continuous move from stationary TLS to mobile, personalized, or drone-based scanning systems has greatly increased the ease of scanning larger forest plots [
11]. Recent studies have also pointed out that personalized or mobile laser devices may provide an improved [
12] or more cost-efficient [
13] alternative to traditional field measurements with calipers and hypsometers for the collection of ground truth for air- or space-borne remote sensing.
At the core of most forest applications of high-density 3D point clouds is the ability to efficiently, with high precision and accuracy, segment the point cloud into different compartments such as stem, leaf, or branches (semantic segmentation) and further into single tree point clouds, hereafter referred to as instance segmentation. Even though the development of segmentation algorithms has been a substantial field of research for many years, both semantic and instance segmentation remains a significant bottleneck to unleashing the full potential of high-density point clouds in the forest context. Most studies have relied on algorithmic approaches (e.g., clustering and circle fitting or voxel-based approaches [
14]) to identify and segment single trees [
15,
16]. In all cases, the segmentation routines tend to produce artifacts, and the single tree point clouds often require manual editing. In addition, such approaches are generally tailored to the specific data set and sensors they were developed on and are seldom transferable to new data.
Recent advances in the field of deep learning are triggering a new wave of studies looking into the possibilities to disentangle the complexity of high-density 3D point clouds and solve semantic [
5,
17], instance segmentation [
18], and regression tasks [
19]. One promising avenue in this field is the development of sensor-agnostic models that can learn general point cloud features and allow their transferability independently from the characteristics of the input point cloud. The advantage of such models is that they can be used off-the-shelf on new data without hyperparameter tuning. One exemplary case of moving in the direction of sensor-agnostic models for forest point clouds is the study by Krisanski et al. [
17], who developed a semantic segmentation model to classify primary features (i.e., ground, wood, and leaf) in forest 3D scenes captured with TLS, ALS, and MLS. While desirable, there are currently no sensor-agnostic tree instance segmentation models for point cloud data. However, steps have been made to integrate sensor-agnostic deep learning semantic models with more traditional algorithmic pipelines to solve the instance segmentation challenge [
17,
19,
20].
Wilkes et al. [
21] addressed the instance segmentation problem in their tool TLS2Trees, which leverages on the FSCT semantic segmentation model published by Krisanski et al. [
17]. In their approach, the wood-classified points from the semantic segmentation are used to construct a graph through the point cloud, then use the shortest path analysis to attribute points to individual stem bases. In the final step, the leaf-classified points are then added to each graph. A key aspect in this pipeline that affects the quality of the downstream products is the initial definition of the clusters performed using the DBSCAN clustering method [
22]. The performance of DBSCAN depends on the separability of the instances, which is tightly linked to the output of the FSCT segmentation model (i.e., wood class parts, including stems, and branches) and to the forest type. In particular, instance clustering can be challenging in dense forests with a substantial amount of woody branches in the lower parts of the crown (e.g., Norway spruce forests). One potential avenue to boost the quality of the initial definition of the instances is to develop new point cloud semantic segmentation models that allow for a clearer separability of the instances by, for example, focusing on the main tree stem (i.e., excluding branches).
In TLS2Trees, the instance segmentation performance depends on a set of hyperparameters that should be individually tuned for a given type of forest to achieve the best possible performance. So far, both in TLS2Trees and other tree segmentation approaches tuning of these types of hyperparameters has traditionally been performed manually by individual researchers for each data set through trial and error processes. However, the possibility for a systematic and automated approach to hyperparameter optimization exists. Several potential methods that could solve the challenge exist (e.g., simulated annealing or Bayesian optimization [
23]). Furthermore, it is also worth keeping in mind that the gradient-based methods may be ill-posed due to the non-convex profile of the hyperparameter space.
Gradient-based methods are powerful optimization algorithms that leverage the gradient of a function to find its minimum or maximum. These techniques are widely used in machine learning and deep learning, especially for training complex models such as neural networks. The general idea is to iteratively adjust the model’s parameters in the opposite direction of the gradient of the loss function (a measure of the model’s prediction error), aiming to reduce the loss [
24]. Common examples include stochastic gradient descent (SGD) and its variants (e.g., Adam, RMSprop). Despite their efficiency, these methods have limitations when applied to non-convex optimization problems, such as hyperparameter tuning. Non-convex optimization landscapes can have many local minima, making it challenging for gradient-based methods to find the global minimum. Additionally, these methods require the computation of gradients, which may not always be possible or practical, especially when dealing with discrete hyperparameters or parameters that do not have values in all their spectrum (i.e., for some arguments function does not have value).
Leveraging on recent advances in semantic segmentation [
17] and instance segmentation approaches [
21], this study introduces Point2Tree which is a new modular framework for semantic and instance segmentation for MLS data. The Point2Tree has two main modules (1) a newly trained Pointnet++-based semantic segmentation model with the classes optimized for coniferous forest. ), and (2) an optimization procedure for instance segmentation hyperparameter optimization based on the Bayesian flow approach [
16]. Point2Tree is modular in the way that each of the components can be easily replaced by an improved module. We evaluate the performance of both the semantic and instance segmentation of Point2Tree with settings including: (a) with and without hyperparameter optimization and (b) with both the new semantic Pointnet++ model (i.e., p2t_semantic) as well as with the semantic model from FSCT [
17], i.e., fsct_semantic. The evaluation is performed against a newly annotated dataset from our study area as well as an existing independent dataset from another part of Europe.
3. Methods
The pipeline used in this work comprises several stages, as presented in
Figure 3 and
Figure 4. It is worth noting that due to the large size of point cloud files, arranging all the steps in the pipeline well and orchestrating their behavior to obtain a good system performance is essential. In some cases, it may be hard to arrive at the processing results due to ineffective data processing which does not account for all the aspects of the data well. This effect may mostly occur when dealing with locally very sparse point clouds (often on borders of the cloud). Therefore, all steps are prepared in a modular fashion and the stages are parameterized so they can be adjusted to different densities and types of point clouds. Furthermore, the steps of the pipeline are prepared in a way that enables smooth substitution of selected components of the system. The elements of the system are interconnected using a programming language agnostic composition strategy as presented in
Figure 3.
Within this work, we used a custom naming convention.
Table 2 presents a set of acronyms and features of different pipelines we partially based our framework on and which we compare against our performance. Point2Tree framework is equipped with optimization, and analytics modules and also enables the incorporation of external modules implemented in different programming languages thanks to its modular architecture. This feature of P2T was used in order to employ semantic segmentation from FSCT and instance segmentation from TLS pipelines.
It is worth noting that “p2t_semantic” was obtained from “fsct_semantic” by replacing the original set of FSCT weights of the Pointnet++ model with the model trained on our data.
3.1. Data Preprocessing
In the preprocessing step, the initial tiling operation is performed. Tile size is adjustable and should be chosen based on the data profile. It is also worth noting that there is usually an entire range of low-density point cloud tiles at the edges of point clouds. These data are difficult to digest for both semantic segmentation and instance extraction part of the pipeline. Therefore, a dedicated procedure to remove these low-density tiles was adopted. The procedure examines all the tiles in terms of their point density. A tile is removed from further processing if the density is below a critical threshold. As may be noticed, the tiles’ granularity strictly affects the point cloud’s shape after the protocol. The effect of the density-based tiling protocol is presented in
Figure 4.
3.2. Semantic Segmentation
In our workflow, Pointnet++ [
17,
27] implemented in Pytorch was used as a base model for semantic segmentation. The model was trained from scratch using the newly annotated dataset (p2t_semantic, see
Table 2).
The point cloud was sliced into cube-shaped regions to prepare the data for Pointnet++. Each cube was shifted to the origin before inference to avoid floating-point precision issues. The preprocessing is performed before training or inference, and each sample is stored in a file to minimize computational time and facilitate taking advantage of parallel processing. The preprocessing also takes advantage of vectorization by using the NumPy package.
During training, we used subsampling and voxelization protocol to 1
. The parameters used in the training process are listed in
Table 3, and the training was performed on Nvidia GV100GL [Tesla V100S PCIe 32GB].
3.3. Instance Segmentation
We employed the
TLS2trees instance segmentation technique [
21]. This method separates the individual tree through a series of steps, including: (i) initial semantic segmentation as input; (ii) tree-wise graph construction using the wood (i.e., or stem based on our proposed semantics) classified points; and (iii) addition of the leaves (or crown) by extending the tree-wise graphs to the rest of the tree crown. A comprehensive explanation of this approach is provided in [
21]. It is important to note that the accuracy of the instance segmentation is strongly affected by the results of the semantic segmentation as well as the quality of the data employed for training this model.
3.4. Evaluation
Evaluating machine learning models and pipelines can be challenging, as it requires providing an appropriate set of metrics and a protocol for applying them in a repeatable and reliable way. While it is much easier to develop a protocol if the point matching at the cloud level is ensured, there is still a way to compare results against the ground truth when that is not the case.
In the solution presented in this paper, the input data is down-sampled during the pre-processing, leaving only a single random point per voxel. As a result, the number of output points is lower than the input points. There are also small distortions introduced related to several point-cloud conversions in the process of mapping between data formats. We provide a method based on the KNN algorithm for point matching. Our method consists of the following steps:
We aggregate results on multiple levels and use a set of common metrics such as the F1-score and IOU (Jaccard index) to assess the performance of the model on a pixel level.
Also, the residual height operating on a tree level (Equation (
5)) as the difference between ground truth height (gt) and predicted height (pred) of trees is calculated.
The square root of the average squared difference between ground truth heights (h_gt) and predicted heights (h_pred) over a dataset is given by Equation (
6)
For large datasets, serial execution of the metrics is pretty slow; thus, a parallel version was implemented and used for experiments in this work.
3.5. Optimization
This work proposes an optimization protocol based on a Bayesian approach [
23,
28,
29]. It is a sequential method that gradually explores the space of hyperparameters, focusing on the most promising manifolds within it. This method is especially suitable for applications where each iteration is time-consuming, as is the case with processing a large volume of point cloud data, presented in this work. In particular, we compute the F1-score (Equation (
3)) as a function of point cloud instance segmentation.
The method works by constructing a probabilistic model, typically a Gaussian Process (GP), to represent the unknown function and then using an acquisition function to balance exploration and exploitation when deciding on the next point to sample. The objective is to find the global optimum with as few evaluations as possible. The GP is defined by a mean function
and a covariance function
, which together describe the function’s behavior. The choice of kernel function is crucial for the performance of Bayesian optimization as it encodes the prior belief about the function’s smoothness. A commonly used kernel is the squared exponential kernel:
where
represents the signal variance and
l is the length scale parameter,
are input vectors for which we want to compute the covariance. They are multi-dimensional and model tree hyperparameters setup.
In the Bayesian optimization framework, we start with a prior distribution over the unknown function, and after each evaluation, we update our beliefs using Bayes’ rule. This results in a posterior distribution, which is used to guide the search for the global optimum [
23].
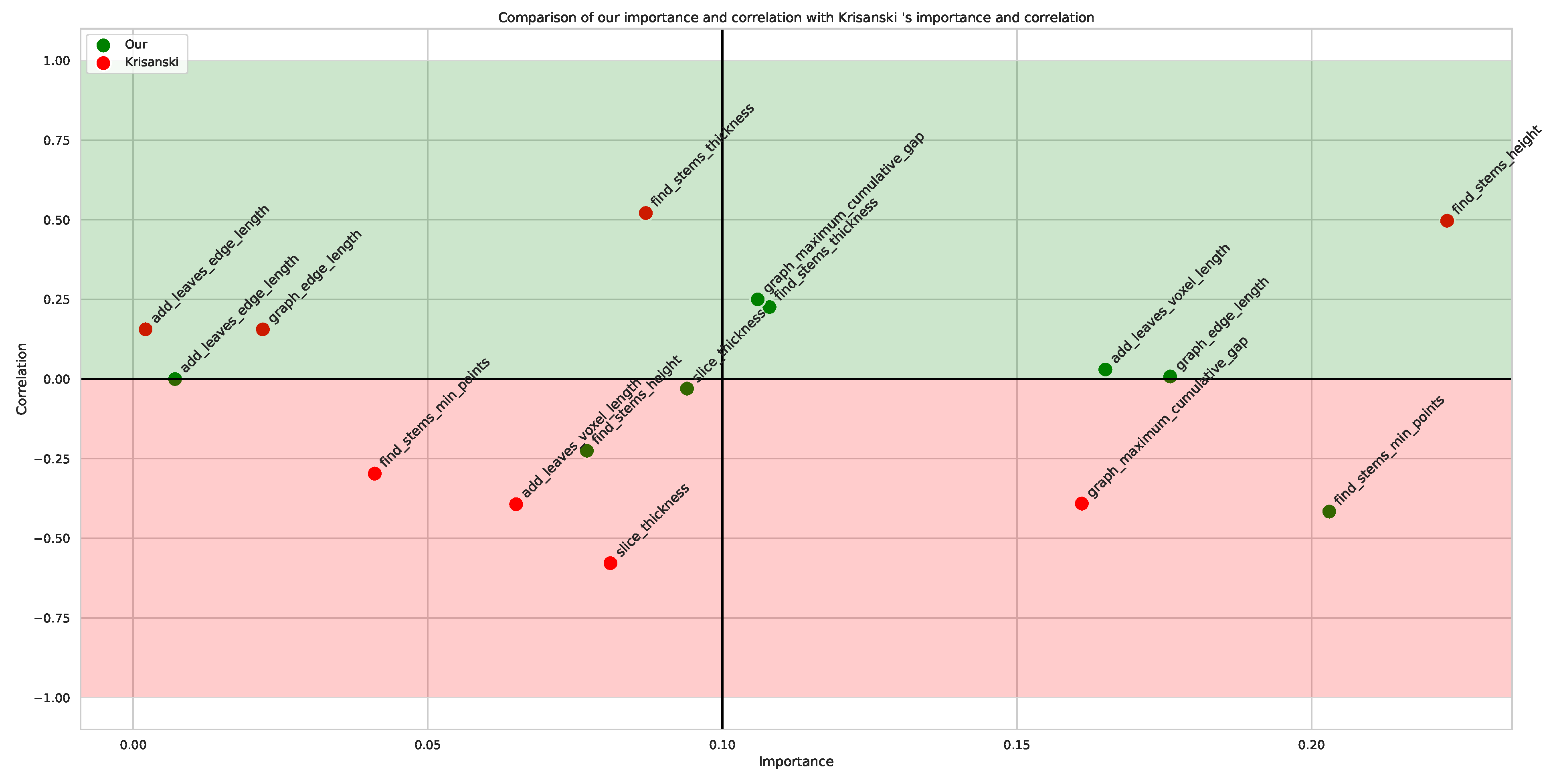
The instance segmentation stage is composed of multiple modules that contain a series of hyperparameters that should be optimized to reach the best possible performance of the model. The most important ones are depicted in
Figure 5, and tested values are shown in
Table 4.
The chosen values of the hyperparameters cover the most promising and useful ranges. It is worth noting that the choice and the number of parameters affect the performance of the optimization algorithm. Consequently, they should be picked according to the specific profile of the forest dataset in question.
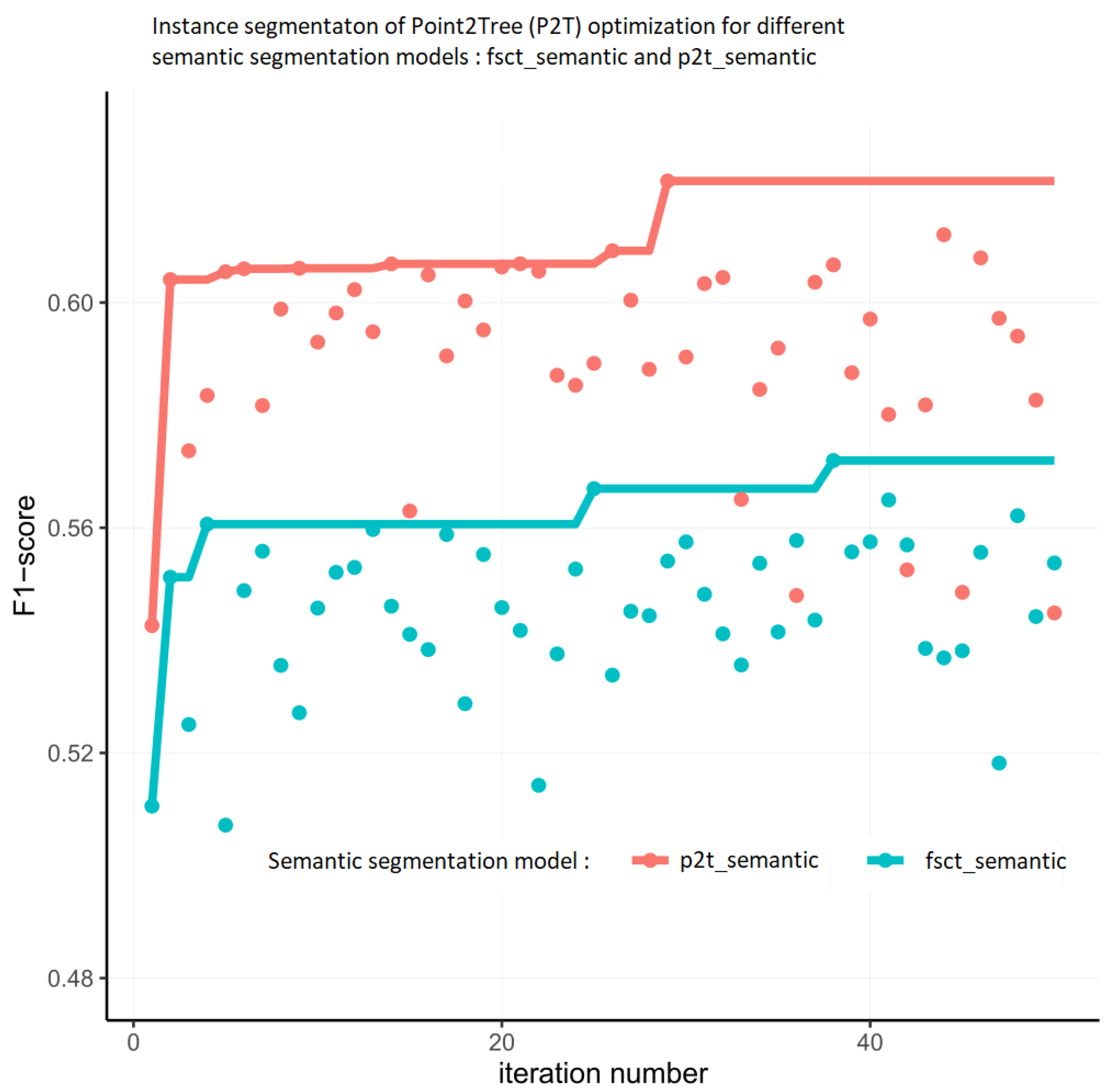
The optimization process of Point2Tree involves many iterations of the pipeline execution with a distinct set of parameters. Therefore, applying a well-structured protocol to address this process is reasonable.
In each iteration of the optimization process, the F1-score is derived from the complete dataset, and the algorithm maximizes its value over the steps of the execution.
The optimization is performed by optimizing the F1-score for the entire set. The overall F1-score is calculated using a three-fold protocol as given by Algorithm 1.
| Algorithm 1 F1-score calculation |
- 1:
for plot in dataset do - 2:
for for tree in plot do - 3:
Compute F1-score - 4:
end for - 5:
Aggregate F1-score per plot - 6:
end for - 7:
Aggregate F1-score per dataset
|
Based on the F1-score the optimization algorithm guides the next steps of the optimization. In our research and experiments, we noticed that it is possible to improve the optimization results by decomposing the process into several stages. After the initial stage (e.g., 40 runs), it is possible to stop the optimization and restart it for a limited and the most important set of parameters. Sample implementation of this approach is given by Algorithm 2.
| Algorithm 2 Optimization Algorithm—two-stage protocol |
Require: Initial parameters - 1:
Run initial optimization - 2:
Select less than four parameters of the highest importance - 3:
Run optimization for the selected parameters
Ensure: Optimized parameters |
Point2Tree provides a module for assessing the importance of hyperparameters in the optimization process. The results are presented in the
Appendix A.
3.6. Final Validation
After completing the optimization, we evaluated the best set of hyperparameters for both Point2Tree (P2T) with fsct_semantic and p2t_semantic. To validate our results, we compared them against the LAUTx dataset, a benchmark for the instance segmentation [
30].
Aside from the F1-score, we evaluated additional metrics, including precision, recall, residual height, detection, commission, and omission rate. Finally, we provided comparisons for the regular model with standard parameters used in [
21] and the optimized set of parameters.
5. Conclusions
This study presents a new framework for point cloud instance segmentation. The framework consists of a series of components that are structured in a flexible way. This allows us to replace selected parts of the pipeline (e.g., instance segmentation) with new or alternative modules. The new modules may be implemented in alternative languages (e.g., C++, java, etc.) and the integration is still possible. The framework is also equipped with an optimization module and insightful parameters visualization.
We also tested the effect of hyperparameter tuning on the TLS2trees instance segmentation pipeline, developed initially for tropical forests, to optimal settings for coniferous forests. Further, we tested the effect of using a semantic segmentation model specifically designed to focus on identifying the stems of coniferous trees on the tree instance segmentation accuracy. Our study found that the hyperparameter tuning positively affected the segmentation output quality of our data. However, when applying the same parameters to the external LAUTx dataset, the performance was poorer than using the default setting. This result indicates that to estimate a more robust and transferable set of hyperparameters, we need to develop more extensive databases of openly available annotated point cloud data spanning a broader range of forest types than those used in this study. When optimized, the effect of using different semantic segmentation models (i.e., P2T with p2t_semantic and fsct_semantic) was marginal. However, it is also true that the instance segmentation relying on the p2t_semantic model seemed less sensitive to the choice of hyperparameters and thus more robust in dense forests or forests with many low branches (e.g., non-self-pruning species). Due to the architecture of the instance segmentation algorithm, there were certain combinations of hyperparameters that led to the failure of execution of the pipeline, thus imposing a constraint in the choice of the protocol for hyperparameter tuning, i.e., the Bayesian approach for which the space of the hyperparameters does not have to be convex.
Overall the performance of the Point2Tree was high, and the approach holds significant promise toward automated semantic and instance segmentation of 3D point clouds. At the same time, the results illustrate several avenues for further improvement and development: (1) training the algorithms on larger sets of data from a broader range of forest types is an obvious avenue for potential improvement, (2) the semantic component of Point2Tree is a deep-learning-based approach while the instance segmentation relies on a more algorithmic (graph-based) approach that relies on a good representation of the individual stems in the point clouds. Replacing the algorithmic component of Point2Tree with a deep-learning-based approach, like segmentation, may be beneficial in terms of computational demands for deployment and less reliance on a good representation of the stem in the instance segmentation. Overall, an end-to-end deep-learning-based approach may be a more successful approach for a more sensor-agnostic (airborne and ground-based applications) semantic and instance segmentation framework which would be a significant step forward for applying dense 3D point clouds in forest management.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}