
Enhanced Local Fisher Discriminant Analysis for Indoor Positioning in Wireless Local Area Network

Abstract
:1. Introduction
2. Proposed E-LFDA Method for WLAN Indoor Positioning
2.1. Motivation
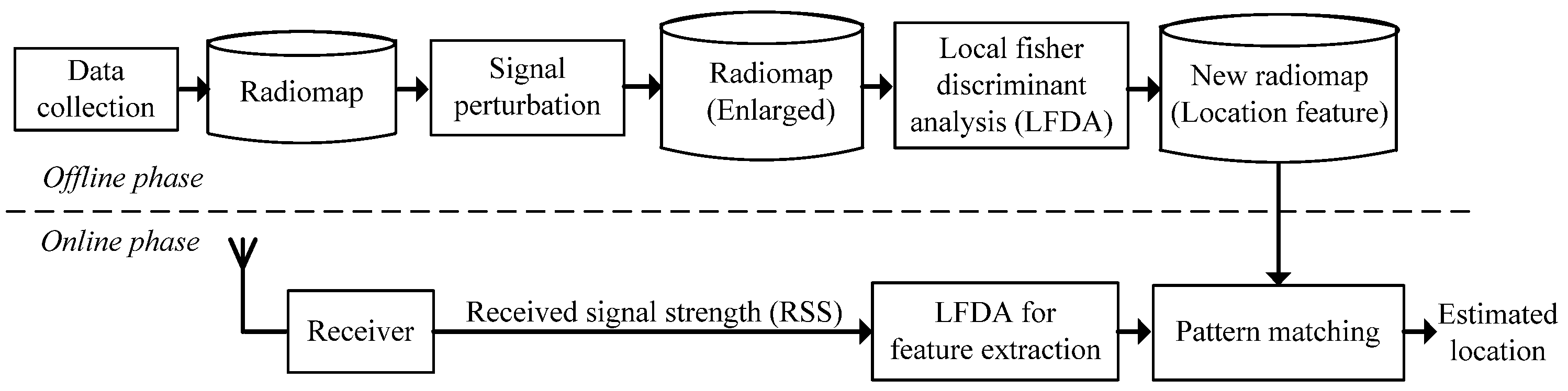
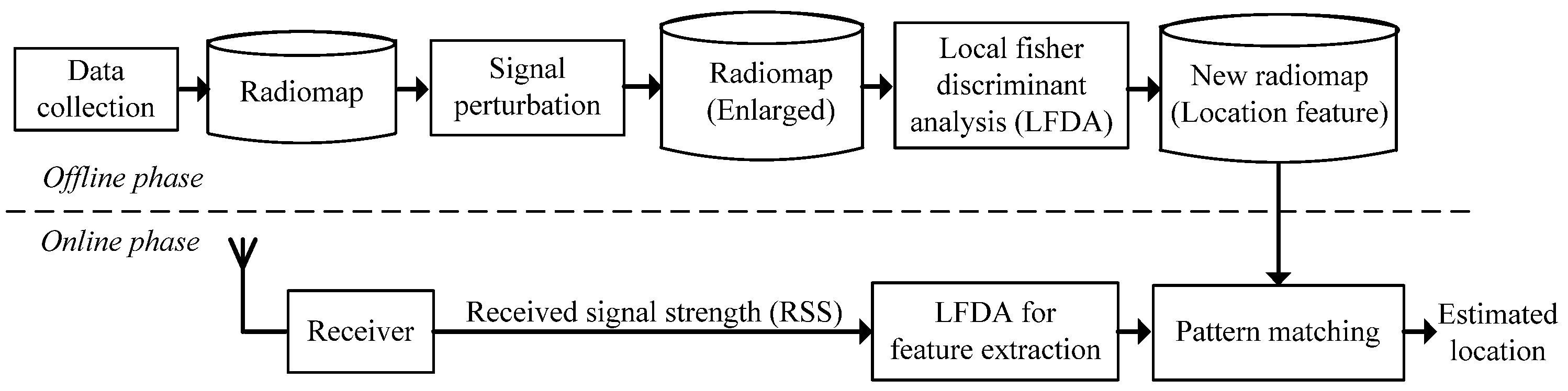
2.2. Overview of the Proposed E-LFDA Method
2.3. LFDA for Location Feature Extraction
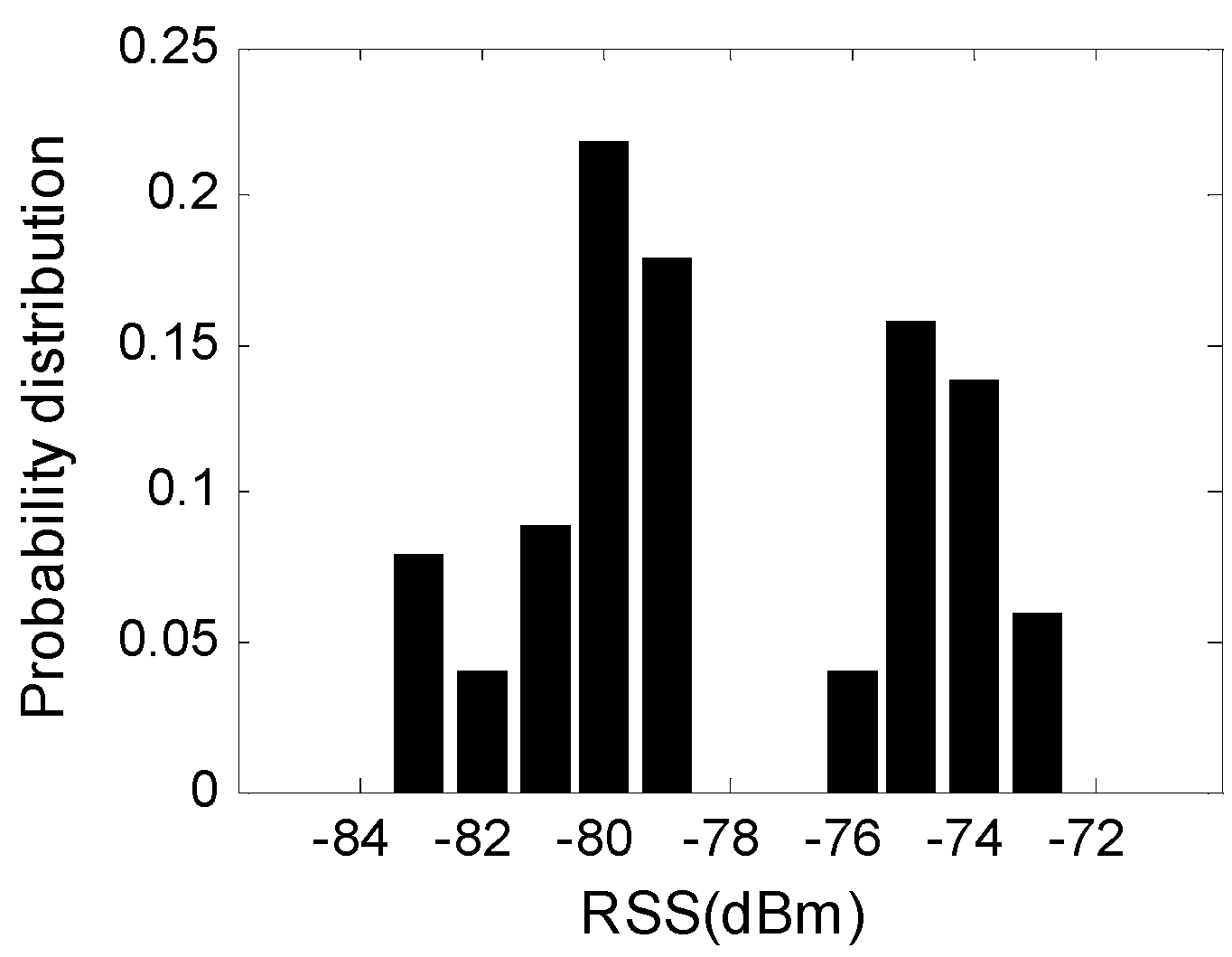
2.4. Signal Perturbation for LFDA
- For a realistic RSS vector sample, the probability of all the samples in the set is identical;
- The existing probability of RSS values from any two APs is independent to each other.
3. Evaluation
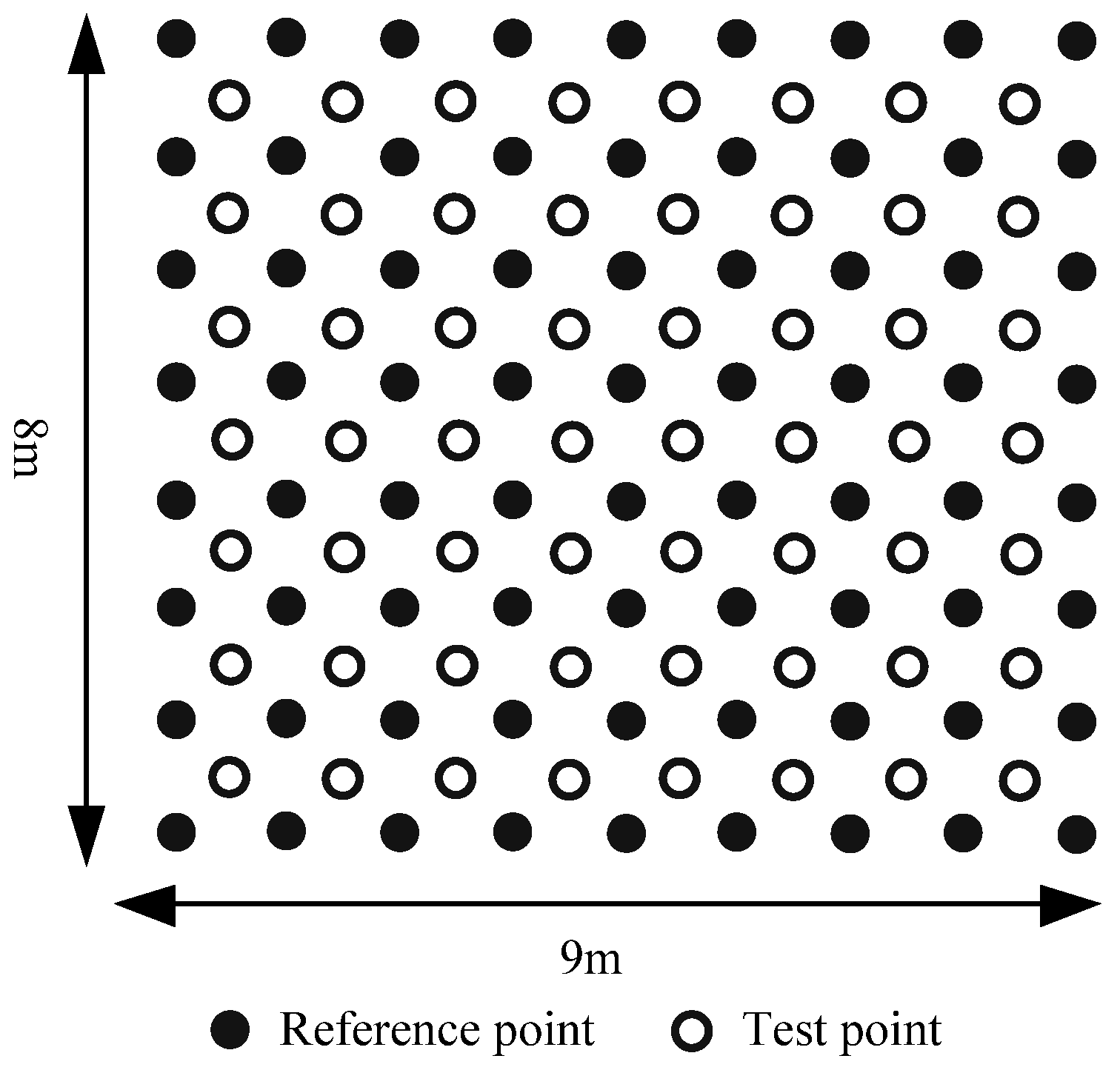
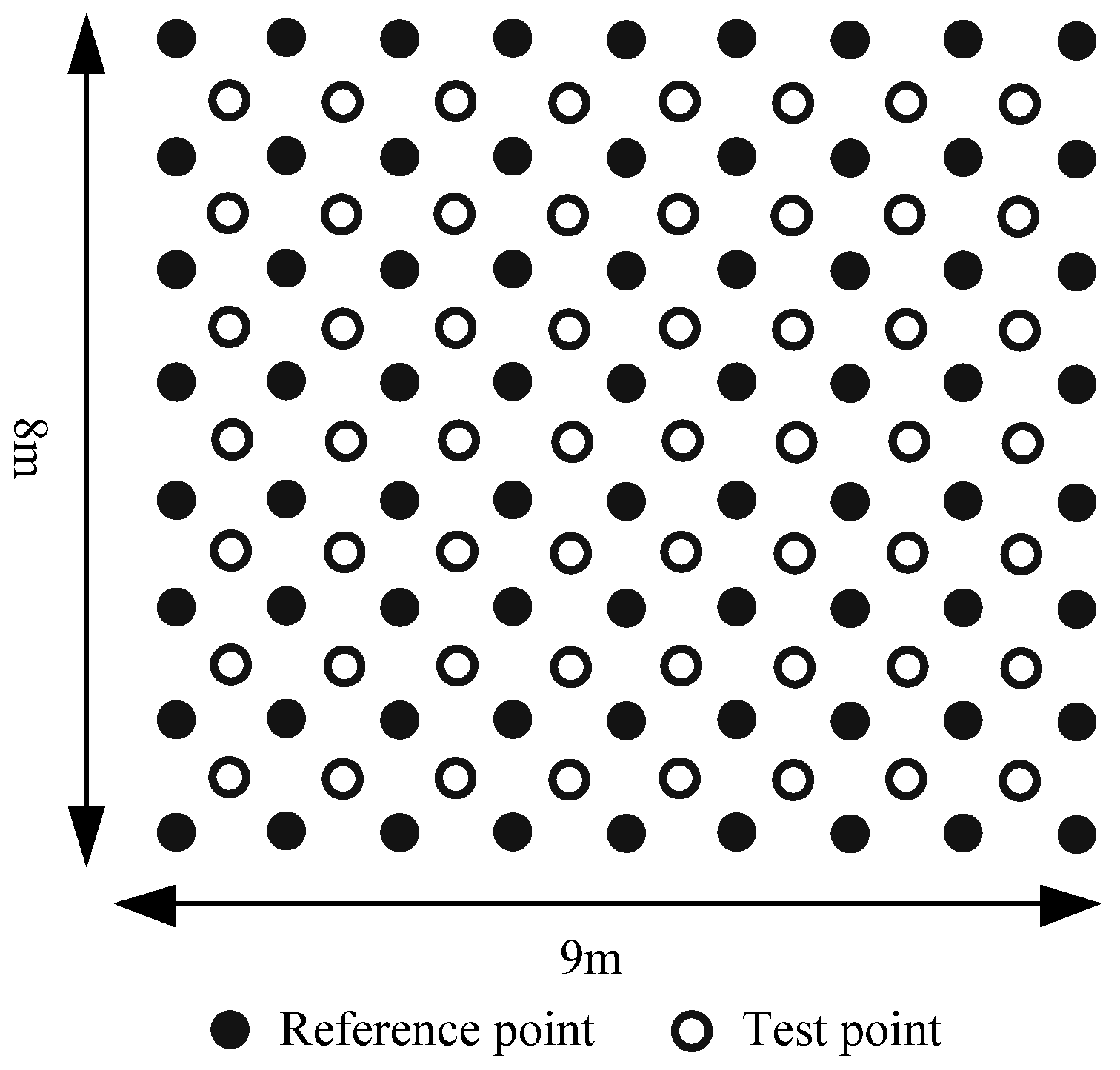
3.1. Experimental Setup
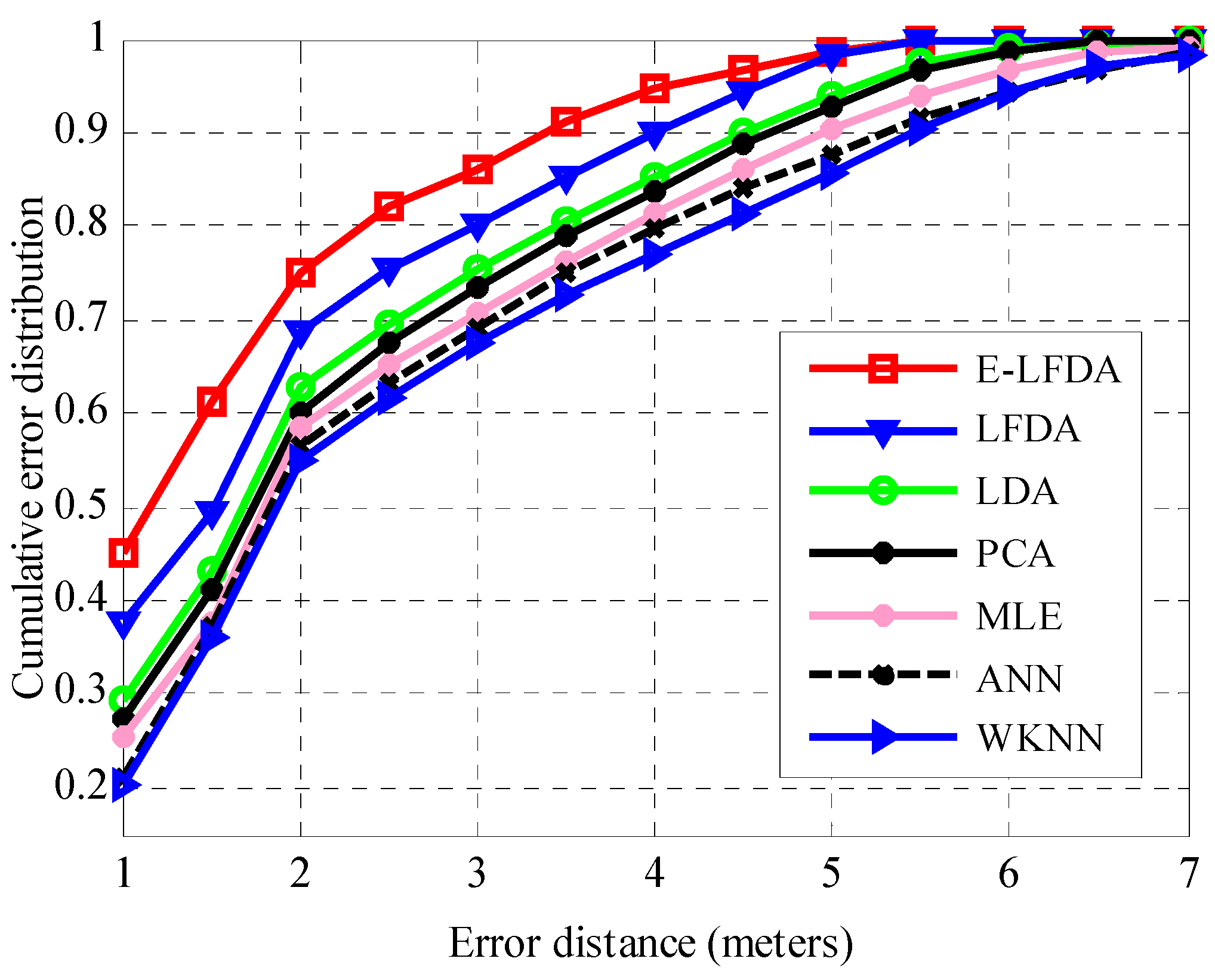
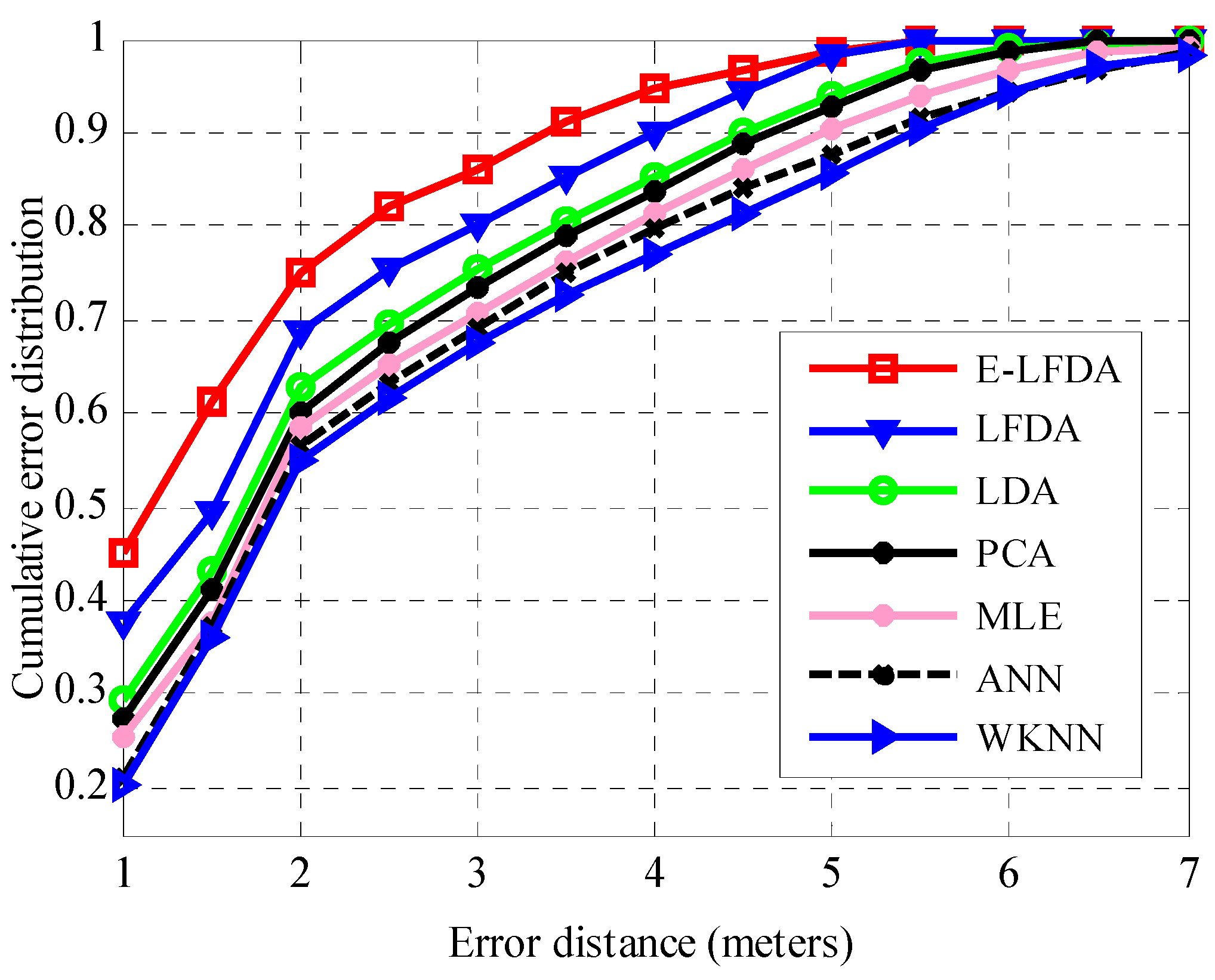
3.2. Positioning Accuracy Comparison
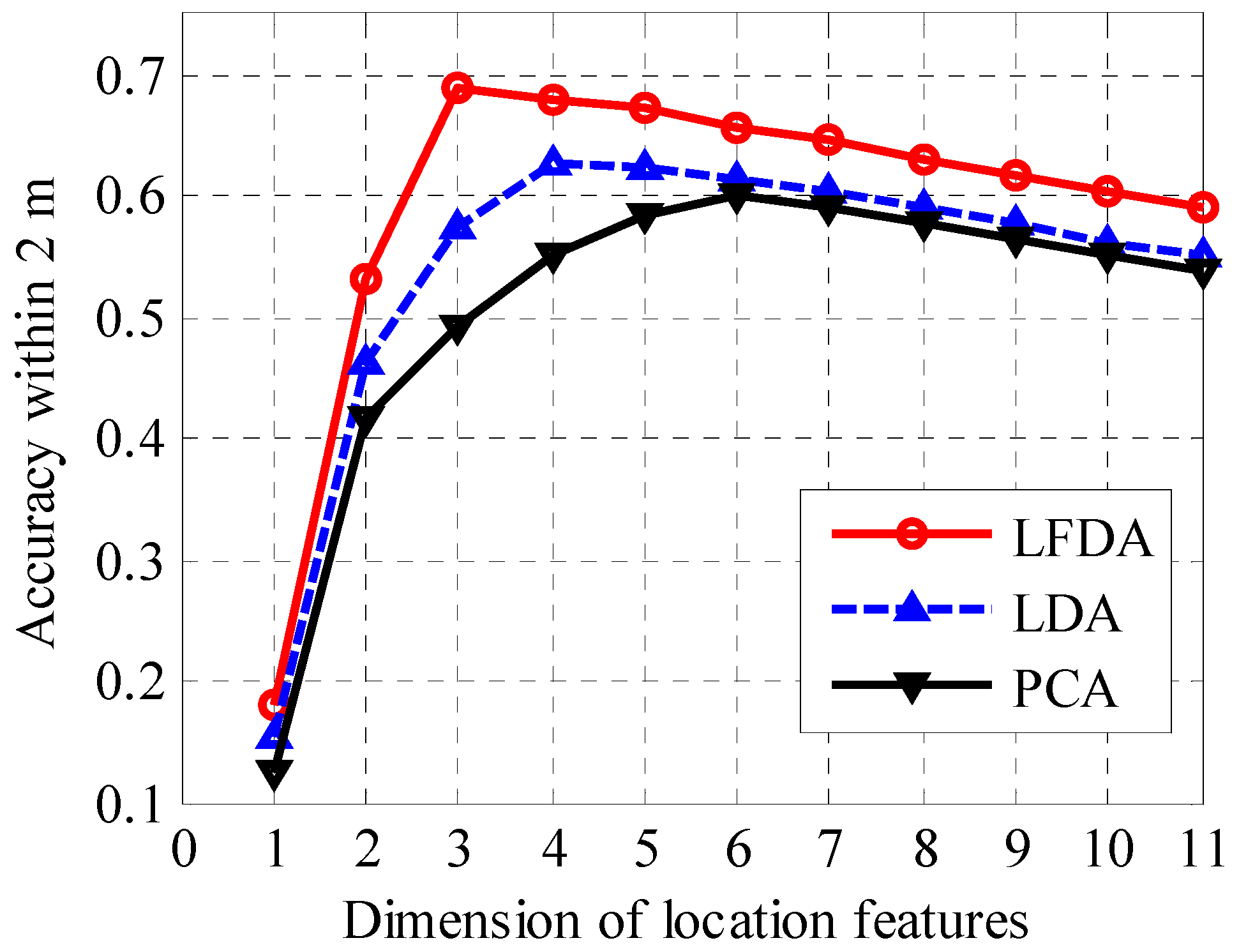
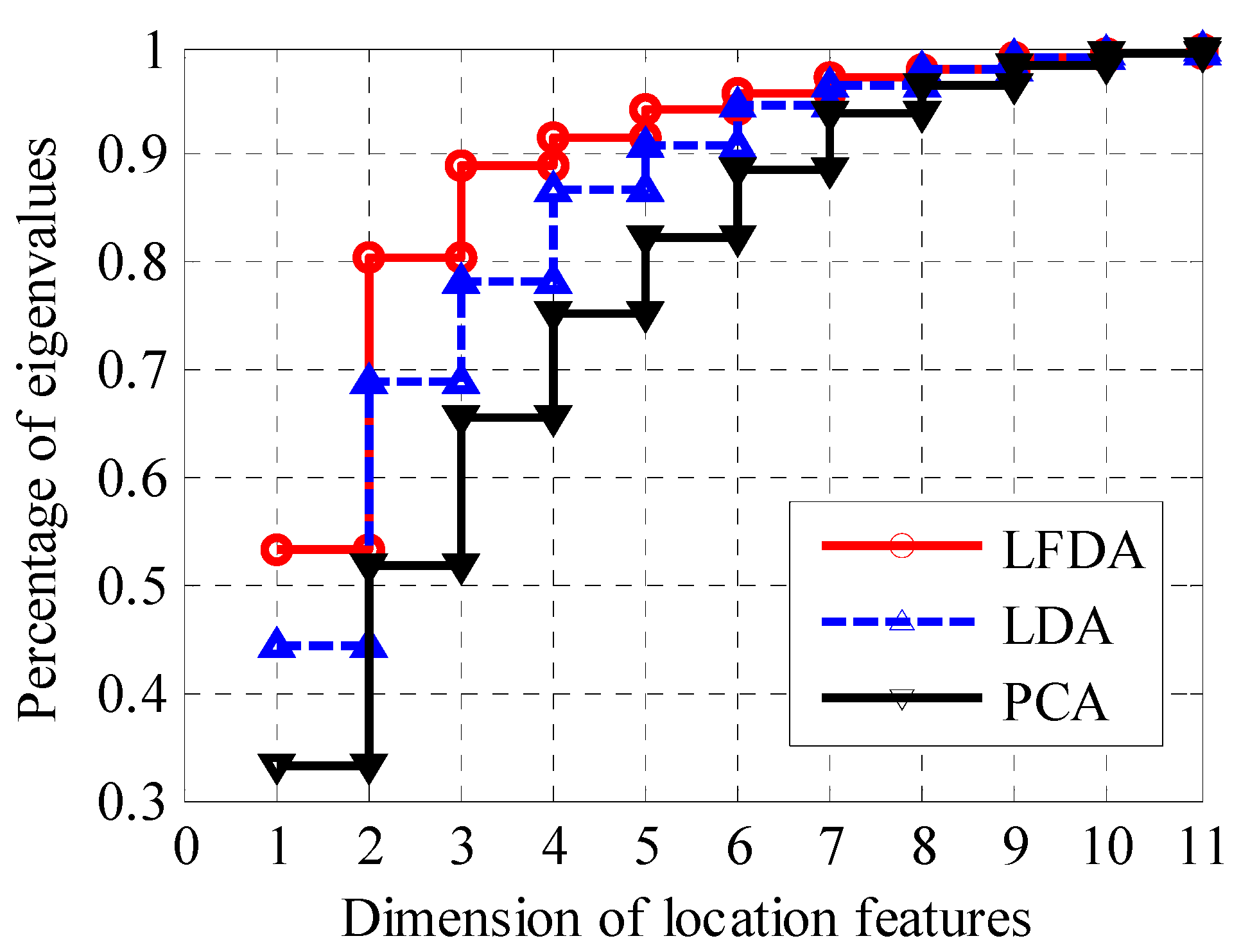
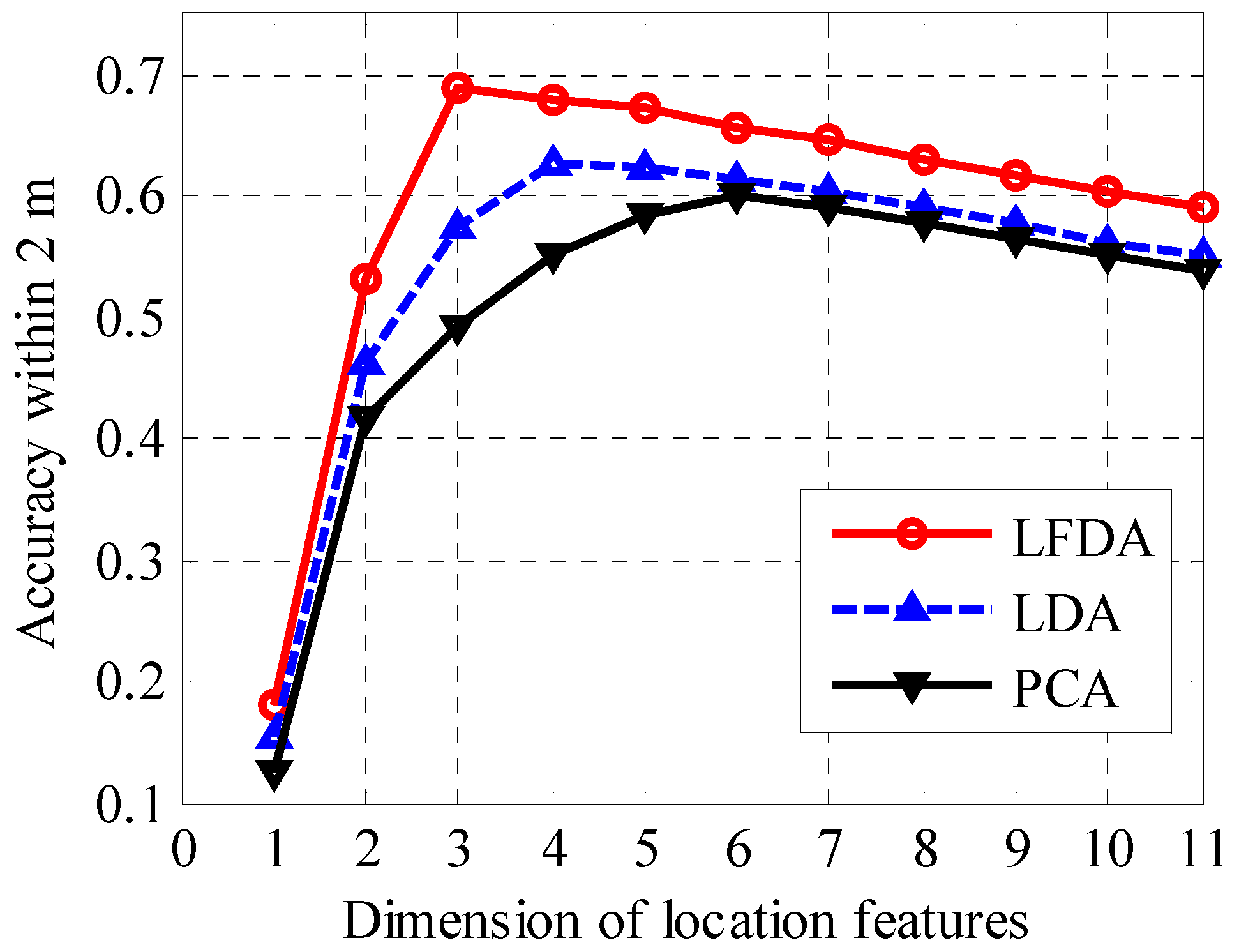
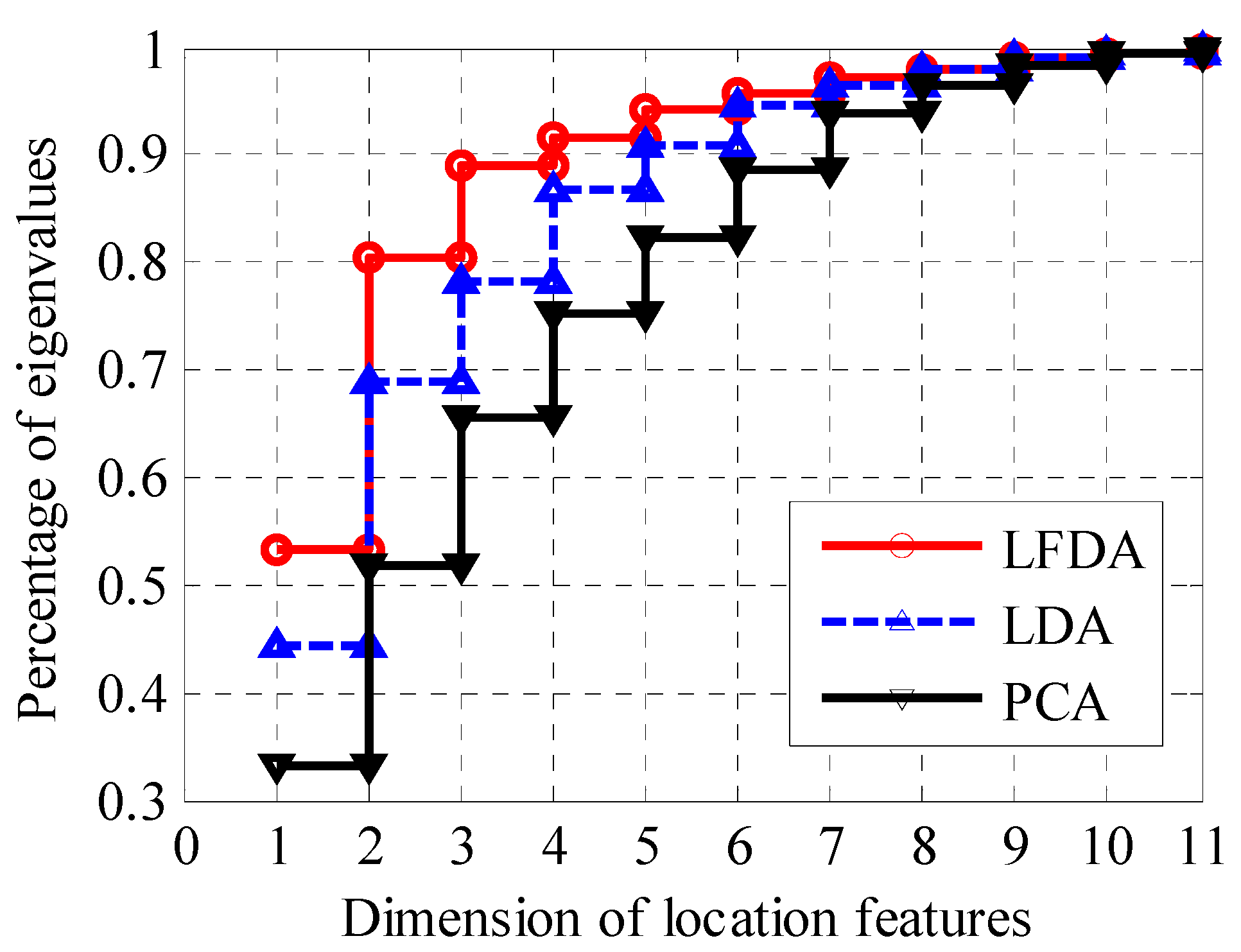
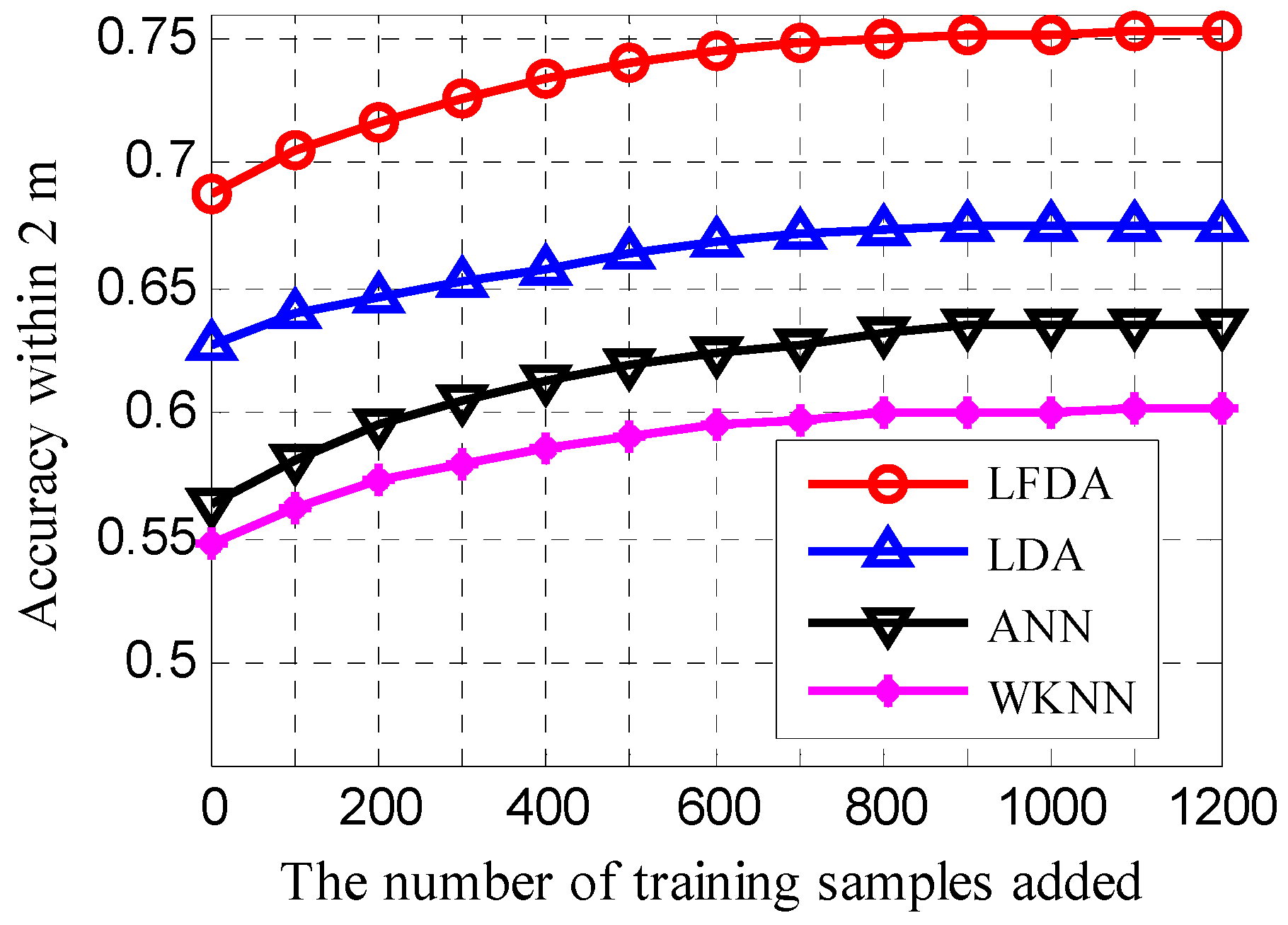
3.3. Effect of Feature Dimensions on Positioning Accuracy
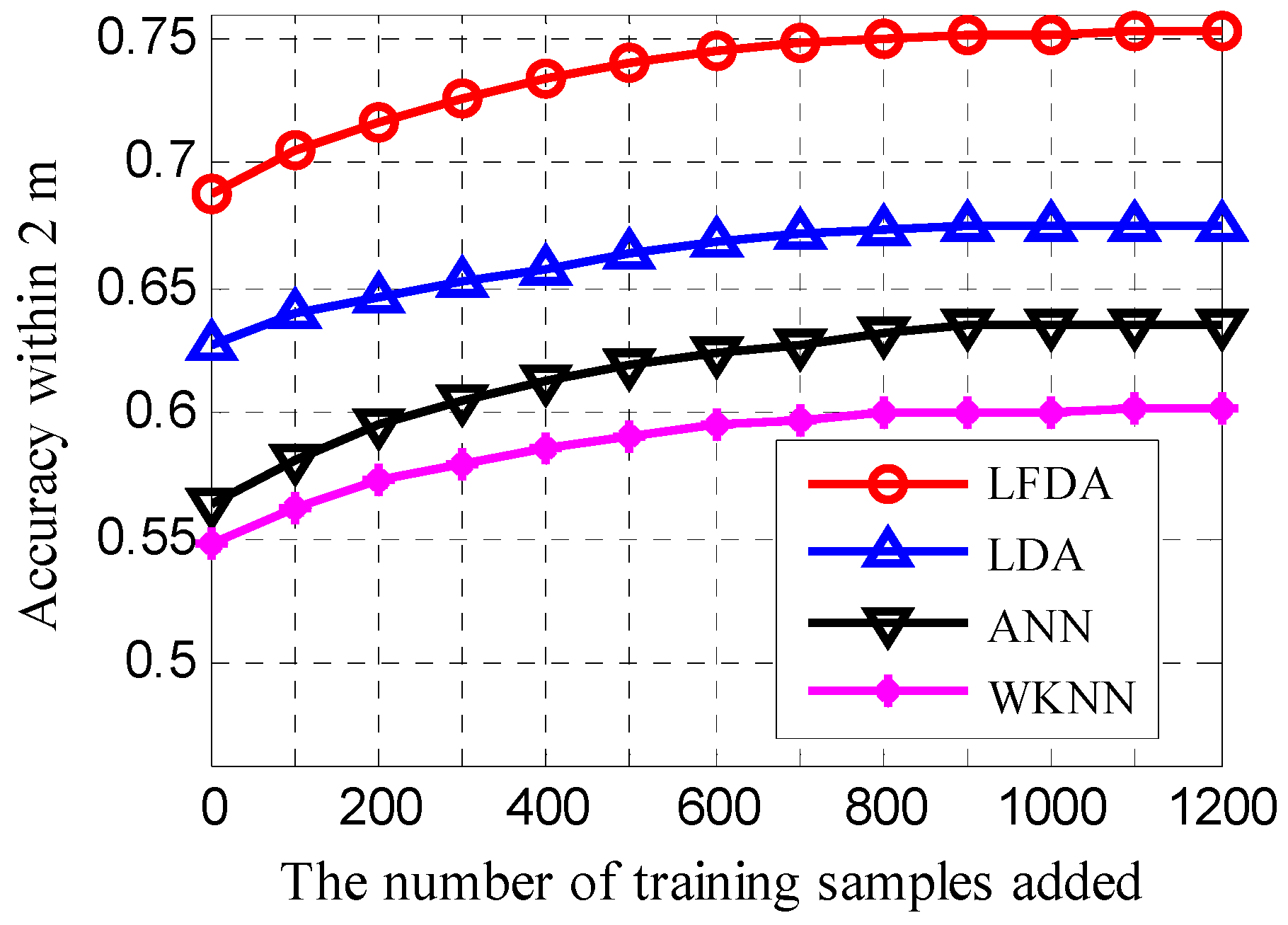
3.4. Effect of Signal Perturbation on Positioning Accuracy
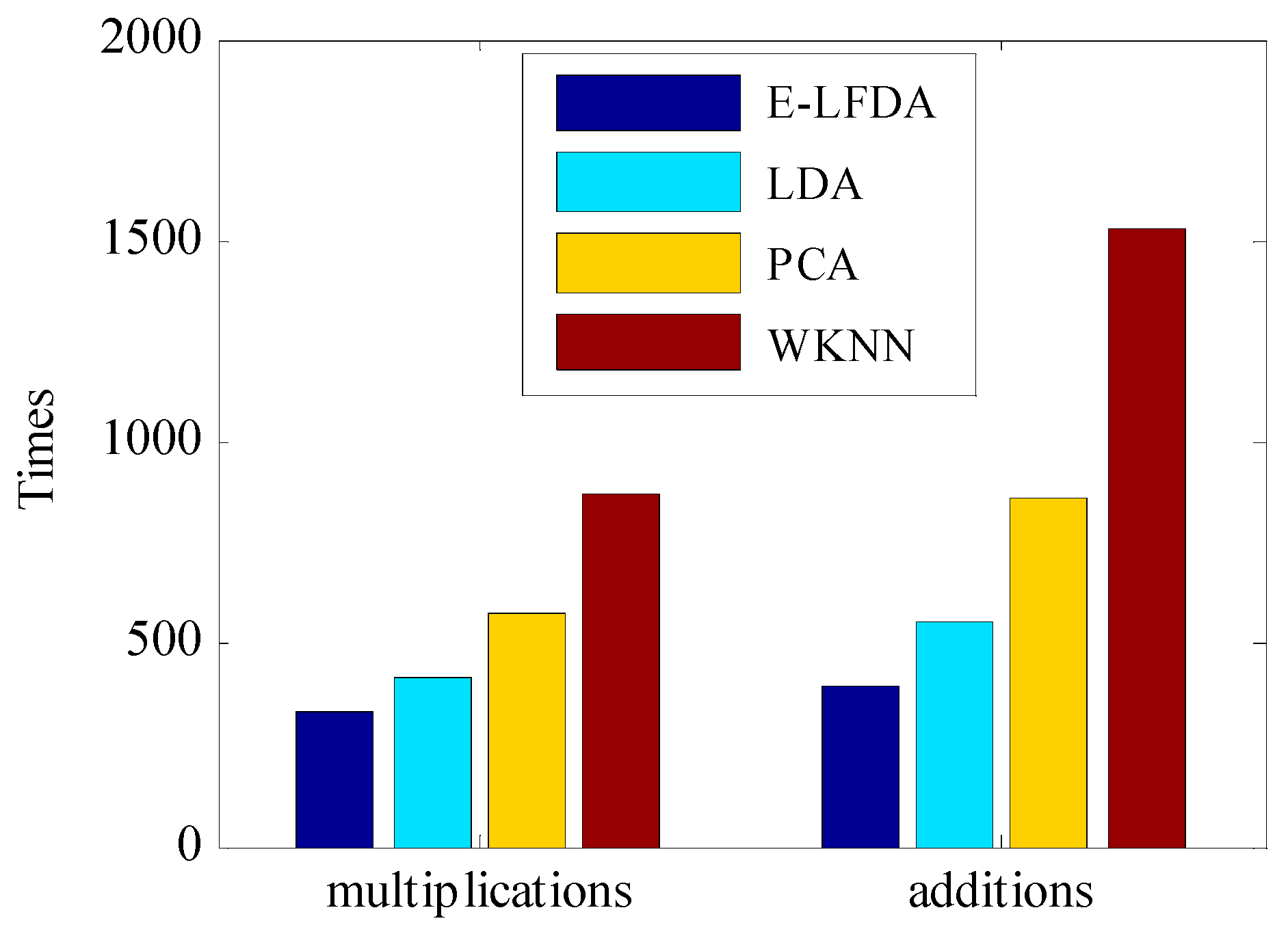
3.5. Online Computation Cost Comparison
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wirola, L.; Laine, T.A.; Syrjarinne, J. Mass-Market Requirements for Indoor Positioning and Indoor Navigation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, Zurich, Switzerland, 15–17 September 2010; pp. 1–7.
- Petrova, K.; Wang, B. Location-based Services Deployment and Demand: A Roadmap Model. Electron. Commer. Res. 2011, 11, 5–29. [Google Scholar] [CrossRef]
- Cheng, X.-Z.; Zhu, D.-R.; Zhang, S.; He, P. Tracking Positioning Algorithm for Direction of Arrival Based on Direction Lock Loop. Future Internet 2015, 7, 214–224. [Google Scholar] [CrossRef]
- Ma, L.; Xu, Y. Received Signal Strength Recovery in Green WLAN Indoor Positioning System Using Singular Value Thresholding. Sensors 2015, 15, 1292–1311. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Zhang, Q.; Xu, K.; Tian, Z.; Wang, Y.; He, W. PRIMAL: Page Rank-Based Indoor Mapping and Localization Using Gene-Sequenced Unlabeled WLAN Received Signal Strength. Sensors 2015, 15, 24791–24817. [Google Scholar] [CrossRef] [PubMed]
- Park, J.G.; Charrow, B.; Curtis, D.; Battat, J.; Minkov, E.; Hicks, J.; Teller, S.; Ledlie, J. Growing an Organic Indoor Location System. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010; pp. 271–284.
- Jiang, Y.; Pan, X.; Li, K.; Lv, Q.; Dick, R.; Hannigan, M.; Shang, L. ARIEL: Automatic Wi-Fi Based Room Fingerprinting for Indoor Localization. In Proceedings of the ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 441–450.
- Zhou, M.; Xu, Y.B.; Ma, L.; Tian, S. On the Statistical Errors of RADAR Location Sensor Networks with Built-In Wi-Fi Gaussian Linear Fingerprints. Sensors 2012, 12, 3605–3626. [Google Scholar] [CrossRef] [PubMed]
- Bahl, P.; Padmanabhan, V.N. RADAR: An In-Building RF-Based User Location and Tracking System. In Proceedings of the 19th IEEE Computer and Communications Societies Conference, Tel Aviv, Israel, 26–30 March 2000; pp. 775–784.
- Youssef, M.; Agrawala, A.; Shankar, U. WLAN Location Determination via Clustering and Probability Distributions. In Proceedings of the First IEEE International Conference on Pervasive Computing and Communications, Fort Worth, TX, USA, 23–26 March 2003.
- Zhou, M.; Xu, Y.B.; Tang, L. Multilayer ANN Indoor Location System with Area Division in WLAN Environment. J. Syst. Eng. Electron. 2010, 21, 914–926. [Google Scholar] [CrossRef]
- Du, Y.; Yang, D.; Xiu, C. Novel Method for Constructing a WIFI Positioning System with Efficient Manpower. Sensors 2015, 15, 8358–8381. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Au, W.S.A.; Valaee, S.; Tan, Z. Received-Signal-Strength-Based Indoor Positioning Using Compressive Sensing. IEEE Trans. Mob. Comput. 2012, 11, 1983–1985. [Google Scholar] [CrossRef]
- Chen, K.Y.; Yang, Q.; Yin, J.; Chai, X.Y. Power-Efficient Access-Point Selection for Indoor location estimation. IEEE Trans. Knowl. Data Eng. 2006, 18, 877–888. [Google Scholar] [CrossRef]
- Mo, Y.; Zhang, Z.; Meng, W.; Ma, L.; Wang, Y. A Spatial Division Clustering Method and Low Dimensional Feature Extraction Technique Based Indoor Positioning System. Sensors 2014, 14, 1850–1876. [Google Scholar] [CrossRef] [PubMed]
- Kushki, A.; Plataniotis, K.N.; Venetsanopoulos, A.N. Kernel-based Positioning in Wireless Local Area Networks. IEEE Trans. Mob. Comput. 2007, 6, 689–705. [Google Scholar] [CrossRef]
- Deng, Z.A.; Xu, Y.B.; Ma, L. Joint AP Selection and Local Discriminant Embedding for Energy Efficient and Accurate Wi-Fi Positioning. KSII Trans. Internet Inf. Syst. 2012, 6, 794–814. [Google Scholar]
- Fang, S.H.; Lin, T.N. Principal Component Localization in Indoor WLAN Environments. IEEE Trans. Mob. Comput. 2012, 11, 100–110. [Google Scholar] [CrossRef]
- Fang, S.H.; Wang, C.H. A Dynamic Hybrid Projection Approach for Improved Wi-Fi Location Fingerprinting. IEEE Trans. Veh. Technol. 2011, 60, 1037–1044. [Google Scholar] [CrossRef]
- Fang, S.H.; Lin, T.N. Indoor location system based on discriminant-adaptive neural network in IEEE 802.11 environments. IEEE Trans. Neural Netw. 2008, 19, 1973–1978. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.L.; Aleix, M.A. Pruning Noisy Bases in Discriminant Analysis. IEEE Trans. Neural Netw. 2008, 19, 148–157. [Google Scholar] [PubMed]
- Pan, J.J.; Kwok, J.T.; Yang, Q.; Chen, Y. Multidimensional Vector Regression for Accurate and Low-Cost Location Estimation in Pervasive Computing. IEEE Tran. Knowl. Data Eng. 2006, 18, 1181–1193. [Google Scholar] [CrossRef]
- Deng, Z.A.; Xu, Y.B.; Ma, L. Indoor Positioning via Nonlinear Discriminative Feature Extraction in Wireless Local Area Network. Comput. Commun. 2012, 35, 738–747. [Google Scholar] [CrossRef]
- Kaemarungsi, K.; Krishnamurthy, P. Properties of Indoor Received Signal Strength for WLAN Location Fingerprinting. In Proceedings of the IEEE First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, Boston, MA, USA, 22–26 August 2004; pp. 14–23.
- Kaemarungsi, K. Distribution of WLAN Received Signal Strength Indication for Indoor Location Determination. In Proceedings of the 1st International Symposium on Wireless Pervasive Computing, Phuket, Thailand, 16–18 January 2006.
- Sugiyama, M. Dimensionality Reduction of Multimodal Labeled Data by Local Fisher Discriminant Analysis. J. Mach. Learn. Res. 2007, 8, 1027–1061. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition, 3rd ed.; Academic Press: London, UK, 2005. [Google Scholar]
- Sheng, Y.; Tan, K.; Chen, G.; Kotz, D.; Campbell, A. Detecting 802.11 MAC Layer Spoofing Using Received Signal Strength. In Proceedings of the 27th Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; pp. 2441–2449.
- Ficco, M.; Esposito, C.; Napolitano, A. Calibrating Indoor Positioning Systems with Low Efforts. IEEE Trans. Mob. Comput. 2014, 13, 737–751. [Google Scholar] [CrossRef]
- Chai, X.; Yang, Q. Reducing the Calibration Effort for Probabilistic Indoor Location Estimation. IEEE Trans. Mob. Comput. 2007, 6, 649–662. [Google Scholar] [CrossRef]
- Torres-Sospedra, J.; Montoliu, R.; Martinez-Uso, A.; Avariento, J.P. UJIIndoorLoc: A new Multi-building and Multi-floor Database for WLAN Fingerprint-based Indoor Localization Problems. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014; pp. 261–270.
- Deng, Z.-A.; Hu, Y.; Yu, J.; Na, Z. Extended Kalman Filter for Real Time Indoor Localization by Fusing WiFi and Smartphone Inertial Sensors. Micromachines 2015, 6, 523–543. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy within 2 m | Accuracy within 3 m | Mean Error | Standard Deviation | Median Error | Maximum Error | Minimum Error |
|---|---|---|---|---|---|---|---|
| E-LFDA | 75.2% | 86.1% | 1.56 | 1.32 | 1.39 | 5.13 | 0.03 |
| LFDA | 68.8% | 80.2% | 1.82 | 1.73 | 1.57 | 5.38 | 0.05 |
| LDA | 62.7% | 75.3% | 2.05 | 1.97 | 1.68 | 6.59 | 0.12 |
| PCA | 60.1% | 73.6% | 2.19 | 2.01 | 1.72 | 6.44 | 0.09 |
| WKNN | 54.8% | 67.4% | 2.54 | 2.64 | 1.91 | 7.58 | 0.24 |
| MLE | 58.3% | 70.7% | 2.31 | 2.27 | 1.78 | 7.34 | 0.15 |
| ANN | 56.4% | 69.2% | 2.43 | 2.52 | 1.87 | 8.25 | 0.07 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Z.-A.; Wu, D.; Zhou, Y.; Na, Z. Enhanced Local Fisher Discriminant Analysis for Indoor Positioning in Wireless Local Area Network. Future Internet 2016, 8, 8. https://doi.org/10.3390/fi8020008
Deng Z-A, Wu D, Zhou Y, Na Z. Enhanced Local Fisher Discriminant Analysis for Indoor Positioning in Wireless Local Area Network. Future Internet. 2016; 8(2):8. https://doi.org/10.3390/fi8020008
Chicago/Turabian StyleDeng, Zhi-An, Di Wu, Yiran Zhou, and Zhenyu Na. 2016. "Enhanced Local Fisher Discriminant Analysis for Indoor Positioning in Wireless Local Area Network" Future Internet 8, no. 2: 8. https://doi.org/10.3390/fi8020008