A Context-Aware Conversational Agent in the Rehabilitation Domain




Abstract
:1. Introduction
- A sophisticated dialogue-management module is being developed using a novel framework which leverages the advantages of two different categories of solutions: The task-oriented and non-task-oriented conversational systems. Thus, in addition to being able to carry out specific tasks, it also possesses the capability to produce “chatty” style dialogues. These functionalities increase the system’s naturalness and user engagement.
- The platform accommodates data from heterogeneous multimodal IoT sensors. Fusing, analysing, and combining data from wearables, cameras, sleep sensors, and blood sugar/pressure levels to monitor the behavior and condition of individuals has not been implemented yet, to the best of our knowledge.
- Likewise, supporting dialogue management from a semantic scope is a field which has not been exploited enough yet in literature. Semantics offer a smart and rich interconnection of the metadata, which combined with the reasoning framework can contribute in the topic selection issue of the dialogue-management system.
- The supported users are not limited to either patients or medical staff, as there have been provisions to cater to the needs of both groups by offering highly sought-after services (based on user requirements).
2. Related Work
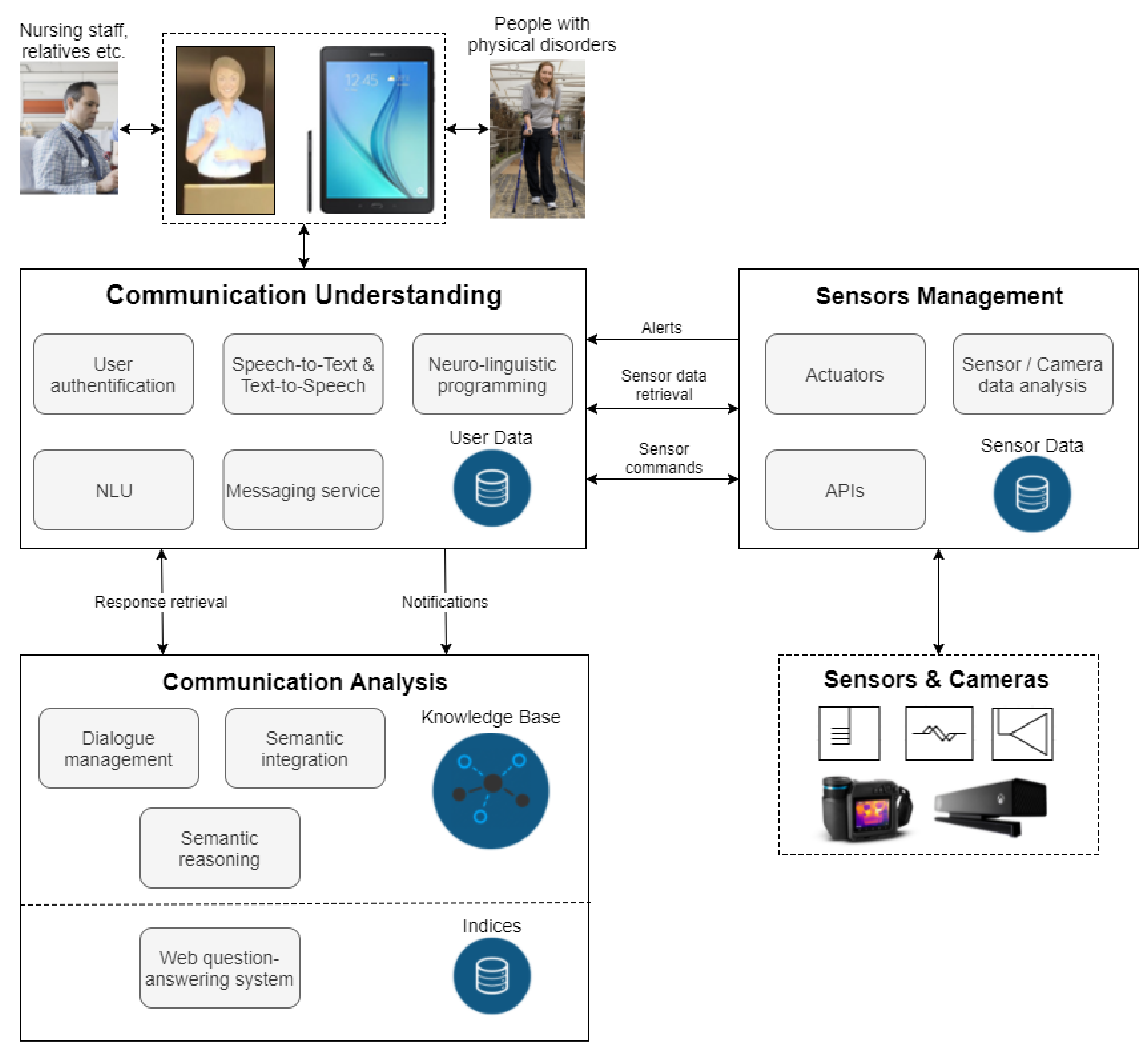
3. System Architecture
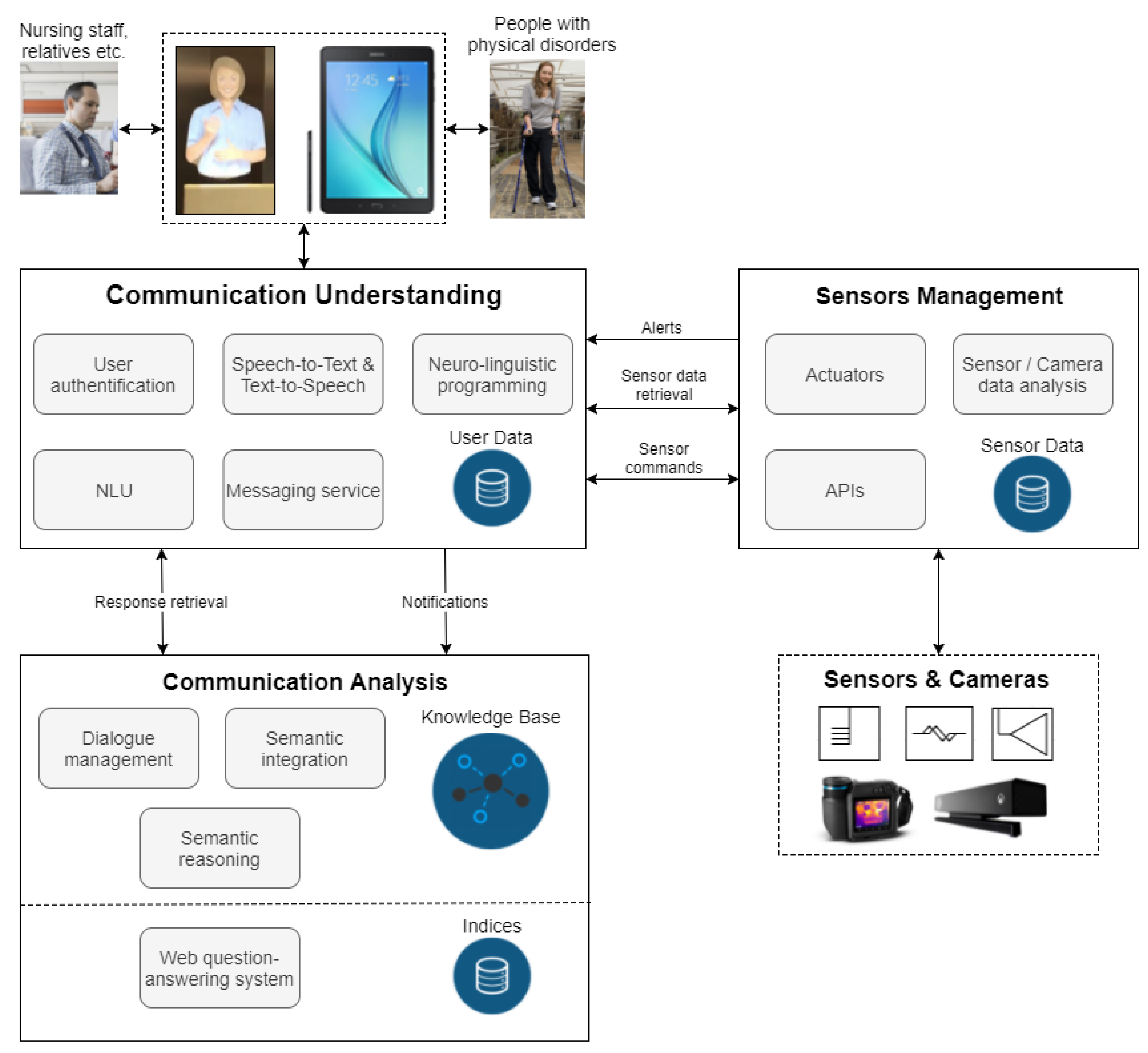
3.1. System Overview
3.2. System Design and Integration
3.2.1. System Conceptualisation
- The communication understanding layer
- The sensor management layer
- The communication analysis layer
3.2.2. Sensor Development
3.2.3. System Integration
4. Data Collection
4.1. Monitoring Sensor Types
- Blood pressure sensor: A traditional off-the-shelf blood-pressure system will be enhanced with wireless connectivity, converting it to a smart IoT device.
- Blood sugar sensor: A wireless module will be integrated to a common blood sugar sensor to imbue WiFi capabilities and to enable cloud communication.
- Sleep quality sensor: To assess a user’s sleep quality, data from a sensor-integrated sheet that is placed beneath his/her bed is used. The embedded sensors include a Wi-Fi module, which, for the duration of the sleep, uploads data to the REA platform for further analysis. Depending on parameters like body movement, posture, and interruptions, a proactive system intervention could be triggered.
- Vision system: It consists of a depth camera, a thermal camera, and an RGB camera, sending data via a USB connection to a local server, which analyses the relevant footage using computer vision models for crowd detection, fall detection, and activity recognition [36].
- Bed management system: Dual gyroscopic sensors and IoT functionality will be added to patient beds that will allow for remote control of both the head and leg section of each bed using voice commands. Moreover, the same applies to each section’s angle, since it is possible for the user, either a patient or a caregiver, to tilt the respective section to the desired position.
- Wearable sensor: Physiological measures like the patient’s temperature, heart rate, and blood oxygen levels are monitored by the REA wearable sensor, which takes the form of a bracelet. The integrated accelerometer and gyroscopic sensors give the potential of an early warning in fall emergencies. Through a Bluetooth Low Energy (BLE) gateway, all readings are forwarded to AWS via Wi-Fi.
4.2. Information Protection and Privacy
5. Language Understanding and Speech Synthesis
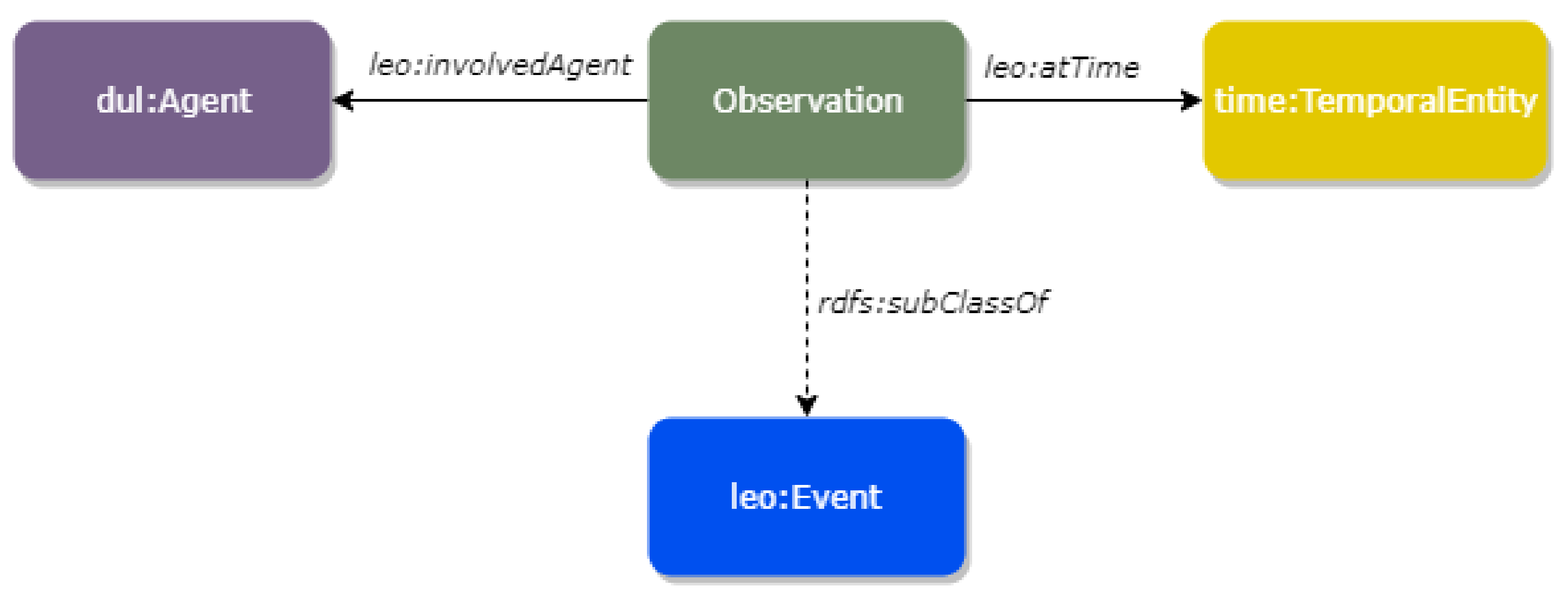
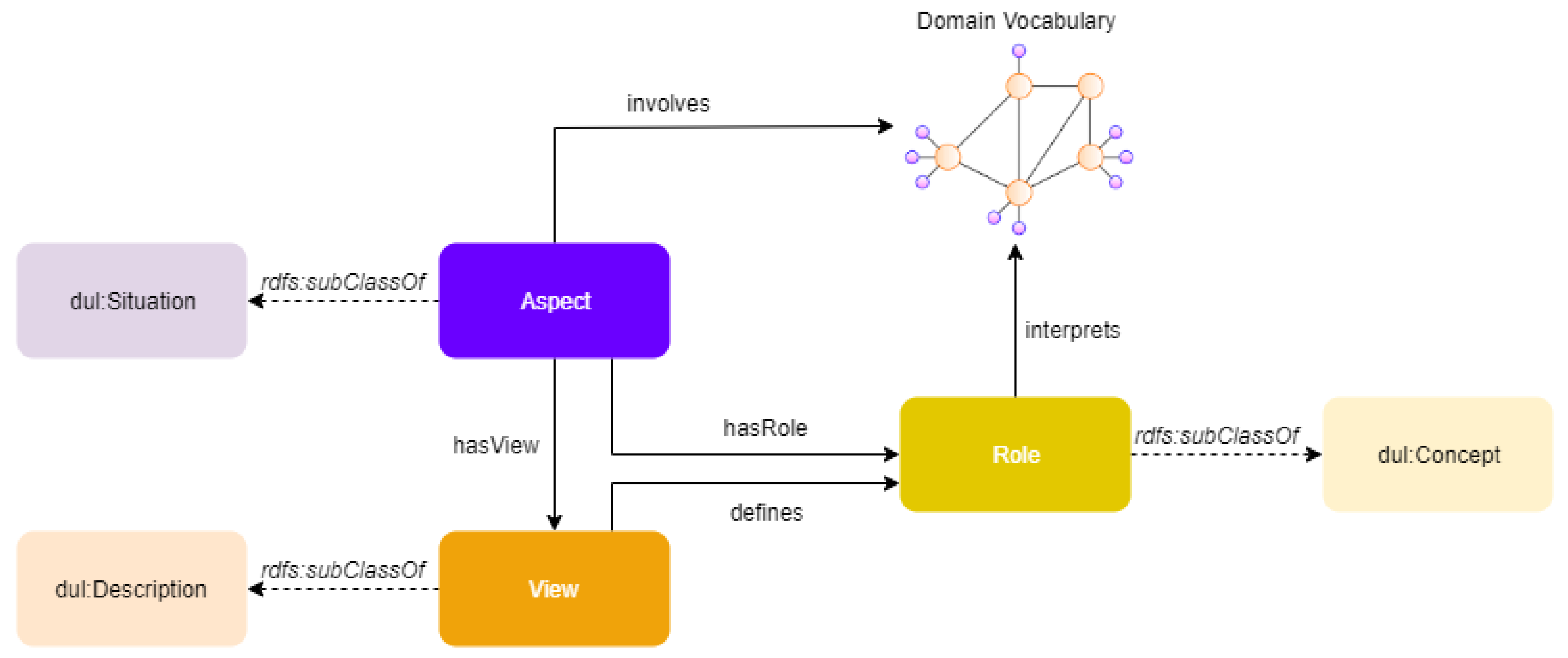
6. Knowledge Representation and Reasoning
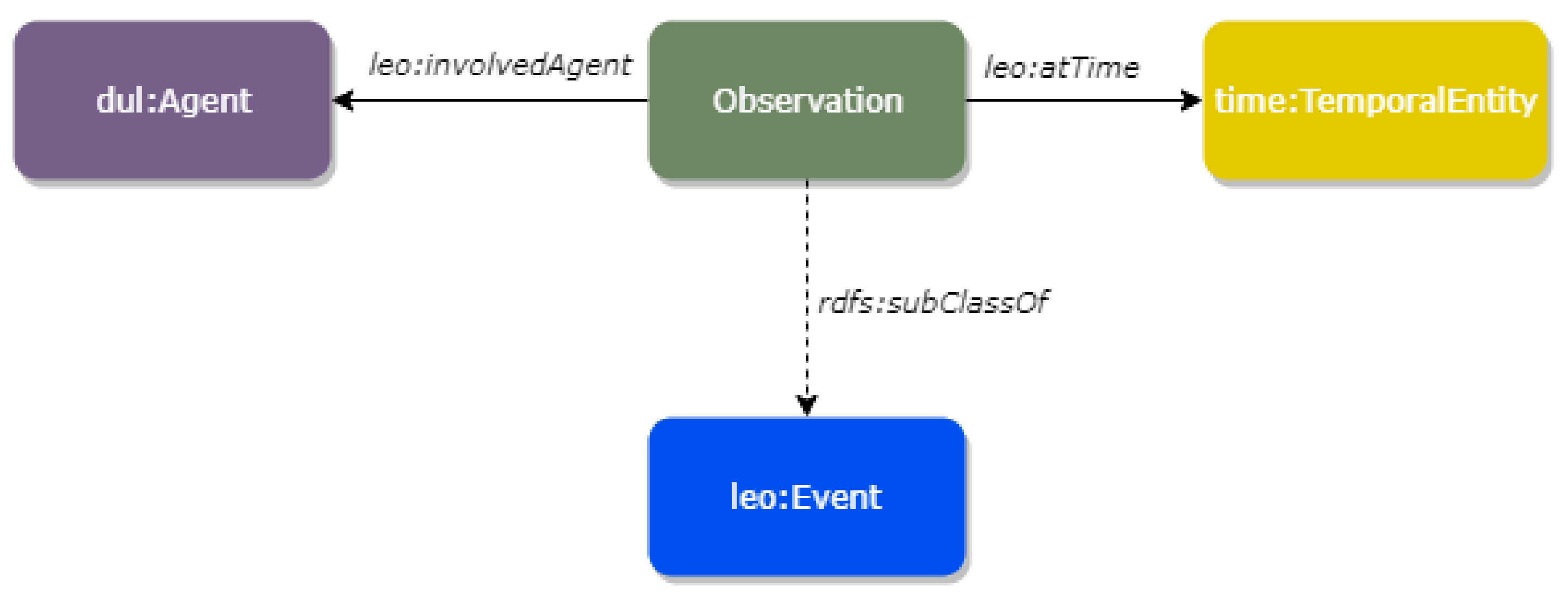
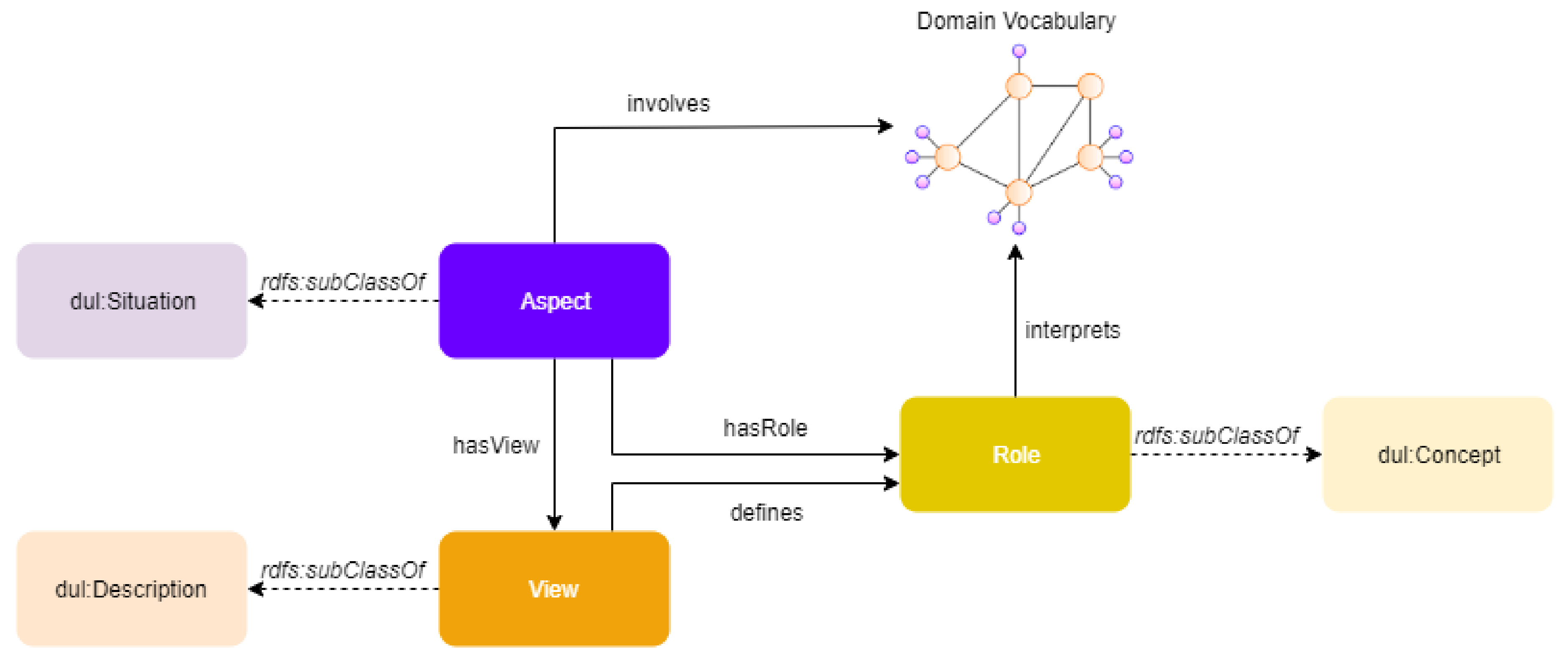
6.1. Multimodal Knowledge Representation
6.2. Data Analytics
- Analysis of wearable sensor data that supports high-level event detection by containing useful information. Surveillance of physical activities is also supported for activities like stress level, quality of sleep metrics, surveillance of lifestyle, and intensity of movement. Each of the activities mentioned above is processed by a different component, which complies with the data formats pertinent to the REA project. For instance, an accelerometer is used in order to detect movement to interpret physical activity and skin conductance, which indicates level of stress. To accomplish this, random forests-based learning techniques are used to apply internal filtering strategies for signal metadata and statistical mechanisms for each measurement [44]. The results return a score relating to the level of stress and intensity of movement in a range from 0 to 5.
- Recognition of human activity is strongly connected with computer vision techniques as mentioned in Reference [36]. The input data, which are coming from depth and IP cameras, include pictures from surrounding areas. This results in the recognition of simple activities like walking, sitting, etc. or more complex ones like eating, washing the dishes, cooking, etc.
6.3. Reasoning
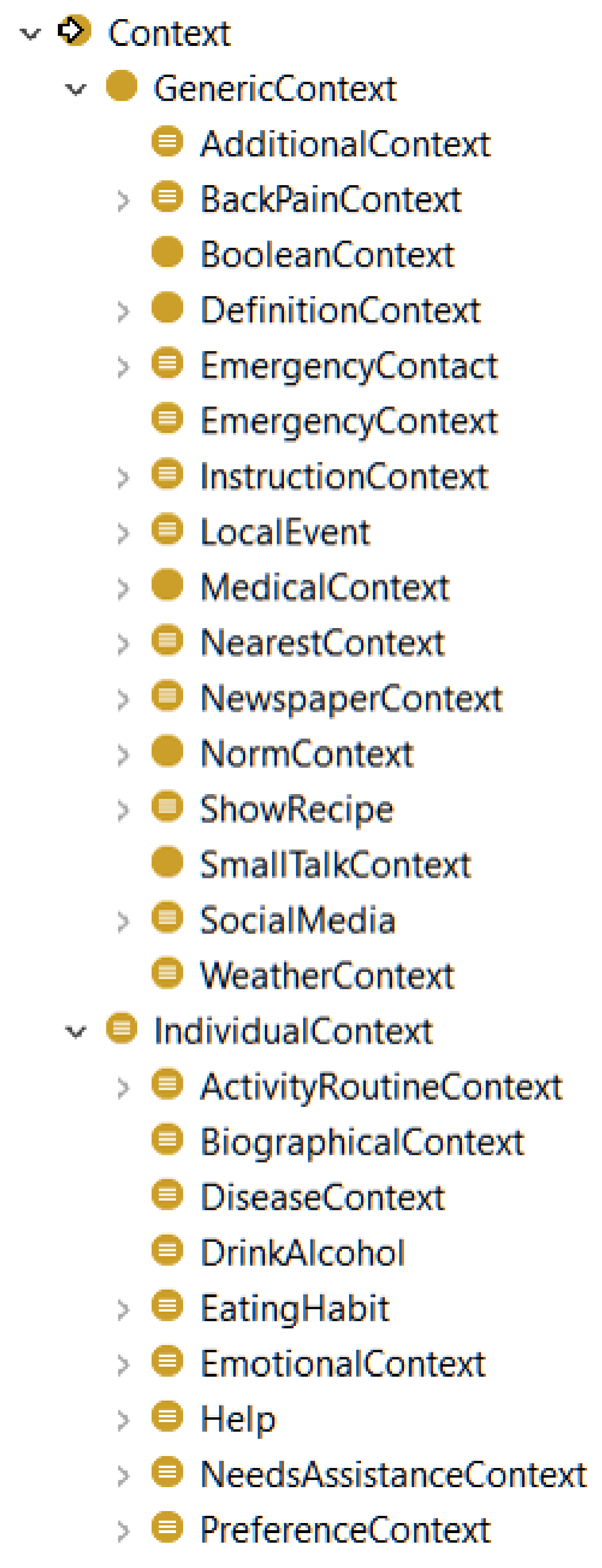
Recognising Topics
7. Dialogue Management and Web-Based Retrieval
7.1. Decision Making
7.2. Web-Based Question Answering Service
8. Testing Settings and Usage Scenarios
8.1. Testing Environments
8.2. A Use-Case Scenario
8.2.1. Language Understanding
8.2.2. Reasoning
8.2.3. Dialogue Management
{
"type": "MedicationAdministration",
"": [
{
"drug": "Drug 1",
"schedule": "Night"
},
{
"drug": "Drug 2",
"schedule": "Night"
}, ...
]
}
8.3. Preliminary User-Centred Evaluation
- The response of the system is too often “Can you repeat the question?” The topic detection task depends solely on the results coming from speech and language analysis, which are used by the underlying reasoner to classify utterance contexts in the topic hierarchy. The current implementation is not able to handle missing information and uncertainty. Therefore, the absence of a term from the input hampers the detection of the correct topic.
- It takes too long to provide a response. The average response time of the framework was 2.4 s that, based on users’ feedback, needs to be further improved. Although ontological reasoning imposes some inherent scalability issues, we plan to investigate more scalable reasoning schemes, such as to reduce, if possible, the expressivity of the models.
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bates, D.W. The quality case for information technology in healthcare. BMC Med. Inform. Decis. Mak. 2002, 2, 7. [Google Scholar] [CrossRef] [PubMed]
- Wickramasinghe, N.; Fadlalla, A.; Geisler, E.; Schaffer, J. A framework for assessing e-health preparedness. In Proceedings of the AMCIS 2004 Proceedings, New York, NY, USA, 6–8 August 2004. [Google Scholar]
- Marohn, D. Biometrics in healthcare. Biom. Technol. Today 2006, 14, 9–11. [Google Scholar] [CrossRef]
- Bellegarda, J.R.; Monz, C. State of the art in statistical methods for language and speech processing. Comput. Speech Lang. 2016, 35, 163–184. [Google Scholar] [CrossRef] [Green Version]
- Ly, K.H.; Ly, A.M.; Andersson, G. A fully automated conversational agent for promoting mental well-being: A pilot RCT using mixed methods. Internet Interv. 2017, 10, 39–46. [Google Scholar] [CrossRef]
- Tanaka, H.; Negoro, H.; Iwasaka, H.; Nakamura, S. Embodied conversational agents for multimodal automated social skills training in people with autism spectrum disorders. PLoS ONE 2017, 12, e0182151. [Google Scholar] [CrossRef]
- Savino, J.A.; Latifi, R. Hospital and Healthcare Transformation over Last Few Decades. In The Modern Hospital; Springer: Berlin, Germany, 2019; pp. 23–29. [Google Scholar]
- Ravindranath, P.A.; Hong, P.; Rafii, M.S.; Aisen, P.S.; Jimenez-Maggiora, G. A step forward in integrating healthcare and voice-enabled technology: Concept demonstration with deployment of automatic medical coding model as an amazon “alexa” skill. Alzheimer’s Dement. J. Alzheimer’s Assoc. 2018, 14, P955. [Google Scholar] [CrossRef]
- Yaghoubzadeh, R.; Kramer, M.; Pitsch, K.; Kopp, S. Virtual agents as daily assistants for elderly or cognitively impaired people. In International Workshop on Intelligent Virtual Agents; Springer: Berlin, Germany, 2013; pp. 79–91. [Google Scholar]
- Fadhil, A. Beyond patient monitoring: Conversational agents role in telemedicine & healthcare support for home-living elderly individuals. arXiv 2018, arXiv:1803.06000. [Google Scholar]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Informat. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef]
- Bickmore, T.W.; Trinh, H.; Olafsson, S.; O’Leary, T.K.; Asadi, R.; Rickles, N.M.; Cruz, R. Patient and consumer safety risks when using conversational assistants for medical information: An observational study of Siri, Alexa, and Google Assistant. J. Med. Internet Res. 2018, 20, e11510. [Google Scholar] [CrossRef]
- Siddharthan, A. Ehud Reiter and Robert Dale. Building Natural Language Generation Systems. Cambridge University Press, 2000. $64.95/£ 37.50 (Hardback). Nat. Lang. Eng. 2001, 7, 271–274. [Google Scholar] [CrossRef]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef]
- Perera, R.; Nand, P. Recent advances in natural language generation: A survey and classification of the empirical literature. Comput. Inform. 2017, 36, 1–32. [Google Scholar] [CrossRef]
- Ze, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Vancouver, Australia, 26–31 May 2013; pp. 7962–7966. [Google Scholar]
- Tokuda, K.; Nankaku, Y.; Toda, T.; Zen, H.; Yamagishi, J.; Oura, K. Speech synthesis based on hidden Markov models. Proc. IEEE 2013, 101, 1234–1252. [Google Scholar] [CrossRef]
- Hough, J. Incremental semantics driven natural language generation with self-repairing capability. In Proceedings of the Second Student Research Workshop associated with RANLP, Hissar, Bulgaria, 13 September 2011; pp. 79–84. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgart, AL, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Zen, H.; Sak, H. Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4470–4474. [Google Scholar]
- Pollet, V.; Zovato, E.; Irhimeh, S.; Batzu, P.D. Unit Selection with Hierarchical Cascaded Long Short Term Memory Bidirectional Recurrent Neural Nets. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 3966–3970. [Google Scholar]
- Zigel, Y.; Litvak, D.; Gannot, I. A method for automatic fall detection of elderly people using floor vibrations and sound—Proof of concept on human mimicking doll falls. IEEE Trans. Biomed. Eng. 2009, 56, 2858–2867. [Google Scholar] [CrossRef] [PubMed]
- Mirmahboub, B.; Samavi, S.; Karimi, N.; Shirani, S. Automatic monocular system for human fall detection based on variations in silhouette area. IEEE Trans. Biomed. Eng. 2012, 60, 427–436. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Monocular 3D head tracking to detect falls of elderly people. In Proceedings of the International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 6384–6387. [Google Scholar]
- Pilcher, J.J.; Ginter, D.R.; Sadowsky, B. Sleep quality versus sleep quantity: Relationships between sleep and measures of health, well-being and sleepiness in college students. J. Psychosom. Res. 1997, 42, 583–596. [Google Scholar] [CrossRef]
- Heit, J.; Srinivasan, S.; Benitez, D.; Andrews, B.W. Device and Method to Monitor, Assess and Improve Quality of Sleep. U.S. Patent 8,348,840, 8 January 2013. [Google Scholar]
- Lison, P. Structured Probabilistic Modelling for Dialogue Management. Ph.D. Thesis, Department of Informatics Faculty of Mathematics and Natural Sciences, University of Oslo, Oslo, Norwey, October 2014. [Google Scholar]
- Graua, B.C.; Horrocksa, I.; Motika, B.; Parsiab, B.; Patel-Schneiderc, P.; Sattlerb, U. Web Semantics: Science, Services and Agents on the World Wide Web. Web Semant. Sci. Serv. Agents World Wide Web 2008, 6, 309–322. [Google Scholar]
- Baader, F.; Calvanese, D.; McGuinness, D.; Patel-Schneider, P.; Nardi, D. The Description Logic Handbook: Theory, Implementation and Applications; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ye, J.; Dasiopoulou, S.; Stevenson, G.; Meditskos, G.; Kontopoulos, E.; Kompatsiaris, I.; Dobson, S. Semantic web technologies in pervasive computing: A survey and research roadmap. Pervasive Mob. Comput. 2015, 23, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Damljanović, D.; Agatonović, M.; Cunningham, H.; Bontcheva, K. Improving habitability of natural language interfaces for querying ontologies with feedback and clarification dialogues. Web Semant. Sci. Serv. Agents World Wide Web 2013, 19, 1–21. [Google Scholar] [CrossRef]
- Dourlens, S.; Ramdane-Cherif, A.; Monacelli, E. Multi levels semantic architecture for multimodal interaction. Appl. Intell. 2013, 38, 586–599. [Google Scholar] [CrossRef]
- Altinok, D. An ontology-based dialogue management system for banking and finance dialogue systems. arXiv 2018, arXiv:1804.04838. [Google Scholar]
- Wessel, M.; Acharya, G.; Carpenter, J.; Yin, M. OntoVPA—An Ontology-Based Dialogue Management System for Virtual Personal Assistants. In Advanced Social Interaction with Agents; Springer: Berlin, Germany, 2019; pp. 219–233. [Google Scholar]
- Avgerinakis, K.; Briassouli, A.; Kompatsiaris, I. Recognition of activities of daily living for smart home environments. In Proceedings of the 9th International Conference on Intelligent Environments, Athens, Greece, 18–19 July 2013; pp. 173–180. [Google Scholar]
- Toshniwal, S.; Kannan, A.; Chiu, C.C.; Wu, Y.; Sainath, T.N.; Livescu, K. A comparison of techniques for language model integration in encoder-decoder speech recognition. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 369–375. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MA, USA, 23–25 June 2014; pp. 55–60. [Google Scholar]
- Mavropoulos, T.; Liparas, D.; Symeonidis, S.; Vrochidis, S.; Kompatsiaris, I. A Hybrid approach for biomedical relation extraction using finite state automata and random forest-weighted fusion. In Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing, Budapest, Hungary, 17–23 April 2017; Springer: Berlin, Germany, 2017; pp. 450–462. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.; Wang, Q.; Shen, J.; Ren, F.; Nguyen, P.; Pang, R.; Moreno, I.L.; Wu, Y.; et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. In Advances in Neural Information Processing Systems; MIT PRESS: Cambridge, MA, USA, 2018; pp. 4480–4490. [Google Scholar]
- Shaw, R.; Troncy, R.; Hardman, L. Lode: Linking open descriptions of events. In Proceedings of the Asian Semantic Web Conference, Shanghai, China, 7–9 December 2009; Springer: Berlin, Germany, 2009; pp. 153–167. [Google Scholar]
- Meditskos, G.; Dasiopoulou, S.; Kompatsiaris, I. MetaQ: A knowledge-driven framework for context-aware activity recognition combining SPARQL and OWL 2 activity patterns. Pervasive Mob. Comput. 2016, 25, 104–124. [Google Scholar] [CrossRef]
- Gangemi, A.; Mika, P. Understanding the semantic web through descriptions and situations. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Catania, Italy, 3–7 November 2003; Springer: Berlin, Germany, 2003; pp. 689–706. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pragst, L.; Miehle, J.; Minker, W.; Ultes, S. Challenges for adaptive dialogue management in the KRISTINA project. In Proceedings of the 1st ACM SIGCHI International Workshop on Investigating Social Interactions with Artificial Agents, Glasgow, UK, 13–17 November 2017; pp. 11–14. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actor | Interaction |
|---|---|
| (i1) Doctor | REA, could you tell me Mr. Doe’s treatment for tonight? |
| (i2) REA | Mr. Doe is going to take (Drug 1) and (Drug 2). However, he complains that (Drug 1) has no effect on him. |
| (i3) Doctor | REA, i would like to know about his medical condition. |
| (i4) REA | Blood pressure is at normal levels, systolic is 105, and diastolic is 65. His heartbeats are 90 per minute, a little higher than expected. Lastly, his body temperature is 36.6 degrees Celsius. |
| (i5) Doctor | That’s all REA. Thank you. |
| (i6) REA | Enjoy the rest of the day Dr. Shepherd! |
| Question | Mean (SD) |
|---|---|
| Provides too little information on treatments | 2.31 ± 0.85 |
| Provides too little information on problems | 2.35 ± 0.89 |
| Addresses user’s information requests | 3.21 ± 1.21 |
| Contradictory information is returned | 3.09 ± 1.56 |
| It takes too long to respond | 2.11 ± 0.9 |
| There are too many “can you please repeat the question?” responses | 1.73 ± 0.95 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mavropoulos, T.; Meditskos, G.; Symeonidis, S.; Kamateri, E.; Rousi, M.; Tzimikas, D.; Papageorgiou, L.; Eleftheriadis, C.; Adamopoulos, G.; Vrochidis, S.; et al. A Context-Aware Conversational Agent in the Rehabilitation Domain. Future Internet 2019, 11, 231. https://doi.org/10.3390/fi11110231
Mavropoulos T, Meditskos G, Symeonidis S, Kamateri E, Rousi M, Tzimikas D, Papageorgiou L, Eleftheriadis C, Adamopoulos G, Vrochidis S, et al. A Context-Aware Conversational Agent in the Rehabilitation Domain. Future Internet. 2019; 11(11):231. https://doi.org/10.3390/fi11110231
Chicago/Turabian StyleMavropoulos, Thanassis, Georgios Meditskos, Spyridon Symeonidis, Eleni Kamateri, Maria Rousi, Dimitris Tzimikas, Lefteris Papageorgiou, Christos Eleftheriadis, George Adamopoulos, Stefanos Vrochidis, and et al. 2019. "A Context-Aware Conversational Agent in the Rehabilitation Domain" Future Internet 11, no. 11: 231. https://doi.org/10.3390/fi11110231