




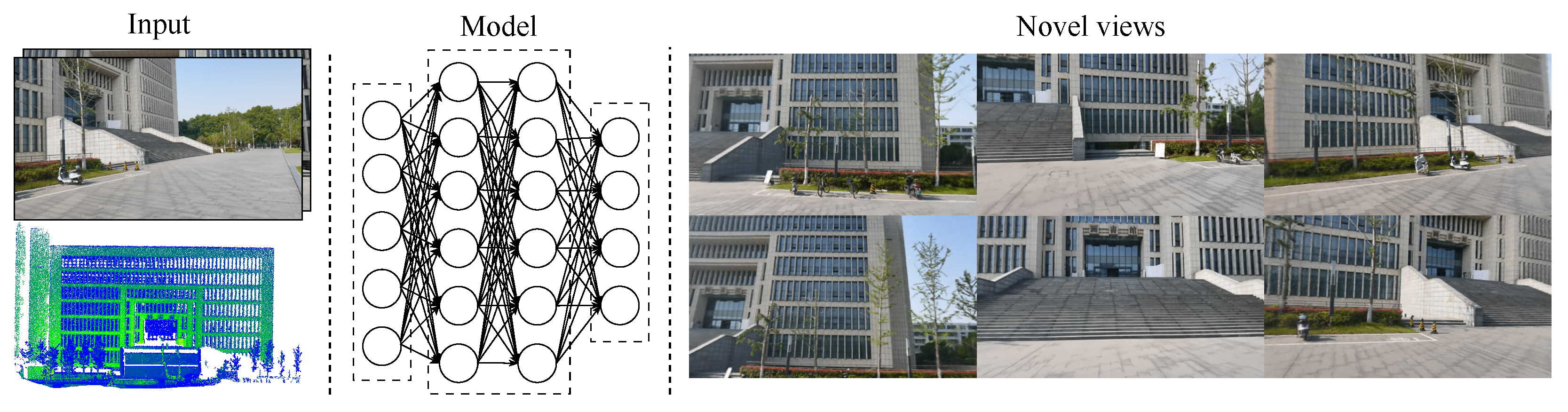
Camera and LiDAR Fusion for Urban Scene Reconstruction and Novel View Synthesis via Voxel-Based Neural Radiance Fields


Abstract
:1. Introduction
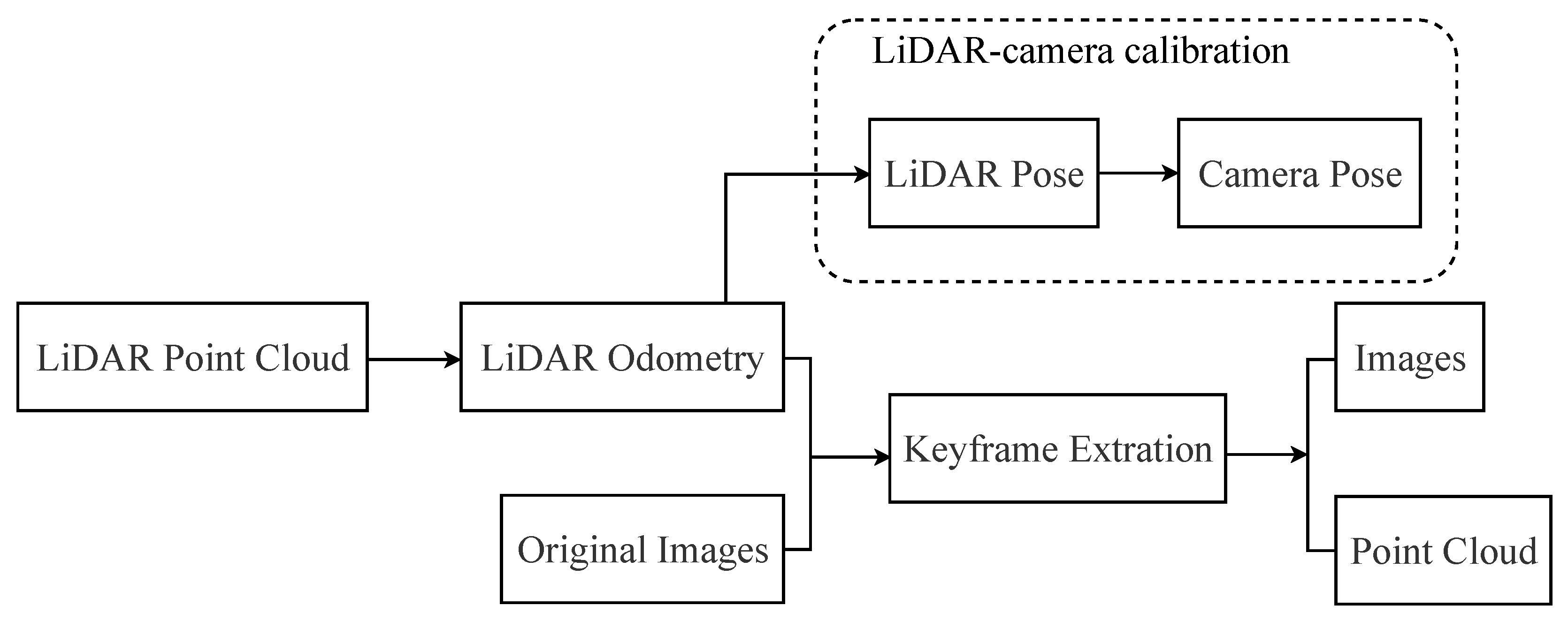
- We can obtain accurate initial camera pose and a priori 3D point cloud models through LiDAR odometry and LiDAR-camera calibration, which can reduce the artifacts in synthesizing novel views and enhance the reconstruction quality.
- We propose a novel NeRF 3D reconstruction algorithm that employs sparse voxel partitioning. By dividing space into sparse voxels and constructing a voxel octree structure, we can accelerate 3D reconstruction for urban scenes and enhance scene geometric consistency.
- Experimental results on four urban outdoor datasets indicate that our method can reduce the training time and significantly improve 3D reconstruction quality compared with the latest NeRF methods.
2. Related Works
2.1. Classic Methods of 3D Reconstruction
2.2. Neural Radiance Fields
2.2.1. Theory of Neural Radiance Fields
2.2.2. Advance in NeRF
2.3. Application of NeRF in Urban Scene
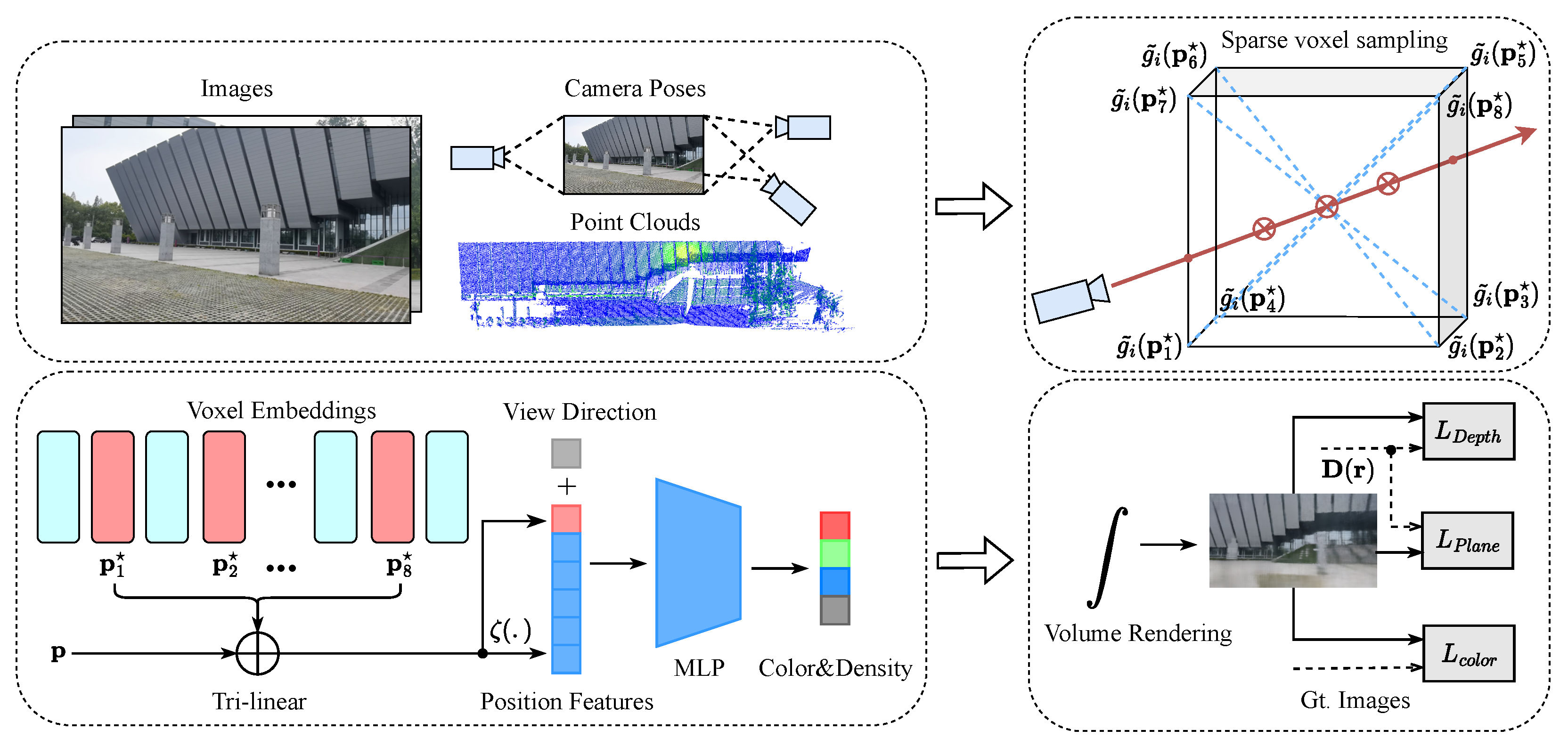
3. Methodology
3.1. Preliminaries
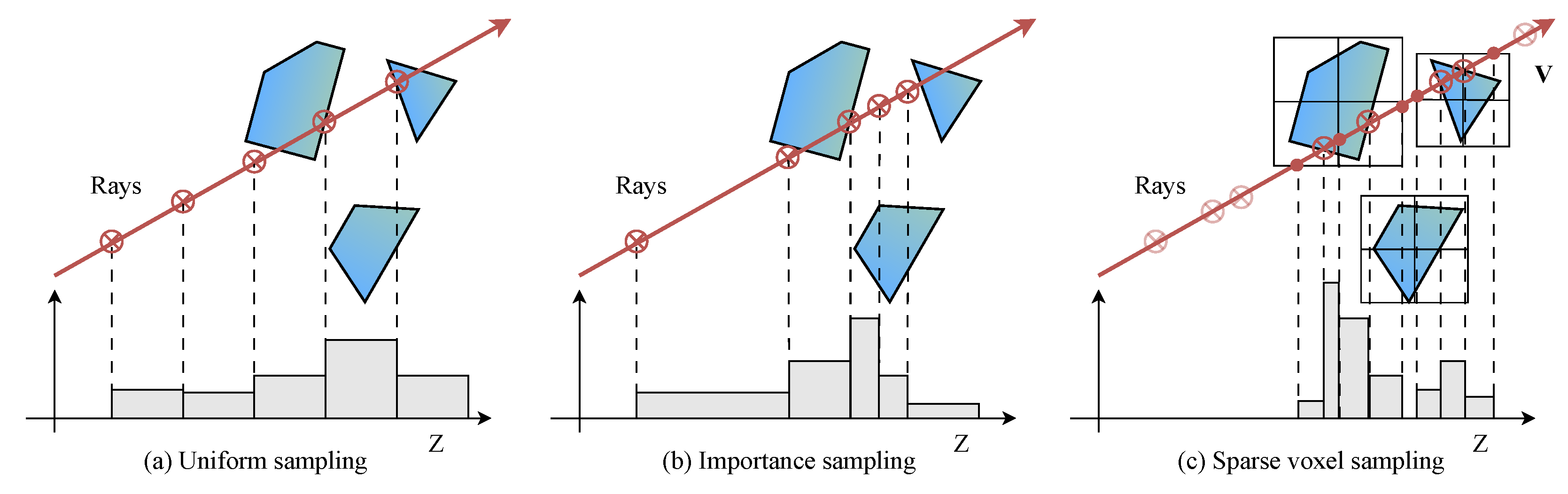
3.2. Sparse Voxel NeRF Representation
Sparse Voxel Sampling Method
3.3. Optimization
3.3.1. Multi-Sensor Fusion
3.3.2. Self-Pruning
3.3.3. Loss Function
4. Experiments
4.1. Experimental Settings
4.1.1. Dataset and Metrics
4.1.2. Baseline Methods
4.1.3. Implementation Details
4.2. Result Analysis
4.3. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
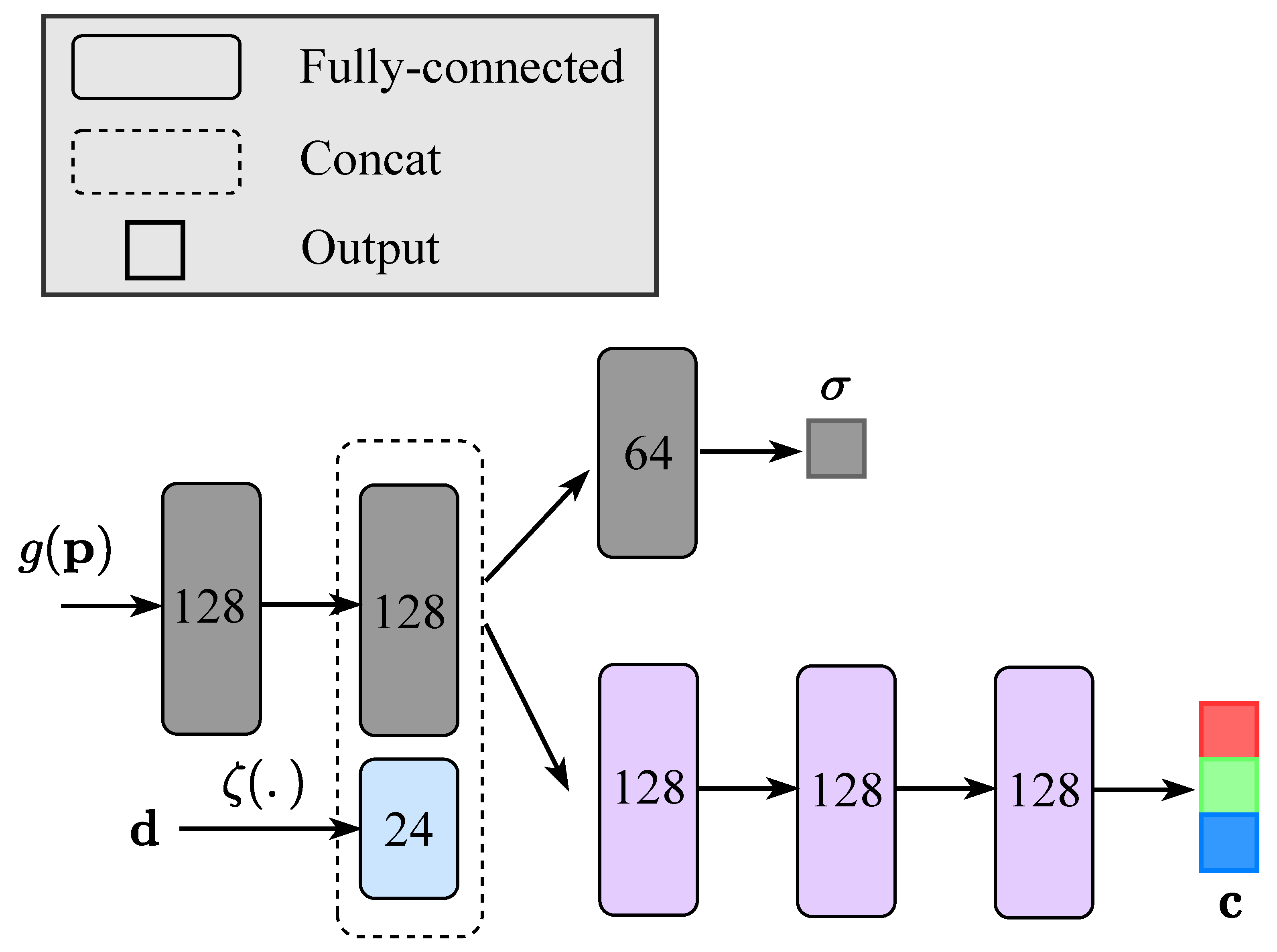
Appendix A. Model Architecture Details

Appendix B. Datasets


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Livox Avia LiDAR | OAK-D-Pro Camera | ||
|---|---|---|---|
| Parameter | Value | Parameter | Value |
| Laser Wavelength | 905 nm | Image Sensor | Sony IMX378 |
| Angular Precision | <0.05° | Active Pixels | 12 MP@60 fps |
| Range Precision | 2 cm1 | EFL | 4.81 |
| Data Latency | ≤2 ms | Focous Type | AF: 8 cm–∞/FF: 50 cm–∞ |
| HFOV/VFOV | 70.4°/77.2° | DFOV/HFOV/VFOV | 81°/69°/55° |
| Noise | <45 dBA | F.NO | 2.0 |
| Weight | 498 g | Shutter Type | Rolling shutter |
| IMU | Built-in: BMI088 | IR Sensitive | No |

References
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 107–124. [Google Scholar]
- Xu, R.; Li, J.; Dong, X.; Yu, H.; Ma, J. Bridging the domain gap for multi-agent perception. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 6035–6042. [Google Scholar]
- Xu, R.; Chen, W.; Xiang, H.; Xia, X.; Liu, L.; Ma, J. Model-agnostic multi-agent perception framework. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1471–1478. [Google Scholar]
- Xu, R.; Xia, X.; Li, J.; Li, H.; Zhang, S.; Tu, Z.; Meng, Z.; Xiang, H.; Dong, X.; Song, R.; et al. V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13712–13722. [Google Scholar]
- Zhang Ning, W.J.X. Dense 3D Reconstruction Based on Stereo Images from Smartphones. Remote Sens. Inf. 2020, 35, 7. [Google Scholar]
- Tai-Xiong, Z.; Shuai, H.; Yong-Fu, L.; Ming-Chi, F. Review of Key Techniques in Vision-Based 3D Reconstruction. Acta Autom. Sin. 2020, 46, 631–652. [Google Scholar] [CrossRef]
- Kamra, V.; Kudeshia, P.; ArabiNaree, S.; Chen, D.; Akiyama, Y.; Peethambaran, J. Lightweight Reconstruction of Urban Buildings: Data Structures, Algorithms, and Future Directions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 902–917. [Google Scholar] [CrossRef]
- Zhou, H.; Ji, Z.; You, X.; Liu, Y.; Chen, L.; Zhao, K.; Lin, S.; Huang, X. Geometric Primitive-Guided UAV Path Planning for High-Quality Image-Based Reconstruction. Remote Sens. 2023, 15, 2632. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, F.; He, F. Reconstruction of Forest and Grassland Cover for the Conterminous United States from 1000 AD to 2000 AD. Remote Sens. 2023, 15, 3363. [Google Scholar] [CrossRef]
- Mohan, D.; Aravinth, J.; Rajendran, S. Reconstruction of Compressed Hyperspectral Image Using SqueezeNet Coupled Dense Attentional Net. Remote Sens. 2023, 15, 2734. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, L.; Sun, J.; Wang, D. Reconstructing Groundwater Storage Changes in the North China Plain Using a Numerical Model and GRACE Data. Remote Sens. 2023, 15, 3264. [Google Scholar] [CrossRef]
- Tarasenkov, M.V.; Belov, V.V.; Engel, M.V.; Zimovaya, A.V.; Zonov, M.N.; Bogdanova, A.S. Algorithm for the Reconstruction of the Ground Surface Reflectance in the Visible and Near IR Ranges from MODIS Satellite Data with Allowance for the Influence of Ground Surface Inhomogeneity on the Adjacency Effect and of Multiple Radiation Reflection. Remote Sens. 2023, 15, 2655. [Google Scholar] [CrossRef]
- Qu, Y.; Deng, F. Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction. Remote Sens. 2023, 15, 4297. [Google Scholar] [CrossRef]
- Yang, X.; Cao, M.; Li, C.; Zhao, H.; Yang, D. Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction. Remote Sens. 2023, 15, 4163. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Tewari, A.; Thies, J.; Mildenhall, B.; Srinivasan, P.; Tretschk, E.; Yifan, W.; Lassner, C.; Sitzmann, V.; Martin-Brualla, R.; Lombardi, S.; et al. Advances in neural rendering. Proc. Comput. Graph. Forum 2022, 41, 703–735. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, L.; Jeon, G.; Yang, X. Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry. Remote Sens. 2023, 15, 3808. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, Y.; Teng, F.; Feng, S.; Yang, B.; Hong, W. Circular SAR Incoherent 3D Imaging with a NeRF-Inspired Method. Remote Sens. 2023, 15, 3322. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar] [CrossRef]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4578–4587. [Google Scholar] [CrossRef]
- Remondino, F.; Karami, A.; Yan, Z.; Mazzacca, G.; Rigon, S.; Qin, R. A Critical Analysis of NeRF-Based 3D Reconstruction. Remote Sens. 2023, 15, 3585. [Google Scholar] [CrossRef]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5501–5510. [Google Scholar] [CrossRef]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar] [CrossRef]
- Sun, C.; Sun, M.; Chen, H.T. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5459–5469. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. Acm Trans. Graph. (ToG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Deng, K.; Liu, A.; Zhu, J.Y.; Ramanan, D. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12882–12891. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar] [CrossRef]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. Nerf++: Analyzing and improving neural radiance fields. Adv. Neural Inf. Process. Syst. 2020. [Google Scholar] [CrossRef]
- Li, Q.; Huang, H.; Yu, W.; Jiang, S. Optimized views photogrammetry: Precision analysis and a large-scale case study in qingdao. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1144–1159. [Google Scholar]
- Maboudi, M.; Homaei, M.; Song, S.; Malihi, S.; Saadatseresht, M.; Gerke, M. A Review on Viewpoints and Path Planning for UAV-Based 3D Reconstruction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5026–5048. [Google Scholar] [CrossRef]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7210–7219. [Google Scholar] [CrossRef]
- Xing, W.; Jia, L.; Xiao, S.; Shao-Fan, L.; Yang, L. Cross-view image generation via mixture generative adversarial network. Acta Autom. Sin. 2021, 47, 2623–2636. [Google Scholar] [CrossRef]
- Xu, Y.; Stilla, U. Toward building and civil infrastructure reconstruction from point clouds: A review Data Key Tech. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2857–2885. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Z.; Shan, J. Optimal model fitting for building reconstruction from point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9636–9650. [Google Scholar] [CrossRef]
- Peng, Y.; Lin, S.; Wu, H.; Cao, G. Point Cloud Registration Based on Fast Point Feature Histogram Descriptors for 3D Reconstruction of Trees. Remote Sens. 2023, 15, 3775. [Google Scholar] [CrossRef]
- Rematas, K.; Liu, A.; Srinivasan, P.P.; Barron, J.T.; Tagliasacchi, A.; Funkhouser, T.; Ferrari, V. Urban radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12932–12942. [Google Scholar] [CrossRef]
- Romanoni, A.; Fiorenti, D.; Matteucci, M. Mesh-based 3d textured urban mapping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3460–3466. [Google Scholar] [CrossRef]
- Debevec, P.E.; Taylor, C.J.; Malik, J. Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 11–20. [Google Scholar]
- Choe, Y.; Shim, I.; Chung, M.J. Geometric-featured voxel maps for 3D mapping in urban environments. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 110–115. [Google Scholar] [CrossRef]
- Truong-Hong, L.; Laefer, D.F. Octree-based, automatic building facade generation from LiDAR data. Comput.-Aided Des. 2014, 53, 46–61. [Google Scholar] [CrossRef]
- Li, W.; Pan, C.; Zhang, R.; Ren, J.; Ma, Y.; Fang, J.; Yan, F.; Geng, Q.; Huang, X.; Gong, H.; et al. AADS: Augmented autonomous driving simulation using data-driven algorithms. Sci. Robot. 2019, 4, eaaw0863. [Google Scholar] [CrossRef]
- Yang, Z.; Chai, Y.; Anguelov, D.; Zhou, Y.; Sun, P.; Erhan, D.; Rafferty, S.; Kretzschmar, H. Surfelgan: Synthesizing realistic sensor data for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11118–11127. [Google Scholar] [CrossRef]
- Ullman, S. The interpretation of structure from motion. Proc. R. Soc. Lond. Ser. Biol. Sci. 1979, 203, 405–426. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef]
- Bessin, Z.; Jaud, M.; Letortu, P.; Vassilakis, E.; Evelpidou, N.; Costa, S.; Delacourt, C. Smartphone Structure-from-Motion Photogrammetry from a Boat for Coastal Cliff Face Monitoring Compared with Pléiades Tri-Stereoscopic Imagery and Unmanned Aerial System Imagery. Remote Sens. 2023, 15, 3824. [Google Scholar] [CrossRef]
- Kajiya, J.T.; Von Herzen, B.P. Ray tracing volume densities. ACM SIGGRAPH Comput. Graph. 1984, 18, 165–174. [Google Scholar] [CrossRef]
- Jang, W.; Agapito, L. Codenerf: Disentangled neural radiance fields for object categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12949–12958. [Google Scholar] [CrossRef]
- Rematas, K.; Brualla, R.M.; Ferrari, V. ShaRF: Shape-conditioned Radiance Fields from a Single View. arXiv 2021, arXiv:2102.08860v2. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, S.; Xie, W.; Chen, M.; Prisacariu, V.A. NeRF–: Neural radiance fields without known camera parameters. arXiv 2021, arXiv:2102.07064. [Google Scholar]
- Lin, C.H.; Ma, W.C.; Torralba, A.; Lucey, S. Barf: Bundle-adjusting neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5741–5751. [Google Scholar]
- Guo, M.; Fathi, A.; Wu, J.; Funkhouser, T. Object-centric neural scene rendering. arXiv 2020, arXiv:2012.08503. [Google Scholar]
- Yu, A.; Li, R.; Tancik, M.; Li, H.; Ng, R.; Kanazawa, A. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5752–5761. [Google Scholar]
- Takikawa, T.; Litalien, J.; Yin, K.; Kreis, K.; Loop, C.; Nowrouzezahrai, D.; Jacobson, A.; McGuire, M.; Fidler, S. Neural geometric level of detail: Real-time rendering with implicit 3d shapes. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11358–11367. [Google Scholar]
- Tancik, M.; Mildenhall, B.; Wang, T.; Schmidt, D.; Srinivasan, P.P.; Barron, J.T.; Ng, R. Learned initializations for optimizing coordinate-based neural representations. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2846–2855. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, P.P.; Deng, B.; Debevec, P.; Freeman, W.T.; Barron, J.T. Nerfactor: Neural factorization of shape and reflectance under an unknown illumination. ACM Trans. Graph. (TOG) 2021, 40, 1–18. [Google Scholar] [CrossRef]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6229–6238. [Google Scholar] [CrossRef]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.; Srinivasan, P.P.; Barron, J.T.; Kretzschmar, H. Block-nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8248–8258. [Google Scholar] [CrossRef]
- Xiangli, Y.; Xu, L.; Pan, X.; Zhao, N.; Rao, A.; Theobalt, C.; Dai, B.; Lin, D. Citynerf: Building nerf at city scale. arXiv 2021, arXiv:2112.05504. [Google Scholar]
- Li, J.; Feng, Z.; She, Q.; Ding, H.; Wang, C.; Lee, G.H. Mine: Towards continuous depth mpi with nerf for novel view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12578–12588. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, X.; Hong, X.; Zhang, F. Pixel-level extrinsic self calibration of high resolution lidar and camera in targetless environments. IEEE Robot. Autom. Lett. 2021, 6, 7517–7524. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar] [CrossRef]







| Methods | Image | Unbounded | Voxel | Depth | LiDAR |
|---|---|---|---|---|---|
| NeRF [15] | ✓ | ||||
| NeRFactor [56] | ✓ | ✓ | |||
| NeRF++ [28] | ✓ | ✓ | |||
| Plenoxels [22] | ✓ | ✓ | ✓ | ||
| DVGO [24] | ✓ | ✓ | ✓ | ||
| DsNeRF [26] | ✓ | ✓ | ✓ | ||
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ |
| Methods | Gym | Office Building | ||||||
|---|---|---|---|---|---|---|---|---|
| Tr. Time | PSNR↑ | SSIM↑ | LPIPS↓ | Tr. Time | PSNR↑ | SSIM↑ | LPIPS↓ | |
| NeRF [15] | 53 h | 19.77 | 0.661 | 0.455 | 53 h | 19.84 | 0.672 | 0.430 |
| NeRFactor [56] | 27 m | 23.78 | 0.769 | 0.224 | 29 m | 22.64 | 0.707 | 0.185 |
| DsNeRF [26] | 8 h | 26.48 | 0.799 | 0.291 | 8 h | 24.05 | 0.779 | 0.267 |
| Plenoxels [22] | 40 m | 24.86 | 0.758 | 0.333 | 37 m | 24.37 | 0.791 | 0.254 |
| DVGO [24] | 49 m | 26.28 | 0.804 | 0.292 | 52 m | 27.26 | 0.868 | 0.193 |
| NeRF++ [28] | 48 h | 28.20 | 0.870 | 0.221 | 48 h | 29.21 | 0.905 | 0.147 |
| Ours | 68 m | 30.96 | 0.909 | 0.175 | 72 m | 31.03 | 0.915 | 0.094 |
| Methods | CS Building | Library | ||||||
|---|---|---|---|---|---|---|---|---|
| Tr. Time | PSNR↑ | SSIM↑ | LPIPS↓ | Tr. Time | PSNR↑ | SSIM↑ | LPIPS↓ | |
| NeRF [15] | 53 h | 17.89 | 0.487 | 0.549 | 53 h | 19.23 | 0.524 | 0.491 |
| NeRFactor [56] | 28 m | 22.38 | 0.681 | 0.335 | 29 m | 21.39 | 0.597 | 0.372 |
| DsNeRF [26] | 8 h | 19.41 | 0.571 | 0.476 | 8 h | 22.70 | 0.648 | 0.411 |
| Plenoxels [22] | 32 m | 19.15 | 0.563 | 0.482 | 35 m | 21.74 | 0.636 | 0.405 |
| DVGO [24] | 54 m | 24.70 | 0.778 | 0.311 | 50 m | 22.56 | 0.656 | 0.412 |
| NeRF++ [28] | 48 h | 26.11 | 0.815 | 0.280 | 48 h | 25.39 | 0.786 | 0.289 |
| Ours | 70 m | 27.72 | 0.868 | 0.202 | 75 m | 26.74 | 0.841 | 0.215 |
| Voxel Size | Tr. Time | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| 0.05 | 2 h | 27.05 | 0.852 | 0.190 |
| 0.08 | 90 m | 26.97 | 0.850 | 0.211 |
| 0.125 | 75 m | 26.74 | 0.841 | 0.215 |
| 0.25 | 55 m | 25.11 | 0.797 | 0.256 |
| 0.40 | 32 m | 24.94 | 0.793 | 0.278 |
| PSNR↑ | SSIM↑ | LPIPS↓ | |||
|---|---|---|---|---|---|
| ☑ | □ | □ | 22.42 | 0.628 | 0.434 |
| ☑ | ☑ | □ | 25.91 | 0.793 | 0.224 |
| ☑ | ☑ | ☑ | 26.74 | 0.841 | 0.215 |
| Image Resolution | PSNR↑ | SSIM↑ | LPIPS↓ | NIQE↓ |
|---|---|---|---|---|
| 720 p | 26.74 | 0.841 | 0.215 | 4.256 |
| 1080 p | 26.91 | 0.839 | 0.202 | 3.849 |
| 2 k | 27.18 | 0.845 | 0.204 | 3.913 |
| 4 k | 27.44 | 0.851 | 0.197 | 3.157 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Song, Z.; Zhou, J.; Xie, D.; Lu, J. Camera and LiDAR Fusion for Urban Scene Reconstruction and Novel View Synthesis via Voxel-Based Neural Radiance Fields. Remote Sens. 2023, 15, 4628. https://doi.org/10.3390/rs15184628
Chen X, Song Z, Zhou J, Xie D, Lu J. Camera and LiDAR Fusion for Urban Scene Reconstruction and Novel View Synthesis via Voxel-Based Neural Radiance Fields. Remote Sensing. 2023; 15(18):4628. https://doi.org/10.3390/rs15184628
Chicago/Turabian StyleChen, Xuanzhu, Zhenbo Song, Jun Zhou, Dong Xie, and Jianfeng Lu. 2023. "Camera and LiDAR Fusion for Urban Scene Reconstruction and Novel View Synthesis via Voxel-Based Neural Radiance Fields" Remote Sensing 15, no. 18: 4628. https://doi.org/10.3390/rs15184628