A Survey of Comics Research in Computer Science


Dept. of Computer Science and Intelligent Systems, Osaka Prefecture University, 1-1 Gakuen-cho, Nakaku, Sakai, Osaka 599-8531, Japan
*
Author to whom correspondence should be addressed.
J. Imaging 2018, 4(7), 87; https://doi.org/10.3390/jimaging4070087
Submission received: 21 May 2018
/
Revised: 15 June 2018
/
Accepted: 20 June 2018
/
Published: 26 June 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Graphic novels such as comic books and mangas are well known all over the world. The digital transition started to change the way people are reading comics: more and more on smartphones and tablets, and less and less on paper. In recent years, a wide variety of research about comics has been proposed and might change the way comics are created, distributed and read in the future. Early work focuses on low level document image analysis. Comic books are complex; they contains text, drawings, balloons, panels, onomatopoeia, etc. Different fields of computer science covered research about user interaction and content generation such as multimedia, artificial intelligence, human–computer interaction, etc. with different sets of values. We review the previous research about comics in computer science to state what has been done and give some insights about the main outlooks.
1. Introduction
Research on comics has been done independently in several research fields such as document image analysis, multimedia, human–computer interaction, etc. with different sets of values. We review the research of all of these fields, and to organize them to understand what can be done with the state of the art methods. We hope that this survey will stimulate new collaborations between the different research fields. We also give some ideas about the future possibility of comics research.
We introduced a brief overview of comics research in computer science [1] during the second edition of the international workshop on coMics ANalysis, Processing and Understanding (MANPU). The first edition of MANPU workshop took place during ICPR 2016 (International Conference on Pattern Recognition) and the second one took place during ICDAR 2017 (International Conference on Document Analysis and Recognition). It shows that comics can interest a large variety of researchers from pattern recognition to document analysis. We think that the multimedia and interface communities could have some interest too, so we propose to present the research about comics analysis with a broader view.
In the next part of the introduction, we explain the importance of comics and its impact on the society, along with a brief overview of the open problems.
1.1. Comics and Society
Comics in the USA, manga in Japan, and bande dessinée in France and Belgium, are graphic novels with a worldwide audience. They represent an important part of the American, Japanese and Francophone cultures. They are often considered as a soft power of these countries, especially mangas for Japan [2,3]. In France, bande dessinée is considered as an art, and is commonly refereed as the “ninth art” [4] (as compared to cinema which is the seventh art). However, several years ago it was not the case. Comics was considered as “children literature” or “sub-literature” as it contains a mixture of images and text. However, more lately, comics got a great deal of interest when people recognized it as a complex form of graphic expression that can convey deep ideas and profound aesthetics [5].
From an economic point of view, the market of comics is large. According to a report published in February 2017 by “The All Japan Magazine and Book Publisher’s and Editor’s Association” (AJPEA), the sale of mangas in Japan represents 445.4 billion yen (approximately 4 billion dollars) in 2016 [6]. In this report, we can see that the market is stable between 2015 and 2014. However, the digital market increased significantly: it almost doubled from 2014 to 2016. The digital format has several advantages for the readers: it can be displayed on smartphones or tablets and be read anytime, anywhere. For the editors, the cost of publication and distribution is much lower as compared to a paper version.
However, even if the format changed from paper to screen, no added value has been proposed to the customer. We think that the democratization of the digital format is a good opportunity for the researchers from all computer science fields to propose new services such as augmented comics, recommendation systems, etc.
1.2. Research and Open Problems
The research about comics is quite challenging because of its nature. Comics contains a mixture of drawings and text. To fully analyze and understand the content of comics, we need to consider natural language processing to understand the story and the dialogues; and computer vision to understand the line drawings, characters, locations, actions, etc. A high-level analysis is also necessary to understand events, emotions, storytelling, the relations between the characters, etc. A lot of related research has been done for covering similar aspect for the case of natural images (i.e., photographic imagery) and videos by classic computer vision. However, the high variety of drawings and the scarceness of labeled data make the task harder than natural images.
We organize the research about comics in the three following categories:
- Content analysis: Getting information from raw images and extracting high- to low-level structured descriptions.
- Content generation and adaption: Comics can be used as an input or output to create or modify contents. Content conversion and augmentation are possible from comics to comics, comics to other media, and other media to comics.
- User interaction: Analyzing human reading behavior and internal states (emotions, interests, etc.) based on comics contents, and, reciprocally, analyzing comics contents based on human behavior and interactions.
Research about comics in computer science has been done covering several aspects but is still an emerging field. Much research has been done by researchers from the DIA (Document Image Analysis) and AI (Artificial Intelligence) communities and focuses on content analysis, understanding, and segmentation. Another part of the research is addressed by graphics and multimedia communities and consists in generating new contents or enriching existing contents such as adding colors to black and white pages, creating animations, etc. The last aspect concerns the interaction between users and comics which is mainly addressed by HCI (Human–Computer Interaction) researchers. These three parts are inter-dependent: segmenting an area of a comic page is important to manipulate and modify it, or to know which area the user is interacting with; and analyzing user behavior can be used to drive the content changes or to measure the impact of these changes on the user.
In Section 3, Section 4 and Section 5, we detail the current state-of-the-art and discuss the open problems. Large datasets with ground truth information such as layout, characters, speech balloon, text, etc. are not available so using deep learning is hardly possible in such conditions. Most researchers proposed handcrafted features or knowledge-driven approaches until very recently. The availability of tools and datasets that can be accessed and shared by the research communities is another very important aspect to transform the research about comics; we discuss the major existing tools and datasets in Section 6.
In this next parts of the paper, manga, bande dessinée or any graphics novels are referred as “comics” to simplify the reading. We start the next section with general information about comics.
2. What Is Comics?
The term comics (as an uncountable noun) refers to the comics medium. Comics is a way to transfer information in a similar way as television, radio, etc. We can also talk about a comic (as a countable noun); in this case, we refer to the instance of the medium, such as a comic book or a comic page.
As for any art, there are strictly no rules for creating comics. The authors are free to draw whatever and however they want. However, some classic layouts or patterns are usually used by the author as they want to tell a story, transmit feelings and emotions, and drive the attention of the readers [7]. The author needs experience and knowledge to drive smoothly the attention of the readers through the comics [8]. Furthermore, the layout of comics is evolving over time [9], moving away from conventional grids to more decorative and dynamic ways.
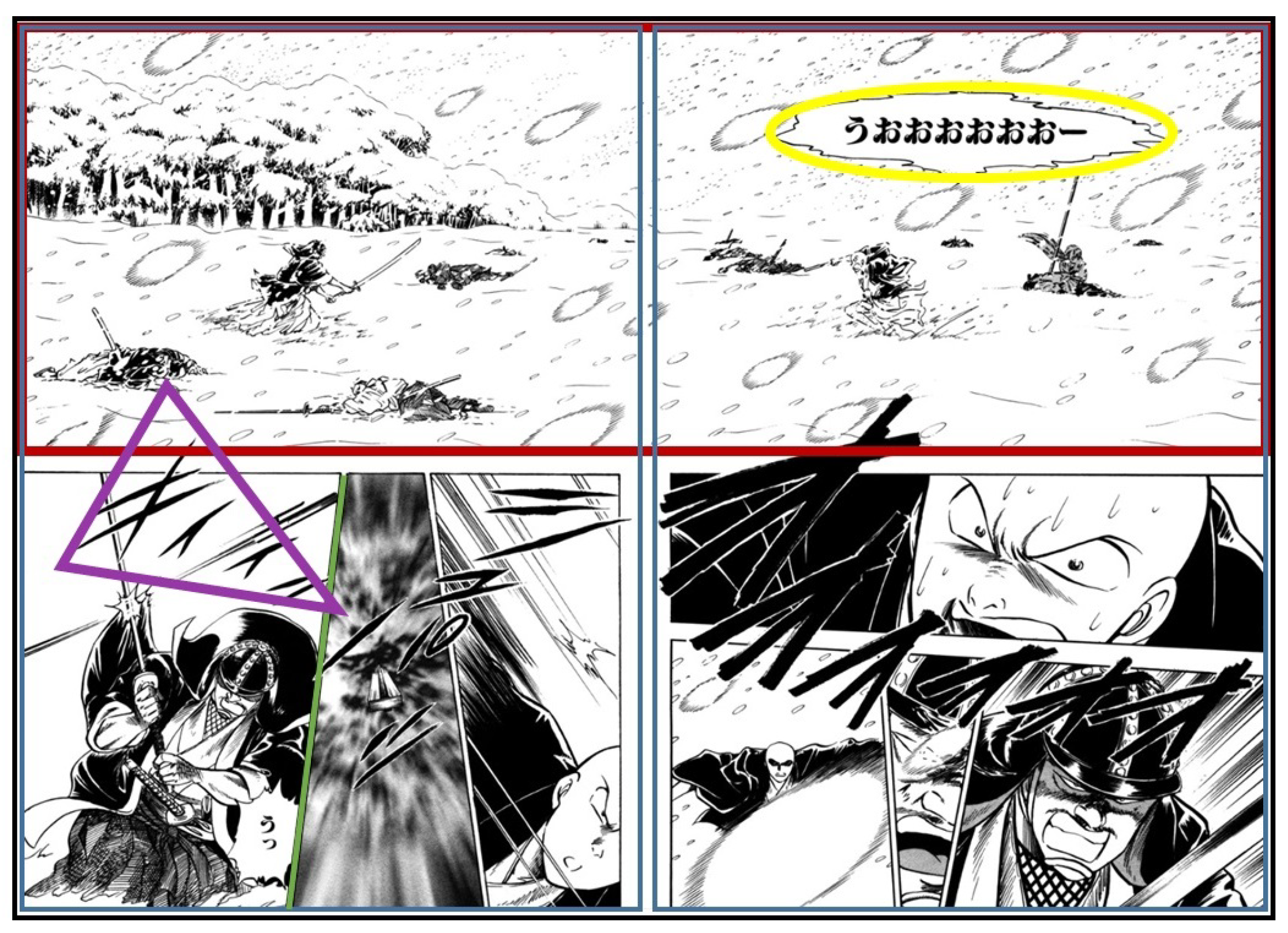
Comics are usually printed on books, and can be seen as single or double pages. When the book is opened, the reader can see both pages. Thus, some authors use this physical layout as part of the story: some drawings can be spread in two pages, and when the reader turn one page something might happen in the next page. Figure 1 illustrates a classic comics content.
A page is usually composed of a set of panels defining a specific action or situation. The panels can be enclosed in a frame, and separated by a white space area named gutter. The reading order of the panels depends on the language. For example, in Japanese, the reading order is usually from right to left and top to bottom. Speech balloons and captions are included in the panel to describe conversations or the narration of the story. The dialog balloons have a specified reading order which is usually the same as the reading order of the panels. Some sound effects or onomatopoeias are included to give more sensations to the reader such as smell or sound. Japanese comics often contains “manpu” (see Figure 2) which are graphic symbols used to visualize the feelings and sensations of the characters such as sweating marks on the head to show that he feels uncomfortable, even if he is not actually sweating.
The authors are free to draw the characters as they want, so they can be deformed or disproportioned as illustrated in Figure 3. In some genres such as fantasy, the characters can also be non-human which makes the segmentation and recognition task challenging. There are also many drawing effects such as speed lines, focusing lines, etc. For example, in Figure 1, a texture surrounding the female character in the lower-right panel represents her warm atmosphere as contrasted with the cold weather.
Even if more and more digitized versions of the printed versions are available, few comics are produced digitally and taking advantage of the new technology. Figure 4 illustrates an example of digital comics taking advantage of tablet functions: the images are animated continuously and the user can tilt the tablet to control the camera angle. This comics is created by Andre Bergs [12] and is freely available on App store and Google Play. We imagine that, in the future, it could be possible to create such interactive comics automatically thanks to the help of computer science algorithms.
We organized the studies about comics in computer science into three main categories that we present in the next three sections. One of the main research fields focuses on analyzing the content of comics images, extracting the text, the characters, segmenting the panels, etc. Another category is about generating or adapting content from or for comics. The last category is about analyzing the reader’s behavior and interaction with comics.
3. Research on Content Analysis
To understand the content of comics and to provide services such as retrieval or recommender systems, it is necessary to extract the content of comics. The DIA community started to cover this problem with classic approaches. Images can be analyzed from the low levels such as screentones [13] or text [14] to the high level such as style [15] or genre [16] recognition.
Some elements are interdependent such as speech balloons and text, as the former contains the latter. The positions can be relative to each other, as the speech balloon is usually coming from the mouth of a character. These elements are usually grouped inside a panel, but not necessarily. As the authors are free to draw whatever and however they want, there is a wide disparity among all comics which make the analysis a complex task. For example, some authors exaggerate the facial deformation of the face of a character to make him angrier or more surprised.
We present the related work from the low level to high-level analysis as follow.
3.1. Textures, Screentones, and Structural Lines
Black and white textures are often used to enrich the visual experience of non-colored comics. It is especially used for creating an illusion of shades or colors. However, the identification and segmentation of the textures is challenging as they can have various forms and are sometimes mixed with the other parts of the drawing. Ito et al. proposed a method for separating the screentones and line drawings [13]. More recently, Liu et al. [17] proposed a method for segmenting the textures in comics.
Extracting the structural lines of comics is another challenging problem which is related to the analysis of the texture. The difference between structural lines and arbitrary ones must be considered carefully. Li et al. [18] recently proposed a deep network model to handle this problem. Finding textures and structural lines is an important analysis step to generate colorized and vectorized comics.
3.2. Text
The extraction of text (such as Latin or Chinese) characters has been investigated by several researchers but is still a difficult problem as many authors write the text by hand.
Arai and Tolle [14] proposed a method to extract frames, balloon, and text based on connected components and fixed thresholds about their sizes. This is a simple approach which works well for “flat” comics, i.e., conventional comics where each panel is defined by a black rectangle and has no overlapping parts.
Rigaud et al. also proposed a method to recognize the panels and text based on the connected components [19]. By adding some other features such as the topological and spatial relations, they successfully increased the performance of [14].
Recently, Aramaki et al. combined connected component and region-based classifications to make a better text detection system [20]. A more recent method also addresses the problem of speech text recognition [21].
To simplify the problem, Hiroe and Hotta have proposed to detect and count the number of exclamation marks to represent a comic book by its distribution of exclamation marks or to find the scene changes [22].
3.3. Faces and Pose
One of the most important elements of comics is the protagonists of the story. However, identifying the characters is challenging because of the posture, occlusions, and other drawing effects. In addition, the characters can be humans, animals, robots or anything with various drawing representations. Sun et al. [23] proposed to locate and identify the characters in comic pages by using local feature matching. New methods have recently been proposed to recognize the face and characters in comics based on deep neural networks [24,25,26].
Estimating the pose of the character is another challenge. As we can see in Figure 5, if the characters have human proportion and are not too deformed, they can be well recognized by a popular approach such as Open Pose [27]. Knowing the character poses could lead to activity recognition, but a method such as Open Pose will fail on almost all comics, so new research on pose estimation for comics character must be done.
3.4. Balloons
The balloons are important components of comics, where most of the information is conveyed by the discussion between the protagonists. Thus, one important step is to detect the balloons [28] and then to associate the balloons to the speaker [29].
The shape of the balloon also conveys information about the speaker’s feelings [30]. For example, a balloon with wavy shape represents anxiety, an explosion shape represents anger, a cloudy shape represents joy, etc.
3.5. Panel
The layout of a comic page is described by Tanaka et al. as a sequence of frames named panels [31]. Several methods have been proposed to segment the panels, mainly based on the analysis of connected components [19,32] or on the page background mask [33].
As these methods based on heuristics rely on white backgrounds and clean gutters, Iyyer et al. recently proposed an approach based on deep learning [34] to process eighty-year-old American comics.
3.6. High Level Understanding
Rigaud et al. proposed a knowledge-driven system that understands the content of comics by segmenting all the sub-parts [35]. However, understanding the narrative structure of comics is much more than simply segmenting its different sub-parts. Indeed, the reader makes inferences about what is happening from one frame to another by looking at all graphical and textual elements [36].
Iyyer et al. introduced some methods to explore how readers connect panels into a coherent story [34]. They show that both text and images are important to guess what is happening in a panel by knowing the previous ones.
Daiku et al. [16] proposed to analyze the comics storytelling by analyzing the genre of each page of the comics. Then, the story of a comic book is represented as a sequence of genres such as: “11 pages of action”, “5 pages of romance”, “8 pages of comedy”, etc.
Analyzing the text of the dialogues and stories has not been investigated yet specifically for comics. Similar research as sentiment analysis [37] could be applied to analyze the psychology of the characters or to analyze and compare the narrative structure of different comics.
From the cognitive point of view, Cohn proposed a theory of “Narrative Grammar” based on linguistics and visual language which are leading the understanding process [38]. The reader is building a representation of the depicted pictures in his mind. This is how we can recognize that two characters drawn in a different way are actually the same; or that a character is doing an action by looking at a still image. These concepts must be inferred by the computer too, in order to obtain a high-level representation of comics.
3.7. Applications
From these analyses, retrieval systems can be built, and some have already been proposed in the literature such as sketch [39,40] or graphs based [41] retrieval. The drawing style has also been studied [15]. The possible applications are artist retrieval, art movement retrieval, and artwork period analysis.
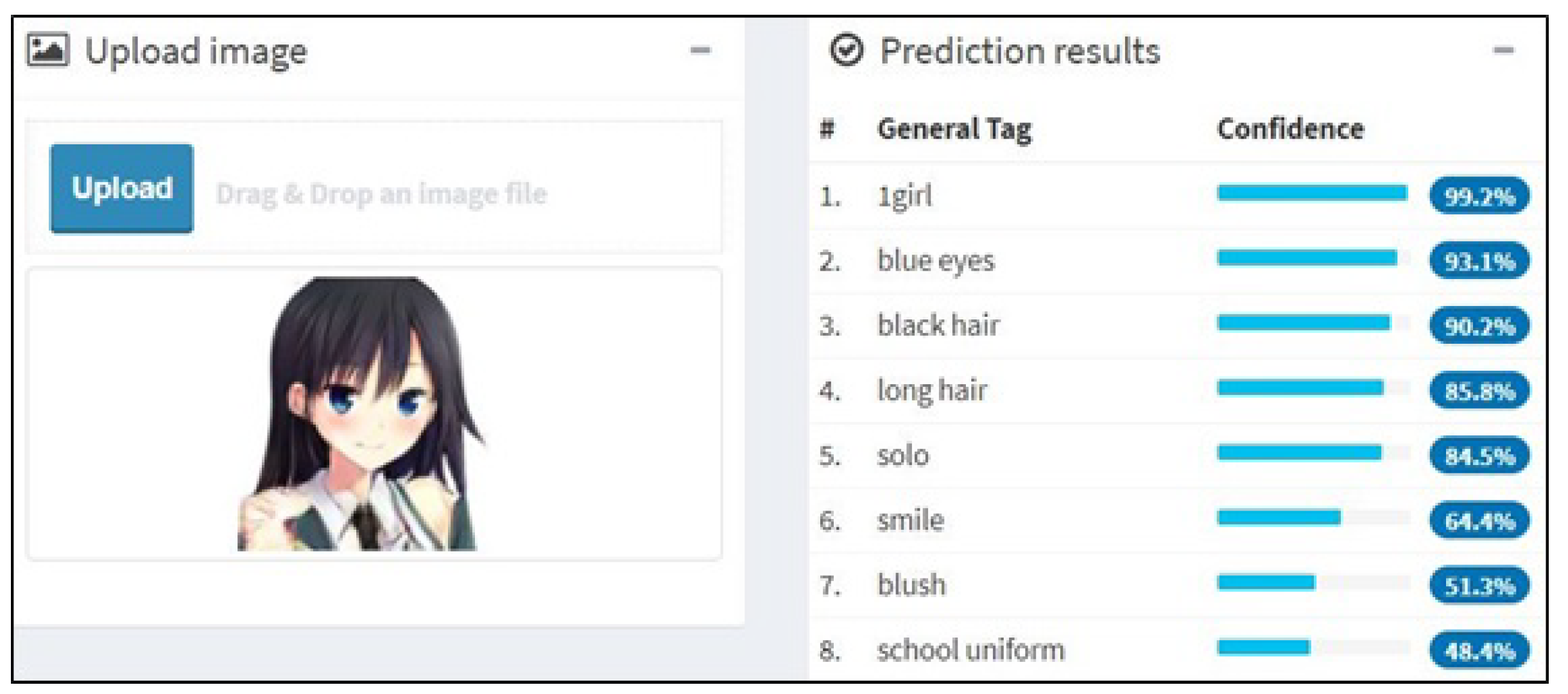
Saito and Matsui proposed a model for building a feature vector for illustrations named illustration2vec [42]. As shown in Figure 6, this model can be used to predict the attributes of a character such as its hair or eye color, hair length, clothes worn, etc. and to research some specific illustrations. Vie et al. proposed a recommender system using the illustration comics covers based on illustration2vec in a cold-start scenario [43].
3.8. Conclusions
Segmenting the panels or reading the text of any comics is still challenging because of the complexity of some layouts and the diversity of the content. Figure 1 illustrates the difficulty of segmenting the panels. Most of the current methods focus on using handcrafted features for the segmentation and analysis, and will fail on an unusual layout or content.
The segmentation of faces and body of the characters is still an open problem and a large amount of labeled data will be necessary to adapt the deep learning approaches.
Even if the text contains very rich information, surprisingly few methods have been proposed to analyze the storyline or the content of comics based on the text. In addition, some parts of comics have not been addressed at all, such as the detection of onomatopoeias.
Future research about high-level information should be considered, as it can be used to represent information that could interest the reader such as the style or genre, the storytelling, etc.
4. Content Generation
The aim of content generation or enrichment is to use comics to generate new content either based on comics or other media.
4.1. Vectorization
As most comics are not created digitally, vectorization is a way to transform scanned comics to a vector representation for real-time rendering with arbitrary resolution [44]. Generating vectorized comics is necessary for visualizing them nicely in digitized environments. This is also an important step for editing the content of comics and one of the basic step of comics enrichment [45].
4.2. Colorization
Several methods have been proposed for automatic colorization [46,47,48,49,50] and color reconstruction [51], as comics with colors can be more attractive for some readers. Colorization is quite a complex problem as the different parts of a character such as his arms, hands, fingers, face, hair, clothes, etc. must be retrieved to color each part in a correct way. Furthermore, the poses of a character can be very different from each other: some parts can appear, disappear or be deformed. An example of colorization is displayed in Figure 7.
Recently, deep learning based colorization approach has been used for creating color version manga books which are distributed by professional companies in Japan [53].
4.3. Comics and Character Generation
One problem for generating comics is to create the layout and to place the different components such as the characters, text balloons, etc. at a correct position to provide a smooth reading experience. Cao et al. proposed a method for creating stylistic layout automatically [54], and another one for placing and organizing the elements in a panel according to high-level user specifications [8].
The relation between real-life environment and the one represented in comics can be used to generate or augment comics. Wu and Aizawa proposed a method to generate a comic image directly from a photograph [55].
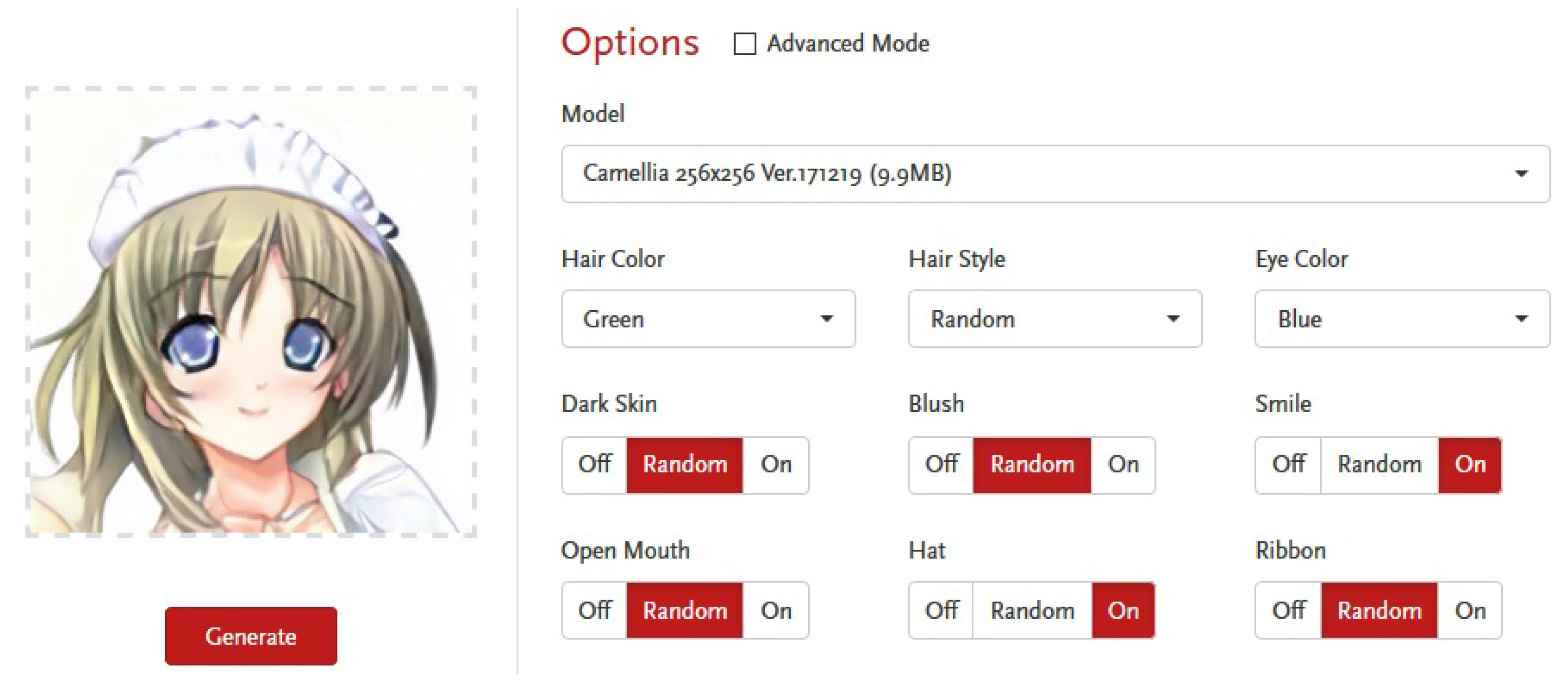
At the end of 2017, Jin et al. [56] presented a method to generate automatically comics characters. An example of a generated character by their online demo [57] is displayed Figure 8. The result of the generation is not always visually perfect, but this is still a powerful tool as an unlimited number of characters can be generated.
4.4. Animation
As comics are still images, a way to enhance the visualization of comics is to generate animations. Recently, some researchers proposed a way for animating still comics images through camera movements [58,59]. Several animation movies and series have been adapted in comics paper book and vice versa. Some possible outlook could be to generate an animated movie from a paper comics or a paper comics from an animated movie.
For the natural images, some methods have been proposed to animate the face of people by using latent space interpolations. As illustrated in Figure 9, the latent vectors can be computed for a neutral and smiling face to generate a smiling animation [60].
Another application is to extract the facial keypoints and to use another source (text, speech, or face) to animate the mouth of the character. This has been used for generating photorealistic video of Obama speech based on a text input [62].
4.5. Media Conversion
More generally, we can imagine converting text, videos, or any content into comics, and vice versa. This problem can be seen as media conversion. For example, Jing et al. proposed a system to convert videos to comics [63]. There are many challenges to successful conversion: summarizing the videos, stylizing the images, generating the layout of comics and positions of text balloons, etc.
An application which has not been done to comics but to natural videos is to add generated sound to a video [64]. No application has been done for comics, but this method could be applied to generate sound effects (swords which are banging to each other, a roaring tailpipe, etc.) or atmosphere sounds (village, countryside, crowd, etc.).
Creating a descriptive text based on comics or generating comics based on descriptive text could be possible in the future, as it has been done for the natural images. Reed et al. [65] proposed a method for automatic synthesis of realistic natural images from text.
4.6. Content Adaptation
The content of comics can also be changed to fit the device in a better way. For example, Arai and Tolle proposed a system to analyze the layout of a manga and then to segment it in order to adapt it to mobile devices such as PDA or smartphones [32].
In the same paper, Arai and Tolle also proposed a method to detect the text in the image and to translate it in another language to adapt the content to the language of the user.
4.7. Conclusions
To generate contents, some models or labeled data are necessary. For example, to generate automatically characters, Jin et al. used around 42,000 images. Deep learning approaches such as Generative Adversarial Networks (GAN) [66] has been widely used for natural image applications such as style transfer [67], reconstructing 3D models of objects from images [68], generating images from text [65], editing pictures [69], etc. These applications could be done for comics too but will need some adaptation.
Another possibility to enhance comics is to add other modes such as sound, vibrations, etc. Adding sounds should be easily possible by using the soundtracks from animation movies. However, to be able to produce these effects at a correct timing, information about the user interactions is necessary. This is possible by using an eye tracker or detecting when the user turns a specific page in real time.
5. User Interaction
Apart from the content analysis and generation, we have identified another category of research based on the interaction between users and comics. One part consists of analyzing the user himself instead of analyzing comics. For example, we would like to understand or predict what the user feels or how he behaves while reading comics. Another part consists in creating new interfaces or interactions between the readers and comics. In addition, new technology can be used to improve the access for impaired people.
5.1. Eye Gaze and Reading Behavior
To know where and when a user is looking at some specific parts of a comic, researchers are using eye tracking systems. By using eye trackers, it is possible to detect how long a user spends reading a specific part of a comic page.
Knowing the user reading behavior and interest is important information that can be used by the author or editors as a feedback. It also can be used to provide other services to readers such as giving more details about the story of a character that a specific user likes, removing part of battle if he does not likes violence, etc.
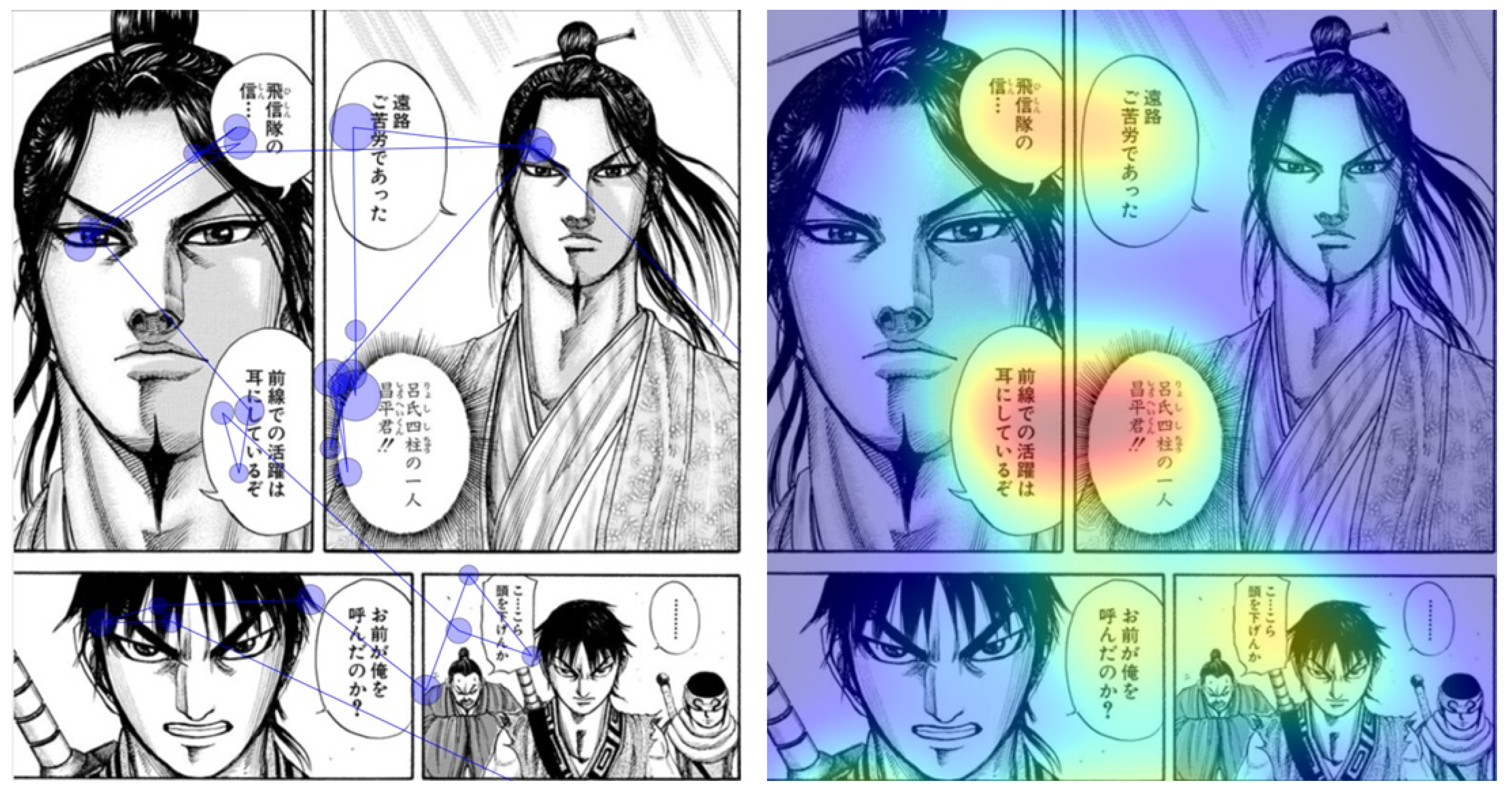
Carroll et al. [70] showed that the readers tend to look at the artworks before reading the text. Rigaud et al. found that, in France, the readers spend most of the time reading the text and looking at the face of the characters [71]. The same experiment repeated in Japan led to the same conclusion, as illustrated in Figure 10.
Another way to analyze how the readers understand the content of comics is to ask them to manually order the panels. Cohn presented different kinds of layouts with empty panels and showed that various manipulations to the arrangement of panels push readers to navigate through the panels in alternate routes [72]. Some cognitive tricks can ensure that most of the readers will follow the same reading path.
To augment comics with new multimedia contents such as sounds, vibration, etc., it is important to trigger these effects at a good timing. In this case, detecting when the user turns a page or estimating which position he is looking at will be important.
5.2. Emotion
Comics contains exciting contents. Many different genres of comics exist such as comedy, romance, horror, etc. and can trigger different kinds of emotions. Much research has been done on emotion detection based on facial image and physiological signals such as electroencephalogram (EEG) while watching videos [73,74,75]. However, such research has not been conducted while reading comics.
By recording and analyzing the physiological signals of the readers, as illustrated in Figure 11, Lima Sanches et al. showed that it is possible to estimate if the user is reading a comedy, a romance or a horror comics, based on the emotions felt by the readers [76]. For example, when reading a horror comic book, the user feels stressful and his skin temperature is decreasing while the electrodermal activity (sweating) increase.
Emotions are usually represented as two axes: arousal and valence, where the arousal represents the strength of the emotion and the valence relates to a positive or negative emotion. Matsubara et al. showed that by analyzing the physiological signals of the reader, it is possible to estimate the reader’s arousal [77].
Both experiments are using the E4 wristband (https://www.empatica.com/en-eu/research/e4/) which contains a photoplethysmogram sensor (to analyze the blood volume pulse), an electrodermal activity sensor (to analyze the amount of sweat), an infrared thermopile sensor (to read the peripheral skin temperature), and a three-axis accelerometer (to capture motion-based activity). Such device is commonly used for stress detection [78,79].
Because each reader has his or her own preferences and feels emotions in a different way while reading, these analyses are quite challenging. Depending on the user state of mind or mood, he or she might prefer to read content that is eliciting specific kind of emotions. Emotion detection could be used by authors or editors to analyze which content better stimulates the readers.
5.3. Visualization and Interaction
Comics can be read on books, tablets, smartphones or any other devices. Visualization and interaction on smartphones can be difficult, especially if the screen is small [80]. The user needs to zoom and do many operations which can be inconvenient. Some researchers are also trying to use more interactive devices such as multi-touch tables to attract users [81].
Another important challenge is to make comics accessible to impaired people. Rayar [82] explained that a multidisciplinary collaborations between Human–Computer Interactions, Cognitive Science, and Education Research are necessary to fulfill such a goal. Up to now, the three main ways to access images for visually impaired people are: audio description, printed Braille description and printed tactile pictures (in relief). Such way could be generated automatically thanks to new research and technology.
5.4. Education
It has been proven that the representation of knowledge as comics can be a good way to attract students to read [85] or to learn language [86]. It could be interesting to measure the impact on the representation of the knowledge. A challenge related to media conversion is then to transform normal textbooks into comics and to compare the interactions of the students with both books.
5.5. Conclusions
The interactions between the user and comics have not been analyzed deeply. Many sensors can be used to analyze the users: brain activity, muscle activity, body movement and posture, heart rate, sweating, breath, pupil dilation, eye movement, etc. Collecting such data can give more information about the readers and comics.
6. Available Materials
In this section, we present some tools and datasets which are publicly available for the research on comics.
6.1. Tools
Several tools for comics image segmentation and analysis are available on the Internet and can be freely used by anybody:
The speech balloon [87] and text segmentation [88] algorithms are available on the author’s Github [92].
As we can see, even if many papers have been published about comics segmentation and understanding, still few tools are available on the Internet. To improve the algorithms significantly and make it possible to compare them, making the code available is an important step for the community.
6.2. Datasets
Few dataset has been made publicly available because of copyright issues. Indeed, it is not possible for researchers to use and share copyrighted materials. Thus, organizing competitions and making reproducible research is not easy. Hopefully, several datasets have been made available recently.
The Graphic Narrative Corpus (GNC) [93] provide metadata information for 207 titles such as the authors, number of pages, illustrators, genres, etc. Unfortunately, the corresponding images are not available because of copyright protections. Thus, the usefulness of this dataset is limited. The authors are willing to share segmentation ground truth and eye gaze data. However, such data have not been released yet.
eBDtheque [94] (http://ebdtheque.univ-lr.fr/registration/) contains 100 comic pages, mainly in the French language. The following elements have been labeled on the dataset: 850 panels, 1092 balloons, 1550 characters and 4691 text lines. Even if the number of images is limited, creating such detailed labeled data is time-consuming and very useful for the community.
Manga109 [10] (http://www.manga109.org/index_en.php) dataset contains 109 manga volumes from 93 different authors. On average, a volume contains 194 pages. These mangas were published between the 1970s and 2010s and are categorized into 12 different genres such as fantasy, humor, sports, etc. Only limited labeled data are available for now such as the text for few volumes. The strong point of this dataset is to provide all pages of one volume which allows analyzing the sequences of pages.
COMICS [34] (https://obj.umiacs.umd.edu/comics/index.html) contains 1,229,664 panels paired with automatic textbox transcriptions from 3948 American comics books published between 1938 and 1954. The dataset includes ground truth labeled data such as the rectangular bounding boxes of panels on 500 pages and 1500 textboxes.
BAM! [11] (https://bam-dataset.org) contains around 2.5 million artistic images such as: 3D computer graphics, comics, oil painting, pen ink, pencil sketches, vector art, and watercolor. The images contain emotion labels (peaceful, happy, gloomy, and scary) and object labels (bicycles, birds, buildings, cars, cats, dogs, flowers, people, and trees). Figure 13 shows a sample of the dataset containing comics. The dataset is interesting due to the labels and large variety of content and languages. However, the images are just examples provided by the authors and cannot always be understood without the previous or following pages.
BAM!, COMICS, Manga109, and eBDtheques are the four main comics datasets that have been made available with the corresponding images. Building such datasets is a time and money consuming task, especially for building the ground truth and labeled data.
The main problem for creating such dataset comes from the legal and copyright protection which prevent the researchers from making publicly available image datasets. The content of the dataset is also important, depending on the research to proceed. For example, it is interesting to have a variety of comics from different countries, with different languages and genres. It is also interesting to have several continuous pages from the same volumes and several volumes from the same series in order to analyze the evolution of the style of an author, the mentality of the character, or the storyline.
7. General Conclusions
The research about comics in computer science has been done about several aspects. We organize the research into three inter-dependent categories: content analysis, content generation, and user interaction. A mutual analysis of the reader and comics is necessary to understand more about how can we augment comics.
A large part of previous work focuses on the low-level image analysis by using handcrafted features and knowledge-driven approaches. Recent research focuses more on deep learning and high-level image understanding. Many applications have been done for natural image, but the research about artworks and comics has received attention only very recently [11].
Many unexplored fields remain, especially for the content generation and augmentation. Only few companies started to use research for automatic colorization ,for example, but it could be possible to help the authors with automatic (or semi-automatic) generation of content or animations.
The analysis of the behavior and emotions of the readers have been superficially covered. However, using the opportunity given by new technologies and sensors could be helpful to build up the next age of comics. It could be also a way to make comics more accessible to disabled people.
For now, few tools and dataset have been made available. Making publicly available copyrighted images is a problem but it would greatly contribute to the improvement of comics research.
Author Contributions
Conceptualization, O.A., M.I and K.K.; Methodology, O.A.; Investigation, O.A.; Writing—Original Draft Preparation, O.A.; Writing—Review & Editing, O.A.; Supervision, K.K.
Funding
This research received no external funding.
Acknowledgments
We would like to thanks the authors of the Manga109 and BAM! datasets for making available comics and mangas images for researcher use.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Augereau, O.; Iwata, M.; Kise, K. An Overview of Comics Research in Computer Science. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 54–59. [Google Scholar]
- Lam, P.E. Japan’s quest for “soft power”: Attraction and limitation. East Asia 2007, 24, 349–363. [Google Scholar] [CrossRef]
- Hall, I.; Smith, F. The struggle for soft power in Asia: Public diplomacy and regional competition. Asian Secur. 2013, 9, 1–18. [Google Scholar] [CrossRef]
- Screech, M. Masters of the Ninth Art: Bandes Dessinées and Franco-Belgian Identity; Liverpool University Press: Liverpool, UK, 2005; Volume 3. [Google Scholar]
- Christiansen, H.C. Comics & Culture: Analytical and Theoretical Approaches to Comics; Museum Tusculanum Press: København, Denmark, 2000. [Google Scholar]
- AJPEA. Manga Market in Japan. 2017. Available online: http://www.ajpea.or.jp/information/20170224/ index.html (accessed on 25 June 2018).
- Jain, E.; Sheikh, Y.; Hodgins, J. Inferring artistic intention in comic art through viewer gaze. In Proceedings of the ACM Symposium on Applied Perception, Los Angeles, CA, USA, 3–4 August 2012; pp. 55–62. [Google Scholar]
- Cao, Y.; Lau, R.W.; Chan, A.B. Look over here: Attention-directing composition of manga elements. ACM Trans. Graph. 2014, 33, 94. [Google Scholar] [CrossRef]
- Pederson, K.; Cohn, N. The changing pages of comics: Page layouts across eight decades of American superhero comics. Stud. Comics 2016, 7, 7–28. [Google Scholar] [CrossRef]
- Fujimoto, A.; Ogawa, T.; Yamamoto, K.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Manga109 dataset and creation of metadata. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; p. 2. [Google Scholar]
- Wilber, M.J.; Fang, C.; Jin, H.; Hertzmann, A.; Collomosse, J.; Belongie, S. BAM! the behance artistic media dataset for recognition beyond photography. arXiv 2017, arXiv:1704.08614. [Google Scholar]
- Bergs, A. Protanopia, a Revolutionary Digital Comic for Iphone and Ipad. Available online: http:// andrebergs.com/protanopia (accessed on 25 June 2018).
- Ito, K.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Separation of Manga Line Drawings and Screentones. In Proceedings of the Eurographics, Zürich, Switzerland, 4–8 May 2015; pp. 73–76. [Google Scholar]
- Arai, K.; Tolle, H. Method for real time text extraction of digital manga comic. Int. J. Image Process. 2011, 4, 669–676. [Google Scholar]
- Chu, W.T.; Cheng, W.C. Manga-specific features and latent style model for manga style analysis. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1332–1336. [Google Scholar]
- Daiku, Y.; Augereau, O.; Iwata, M.; Kise, K. Comic Story Analysis Based on Genre Classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 60–65. [Google Scholar]
- Liu, X.; Li, C.; Wong, T.T. Boundary-aware texture region segmentation from manga. Comput. Vis. Media 2017, 3, 61–71. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Liu, X.; Wong, T.T. Deep extraction of manga structural lines. ACM Trans. Graph. 2017, 36, 117. [Google Scholar] [CrossRef]
- Rigaud, C.; Tsopze, N.; Burie, J.C.; Ogier, J.M. Robust frame and text extraction from comic books. In Graphics Recognition. New Trends and Challenges; Springer: Heidelberg/Berlin, Germany, 2013; pp. 129–138. [Google Scholar]
- Aramaki, Y.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Text detection in manga by combining connected-component-based and region-based classifications. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2901–2905. [Google Scholar]
- Rigaud, C.; Burie, J.C.; Ogier, J.M. Segmentation-Free Speech Text Recognition for Comic Books. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 29–34. [Google Scholar]
- Hiroe, S.; Hotta, S. Histogram of Exclamation Marks and Its Application for Comics Analysis. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 66–71. [Google Scholar]
- Sun, W.; Burie, J.C.; Ogier, J.M.; Kise, K. Specific comic character detection using local feature matching. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 275–279. [Google Scholar]
- Chu, W.T.; Li, W.W. Manga FaceNet: Face Detection in Manga based on Deep Neural Network. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 412–415. [Google Scholar]
- Qin, X.; Zhou, Y.; He, Z.; Wang, Y.; Tang, Z. A Faster R-CNN Based Method for Comic Characters Face Detection. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Bucharest, Romania, 6–9 June 2017; pp. 1074–1080. [Google Scholar]
- Nguyen, N.V.; Rigaud, C.; Burie, J.C. Comic Characters Detection Using Deep Learning. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 41–46. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Correia, J.M.; Gomes, A.J. Balloon extraction from complex comic books using edge detection and histogram scoring. Multimed. Tools Appl. 2016, 75, 11367–11390. [Google Scholar] [CrossRef]
- Rigaud, C.; Le Thanh, N.; Burie, J.C.; Ogier, J.M.; Iwata, M.; Imazu, E.; Kise, K. Speech balloon and speaker association for comics and manga understanding. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 351–355. [Google Scholar]
- Yamanishi, R.; Tanaka, H.; Nishihara, Y.; Fukumoto, J. Speech-balloon Shapes Estimation for Emotional Text Communication. Inf. Eng. Express 2017, 3, 1–10. [Google Scholar]
- Tanaka, T.; Shoji, K.; Toyama, F.; Miyamichi, J. Layout Analysis of Tree-Structured Scene Frames in Comic Images. In Proceedings of the 20th International Joint Conference on Artifical intelligence, Hyderabad, India, 6–12 January 2007; pp. 2885–2890. [Google Scholar]
- Arai, K.; Tolle, H. Automatic e-comic content adaptation. Int. J. Ubiquit. Comput. 2010, 1, 1–11. [Google Scholar]
- Pang, X.; Cao, Y.; Lau, R.W.; Chan, A.B. A robust panel extraction method for manga. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, Florida, USA, 3–7 November 2014; pp. 1125–1128. [Google Scholar]
- Iyyer, M.; Manjunatha, V.; Guha, A.; Vyas, Y.; Boyd-Graber, J.; Daumé III, H.; Davis, L. The Amazing Mysteries of the Gutter: Drawing Inferences Between Panels in Comic Book Narratives. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rigaud, C.; Guérin, C.; Karatzas, D.; Burie, J.C.; Ogier, J.M. Knowledge-driven understanding of images in comic books. Int. J. Doc. Anal. Recognit. 2015, 18, 199–221. [Google Scholar] [CrossRef]
- McCloud, S. Understanding Comics: The Invisible Art; HarperCollins Publishers: New York, NY, USA, 1993. [Google Scholar]
- Mohammad, S.M. Sentiment analysis: Detecting valence, emotions, and other affectual states from text. In Emotion Measurement; Elsevier: New York, NY, USA, 2016; pp. 201–237. [Google Scholar]
- Cohn, N. Visual narrative structure. Cognit. Sci. 2013, 37, 413–452. [Google Scholar] [CrossRef] [PubMed]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Narita, R.; Tsubota, K.; Yamasaki, T.; Aizawa, K. Sketch-Based Manga Retrieval Using Deep Features. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 49–53. [Google Scholar]
- Le, T.N.; Luqman, M.M.; Burie, J.C.; Ogier, J.M. Retrieval of comic book images using context relevance information. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; p. 12. [Google Scholar]
- Saito, M.; Matsui, Y. Illustration2vec: a semantic vector representation of illustrations. In Proceedings of the SIGGRAPH Asia 2015 Technical Briefs, Kobe, Japan, 2–6 November 2015; p. 5. [Google Scholar]
- Vie, J.J.; Yger, F.; Lahfa, R.; Clement, B.; Cocchi, K.; Chalumeau, T.; Kashima, H. Using Posters to Recommend Anime and Mangas in a Cold-Start Scenario. arXiv 2017, arXiv:1709.01584. [Google Scholar] [Green Version]
- Yao, C.Y.; Hung, S.H.; Li, G.W.; Chen, I.Y.; Adhitya, R.; Lai, Y.C. Manga Vectorization and Manipulation with Procedural Simple Screentone. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1070–1084. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.H.; Chen, T.; Zhang, Y.F.; Hu, S.M.; Martin, R.R. Vectorizing cartoon animations. IEEE Trans. Vis. Comput. Graph. 2009, 15, 618–629. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Wong, T.T.; Heng, P.A. Manga colorization. ACM Trans. Graph. 2006, 25, 1214–1220. [Google Scholar] [CrossRef]
- Sato, K.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Reference-based manga colorization by graph correspondence using quadratic programming. In Proceedings of the SIGGRAPH Asia 2014 Technical Briefs, Shenzhen, China, 3–6 December 2014; p. 15. [Google Scholar]
- Cinarel, C.; Zhang, B. Into the Colorful World of Webtoons: Through the Lens of Neural Networks. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 35–40. [Google Scholar]
- Furusawa, C.; Hiroshiba, K.; Ogaki, K.; Odagiri, Y. Comicolorization: semi-automatic manga colorization. In Proceedings of the SIGGRAPH Asia 2017 Technical Briefs, Bangkok, Thailand, 27–30 November 2017; p. 12. [Google Scholar]
- Zhang, L.; Ji, Y.; Lin, X. Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier GAN. arXiv 2017, arXiv:1706.03319. [Google Scholar]
- Kopf, J.; Lischinski, D. Digital reconstruction of halftoned color comics. ACM Trans. Graph. 2012, 31, 140. [Google Scholar] [CrossRef]
- lllyasviel. Style2paints Github. Available online: https://github.com/lllyasviel/style2paints (accessed on 25 June 2018).
- Preferred Networks. Hakusensha and Hakuhodo DY Digital Announces the Launch of Colorized Manga Products Using PaintsChainer. 2018. Available online: https://www.preferred-networks.jp/en/news/ pr20180206 (accessed on 25 June 2018).
- Cao, Y.; Chan, A.B.; Lau, R.W. Automatic stylistic manga layout. ACM Trans. Graph. 2012, 31, 141. [Google Scholar] [CrossRef]
- Wu, Z.; Aizawa, K. MangaWall: Generating manga pages for real-time applications. In Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 679–683. [Google Scholar]
- Jin, Y.; Zhang, J.; Li, M.; Tian, Y.; Zhu, H.; Fang, Z. Towards the Automatic Anime Characters Creation with Generative Adversarial Networks. arXiv 2017, arXiv:1708.05509. [Google Scholar]
- Jin, Y.; Zhang, J.; Li, M.; Tian, Y.; Zhu, H.; Fang, Z. MakeGirlsMoe. Available online: http://make.girls. moe/#/ (accessed on 25 June 2018).
- Cao, Y.; Pang, X.; Chan, A.B.; Lau, R.W. Dynamic Manga: Animating Still Manga via Camera Movement. IEEE Trans. Multimed. 2017, 19, 160–172. [Google Scholar] [CrossRef]
- Jain, E.; Sheikh, Y.; Hodgins, J. Predicting Moves-on-Stills for Comic Art Using Viewer Gaze Data. IEEE Comput. Graph. Appl. 2016, 36, 34–45. [Google Scholar] [CrossRef] [PubMed]
- White, T.; Loh, I. Generating Animations by Sketching in Conceptual Space. In Proceedings of the Eighth International Conference on Computational Creativity, Atlanta, GA, USA, 19–June 23 2017. [Google Scholar]
- White, T.; Loh, I. TopoSketch, Generating Animations by Sketching in Conceptual Space. Available online: https://vusd.github.io/toposketch/ (accessed on 25 June 2018).
- Kumar, R.; Sotelo, J.; Kumar, K.; de Brebisson, A.; Bengio, Y. ObamaNet: Photo-realistic lip-sync from text. arXiv 2017, arXiv:1801.01442. [Google Scholar]
- Jing, G.; Hu, Y.; Guo, Y.; Yu, Y.; Wang, W. Content-aware video2comics with manga-style layout. IEEE Trans. Multimed. 2015, 17, 2122–2133. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, Z.; Fang, C.; Bui, T.; Berg, T.L. Visual to Sound: Generating Natural Sound for Videos in the Wild. arXiv 2017, arXiv:1712.01393. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. arXiv 2016, arXiv:1609.03552. [Google Scholar]
- Carroll, P.J.; Young, J.R.; Guertin, M.S. Visual analysis of cartoons: A view from the far side. In Eye Movements and Visual Cognition; Springer: Heidelberg/Berlin, Germany, 1992; pp. 444–461. [Google Scholar]
- Rigaud, C.; Le, T.N.; Burie, J.C.; Ogier, J.M.; Ishimaru, S.; Iwata, M.; Kise, K. Semi-automatic Text and Graphics Extraction of Manga Using Eye Tracking Information. In Proceedings of the 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 120–125. [Google Scholar]
- Cohn, N.; Campbell, H. Navigating Comics II: Constraints on the Reading Order of Comic Page Layouts. Appl. Cognit. Psychol. 2015, 29, 193–199. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Soleymani, M.; Asghari-Esfeden, S.; Fu, Y.; Pantic, M. Analysis of EEG signals and facial expressions for continuous emotion detection. IEEE Trans. Affect. Comput. 2016, 7, 17–28. [Google Scholar] [CrossRef]
- Lima Sanches, C.; Augereau, O.; Kise, K. Manga content analysis using physiological signals. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; p. 6. [Google Scholar]
- Matsubara, M.; Augereau, O.; Lima Sanches, C.; Kise, K. Emotional Arousal Estimation While Reading Comics Based on Physiological Signal Analysis. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; pp. 7:1–7:4. [Google Scholar]
- Kalimeri, K.; Saitis, C. Exploring multimodal biosignal features for stress detection during indoor mobility. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 53–60. [Google Scholar]
- Greene, S.; Thapliyal, H.; Caban-Holt, A. A survey of affective computing for stress detection: Evaluating technologies in stress detection for better health. IEEE Consum. Electron. Mag. 2016, 5, 44–56. [Google Scholar] [CrossRef]
- Augereau, O.; Matsubara, M.; Kise, K. Comic visualization on smartphones based on eye tracking. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; p. 4. [Google Scholar]
- Andrews, D.; Baber, C.; Efremov, S.; Komarov, M. Creating and using interactive narratives: Reading and writing branching comics. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1703–1712. [Google Scholar]
- Rayar, F. Accessible Comics for Visually Impaired People: Challenges and Opportunities. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 3, pp. 9–14. [Google Scholar]
- Meyer, D.J.; Wiertlewski, M.; Peshkin, M.A.; Colgate, J.E. Dynamics of ultrasonic and electrostatic friction modulation for rendering texture on haptic surfaces. In Proceedings of the Haptics Symposium (HAPTICS), Houston, TX, USA, 23–26 February 2014; pp. 63–67. [Google Scholar]
- Tanvas. TanvasTouch. Available online: https://youtu.be/ohL_B-6Vy6o?t=19s (accessed on 25 June 2018).
- Eneh, A.; Eneh, O. Enhancing Pupils’ Reading Achievement by Use of Comics and Cartoons in Teaching Reading. J. Appl. Sci. 2008, 11, 8058–62. [Google Scholar]
- Sarada, P. Comics as a powerful tool to enhance English language usage. IUP J. Engl. Stud. 2016, 11, 60. [Google Scholar]
- Rigaud, C.; Burie, J.C.; Ogier, J.M. Text-Independent Speech Balloon Segmentation for Comics and Manga. In Proceedings of the Graphic Recognition. Current Trends and Challenges: 11th International Workshop, GREC 2015, Nancy, France, 22–23 August 2015; Lamiroy, B., Dueire Lins, R., Eds.; Springer: Heidelberg/Berlin, Germany, 2015; pp. 133–147. [Google Scholar]
- Rigaud, C.; Pal, S.; Burie, J.C.; Ogier, J.M. Toward Speech Text Recognition for Comic Books. In Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; pp. 8:1–8:6. [Google Scholar]
- cbrTekStraktor. Available online: https://sourceforge.net/projects/cbrtekstraktor (accessed on 25 June 2018).
- Furusawa, C.; Hiroshiba, K.; Ogaki, K.; Odagiri, Y. Semi-Automatic Manga Colorization. Available online: https://github.com/DwangoMediaVillage/Comicolorization (accessed on 25 June 2018).
- Saito, M.; Matsui, Y. illustration2vec. Available online: https://github.com/rezoo/illustration2vec (accessed on 25 June 2018).
- Rigaud, C. Christophe Rigaud’s Github webpage. Available online: https://github.com/crigaud (accessed on 25 June 2018).
- Dunst, A.; Hartel, R.; Laubrock, J. The Graphic Narrative Corpus (GNC): Design, Annotation, and Analysis for the Digital Humanities. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 15–20. [Google Scholar]
- Guérin, C.; Rigaud, C.; Mercier, A.; Ammar-Boudjelal, F.; Bertet, K.; Bouju, A.; Burie, J.C.; Louis, G.; Ogier, J.M.; Revel, A. eBDtheque: A representative database of comics. In Proceedings of the Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 1145–1149. [Google Scholar]
Figure 1.
An example of a double comic pages. The largest black rectangle encloses two pages which are represented by blue rectangles. The red rectangles are examples of panel frames. They can be small or large, overlap each other and have different shapes. Some panels do not have frames and some others can be drawn on more than a page. The green lines are examples of gutters, a white area used for separating two panels. The yellow ellipses are examples of dialogue balloons. They can have different shapes to represent the feelings of the speaker. The purple triangles are examples of onomatopoeias; they represent the sound made by people (such as footsteps), objects (water falling, metal blades knocking each other), etc. Source: images extracted from the Manga109 dataset [10], ©Sasaki Atsushi.
Figure 1.
An example of a double comic pages. The largest black rectangle encloses two pages which are represented by blue rectangles. The red rectangles are examples of panel frames. They can be small or large, overlap each other and have different shapes. Some panels do not have frames and some others can be drawn on more than a page. The green lines are examples of gutters, a white area used for separating two panels. The yellow ellipses are examples of dialogue balloons. They can have different shapes to represent the feelings of the speaker. The purple triangles are examples of onomatopoeias; they represent the sound made by people (such as footsteps), objects (water falling, metal blades knocking each other), etc. Source: images extracted from the Manga109 dataset [10], ©Sasaki Atsushi.

Figure 2.
Some examples of “manpu”: a mark used to represent the emotions of the characters such as anger, surprise, embarrassment, confidence, etc. The original images are extracted from the Manga109 dataset [10], ©Yoshi Masako, ©Kobayashi Yuki, ©Arai Satoshi, ©Okuda Momoko, ©Yagami Ken.
Figure 2.
Some examples of “manpu”: a mark used to represent the emotions of the characters such as anger, surprise, embarrassment, confidence, etc. The original images are extracted from the Manga109 dataset [10], ©Yoshi Masako, ©Kobayashi Yuki, ©Arai Satoshi, ©Okuda Momoko, ©Yagami Ken.

Figure 3.
Different examples of comics character faces. Some parts of the face such as the nose, eyes, or mouth can be deformed to emphasize the emotion of the character. The original images are extracted from the BAM! dataset [11].
Figure 3.
Different examples of comics character faces. Some parts of the face such as the nose, eyes, or mouth can be deformed to emphasize the emotion of the character. The original images are extracted from the BAM! dataset [11].

Figure 4.
The digital comic book “Protanopia” created by Andre Bergs. The reader can control the camera angle by tilting the screen. The panel are animated with continuous loops. Image extracted from the author’s website [12].
Figure 4.
The digital comic book “Protanopia” created by Andre Bergs. The reader can control the camera angle by tilting the screen. The panel are animated with continuous loops. Image extracted from the author’s website [12].

Figure 5.
Some examples of Open Pose application on comic pages [27]. This model works well for comics as long as the drawings are realistic, so it fails in most cases. Source: images extracted from the Manga109 dataset [10], ©Yoshi Masako, ©Kanno Hiroshi.

Figure 6.
Example application of illustration2vec [42]. The model recognizes several attributes of the character such as her haircut and clothes. The web demo used to generate this image is not online anymore.
Figure 6.
Example application of illustration2vec [42]. The model recognizes several attributes of the character such as her haircut and clothes. The web demo used to generate this image is not online anymore.

Figure 7.
Example of colorization process based on style2paints. Image downloaded from [52].
Figure 7.
Example of colorization process based on style2paints. Image downloaded from [52].

Figure 8.
Example of a random character generation based on Jin and coworkers’ method [56]. In this example, we set some attributes such as green hair color, blue eyes, smile and hat. Image captured from the online demo [57].

Figure 9.
Example of smiling animation in the conceptual space [60]. Similar animation could be obtained for comics images. Image downloaded from the online demo [61].

Figure 10.
(left) Eye gaze fixations (blue circles) and saccades (segment between circles) of one reader; and (right) heat map accumulated over several readers, where red corresponds to longer fixation time.
Figure 10.
(left) Eye gaze fixations (blue circles) and saccades (segment between circles) of one reader; and (right) heat map accumulated over several readers, where red corresponds to longer fixation time.

Figure 11.
A user wearing an E4 wristband, measuring his physiological signals such as heartbeat, skin conductance and skin temperature.
Figure 11.
A user wearing an E4 wristband, measuring his physiological signals such as heartbeat, skin conductance and skin temperature.

Figure 12.
Tanvas tablet enable the user to feel different textures. This could be used to enhance the interaction with comics. Image downloaded from [84].
Figure 12.
Tanvas tablet enable the user to feel different textures. This could be used to enhance the interaction with comics. Image downloaded from [84].

Figure 13.
Example of comics contained in the BAM! dataset [11]. From left to right we selected two images containing the following labels: bicycles, birds, buildings, cars, dogs, and flowers.
Figure 13.
Example of comics contained in the BAM! dataset [11]. From left to right we selected two images containing the following labels: bicycles, birds, buildings, cars, dogs, and flowers.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Augereau, O.; Iwata, M.; Kise, K. A Survey of Comics Research in Computer Science. J. Imaging 2018, 4, 87. https://doi.org/10.3390/jimaging4070087
AMA Style
Augereau O, Iwata M, Kise K. A Survey of Comics Research in Computer Science. Journal of Imaging. 2018; 4(7):87. https://doi.org/10.3390/jimaging4070087
Chicago/Turabian StyleAugereau, Olivier, Motoi Iwata, and Koichi Kise. 2018. "A Survey of Comics Research in Computer Science" Journal of Imaging 4, no. 7: 87. https://doi.org/10.3390/jimaging4070087
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.