Benchmarking of Document Image Analysis Tasks for Palm Leaf Manuscripts from Southeast Asia

 ,
,
Abstract
:1. Introduction
2. Palm Leaf Manuscripts from Southeast Asia
2.1. Balinese Palm Leaf Manuscripts—Collection from Bali, Indonesia
2.1.1. Corpus
2.1.2. Balinese Script and Language
2.2. Khmer Palm Leaf Manuscripts—Collection from Cambodia
2.2.1. Corpus
2.2.2. Khmer Script and Language
2.3. Sundanese Palm Leaf Manuscripts—Collection from West Java, Indonesia
2.3.1. Corpus
2.3.2. Sundanese Script and Language
2.4. Challenges of Document Image Analysis for Palm Leaf Manuscripts
3. Document Image Analysis Tasks and Investigated Methods
3.1. Binarization
3.1.1. Global Thresholding
3.1.2. Local Adaptive Binarization
3.1.3. Training-Based Binarization
3.2. Text Line Segmentation
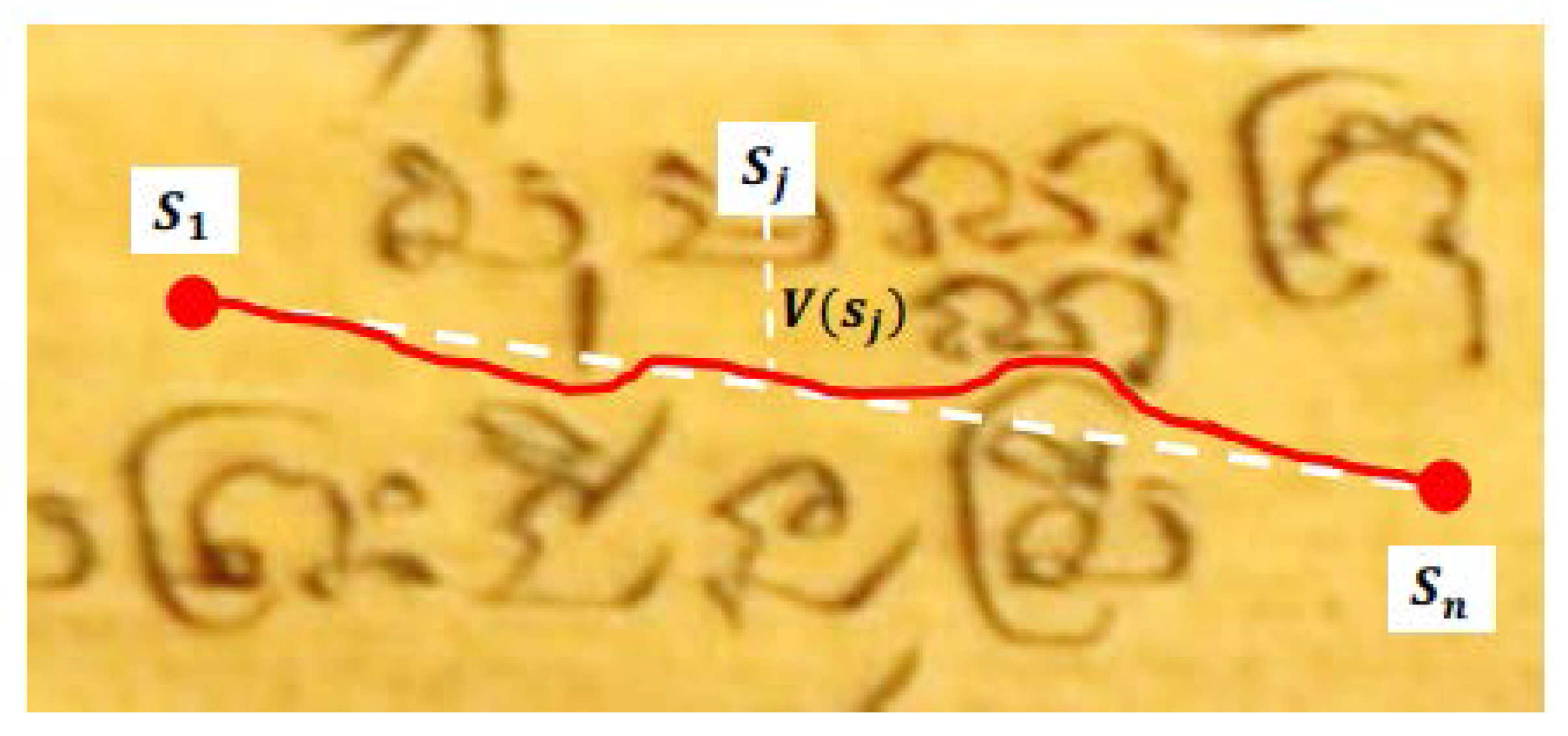
3.2.1. Seam Carving Method
3.2.2. Adaptive Path Finding Method
3.3. Isolated Character/Glyph Recognition
3.3.1. Handcrafted Feature Extraction Methods
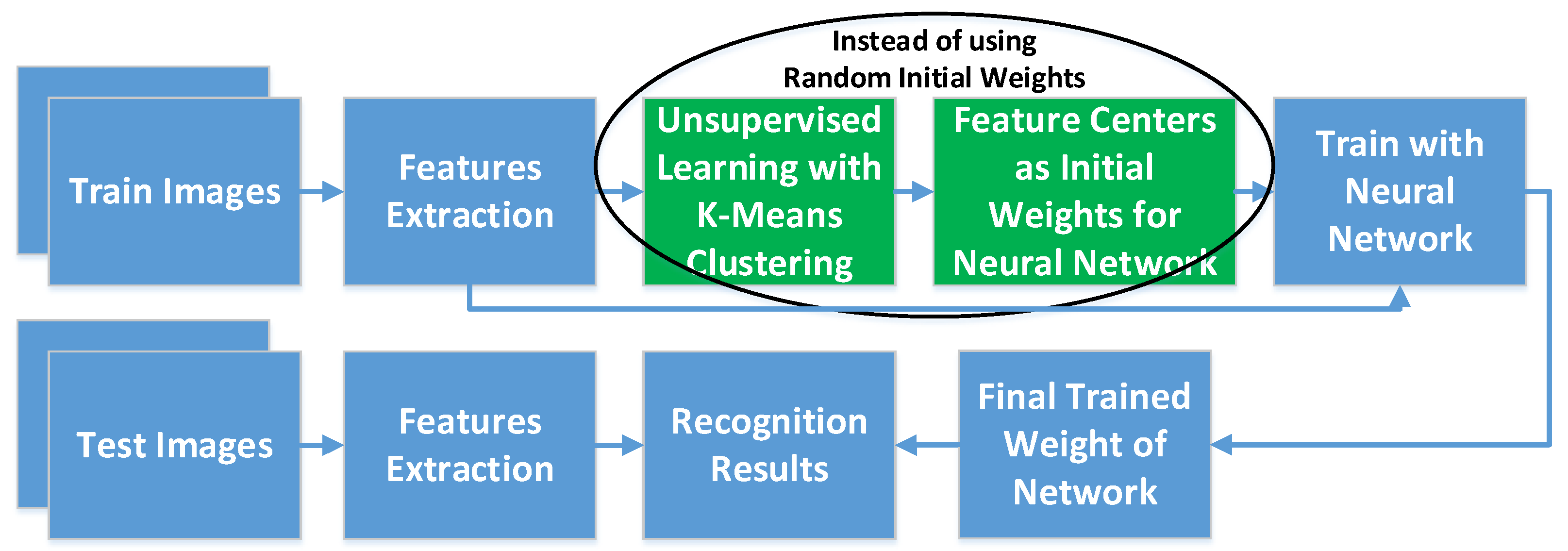
3.3.2. Unsupervised Learning Feature and Neural Network
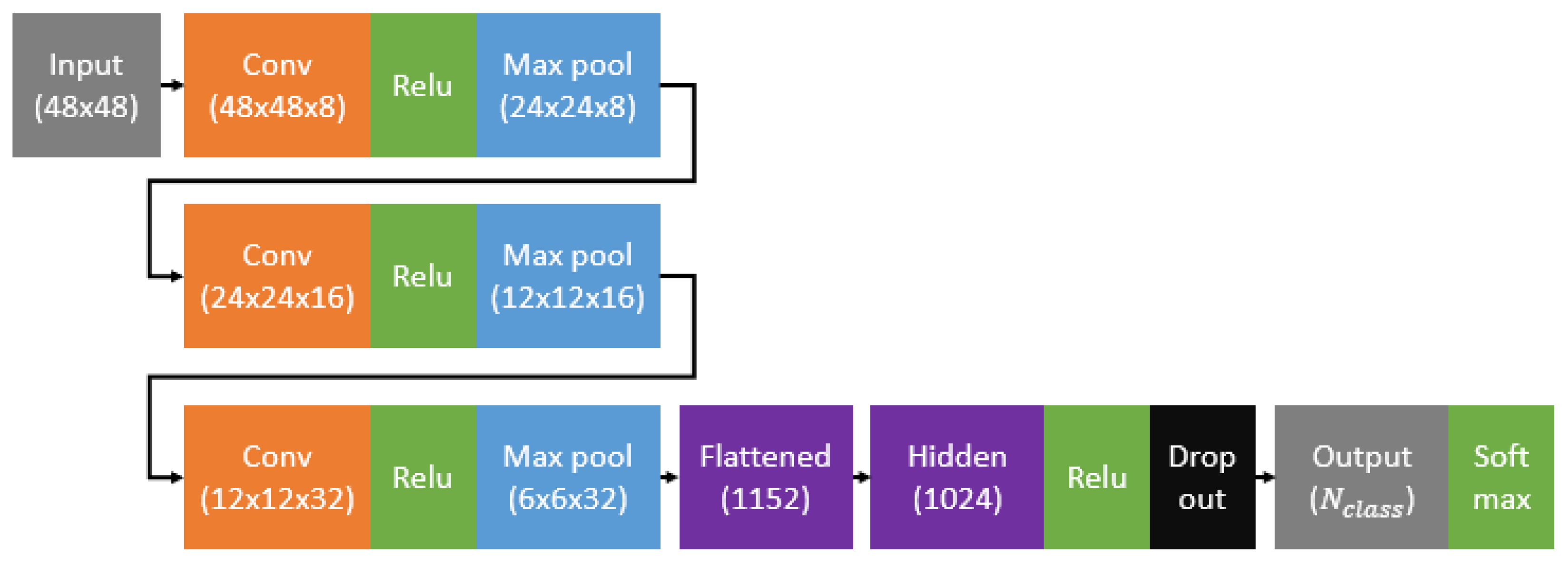
3.3.3. Convolutional Neural Network
3.4. Word Recognition and Transliteration
RNN/LSTM-Based Methods
4. Experiments: Datasets and Evaluation Methods
4.1. Binarization
4.1.1. Datasets
4.1.2. Evaluation Method
4.2. Text Line Segmentation
4.2.1. Datasets
4.2.2. Evaluation Method
4.3. Isolated Character/Glyph Recognition
4.3.1. Datasets
4.3.2. Evaluation Method
4.4. Word Recognition and Transliteration
4.4.1. Datasets
4.4.2. Evaluation Method
5. Experimental Results and Discussion
5.1. Binarization
5.2. Text Line Segmentation
5.3. Isolated Character/Glyph Recognition
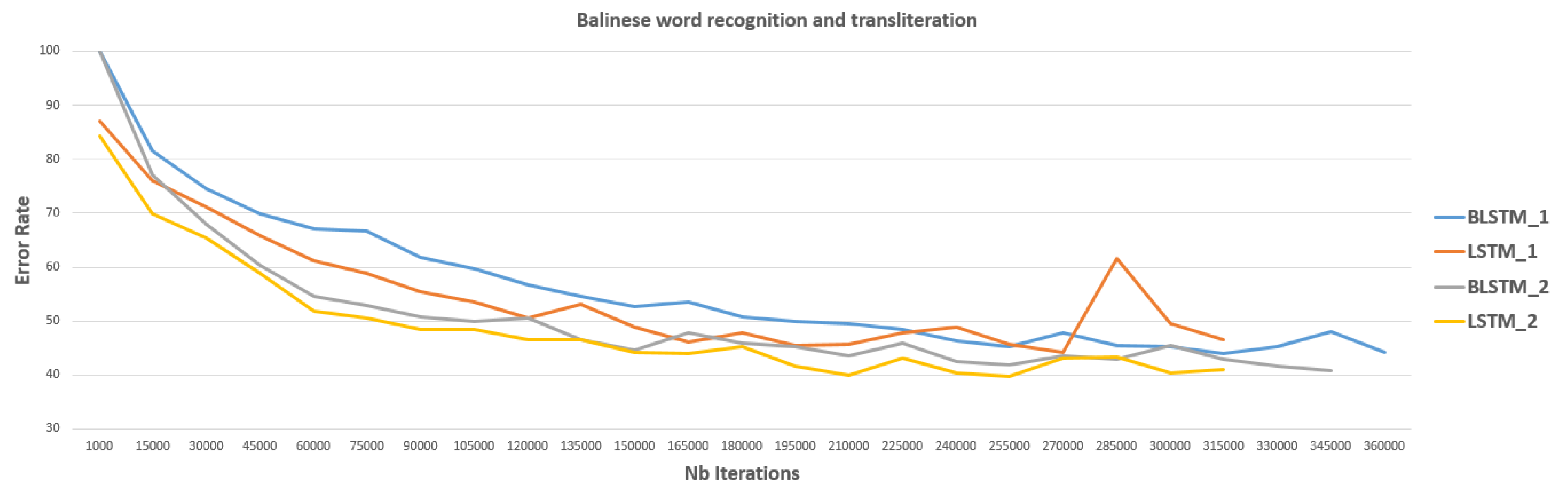
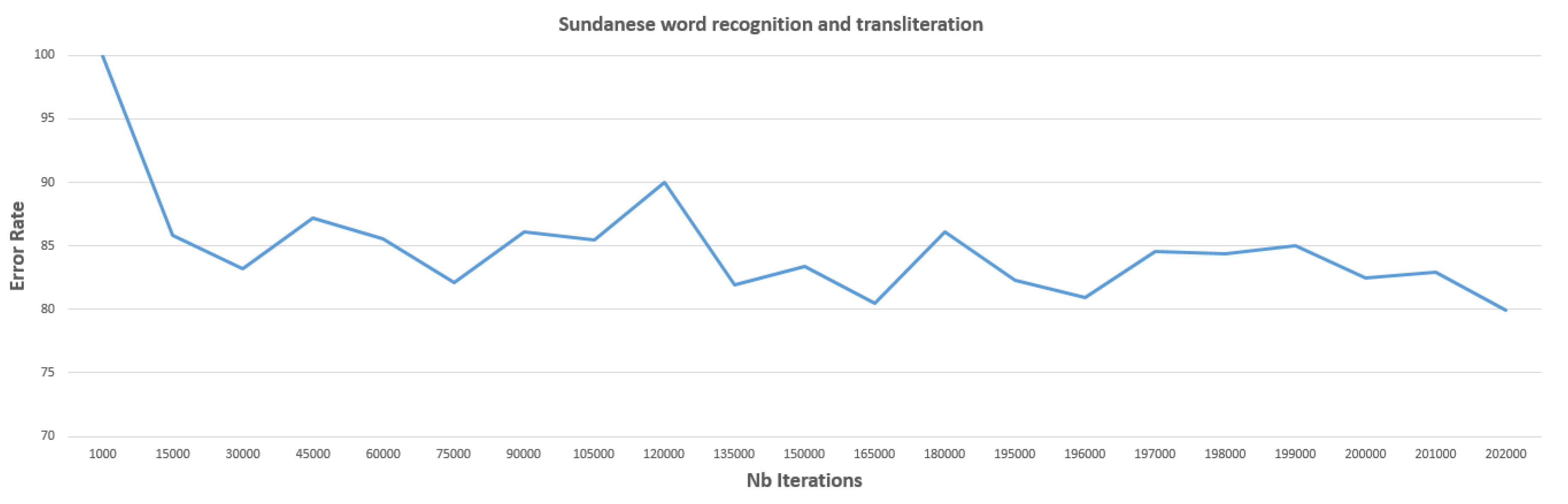
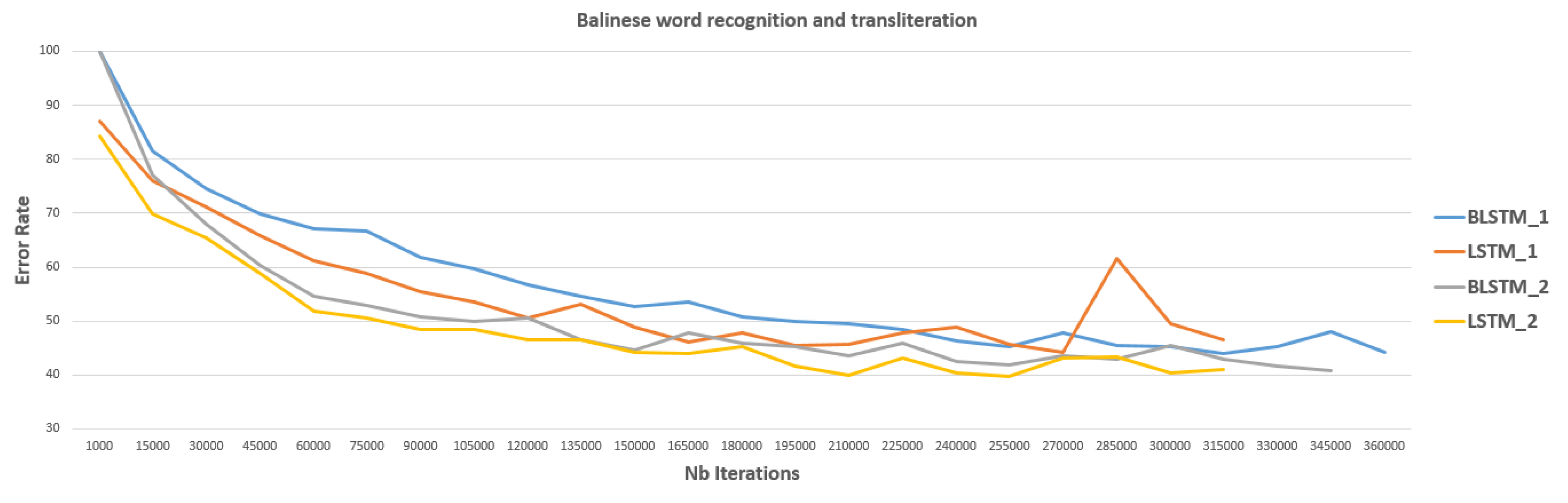
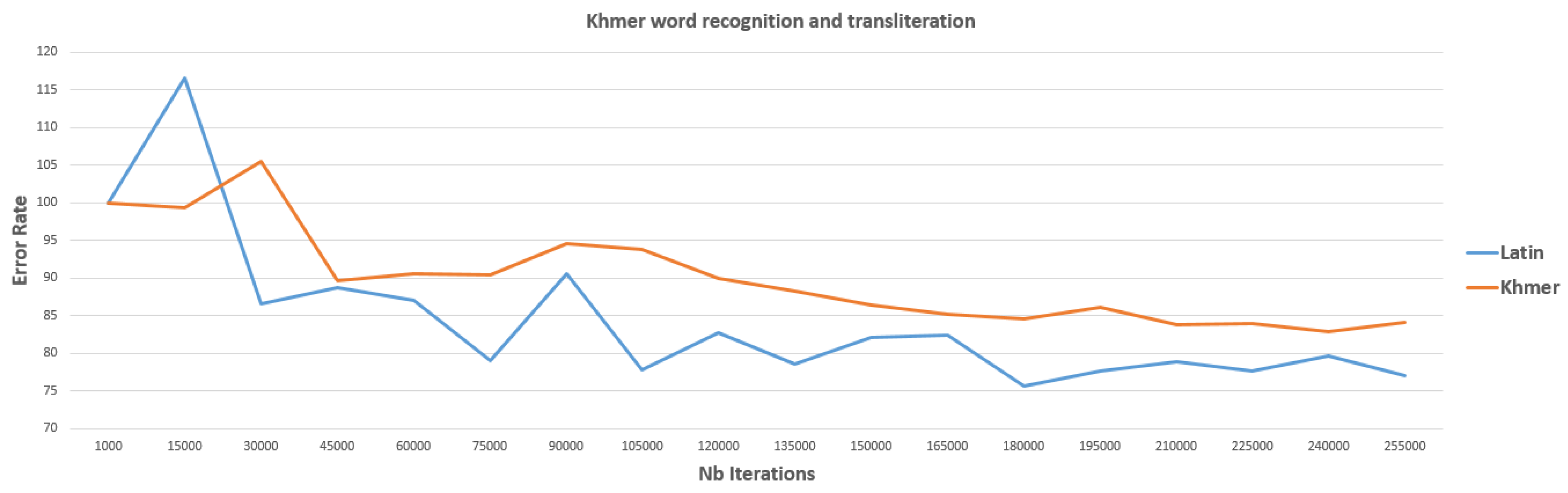
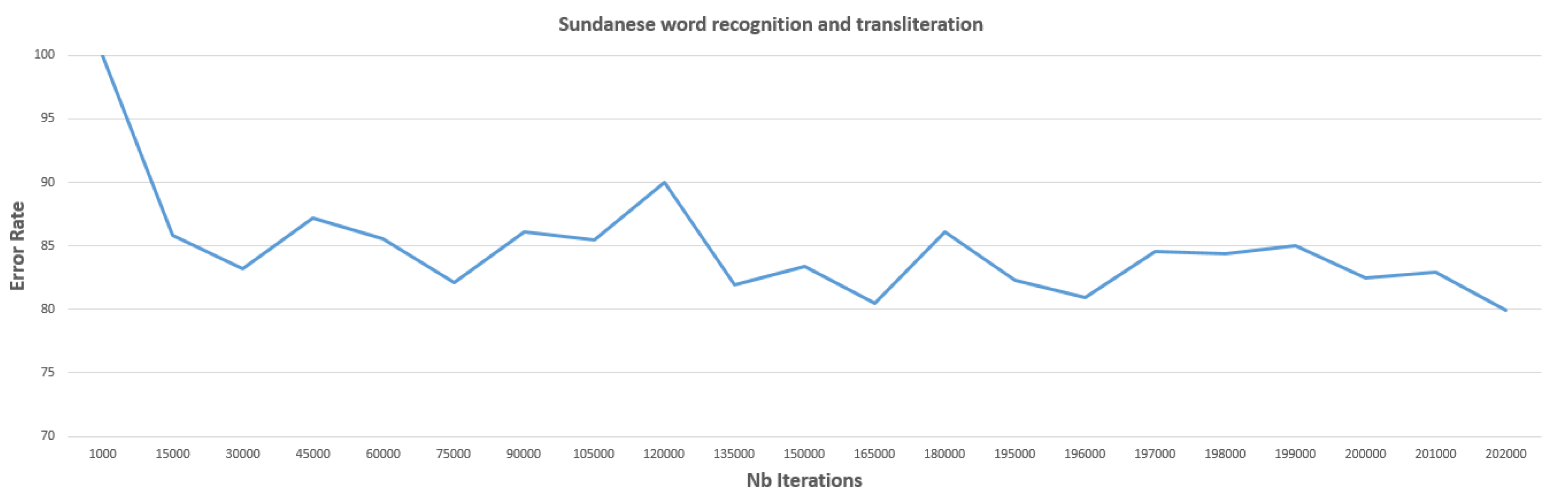
5.4. Word Recognition and Transliteration
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- tranScriptorium. Available online: http://transcriptorium.eu/ (accessed on 20 February 2018).
- READ Project—Recognition and Enrichment of Archival Documents. Available online: https://read.transkribus.eu/ (accessed on 20 February 2018).
- IAM Historical Document Database (IAM-HistDB)—Computer Vision and Artificial Intelligence. Available online: http://www.fki.inf.unibe.ch/databases/iam-historical-document-database (accessed on 20 February 2018).
- Ancient Lives: Archive. Available online: https://www.ancientlives.org/ (accessed on 20 February 2018).
- Document Image Analysis—CVISION Technologies. Available online: http://www.cvisiontech.com/library/pdf/pdf-document/document-image-analysis.html (accessed on 20 February 2018).
- Ramteke, R.J. Invariant Moments Based Feature Extraction for Handwritten Devanagari Vowels Recognition. Int. J. Comput. Appl. 2010, 1, 1–5. [Google Scholar] [CrossRef]
- Siddharth, K.S.; Dhir, R.; Rani, R. Handwritten Gurmukhi Numeral Recognition using Different Feature Sets. Int. J. Comput. Appl. 2011, 28, 20–24. [Google Scholar] [CrossRef]
- Sharma, D.; Jhajj, P. Recognition of Isolated Handwritten Characters in Gurmukhi Script. Int. J. Comput. Appl. 2010, 4, 9–17. [Google Scholar] [CrossRef]
- Aggarwal, A.; Singh, K.; Singh, K. Use of Gradient Technique for Extracting Features from Handwritten Gurmukhi Characters and Numerals. Procedia Comput. Sci. 2015, 46, 1716–1723. [Google Scholar] [CrossRef]
- Lehal, G.S.; Singh, C.A. Gurmukhi script recognition system. In Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; pp. 557–560. [Google Scholar]
- Rothacker, L.; Fink, G.A.; Banerjee, P.; Bhattacharya, U.; Chaudhuri, B.B. Bag-of-features HMMs for segmentation-free Bangla word spotting. In Proceedings of the 4th International Workshop on Multilingual OCR, Washington, DC, USA, 24 August 2013; p. 5. [Google Scholar]
- Ashlin Deepa, R.N.; Rao, R.R. Feature Extraction Techniques for Recognition of Malayalam Handwritten Characters: Review. Int. J. Adv. Trends Comput. Sci. Eng. 2014, 3, 481–485. [Google Scholar]
- Kasturi, R.; O’Gorman, L.; Govindaraju, V. Document image analysis: A primer. Sadhana 2002, 27, 3–22. [Google Scholar] [CrossRef]
- Paper History, Case Pap. Available online: http://www.casepaper.com/company/paper-history/ (accessed on 20 February 2018).
- Doermann, D. Handbook of Document Image Processing and Recognition; Tombre, K., Ed.; Springer London: London, UK, 2014; p. 1055. [Google Scholar]
- Chamchong, R.; Fung, C.C.; Wong, K.W. Comparing Binarisation Techniques for the Processing of Ancient Manuscripts; Nakatsu, R., Tosa, N., Naghdy, F., Wong, K.W., Codognet, P., Eds.; Springer Berlin: Berlin, Germany, 2010; pp. 55–64. [Google Scholar]
- Kesiman, M.W.A.; Burie, J.-C.; Ogier, J.-M.; Wibawantara, G.N.M.A.; Sunarya, I.M.G. AMADI_LontarSet: The First Handwritten Balinese Palm Leaf Manuscripts Dataset. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 168–172. [Google Scholar]
- The Unicode® Standard, version 9.0—Core Specification; The Unicode Consortium: Mountain View, CA, USA, 2016.
- Balinese Alphabet, Language and Pronunciation. Available online: http://www.omniglot.com/writing/balinese.htm (accessed on 20 February 2018).
- Khmer Manuscript—Recherche. Available online: http://khmermanuscripts.efeo.fr/ (accessed on 20 February 2018).
- Valy, D.; Verleysen, M.; Chhun, S.; Burie, J.-C. A New Khmer Palm Leaf Manuscript Dataset for Document Analysis and Recognition—SleukRith Set. In Proceedings of the 4th International Workshop on Historical Document Imaging and Processing, Kyoto, Japan, 10–11 November 2017; pp. 1–6. [Google Scholar]
- Suryani, M.; Paulus, E.; Hadi, S.; Darsa, U.A.; Burie, J.-C. The Handwritten Sundanese Palm Leaf Manuscript Dataset From 15th Century. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 796–800. [Google Scholar]
- Kesiman, M.W.A.; Prum, S.; Burie, J.-C.; Ogier, J.-M. An Initial Study on the Construction of Ground Truth Binarized Images of Ancient Palm Leaf Manuscripts. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), Nancy, France, 23–26 August 2015; pp. 656–660. [Google Scholar]
- Kesiman, M.W.A.; Prum, S.; Sunarya, I.M.G.; Burie, J.-C.; Ogier, J.-M. An Analysis of Ground Truth Binarized Image Variability of Palm Leaf Manuscripts. In Proceedings of the 5th International Conference Image Processing Theory Tools Application (IPTA 2015), Orleans, France, 10–13 November 2015; pp. 229–233. [Google Scholar]
- Burie, J.-C.; Coustaty, M.; Hadi, S.; Kesiman, M.W.A.; Ogier, J.-M.; Paulus, E.; Sok, K.; Sunarya, I.M.G.; Valy, D. ICFHR 2016 Competition on the Analysis of Handwritten Text in Images of Balinese Palm Leaf Manuscripts. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 596–601. [Google Scholar]
- Kesiman, M.W.A.; Valy, D.; Burie, J.-C.; Paulus, E.; Sunarya, I.M.G.; Hadi, S.; Sok, K.H.; Ogier, J.-M. Southeast Asian palm leaf manuscript images: A review of handwritten text line segmentation methods and new challenges. J. Electron. Imaging. 2016, 26, 011011. [Google Scholar] [CrossRef]
- Valy, D.; Verleysen, M.; Sok, K. Line Segmentation for Grayscale Text Images of Khmer Palm Leaf Manuscripts. In Proceedings of the 7th International Conference Image Processing Theory Tools Application (IPTA 2017), Montreal, QC, Canada, 28 November–1 December 2017. [Google Scholar]
- Kesiman, M.W.A.; Prum, S.; Burie, J.-C.; Ogier, J.-M. Study on Feature Extraction Methods for Character Recognition of Balinese Script on Palm Leaf Manuscript Images. In Proceedings of the 23rd International Conference Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 4017–4022. [Google Scholar]
- Kesiman, M.W.A.; Burie, J.-C.; Ogier, J.-M. A Complete Scheme of Spatially Categorized Glyph Recognition for the Transliteration of Balinese Palm Leaf Manuscripts. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 125–130. [Google Scholar]
- Bezerra, B.L.D. Handwriting: Recognition, Development and Analysis; Bezerra, B.L.D., Zanchettin, C., Toselli, A.H., Pirlo, G., Eds.; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2017; ISBN 978-1-53611-957-2. [Google Scholar]
- Arica, N.; Yarman-Vural, F.T. Optical character recognition for cursive handwriting. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 801–813. [Google Scholar] [CrossRef]
- Blumenstein, M.; Verma, B.; Basli, H. A novel feature extraction technique for the recognition of segmented handwritten characters. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 3–6 August 2003; pp. 137–141. [Google Scholar]
- O’Gorman, L.; Kasturi, R. Executive briefing: Document Image Analysis; IEEE Computer Society Press: Los Alamitos, CA, USA, 1997; p. 107. [Google Scholar]
- Naveed Bin Rais, M.S.H. Adaptive thresholding technique for document image analysis. In Proceedings of the 8th International Multitopic Conference, Lahore, Pakistan, 24–26 December 2004; pp. 61–66. [Google Scholar]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. An Objective Evaluation Methodology for Document Image Binarization Techniques. In Proceedings of the Eighth IAPR International Workshop Document Annual System 2008, Nara, Japan, 16–19 September 2008; pp. 217–224. [Google Scholar]
- He, J.; Do, Q.D.M.; Downton, A.C.; Kim, J.H. A comparison of binarization methods for historical archive documents. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR'05), Seoul, South Korea, 31 August–1 September 2005; pp. 538–542. [Google Scholar]
- Gatos, B.; Ntirogiannis, K.; Pratikakis, I. DIBCO 2009: Document image binarization contest. Int. J. Doc. Anal. Recognit. 2011, 14, 35–44. [Google Scholar] [CrossRef]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICDAR 2013 Document Image Binarization Contest (DIBCO 2013). In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1471–1476. [Google Scholar]
- Howe, N.R. Document binarization with automatic parameter tuning. Int. J. Doc. Anal. Recognit. 2013, 16, 247–258. [Google Scholar] [CrossRef]
- ICFHR2016 Competition on the Analysis of Handwritten Text in Images of Balinese Palm Leaf Manuscripts. Available online: http://amadi.univ-lr.fr/ICFHR2016_Contest/ (accessed on 20 February 2018).
- Gupta, M.R.; Jacobson, N.P.; Garcia, E.K. OCR binarization and image pre-processing for searching historical documents. Pattern Recognit. 2007, 40, 389–397. [Google Scholar] [CrossRef]
- Feng, M.-L.; Tan, Y.-P. Contrast adaptive binarization of low quality document images. IEICE Electron. Express 2004, 1, 501–506. [Google Scholar] [CrossRef]
- Global image threshold using Otsu’s method—MATLAB graythresh—MathWorks France. Available online: https://fr.mathworks.com/help/images/ref/graythresh.html?requestedDomain=true (accessed on 20 February 2018).
- Khurshid, K.; Siddiqi, I.; Faure, C.; Vincent, N. Comparison of Niblack Inspired Binarization Methods for Ancient Documents. In Proceedings of the Document Recognition and Retrieval XVI, 72470U, San Jose, CA, USA, 21 January 2009; p. 72470U. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Wolf, C.; Jolion, J.-M.; Chassaing, F. Text Localization, Enhancement and Binarization in Multimedia Documents. In Proceedings of the Object recognition supported by user interaction for service robots, Quebec City, QC, Canada, 11–15 August 2002; pp. 1037–1040. [Google Scholar]
- Arvanitopoulos, N.; Susstrunk, S. Seam Carving for Text Line Extraction on Color and Grayscale Historical Manuscripts. In Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition, Heraklion, Greece, 1–4 September 2014; pp. 726–731. [Google Scholar]
- Hossain, M.Z.; Amin, M.A.; Yan, H. Rapid Feature Extraction for Optical Character Recognition. Available online: http://arxiv.org/abs/1206.0238 (accessed on 20 February 2018).
- Fujisawa, Y.; Shi, M.; Wakabayashi, T.; Kimura, F. Handwritten numeral recognition using gradient and curvature of gray scale image. In Proceedings of the Fifth International Conference on Document Analysis and Recognition. ICDAR '99, Bangalore, India, 22 September 1999; pp. 277–280. [Google Scholar]
- Kumar, S. Neighborhood Pixels Weights-A New Feature Extractor. Int. J. Comput. Theory Eng. 2009, 2, 69–77. [Google Scholar] [CrossRef]
- Bokser, M. Omnidocument technologies. Proc. IEEE. 1992, 80, 1066–1078. [Google Scholar] [CrossRef]
- Coates, A.; Lee, H.; Ng, A.Y. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Coates, A.; Carpenter, B.; Case, C.; Satheesh, S.; Suresh, B.; Wang, T.; Wu, D.J.; Ng, A.Y. Text Detection and Character Recognition in Scene Images with Unsupervised Feature Learning. In Proceedings of the International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 440–445. [Google Scholar]
- Shishtla, P.; Ganesh, V.S.; Subramaniam, S.; Varma, V. A language-independent transliteration schema using character aligned models at NEWS 2009. In Proceedings of the Association for Computational Linguistics, Suntec, Singapore, 7 August 2009; p. 40. [Google Scholar] [CrossRef]
- Ul-Hasan, A.; Breuel, T.M. Can we build language-independent OCR using LSTM networks? In Proceedings of the 4th International Workshop on Multilingual OCR, Washington, DC, USA, 24 August 2013. [Google Scholar]
- Ocropy: Python-Based Tools for Document Analysis and OCR, 2018. Available online: https://github.com/tmbdev/ocropy (accessed on 20 February 2018).
- Homemade Manuscript OCR (1): OCRopy, Sacré Grl. Available online: https://graal.hypotheses.org/786 (accessed on 20 February 2018).
- Breuel, T.M.; Ul-Hasan, A.; Al-Azawi, M.A.; Shafait, F. High-Performance OCR for Printed English and Fraktur Using LSTM Networks. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 683–687. [Google Scholar] [CrossRef]
- Valy, D.; Verleysen, M.; Sok, K. Line Segmentation Approach for Ancient Palm Leaf Manuscripts using Competitive Learning Algorithm. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016. [Google Scholar]
- Saund, E.; Lin, J.; Sarkar, P. PixLabeler: User Interface for Pixel-Level Labeling of Elements in Document Images. In Proceedings of the 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 646–650. [Google Scholar] [CrossRef]
- Stamatopoulos, N.; Gatos, B.; Louloudis, G.; Pal, U.; Alaei, A. ICDAR 2013 Handwriting Segmentation Contest. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1402–1406. [Google Scholar] [CrossRef]
- PRImA. Available online: http://www.primaresearch.org/tools/Aletheia (accessed on 20 February 2018).
- Clausner, C.; Pletschacher, S.; Antonacopoulos, A. Aletheia—An Advanced Document Layout and Text Ground-Truthing System for Production Environments. In Proceedings of the International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 48–52. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manuscripts | Train | Test | Ground Truth | Dataset |
|---|---|---|---|---|
| Balinese | 50 pages | 50 pages | 2 × 100 pages | Extracted from AMADI_LontarSet [17,25,40] |
| Khmer | - | 46 pages | 1 × 46 pages | Extracted from EFEO [20,59] |
| Sundanese | - | 61 pages | 2 × 61 pages | Extracted from Sunda Dataset ICDAR2017 [22] |
| Manuscripts | Pages | Text Lines | Dataset |
|---|---|---|---|
| Balinese 1 | 35 pages | 140 text lines | Extracted from AMADI_LontarSet [17,26,40] |
| Balinese 2 | Bali-2.1: 47 pages Bali-2.2: 49 pages | 181 text lines 182 text lines | Extracted from AMADI_LontarSet [17] |
| Khmer 1 | 43 pages | 191 text lines | Extracted from EFEO [20,26,59] |
| Khmer 2 | 100 pages | 476 text lines | Extracted from SleukRith Set [21,27] |
| Khmer 3 | 200 pages | 971 text lines | Extracted from SleukRith Set [21] |
| Sundanese 1 | 12 pages | 46 text lines | Extracted from Sunda Dataset [26] |
| Sundanese 2 | 61 pages | 242 text lines | Extracted from Sunda Dataset [22] |
| Manuscripts | Classes | Train | Test | Dataset |
|---|---|---|---|---|
| Balinese | 133 classes | 11,710 images | 7673 images | AMADI_LontarSet [17,25,28] |
| Khmer | 111 classes | 113,206 images | 90,669 images | SleukRith Set [21] |
| Sundanese | 60 classes | 4555 images | 2816 images | Sunda Dataset [22] |
| Manuscripts | Train | Test | Text | Published |
|---|---|---|---|---|
| Balinese | 15022 images from 130 pages | 10475 images from 100 pages | Latin | AMADI_LontarSet [17,25] |
| Khmer | 16333 images (part of 657 pages) | 7791 images (part of 657 pages) | Latin and Khmer | SleukRith Set [21] |
| Sundanese | 1427 images from 20 pages | 318 images from 10 pages | Latin | Sunda Dataset [22] |
| Methods | Parameter | Manuscripts | FM (%) | NRM | PSNR (%) |
|---|---|---|---|---|---|
| OtsuGray [34,41] | Otsu from gray image Using Matlab graythresh [43] | Balinese | 18.98178 | 0.398894 | 5.019868 |
| Khmer | 23.92159 | 0.313062 | 7.387765 | ||
| Sundanese | 23.70566 | 0.326681 | 9.998433 | ||
| OtsuRed [34,41] | Otsu from red image channel Using Matlab graythresh | Balinese | 29.20352 | 0.300145 | 10.94973 |
| Khmer | 21.15379 | 0.337171 | 5.907433 | ||
| Sundanese | 21.25153 | 0.38641 | 12.60233 | ||
| Sauvola [34,36,41,42,44,45] | window = 50, k = 0.5, R = 128 | Balinese | 13.20997 | 0.462312 | 27.69732 |
| Khmer | 44.73579 | 0.268527 | 26.06089 | ||
| Sundanese | 6.190919 | 0.479984 | 24.78595 | ||
| Sauvola2 [34,36,41,42,44,45] | window = 50, k = 0.2, R = 128 | Balinese | 40.18596 | 0.274551 | 25.0988 |
| Khmer | 47.55924 | 0.155722 | 21.96846 | ||
| Sundanese | 43.04994 | 0.299694 | 23.65228 | ||
| Sauvola3 [34,36,41,42,44,45] | window = 50, k = 0.0, R = 128 | Balinese | 35.38635 | 0.165839 | 17.05408 |
| Khmer | 30.5562 | 0.190081 | 12.78953 | ||
| Sundanese | 40.29642 | 0.181465 | 16.25056 | ||
| Niblack [34,36,41,42,44] | window = 50, k = −0.2 | Balinese | 41.55696 | 0.175795 | 21.24452 |
| Khmer | 38.01222 | 0.160807 | 16.84153 | ||
| Sundanese | 46.79678 | 0.195015 | 20.31759 | ||
| Niblack2 [34,36,41,42,44] | window = 50, k = 0.0 | Balinese | 35.38635 | 0.165839 | 17.05408 |
| Khmer | 30.5562 | 0.190081 | 12.78953 | ||
| Sundanese | 40.29642 | 0.181465 | 16.25056 | ||
| NICK [44] | window = 50, k= −0.2 | Balinese | 37.85919 | 0.328327 | 27.59038 |
| Khmer | 51.2578 | 0.176003 | 24.51998 | ||
| Sundanese | 29.5918 | 0.390431 | 24.26187 | ||
| Rais [34] | window = 50 | Balinese | 34.46977 | 0.171096 | 16.84049 |
| Khmer | 31.59138 | 0.187948 | 13.52816 | ||
| Sundanese | 40.65458 | 0.177016 | 16.35472 | ||
| Wolf [42,44] | window = 50, k = 0.5 | Balinese | 27.94817 | 0.392937 | 27.1625 |
| Khmer | 46.78589 | 0.23739 | 25.1946 | ||
| Sundanese | 42.40799 | 0.299157 | 23.61075 | ||
| Howe1 [39] | Default values [39] | Balinese | 44.70123 | 0.267627 | 28.35427 |
| Khmer | 40.20485 | 0.280604 | 25.59887 | ||
| Sundanese | 45.90779 | 0.235175 | 21.90439 | ||
| Howe2 [39] | Default values | Balinese | 40.5555 | 0.273994 | 28.02874 |
| Khmer | 32.35603 | 0.294016 | 25.96965 | ||
| Sundanese | 35.35973 | 0.274865 | 22.36583 | ||
| Howe3 [39] | Default values | Balinese | 42.15377 | 0.304962 | 28.38466 |
| Khmer | 30.7186 | 0.382087 | 26.36983 | ||
| Sundanese | 25.77321 | 0.350349 | 23.66912 | ||
| Howe4 [39] | Default values | Balinese | 45.73681 | 0.273018 | 28.60561 |
| Khmer | 36.48396 | 0.280519 | 25.83969 | ||
| Sundanese | 38.98445 | 0.281118 | 22.83914 | ||
| ICFHR G1 | See ref. [25] | Balinese | 63.32 | 0.15 | 31.37 |
| Khmer | 52.65608 | 0.250503 | 28.16886 | ||
| Sundanese | 38.95626 | 0.329042 | 24.15279 | ||
| ICFHR G2 | See ref. [25] | Balinese | 68.76 | 0.13 | 33.39 |
| Khmer | - | - | - | ||
| Sundanese | - | - | - | ||
| ICFHR G3 | See ref. [25] | Balinese | 52.20 | 0.18 | 26.92 |
| Khmer | - | - | - | ||
| Sundanese | - | - | - | ||
| ICFHR G4 | See ref. [25] | Balinese | 58.57 | 0.17 | 29.98 |
| Khmer | - | - | - | ||
| Sundanese | - | - | - |
| Methods | Manuscripts | N | M | o2o | DR (%) | RA (%) | FM (%) |
|---|---|---|---|---|---|---|---|
| Seam carving [47] | Balinese 1 | 140 | 167 | 128 | 91.42 | 76.64 | 83.38 |
| Bali-2.1 | 181 | 210 | 163 | 90.05 | 77.61 | 83.37 | |
| Bali-2.2 | 182 | 219 | 161 | 88.46 | 73.51 | 80.29 | |
| Khmer 1 | 191 | 145 | 57 | 29.84 | 39.31 | 33.92 | |
| Khmer 2 | 476 | 665 | 356 | 53.53 | 74.79 | 62.40 | |
| Khmer 3 | 971 | 1046 | 845 | 87.02 | 80.78 | 83.78 | |
| Sundanese 1 | 46 | 43 | 36 | 78.26 | 83.72 | 80.89 | |
| Sundanese 2 | 242 | 257 | 218 | 90.08 | 84.82 | 87.37 | |
| Adaptive Path Finding [27] | Balinese 1 | 140 | 143 | 132 | 94.28 | 92.30 | 93.28 |
| Bali-2.1 | 181 | 188 | 159 | 87.84 | 84.57 | 86.17 | |
| Bali-2.2 | 182 | 191 | 164 | 90.10 | 85.86 | 87.93 | |
| Khmer 1 | 191 | 169 | 118 | 61.78 | 69.82 | 65.55 | |
| Khmer 2 | 476 | 484 | 446 | 92.15 | 93.70 | 92.92 | |
| Khmer 3 | 971 | 990 | 910 | 93.71 | 91.91 | 92.80 | |
| Sundanese 1 | 46 | 50 | 41 | 89.13 | 82.00 | 85.41 | |
| Sundanese 2 | 242 | 253 | 222 | 91.73 | 87.74 | 89.69 |
| Methods | Balinese | Khmer | Sundanese |
|---|---|---|---|
| Handcrafted Feature (HoG-NPW-Kirsch-Zoning) with k-NN [28] | 85.16 | - | 72.91 |
| Handcrafted Feature (HoG-NPW-Kirsch-Zoning) with NN [29] | 85.51 | 92.15 | 79.69 |
| Handcrafted Feature (HoG-NPW-Kirsch-Zoning) with UFL + NN [29] | 85.63 | 92.44 | 79.33 |
| CNN 1 [28] | 84.31 | - | - |
| CNN 2 | 85.39 | 93.96 | 79.05 |
| ICFHR G1: VCMF [25] | 87.44 | - | - |
| ICFHR G1: VMQDF [25] | 88.39 | - | - |
| ICFHR G3 [25] | 77.83 | - | - |
| ICFHR G5 [25] | 77.70 | - | - |
| Methods (with OCRopy [56] Framework) | Balinese | Khmer | Sundanese |
|---|---|---|---|
| BLSTM 1 (seq_depth 60, neuron size 100) | 43.13 | Latin text: 73.76 Khmer text: 77.88 | 75.52 |
| LSTM 1 (seq_depth 100, neuron size 100) | 42.88 | - | - |
| BLSTM 2 (seq_depth 100, neuron size 200) | 40.54 | - | - |
| LSTM 2 (seq_depth 100, neuron size 200) | 39.70 | - | - |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kesiman, M.W.A.; Valy, D.; Burie, J.-C.; Paulus, E.; Suryani, M.; Hadi, S.; Verleysen, M.; Chhun, S.; Ogier, J.-M. Benchmarking of Document Image Analysis Tasks for Palm Leaf Manuscripts from Southeast Asia. J. Imaging 2018, 4, 43. https://doi.org/10.3390/jimaging4020043
Kesiman MWA, Valy D, Burie J-C, Paulus E, Suryani M, Hadi S, Verleysen M, Chhun S, Ogier J-M. Benchmarking of Document Image Analysis Tasks for Palm Leaf Manuscripts from Southeast Asia. Journal of Imaging. 2018; 4(2):43. https://doi.org/10.3390/jimaging4020043
Chicago/Turabian StyleKesiman, Made Windu Antara, Dona Valy, Jean-Christophe Burie, Erick Paulus, Mira Suryani, Setiawan Hadi, Michel Verleysen, Sophea Chhun, and Jean-Marc Ogier. 2018. "Benchmarking of Document Image Analysis Tasks for Palm Leaf Manuscripts from Southeast Asia" Journal of Imaging 4, no. 2: 43. https://doi.org/10.3390/jimaging4020043