Mapping Urban Land Use at Street Block Level Using OpenStreetMap, Remote Sensing Data, and Spatial Metrics

 , ,
, ,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
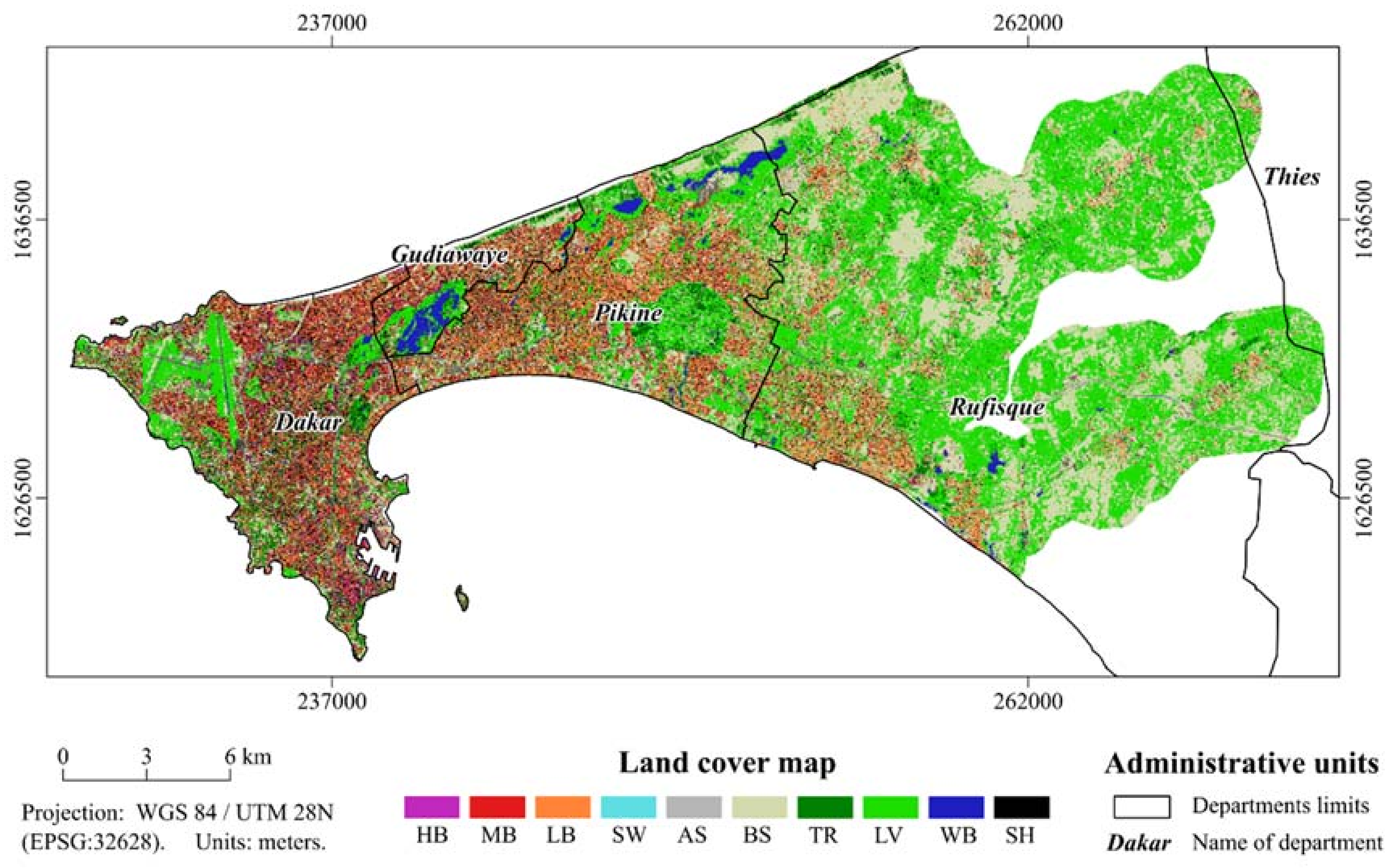
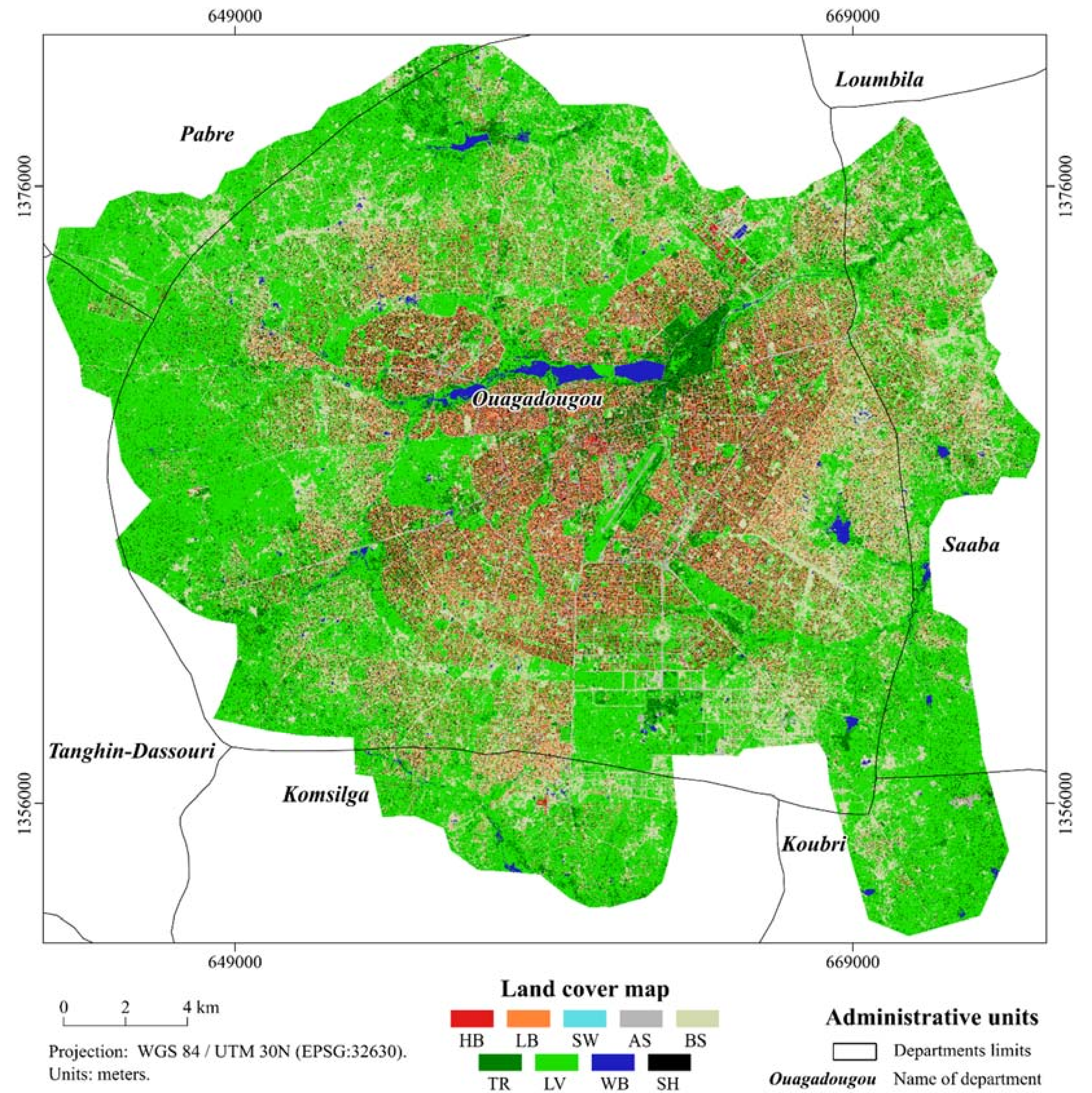
2.1. Study Areas
2.2. Input Data
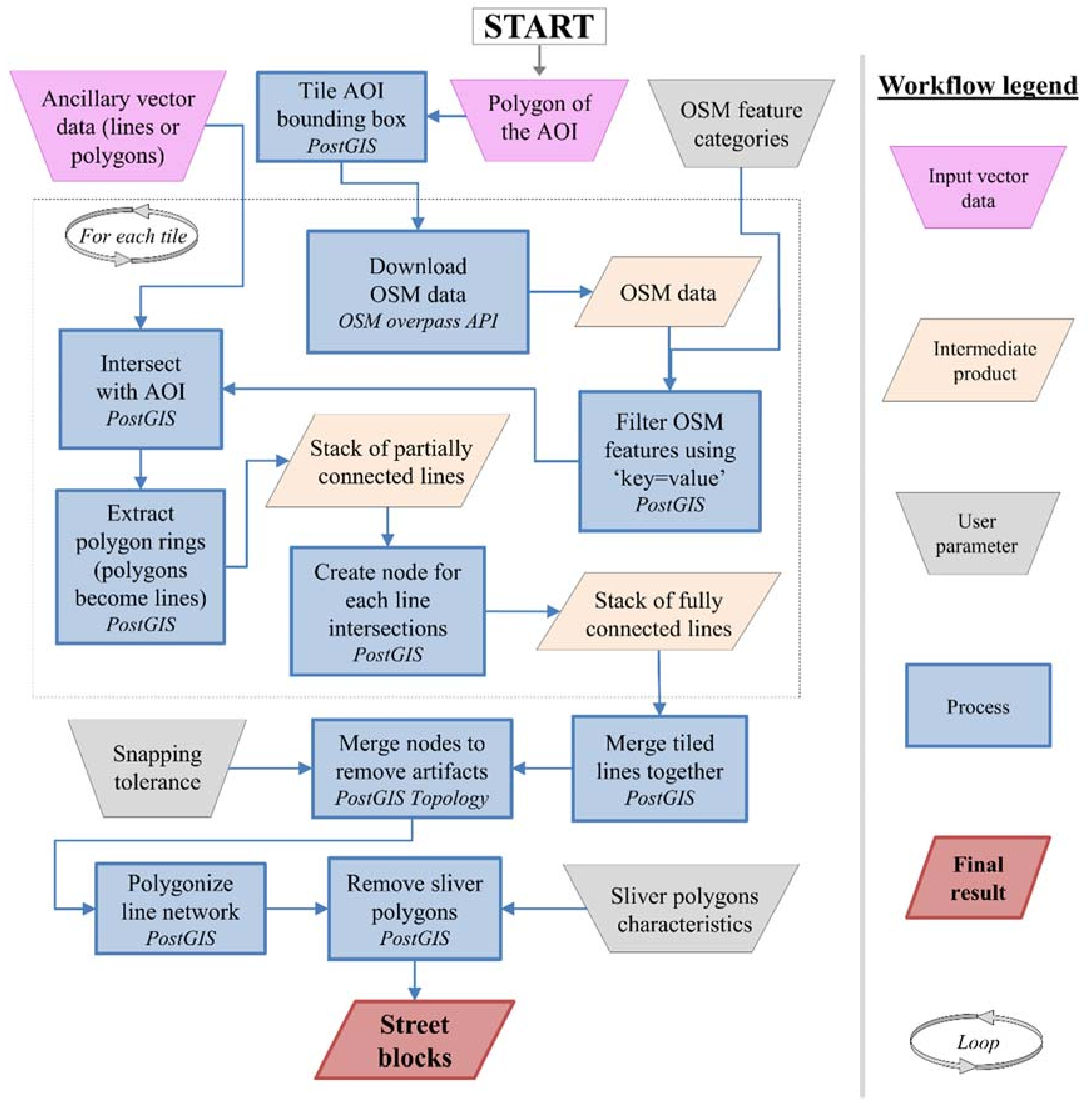
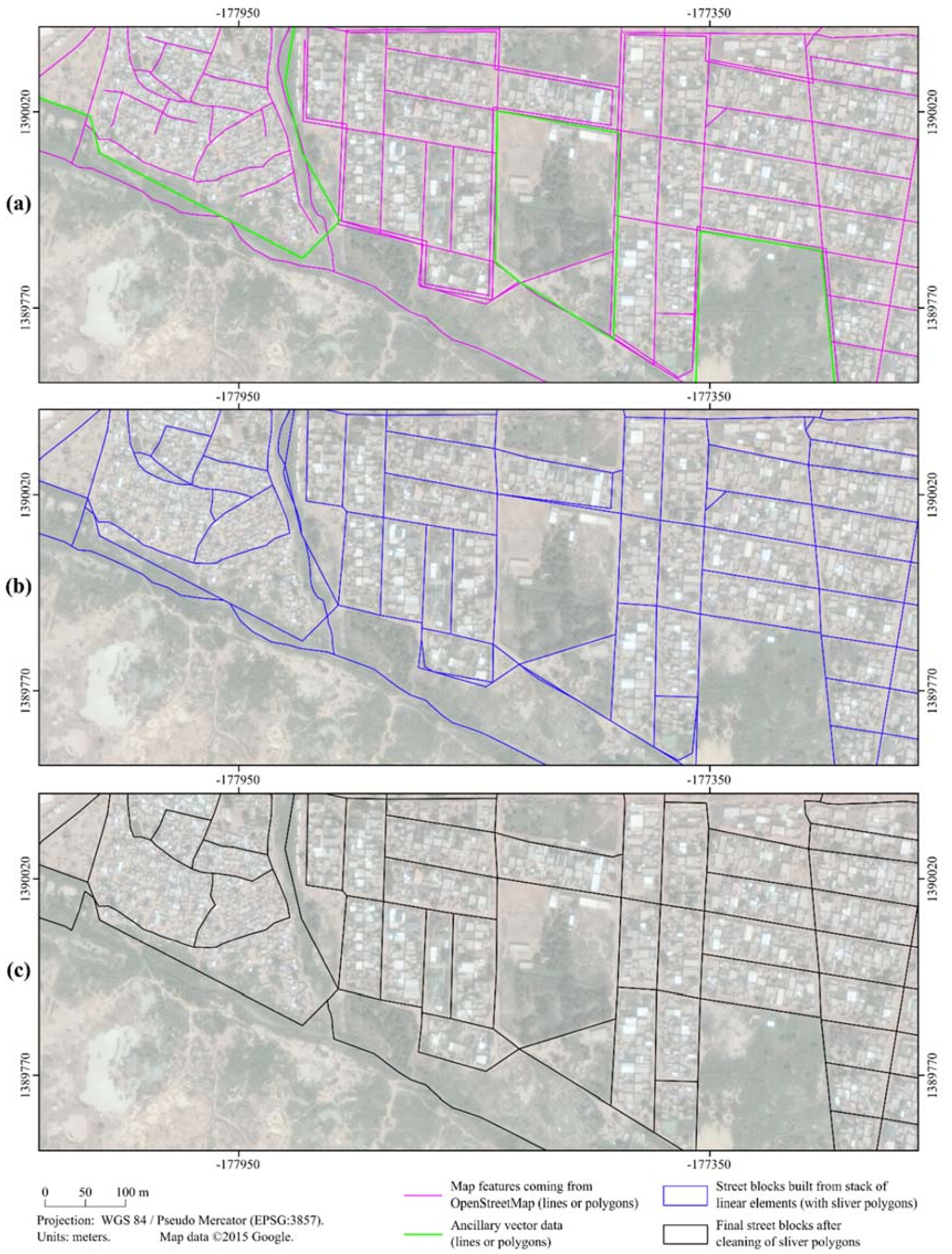
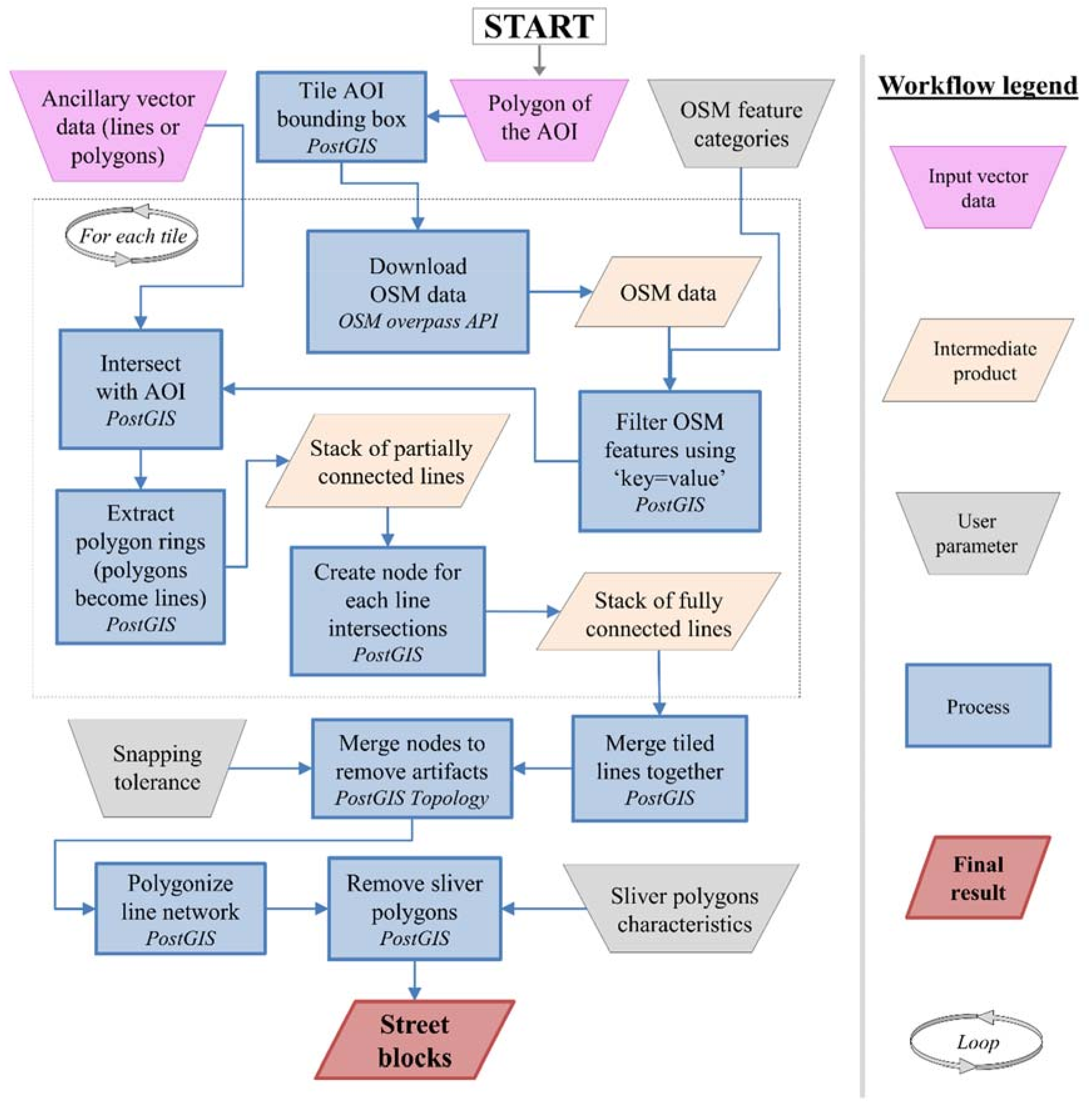
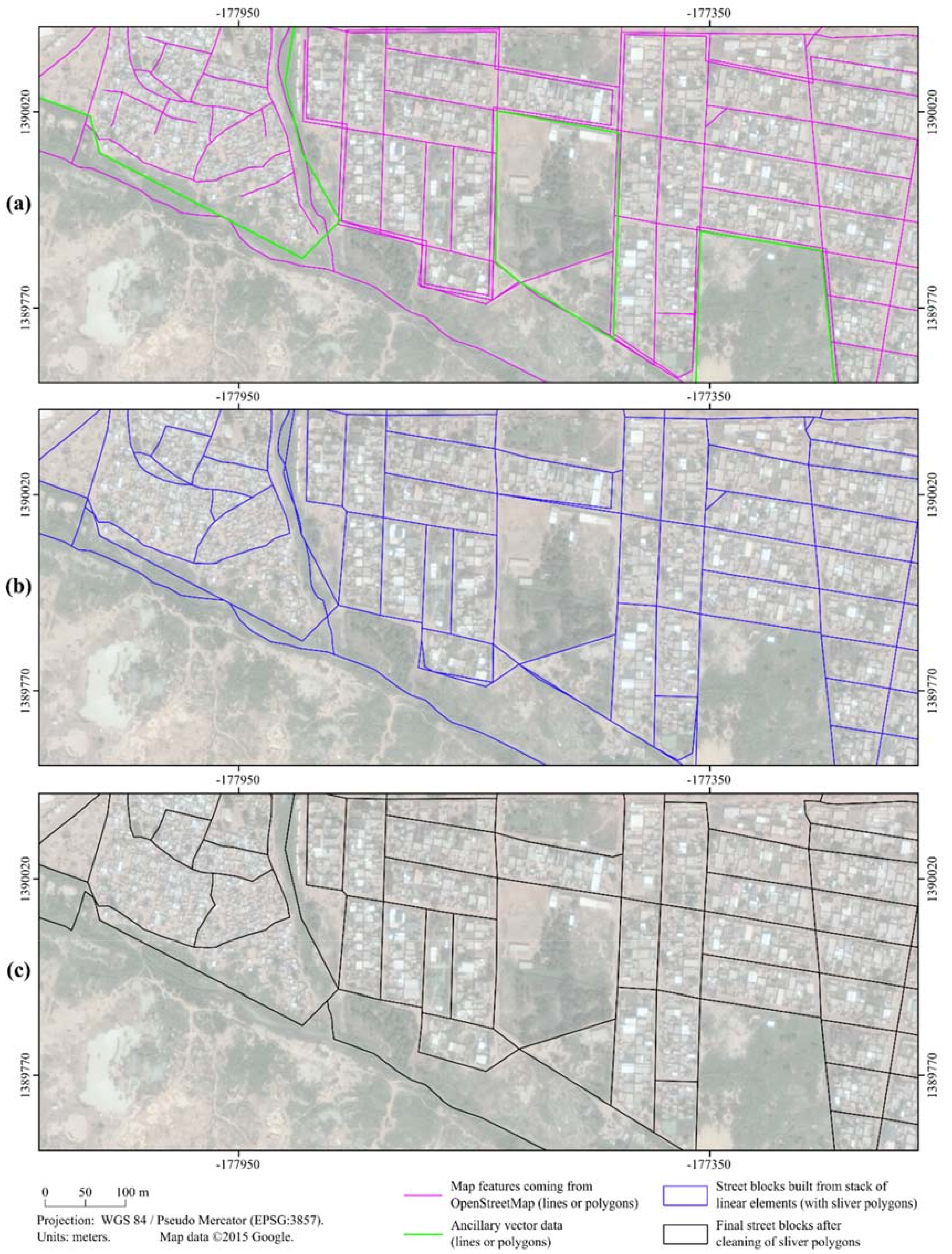
2.3. Extraction of Street Block Geometries Using OpenStreetMap
2.4. Computing Street Block Features
2.4.1. Street Blocks’ Spatial Metrics (Patch-Based Metrics)
2.4.2. Additional Street Block’s Features
2.5. Land Use Scheme and Sampling
2.6. Feature Selection and Classification Using Machine Learning
3. Results
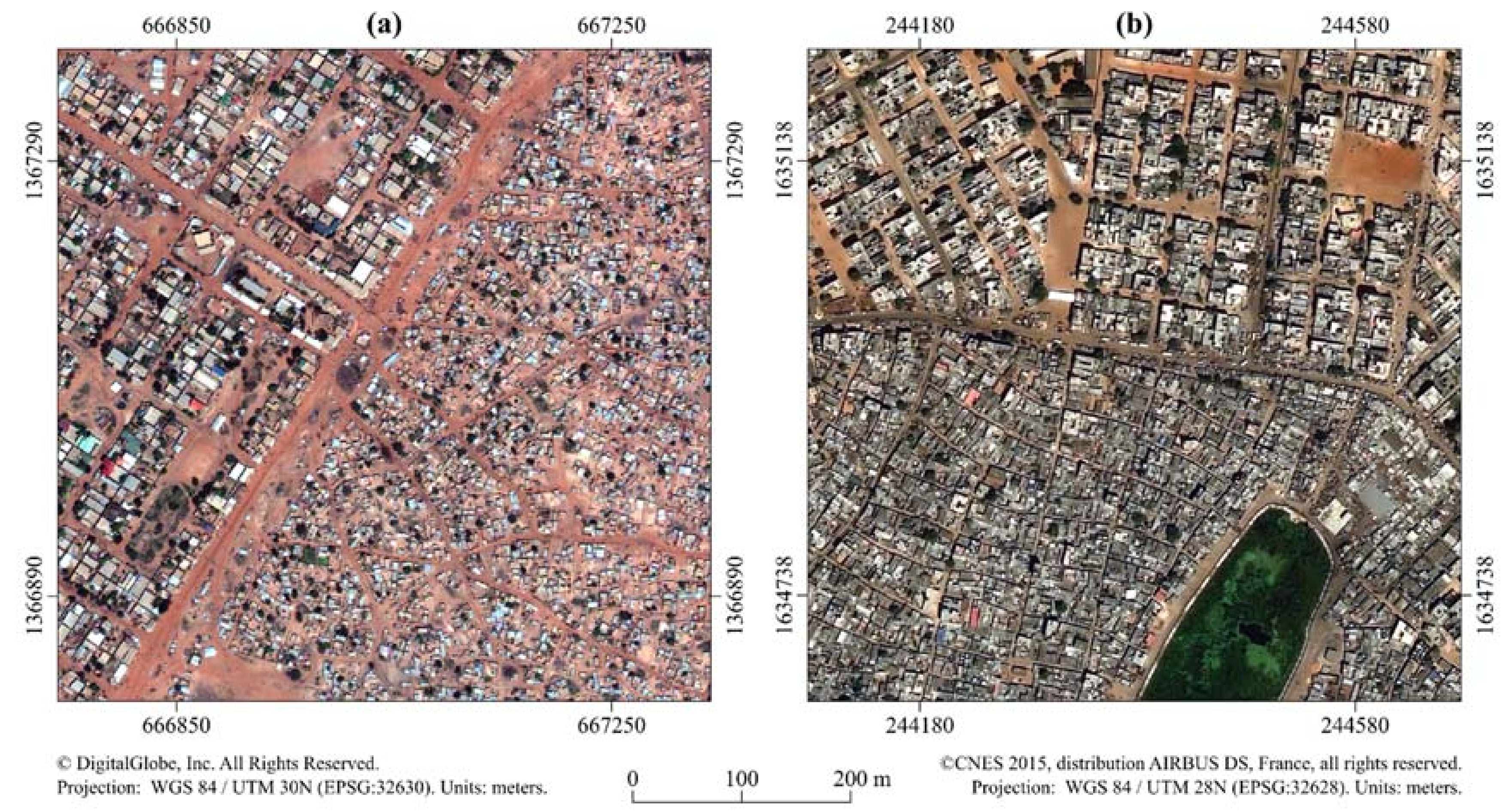
3.1. Extraction of Street Block Geometries
3.2. Automated Feature Selection
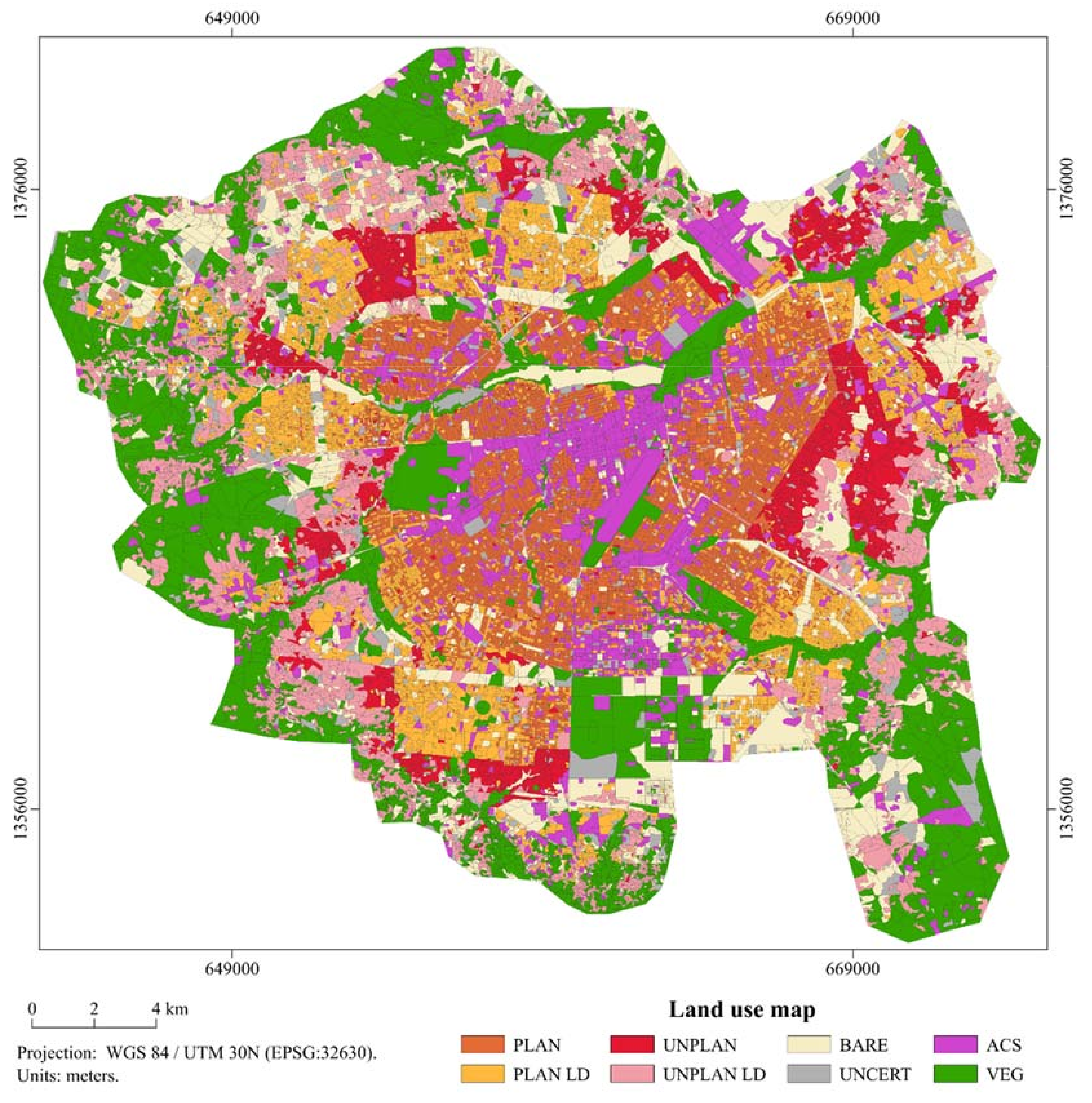
3.3. Land-Use Classification Using Random Forest
3.4. Introduction of Uncertainty and Thematic Improvement of Final Products
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level of Computation | Metric |
|---|---|
| Landscape level All land-cover classes together | Dominance |
| Pielou | |
| Renyi | |
| Richness | |
| Shannon | |
| Simpson | |
| Class level On binary maps (for each land-cover class separately) | Patch number |
| Patch density | |
| Mean patch size | |
| SD of patch size | |
| Patch size coef. of variation | |
| Range of patch size | |
| Shape index | |
| Proportion |
| Source of Information | Blocks Feature |
|---|---|
| Spectral | NDVI median |
| NDVI mean | |
| NDWI median | |
| NDWI mean | |
| nDSM models Built-up mask (from land-cover map) | Mean height of built pixels |
| Number of built pixels | |
| Block morphology (shape features) | Area |
| Perimeter | |
| Compactness relative a to square | |
| Compactness relative a to circle | |
| Fractal dimension |
Appendix B
- Ouagadougou land-cover map [62] is referenced and available on https://doi.org/10.5281/zenodo.1290653. The version used in this research is referred as v1.0 (10.5281/zenodo.1290654).
- Dakar land-cover map [63] is referenced and available on https://doi.org/10.5281/zenodo.1290799. The version used in this research is referred as v1.0 (10.5281/zenodo.1290800).
- Ouagadougou land-use map [64] is referenced and available on https://doi.org/10.5281/zenodo.1291384. The version produced in this research is referred as v1.0 (10.5281/zenodo.1291385).
- Dakar land-use map [65] is referenced and available on https://doi.org/10.5281/zenodo.1291388. The version produced in this research is referred as v1.0 (10.5281/zenodo.1291389).
References
- UN DESA. World Urbanization Prospects: The 2018 Revision, Online ed; United nations, Department of Economic and Social Affairs: New York, NY, USA, 2018. [Google Scholar]
- Novack, T.; Kux, H.; Feitosa, R.; Costa, G. Per block urban land use interpretation using optical VHR data and the knowledge-based system Interimage. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 6. [Google Scholar]
- Mennecke, B.E.; West, L.A., Jr. Geographic Information Systems in Developing Countries: Issues in Data Collection, Implementation and Management. J. Glob. Inf. Manag. 2001, 9, 44–54. [Google Scholar] [CrossRef]
- Eria, S. The State of GIS in Developing Countries: A Diffusion and GIS & Society Analysis of Uganda, and the Potential for Mobile Location-Based Services. Ph.D. Thesis, University of Minnesota, Minneapolis, MN, USA, 2012. [Google Scholar]
- Tumba, A.G.; Ahmad, A. Geographic information system and spatial data infrastructure: A developing societies’ perception. Univers. J. Geosci. 2014, 2, 85–92. [Google Scholar] [CrossRef]
- Schwabe, C.A. The geoinformation industry in Africa: Prospects and potentials. In Proceedings of the Fourth Meeting of the Committee on Development Information (CODI IV), Addis Ababa, Ethiopia, 23–28 April 2005. [Google Scholar]
- Schwabe, C. Getting Geoinformation and SDI to Work for Africa–Part 2; PositionIT: Gauteng, South Africa, 2010. [Google Scholar]
- Economic Commission for Africa, United Nations. Geospatial Information for Sustainable Development in Africa: African Action Plan on Global Geospatial Information Management; Economic Commission for Africa, United Nations: Addis Ababa, Ethiopia, 2017. [Google Scholar]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Walde, I.; Hese, S.; Berger, C.; Schmullius, C. From land cover-graphs to urban structure types. Int. J. Geogr. Inf. Sci. 2014, 28, 584–609. [Google Scholar] [CrossRef]
- Vanderhaegen, S.; Canters, F. Mapping urban form and function at city block level using spatial metrics. Landsc. Urban Plan. 2017, 167, 399–409. [Google Scholar] [CrossRef]
- Voltersen, M.; Berger, C.; Hese, S.; Schmullius, C. Object-based land cover mapping and comprehensive feature calculation for an automated derivation of urban structure types at block level. Remote Sens. Environ. 2014, 154, 192–201. [Google Scholar] [CrossRef]
- Siksna, A. The effects of block size and form in North American and Australian city centres. Urban Morphol. 1997, 1, 19–33. [Google Scholar]
- Almeida, C.M.D.; Monteiro, A.M.V.; Câmara, G.; Soares-Filho, B.S.; Cerqueira, G.C.; Pennachin, C.L.; Batty, M. GIS and remote sensing as tools for the simulation of urban land-use change. Int. J. Remote Sens. 2005, 26, 759–774. [Google Scholar] [CrossRef]
- Bochow, M.; Taubenbock, H.; Segl, K.; Kaufmann, H. An automated and adaptable approach for characterizing and partitioning cities into urban structure types. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 1796–1799. [Google Scholar] [CrossRef]
- Grippa, T. Osm Street Blocks Extraction (Version V1.0). Zenodo 2018. [Google Scholar] [CrossRef]
- Fonte, C.; Minghini, M.; Patriarca, J.; Antoniou, V.; See, L.; Skopeliti, A. Generating Up-to-Date and Detailed Land Use and Land Cover Maps Using OpenStreetMap and GlobeLand30. ISPRS Int. J. Geo-Inf. 2017, 6, 125. [Google Scholar] [CrossRef]
- Long, Y.; Liu, X. Automated identification and characterization of parcels (AICP) with OpenStreetMap and Points of Interest. Environ. Plan. B Plan. Des. 2016, 43, 341–360. [Google Scholar]
- Fan, H.; Yang, B.; Zipf, A.; Rousell, A. A polygon-based approach for matching OpenStreetMap road networks with regional transit authority data. Int. J. Geogr. Inf. Sci. 2016, 30, 748–764. [Google Scholar] [CrossRef]
- Simwanda, M.; Murayama, Y. Integrating Geospatial Techniques for Urban Land Use Classification in the Developing Sub-Saharan African City of Lusaka, Zambia. ISPRS Int. J. Geo-Inf. 2017, 6, 102. [Google Scholar] [CrossRef]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Aubrecht, C.; Steinnocher, K.; Hollaus, M.; Wagner, W. Integrating earth observation and GIScience for high resolution spatial and functional modeling of urban land use. Comput. Environ. Urban Syst. 2009, 33, 15–25. [Google Scholar] [CrossRef]
- McGarigal, K.; Marks, B.J. FRAGSTATS: Spatial Pattern Analysis Program for Quantifying Landscape Structure; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 1995. [Google Scholar]
- Turner, M.G.; Gardner, R.H. Landscape Ecology in Theory and Practice; Springer: New York, NY, USA, 2015; ISBN 978-1-4939-2793-7. [Google Scholar]
- Urban, D.L.; O’Neill, R.V.; Shugart, H.H. Landscape Ecology. BioScience 1987, 37, 119–127. [Google Scholar] [CrossRef]
- Uuemaa, E.; Mander, Ü.; Marja, R. Trends in the use of landscape spatial metrics as landscape indicators: A review. Ecol. Indic. 2013, 28, 100–106. [Google Scholar] [CrossRef]
- Lowry, J.H.; Lowry, M.B. Comparing spatial metrics that quantify urban form. Comput. Environ. Urban Syst. 2014, 44, 59–67. [Google Scholar] [CrossRef]
- Luck, M.; Wu, J. A gradient analysis of urban landscape pattern: A case study from the Phoenix metropolitan region, Arizona, USA. Landsc. Ecol. 2002, 17, 327–339. [Google Scholar] [CrossRef]
- Herold, M.; Scepan, J.; Clarke, K.C. The use of remote sensing and landscape metrics to describe structures and changes in urban land uses. Environ. Plan. A 2002, 34, 1443–1458. [Google Scholar] [CrossRef]
- Petrov, A. One Hundred Years of Dasymetric Mapping: Back to the Origin. Cartogr. J. 2012, 49, 256–264. [Google Scholar] [CrossRef]
- Mennis, J. Generating Surface Models of Population Using Dasymetric Mapping. Prof. Geogr. 2003, 55, 31–42. [Google Scholar] [CrossRef]
- Gisbert, F.J.G.; Martí, I.C.; Gielen, E. Clustering cities through urban metrics analysis. J. Urban Des. 2017, 22, 689–708. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Grippa, T.; Lennert, M.; Beaumont, B.; Vanhuysse, S.; Stephenne, N.; Wolff, E. An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification. Remote Sens. 2017, 9, 358. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S.; Vanhuysse, S.G.; Lennert, M.; Wolff, E. A local segmentation parameter optimization approach for mapping heterogeneous urban environments using VHR imagery. In Proceedings of the Remote Sensing Technologies and Applications in Urban Environments II, Warsaw, Poland, 4 October 2017; Volume 10431. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Lennert, M.; Vanhuysse, S.; Wolff, E. SPUSPO: Spatially Partitioned Unsupervised Segmentation Parameter Optimization for efficiently segmenting large heterogeneous areas. In Proceedings of the 2017 Conference on Big Data from Space (BiDS’17), Toulouse, France, 28–30 November 2017. [Google Scholar]
- Vanhuysse, S.; Grippa, T.; Lennert, M.; Wolff, E.; Idrissa, M. Contribution of nDSM derived from VHR stereo imagery to urban land-cover mapping in Sub-Saharan Africa. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017. [Google Scholar]
- Barrington-Leigh, C.; Millard-Ball, A. The world’s user-generated road map is more than 80% complete. PLoS ONE 2017, 12, e0180698. [Google Scholar] [CrossRef] [PubMed]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Proceedings of the 20th International Conference on Electronic Publishing; Göttingen, Germany, 7–9 June 2016; pp. 87–87. [Google Scholar] [CrossRef]
- McGarigal, K. FRAGSTATS help v.4.2 2015. Available online: https://www.umass.edu/landeco/research/fragstats/documents/fragstats.help.4.2.pdf (accessed on 1 June 2018).
- OpenStreetMap Wiki contributors Overpass API—OpenStreetMap Wiki. 2018. Available online: https://wiki.openstreetmap.org/wiki/Overpass_API (accessed on 1 June 2018).
- Davidovic, N.; Mooney, P.; Stoimenov, L.; Minghini, M. Tagging in Volunteered Geographic Information: An Analysis of Tagging Practices for Cities and Urban Regions in OpenStreetMap. ISPRS Int. J. Geo-Inf. 2016, 5, 232. [Google Scholar] [CrossRef]
- Vandecasteele, A.; Devillers, R. Improving Volunteered Geographic Information Quality Using a Tag Recommender System: The Case of OpenStreetMap. In OpenStreetMap in GIScience; Arsanjani, J.J., Zipf, A., Mooney, P., Helbich, M., Eds.; Lecture Notes in Geoinformation and Cartography; Springer: Basel, Switzerland, 2015; pp. 59–80. ISBN 978-3-319-14279-1. [Google Scholar]
- Li, Q.; Fan, H.; Luan, X.; Yang, B.; Liu, L. Polygon-based approach for extracting multilane roads from OpenStreetMap urban road networks. Int. J. Geogr. Inf. Sci. 2014, 28, 2200–2219. [Google Scholar] [CrossRef]
- Grippa, T. Street Blocks Features Computation (Version V1.0). Zenodo 2018. [Google Scholar] [CrossRef]
- McGarigal, K.; Tagil, S.; Cushman, S.A. Surface metrics: An alternative to patch metrics for the quantification of landscape structure. Landsc. Ecol. 2009, 24, 433–450. [Google Scholar] [CrossRef]
- Porta, C.; Spano, L.D.; Metz, M.; GRASS Development Team. Module r.li.*. 2017. Available online: https://grass.osgeo.org/grass74/manuals/r.li.html (accessed on 1 June 2018).
- Neteler, M.; Mitasova, H. Open Source GIS—A GRASS GIS Approach; Springer: New York, NY, UISA, 2008. [Google Scholar]
- Neteler, M.; Beaudette, D.E.; Cavallini, P.; Lami, L.; Cepicky, J. Grass gis. In Open Source Approaches in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2008; pp. 171–199. ISBN 978-3-540-74831-1. [Google Scholar]
- Lennert, M.; GRASS Development Team. Addon i.segment.stats. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3.; Open Source Geospatial Foundation: Chicago, IL, USA, 2016. [Google Scholar]
- Borderon, M.; Oliveau, S.; Machault, V.; Vignolles, C.; Lacaux, J.-P.; N’Donky, A. Qualifier les espaces urbains à Dakar, Sénégal. Cybergeo Eur. J. Geogr. 2014. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Cushman, S.A.; McGarigal, K.; Neel, M.C. Parsimony in landscape metrics: Strength, universality, and consistency. Ecol. Indic. 2008, 8, 691–703. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2015, 7, 19–33. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; Version 3.5.0; R Foundation for Statistical Computing: Vienna, Austria, 2008; ISBN 3-900051-07-0. [Google Scholar]
- Baumer, B.; Cetinkaya-Rundel, M.; Bray, A.; Loi, L.; Horton, N.J. R Markdown: Integrating a reproducible analysis tool into introductory statistics. arXiv, 2014; arXiv:1402.1894. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Chunyang, L. Probability Estimation in Random Forests. Master’s Thesis, Department of Mathematics and Statistics, Utah State University, Logan, UT, USA, 2013. [Google Scholar]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2017, 1. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S. Ouagadougou Very-High Resolution Land Cover Map (Version V1.0) [Data set]. Zenodo 2018. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S. Dakar Very-High Resolution Land Cover Map (Version V1.0) [Data set]. Zenodo 2018. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S. Ouagadougou Land Use Map at Street Block Level (Version V1.0) [Data set]. Zenodo 2018. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S. Dakar Land Use Map at Street Block Level (Version V1.0) [Data set]. Zenodo 2018. [Google Scholar] [CrossRef]




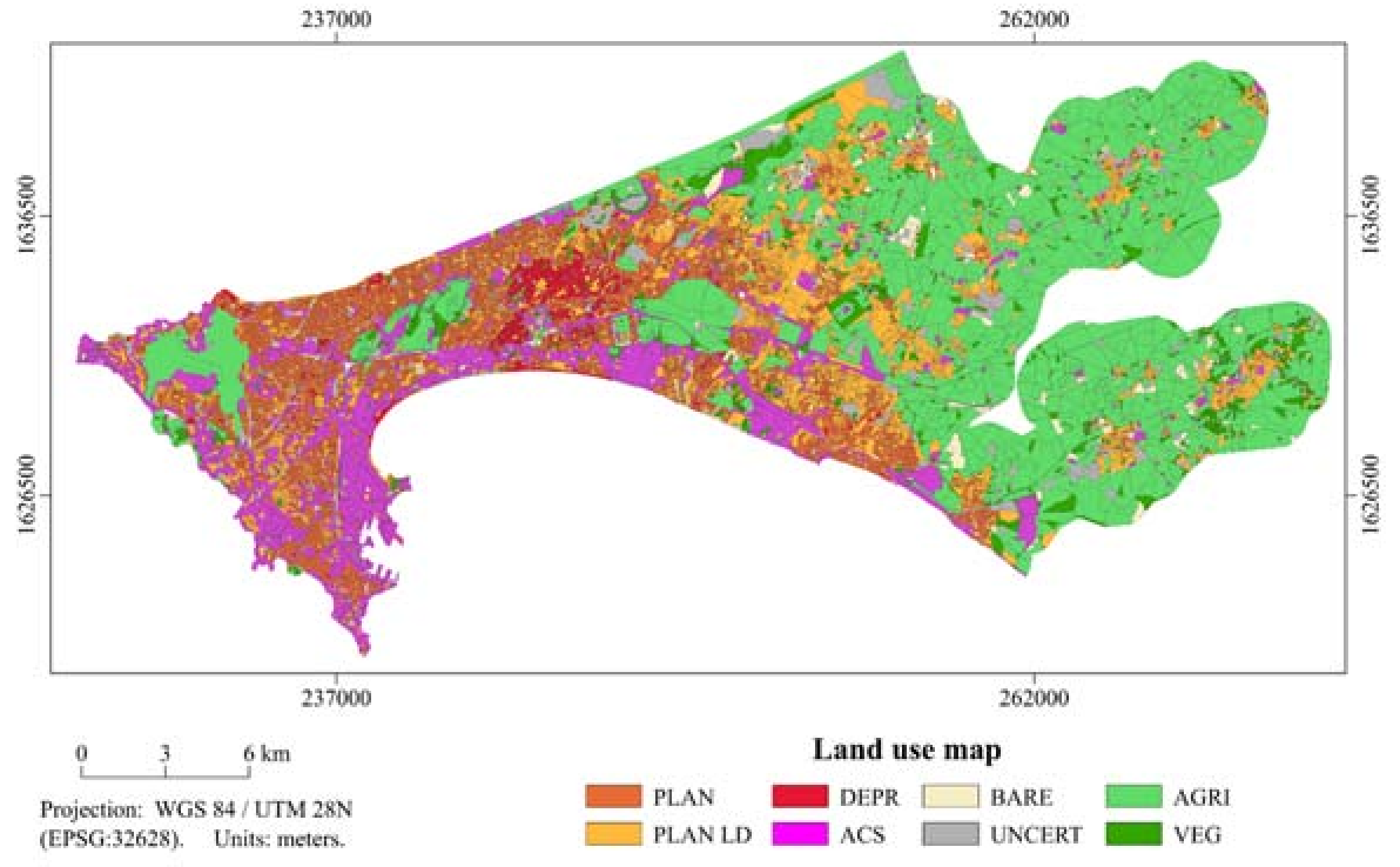

| Ouagadougou—Burkina Faso | Dakar—Senegal | ||
|---|---|---|---|
| Class | Abbreviation | Class | Abbreviation |
| High buildings (>3 m) | HB | High buildings (>10 m) | HB |
| Low buildings (<3 m) | LB | Medium buildings (5–10 m) | MB |
| - | - | Low buildings (<5 m) | LB |
| Swimming pools | SW | Swimming pools | SW |
| Asphalt surfaces | AS | Artificial ground surfaces | AS |
| Bare soils | BS | Bare soils | BS |
| Trees | TR | Trees | TR |
| Low vegetation | LV | Low vegetation | LV |
| Water bodies | WB | Inland waters | WB |
| Shadows | SH | Shadows | SH |
| Class | Abbreviation | Training Set Size | Test Set Size |
|---|---|---|---|
| Ouagadougou—Burkina Faso | |||
| Vegetation | VEG | 122 | 41 |
| Bare soils | BARE | 173 | 57 |
| Non-residential built-up (administrative, commercial, services, etc.) | ACS | 220 | 68 |
| Planned residential built-up | PLAN | 268 | 83 |
| Unplanned residential built-up | UNPLAN | 302 | 90 |
| Dakar—Senegal | |||
| Agricultural vegetation | AGRI | 93 | 42 |
| Natural vegetation | VEG | 86 | 30 |
| Bare soils | BARE | 57 | 18 |
| Non-residential built-up (administrative, commercial, services, etc.) | ACS | 153 | 46 |
| Planned residential built-up | PLAN | 872 | 277 |
| Deprived residential built-up | DEPR | 209 | 68 |
| Case Studies | ||
|---|---|---|
| Street Block Features | Ouagadougou | Dakar |
| Landscape composition | ||
| Shannon | X | X |
| Dominance | X | |
| Features relative to building class | ||
| High buildings mean patch size | X | |
| SD of high buildings patch area | X | |
| Proportion of high buildings pixels in the block | X | |
| Proportion of medium buildings | NA | X |
| Proportion of low building pixels in the block | X | X |
| SD of low building patch area | X | |
| Low building patch density | X | X |
| Low building patch number | X | |
| Count of built pixels | X | |
| Mean height of built pixels | X | X |
| Features relative to shadow class | ||
| Proportion of shadows pixels in the block | X | |
| Shadows patch density | X | X |
| Shadows patch number | X | |
| Features relative to other land-cover classes | ||
| Artificial surface shape index | X | |
| Range of artificial surfaces patch area | X | |
| SD of asphalt surface patch area | X | |
| Bare soils patch density | X | |
| Features relative to vegetation classes | ||
| Low vegetation patch density | X | |
| Range of low vegetation patch area | X | |
| Range of trees patch area | X | |
| Trees mean patch size | X | |
| Remote sensing indices | ||
| NDVI median | X | X |
| NDWI SD | X | |
| Features relative to block morphology | ||
| Block perimeter | X | |
| Compactness relative to a circle | X | |
| Compactness relative to a square | X | |
| Total | 21 | 13 |
| Reference | ||||||
|---|---|---|---|---|---|---|
| Classes | VEG | BARE | ACS | PLAN | UNPLAN | |
| Prediction | VEG | 36 | 7 | 0 | 0 | 2 |
| BARE | 5 | 47 | 4 | 0 | 2 | |
| ACS | 0 | 0 | 47 | 7 | 0 | |
| PLAN | 0 | 2 | 14 | 79 | 2 | |
| UNPLAN | 0 | 1 | 3 | 4 | 77 | |
| F-score | 0.84 | 0.82 | 0.77 | 0.84 | 0.92 | |
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Classes | AGRI | VEG | BARE | ACS | PLAN | DEPR | |
| Prediction | AGRI | 34 | 3 | 0 | 1 | 1 | 0 |
| VEG | 6 | 17 | 2 | 4 | 3 | 0 | |
| BARE | 1 | 3 | 12 | 0 | 0 | 0 | |
| ACS | 1 | 4 | 1 | 24 | 8 | 1 | |
| PLAN | 0 | 3 | 2 | 15 | 253 | 25 | |
| DEPR | 0 | 0 | 1 | 1 | 12 | 42 | |
| F-score | 0.84 | 0.55 | 0.71 | 0.57 | 0.88 | 0.68 | |
| Land Use Classes | ||||||
|---|---|---|---|---|---|---|
| Street Blocks Features | PLAN | UNPLAN | ACS | BARE | VEG | Overall |
| Mean height of built pixels | 0.078 | 0.137 | 0.106 | 0.061 | 0.034 | 0.091 |
| Proportion of high buildings patch | 0.124 | 0.089 | 0.065 | 0.082 | 0.071 | 0.090 |
| Low building patch density | 0.085 | 0.120 | 0.024 | 0.045 | 0.165 | 0.084 |
| Proportion of Low building patch | 0.071 | 0.077 | 0.010 | 0.089 | 0.150 | 0.072 |
| High buildings mean patch size | 0.061 | 0.030 | 0.065 | 0.048 | 0.051 | 0.051 |
| Low vegetation patch density | 0.048 | 0.047 | 0.048 | −0.004 | 0.032 | 0.038 |
| NDVI median | 0.006 | 0.030 | 0.007 | 0.015 | 0.257 | 0.042 |
| Shadows patch density | 0.024 | 0.087 | 0.018 | 0.076 | −0.011 | 0.043 |
| SD of high buildings patch area | 0.039 | 0.047 | 0.055 | 0.042 | 0.043 | 0.045 |
| Trees mean patch size | 0.023 | 0.010 | 0.063 | 0.008 | 0.003 | 0.023 |
| Land Use Classes | |||||||
|---|---|---|---|---|---|---|---|
| Street Blocks Features | PLAN | DEPR | ACS | BARE | AGRI | VEG | Overall |
| Proportion of low buildings patch | 0.070 | 0.164 | 0.017 | 0.100 | 0.259 | 0.122 | 0.098 |
| Shadows patch density | 0.080 | 0.055 | 0.032 | 0.039 | 0.047 | 0.097 | 0.069 |
| Low buildings patch density | 0.044 | 0.075 | 0.029 | 0.008 | 0.248 | 0.018 | 0.061 |
| Mean height of built pixels | 0.067 | 0.056 | 0.037 | 0.064 | 0.020 | 0.092 | 0.060 |
| NDVI median | 0.065 | 0.030 | 0.016 | 0.020 | 0.181 | 0.193 | 0.072 |
| Proportion of shadows patch | 0.050 | 0.095 | 0.004 | 0.051 | 0.080 | 0.066 | 0.055 |
| Range of low vegetation patch area | 0.024 | 0.016 | −0.001 | 0.010 | 0.389 | 0.010 | 0.049 |
| Count of built pixels | 0.036 | 0.022 | 0.025 | 0.115 | 0.037 | 0.097 | 0.040 |
| Range of artificial surfaces patch area | 0.025 | 0.018 | 0.132 | 0.006 | 0.012 | 0.021 | 0.033 |
| Proportion of medium buildings patch | 0.065 | 0.002 | 0.002 | 0.025 | 0.088 | 0.013 | 0.047 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grippa, T.; Georganos, S.; Zarougui, S.; Bognounou, P.; Diboulo, E.; Forget, Y.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E. Mapping Urban Land Use at Street Block Level Using OpenStreetMap, Remote Sensing Data, and Spatial Metrics. ISPRS Int. J. Geo-Inf. 2018, 7, 246. https://doi.org/10.3390/ijgi7070246
Grippa T, Georganos S, Zarougui S, Bognounou P, Diboulo E, Forget Y, Lennert M, Vanhuysse S, Mboga N, Wolff E. Mapping Urban Land Use at Street Block Level Using OpenStreetMap, Remote Sensing Data, and Spatial Metrics. ISPRS International Journal of Geo-Information. 2018; 7(7):246. https://doi.org/10.3390/ijgi7070246
Chicago/Turabian StyleGrippa, Taïs, Stefanos Georganos, Soukaina Zarougui, Pauline Bognounou, Eric Diboulo, Yann Forget, Moritz Lennert, Sabine Vanhuysse, Nicholus Mboga, and Eléonore Wolff. 2018. "Mapping Urban Land Use at Street Block Level Using OpenStreetMap, Remote Sensing Data, and Spatial Metrics" ISPRS International Journal of Geo-Information 7, no. 7: 246. https://doi.org/10.3390/ijgi7070246