1. Introduction
When investigating and analyzing crimes, it is important to have precise temporal information. Whilst aggregating burglaries might show an increase of crimes on certain weekdays, the temporal analysis might indicate more complex patterns, as the temporal resolution is changed, e.g., from days to hours. Further, the temporal information of different crime categories conveys different information about the crime category or about the perpetrator, e.g., when a crime was committed might help rule out a large group of possible perpetrators. As such, having precise temporal information available is important to law enforcement agencies during, e.g., spatio-temporal analyses or hotspot analyses.
However, crime data often contain uncertainties, e.g., if the crime was committed without any witnesses, it might be difficult to collect complete, precise information. Some crime categories, e.g., unattended property theft, such as burglaries, often lack precise temporal information. They are often reported to have taken place sometime within a time interval of various length [
1,
2]. The lack of accurate temporal data regarding certain crime types is unfortunate, since it renders the analysis of crime more difficult [
3]. Consequently, there is a need for methods with the ability to, based on imprecise temporal data, estimate a more accurate time of occurrence for offenses.
Estimating the actual time of occurrence can be resource demanding, as the number of crimes available and the temporal resolution vary, e.g., hour of the day or month in the year. There exist multiple methods for estimating the occurrence time of a crime [
1]. The estimated occurrence times are affected by the estimation method used. However, no thorough comparison of existing methods in different temporal configurations has been conducted within the research community.
The present study therefore sets out to fill this research gap by evaluating five existing methods, and one novel method, in order to determine which methods most accurately estimate temporal patterns given different temporal resolutions and crime sample sizes. Choosing a suitable method is important, as the choice of method affects the end analysis result and, thereby, also law enforcement agencies’ ability to perform crime analysis, as well as their knowledge concerning temporal crime patterns.
1.1. Aim and Scope
The aim of this study is to investigate which of six temporal analysis methods most accurately approximates the temporal distribution of residential burglaries with known precise offense times in various temporal configurations. The evaluations are made with respect to the following four temporal resolutions: (1) hour of the day; (2) day of the week; (3) month of the year and (4) day of the year. For each of these temporal resolutions, the temporal analysis methods are investigated using both a dataset that contains all available burglary data, as well as a dataset with samples of the offenses, i.e., only a limited number of cases included in the analysis. Thus, each temporal analysis method is evaluated in eight configurations with both varying temporal resolution and amount of available burglary data during analysis. It should be emphasized that the main result from this study is not the temporal patterns created from the data, but rather the performance of the investigated temporal analysis methods in predicting the temporal distribution in various temporal configurations, i.e., in different temporal resolutions and crime sample sizes.
The scope of this study is limited to the evaluation of the performance of six temporal analysis methods on a dataset that consists of all reported Swedish residential burglaries between 2010 and 2014. All methods will be evaluated on the eight configurations described above.
1.2. Outline
In the next section, the related work is presented, followed by the introduction of the six temporal analysis methods in
Section 3. Then, the dataset used is described in
Section 4, and the experiments in which the performance of the analysis methods are evaluated are introduced in
Section 5. The results from the experiments are presented in
Section 6 and analyzed in
Section 7. Finally,
Section 8 concludes the work and presents future work.
2. Related Work
Analytical methods for predicting crimes include approaches for making use of historical crime data, e.g., crime mapping, hot spot identification and risk terrain analysis [
2,
3,
4,
5]. The impact of hurricanes on burglaries has also been investigated [
6]. Within environmental criminology, [
7] study environmental factors influencing criminal activities. Other important approaches involve repeat, or near-repeat, victimization, as well as spatio-temporal analysis methods [
3]. The work in [
8] investigates 10 cities in five countries and finds that the risk of residential burglary is temporarily increased for at least two weeks within a 200-m radius around burgled residences. Research into criminal behavior involves using journey-to-crime theory to suggest how burglars are likely to identify target houses prior to offending [
9,
10]. As such, targets are more likely to be located close to an area familiar to the offender.
A majority of the previous research has been focused on methods involving the analysis of spatial data, leaving temporal analysis methods less explored [
11,
12]. However, this does not imply that temporal data are of less importance from a crime prediction perspective [
13,
14].
The work in [
15] investigates how temporal information can be represented according to five categories: moments, duration, structured time, time as distance and space as clock. The latter can be used to depict how an area changes over time (e.g., a seasonal map). However, the previous four categories are considered more interesting for crime analysis and prediction [
3]. A moment is a singular point in time, often when something happened. This could be an estimated point or a known exact time. A duration of time is the time between two points, e.g., the event is estimated to have happened between time
x and
y. Time as distance is the measurement of how far it would be possible to travel within a time duration, e.g., a light year [
3]. Finally, structured time is the representation of time as, e.g., minutes and hours. More specifically, it is the structuring of time into pieces that are more easily managed.
In addition to the five temporal categories listed above, time span has been identified as another time representation. Time span is a duration in which a moment or a duration could have taken place, but one is unsure about the specifics [
3]. Although offenses have durations themselves, e.g., the offense took 10 minutes to perform, they are often regarded as moments since these durations for burglaries are considerably shorter compared to the time spans in which the offenses have occurred.
Studies on the temporal characteristics of different types of crimes have been conducted to increase the understanding of criminal behavior, e.g., when offenders commit crimes [
14,
16]. For instance, offenses have been found to be more likely to be committed in the afternoon or early evening [
11,
13], while nighttime burglaries were found to be more likely during weekends [
17]. This would suggest that knowledge of victim behavior is essential to the criminal behavior, e.g., late mornings and early afternoon are more likely to result in empty houses due to work hours. This is also supported by the routine activity theory, i.e., that offenders identify opportunities during routine activities, such as driving to work [
13].
Reported household disturbances are found to increase during holidays compared to other days [
18]. The rationale behind this is in the line of routine activities and that changes in regular activities lead to increased risk of victimization [
17]. Furthermore, various types of crimes have been studied in relation to national holidays in a U.S. setting [
19]. It is concluded that crime rates vary not only with the type of holiday, but also with the type of crime. During major holidays, increased frequencies of violent crimes are reported, while the opposite is true for property crimes. It is hypothesized that minor holidays have little or no impact on crime rates. The routine activity theory indicates that only holidays that influence peoples’ regular activities should have an effect on crime rates, i.e., major holidays should have a larger influence compared to minor holidays.
Producing accurate temporal maps of when crimes occur is a difficult task [
2]. Nevertheless, several methods exist that can represent crimes either as moments or to account for the estimated time spans. Circular statistics has been used when analyzing the number of incidents reported to the police by time of the day and day of the week [
20]. Further, the temporal distribution of offenses has been investigated by mapping the crimes into quartile minutes [
13]. This allows the comparison of the crime time distribution between cities and geographical areas.
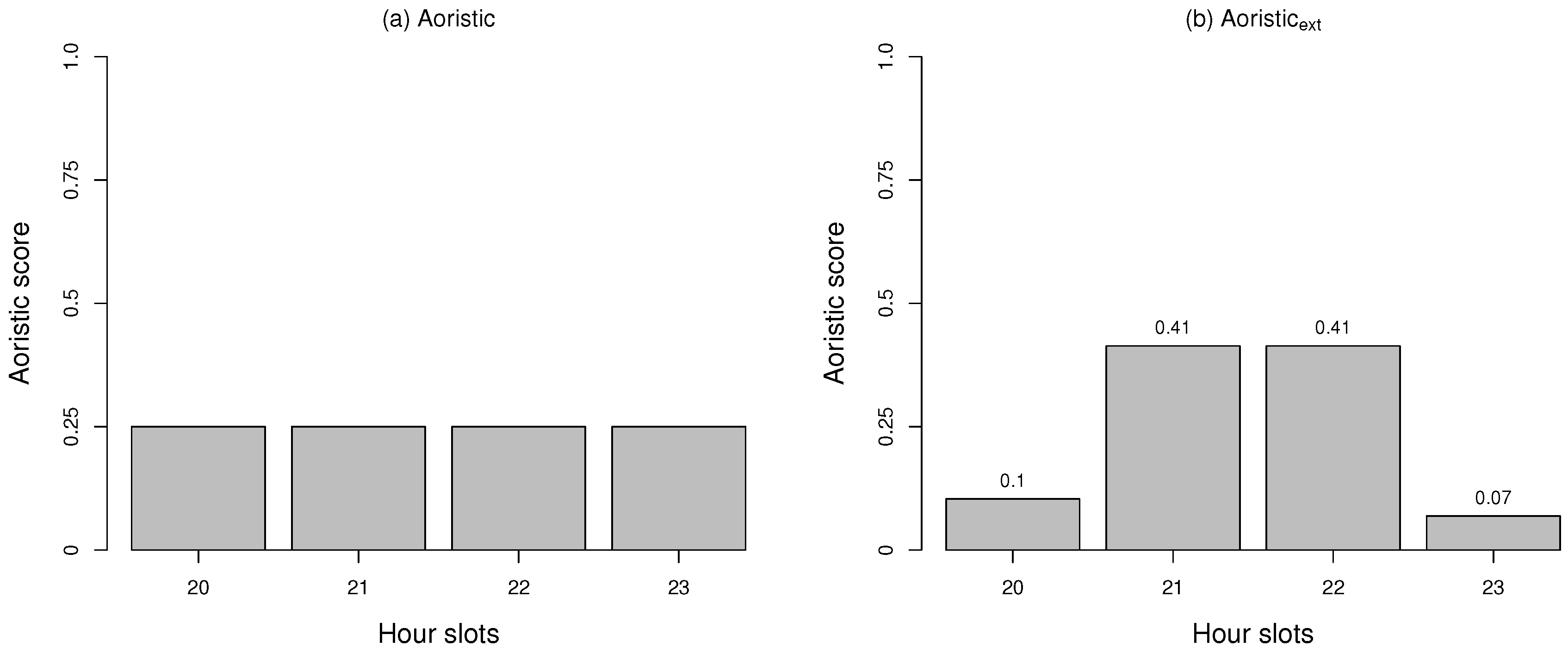
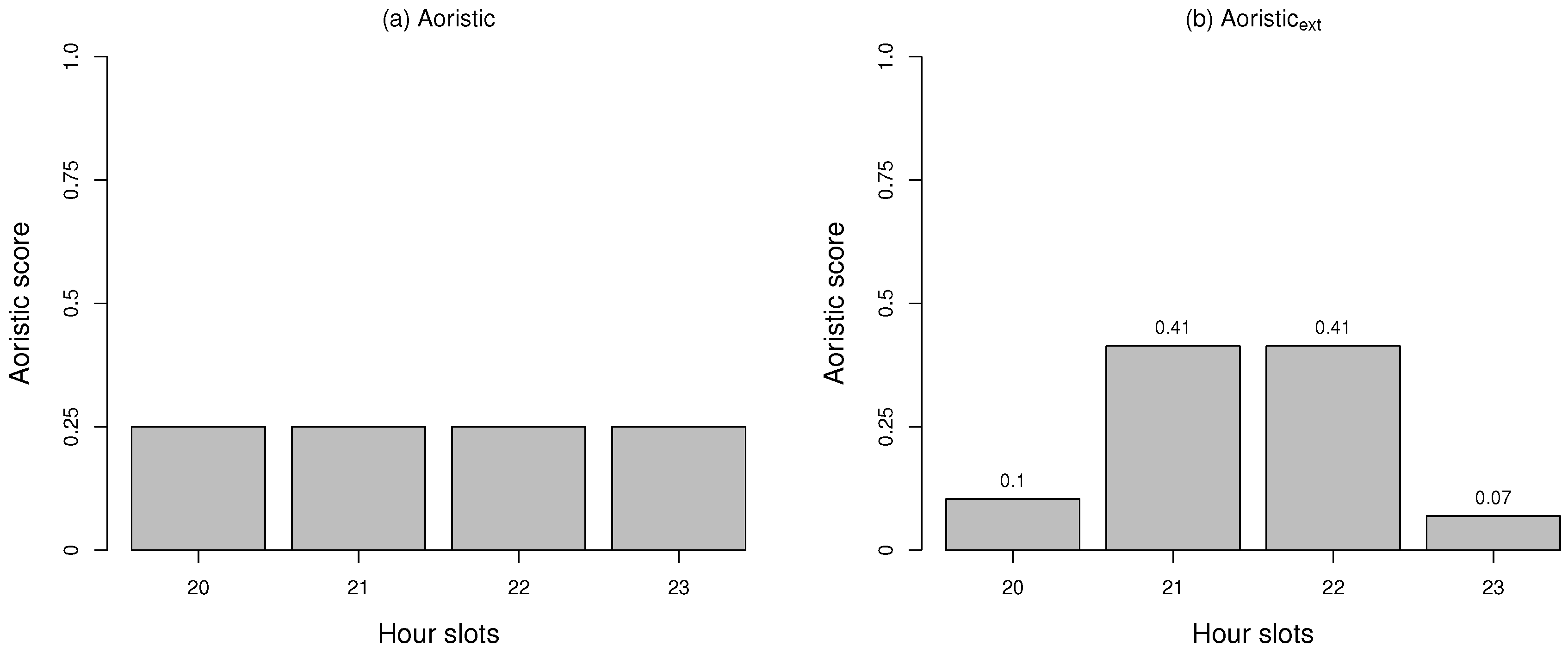
One temporal analysis method often included in crime analytics software is the aoristic method that can handle crimes without a known specific occurrence time, i.e., represented as a time span instead [
1,
12,
16]. It works by choosing a structured time or temporal unit, e.g., hours or days. It works by giving each offense a point of
, which then is evenly divided among the units within the time span. This is repeated for every crime investigated. The points of every temporal unit are then summarized and used to indicate high profile time periods, which evenly distributes the likelihood of when a crime occurred across the possible temporal units.
The accuracy of temporal analysis methods has been evaluated on their ability to estimate the exact offense time for bicycle thefts [
11]. The study evaluates how accurately five methods can estimate the true offense time in terms of hour of the day. It was concluded that the aoristic method best manages to estimate the offense time in that context. However, the study does not evaluate the methods in different configurations and only includes 303 crimes in the analysis.
Research gaps identified within the present study include a lack of the evaluation of temporal analysis methods over multiple temporal resolutions, e.g., months in the year or hour in the day. Single types of structured time have been evaluated on different types of crimes, e.g., bicycle and car thefts, as well as assaults [
11,
12]. The functionality of the aoristic method does not take into account whether time slots are fully or only partially covered when distributing the point, e.g., if the temporal resolution is days, then the aoristic method does not consider whether a certain day is fully covered or not. That is, a time slot that is only covered marginally is given the same amount of points as a time slot that is fully covered. Finally, previous work has to a large extent been studied within the U.S. and U.K. contexts.
4. Data
In this section, the data collection, representation and cleaning processes that this study relies on are described. The temporal analysis methods are evaluated on official criminal records of residential burglaries provided by the Swedish police. Both attempted and completed burglaries were included. Attempted burglaries were included because they indicate the offender’s objective to gain unlawful entrance to a residence, although the burglaries were interrupted. In the remainder of this work, the term burglaries refers to both completed and attempted burglaries.
The dataset consists of all burglaries registered in Sweden during five years, from 1 January 2010 to 31 December 2014. A total of 103,029 burglaries are included in the dataset.
4.1. Data Cleaning
As shown in
Table 1, roughly 3.7% of the data records were removed from the dataset due to inconsistencies or missing attributes. These records were removed due to either:
missing attribute, e.g., missing temporal attribute, or
erroneous temporal attribute, e.g., start time greater than end time.
Inconsistencies in the records were most likely due to human error introduced when filing out the criminal reports. No patterns in how the erroneous records were dispersed in the dataset were found, i.e., they were not grouped at any particular time intervals. Therefore, the erroneous records are assumed to be uniformly distributed throughout the dataset. Although, such errors are slightly more common in 2012–2014 compared to the earlier years. After inconsistent data records were removed, a total of 103,029 burglaries remained, and they make up the dataset used in this study; see
Table 1. The process of cleaning crime records was carried out in the statistical software suite
R.
4.2. Data Representation
Each burglary in the dataset is represented using four attributes. The attributes, listed in
Table 2, are similar to the temporal concepts explained in
Section 3.
denotes the first date on which an offense could have occurred, while
denotes the last date. Similarly, the times
and
denote the first and last time on a certain date, respectively.
As an exact offense date and time usually are not available for burglaries, the temporal aspect needs to be represented as a time span instead of a specific moment. As such, the temporal data were grouped as two points in time representing the boundaries of the time span. Each point was represented as a combination of both a DATE and TIME data type in the MySQL database used.
The difference between the start and end time in seconds was also calculated for each burglary and stored in the database. A difference of zero seconds represents an exactly known offense time, while a difference of 86,400 s
represents a time span of one day during which a burglary could have occurred at any time with equal probability.
Table 3 shows the distribution of these time durations within the dataset. An exact offense time is available for
(10,295) of the burglaries, and
(45,071) of the burglaries occurred within a six-hour time span. On the other hand,
(7009) of burglaries had a time span longer than one week, while merely
(1547) of the burglaries had a time span longer than 30 days.
4.3. Evaluation Dataset
In order to estimate the performance of the six temporal methods, each method’s ability to approximate the distribution of known exact offense times for burglaries is measured. Th crimes with an exact offense time represent the ground truth regarding how burglaries are distributed throughout time. There are 10,295 burglaries with a known exact offense time in the dataset, which represent in the complete dataset. For these crimes, the exact points in time when the offenders committed them are known. However, the exact offense time is not known for the rest of the burglaries. Some of the offense durations rather reflect the plaintiffs’ routine activities, e.g., work hours, than the activities of the offenders. The reasons that some burglaries have an exact offense time is due to burglar alarms with time logs (), burglaries where the plaintiff is home (or returns home) during the offense () and witnesses of the offense (). Note that these reasons are not mutually exclusive and add up to more than , i.e., it is possible to have both a witness and a burglary time log event of a burglary.
In this study, the evaluation is thus based on the assumption that 10.0% of the offenses represent how Swedish burglaries are distributed in time. A similar approach of using a subset of the offenses for evaluation purposes has been used in previous studies, e.g., the study by Ashby et al. [
11]. The motivation behind this assumption is that the exact offense time is determined by external events, such as witnesses and burglary alarm time logs available for different types of burglaries. In addition, before making this assumption, it was discussed with domain experts in both the criminal intelligence in Stockholm, as well as the national Swedish serial crime group, specifically targeting volume crimes, such as burglaries.
5. Experiments
The present study includes eight experiments that test how accurately the six analysis methods approximate the temporal distribution of burglaries with a known exact offense time. This is done with regard to four different temporal resolutions relative to a short perspective (hours of the day), medium perspective (days in the week) and long perspective (months per year and day in the year). Each method produces four approximations, henceforth denoted , , and .
In the first four experiments, a one-factor within-subjects design is used when the temporal resolutions are investigated using all available burglary data. The factor is the temporal methods described in
Section 3.2, i.e., six levels. These also constitute the independent variable. The dependent variables are four statistical measures to be presented in
Section 5.3.
Furthermore, since smaller sample sizes are to be expected in most cases, how a reduction of residential burglary cases affects the accuracy is also investigated in four additional experiments with a two-factor within-subjects design. The additional factor is the dataset that is randomly reduced by 50% ten times, i.e., the factor has ten levels. The result is ten reduced datasets, each including 50% of the burglaries in the previous one. The independent variables are both the candidate methods and the reduced datasets, while the dependent variable is Pearson’s measure.
In all eight experiments, the temporal methods are evaluated by measuring how well they approximate the ground truth represented as:
, which is the 24 h of the day with a slot size of
h according to Ashby et al. [
11], i.e., one day consists of 48 half-hour slots.
that represents the seven days of the week with a slot size of 1 day.
that represents the twelve months in a year with a slot size of 1 month.
that represents the 365 days per year, or 366 in leap years, with a slot size of 1 day.
The similarity or divergence between the approximation and actual distribution is measured per year using the evaluation metrics described in
Section 5.3. Then, the mean and standard deviation are calculated over the five years for each method. The results are used to suggest which temporal analysis methods are more suitable for determining the temporal distribution of burglaries with regards to the four temporal resolutions.
5.1. Validity Threats
Extracting burglaries with a precisely-known offense time from the dataset and using them for evaluation could potentially be a threat to internal validity. If the extracted subset is not representative of the population of Swedish residential burglaries, there is a risk of biases being introduced. However, this approach has been discussed in previous high-quality research [
11]. In addition, domain-experts in the Swedish law enforcement agreed that the assumption that the extracted subset was representative was valid, The reason that some burglaries have known offense times is due to external events, e.g., alarm records, witnesses or the plaintiffs being home during the offense.
Since the data in the present study come from Swedish residential burglaries it is unlikely that the temporal distributions for the four temporal resolutions being investigated could be generalized to other countries. However, since the aim of this work is rather to evaluate the investigated temporal analysis methods’ performance in approximating offense times, this is not an issue.
5.2. Experiment Environment
The residential burglaries’ temporal distributions are produced according to four resolutions. As described in
Section 5, the actual distributions are produced based on the burglaries in the dataset for each of the five years individually. Similarly, each methods’ approximate distribution is also produced per year. For each year and representation, the approximate distribution is compared to the actual distribution and the difference measured. For each evaluation measure, the difference between the actual and approximate distribution is averaged over the five years.
The comparison between the methods’ approximation of the ground truth is carried out per year. Since the dataset consists of five years’ worth of burglaries, each distribution is produced per year, resulting in five distributions per resolution, which then are averaged.
5.3. Evaluation Measurement
The performance of the methods is compared against the ground truth, i.e., crime cases with a known exact , using four measurements for comparing distributions: Pearson’s , Euclidean distance, Spearman’s ρ and Kullback–Leibler.
Pearson’s
test is used to compare two sets to investigate the correlation between sets of data. Pearson’s
value should be as small as possible. Since the data used in the experiment are binned, other well-used nonparametric tests, such as Kolmogorov–Smirnov, are not applicable [
21]. Therefore, Pearson’s
is used to investigate how well the approximated distribution correlates with the actual distribution. Pearson’s
test, due to its suitability and popularity, will be used as the evaluation measurement for the statistical tests.
The Euclidean distance is used to measure the distance between two distributions, in this case between the actual distributions and the approximations produced by the methods. The Euclidean distance is defined in Equation (
6), where
and
indicate the
i-th data point in the respective distribution.
Spearman’s
ρ is a non-parametric rank-based correlation measurement between two variables. The measure ranges between
and 1, where 0 indicates no correlation between the variables and 1 indicates a positive correlation [
22]. The test is used to investigate how well the approximated distribution correlates with the actual distribution.
The Kullback–Leibler divergence is a non-symmetric measure of the information loss when one probability distribution is used for approximating another [
23]. It is also known as the information gain, or relative entropy, of one distribution to another. This is measured in the number of extra bits that are required when approximating the first distribution based on the other, i.e., a lower value indicates that two distributions are more similar.
5.4. Statistical Analysis
To evaluate the difference between the methods, the Kruskal-Wallis test is used to investigate whether a significant difference exists between different methods. Kruskal-Wallis is a non-parametric rank-based statistical test for investigating whether two or more samples are from the same distribution [
22]. Kruskal-Wallis is used instead of the parametric one-way ANOVA test, as the data were not found to be normally distributed [
22]. If a difference exists according to the Kruskal-Wallis test, the Dunn post hoc test is used to investigate between which pairs of methods differences exist. To correct for multiple comparisons, Benjamini-Hochberg adjustment is used [
24]. The Benjamini-Hochberg adjustment is used instead of Bonferroni adjustment, as it provides a less restrictive tradeoff with regards to statistical power, although it allows false positives. Additionally, the Benjamini-Hochberg adjustment controls the false discovery rate, whereas the Bonferroni adjustment controls the family-wise error rate.
Further, to evaluate the methods over different sample sizes, Friedman’s test is used. Friedman’s test is a non-parametric two-way analysis of variance [
21]. The Nemenyi test is used as a post hoc test to investigate how the methods differ from each other. The Nemenyi test calculates a critical difference (CD) using Tukey’s distribution, and any difference in rank between method pairs that is greater than the CD is considered significantly different [
25,
26].
5.5. Tools
The crime data were stored in a MySQL relational database. All crime evaluation methods that are evaluated in this work were implemented as scripts in the statistical language R. The scripts make use of the RMySQL, Lubridate and Ggplot2 packages for their internal workings, and they will be available upon request to the corresponding author. Statistical evaluations have used corresponding packages in R.
7. Analysis and Discussion
Today, law enforcement uses an ad hoc approach to estimating the temporal distribution of residential burglaries. This approach could influence resource planning negatively, as it is difficult to predict how crimes distributions will change over time. Often, experience is prevalent in the decision making process. In this paper, multiple approaches for estimating an approximate temporal distribution of residential burglaries have been investigated.
A method that is able to approximate the temporal distribution of crimes is a key component, together with spatial data, when for instance, law enforcement agencies schedule patrols and other resources more efficiently to better be in sync when crimes actually occur. For example, having a set of hourly approximations that corresponds well to the actual temporal distributions of residential burglaries in different areas of a municipality allows patrols to be present in the correct area when there is a higher likelihood of a residential burglary taking place, i.e., a prioritization of the patrol route.
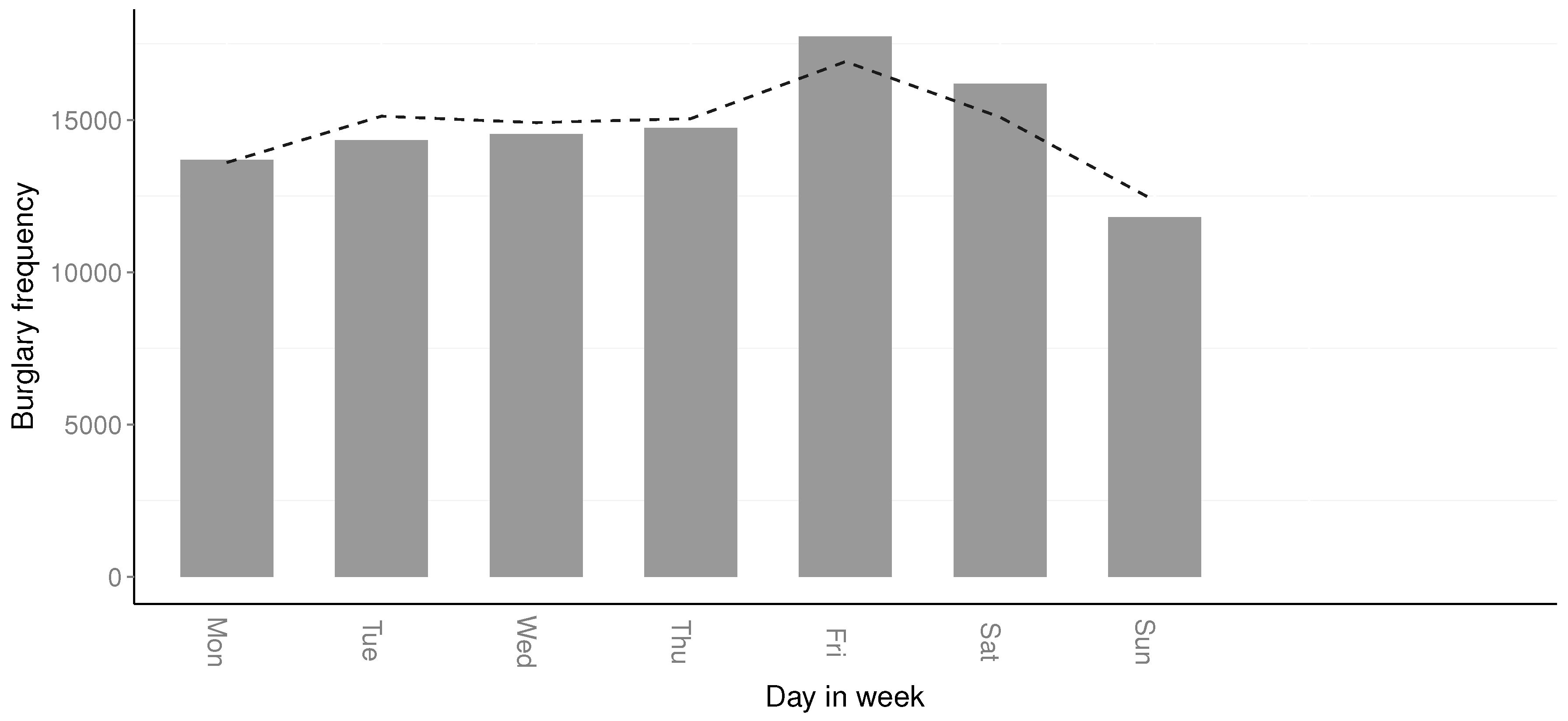
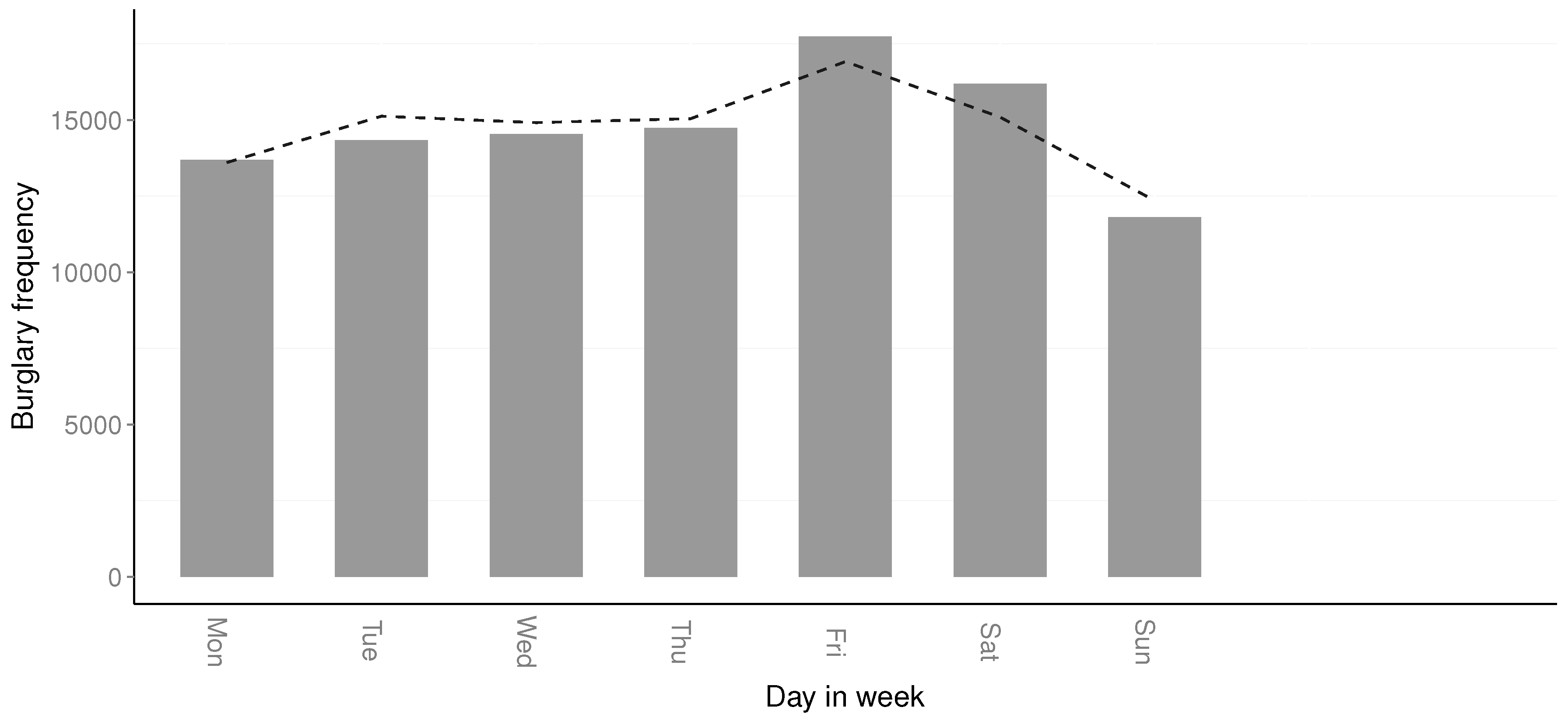
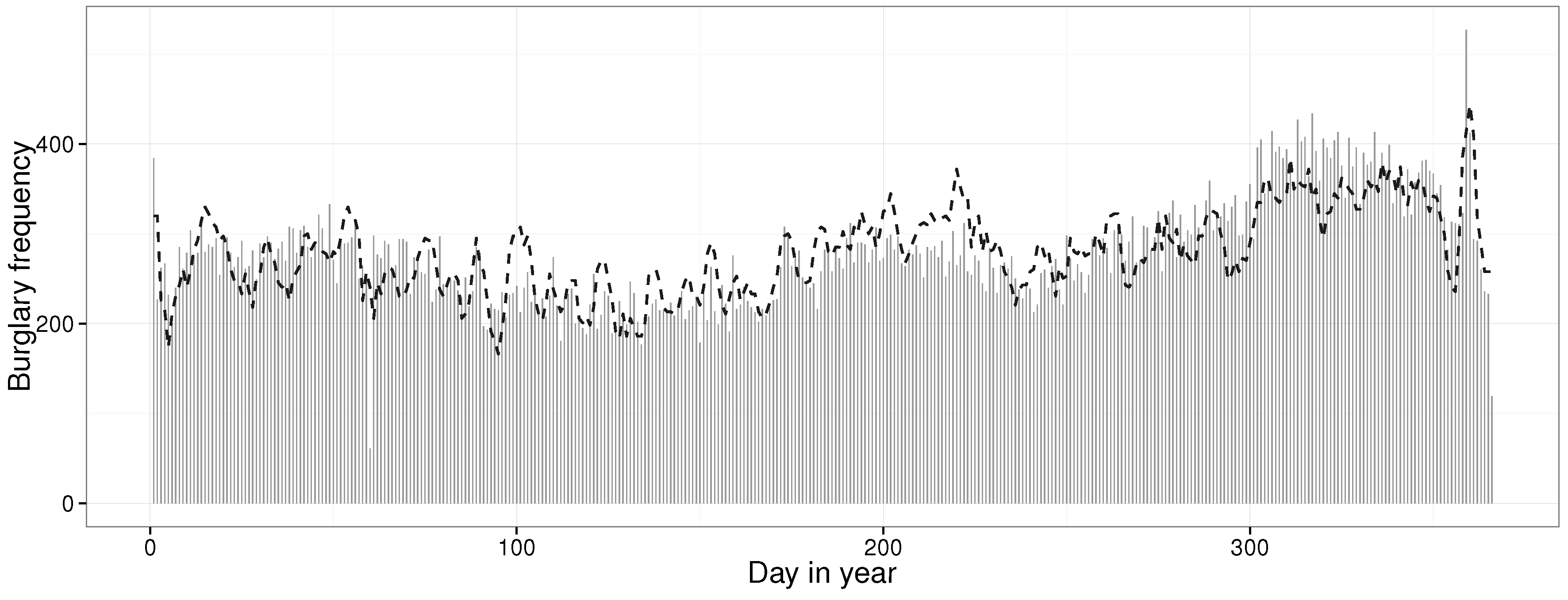
By approximating the temporal distribution of residential burglaries over days in the week allows law enforcement administration to better schedule law enforcement officers for different tasks. The temporal distribution regarding weekdays in
Table 3 suggests that there is a spike in residential burglaries on Fridays and Saturdays, to then decrease on Sundays. This suggests that it is more efficient to have law enforcement officers focus on residential burglaries on Fridays and Saturdays, than on Sundays. Further,
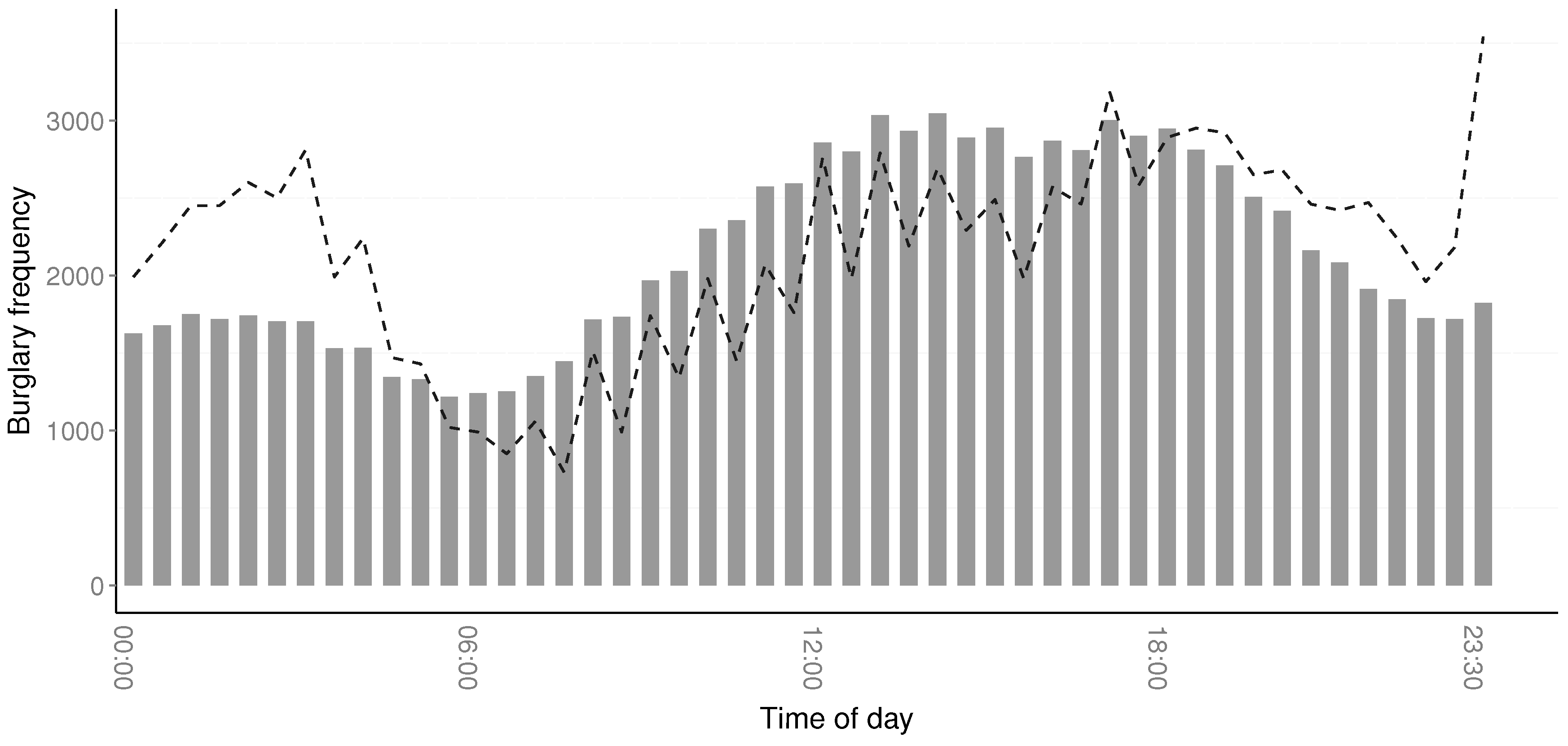
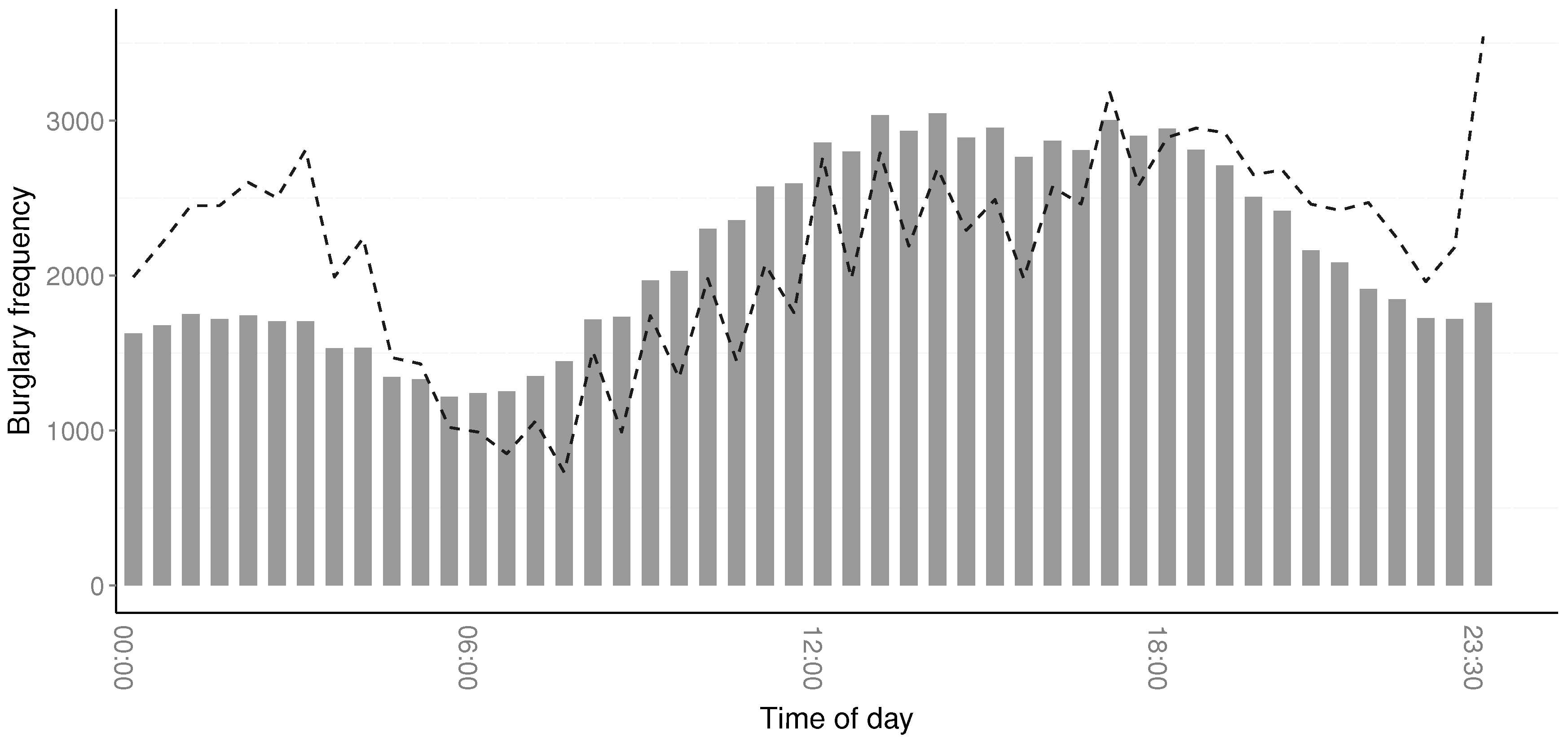
Table 2 suggests that most residential burglaries take place during working hours. Having an analysis on different geographical areas and specific days would allow law enforcement to further distinguish patterns in the data.
Looking at the actual distributions, the data suggest that
burglaries are committed during a span of at least one hour;
of the residential burglaries occur within six hours. As time increases, the amount of burglaries that span long segments is decreasing;
of crimes are committed during a time period of more than one day, i.e., the crime could have been committed during that time span; only
of the residential burglaries are committed sometime during a time span of more than one week, which means crimes can go unreported for a long time. In the data,
represent an absolute number of 7009 burglaries over five years. That is quite a large number of burglaries that is unreported for a long time. It can be noted, however, that most crimes occur within a six-hour time span. As such, being able to detect changes in trends requires the ability to determine the distribution on an hourly resolution. If the estimation of the crime distribution only occurs on a longer time span, the details will be lost. This puts further emphasis on the need to accurately estimate the crime distribution on an hourly scale [
13].
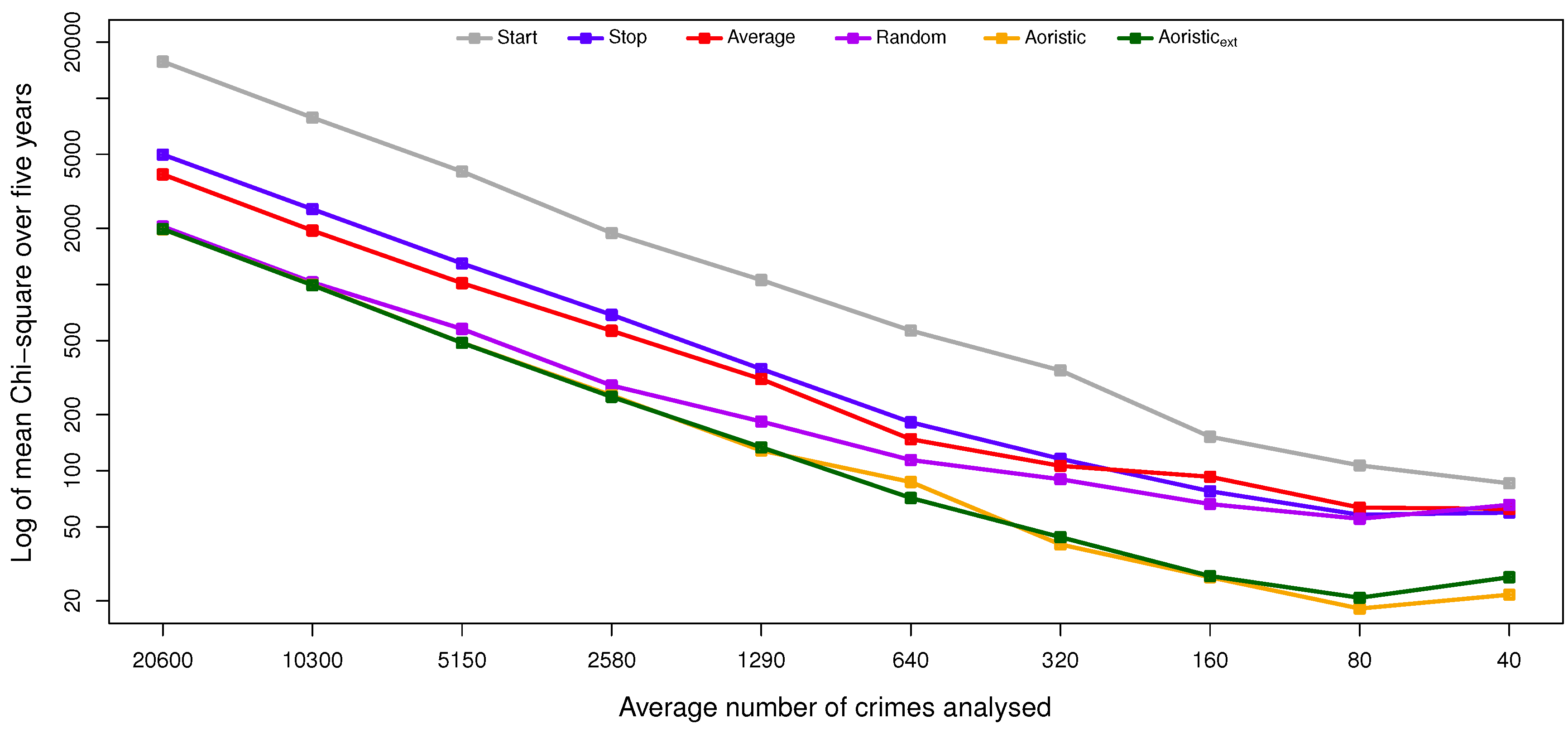
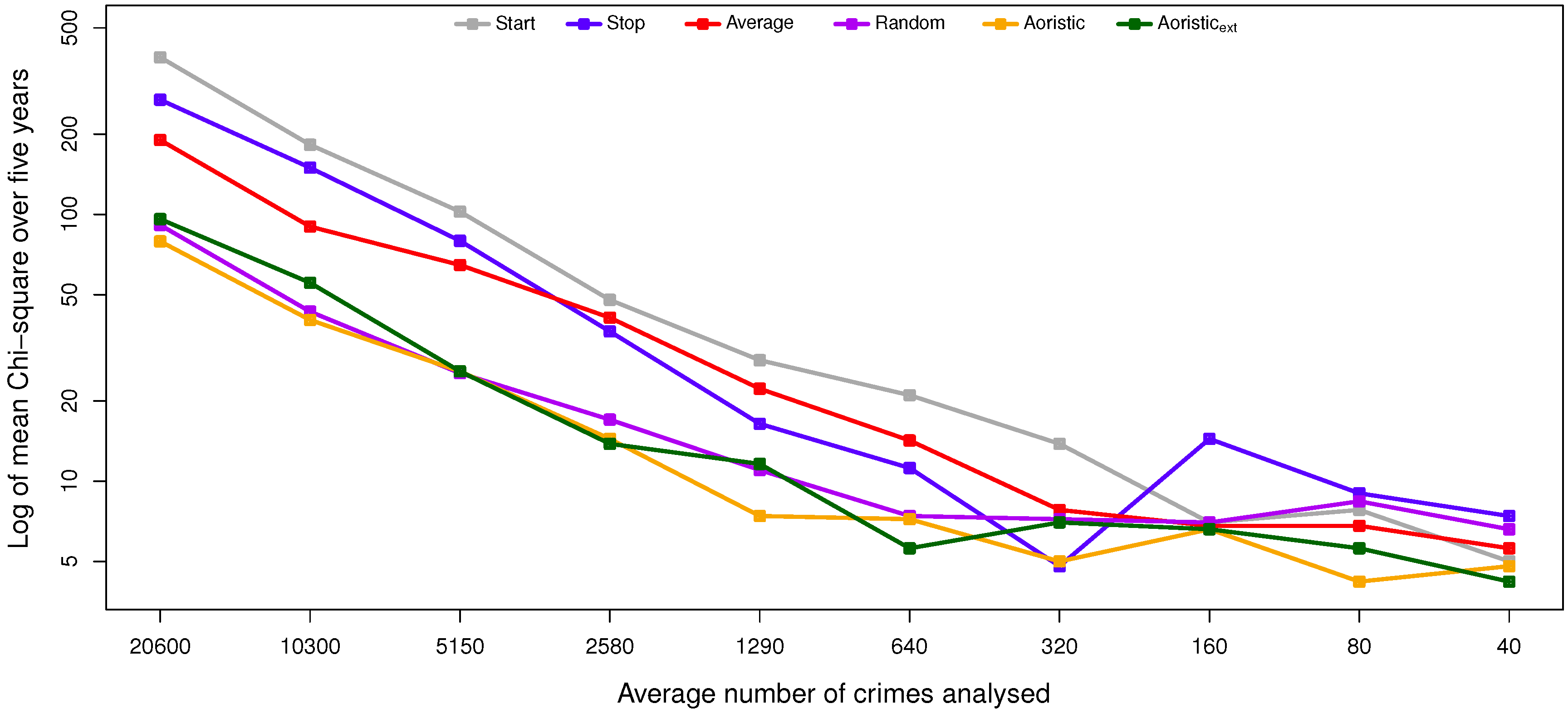
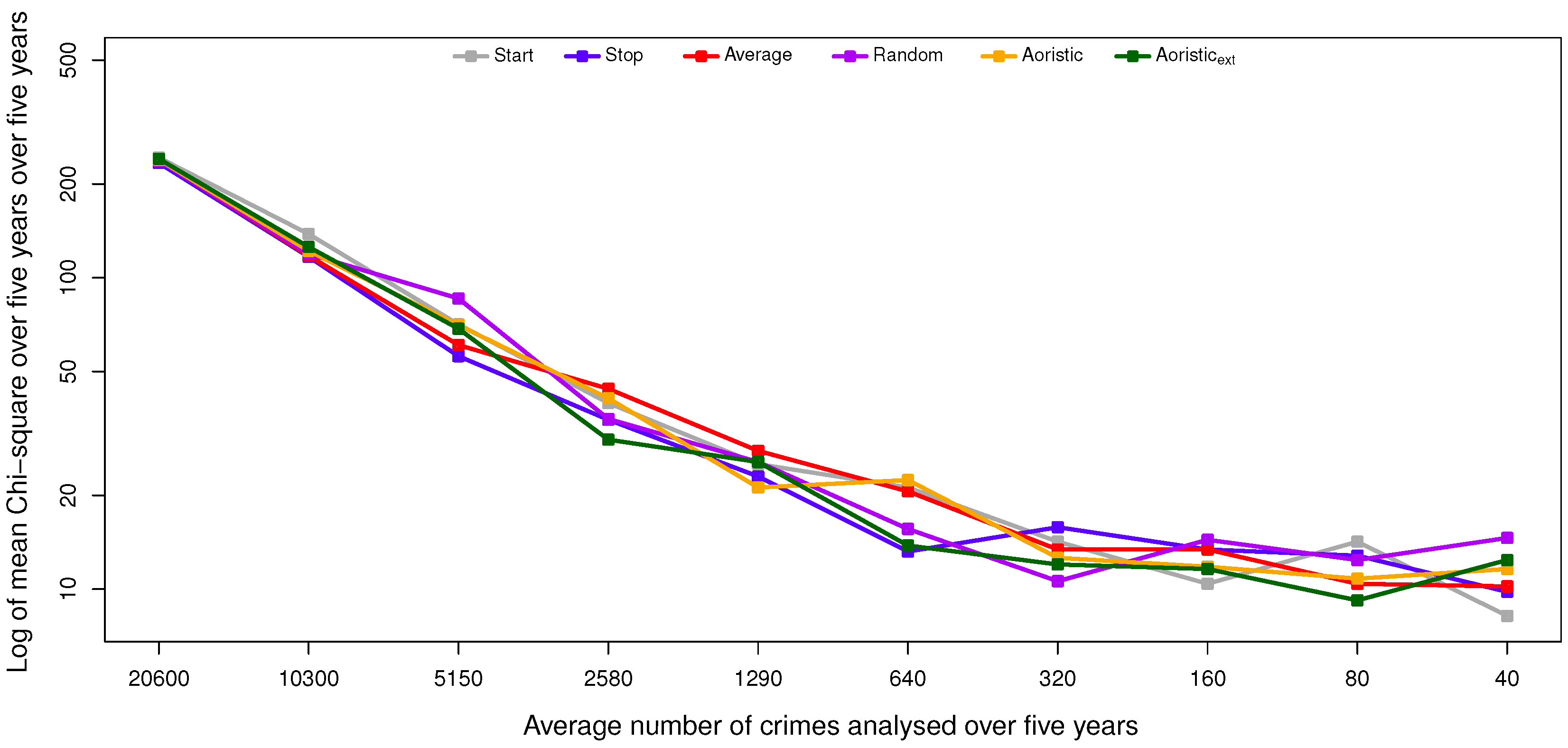
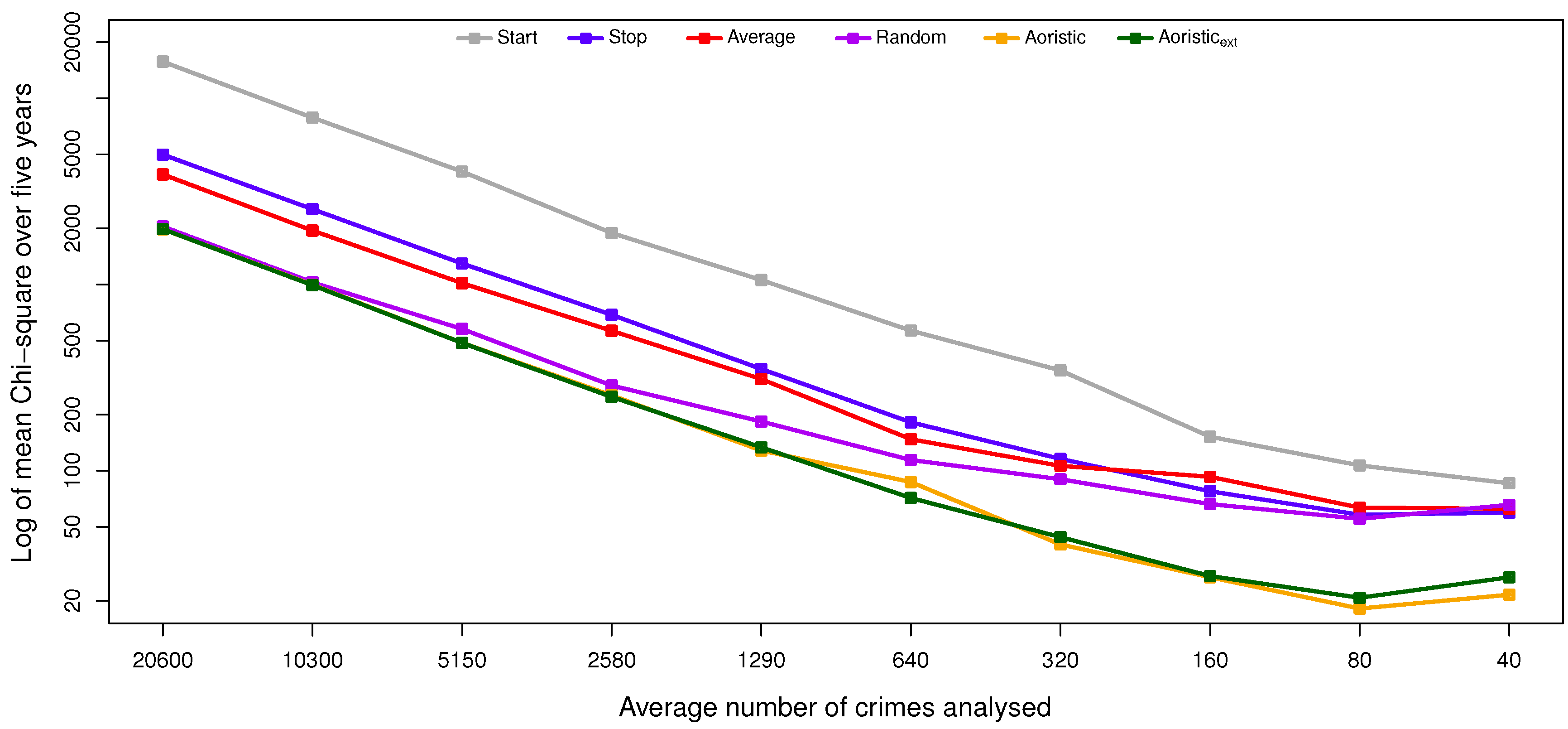
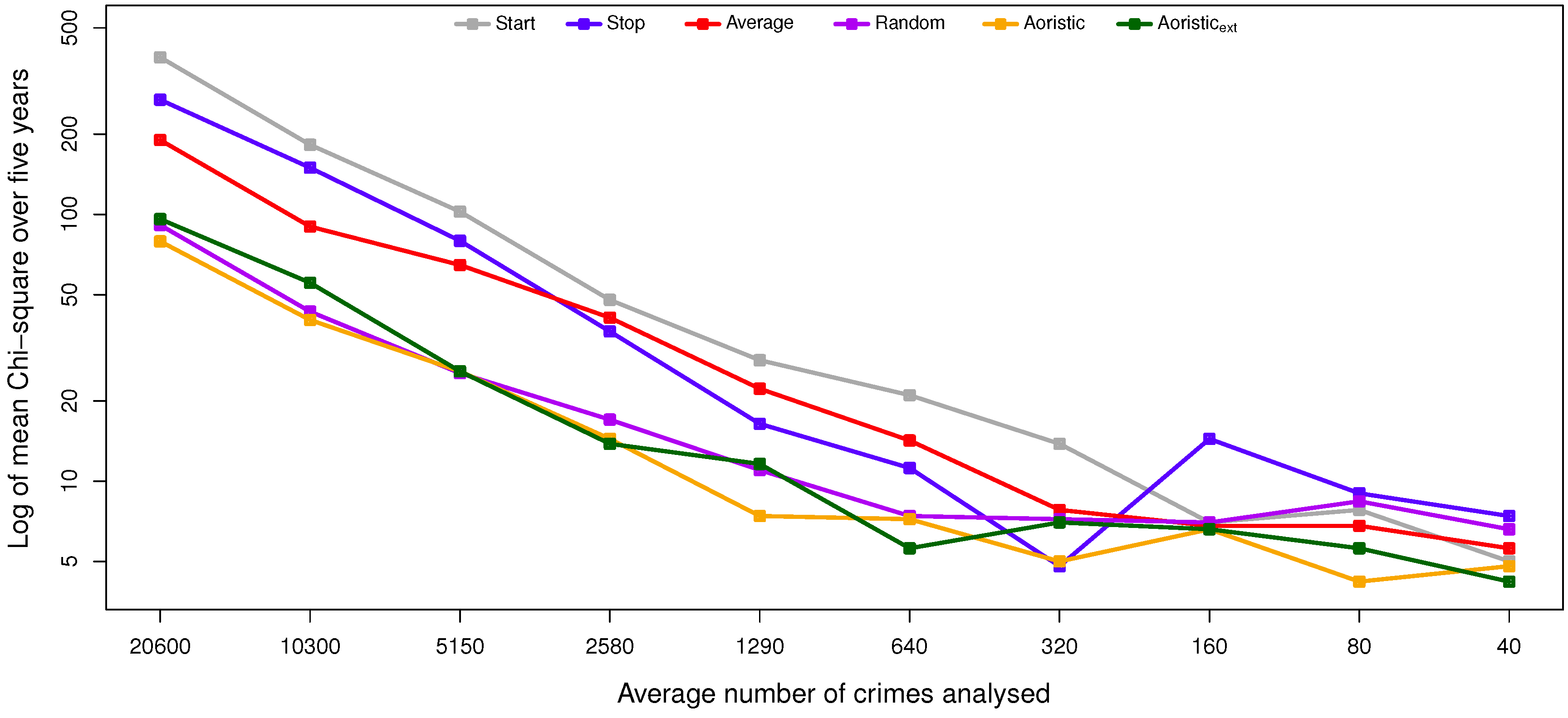
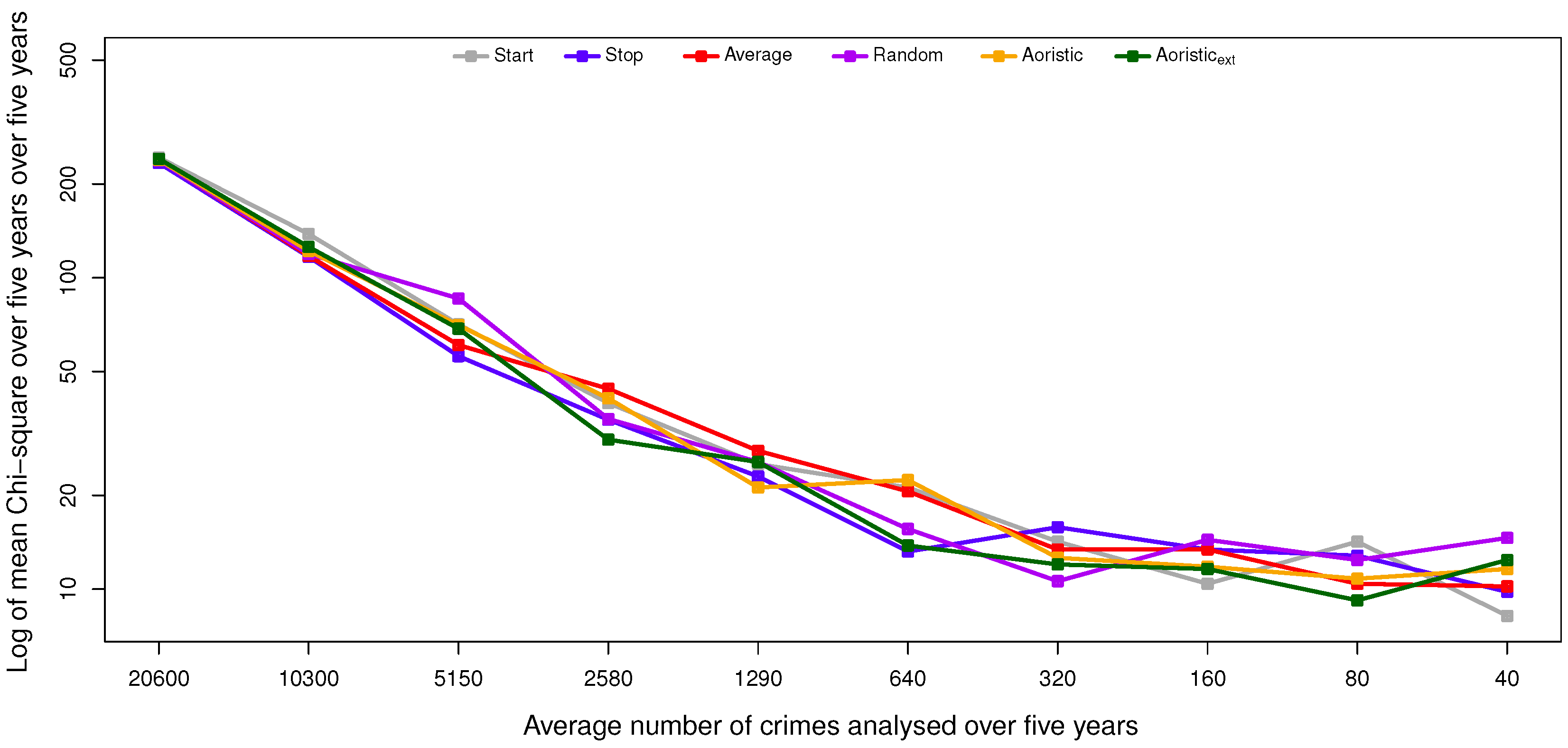
The results and the statistical analysis suggest that the aoristic and aoristic methods are preferred over the other methods for estimating the temporal distribution of residential burglaries, as they perform significantly better than the stop, average and start method in multiple configurations. The aoristic method is quite complex compared to the aoristic method, and it does not suggest improved results when compared to the aoristic method. We hypothesize that this is due to limited detail in the temporal data to support the aoristic method, e.g., because both plaintiffs and witnesses could round off the time of their observations to structured time units, such as quarters, half-hours or even whole hours. That way, the temporal resolution in the data is decreased.
However, when the temporal resolution is instead unique days in the year, such subtle differences have a negligible effect. In that particular case, the aoristic method also comes out as the most suitable candidate, but interestingly, this does not apply when estimating the day in the week or month in the year. Those deviations could depend on the rather low granularity in those cases, i.e., seven and 12 slots, respectively. In the end, both aoristic methods produce usable results; the trade-off is one between accuracy and time complexity, i.e., execution times, given that temporal data with sufficient resolution exist. If the main focus is on time complexity, then a random method that, rather than a uniform distribution, instead uses the distribution of crimes with known offense time would probably render usable results as long as sufficiently many crimes are included in the analysis.
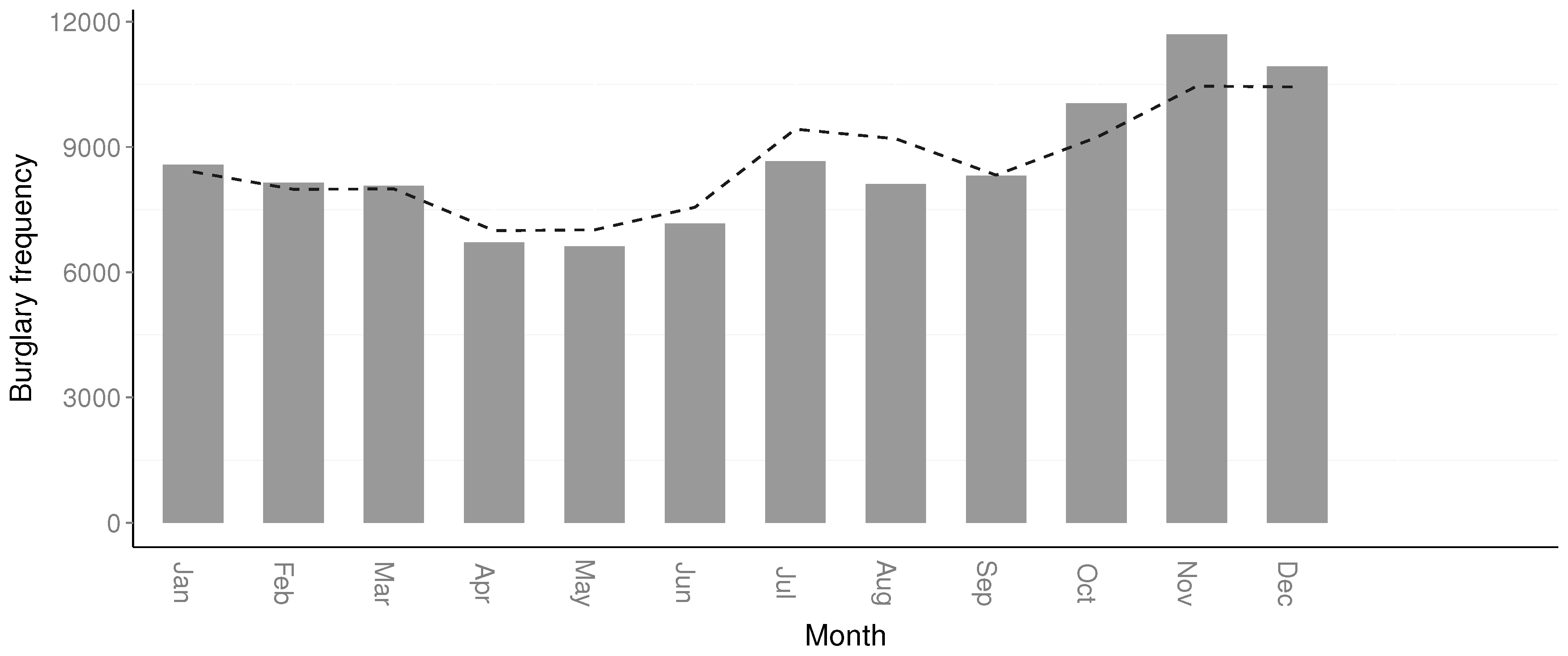
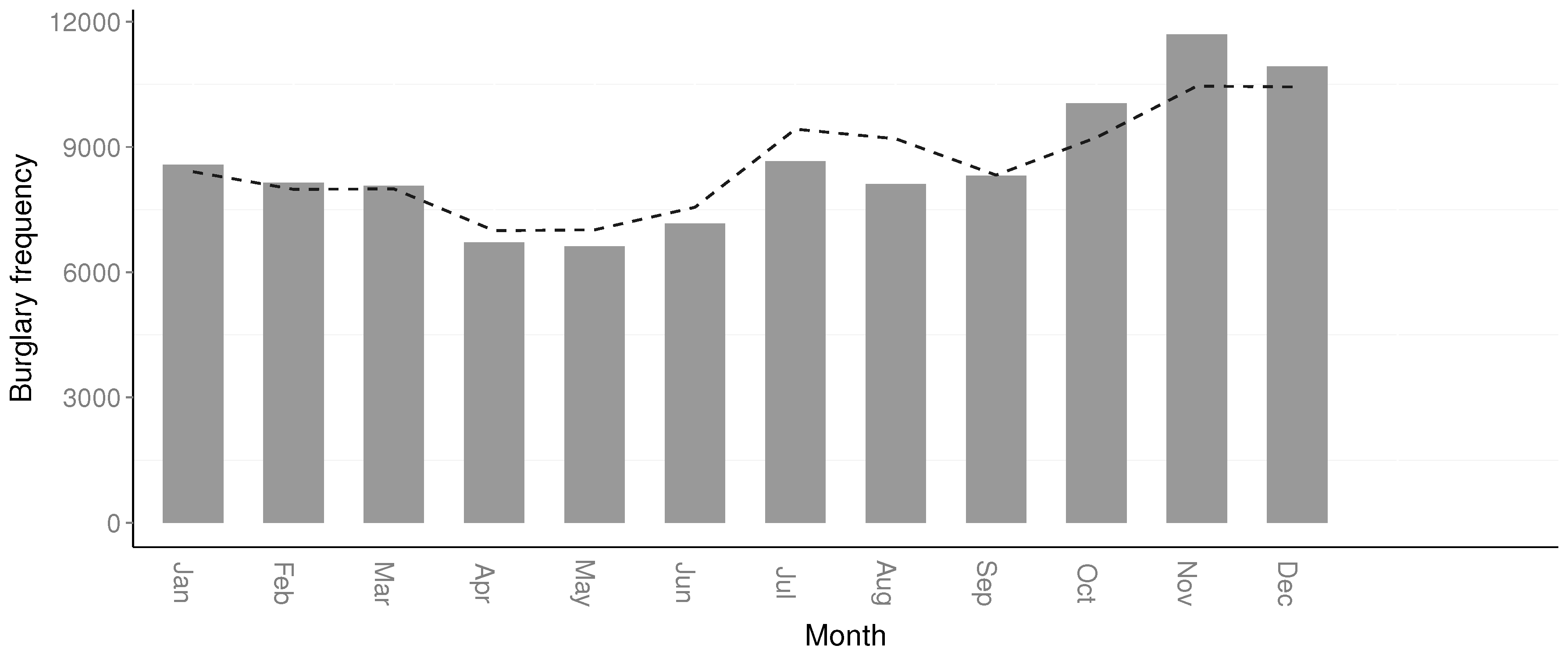
The scenarios with a reduced number of crimes included in this study are important, as in practice, smaller sample sizes are more likely. Further, by having large sample sizes, it is more likely that various trends or other variables are “smoothed”. This is a concern for, e.g., the hour, day in week, and month resolutions, as seasonal changes might impact the trend in the short term [
19]. Smaller timescales will be more successful in providing short-term forecasts. However, as the goal of this study was to identify the algorithm most efficient at approximating the temporal distribution, this is not deemed problematic. Even with a reduced dataset, the findings still hold.
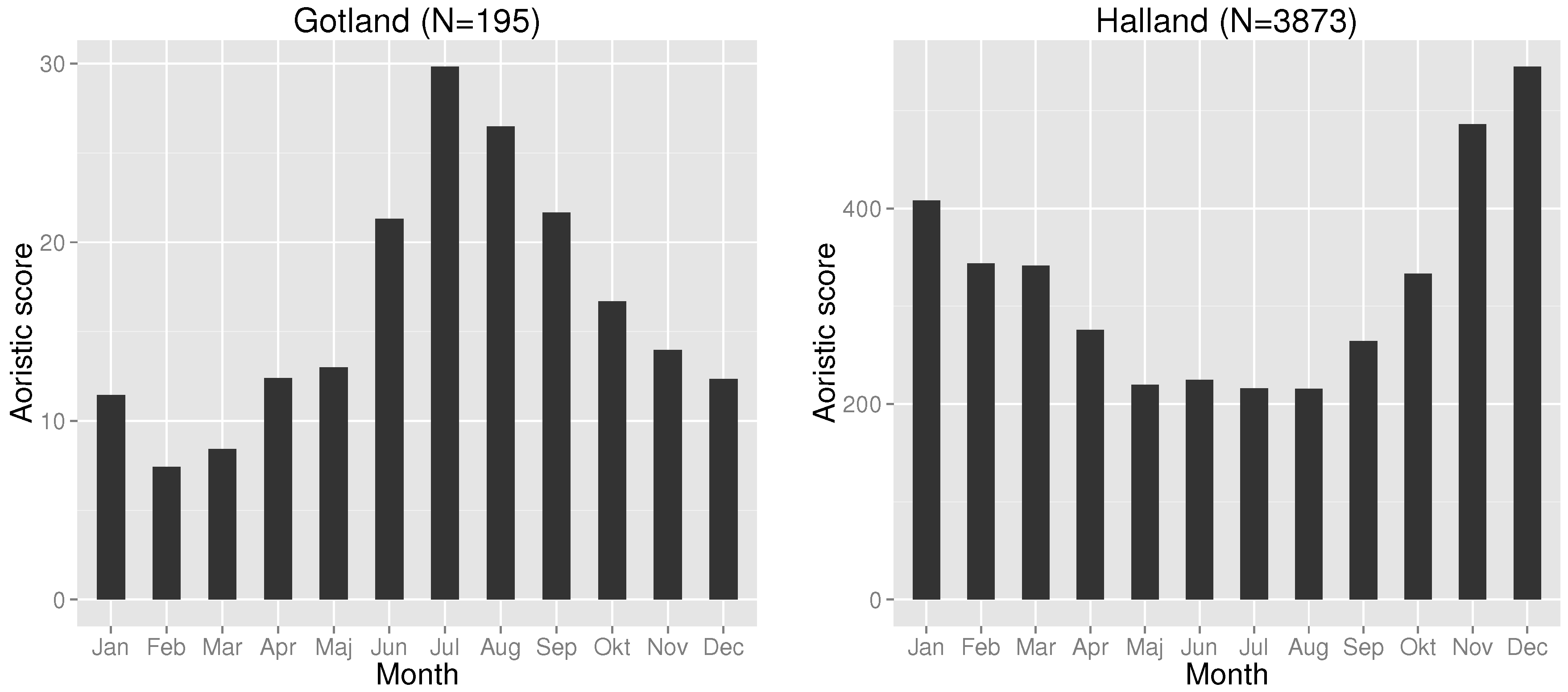
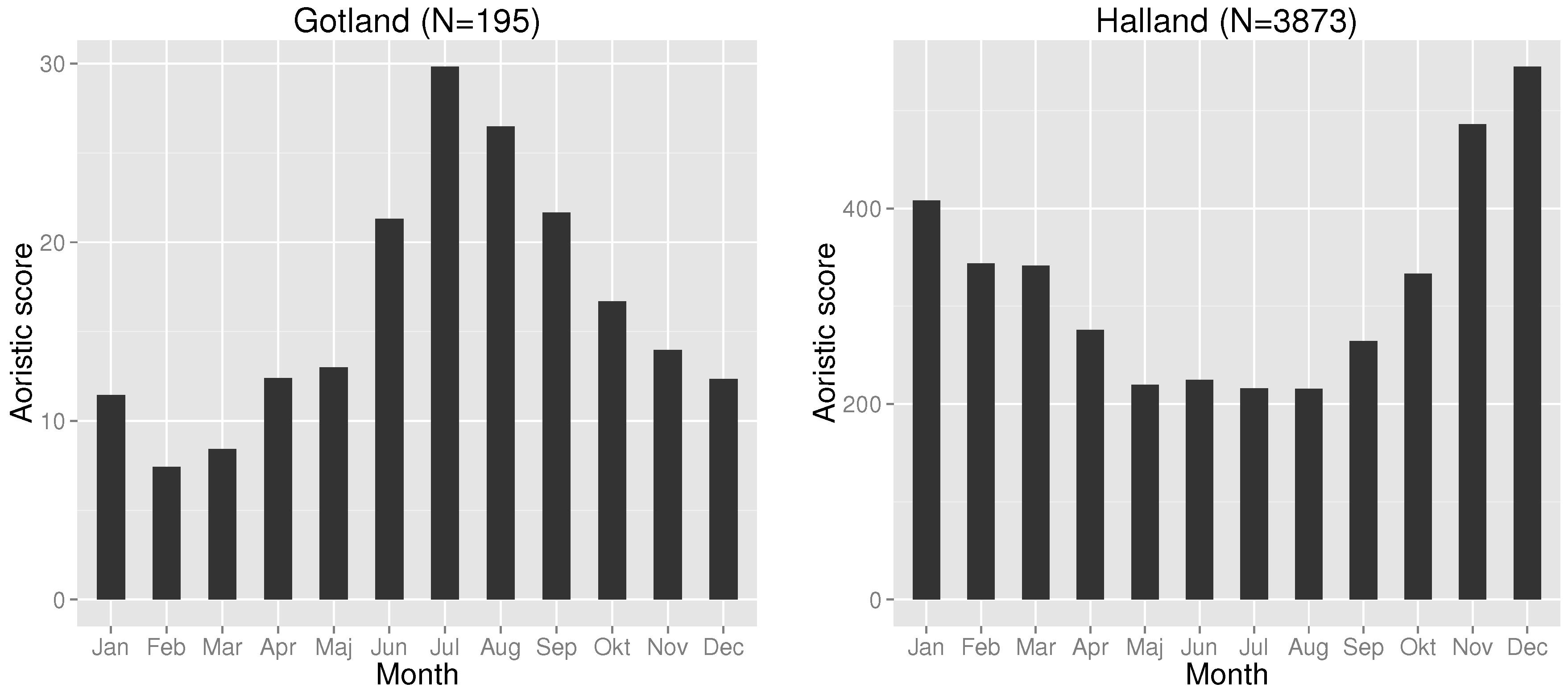
While a smaller temporal window is likely to be preferred for temporal forecasting, a smaller geographical area is likewise more likely to improve results. Criminals operate under different constraint in different geographical areas and affect the temporal distribution. Further, seasonal changes affect regions and crime opportunities differently, e.g., in vacation areas. This also allows different areas to be forecast differently and, as such, might further optimize resource scheduling. An initial study showed that the temporal distribution for the Swedish county of Halland differed quite a bit from the county of Gotland; see
Figure 9. During the summer, residential burglaries decreased in Halland, but increased in Gotland due to vast numbers of tourists visiting the island. While it might be argued that the geographical division at this level is still too large, the differences are still visible.
Estimating the temporal distributions and using in forecasting crime trends would allow an administrative overview enabling the simplification of resource scheduling. For example, extra patrols might be present during Friday and Saturday evenings in residential areas or weekday evenings have a lower amount of patrols in residential areas. The temporal distribution allows law enforcement agencies to, based on knowledge of when crimes most likely occur, schedule their personnel and determine when targeted measures could result in optimal effect.
The data used in this study have minute precision for the start and end of time spans, i.e., a crime occurrence time can span between, for instance, 10:29–14:53. However, in of burglaries, the start time is reported with an hour precision, while this is true for of end times. Most likely, this is due to uncertainties of when the crime started and the reported time being rounded to the closest hour. The lack of precision in the data is most likely why the results for the aoristic method are not better than the aoristic method. The lack of precision in reported time span, together with the longer time spans, drown out any improvement that the aoristic method offers against the aoristic method.
Limitations
While the aoristic
method extends the aoristic method with a level of complexity that has the possibility of increasing the precision of the estimated time, it also requires a more precise data collection, i.e., the time span collected must be more precise, for both the start and end time. If the collected crime information only states that the crime occurred between 13 and 16 on a given day, the aoristic
method will not be better than the aoristic method. In that case, the aoristic
should fall back to the aoristic method’s relatively simpler approach. The same holds for time spans where either the start or the end time is not precise enough. In that case, the point distribution will be similar to the aoristic method (given that the time span exceeds a certain number of time units). However, if the collected temporal information, in the span, contains minutes, the precision is potentially improved. This is reasonable, as
Table 3 suggests that a majority of the crimes (>50%) has a reported time span of less than twelve hours.
For longer time spans, there is less likelihood that the data are collected with such precision that the aoristic will yield improved results. Further, with longer time spans, the lower resolution will have less impact, as the points affect the final distribution to a lesser extent (points are more spread out). The same is true for the aoristic method, as well.
8. Conclusions
Crime analysis requires precise temporal information. In many cases, the temporal information is uncertain or available as a time span. Consequently, approximating offense times of crimes that often lack precise time information is important. In an experiment, the accuracy of six temporal analysis methods, five existing and one novel, was evaluated regarding their ability to approximate offense times.
The results indicate that the aoristic and aoristic methods performed significantly better than the average, start and stop methods. However, the novel aoristic method was not significantly better than the aoristic method. The aoristic method does in the worst case scenario behave similar to the aoristic method. Given a certain level of precision in the collected data, the estimated time for crimes will be more precise. However, if such a level of precision in the estimated time is not needed, the added complexity of the aoristic method does not justify its use over the aoristic method.
For future work, a simulation-based evaluation of temporal analysis methods using another dataset would be interesting to carry out as a complement to the present study. It would also be interesting to investigate if small sample sizes on specific geographic areas would suggest whether the results still hold for, e.g., a specific city or different areas of a city. Further, investigating whether temporal distributions for different geographic areas affect each other and if methods can be developed to estimate links between geographically-limited distributions automatically. This would allow law enforcement to observe how residential burglary trends move across geographic areas.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}