1. Introduction
In order to encourage the local economy and to establish the identity and placeness (sense of place) of an area, various streets have been created in USA. For example, Broadway and Wall Street in New York City and Hollywood Boulevard in Los Angeles are well-known themed streets and can easily be found online or in a web map service. These types of themed streets not only offer areas of special characteristics for a city, but also provide a place where the community can spend their leisure time. It is also known that the development of themed streets increases as a city matures [
1].
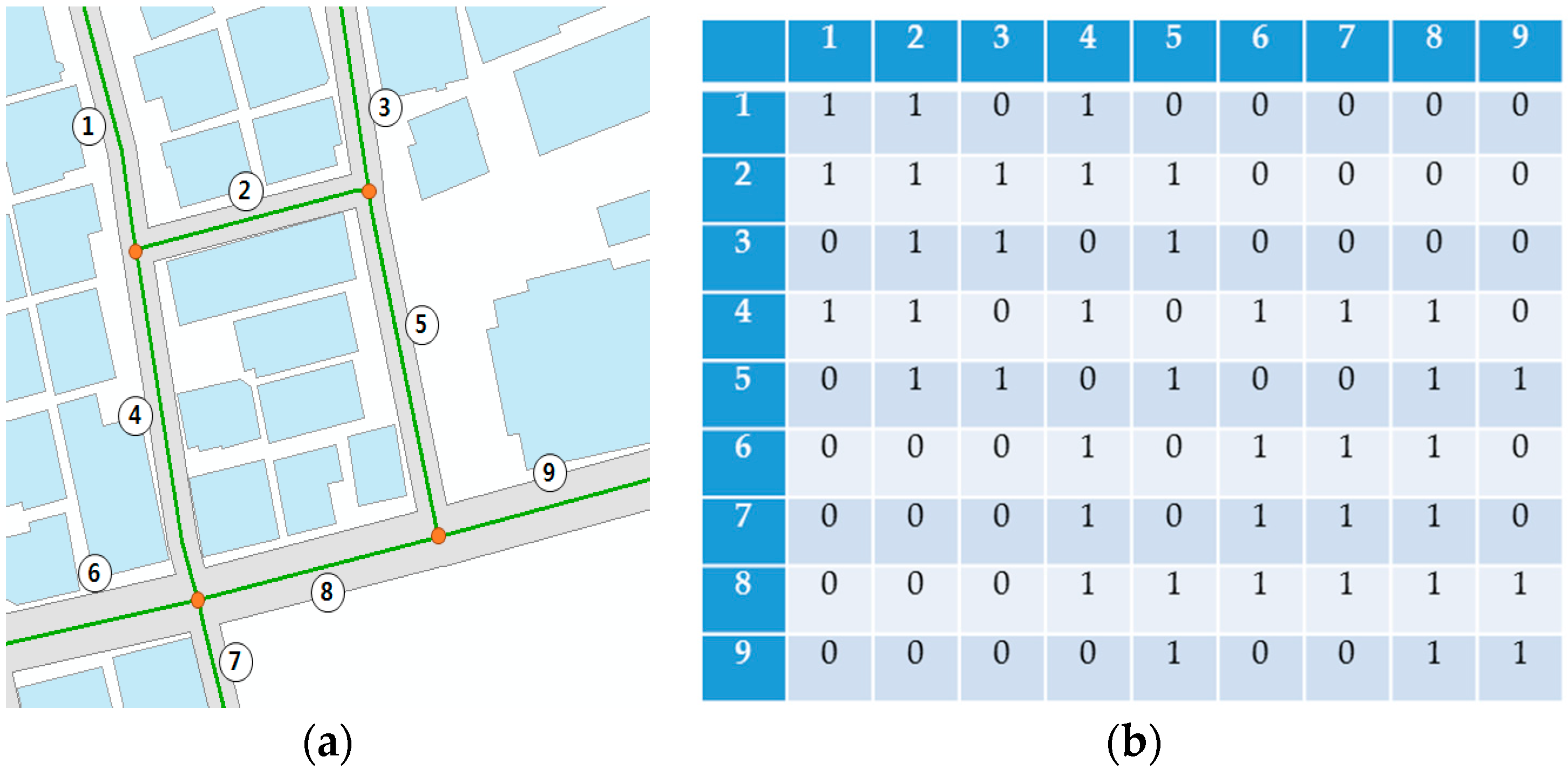
While a themed street is recognized by the public, it is difficult to illustrate its exact boundary because the themed street is usually expressed as lines on a map. Since density based clustering or aggregation of polygons is normally used to draw the boundaries as areal shapes on maps, illustrating a line-based area such as a themed street is limited.
In reality, people travel via roads and their activity areas are based on roads. The road is the first impression of a city; the features of interest along a road are, therefore, strongly related to the features of interest of the city [
2]. In other words, the image of a street area as seen from the road can form an impression of the city within which it is located. From this perspective, a boundary of a special space should be expressed based on the road in order to ensure the public understands the city intuitively.
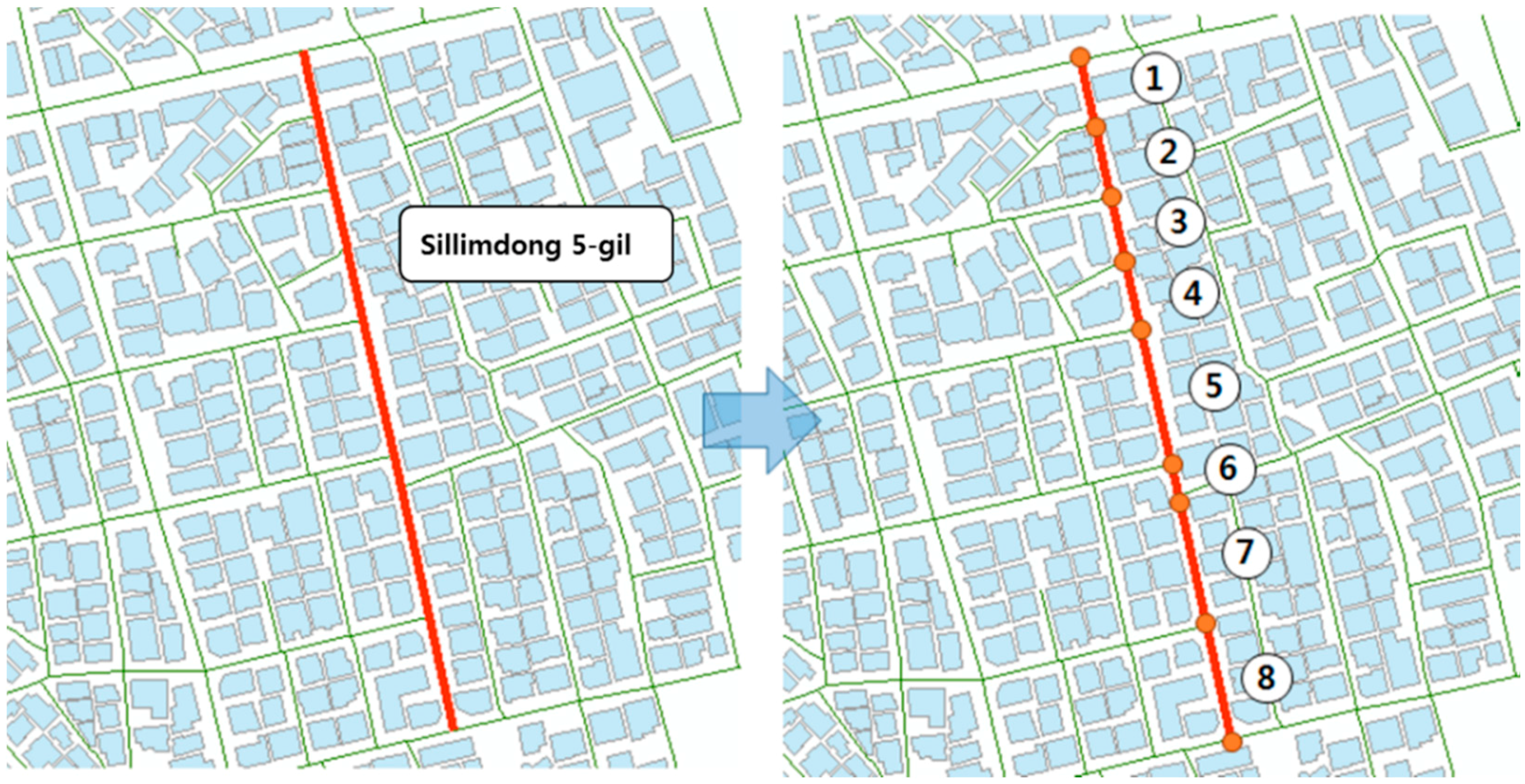
To express a place based on a road, the characteristics of the road need to be determined. In most cases, the characteristics are formed according to the points of interest (POIs) on the roads. By categorizing the POIs and assigning them to the road, various types of themes on the roads can be identified. However, few research papers have focused on detecting themes on roads. Even the related researches only show one measured phenomenon, such as the level of crime on the roads. With this method, the face of a city where various events occur cannot be illustrated.
This study, therefore, used data on peoples’ behavior and POIs obtained from mobile GPS and Wi-Fi sensors to detect various themed streets. The Themed Street Clustering Method (the TSCM) is suggested for this purpose. For this study, two subtle words are introduced; “the hot street” and “the themed street”. Although the two words can be used interchangeably, the meaning of each is still defined for this study. As a hot spot is a clustered area of relatively high values, it represents a road that has a high value of a unique index. For example, the popularity index of a street is high if the street is popular. A themed street, however, is a street with a special placeness that is due to the close co-location of popular places; therefore, in addition to the popularity of a themed street, it is also known for a specialty. It was confirmed through this study that various themed streets have been detected via the use of a mobile sensor and collected data according to the TSCM.
2. Related Works
To analyze the life pattern and characteristics of people according to space, the “Livehoods” project was conducted [
3]. Check-in data (a user manually tells the application when he/she is at a certain location by selecting from a list of venues on a smart device) was used, as acquired from the Foursquare service and the spectral clustering method, which aggregates similar data and creates clusters. Using the method, “Livehoods” clustered sections were generated by calculating similar values of locations and attributes. However, it was difficult to distinguish the exact themes of the sectioned area since the data was not categorized in a manner that allowed for this. That is, “Livehoods” places more significance on determining geographic boundaries than on detecting themes associated with such boundaries.
Meanwhile, a study was conducted to analyze hot spots using check-in data from Jiepang, a Chinese location based social media service [
4]. The testing area was divided into fishnet grids and the number of check-in data was counted. Each grid was colored based on the significance level that expresses hot spots of the check-in. With the result, the researchers insisted that the check-in data indirectly reflect the population and economy of its area by showing the correlation between population census and the number of counted check-in data. While this study is a good reference in terms of research on socio-economic active areas, different results can arise when the fishnet grid size changes (also known as modifiable areal unit problem). In addition, the study only defined the area in which many check-ins occurred, only representing the check-in hot spots. Therefore, the themed regions cannot be understood through this type of analysis.
The studies introduced above ([
3]) have limitations, whereby the results can only be expressed as areal shapes (polygons). Other problems arose, such as the lack of any meaning for the division of areas, since the study measures only check-in frequency. Again, with the methods introduced by previous studies, identifying themed streets presents a challenge.
In the meantime, studies on network-based clustering methods have been conducted in order to supplement the limitations of areal based clustering methods. One of the most popular and widely used methods for analyzing point distribution is known as kernel density estimation (KDE) [
5]. However, conventional KDE has many faults in finding hot spots on road networks. One of the main flaws is that the density area of not only in the networks but also of the other areas are detected and this leads to skewed results. For this reason, network kernel density estimation (NKDE) was suggested [
6] and it has been used for various applications such as detection of the likelihood of a hot spot in vehicle incidents [
7]. Not only NKDE, but also network spatial and temporal analysis of crime (NT-STAC) and network spatial scan statistics (NT-SaTScan) were introduced to detect crime occurrences (robbery, burglary, drug deals/use, etc.) on road networks [
8]. In the study, the researchers insisted that using STAC and SaTScan to detect hot spots results is producing round shaped clusters on a 2-D space, and argued that the methods are limited when linear spaces are analyzed. Therefore, they demonstrated that NT-STAC and NT-SaTScan can successfully detect the crime areas on road networks throughout their research.
In hot spot detection studies based on road networks, hot spots were found in linear spaces; however, these studies mostly focused on the clustering data overlaid on road networks and the road networks themselves were not considered. That is, the results only connect point data to linear shapes and do not provide significant information about the road networks.
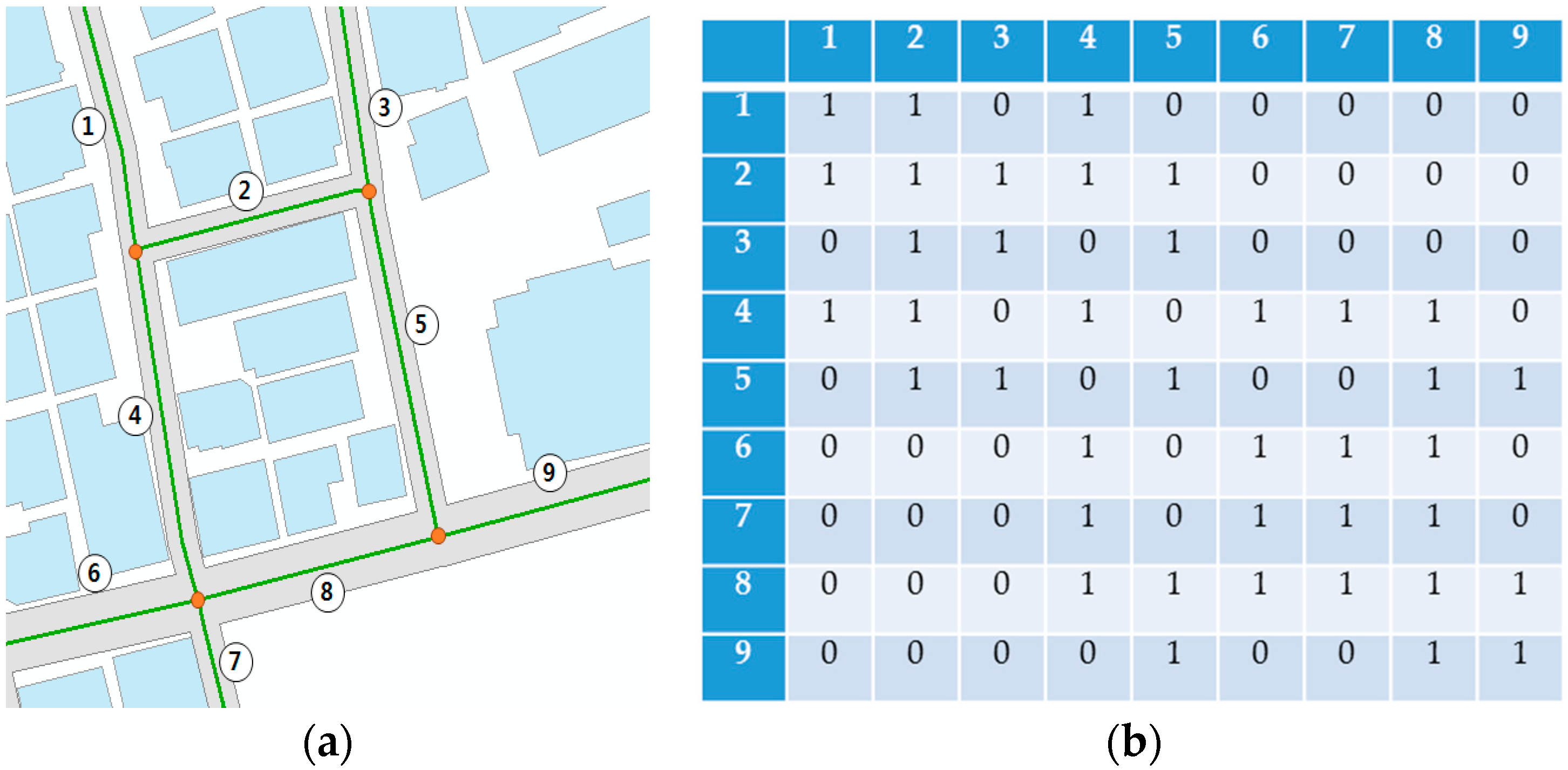
To overcome the above limitations, Lu (2005) explained the phenomenon of public socio-economic activities constrained by roads in a city by expanding the point data clustering method, which shows hot spots in 2-D spaces, to road networks [
9]. Particularly, the term “hot street”, a road network acting as a hot spot, was introduced by conducting clustering testing of vehicle burglary point data on street segments, where the basic analysis involved dividing the units by each junction. Finally, the statistically significant hot streets were detected using Poisson distribution on each street segment. Nevertheless, the limitations of the research can be summarized as follows. First, the data used in the study only show the locations of vehicle burglaries on road networks. Second, the Poisson distribution can only analyze discrete data, such as the number of counted point data. Lastly, since the lengths of road segments differ, the incident cases according to the length of road segments could not be normalized.
Previously published studies do not include methods for detecting various themed streets containing abundant attributes. Furthermore, it has been recognized that a themed street cluster analysis and visualization based on road segments needed. Therefore, this study suggested the TSCM to address the limits of the previous studies.
4. Results and Analysis
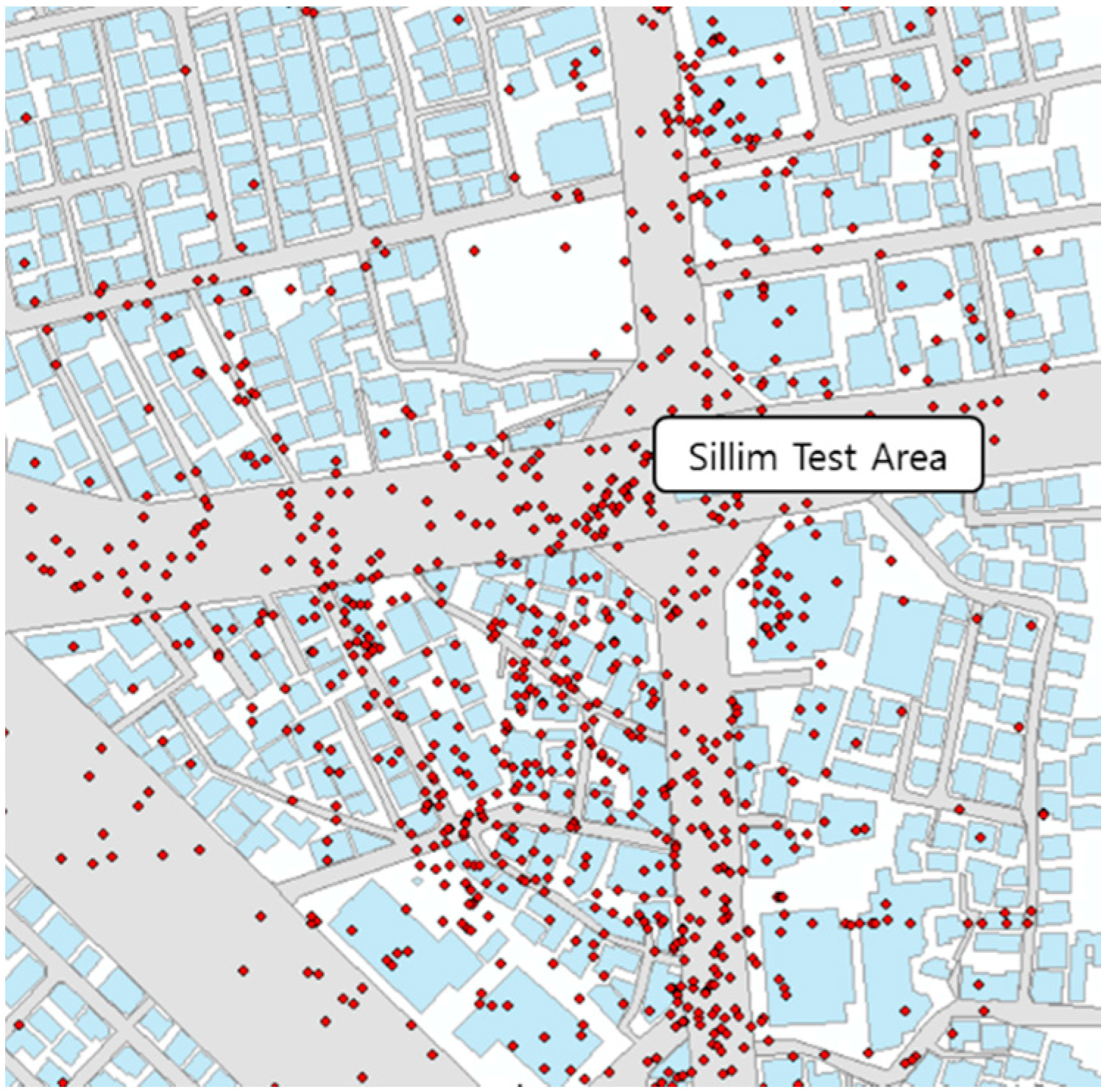
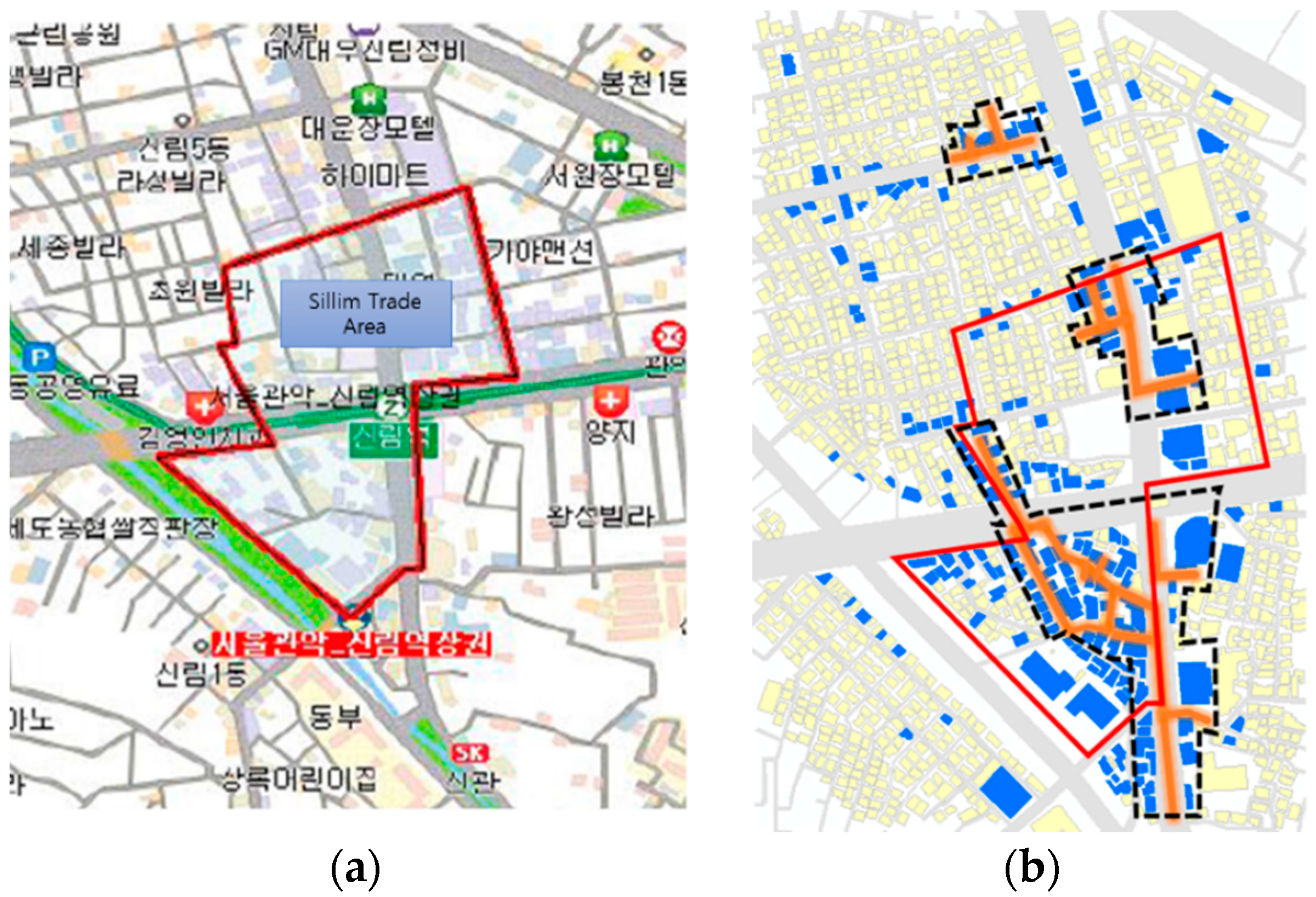
Sillim and Gangnam, two districts in Seoul, were chosen for the examination of the results and the versatility of the suggested method.
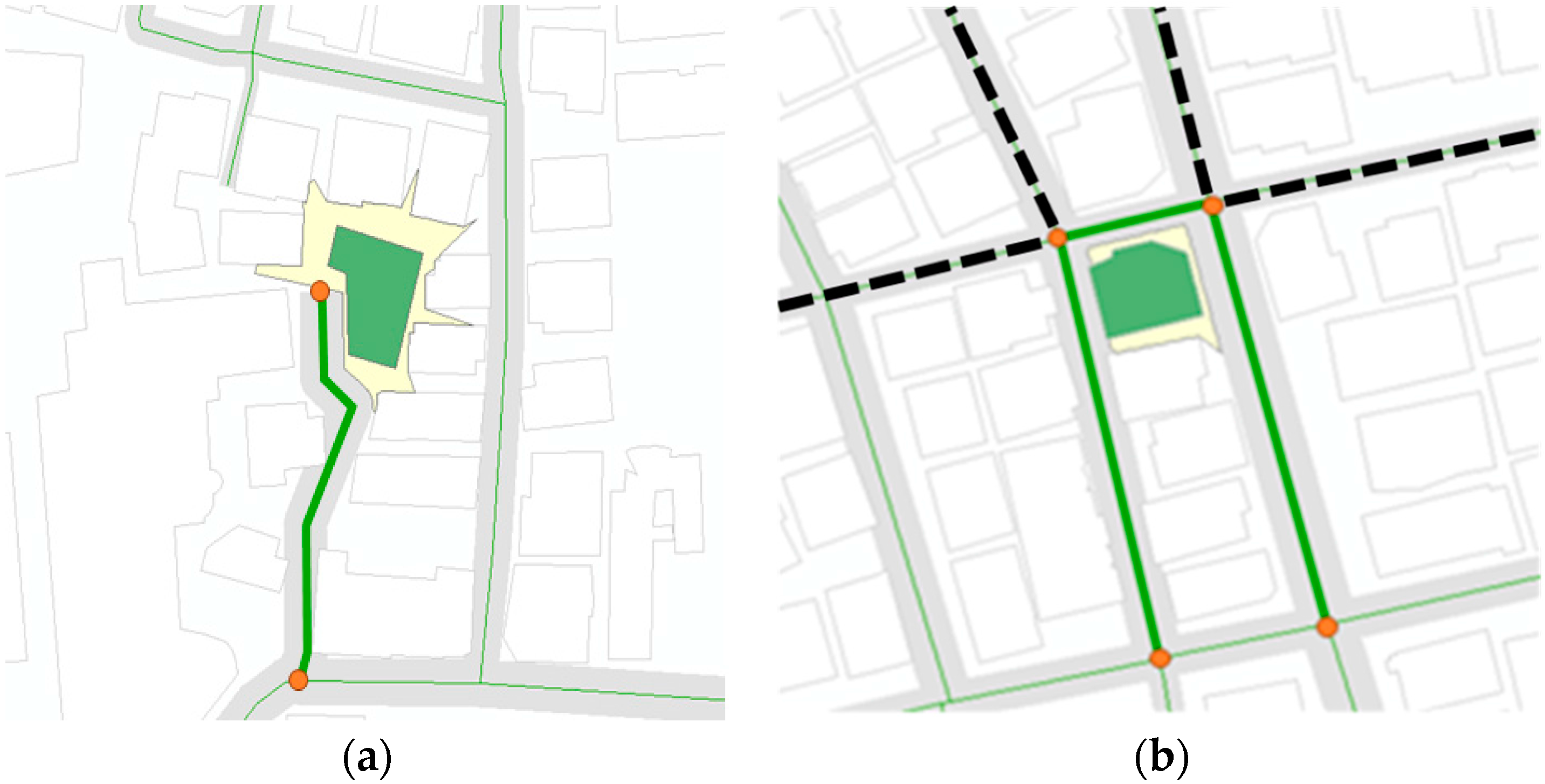
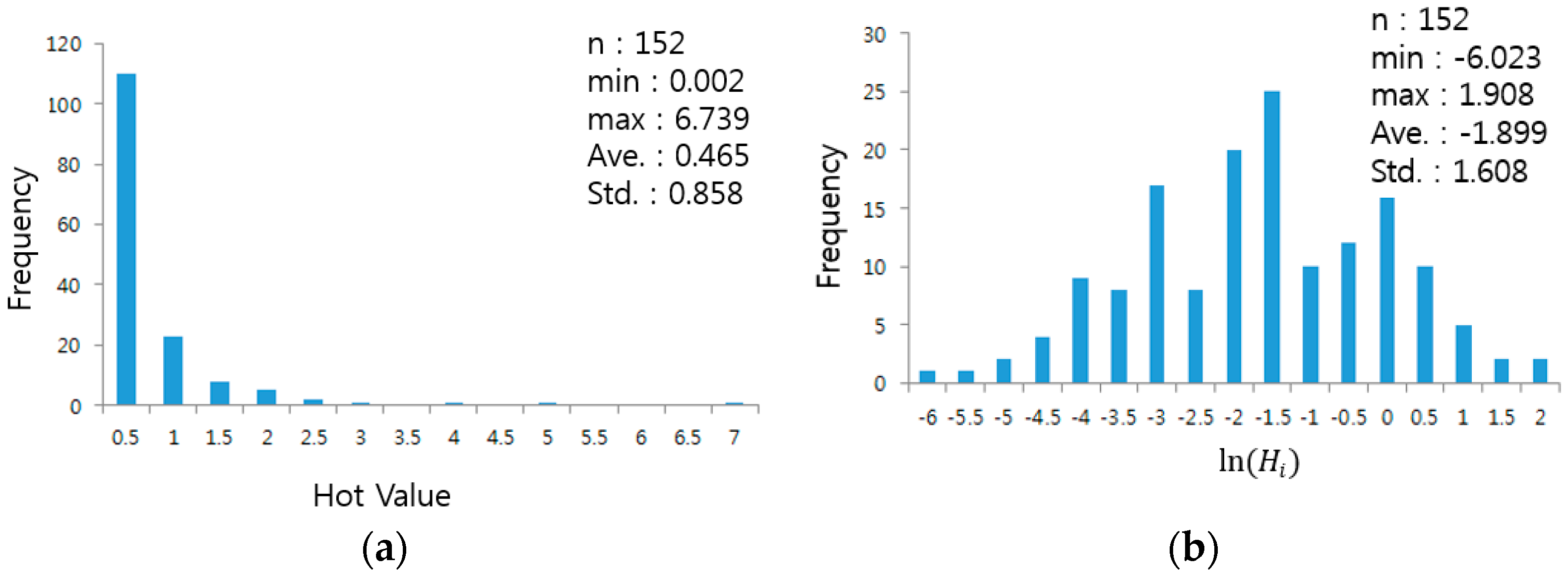
The total number of venue data is 312 in the Sillim test area. It was confirmed that the number of venue buildings and matched road segments to the buildings is 154 and 152, respectively.
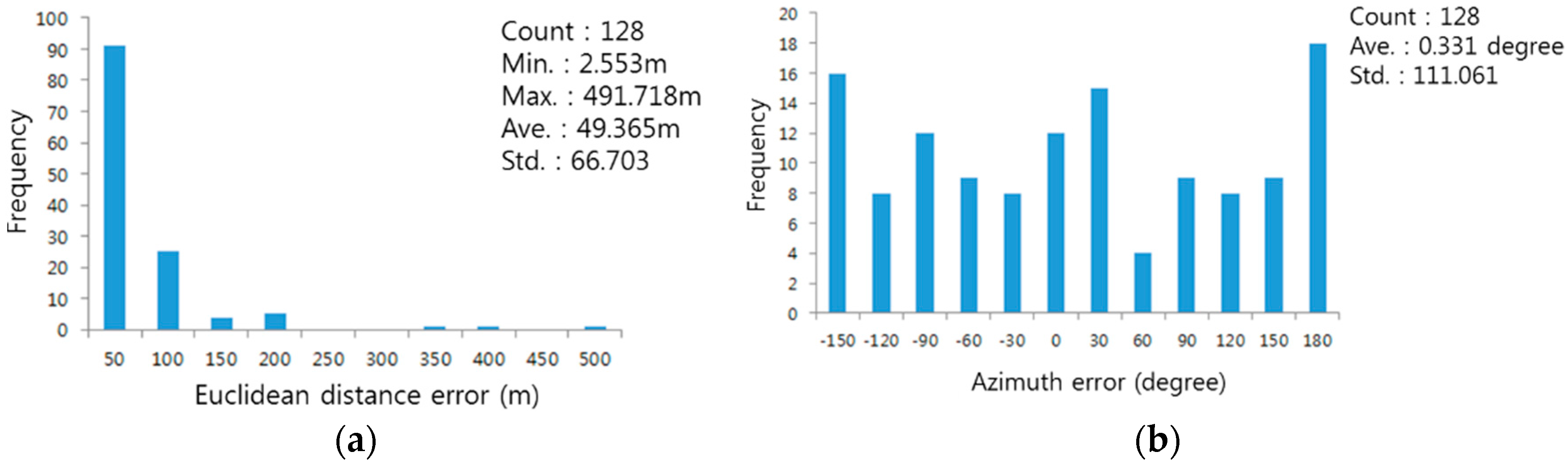
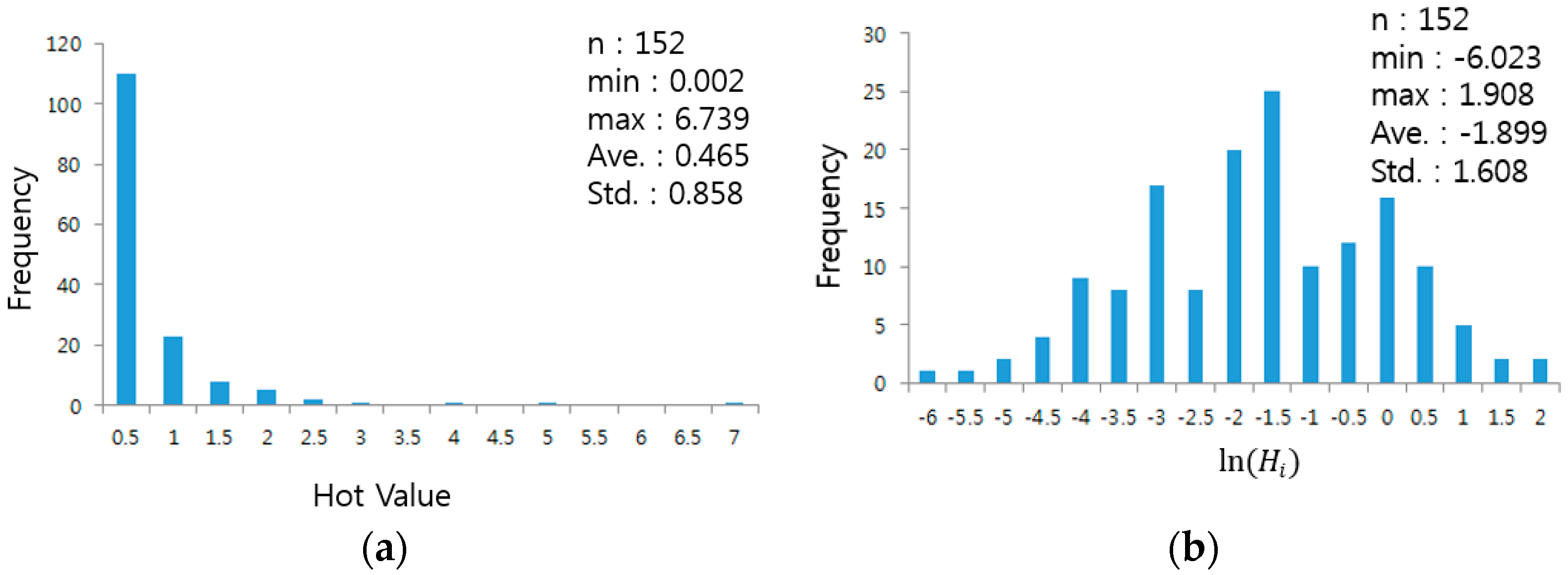
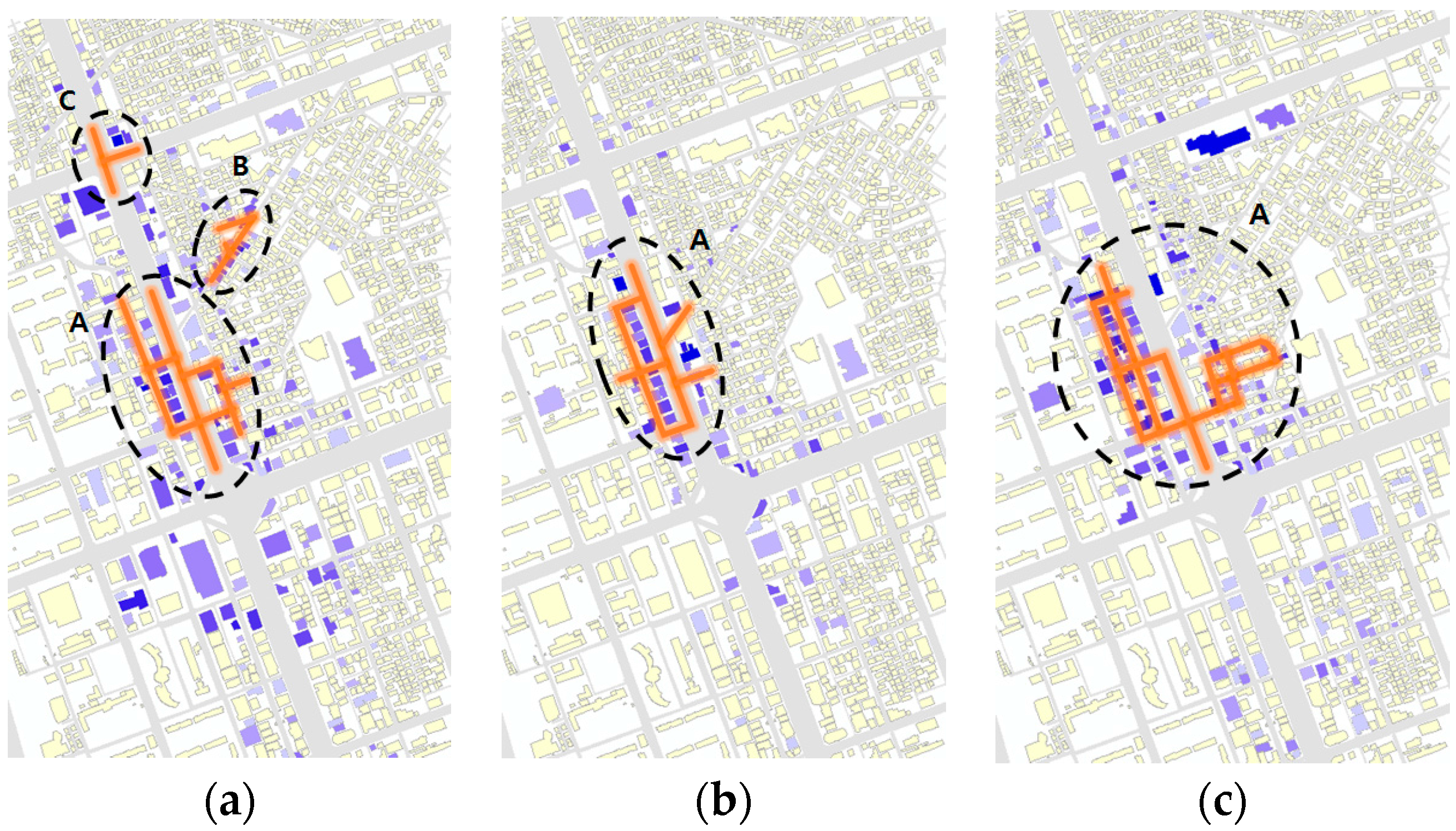
The results of the analysis of the restaurant themed street clusters in the Sillim test area are illustrated in
Figure 8b. The red colored streets have a
value that satisfies the significance level of 0.05 and are regarded as themed streets, while the blue colored buildings refer to the scale of popular venues (
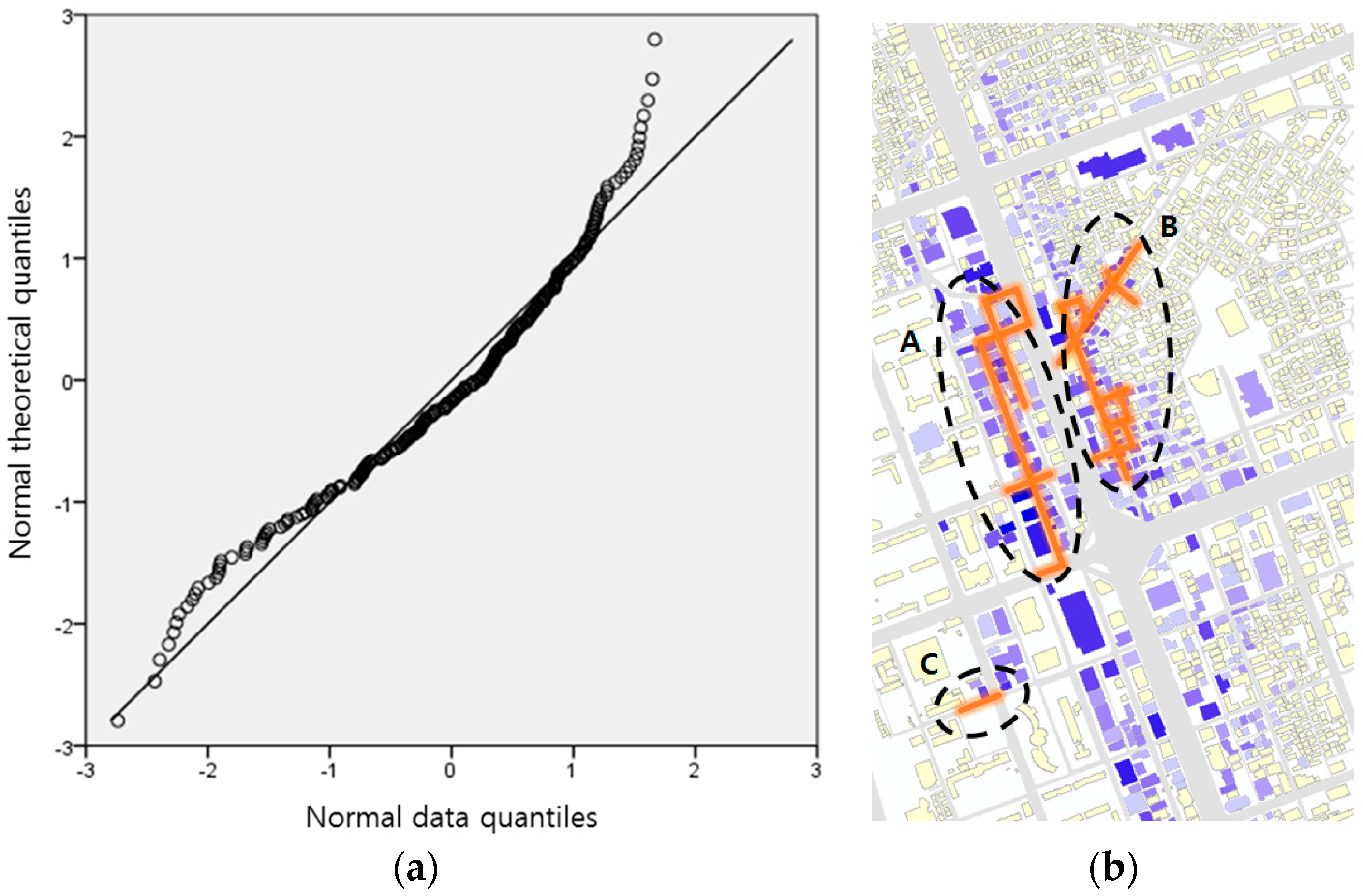
). To verify the normalization of the
distribution of the restaurant theme, a normal Q-Q plot was drawn (
Figure 8a).
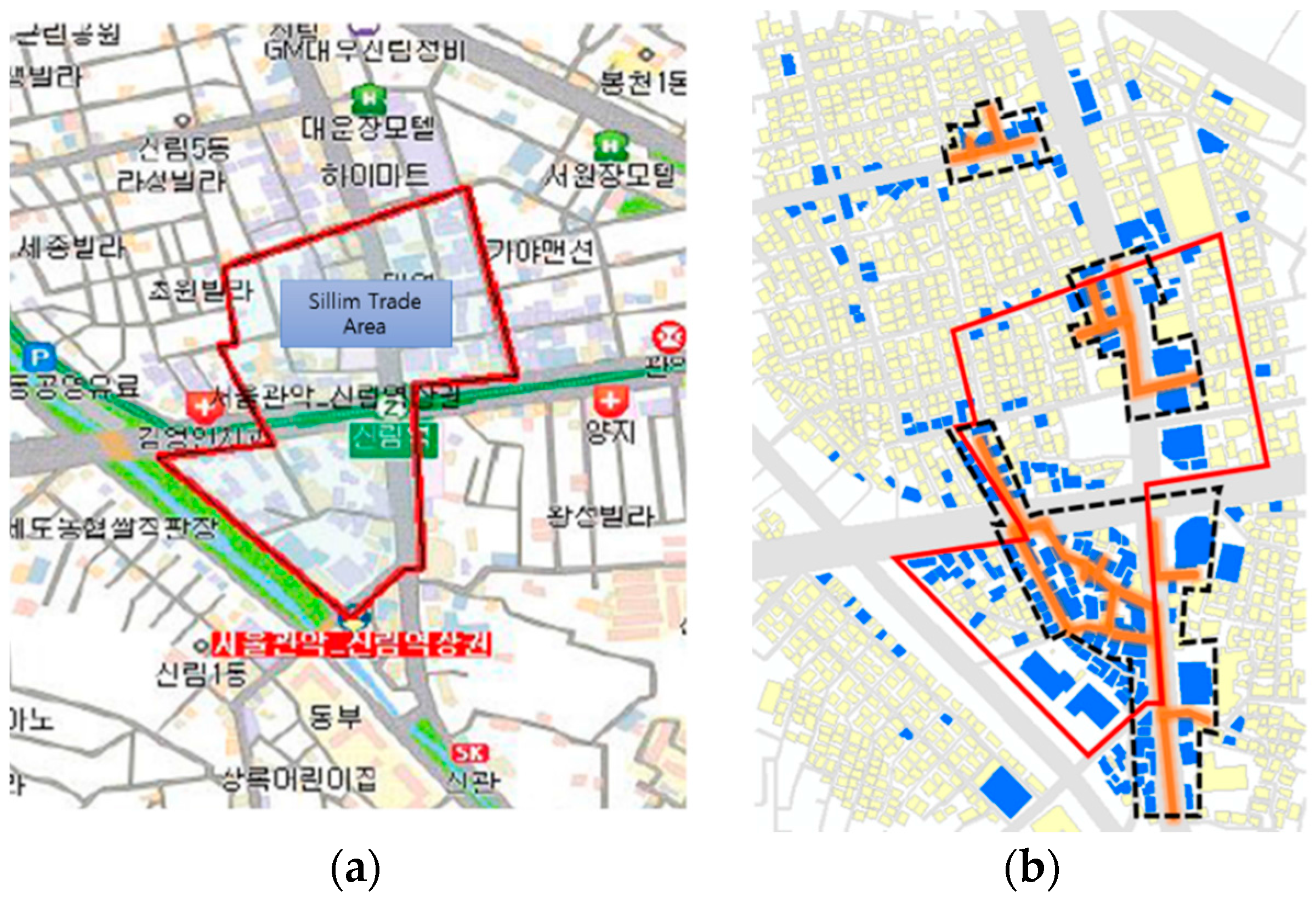
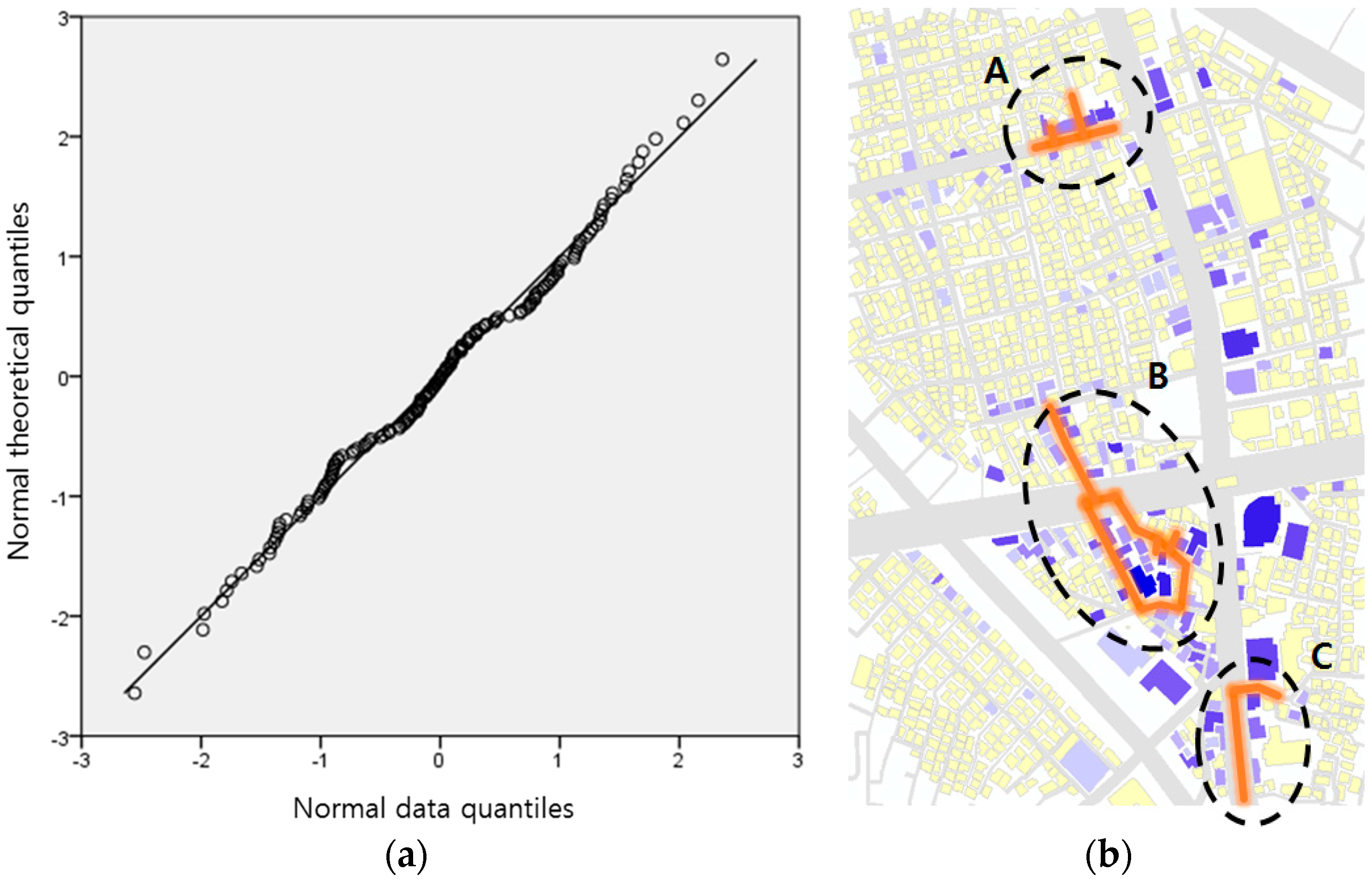
The test area has three large restaurant themed street clusters. District A is relatively smaller than the other districts and is located some distance from them. District A is named a “Fashion and Cultural Street”, originally developed by the local government. However, the public has criticized the development, stating that tax money was wasted and the original aim of the development was not met, since most of the fashion-related stores are closed and restaurants now line the street [
19]. District A reflects the actual condition directly by showing the functionality of the street as a food alley.
It was observed that district B has many restaurants, with 92 restaurant venues within the district. Among these, about half are related to selling Korean sausages (named “sundae” in Korean) (44 out of 92 venues sell Korean sausages). This unusual restaurant distribution was reported in the market analysis report on Sillim published by the Small Business Development Center (SBDC). The area is named “Sundae Town”, the Korean term for “Sausage Town”. The report was confirmed again through the test result.
District C has various restaurants such as Pizza Hut, McDonald’s, Chicken barbecue, etc. along with Sillim-ro (Sillim Avenue). District C, is located close to district B, to the south; however, the two districts have not merged as one large cluster. This shows that the restaurant venues between districts B and C do not receive enough attention, which separates B and C as different districts.
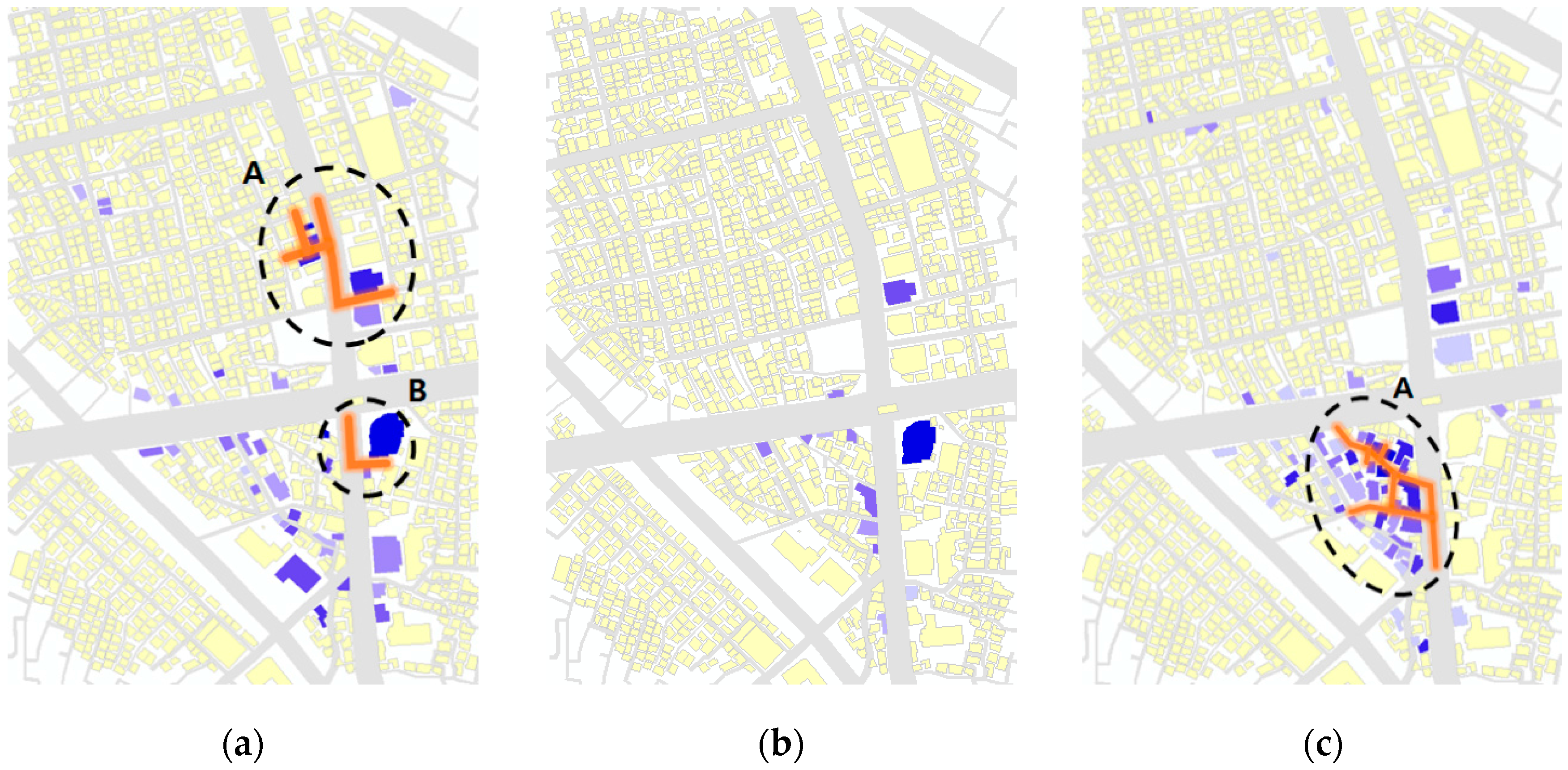
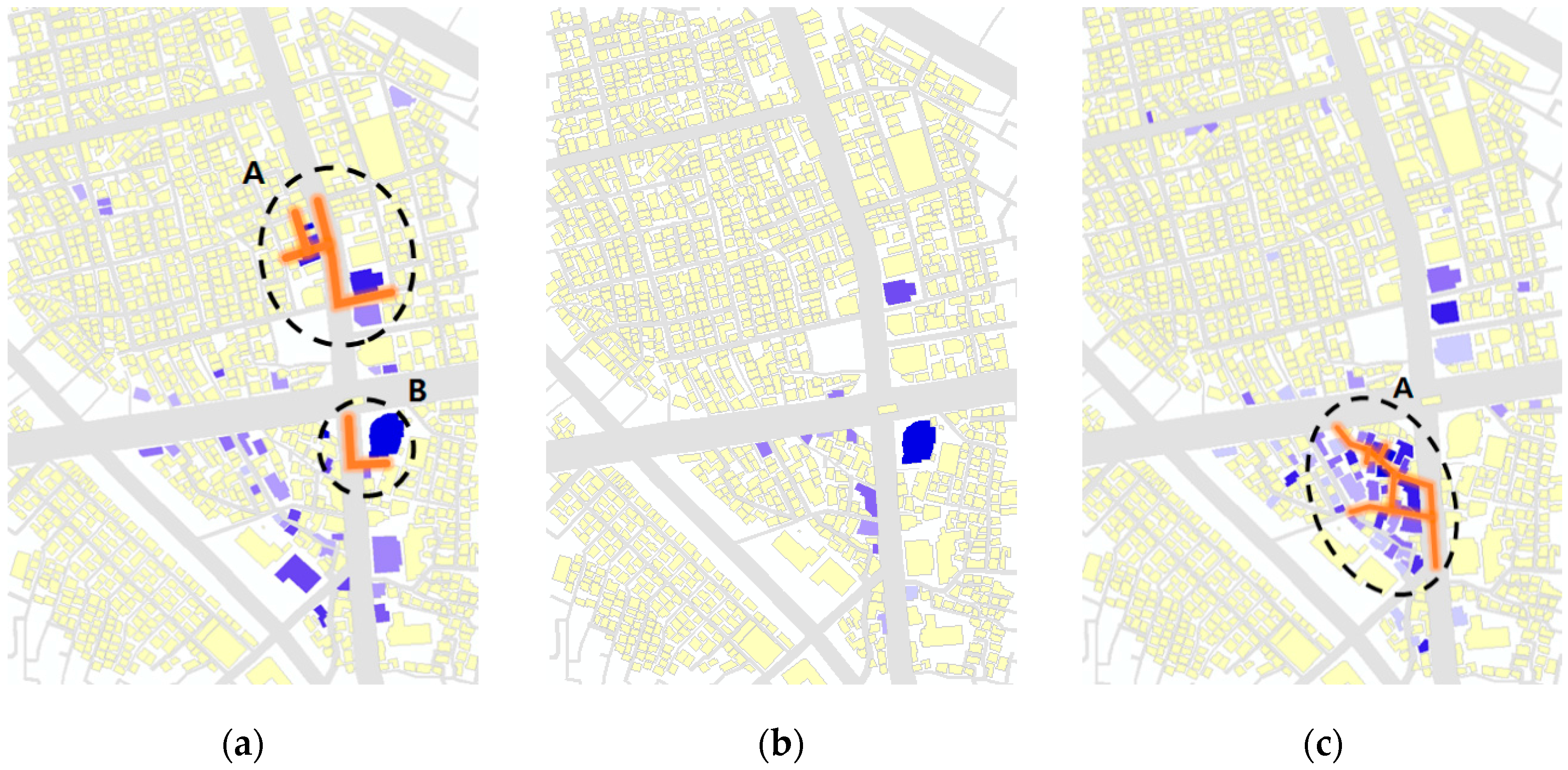
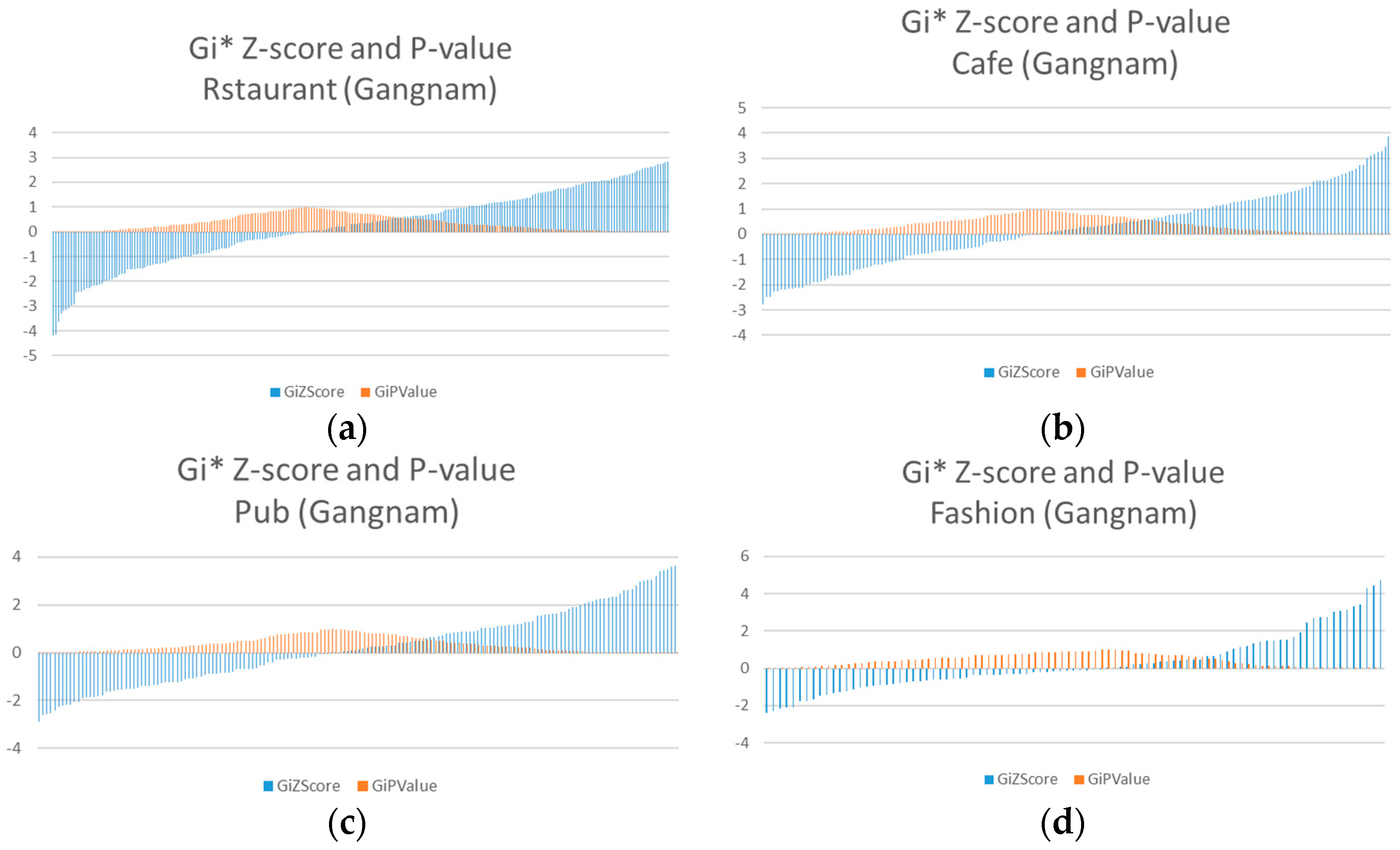
To deduce the various themed streets, not only the restaurants, but also the themes of cafés (
Figure 9a), fashion stores (
Figure 9b), and entertainment facilities (
Figure 9c) were tested using the same method. The most noticeable aspect of
Figure 9 is that a fashion themed street cluster was not detected (
Figure 9b). None of the road segments satisfies the
value of the significant level of 0.05, although a few fashion venues appear in the data. However, a building located to the southeast side of the intersection in the test area shows the highest popularity. It can be seen that the popular fashion stores are entered through a mall rather than via streets.
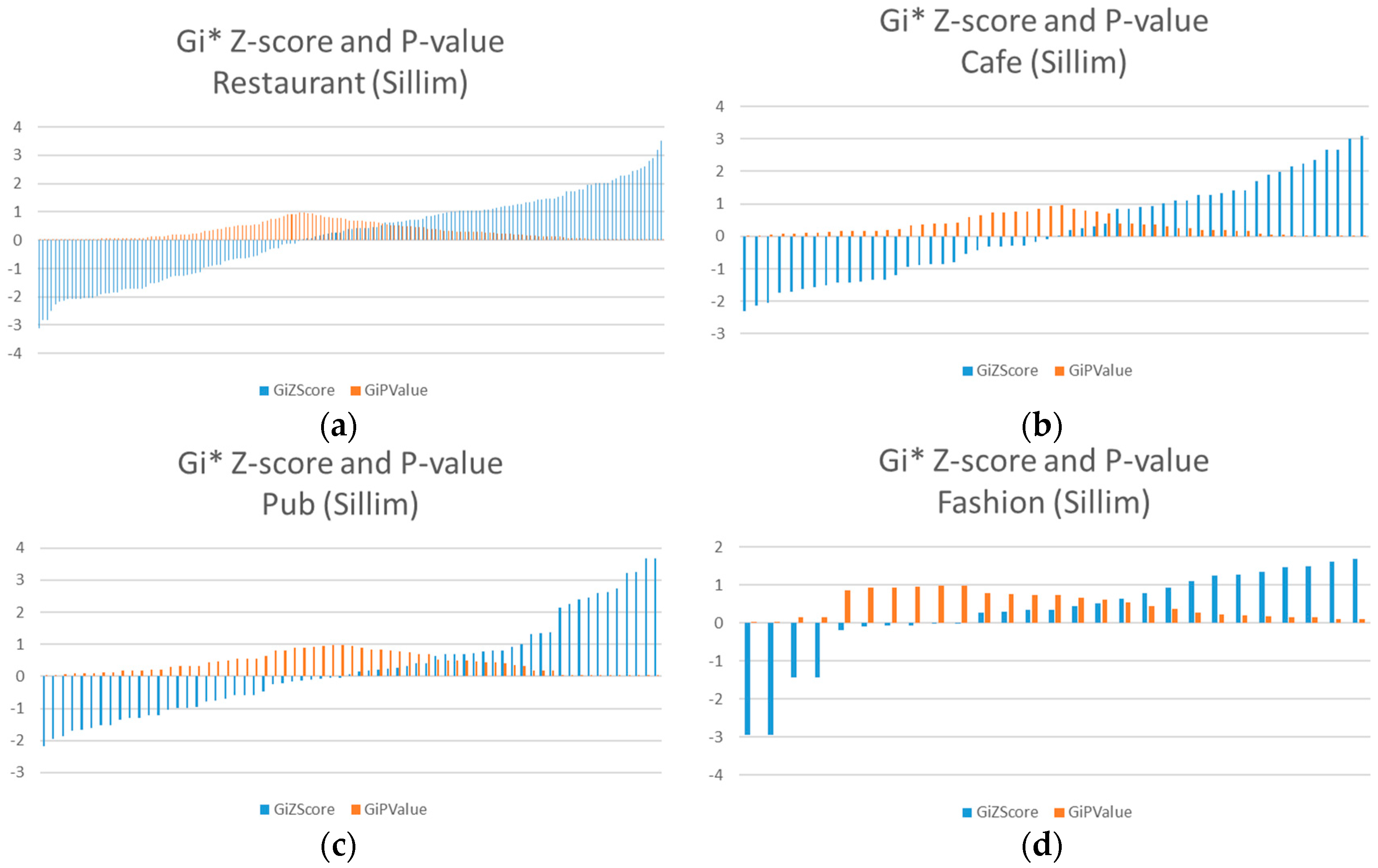
The
z-score and
p-value of each theme are plotted so that the overall detections of the themed streets can be observed (
Figure 10). The values are ordered according to the z-score in accordance with its
p-value. Notice that the data shows the
calculations of the road segments that contain venue information. Furthermore, the frequency of each theme is different because not all of the road segments contains venues. The roads that do not contain any data were disregarded.
Four different venues were used to detect the various themed street clusters. While themed streets represent the placeness of a region, they are also important in forming the business district. Therefore, the sum of all the themed street clusters mentioned above can be regarded as a business district. The total area was visually compared to that in a market analysis report from the SBDC of Korea, presented in June 2008.
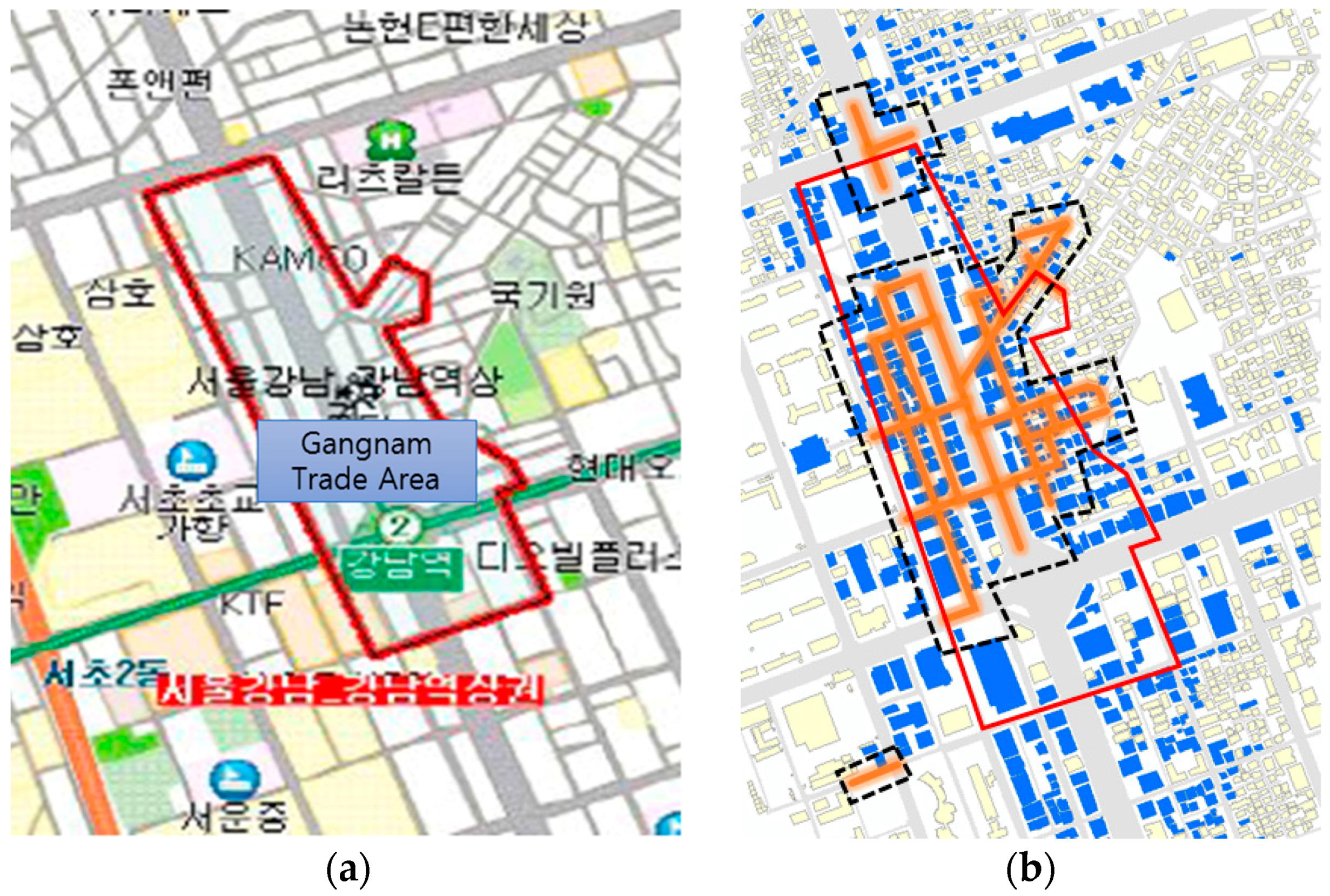
A map of the trade area from the market analysis report (
Figure 11a) and the themed street clusters along with buildings (
Figure 11b) is illustrated below. The test result did not reveal abnormally incorrect areas and most of the areas created by the test were inside of the area described in the SBDC report. From this visual comparison, it can be seen that the test method is reliable. It was observed that the market report presented in 2008 did not provide updated information. The themed street clusters had expanded to the south compared to the 2008 report. Also, the Fashion and Cultural street was not surveyed by the SBDC, so it was not possible to make a comparison.
In the meantime, the total number of venues in the Gangnam test area is 1570 and the number of confirmed venue buildings and matched road segments to the buildings is 425 and 242, respectively. The normal Q-Q plot indicates that the distribution of
of restaurant venues in the Gangnam area is slightly negatively skewed (skewness of −0.61) as shown in
Figure 12a. As previously mentioned though, a strict following of the normal distribution is not critical since Getis-Ord’s
does not provide clear equations for the calculation of the variance and the expected value [
17]. The detection of the themed street clusters from the test results of the Gangnam area are illustrated in
Figure 12b.
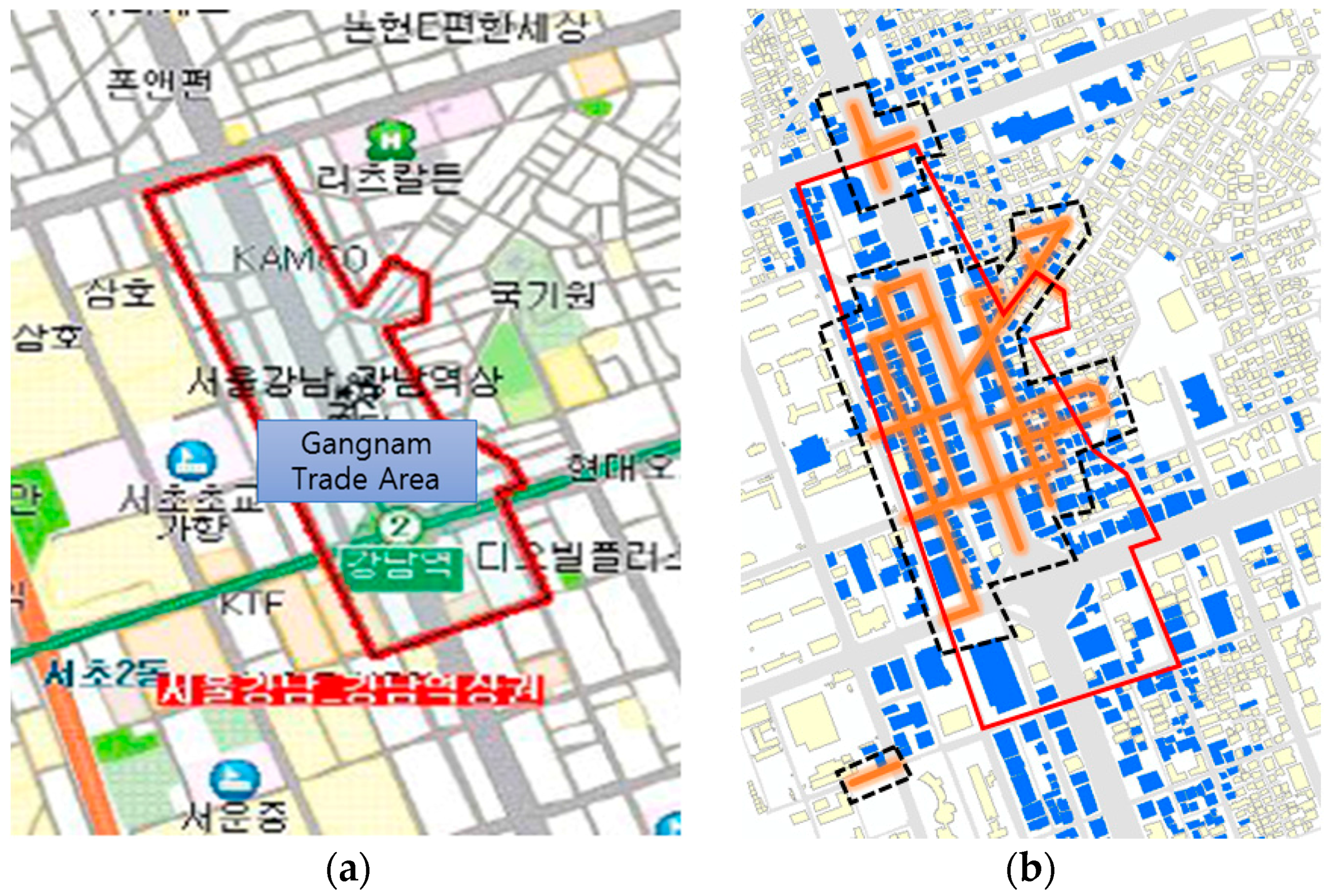
Three restaurant themed street clusters are detected in the Gangnam area. The special aspect of the area is that districts A and B form the back alleys of Gangnam-daero (the widest road shown in
Figure 12b). It was reported that many restaurants and pubs are densely located in the back alleys of the Gangname-daero [
20]. Considering the study, it can be concluded that the test result has objective accuracy. Unlike districts A and B, district C reveals a limitation of the test method. In fact, district C is not a cluster, but it is detected as only a single hot street (a street acting as a hot spot) segment. Only one restaurant venue building was assigned to the target road segment, and the z score of
was 1.98, with a significance level of 0.05, whose values are within the average range of the study areas. However, the popularity value
was 1045. This value is extremely high considering that the average
in the Gangnam area is around 80. This shows that an extremely high value of
could render a road segment as a themed street.
The
z-score and
p-value of each themes are plotted in
Figure 14.
The SBDC market analysis report of Gangnam was presented in May 2008, in which all of the themed street clusters in the Gangnam area were visually compared.
Figure 15 shows a map of the trade area from the market analysis report (
Figure 15a) and the themed street clusters along with buildings that have venue data (
Figure 15b). Excluding district C in
Figure 12b, which as explained above, reveals the limitation of the testing method, the SBDC market analysis report shows that most of the themed street clusters are located inside of the area. This demonstrates that the test method has reliability and versatility.
5. Conclusions
The TSCM has been suggested throughout this study to detect themed streets. Themed streets encourage local economy and provide social and cultural spaces. The TSCM is not limited to merely detecting areas where similar stores are densely located, but also detects various themed streets using LBSM data, providing rich information.
Comparing the trade areas from the market analysis report prepared from a field survey with the test results of this study, the reliability of the method was confirmed.
The most significant contribution of this study is that various themes were detected using the suggested TSCM and that the method produced consistent results. Also, through the identification of themed streets, local governments may be able to understand the socio-dynamics of target areas, or they may engage in the re-development of the existing town planning [
21]. Using this method, planners can receive up-to-date data regarding the specific usage of urban areas without the need for field surveys or the risk of outdated literature investigations, and budgetary spending is consequently reduced. Besides, like the finding of this study whereby the “Fashion and Cultural Street” in Sillim test area is used for different purposes, planners can identify the way that official planning outcomes have been transformed. With these perspectives, an enhanced decision making process can be used for re-development of urban areas.
Furthermore, the TSCM produced objective results irrespective of the location of the test area, since the method converts LBSM data attributes to mathematical values. Also, using road segments as basic spatial units for analysis, the test results were intuitive and distinguishable by avoiding formation of ambiguous spatial areas such as those created by KDE or conventional hot spot areas. Finally, not only the number of POIs and check-in counts, but also other attributes were mathematically measured to find meaningful themed streets.
However, this study also has some limitations. First, a quantitative measurement to evaluate the themed street clusters was not carried out. Second, the age range of people using the Foursquare service is limited. Although this is a general problem of the analyses for which LBSM data are used, additional data from different sources can be used to represent the whole population. Third, human error and participation leads to mistakes like typos and subjective opinions of venues when LBSMs are used. Also, internet access and other types of physical limitations could lead to the ununiformed distribution of LBSM data. Such limitations should be known by those researchers who utilize LBSM data. Lastly, a number stores or buildings (venues), such as large malls or well-known restaurants, can skew the detection of themed streets if their popularity levels are extremely high.
To overcome the abovementioned limits, an evaluation method needs to be studied. Also, errors caused by a few venues should be avoided and continuously identified and investigated by modifying the hot value (), which reflects the characteristics of road segments.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}