
How? Why? What? Where? When? Who? Grounding Ontology in the Actions of a Situated Social Agent

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
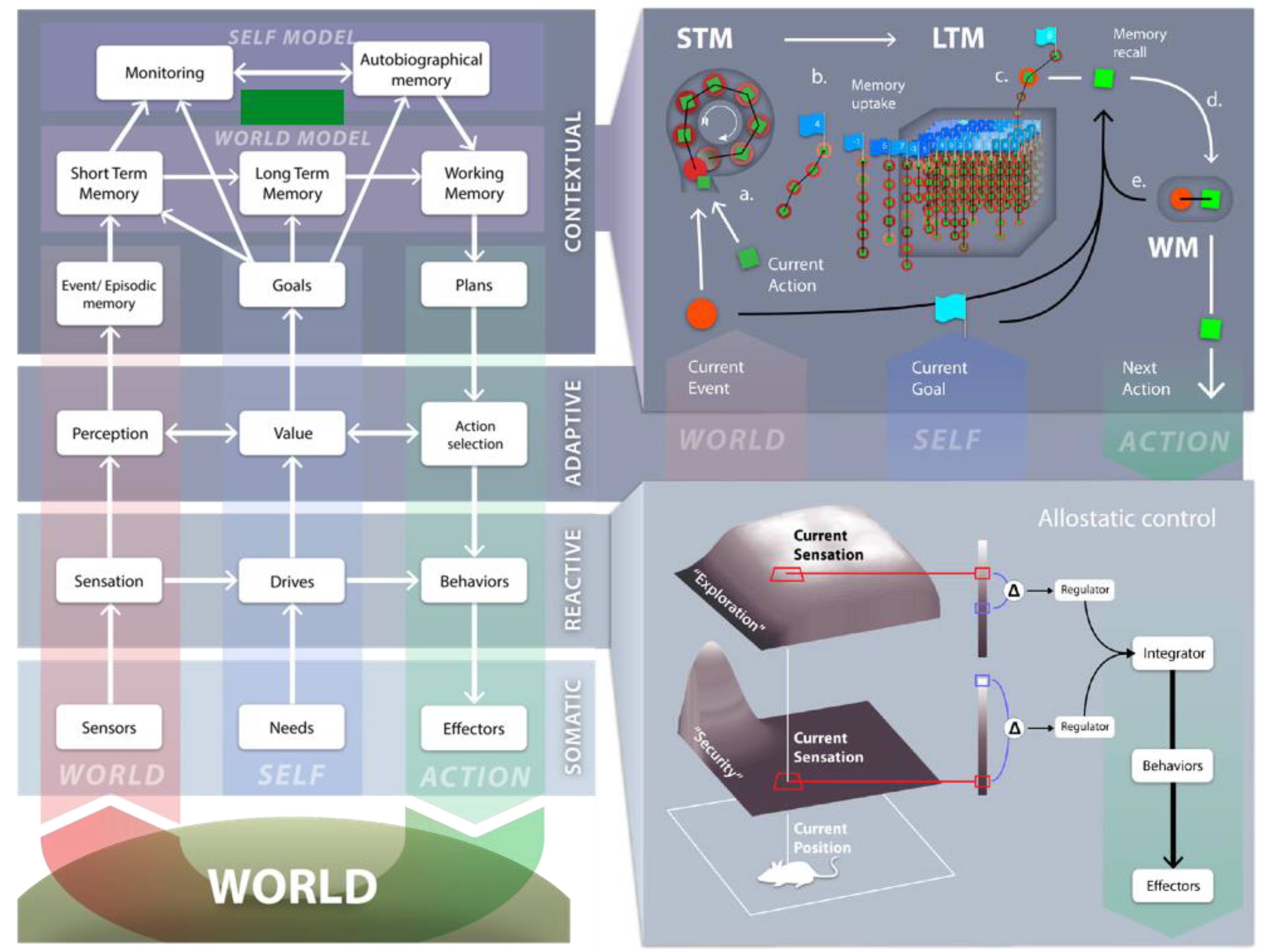
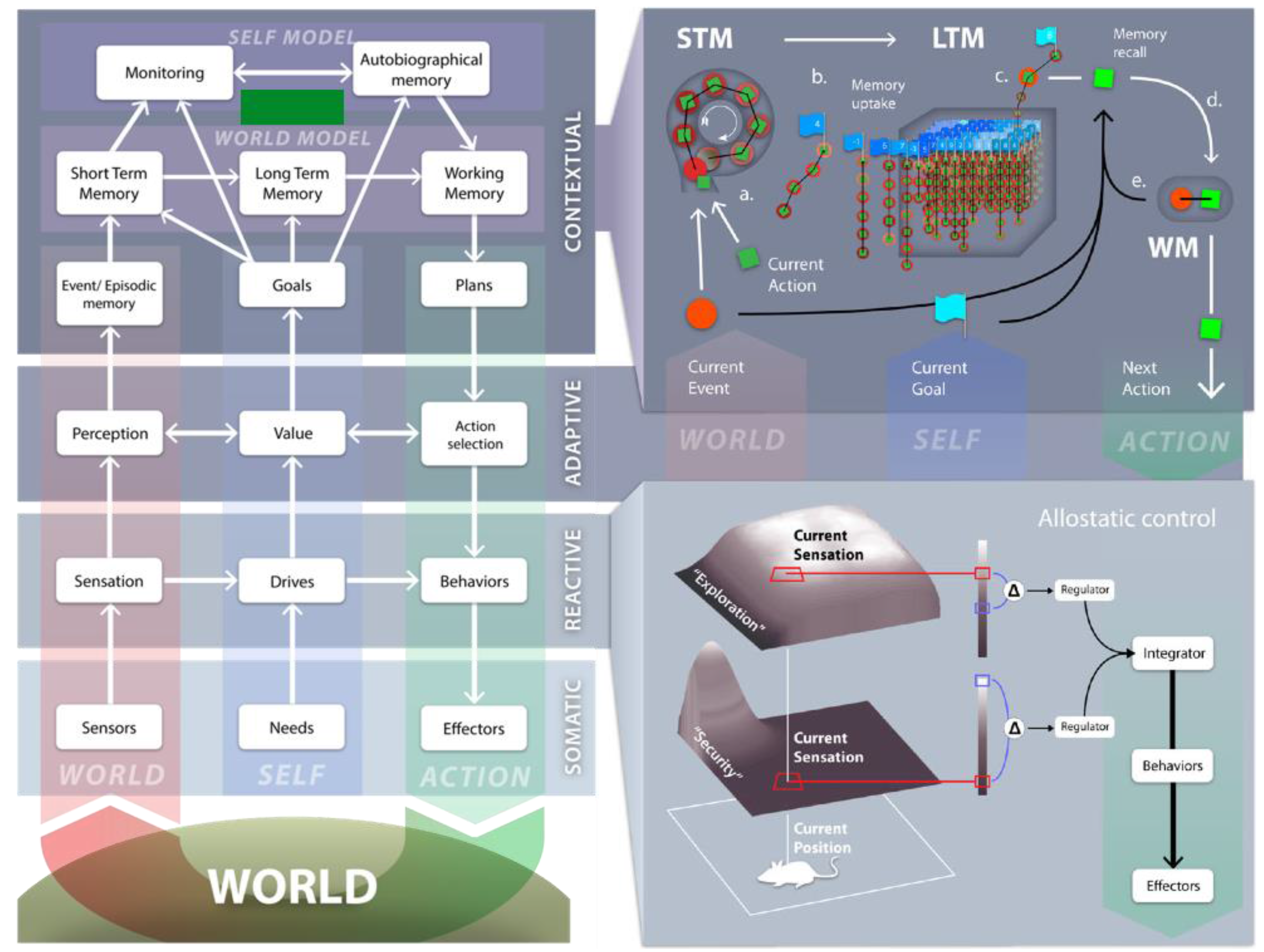
2. DAC Overview
3. Ontology of H5W
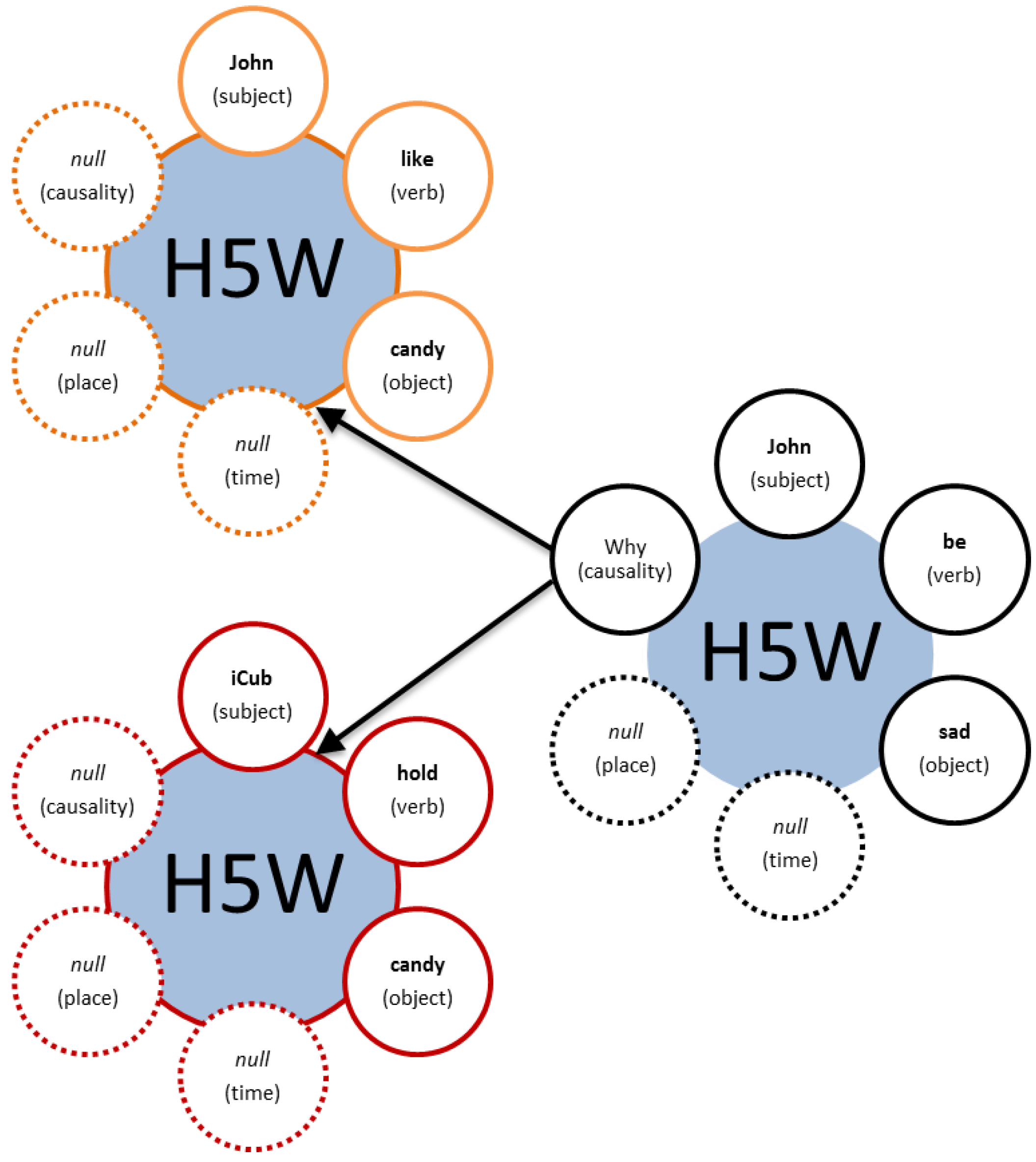
3.1. H5W Definition: How, Who, What, When, Where, Why?
- Who is there? (subject)
- What is there? (object)
- How they behave? (action/verb)
- When it happens? (time)
- When it take place? (place)
- Why do they behave like this? (motivation/causality)
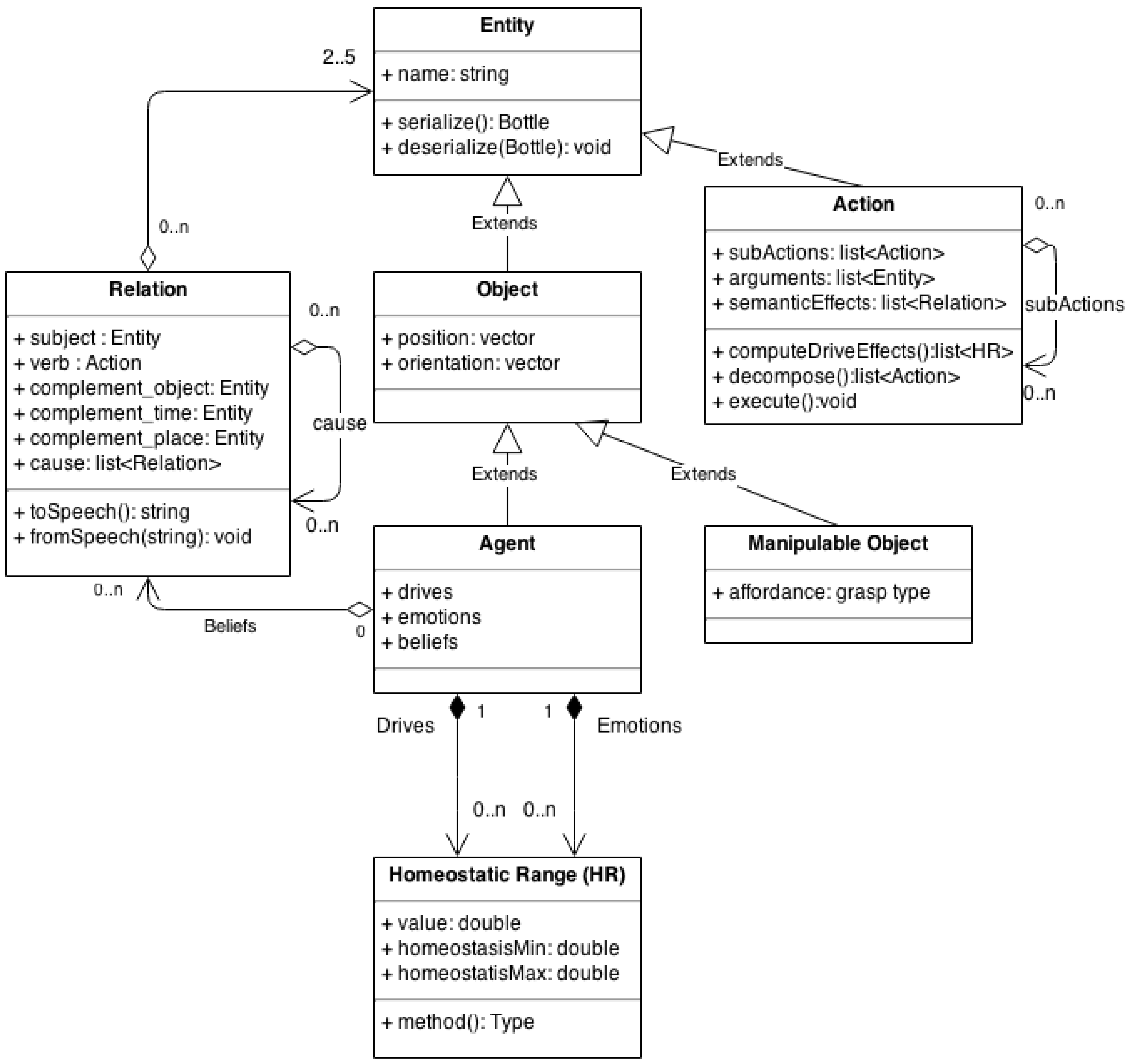
3.2. The H5W Data-Structures
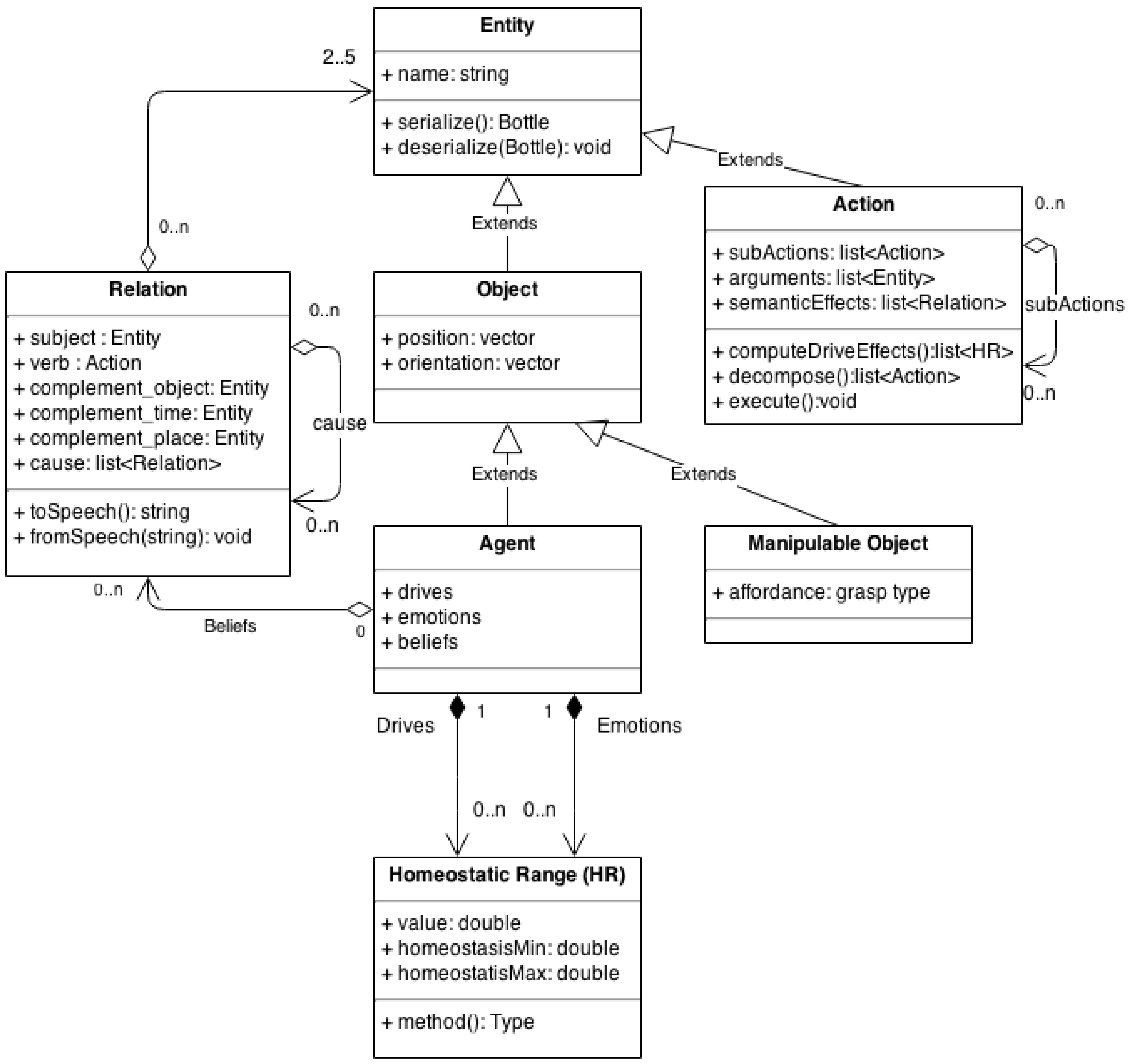
3.2.1. Relation
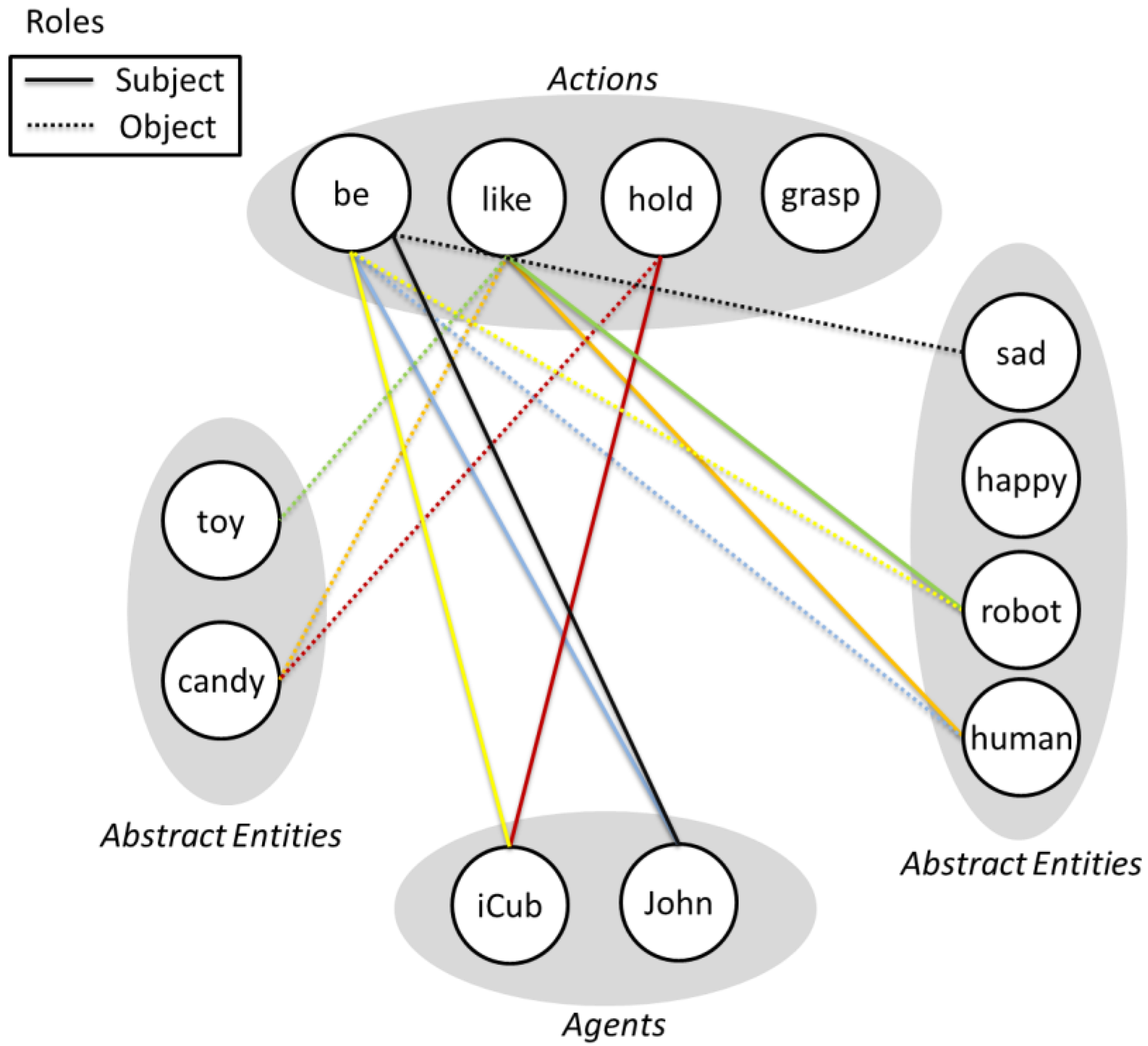

3.2.2. Object
3.2.3. Manipulable Objects
3.2.4. Agent
3.2.5. Action

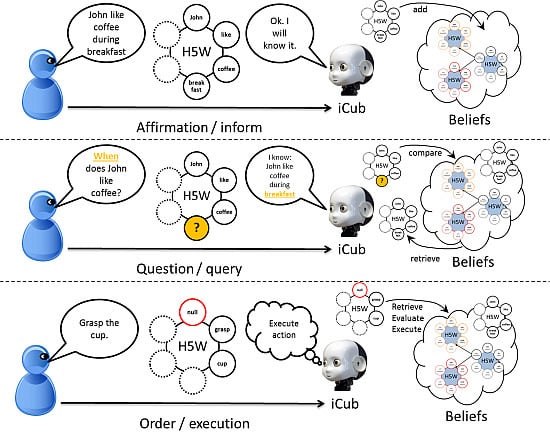
4. The H5W Acquisition and Transfer through Dialog
4.1. Mapping between Natural Language and H5W Semantic
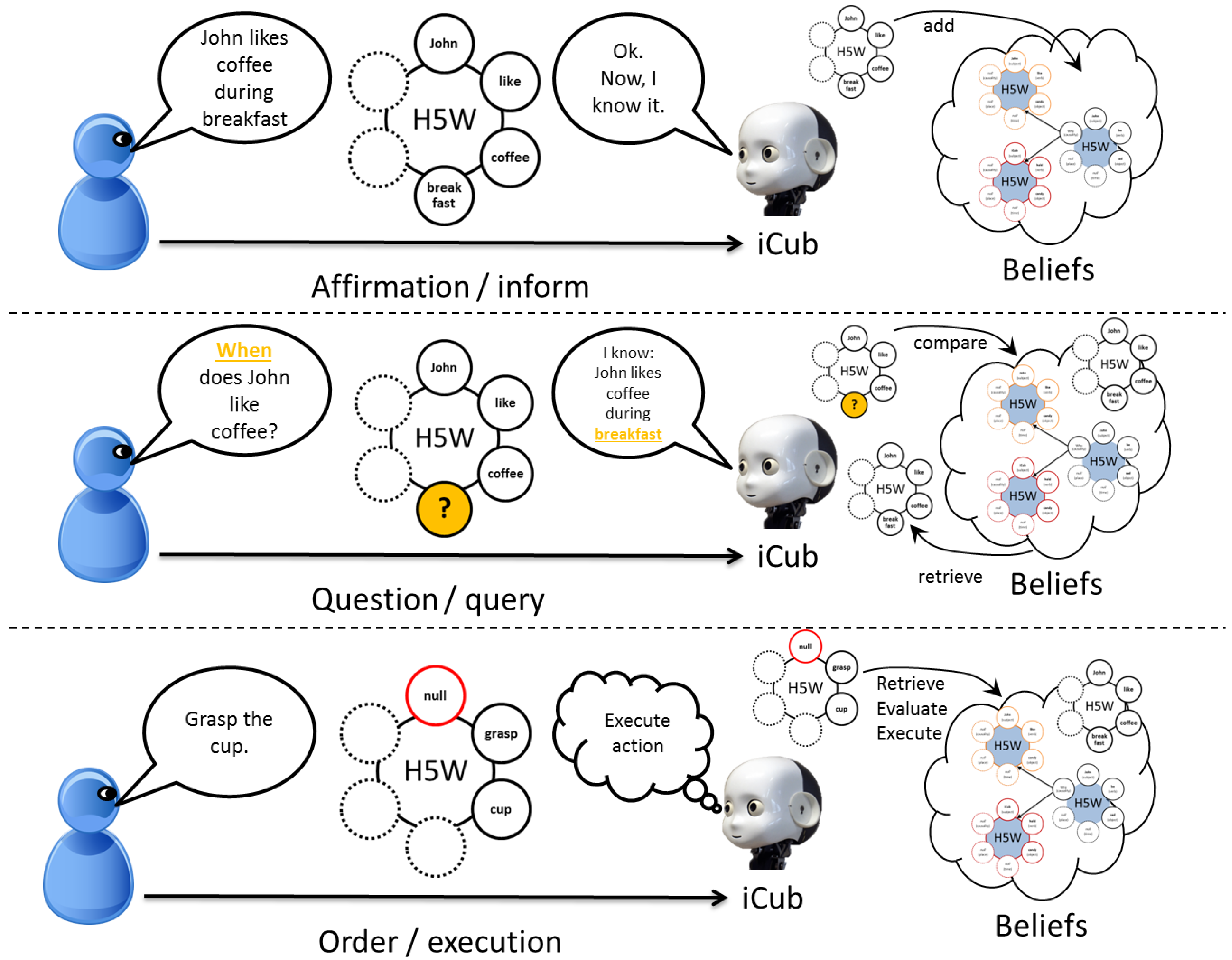
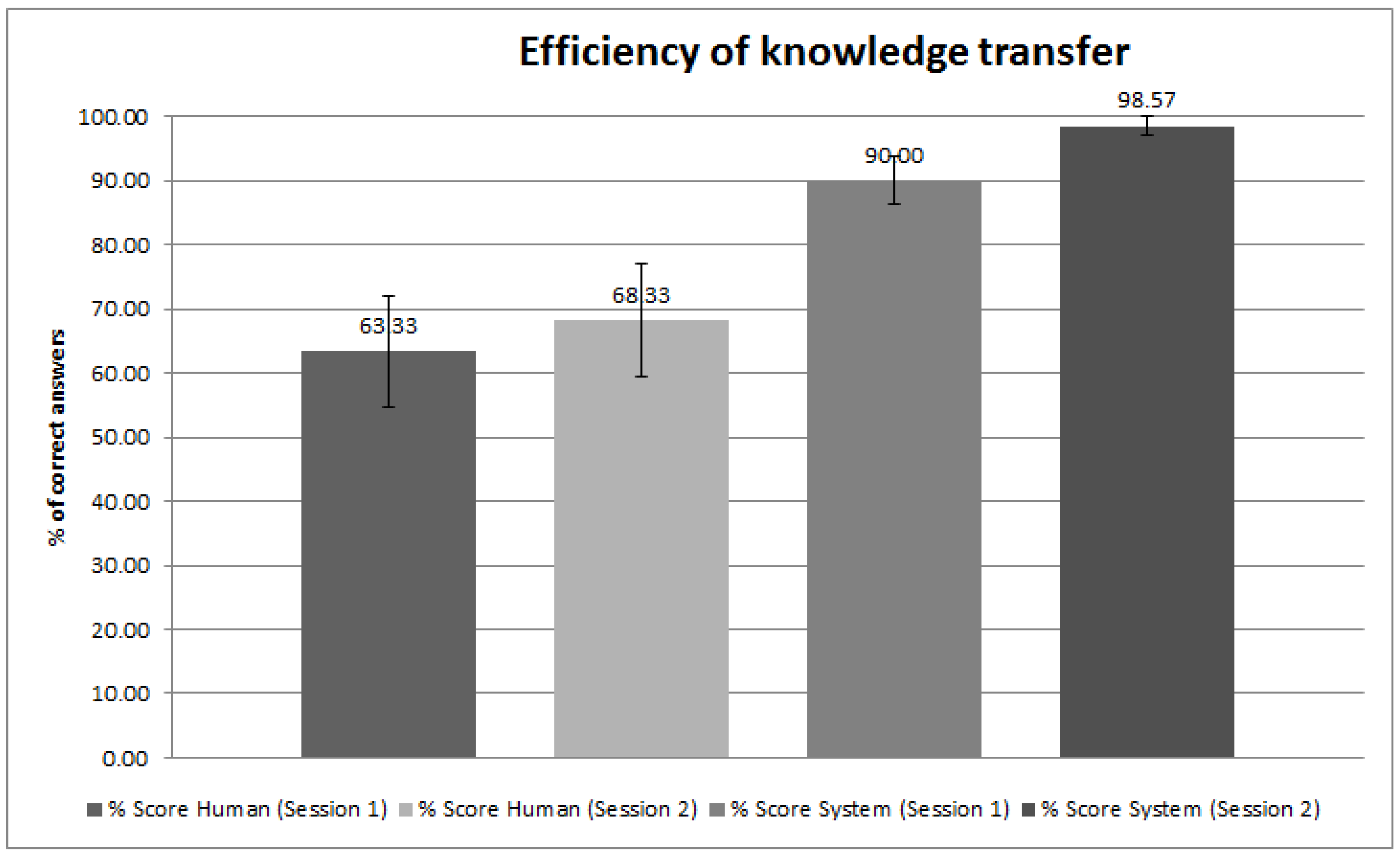
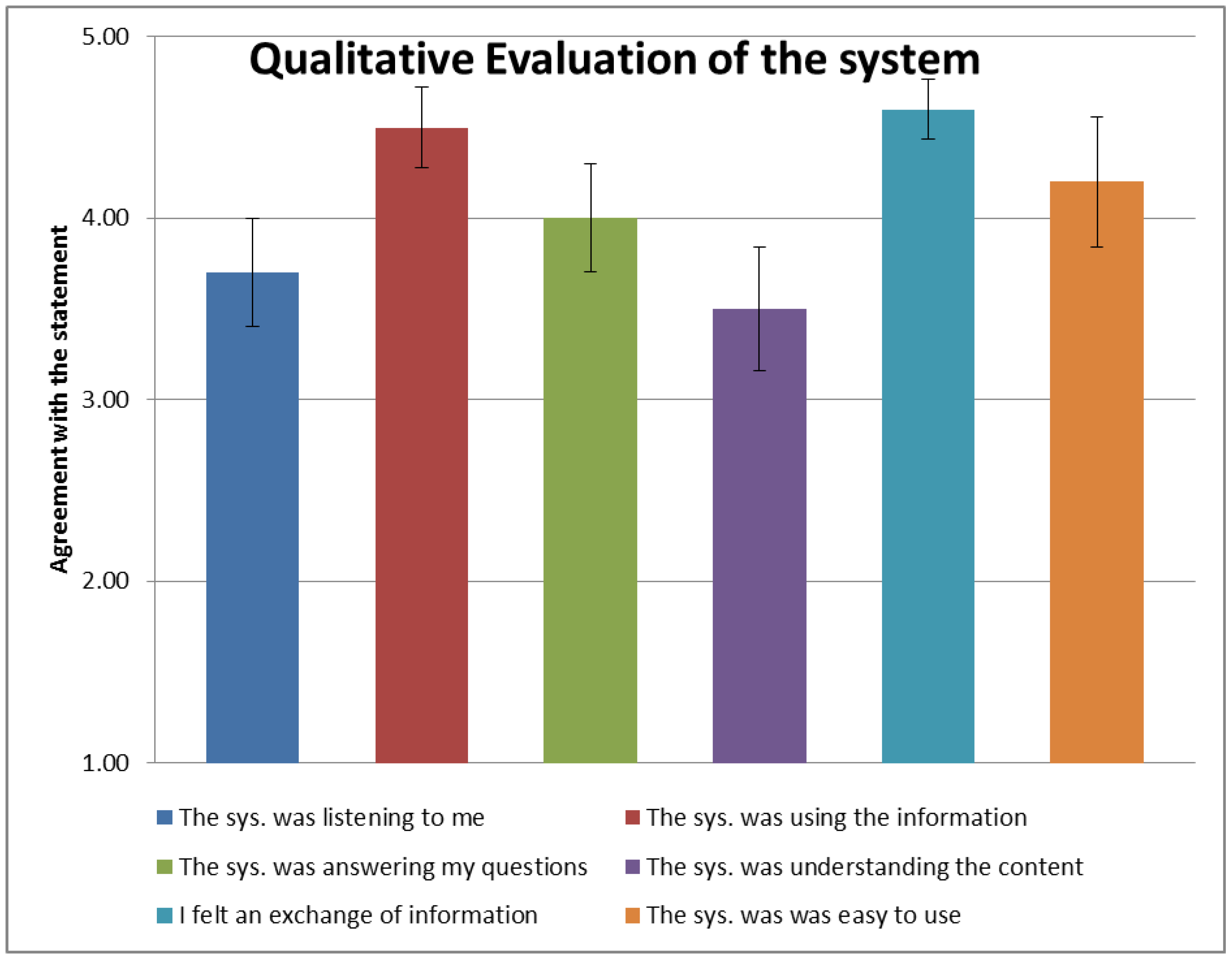
4.2. Benchmarking H5W for Information Exchange
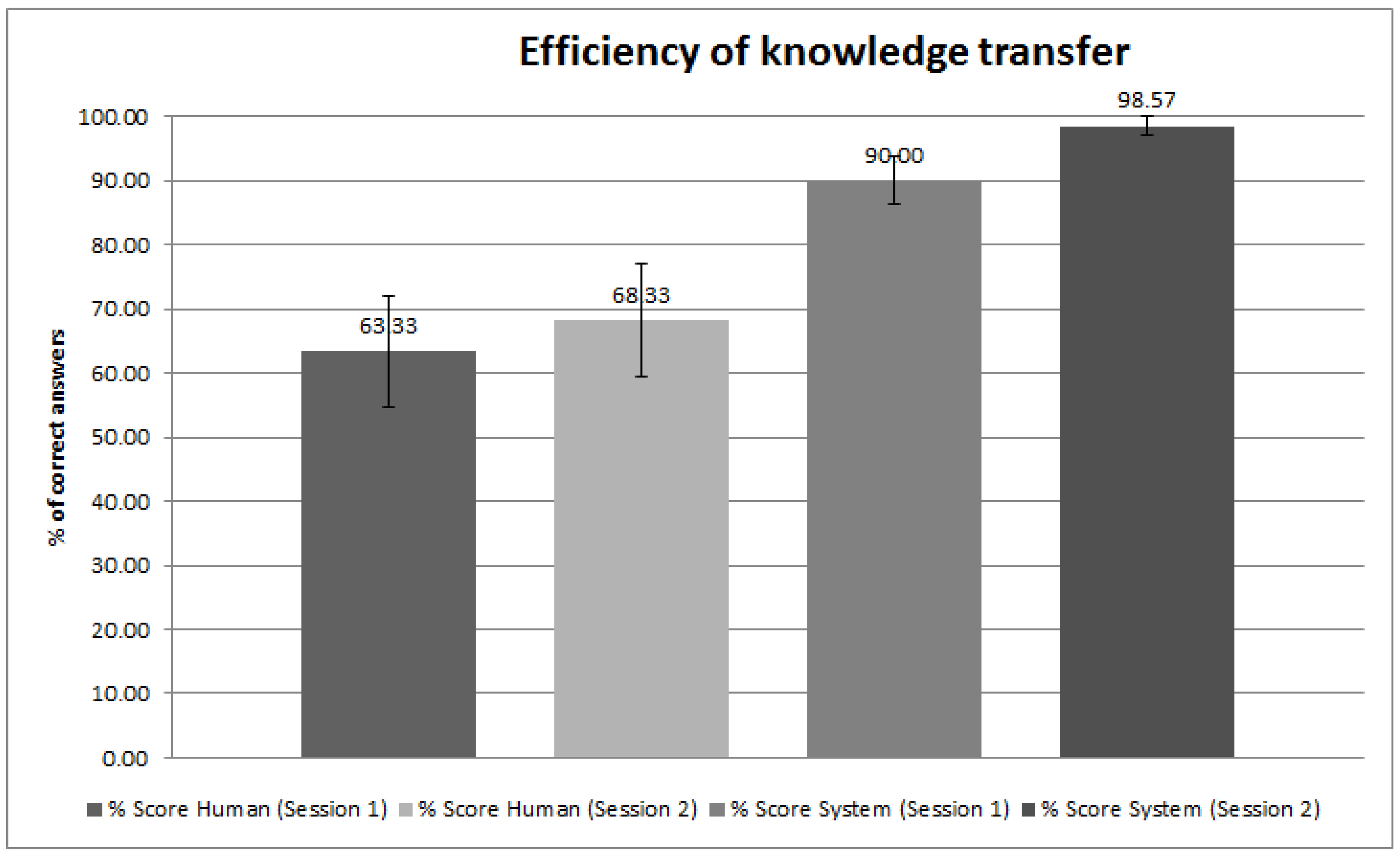
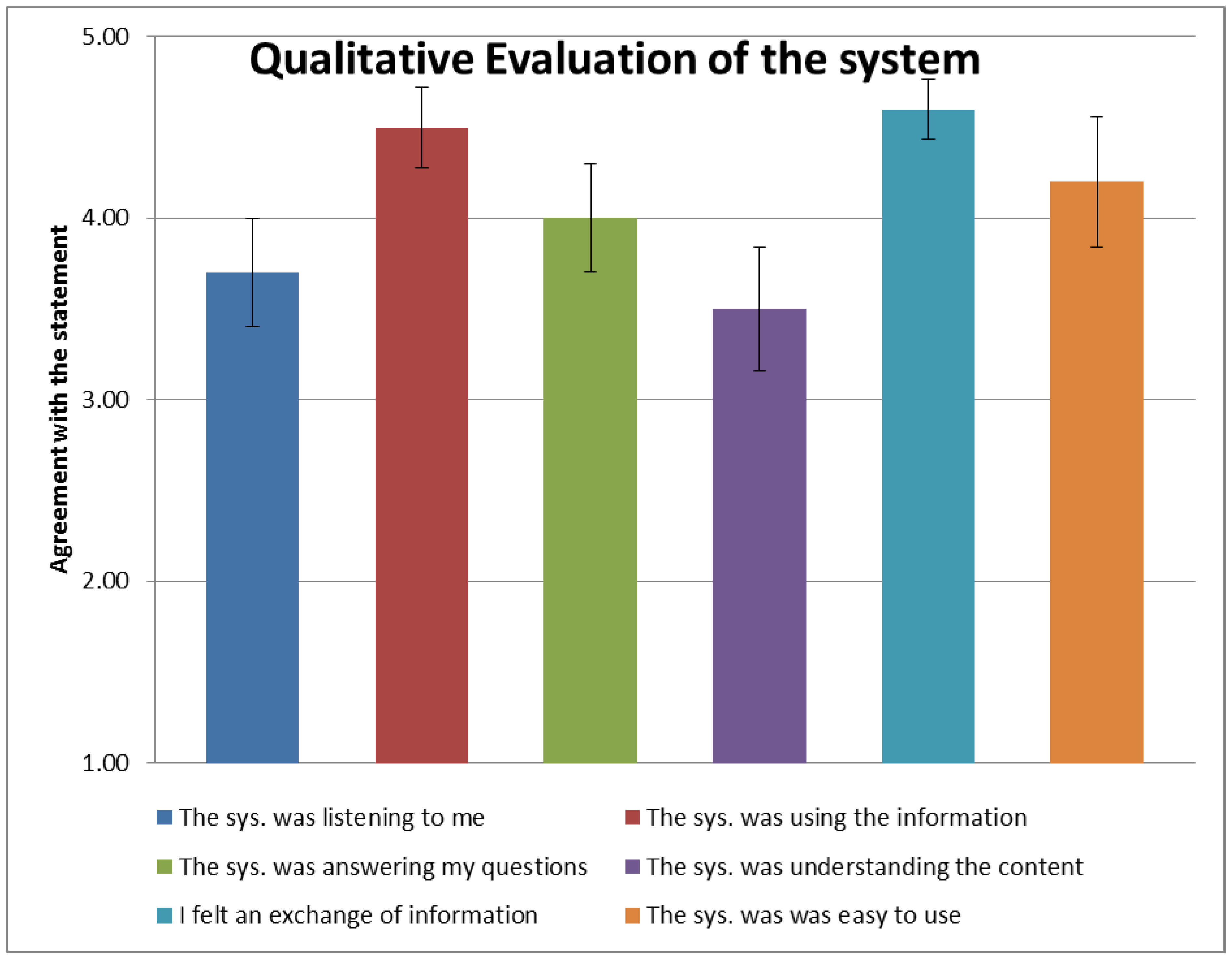
5. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Sundmaeker, H.; Guillemin, P.; Friess, P.; Woelfflé, S. Vision and Challenges for Realising the Internet of Things; Publications Office of the European Union: Luxembourg, Luxembourg, 2010. [Google Scholar]
- Ashton, K. That ‘Internet Of Things’ thing. RFID J. 2009, 22, 97–114. [Google Scholar]
- McAfee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute: Summit, NJ, USA, 2011. [Google Scholar]
- Lohr, S. The age of big data. Available online: http://wolfweb.unr.edu/homepage/ania/NYTFeb12.pdf (accessed on 18 February 1015).
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Norwell, MA, USA, 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; The MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167.
- Coradeschi, S.; Saffiotti, A. An introduction to the anchoring problem. Rob. Auton. Syst. 2003, 43, 85–96. [Google Scholar] [CrossRef]
- Coradeschi, S.; Saffiotti, A. Anchoring symbols to sensor data: Preliminary report. In AAAI/IAAI; Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 2000. [Google Scholar]
- Harnad, S. The symbol grounding problem. Phys. D 1990, 42, 335–346. [Google Scholar] [CrossRef]
- Verschure, P. Distributed adaptive control: A theory of the mind, brain, body nexus. Biol. Inspired Cogn. Archit. 2012, 1, 55–72. [Google Scholar] [CrossRef]
- Beeson, P.; Kortenkamp, D.; Bonasso, R.P.; Persson, A.; Loutfi, A.; Bona, J.P. An ontology-based symbol grounding system for human-robot interaction. In Proceedings of the 2014 AAAI Fall Symposium Series, Arlington, MA, USA, 13–15 November 2014.
- Prescott, T.J.; Lepora, N.F.; Verschure, P.F.M.J. A future of living machines?: International trends and prospects in biomimetic and biohybrid systems. In Proceedings of the SPIE 9055, Bioinspiration, Biometrics and Bioreplication, San Diego, CA, USA, 9–12 March 2014.
- Verschure, P. Formal minds and biological brains II: From the mirage of intelligence to a science and engineering of consciousness. IEEE Intell. Syst. Trends Controv. 2013, 7–10. [Google Scholar]
- Pfeifer, R.; Verschure, P. Distributed adaptive control: A paradigm for designing autonomous agents. In Toward a Practice of Autonomous Systems: Proceedings of the First European Conference on Artificial Life; MIT Press: Cambridge, MA, USA, 1992; pp. 21–30. [Google Scholar]
- Verschure, P.; Kröse, B.; Pfeifer, R. Distributed adaptive control: The self-organization of structured behavior. Rob. Auton. Syst. 1992, 9, 181–196. [Google Scholar] [CrossRef]
- Verschure, P. Connectionist explanation: Taking positions in the Mind-Brain dilemma. In Neural Networks and a New Artificial Intelligence; International Thomson Computer Press: Boston, MA, USA, 1997. [Google Scholar]
- Lallée, S.; Vouloutsi, V.; Blancas, M.; Grechuta, K.; Puigbo, J.; Sarda, M.; Verschure, P.F.M. Towards the synthetic self: Making others perceive me as an other. Paladyn J. Behav. Robot. 2015. submit. [Google Scholar]
- Vouloutsi, V.; Lallée, S.; Verschure, P. Modulating behaviors using allostatic control. In Biomimetic and Biohybrid Systems; Springer: Berlin, Germany, 2013; pp. 287–298. [Google Scholar]
- Vouloutsi, V.; Grechuta, K.; Lallée, S.; Verschure, P. The Influence of behavioral complexity on robot perception. In Biomimetic and Biohybrid Systems; Springer: Berlin, Germany, 2014; pp. 332–343. [Google Scholar]
- Verschure, P.F.; Pennartz, C.M.; Pezzulo, G. The why, what, where, when and how of goal-directed choice: neuronal and computational principles. Philos. Trans. R. Soc. London B Biol. Sci. 2014, 369, 20130483. [Google Scholar] [CrossRef] [PubMed]
- Antoniou, G.; Harmelen, F. Web ontology language: Owl. In Handbook on Ontologies; Springer: Berlin, Germany, 2009. [Google Scholar]
- Avraham, S.; Tung, C.; Ilic, K. The Plant Ontology Database: A community resource for plant structure and developmental stages controlled vocabulary and annotations. Nucleic Acids Res. 2008, 36, D449–D454. [Google Scholar] [CrossRef] [PubMed]
- Consortium, G.O. The Gene Ontology (GO) database and informatics resource. Nucleic Acids Res. 2004, 32, D258–D261. [Google Scholar] [CrossRef] [PubMed]
- Soldatova, L.; Clare, A.; Sparkes, A.; King, R. An ontology for a Robot Scientist. Bioinformatics 2006, 22, e464–e471. [Google Scholar] [CrossRef] [PubMed]
- Tenorth, M.; Clifford Perzylo, A.; Lafrenz, R.; Beetz, M.; Perzylo, A. The RoboEarth language: Representing and exchanging knowledge about actions, objects, and environments. In Proceedings of the Twenty-Third international joint conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1284–1289.
- Lemaignan, S.; Ros, R. ORO, a knowledge management platform for cognitive architectures in robotics. In Proceedings of the 2010 IEEE/RSJ International Conference on, Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 3548–3553.
- Tenorth, M.; Beetz, M. KnowRob: A knowledge processing infrastructure for cognition-enabled robots. Int. J. Robot. Res. 2013, 32, 566–590. [Google Scholar] [CrossRef]
- Ros, R.; Lemaignan, S.; Sisbot, E. Which one? Grounding the referent based on efficient human-robot interaction. In Proceedings of the 2010 IEEE RO-MAN, Viareggio, Italy, 13–15 September 2010; pp. 570–575.
- Zweigle, O.; Andrea, R.; Häussermann, K. RoboEarth—Connecting robots worldwide. In Proceedings of the 2nd International Conference on Interaction Sciences: Information Technology, Culture and Human, Seoul, Korea, 24–26 November 2009; pp. 184–191.
- Chella, A.; Kurup, U.; Laird, J.; Trafton, G.; Vinokurov, J.; Chandrasekaran, B. The challenge of robotics for cognitive architectures. In Proceedings of the International Conference on Cognitive Modeling, Ottawa, ON, Canada, 11–14 July 2013; pp. 287–290.
- Searle, J. Minds, brains, and programs. Behav. Brain Sci. 1980, 3, 417–424. [Google Scholar] [CrossRef]
- Lallee, S.; Madden, C.; Hoen, M.; Dominey, P.F. Linking language with embodied and teleological representations of action for humanoid cognition. Front. Neurorobot. 2010, 4, 12. [Google Scholar] [CrossRef] [PubMed]
- Oudeyer, P. Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 2007, 11, 265–286. [Google Scholar] [CrossRef]
- Maslow, A. A theory of human motivation. Psychol. Rev. 1943, 50, 370–396. [Google Scholar] [CrossRef]
- Breazeal, C. A Motivational system for regulating human-robot interaction. In AAAI/IAAI; Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 1998. [Google Scholar]
- Hawes, N. A survey of motivation frameworks for intelligent systems. Artif. Intell. 2011, 175, 1020–1036. [Google Scholar] [CrossRef]
- Verschure, P. F. M. J. Formal Minds and Biological Brains II: From the Mirage of Intelligence to a Science and Engineering of Consciousness. IEEE Intell. Syst. Trends Controv. 2013, 28, 7–10. [Google Scholar]
- White, D.R.D.; Reitz, K.P.K. Graph and semigroup homomorphisms on networks of relations. Soc. Netw. 1983, 5, 193–234. [Google Scholar] [CrossRef]
- Spelke, E. Principles of object perception. Cogn. Sci. 1990, 14, 29–56. [Google Scholar] [CrossRef]
- Gibson, J. The Theory of Affordances; Lawrence Erlbaum Assoociates, Inc.: Hilldale, NJ, USA, 1977. [Google Scholar]
- Lockman, J.; McHale, J. Object manipulation in infancy. In Action in Social Context; Springer Publishing: New York, NY, USA, 1989; pp. 129–167. [Google Scholar]
- Tikhanoff, V.; Pattacini, U.; Natale, L.; Metta, G. Exploring affordances and tool use on the iCub. In IEEE-RAS International Conference on Humanoid Robots (Humanoids), Atlanta, GA, USA, 15–17 October 2013.
- Moldovan, B.; Moreno, P. Learning relational affordance models for robots in multi-object manipulation tasks. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 4373–4378.
- Moldovan, B.; van Otterlo, M. Satistical relational learning of object affordances for robotic manipulation. In Proceedings of the International Conference on Inductive Logic Programming, Dubrovnik, Croatia, 17–19 September 2012.
- Leslie, A. A theory of agency. In Causal cognition: A multidisciplinary debate; Sperber, D., Premack, D., Premack, A. J., Eds.; Oxford University Press: New York, NY, 1995; pp. 121–141. [Google Scholar]
- Csibra, G.; Gergely, G.; Bíró, S.; Koós, O.; Brockbank, M. Goal attribution without agency cues: The perception of ‘pure reason’ in infancy. Cognition 1999, 72, 237–267. [Google Scholar] [CrossRef]
- Reeves, B.; Nass, C. How People Treat Computers, Television, and New Media Like Real People and Places; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Brennan, A.; Mantzoros, C. Drug insight: The role of leptin in human physiology and pathophysiology—Emerging clinical applications. Nat. Clin. Pract. Endocrinol. Metab. 2006, 2, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Sanchez-Fibla, M. Allostatic control for robot behavior regulation: A comparative rodent-robot study. Adv. Complex Syst. 2010, 13, 377–403. [Google Scholar] [CrossRef]
- Frijda, N. The Emotions; Cambridge University Press: Cambridge, UK, 1987. [Google Scholar]
- Fellous, J.; LeDoux, J.; Arbib, M. Toward basic principles for emotional processing: What the fearful brain tells the robo. In Who Needs Emotion Brain Meets Robot; Oxford University Press: Oxford, UK, 2005; pp. 245–270. [Google Scholar]
- Adolphs, R.; Tranel, D.; Damasio, A.R. Dissociable neural systems for recognizing emotions. Brain Cogn. 2003, 52, 61–69. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Wimmer, H.; Perner, J. Beliefs about beliefs: Representation and constraining function of wrong beliefs in young children’s understanding of deception. Cognition 1983, 13, 103–128. [Google Scholar] [CrossRef]
- Baron-Cohen, S.; Leslie, A.; Frith, U. Does the autistic child have a ‘theory of mind’? Cognition 1985, 21, 37–46. [Google Scholar] [CrossRef]
- Bloom, P.; German, T.P. Two reasons to abandon the false belief task as a test of theory of mind. Cognition 2000, 77, 25–31. [Google Scholar] [CrossRef]
- Milliez, G.; Warnier, M. A framework for endowing an interactive robot with reasoning capabilities about perspective-taking and belief management. In Proceedings of the 2014 RO-MAN: The 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, Scotland, 25–29 August 2014.
- Sindlar, M.; Dastani, M.; Meyer, J. BDI-based development of virtual characters with a theory of mind. Intell. Virtual Agents 2009, 5773, 34–41. [Google Scholar]
- Hyman, J.; Steward, H. Agency and Action; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Gardenfors, P.; Warglien, M. Using conceptual spaces to model actions and events. J. Semant. 2012, 29, 487–519. [Google Scholar] [CrossRef]
- Corkill, D. Hierarchical planning in a distributed environment. IJCAI 1979, 79, 168–175. [Google Scholar]
- Whiten, A.; Flynn, E.; Brown, K.; Lee, T. Imitation of hierarchical action structure by young children. Dev. Sci. 2006, 9, 574–582. [Google Scholar] [CrossRef] [PubMed]
- McDermott, D.; Ghallab, M.; Howe, A.; Knoblock, C. PDDL—The Planning Domain Definition Language; Technical Report CVC TR98-003/DCS TR-1165; Yale Center for Computational Vision and Control: New Haven, CT, USA, 1998. [Google Scholar]
- Alili, S.; Warnier, M.; Ali, M.; Alami, R. Planning and plan-execution for human-robot cooperative task achievement. In Proceedings of the 19th International Conference on Automated Planning and Scheduling, Thessaloniki, Greece, 19–23 September 2009.
- Lenz, A.; Lallee, S.; Skachek, S.; Pipe, A.G.; Melhuish, C.; Dominey, P.F. When shared plans go wrong: From atomic- to composite actions and back. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 4321–4326.
- Lallée, S.; Lemaignan, S. Towards a platform-independent cooperative human-robot interaction system: I. perception. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 4444–4451.
- Lallée, S.; Pattacini, U.; Lallee, S.; Boucher, J.D.; Lemaignan, S.; Lenz, A.; Melhuish, C.; Natale, L.; Skachek, S.; Hamann, K.; et al. Towards a platform-independent cooperative human-robot interaction system: Ii. perception, execution and imitation of goal directed actions. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 2895–2902.
- Lallée, S.; Wierenga, S.; Pattacini, U.; Verschure, P. EFAA—A companion emerges from integrating a layered cognitive architecture. In Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, Bielefeld, Germany, 3–6 March 2014; p. 2008.
- Google Speech Recognition Engine. Available online: http://www.google.com/intl/fr/chrome/demos/speech.html (accessed on 18 February 2015).
- WYSIWYD Speech Recognizer. Available online: https://github.com/robotology/speech (accessed on 18 February 2015).
- What You Say Is What You Did (WYSIWYD) Project. Available online: http://wysiwyd.upf.edu/ (accessed on 18 February 2015).
- Lallée, S.; Hamann, K.; Steinwender, J.; Warneken, F.; Martienz, U.; Barron-Gonzales, H.; Pattacini, U.; Gori, I.; Petit, M.; Metta, G.; et al. Cooperative human robot interaction systems: IV. Communication of shared plans with Naïve humans using gaze and speech. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013.
- Pointeau, G.; Petit, M.; Dominey, P. Successive developmental levels of autobiographical memory for learning through social interaction. IEEE Trans. Auton. Ment. Dev. 2014, 6, 200–212. [Google Scholar] [CrossRef]
- Pointeau, G.; Petit, M.; Dominey, P. Embodied simulation based on autobiographical memory. Biomim. Biohybrid Syst. 2013, 8064, 240–250. [Google Scholar]
- Pointeau, G.; Petit, M.; Dominey, P.F. Robot learning rules of games by extraction of intrinsic properties. In Proceedings of the Sixth International Conference on Advances in Computer-Human Interactions, Nice, France, 24 February–1 March 2013; pp. 109–116.
- Pointeau, G.; Petit, M.; Gibert, G.; Dominey, P. Emergence of the use of pronouns and names in triadic human-robot spoken interaction. In Proceedings of the 2014 Joint IEEE International Conferences on Development and Learning and Epigenetic Robotics (ICDL-Epirob), Genoa, Italy, 13–16 October 2014.
- Petit, M.; Lallée, S.; Boucher, J.; Pointeau, G.; Cheminade, P.; Ognibene, D.; Chinellato, E.; Pattacini, U.; Gori, I.; Martinez-hernandez, U.; et al. The coordinating role of language in real-time multi-modal learning of cooperative tasks. Trans. Auton. Ment. Dev. 2013, 5, 3–17. [Google Scholar] [CrossRef]
- Hinaut, X.; Petit, M.; Pointeau, G.; Dominey, P.F. Exploring the acquisition and production of grammatical constructions through human-robot interaction with echo state networks. Front. Neurorobot. 2014, 8. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lallee, S.; Verschure, P.F.M.J. How? Why? What? Where? When? Who? Grounding Ontology in the Actions of a Situated Social Agent. Robotics 2015, 4, 169-193. https://doi.org/10.3390/robotics4020169
Lallee S, Verschure PFMJ. How? Why? What? Where? When? Who? Grounding Ontology in the Actions of a Situated Social Agent. Robotics. 2015; 4(2):169-193. https://doi.org/10.3390/robotics4020169
Chicago/Turabian StyleLallee, Stephane, and Paul F.M.J. Verschure. 2015. "How? Why? What? Where? When? Who? Grounding Ontology in the Actions of a Situated Social Agent" Robotics 4, no. 2: 169-193. https://doi.org/10.3390/robotics4020169