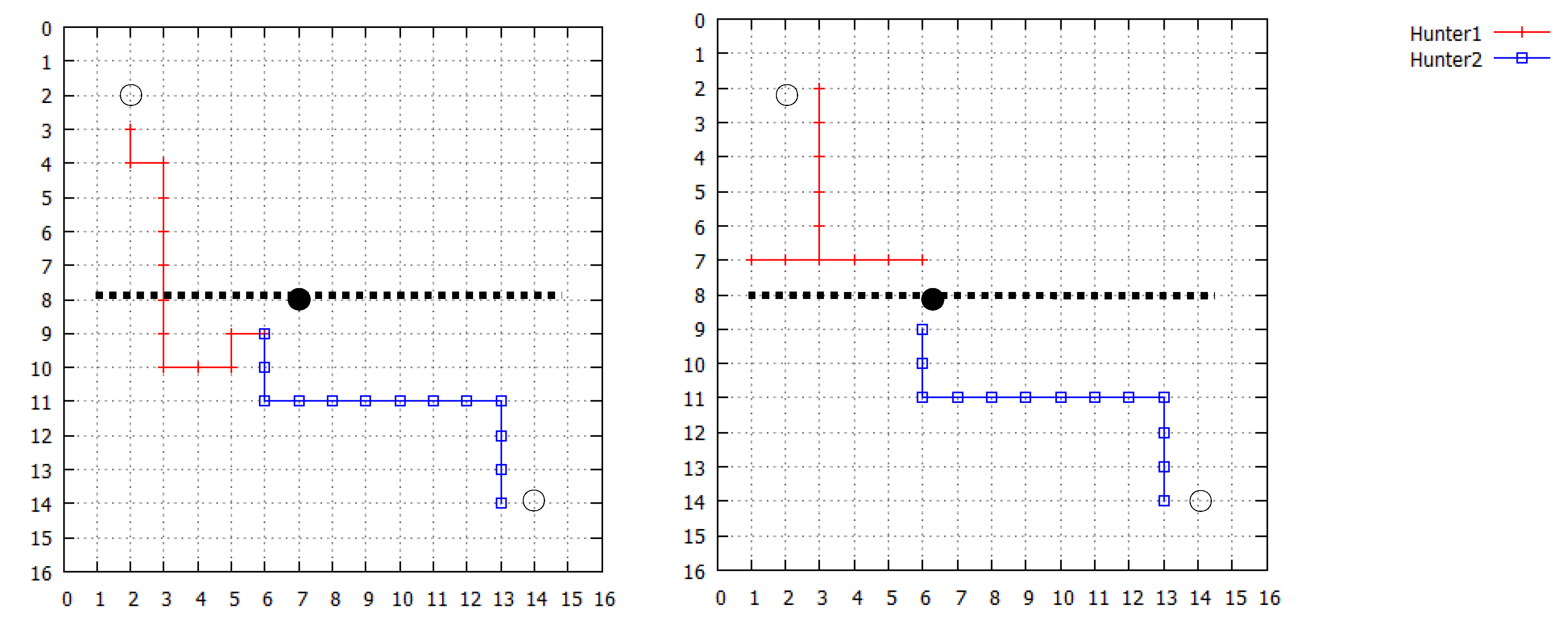
1. Introduction
“Reinforcement” is first used by Pavlov in his famous conditioned reflex theory of the 1920s. It explains that the stimulus from the external environment can be categorized as rewards or punishments and they change the nature of the brain and the behavior of animals. The concept of reinforcement has been introduced in artificial intelligence (AI) from the 1950s and, as a bio-inspired machine learning method, reinforcement learning (RL) has been developed rapidly since the 1980s [
1]. As analyzed by Doya, RL may take place in the basal ganglia of the brain: even the parameters used in RL may involve neuromodulators such as dopamine, serotonin, noradrenaline and acetylcholine [
2]. In recent years, RL has been widely used in game theory [
1], autonomous robotics [
3,
4], intelligent control [
5,
6], nonlinear forecasting [
7,
8,
9,
10], multi-agent systems (MASs) [
11,
12,
13,
14,
15,
16,
17,
18], and so on.
In [
3], Asada
et al. proposed a vision-based RL method to acquire cooperative behaviors of mobile robots in dynamically changing real worlds. In [
4], Kollar and Roy combined RL with extended Kalman filter (EKF) to realize trajectory optimization of autonomous mobile robots in an unknown environment. Jouffe proposed a fuzzy inference system with RL to solve nonlinear control problems in [
5], meanwhile Obayashi
et al. realized robust RL for control systems adopting slide mode control concept in [
6]. In our previous works, several kinds of neuro-fuzzy network types RL systems have been proposed as the time series predictors [
7,
8,
9,
10], and the internal models of agents to solve the goal-directed exploration problems in unknown environments [
11,
12,
13,
14]. Kobayashi
et al. adopted attention degree into an RL named Q learning (QL) for multi-agent system (MAS) [
15,
16,
17] acquiring adaptive cooperative behaviors of agents and confirmed the effectiveness of their improved RL by simulations of the pursuit problem (hunting game) [
18].
The principle of RL can be summarized as using the adaptive state-action pairs to realize the optimal state transition process where optimal solution means that the maximum rewards are obtained by the minimum costs. The rewards from the environment are changed to be the values of states, actions, or state-action pairs in RL. Almost all well-known RL methods [
1,
19,
20,
21,
22] use the value functions to change the states of the learner to find the optimized state transitions. However, when the learner (agent) observes the state of environment partially or the state of the environment is uncertain, it is difficult to select adaptive actions (behaviors). For example, in a multi-agent system (MAS),
i.e., multiple agents exploring an unknown environment, neighborhood information is dynamic and the action decision needs to be given dynamically, the autonomy of agents makes the state of the environment uncertain and not completely observable [
11,
12,
13,
14,
15,
16,
17,
18]. When RL is applied to MASs, problems such as “curse of dimension” (the explosion of state-action space), “perceptual aliasing problem” (such as the state transition in partially observable Markov decision process (POMDP)), and uncertainty of the environment come to be high hurdles.
The action selection policy in RL plays a role of motivation of the learner. The learning process of RL is to find the optimal policy to decide the valuable actions during the transition of states. The behavior decision process by RL is clear and logical, based on the reward/punishment prediction. Meanwhile, to decide an action/behavior, high order animals, especially human beings may not only use the thinking brain,
i.e., logical judgment, but also the emotional brain,
i.e., instinctive response. Recently, neuroscience suggests that there are two paths for producing emotion: a low road is from the amygdala to the brain and body, and it is twice as fast as another high road which carries the same emotional information from the thalamus to the neocortex [
23,
24]. So it is possible for our brains to register the emotional meaning of a stimulus before that stimulus has been fully processed by the perceptual system, and the initial precognitive, perceptual, emotional processing of the low road, fundamentally, is highly adaptive because it allows people to respond quickly to important events before complex and time-consuming processing has taken place [
23].
So, in contrast with the value based RL, behavior acquisition for autonomous mobile robots have also been approached by computational emotion models recently. For example, the Ide and Nozawa groups proposed a series of emotion-to-behavior rules for the goal exploration in unknown environment of plural mobile robots [
25,
26]. They used a simplified circumplex model of emotion given by Larson and Diener [
27] which comes from a circumplex model of affect by Russell [
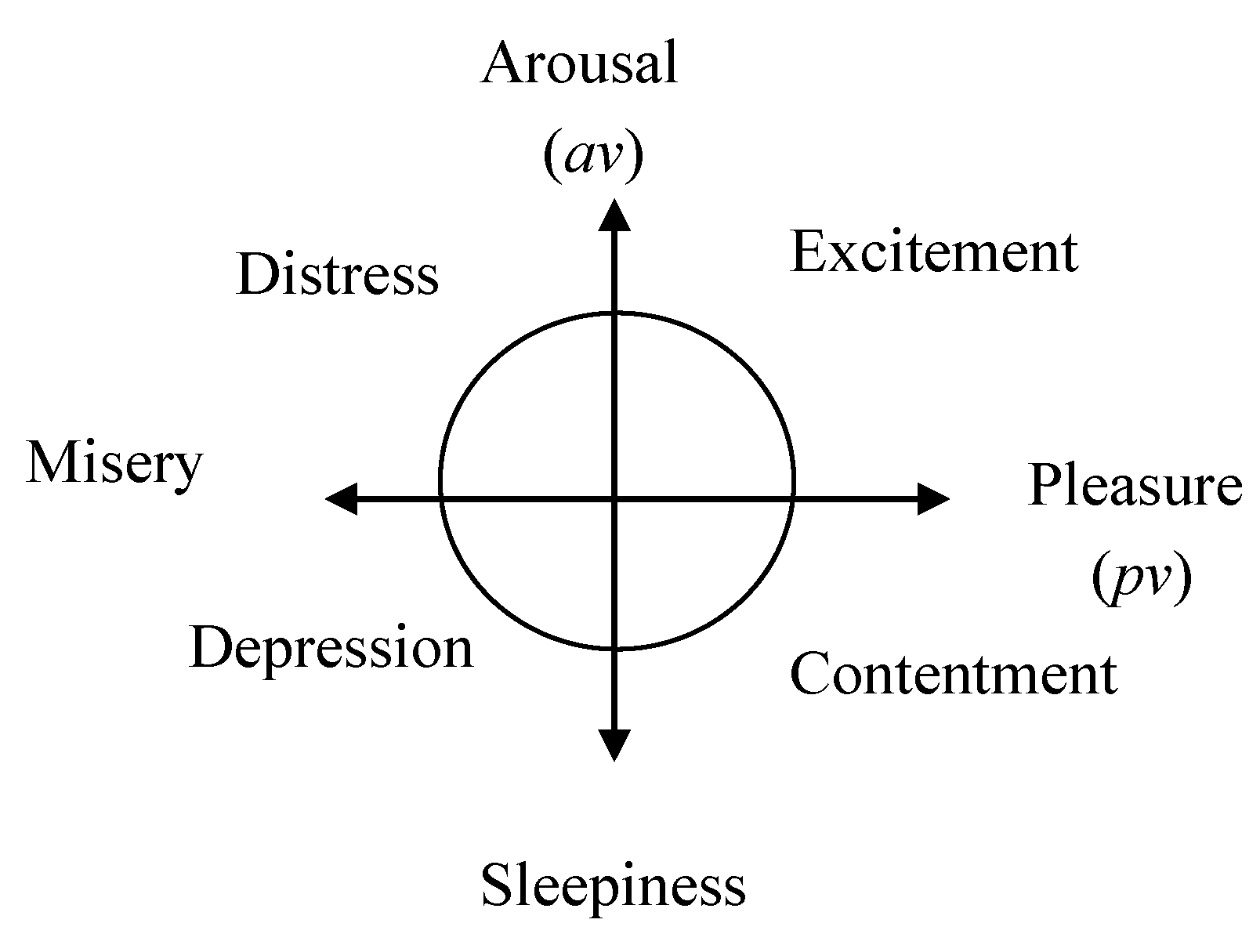
28]. The affect model of Russell [
28] is concluded by the statistical categorization of psychological (self-evaluate) experiments, and it suggests eight main affects named “Arousal”, “Excitement”, “Pleasure”, “Contentment”, “Sleepiness”, “Depression”, “Misery”, and “Distress” with a relationship map of circulus. These affect factors are abstracted in a two-basic dimension space with “Pleasant-Unpleasant” (valence dimension) and “High Activation-Low Activation” (arousal dimension) axes by Larson and Diener [
27]. Using these emotional factors, Ide and Nozawa introduced a series of rules to drive robots to pull or push each other to realize the avoidance of obstacles and cooperatively find a goal in an unknown environment [
25,
26]. To overcome problems such as dead-lock and multiple goal exploration when the complex environment was applied, Kuremoto
et al. improved the emotion-to-behavior rules by adding another psychological factor: “curiosity” in [
29,
30]. However, all these emotional behavior rules for mobile robots only drive robots to move towards the static goals. Moreover, learning function, which is an important characteristic of intelligent agent, is not equipped with the model. So, agents can explore the goal(s), but cannot find the optimal route to the goal(s).
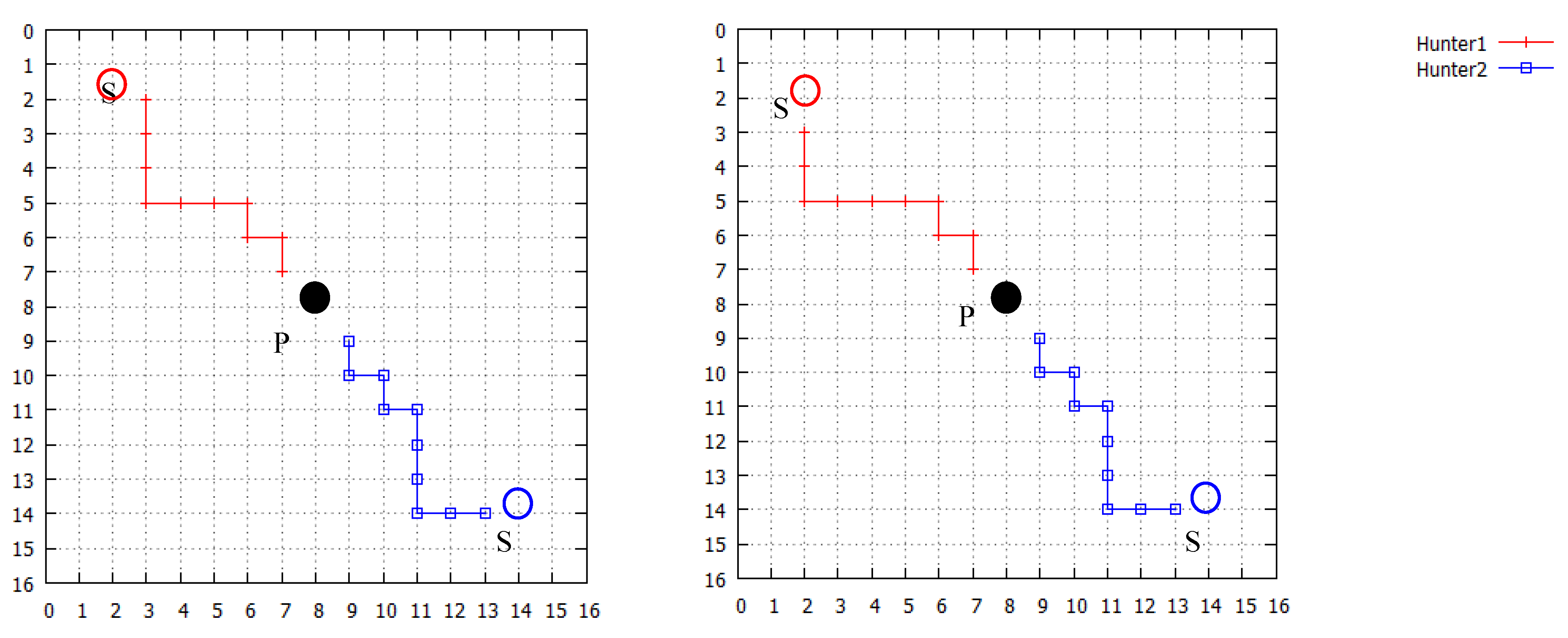
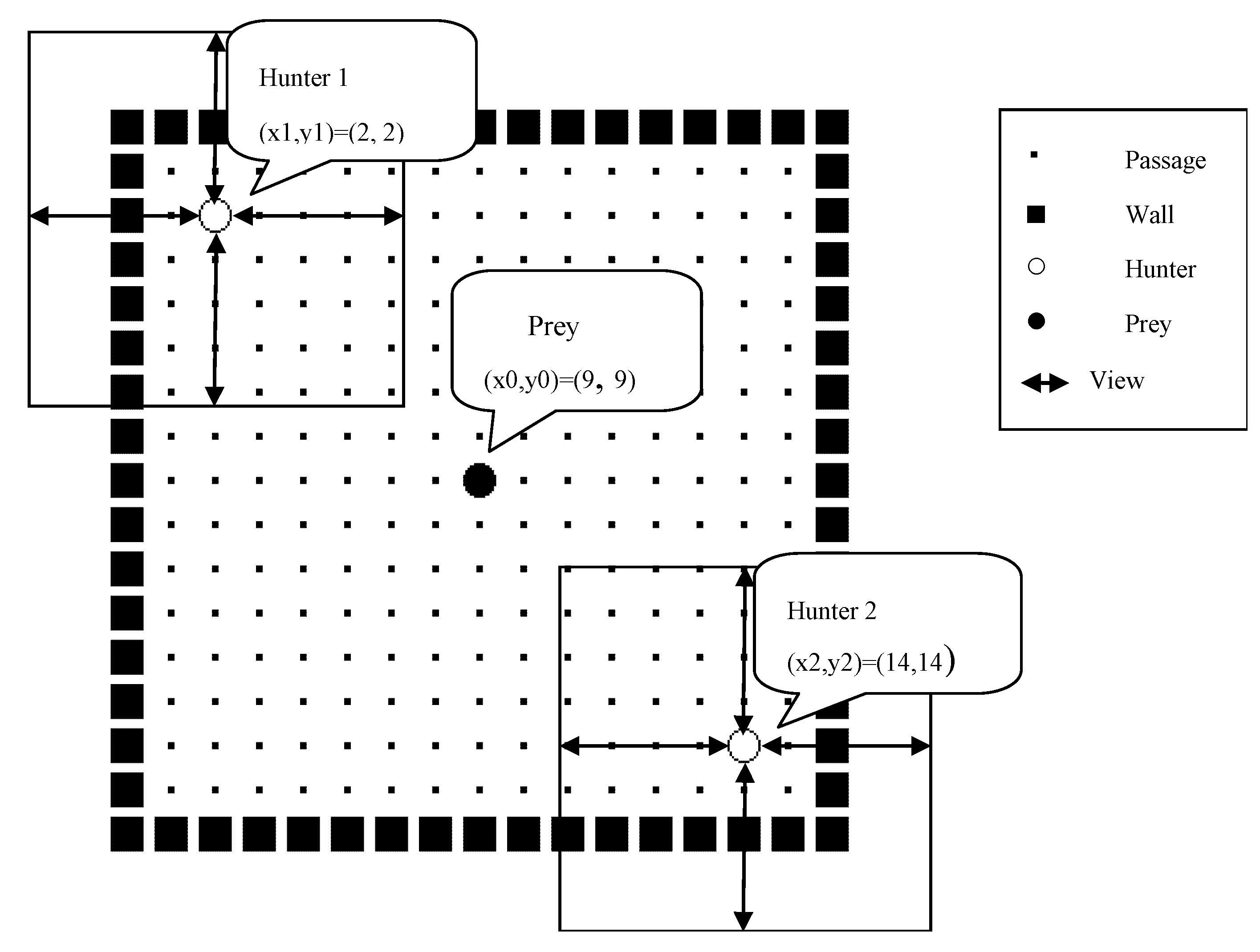
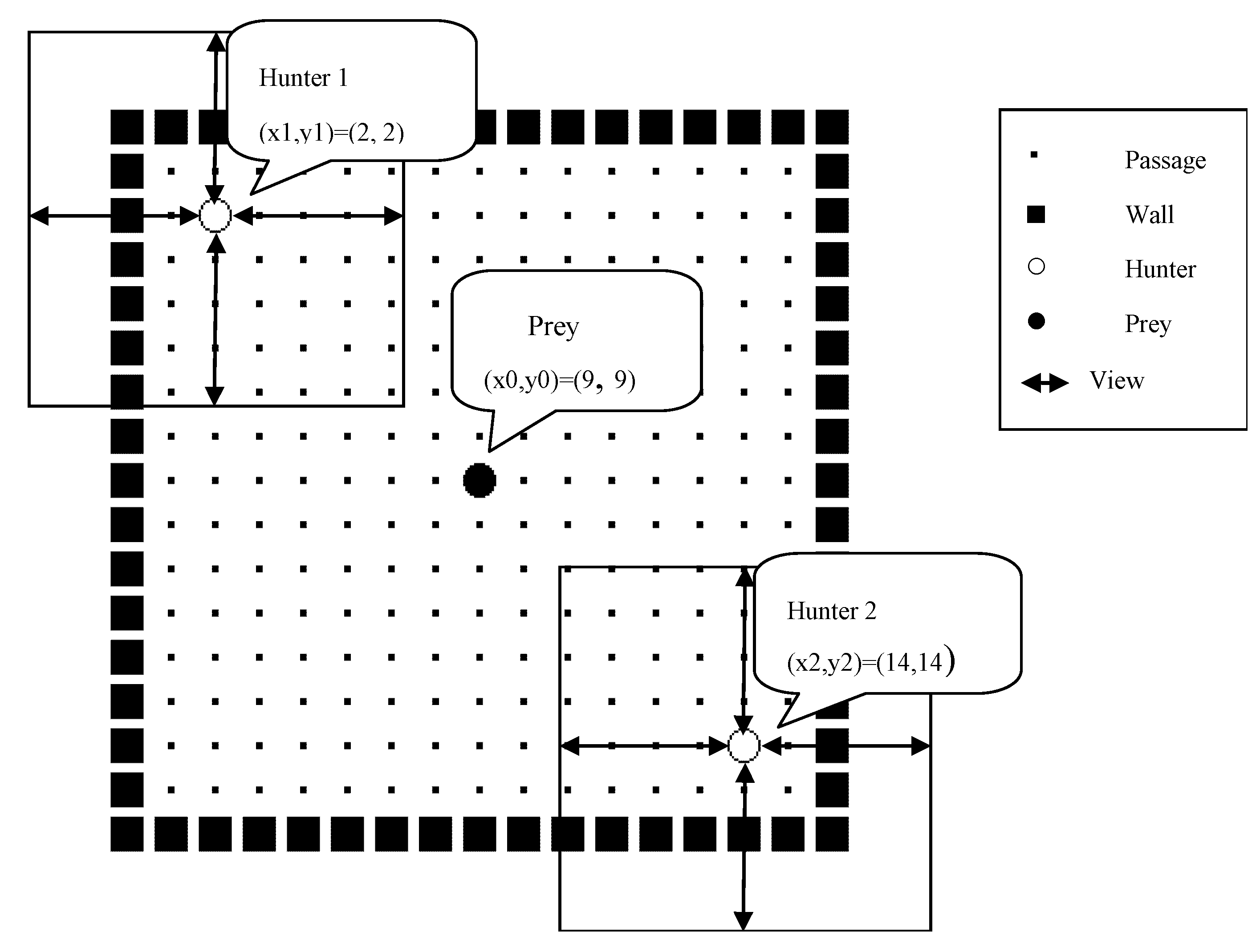
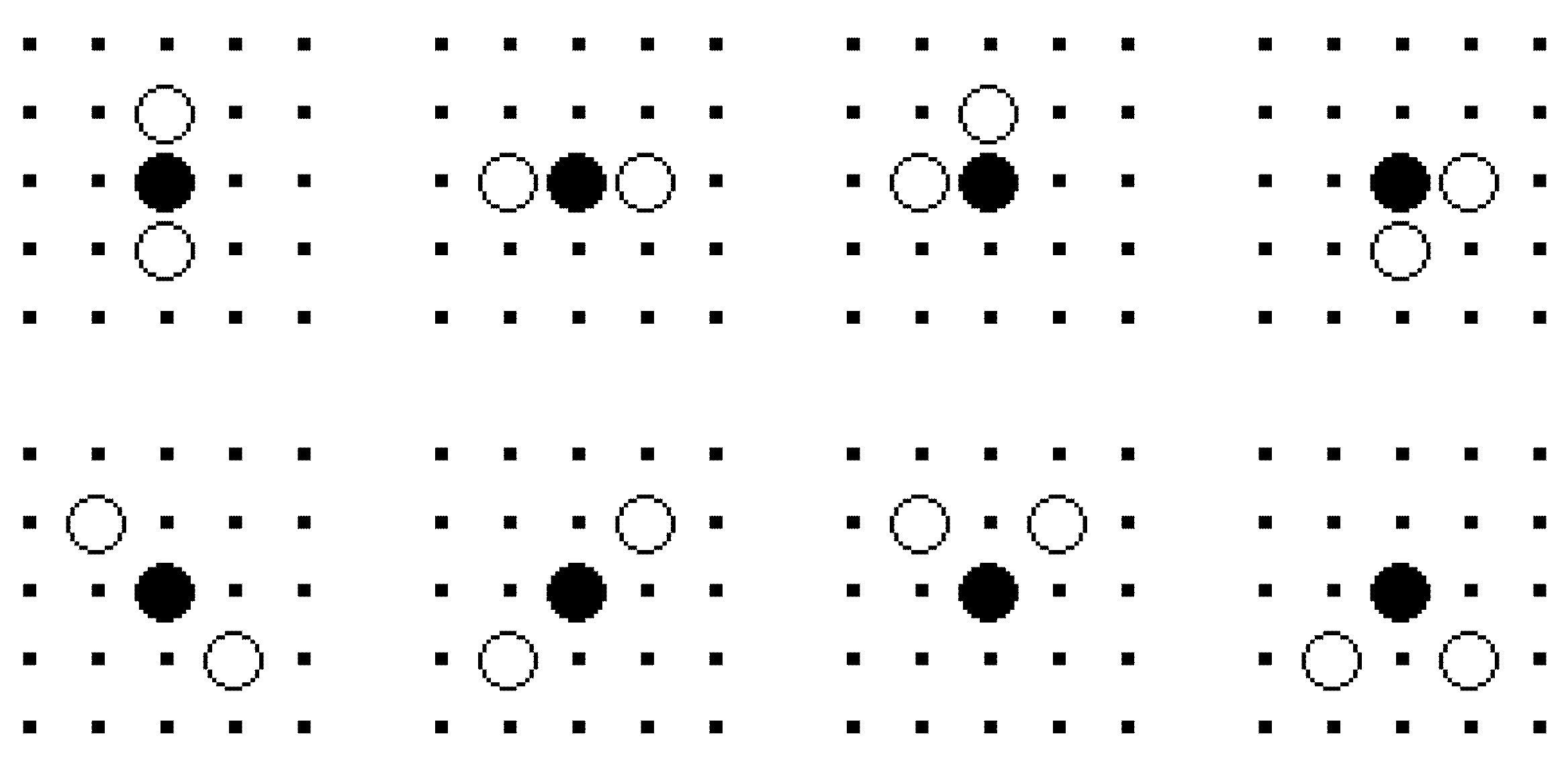
In this paper, we propose adopting affect factors into conventional RL to improve the learning performance of RL in MAS. We suggest that the fundamental affect factors “Arousal” and “Pleasure” are multiplied to produce an emotion function, and the emotion function is linearly combined with Q function which is the state-action value function in Q-learning (QL), a well-known RL method, to compose a motivation function. The motivation function is adopted into the stochastic policy function of RL instead of Q function in QL. Agents select available behaviors not only according to the states they observed from the environment, but also referring to their internal affective responses. The emotion function is designed by calculating the distance from agent to the goal, and the distance between the agent and other agents is perceived in the field of view. So the cooperative behaviors may be generated during the goal exploration of plural agents.
The rest of this paper is structured as follows. In
Section 2, Russell’s affect model is introduced simply at first, then, a computational emotion function is described in detail. Combining the emotion function with a well-known reinforcement learning method “Q-learning” (QL), a motivation function is constructed and it is used as the action selection policy as the improved RL of this paper. In
Section 3, to confirm the effectiveness of the proposed method, we applied it to two kinds of pursuit problems: a pursuit problem simulation with a static prey and a simulation with a dynamic prey, and the results of simulations are reported. Discussions and conclusions are stated in
Section 4,
Section 5 respectively.
4. Discussions
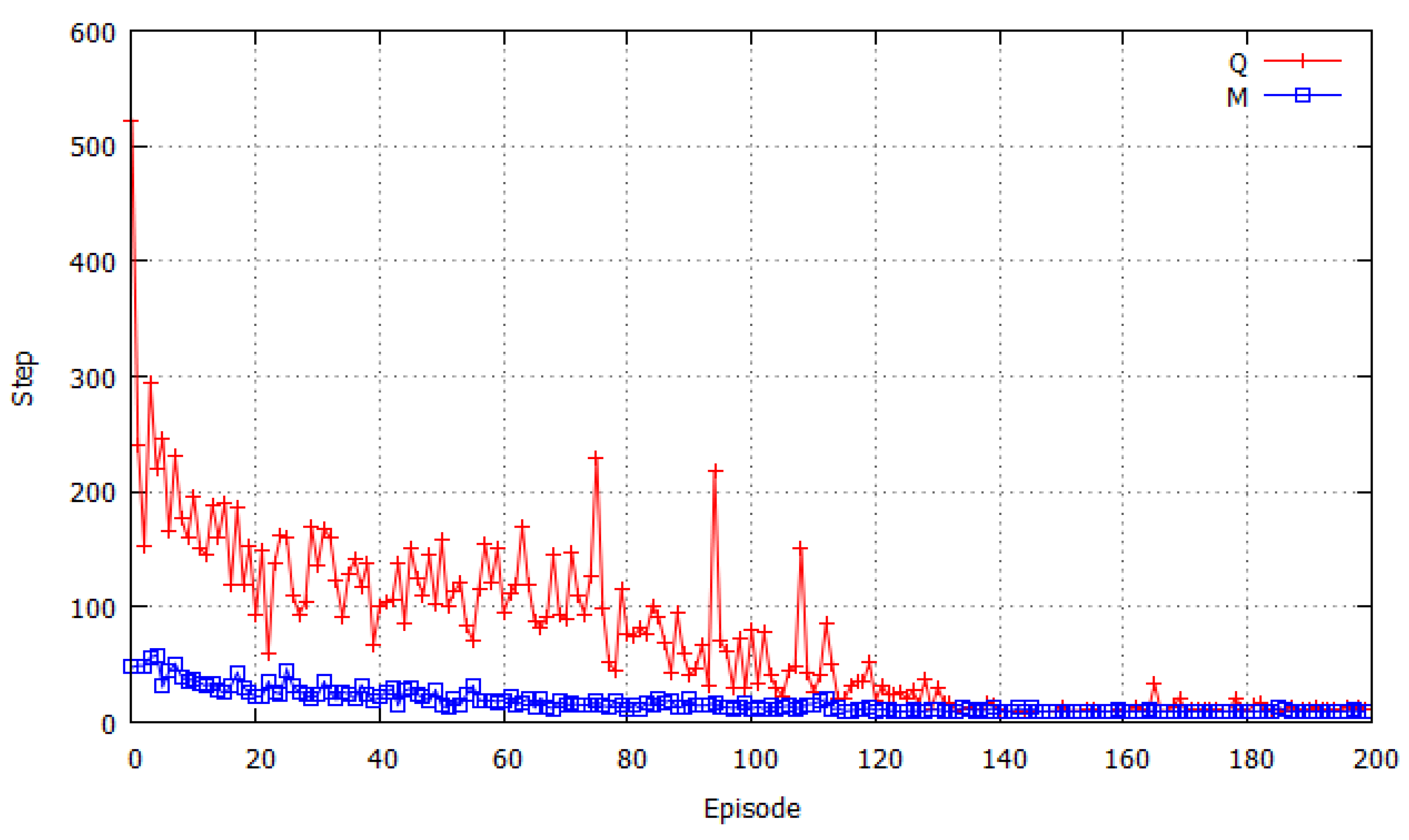
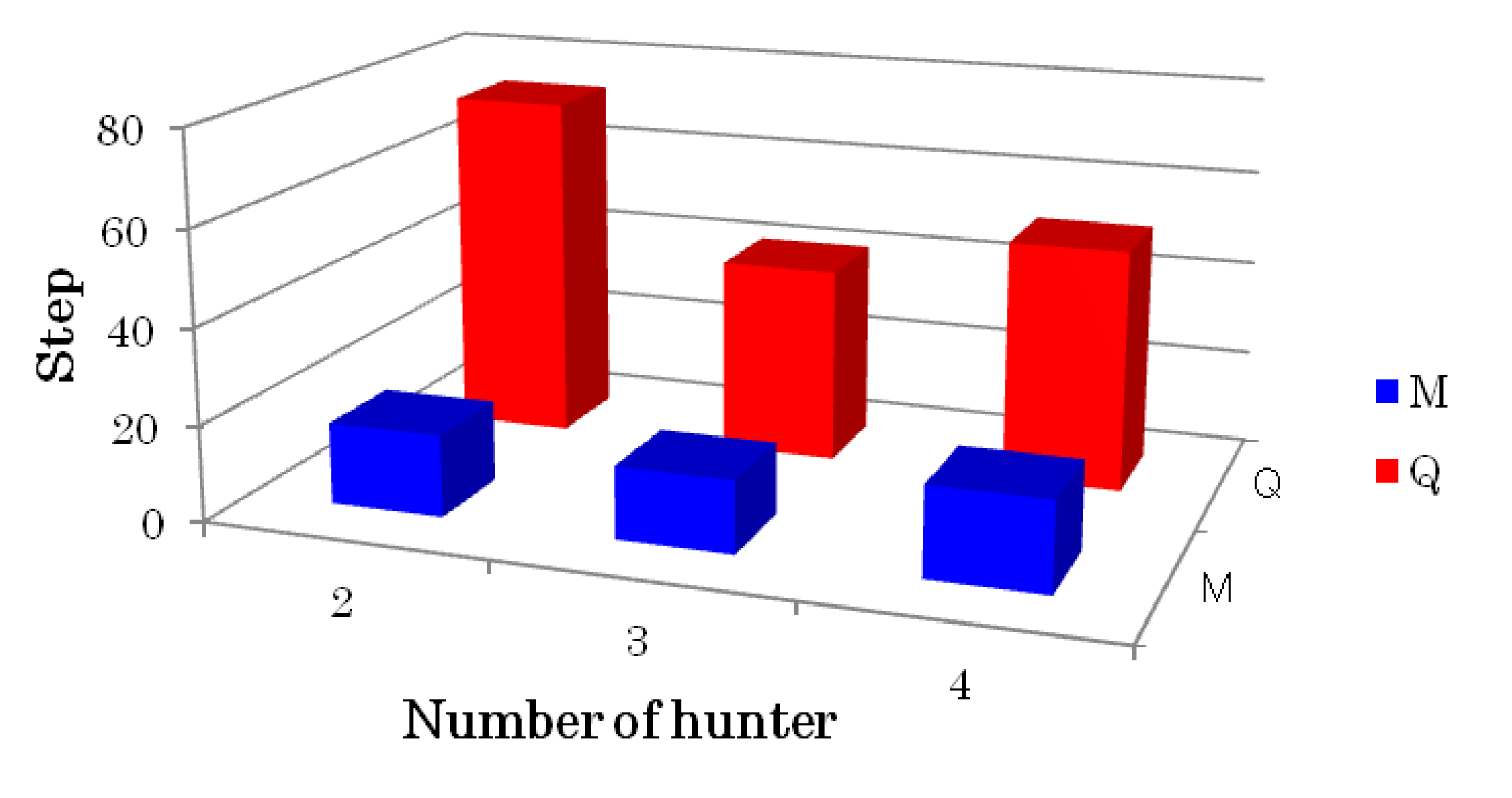
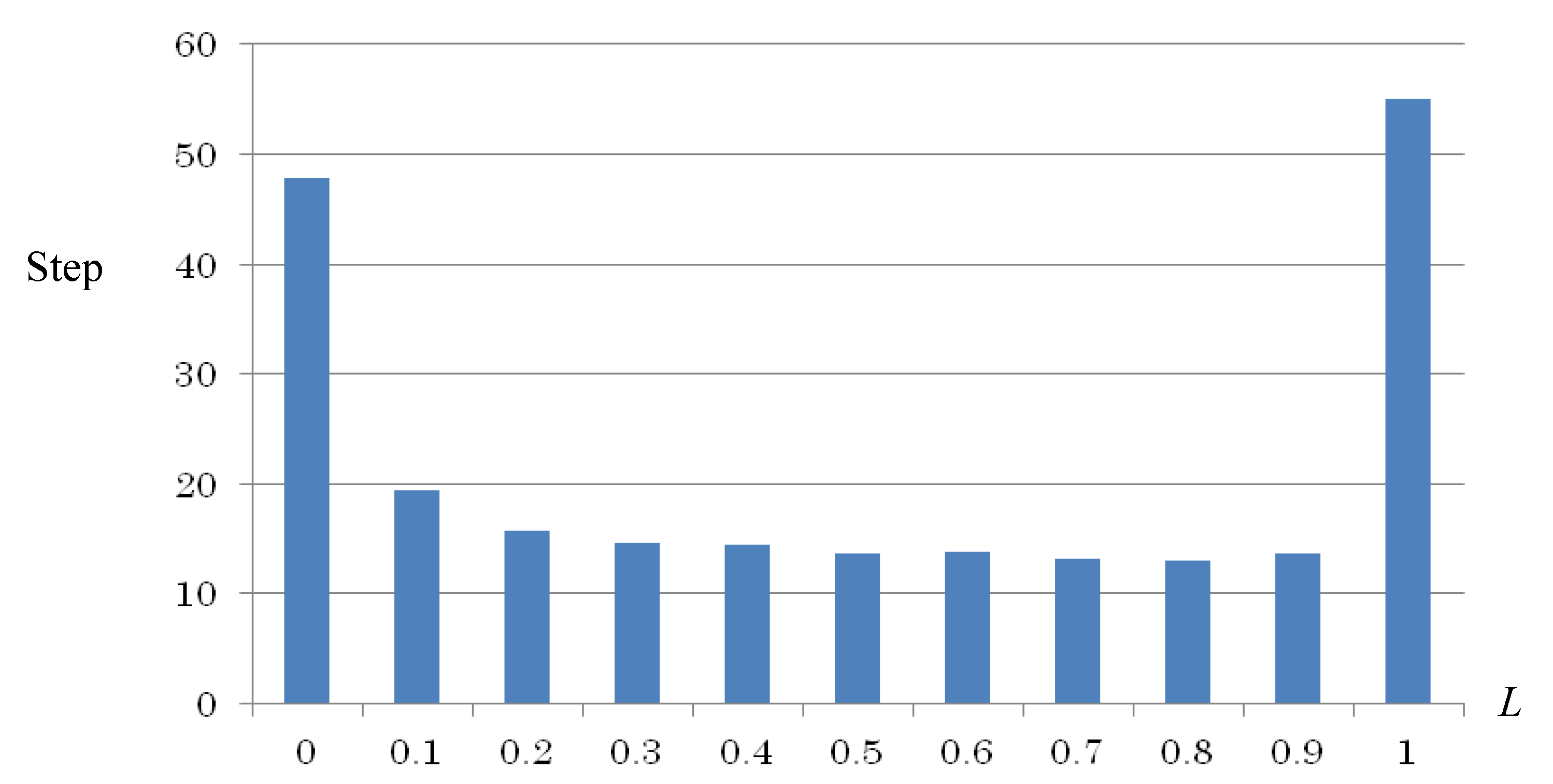
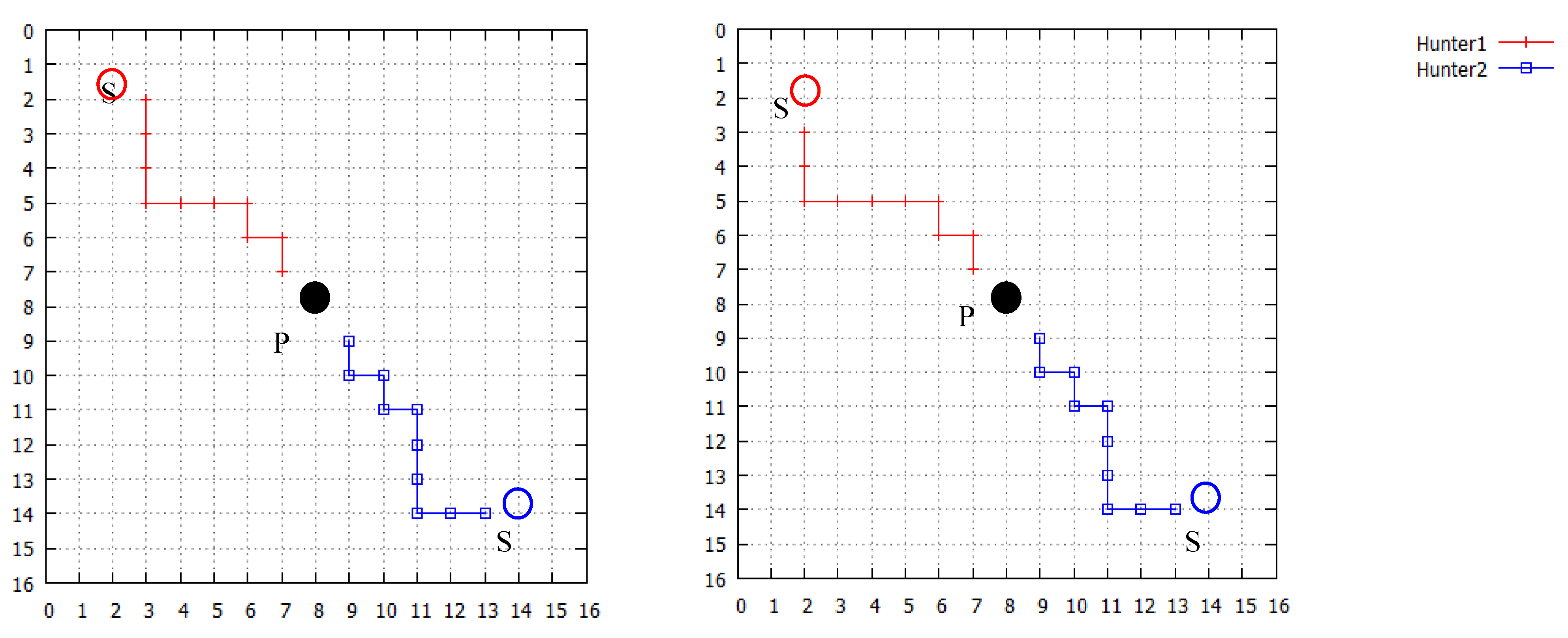
As the results of pursuit problem simulations, the proposed learning method which combined QL and affect factors enhanced the learning efficiency compared to the conventional QL. Parameters used in all methods were optimal values from experiments. For example, different values of balance coefficient
L in Equation (7) may yield different learning performance.
L = 0.5 was used either in static prey simulation as shown in
Table 3, or in dynamic prey simulation as shown in
Table 5 because the optimal value yielded the shortest path for each simulation. In
Figure 10, a case of a simulation with three hunters and one dynamical prey was shown. The value of L increased from 0 to 1.0 by a difference of 0.1 in the horizontal axis, and the lowest value of the vertical axis shows the average length (steps) of the 10 simulations of the capture process to be 13.11 steps at
L = 0.8, so
L = 0.8 was used as the optimal parameter value in this case.
Figure 10.
Comparison of the change of exploration costs (the number of steps from start to final states) by different Q-M balance coefficient L in Equation (7) during learning process in 3-hunter-1-dynamic-prey problem simulation (average of 10 simulations).
Figure 10.
Comparison of the change of exploration costs (the number of steps from start to final states) by different Q-M balance coefficient L in Equation (7) during learning process in 3-hunter-1-dynamic-prey problem simulation (average of 10 simulations).
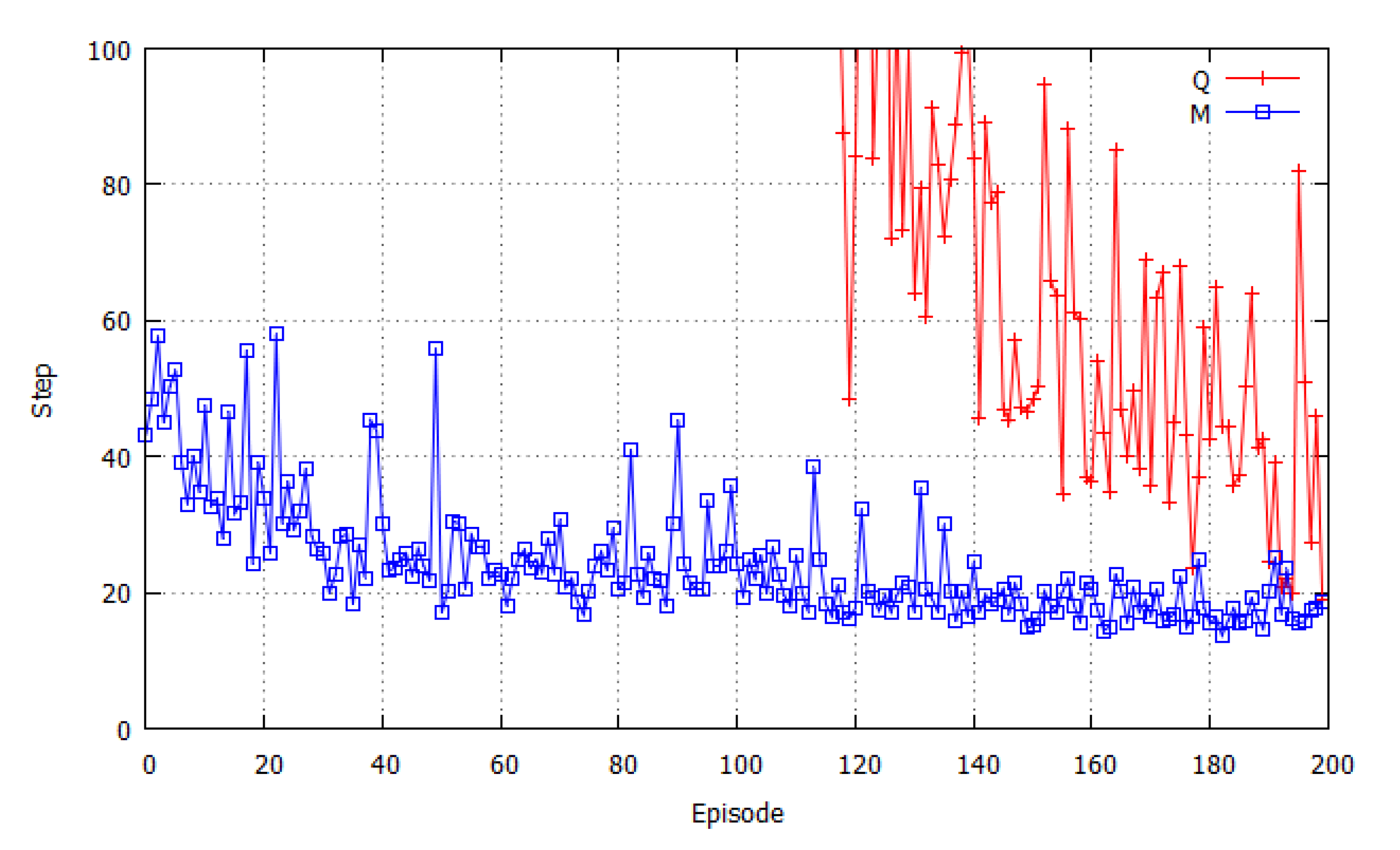
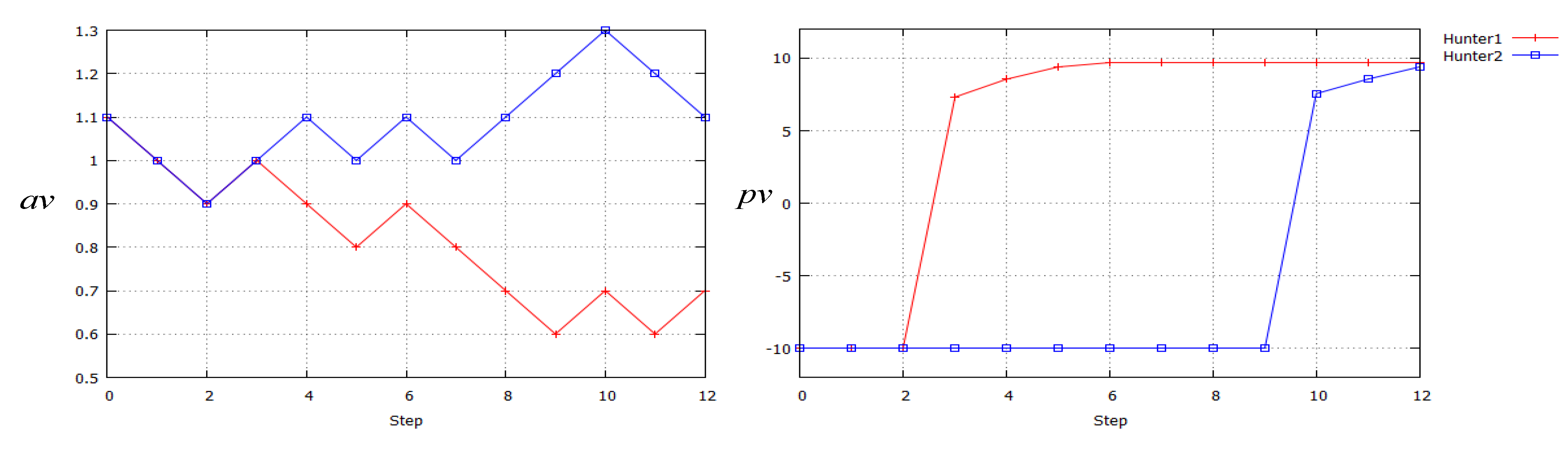
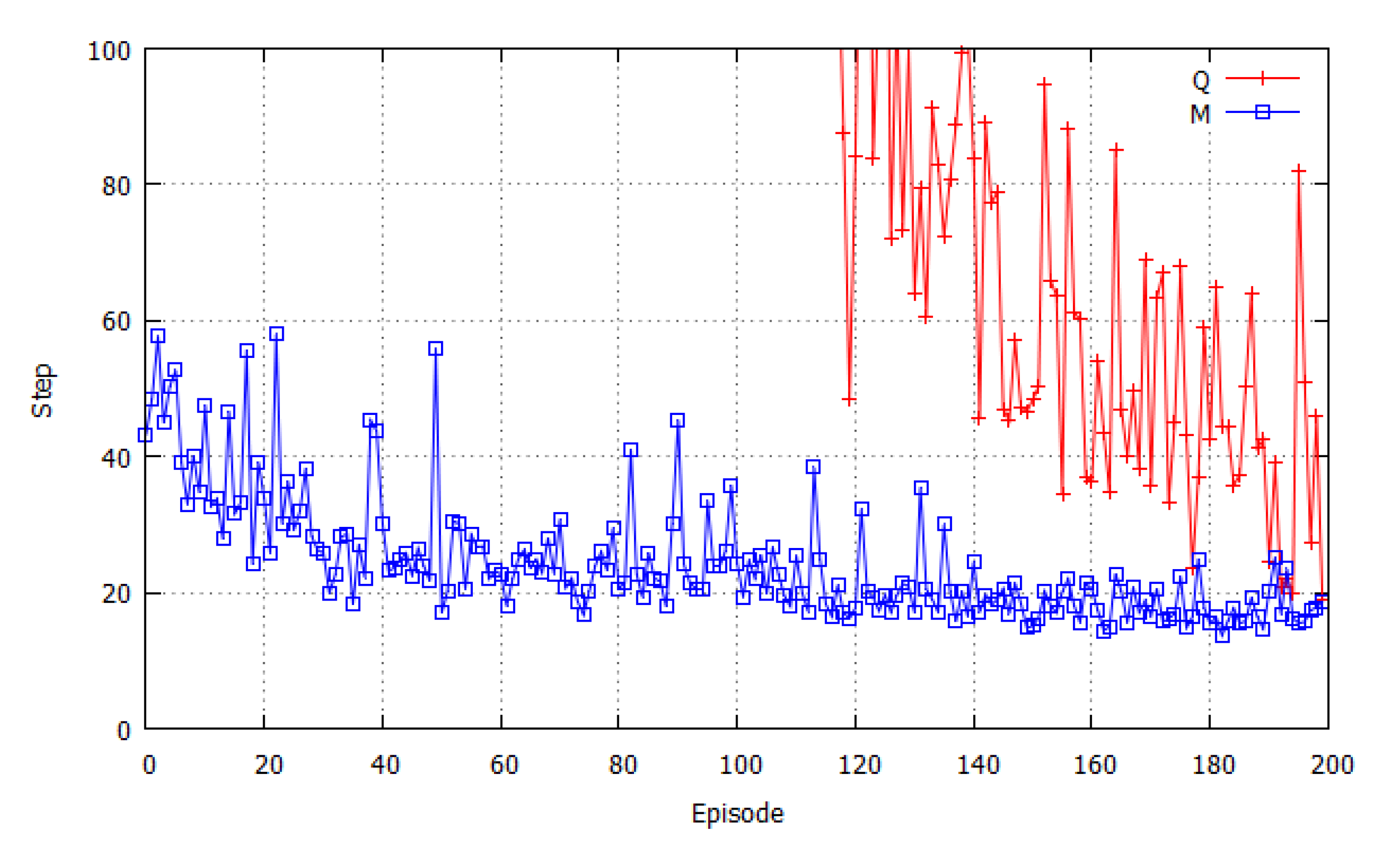
It is interesting to investigate how
Arousal av and
Pleasure pv values changed during the exploration and learning process in the simulation of pursuit problem. In
Figure 11, the change of these affect factors in the 2-hunter-1-dynamic-prey simulation is depicted. In
Figure 11(a), Arousal values of Hunters 1 and 2 changed together in the first three-step period, and then separated. This suggests that the state of the local environment observed by Hunter 1 changed more dramatically than the situation of Hunter 2, so
Arousal av of Hunter 1 dropped according to the exploration steps. This is the result of Equation (4), the definition of
Arousal av. In contrast, in
Figure 11(b),
Pleasure pv of Hunter 1 rose steeply to high values from step 2, corresponding to the dramatic change of the observed state: it might find and move to the prey straight ahead. From the 9th step, the
Pleasure value of Hunter 2 also rose to high values for finding the prey or perceiving the high
Pleasure value of Hunter 1.
From this analysis of the change of affect factors, it can be judged that the proposed method worked efficiently in the reinforcment learning process and it results in the improvement of learning performance of the MAS.
Figure 11.
The change of Arousal av and Pleasure pv values of two hunters during the exploration in dynamic prey problem simulation. (a) The change of Arousal av; (b) The change of Pleasure pv.
Figure 11.
The change of Arousal av and Pleasure pv values of two hunters during the exploration in dynamic prey problem simulation. (a) The change of Arousal av; (b) The change of Pleasure pv.
5. Conclusions and Future Works
To improve the learning performance of reinforcement learning for multi-agent systems (MASs), a novel Q-learning (QL) was proposed in this paper. The main idea of the improved QL is the adoption of affect factors of agents which constructed “situation-oriented emotion” and a motivation function which is the combination of conventional state-action value function and the emotion function.
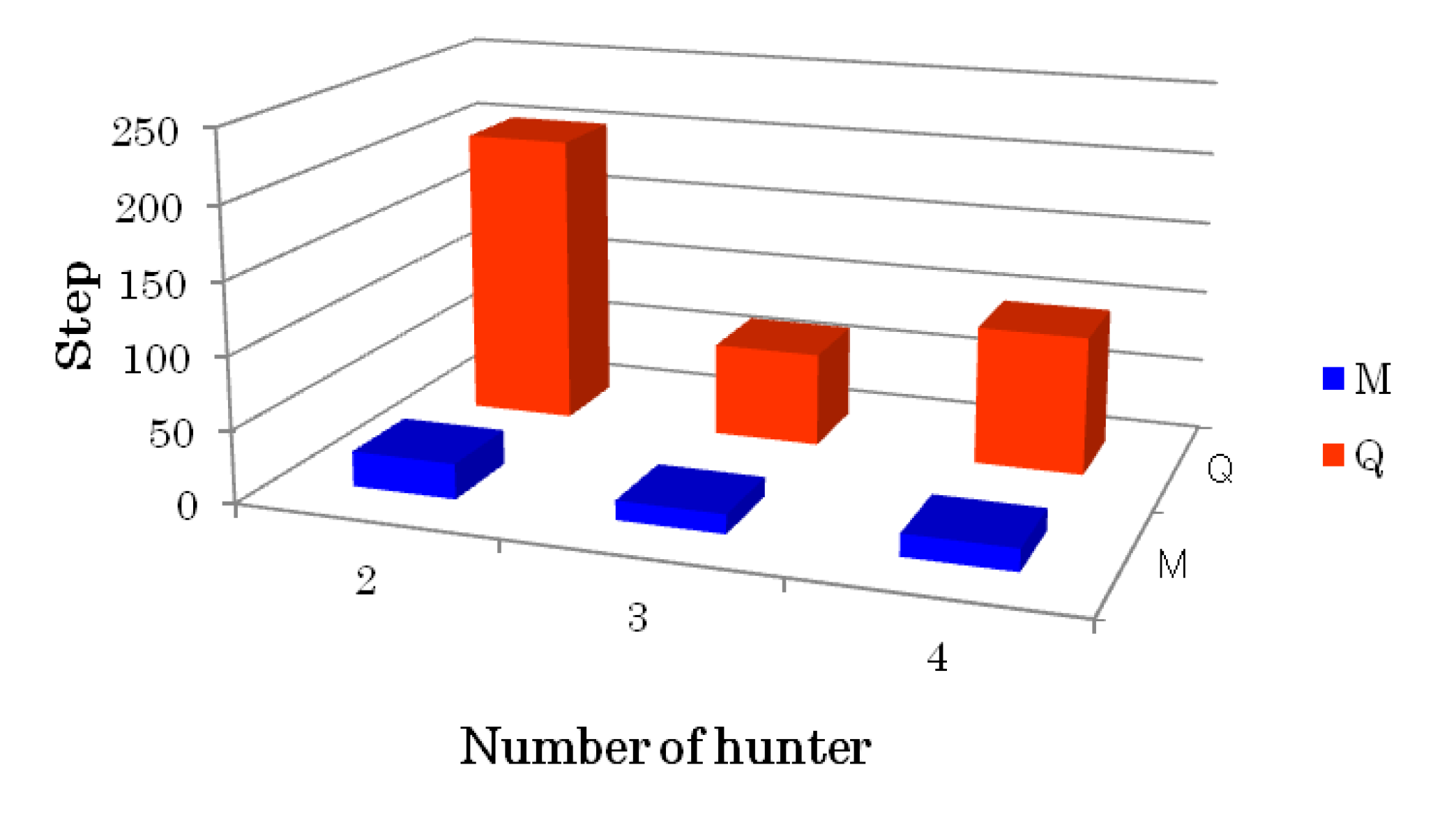
Compared with the conventional QL, the effectiveness of the proposed method was confirmed by simulation results of pursuit problems with static and dynamic preys in the sense of learning costs and convergence properties.
The fundamental standpoint of this study to use affective and emotional factors in the learning process is in agreement with Greenberg [
24]: “Emotion moves us and reason guides us”. Conventional QL may only pay attention to “reasoning” from “the thinking brain” [
24], or basal ganglia [
2]. Meanwhile, in the proposed method we also considered the role of “the emotion brain” [
23], amygdala or limbic system [
24].
Therefore, as expected, future works will identify functions such as the neuro-fuzzy networks [
9,
10,
11,
12,
13,
14], and more emotion functions such as fear, anger,
etc. [
31,
32,
37,
38], and other behavior psychological views [
39] may be added to the proposed method. All these function modules may contribute to a higher performance of autonomous agents and it is interesting to apply these agents to develop intelligent robots.

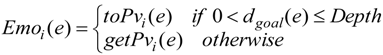
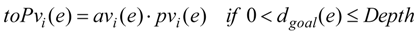
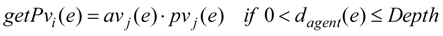
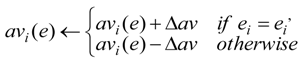
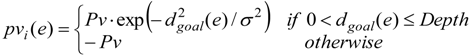
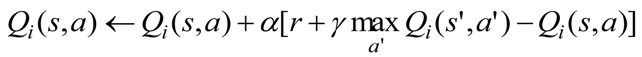
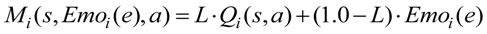
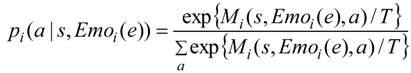

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}