
Analyzing the Effect and Performance of Lossy Compression on Aeroacoustic Simulation of Gas Injector

Abstract
:1. Introduction
Simulation Method
2. Related Work
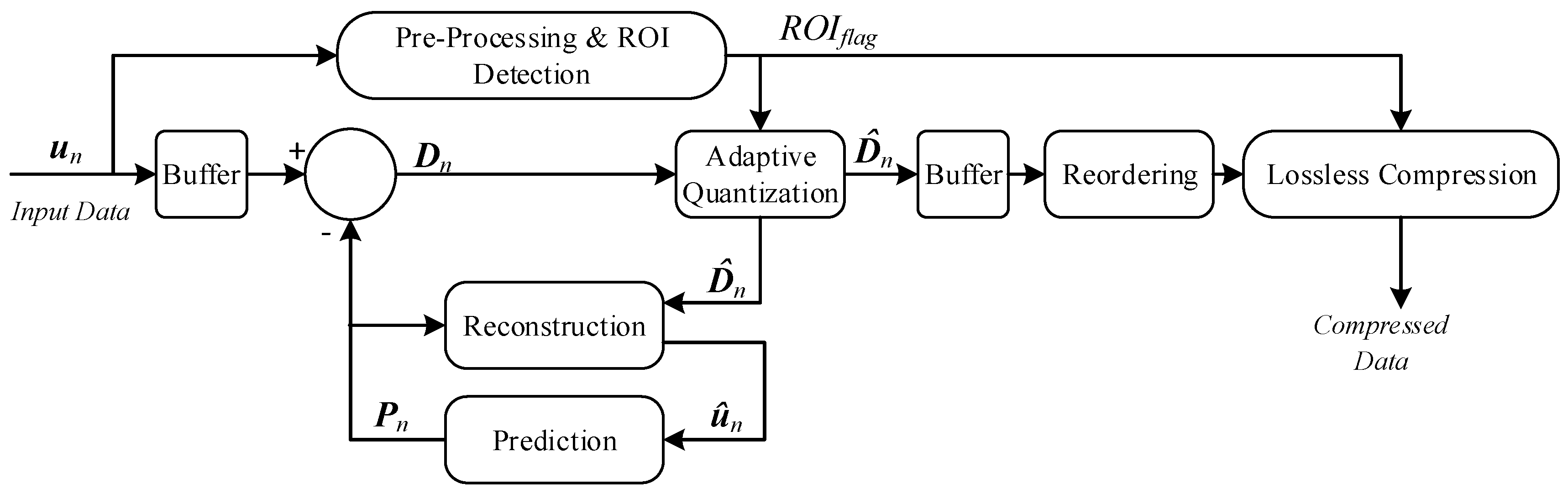
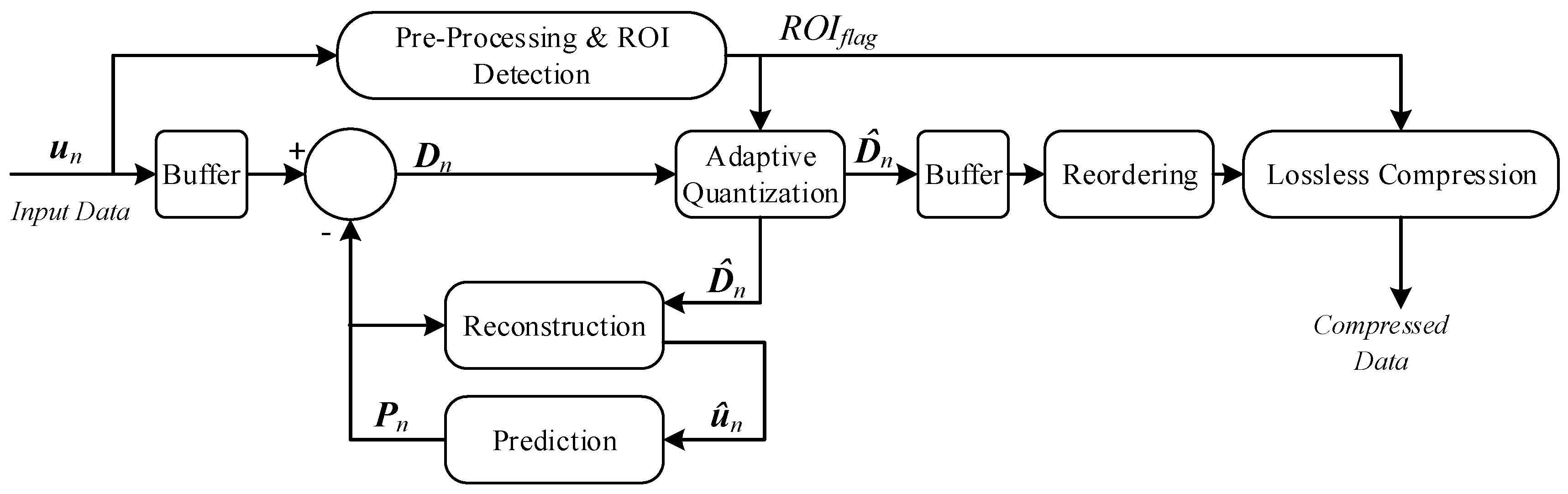
3. Data Compression Method
3.1. Pre-Processing and ROI Detection
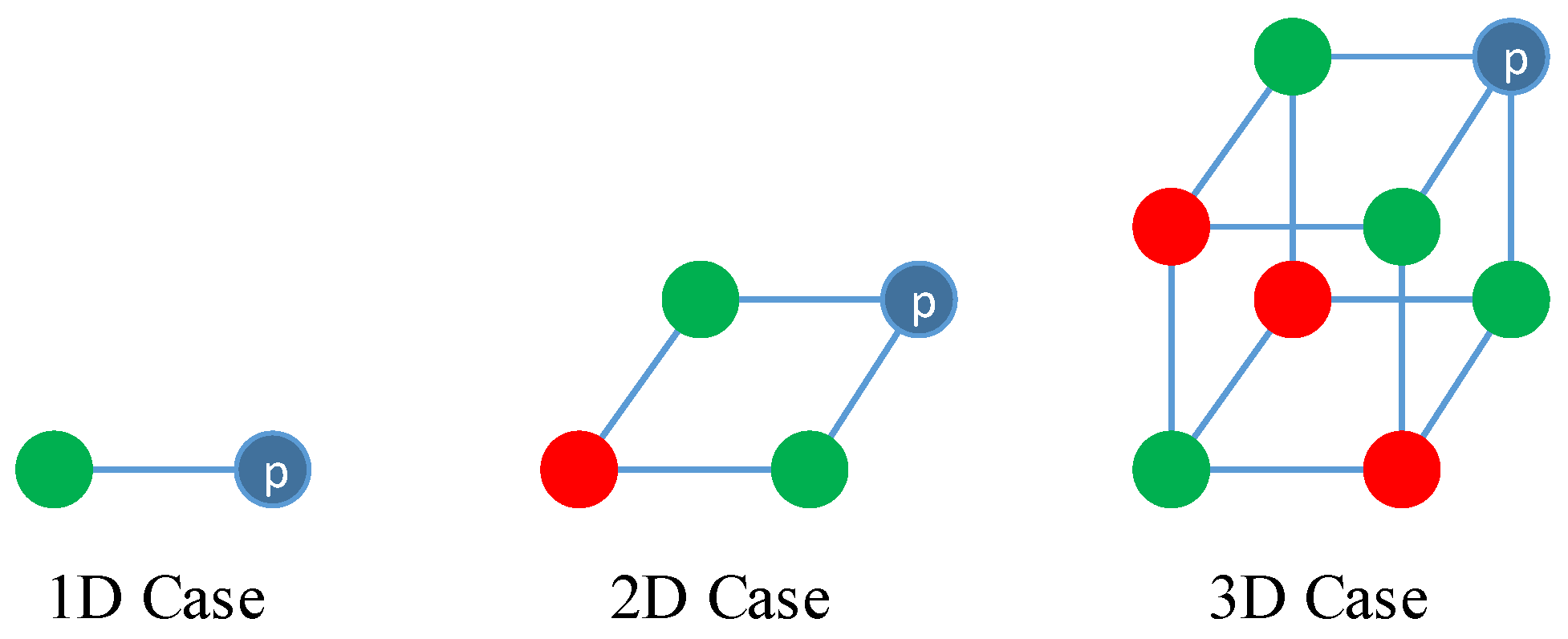
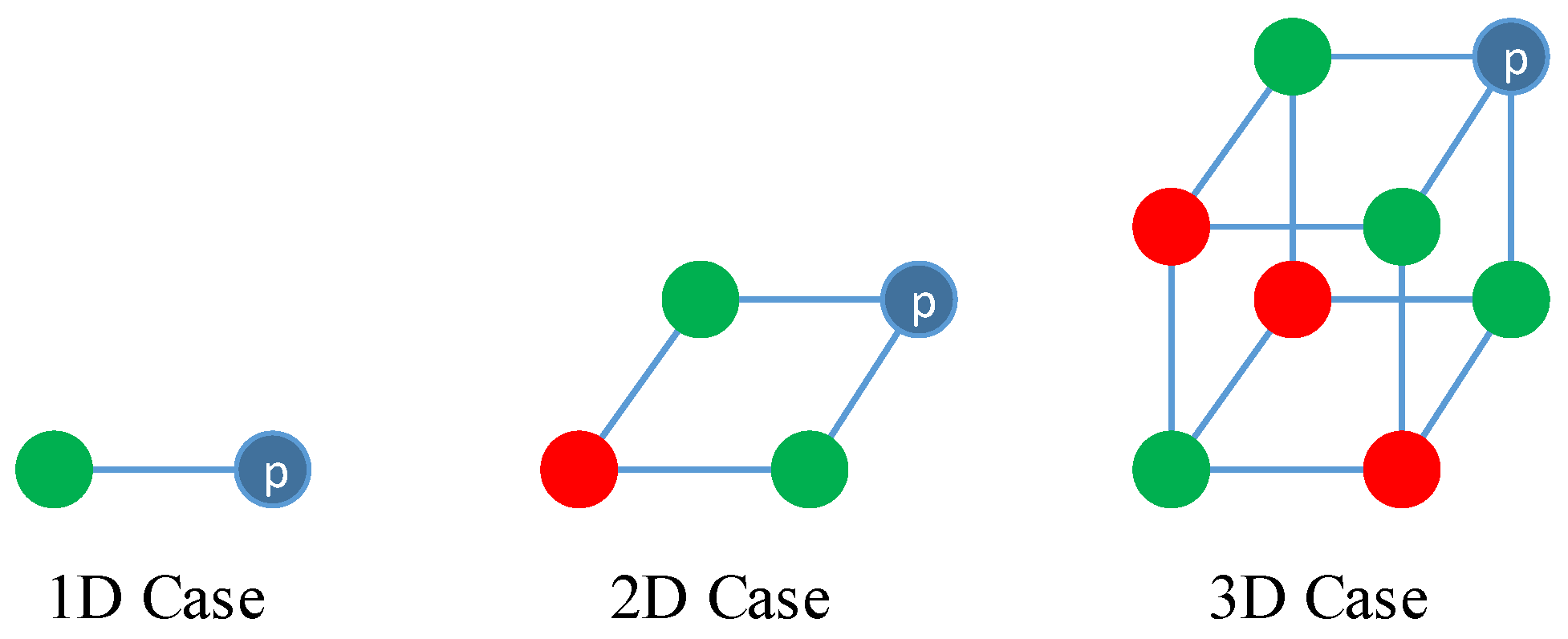
3.2. Prediction and Reconstruction
3.3. Adaptive Quantization
3.4. Reordering and Lossless Compression
4. Adaptive Compression Framework
Optimization
5. Results and Discussion
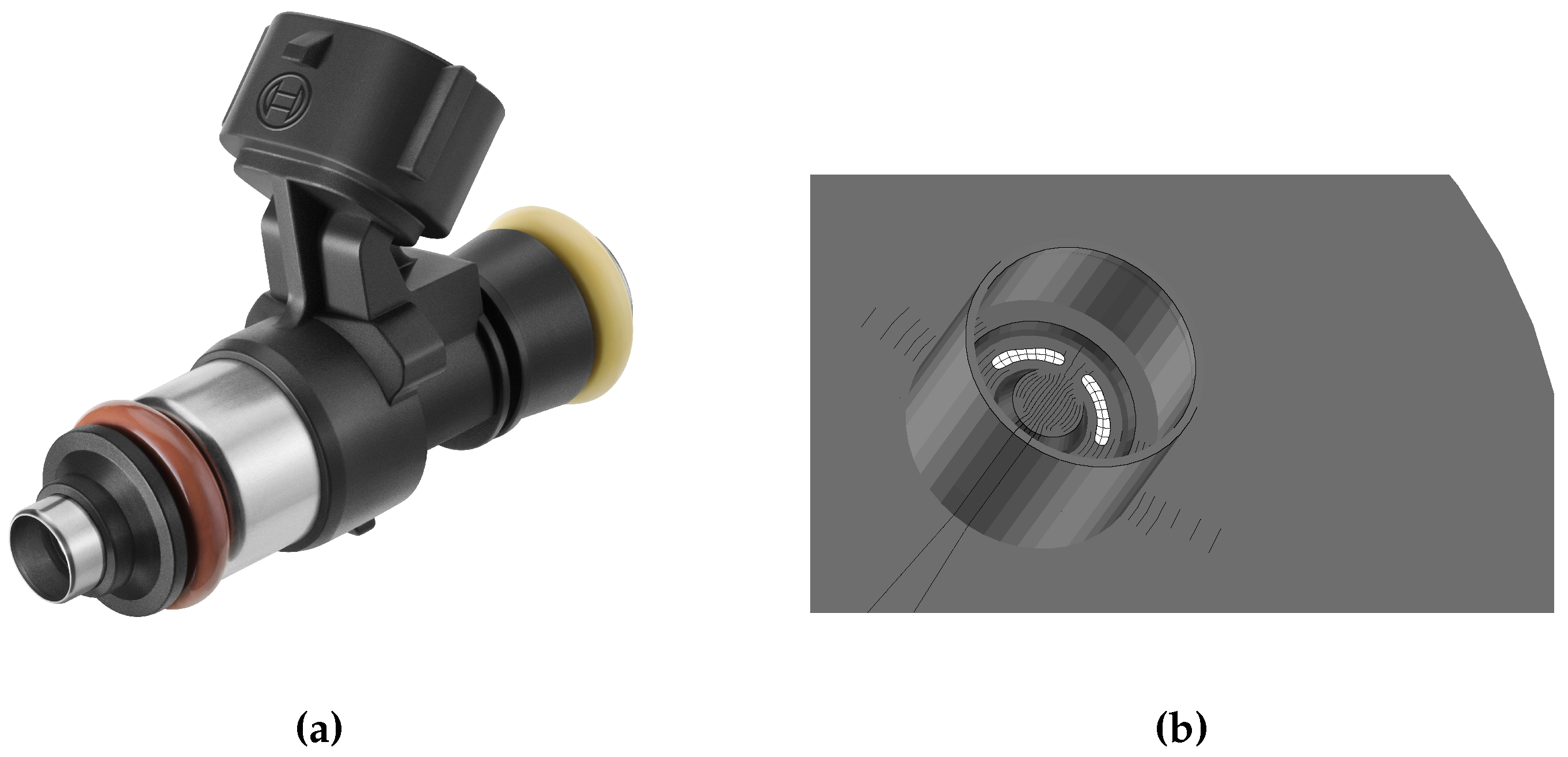
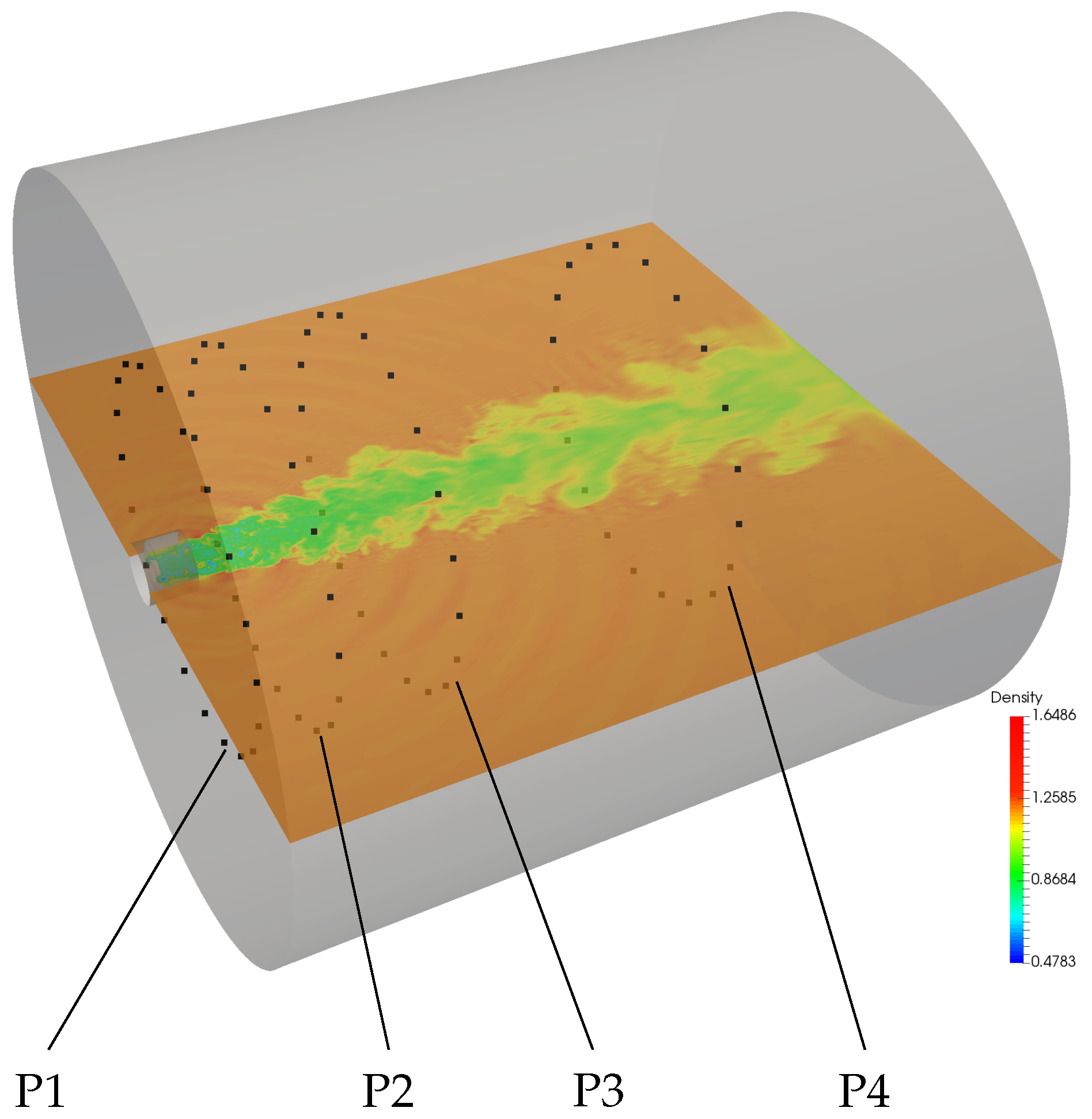
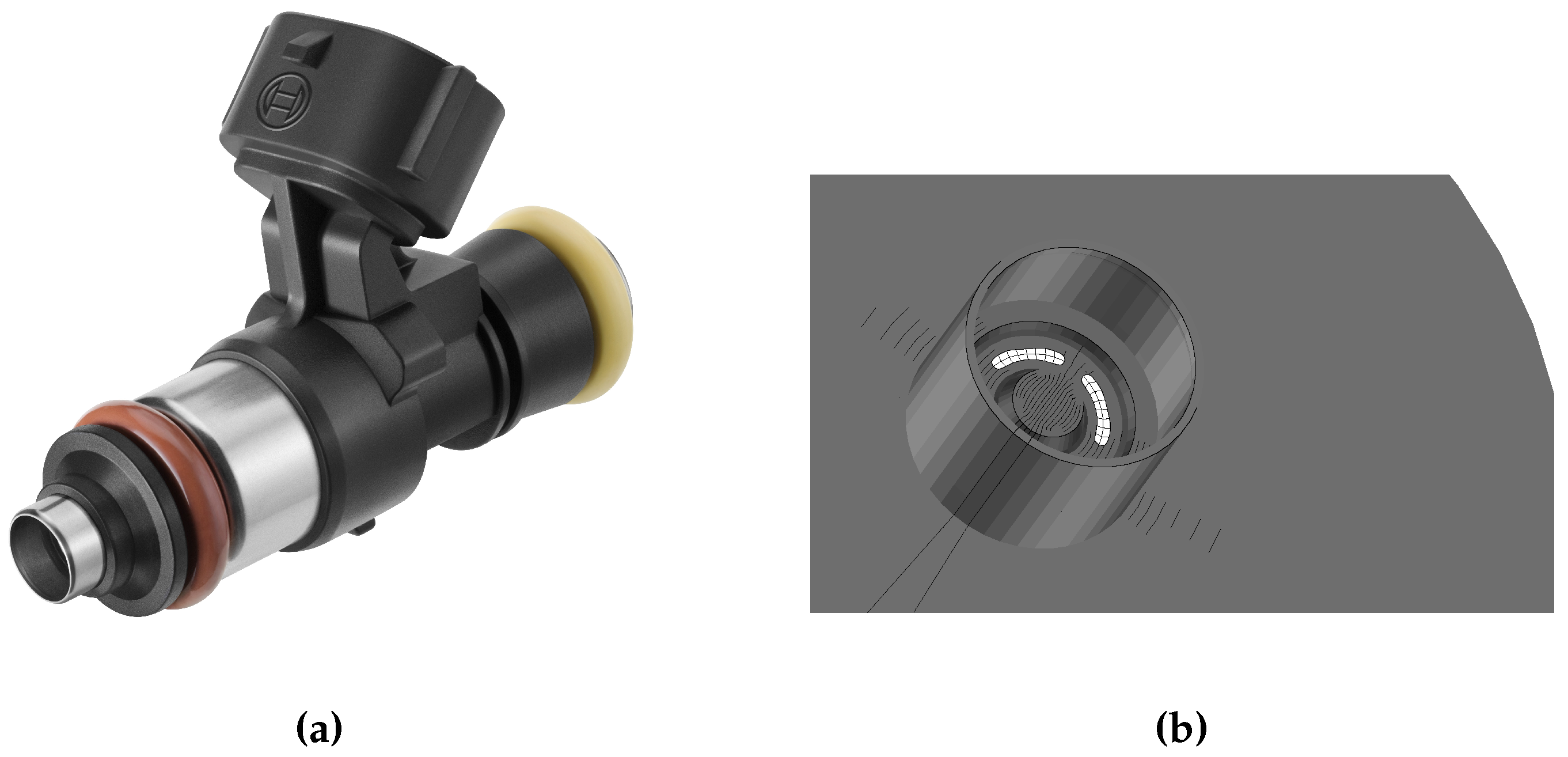
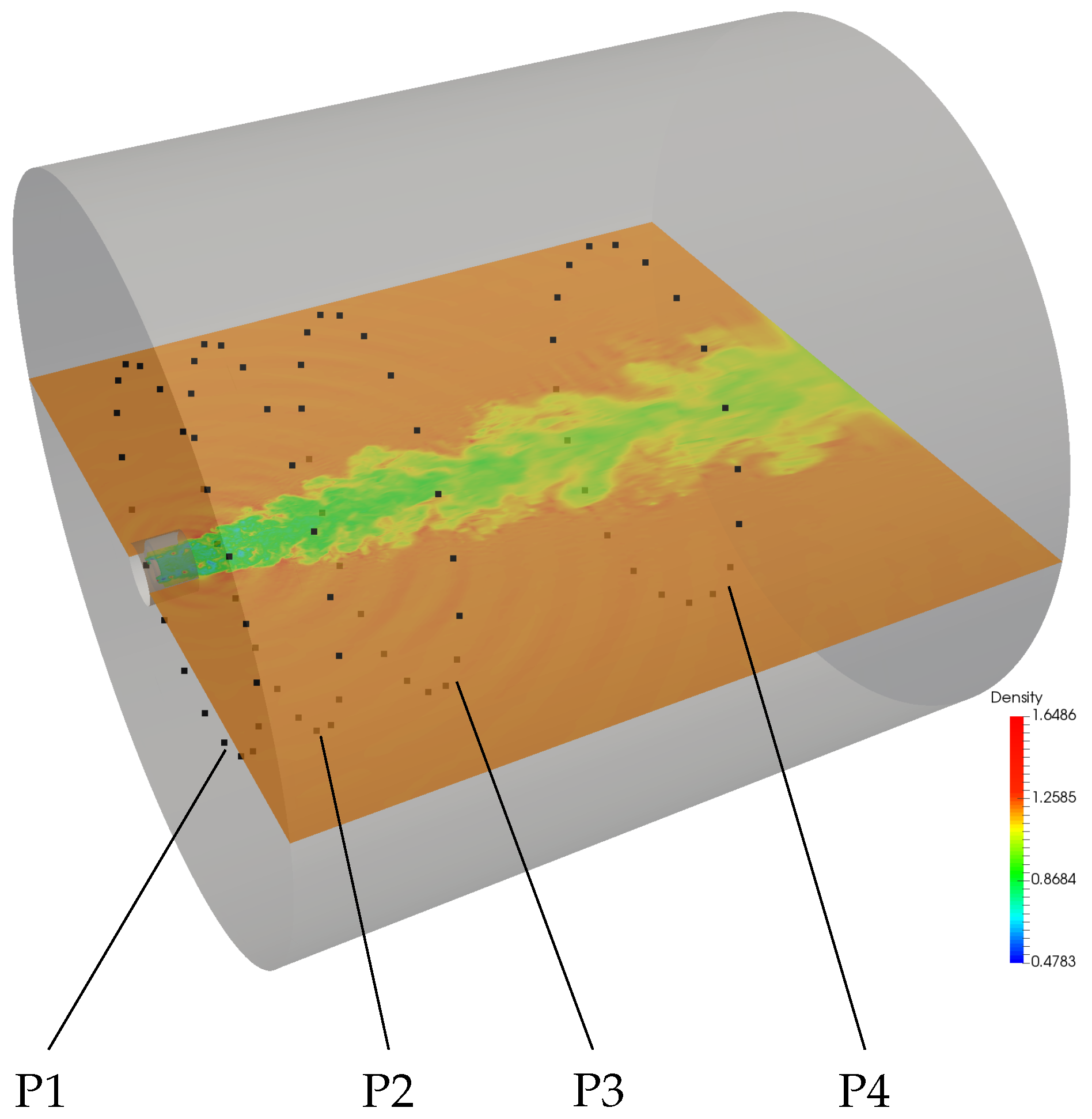
5.1. Simulation Case
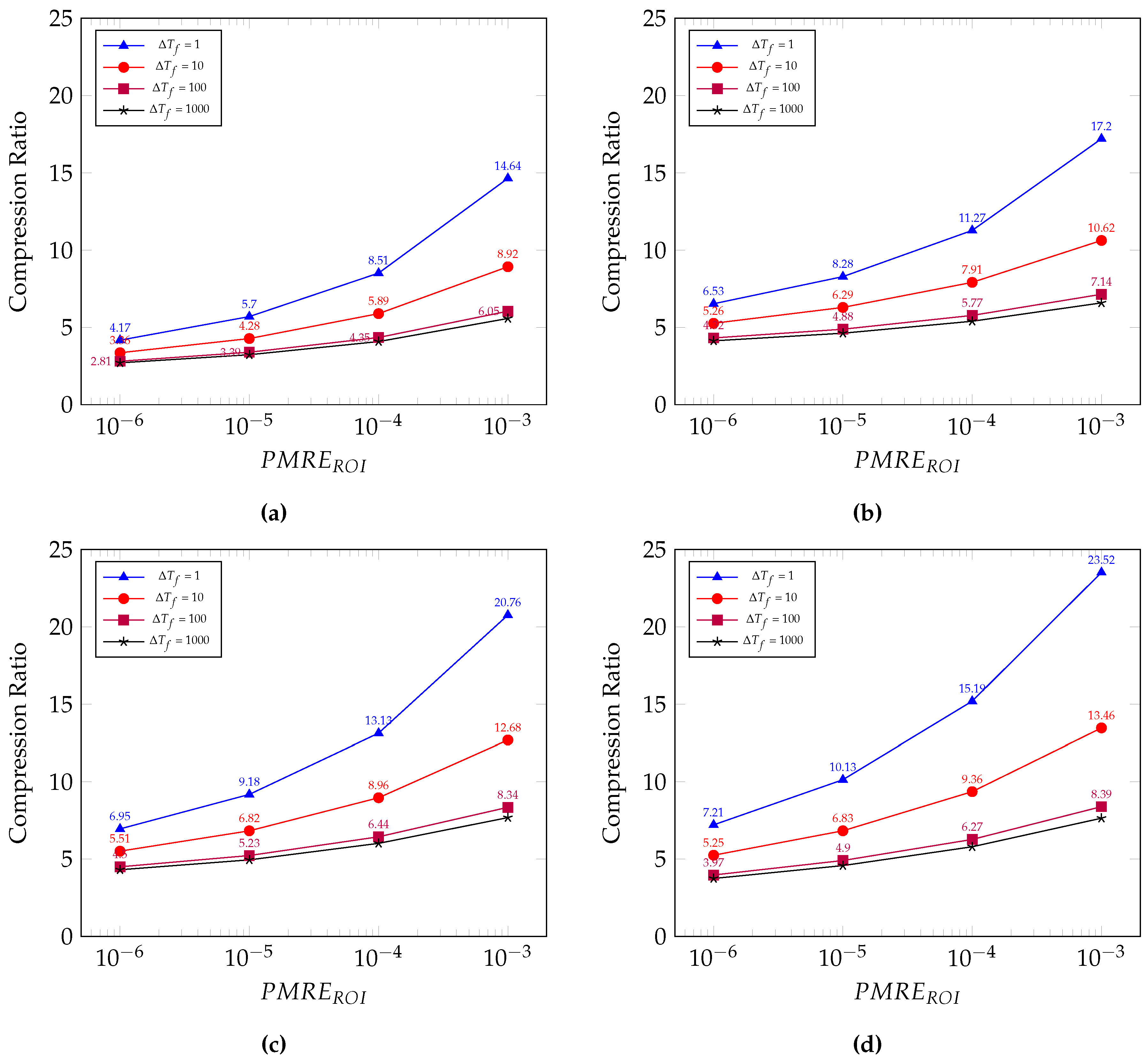
5.2. Compression Ratio
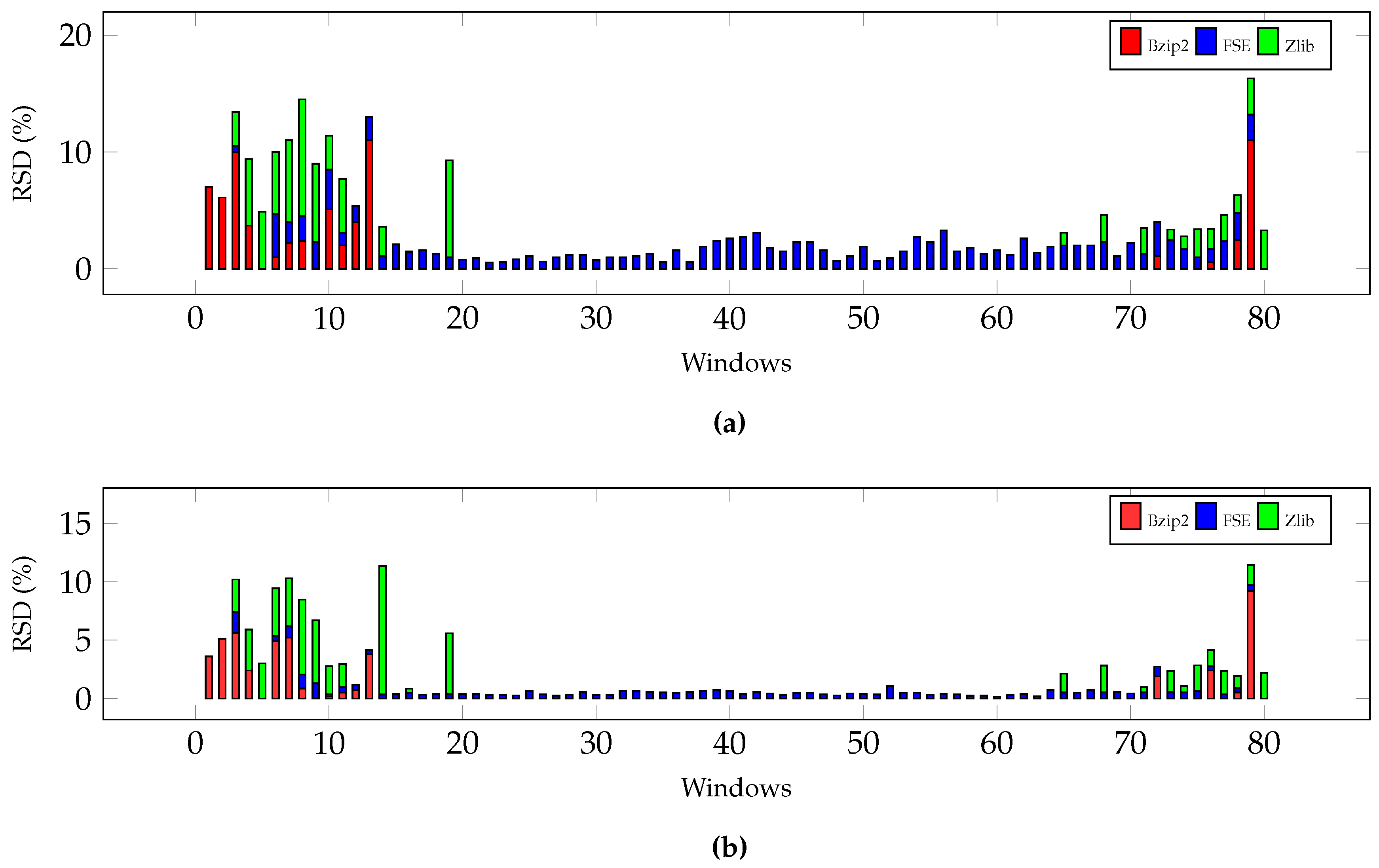
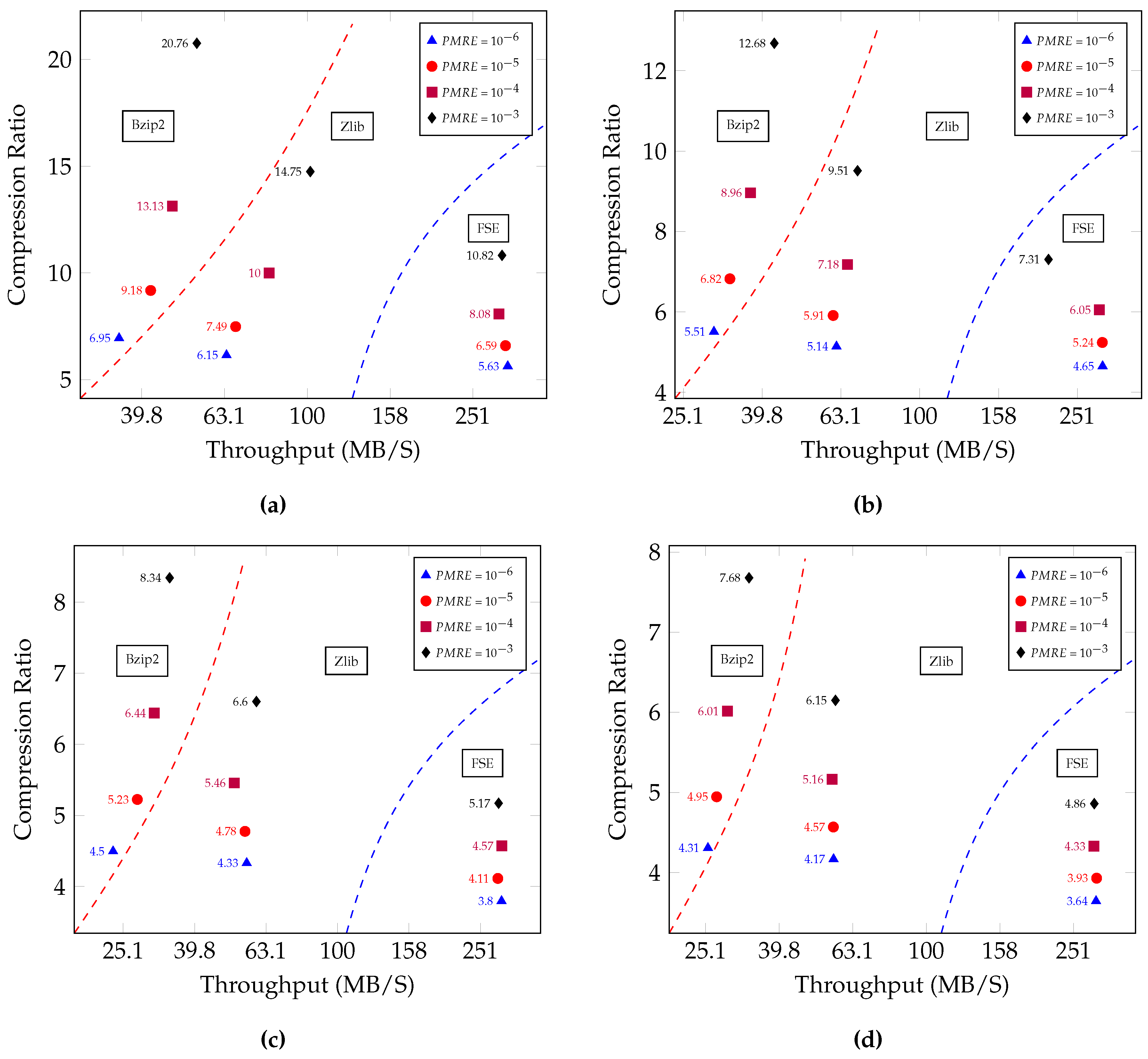
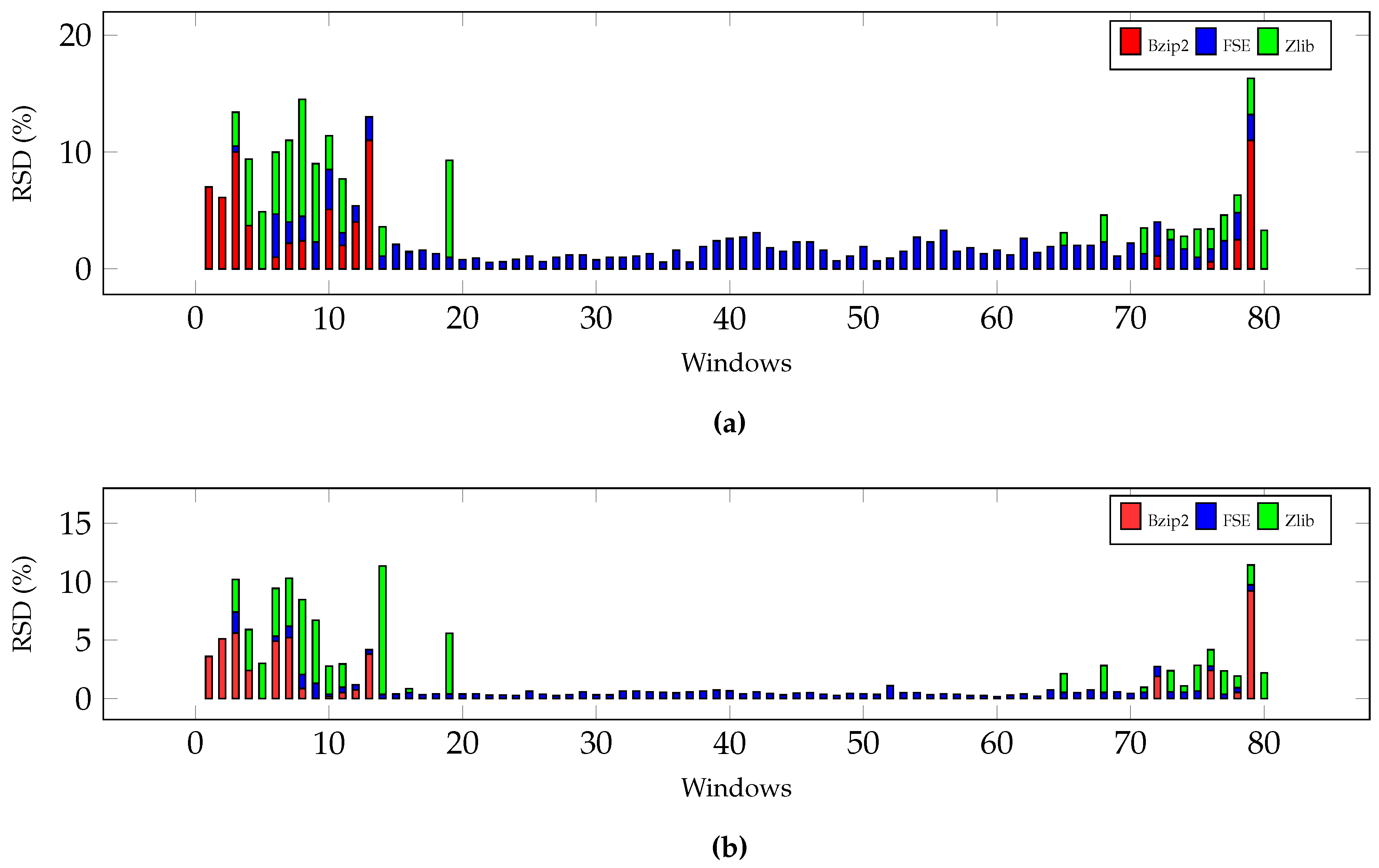
5.3. Compression Performance
5.4. Compression Algorithm Comparison
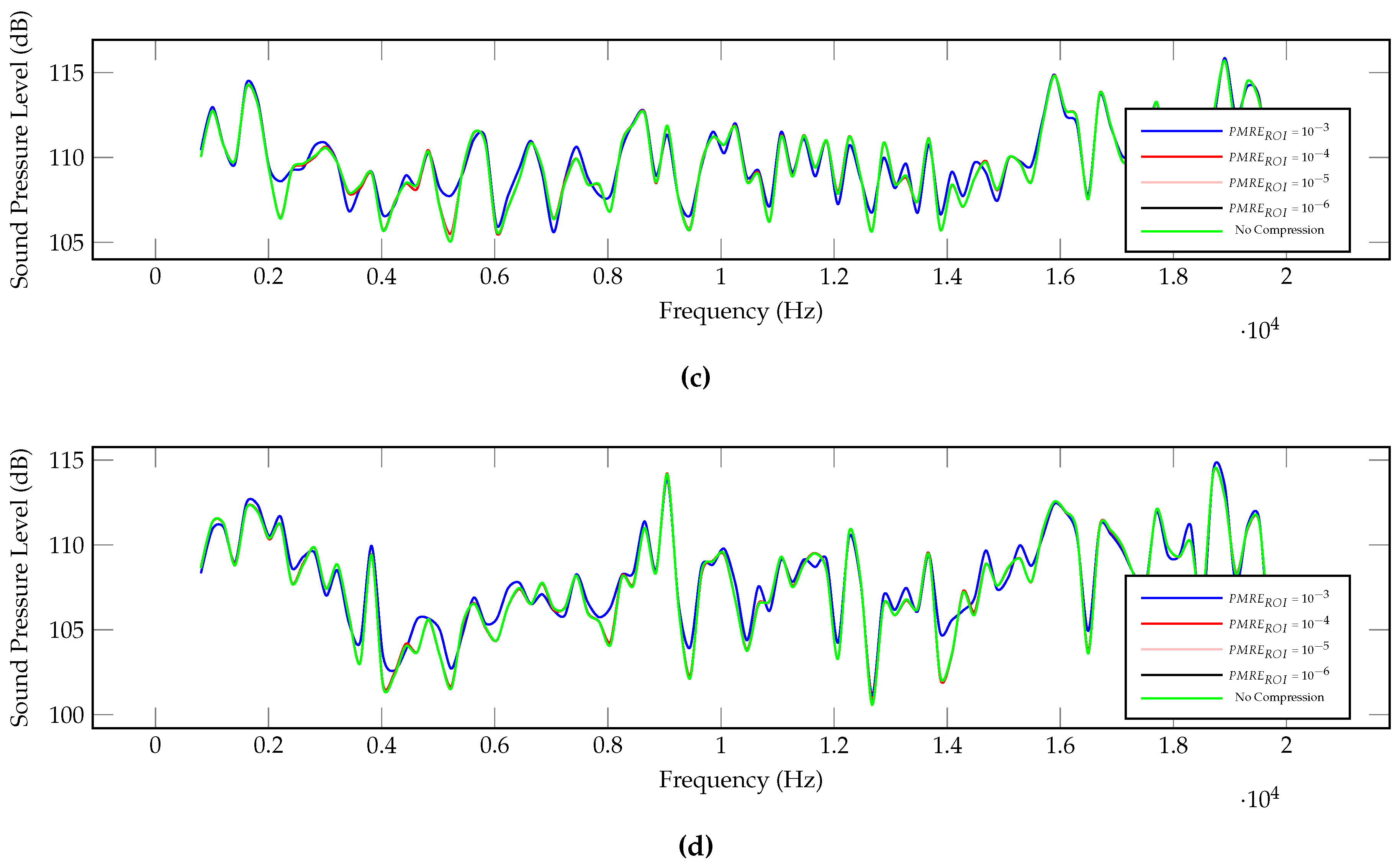
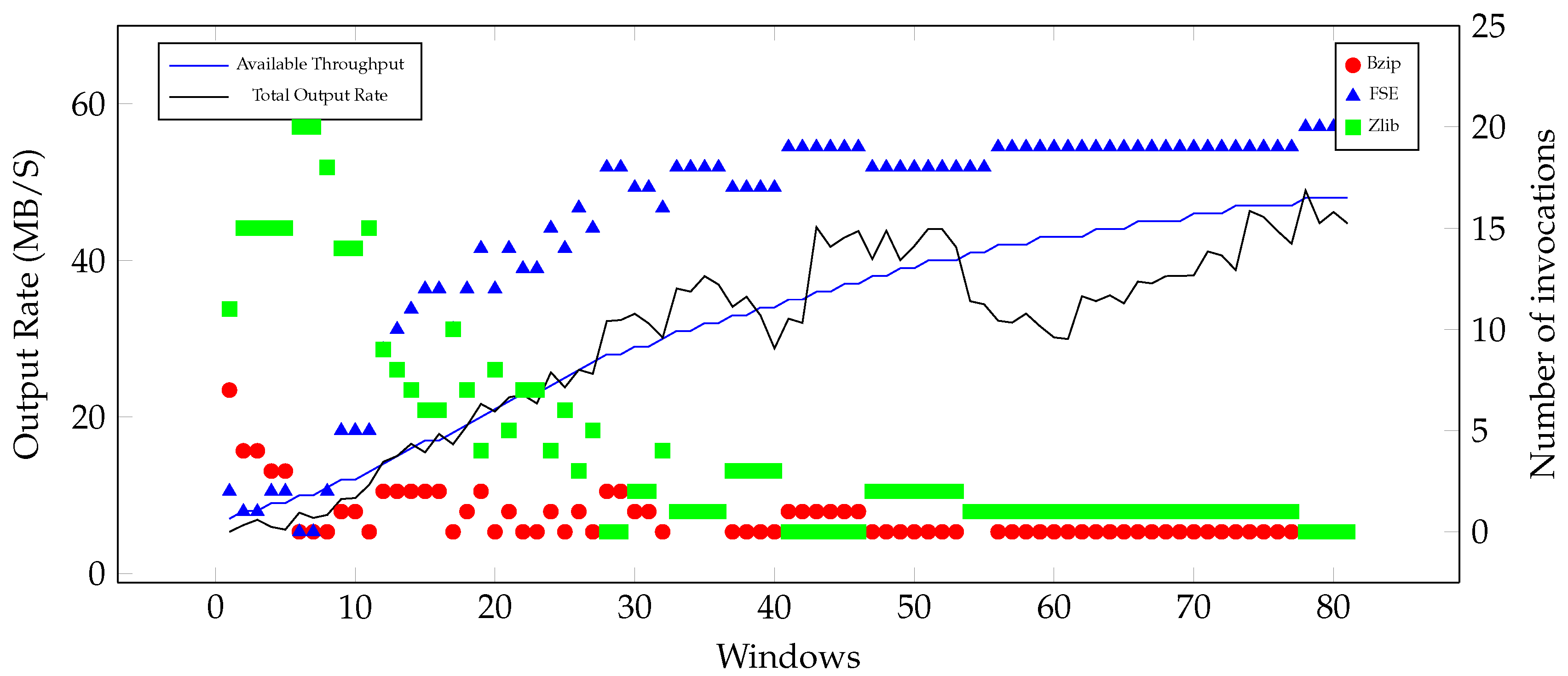
5.5. Adaptive Compression
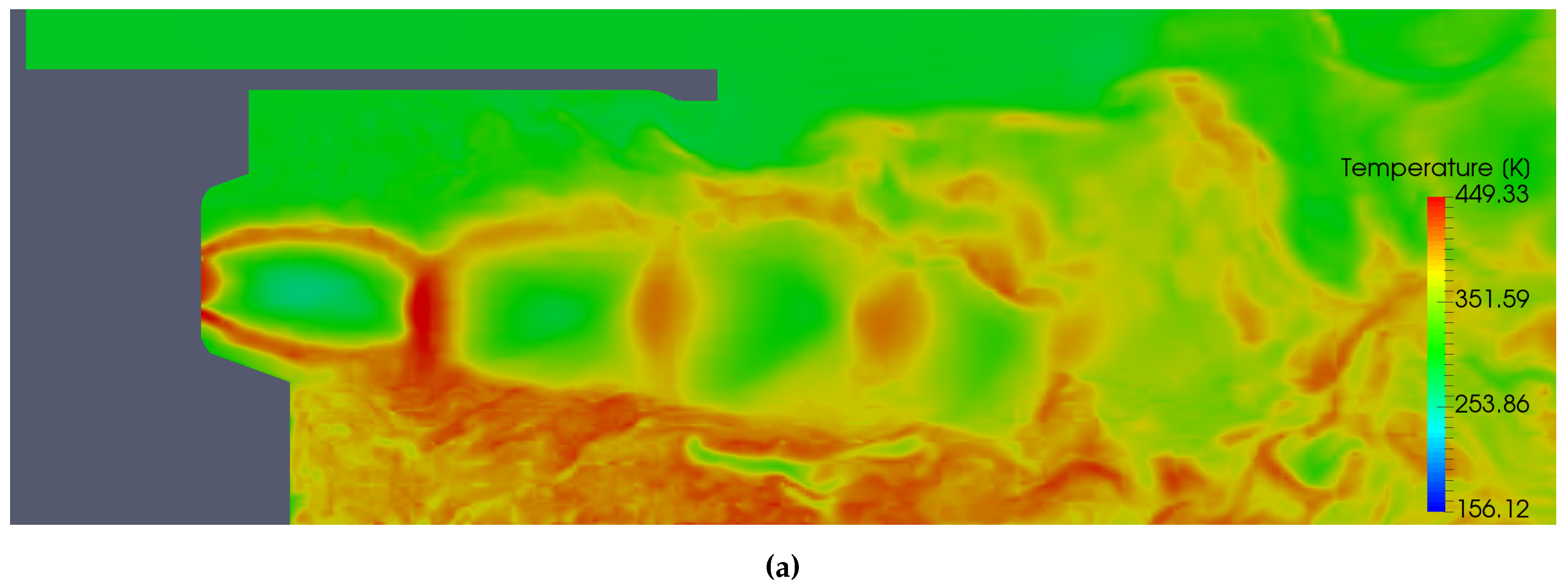
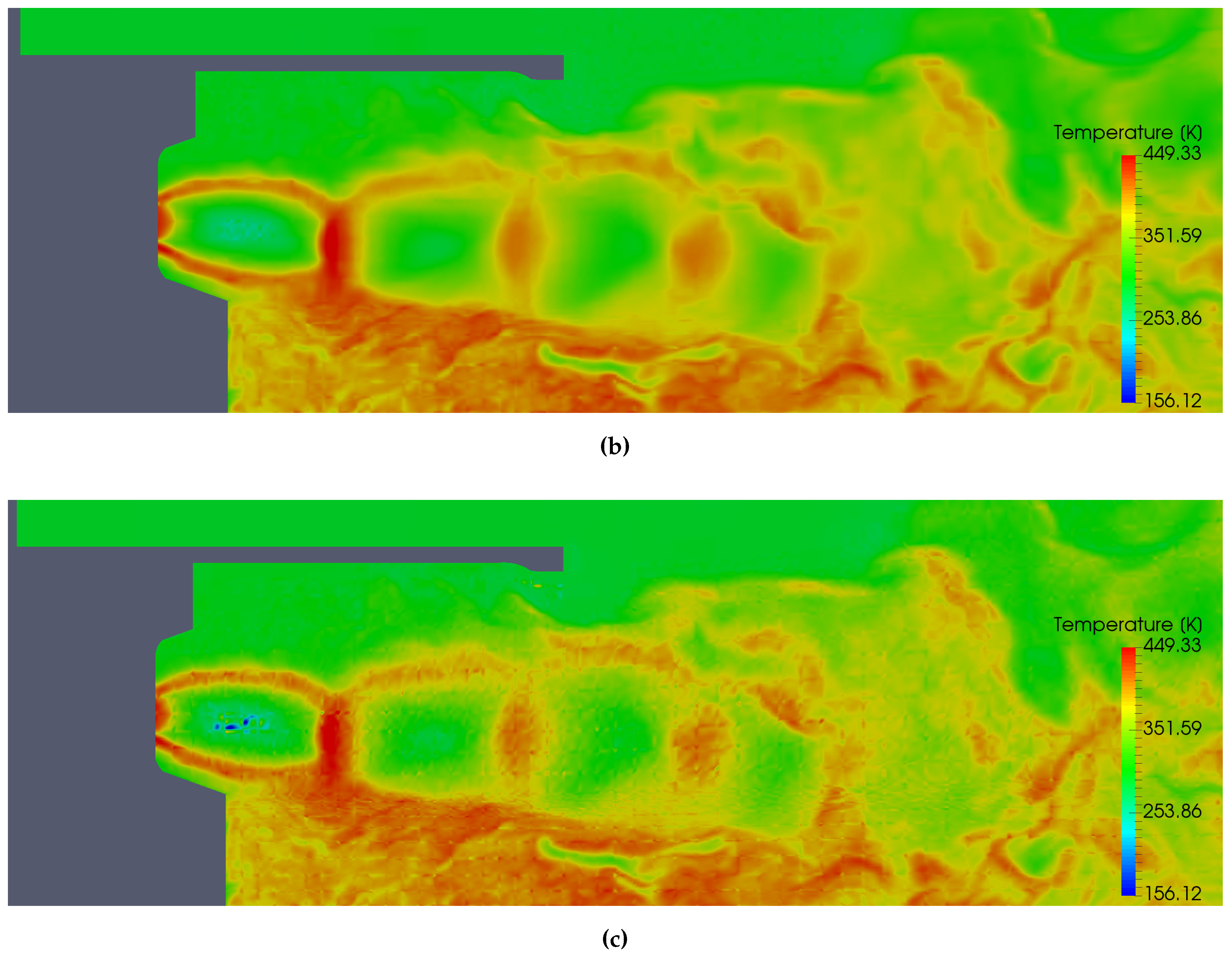
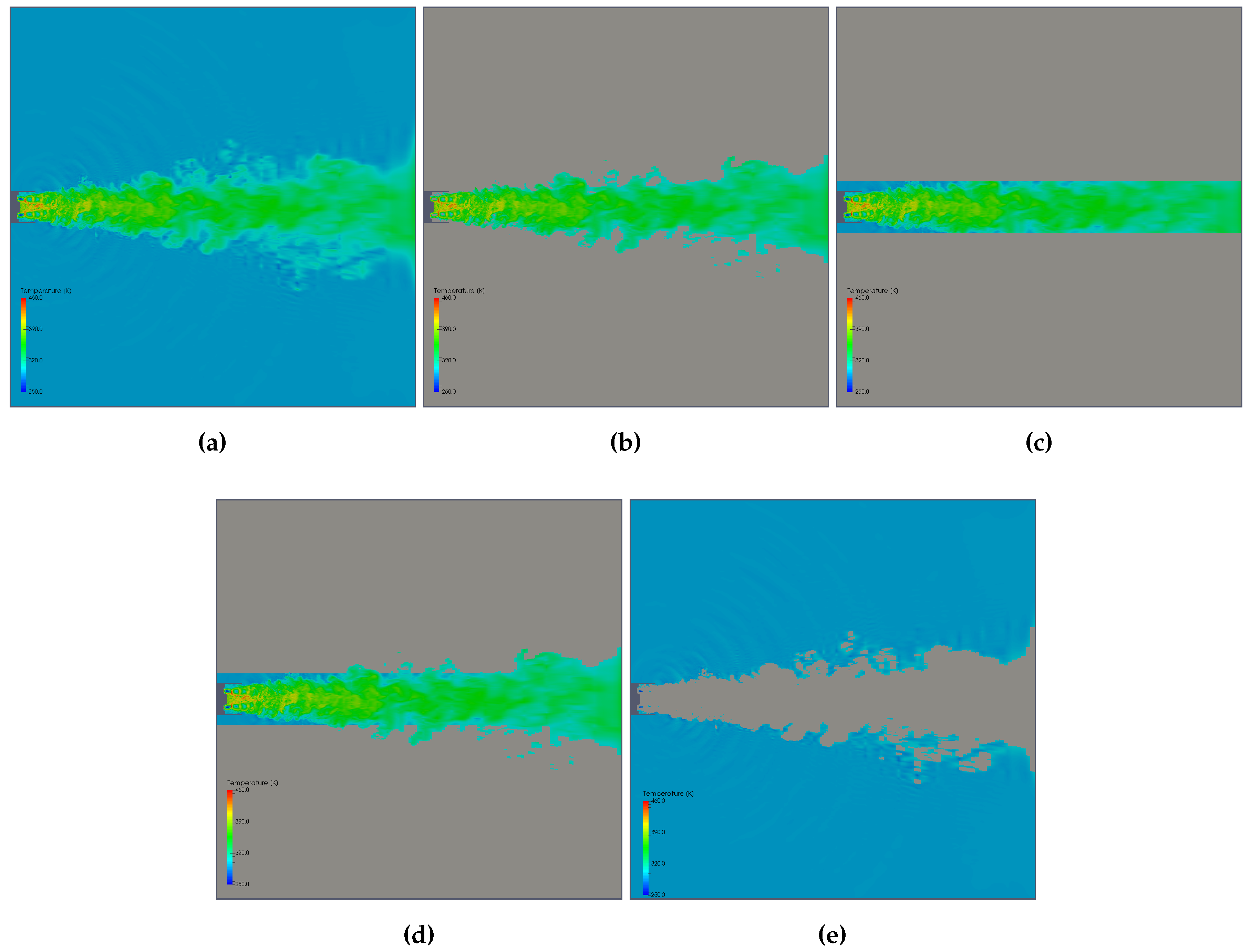
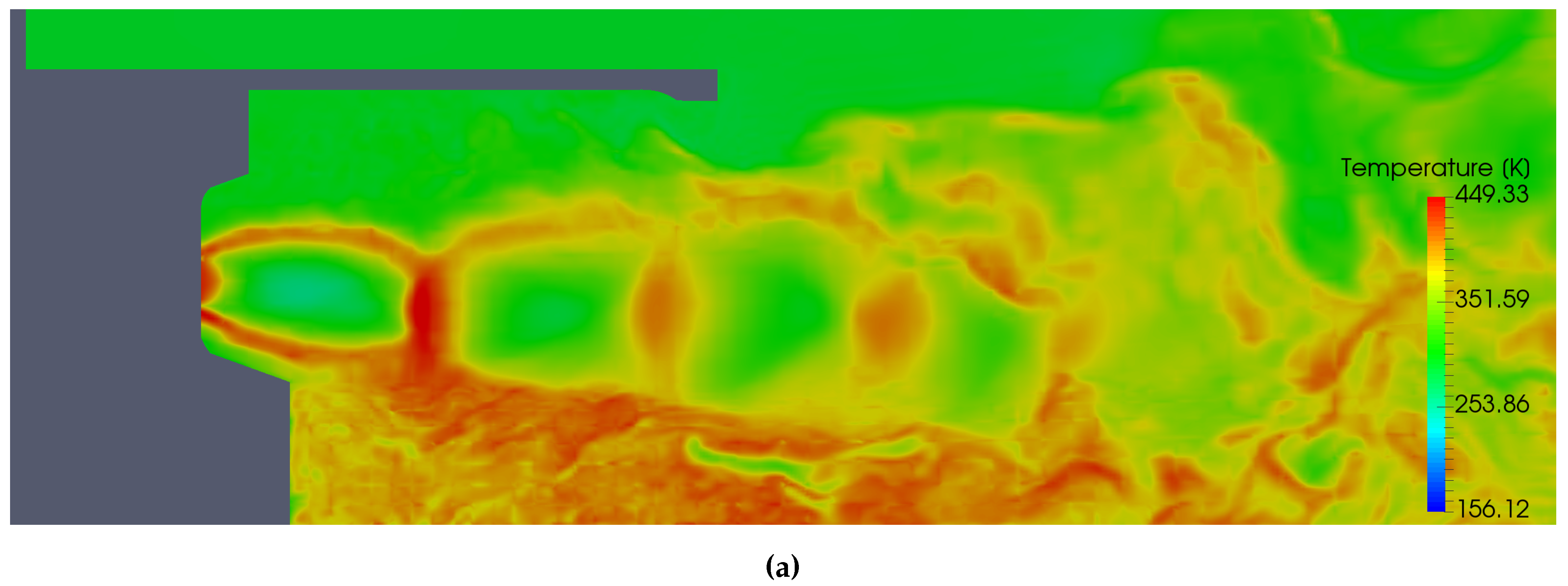
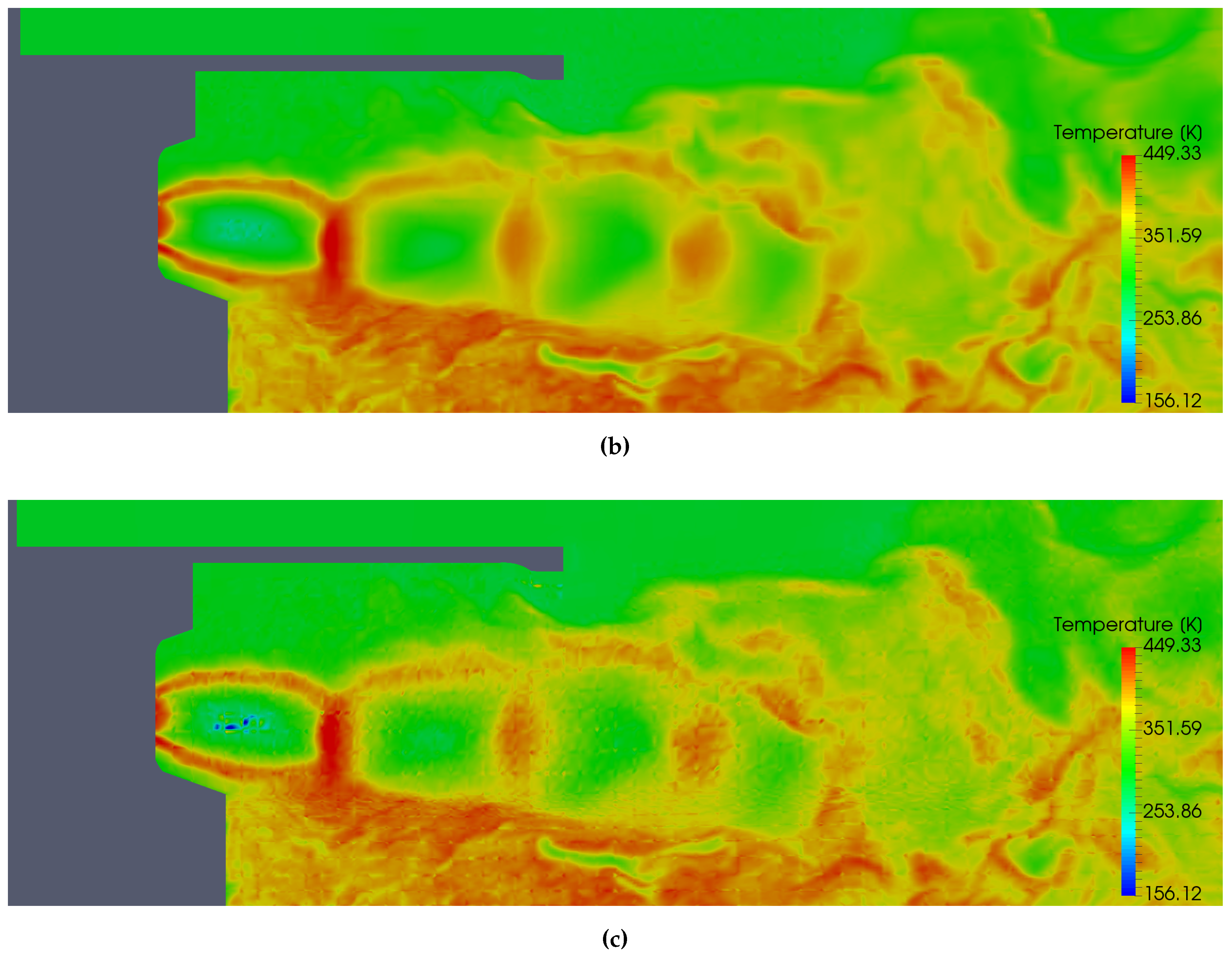
5.6. Temperature Analysis
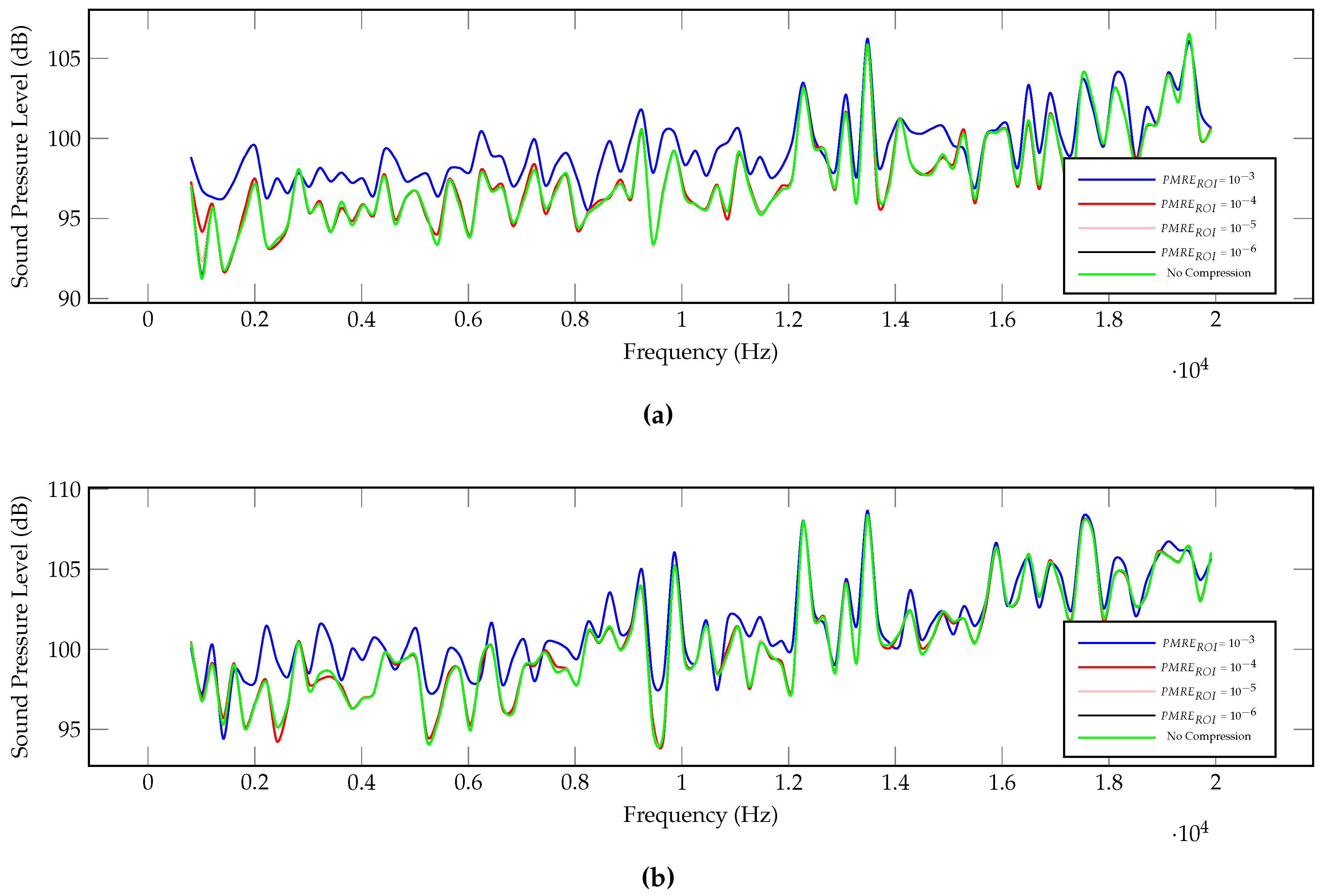
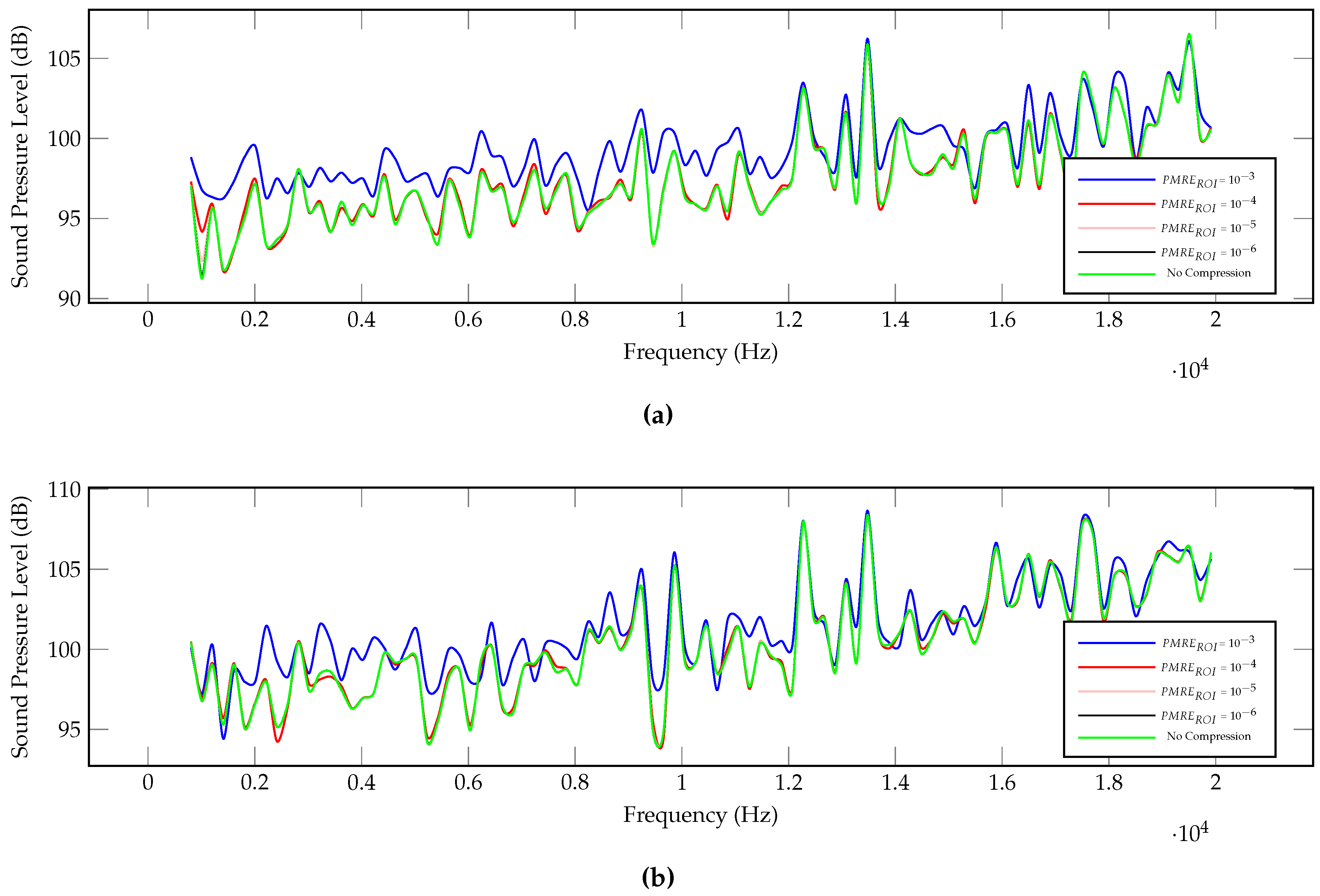
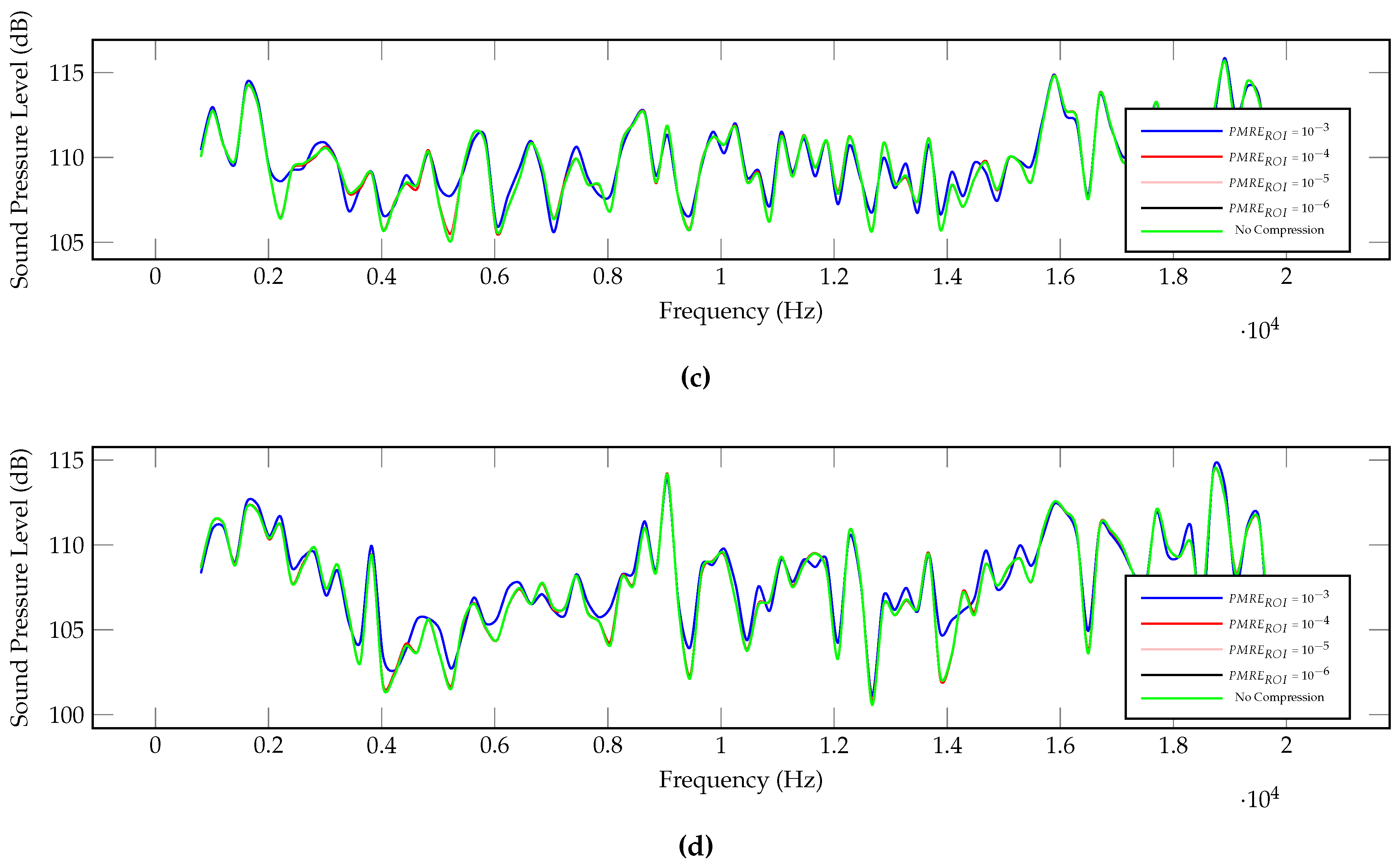
5.7. Sound Pressure Level Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ROI | Region of interest |
| CFD | Computational fluid dynamics |
| SPL | Sound pressure level |
| PMRE | Permissible maximum relative error |
| MRE | Maximum relative error |
| RMSE | Root mean square error |
| DWT | Discrete wavelet transform |
| FSE | Finite state entropy |
| MB | Mega bytes |
| DG | Discontinuous Galerkin |
| DG SEM | Discontinuous Galerkin spectral element method |
| DOF | Degrees of freedom |
| RSD | Relative standard deviatio |
| DCT | Discrete cosine transform |
| NGI | Natural gas injector |
References
- Strohmaier, E.; Dongarra, J.; Simon, H.; Meuer, M. Top500 List—June 2016. Available online: https://www.top500.org/list/2016/06/ (accessed on 5 June 2016).
- Hindenlang, F.; Gassner, G.J.; Altmann, C.; Beck, A.; Staudenmaier, M.; Munz, C.D. Explicit discontinuous Galerkin methods for unsteady problems. Comput. Fluids 2012, 61, 86–93. [Google Scholar] [CrossRef]
- Atak, M.; Beck, A.; Bolemann, T.; Flad, D.; Frank, H.; Munz, C.D. High Fidelity Scale-Resolving Computational Fluid Dynamics Using the High Order Discontinuous Galerkin Spectral Element Method. In High Performance Computing in Science and Engineering, Transactions of the High Performance Computing Center, Stuttgart (HLRS) 2015; Nagel, E.W., Kröner, H.D., Resch, M.M., Eds.; Springer: Cham, Switzerland, 2016; pp. 511–530. [Google Scholar]
- Cetin, M.O.; Pogorelov, A.; Lintermann, A.; Cheng, H.J.; Meinke, M.; Schröder, W. Large-Scale Simulations of a Non-Generic Helicopter Engine Nozzle and a Ducted Axial Fan. In High Performance Computing in Science and Engineering, Transactions of the High Performance Computing Center, Stuttgart (HLRS) 2015; Nagel, E.W., Kröner, H.D., Resch, M.M., Eds.; Springer: Cham, Switzerland, 2016; pp. 389–405. [Google Scholar]
- Burtscher, M.; Mukka, H.; Yang, A.; Hesaaraki, F. Real-Time Synthesis of Compression Algorithms for Scientific Data. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’16, Salt Lake City, UT, USA, 13–18 November 2016; IEEE Press: Piscataway, NJ, USA, 2016; pp. 23:1–23:12. [Google Scholar]
- Treib, M.; Bürger, K.; Wu, J.; Westermann, R. Analyzing the Effect of Lossy Compression on Particle Traces in Turbulent Vector Fields. In Proceedings of the 6th International Conference on Information Visualization Theory and Applications, Berlin, Germany, 11–14 March 2015; pp. 279–288. [Google Scholar]
- Laney, D.; Langer, S.; Weber, C.; Lindstrom, P.; Wegener, A. Assessing the Effects of Data Compression in Simulations Using Physically Motivated Metrics. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, SC ’13, Denver, CO, USA, 17–22 November 2013; ACM: New York, NY, USA, 2013; pp. 76:1–76:12. [Google Scholar]
- Baker, A.H.; Hammerling, D.M.; Mickelson, S.A.; Xu, H.; Stolpe, M.B.; Naveau, P.; Sanderson, B.; Ebert-Uphoff, I.; Samarasinghe, S.; de Simone, F.; et al. Evaluating lossy data compression on climate simulation data within a large ensemble. Geosci. Model Dev. 2016, 9, 4381–4403. [Google Scholar] [CrossRef]
- Toro, E.F. Riemann Solvers and Numerical Methods for Fluid Dynamics—A Practical Introduction, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Schmalzl, J. Using standard image compression algorithms to store data from computational fluid dynamics. Comput. Geosci. 2003, 29, 1021–1031. [Google Scholar] [CrossRef]
- Kang, H.; Lee, D.; Lee, D. A study on CFD data compression using hybrid supercompact wavelets. KSME Int. J. 2003, 17, 1784–1792. [Google Scholar] [CrossRef]
- Sakai, R.; Sasaki, D.; Nakahashi, K. Parallel implementation of large-scale CFD data compression toward aeroacoustic analysis. Comput. Fluids 2013, 80, 116–127. [Google Scholar] [CrossRef]
- Sakai, R.; Sasaki, D.; Obayashi, S.; Nakahashi, K. Wavelet-based data compression for flow simulation on block-structured Cartesian mesh. Int. J. Numer. Methods Fluids 2013, 73, 462–476. [Google Scholar] [CrossRef]
- Sakai, R.; Sasaki, D.; Nakahashi, K. Data Compression of Large-Scale Flow Computation Using Discrete Wavelet Transform. In Proceedings of the 48th AIAA Aerospace Sciences Meeting Including the New Horizons Forum and Aerospace Exposition, Orlando, FL, USA, 4–7 January 2010; Volume 1325. [Google Scholar]
- Sakai, R.; Onda, H.; Sasaki, D.; Nakahashi, K. Data Compression of Large-Scale Flow Computation for Aerodynamic/Aeroacoustic Analysis. In Proceedings of the 49th AIAA Aerospace Sciences Meeting Including the New Horizons Forum and Aerospace Exposition, Orlando, FL, USA, 4–7 January 2011. [Google Scholar]
- Ballester-Ripoll, R.; Pajarola, R. Lossy volume compression using Tucker truncation and thresholding. Vis. Comput. 2016, 32, 1433–1446. [Google Scholar] [CrossRef]
- Austin, W.; Ballard, G.; Kolda, T.G. Parallel Tensor Compression for Large-Scale Scientific Data. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 912–922. [Google Scholar]
- Lakshminarasimhan, S.; Shah, N.; Ethier, S.; Ku, S.H.; Chang, C.S.; Klasky, S.; Latham, R.; Ross, R.B.; Samatova, N.F. ISABELA for effective in situ compression of scientific data. Concurr. Comput. Pract. Exp. 2013, 25, 524–540. [Google Scholar] [CrossRef]
- Iverson, J.; Kamath, C.; Karypis, G. Fast and Effective Lossy Compression Algorithms for Scientific Datasets. In Lecture Notes in Computer Science, Processings of the Euro-Par 2012: Parallel Processing Workshops, Rhodes Island, Greece, 27–31 August 2012; Kaklamanis, C., Papatheodorou, T., Spirakis, P.G., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 843–856. [Google Scholar]
- Lindstrom, P.; Isenburg, M. Fast and Efficient Compression of Floating-Point Data. IEEE Trans. Vis. Comput. Graph. 2006, 12, 1245–1250. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Son, S.W.; Hendrix, W.; Agrawal, A.; Liao, W.K.; Choudhary, A. NUMARCK: Machine Learning Algorithm for Resiliency and Checkpointing. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’14, New Orleans, LA, USA, 16–21 November 2014; IEEE Press: Piscataway, NJ, USA, 2014; pp. 733–744. [Google Scholar]
- Lakshminarasimhan, S.; Shah, N.; Ethier, S.; Klasky, S.; Latham, R.; Ross, R.; Samatova, N.F. Compressing the Incompressible with ISABELA: In-Situ Reduction of Spatio-Temporal Data. In Lecture Notes in Computer Science, Processings of the 17th International European Conference on Parallel and Distributed Computing Euro-Par 2011, Bordeaux, France, 29 August–2 September 2011; Jeannot, E., Namyst, R., Roman, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 366–379. [Google Scholar]
- Lindstrom, P. FPZIP Version 1.1.0. Available online: https://computation.llnl.gov/casc/fpzip (accessed on 10 March 2017).
- Lindstrom, P. Fixed-Rate Compressed Floating-Point Arrays. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2674–2683. [Google Scholar] [CrossRef] [PubMed]
- Ibarria, L.; Lindstrom, P.; Rossignac, J.; Szymczak, A. Out-of-core compression and decompression of large n-dimensional scalar fields. Comput. Graph. Forum 2003. [Google Scholar] [CrossRef]
- Sayood, K. Introduction to Data Compression, 2nd ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2000. [Google Scholar]
- Fout, N.; Ma, K.L. An Adaptive Prediction-Based Approach to Lossless Compression of Floating-Point Volume Data. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2295–2304. [Google Scholar] [CrossRef] [PubMed]
- Seward, J. bzip2. Available online: http://www.bzip.org/ (accessed on 20 October 2016).
- Gailly, J.; Adler, M. zlib. Available online: http://www.zlib.net/ (accessed on 20 October 2016).
- Collet, Y. New Generation Entropy Codecs: Finite State Entropy. Available online: https://github.com/Cyan4973/FiniteStateEntropy (accessed on 20 October 2016).
- Schrijver, A. Theory of Linear and Integer Programming; John Wiley & Sons, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Boblest, S.; Hempert, F.; Hoffmann, M.; Offenhäuser, P.; Sonntag, M.; Sadlo, F.; Glass, C.W.; Munz, C.D.; Ertl, T.; Iben, U. Toward a Discontinuous Galerkin Fluid Dynamics Framework for Industrial Applications. In High Performance Computing in Science and Engineering’ 15; Heidelberg, S.B., Ed.; Springer: Heidelberg, Geramny, 2015; pp. 531–545. [Google Scholar]
- Kraus, T.; Hindenlang, F.; Harlacher, D.; Munz, C.D.; Roller, S. Direct Noise Simulation of Near Field Noise during a Gas Injection Process with a Discontinuous Galerkin Approach. In Proceedings of the 33rd AIAA Aeroacoustics Conference, Colorado Springs, CO, USA, 4–6 June 2012. [Google Scholar]
- Hempert, F.; Hoffmann, M.; Iben, U.; Munz, C.D. On the simulation of industrial gas dynamic applications with the discontinuous Galerkin spectral element method. J. Therm. Sci. 2016, 25, 250–257. [Google Scholar] [CrossRef]
- Ku, H.H. Notes on the use of propagation of error formulas. J. Res. Natl. Bur. Stand. C Eng. Instrum. 1966, 70, 263–273. [Google Scholar] [CrossRef]
- Robinson, M.; Hopkins, C. Effects of signal processing on the measurement of maximum sound pressure levels. Appl. Acoust. 2014, 77, 11–19. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PMRE | |||
|---|---|---|---|
| Proposed Algorithm = 1000, 100, 10, 1 | 6.4, 7, 10.7, 17.8 | 4.6, 4.8, 6.7, 10.3 | 3.4, 3.6, 4.7, 6.4 |
| Lorenzo Predictor-1D | 8.1 | 5.4 | 3.9 |
| Lorenzo Predictor-2D | 9 | 5.9 | 4.2 |
| Lorenzo Predictor-3D | 9.48 | 6.28 | 4.5 |
| FPZIP | 6.7 | 5.4 | 4 |
| ZFP * | 7.9 | 4.1 | 2.6 |
| ISABELA | 3.9 | 2.9 | 2.4 |
| PMRE | |||
|---|---|---|---|
| Proposed Algorithm = 1000, 100, 10, 1 | 30.9, 33.1, 37.2, 47.1 | 24.2, 25.4, 32.7, 36.2 | 22.3, 22.9, 25.3, 31.8 |
| Lorenzo Predictor-1D | 32.3 | 28.8 | 23.1 |
| Lorenzo Predictor-2D | 36.2 | 30.4 | 23.6 |
| Lorenzo Predictor-3D | 36.9 | 30.3 | 25.6 |
| FPZIP | 89.1 | 73.1 | 63.5 |
| ZFP * | 63.97 | 54.21 | 40.1 |
| ISABELA | 3.7 | 4.4 | 5.1 |
| Cons. Var. | Temperature | Compression Ratio | ||||||
|---|---|---|---|---|---|---|---|---|
| PMRE | MRE | RMSE | ||||||
| ROI | non-ROI | ROI | non-ROI | ROI | non-ROI | ROI | non-ROI | |
| 0.0397 | 0.34 | 14.60 | 149.4 | 2.7 | 2.07 | 38.77 | ||
| 0.0043 | 0.032 | 1.43 | 14.57 | 0.28 | 1.42 | 20.76 | ||
| 0.00042 | 0.0030 | 0.13 | 1.4 | 0.0277 | 0.22 | 11.88 | ||
| 0.00004 | 0.0003 | 0.014 | 0.14 | 0.0027 | 0.023 | 7.54 | ||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Najmabadi, S.M.; Offenhäuser, P.; Hamann, M.; Jajnabalkya, G.; Hempert, F.; Glass, C.W.; Simon, S. Analyzing the Effect and Performance of Lossy Compression on Aeroacoustic Simulation of Gas Injector. Computation 2017, 5, 24. https://doi.org/10.3390/computation5020024
Najmabadi SM, Offenhäuser P, Hamann M, Jajnabalkya G, Hempert F, Glass CW, Simon S. Analyzing the Effect and Performance of Lossy Compression on Aeroacoustic Simulation of Gas Injector. Computation. 2017; 5(2):24. https://doi.org/10.3390/computation5020024
Chicago/Turabian StyleNajmabadi, Seyyed Mahdi, Philipp Offenhäuser, Moritz Hamann, Guhathakurta Jajnabalkya, Fabian Hempert, Colin W. Glass, and Sven Simon. 2017. "Analyzing the Effect and Performance of Lossy Compression on Aeroacoustic Simulation of Gas Injector" Computation 5, no. 2: 24. https://doi.org/10.3390/computation5020024