The Evolution of Contextual Information Processing in Informatics

Department of Informatics, Ionian University, Platia Tsirigoti 7, PC 49100 Corfu, Greece
Information 2018, 9(3), 47; https://doi.org/10.3390/info9030047
Submission received: 14 December 2017
/
Revised: 22 February 2018
/
Accepted: 22 February 2018
/
Published: 27 February 2018
(This article belongs to the Special Issue Context Awareness)
Abstract
:After many decades of flourishing computer science it is now rather evident that in a world dominated by different kinds of digital information, both applications and people are forced to seek new, innovative structures and forms of data management and organization. Following this blunt observation, researchers in informatics have strived over the recent years to tackle the non-unique and rather evolving notion of context, which aids significantly the data disambiguation process. Motivated by this environment, this work attempts to summarize and organize in a researcher-friendly tabular manner important or pioneer related research works deriving from diverse computational intelligence domains: Initially, we discuss the influence of context with respect to traditional low-level multimedia content analysis and search, and retrieval tasks and then we advance to the fields of overall computational context-awareness and the so-called human-generated contextual elements. In an effort to provide meaningful information to fellow researchers, this brief survey focuses on the impact of context in modern and popular computing undertakings of our era. More specifically, we focus to the presentation of a short review of visual context modeling methods, followed by the depiction of context-awareness in modern computing. Works dealing with the interpretation of context by human-generated interactions are also discussed herein, as the particular domain gains an ever-increasing proportion of related research nowadays. We then conclude the paper by providing a short discussion on (i) the motivation behind the included context type categorization into three main pillars; (ii) the findings and conclusions of the survey for each context category; and (iii) a couple of brief advices derived from the survey for both interested developers and fellow researchers.
1. Introduction
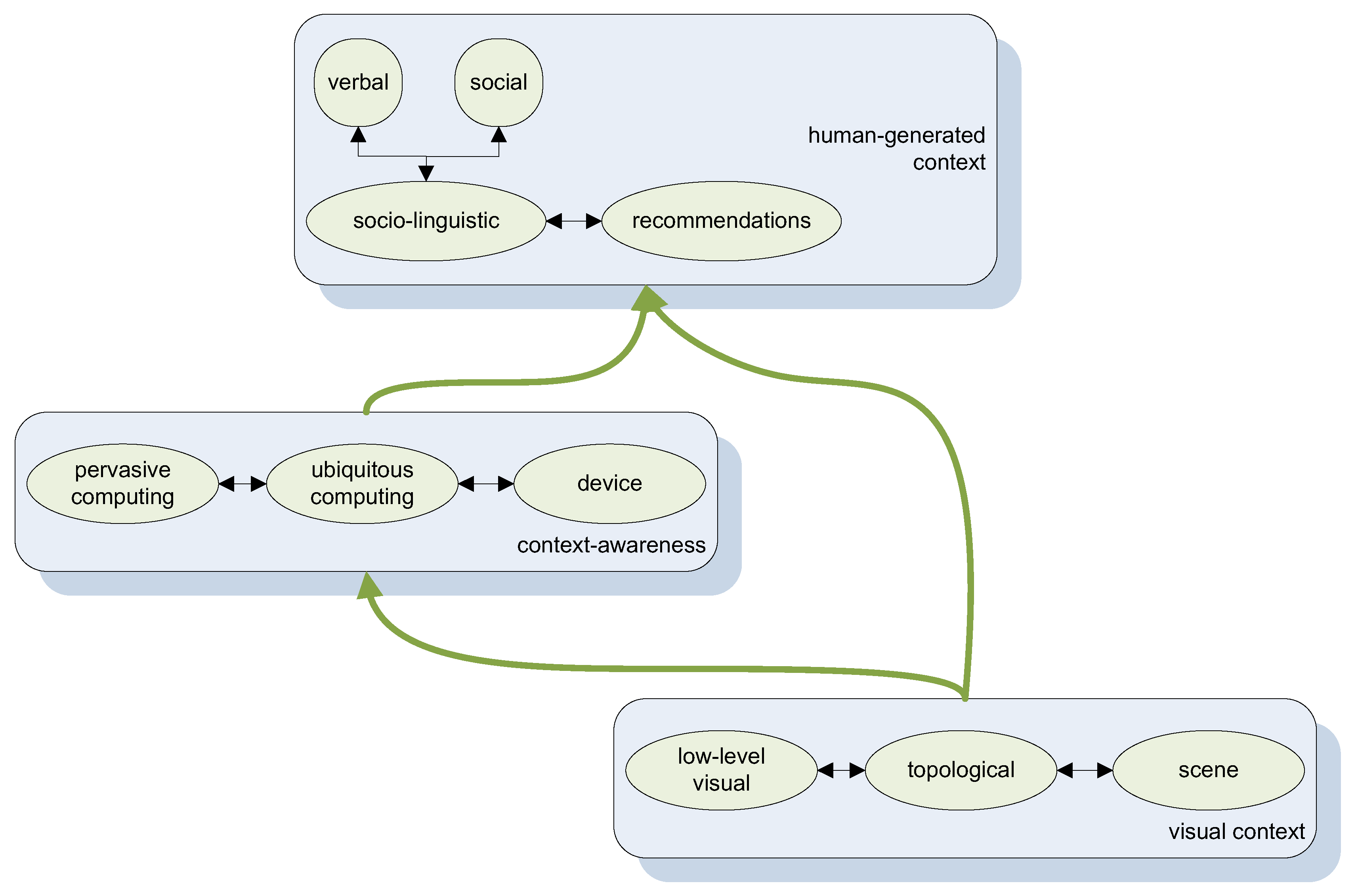
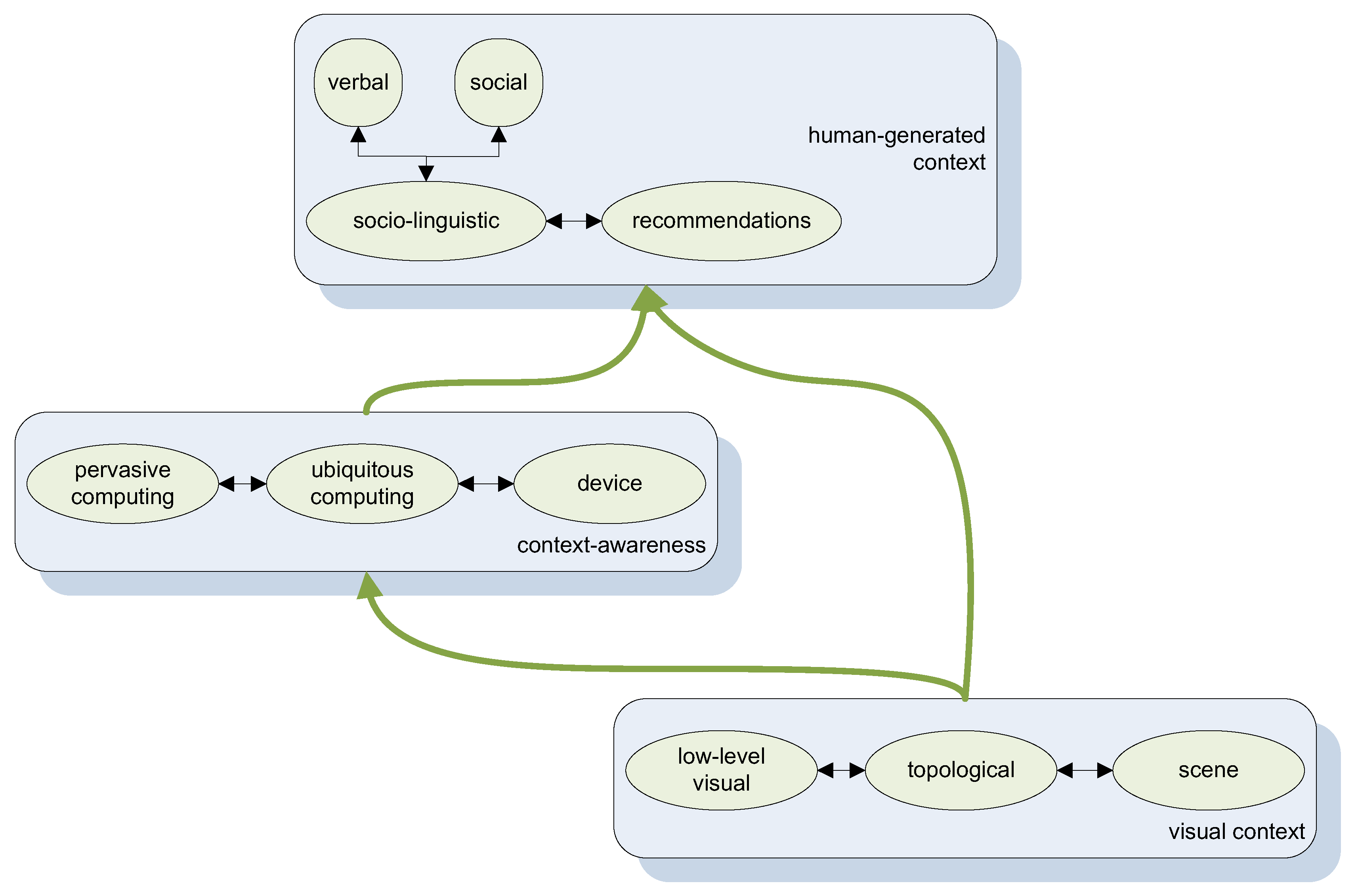
Over the last years numerous researchers attempted to provide various meanings and definitions to the notion of context, but in principle one main observation remains solid: There is no unique, single-minded definition to identify it and thus to cover all aspects of its utilization in modern computing tasks. The latter have clearly evolved over time, as it would have been expected, but at the same time they have left room for innovative information and knowledge processing. Due to the nature of human cognition, a primary problem tackled via access to and processing of digital information is the bridging of the so-called semantic and sensory gaps [1,2]. In this framework, after more than a decade of related studies and research efforts, it is now well-acknowledged that a particular type of knowledge is to be identified; contextual knowledge is the one to be held responsible for the advances towards efficiently tackling both gaps by modern computational systems. In this paper we attempt to focus on the sub-fields of computer science that undertake their own way of understanding, and thus defining, what the term context (Figure 1) really represents.
For the sake of both space and clarity, we shall omit in the following the analytical presentations included in our past attempts to identify and categorize context, mainly because at the time they focused in primitive context aspects that aided towards the establishment of the term, but currently are considered to be rather obsolete in nature; of course, the interested reader may consult them in detail for the sake of completeness [3,4]. Still, the evolving nature of the notion of context, coupled together with updated, recent advances in modern informatics and the introduction of aspects that did not exist only a couple of years ago, constitute this survey work a necessity of great research significance. The criterion for including papers in this survey was twofold and in a sense rather contradictory, i.e., on the one hand we felt obliged to include representative, long-established contextual aspects of informatics, and on the other we acknowledged the need to include new innovative contextual directives of the recent era. As it would be apparent from the research works depicted within the following sections, one of the most complex and difficult things to model is the relationship between context and the actual user involvement, either in the form of her/his interests or even the actual decision-making. In some cases the complexity of the problem at hand is further escalated since several types of contextual information are difficult to grasp in the first place as the acquisition process interferes with the decision making process (e.g., when dealing with the image of a sofa in a meadow, is the meadow considered to be contextual information for the sofa or just a data outlier?). As a result, extreme caution should be followed when tackling the notion of context within the modern informatics environment, so as to avoid ambiguities and erroneous interpretations, and this work comes to fill the gap in providing a meaningful categorization of the main contextual aspects in important fields.
The structure of the rest of this paper is as follows: In Section 2 we explain in more detail our motivation behind investigating contextual information processing in informatics with respect to a handful of identified contextual types (see Figure 2). Section 3 discusses all three variations to be identified with respect to the primitive notion of visual context, namely low-level context, topological, and scene context. In Section 4 we present an overview of context-aware approaches, whereas in Section 5 we present the identified human-generated contextual elements and the way they affect related research literature. Finally, Section 6 discusses briefly the resulted findings, conclusions and future perspectives of each one of the contextual building blocks of the survey and concludes this work.
2. Motivation
After the first identifying actions in the early stages of computer science, where the boundaries of computer applications, systems and tasks were solidly set, nowadays we are facing difficulties to identify them. Progress made over the last decades in several computer science sub-domains, like hardware and software development, communication and networking issues, as well as algorithmic achievements towards the “brave new digital world”, resulted in unprecedented achievements and de facto utilization. The greatest paradigm of all is the recent proliferation of user-generated, multimedia content production, sharing and consumption over Internet-based social networks that literally transformed the so far known society structure by allowing the establishment of digital communities.
Still, a skeptic may wonder why traditional multimedia indexing, search and retrieval approaches are not to be implemented in this case. The plain and simple answer dictated by the actual everyday computing is that, apart from the obvious efficiency and/or efficacy problems that have been risen, the form of multimedia usage and applications changed radically in the social media era, in the sense that revolutionary and out-of-the-box approaches are now desperately required. More specifically, the easiness of the aforementioned user content capturing and sharing process, combined together with hardware advances that resulted to market changes towards better and cheaper hardware, concluded to the need for efficient handling of huge amounts of shared multimedia content within generated social media collections that imposed shifting of research towards new or parallel to traditional domains, like the advanced exploitation of metadata information and/or additional kinds of semantic knowledge.
Moreover, the evolution of modern informatics in terms of both hardware and software is evident in everyday life. Nowadays, smartphones and haptic devices dominate the computing landscape; almost all data chunks are interconnected and almost everything/everyone interacts digitally with something/someone else. Touch screens, hand and finger motion control, and cloud-based services are the direction computing is moving on now and in this sense one may identify clear sub-trends in the process. A careful analysis of the latter will reveal the fact that almost everything spins around multimedia content, mainly due to the fact that there is an inherent trend for user-generated content to include photos and/or videos when capturing human activities. Thus, low-level, but, at the same time, smart interpretation of multimedia content plays a central role and drives visual context research depicted in Section 3.
Originating from the ubiquitous computing sub-field, context awareness is a property of current “smart” devices that characterizes them, especially in the popular case of smartphone users. It summons the impression that computers and devices may exploit or even perceive information about their operational environment that would lead them to re-act according to a predefined or even dynamic set of guidelines (Section 4). Last but not least, comes the so-called verbal context category, which introduces the human-generated aspect of informatics in the sense that it provides contextual elements that arise mostly from human-computer interaction. The latter could of course take either traditional (e.g., click-through) or innovative (e.g., continuous monitoring of touch interface interactions) information, leading to interesting research results summarized in the following Section 5.
3. Visual Context
Visual context refers to the variety of environmental or physical parameters encountered mostly in the case of applications and systems dealing with the so-called digital multimedia content. These parameters are typically extracted from low-level visual features and may be combined with higher-level concepts and interpretations. This contextual aspect is nowadays considered to be the very first, basic aspect of contextual information. As depicted in our past works on the subject [3,4], it is safe to presume that visual context forms a long-established approach to context, interpreting it from an integrated view on environmental parameters inherent in content items processing. Being a rather exploited and analyzed field, visual context is considered today as the fundamental layer (see Figure 2) on top of which all other, newer contextual aspects are built.
For the sake of completeness of this survey, we include in the following a threefold visual context categorization. The first part focuses on the combination of contextual parameters extracted from low-level visual features with higher-level concepts and interpretation (e.g., fuzzy set theory) to support additional knowledge processing tasks like reasoning. As expected, corresponding Table 1 contains only pioneer works from the early stages of context analysis. The second and third parts consider extracted high-level concepts during the so-called multimedia content analysis, so as to identify and express the specific context in a structural manner; this context may be then used for the so called knowledge-assisted content analysis, as well as traditional information retrieval tasks, such as indexing or searching. For the sake of clarity, we further analyze this categorization into an important, standalone variation of visual context called topological context associated to spatial relationships between objects or regions in a digital content item (respective works presented in Table 2), and the visual context aspect that it is used mostly within the framework of recent multimedia content applications, entitled scene context and defined by typical relationships among locations of different materials in a multimedia scene (respective works included in Table 3).
3.1. Low Level Context
By low-level context in the sequel we will refer to all information related to a multimedia content item, such as its chromatic scale, texture, shape, motion et al. that may be exploited within its low-level visual analysis. In principal, the aforementioned visual features provide a qualitative or quantitative description of the visual properties of content; these features are often standardized in the literature in the form of visual descriptors [5]. The aid of contextual information in this field is mostly summoned towards two popular research problems, namely scene classification and object detection. The in-context solution to these problems is typically achieved through modeling of visual concept descriptors in one or more suitable knowledge structures, like context domain ontologies, and ontology learning/visual concept detection techniques utilizing low-level context information in the process.
Since this is a well-known and somehow obsolete sub-field of visual context utilization we shall only include herein some pioneer works worth mentioning, like the one proposed in [6], where a list of semantic objects is used for semantic indexing and retrieval of video. Another related work [7] focuses on the color low-level feature to be able to detect higher-level concepts, whereas the work one needs to cite when dealing with content-based image retrieval is the one in [8]. Lastly, a novel exemplar-based approach has been also introduced that uses contextual information in the form of a combination of color and texture features to classify sub-blocks in an outdoor scene [9]. Although, only the first work is focusing on video sequences, whereas the remaining three works deal with handling of static digital images, the fundamental approach of all approaches remains common: They all four exploit different aspects of low-level visual context in an effort to optimize the—at the time—traditional techniques and methodologies of each research sub-field (namely: Semantic indexing and retrieval, image annotation, region-based semantic analysis, and semantic object detection). In order to achieve this, they all introduce novel contextual characteristics that other approaches did not envisage. Still, all four lack on the utilization of scene context, which later on proved to be a key component in semantic content-based image retrieval.
Table 1 provides a brief comparative overview of the above fundamental low-level visual context research efforts. Still, their main drawback remains the fact that they all tend to examine isolated strips of pure object materials, without taking into consideration the low-level context of the scene or of individual objects themselves, a fact rather important and also extremely challenging even for human observers further tackled in the next part. As it would be the case with all tables to follow, Table 1 includes six columns: The first contains each work’s bibliographic reference number; the second describes the main task the particular work attempts to tackle; the third focuses on the depicted methodology the authors propose or utilize in order to solve the particular research task at hand; the fourth column presents a representative set of positive characteristics (if applicable); the fifth column presents a representative set of negative characteristics (if applicable); the sixth column provides information on the utilized dataset (if any).
3.2. Topological Context
The basic idea behind the introduction of topological context is rather twofold in principle: It tackles both the utilization of spatial relationships and the notion of proximity that may exist between objects or regions of a multimedia content item, as well as the actual positioning of the item itself. Consequently, it may be defined as the synthesis of information and relationships acquired from the spatial environment of the latter [10]. Initially, we may identify methods trying to determine the actual location in computing applications. This task may take several instances, such as an individual’s or sensor’s location or activity, as well as the proximity to other people or objects and devices [11].
Another approach is to try and “predict” the device’s location [12], a rather much easier task compared against the actual image content location depiction; the latter is efficiently handled in [13] by monitoring related patterns within a human photo-interested community and adjusting meaningful weights based on past experience and intuition. Thus, the significant distinction should be clearly noted at this point: Part of the research is directed to methods that focus on depicting the location where the actual image has been captured [12], whereas other ones try to depict the location of the actual content item [13,14]. This indistinctness may be resolved by considering additional characteristics or still image metadata; for instance, authors in [15] successfully point out that when two still images are captured in the same nearby geo-tagged location within a rather close time span, they are most likely referring to the same place.
A second group of works to be considered resolves the location of the content item by taking into account spatial metadata in the process. The obvious paradigm is to exploit location or human social information to extract meaningful contextual patterns. This functionality, called reasoning, may be aided by machine learning algorithms (like deep learning approaches) in order to be able to actually learn from previous operation and fine-tune the relative aspects and criteria of location-determining characteristics [16]. The field is prosperous to raise several research issues and a lot of research is conducted with respect to nearby sub-fields, e.g., context modeling, with the simplest, yet robust approach, being the utilization of a plain context model based on environment variables [17].
Last but not least, one should also consider in this survey part the process of building relationship models that define the spatial arrangement and distribution of objects of interest within an entire scene. Thus, acting also as a bridge to the next survey section and despite their efficiency limitations, we must also emphasize on works using high-level scene models for spatial context-based material detection, such as the one from [18]. Another effort is the one from [19], which introduces the rather novel configuration-based scene modeling way of tacking the problem at hand. Finally, a rather holistic approach to natural object classification that utilizes spatial context constraints to increase the accuracy of the initial classification by constraining the beliefs to conform to the spatial context models is introduced in [20]. All in all, following Table 2 provides a short indication of the discussed topological context efforts.
Despite their diversity, one may recognize common grounds within the above set of research efforts. Initially, a distinct set of four sub-groups may be identified, namely a sub-group dealing with spatial relations towards efficient image retrieval and localization [10,14,18,20], a sub-group utilizing geo-tagging information for various tasks [12,15,16], a sub-group modeling context and combining multiple (i.e., spatial, temporal and social) context types in the process [13,17,19], and, lastly, a group of survey papers in the field [11]. Still, similarities may also be identified, since, for instance, all three [17,18,20] utilize spatial contextual relations to achieve their distinct goals, whereas all four papers belonging to the first sub-group provide significant optimizations and increased accuracy within their results. In terms of modalities, the vast majority of research works [12,13,14,15,16,18,19,20] focus on static digital images, [10] focuses on cartographic objects, [17] focuses on web objects, whereas [11] deals solely with the mobile computing field. Quite interestingly, none of the above works utilizes video sequences, although one may claim that most of the static digital images methodologies will indeed match in the case of moving images, as well. Last but not least, a critical view on the above discussed works is their lack of updating, i.e., only a single work dates within the last five years [12], a fact that rings a bell with respect to the utilization and evolution of respective topological context research.
3.3. Scene Context
Within this aspect of visual context known in the literature as scene context the description of the entire scene is analyzed. It tackles traditional multimedia content analysis problems [21] by effectively combining both local and global information in the process. Most key research propositions, such as the ones based on color histograms and/or local texture statistics [22,23], lack the ability to capture a scene’s global configuration. In other words, typical object detection research efforts handle content items as primitive parts without taking into account any contextual information in the process [24,25,26], a technique that one may easily understand that distances itself from optimal [4]. Interestingly enough, some attempts have also been made in using scene classification to facilitate object detection, like the one depicted in [27]. A rather recent related research sub-field is the one of salient object detection; it has recently witnessed substantial progress due to powerful features extracted using deep convolutional neural networks [28]. Other approaches either unify the scene labeling approach, by utilizing context modeling and fusion techniques in the process [29], or tackle directly the semantic scene classification problem, by (semi-) automatically categorizing images into a discrete set of classes [30]. Table 3 summarizes briefly the above mentioned scene context efforts.
In the case of scene context, things are quite straightforward: Most approaches deals with visual object detection, constituting the utilization of this context type a must for the respective task. Still, three main sub-groups are to be identified herein. Works dealing with search and retrieval [21,22,23], and the ones dealing mostly with detection or even recognition of objects/concepts [24,25,26,27,28] clearly dominate the research sub-domain. The third sub-group is formed by the rest of the works as they deal with semantic labeling [29] or classification of scenes [30]. Apart from the obvious similarities/dissimilarities summarized within the above table, we may also point out the fact that the utilization of global/scene contextual information in the object detection task results into improved results, whereas this seems not be such a strong case in the case of the search and retrieval task. Quite interestingly, the latter approaches do not utilize well-known datasets to evaluate their findings, which might be the reason that justifies the previous remark. Finally, it becomes also apparent from the examination of all herein discussed research efforts that the exploitation of scene context forms a standalone computational task, which does not act in conjunction to other contextual types.
4. Context-Awareness
Context-awareness defines the ability of computing applications and systems to gather information about their environment at any given time and adapt their behaviors accordingly, i.e., provide services with full awareness of their current environment, which actually guides their responses. Thus, taking the scope of the current survey a step further from the traditional contextual interpretations of the past, we may agree that the current computing era is characterized by the ubiquity and popularity of “unconventional” computing environments, such as smartphones and/or tablets. These devices base a large chunk of their popularity and effectiveness in the combination of functionalities and mobility they offer. Effective use of available contextual information within such structures remains an open and challenging problem, although a categorization of context-aware applications according to subjective criteria has been tried out early enough [31], together with its complementary context modeling later on [32]. Taking into account numerous environmental parameters that influence the provision of desired services is widely recognized as one of the foundations of modern mobile and ubiquitous systems [33,34], but, of course, there is still room for improvements for both its quality evaluation, as well as several newly awaken concerns about information sharing and privacy issues. The latest boom phase of related context management leads to the appearance of infomobility systems that provide access to personalized information, routes, and services based on the user’s geographic location [35]; in this case context allows to find a route that satisfies user’s preferences and to adjust the route in real-time in case of user or environment situation changes.
Going back to the roots of context-aware applications’ classification the first works that encompassed context as information about each user’s location, environment, identity and time are considered to be [36,37]. In a historically successive manner, a broader interpretation of a four-fold context type was introduced in [38]. The latter included the four notions of location, identity, time and activity. Finally, a more recent effort to summarize the key aspects of context with respect to human-computer interaction is proposed in [39]. Since above interpretations were already closing on the semantically similar notion of pervasive computing, it was only a matter of time before a related research work would emerge [40]; in order to identify context, it acknowledges human activity and its inter-relationships, according to the devices used and/or the available resources. In [41] authors propose an approach that relies on ontologies to model specific knowledge aspects in a twofold approach that ultimately allowed for the modeling of both low- and high-level information. The cherry on the cake has been put by a recent survey on pervasive social context that concludes the field as it meets modern social networks [42].
Following the recent trends of informatics and in line with the vast amounts of data being exchanged within the emerged online social communities, the research sub-field of big data analytics emerged rapidly and provided updated information about contextual information, as well as its impact [43,44]. The ultimate research challenge in the field remains, of course, the efficient illustration of contextual information in such a manner that would allow for the merging of the gap between applications using contextual information and the deployment of context-aware services [45], keeping always in mind that efficient development of such applications, like the one dealing with spam detection [46], demands clearly defined models of context, as depicted in an extremely recent related research effort [47]. Table 4 summarizes the most representative context-aware approaches.
Due to its inherent nature, the sub-field of context-awareness allows for great diversity in the research works tackling it. They range from the ones dealing with computing applications and systems in general [31,33,34,37], to the ones focusing on context modeling [40,41,44], human-computer interaction [39], big and social data analytics [43,45,46,47], as well as survey papers [32,38,42]. Specific, targeted apps and systems, like infomobility [35] or archaeology [36], are also included herein. As apparent from the above table, it is quite common in almost all approaches not to handle a well-known dataset. This results into poor evaluation paradigms, especially in the computing applications and systems, as well as respective context modeling sub-groups. A clear trend over the most recent works is the one tackling data deriving in large quantities from social networks, where one is identify quite diverse contextual aspects ranging from structured, database-like representations to textual, NLP-based analytics. Lastly, the survey papers included herein provide an integrated overview of the particular context category: [38] is the oldest one and focuses on defining the notion of context-aware computing, [32] is the intermediate one and analyzes and compares available context-aware data models, whereas [42] is the most recent one dealing more with the modern human aspect of pervasive context, i.e., information that arises out of direct or indirect interaction with people carrying sensor-equipped pervasive devices.
5. Verbal Context
The verbal context category includes research approaches that deal with human-generated contextual elements. The most representative ones are past user queries and click-through information measuring the amount of times a page is clicked or the amount of times it’s been viewed but not clicked, i.e., the so called impression data. In one of the most recent attempts to model verbal context, authors in [48] propose a verbal context folksonomy graph coupled together with a ranking method; the latter is influenced by issued queries and extracted user profiles. An earlier idea on the subject was developed in [49,50], where the Open Directory Project (DMOZ) categories have been exploited in order to represent contextual information of web pages, focusing on five specific items, namely: Interaction-, collection-, task-, historic-, and social-related sources. Around the same time period, other researchers proposed a context-aware query suggestion model [51] using click-through and session data. Their main novelty and differentiation against other related similar efforts, like [52], is the fact that they group similar queries into concepts and therefore utilize sequences of concepts as their contextual information model. Still, authors of [52] utilize a novel combination of related contextual information, in terms of document-clicks and user sessions, to cluster the refinements of a user search query, so as to improve the selection and placement of potential query suggestions proposed by a search engine.
Being a prosperous research field, verbal context analysis and modeling led to the arising of works that proved it is beneficial to other important—and at the same time considered as traditional—information retrieval tasks, like, for instance, the actual query segmentation according to human interests. In [53], authors proposed using user query sequences in sessions for the tasks of sequence classification, labeling, prediction, and similarity; verbal context is used in the sense of recent user history exploitation. In another attempt to bridge verbal context with the important sub-domain of semantics, some pioneer works in the field [54] considered context using ontological terms and semantic relationships. In particular, the authors proposed the notion of semantic runtime context, which they defined as the background topics under which activities of a user occur within a given unit of time in a recommender system; the latter is represented by a set of weighted concepts from domain ontologies, obtained by collecting the concepts that have been involved in users’ actions (e.g., accessed items) during a user session, and is linked to user preferences through identified existing relations between concepts in the utilized ontologies. However, we must also not forget that researchers deriving from the linguistic, rather than the computer science, community attempted also to analyze this type of contextual information with great success; in [55] authors focused on the textual level and successfully analyzed different writing conventions of Twitter micro-texts imposed by humans. Although the discussed approach was based only on statistical processing of acquired corpus and the notion of context utilized focused solely on—mostly environmental—user influences before posting, it formed an innovative methodology for contextualized analysis of lexical transformations in microtext social media data. All in all, verbal context remains nowadays an active research field with several open challenges. As a result following Table 5 provides only a short overview of the discussed verbal context research efforts by categorizing them according to their context type incorporated, illustrates their advantages and disadvantages and reasons on their suitability within the broader research field.
In the verbal context case, research works vary with respect to their focus. Again, context modeling is evident in [48], but there also works focusing solely on the linguistic aspect of verbal context, as well [55]. The interesting topic of efficiently predicting or even expanding user interests and preferences is enabled by respective contextual approaches in [49,50,54]. Traditional personalization tasks, like query suggestion and processing are also benefited from this context category [51,52,53]. An attention-grabbing observation is the fact that within the latter sub-group are utilized quite distinctive approaches to grasp pretty much the same contextual notion: The first one analyzes large-scale search logs of a commercial search engine, the second one utilizes clustering as its main means of verification and the third one exploits a vocabulary-based approach incorporating local and global features in the process. In terms of modalities, focus has been clearly shifted away from multimedia (i.e., still or moving images) and various forms of text dominate the contextual category domain (e.g., plain text, logs, microtexts, etc.). Finally, utilization of well-known large datasets is prevailing in this case, as it is empowered by the utilization and computational processing of typically low complexity and size textual data.
6. Short Discussion and Conclusions
Bothered by the diverse notion of context for over a decade now, in this work we decided to follow a somehow broad approach. The goal of this brief survey was to provide an overview of several, yet distinct, fields of informatics heavily “affected” by contextual information, instead of focusing on a single application sub-domain. On the one hand, this decision is justified by the fact that typically a survey paper should be broad enough to present a variety of interesting research topics, so as for them to lead to more future research opportunities, and on the other hand, it was partially driven by the popularity of the herein discussed approaches: The current proliferation of digital multimedia-related apps and systems, either in terms of user-generated content, or third-party/professionally produced content, constitutes a visual context discussion a necessity, ubiquitous computing and new human-computer interaction interfaces impose context-awareness, whereas the brave new social media/networks world demands a consideration of verbal context.
One apparent finding of the survey is that lately there is an ongoing focus shift from raw multimedia-related apps and research to more complicated/higher level ones that typically combine multimedia and metadata (e.g., travel route planning). This trend clearly inputs new dimensions to context modeling and context management, since it elevates the significance and role of context handling in both the development and user base acquisition phases of apps. Furthermore, as it is almost always the case with context, apart from being part of the broad informatics family, one may not identify a unique, unified context theme across contextual-based research works. The latter forms a fact that motivates researchers to keep dealing with tasks, such as context modeling, analysis, exploitation, etc. regardless of their practical utilization.
Following this observation, we initiated this survey by discussing some relevant research structures and techniques for representing and exploiting visual contextual information; the latter are nowadays considered to be compulsory preconditions for the smooth operability of any multimedia content analysis task. We also observed why fundamental aspects of contextual information, like visual context, might be particularly supportive in knowledge extraction and management tasks, principally when tackling traditional multimedia analysis problems closely related to aspects of content processing, like scene classification and object detection. Combined with the aforementioned focus shift, if we were to identify room for future research with respect to visual context, this would go in the direction of cognition, hand in hand with recent artificial intelligence advances, and would focus on the way the human brain analyzes associations between visual objects and their specific context, since objects in our human environment tend to be grouped according to (our) visual context. We may also not neglect the exploitation of visual context in cases of multimedia search attempts (e.g., in the sense defined by the Google Images (https://www.google.gr/imghp) or VIRaL (http://viral.image.ntua.gr/) approaches), in conjunction with topological context (location-based) services, proximity search algorithms (e.g., closest pattern matching) and other deep learning implementations. One of the main challenges identified by the works tackling this pillar would be to exploit contextual information towards optimizing the algorithmic search retrieval results, taking into account the potential introduced by deep learning software and hardware facilities, such as convolutional neural networks and the first personal supercomputers available for leading-edge AI development.
In the human-computer interaction domain, the superficial, tabular analysis of the characteristics of the herein included research works allows us to draw two main conclusions. First, the complexity of the context-modeling problem in the context-aware applications field varies significantly depending on the application’s target group. Second, the massive amount of different applications and systems, leads to various context information models, almost each one suitable for the particular service. As rather obvious from the above, a unique interpretation is still not possible and exploitation of contextual information remains in this informatics sub-field at the discretion of each researcher, thus hindering the overall process and imposing challenging research tasks for interested researchers.
Verbal context forms the most quantifiable research path, since it typically tackles measurable factors, such as user queries or click-through (meta-)data. The tangible nature of the latter leads to more solid context modeling and processing approaches, most of which rely on formal knowledge representations (as also depicted in the corresponding table). Of course, new innovative contextual information representations and models are also encouraged. In addition, the exploitation of social media and networks is expected to aid researchers in the field and we honestly expect the contextual aspect of informatics associated to social interactions of users within the digital social space to blossom in the near future. We are confident that the popularity of related apps and systems will support our finding and as a result verbal context will form an important and promising research direction with open future research challenges.
In a further attempt to identify the similarities and differences among the three types of context presented in the previous sections, we may start from a rather obvious remark: Being the ones that initially founded the notion of context in informatics, the three long-established visual context aspects form a basic level of contextual information handling and may be used in all other hardware or software implementations of computer systems and applications. Their fundamental interpretation allows for exploitation of enhanced characteristics in apps and systems, that otherwise would not have been possible. They have also set the roots of context information management for all three herein discussed aspects, in the sense that they have made researchers seek additional information sources when dealing with particular problems irrespective of their nature, because the latter would allow them to solve their problems more efficiently. In other words, the influence of contextual info in solving particular research tasks remains important even if one tackles the low-level visual domain, environmental parameters or social/verbal aspects. In addition, the fundamental principle of all three context-based approaches is that context allows for computer science applications to be used as the starting point for the development of related scientific ideas, a fact that at a first glance contrasts conventional or traditional approaches that typically cover scientific ideas first, before looking at applications. Finally, they do share affective, behavioral and cognitive aims, which encompass a number of objectives, such as to broaden the appeal of informatics by illustrating how it relates to people’s lives, to develop effective understanding of research ideas, and to engage and motivate fellow researchers in the field.
Still, it is also clear that the herein discussed context variations have also identifiable differences. Verbal context forms a rather high-level interpretation and normally is not based on solid, quantifiable features, like for instance a color histogram or a set of spatial relations in the case of visual or context-aware aspects; its main features are based on semantics and machine learning tasks. In addition, the focus of verbal context is on the human aspect and each individual’s mental activity and social circumstances, whereas visual context or context-aware applications focus on the computational system, the application or even the algorithmic aspect of software. This apparent difference is also the one that in our opinion distinguishes the ongoing and increasing influence of verbal context over the recent years, as we move from an era where computation itself was the important aspect to the one that data and information are on the epicenter. Thus, one may claim visual context-based and context-aware computing targeted the optimization of the machine, whereas verbal context targets the human interaction with the machine. A further distinction between visual context and its context-aware successor type is the fact that the first one typically deals with static computing environments that did not change much over their course and there was little variance in the situations surrounding them. Hence, there was no need for related research approaches to adapt to different environments, which fundamentally lies to the opposite site of context-aware computing.
Finally, one should also take into account not only the researchers’, but also the developers’ point of view on the matter. Developers are encouraged to take this survey’s observations with respect to context into account, but at the same time they would need to do so without sacrificing the required usability or without increasing the related computational complexity of their applications in the process. In other words, one should follow a “make it context-aware, but make it simple” approach. Context has been around informatics for quite a long time now, it keeps evolving together with the different aspects of the latter and all researchers agree that it is here to help, not to hinder, related information and knowledge processing and analysis tasks. Under this perception it is also common to utilize multiple context models that suit user requirements and needs according to the problem at hand, whereas extensions of existing models are acceptable, but not favored in the community, due to their specificity. All these remarks are considered to be crucial for enabling sufficient and innovative contextual information distribution in wide-area, real-life deployments, both within current and future informatics’ applications and systems. And as a last conclusion of this survey, the lesson learned from reviewing the selected three pillars of informatics herein is the following: On the first look, contextual information might present itself as a vague, peculiar concept; however, if tackled with care, context might be a powerful tool, taking numerous forms and expressions, that will allow fellow researchers to efficiently utilize it to the benefit of information processing in modern informatics.
Acknowledgments
The financial support by the European Union and Greece (Partnership Agreement for the Development Framework 2014–2020) under the Regional Operational Programme Ionian Islands 2014–2020, for the project “Smart vine variety selection & management using ICT—EYOINOS” is gratefully acknowledged.
Conflicts of Interest
The author declares no conflict of interest.
References
- Liu, C.; Song, G. A method of measuring the semantic gap in image retrieval: Using the information theory. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing (IASP), Wuhan, China, 21–23 October 2011; pp. 287–291. [Google Scholar]
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-Based Image Retrieval at the End of the Early Years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Mylonas, P. An overview of context types within multimedia and social computing. In Proceedings of the 4th Mining Humanistic Data Workshop (MHDW 2015) in Conjunction with 16th EANN Conference, Rhodes, Greece, 25–28 September 2015. [Google Scholar]
- Mylonas, P. Understanding How Visual Context Influences Multimedia Content Analysis Problems. In Artificial Intelligence: Theories and Applications, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7297, pp. 361–368. [Google Scholar]
- Wang, Y.; Liu, Z.; Huang, J.-C. Multimedia content analysis using both audio and visual clues. IEEE Signal Process. Mag. 2000, 17, 12–36. [Google Scholar] [CrossRef]
- Naphade, M.; Huang, T.S. A factor graph framework for semantic indexing and retrieval in video. In Proceedings of the CVPR Workshop on Content-Based Image and Video Retrieval, Hilton Head Island, SC, USA, 12 June 2000. [Google Scholar]
- Saber, E.; Tekalp, A.M.; Eschbach, R.; Knox, K. Automatic image annotation using adaptive color classification. CVGIP: Graph. Model. Image Process. 1996, 58, 115–126. [Google Scholar] [CrossRef]
- Smith, J.; Li, C.-S. Decoding image semantics using composite region templates. In Proceedings of the IEEE International Workshop on Content-Based Access of Image & Video Database, Santa Barbara, CA, USA, 21 June 1998. [Google Scholar]
- Vailaya, A.; Jain, A.K. Detecting sky and vegetation in outdoor images. In Storage and Retrieval for Media Databases 2000; International Society for Optics and Photonics: Bellingham, WA, USA, 1999; Volume 3972, pp. 411–421. [Google Scholar]
- Mustière, S.; Moulin, B. What is spatial context in cartographic generalisation? In Proceedings of the Symposium on Geospatial Theory, Processing and Applications, Ottawa, ON, Canada, 9–12 July 2002.
- Guanling, C.; Kotz, D. A Survey of Context-Aware Mobile Computing Research; Dartmouth Computer Science Technical Report TR2000-381; Dartmouth College: Hanover, NH, USA, 2000. [Google Scholar]
- Kumar, J.; Devi, B.R. Inferring Location from Geotagged Photos. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 902–906. [Google Scholar]
- Davis, M.; King, S.; Good, N.; Sarvas, R. From context to content: Leveraging context to infer media metadata. In Proceedings of the 12th annual ACM international Conference on Multimedia (MULTIMEDIA ’04), New York, NY, USA, 10–16 October 2004; pp. 188–195. [Google Scholar]
- Kalantidis, Y.; Tolias, G.; Avrithis, Y.; Phinikettos, M.; Spyrou, E.; Mylonas, P.; Kollias, S. VIRaL: Visual Image Retrieval and Localization. Multimedia Tools Appl. 2011, 51, 555–592. [Google Scholar] [CrossRef]
- Rost, M.; Cramer, H.; Holmquist, L.E. Mobile Exploration of Geo-tagged Photos. Pers. Ubiquitous Comput. 2012, 16, 665–676. [Google Scholar] [CrossRef]
- Toyama, K.; Logan, R.; Roseway, A. Geographic Location Tags on Digital Images. In Proceedings of the 11th Annual ACM International Conference on Multimedia (MM2003), Berkeley, CA, USA, 2–8 November 2003; ACM Press: New York, NY, USA, 2003; pp. 156–166. [Google Scholar]
- Kindberg, T.; Barton, J.; Morgan, J.; Becker, G.; Caswell, D.; Debaty, P.; Gopal, G.; Frid, M.; Krishnan, V.; Morris, H.; et al. People, Places, Things: Web Presence for the Real World. Mob. Netw. Appl. 2002, 7, 365–376. [Google Scholar] [CrossRef]
- Singhal, A.; Luo, L.; Zhu, W. Probabilistic spatial context models for scene content understanding. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’03), IEEE Computer Society, Washington, DC, USA, 18–20 June 2003; pp. 235–241. [Google Scholar]
- Lipson, P.; Grimson, E.; Sinha, P. Configuration based scene classification and image indexing. In Proceedings of the IEEE International Conference on Computer Vision & Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Luo, J.; Singhal, A.; Zhu, W. Natural object detection in outdoor scenes based on probabilistic spatial context models. In Proceedings of the International Conference on Multimedia and Expo (ICME 2003), Baltimore, MD, USA, 6–9 July 2003. [Google Scholar]
- Pereira, E.; Castelhano, M. On-Line Contributions of Peripheral Information to Visual Search in Scenes: Further Explorations of Object Content and Scene Context. J. Vis. 2012, 12, 740. [Google Scholar] [CrossRef]
- Ashley, J.; Flickner, M.; Lee, D.; Niblack, W.; Petkovic, D. Query by Image Content and Its Applications; IBM Research Report, RJ 9947 (87906); IBM Academy of Technology: Armonk, NY, USA, 1995. [Google Scholar]
- Smith, J.; Chang, S. Local color and texture extraction and spatial query. In Proceedings of the IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996. [Google Scholar]
- Viola, P.; Jones, M. Robust real-time object detection. Int. J. Comput. Vis. 2002, 57, 137–154. [Google Scholar] [CrossRef]
- Papageorgiou, C.; Poggio, T. A trainable system for object detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Torralba, A.; Sinha, P. Detecting Faces in Impoverished Images; Technical Report 028; MIT AI Lab: Cambridge, MA, USA, 2001. [Google Scholar]
- Murphy, K.; Torralba, A.; Freeman, B. Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes. In Proceedings of the NIPS’ 03, Vancouver, BC, Canada, 8–13 December 2003. [Google Scholar]
- Li, G.; Yu, Y. Deep Contrast Learning for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, Z.; Gan, Y.; Liang, X.; Yu, Y.; Cheng, H.; Lin, L. LSTM-CF: Unifying Context Modeling and Fusion with LSTMs for RGB-D Scene Labeling. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Boutell, M. Exploiting Context for Semantic Scene Classification. Ph.D. Thesis, University of Rochester, Rochester, NY, USA, 2006. [Google Scholar]
- Schilit, B.; Adams, N.; Want, R. Context-Aware Computing Applications. In Proceedings of the IEEE Workshop on Mobile Computing Systems and Applications, Santa Cruz, CA, USA, 8–9 December 1994. [Google Scholar]
- Bolchini, C.; Curino, C.A.; Quintarelli, E.; Schreiber, F.A.; Tanca, L. A Data-oriented Survey of Context Models. SIGMOD Rec. 2007, 36, 19–26. [Google Scholar] [CrossRef]
- Bolchini, C.; Curino, C.A.; Orsi, G.; Quintarelli, E.; Rossato, R.; Schreiber, F.A.; Tanca, L. And What Can Context do for Data? Commun. ACM 2009, 52, 136–140. [Google Scholar] [CrossRef]
- Jones, Q.; Grandhi, S.A. P3 systems: Putting the place back into social networks. IEEE Internet Comput. 2005, 9, 38–46. [Google Scholar] [CrossRef]
- Smirnov, A.; Teslya, N.; Shilov, N.; Kashevnik, A. Context-Based Trip Planning in Infomobility System for Public Transport. In Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI’16); Abraham, A., Kovalev, S., Tarassov, V., Snášel, V., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2016; Volume 450. [Google Scholar]
- Ryan, N.; Pascoe, J.; Morse, D. Enhanced Reality Fieldwork: The Context-Aware Archaeological Assistant. In Computer Applications in Archaeology; Gaffney, V., van Leusen, M., Exxon, S., Eds.; Tempus Reparatum: Oxford, UK, 1997. [Google Scholar]
- Ward, A.; Jones, A.; Hopper, A. A new location technique for the active office. Pers. Commun. 1997, 4, 42–47. [Google Scholar] [CrossRef]
- Abowd, G.; Dey, A.K.; Brown, P.J.; Davies, N.; Smith, M.; Steggles, P. Towards a better understanding of context and context-awareness. In Proceedings of the 1st International Symposium on Handheld and Ubiquitous Computing (HUC ’99), Karlsruhe, Germany, 27–29 September 1999; Gellersen, H.-W., Ed.; Springer: London, UK, 1999; pp. 304–307. [Google Scholar]
- Duric, Z.; Gray, W.D.; Heishman, R.; Li, F.; Rosenfeld, A.; Schoelles, M.J.; Schunn, C.; Wechsler, H. Integrating perceptual and cognitive modeling for adaptive and intelligent human-computer interaction. Proc. IEEE 2002, 90, 1272–1289. [Google Scholar] [CrossRef]
- Henricksen, K.; Indulska, J.; Rakotonirainy, A. Modeling context information in pervasive computing systems. In Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2002; pp. 167–180. [Google Scholar]
- Gu, T.; Wang, X.H.; Pung, H.K.; Zhang, D.Q. An ontology-based context model in intelligent environments. In Proceedings of the Communication Networks and Distributed Systems Modeling and Simulation Conference, San Diego, CA, USA, 18–24 January 2004; pp. 270–275. [Google Scholar]
- Schuster, D.; Rosi, A.; Mamei, M.; Springer, T.; Endler, M.; Zambonelli, F. Pervasive social context: Taxonomy and survey. ACM Trans. Intell. Syst. Technol. 2013, 4, 46. [Google Scholar] [CrossRef]
- Lin, J.; Ryaboy, D. Scaling big data mining infrastructure: The twitter experience. SIGKDD Explor. Newsl. 2013, 14, 6–19. [Google Scholar] [CrossRef]
- Lemen, C. The new knowledge processing: Integrating semantic web with web 2.0. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM), Taiyuan, China, 22–24 October 2010; Volume 2, pp. 314–317. [Google Scholar]
- Chen, H.; Chiang, R.H.L.; Storey, V.C. Business Intelligence and Analytics: From Big Data to Big Impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar]
- Brown, G.; Howe, T.; Ihbe, M.; Prakash, A.; Borders, K. Social Networks and Context-Aware Spam. In Proceedings of the CSCW’08, San Diego, CA, USA, 8–12 November 2008. [Google Scholar]
- Anagnostopoulos, I.; Zeadally, S.; Exposito, E. Handling big data: Research challenges and future directions. J. Supercomput. 2016, 72, 1494–1516. [Google Scholar] [CrossRef]
- Xie, H.; Li, X.; Wang, T.; Chen, L.; Li, K.; Wang, F.L.; Cai, Y.; Li, Q.; Min, H. Personalized search for social media via dominating verbal context. Neurocomputing 2016, 172, 27–37. [Google Scholar] [CrossRef]
- White, R.; Bailey, P.; Chen, L. Predicting user interests from contextual information. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; ACM: New York, NY, USA, 2009; pp. 363–370. [Google Scholar]
- White, R.; Bennett, P.; Dumais, S. Predicting short-term interests using activity-based search context. In Proceedings of the 19th International Conference on Information and Knowledge Management (CIKM’10), Toronto, ON, Canada, 26–30 October 2010; pp. 1009–1018. [Google Scholar]
- Liao, Z.; Jiang, D.; Chen, E.; Pei, J.; Cao, H.; Li, H. Mining concept sequences from large-scale search logs for context-aware query suggestion. ACM Trans. Intell. Syst. Technol. 2011, 3, 17. [Google Scholar] [CrossRef]
- Sadikov, E.; Madhavan, J.; Wang, L.; Halevy, A. Clustering query refinements by user intent. In Proceedings of the International World Wide Web Conference (WWW’10), Raleigh, NC, USA, 26–30 April 2010; pp. 841–850. [Google Scholar]
- Mei, Q.; Klinkner, K.; Kumar, R.; Tomkins, A. An analysis framework for search sequences. In Proceedings of the 18th ACM Conference on Information and Knowledge Management (CIKM’09), Hong Kong, China, 2–6 November 2009; pp. 1991–1996. [Google Scholar]
- Cantador, I.; Castells, P. Semantic contextualization in a news recommender system. In Proceedings of the 1st International Workshop on Context-Aware Recommender Systems, New York, NY, USA, 22–25 October 2009. [Google Scholar]
- Gouws, S.; Metzler, D.; Cai, C.; Hovy, E. Contextual Bearing on Linguistic Variation in Social Media. In Proceedings of the Workshop on Language in Social Media (LSM 2011), Portland, OR, USA, 23 June 2011; pp. 20–29. [Google Scholar]
Figure 1.
Word cloud produced by the 187 unique keywords of the 50 herein discussed papers (Created with https://wordart.com/create/ public web service).
Figure 1.
Word cloud produced by the 187 unique keywords of the 50 herein discussed papers (Created with https://wordart.com/create/ public web service).

Figure 2.
Diagrammatic scheme of identified contextual types.

{kind=link}
{kind=link}
Table 1.
Low-level visual context approaches.
| Work | Task(s) | Method | Pros | Cons | Dataset |
|---|---|---|---|---|---|
| [6] | semantic indexing and retrieval of videos | network of semantic objects | novel factor graph semantic modeling | not considering scene context | 8 movies, 1800 training frames, 9400 testing frames |
| [7] | automatic annotation and natural object detection | supervised color classification | simplicity of approach, easy to scale | not considering scene context, small dataset | 31 annotated images |
| [8] | content-based image retrieval | spatial arrangement through composite color region templates | retrieval effectiveness | not considering scene context, limited dataset | 893 (357 + 536) photographs, 10 semantic classes, 3 image queries |
| [9] | sub-block classification in outdoor scenes | combination of color and texture features | context orientation information utilization | not considering scene context | -- |
Table 2.
Topological context approaches.
| Work | Task(s) | Method | Pros | Cons | Dataset |
|---|---|---|---|---|---|
| [10] | study of context representation in the cartographic generalization process | 3 types of context relations (group, area, surrounding objects) | proposed novel context relations | limited application field, focus only on cartography | -- |
| [11] | context-aware computing survey | list-based approach, focus on wireless characteristics | in-depth contextual types analysis and modeling | limited impact , focus on mobile computing, heavily outdated | -- |
| [12] | photo annotation utilization for location inference | location probability maps for tag annotations | algorithmic interpretation was packaged into an integrated system | no exploitation of tags’ context | 1 M geotagged photos |
| [13] | infer location information for digital photos | use spatial, temporal & social context to generate photo metadata | combination of 3 context types, integrated system | minimal subjective evaluation (55 persons) | -- |
| [14] | visual image retrieval and localization | visual and textual context similarity | fast, reliable approach, pioneer work | only basic textual context exploitation, outdated | 2 M geotagged images |
| [15] | mobile app utilizing geotagged photos | emphasis on contextual familiarity | novel approach, familiar/unfamiliar places distinction | primitive context exploitation, no real evaluation, focused on mobiles | -- |
| [16] | capitalization on geo-location metadata of digital images | web-based geo-coded image sharing | spatial context exploitation, context map visualization | post-capture, only spatial context type utilization | World Wide Media eXchange (WWMX) |
| [17] | topological context modeling | a web-based context model | novel unstructured context model | informal context model, outdated | -- |
| [18] | spatial context modeling | scene content understanding | increased accuracy of initial classification, reduced misclassifications | narrow application level | -- |
| [19] | spatial context modeling | configuration based scene modeling | utilization of qualitative & photometric object relations in a spatial sense | quite outdated | -- |
| [20] | spatial context-aware object-detection | combination of object detectors with spatial context | improved accuracy of natural object detection | narrow field of application, poor performance of natural object detectors | 780 images containing at least 2 object types |
Table 3.
Scene context approaches.
| Work | Task(s) | Method | Pros | Cons | Dataset |
|---|---|---|---|---|---|
| [21] | study on multimedia search strategies | combination of local (object) & global (scene) context | novel approach (examination of search strategies) | narrow field of application | -- |
| [22] | image retrieval from large databases using image contents | utilization of color, texture, shape and layout characteristics | pioneer work, early contextual cues exploit for efficient information retrieval | nominal contextual information utilization | -- |
| [23] | color and texture region extraction from images | extraction, representation and query of spatially localized regions | pioneer novel binary region representation that allowed easy indexing | utilization only of spatial contextual information | -- |
| [24] | visual object detection in images | novel image representation, visual features selection, classifier combination | quick approach, high detection rate | marginal context exploitation in the sense of feature selection | real-world dataset of 130 images |
| [25] | visual object detection for static images | novel (Haar wavelets) object class representation | good results shown for face, people, and car detection | very basic spatial context exploitation | 5,335,982 training patterns |
| [26] | visual face detection | influence of luminance contrast, image orientation & local context | local context exploitation for face detection | poor subjective evaluation | 10 human subjects |
| [27] | visual object detection, global scene recognition | utilization of scene context in the detection process | combination of global and local image features, novel utilization of scene context | very basic evaluation, no utilization of well-known datasets | 13 filters, 30 spatial templates |
| [28] | identification of the most visually distinctive parts in images (salient object detection) | utilization of convolutional neural networks | contextual features exploitation in 4 different scales, performance of proposed method | focus solely on spatial coherence, no implication of other contextual types | 5 public datasets: MSRA-B, PASCAL-S, DUTOMRON, HKU-IS, SOD |
| [29] | semantic scene labeling of images | introduction of long & short-term memorized contextual fusion model | fused contextual representation from multiple sources (depth & photometric data) | performance issues with respect to boundary labeling | 37 categories, large-scale public datasets: SUNRGBD (10,355 images, including NYUDv2 & SUN3D |
| [30] | semantic scene classification | exploitation of 3 contextual types: spatial, temporal, and image capture condition | developed graphical context models | limitations on utilization of each context type | several real-life datasets |
Table 4.
Context-awareness approaches.
| Work | Task(s) | Method | Pros | Cons | Dataset |
|---|---|---|---|---|---|
| [31] | study systems that examine and react to an individual’s changing context | define context-aware computing, describe 4 categories of context-aware applications | definition of 4 context-aware applications, introduction of a prototype | no real evaluation of proposed model | -- |
| [32] | context-awareness modeling with respect to data tailoring | survey on context modeling approaches | context model features and systems comparison | outdated work, context model bounded to a single target application | -- |
| [33] | reduce information overload of large-scale information systems | context-guided data tailoring methodology | introduction of the Context Dimension Tree (CDT) model | no real evaluation of proposed model | example of 1400 contexts |
| [34] | geographically contextualized personal information exploitation | link people-to-people-to-geographical-places (P3 system) | geotemporal social matching based on contextual information | sharing information & privacy concerns | 14 place types, 500+ respondents |
| [35] | contextual trip planning using public transport network | context management and weighting of graph dynamic edges | applied evaluation on real-life dataset | -- | 6.962 public transport stops, 965 routes, 19.773 multigraph edges |
| [36] | context-aware tools for fieldwork data processing in archaeology and other environmental sciences | generalized context view to cover physical and logical attributes of the user’s environment for field applications | perception of context as metadata, development of a pilot application | extremely limited application domain, did not conduct field trials | -- |
| [37] | context-aware location identification for indoor environments | sensor-based ultrasonic system for location-aware computing | efficient object location and orientation determination | no real evaluation of proposed methodology | -- |
| [38] | context-aware computing study | context-aware computing definition, identification of 3 related behaviors | early attempt to define context-aware computing | superficial discussion with no real impact on research community | -- |
| [39] | intelligent Human-Computer Interaction (HCI) | proposition of a 4-stage context adaptive and intelligent HCI framework | rich behavioral interactions, nonverbal information, utilization of cognition model, computer interface adaptation | methodology has not been implemented in a running system, lack of evaluation | -- |
| [40] | development of appropriate context modeling concepts for pervasive computing | proposition of a particular context model suitable for pervasive computing | generic enough to capture arbitrary types of contextual information | no evaluation or proof of concept for the proposed model | -- |
| [41] | semantic context representation, context reasoning & knowledge sharing | a formal context model based on OWL ontologies | integrated system, formal and extensible context model | implementation of prototype under construction | -- |
| [42] | pervasive social computing | provide taxonomy to classify pervasive social context along 4 dimensions (space, time, people, information source) | answers 5 WH (who, what, where, when, why) questions with regard to pervasive social context. | -- | -- |
| [43] | data mining on “big data” from social media | “big data” mining cycle, user behavior monitoring, Twitter case study | contributions to building and running big data analytics infrastructure | minor contextual information impact within the discussed approach | -- |
| [44] | organizational knowledge management, knowledge processing models | a 5-layered knowledge processing framework integrating Semantic Web with Web 2.0 | comparative analysis of relationships between Semantic Web and Web2.0 | no evaluation | -- |
| [45] | business intelligence and analytics (BI&A) | a report on different types of BI&A-related context-awareness | mapping of important contextual facets of BI&A knowledge | Mostly business- than research-oriented | -- |
| [46] | context-aware e-mail spam within modern social networks | context-aware e-mail analysis on Facebook to identify potential spamming | novel context-aware classification of spam into 3 types | limited, Facebook-only application domain | 7000+ randomly accessed Facebook profiles |
| [47] | big data analytics with respect to the 4 Vs (volume, velocity, variety, veracity) | discussion on big data proliferation drivers & the main platforms that satisfy their 4V characteristics | detailed classification of big data challenges, recent work | -- | -- |
Table 5.
Verbal context approaches.
| Work | Task(s) | Method | Pros | Cons | Dataset |
|---|---|---|---|---|---|
| [48] | verbal context model overview | verbal context graph | folksonomy, mathematical notation, comparison against baselines | -- | Movielens (10.681 movies) |
| [49] | user interest modeling | study of 5 context sources | novel association between context types and time | study conducted solely on logs | -- |
| [50] | users’ search interests prediction | activity-based context study | combination of 3 context types (queries, clicks, web-page visits) | proposed model’s simplicity | -- |
| [51] | query suggestion | context-aware query suggestion model | mining latent concept patterns | -- | 3.957 M queries, 5.918 M clicks, 1.872 M query sessions |
| [52] | refinement of user search queries | contextual query clustering to improve query suggestions | novel combination of contextual info (document-clicks & user sessions) | treatment of ambiguous queries | 6 months of Google.com search query logs |
| [53] | study user query sequences | user behavior capture framework (vocabulary, features, baselines) | detailed evaluation, utilization of local & global features | narrow application domain (search sequences) | 1.2 M queries & 17.355 queries |
| [54] | study of context in a recommender system | semantic interpretation, ontological terms, semantic relations | evaluation, novel notion of semantic runtime context | semantic ambiguities problems | 17 ontologies, 137.254 Wikipedia entries |
| [55] | study of microtexts’ linguistic variation | investigation of lexical transformations properties from Twitter posts & news articles | novel methodology for contextualized analysis of lexical transformations | poor empirical evaluation, solely statistical processing | 1 M Twitter posts |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mylonas, P. The Evolution of Contextual Information Processing in Informatics. Information 2018, 9, 47. https://doi.org/10.3390/info9030047
AMA Style
Mylonas P. The Evolution of Contextual Information Processing in Informatics. Information. 2018; 9(3):47. https://doi.org/10.3390/info9030047
Chicago/Turabian StyleMylonas, Phivos. 2018. "The Evolution of Contextual Information Processing in Informatics" Information 9, no. 3: 47. https://doi.org/10.3390/info9030047
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.