2.1. Prediction Model for Diabetes and Hypertension
Diabetes has turned into a worldwide pandemic that puts a grave load on healthcare systems, particularly in developing countries [
4]. On a global stage, the total number of diabetic patients is estimated to increase from 171 million to 366 million in 2000 and 2030, respectively [
39]. T2D is an advanced stage in which the body becomes stiff to normal effects of insulin and slowly loses the capacity to generate enough insulin in the pancreas. It is necessary for persons ≥45 years, with a BMI ≥25 kg/m
2, to experience screening to detect pre-diabetes and diabetes [
2]. Furthermore, hypertension, which is usually referred as systolic blood pressure ≥140 mmHg and diastolic blood pressure ≥90 mmHg, is a normal long-term disease that presently impacts 77 million Americans [
40,
41,
42]. It is a noteworthy risk element for the lethal cardiovascular diseases, developing heart failure in 91% of cases; it is present in 69% of persons who suffer their first heart attack and in 77% of those having their first stroke [
41]. Past studies have shown firm positive relationships among blood pressure, danger of cardiovascular diseases, and mortality [
43,
44]. Together, hypertension and diabetes are stroke risk factors, but they can be avoided if individuals take a healthy diet as well as physical exercise every day [
45]. Therefore, in the future, a prediction model that notifies people on the chance of diabetes and hypertension is required, and it would permit them to take preemptive action. The machine learning algorithms can be used to diagnose diabetes and hypertension that is based on the present condition of patients.
Several studies have shown a positive impact of the application of machine learning for diabetes classification. Patil et al. proposed HPM for T2D [
13]. The proposed model consists of a K-means algorithm to remove incorrectly classified instance and C4.5 to classify the diabetes dataset. The Pima Indian dataset and k-fold cross-validation are utilized. The result revealed that the HPM showed the highest accuracy, as high as 92.38%, among other methods. Wu et al. utilized an HPM for predicting T2D [
14]. The model consists of an improved K-means and the logistic regression model. The improved K-means algorithm was used to confiscate incorrect clustered data, later the logistic regression algorithm was used to classify the remaining data. The findings indicated that the proposed model demonstrated greater prediction accuracy as compared with past work. Previous literature compared the performance of logistic regression, artificial neural networks (ANNs), and decision tree models for anticipating diabetes or prediabetes employing common risk factors [
15]. The dataset was gathered from Guangzhou, China, and 735 patients were validated as having diabetes or prediabetes, while 752 were normal controls. The findings indicated that the greatest classification accuracy as compared to other model is shown by decision tree model C5.0. Finally, past literature proposed a machine learning model to predict the prevalence of diabetes and hypertension, with a dataset having 13,647,408 medical records for diverse ethnicities in Kuwait [
16]. The classification models, for example, logistic regression, K-Nearest Neighbors (KNN), Multi-factor Dimensionality Reduction (MDR), and Support Vector Machines (SVM), were used and indicated noteworthy finding on predicting diabetes and hypertension. Besides, the study inferred that ethnicity is a critical ingredient for anticipating diabetes.
Furthermore, several studies have been conducted and revealed that the machine learning algorithms provide early prediction as well as treatment for hypertension. Koren et al. investigated the advantage of machine learning for treatment of hypertension [
17]. They used machine learning methods to distinguish determinants that add to the accomplishment of hypertension drug treatment on a massive set of patients. The result showed that a fully connected neural network could achieve AUC as much as 0.82. The result of their study showed that machine learning algorithms can provide the hypertension treatment with combinations of three or four medications. Tayefi et al. built up a decision tree model to distinguish the risk factors that are related to hypertension [
18]. A dataset comprising of 9078 subjects was part to 70% as training set and 30% as the testing dataset to assess the performance of the decision tree. Two models are proposed based on different risk factors. The result showed that the accuracy of the decision tree for both models could be as much as 73% and 70%, respectively. The finding is assumed to distinguish the risk factors that are related to hypertension that may be utilized to create programs for hypertension management. Finally, Golino et al. presented the Classification and Regression Tree (CART) to predict hypertension based on several factor such as body mass index (BMI), waist (WC), and hip circumference (HC), and waist hip ratio (WHR) [
19]. The finding demonstrates that, for women, BMI, WC, and WHR is the blend that creates the best prediction, while for men, BMI, WC, HC, and WHC are the topmost risk factors.
Random Forest is an ensemble prediction technique by amassing the finding of individual decision trees [
46]. Generally, Random Forest works by utilizing the bagging method to generate subsets of training data. For each training dataset, a decision tree algorithm is utilized. Lastly, the prediction results are acquired from the model (most frequent class) of every decision tree in the forest. A study regarding RF for early prediction of diabetes as well hypertension has been conducted and shown significant results. Nai-arun et al. utilized Random Forest as a classifier for diabetes risk prediction [
20]. The dataset was gathered from 30,122 persons in Sawanpracharak Regional Hospital, Thailand, between 2012 and 2013. The features comprise of medical information for example BMI, age, weight, height, blood pressure, a history of diabetes, and hypertension in the family, gender, and liquor and smoking patterns. The findings manifest that RF performance is excellent as compared to rest of algorithms. Finally, Alghamdi et al. used an ensembling strategy that consolidated three decision tree classification strategies (RF, Naïve Bayes [NB] Tree, and Logistic Model Tree [LMT]) for foreseeing the diabetes [
21]. The finding demonstrated that the performance of the predictive model has accomplished topmost accuracy for anticipating incident diabetes using cardiorespiratory fitness data among models. Furthermore, RF also showed a significant result for hypertension prediction. Sakr et al. evaluated and compared the performance of various machine learning methods on foreseeing the people in danger of growing hypertension [
22]. The dataset utilized data of 23,095 patients at Henry Ford Health Systems from 1991 to 2009. Six machine learning methods were researched: LogitBoost (LB), Bayesian Network classifier (BN), Locally Weighted Naïve Bayes (LWB), ANN, SVM, and Random Tree Forest (RTF). The result showed that the RTF model had the best performance (AUC = 0.93) among the machine learning methods that were investigated in this study. Finally, Sun et al. utilized the RF classifier as a model for transitions in hypertension control [
23]. The dataset consisted of 1294 patients with hypertension at the Vanderbilt University Medical Center. The result showed that proposed RF accomplished exact forecast of change points of hypertension control status. The result of their study is expected to be used for personalized hypertension management plans.
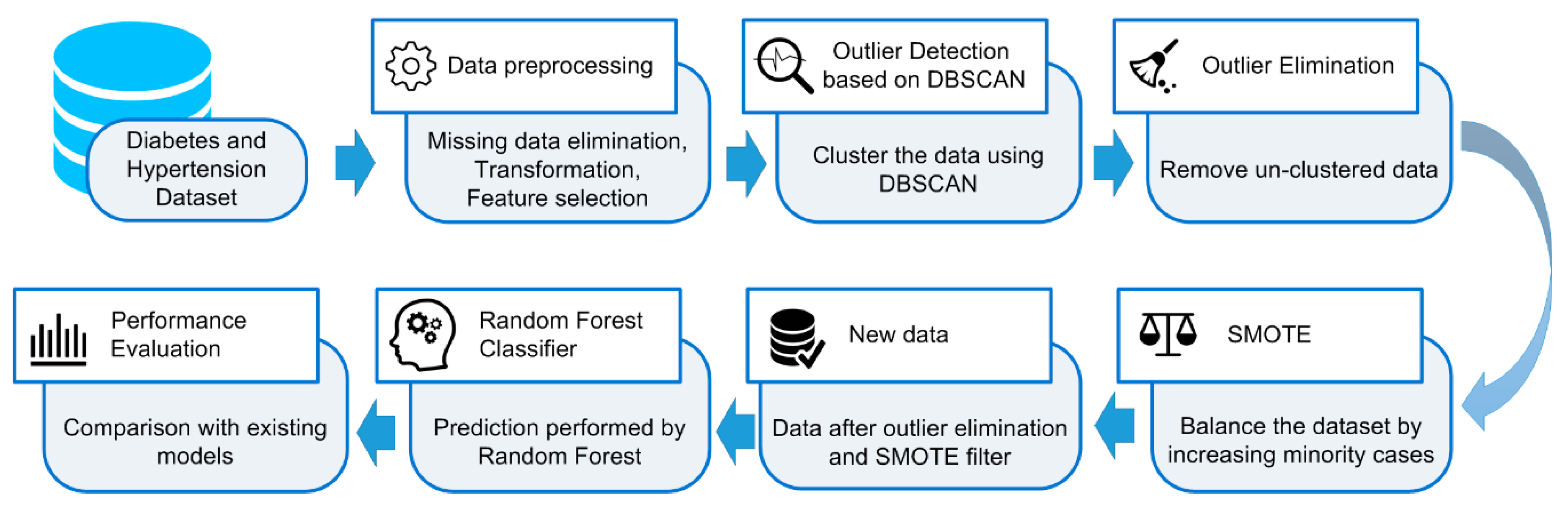
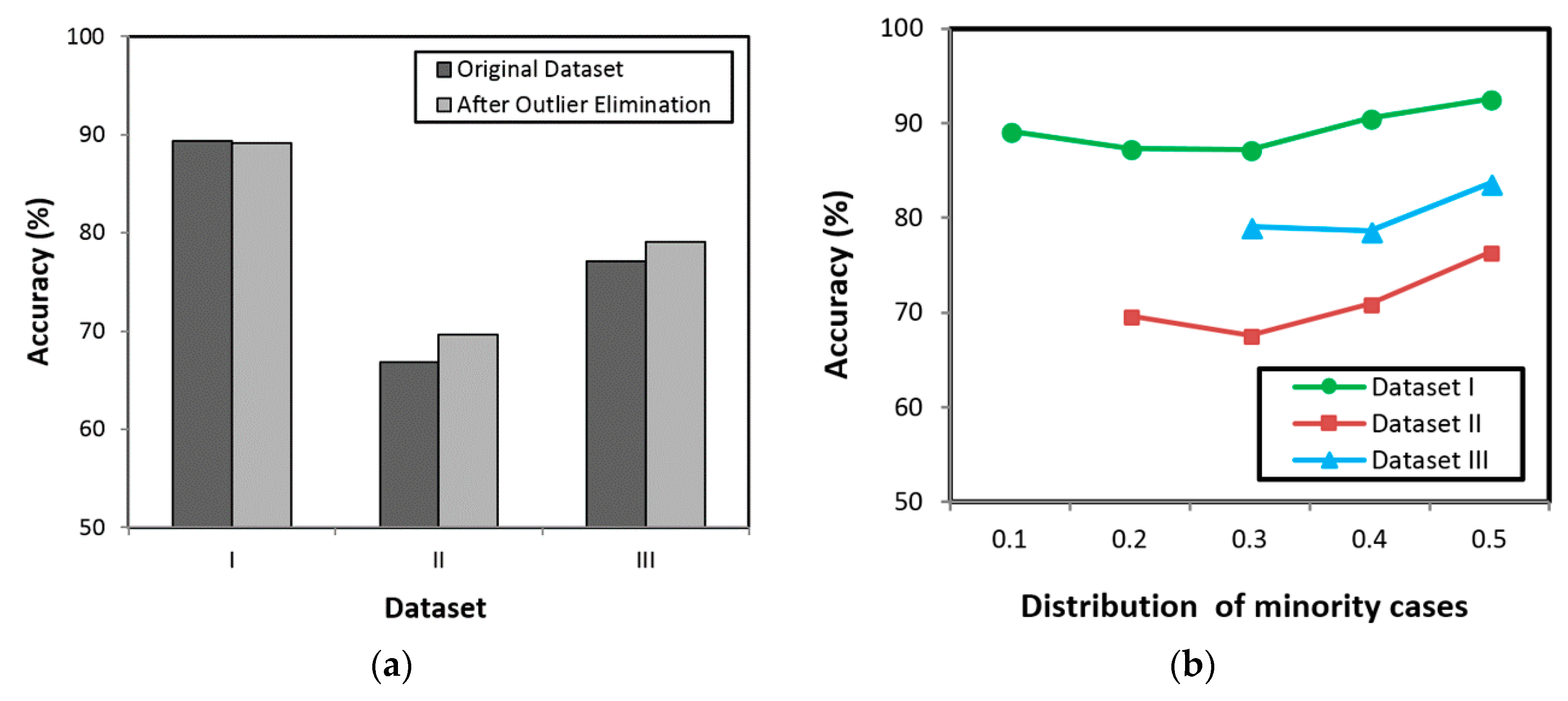
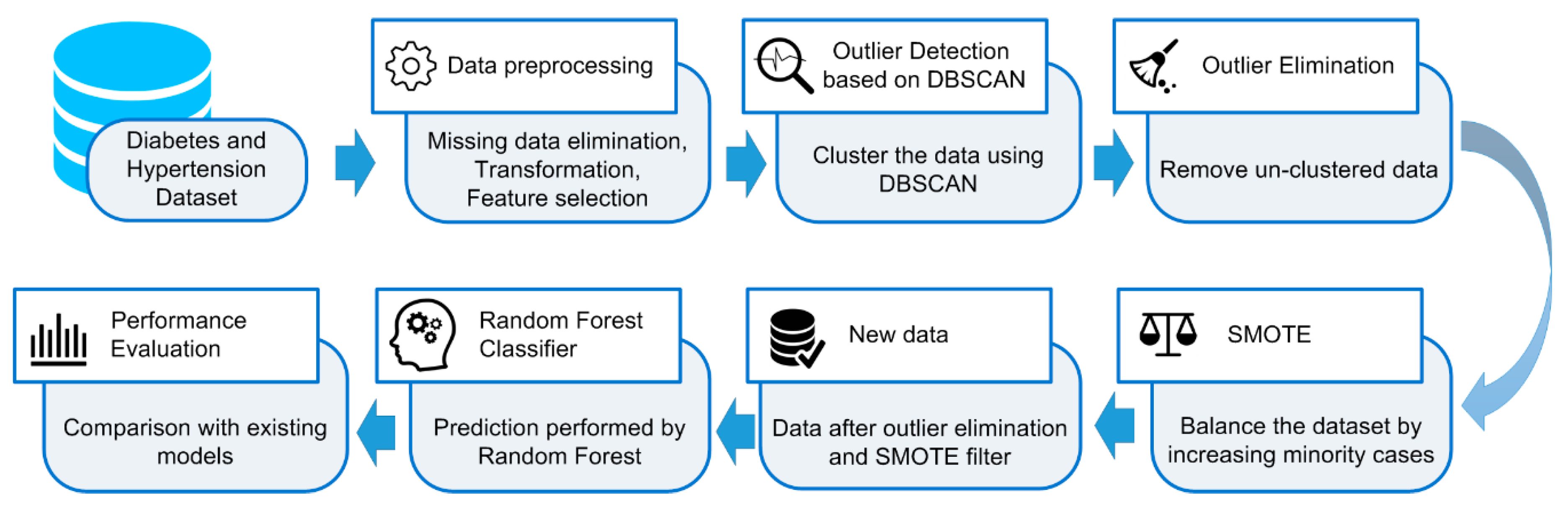
Existing studies show that the RF can be utilized for early prediction of diabetes as well as hypertension with high classification accuracy. However, several studies have revealed that the outlier data as well as imbalanced datasets are challenging problems in classification, as they can reduce the system performance. Hence, the present study proposes an HPM that consists of DBSCAN-based outlier detection to remove the outlier data, SMOTE for balancing the distribution of class, and RF to discover the diabetes and hypertension at an earlier stage. By removing the outlier data as well as balancing the dataset, the RF is expected to provide high classification accuracy.
2.2. Outlier Detection Method
Most existing research focuses on developing more accurate models rather than on the importance of data pre-processing. The outlier detection method can be utilized in the pre-processing step to identify inconsistencies in data/outliers; thus, a good classifier can be generated for better decision making. Eliminating the outliers from the training dataset will enhance the classification accuracy. Outlier detection constitutes an important issue for many research areas, including medical, document management, social network, and sensor networks. Several studies have been conducted and showed significant results of outlier detection on improving the classification accuracy. Shin et al. studied text classification in order to improve document management utilizing outlier detection and kNN classifier [
47]. The findings indicated that omitting outliers from the training data considerably refined the kNN classifier. In a general case study, Tallon-Ballesteros and Riquelme evaluated the outlier effect in classification problems [
48]. The study proposed a statistical outlier detection method to determine the outliers based on inter-quartile range (lQR) by classes. The result showed that by partially eliminating the outliers from training dataset, the classification performance of C4.5 was enhanced. Furthermore, in the case of medical application, the outlier detection showed significant result. Past literature used an outlier prediction technique that can enhance the classification performance in the medical dataset [
49]. The findings showed that, by eliminating the detected outliers from training set, the classification accuracy was enhanced particularly for Naïve Bayes classifier. Finally, past literature builds up a burn tissue classification device to help burn surgeons in planning and executing debridement surgery [
50]. The study used the multistage technique to build on Z-test and univariate analysis to recognize and eliminate outliers from the training dataset. The findings demonstrated that the outlier detection and elimination technique lessened the difference of the training data and enhanced the classification accuracy.
Clustering method is a technique that can be used for outlier detection. The clustering method depends on the fundamental supposition that normal cases correspond to big and dense clusters, while outliers make little groups or do not have a place with any cluster whatsoever [
51]. DBSCAN is clustering based outlier detection technique that can be utilized to distinguish the outliers [
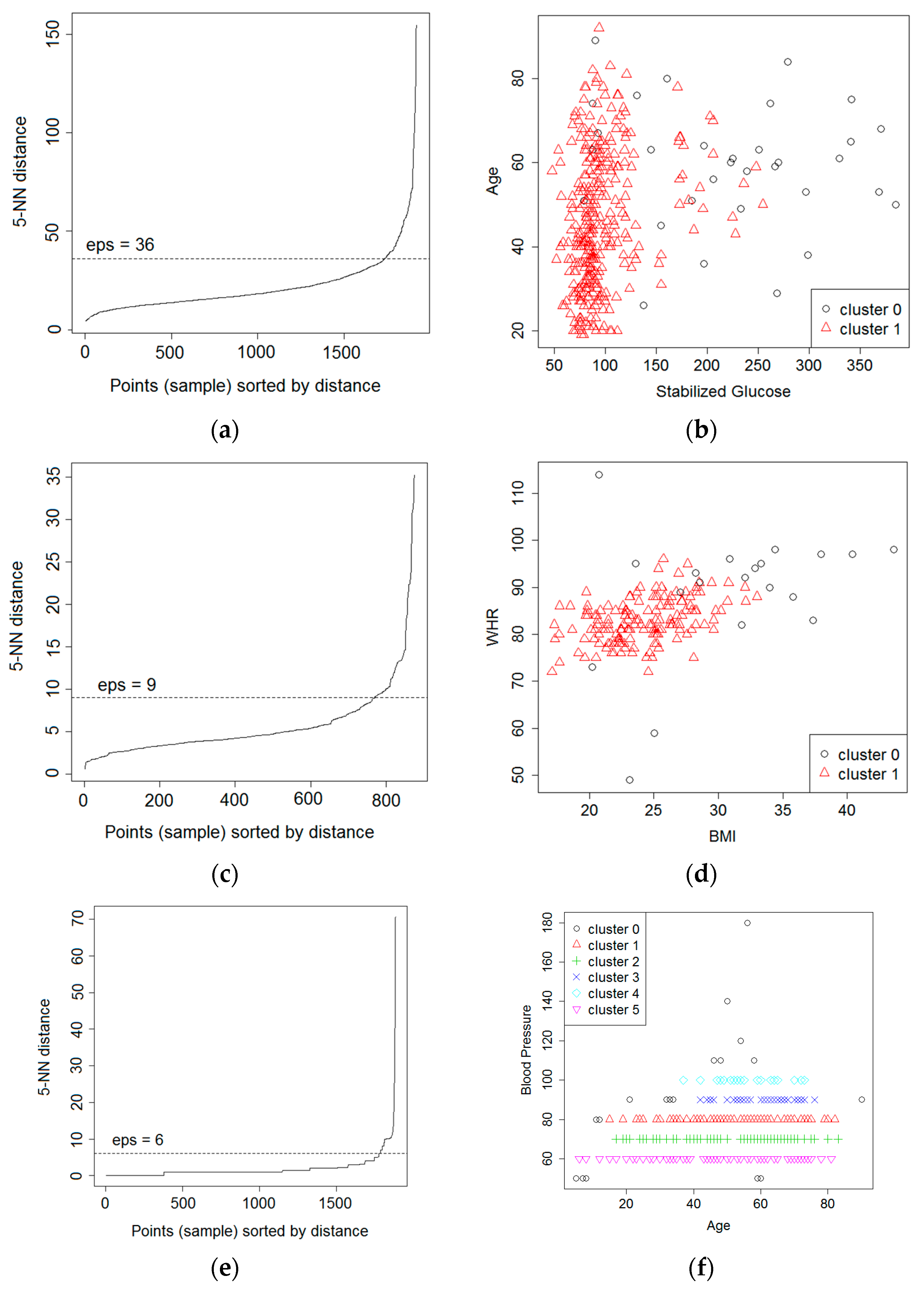
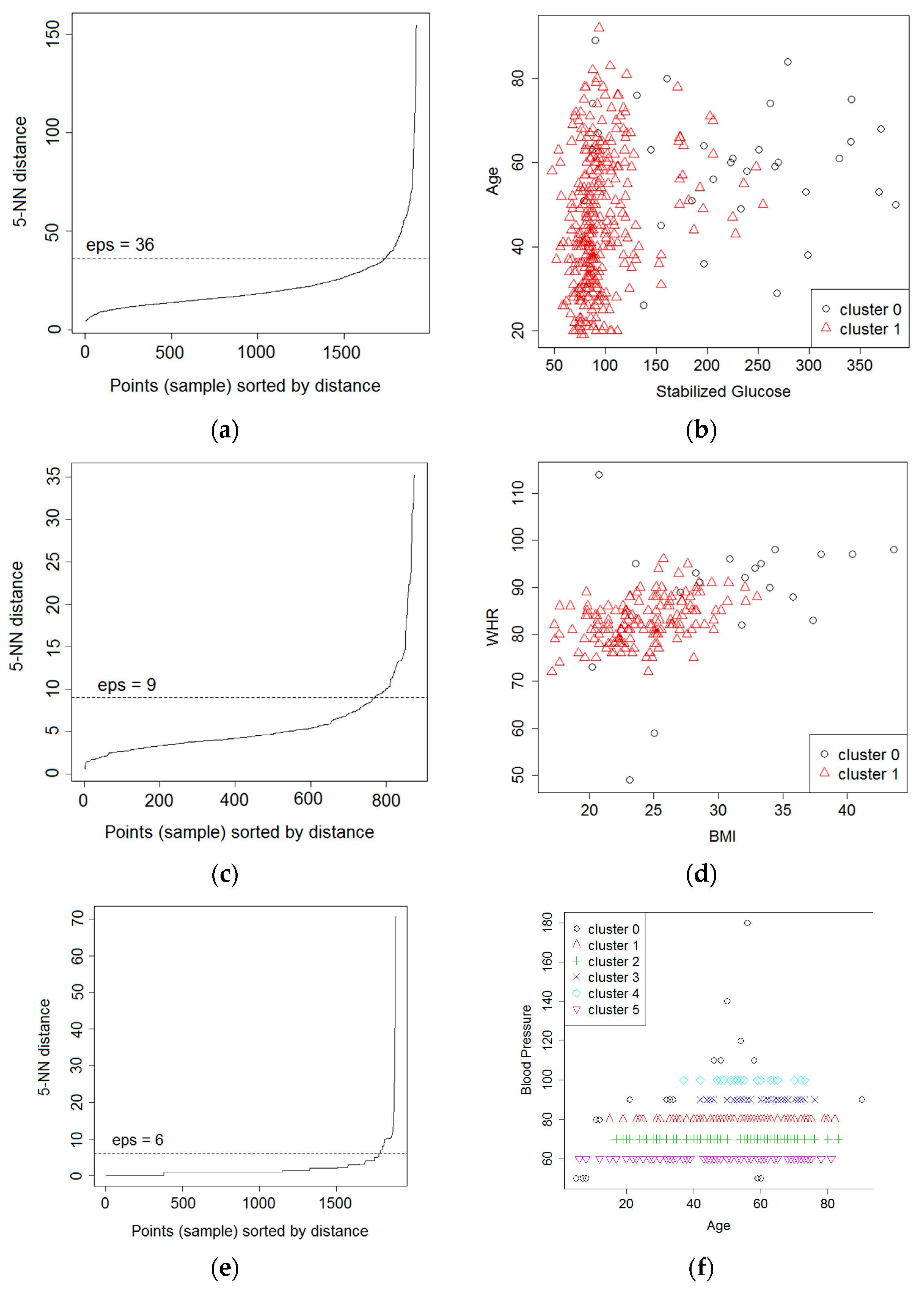
52]. The objective is to recognize the dense regions, which might be calculated by the quantity of objects near a given point. Outliers are the points that do not belong to any cluster. The DBSCAN relies on two important parameters: epsilon (
eps) and minimum points (
MinPts). The
eps represents the radius of neighborhood about a point x (
ε-neighborhood of x), while
MinPts represents the minimum number of neighbors within the
eps radius.
Regarding application of DBSCAN for outlier detection, several studies have been conducted and showed significant results in identifying outliers as well as improving the classification result. Past literature showed that by removing noise the quality of real datasets is enhanced [
24]. Support vector data description (SVDD) was utilized to classify the dataset. The University of California, Irvine (UCI) dataset has been utilized for the experimental scenario and the proposed method showed an efficient result. In the case of social network, ElBarawy et al. utilized DBSCAN to emphasize community detection. The result showed that the DBSCAN successfully identifies outliers [
25]. Eliminating the outliers prompts a precise clustering result that assists with the community identification issue in the area of social network analysis. The DBSCAN-based outlier detection also showed significant results on detecting the outlier sensor data. Alfian et al. proposed a real-time monitoring system that is based on smartphone sensors for perishable food [
26]. As outliers arise in sensor data due to inadequacies in sensing devices and network communication glitches, Alfian et al. used outlier detection that is based on DBSCAN to refine the outlier data. The findings demonstrated that DBSCAN was utilized to effectively recognize/characterize outlier data as isolated from normal sensor data. Abid et al. proposed outlier detection based on DBSCAN for sensor data in wireless sensor networks [
27]. The proposed model successfully separated outliers from normal sensors data. Based on the experiment on synthetic datasets, their proposed model showed significant results in detecting outliers, with an accuracy rate of 99%. Finally, Tian et al. proposed an outlier detection method of soft sensor modeling of time series [
28]. They utilized DBSCAN for the outlier detection method. The experiment showed that the proposed outlier detection method generated good performance.
Utilizing DBSCAN-based outlier detection provides an efficient way for detecting the outlier data. The current literatures showed that removing outliers improves the classification accuracy. Furthermore, the majority of real-world datasets are imbalanced; thus, an oversampling method to generate artificial data from minority class is needed to improve the classification accuracy. A previous study showed that the combination data cleaning (outlier removal) and oversampling method generated a significant result [
34]. In this manner, combining DBSCAN-based outlier detection and oversampling technique is predicted to enhance the accuracy of classification model.
2.3. Oversampling Method for Imbalance Dataset
Classification datasets usually have great differences of distribution between the quantities of majority class and the minority class, which is alluded as an imbalanced dataset. Learning from imbalanced datasets is a demanding problem in supervised learning as standard classification algorithms are intended to explain balanced class distributions. One of the methods is called oversampling, and it works by creating artificial data to attain a balanced class distribution. SMOTE is a kind of oversampling technique that has appeared to be great and it is generally utilized as a part of machine learning to balance imbalanced data. The SMOTE creates arbitrarily new instances of minority class from the closest neighbors of the minority class sample. These instances are made in view of the features of the original dataset with the goal that they end up like the original instances of the minority class [
53].
Regarding the implementation of oversampling method, several studies have been conducted and have showed significant results. The SMOTE has been integrated with classification algorithms and it has improved the performance of prediction systems, such as in network intrusion detection, bankruptcy prediction, credit scoring, and medical diagnosis. Yan et al. proposed Region Adaptive Synthetic Minority Oversampling Technique (RA-SMOTE) and applied it to intrusion detection to recognize the attack behaviours in the network [
29]. Three distinct sorts of classifiers, including SVM, BP neural system (BPNN), and RFs, were utilized to test the capability of the algorithm. The findings demonstrated that the proposed algorithm could successfully take care of the class imbalance issue and enhance the detection rate of low-visit attacks. Sun et al. proposed a hybrid model by utilizing SMOTE for imbalanced dataset to be used as a tool for bank to evaluate the enterprise credit [
30]. The proposed model was applied to the financial data of 552 Chinese listed companies and outperformed the traditional models. Le et al. used numerous oversampling methods to manage imbalance problems on the financial related dataset that was gathered from Korean organizations between 2016 and 2017 [
31]. The findings showed a blend of SMOTE and Edited Nearest Neighbor (SMOTE + ENN), as well as RF achieved highest accuracy on bankruptcy prediction. Finally, a past study proposed a method combining SMOTE with SVM to enhance the predication accuracy for old banknotes [
32]. The findings revealed that the proposed method could enhance the performance by as much as 20% when compared with standard SVM algorithm. Generally, greater prediction performance can be attained with balanced data. Past study integrated the SMOTE, the particle swarm optimization (PSO), and radial basis function (RBF) classifier [
33]. The experimental results showed that the SMOTE + PSO-RBF provides an extremely well-defined explanation for other present advanced techniques for fighting imbalanced problems. Verbiest et al. utilized data-cleaning before and after applying SMOTE by proposing selection techniques that are based on fuzzy rough set theory to remove the noisy instances from the dataset [
34]. The results indicated that their proposed technique upgrades present pre-processing methods for imbalanced classification. Past study proposed the SMOTE–IPF (Iterative-Partitioning Filter), which can tackle the issues that are created by noisy and borderline cases in imbalanced datasets [
35]. The findings revealed that the proposed model worked superior than the present SMOTE. Finally, Douzas et al. presented an impressive oversampling method based on k-means clustering and SMOTE, which can prevent the creation of noise and successfully beats imbalances between and within classes [
36]. The result showed that their proposed method was applied to 90 datasets and improved the performance of classification.
In the case of medical diagnosis or disease classification, the combination of SMOTE with classification algorithms has shown significant results. Wang et al. proposed hybrid algorithm by utilizing well-known classifier, SMOTE, and particle swarm optimization (PSO) to improve the competence of classification for five-year survivability of breast cancer patients from a gigantic dataset with imbalanced property [
37]. The findings revealed that the hybrid algorithm surpassed other algorithms. Moreover, applying SMOTE in appropriate searching algorithms, for example, PSO and classifiers, such as C5, can considerably enhance the efficiency of classification for gigantic imbalanced data sets. Furthermore, Alghamdi et al. investigated the performance of machine learning methods for predicting diabetes incidence while using medical records of cardiorespiratory fitness [
21]. The dataset consists of 32,555 patients of whom 5099 have developed diabetes after five years. The dataset contained 62 attributes that are classified into four categories: demographic characteristics, disease history, medication use history, and stress test vital signs. The study utilized SMOTE to deal with imbalance dataset. The result showed that, with the help of SMOTE, the performance of the predictive model was enhanced. Furthermore, the study showed that ensembling and SMOTE approaches achieve the highest accuracy for predicting incident diabetes while using cardiorespiratory fitness data.
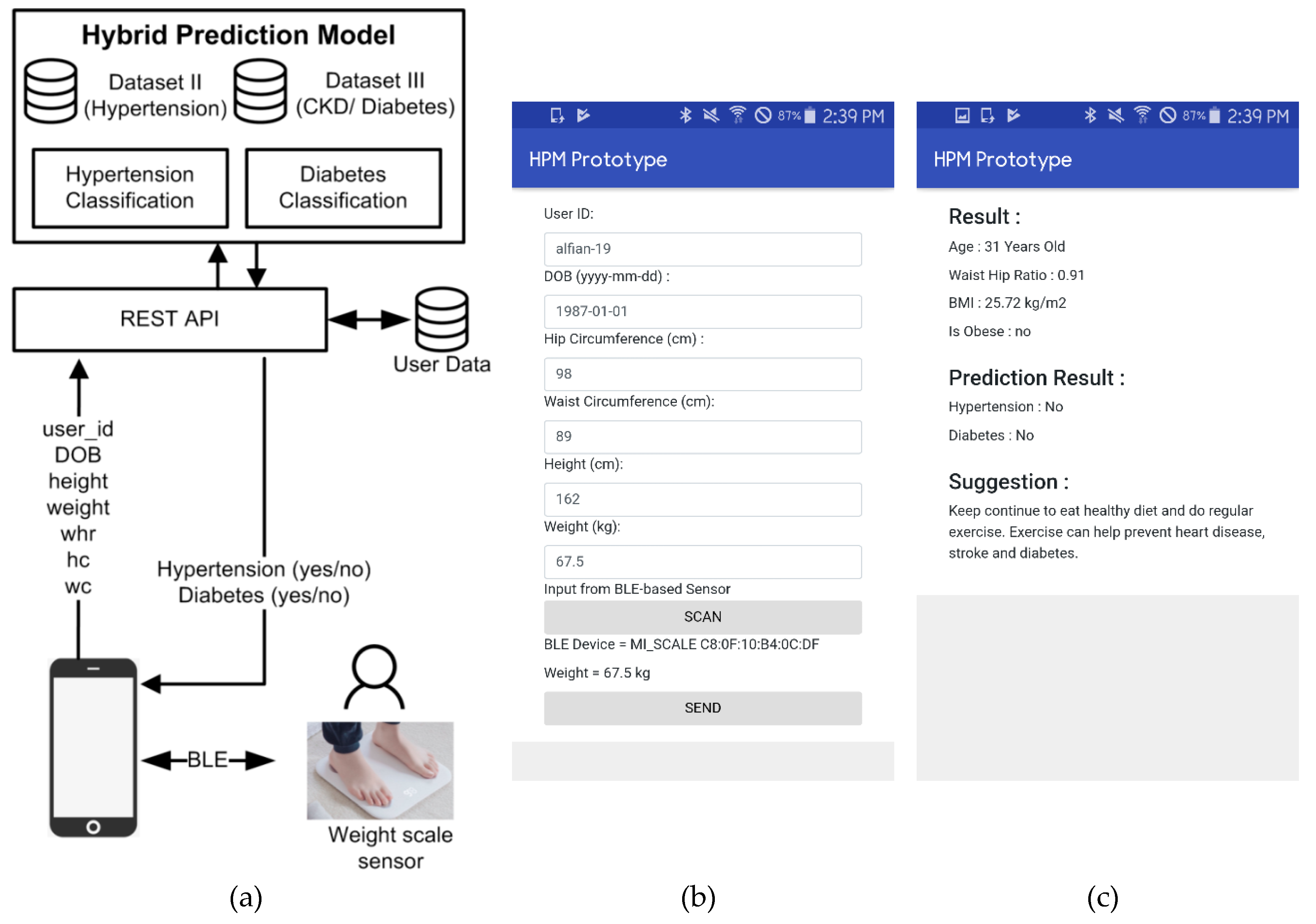
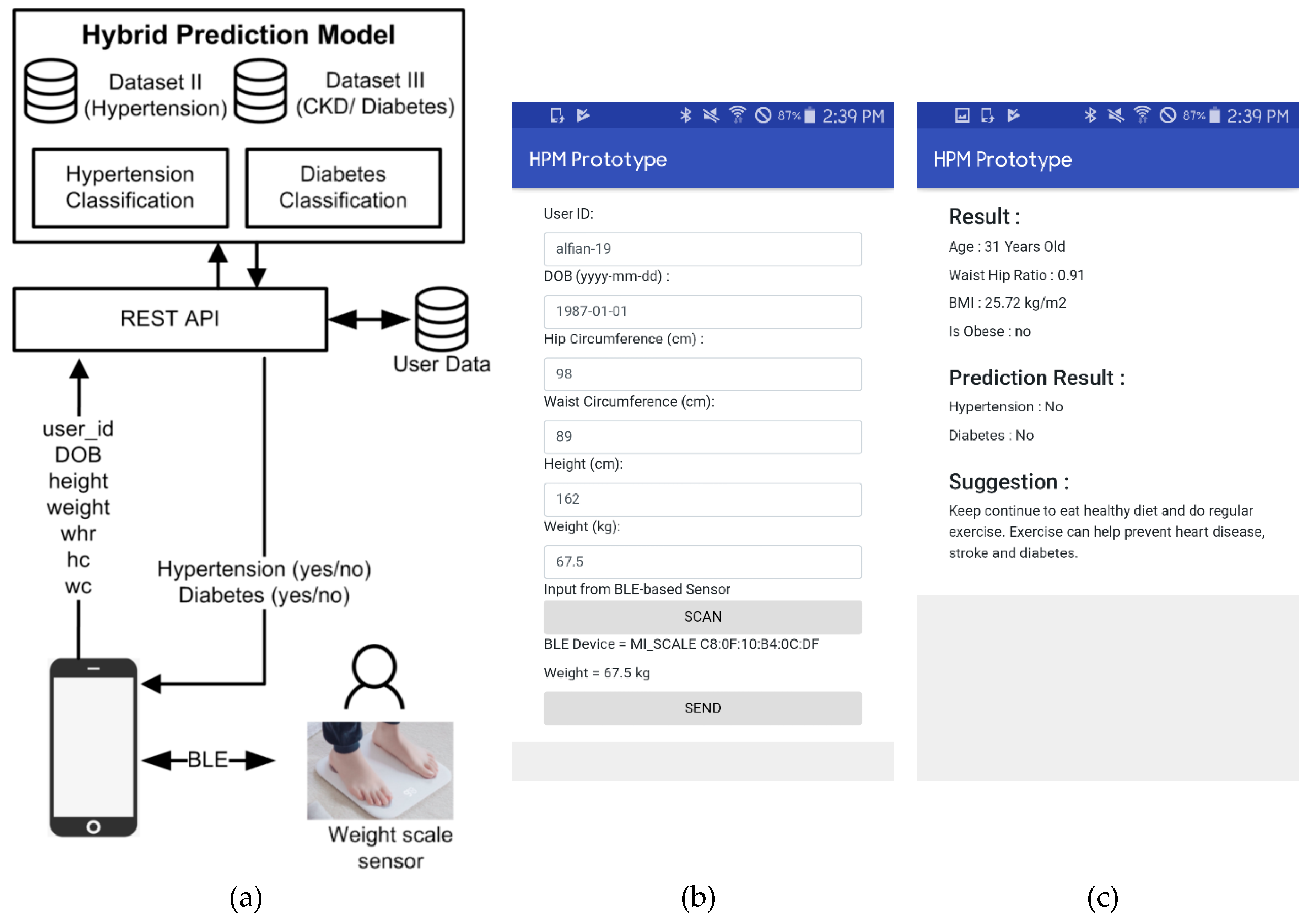
The present literature demonstrates that greater prediction performance is attained by utilizing SMOTE to balance data. Therefore, an HPM that consists of DBSCAN-based outlier detection to identify and remove the outlier and SMOTE to balance the distribution dataset is proposed in our study. The hybrid model is predicted to enhance the classification accuracy, in this way helping people to detect the danger of diabetes and hypertension at the initial stage. Along these lines, a person can evade the most exceedingly bad conditions later on.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}