1. Introduction
The next generation of mobile broadband communications, 5G, is expected to bring unique network and service capabilities. It will offer low latency (<1 ms end-to end service), multi-tenancy, high capacity, high-speed communications (≈1 Gbps data rate), resource virtualization, coordinated automation or heterogeneous technology convergence among other functionalities. Moreover, supporting the ever-increasing number of connected devices (up to 100-fold), offering a variety of services as online gaming, video streaming or Voice over IP (VoIP) while reducing capital (CAPEX) and operational costs (OPEX) and energy consumption are some of the challenges that emerging 5G technologies will have to overcome [
1].
In order to support the increasing number of connected devices, 5G will require transport networks to cope with enormous amounts of traffic with minimum latency. Therefore, not only the radio access network, but the metro and transport networks must be redefined from an architectural point of view. One of the most important enabling technologies for that redesign is the Centralized/Cloud Radio Access Networks (C-RAN) architecture.
In C-RAN, the base station (BS) functionalities are divided into two separate entities: Remote Radio Heads (RRH) and Based Band Units (BBU). BBUs can be placed in the same location as RRH, but economical efficiencies are achieved when BBUs are placed at higher hierarchy premises (together with other BBUs, increasing the flexibility and reducing costs).
In this architecture, the BBUs connect with the RRH through the so-called Mobile Fronthaul (MFH) segment and commonly implement the CPRI protocol to transport the traffic between RRHs and BBUs [
2,
3]. Since the fronthaul traffic between RRHs and BBUs is usually the sampled, quantized and encoded radio signal [
4,
5], it requires C-RAN to rely on networks with high capacity and guaranteed latencies. These restrictions constraint the location of the BBUs, e.g., to be hosted at the first aggregation site, although location at higher aggregation sites has been studied in Reference [
6]. Moreover, 5G is expected to require CPRI rates significantly larger than the available bandwidth in current networks. For this reason, other functional splits, i.e., other divisions between the functionality that remains at the antenna site and the functionality deployed in the operator premises are considered to be deployed in 5G access networks [
7]. In References [
8,
9] the BBUs are divided into two entities: Distributed Unit (DU), which provides the physical layer processes and the real-time functionalities of the network, and the Central Unit (CU), which deploys non-real-time wireless high-level protocol function. Nonetheless, C-RAN latency and capacity requirements render optical technologies as the perfect candidate for the 5G fronthaul segments [
2].
On the other hand, Mobile Edge Computing (MEC) technology will also contribute to the realization of 5G. MEC is a technology that provides cloud computing services at the edge of the network, i.e., closer to the end-user. Therefore, bringing the data processing to the edge node avoids the traffic to travel long distances incurring in propagation delays and, consequently, it can help to significantly reduce latency [
10]. MEC and C-RAN seem to be colliding concepts, since MEC aims to distribute the data processing among the edge nodes of the network, whereas C-RAN aims to centralize the data processing in the BBU pools in the operator premises. However, its use in conjunction in the network can enable the reduction of latency, cost and energy consumption. This is done by using virtualized BBUs, i.e., virtual functions running on multicommodity servers (i.e., those from MEC) implementing the functionality of a BBU [
3]. Examples of architectures addressing that idea are the Heterogeneous Cloud Radio Access Network (H-CRAN) [
11], which combines C-RAN with cloud computation techniques deployed at some nodes of the network, or the Cloud/Fog RAN architecture [
12], which places Local Processing Units at the network cells to deploy cloud services and, therefore, virtual BBU (vBBU) functions, closer to the end user.
Network Function Virtualization (NFV) and Software Defined Networking (SDN) are also facilitating the realization of 5G by changing the manner in which operators deploy their end-user services. Nowadays, operators offer services like video streaming, web browsing, data transmission or voice services by executing specific tasks, known as network functions. Modern networks deploy network functions on dedicated hardware or middleboxes. Since middleboxes are costly and inflexible, operators incur an increase in capital and operational expenditures any time they deploy new and complex services. NFV is a technology that deploys network functions as software appliances called Virtual Network Functions (VNFs). VNFs are instantiated in Commercial-Off-The-Shelf (COTS) servers, which can host multiple instances of different VNFs, thus facilitating the deployment of complex network services and the efficient dimensioning of the network. Moreover, COTS hardware can be placed at data centers, Central Offices (CO) [
13], but also optical network edge nodes can be NFV-enabled nodes thanks to the MEC approach. Consequently, NFV facilitates the deployment of new network services avoiding a rise in the network cost.
The traffic associated to each service must traverse a Service Chain (SC), i.e., a set of VNFs concatenated in a specific order while satisfying latency, and bandwidth requirements, as well as computing resources and the maximum number of concurrent users per VNF requirements. Therefore, deciding where to host VNFs and which particular instances should be concatenated to set up SCs while satisfying the aforementioned requirements are some of the problems that operators face when implementing NFV. We refer to this problem as the VNF-Provisioning problem. Lastly, operators must decide whether to perform the VNF-Provisioning at peak loads, which may cause an inefficient use of resources, or take advantage of the benefits of NFV and SDN and perform periodic network re-plannings to adapt the resources to the actual traffic.
In this paper, we address the NFV-based network dimensioning problem in a 5G network to deploy services like Video Streaming, VoIP or Web browsing. To achieve this objective, we consider the implementation of Heterogeneous Cloud Radio Access Network (H-CRAN) in the network using traditional C-RAN technology (i.e., without splitting BBUs into DUs and CUs) and including MEC servers at the first aggregation site, i.e., at the Access Office (AO) serving each cell of the network, in order to deploy both VNF and vBBUs functions. We assume that RRHs connect to the virtualized BBUs deployed at the AO using optical communications, in a similar manner as [
6,
12]. We extend the Fog/Cloud RAN architecture in Reference [
12] to benefit from the advantages of the MEC paradigm. Therefore, the AO also hosts a MEC server to deploy the virtual BBUs and other possible VNFs. We use optical technologies to connect the AO to the CO, equipped with IT resources and assume that the VNFs required to deploy the selected services can be deployed either on the MEC server at the AO or on the CO.
Firstly, we propose a genetic algorithm to solve the VNF-Provisioning problem. The algorithm (inspired on a previous work presented in Reference [
14]) considers (i) the IT resources in the AO and the CO and (ii) the optical network resources to minimize the service blocking ratio and to reduce the CPU usage. Then, we extend the work by evaluating its performance in a more realistic scenario, with dynamic traffic, and by incorporating a learning technique to improve its performance. Moreover, we also demonstrate the advantages of performing a dynamic reconfiguration of the VNF provisioning in order to reduce service blocking ratio and CPU usage (and, therefore, the energy consumption).
The rest of the paper is organized as follows.
Section 2 discusses some related work. Then,
Section 3 details the proposed 5G architecture and the VNF-Provisioning solving algorithms.
Section 4 describes the simulation scenario and analyses the performance of the proposed methods. Lastly,
Section 5 presents the conclusions of this study.
2. Related Work
C-RAN technology is a promising approach to reduce latency in 5G networks and the literature has largely covered this topic since authors in Reference [
2] made one of the first C-RAN system architecture proposals, suggesting two kinds of solutions: The “full centralization”, in which all Layer 1, 2, and 3 Base Station functions are located in the BBU and the “partial centralization” where baseband functions are located in the RRH while the higher layer functions are located in BBU. But the development of 5G over C-RAN poses different challenges regarding the transport network and the achievement of 5G benchmarks, in particular with latency and bandwidth. In 2015, Pfeiffer [
3] stated the necessity of revisiting the Common Public Radio Interface (CPRI) approach to building the MFH to support the increasing traffic while satisfying the challenges in the time and frequency domain. The author proposes moving from distributed to centralized RAN architectures to reduce CAPEX and OPEX and facilitate the implementations of radio techniques as Coordinated Multi Point (CoMP), using Passive Optical Network (PON) technologies like WDM-PON or TDM-PON to support the bandwidth requirements, in combination with split processing to relax the bandwidth and latency requirements in the fronthaul. Kani et al. [
15] explored different PON technologies for the construction of the MFH to satisfy its bandwidth and latency requirements, as TDM-PON for its cost-effectiveness, TWDM-PON for its suitability in scenarios where the high traffic points dynamically move, and WDM-PON or Point-to-Point architectures for their high bandwidth. Furthermore, the scientific community is considering different functional splits to ease the bandwidth and capacity requirements of 5G over C-RAN [
7]. In References [
8,
9], C-RAN is divided into three entities: The RRUs, the DU and the CU. The RRUs may keep radio and some layer-1 functions, whereas the DU provides the rest of layer-1 processes and real-time functionality, as Hard Automatic Repeat request (HARQ) and Automatic Repeat request (ARQ), and the CU the non-real-time, high-level wireless protocol functionality. In this architecture, the fronthaul remains the segment connecting RRHs and DUs, while the segment between the DU and the CU is called Midhaul (MH). With this split, the shorter fronthaul, which remains the segment between RRH and DU, and the relaxed bandwidth and latency requirements favor the support of the real-time processes of the e-node.
In Reference [
6], Musumeci et al. studied the impact of the latency requirements in the BBU consolidation in a C-RAN architecture. The authors considered WDM Aggregation Networks and three kinds of BBU split architectures in which the BBU were stored at the cabinet of the base station, at the CO at the first level of aggregation or at CO in further levels of aggregation, depending on the latency restrictions. Authors in Reference [
11] introduced the Heterogeneous Cloud Radio Access Networks (H-CRAN), which combines cloud computing technologies and C-RAN to improve the performance of HetNets in terms of energy consumption and spectral efficiency.
Tinini et al. [
12] extended the Hybrid C-RAN in Reference [
11] to integrate the Fog Computing and NFV paradigms, by adding Local Processing Units to each Cell Site (CS) in which implement vBBUs. The authors also proposed an Integer Linear Programming (ILP) formulation to solve the BBU placement problem in the TWDM-PON based Fog/Cloud RAN architecture, with the objective of supporting high-traffic demands minimizing the energy consumption. In our work, we extend these architectures to create virtual BBU functions in a MEC server located at the first level aggregation site and, in this manner, combine MEC technologies and C-RAN and enable the possibility of virtualizing network functions.
The coexistence of MEC and C-RAN has also been covered in the literature. Rimal et al. [
16] discussed MEC as a pathway for 5G realization, introduced different 5G-service scenarios and design challenges and proposed and explored the feasibility of MEC over Fiber Wireless Networks for different RAN scenarios, including the coexistence of MEC and C-RAN. Authors in References [
17,
18] studied the integration of MEC and C-RAN from a resource allocation viewpoint, proposing techniques for resource allocation to reduce the energy consumption, while in Reference [
19], authors proposed different coordination techniques to reduce the end-to-end latency in C-RAN with MEC. Lastly, Blanco et al. [
20] explored the role that MEC, together with SDN and NFV will play to address the challenges 5G aims to undertake. None of the studies on the integration of MEC and C-RAN explores the use of NFV to deploy specific VNFs to offer final user services, such as video streaming, VoIP, or web browsing.
The VNF placement and service chaining problem has also attracted the interest of the research community. In static scenarios, Lin et al. [
21] solved the resource allocation problem with a mixed-integer program to optimally serve end-to-end requests, minimizing CAPEX and OPEX and added a method to consider limited physical resources. In Reference [
13], Savi et al. studied the resource allocation and chaining problem considering the impact of IT resource-sharing among VNFs and the scalability issues that may appear when multiple SCs are deployed in a network through an ILP model. But the VNF placement problem is known to be NP-Hard and ILP models require large computation time to solve the problem for large networks [
22]. Thus, heuristics and metaheuristics are employed to find sub-optimal solutions in polynomial time. For instance, authors in Reference [
23] proposed a heuristic algorithm to study the impact of latency on VNF placement, showing that when the latency requirement of a service is strict, it can only be satisfied by deploying VNFs closer to the end user, in the metro/access network. Besides Carpio et al. [
24] proposed a genetic algorithm for solving the VNF placement problem in Data Centers with the purpose of improving the load balancing. However, these efforts explore the VNF provisioning problem only on static scenarios.
Several studies explore the VNF resource allocation problem in dynamic scenarios. For example, Zeng et al. [
25] addressed the VNF-Provisioning problem in an Inter-Data Center Elastic Optical Network for both static network planning and online provisioning through a Mixed-Integer Linear Programming (MILP) model, with the aim of reducing costs. More recently, authors in Reference [
26] proposed an online algorithm to solve the VNF placement and chaining problem across geo-distributed datacenters, minimizing the operational costs. Authors in References [
27,
28] explore the online VNF-Provisioning problem within datacenters. The first work proposes an algorithm to solve the VNF-Placement problem reducing provisioning costs and considering traffic rates between adjacent VNFs and server resource capacities, whereas the second study proposes an algorithm for service chain deployment and scaling that takes into consideration traffic fluctuations, to reduce deployment costs and link utilization. Rankothge et al. [
29] presented a resource allocation algorithm based on Genetic Algorithms to solve the VNF placement in a Data Center minimizing the usage of IT resources. Otokura et al. [
30] presented an online VNF placement problem solving method based on genetic algorithms which aims to minimize the required time to obtain feasible solutions. Moreover, authors in Reference [
31] addressed the resource allocation problem in an NFV system, which aims to minimize the system cost and maximize the number of served requests. Lastly, authors in References [
32,
33] proposed a heuristic for online VNF placement and chaining in a realistic 5G scenario, aiming to reduce the service blocking rate, and taking into consideration computational resources and optical network capacity.
In contrast with those previous works, in this paper we propose a genetic algorithm for VNF-Provisioning in order to minimize both the service blocking ratio and the CPU usage in a 5G access network. We consider that RRHs are connected to an AO following a hybrid Cloud/MEC RAN architecture, based on the one proposed in Reference [
12]. However, we extend said architecture by equipping MEC servers with different capabilities at each AO in order to deploy both virtualized BBUs and other VNFs. AOs connect to the Central Office, which hosts IT resources, via dedicated optical links. We test our proposal in both static and dynamic scenarios and propose a new version of the method by adding a simple learning capability with the purpose of improving the results in terms of service blocking ratio and CPU usage. Finally, we also demonstrate the advantages of reconfiguring the VNF provisioning in contrast with making a static planning and show the performance of our proposed method in that scenario.
3. Genetic Algorithm for VNF-Mapping in Cloud/MEC RAN-Based 5G Architectures
3.1. Network Architecture
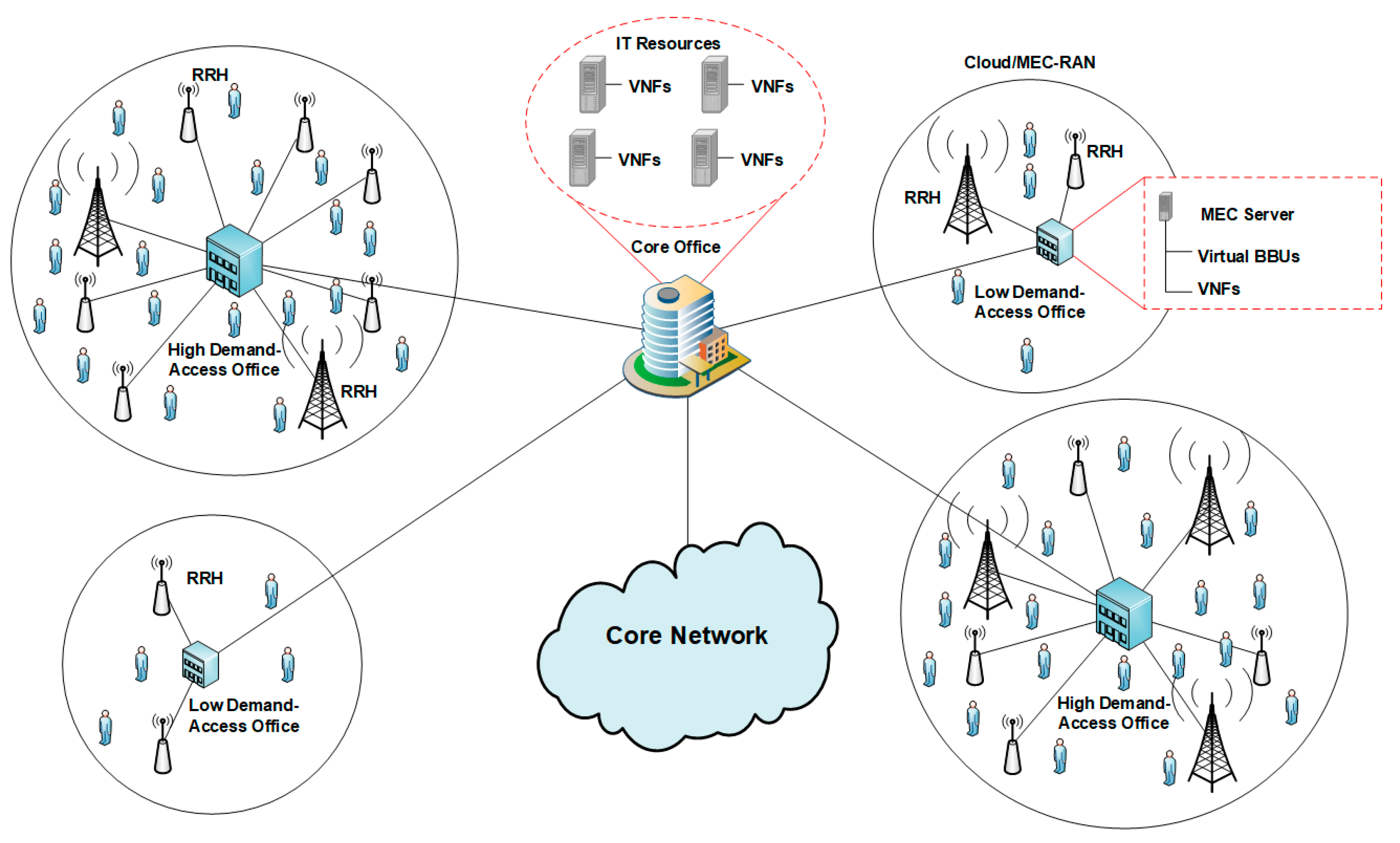
We consider a Cloud/MEC RAN architecture based on the one proposed in Reference [
12] which is shown in
Figure 1. In this architecture, RRHs connect via optical networks (using dedicated links or PON) to an AO. The AO hosts a MEC server to bring cloud services and function virtualization closer to the end user. This server will host instances of VNFs, including vBBUs. Since the closest AO to the RRH hosts the vBBU attending the RRH, we reduce the physical distance between both elements, ensuring that the stringent 5G latency requirement is fulfilled. We distinguish between two kinds of AOs: HD-AO (High Demand AO) and LD-AO (Low Demand AO). HD-AO serves a higher number of average end users than LD-AO and, consequently, the MEC servers at the HD-AO will be equipped with higher computing resources than the servers at the LD-AO. That definition is also compatible with the division in macrocells and microcells in current mobile networks. Lastly, each AO can connect to the CO via dedicated optical links, optical networks featuring Wavelength Division Multiplexing (WDM) like in References [
6,
8,
9] or even PON technology. We assume that the CO hosts IT resources to deploy VNF instances, but it will not host virtual BBUs. This architecture does not consider splitting the BBUs into DUs and CUs [
8,
9]. However, it is completely compatible with that architecture by simply hosting the DUs in the AOs while the non-time sensitive CU can be hosted in the CO.
3.2. Problem Description
The VNF-Provisioning problem consists of two parts: The VNF-Placement (i.e., planning) and the VNF-Chaining (i.e., operation) [
27,
28]. The planning methods must decide how many instances of the VNFs must be allocated to each VNF-enabled host of the network [
30]. The chaining methods, on the other hand, must dynamically create the necessary SCs to serve each service request from the user [
31,
32,
33]. The chaining stage is closely related to the planning one, since the establishment of the SC must use the VNF currently allocated in the network, and if an SC requires not-available VNFs instances or if the network does not have enough capacity to support the establishment of the SC, the user request will fail, and the service blocking rate will increase.
The operation problem must be solved online each time that the network receives a user service request, since only at the request arrival time does the network know which type of traffic request must process and, consequently, the type of SC that must establish, and thus takes into account real service requests. However, the VNF planning problem is solved offline, based on traffic estimations, and leads to a static or a semi-static solution. In the latter case, the VNF planning problem is periodically solved, and involves the reconfiguration of the VNF mapping in order to better adapt to the current or near-term predicted traffic demand. The use of a completely dynamic method for planning is not a pragmatic approach, since setting up the VNF may take tens of seconds [
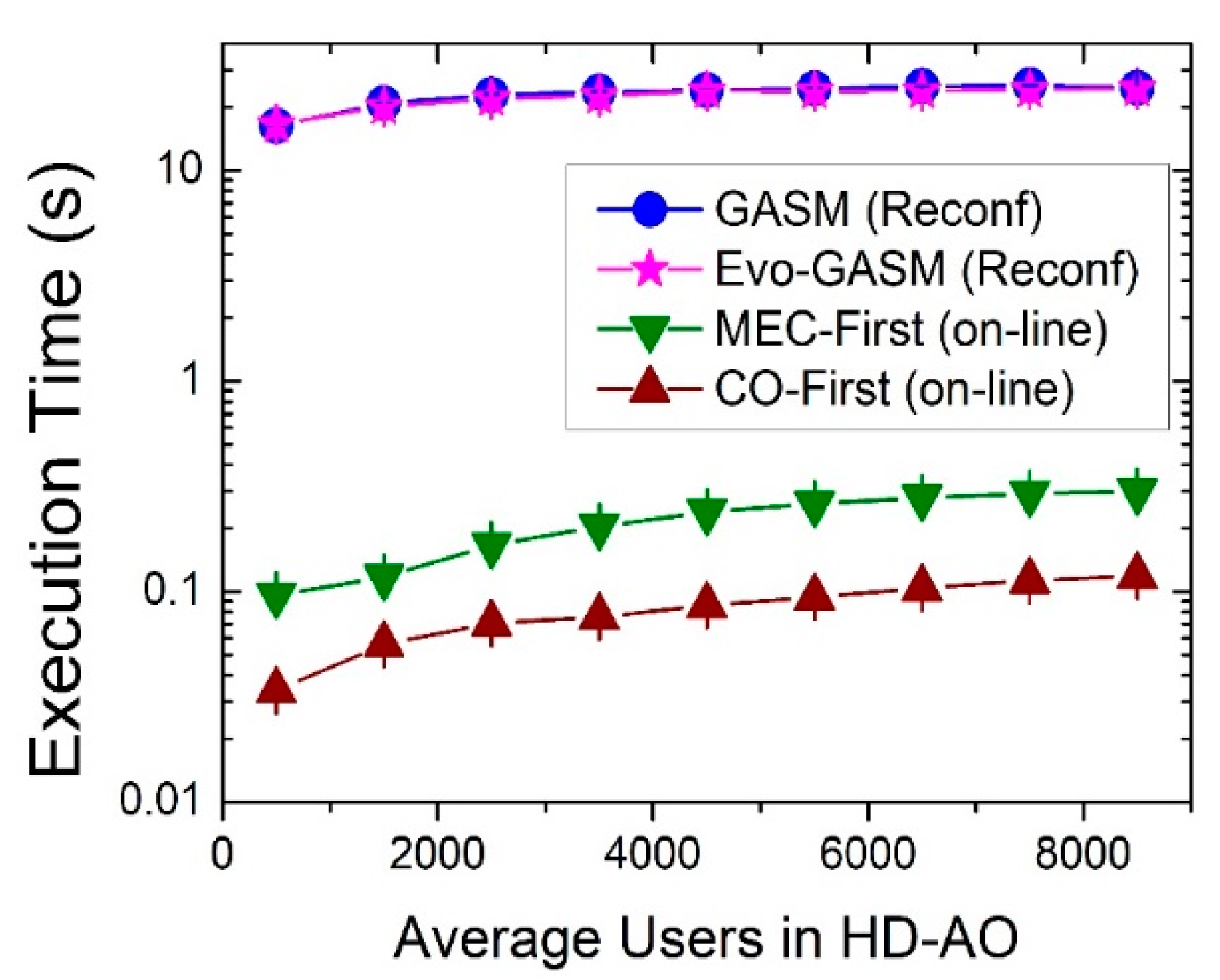
34], and that increases the delay to initialize the service.
The planning algorithms receive as input the average service requests from traffic monitors, including the number and type of the requests. Moreover, they consider the MEC/Cloud RAN architecture presented in the previous section and take into account the availability of IT resources (i.e., CPU, RAM and disk) and the network bandwidth. With those inputs and knowing the requirements in terms of IT and network resources to setup a VNF in a virtual machine, the planning methods should provide the optimal (or a close-to-optimal) distribution of the VNFs at the CO and at each AO of the network for the future requests. This stage is solved offline considering two possible scenarios: A static scenario in which the placement does not change with time, and a reconfigurable scenario in which the VNF-Placement can be modified to be adapted to the current requests.
The algorithms to solve the VNF-Chaining problem receive service requests in real time. Considering the established VNFs and both the VNF and the network availability, they must provide the SC to serve the user service request. When there are not enough resources to establish that SC, the service request is blocked.
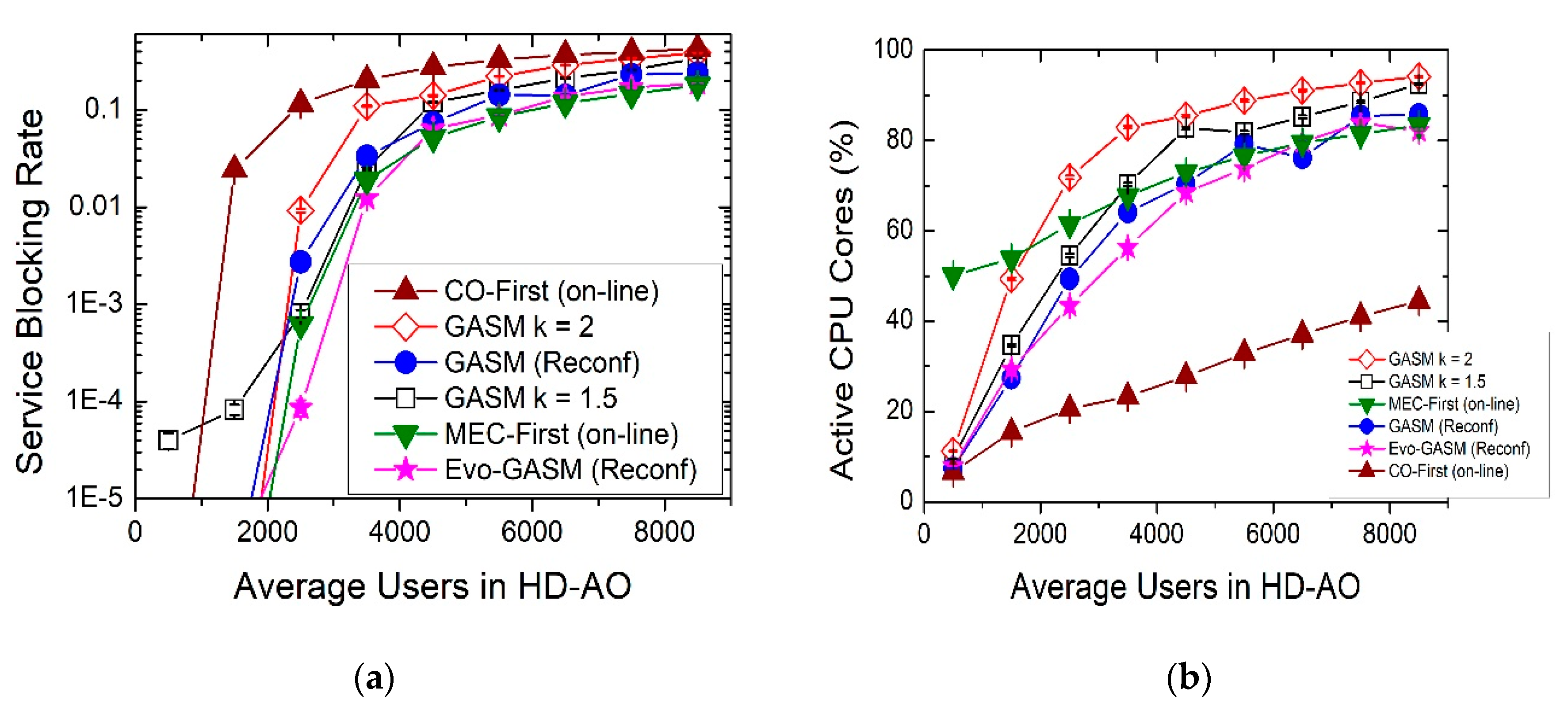
In this paper, we propose planning methods, based on genetic algorithms, with the objective of minimizing both the service blocking rate and CPU usage (and, therefore, the energy consumption). Moreover, we also show that the performance of the networks can improve by reconfiguring the VNF mapping.
3.3. VNF-Chaining Algorithms
As we have previously mentioned, the VNF-Provisioning problem consists of the VNF-Placement and the VNF-Chaining subproblems. This paper mainly proposes VNF-Placement algorithms. However, rather than operating in a completely agnostic way, those algorithms take into count how the VNF-Chaining subproblem is solved, in order to provide better solutions. Therefore, in this section we explain several approaches for solving the VNF-Chaining subproblem.
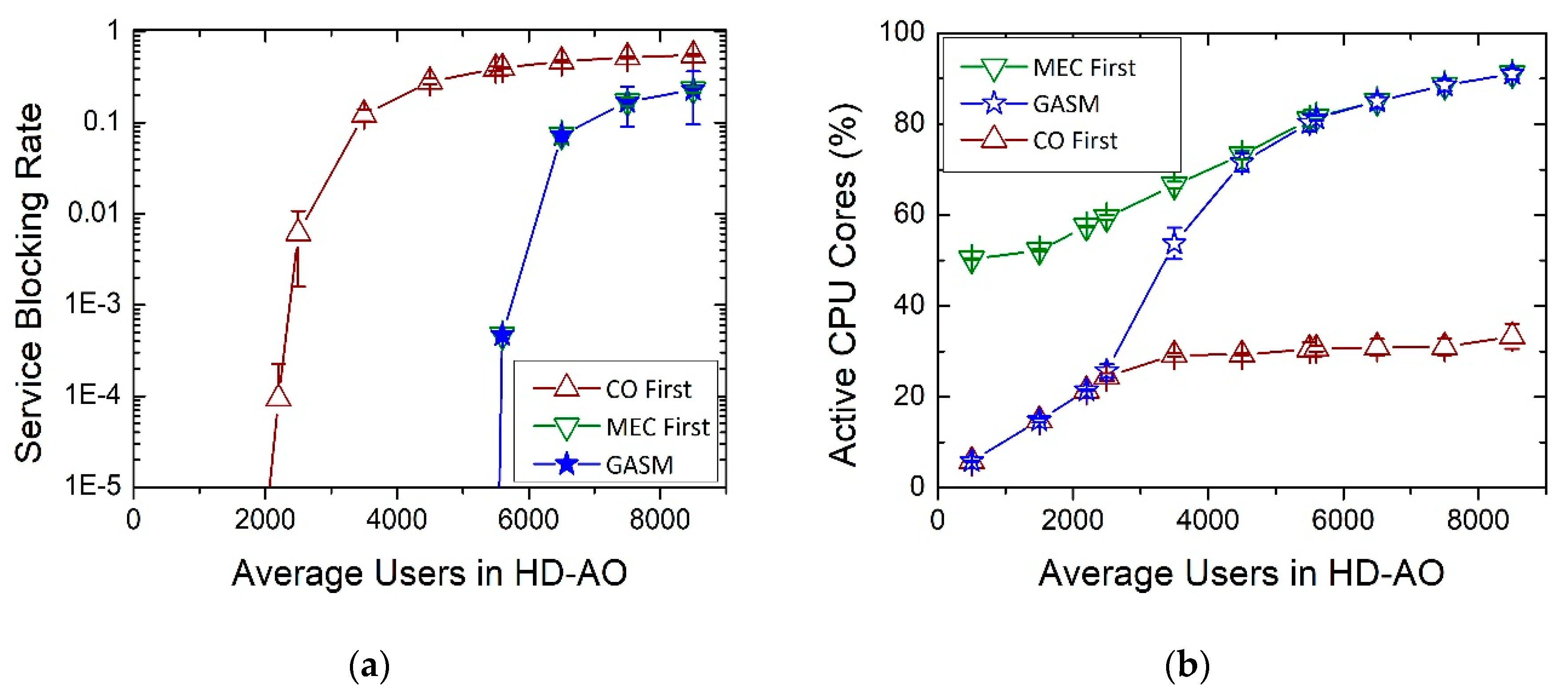
Authors in References [
32,
33] proposed a method to solve the complete VNF-Provisioning problem dynamically. That method, henceforth MEC-First, operates in the following manner: When a user service request arrives, the algorithm starts the chaining process by searching available instances of the VNF at the MEC server located at the AO serving the end user. If there are not available instances of the VNF, but the MEC server has enough idle IT resources to set up the required instances, the algorithm creates them. If the algorithm cannot concatenate more VNFs hosted in the MEC server at the local AO, due to either lack of instances or to lack of IT resources, and there is enough available network bandwidth between the local AO and the CO, the chaining process continues at the CO. In the CO the algorithm repeats the same procedure, that is, it tries to utilize existing VNF instances and, if unable, tries to create new ones. If the algorithm cannot utilize either the existing VNF instances or the IT resources of the CO, it will not look for existing resources back at any local MEC server (i.e., there are no loops or backtracking). Finally, the request is served if the SC is established, otherwise it is blocked. That methodology does not take into account the time required to set-up a VNF.
Based on MEC-First, we have developed a version of the method which only solves the VNF-Chaining problem. Therefore, the modified MEC-First dynamically solves the SC for each request, but it only employs the existing VNF instances that the planning method computed and allocated in the AOs and CO in the first stage, and it is not able to set up new ones at any node of the network. Consequently, when there are not enough VNF instances or network bandwidth to build the SC, the service is blocked.
Moreover, inspired in MEC-First, we also propose another method called CO-First, which operates in a similar manner: The algorithm starts the chaining process at the CO, first looking for existing instances of the required VNFs to establish the SC associated to the demanded traffic type. If there are not available instances, but there are enough IT resources at the CO, the algorithm sets up the necessary instances. If the chaining process cannot continue at the CO, due to lack of resources and there is enough available bandwidth between the CO and the local AO serving the end user, the chaining process continues at the local AO in the same manner, i.e., first employing existing instances of the required VNFs, then creating them if possible. Once in the AO, the algorithm is not able to use instances of the CO again. As in the previous method, if the SC is established then the traffic demand is served, otherwise is blocked. This method will be mainly used for performance comparison purposes.
In this paper, we use the modified MEC-First in order to solve the VNF-Chaining subproblem and, therefore, no VNF instances are created during the operation. The following subsections present the proposed method to solve the first stage, i.e., the VNF-Placement (or planning) method.
3.4. Genetic Algorithm for Service Mapping
Genetic algorithms are metaheuristics based on the mechanics of natural selection and evolution, which are commonly used to solve search and optimization problems [
35]. In this section, we present GASM (Genetic Algorithm for Service Mapping), a genetic algorithm that solves the VNF-Placement problem by planning the type and number of VNF instances to be instantiated in the MEC resource of AOs and CO. The algorithm takes into account the method used to build the required SCs to satisfy all the service requests of the users. Thanks to its use, it is possible to minimize, as its primary objective, the service blocking rate, and, as its secondary objective, the number of active CPU cores (and hence, the energy consumption), while considering restrictions in both the IT and network resources.
The basic version of GASM, which only operates on static scenarios, was presented in Reference [
14]. In GASM, each potential solution is considered as an individual and it is represented by a chromosome composed of genes. Each gene encodes the number of instances of a given VNF that each node must host.
Figure 2 shows an example of a chromosome employed by GASM. In this example, the AO
1 would host one instance of the VNF
1 and would not host instances of the VNF
n, whereas AO
m would host two instances of VNF
1 and four of VNF
n and the CO would host five instances of both VNFs.
When translating the chromosome (i.e., converting the chromosome into a solution of the problem), GASM simulates the creation of the number of instances of each VNF at each location as described in the chromosome. Next, the algorithm sorts the user service requests, according to the operator preferred priority. After that, the algorithm establishes the SC for each request, i.e., checks the corresponding SC associated with the service and searches for the required VNFs to build the chain. For the chaining process, the algorithm employs the modified MEC-First method described in the previous section, which only uses the existing instances that were established in the previous stage. Therefore, the policy initially searches for the required VNFs at the MEC server hosted at the AO attending the request. If the local MEC server does not host an available instance of the VNF, the algorithm tries to find an available one at the CO. Once in the CO, the algorithm will not look for instances of the VNF back at any local MEC server. A service blocking occurs when the algorithm is unable to set up the SC, be it for lack of IT resources or bandwidth availability in the network.
For the evolution GASM uses a classical genetic algorithm loop (Algorithm 1) [
35]. Firstly, it generates an initial population composed of a set of individuals randomly generated. Two ad-hoc individuals are also included to boost the performance of the algorithm. The first ad-hoc individual is the result of solving the VNF provisioning problem with the MEC-First policy as proposed in References [
32,
33], which was described in detail in the previous subsection. The second individual is the result of solving the VNF-Provisioning problem using the CO-First policy described in the previous subsection.
The next step executes classical genetic operators (“crossover” and “mutation”) [
35] in the population. The crossover (Algorithm 2) is done by randomly selecting two individuals from the population (parents), selecting an equal random position in both chromosomes, and then dividing those chromosomes into two parts. The offspring is produced by interchanging the second part of the parent chromosomes. The mutation (Algorithm 3) is applied to each gene with a probability:
mutationProbability. When the gene has to be mutated, a new value of that gene is generated using a random uniform distribution among the possible values of the gene. The resulting individual undergoes a validation procedure in which the algorithm tries to translate the solution, emulating the creation of the number of VNF instances in every host as its chromosome specifies. If the individual created is not valid, i.e., if the algorithm cannot create the indicated instances of each VNF in every host, due to lack of IT or network resources, it discards the chromosome and creates a new individual using the genetic operators (i.e., crossover and mutation). The algorithm repeats the process until achieving a desired population size. The last step is the calculation of two fitness parameters for each individual: The service blocking ratio and the percentage of required active CPU cores. The algorithm then selects the individuals with the best fitness performances to be the parent population of the following generation: GASM selects as preferred those individuals with a lower service blocking ratio and, to resolve the ties, it uses the number of actives CPU cores. The algorithm repeats this operation for as many generations as desired.
| Algorithm 1: GASM |
| 1: | procedure GASM(trafficEstimation, populationSize, nextPopulationSize, numberOfGenerations) |
| 2: | solution ← Ø |
| 3: | population ← Ø |
| 4: | population ← generateAdHocIndividuals |
| 5: | while size(population) < populationSize do |
| 6: | population ← population ∪ generateRandomIndividual |
| 7: | discardNonFeasibleSolutions(population) |
| 8: | end while |
| 9: | i ← 0 |
| 10: | while i < numberOfGenerations do |
| 11: | nextPopulation ← Ø |
| 12: | while size(nextPopulation) < nextPopulationSize do |
| 13: | nextPopulation ← nextPopulation ∪ crossover(population) |
| 14: | end while |
| 15: | nextPopulation ← mutation(nextPopulation) |
| 16: | discardNonFeasibleSolutions(nextPopulation) |
| 17: | nextPopulation ← population ∪ nextPopulation |
| 18: | nextPopulationIndividualFitness ← fitnessEvaluation(nextPopulation) |
| 19: | population, populationIndividualFitness ← selectFittestIndividuals(nextPopulation, nextPopulationIndividualFitness,
size = populationSize) |
| 20: | i ← i + 1 |
| 21: | end while |
| 22: | solution ← selectFittestIndividuals(population, populationIndividualFitness, size = 1) |
| 23: | if solution ≠ currentlyEstablishedSolution then |
| 24: | establishVNF(solution) |
| 25: | end if |
| 26: | end procedure |
At the end of the procedure, the algorithm returns the individual presenting the best performance in terms of service blocking ratio, or the solution with minor CPU core usage, if any tie appears. Hence, the result will represent the configuration of the NFV-enabled 5G network.
| Algorithm 2: Crossover |
| 1: | procedure crossover(population) |
| 2: | parentA ← random(population) |
| 3: | parentB ← random(population) |
| 4: | if parentA ≠ parentB then |
| 5: | randomPoint ← random(0, size(individualA)) |
| 6: | newIndividual[0, randomPoint −1] ← parentA[0, randomPoint −1] |
| 7: | newIndividual[randomPoint, size(parentB)-1] ← parentB[randomPoint, size(individual)-1] |
| 8: | end if |
| 9: | return result |
| 10: | end procedure |
| Algorithm 3: Mutation |
| 1: | procedure mutation(population, maxVNFPerLocation, mutationProbability) |
| 2: | for individual in population do |
| 3: | i ← 0 |
| 4: | while i < size(individual) do |
| 5: | if random(0, 1) < mutationProbability then |
| 6: | individual[gene] ← random(0, maxVNFPerLocation) |
| 7: | end if |
| 8: | i ← i + 1 |
| 9: | end while |
| 10: | end for |
| 11: | return population |
| 12: | end procedure |
3.5. Reconfiguring VNF Provisioning with GASM
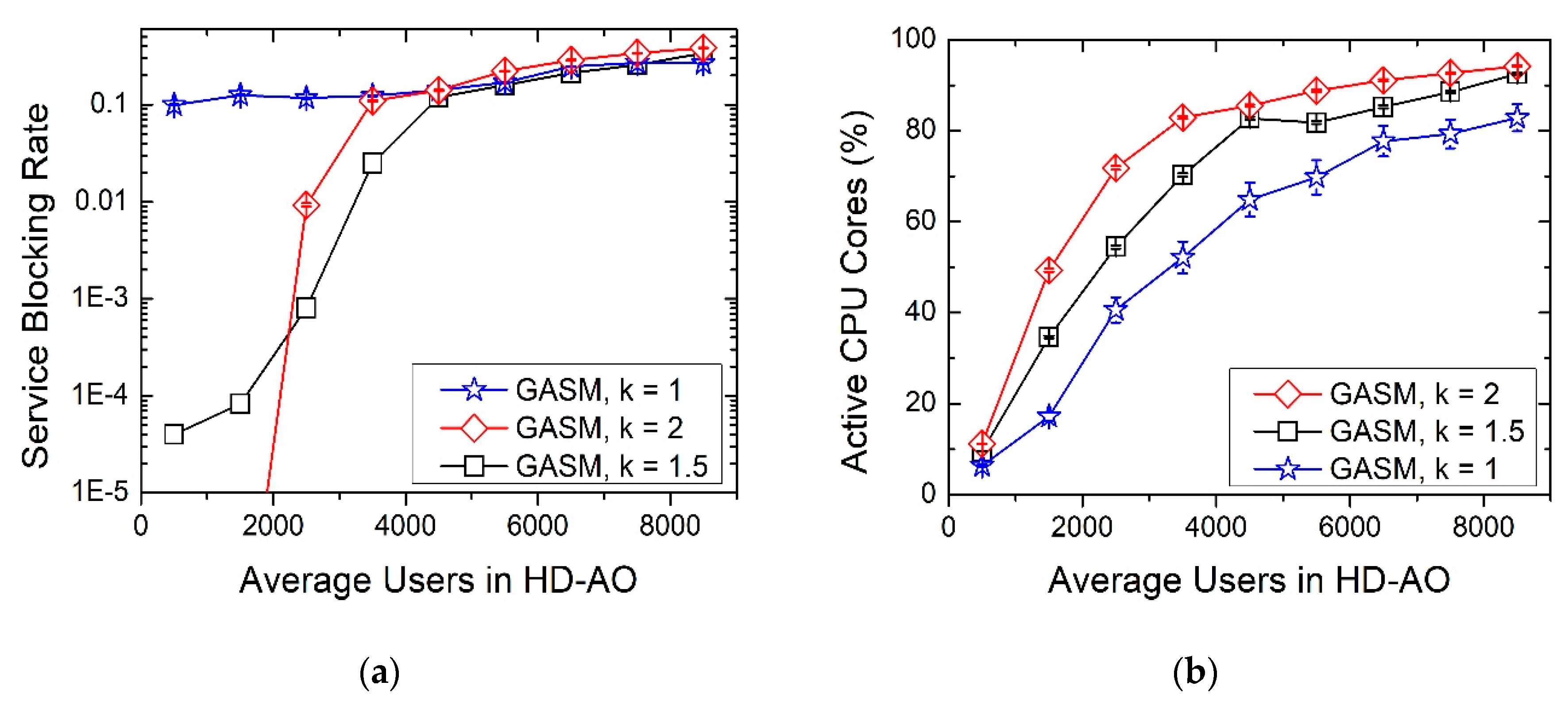
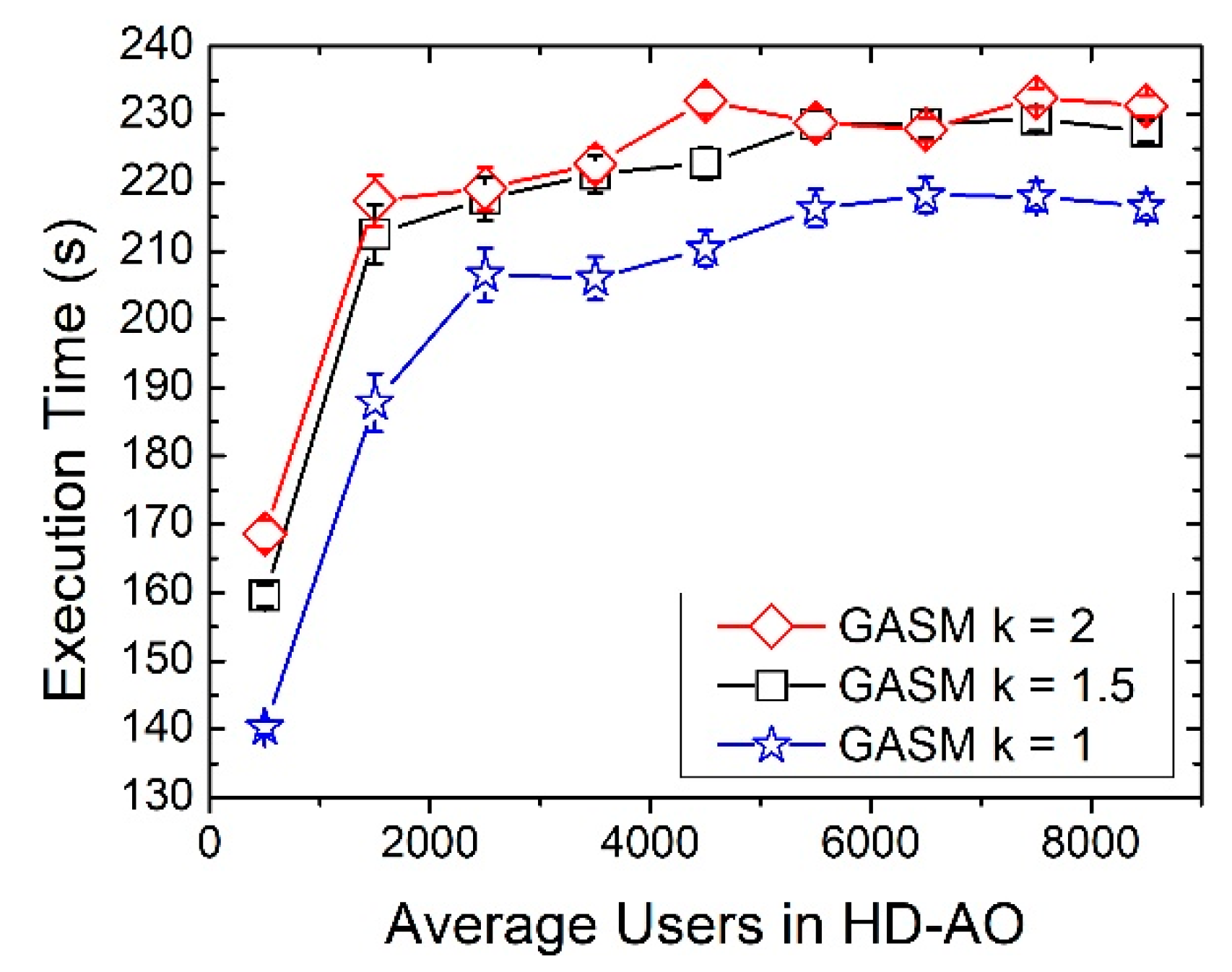
GASM provides a VNF-enabled network configuration well fitted to solve the service requests coming from a certain number of users, estimated as an average value. However, this kind of network design is not adapted to the time-varying traffic, therefore causing inefficient usage of IT resources. Consequently, a rise of the service blocking ratio may appear when the number of users is higher than the average. However, a decrease in the number of users may cause the over-consumption of IT resources, leading to a higher energy consumption.
In order to increase the performance of the network in a dynamic scenario, the best alternative is to reconfigure the VNF mapping. When a reconfiguring scenario is considered, the time is divided into time slots and the VNF provisioning algorithms are launched at the beginning of each slot. In order to predict the traffic in the following slot, we have considered a very simple method, shown in Equation (1):
where
represents the number of users at the next time slot (i.e., the estimation),
represents the current slot total number of users and
represents the total number of users at the previous temporal slot. The scale factor
is the maximum variation in the number of users (measured with traffic monitors) from one time slot to the next one, typically considering only a window of time, i.e., a day or a week. Despite its simplicity, this basic estimation method provides satisfactory results as will be shown in the following section. Once the traffic for the following time slot is estimated, GASM uses that information to determine a VNF provisioning and establish the new mapping in the IT resources of the MEC and CO.
3.6. Evolutive GASM
The performance of GASM in reconfiguration scenarios can be improved by including a simple learning technique. We will denote this new version of GASM by Evolutive GASM.
Since the simulation time is divided into discrete time slots, if the granularity of the step interval is sufficiently small, it is possible to assume that the traffic will not drastically change from one time slot to the next and, in consequence, it could be expected that the configuration for the current time slot will also present an adequate performance in the next. Therefore, Evolutive GASM utilizes the current provisioning configuration as one of the individuals of the initial population together with the ad-hoc individuals and the randomly generated ones, until completing the desired population size. The addition of this individual is expected to facilitate the search of a solution with better performance in terms of services blocking ratio or CPU usage than the resulting individual that GASM returns.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}