
Psychoacoustic Approaches for Harmonic Music Mixing †


Abstract
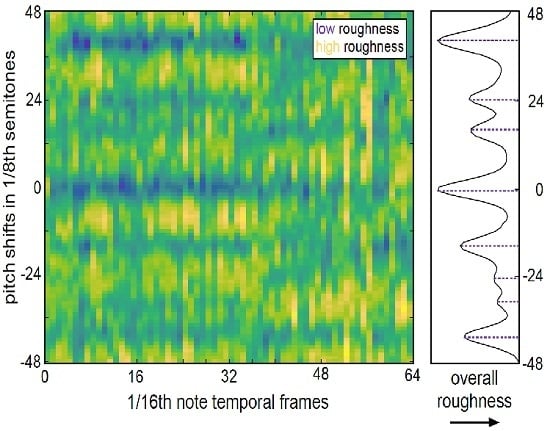
:
1. Introduction
2. Consonance Models
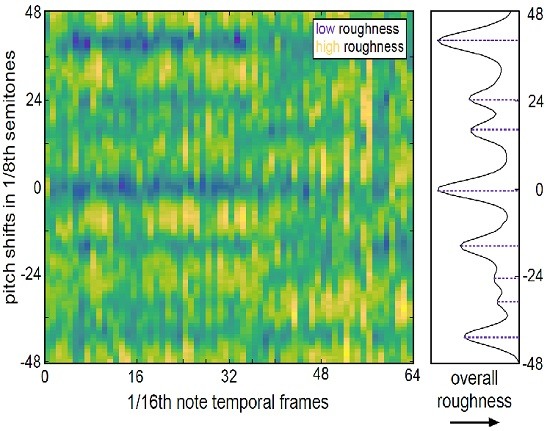
2.1. Roughness Model
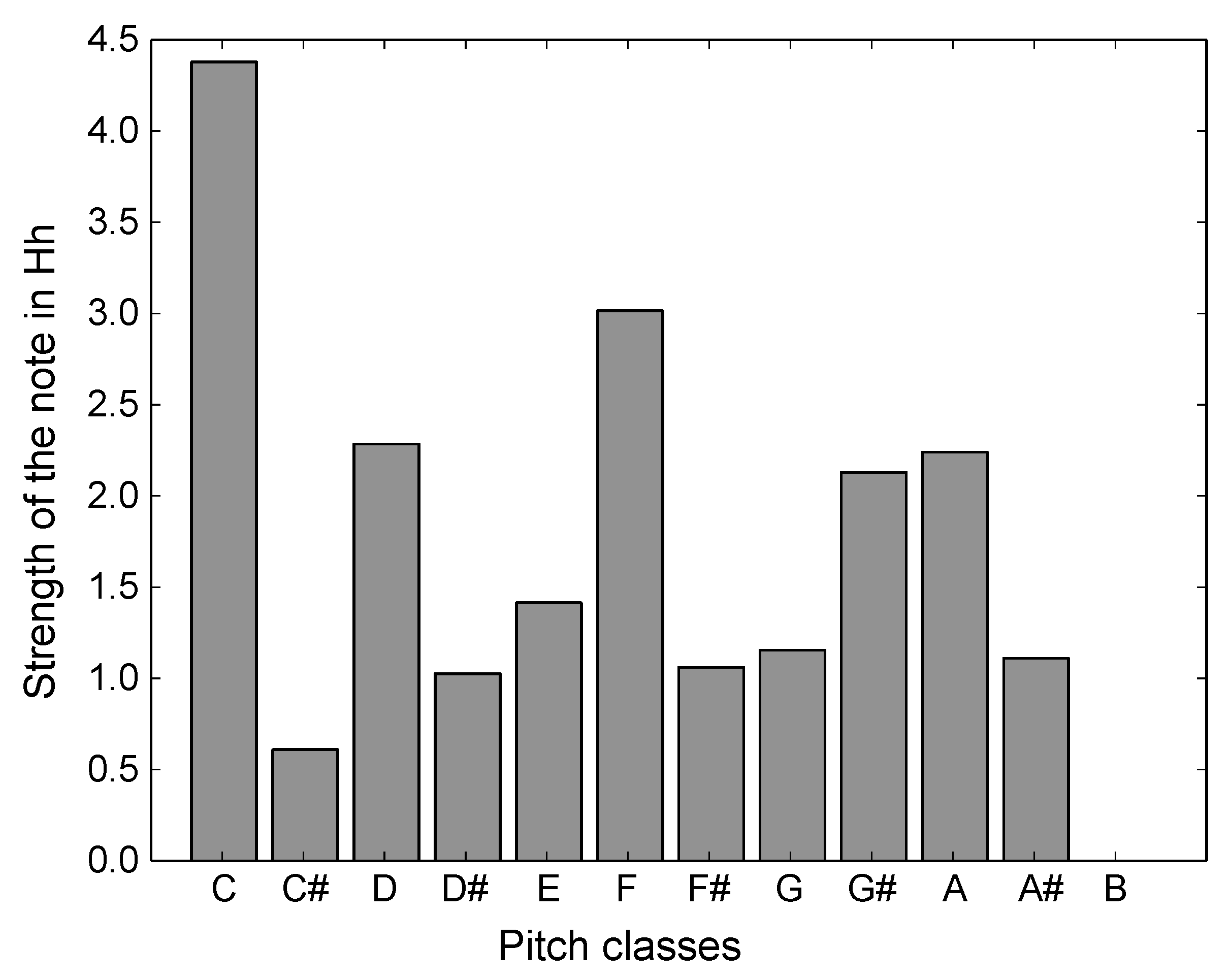
2.2. Pitch Commonality Model
2.2.1. Pitch Categorization
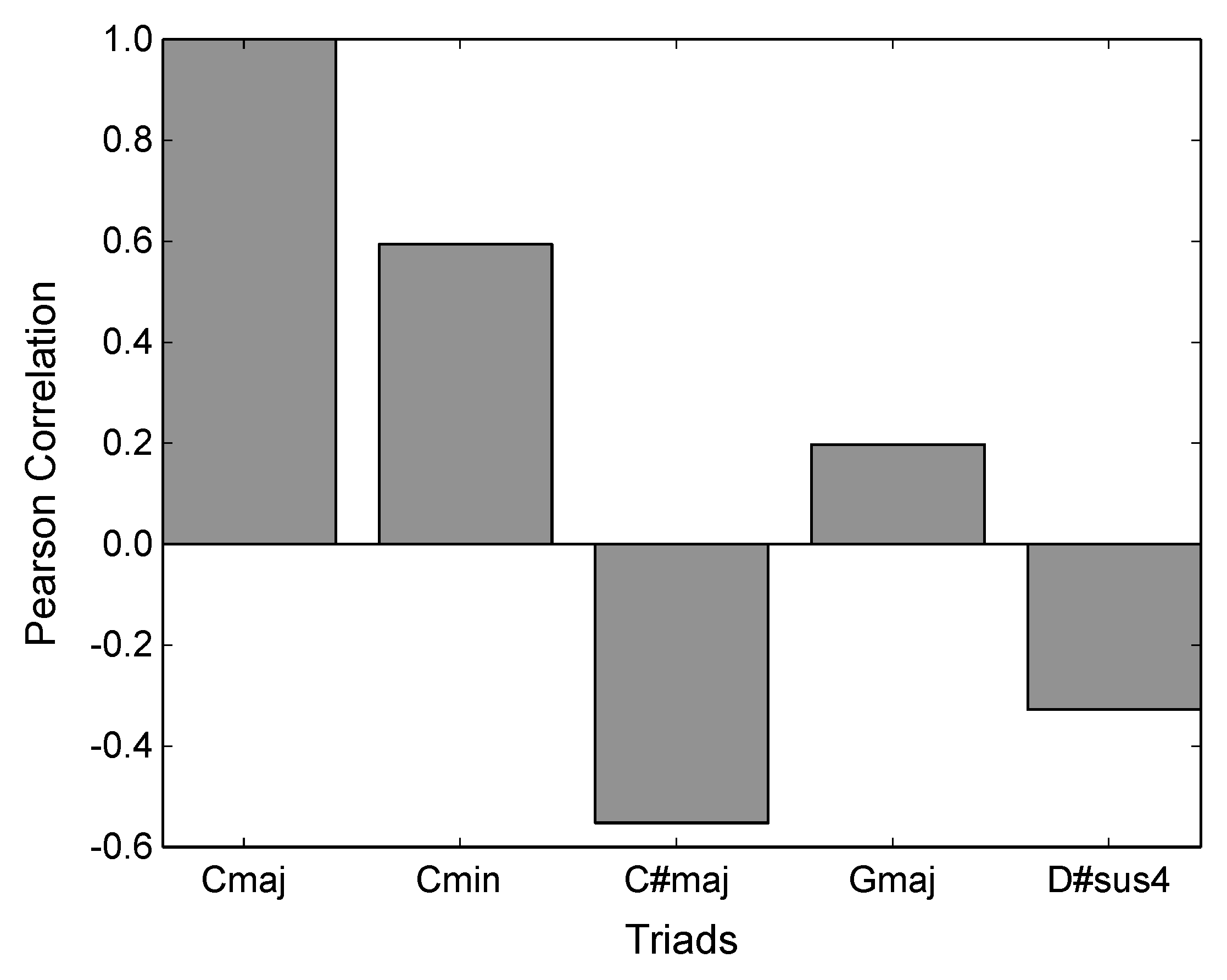
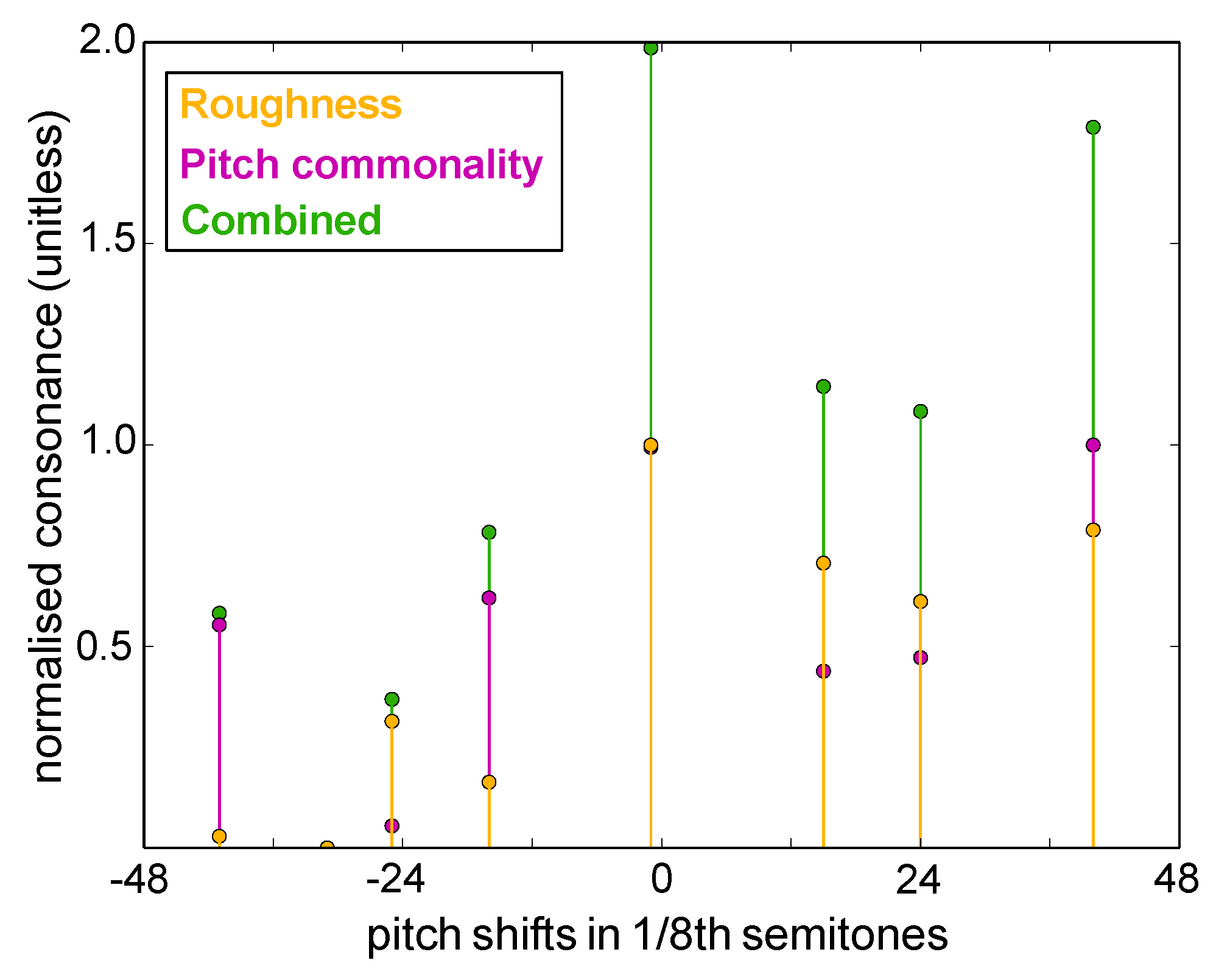
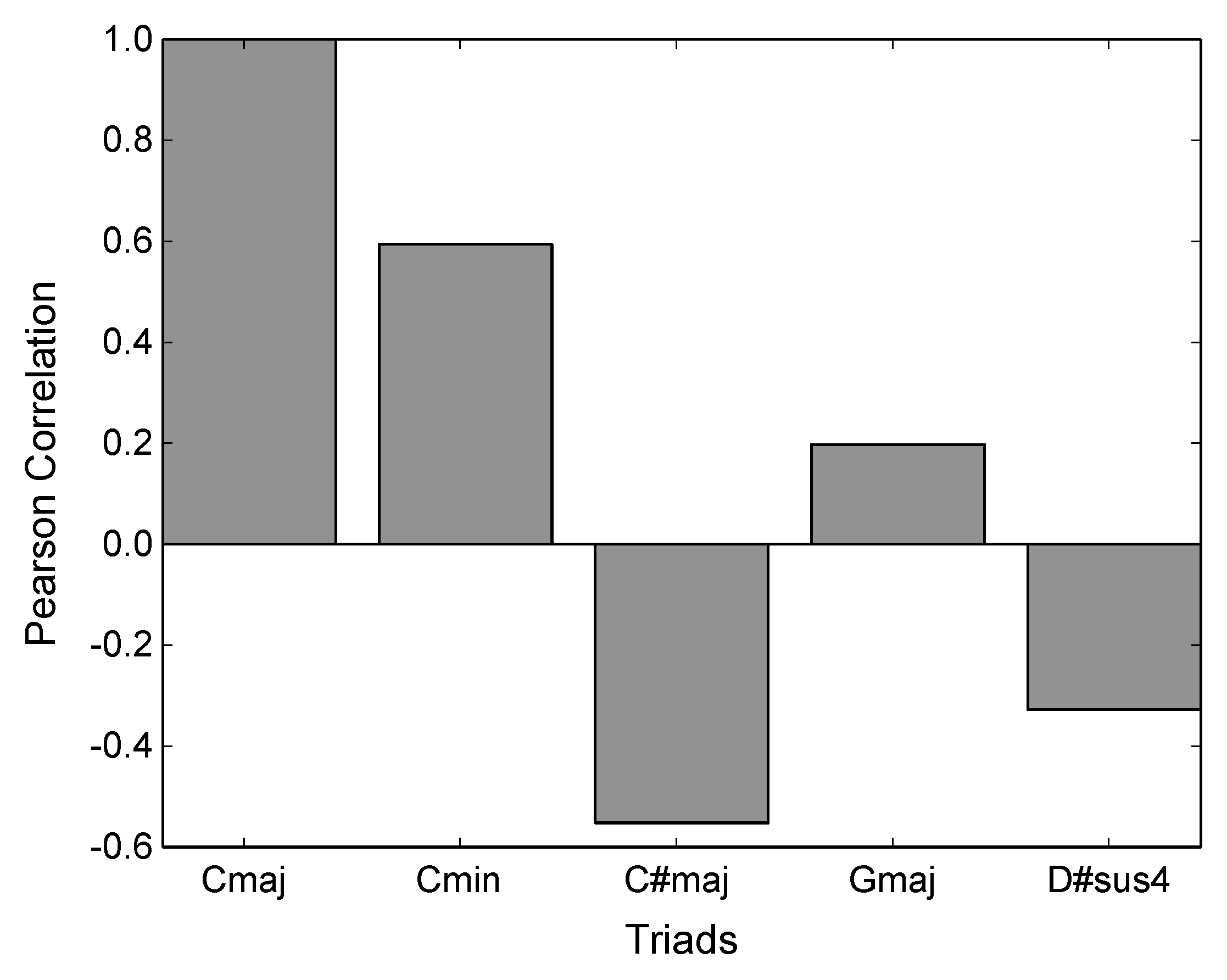
2.2.2. Pitch-Set Commonality and Harmonic Consonance
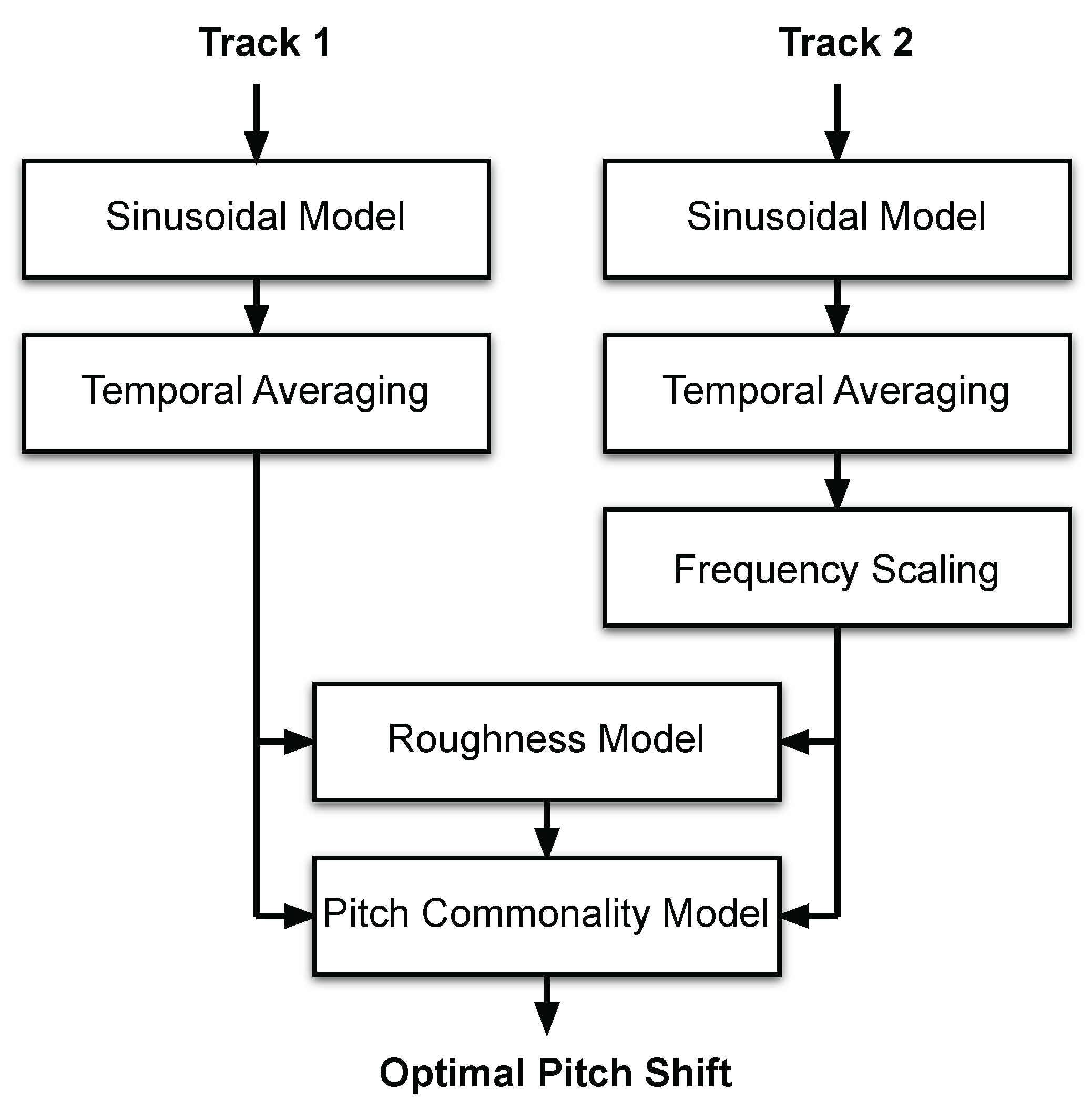
3. Consonance-Based Mixing
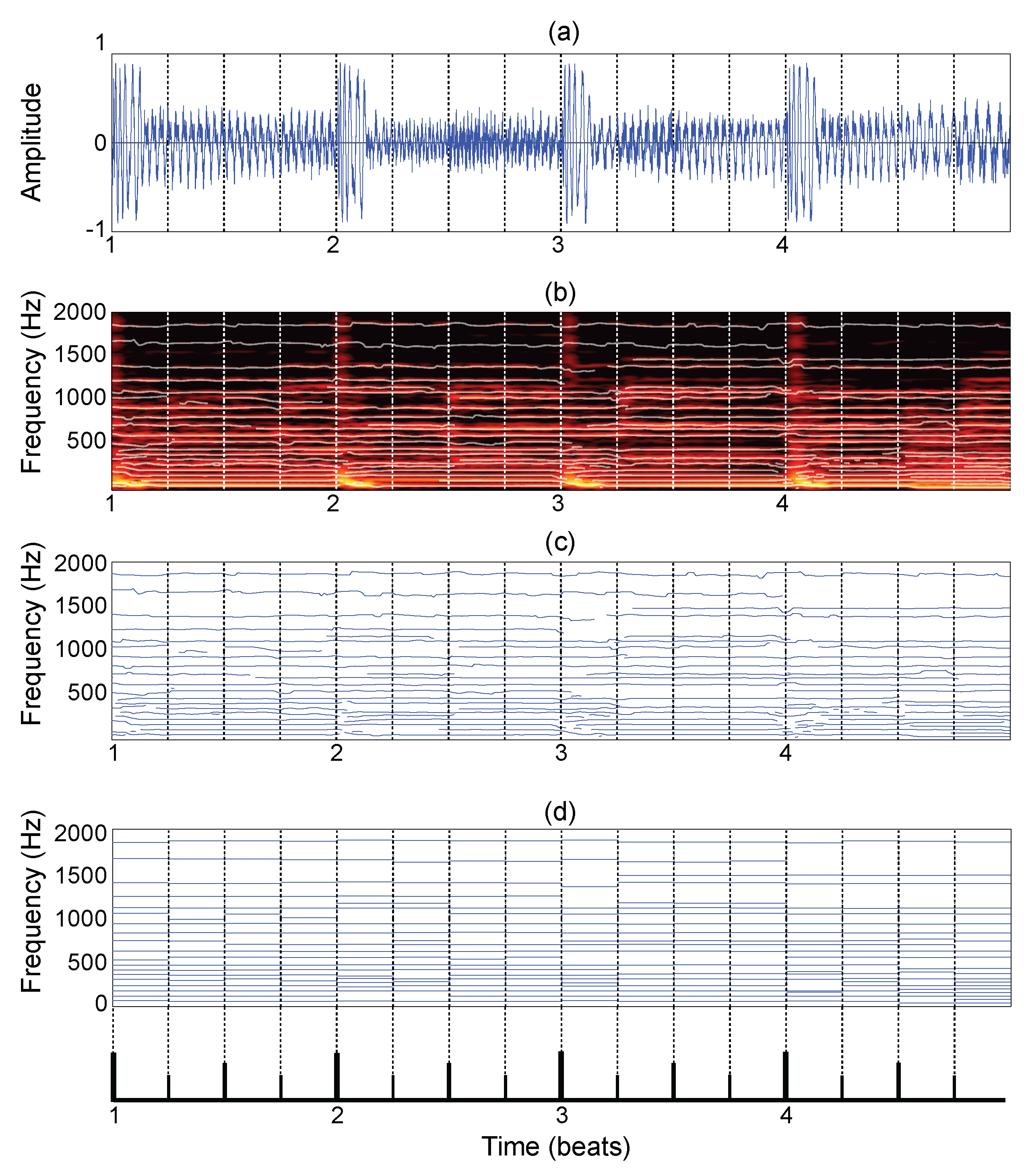
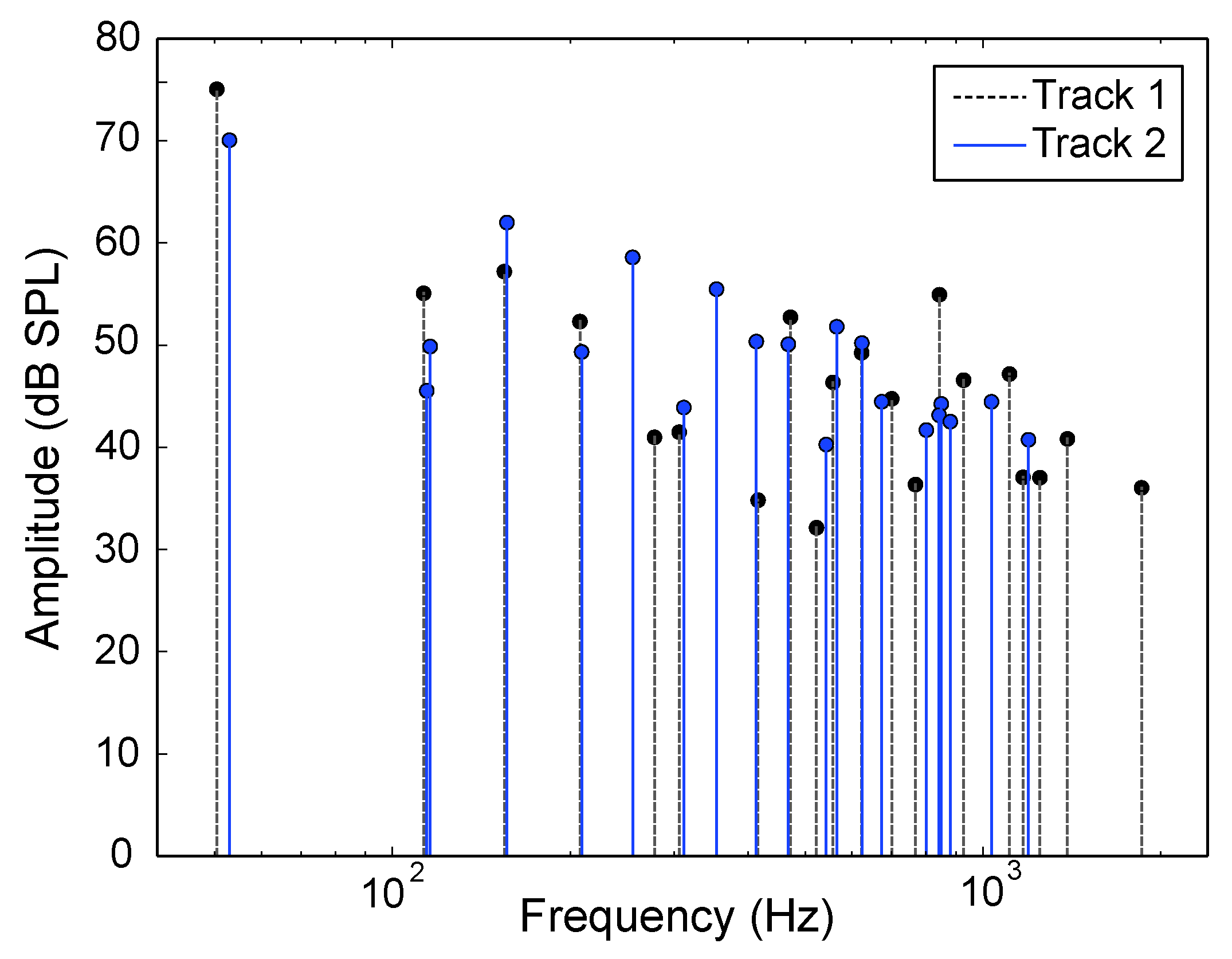
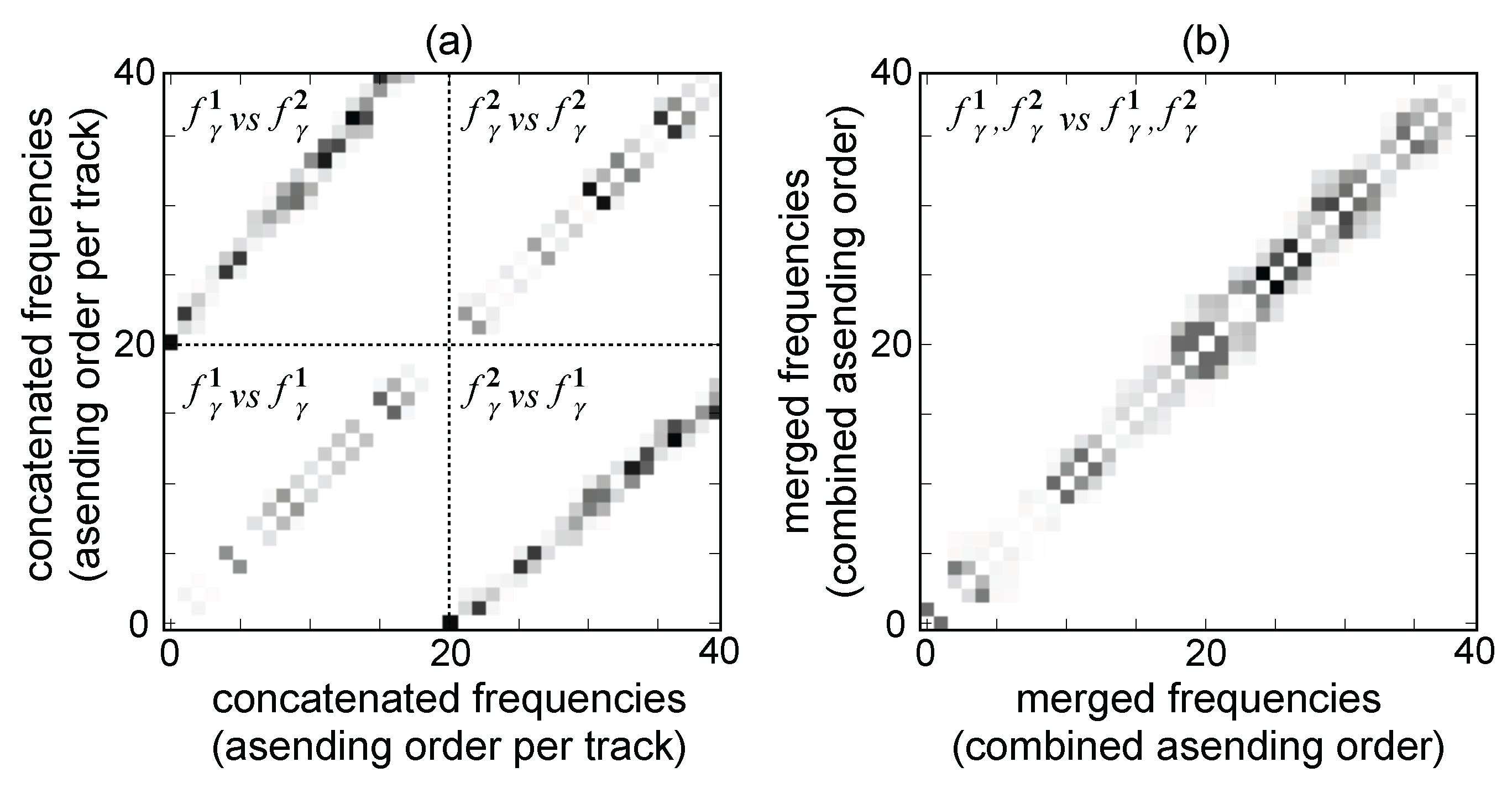
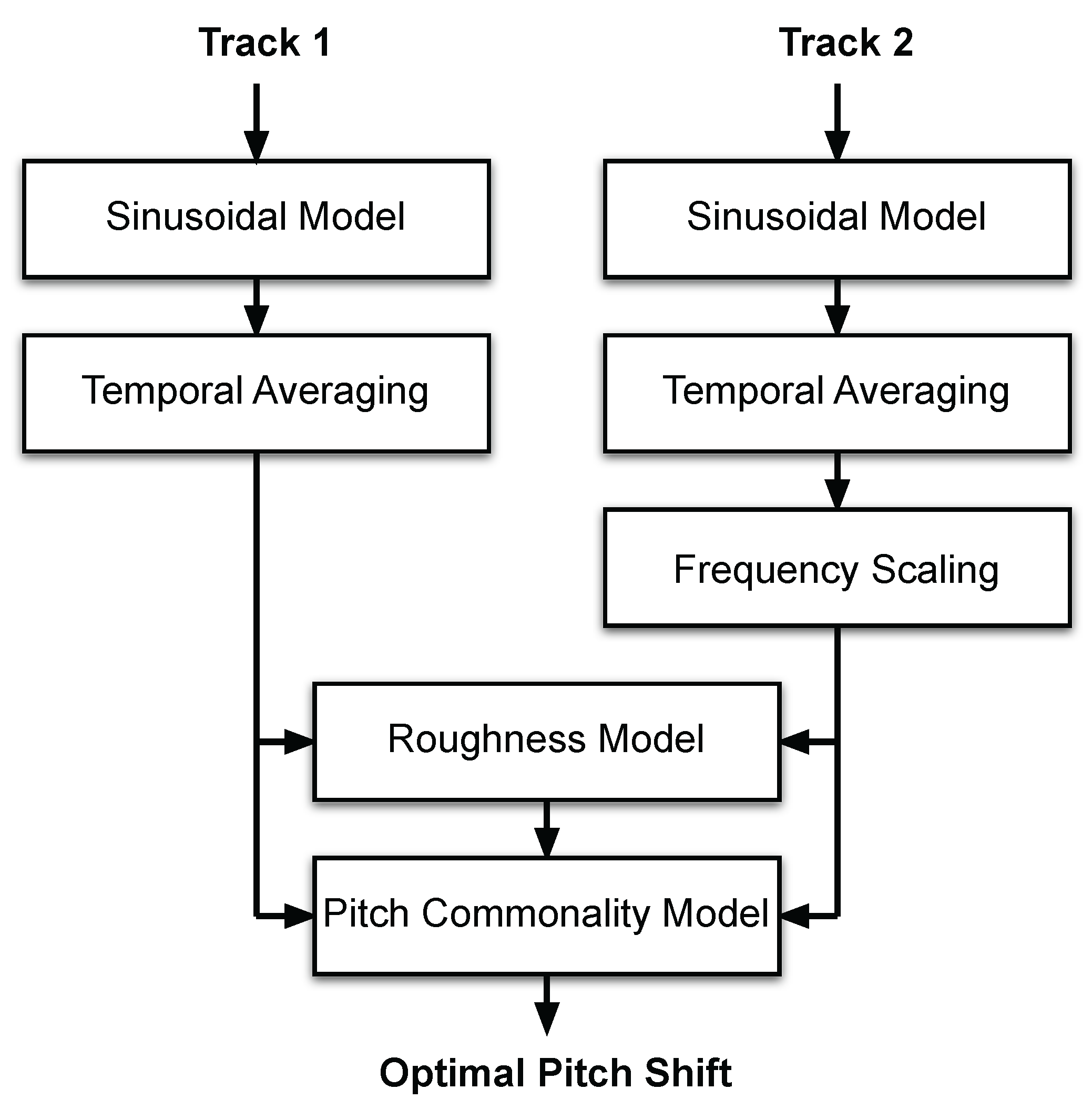
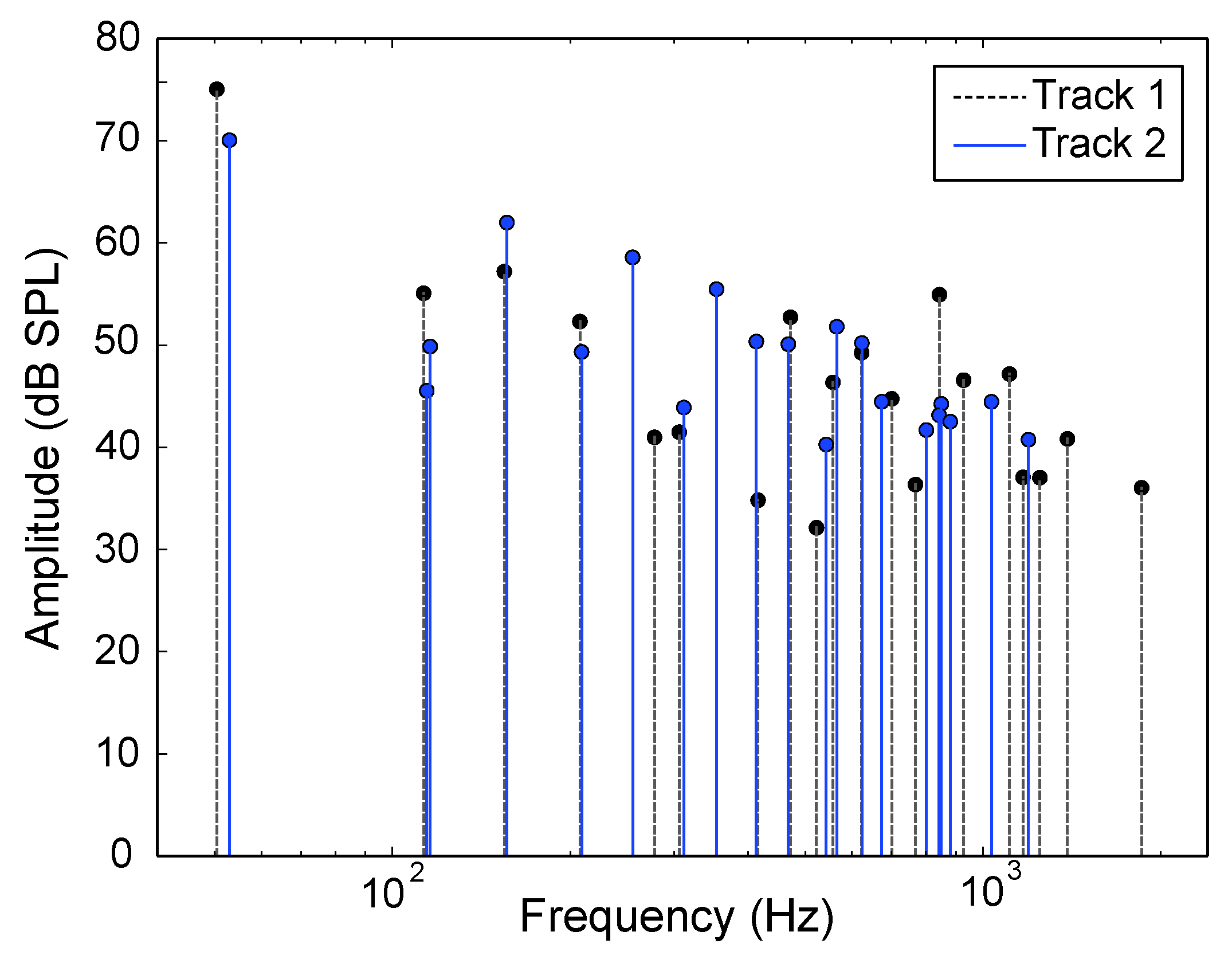
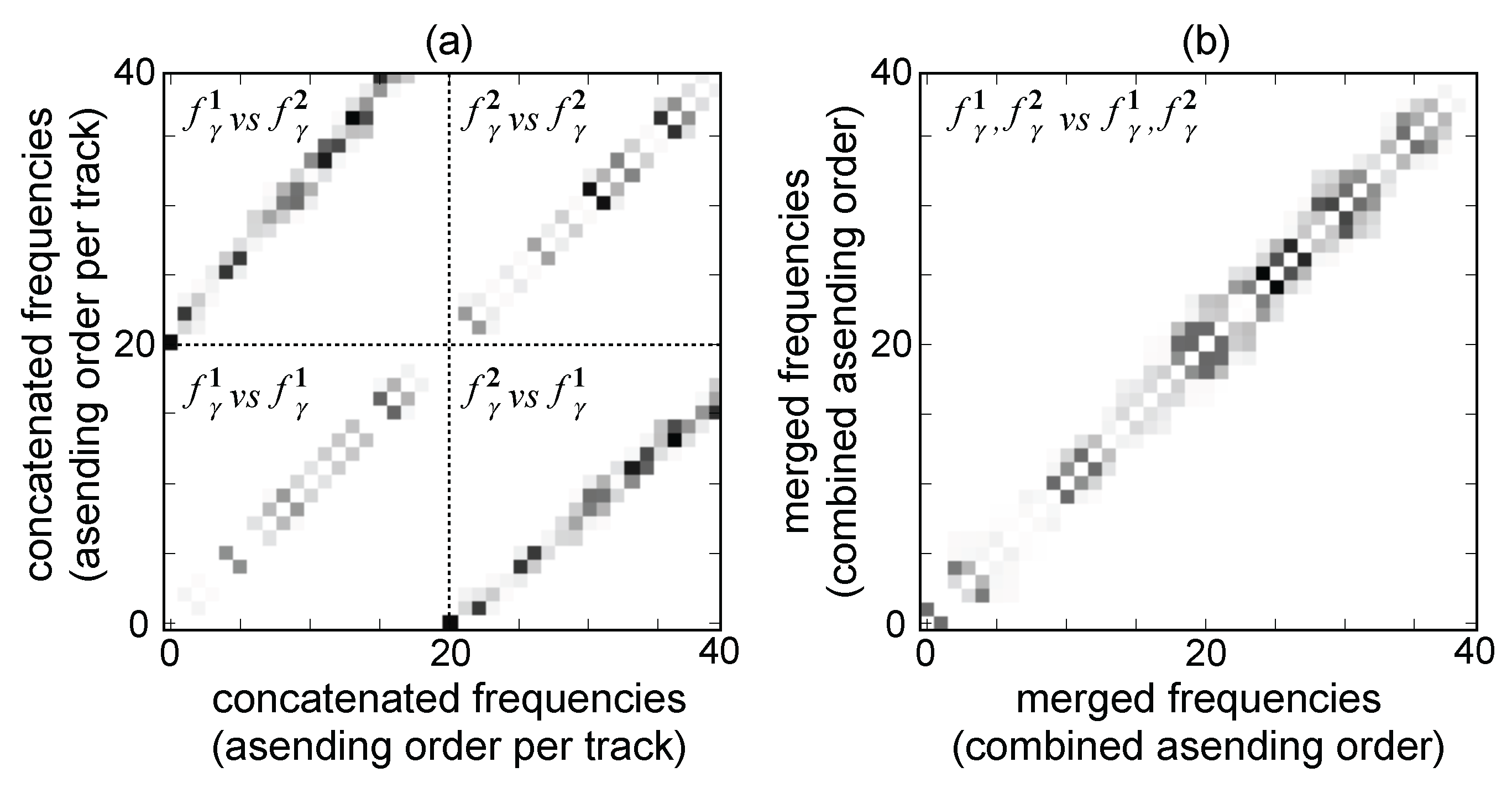
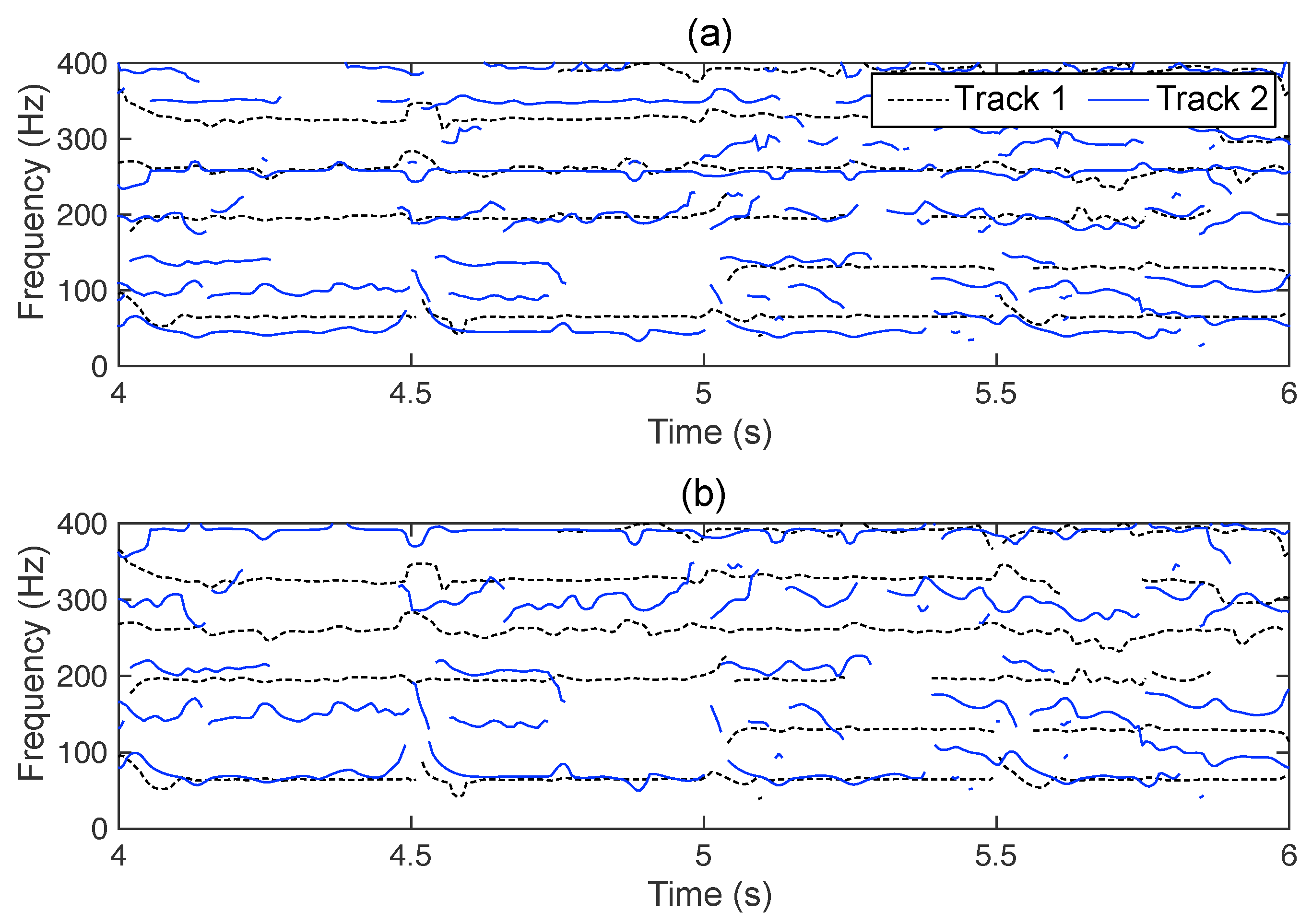
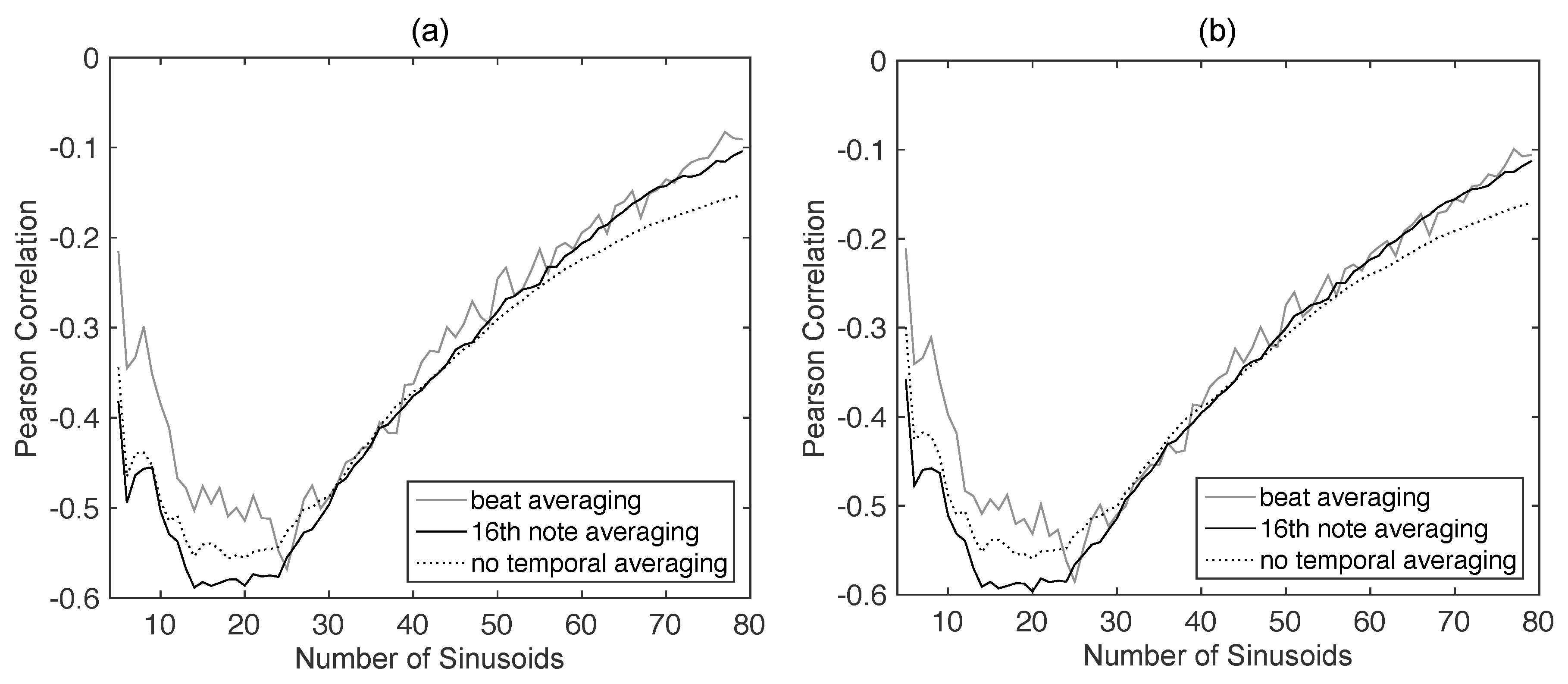
3.1. Data Collection and Pre-Processing
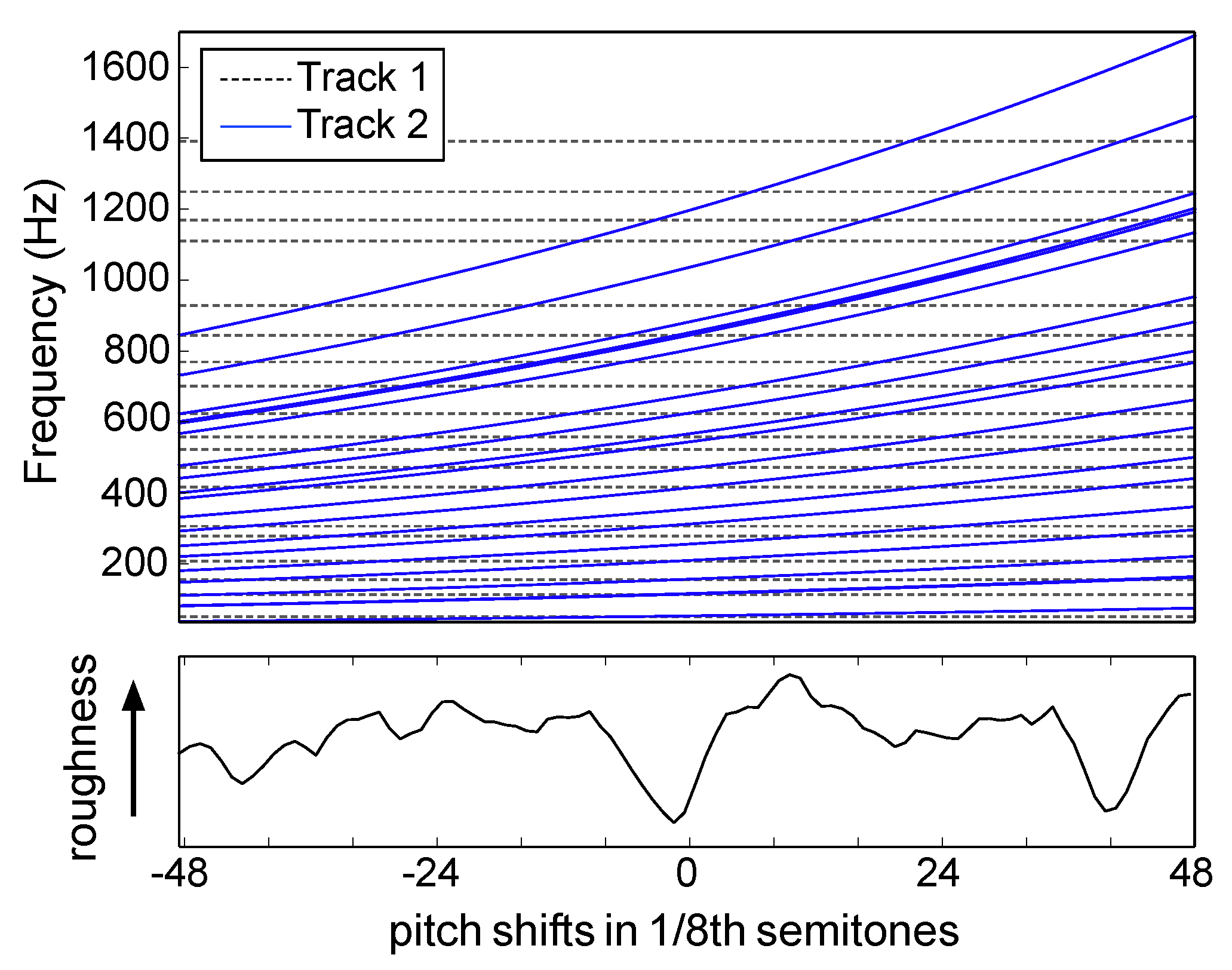
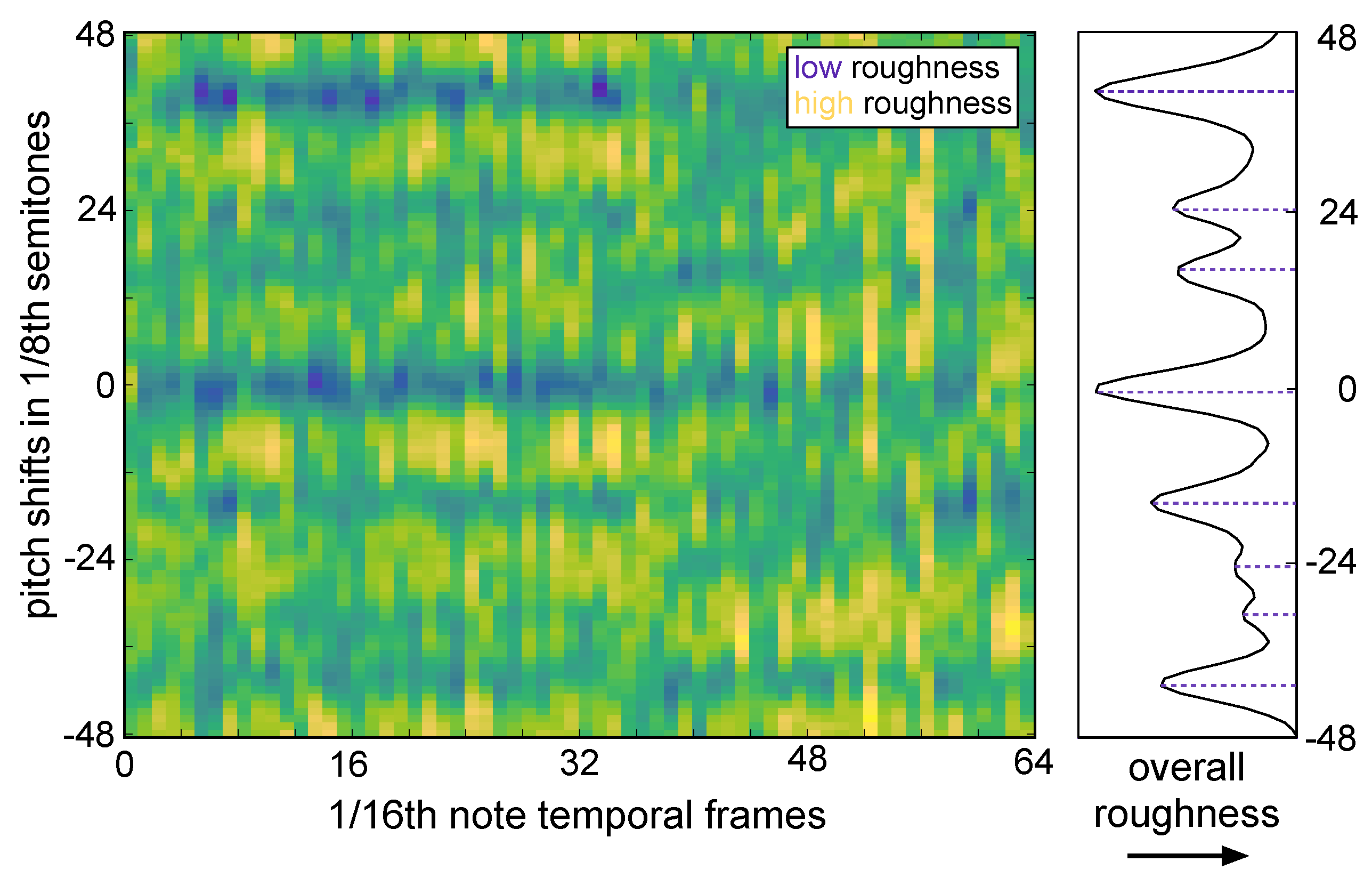
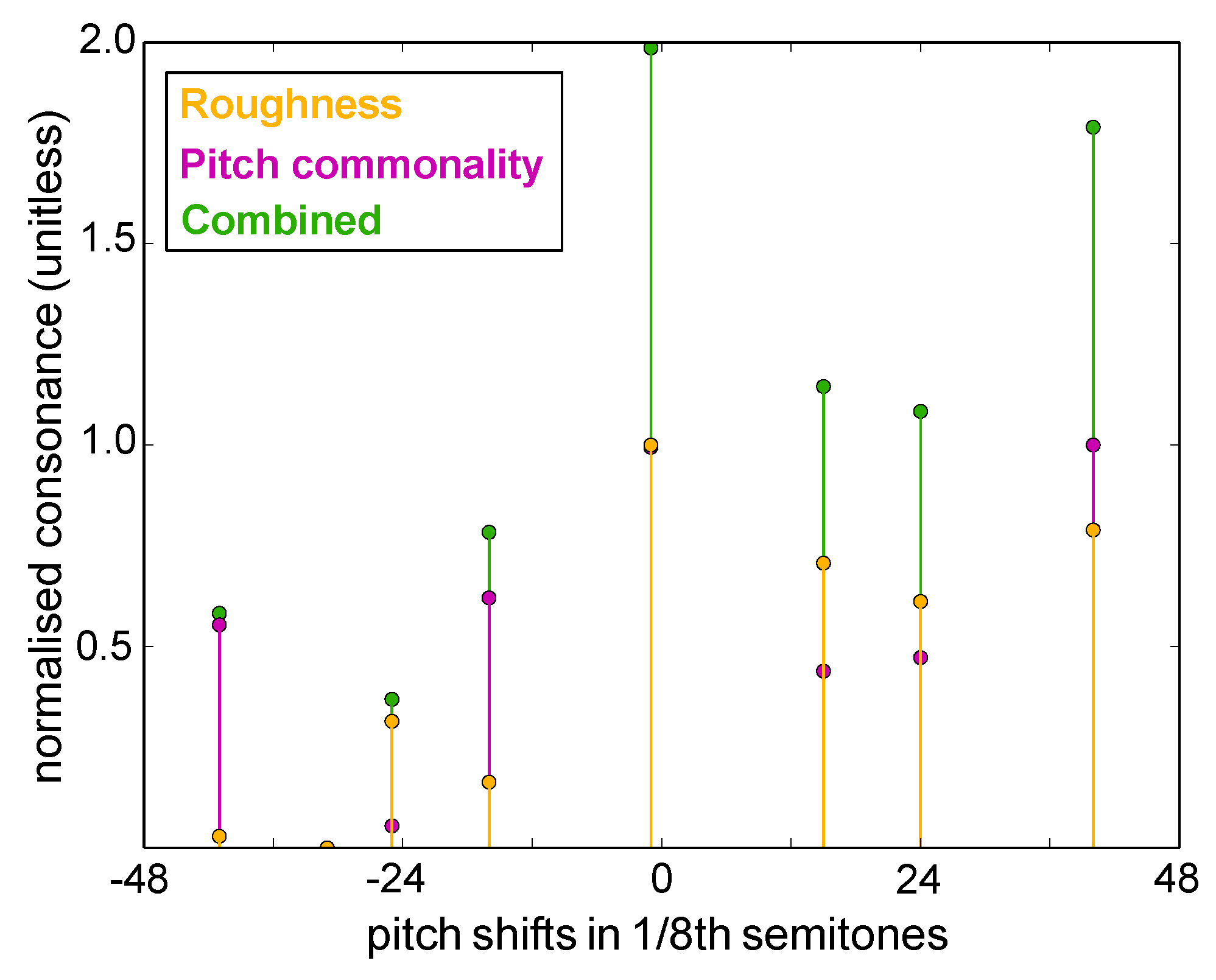
3.2. Consonance-Based Alignment
3.3. Post-Processing
4. Evaluation
4.1. Listening Test
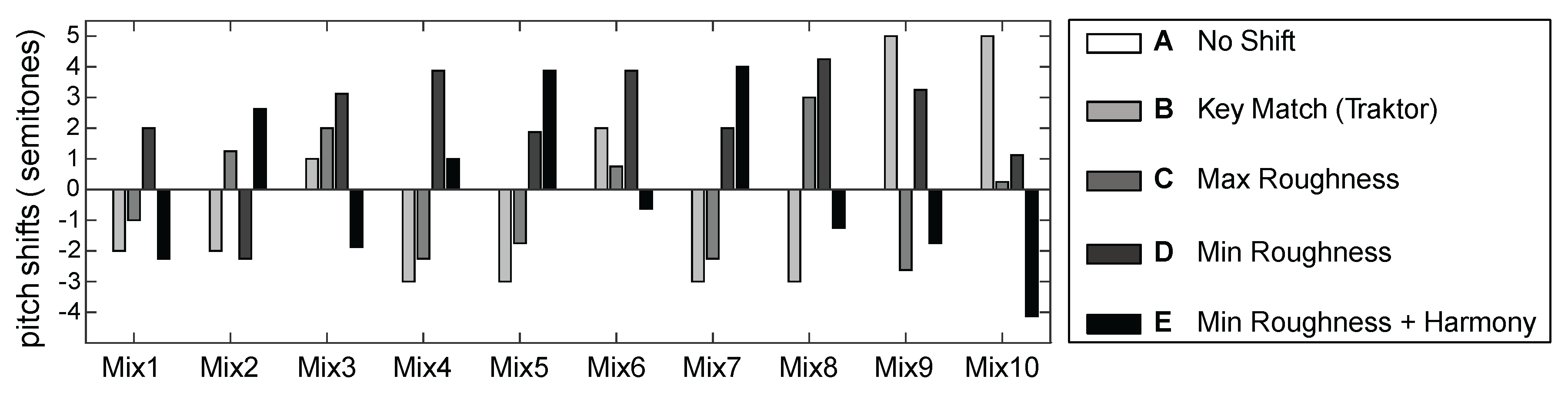
- A No shift: no attempt to harmonically align the excerpts; instead, the excerpts were only aligned in time by beat-matching.
- B Key match (Traktor): each excerpt was analyzed by Traktor 2 and the automatically-detected key recorded. The key-based mix was created by finding the smallest pitch shift necessary to create a harmonically-compatible mix according to the circle of fifths, as per the description in the Introduction.
- C Max roughness: the roughness curve was analyzed for local maxima, and the pitch shift with the highest roughness (i.e., most dissonant) was chosen to mix the excerpts.
- D Min roughness: the roughness curve was analyzed for local minima, and the pitch shift with the lowest roughness (i.e., most consonant) was chosen to mix the excerpts.
- E Min roughness and harmony: from the set of extracted minima in Condition D, the combined harmonic consonance and roughness was calculated, and the pitch shift yielding the maximum overall consonance was selected to mix the excerpts.
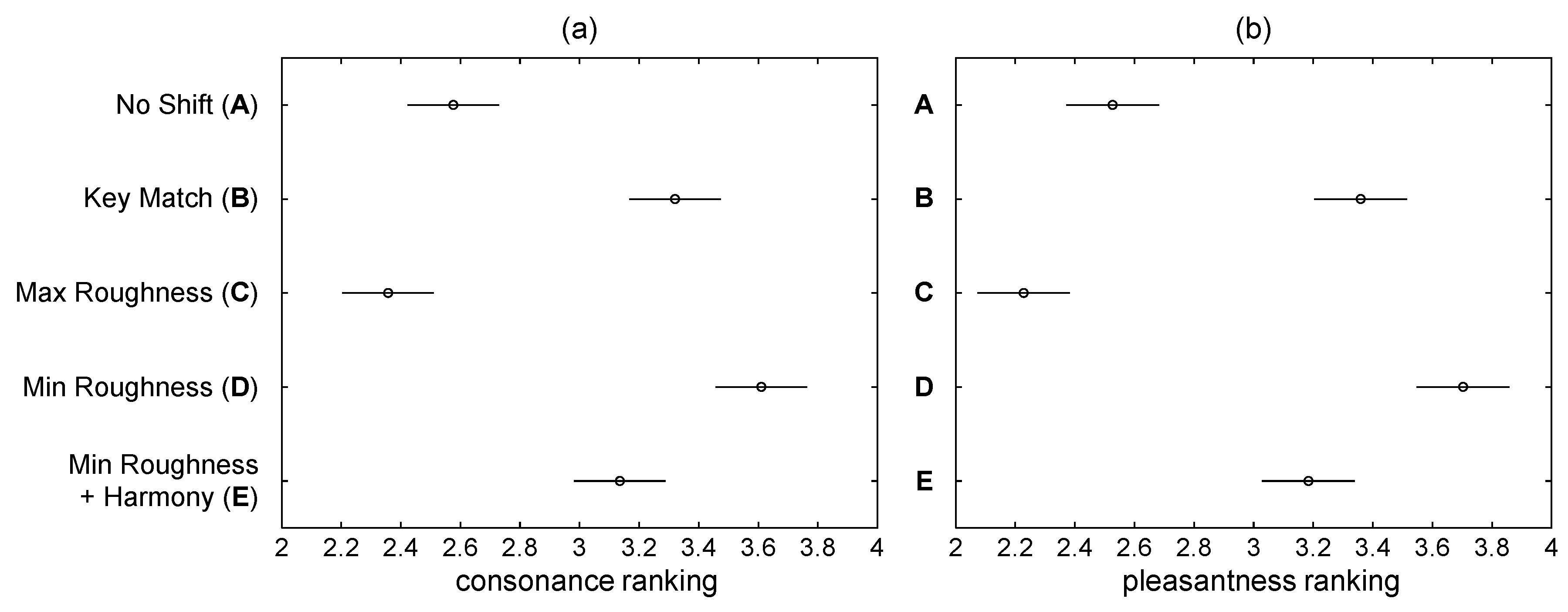
4.2. Results
4.2.1. Statistical Analysis
4.2.2. Effect of Parameterization
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ishizaki, H.; Hoashi, K.; Takishima, Y. Full-automatic DJ mixing with optimal tempo adjustment based on measurement function of user discomfort. In Proceedings of the International Society for Music Information Retrieval Conference, Kobe, Japan, 26–30 October 2009; pp. 135–140.
- Sha’ath, I. Estimation of Key in Digital Music Recordings. Master’s Thesis, Birkbeck College, University of London, London, UK, 2011. [Google Scholar]
- Davies, M.E.P.; Hamel, P.; Yoshii, K.; Goto, M. AutoMashUpper: Automatic creation of multi-song mashups. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1726–1737. [Google Scholar] [CrossRef]
- Lee, C.L.; Lin, Y.T.; Yao, Z.R.; Li, F.Y.; Wu, J.L. Automatic Mashup Creation By Considering Both Vertical and Horizontal Mashabilities. In Proceedings of the International Society for Music Information Retrieval Conference, Malaga, Spain, 26–30 October 2015; pp. 399–405.
- Terhardt, E. The concept of musical consonance: A link between music and psychoacoustics. Music Percept. 1984, 1, 276–295. [Google Scholar] [CrossRef]
- Terhardt, E. Akustische Kommunikation (Acoustic Communication); Springer: Berlin, Germany, 1998. (In German) [Google Scholar]
- Gebhardt, R.; Davies, M.E.P.; Seeber, B. Harmonic Mixing Based on Roughness and Pitch Commonality. In Proceedings of the 18th International Conference on Digital Audio Effects (DAFx-15), Trondheim, Norway, 30 November–3 December 2015; pp. 185–192.
- Hutchinson, W.; Knopoff, L. The significance of the acoustic component of consonance of Western triads. J. Musicol. Res. 1979, 3, 5–22. [Google Scholar] [CrossRef]
- Parncutt, R. Harmony: A Psychoacoustical Approach; Springer: Berlin, Germany, 1989. [Google Scholar]
- Hofman-Engl, L. Virtual Pitch and Pitch Salience in Contemporary Composing. In Proceedings of the VI Brazilian Symposium on Computer Music, Rio de Janeiro, Brazil, 19–22 July 1999.
- Parncutt, R.; Strasburger, H. Applying psychoacoustics in composition: “Harmonic” progressions of “non-harmonic” sonorities. Perspect. New Music 1994, 32, 1–42. [Google Scholar] [CrossRef]
- Hutchinson, W.; Knopoff, L. The acoustic component of western consonance. Interface 1978, 7, 1–29. [Google Scholar] [CrossRef]
- Plomp, R.; Levelt, W.J.M. Tonal consonance and critical bandwidth. J. Acoust. Soc. Am. 1965, 38, 548–560. [Google Scholar] [CrossRef] [PubMed]
- Sethares, W. Tuning, Tibre, Spectrum, Scale, 2nd ed.; Springer: London, UK, 2004. [Google Scholar]
- Bañuelos, D. Beyond the Spectrum of Music: An Exploration through Spectral Analysis of SoundColor in the Alban Berg Violin Concerto; VDM: Saarbrücken, Germany, 2008. [Google Scholar]
- Parncutt, R. Parncutt’s Implementation of Hutchinson & Knopoff. 1978. Available online: http://uni-graz.at/parncutt/rough1doc.html (accessed on 28 January 2016).
- Moore, B.; Glassberg, B. Suggested formulae for calculating auditory-filter bandwidths and excitation patterns. J. Acoust. Soc. Am. 1983, 74, 750–753. [Google Scholar] [CrossRef] [PubMed]
- MacCallum, J.; Einbond, A. Real-Time Analysis of Sensory Dissonance. In Computer Music Modeling and Retrieval. Sense of Sounds; Kronland-Martinet, R., Ystad, S., Jensen, K., Eds.; Springer: Berlin, Germany, 2008; Volume 4969, pp. 203–211. [Google Scholar]
- Vassilakis, P.N. SRA: A Web-based Research Tool for Spectral and Roughness Analysis of Sound Signals. In Proceedings of the Sound and Music Computing Conference, Lefkada, Greece, 11–13 July 2007; pp. 319–325.
- Terhardt, E.; Seewan, M.; Stoll, G. Algorithm for Extraction of Pitch and Pitch Salience from Complex Tonal Signals. J. Acoust. Soc. Am. 1982, 71, 671–678. [Google Scholar] [CrossRef]
- Hesse, A. Zur Ausgeprägtheit der Tonhöhe gedrosselter Sinustöne (Pitch Strength of Partially Masked Pure Tones). In Fortschritte der Akustik; DPG-Verlag: Bad-Honnef, Germany, 1985; pp. 535–538. (In German) [Google Scholar]
- Apel, W. The Harvard Dictionary of Music, 2nd ed.; Harvard University Press: Cambridge, UK, 1970. [Google Scholar]
- Hofman-Engl, L. Virtual Pitch and the Classification of Chords in Minor and Major Keys. In Proceedings of the ICMPC10, Sapporo, Japan, 25–29 August 2008.
- Rubber Band Library. Available online: http://breakfastquay.com/rubberband/ (accessed on 19 January 2016).
- Serra, X. SMS-tools. Available online: https://github.com/MTG/sms-tools (accessed on 19 January 2016).
- Serra, X.; Smith, J. Spectral modeling synthesis: A sound analysis/synthesis based on a deterministic plus stochastic decomposition. Comput. Music J. 1990, 14, 12–24. [Google Scholar] [CrossRef]
- Robinson, D. Perceptual Model for Assessment of Coded Audio. Ph.D. Thesis, University of Essex, Colchester, UK, March 2002. [Google Scholar]
- Native Instruments Traktor Pro 2 (version 6.1). Available online: http://www.native-instruments.com/en/products/traktor/dj-software/traktor-pro-2/ (accessed on 28 January 2016).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | A | B | C | D | E |
|---|---|---|---|---|---|
| A | x | 92 | 7 | 56 | 45 |
| B | x | 2 | 100 | 81 | |
| C | x | 0 | 0 | ||
| D | x | 385 | |||
| E | x |
| Mix No. | Artist | Track Title | Annotated Key |
|---|---|---|---|
| 1a | Person Of Interest | Plotting With A Double Deuce | (E) |
| 1b | Locked Groove | Dream Within A Dream | A maj |
| 2a | Stephen Lopkin | The Haggis Trap | (A) |
| 2b | KWC 92 | Night Drive | D# min |
| 3a | Legowelt | Elementz Of Houz Music (Actress Mix 1) | B min |
| 3b | Aroy Dee | Blossom | D# min |
| 4a | ##### | #####.1 | A min |
| 4b | Barnt | Under His Own Name But Also Sir | C min |
| 5a | Julius Steinhoff | The Cloud Song | D min |
| 5b | Donato Dozzy & Tin Man | Test 7 | F min |
| 6a | R-A-G | Black Rain (Analogue Mix) | (E) |
| 6b | Lauer | Highdimes | (F) |
| 7a | Massimiliano Pagliari | JP4-808-P5-106-DEP5 | (C) |
| 7b | Levon Vincent | The Beginning | D# min |
| 8a | Roman Flügel | Wilkie | C min |
| 8b | Liit | Islando | D# min |
| 9a | Tin Man | No New Violence | C min |
| 9b | Luke Hess | Break Through | A min |
| 10a | Anton Pieete | Waiting | A min |
| 10b | Voiski | Wax Fashion | (E) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gebhardt, R.B.; Davies, M.E.P.; Seeber, B.U. Psychoacoustic Approaches for Harmonic Music Mixing. Appl. Sci. 2016, 6, 123. https://doi.org/10.3390/app6050123
Gebhardt RB, Davies MEP, Seeber BU. Psychoacoustic Approaches for Harmonic Music Mixing. Applied Sciences. 2016; 6(5):123. https://doi.org/10.3390/app6050123
Chicago/Turabian StyleGebhardt, Roman B., Matthew E. P. Davies, and Bernhard U. Seeber. 2016. "Psychoacoustic Approaches for Harmonic Music Mixing" Applied Sciences 6, no. 5: 123. https://doi.org/10.3390/app6050123