A Catalog of Photometric Redshift and the Distribution of Broad Galaxy Morphologies


Department of Math and Computer Science, Lawrence Technological University, Southfield, MI 48075, USA
*
Author to whom correspondence should be addressed.
Galaxies 2018, 6(2), 64; https://doi.org/10.3390/galaxies6020064
Submission received: 4 April 2018
/
Revised: 31 May 2018
/
Accepted: 8 June 2018
/
Published: 11 June 2018
(This article belongs to the Special Issue Application of Machine-Learning Techniques in Astronomical Data Analysis)
Abstract
:We created a catalog of photometric redshift of ∼3,000,000 SDSS galaxies annotated by their broad morphology. The photometric redshift was optimized by testing and comparing several pattern recognition algorithms and variable selection strategies, and was trained and tested on a subset of the galaxies in the catalog that had spectra. The galaxies in the catalog have i magnitude brighter than 18 and Petrosian radius greater than 5.5. The majority of these objects are not included in previous SDSS photometric redshift catalogs such as the photoz table of SDSS DR12. Analysis of the catalog shows that the number of galaxies in the catalog that are visually spiral increases until redshift of ∼0.085, where it peaks and starts to decrease. It also shows that the number of spiral galaxies compared to elliptical galaxies drops as the redshift increases.
1. Introduction
Most galaxies can be broadly separated into two morphological types: spiral and elliptical [1]. Galaxy Zoo [2] was the first attempt to analyze the distribution of a large number of spiral and elliptical galaxies in the local universe. Using the power of crowd sourcing, it provided morphological classifications of nearly 900,000 galaxies. Subsets of “clean” and “superclean” datasets were used to deduce the distribution of elliptical and spiral galaxies in the local universe [3,4,5].
A more recent catalog of galaxy morphology is the catalog of ∼3,000,000 Sloan Digital Sky Survey (SDSS) galaxies [6] classified automatically using machine learning [7,8]. While the catalog is large, it is limited in the sense that the vast majority of the galaxies in that catalog do not have spectroscopic data.
Photometric redshift (photo-z) plays a vital role in the study of astronomy and cosmology. Spectroscopic measurements of millions of celestial objects is technically daunting and expensive compared to photometric measurements. The redshift can be estimated from the photometric measurements, and that estimation is often sufficient for many applications involving statistical analysis of a large population of astronomical objects [9]. Clearly, photometric measurements can provide more redshift estimates per unit telescope time compared to spectroscopic measurements [10]. Therefore, during the past decade significant efforts have been aimed toward developing photometric redshift estimation methods, most of them can be classified into two types: template-fitting and empirical methods [11].
Empirical methods use celestial objects with known spectroscopic redshift as training data to estimate the redshift based on patterns in the photometric measurements. The performance of empirical methods is limited to the range of the spectroscopic redshift of the samples in the training set. Template-based methods estimate the photometric redshift by using spectral templates. The estimation is accomplished by selecting the Spectral Energy Distribution (SED) from a library of templates such that the SED best reproduces the observed fluxes in the broadband filters [9]. These methods are preferred when exploring new regimes, while empirical methods are preferred when large training sets with spectroscopic redshift are available [11]. In general, empirical methods provide better accuracy [11]. For detailed discussion of photometric redshift techniques see reviews [11,12].
In some cases hybrid methods that combine empirical and template approaches can improve the accuracy of the photometric redshift reconstruction. Examples of empirical methods include predication trees and random forests [13,14], Polynomial Fitting [15], the Nearest Neighbour Polynomial (NNP) technique [16], Decision Trees [17], Artificial Neural Networks [18,19], and Support Vector Machines [20]. Gaussian Process Regression (GPR) can provide competitive results compared to ANN and least-square fitting methods [21]. Some studies showed improved prediction accuracy using the combination of templates and magnitude priors [22]. The inclusion of near IR magnitude and angular size also showed significant contribution to the accuracy of the photometric redshift prediction [23]. The combination of morphological and photometric variables have shown to increase the accuracy, especially in cases where fewer bands are available [24].
Examples of photometric redshift catalogs include the catalog of ∼10 SDSS DR4 objects with redshift values in the range of [18], and the catalog of SDSS DR9 galaxies, in which an artificial neural network was used [25]. The ANNz2 artificial neural network [26] was used to create a photometric redshift catalog of ∼3.9 × 10 for the Kilo-Degree Survey Data Release 3 [27]. Another large catalog is contains the photometric redshift catalog of about ∼2 × 10 galaxies from SDSS DR12, with redshift range of 0.8 [28].
Here we test several machine learning algorithms and sets of photometric variables for the purpose of photometric redshift estimation, and apply the method to create a catalog of ∼3,000,000 galaxies that have information about their broad morphology and their photometric redshift. That information can be used to profile the distribution of broad morphology of galaxies in different redshift ranges.
2. Data
The initial data were taken from the catalog of ∼3 × 10 SDSS galaxies separated by their broad morphology into elliptical and spiral galaxies [6], all taken from SDSS DR8 [29]. The vast majority of these DR8 galaxies do not have photometric redshift computed through previous catalogs. For instance, a joint query with the redshift catalog of ∼2 × 10 SDSS DR12 galaxies [28] only includes 827,591 of the galaxies in the catalog, which is merely about 27.6%.
The reason for the exclusion of these galaxies from the photoz table [28] of SDSS DR12 could be that the galaxies in the photoz table are objects identified as galaxies by all primary photometric measurements included in the GalaxyTag view [28], while the objects in the catalog of broad morphology were selected by using the “type” field of the PhotoObjAll table, and then filtered by applying further analysis of the image based on the morphology of the object. Therefore, many objects that have an object type “galaxy” (type = 3) in the PhotoObjAll table and are included in the catalog of broad morphology might not have been included in the set objects included in the photoz table. For instance, DR12 has 48,528,684 objects with model i magnitude smaller than 19 and identified to have the type “galaxy”, while just 11,761,054 of these objects are included in the photoz table. Figure 1 shows examples of objects identified as galaxies in SDSS DR12 PhotoObjAll, but are not included in the photoz table of DR12.
The catalog also has the certainty of each galaxy to belong in each of the broad morphological classes, and the threshold can be used to control the consistency of the subset [6]. The certainty values are used in a similar fashion to the way the degree of agreement between human annotators is used in Galaxy Zoo [2]. By using a certainty threshold of 0.54 for the spiral galaxies and 0.8 for the elliptical galaxies, the catalog contains ∼9 × 10 spiral galaxies and ∼6 × 10 elliptical galaxies with consistency of ∼98% with the Galaxy Zoo debiased “superclean” dataset [2], as thoroughly described in [6]. All galaxies are bright (i magnitude brighter than 18) and large (Petrosian radius measured in the r band larger than 5.5), and therefore allow the identification of the morphologies of the galaxies in the catalog while excluding small and faint objects that their morphology cannot be identified.
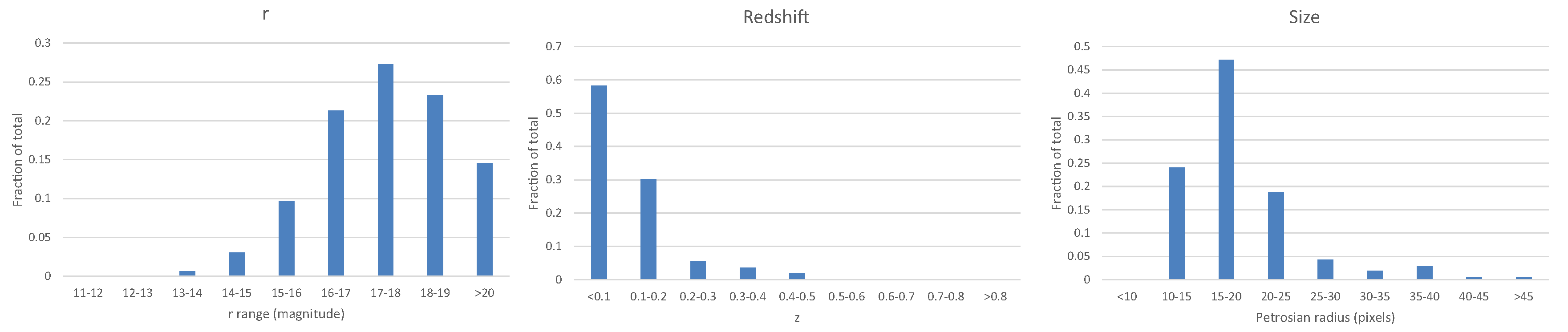
The source code used to create the catalog is also publicly available [30]. Figure 2 shows the distribution of the r model magnitude, the Petrosian radius measured in the r band, and the distribution of the redshift among 115,359 galaxies included in the catalog that also had spectra.
A subset of 20,000 galaxies that have spectra was used for training and testing the algorithm. Naturally, these galaxies need to have spectra so that the predicted photometric redshift can be compared to their spectroscopic redshift to deduce the efficacy of the algorithm. The photometric information was taken from the PhotoObjAll table of SDSS DR8.
The purpose of the set of galaxies with spectra is to train and test a model to estimate the redshift of the galaxies in the catalog of SDSS galaxies with broad morphology classification [6]. For that purpose, the set of galaxies with spectra that are used for training and testing needs to be as similar as possible to the entire population of galaxies in the catalog it aims at analyzing. Figure 3 shows the distribution of the magnitude and size of the galaxies in the catalog of galaxies with broad morphological classification. As the figure shows, the brightness and size of the galaxies in the catalog is very similar to the brightness and size of the galaxies in the training set.
Selecting training samples from the same set of galaxies that need to be classified might lead to performance evaluation that reflects the sample from which the galaxies were taken, and not necessarily the entire set of SDSS galaxies, which also includes small and faint galaxies. Also, the training set contains galaxies that were selected as spectroscopic targets, and are therefore not necessarily a random representation of SDSS general galaxy population. However, since the purpose of the algorithm is to estimate the redshift only for galaxies within that sample, higher accuracy can be achieved if the population of the samples in the training set is similar to the population of the samples that will be classified with the machine learning system. The galaxies in both the catalog and the training set are galaxies that were selected using the same criteria, and Figure 2 and Figure 3 show that the population of galaxies in the catalog is similar to the population of galaxies included in the training set. The training set does not include random galaxies from SDSS spectroscopic sample, but just galaxies that are part of the catalog, and their population is similar to the galaxy population in the catalog. While the solution is expected to achieve poor performance for galaxies outside of that sample, it is designed specifically for a certain catalog.
3. Methods
3.1. Pattern Recognition Algorithms
Several supervised machine learning algorithms were tested, and the performance was evaluated to identify the algorithms that demonstrated the highest efficacy. These algorithms included Simple Linear Regression, MultiLayer Perceptron [31], M5P [32], ZeroR, Decision Table [33], and Random Forest [34]. Given the photometric redshift is a continuous value and not a crisp class, suitable algorithms need to be able to perform a regression and compute a continuous value as their output.
The Logistic Regression algorithm predicts a multi-dimensional point by minimizing its squared error. MultiLayer Perceptron builds a multi-layer neural network of weighted perceptron nodes. Each node receives several input values, and “fires” a value to the next layer if the results of the function (called “activation function”) using these input values as parameters reaches a certain threshold weight [35]. The weights in the nodes are optimized by running the training samples through the network iteratively, and adjusting the weights based on the results of the training samples. Given the output layer contains multiple perceptrons, their values can be interpolated to provide a continuous value.
The M5P algorithm implements M5 model trees and rules [32]. As each leaf in the M5 model is a linear regression function, it is suitable for predicting continuous values rather than a crisp class. ZeroR is a simple classifier that makes a prediction based on the frequency of the output variable in the training set. A Decision Table [33] is a rule-based method that uses a frequency table to make a prediction. The frequency table is built based on the frequency of the features in the training samples, and their distribution in different ranges [33]. The tree-based Random Forest algorithm [34] builds a classifier using a large number of random decision tree classifiers. Each decision tree is created randomly such that each node is a different feature, and the decision is made based on the value of that feature in a specific given test sample, until reaching the leaf that is assigned with an output value. These trees are used to create an ensemble classifier such that each tree is a classifier, and the output is determined by an interpolation of the results of all decision trees. Given each decision tree provides an output, the high number of outputs being interpolated makes the method suitable also for the prediction of continuous values. The implementation of the algorithm was taken from the Weka open source machine learning toolbox [36].
3.2. Variable Selection
Feature selection in a multidimensional environment is a complex task that often requires heuristics or assumptions, which can then be tested empirically. Several different methods were used for variable selection, including hand-crafted variable selection and automatic statistical selection of the variables. The hand-crafted set of variables is the variables used in [25] to compute the photometric redshift of SDSS DR9 objects. These variables are listed in Table 1, and a short description of each variable can be found in Table A1.
Another method of variable selection is based on computing the variable’s analysis of variance (ANOVA) F-value, and then selecting the highest rated features [37]. That was done by using the python library scikit-learn 1. The function sklearn.feature_sclection.SelectKBest takes a dataset and a comparison function to choose the most informative features. For the comparison function, we used the ANOVA F-value computation function sklearn.feature_selection.f_classif. These variables are selected automatically, and therefore some of the variables might not necessarily have a straightforward physical explanation, but in the context of the database can provide useful patterns when used in combination with other variables. We chose the top 13 (KBest13), 21 (KBest21), and 31 (KBest31) variables and ran the random forest algorithm on each subset of variables.
Table 2 shows the mean absolute error when using the different feature sets. The mean absolute error is defined by , where is the photometric redshift of galaxy i, is the spectroscopic redshift of galaxy i, and N is the total number of galaxies in the test samples. That process is repeated 10 times using a 10-fold cross-validation test strategy, meaning that the test is performed 10 times such that in each run a different set of 10% of the samples are used for testing, and the remaining 90% for training.
As Table 2 shows, using 21 variables provided the best performance, and the larger feature set did not lead to better accuracy, although the difference in performance when using different sets of variables is small. All experiments were performed with a standard 10-fold cross-validation testing strategy.
Finally, the set of KBest21 variables was enhanced with the four color variables, that are not included in SDSS and were therefore not analyzed by ANOVA, creating the KBestMod variable set. That variable set included the following variables: deVMag_g, deVMag_r, deVMag_u, dered_g, dered_r, dered_u, expMag_g, expMag_r, fiberMag_g, fiberMag_u, g, petroMag_g, petroMag_r, psfMag_g, psfMag_u, ra, dec, i, r, u, u-g, g-r, r-i, i-z.
3.3. Performance Evaluation
In order to evaluate the performance we used three metrics of the performance: The mean absolute error, the root square error, and the normalized error. The root mean square error (RMSE) is defined by Equation (1)
The normalized Z error is defined by Equation (2).
and the mean normalized error is the mean of the test galaxies.
Table 3 shows the performance for the different variable sets when using the random forest classifier. As the table shows, the KBestMod feature set performs better than the other feature sets for all three performance metrics.
Additionally, the random forest algorithm performs better than other algorithms. Table 4 shows the performance of the Simple Linear Regression, MultiLayer Perceptron, M5P, ZeroR, Decision Table, and Random Forest machine learning algorithms when using the KBestMod feature set.
As the table shows, the random forest algorithm provided the best performance, with of ∼0.0022, lower than any of the other algorithms. The standard deviation of the normalized error is also the lowest when using the random forest classifier (0.0107). The median absolute deviation of the random forest classifier is ∼0.056. M5P produced a marginally better mean absolute error and root square error of and , respectively. Simple Linear Regression provided the worst performance, with a mean absolute error of and root absolute error of .
It should be mentioned that the performance figures provided in Table 4 reflect the performance on the galaxy sample of the catalog described in Section 2, but not the entire galaxy population in SDSS.
The performance of the algorithm was also compared to the performance of the redshift estimation using Multilayer Perceptron, as well as the photometric redshift methods based on the Nearest Neighbour Polynomial (NNP), and the neural network algorithms CC2 and D1 [9]. Table 5 shows that the photometric redshift estimation based on the random forest is favorably comparable to other methods, and therefore can provide a solution to the estimation of the redshift of the galaxies in the catalog.
Photometric redshift accuracy can change in different color ranges. Figure 4 and Figure 5 show the change in the absolute and normalized error, respectively, at different magnitudes in the different bands. The red lines show the least square error linear regression.
Figure 6 and Figure 7 show the absolute and normalized error, respectively, as a function of the color.
The figures show that the error increases when the objects get dimmer. The correlation between the error and the magnitude can be expected as the dimmer galaxies also tend to have higher redshift, and the error expected to increase as the redshift gets higher. The threshold of 0.54 was selected based on previous experiments by comparing it to the Galaxy Zoo “superclean” samples [6]. Any threshold higher than 0.54 does not increase the consistency of the dataset substantially.
As Figure 6 and Figure 7 show, the error also tends to decrease slightly when the galaxies are bluer. That can be explained by the observation that spiral galaxies in the catalog tend to have lower redshift. Since spiral galaxies also tend to be bluer than elliptical galaxies, bluer galaxies in the catalog have lower redshift, and therefore their estimated photometric redshifts have a lower error.
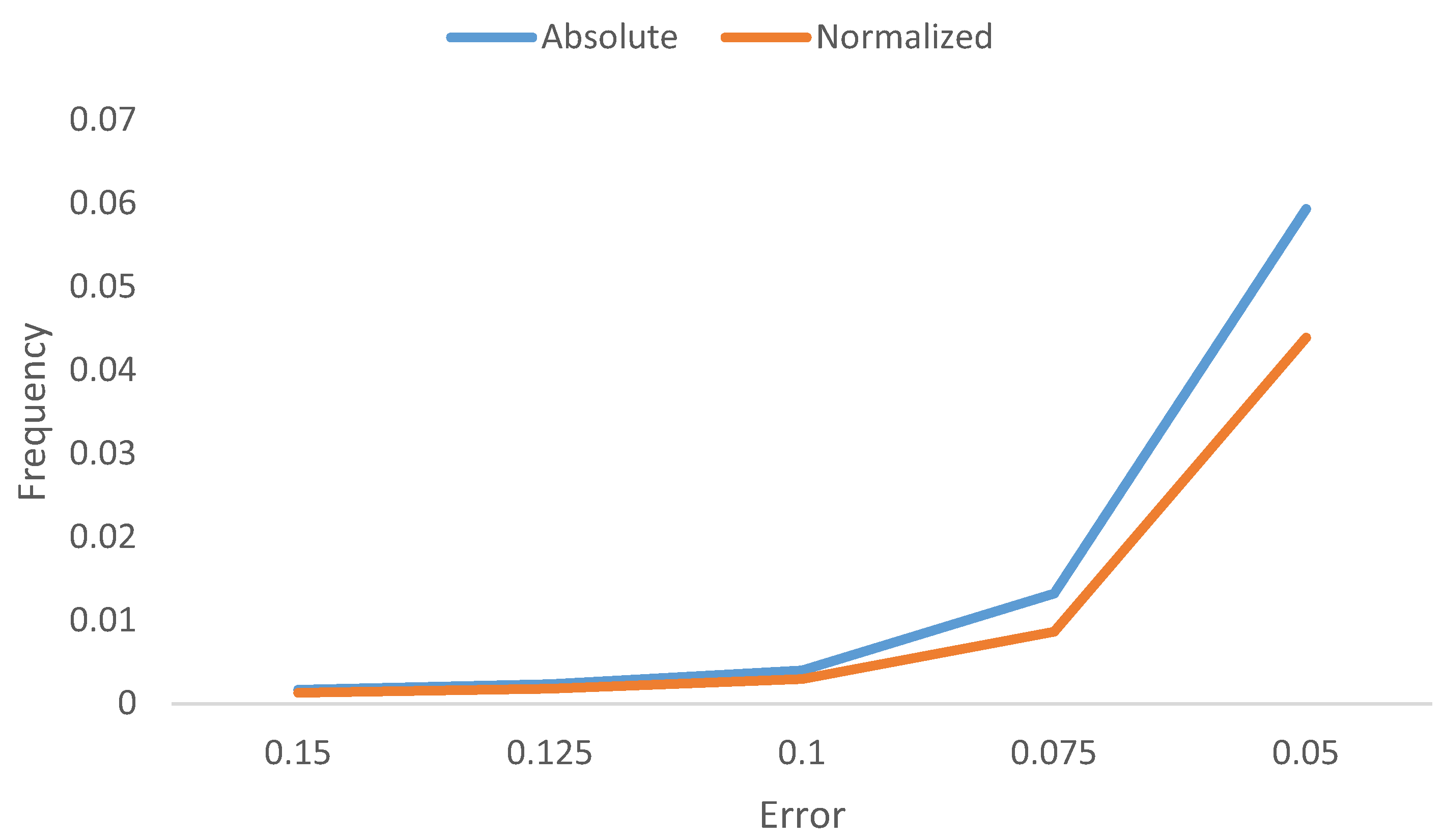
Figure 8 shows the frequency of galaxies as a function of the normalized and absolute error. As the figure shows, catastrophic outliers with error of more than 0.15 are very rare, and are less than 0.2% of the cases.
3.4. Dependence on the Size of the Training Set
The performance of machine learning algorithms is heavily dependent on the size of the dataset on which they are trained, and larger training sets normally lead to improved performance of the algorithm. However, the accuracy does not grow with the size of the training set in a linear fashion, and at a certain point it is expected that increasing the size of the training set has a negligible contribution to the performance of the machine learning algorithm [38].
To determine the effect of the size of the training set on the performance, the random forest algorithm and the KBestMod feature set were used with several training set sizes ranging from 1000 to 20,000 galaxies. The results of these experiments are shown in Table 6. As the table shows, the accuracy of the algorithm improves as the size of the dataset gets larger, but the improvement in the becomes negligible when the number of training samples reaches ∼5000. The mean absolute error and the root error also show a very small decrease beyond 5000 training samples, but the decrease is more substantial compared to the . Therefore, more than 5000 training samples will make a minor contribution to the , while having somewhat higher impact on the mean absolute error and the root error. It should be noted that for the machine learning algorithms used in this study, using large training sets as shown in the table does not add substantial computing requirements.
4. Catalog
The purpose of the photometric redshift methods described in Section 3 is to compute the photometric redshifts of the objects in the catalog of galaxy morphologies described in Section 2. The photometric redshift of the galaxies in the catalog was computed with the KBest_mod feature set and the random forest algorithm.
The catalog contains the 2,912,341 SDSS galaxies classified automatically to spiral and elliptical galaxies [6]. For each galaxy, the catalog contains the SDSS DR8 object ID of the galaxy, its right ascension, declination, elliptical and spiral marginal probabilities, and the computed photometric redshift.
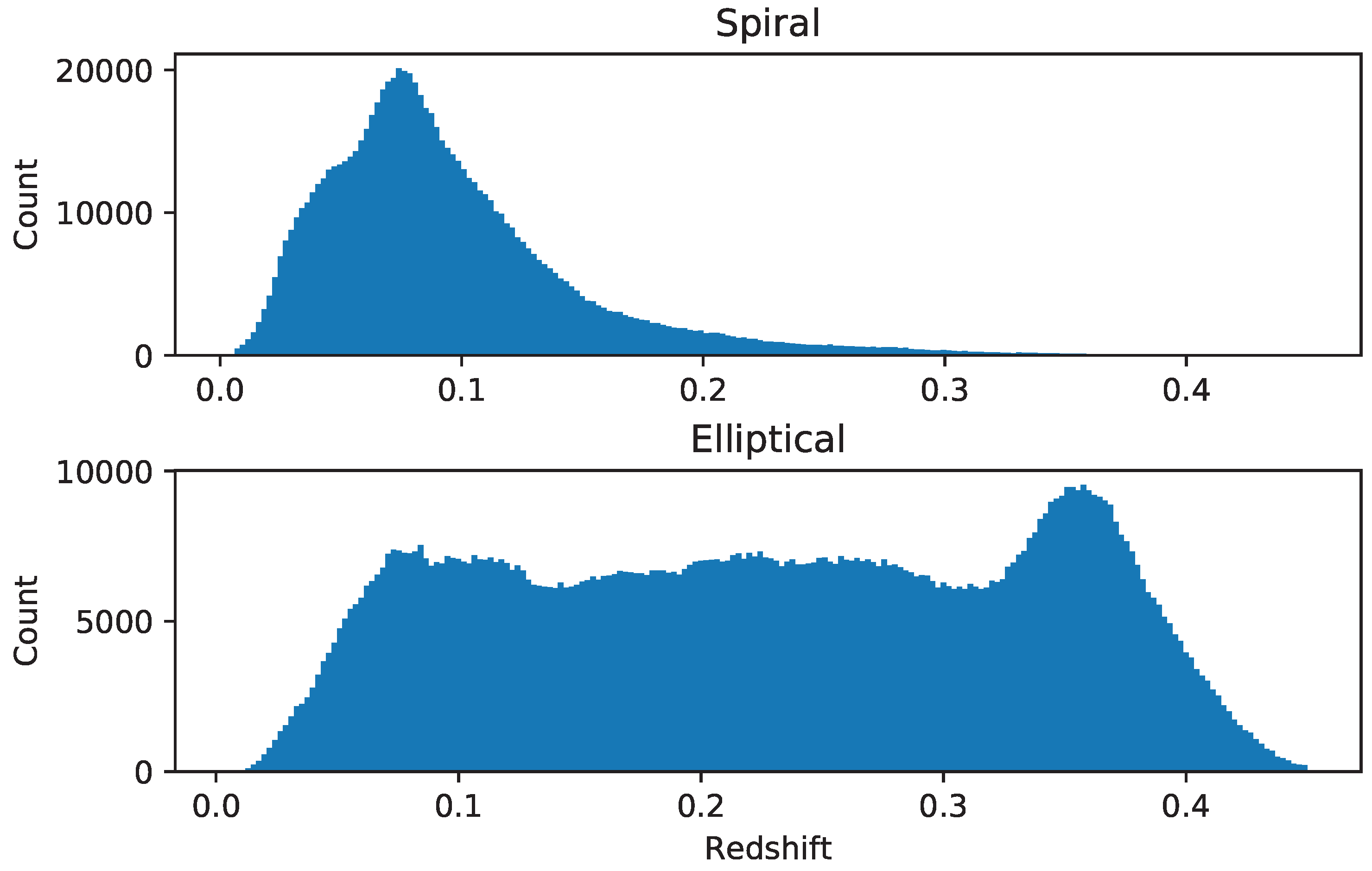
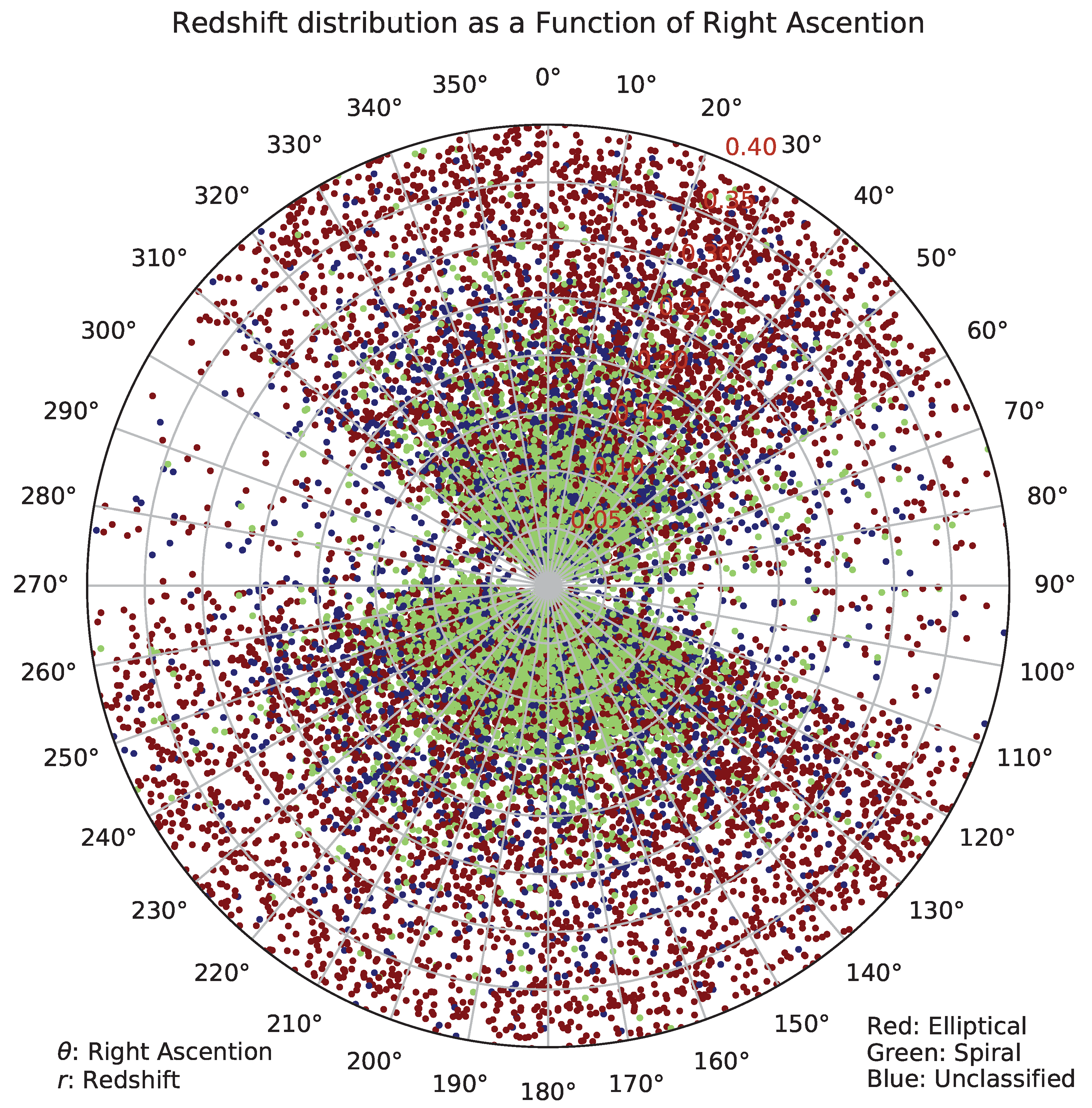
Figure 9 displays the distribution of the galaxies in the catalog across different photometric redshift ranges. The figures shows that the number of elliptical galaxies remains fairly constant across the redshift ranges, but increases at around redshift of 0.35. The higher number of galaxies in that redshift range is aligned with previous studies, showing a peak in the total number of galaxies at around z = 0.35 [39]. On the other hand, it should be noted that the drop in the number of elliptical galaxies beyond z = 0.35 can be related to the limiting magnitude of the catalog. Galaxies with i magnitude dimmer than 18 are excluded from the catalog, and the number of galaxies with redshift greater than 0.35 that satisfy the magnitude threshold is small, and gets smaller as the redshift increases and consequently the galaxies get dimmer. The number of spiral galaxies peaks at around redshift of 0.085, and then decreases gradually.
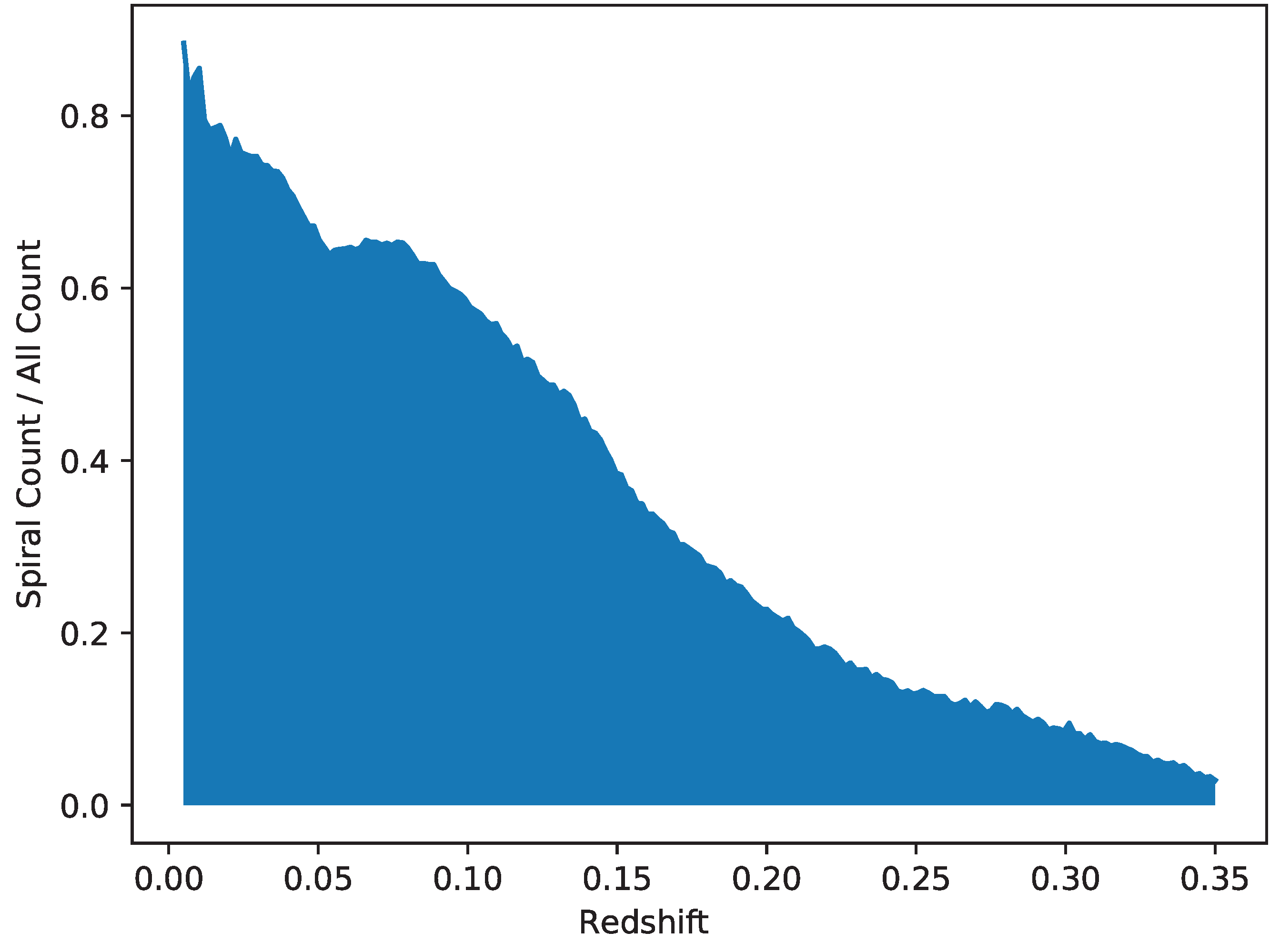
The catalog was also analyzed regarding the distribution of broad morphology of the galaxies in each redshift range. Figure 10 shows the fraction of galaxies identified as spiral among the total number of galaxies within each photometric redshift range. As the figure shows, the proportion of spiral galaxies in the catalog drops as the redshift gets higher. In the redshift range of 0.05–0.1 the fraction of spiral galaxies in the total number of galaxies is ∼0.62, while it is ∼0.4 at the redshift of 0.15, and drops to less than 0.2 when the redshift is 0.2 or higher.
It should be noted that the population of galaxies in the catalog might not represent a random sample of the galaxies in the local universe, but is limited to galaxies that are sufficiently bright and sufficiently large to be analyzed morphologically given the limitation of SDSS imaging power. Elliptical galaxies are brighter than spiral galaxies [40], and therefore the magnitude threshold (i magnitude < 18) can lead to the higher number of elliptical galaxies that meet that threshold to be included in the catalog. Because the redshift and magnitude are strongly correlated, at higher redshifts more elliptical galaxies pass the magnitude threshold compared to spiral galaxies, consequently leading to the higher population of elliptical galaxies compared to spiral galaxies at these redshift ranges.
The increased population of elliptical galaxies at higher redshifts can also be the result of the fact that spiral patterns become more difficult to identify in fainter and smaller galaxies, although the galaxies are all relatively large (Petrosian radius larger than 5.5) and bright (i magnitude < 18), and the annotations of the morphologies of these galaxies agree to a very high extent of ∼98% with the debiased “superclean” annotations of Galaxy Zoo. Because the initial selection of galaxies is based on the magnitude, more elliptical galaxies with higher photometric redshift can be included in the catalog, and therefore the increase of their population at higher redshifts does not necessarily reflect higher population in the higher redshift ranges of this catalog. On the other hand, the size threshold ensures that only large objects are selected, so that bright and small objects are excluded from the catalog.
Figure 11 shows the distribution of the galaxies in the catalog by their broad morphology, right ascension, and photometric redshift. Similarly to Figure 10, the lower redshift range has a much higher number of spiral galaxies, which can be also related to the fact that spiral patterns are more difficult to identify as the redshift gets higher.
The redshift range of the galaxies used in the catalog is relatively small in terms of galaxy evolution. Some observations within that redshift range have been noted, such as the higher population of faint blue galaxies at redshift range of 0.3 to ∼1 [41]. A more recent observation showed that the population of settled disk galaxies changes in the range of [42]. The absolute magnitude of galaxies also increases (becomes dimmer) when the redshift increases in the range of [39]. Another study showed a decrease in the population of massive late type galaxies in the , which largely agrees with the distribution of the late-type galaxies in this catalog [43].
5. Conclusions
The primary goals of this study are to test machine learning and variable selection algorithms for computing photometric redshift, optimize it for a specific population of galaxies, and mainly apply these algorithms to provide a large catalog of galaxy morphology and photometric redshift.
The catalog presented in this paper is similar to the early Galaxy Zoo 1 catalog, but because it was classified automatically it provides a much higher number of galaxies. Of the ∼3 × 10 galaxies in the catalog, ∼1.5 × 10 are galaxies with 98% agreement rate with the Galaxy Zoo 1 debiased “superclean” accuracy. It is limited in the sense that, like Galaxy Zoo, it represents the galaxies in the catalog, and not necessarily a complete and unbiased sample of SDSS galaxies.
The catalog is publicly available at https://figshare.com/articles/Morphology_and_photometric_redshift_catalog/4833593. The source code used to create the catalog is also publicly available [30,44].
Author Contributions
N.P. and N.V. performed the experiments and created the catalog. N.P. and L.S. designed the experiments and prepared the manuscript.
Funding
This research was funded by NSF grant IIS-1546079.
Acknowledgments
This study was supported by NSF grant IIS-1546079. Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, the US Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web Site is http://www.sdss.org/. The SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, University of Cambridge, Case Western Reserve University, University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max Planck Institute for Astronomy (MPIA), the Max Planck Institute for Astrophysics (MPA), New Mexico State University, Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory and the University of Washington.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Variable Description
Table A1 provides a short description of the variables used in the different experiments. A more detailed description is available in the Sloan Digital Sky Survey documentation [45]. The variables that were used for the photometric redshift are only the variables included in the KbestMod feature set described in Section 3.2, and not the entire list of variables described in the table.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Variables used for photometric redshift estimation. The variables used for the photometric redshift are the subset of variables included in the KbestMod feature set, and not the entire set of variables included in the table.
Table A1.
Variables used for photometric redshift estimation. The variables used for the photometric redshift are the subset of variables included in the KbestMod feature set, and not the entire set of variables included in the table.
| Variable | Description |
|---|---|
| u | The best of the exponential fit magnitude and the DeVaucouleurs fit magnitude in the u band |
| g | The best of the exponential fit magnitude and the DeVaucouleurs fit magnitude in the g band |
| r | The best of the exponential fit magnitude and the DeVaucouleurs fit magnitude in the r band |
| i | The best of the exponential fit magnitude and the DeVaucouleurs fit magnitude in the i band |
| z | The best of the exponential fit magnitude and the DeVaucouleurs fit magnitude in the z band |
| deVMag_u | DeVaucouleurs fit magnitude in the u band |
| deVMag_g | DeVaucouleurs fit magnitude in the g band |
| deVMag_r | DeVaucouleurs fit magnitude in the r band |
| deVMag_i | DeVaucouleurs fit magnitude in the i band |
| deVMag_z | DeVaucouleurs fit magnitude in the z band |
| fiberMag_u | Magnitude measured in 3 arcsec diameter fiber radius in the u band |
| fiberMag_g | Magnitude measured in 3 arcsec diameter fiber radius in the g band |
| fiberMag_r | Magnitude measured in 3 arcsec diameter fiber radius in the r band |
| fiberMag_i | Magnitude measured in 3 arcsec diameter fiber radius in the i band |
| fiberMag_z | Magnitude measured in 3 arcsec diameter fiber radius in the z band |
| expMag_u | Exponential magnitude in the u band |
| expMag_g | Exponential magnitude in the g band |
| expMag_r | Exponential magnitude in the r band |
| expMag_i | Exponential magnitude in the i band |
| expMag_z | Exponential magnitude in the z band |
| petroMag_u | Petrosian magnitude in the u band |
| petroMag_g | Petrosian magnitude in the g band |
| petroMag_r | Petrosian magnitude in the r band |
| petroMag_i | Petrosian magnitude in the i band |
| petroMag_z | Petrosian magnitude in the z band |
| psfMag_u | PSF magnitude in the u band |
| psfMag_g | PSF magnitude in the g band |
| psfMag_r | PSF magnitude in the r band |
| psfMag_i | PSF magnitude in the i band |
| psfMag_z | PSF magnitude in the z band |
| psfMagErr_u | PSF magnitude error in the u band |
| psfMagErr_g | PSF magnitude error in the g band |
| psfMagErr_r | PSF magnitude error in the r band |
| psfMagErr_i | PSF magnitude error in the i band |
| psfMagErr_z | PSF magnitude error in the z band |
| extinction_u | extinction in the u band [46] |
| extinction_g | extinction in the g band |
| extinction_ r | extinction in the r band |
| extinction_i | extinction in the i band |
| extinction_z | extinction in the z band |
| photozcc2 | CC2 algorithm estimation |
| photozd1 | D1 algorithm estimation |
| dered_u | Model magnitude subtracted by the extinction in the u band |
| dered_g | Model magnitude subtracted by the extinction in the g band |
| dered_r | Model magnitude subtracted by the extinction in the r band |
| dered_i | Model magnitude subtracted by the extinction in the i band |
| dered_z | Model magnitude subtracted by the extinction in the z band |
| isoA_u | Isophotal major axis in the u band |
| isoB_u | Isophotal minor axis in the u band |
| isoBGrad_u | Gradient in minor axis in the u band |
| isoCocl_u | Isophotal column centroid in the u band |
| isoPhi_u | Isophotal position angle in the u band |
| isoRowcGrad_u | Gradient in row centroid in the u band |
References
- Hubble, E.P. Extragalactic nebulae. Astrophys. J. 1926, 64, 321–369. [Google Scholar] [CrossRef]
- Lintott, C.; Schawinski, K.; Bamford, S.; Slosar, A.; Land, K.; Thomas, D.; Edmondson, E.; Masters, K.; Nichol, R.C.; Raddick, M.J.; et al. Galaxy Zoo 1: Data release of morphological classifications for nearly 900,000 galaxies. Mon. Not. R. Astron. Soc. 2011, 410, 166–178. [Google Scholar] [CrossRef] [Green Version]
- Bamford, S.P.; Nichol, R.C.; Baldry, I.K.; Land, K.; Lintott, C.J.; Schawinski, K.; Slosar, A.; Szalay, A.S.; Thomas, D.; Torki, M.; et al. Galaxy Zoo: The dependence of morphology and colour on environment. Mon. Not. R. Astron. Soc. 2009, 393, 1324–1352. [Google Scholar] [CrossRef] [Green Version]
- Schawinski, K.; Lintott, C.; Thomas, D.; Sarzi, M.; Andreescu, D.; Bamford, S.P.; Kaviraj, S.; Khochfar, S.; Land, K.; Murray, P.; et al. Galaxy Zoo: A sample of blue early-type galaxies at low redshift. Mon. Not. R. Astron. Soc. 2009, 396, 818–829. [Google Scholar] [CrossRef] [Green Version]
- Skibba, R.A.; Bamford, S.P.; Nichol, R.C.; Lintott, C.J.; Andreescu, D.; Edmondson, E.M.; Murray, P.; Raddick, M.J.; Schawinski, K.; Slosar, A.; et al. Galaxy Zoo: Disentangling the environmental dependence of morphology and colour. Mon. Not. R. Astron. Soc. 2009, 399, 966–982. [Google Scholar] [CrossRef] [Green Version]
- Kuminski, E.; Shamir, L. A Computer-generated visual morphology catalog of 3,000,000 SDSS galaxies. Astrophys. J. Suppl. Ser. 2016, 223, 20. [Google Scholar] [CrossRef]
- Shamir, L. Automatic morphological classification of galaxy images. Mon. Not. R. Astron. Soc. 2009, 399, 1367–1372. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuminski, E.; George, J.; Wallin, J.; Shamir, L. Combining human and machine learning for morphological analysis of galaxy images. Publ. Astron. Soc. Pac. 2014, 126, 959. [Google Scholar] [CrossRef]
- Oyaizu, H.; Lima, M.; Cunha, C.E.; Lin, H.; Frieman, J.; Sheldon, E.S. A galaxy photometric redshift catalog for the Sloan Digital Sky Survey data release 6. Astrophys. J. 2008, 674, 768. [Google Scholar] [CrossRef]
- Hildebrandt, H.; Arnouts, S.; Capak, P.; Moustakas, L.; Wolf, C.; Abdalla, F.B.; Assef, R.; Banerji, M.; Benítez, N.; Brammer, G.; et al. PHAT: PHoto-z accuracy testing. Astron. Astrophys. 2010, 523, A31. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, Y. Review of techniques for photometric redshift estimation. In Proceedings of the Software and Cyberinfrastructure for Astronomy II (SPIE Astronomical Telescopes + Instrumentation, International Society for Optics and Photonics), Amsterdam, The Netherlands, 24 September 2012; p. 845134. [Google Scholar]
- Ball, N.M.; Brunner, R.J. Data mining and machine learning in astronomy. Int. J. Mod. Phys. D 2010, 19, 1049–1106. [Google Scholar] [CrossRef]
- Kind, M.C.; Brunner, R.J. TPZ: Photometric redshift PDFs and ancillary information by using prediction trees and random forests. Mon. Not. R. Astron. Soc. 2013, 432, 1483–1501. [Google Scholar] [CrossRef]
- Carliles, S.; Budavári, T.; Heinis, S.; Priebe, C.; Szalay, A.S. Random forests for photometric redshifts. Astrophys. J. 2010, 712, 511. [Google Scholar] [CrossRef]
- Connolly, A.; Csabai, I.; Szalay, A.; Koo, D.; Kron, R.; Munn, J. Slicing through multicolor space: Galaxy redshifts from broadband photometry. arXiv, 1995; arXiv:astro-ph/9508100. [Google Scholar]
- Cunha, C.E.; Lima, M.; Oyaizu, H.; Frieman, J.; Lin, H. Estimating the redshift distribution of photometric galaxy samples–II. Applications and tests of a new method. Mon. Not. R. Astron. Soc. 2009, 396, 2379–2398. [Google Scholar] [CrossRef]
- Gerdes, D.W.; Sypniewski, A.J.; McKay, T.A.; Hao, J.; Weis, M.R.; Wechsler, R.H.; Busha, M.T. ArborZ: Photometric redshifts using boosted decision trees. Astrophys. J. 2010, 715, 823. [Google Scholar] [CrossRef]
- Collister, A.; Lahav, O.; Blake, C.; Cannon, R.; Croom, S.; Drinkwater, M.; Edge, A.; Eisenstein, D.; Loveday, J.; Nichol, R.; et al. MegaZ-LRG: A photometric redshift catalogue of one million SDSS luminous red galaxies. Mon. Not. R. Astron. Soc. 2007, 375, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Vanzella, E.; Cristiani, S.; Fontana, A.; Nonino, M.; Arnouts, S.; Giallongo, E.; Grazian, A.; Fasano, G.; Popesso, P.; Saracco, P.; et al. Photometric redshifts with the Multilayer Perceptron Neural Network: Application to the HDF-S and SDSS. Astron. Astrophys. 2004, 423, 761–776. [Google Scholar] [CrossRef]
- Wadadekar, Y. Estimating photometric redshifts using support vector machines. Publ. Astron. Soc. Pac. 2005, 117, 79. [Google Scholar] [CrossRef]
- Way, M.J.; Foster, L.; Gazis, P.; Srivastava, A. New approaches to photometric redshift prediction via Gaussian process regression in the Sloan digital sky survey. Astrophys. J. 2009, 706, 623. [Google Scholar] [CrossRef]
- Schmidt, S.J.; Thorman, P. Improved photometric redshifts via enhanced estimates of system response, galaxy templates and magnitude priors. Mon. Not. R. Astron. Soc. 2013, 431, 2766–2777. [Google Scholar] [CrossRef] [Green Version]
- Gomes, Z.; Jarvis, M.J.; Almosallam, I.A.; Roberts, S.J. Improving photometric redshift estimation using GPz: size information, post processing, and improved photometry. Mon. Not. R. Astron. Soc. 2017, 475, 331–342. [Google Scholar] [CrossRef] [Green Version]
- Soo, J.Y.; Moraes, B.; Joachimi, B.; Hartley, W.; Lahav, O.; Charbonnier, A.; Makler, M.; Pereira, M.E.; Comparat, J.; Erben, T.; et al. Morpho-z: Improving photometric redshifts with galaxy morphology. Mon. Not. R. Astron. Soc. 2017, 475, 3613–3632. [Google Scholar] [CrossRef]
- Brescia, M.; Cavuoti, S.; Longo, G.; De Stefano, V. A catalogue of photometric redshifts for the SDSS-DR9 galaxies. Astron. Astrophys. 2014, 568, A126. [Google Scholar] [CrossRef]
- Sadeh, I.; Abdalla, F.B.; Lahav, O. ANNz2: Photometric redshift and probability distribution function estimation using machine learning. Publ. Astron. Soc. Pac. 2016, 128, 104502. [Google Scholar] [CrossRef]
- Bilicki, M.; Hoekstra, H.; Amaro, V.; Blake, C.; Brown, M.; Cavuoti, S.; de Jong, J.; Hildebrandt, H.; Wolf, C.; Amon, A.; et al. Photometric redshifts for the Kilo-Degree Survey. Machine-learning analysis with artificial neural networks. arXiv, 2017; arXiv:1709.04205. [Google Scholar]
- Beck, R.; Dobos, L.; Budavári, T.; Szalay, A.S.; Csabai, I. Photometric redshifts for the SDSS Data Release 12. Mon. Not. R. Astron. Soc. 2016, 460, 1371–1381. [Google Scholar] [CrossRef] [Green Version]
- Rykoff, E.; Rozo, E.; Busha, M.; Cunha, C.; Finoguenov, A.; Evrard, A.; Hao, J.; Koester, B.; Leauthaud, A.; Nord, B.; et al. redMaPPer. I. Algorithm and SDSS DR8 Catalog. Astrophys. J. 2014, 785, 104. [Google Scholar] [CrossRef]
- Shamir, L.; Orlov, N.; Eckley, D.M.; Macura, T.; Johnston, J.; Goldberg, I. WND-CHARM: Multi-Purpose Image Classifier, Astrophysics Source Code Library, 2013; ascl:1312.002.
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; Volume 92, pp. 343–348. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2005. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belue, L.M.; Bauer, K.W., Jr. Determining input features for multilayer perceptrons. Neurocomputing 1995, 7, 111–121. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Trigg, L.E.; Hall, M.A.; Holmes, G.; Cunningham, S.J. Weka: Practical Machine Learning Tools and Techniques with Java Implementations; University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]
- Raschka, S. Python Machine Learning; PACKT Publishing: Birmingham, UK, 2016. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Zaninetti, L. On the number of galaxies at high redshift. Galaxies 2015, 3, 129–155. [Google Scholar] [CrossRef]
- Tempel, E.; Saar, E.; Liivamägi, L.; Tamm, A.; Einasto, J.; Einasto, M.; Müller, V. Galaxy morphology, luminosity, and environment in the SDSS DR7. Astron. Astrophys. 2011, 529, A53. [Google Scholar] [CrossRef] [Green Version]
- Lilly, S.J.; Le Fevre, O.; Hammer, F.; Crampton, D. The Canada-France Redshift Survey: the luminosity density and star formation history of the Universe to z~ 1. Astrophys. J. Lett. 1996, 460, L1. [Google Scholar] [CrossRef]
- Kassin, S.A.; Weiner, B.J.; Faber, S.; Gardner, J.P.; Willmer, C.; Coil, A.L.; Cooper, M.C.; Devriendt, J.; Dutton, A.A.; Guhathakurta, P.; et al. The epoch of disk settling: z~ 1 to now. Astrophys. J. 2012, 758, 106. [Google Scholar] [CrossRef]
- Conselice, C.J. The evolution of galaxy structure over cosmic time. Ann. Rev. Astron. Astrophys. 2014, 52, 291–337. [Google Scholar] [CrossRef]
- Shamir, L.; Orlov, N.; Eckley, D.M.; Macura, T.; Johnston, J.; Goldberg, I.G. Wndchrm—An open source utility for biological image analysis. Source Code Biol. Med. 2008, 3, 13. [Google Scholar] [CrossRef] [PubMed]
- Aihara, H.; Prieto, C.A.; An, D.; Anderson, S.F.; Aubourg, É.; Balbinot, E.; Beers, T.C.; Berlind, A.A.; Bickerton, S.J.; Bizyaev, D.; et al. The eighth data release of the Sloan Digital Sky Survey: First data from SDSS-III. Astrophys. J. Suppl. Ser. 2011, 193, 29. [Google Scholar] [CrossRef] [Green Version]
- Schlegel, D.J.; Finkbeiner, D.P.; Davis, M. Maps of dust infrared emission for use in estimation of reddening and cosmic microwave background radiation foregrounds. Astrophys. J. 1998, 500, 525. [Google Scholar] [CrossRef]
| 1. |
Figure 1.
Examples of objects identified as galaxies by DR12 PhotoObjAll table, but are not included in the photoz table of DR12.
Figure 1.
Examples of objects identified as galaxies by DR12 PhotoObjAll table, but are not included in the photoz table of DR12.

Figure 2.
Distribution of the redshift, r magnitude, and Petrosian radius measured on the r band of the 115,359 galaxies that have spectra. These galaxies were used for training and testing the photometric redshift algorithms.
Figure 2.
Distribution of the redshift, r magnitude, and Petrosian radius measured on the r band of the 115,359 galaxies that have spectra. These galaxies were used for training and testing the photometric redshift algorithms.
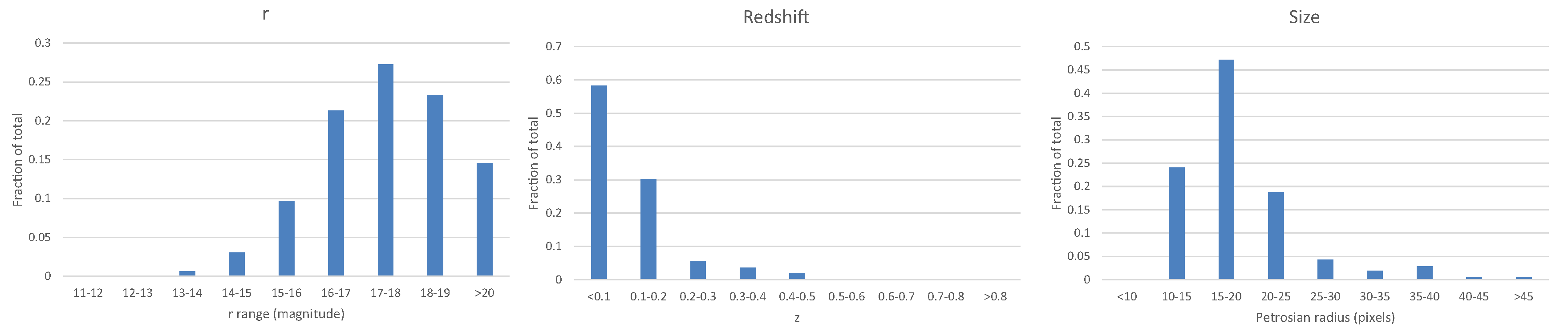
Figure 3.
Spectroscopic redshift distribution of the galaxies in the catalog of broad galaxy morphology.
Figure 3.
Spectroscopic redshift distribution of the galaxies in the catalog of broad galaxy morphology.
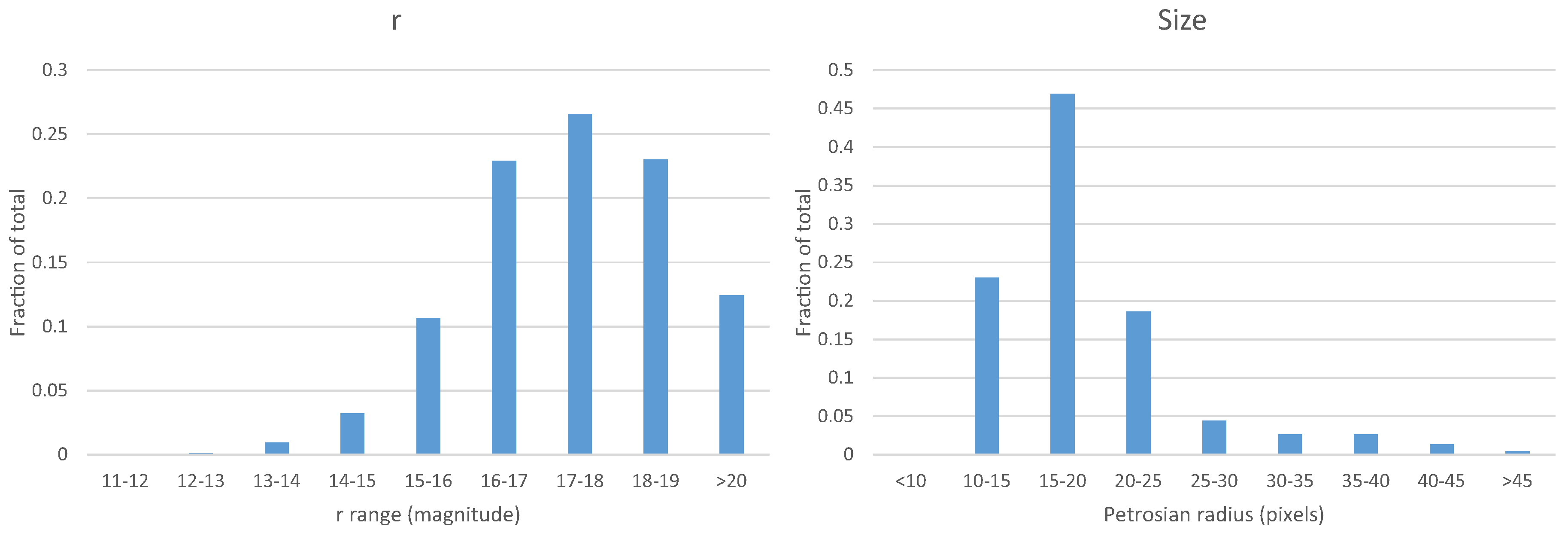
Figure 4.
Absolute error when using the random forest classifier and different magnitude ranges. The red lines show the least square error linear regression.
Figure 4.
Absolute error when using the random forest classifier and different magnitude ranges. The red lines show the least square error linear regression.

Figure 5.
Normalized error when using the Random Forest classifier and different magnitude ranges.

Figure 6.
Absolute error when using the Random Forest classifier and different color ranges.

Figure 7.
Normalized error when using the Random Forest classifier and different color ranges.

Figure 8.
Frequency of galaxies as a function of the normalized and absolute error.
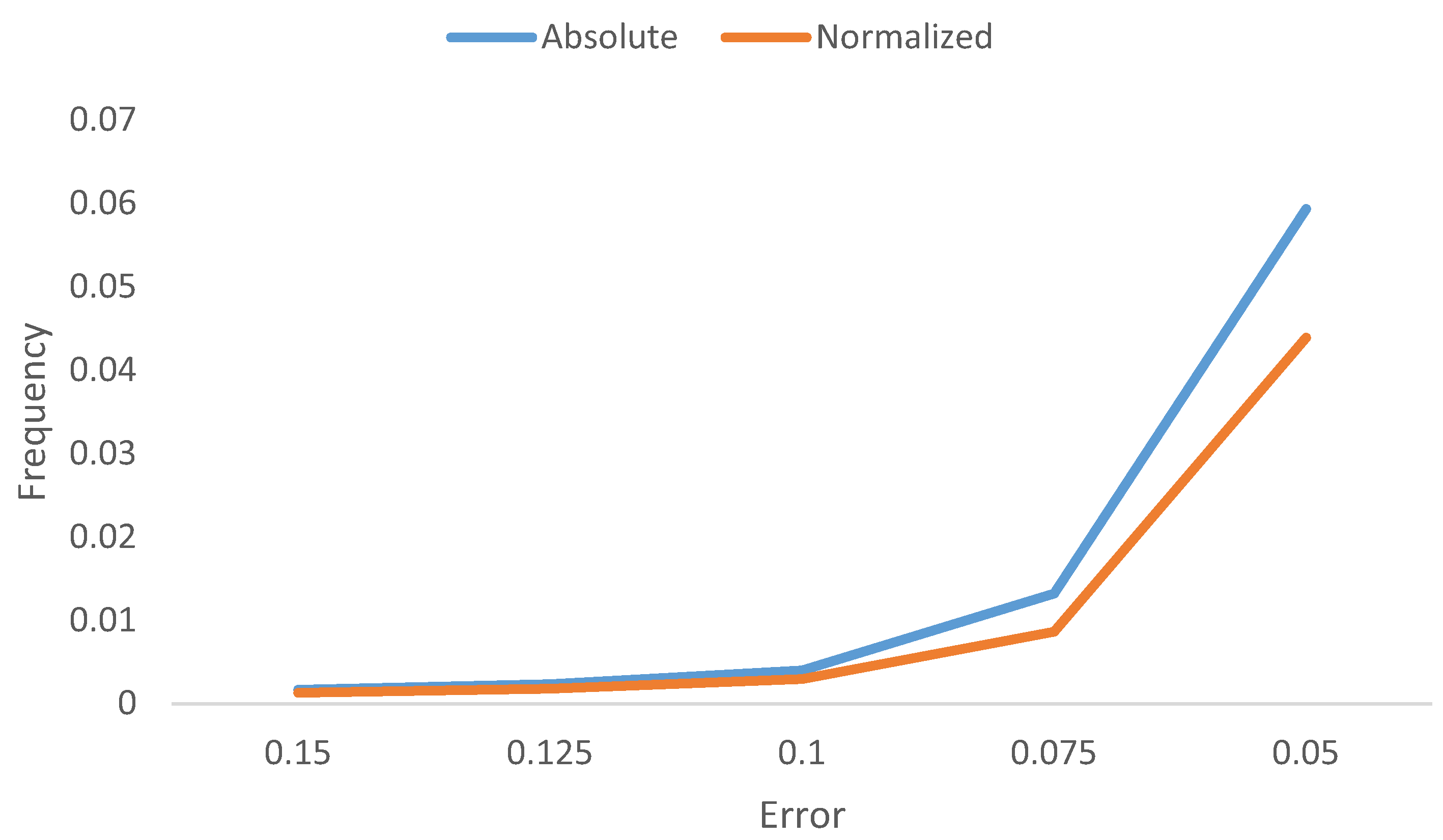
Figure 9.
Redshift distribution of the elliptical and spiral galaxies in the catalog.
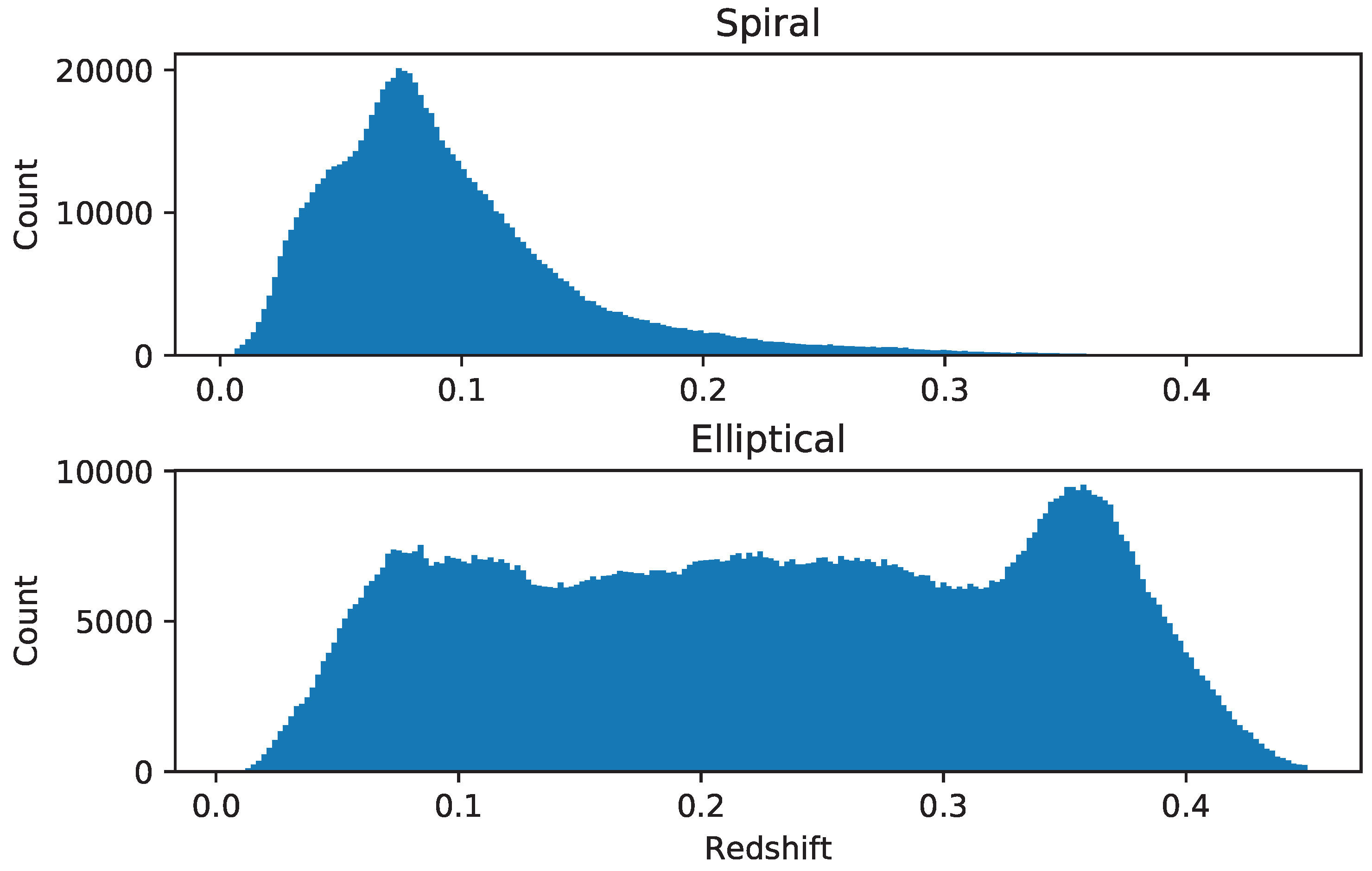
Figure 10.
Ratio of spiral galaxies over all galaxies in the catalog in different redshift ranges.
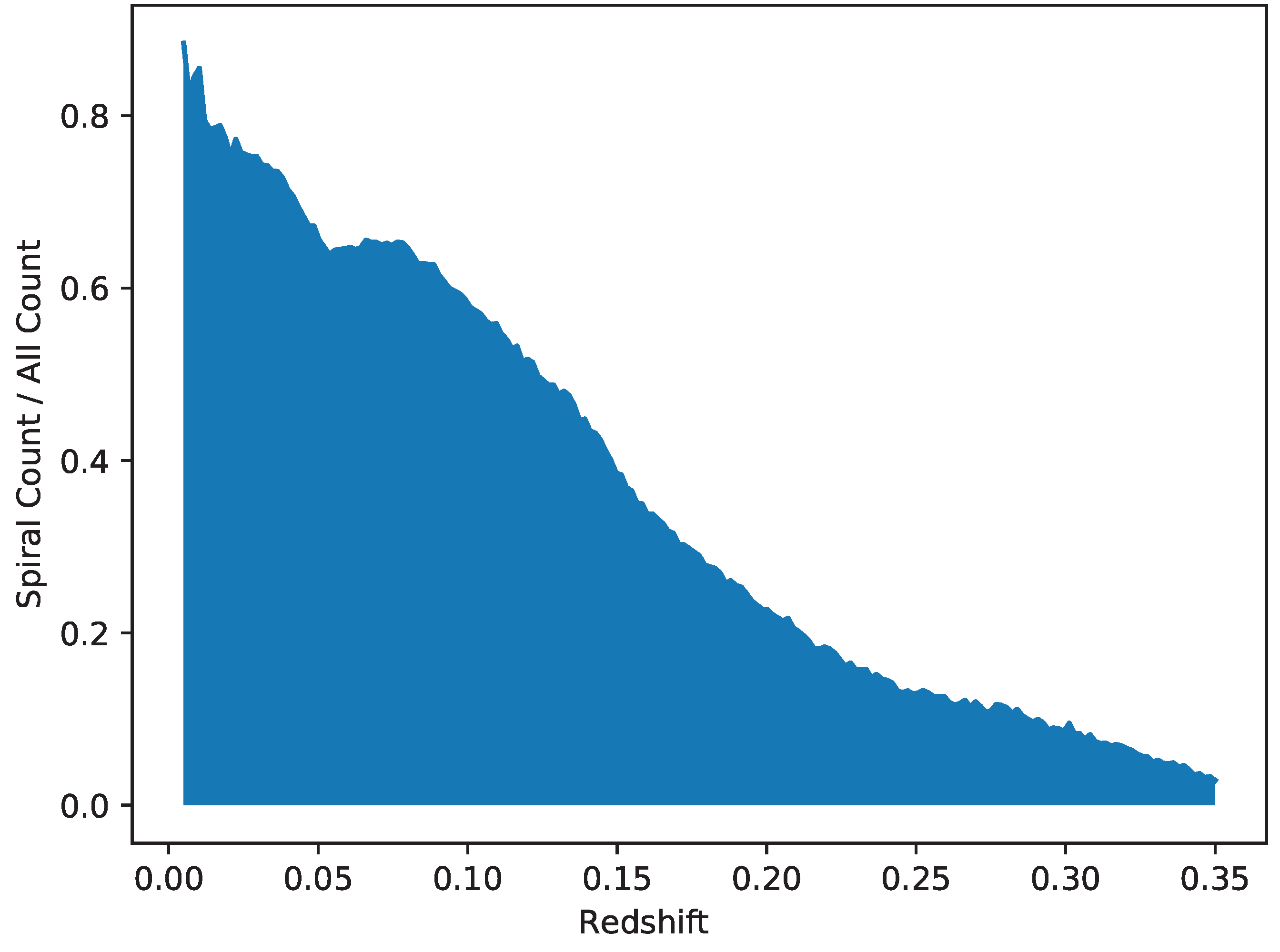
Figure 11.
Distribution of spiral and elliptical galaxies by photometric redshift and right ascension. The range of the photoz is 0 to 0.4.
Figure 11.
Distribution of spiral and elliptical galaxies by photometric redshift and right ascension. The range of the photoz is 0 to 0.4.
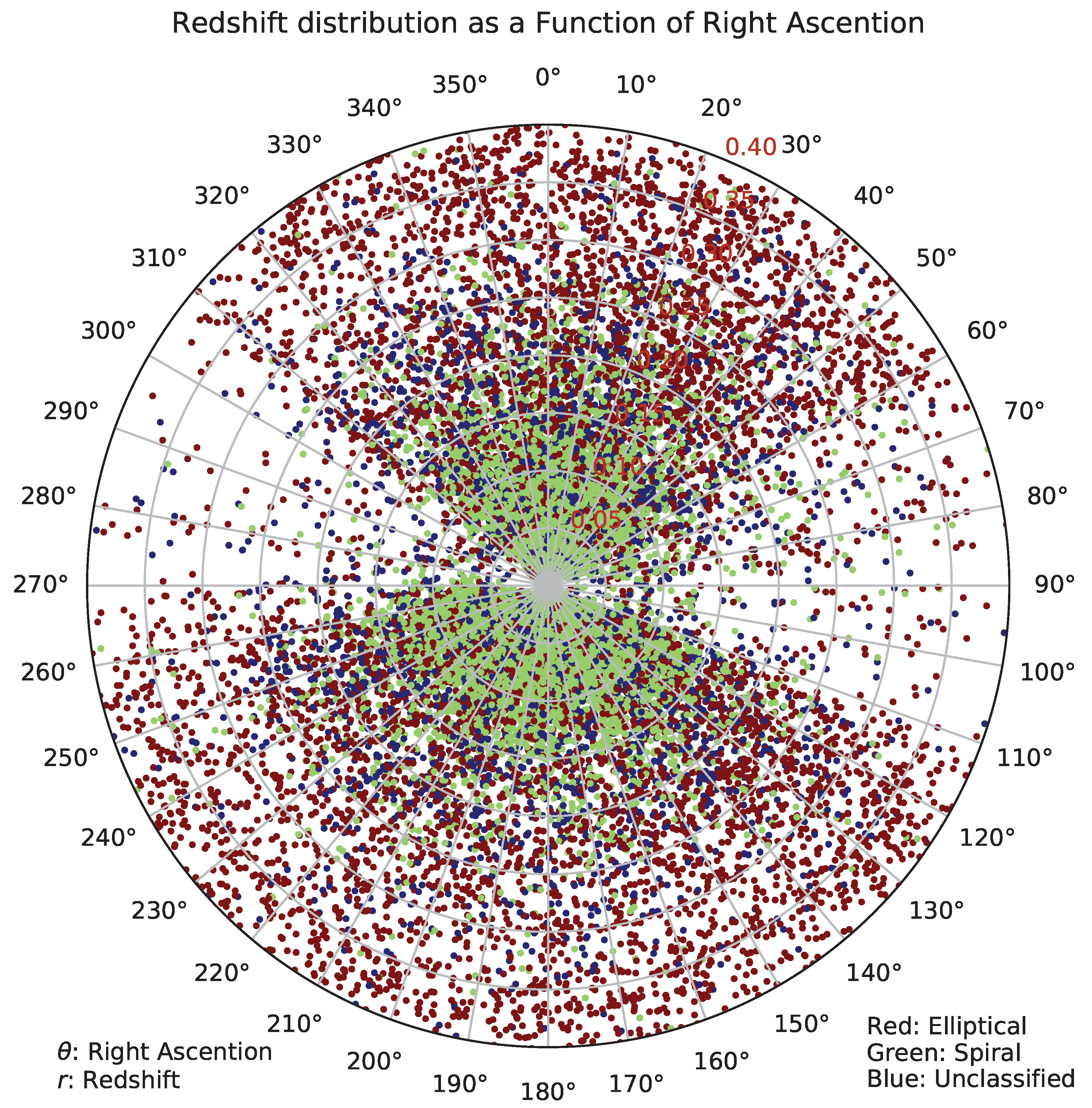
Table 1.
Variable sets.
| Name | Variables |
|---|---|
| [25] | ra, dec, g, r, i, z, psfMagErr u, psfMagErr g, psfMagErr r, psfMagErr i, psfMagErr z, extinction u, extinction g, extinction r, extinction i, extinction z, u-g, u-r, u-i, u-z |
| KBest13 | deVMag_g, deVMag_r, dered_g, dered_u, expMag_g, expMag_r, fiberMag_u, g, petroMag_g, photozcc2, photozd1, u |
| KBest21 | deVMag_g, deVMag_r, deVMag_u, dered_g, dered_r, dered_u, expMag_g, expMag_r, fiberMag_g, fiberMag_u, g, petroMag_g, petroMag_r, photozcc2, photozd1, psfMag_g, psfMag_u, r, u |
| KBest30 | deVMag_g, deVMag_i, deVMag_r, deVMag_u, dered_g, dered_r, dered_u, expMag_g, expMag_i, expMag_r, expPhiErr z, fiberMag_g, fiberMag_u, g, isoA_u, isoBGrad_u, isoB_u, isoCocl_u, isoPhi_u, isoRowcGrad_u, petroMag_g, petroMag_r, petroMag_u, photoscc2, photozd1, psfMag_g, psfMag_u, r, u |
| KBestMod | deVMag_g, deVMag_r, deVMag_u, dered_g, dered_r, dered_u, expMag_g, expMag_r, fiberMag_g, fiberMag_u, g, petroMag_g, petroMag_r, psfMag_g, psfMag_u, ra, dec, i, r, u, u-g, g-r, r-i, i-z |
Table 2.
Mean absolute error for three different feature sets when using the random forest algorithm and the 10-fold cross-validation test strategy.
Table 2.
Mean absolute error for three different feature sets when using the random forest algorithm and the 10-fold cross-validation test strategy.
| Feature Set | Mean Abs Error |
|---|---|
| KBest13 | 0.00749 |
| KBest21 | 0.00741 |
| KBest30 | 0.00748 |
Table 3.
Performance of random forest on 20,000 galaxies with different feature sets.
| Feature Set | Mean Abs. Err. | Root Err. | |
|---|---|---|---|
| Brescia et al. [25] | 0.00747 | 0.01492 | 0.00246 |
| KBest13 | 0.00749 | 0.01728 | 0.00305 |
| KBest21 | 0.00741 | 0.01561 | 0.00259 |
| KBestMod | 0.00617 | 0.01294 | 0.00222 |
Table 4.
The 10-fold cross-validation performance of the different machine learning methods on a set of 20,000 galaxies using the KBestMod feature set.
Table 4.
The 10-fold cross-validation performance of the different machine learning methods on a set of 20,000 galaxies using the KBestMod feature set.
| Algorithm | Mean Abs. Err. | Root Err. | ||
|---|---|---|---|---|
| Simple Linear Regression | 0.00621 | 0.01321 | 0.01273 | 0.0347 |
| MultiLayer Perceptron | 0.00617 | 0.01313 | 0.01041 | 0.0159 |
| M5P | 0.00611 | 0.01288 | 0.00562 | 0.019 |
| ZeroR | 0.00616 | 0.01304 | 0.06581 | 0.0719 |
| Decision Table | 0.00616 | 0.01301 | 0.01586 | 0.0231 |
| Random Forest | 0.00617 | 0.01294 | 0.00222 | 0.0107 |
Table 5.
Error of the different photometric redshift algorithms in different redshift ranges.
| Measurement | |||
|---|---|---|---|
| 0.177 | |||
| Random Forest | 0.002 | 0.002 | 0.003 |
| Mean Abs. Err. Random Forest | 0.006 | 0.006 | 0.009 |
| Root Err. Random Forest | 0.008 | 0.009 | 0.014 |
| Multilayer Perceptron | 0.02 | 0.01 | 0.08 |
| Mean Abs. Err. Multilayer Perceptron | 0.03 | 0.02 | 0.36 |
| Root Abs. Err. Multilayer Perceptron | 0.044 | 0.04 | 0.41 |
| Err. NNP | 0.062 | 0.108 | 0.16 |
| Mean Abs. Err. NNP | 0.067 | 0.118 | 0.19 |
| Root Err. NNP | 0.082 | 0.128 | 0.21 |
| Err. CC2 | 0.014 | 0.015 | 0.04 |
| Mean Abs. Err. CC2 | 0.015 | 0.017 | 0.05 |
| Root Err. CC2 | 0.058 | 0.058 | 0.13 |
| Err. D1 | 0.024 | 0.018 | 0.06 |
| Mean Abs. Err. D1 | 0.026 | 0.021 | 0.11 |
| Root Err. D1 | 0.148 | 0.058 | 0.27 |
Table 6.
Statistics for various training set sizes. The KBestMod feature set was used with the random forest algorithm.
Table 6.
Statistics for various training set sizes. The KBestMod feature set was used with the random forest algorithm.
| Training Set Size | Mean Abs. Err. | Root Err. | |
|---|---|---|---|
| 1000 | 0.00836 | 0.02027 | 0.00266 |
| 5000 | 0.00646 | 0.01446 | 0.00219 |
| 10,000 | 0.00626 | 0.01342 | 0.00221 |
| 20,000 | 0.00617 | 0.01294 | 0.00222 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Paul, N.; Virag, N.; Shamir, L. A Catalog of Photometric Redshift and the Distribution of Broad Galaxy Morphologies. Galaxies 2018, 6, 64. https://doi.org/10.3390/galaxies6020064
AMA Style
Paul N, Virag N, Shamir L. A Catalog of Photometric Redshift and the Distribution of Broad Galaxy Morphologies. Galaxies. 2018; 6(2):64. https://doi.org/10.3390/galaxies6020064
Chicago/Turabian StylePaul, Nicholas, Nicholas Virag, and Lior Shamir. 2018. "A Catalog of Photometric Redshift and the Distribution of Broad Galaxy Morphologies" Galaxies 6, no. 2: 64. https://doi.org/10.3390/galaxies6020064
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.