Generalized Interval Neutrosophic Choquet Aggregation Operators and Their Applications


1
College of Arts and Sciences, Shanghai Maritime University, Shanghai 201306, China
2
School of Arts and Sciences, Shaanxi University of Science & Technology, Xi’an 710021, China
3
Department of Mathematics, Hanyang University, Seoul 04763, South Korea
*
Author to whom correspondence should be addressed.
Symmetry 2018, 10(4), 85; https://doi.org/10.3390/sym10040085
Submission received: 14 March 2018
/
Revised: 26 March 2018
/
Accepted: 26 March 2018
/
Published: 28 March 2018
(This article belongs to the Special Issue Algebraic Structures of Neutrosophic Triplets, Neutrosophic Duplets, or Neutrosophic Multisets)
Abstract
:The interval neutrosophic set (INS) is a subclass of the neutrosophic set (NS) and a generalization of the interval-valued intuitionistic fuzzy set (IVIFS), which can be used in real engineering and scientific applications. This paper aims at developing new generalized Choquet aggregation operators for INSs, including the generalized interval neutrosophic Choquet ordered averaging (G-INCOA) operator and generalized interval neutrosophic Choquet ordered geometric (G-INCOG) operator. The main advantages of the proposed operators can be described as follows: (i) during decision-making or analyzing process, the positive interaction, negative interaction or non-interaction among attributes can be considered by the G-INCOA and G-INCOG operators; (ii) each generalized Choquet aggregation operator presents a unique comprehensive framework for INSs, which comprises a bunch of existing interval neutrosophic aggregation operators; (iii) new multi-attribute decision making (MADM) approaches for INSs are established based on these operators, and decision makers may determine the value of by different MADM problems or their preferences, which makes the decision-making process more flexible; (iv) a new clustering algorithm for INSs are introduced based on the G-INCOA and G-INCOG operators, which proves that they have the potential to be applied to many new fields in the future.
1. Introduction
The neutrosophic set (NS) is a powerful comprehensive framework that comprises the concepts of the classic set, fuzzy set (FS), intuitionistic fuzzy set (IFS), hesitant fuzzy set (HFS), paraconsistent set, paradoxist set, and interval-valued fuzzy set (IVFS) [1,2,3,4]. It was introduced by Smarandache to deal with incomplete, indeterminate, and inconsistent decision information, which includes the truth membership, falsity membership, and indeterminacy membership, and their functions are non-standard subsets of [5]. However, without a specific description, it is difficult to apply the NS in practical application. Therefore, scholars proposed the interval neutrosophic set (INS), single-valued neutrosophic set (SVNS), rough neutrosophic set (RNS), multi-valued neutrosophic set (MVNS) as some special cases of the NS, and studied their related properties in [6,7,8,9]. Recently, numbers of new neutrosophic theories have been proposed and applied to image segmentation, image processing, rock mechanics, stock market, computational intelligence, multi-attribute decision making (MADM), medical diagnosis, fault diagnosis, and optimization design as described in [10,11,12,13].
The INS is a subclass of the NS and generalization of the IFS and IVIFS, which was proposed by Wang [6]. Motivated by some aggregation operators and decision-making methods for IFSs, IVIFSs, and NSs [14,15,16,17,18,19], a lot of theories about INSs have been put forward successively, and their basic concepts and aggregation tools play important roles in practical applications. For instance, Wang et al. [6] defined the basic operational relations for INSs and Zhang et al. [20] pointed out some drawbacks of these operational laws and improved them. Then they also put forward some basic aggregation operators to deal with MADM problems with interval neutrosophic information. Besides, Broumi [21] introduced the definition of correlation coefficient between INSs. Then Zhang et al. [22] pointed out some shortcomings of the existing correlation coefficient and they also proposed the definition of improved weighted correlation coefficient. Ye [23] defined some distance measures and similarity measures for INSs and applied these measures in practical MADM problems, and he also [24] proposed the interval neutrosophic ordered weighted arithmetic and geometric averaging operators, and further constructed a possibility degree ranking method under the interval neutrosophic environment. Moreover, Liu et al. [25,26,27] proposed the power generalized aggregation operators, the prioritized ordered weighted aggregation operators and induced generalized interval neutrosophic Shapley hybrid geometric averaging/mean operators for INSs under an interval neutrosophic environment.
For some practical problems, there exists mutual influence and interaction among attributes, which should be considered in decision-making or other analyzing process. The interaction between attributes can be classified into three types, which are positive interaction, negative interaction, and non-interaction [28,29]. Failure to consider the interactions among attributes may directly lead to errors of decision results. To solve this problem under the interval neutrosophic environment, we first intend to define some aggregation operators in this paper by combining the definition of Choquet integral to process the mutual influence and interaction among attributes with respect to fuzzy measure [30,31].
Besides, cluster analysis, or clustering, is defined as the unsupervised process of group (a set of data objects) in such a way that objects in the same group (called a cluster) are somehow more similar to each other than those in other groups (clusters) [32]. There are many algorithms for clustering which differ significantly in their notion of what constitutes a cluster and how to efficiently find them. Under a hesitant fuzzy environment, Chen et al. [33] proposed an algorithm to cluster hesitant fuzzy data into different clusters. Using the algorithm as a reference, we also intend to propose an effective new clustering algorithm under the interval neutrosophic environment.
Moreover, the generalized aggregation operators are a new class of operators, which have been widely applied in fuzzy areas, since they can be used to synthesize multi-dimensional evaluation values represented by kinds of hesitant fuzzy values or intuitionstic fuzzy values into collective values. Overall, this paper aims at proposing new generalized Choquet aggregation operators for INSs—namely, the G-INCOA operator and G-INCOG operator—which can be applied in MADM and clustering using interval neutrosophic information. In some special cases, each generalized aggregation operator reduces to various existing non-generalized interval neutrosophic aggregation operators.
To do so, the rest of this paper is organized as follows: Section 2 introduces some basic definitions about the Choquet integral and INS. In Section 3, the G-INCOA operator and G-INCOG operator are put forward and some desirable properties of them are discussed and proved. We also consider special cases of these operators and distinguish them in two main classes, the first class focuses on the parameter , and the second class on the fuzzy measure . In Section 4, we put forward some novel MADM methods based on the proposed operators to deal with interval neutrosophic information and utilize an illustrative example to validate the proposed MADM approaches by taking different values of parameter of the proposed operators. In Section 5, a new clustering algorithm for INSs is introduced based on the G-INCOA operator and the G-INCOG operator. Then, a numerical example concerning clustering is utilized as the demonstration of the application and effectiveness of the proposed clustering algorithm. Finally, conclusions and future research directions are drawn in Section 6.
2. Preliminaries
To facilitate the following discussion, some basic definitions about the Choquet integral and INS are briefly introduced in this section.
2.1. Interval Neutrosophic Sets (INS)
The NS was firstly introduced by Smarandache [5], which is a comprehensive framework for expressing and processing incomplete and indeterminate information.
Definition 1.
([5]) Let X be a non-empty fixed set, a NS on X is defined as:
where representing the truth membership function, indeterminacy membership function and falsity membership function, respectively, and satisfying the limit:
It is not difficult to find that the NS is difficult to apply in the real applications. Therefore, Wang et al. [6] proposed the interval neutrosophic set (INS) as an instance of the NS, which is defined as:
Definition 2.
([6]) Let X be a non-empty finite set, an INS in X is expressed by:
where representing truth, indeterminacy, and falsity membership functions of the element , and satisfying limits:.
For convenience, we call an interval neutrosophic element (INN). The basic operational relations of INNs are defined as:
Definition 3.
([6]) Let and be two INNs, then:
- ;
- .
2.2. Some Concepts of INSs
On the basis of the distance measures of INSs [23], Ye defined some similarity measures between INSs and , which can be given as:
Definition 4.
Let and be two INNs, thus, the similarity function between and is defined by:
According to the value range of the similarity measures, we can obtain the value range of the cosine function, we can obtain the following property . Suppose the best ideal alternative , then, the similarity measures between and can be described as:
The score function are effective tools to rank INNs, and here we give its definition:
Definition 5.
2.3. The Fuzzy Measure and Choquet Integral
The Choquet integral is a powerful operator to aggregate kinds of fuzzy information in MADM with respect to fuzzy measure.
Definition 6.
([30]) Let be a measurable space and , if it satisfies the conditions:
then, we call be a fuzzy measure defined by Sugeno M.
To avoid the problems with computational complexity in paractical applications, fuzzy measure also called -fuzzy measure, was proposed by Sugeno M [30], which satisfies an additional properties: for all and . Specially, the expression of fuzzy measure defined on a finite set X = {} can be simplified as:
Theorem 1.
Then, the Choquet integral with respect to fuzzy measures, is defined as:
Definition 7.
([31]) When is a fuzzy measure, X = {} is a finite set. The Choquet integral of a function with respect to fuzzy measure can be expressed as:
where is a permutation of such that and
3. Generalized Interval Neutrosphic Choquet Aggregation Operators
In what follows, based on the operational relations of INNs and Choquet aggregation operator, we shall develop new generalized Choquet aggregation operators under the interval neutrosophic environment, such as the generalized interval neutrosophic Choquet ordered averaging (G-INCOA) operator and generalized interval neutrosophic Choquet ordered geometric (G-INCOG) operator.
3.1. The G-INCOA and G-INCOG Operators
Definition 8.
When is a collection of INNs, X= {} is the set of attributes and measure on X, the G-INCOA and G-INCOG operators are defined as:
where . where is a permutation of such that and
Theorem 2.
When is a collection of INNs, then the aggregated value obtained by the G-INCOA operator is also a INN, and:
Similarly, the aggregated value obtained by the G-INCOG operator is also a INN,
Proof.
The result of follows quickly from Definition 8, below we prove Equations (10) and (11) by means of mathematical induction on m, here, take Equation (11) as an example.
(a) For based on the operation relations of INNs defined in Definition 3, we have:
thus, for the can be obtained as:
thus, Equation (11) holds for .
(b) If Equation (11) holds for , then:
For
That is, for the Equation (11) still holds, by the proof Equation (11), it is not difficult to get Equation (10).
This completes the proof of Theorem 2. ☐
Theorem 4.
The G-INCOA and G-INCOG operators have the following desirable properties, taking the G-INCOA operator as:
- (Idempotency) Let for all and , then:
- (Boundedness) Let
- (Commutativity) If is a permutation of , then,
- (Monotonity) If for , then,
Proof.
Suppose is a permutation such that
1. For , according to Theorem 1, it follows that:
Since thus,
2. For any we have,
Since is a monotone increasing function when and values in the G-INCOA operator are all valued in [0, 1], therefore,
Since , the above equation is equivalent to:
Analogously, we have:
and
Since , namely,
3. Suppose is a permutation of both and such that , then,
4. In general, it can be derived from the second theorem.
This completes the proof of Theorem 4. ☐
3.2. Families of G-INCOA and G-INCOG Operators
In this section, we consider special cases of the G-INCOA and G-INCOG operators and distinguish them in two main classes, the first class focuses on the parameter , and the second class on the fuzzy measure .
3.2.1. Analyzing the Parameter
Like other generalized operators, both the G-INCOA and G-INCOG can reduce to some general circumstances when the parameter takes different values, which are described as:
- (1)
- When , the G-INCOA operator reduces to the interval neutrosophic Choquet ordered averaging (INCOA) operator,
Similarly, the G-INCOG operator reduces to the interval neutrosophic Choquet ordered geometric (INCOG) operator when .
- (2)
- If , the G-INCOA operator reduces to the INCOG operator,
Similarly, the G-INCOG operator reduces to the INCOA operator.
- (3)
- When , the G-INCOA operator can reduce to the interval neutrosophic Choquet ordered quadratic averaging (INCOQA) operator,
Similarly, then the G-INCOG operator can reduce to the interval neutrosophic Choquet ordered quadratic geometric (INCOQG) operator.
- (4)
- If , then the G-INCOA operator can reduce to the interval neutrosophic Choquet ordered cubic averaging (INCOCA) operator,
Similarly, then the G-INCOG operator can reduce to the interval neutrosophic Choquet ordered cubic geometric (INCOCG) operator.
3.2.2. Analyzing the Fuzzy Measure
When considering different circumstances of the fuzzy measure , some special cases of the G-INCOA and G-INCOG operators are given as:
- (1)
- When , then ;
- (2)
- When , then
- (3)
- The G-INCOA operator reduces to the generalized interval neutrosophic weighted averaging (G-INWA) operator, if the independent condition holds.
- (4)
- When , both the G-INCOA and G-INWA operators reduce to the generalized interval neutrosophic averaging (G-INA) operator, which is defined as:
- (5)
- When for all where is the number of elements in F, then where such that and . In such a situation, the G-INCOA operator reduces to the generalized interval neutrosophic ordered weighted averaging (G-INOWA) operator as:
Particularly, when , for all then the G-INCOA operator and G-INOWA operator can reduce to the G-INA operator. Similarly, the G-INCOG can reduce to G-INOWG operator, the G-ING operator, the G-INOWG operator and others.
4. Application in MADM under Interval Neutrosophic Environment
This section puts forward new approaches based on the G-INCOA and G-INCOG operators for MADM problems with interval neutrosophic information, where the characteristics of the alternatives are represented by INSs and the interaction relationship among attributes can be considered. Thus, the remaining issue is to use these aggregation operators in practical MADM problems to verify the correctness and practicality of them.
4.1. Approaches Based on the G-INCOA and G-INCOG Operators for MADM
Let be a finite set of m inter-related attributes and be a set of n choices. Suppose that with respect to the attributes, the alternatives denoted by an interval neutrosophic matrix , in detail, indicate the truth, indeterminacy and falsity membership function of satisfying given by decision-makers, respectively. Next, to get the best choice, the G-INCOA and G-INCOG operators are utilized to establish MADM methods with interval neutrosophic information, which involves the following steps:
Step 1. Reorder the decision matrix
With respect to attributes reorder m INNs of from smallest to largest, according to their score function values calculated by Equation (5), the reorder sequence for is ;
Step 2. Confirm fuzzy measures of m attributes
Use fuzzy measure defined in Equation (6) to determine fuzzy measures of , in which the interaction relationship among attributes is considered;
Step 3. Aggregate decision information by the G-INCOA or G-INCOG operators
Aggregate m INNs of based on the G-INCOA and G-INCOG operator defined in Equation (8) or (9), with respect to attributes as proved by Theorem 2, the aggregated values obtained by the G-INCOA and G-INCOG operators are also INNs;
Step 4. Rank all alternatives
Rank all alternatives to select the most desirable one by their score function values between , described in Equation (5).
4.2. Numerical Example
An illustrative example concerning selecting is utilized to verify feasibility of the proposed MADM approaches. Suppose that a fund manager in a wealth management firm is assessing four potential investment opportunities, there is a panel with four possible alternatives denoted by During MADM process, some attributes should be taken into account: (1) is risk; (2) is growth; (3) is socio-political issues and environmental impacts. Experts are required to evaluate the four possible enterprises under these attributes, and interval neutrosophic decision matrix is constructed as:
Step 1. Get score function values of calculated by Equation (5), shown as Table 1,
To facilitate the following calculation and accord to their score function values, the reordered decision matrix can be constructed as:
Step 2. First, if the fuzzy measures of all inter-related attributes are given as follows: . According to Equation (6), the value of is obtained: . Thus, we have .
Step 3. Aggregate by utilizing the G-INCOA operator (in which ) to derive the comprehensive score values for
Step 4. Ranking the comprehensive score values for , we get:
Therefore, we have and is the best choice.
If we utilize the G-INCOG operator for this MADM problem, aggregate to derive the comprehensive score value for
Then, ranking the score function values of INNs, we get:
Rank according to the score values . Therefore, we can see that is the best choice. Obviously, the above two kinds of ranking orders are the same, therefore, the above example clearly indicates that the proposed MADM methods are applicable and effective under an interval neutrosophic environment.
4.3. Rank Alternatives for Different Values of
In real life, decision makers may determine the value of by different MADM problems or their preferences, which makes the decision-making process more flexible. In this section, we use different values of parameter of the G-INCOA and G-INCOG operators, such as to rank alternatives of the numerical example in Section 4.2.
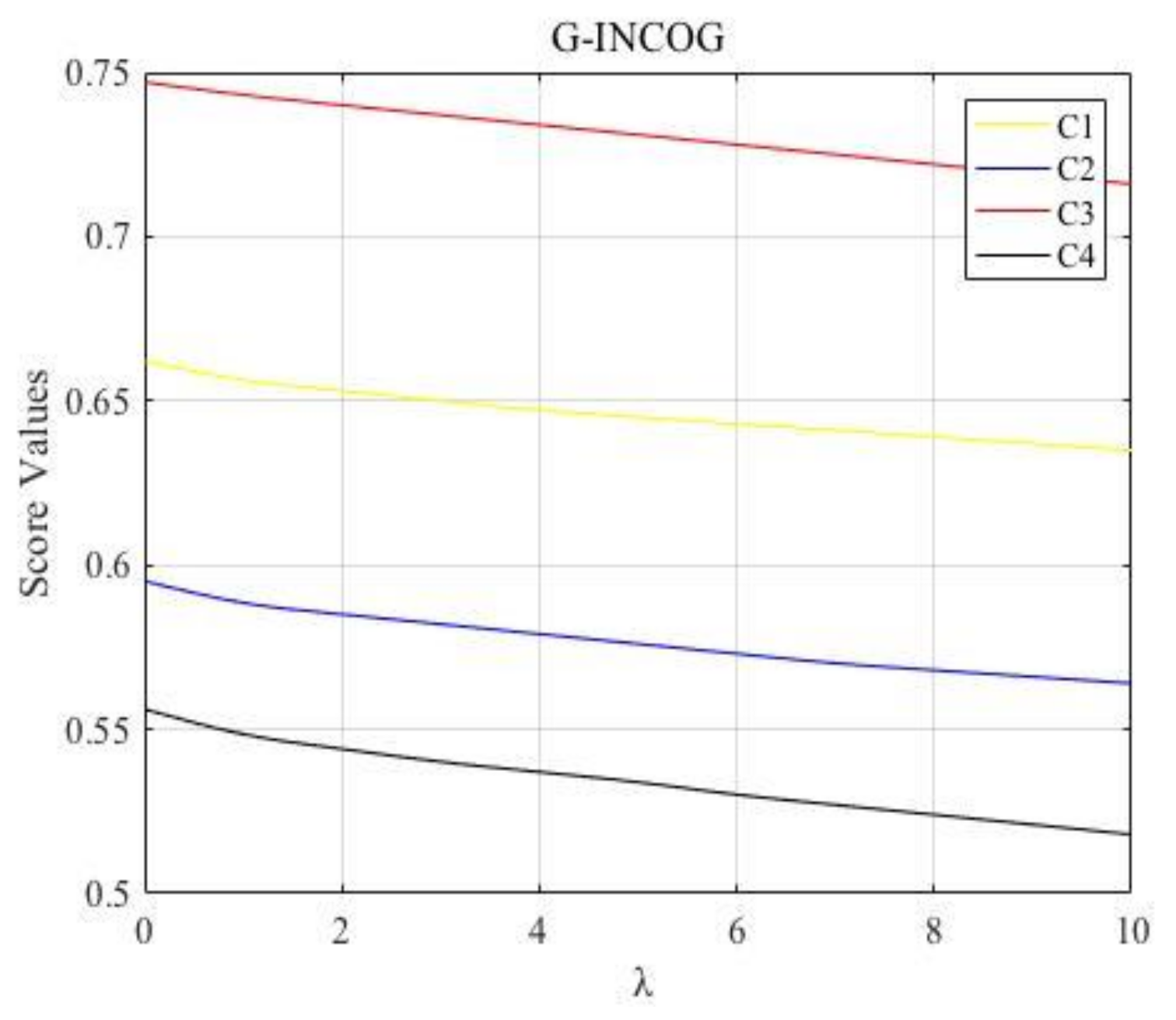
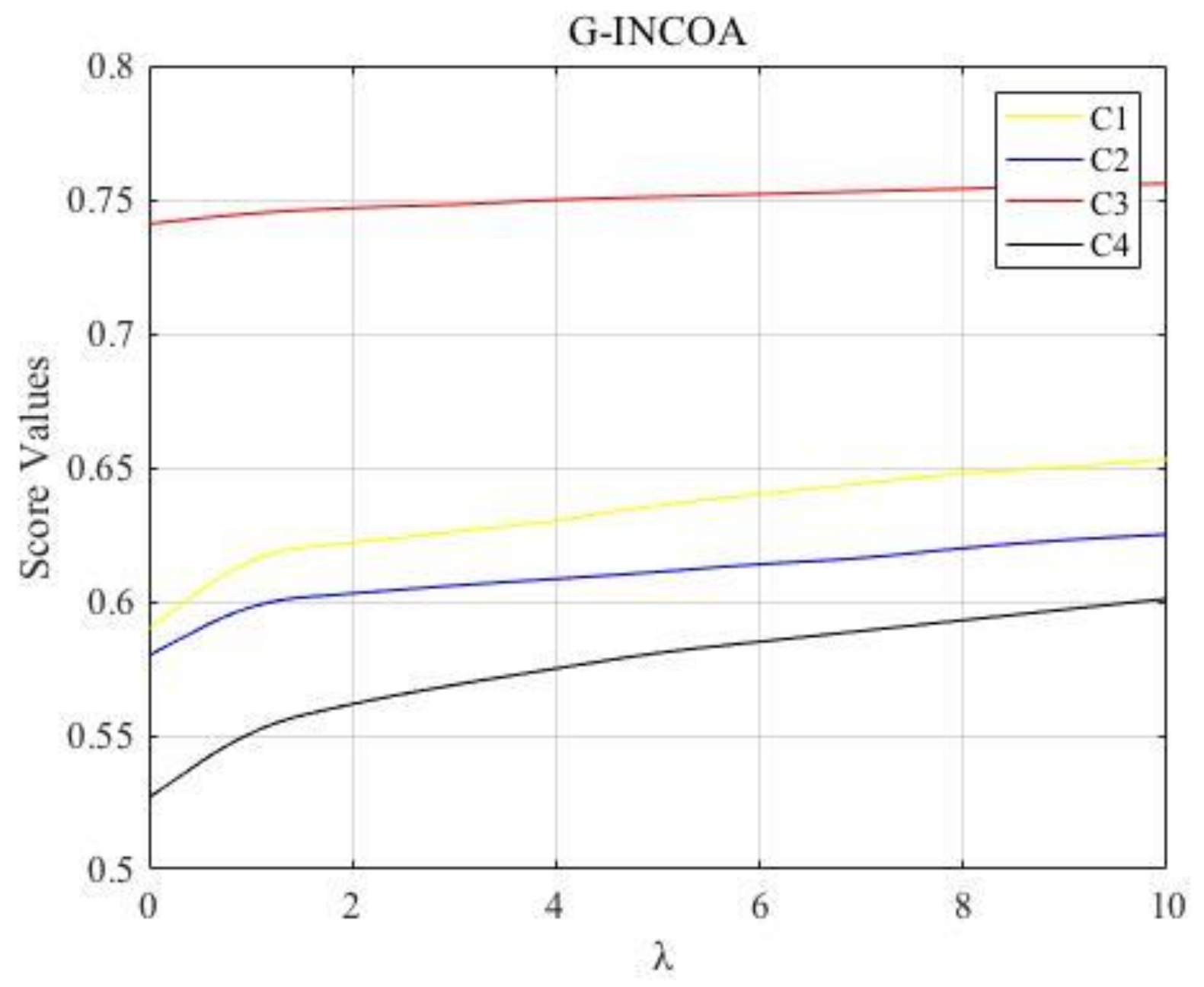
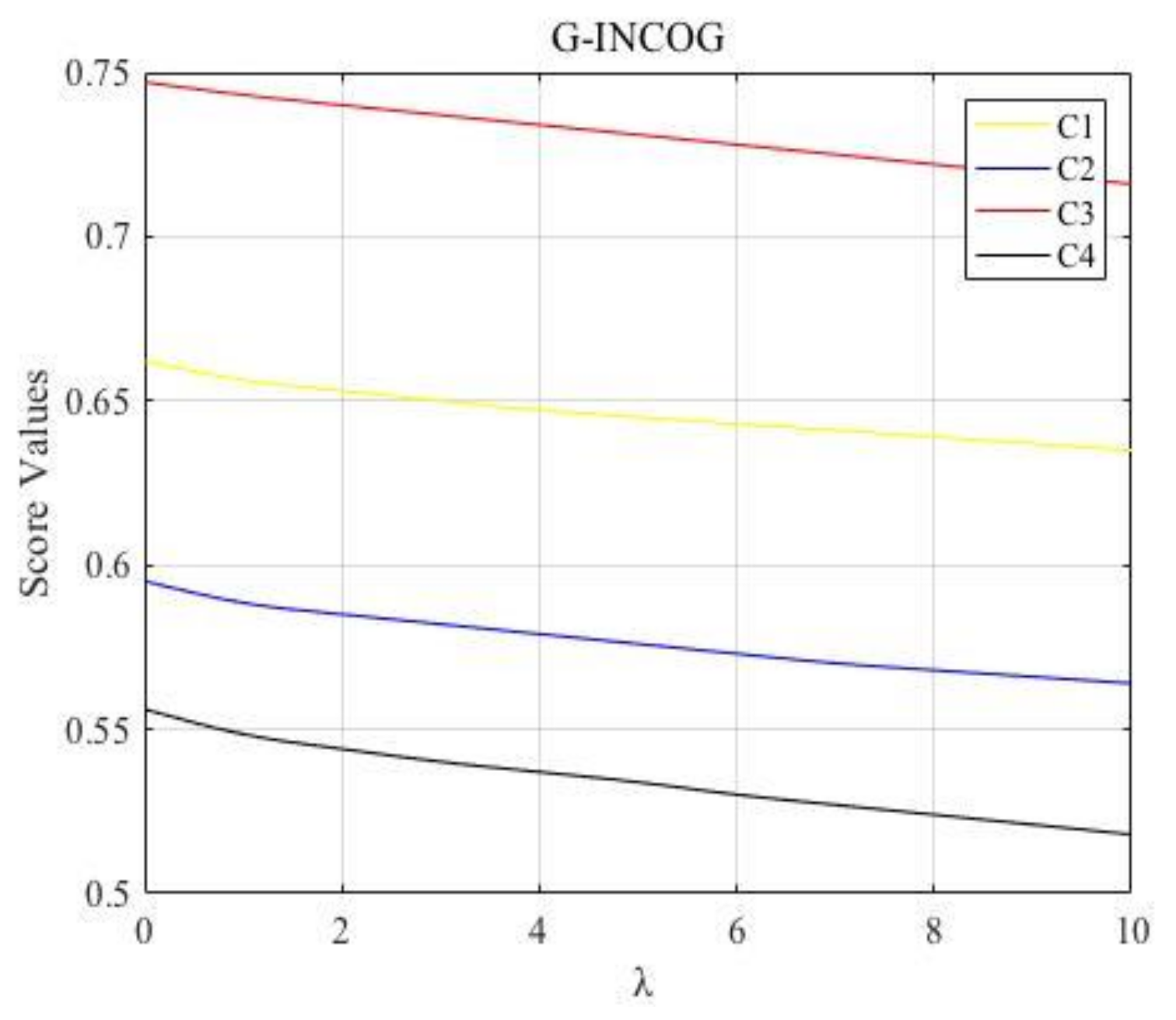
Combined with the proposed approaches for MADM with interval neutrosophic information, we can obtain their score function values of four alternatives, the ranking results for different values of determined by the G-INCOA and G-INCOG operator are shown in Figure 1 and Figure 2, respectively. As shown in Figure 1 and Figure 2, the best choice is always and the worst alternative is always , which means they have higher accuracy and greater reference value. Besides, the changing trends of decision results with parameter calculated by the G-INCOA operator presents an increasing trend, meanwhile, the changing trends of decision results with calculated by the G-INCOG operator shows a declining trend, which further validates the duality of the proposed operators.
5. Apply the Proposed Operators for INSs to Cluster Analysis
5.1. New Clustering Algorithm for INSs
In this section, we intend to propose a new clustering algorithm for INSs to illustrate the efficiency of the proposed operators. Let be a matrix of INNs on , the algorithm can be described as:
Step 1. Using the proposed operator, here, take the G-INCOA operator as an example, to aggregate m INNs of each alternative to an comprehensive INN ; Using the similarity measures function defined in Equation (3) to calculate measures between and , the corresponding results are recorded in a matrix ;
Step 2. Check whether the measure matrix S satisfies where and If it does not hold, then construct the equivalent matrix: until ;
Step 3. For a given confident level construct a -cutting matrix , where is defined as:
Step 4. Classify the INSs by the rule: if all elements of the jth line in are the same as the corresponding elements of the kth line, thus, the INSs and are supposed as the same type.
5.2. Numerical Example
A numerical example concerning investing is utilized to demonstrate the application of these aggregation operators, as well as the effectiveness of them. Suppose there are five attributes to be considered: (1) profitability; (2) operating capacity; (3) market competition. The fuzzy measures of attributes in X are given as follows: . Firstly, according to Equation (7), the value of is obtained: . Thus,. Experts are required to evaluate 10 firms under the three attributes, and interval neutrosophic decision matrix is constructed as:
In the following, we use the proposed clustering algorithm to cluster these alternatives:
Step 1. Aggregated the G-INCOA operator defined in Equation (8) and calculated by the similarity measure function defined in Equation (5), the weighted measures between each pair of alternatives are recorded in a matrix .
Step 2. The equivalent measure matrix can be constructed as follows, as , therefore, is an equivalent measure matrix.
Step 3. For a given confident level we can construct a -cutting matrix for , different produces different -cutting matrix, for example, if the -cutting matrix can be constructed as , since .
Step 4. Based on the -cutting matrix we can classify 10 alternatives into different clusters, the possible classification of these choices is shown in Table 2.
With respect to different values of , different clusters of 10 alternatives are shown in Table 2. When all alternatives belong to the same cluster, then 10 alternatives are divided in to two clusters, namely, and until , each alternative is an independent cluster.
6. Conclusions
This paper studies new MADM methods and clustering algorithm under an interval neutrosophic environment, in which the attributes are inter-related. Motivated by the idea of the generalized operator, we proposed the G-INCOA and G-INCOG operators based on the related research of the NS and SVNS theories, which can reduce to the existing aggregation operators of INSs and have some desirable properties. By taking different values of the parameters and comparing them with existing methods for MADM problems, under interval neutrosophic environment, results obtained by the proposed operators are consistent and accurate, which illustrates their practicability in application. The new clustering algorithm are established on the G-INCOA and G-INCOG operators, a numerical example concerning investing is utilized as the demonstration of the application of the proposed aggregation operators, as well as the effectiveness of them. In the future, motivated by different MADM methods under linguistic environment [34,35], it is worth investigating the use granular computing techniques to develop new MADM methods with interval neutrosophic linguistic information.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant Numbers 61573240, 61473239).
Author Contributions
All authors have contributed equally to this paper. The individual responsibilities and contribution of all authors can be described as follows: the idea of this whole thesis was put forward by Xiaohong Zhang, he also completed the preparatory work of the paper. Xin Li analyzed the existing work of interval neutrosophic sets and wrote part of the paper. The revision and submission of this paper was completed by Choonkil Park.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ye, J. Multicriteria decision-making method using the correlation coefficient under single-valued neutrosophic environment. Int. J. Gen. Syst. 2013, 42, 386–394. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Torra, V.; Narukawa, Y. On hesitant fuzzy sets and decision. In Proceedings of the 18th IEEE International Conference on Fuzzy Systems, Jeju Island, Korea, 20–24 August 2009; pp. 1378–1382. [Google Scholar] [CrossRef]
- Zhang, X.H. Fuzzy anti-grouped filters and fuzzy normal filters in pseudo-BCI algebras. J. Intell. Fuzzy Syst. 2017, 33, 1767–1774. [Google Scholar] [CrossRef]
- Smarandache, F. A Unifying Field in Logics: Neutrosophic Logic, Neutrosophy, Neutrosophic Set, Neutrosophic Probability; American Research Press: Rehoboth, DE, USA, 1999. [Google Scholar]
- Wang, H.; Madiraju, P. Interval-neutrosophic Sets. J. Mech. 2004, 1, 274–277. [Google Scholar]
- Wang, H.; Smarandache, F.; Sunderraman, R. Single-valued neutrosophic sets. Rev. Air Force Acad. 2013, 17, 10–13. [Google Scholar]
- Broumi, S.; Smarandache, F.; Dhar, M. Rough neutrosophic sets. Ital. J. Pure. Appl. Math. 2014, 32. [Google Scholar] [CrossRef]
- Peng, J.; Wang, J.; Wu, X. Multi-valued neutrosophic sets and power aggregation operators with their applications in multi-criteria group decision-making problems. Int. J. Comput. Int. Syst. 2015, 8, 345–363. [Google Scholar] [CrossRef]
- Guo, Y.H.; Ümit, B.; Şengür, A.; Smarandache, F. A Retinal Vessel Detection Approach Based on Shearlet Transform and Indeterminacy Filtering on Fundus Images. Symmetry 2017, 9, 235–244. [Google Scholar] [CrossRef]
- Chen, J.Q.; Ye, J.; Du, S.G. Scale Effect and Anisotropy Analyzed for Neutrosophic Numbers of Rock Joint Roughness Coefficient Based on Neutrosophic Statistics. Symmetry 2017, 9, 14–27. [Google Scholar] [CrossRef]
- Zhang, X.H.; Bo, C.X.; Smarandache, F.; Dai, J.H. New inclusion relation of neutrosophic sets with applications and related lattice structrue. Int. J. Mach. Learn. Cybern. 2018. accepted. [Google Scholar]
- Akbulut, Y.; Sengur, A.; Guo, Y.H.; Smarandache, F. A Novel Neutrosophic Weighted Extreme Learning Machine for Imbalanced Data Set. Symmetry 2017, 9, 142. [Google Scholar] [CrossRef]
- Xu, Z.S.; Gou, X.J. An overview of interval-valued intuitionistic fuzzy information aggregations and applications. Granul. Comput. 2017, 2, 13–39. [Google Scholar] [CrossRef]
- Wang, C.Q.; Fu, X.G.; Meng, S.; He, Y. Multi-attribute decision making based on the SPIFGIA operators. Granul. Comput. 2017, 2, 321–331. [Google Scholar] [CrossRef]
- Jiang, Y.; Xu, Z.S.; Shu, Y.H. Interval-valued intuitionistic multiplicative aggregation in group decision making. Granul. Comput. 2017, 2, 387–407. [Google Scholar] [CrossRef]
- Joshi, B.P. Moderator intuitionistic fuzzy sets with applications in multi-criteria decision-making. Granul. Comput. 2018, 3, 61–73. [Google Scholar] [CrossRef]
- Chen, J.Q.; Ye, J.; Du, S.G. Vector Similarity Measures between Refined Simplified Neutrosophic Sets and Their Multiple Attribute Decision-Making Method. Symmetry 2017, 9, 153. [Google Scholar] [CrossRef]
- Hu, K.L.; Fan, E.; Ye, J.; Fan, C.; Shen, S.; Gu, Y. Neutrosophic Similarity Score Based Weighted Histogram for Robust Mean-Shift Tracking. Information 2017, 8, 122. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Wang, J.Q.; Chen, X.H. Inverval neutrosophic sets and their application in multicriteria decision making problems. Sci. World J. 2014, 2014, 645953. [Google Scholar] [CrossRef]
- Broumi, S.; Smarandache, F. Correlation Coefficient of Interval Neutrosophic Set. Appl. Mech. Mater. 2013, 436, 511–517. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Ji, P.; Wang, J.Q.; Chen, X.H. An Improved Weighted Correlation Coefficient Based on Integrated Weight for Interval Neutrosophic Sets and its Application in Multi-criteria Decision-making Problems. Int. J. Comput. Int. Syst. 2015, 8, 1027–1043. [Google Scholar] [CrossRef]
- Ye, J. Similarity measures between interval neutrosophic sets and their multicriteria decision-making method. J. Intell. Fuzzy Syst. 2014, 26, 165–172. [Google Scholar]
- Ye, J. Multiple attribute decision-making method based on the possibility degree ranking method and ordered weighted aggregation operators of interval neutrosophic numbers. J. Intell. Syst. 2015, 28, 1307–1317. [Google Scholar] [CrossRef]
- Liu, P.D.; Tang, G.L. Some power generalized aggregation operators based on the interval neutrosophic numbers and their application to decision making. J. Intell. Fuzzy. Syst. 2015, 30, 2517–2528. [Google Scholar] [CrossRef]
- Liu, P.D.; Teng, F. Multiple attribute decision making method based on normal neutrosophic generalized weighted power averaging operator. Int. J. Mach. Learn. Cybern. 2015, 1–13. [Google Scholar] [CrossRef]
- Liu, P.D.; Wang, Y.M. Interval neutrosophic prioritized OWA operator and its application to multiple attribute decision making. J. Syst. Sci. Complex. 2016, 29, 681–697. [Google Scholar] [CrossRef]
- Zhang, X.H.; She, Y.H. Fuzzy Quantifies with Integral Semantics; Science Press: Beijing, China, 2017; ISBN 978-7-03053-480-4. Available online: http://product.dangdang.com/25113577.html (accessed on 1 July 2017).
- Ju, Y.B.; Yang, S.H.; Liu, X.Y. Some new dual hesitant fuzzy aggregation operators based on Choquet integral and their applications to multiple attribute decision making. J. Intell. Fuzzy Syst. 2014, 27, 2857–2868. [Google Scholar] [CrossRef]
- Choquet, G. Theory of capacities. Ann. Inst. Fourier. 1953, 5, 131–295. [Google Scholar] [CrossRef]
- Sugeno, M. Theory of Fuzzy Integral and its Application. Ph.D. Thesis, Tokyo Institute of Technology, Tokyo, Japan, 22 January 1975. [Google Scholar]
- Liao, H.C.; Xu, Z.S.; Zeng, X.J. Novel correlation coefficients between hesitant fuzzy sets and their application in decision making. Knowl. Based Syst. 2015, 82, 115–127. [Google Scholar] [CrossRef]
- Chen, N.; Xu, Z.S.; Xia, M.M. Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl. Math. Model. 2013, 37, 2197–2211. [Google Scholar] [CrossRef]
- Liu, P.D.; You, X.L. Probabilistic linguistic TODIM approach for multiple attribute decision making. Granul. Comput. 2017, 2, 333–342. [Google Scholar] [CrossRef]
- Xu, Z.S.; Wang, H. Managing multi-granularity linguistic information in qualitative group decision making: An overview. Granul. Comput. 2016, 1, 21–35. [Google Scholar] [CrossRef]
Figure 1.
The changing trends of decision results with calculated by the G-INCOA operator.
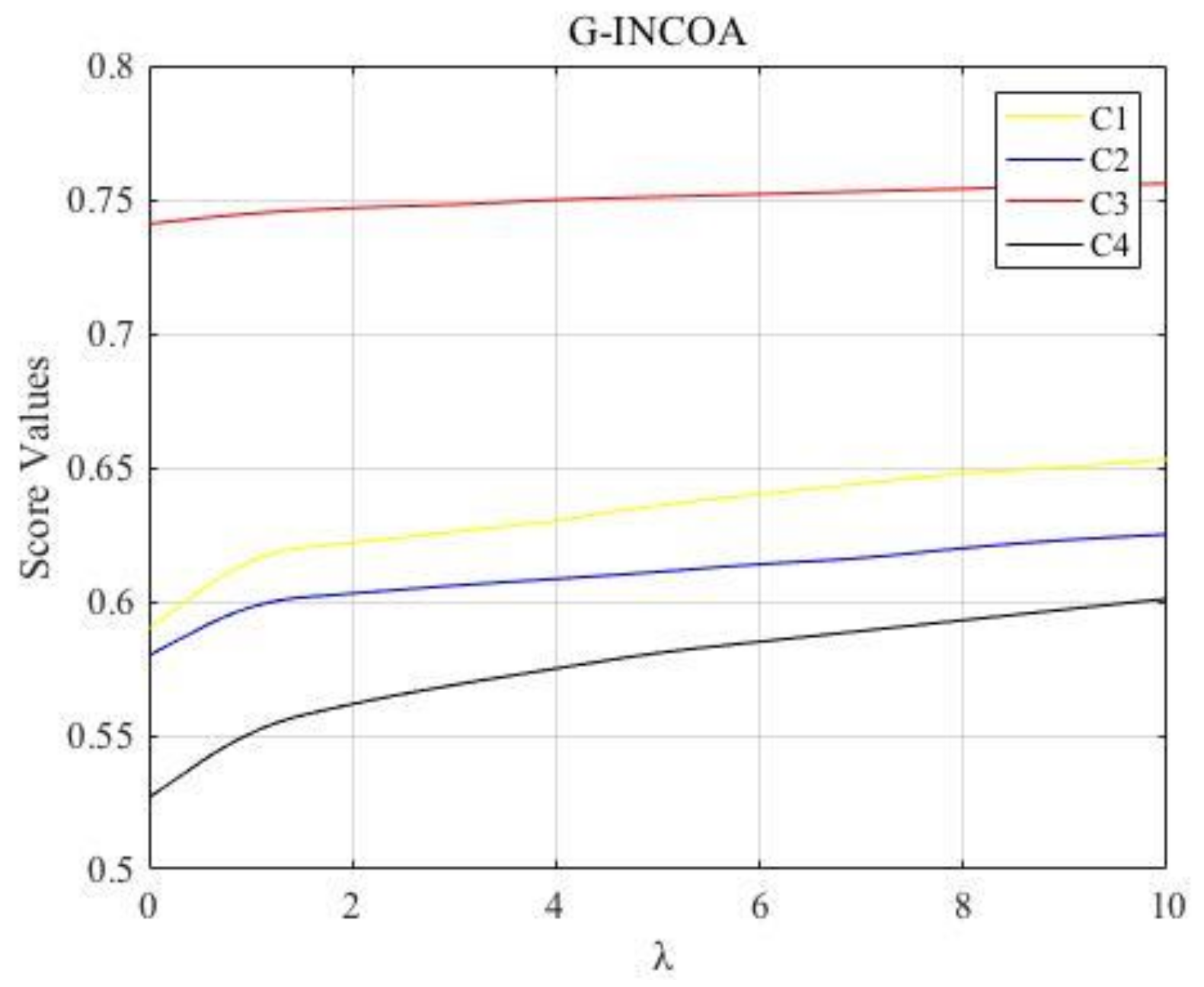
Figure 2.
The changing trends of decision results with calculated by the G-INCOG operator.

{kind=link}
{kind=link}
Table 1.
Score values of .
Table 2.
Different clusters of 10 alternatives with respect to different .
| Class | Confidence Level | Clusters |
|---|---|---|
| 8 | ||
| 7 | ||
| 6 | ||
| 5 | ||
| 4 | ||
| 3 | ||
| 2 | ||
| 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, X.; Zhang, X.; Park, C. Generalized Interval Neutrosophic Choquet Aggregation Operators and Their Applications. Symmetry 2018, 10, 85. https://doi.org/10.3390/sym10040085
AMA Style
Li X, Zhang X, Park C. Generalized Interval Neutrosophic Choquet Aggregation Operators and Their Applications. Symmetry. 2018; 10(4):85. https://doi.org/10.3390/sym10040085
Chicago/Turabian StyleLi, Xin, Xiaohong Zhang, and Choonkil Park. 2018. "Generalized Interval Neutrosophic Choquet Aggregation Operators and Their Applications" Symmetry 10, no. 4: 85. https://doi.org/10.3390/sym10040085
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.