Neutrosophic Association Rule Mining Algorithm for Big Data Analysis



1
Department of Operations Research, Faculty of Computers and Informatics, Zagazig University, Sharqiyah 44519, Egypt
2
Math & Science Department, University of New Mexico, Gallup, NM 87301, USA
3
International Business School Suzhou, Xi’an Jiaotong-Liverpool University, Wuzhong, Suzhou 215123, China
*
Authors to whom correspondence should be addressed.
Symmetry 2018, 10(4), 106; https://doi.org/10.3390/sym10040106
Submission received: 5 March 2018
/
Revised: 29 March 2018
/
Accepted: 9 April 2018
/
Published: 11 April 2018
(This article belongs to the Special Issue Algebraic Structures of Neutrosophic Triplets, Neutrosophic Duplets, or Neutrosophic Multisets)
Abstract
:Big Data is a large-sized and complex dataset, which cannot be managed using traditional data processing tools. Mining process of big data is the ability to extract valuable information from these large datasets. Association rule mining is a type of data mining process, which is indented to determine interesting associations between items and to establish a set of association rules whose support is greater than a specific threshold. The classical association rules can only be extracted from binary data where an item exists in a transaction, but it fails to deal effectively with quantitative attributes, through decreasing the quality of generated association rules due to sharp boundary problems. In order to overcome the drawbacks of classical association rule mining, we propose in this research a new neutrosophic association rule algorithm. The algorithm uses a new approach for generating association rules by dealing with membership, indeterminacy, and non-membership functions of items, conducting to an efficient decision-making system by considering all vague association rules. To prove the validity of the method, we compare the fuzzy mining and the neutrosophic mining. The results show that the proposed approach increases the number of generated association rules.
1. Introduction
The term ‘Big Data’ originated from the massive amount of data produced every day. Each day, Google receives cca. 1 billion queries, Facebook registers more than 800 million updates, and YouTube counts up to 4 billion views, and the produced data grows with 40% every year. Other sources of data are mobile devices and big companies. The produced data may be structured, semi-structured, or unstructured. Most of the big data types are unstructured; only 20% of data consists in structured data. There are four dimensions of big data:
- (1)
- Volume: big data is measured by petabytes and zettabytes.
- (2)
- Velocity: the accelerating speed of data flow.
- (3)
- Variety: the various sources and types of data requiring analysis and management.
- (4)
- Veracity: noise, abnormality, and biases of generated knowledge.
Consequently, Gartner [1] outlines that big data’s large volume requires cost-effective, innovative forms for processing information, to enhance insights and decision-making processes.
- (1)
- Business domain.
- (2)
- Technology domain.
- (3)
- Health domain.
- (4)
- Smart cities designing.
These various applications help people to obtain better services, experiences, or be healthier, by detecting illness symptoms much earlier than before [2]. Some significant challenges of managing and analyzing big data are [4,5]:
- (1)
- Analytics Architecture: The optimal architecture for dealing with historic and real-time data at the same time is not obvious yet.
- (2)
- Statistical significance: Fulfill statistical results, which should not be random.
- (3)
- Distributed mining: Various data mining methods are not fiddling to paralyze.
- (4)
- Time evolving data: Data should be improved over time according to the field of interest.
- (5)
- Compression: To deal with big data, the amount of space that is needed to store is highly relevant.
- (6)
- Visualization: The main mission of big data analysis is the visualization of results.
- (7)
- Hidden big data: Large amounts of beneficial data are lost since modern data is unstructured data.
Due to the increasing volume of data at a matchless rate and of various forms, we need to manage and analyze uncertainty of various types of data. Big data analytics is a significant function of big data, which discovers unobserved patterns and relationships among various items and people interest on a specific item from the huge data set. Various methods are applied to obtain valid, unknown, and useful models from large data. Association rule mining stands among big data analytics functionalities. The concept of association rule (AR) mining already returns to H’ajek et al. [6]. Each association rule in database is composed from two different sets of items, which are called antecedent and consequent. A simple example of association rule mining is “if the client buys a fruit, he/she is 80% likely to purchase milk also”. The previous association rule can help in making a marketing strategy of a grocery store. Then, we can say that association rule-mining finds all of the frequent items in database with the least complexities. From all of the available rules, in order to determine the rules of interest, a set of constraints must be determined. These constraints are support, confidence, lift, and conviction. Support indicates the number of occurrences of an item in all transactions, while the confidence constraint indicates the truth of the existing rule in transactions. The factor “lift” explains the dependency relationship between the antecedent and consequent. On the other hand, the conviction of a rule indicates the frequency ratio of an occurring antecedent without a consequent occurrence. Association rules mining could be limited to the problem of finding large itemsets, where a large itemset is a collection of items existing in a database transactions equal to or greater than the support threshold [7,8,9,10,11,12,13,14,15,16,17,18,19,20]. In [8], the author provides a survey of the itemset methods for discovering association rules. The association rules are positive and negative rules. The positive association rules take the form , and , where are antecedent and consequent and is a set of items in database. Each positive association rule may lead to three negative association rules, , , and . Generating association rules in [9] consists of two problems. The first problem is to find frequent itemsets whose support satisfies a predefined minimum value. Then, the concern is to derive all of the rules exceeding a minimum confidence, based on each frequent itemset. Since the solution of the second problem is straightforward, most of the proposed work goes in for solving the first problem. An a priori algorithm has been proposed in [19], which was the basis for many of the forthcoming algorithms. A two-pass algorithm is presented in [11]. It consumes only two database scan passes, while a priori is a multi-pass algorithm and needs up to c+1 database scans, where c is the number of items (attributes). Association rules mining is applicable in numerous database communities. It has large applications in the retail industry to improve market basket analysis [7]. Streaming-Rules is an algorithm developed by [9] to report an association between pairs of elements in streams for predictive caching and detecting the previously undetectable hit inflation attacks in advertising networks. Running mining algorithms on numerical attributes may result in a large set of candidates. Each candidate has small support and many rules have been generated with useless information, e.g., the age attribute, salary attribute, and students’ grades. Many partitioning algorithms have been developed to solve the numerical attributes problem. The proposed algorithms faced two problems. The first problem was the partitioning of attribute domain into meaningful partitions. The second problem was the loss of many useful rules due to the sharp boundary problem. Consequently, some rules may fail to achieve the minimum support threshold because of the separating of its domain into two partitions.
Fuzzy sets have been introduced to solve these two problems. Using fuzzy sets make the resulted association rules more meaningful. Many mining algorithms have been introduced to solve the quantitative attributes problem using fuzzy sets proposed algorithms in [13,14,15,16,17,18,19,20,21,22,23,24,25,26,27] that can be separated into two types related to the kind of minimum support threshold, fuzzy mining based on single-minimum support threshold, and fuzzy mining based on multi-minimum support threshold [21]. Neutrosophic theory was introduced in [28] to generalize fuzzy theory. In [29,30,31,32], the neutrosophic theory has been proposed to solve several applications and it has been used to generate a solution based on neutrosophic sets. Single-valued neutrosophic set was introduced in [33] to transfer the neutrosophic theory from the philosophic field into the mathematical theory, and to become applicable in engineering applications. In [33], a differentiation has been proposed between intuitionistic fuzzy sets and neutrosophic sets based on the independence of membership functions (truth-membership function, falsity-membership function, and indeterminacy-membership function). In neutrosophic sets, indeterminacy is explicitly independent, and truth-membership function and falsity-membership function are independent as well. In this paper, we introduce an approach that is based on neutrosophic sets for mining association rules, instead of fuzzy sets. Also, a comparison resulted association rules in both of the scenarios has been presented. In [34], an attempt to express how neutrosophic sets theory could be used in data mining has been proposed. They define SVNSF (single-valued neutrosophic score function) to aggregate attribute values. In [35], an algorithm has been introduced to mining vague association rules. Items properties have been added to enhance the quality of mining association rules. In addition, almost sold items (items has been selected by the customer, but not checked out) were added to enhance the generated association rules. AH-pair Database consisting of a traditional database and the hesitation information of items was generated. The hesitation information was collected, depending online shopping stores, which make it easier to collect that type of information, which does not exist in traditional stores. In this paper, we are the first to convert numerical attributes (items) into neutrosophic sets. While vague association rules add new items from the hesitating information, our framework adds new items by converting the numerical attributes into linguistic terms. Therefore, the vague association rule mining can be run on the converted database, which contains new linguistic terms.
Research Contribution
Detecting hidden and affinity patterns from various, complex, and big data represents a significant role in various domain areas, such as marketing, business, medical analysis, etc. These patterns are beneficial for strategic decision-making. Association rules mining plays an important role as well in detecting the relationships between patterns for determining frequent itemsets, since classical association rules cannot use all types of data for the mining process. Binary data can only be used to form classical rules, where items either exist in database or not. However, when classical association rules deal with quantitative database, no discovered rules will appear, and this is the reason for innovating quantitative association rules. The quantitative method also leads to the sharp boundary problem, where the item is below or above the estimation values. The fuzzy association rules are introduced to overcome the classical association rules drawbacks. The item in fuzzy association rules has a membership function and a fuzzy set. The fuzzy association rules can deal with vague rules, but not in the best manner, since it cannot consider the indeterminacy of rules. In order to overcome drawbacks of previous association rules, a new neutrosophic association rule algorithm has been introduced in this research. Our proposed algorithm deals effectively and efficiently with vague rules by considering not only the membership function of items, but also the indeterminacy and the falsity functions. Therefore, the proposed algorithm discovers all of the possible association rules and minimizes the losing processes of rules, which leads to building efficient and reliable decision-making system. By comparing our proposed algorithm with fuzzy approaches, we note that the number of association rules is increased, and negative rules are also discovered. The separation of negative association rules from positive ones is not a simple process, and it helps in various fields. As an example, in the medical domain, both positive and negative association rules help not only in the diagnosis of disease, but also in detecting prevention manners.
The rest of this research is organized as follows. The basic concepts and definitions of association rules mining are presented in Section 2. A quick overview of fuzzy association rules is described in Section 3. The neutrosophic association rules and the proposed model are presented in Section 4. A case study of Telecom Egypt Company is presented in Section 5. The experimental results and comparisons between fuzzy and proposed association rules are discussed in Section 6. The conclusions are drawn in Section 7.
2. Association Rules Mining
In this section, we formulate the |D| transactions from the mining association rules for a database D. We used the following notations:
- (i)
- represents all the possible data sets, called items.
- (ii)
- Transaction set is the set of domain data resulting from transactional processing such as T ⊆ I.
- (iii)
- For a given itemset X ⊆ I and a given transaction T, we say that T contains X if and only if X ⊆ T.
- (iv)
- : the support frequency of X, which is defined as the number of transactions out of D that contain X.
- (v)
- : the support threshold.
X is considered a large itemset, if . Further, an association rule is an implication of the form , where and .
An association rule is addressed in D with confidence c if at least c transactions out of D contain both X and Y. The rule is considered as a large itemset having a minimum support s if: .
For a specific confidence and specific support thresholds, the problem of mining association rules is to find out all of the association rules having confidence and support that is larger than the corresponding thresholds. This problem can simply be expressed as finding all of the large itemsets, where a large itemset L is:
3. Fuzzy Association Rules
Mining of association rules is considered as the main task in data mining. An association rule expresses an interesting relationship between different attributes. Fuzzy association rules can deal with both quantitative and categorical data and are described in linguistic terms, which are understandable terms [26].
Let be a database transactions. Each transaction consists of a number of attributes (items). Let = be a set of categorical or quantitative attributes. For each attribute , , we consider associated fuzzy sets. Typically, a domain expert determines the membership function for each attribute.
The tuple is called the fuzzy itemset, where X ⊆ I (set of attributes) and is a set of fuzzy sets that is associated with attributes from .
Following is an example of fuzzy association rule:
IF salary is high and age is old THEN insurance is high
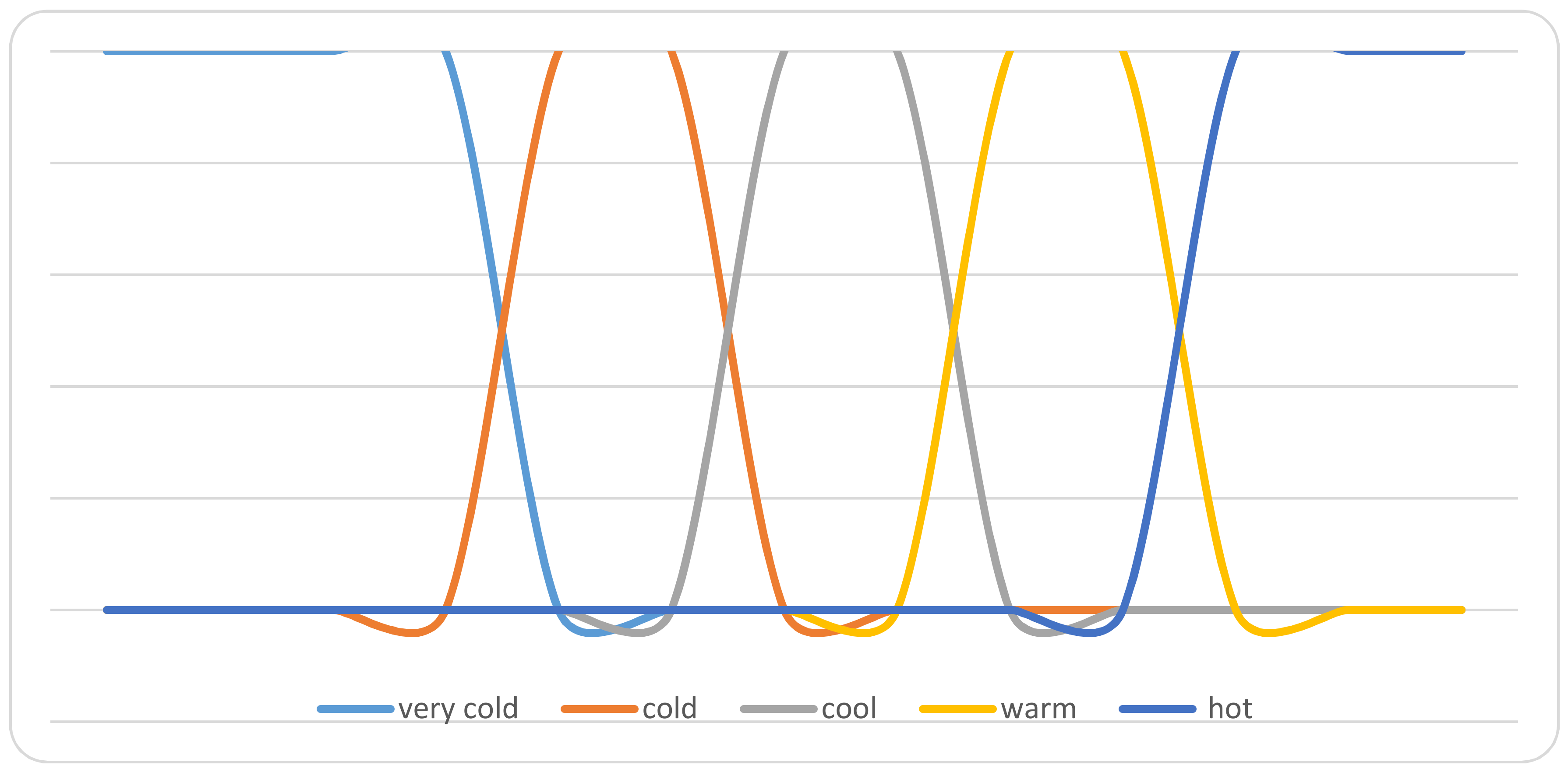
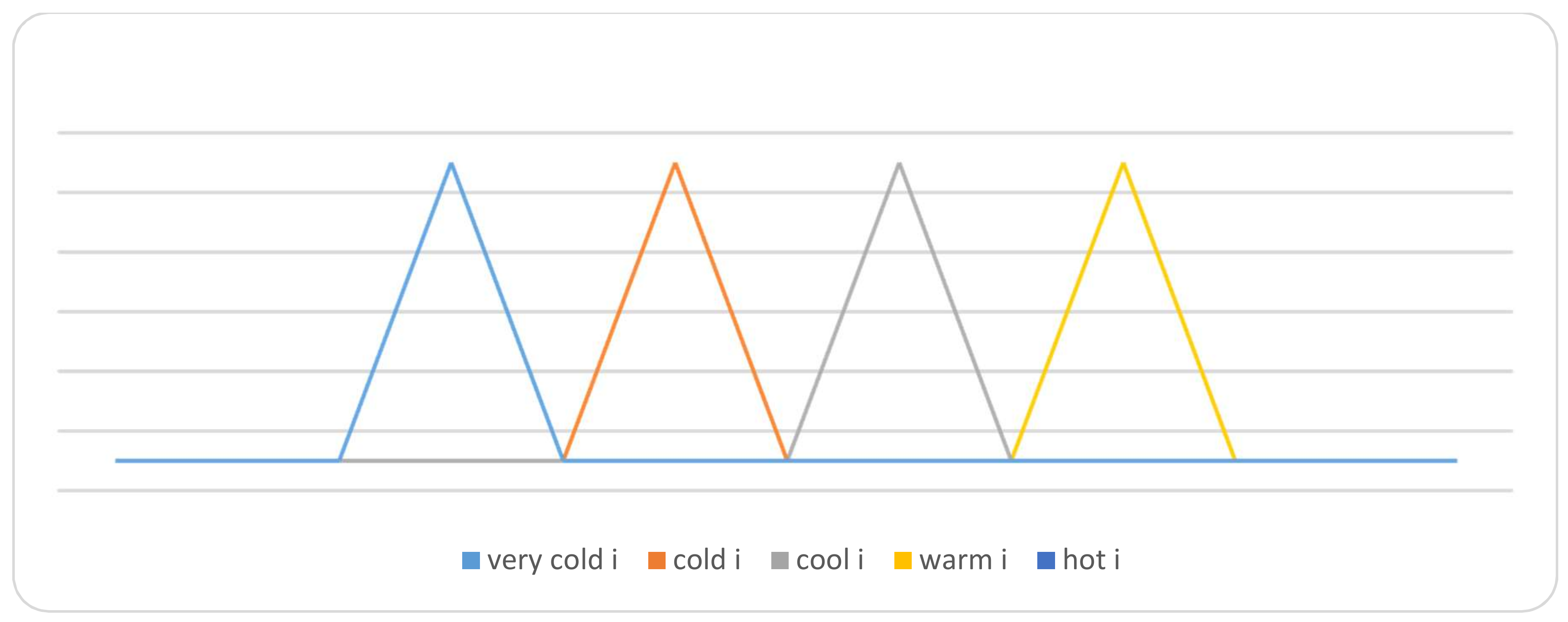
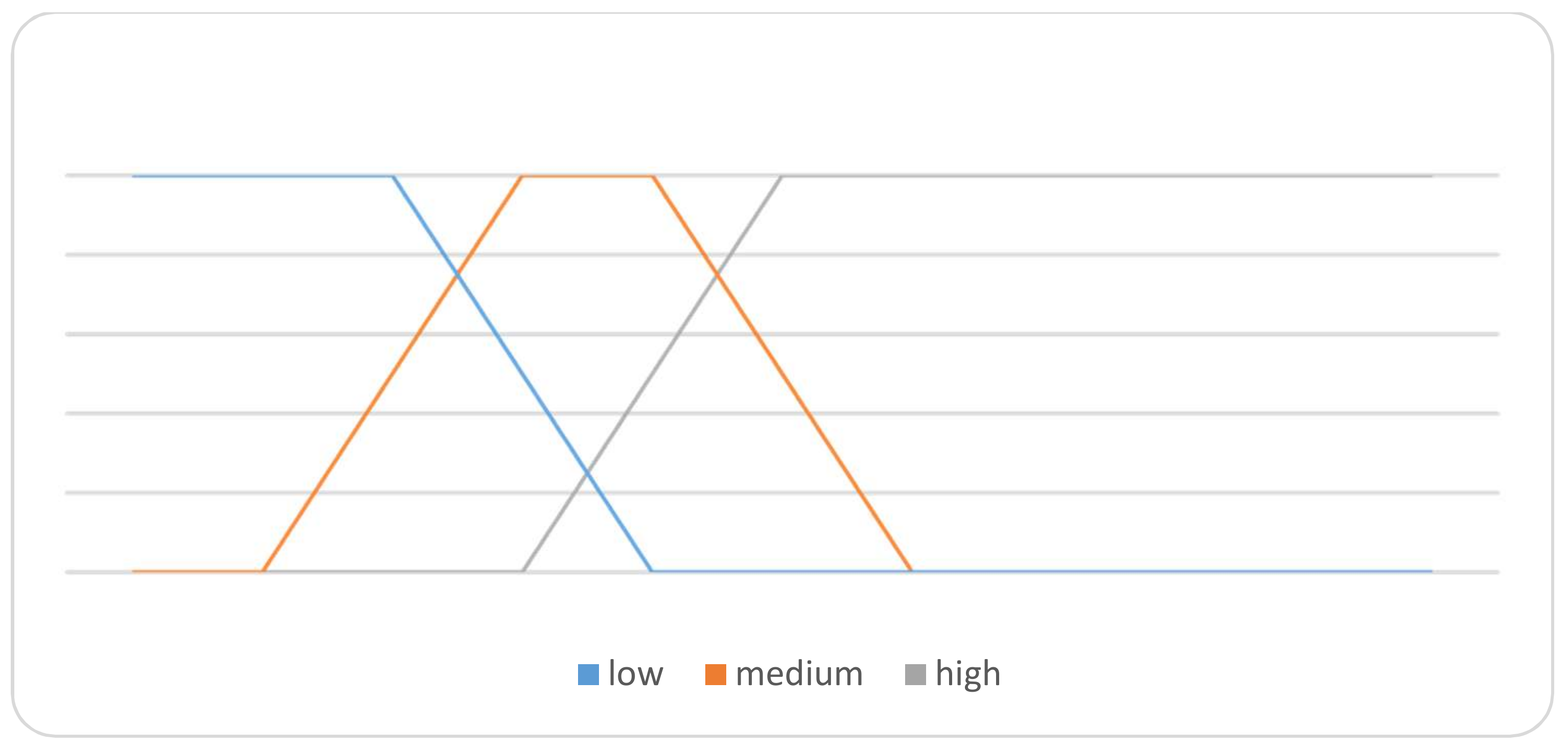
Before the mining process starts, we need to deal with numerical attributes and prepare them for the mining process. The main idea is to determine the linguistic terms for the numerical attribute and define the range for every linguistic term. For example, the temperature attribute is determined by the linguistic terms {very cold, cold, cool, warm, hot}. Figure 1 illustrates the membership function of the temperature attribute.
The membership function has been calculated for the following database transactions illustrated in Table 1.
We add the linguistic terms {very cold, cold, cool, warm, hot} to the candidate set and calculate the support for those itemsets. After determining the linguistic terms for each numerical attribute, the fuzzy candidate set have been generated.
Table 2 contains the support for each itemset individual one-itemsets. The count for every linguistic term has been calculated by summing its membership degree over the transactions. Table 3 shows the support for two-itemsets. The count for the fuzzy sets is the summation of degrees that resulted from the membership function of that itemset. The count for two-itemset has been calculated by summing the minimum membership degree of the 2 items. For example, {cold, cool} has count 0.8, which resulted from transactions T2 and T3. For transaction T2, membership degree of cool is 0.6 and membership degree for cold is 0.4, so the count for set {cold, cool} in T2 is 0.4. Also, T3 has the same count for {cold, cool}. So, the count of set {cold, cool} over all transactions is 0.8.
In subsequent discussions, we denote an itemset that contains items as −itemset. The set of all −itemsets in is referred as .
4. Neutrosophic Association Rules
In this section, we overview some basic concepts of the NSs and SVNSs over the universal set , and the proposed model of discovering neutrosophic association rules.
4.1. Neutrosophic Set Definitions and Operations
Definition 1.
([33]) Let be a space of points and x∈X. A neutrosophic set (NS) in is definite by a truth-membership function , an indeterminacy-membership function and a falsity-membership function . , and are real standard or real nonstandard subsets of ]−0, 1+[. That is (): X → ]−0, 1+[, : X → ]−0, 1+[ and : X → ]−0, 1+[. There is no restriction on the sum of , and , so 0− ≤ sup + sup + sup ≤ 3+.
Neutrosophic is built on a philosophical concept, which makes it difficult to process during engineering applications or to use it to real applications. To overcome that, Wang et al. [31], defined the SVNS, which is a particular case of NS.
Definition 2.
Let be a universe of discourse. A single valued neutrosophic set (SVNS) over is an object taking the form = {〈x,(x), , 〉: x∈X}, where : X → [0, 1], : X → [0, 1] and : X → [0, 1] with 0 ≤ + + ≤ 3 for all x∈X. The intervals , and represent the truth-membership degree, the indeterminacy-membership degree and the falsity membership degree of to , respectively. For convenience, a SVN number is represented by = (a, b, c), where a, b, c∈[0, 1] and a + b + c ≤ 3.
Definition 3 (Intersection).
([31]) For two SVNSs and , the intersection of these SVNSs is again an SVNSs which is defined as whose truth, indeterminacy and falsity membership functions are defined as , and .
Definition 4 (Union).
([31]) For two SVNSs and , the union of these SVNSs is again an SVNSs which is defined as whose truth, indeterminacy and falsity membership functions are defined as , and .
Definition 5 (Containment).
([31]) A single valued neutrosophic set contained in the other SVNS , denoted by if and only if , and for all in .
Next, we propose a method for generating the association rule under the SVNS environment.
4.2. Proposed Model for Association Rule
In this paper, we introduce a model to generate association rules of form:
where and are neutrosophic sets.
Our aim is to find the frequent itemsets and their corresponding support. Generating an association rule from its frequent itemsets, which are dependent on the confidence threshold, are also discussed here. This has been done by adding the neutrosophic set into , where is all of the possible data sets, which are referred as items. So where is neutrosophic set and is classical set of items. The general form of an association rule is an implication of the form , where , .
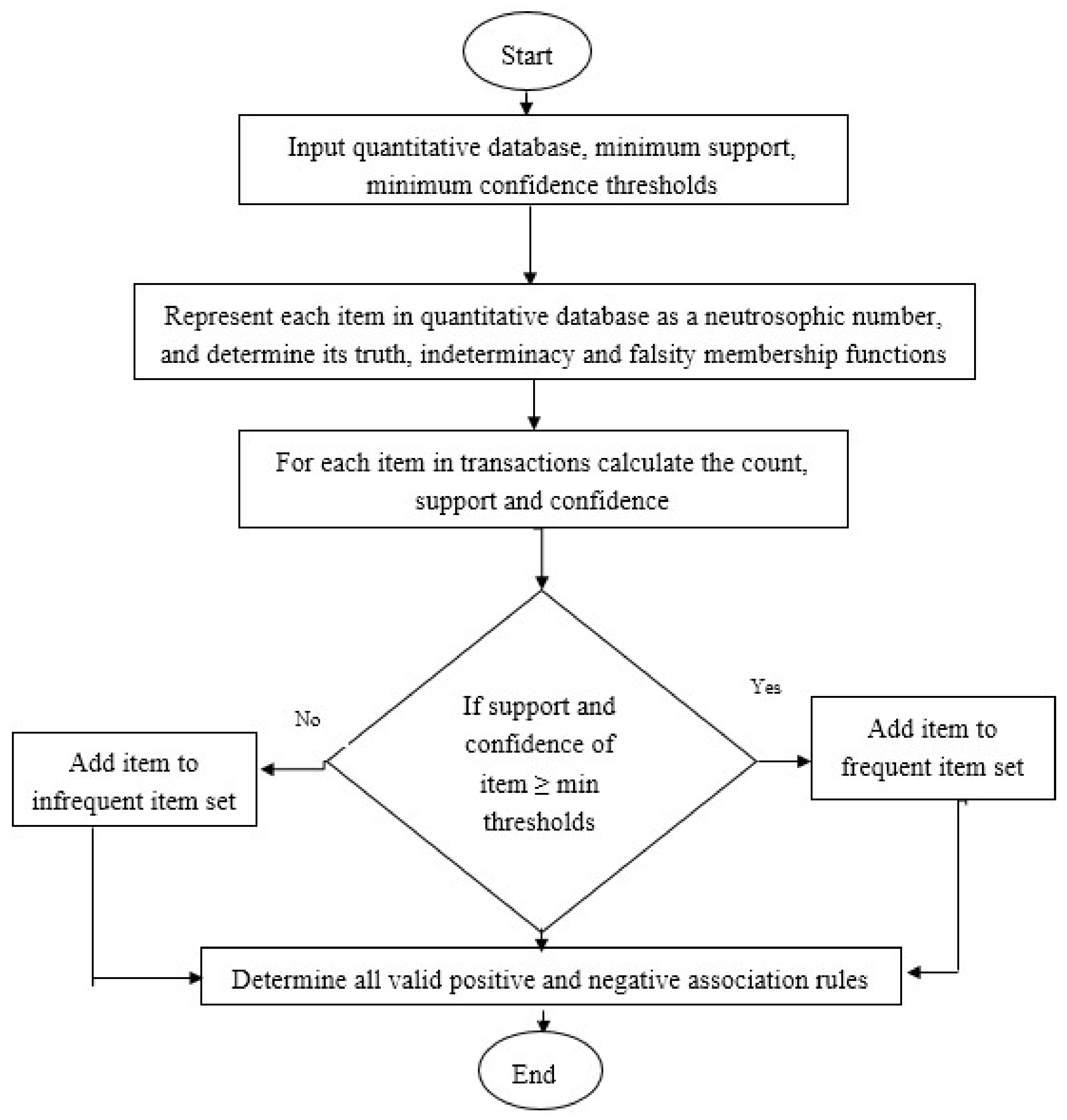
Therefore, an association rule is addressed in Database with confidence ‘’ if at least transactions out of contains both and . On the other hand, the rule is considered a large item set having a minimum support if . Furthermore, the process of converting the quantitative values into the neutrosophic sets is proposed, as shown in Figure 2.
The proposed model for the construction of the neutrosophic numbers is summarized in the following steps:
- Step 1
- Set linguistic terms of the variable, which will be used for quantitative attribute.
- Step 2
- Define the truth, indeterminacy, and the falsity membership functions for each constructed linguistic term.
- Step 3
- For each transaction in , compute the truth-membership, indeterminacy-membership and falsity-membership degrees.
- Step 4
- Extend each linguistic term l in set of linguistic terms L into TL, IL, and FL to denote truth-membership, indeterminacy-membership, and falsity-membership functions, respectively.
- Step 5
- For each item set where , and number of iterations.
- calculate count of each linguistic term by summing degrees of membership for each transaction as where is or .
- calculate support for each linguistic term
- Step 6
- The above procedure has been repeated for every quantitative attribute in the database.
In order to show the working procedure of the approach, we consider the temperature as an attribute and the terms “very cold”, “cold”, “cool”, “warm”, and “hot” as their linguistic terms to represent the temperature of an object. Then, following the steps of the proposed approach, construct their membership function as below:
- Step 1
- The attribute “temperature’ has set the linguistic terms “very cold”, “cold”, “cool”, “warm”, and “hot”, and their ranges are defined in Table 4.
- Step 2
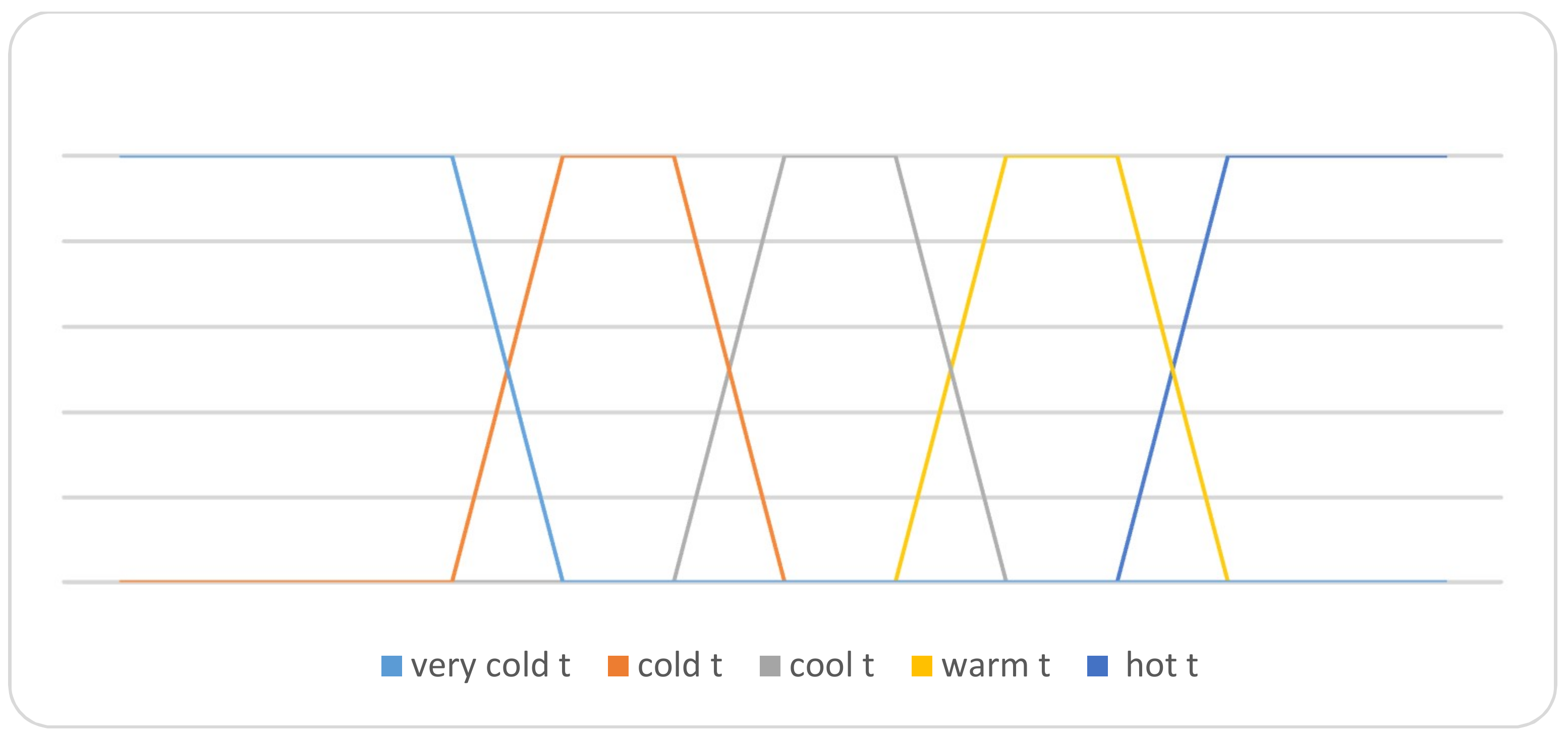
- Based on these linguistic term ranges, the truth-membership functions of each linguistic variable are defined, as follows:
The falsity-membership functions of each linguistic variable are defined as follows:
The indeterminacy membership functions of each linguistic variables are defined as follows:
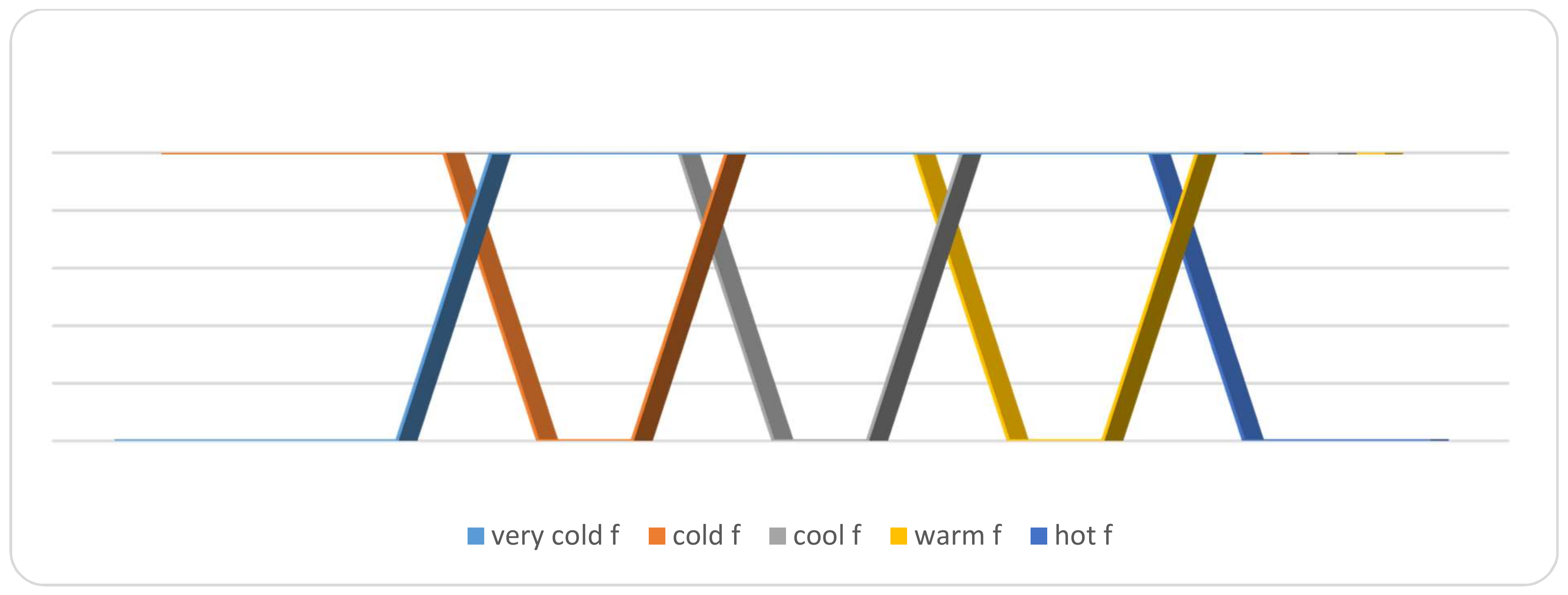
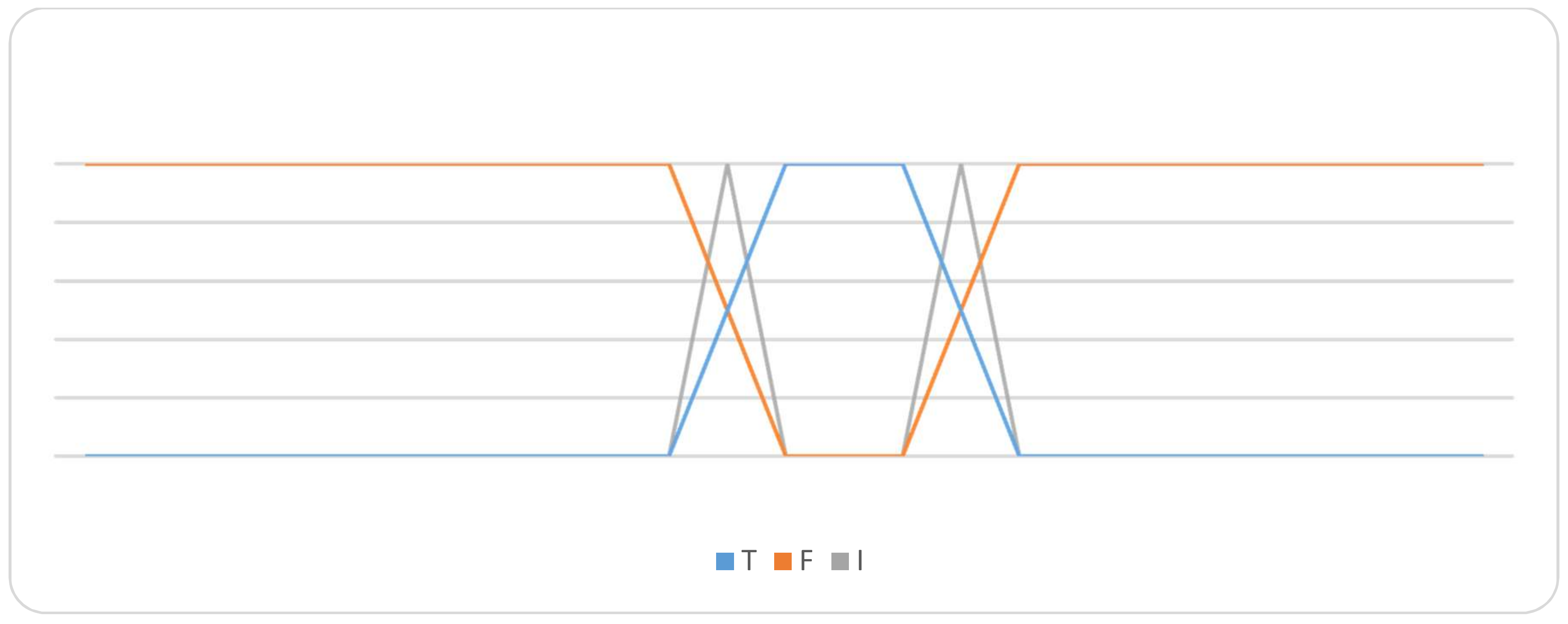
The graphical membership degrees of these variables are summarized in Figure 3. The graphical falsity degrees of these variables are summarized in Figure 4. Also, the graphical indeterminacy degrees of these variables are summarized in Figure 5. On the other hand, for a particular linguistic term, ‘Cool’ in the temperature attribute, their neutrosophic membership functions are represented in Figure 6.
- Step 3
- Based on the membership grades, different transaction has been set up by taking different sets of the temperatures. The membership grades in terms of the neutrosophic sets of these transactions are summarized in Table 5.
- Step 4
- Now, we count the set of linguistic terms {very cold, cold, cool, warm, hot} for every element in transactions. Since the truth, falsity, and indeterminacy-memberships are independent functions, the set of linguistic terms can be extended to where means not worm and means not sure of warmness. This enhances dealing with negative association rules, which is handled as positive rules without extra calculations.
- Step 5
Similarly, the two-itemset support is illustrated in Table 7 and the rest of itemset generation (itemset for are obtained similarly. The count for item set in database record is defined by minimum count of each one-itemset exists.
For example: {TCold, TCool} count is 0.8
Because they exists in both T2 and T3.
In T2: TCold = 0.4 and TCool = 0.6 so, count for {TCold, TCool} in T2 = 0.4
In T3: TCold = 0.6 and TCool = 0.4 so, count for {TCold, TCool} in T2 = 0.4
Thus, count of {TCold, TCool} in (Database) DB is 0.8.
5. Case Study
In this section, the case of Telecom Egypt Company stock records has been studied. Egyptian stock market has many companies. One of the major questions for stock market users is when to buy or to sell a specific stock. Egyptian stock market has three indicators, EGX30, EGX70, and EGX100. Each indicator gives a reflection of the stock market. Also, these indicators have an important impact on the stock market users, affecting their decisions of buying or selling stocks. We focus in our study on the relation between the stock and the three indicators. Also, we consider the month and quarter of the year to be another dimension in our study, while the sell/buy volume of the stock per day is considered to be the third dimension.
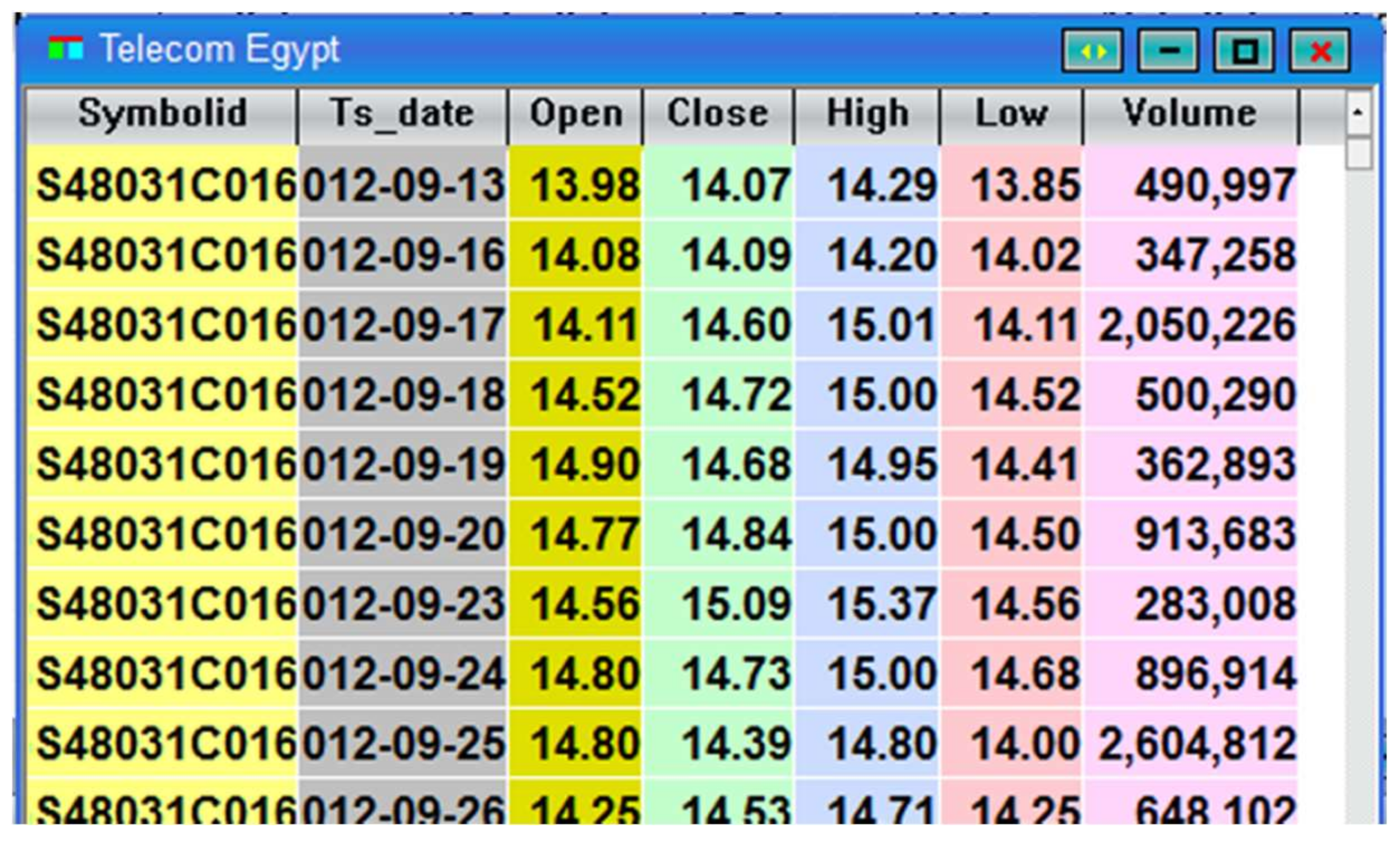
In this study, the historical data has been taken from the Egyptian stock market program (Mist) during the program September 2012 until September 2017. For every stock/indicator, Mist keeps a daily track of number of values (opening price, closing price, high price reached, low price reached, and volume). The collected data of Telecom Egypt Stock are summarized in Figure 7.
In this study, we use the open price and close price values to get price change rate, which are defined as follows:
and change the volume to be a percentage of total volume of the stock with the following relation:
The same was performed for the stock market indicators. Now, we take the attributes as “quarter”, “month”, “stock change rate”, “volume percentage”, and “indicators change rate”. Table 8 illustrates the segment of resulted data after preparation.
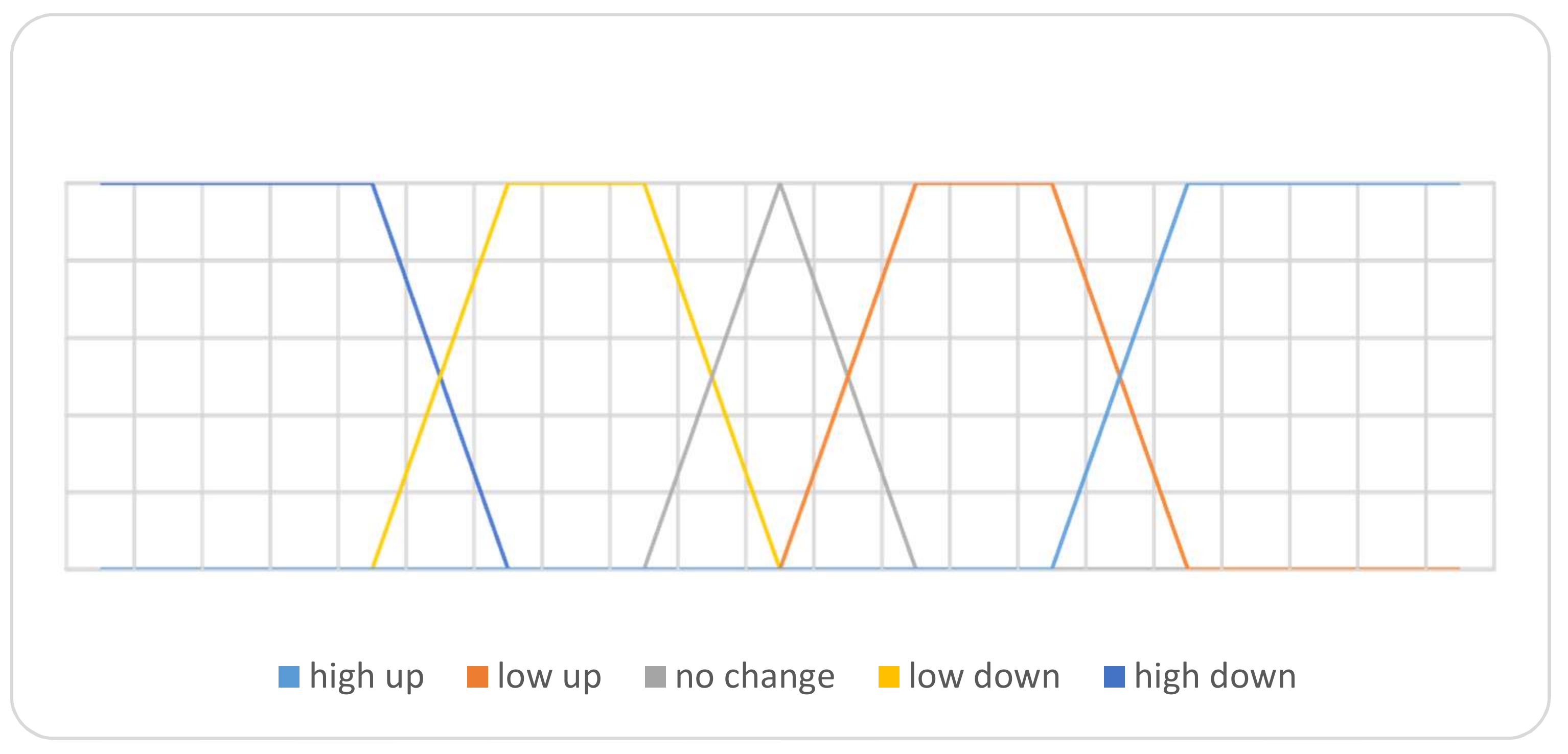
Based on these linguistic terms, define the ranges under the SVNSs environment. For this, corresponding to the attribute in “change rate” and “volume”, the truth-membership functions by defining their linguistic terms as {“high up”, “high low”, “no change”, “low down”, “high down”} corresponding to attribute “change rate”, while for the attribute “volume”, the linguistic terms are (low, medium, and high) and their ranges are summarized in Figure 8 and Figure 9, respectively. The falsity-membership function and indeterminacy-membership function have been calculated and applied as well for change rate attribute.
6. Experimental Results
We proceeded to a comparison between fuzzy mining and neutrosophic mining algorithms, and we found out that the number of generated association rules increased in neutrosophic mining.
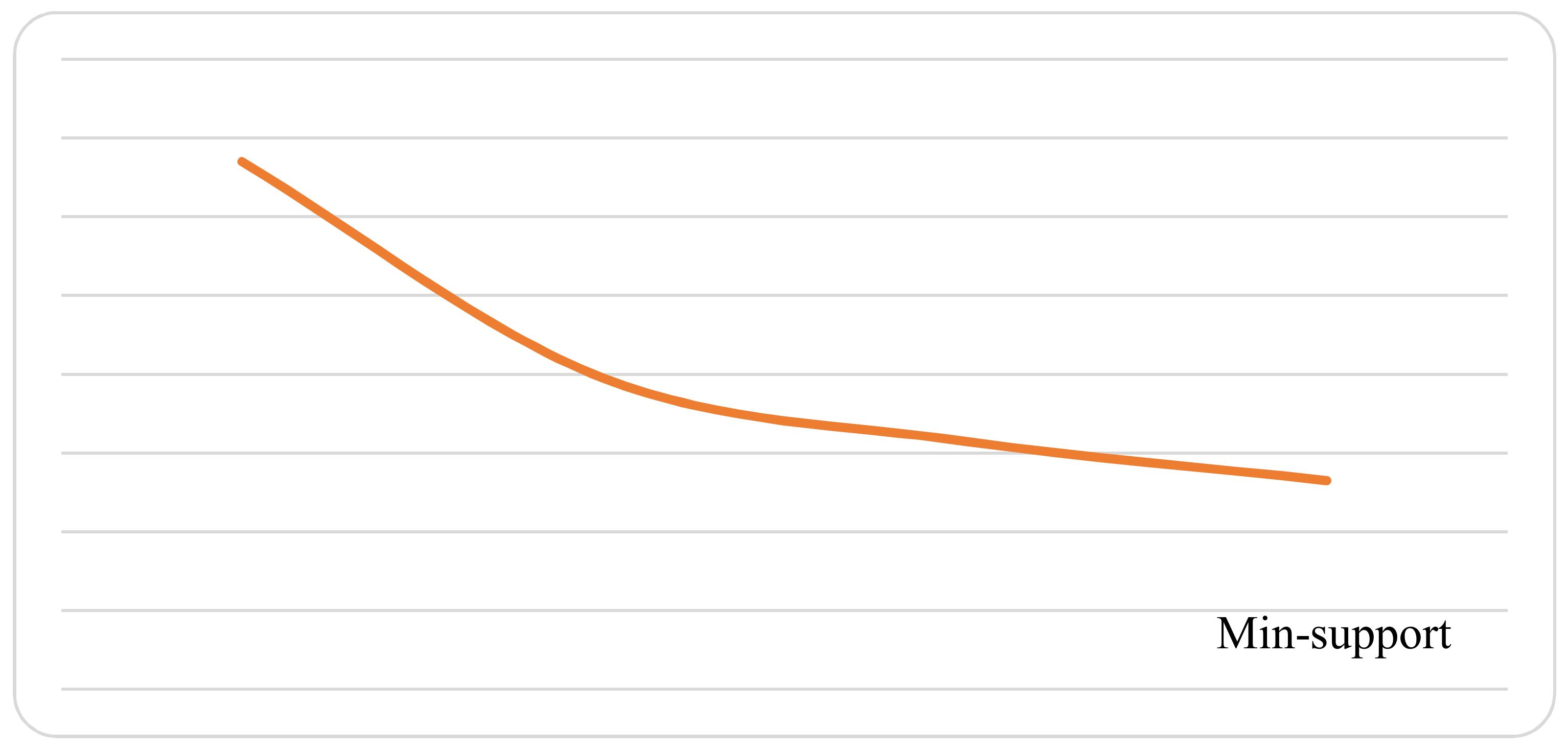
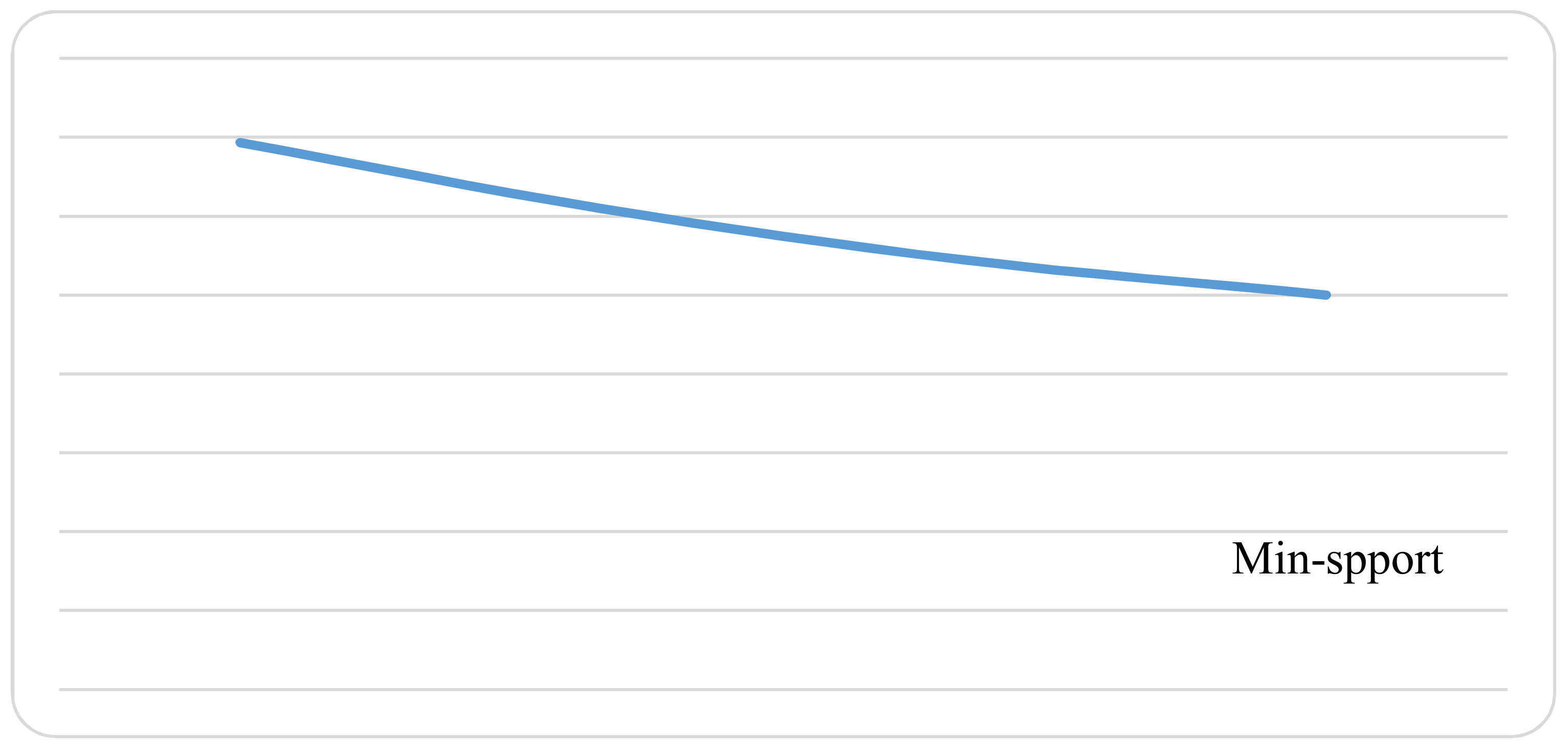
A program has been developed to generate large itemsets for Telecom Egypt historical data. VB.net has been used in creating this program. The obtained data have been stored in an access database. The comparison depends on the number of generated association rules in a different min-support threshold. It should be noted that the performance cannot be part of the comparison because of the number of items (attributes) that are different in fuzzy vs. neutrosophic association rules mining. In fuzzy mining, the number of items was 14, while in neutrosophic mining it is 34. This happens because the number of attributes increased. Spreading each linguistic term into three (True, False, Indeterminacy) terms make the generated rules increase. The falsity-generated association rules can be considered a negative association rules. As pointed out in [36], the conviction of a rule is defined as the ratio of the expected frequency that happened without falsity-association rules to be used to generate negative association rules if . In Table 9, the number of generated fuzzy rules in each itemset using different min-support threshold are reported, while the total generated fuzzy association rule is presented in Figure 10.
As compared to the fuzzy approach, by applying the same min-support threshold, we get a huge set of neutrosophic association rules. Table 10 illustrates the booming that happened to generated neutrosophic association rules. We stop generating itemsets at iteration 4 due to the noted expansion in the results shown in Figure 11, which shows the number of neutrosophic association rules.
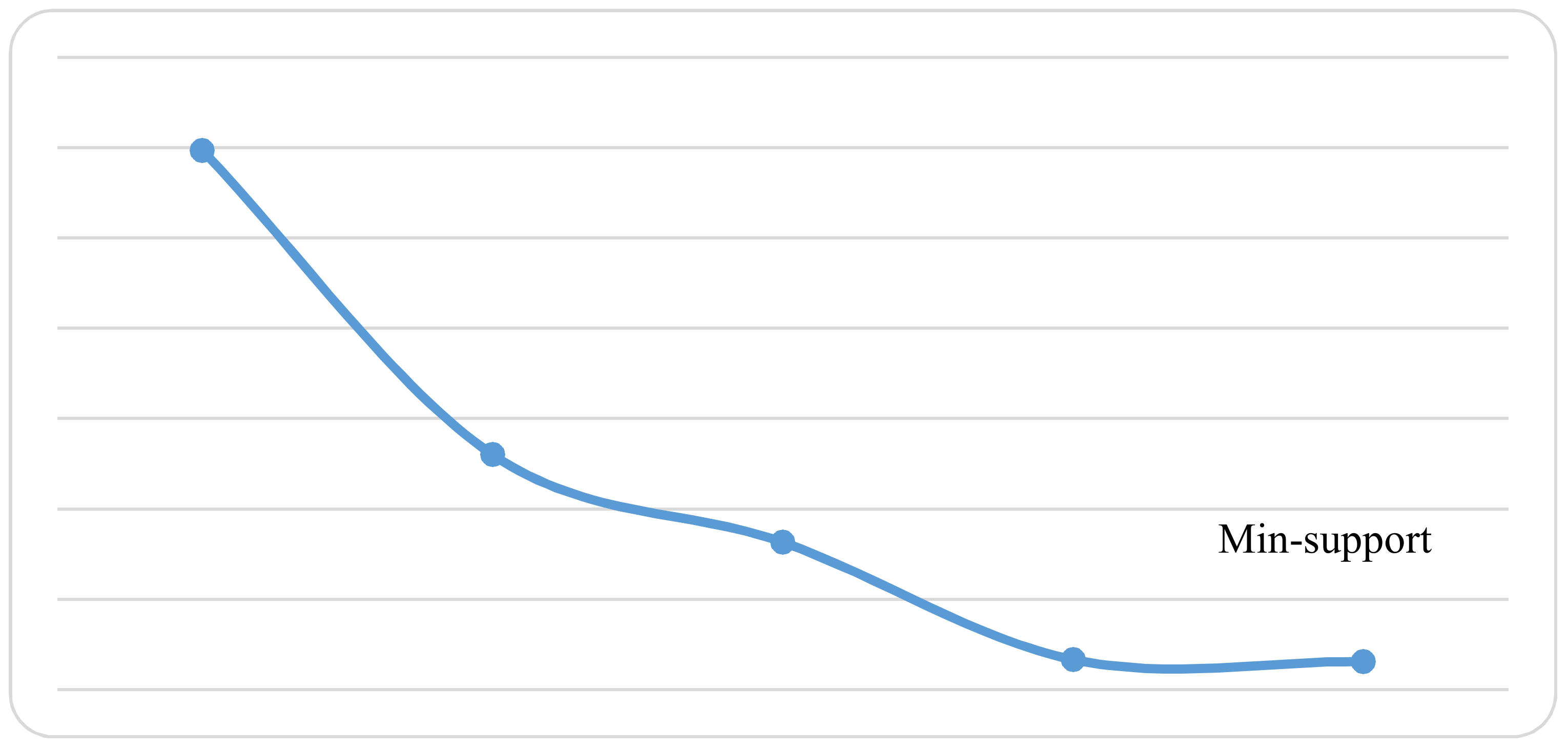
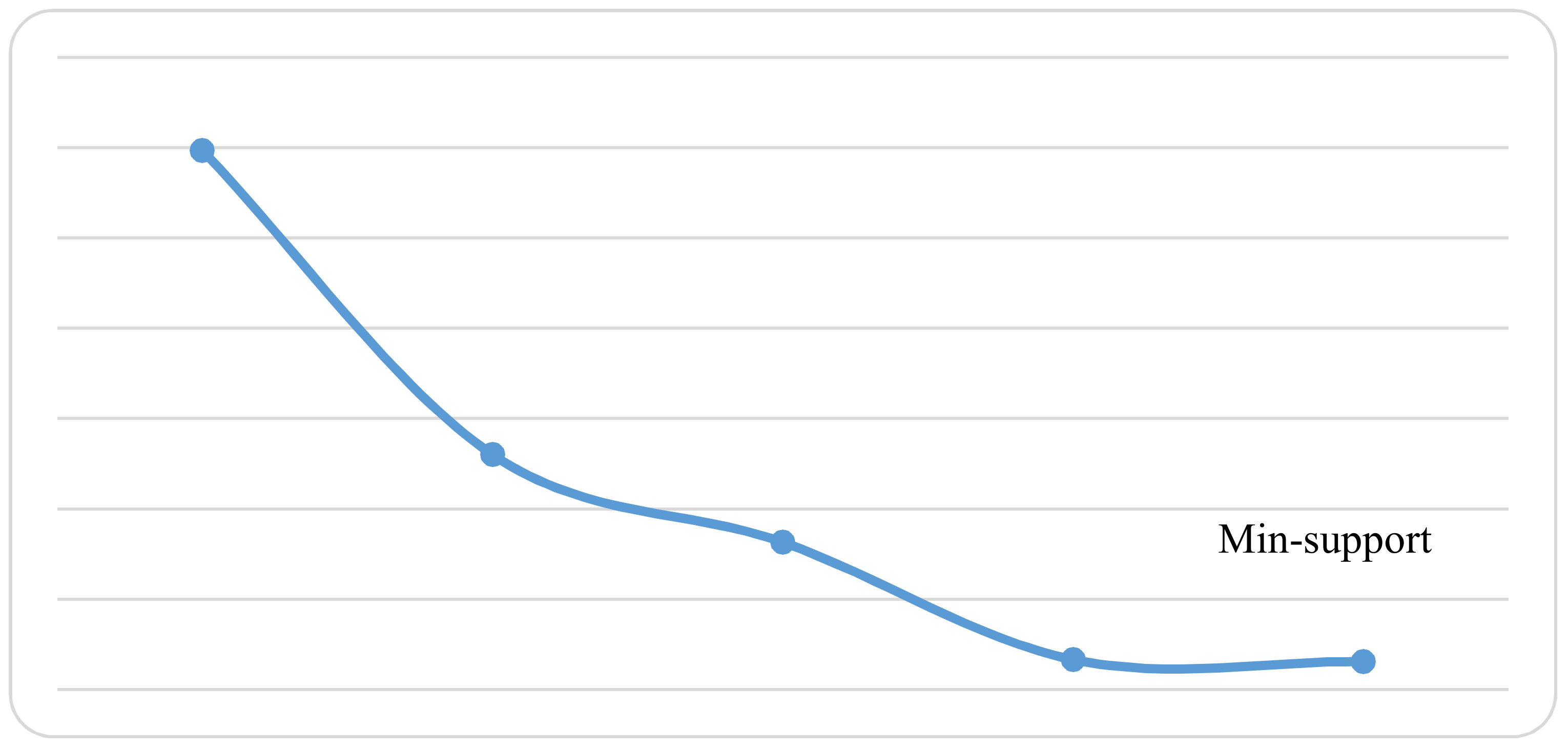
Experiment has been re-run using different min-support threshold values and the resulted neutrosophic association rules counts has been noted and listed in Table 11. Note the high values that are used for min-support threshold. Figure 12 illustrates the generated neutrosophic association rules for min-support threshold from 0.5 to 0.9.
Using the neutrosophic mining approach makes association rules exist for most of the min-support threshold domain, which may be sometimes misleading. We found that using the neutrosophic approach is useful in generating negative association rules beside positive association rules minings. Huge generated association rules provoke the need to re-mine generated rules (mining of mining association rules). Using suitable high min-support values may help in the neutrosophic mining process.
7. Conclusions and Future Work
Big data analysis will continue to grow in the next years. In order to efficiently and effectively deal with big data, we introduced in this research a new algorithm for mining big data using neutrosophic association rules. Converting quantitative attributes is the main key for generating such rules. Previously, it was performed by employing the fuzzy sets. However, due to fuzzy drawbacks, which we discussed in the introductory section, we preferred to use neutrosophic sets. Experimental results showed that the proposed approach generated an increase in the number of rules. In addition, the indeterminacy-membership function has been used to prevent losing rules from boundaries problems. The proposed model is more effective in processing negative association rules. By comparing it with the fuzzy association rules mining approaches, we conclude that the proposed model generates a larger number of positive and negative association rules, thus ensuring the construction of a real and efficient decision-making system. In the future, we plan to extend the comparison between the neutrosophic association rule mining and other interval fuzzy association rule minings. Furthermore, we seized the falsity-membership function capacity to generate negative association rules. Conjointly, we availed of the indeterminacy-membership function to prevent losing rules from boundaries problems. Many applications can emerge by adaptions of truth-membership function, indeterminacy-membership function, and falsity-membership function. Future work will benefit from the proposed model in generating negative association rules, or in increasing the quality of the generated association rules by using multiple support thresholds and multiple confidence thresholds for each membership function. The proposed model can be developed to mix positive association rules (represented in the truth-membership function) and negative association rules (represented in the falsity-membership function) in order to discover new association rules, and the indeterminacy-membership function can be put forth to help in the automatic adoption of support thresholds and confidence thresholds. Finally, yet importantly, we project to apply the proposed model in the medical field, due to its capability in effective diagnoses through discovering both positive and negative symptoms of a disease. All future big data challenges could be handled by combining neutrosophic sets with various techniques.
Author Contributions
All authors have contributed equally to this paper. The individual responsibilities and contribution of all authors can be described as follows: the idea of this whole paper was put forward by Mohamed Abdel-Basset and Mai Mohamed, Victor Chang completed the preparatory work of the paper. Florentin Smarandache analyzed the existing work. The revision and submission of this paper was completed by Mohamed Abdel-Basset.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gartner. Available online: http://www.gartner.com/it-glossary/bigdata (accessed on 3 December 2017).
- Intel. Big Thinkers on Big Data (2012). Available online: http://www.intel.com/content/www/us/en/bigdata/ big-thinkers-on-big-data.html (accessed on 3 December 2017).
- Aggarwal, C.C.; Ashish, N.; Sheth, A. The internet of things: A survey from the data-centric perspective. In Managing and Mining Sensor Data; Springer: Berlin, Germany, 2013; pp. 383–428. [Google Scholar]
- Parker, C. Unexpected challenges in large scale machine learning. In Proceedings of the 1st International Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, Beijing, China, 12 August 2012; pp. 1–6. [Google Scholar]
- Gopalkrishnan, V.; Steier, D.; Lewis, H.; Guszcza, J. Big data, big business: Bridging the gap. In Proceedings of the 1st International Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, Beijing, China, 12 August 2012; pp. 7–11. [Google Scholar]
- Chytil, M.; Hajek, P.; Havel, I. The GUHA method of automated hypotheses generation. Computing 1966, 1, 293–308. [Google Scholar]
- Park, J.S.; Chen, M.-S.; Yu, P.S. An effective hash-based algorithm for mining association rules. SIGMOD Rec. 1995, 24, 175–186. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. Mining large itemsets for association rules. IEEE Data Eng. Bull. 1998, 21, 23–31. [Google Scholar]
- Savasere, A.; Omiecinski, E.R.; Navathe, S.B. An efficient algorithm for mining association rules in large databases. In Proceedings of the 21th International Conference on Very Large Data Bases, Georgia Institute of Technology, Zurich, Swizerland, 11–15 September 1995. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference of Very Large Data Bases (VLDB), Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Hidber, C. Online association rule mining. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 31 May–3 June 1999; Volume 28. [Google Scholar]
- Valtchev, P.; Hacene, M.R.; Missaoui, R. A generic scheme for the design of efficient on-line algorithms for lattices. In Conceptual Structures for Knowledge Creation and Communication; Springer: Berlin/Heidelberg, Germany, 2003; pp. 282–295. [Google Scholar]
- Verlinde, H.; de Cock, M.; Boute, R. Fuzzy versus quantitative association rules: A fair data-driven comparison. IEEE Trans. Syst. Man Cybern. Part B 2005, 36, 679–684. [Google Scholar] [CrossRef]
- Huang, C.-H.; Lien, H.-L.; Wang, L.S.-L. An Empirical Case Study of Internet Usage on Student Performance Based on Fuzzy Association Rules. In Proceedings of the 3rd Multidisciplinary International Social Networks Conference on Social Informatics 2016 (Data Science 2016), Union, NJ, USA, 15–17 August 2016; p. 7. [Google Scholar]
- Hui, Y.Y.; Choy, K.L.; Ho, G.T.; Lam, H. A fuzzy association Rule Mining framework for variables selection concerning the storage time of packaged food. In Proceedings of the 2016 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Vancouver, BC, Canada, 24–29 July 2016; pp. 671–677. [Google Scholar]
- Huang, T.C.-K. Discovery of fuzzy quantitative sequential patterns with multiple minimum supports and adjustable membership functions. Inf. Sci. 2013, 222, 126–146. [Google Scholar] [CrossRef]
- Hong, T.-P.; Kuo, C.-S.; Chi, S.-C. Mining association rules from quantitative data. Intell. Data Anal. 1999, 3, 363–376. [Google Scholar] [CrossRef]
- Pei, B.; Zhao, S.; Chen, H.; Zhou, X.; Chen, D. FARP: Mining fuzzy association rules from a probabilistic quantitative database. Inf. Sci. 2013, 237, 242–260. [Google Scholar] [CrossRef]
- Siji, P.D.; Valarmathi, M.L. Enhanced Fuzzy Association Rule Mining Techniques for Prediction Analysis in Betathalesemia’s Patients. Int. J. Eng. Res. Technol. 2014, 4, 1–9. [Google Scholar]
- Lee, Y.-C.; Hong, T.-P.; Wang, T.-C. Multi-level fuzzy mining with multiple minimum supports. Expert Syst. Appl. 2008, 34, 459–468. [Google Scholar] [CrossRef]
- Chen, C.-H.; Hong, T.-P.; Li, Y. Fuzzy association rule mining with type-2 membership functions. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Bali, Indonesia, 23–25 March 2015; pp. 128–134. [Google Scholar]
- Sheibani, R.; Ebrahimzadeh, A. An algorithm for mining fuzzy association rules. In Proceedings of the International Multi Conference of Engineers and Computer Scientists, Hong Kong, China, 19–21 March 2008. [Google Scholar]
- Lee, Y.-C.; Hong, T.-P.; Lin, W.-Y. Mining fuzzy association rules with multiple minimum supports using maximum constraints. In Knowledge-Based Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1283–1290. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: New York, NY, USA, 2011. [Google Scholar]
- Hong, T.-P.; Lin, K.-Y.; Wang, S.-L. Fuzzy data mining for interesting generalized association rules. Fuzzy Sets Syst. 2003, 138, 255–269. [Google Scholar] [CrossRef]
- Au, W.-H.; Chan, K.C. Mining fuzzy association rules in a bank-account database. IEEE Trans. Fuzzy Syst. 2003, 11, 238–248. [Google Scholar]
- Dubois, D.; Prade, H.; Sudkamp, T. On the representation, measurement, and discovery of fuzzy associations. IEEE Trans. Fuzzy Syst. 2005, 13, 250–262. [Google Scholar] [CrossRef]
- Smarandache, F. Neutrosophic set-a generalization of the intuitionistic fuzzy set. J. Def. Resour. Manag. 2010, 1, 107. [Google Scholar]
- Abdel-Basset, M.; Mohamed, M. The Role of Single Valued Neutrosophic Sets and Rough Sets in Smart City: Imperfect and Incomplete Information Systems. Measurement 2018, 124, 47–55. [Google Scholar] [CrossRef]
- Ye, J. A multicriteria decision-making method using aggregation operators for simplified neutrosophic sets. J. Intell. Fuzzy Syst. 2014, 26, 2459–2466. [Google Scholar]
- Ye, J. Vector Similarity Measures of Simplified Neutrosophic Sets and Their Application in Multicriteria Decision Making. Int. J. Fuzzy Syst. 2014, 16, 204–210. [Google Scholar]
- Hwang, C.-M.; Yang, M.-S.; Hung, W.-L.; Lee, M.-G. A similarity measure of intuitionistic fuzzy sets based on the Sugeno integral with its application to pattern recognition. Inf. Sci. 2012, 189, 93–109. [Google Scholar] [CrossRef]
- Wang, H.; Smarandache, F.; Zhang, Y.; Sunderraman, R. Single valued neutrosophic sets. Rev. Air Force Acad. 2010, 10, 11–20. [Google Scholar]
- Mondal, K.; Pramanik, S.; Giri, B.C. Role of Neutrosophic Logic in Data Mining. New Trends Neutrosophic Theory Appl. 2016, 1, 15. [Google Scholar]
- Lu, A.; Ke, Y.; Cheng, J.; Ng, W. Mining vague association rules. In Advances in Databases: Concepts, Systems and Applications; Kotagiri, R., Krishna, P.R., Mohania, M., Nantajeewarawat, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4443, pp. 891–897. [Google Scholar]
- Srinivas, K.; Rao, G.R.; Govardhan, A. Analysis of coronary heart disease and prediction of heart attack in coal mining regions using data mining techniques. In Proceedings of the 5th International Conference on Computer Science and Education (ICCSE), Hefei, China, 24–27 August 2010; pp. 1344–1349. [Google Scholar]
Figure 1.
Linguistic terms of the temperature attribute.
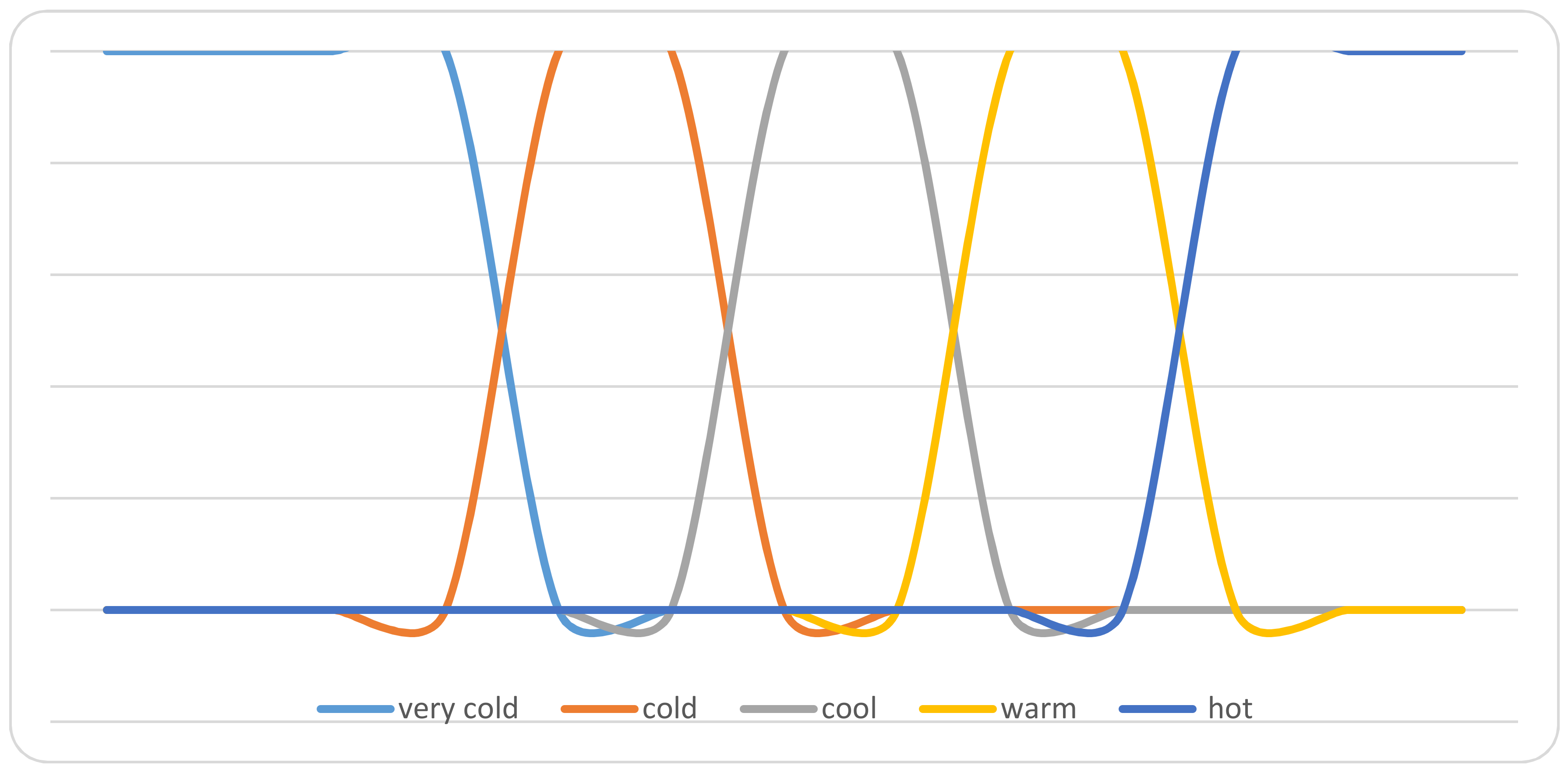
Figure 2.
The proposed model.

Figure 3.
Truth-membership function of temperature attribute.
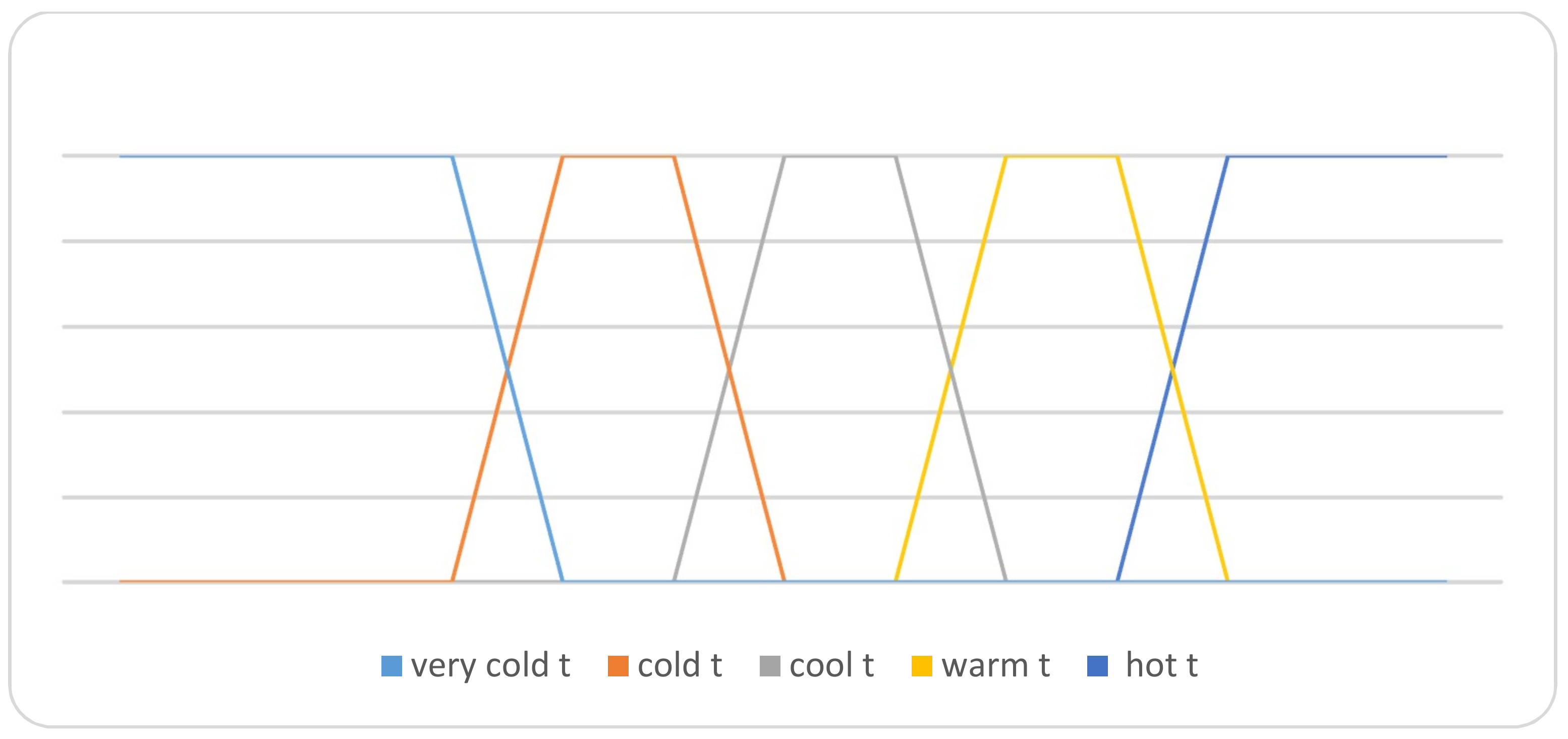
Figure 4.
Falsity-membership function of temperature attribute.
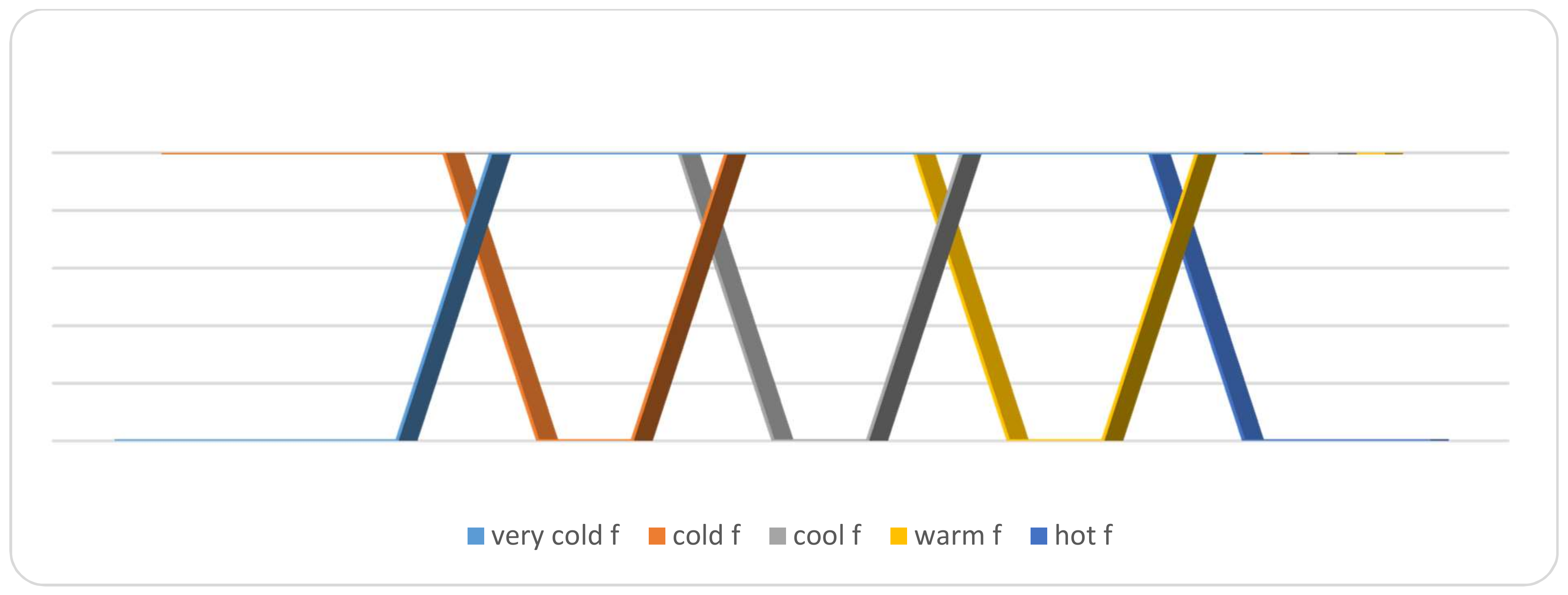
Figure 5.
Indeterminacy-membership function of temperature attribute.
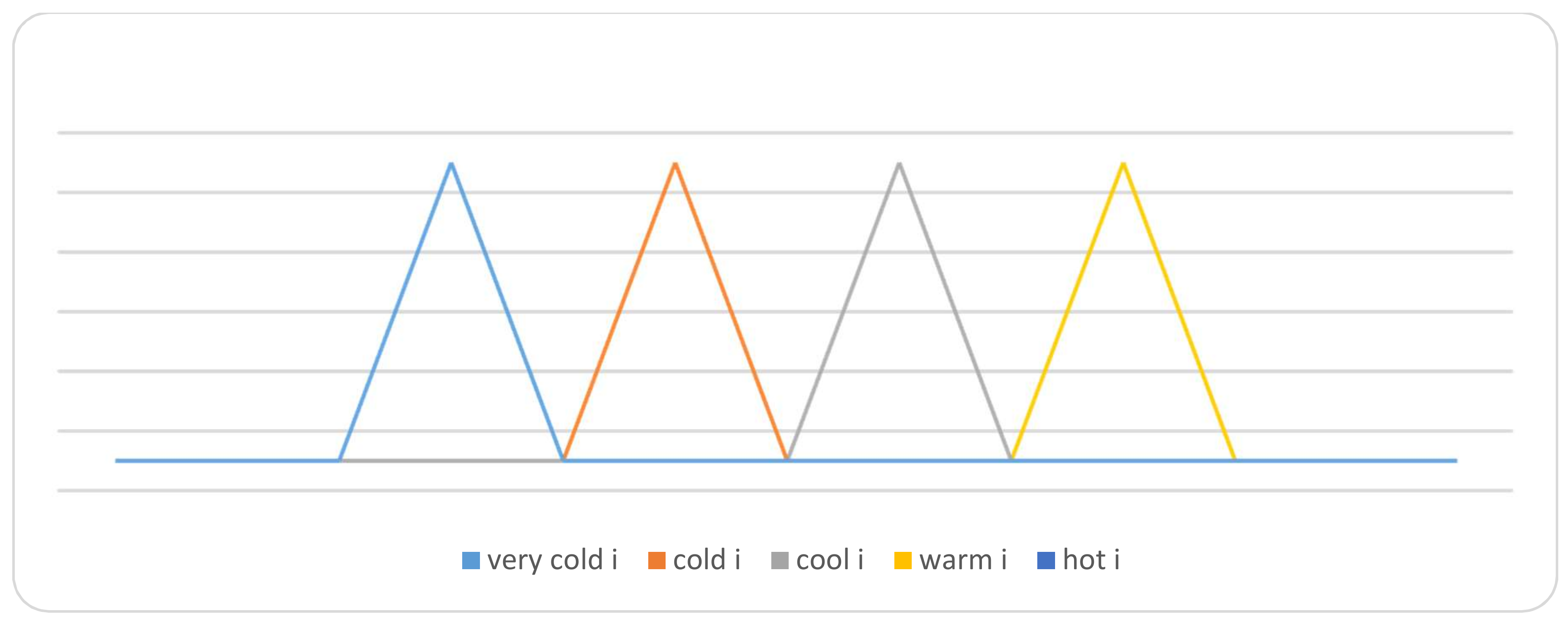
Figure 6.
Cool (T, I, F) for temperature attribute.

Figure 7.
Telecom Egypt stock records.
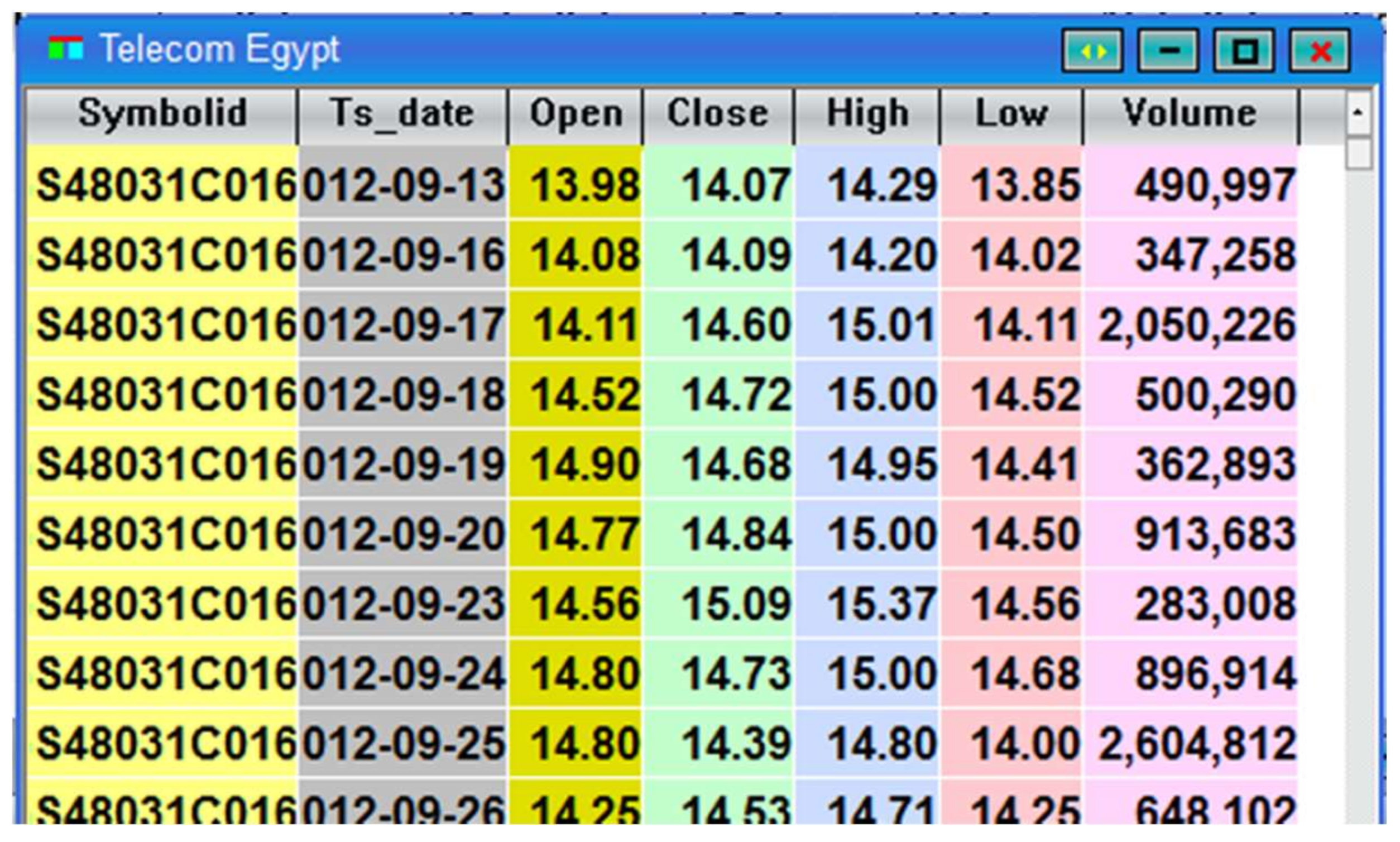
Figure 8.
Change rate attribute truth-membership function.
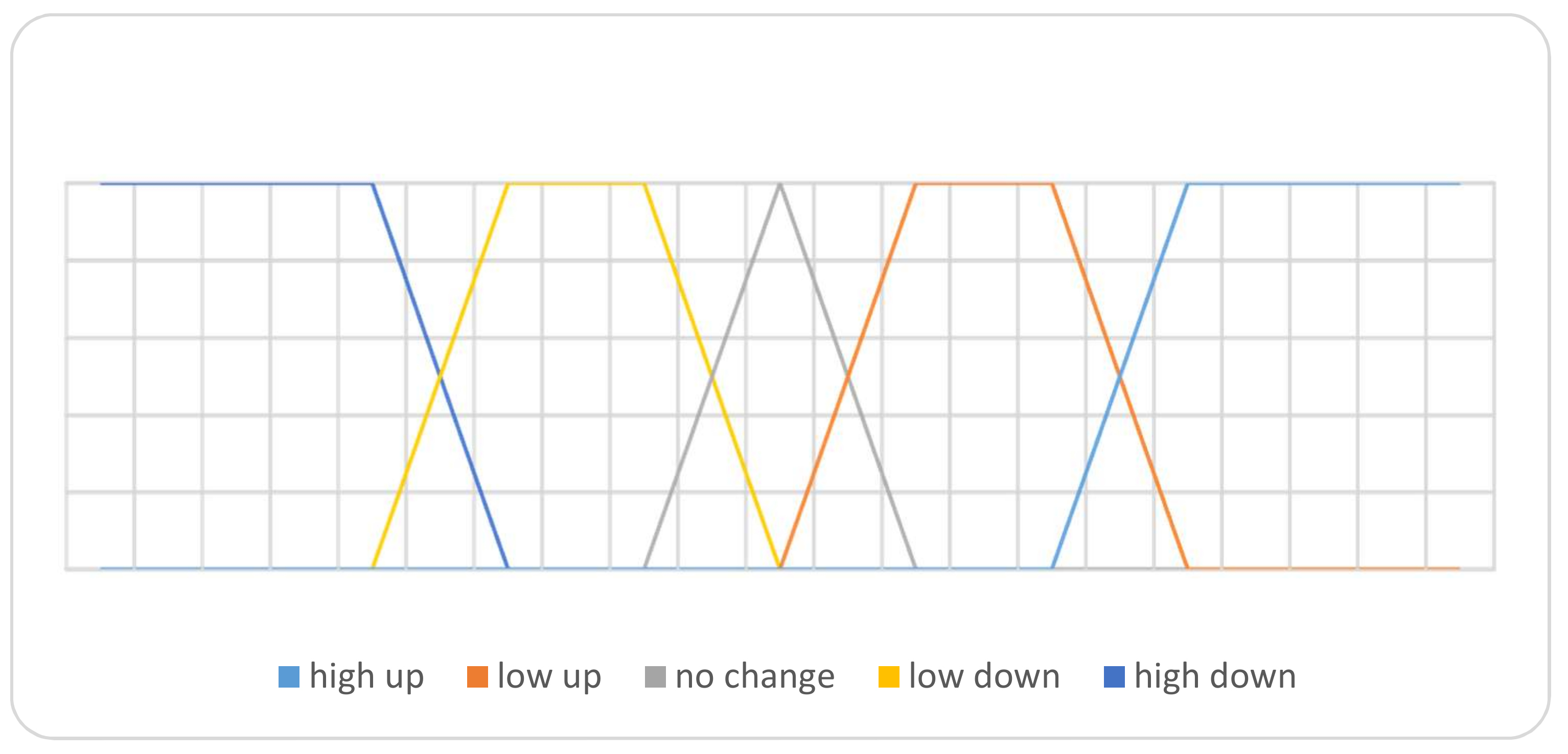
Figure 9.
Volume attribute truth-membership function.
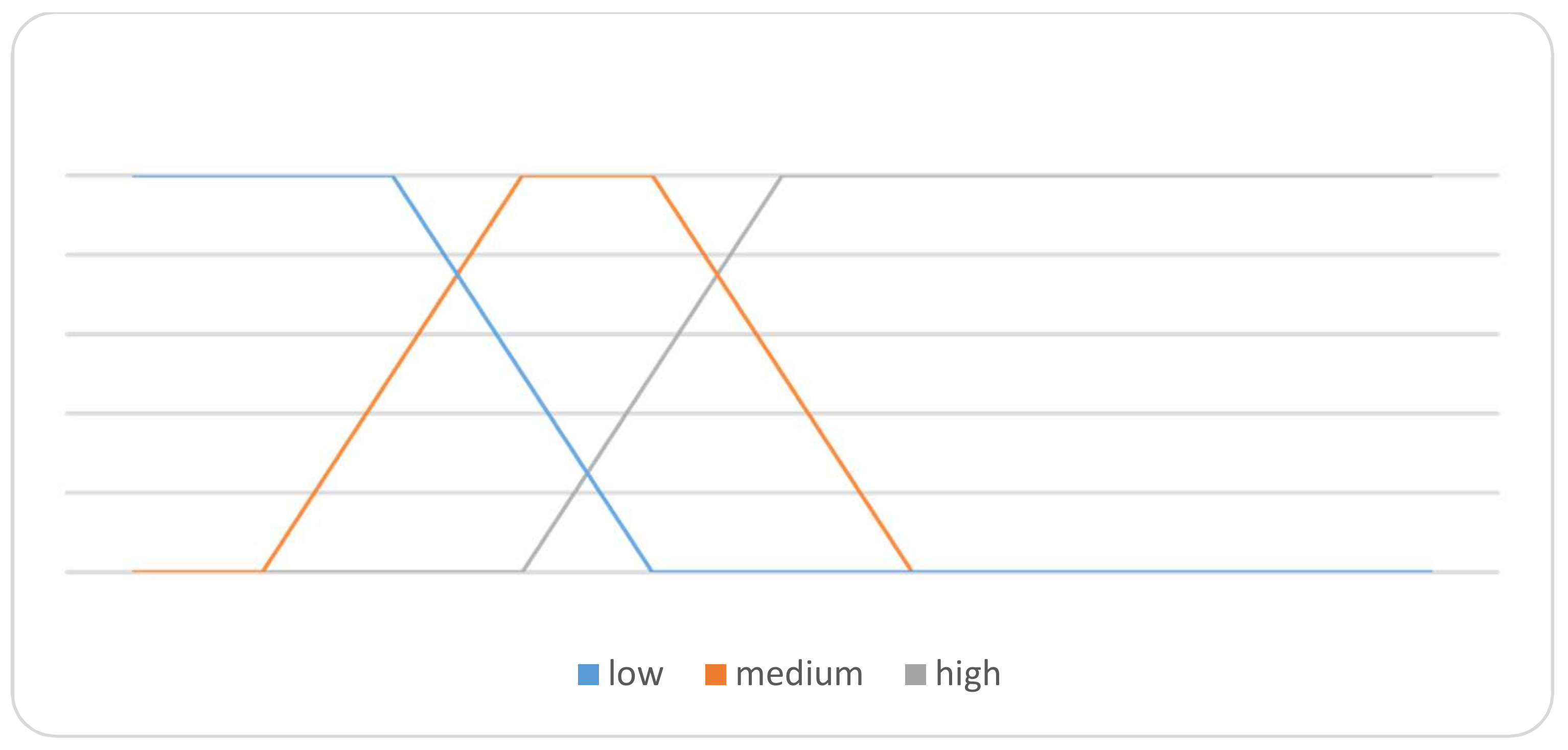
Figure 10.
No. of fuzzy association rules with different min-support threshold.
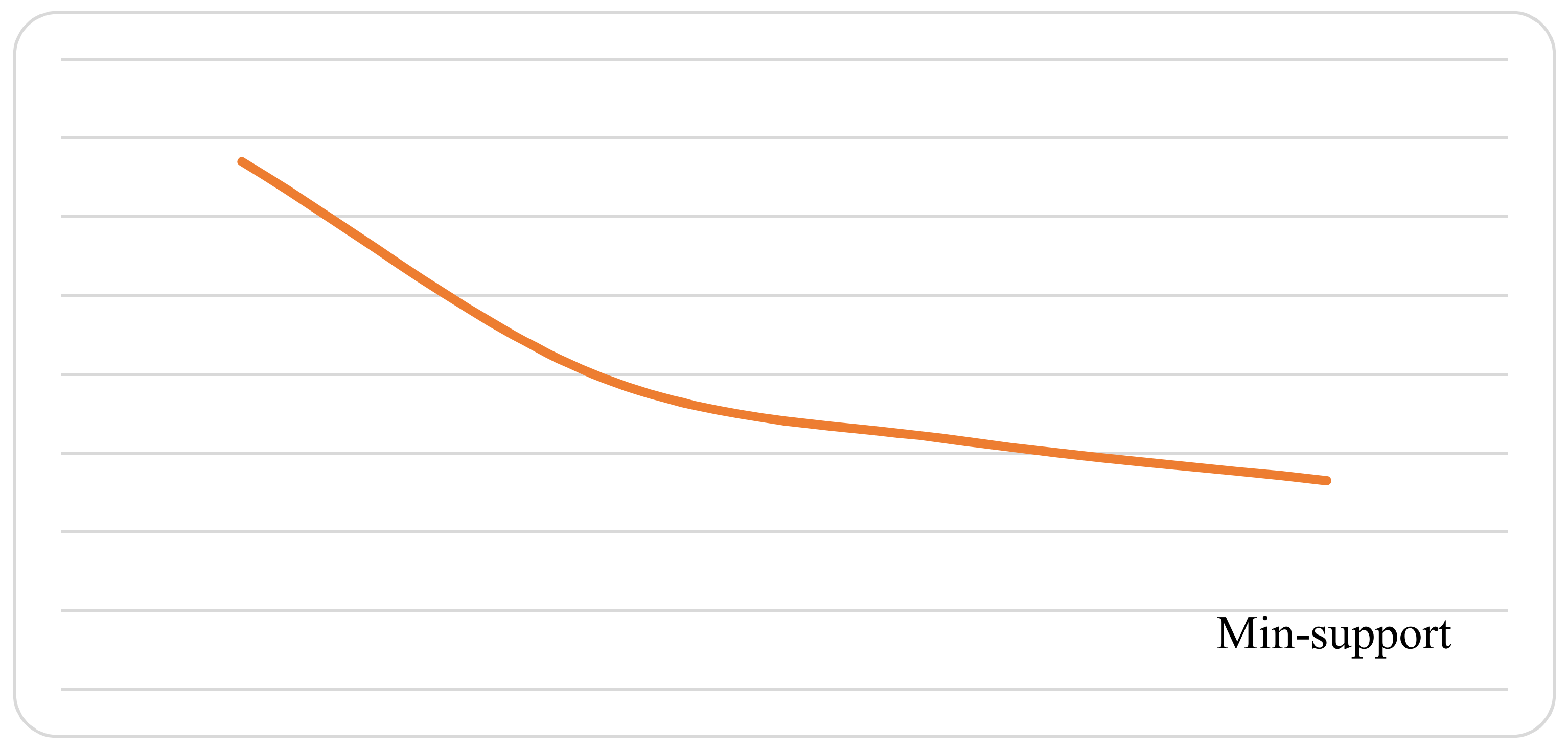
Figure 11.
No. of neutrosophic association rules with different min-support threshold.

Figure 12.
No. of neutrosophic rules for min-support threshold from 0.5 to 0.9.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Membership function for Database Transactions.
| Transaction | Temp. | Membership Degree |
|---|---|---|
| T1 | 18 | 1 cool |
| T2 | 13 | 0.6 cool, 0.4 cold |
| T3 | 12 | 0.4 cool, 0.6 cold |
| T4 | 33 | 0.6 warm, 0.4 hot |
| T5 | 21 | 0.2 warm, 0.8 cool |
| T6 | 25 | 1 warm |
Table 2.
1-itemset support.
| 1-itemset | Count | Support |
|---|---|---|
| Very cold | 0 | 0 |
| Cold | 1 | 0.17 |
| Cool | 2.8 | 0.47 |
| Warm | 1.6 | 0.27 |
| Hot | 0.6 | 0.1 |
Table 3.
2-itemset support.
| 2-itemset | Count | Support |
|---|---|---|
| {Cold, cool} | 0.8 | 0.13 |
| {Warm, hot} | 0.4 | 0.07 |
| {warm, cool} | 0.2 | 0.03 |
Table 4.
Linguistic terms ranges.
| Linguistic Term | Core Range | Left Boundary Range | Right Boundary Range |
|---|---|---|---|
| Very Cold | −∞–0 | N/A | 0–5 |
| Cold | 5–10 | 0–5 | 10–15 |
| Cool | 15–20 | 10–15 | 20–25 |
| Warm | 25–30 | 20–25 | 30–35 |
| Hot | 35–∞ | 30–35 | N/A |
Table 5.
Membership function for database Transactions.
| Transaction | Temp. | Membership Degree |
|---|---|---|
| T1 | 18 | Very-cold <0,0,1> cold <0,0,1> cool <1,0.1,0> warm <0,0.1,1> hot <0,0,1> |
| T2 | 13 | Very cold <0,0,1> cold <0.4,0.9,0.6> cool <0.6,0.9,0.4> warm <0,0,1> hot <0,0,1> |
| T3 | 12 | Very cold <0,0,1> cold <0.6,0.9,0.4> cool <0.4,0.9,0.6> warm <0,0,1> hot <0,0,1> |
| T4 | 33 | Very cold <0,0,1> cold <0,0,1> cool <0,0,1> warm <0.4,0.9,0.6> hot <0.6,0.9,0.4> |
| T5 | 21 | Very cold <0,0,1> cold <0,0,1> cool <0.8,0.7,0.2> warm <0.2,0.7,0.8> hot <0,0,1> |
| T6 | 25 | Very cold <0,0,1> cold <0,0,1> cool <0,0,1> warm <1,0.5,0> hot <0,0,1> |
Table 6.
Support for candidate 1-itemset neutrosophic set.
| 1-itemset | Count | Support |
|---|---|---|
| Tverycold | 0 | 0 |
| TCold | 1 | 0.17 |
| TCool | 2.8 | 0.47 |
| TWarm | 1.6 | 0.27 |
| THot | 0.6 | 0.1 |
| Iverycold | 0 | 0 |
| ICold | 1.8 | 0.3 |
| ICool | 2.6 | 0.43 |
| IWarm | 2.2 | 0.37 |
| IHot | 0.9 | 0.15 |
| Fverycold | 6 | 1 |
| FCold | 5 | 0.83 |
| FCool | 3.2 | 0.53 |
| FWarm | 4.4 | 0.73 |
| FHot | 5.4 | 0.9 |
Table 7.
Support for candidate 2-itemset neutrosophic set.
| 2-itemset | Count | Support | 2-itemset | Count | Support |
|---|---|---|---|---|---|
| {TCold, TCool} | 0.8 | 0.13 | {ICold, ICool} | 1.8 | 0.30 |
| {TCold, ICold} | 1 | 0.17 | {ICold, Fverycold} | 1.8 | 0.30 |
| {TCold, ICool} | 1 | 0.17 | {ICold, FCold} | 1 | 0.17 |
| {TCold, Fverycold} | 1 | 0.17 | {ICold, FCool} | 1 | 0.17 |
| {TCold, FCold} | 0.8 | 0.13 | {ICold, FWarm} | 1.8 | 0.30 |
| {TCold, FCool} | 1 | 0.17 | {ICold, FHot} | 1.8 | 0.30 |
| {TCold, FWarm} | 1 | 0.17 | {ICool, IWarm} | 0.8 | 0.13 |
| {TCold, FHot} | 1 | 0.17 | {ICool, Fverycold} | 2.6 | 0.43 |
| {TCool, TWarm} | 0.2 | 0.03 | {ICool, FCold} | 1.8 | 0.30 |
| {TCool, ICold} | 1 | 0.17 | {ICool, FCool} | 1.2 | 0.20 |
| {TCool, FCool} | 1.8 | 0.30 | {ICool, FWarm} | 2.6 | 0.43 |
| {TCool, IWarm} | 0.8 | 0.13 | {ICool, FHot} | 2.6 | 0.43 |
| {TCool, Fverycold} | 2.8 | 0.47 | {IWarm, IHot} | 0.9 | 0.15 |
| {TCool, FCold} | 2.8 | 0.47 | {IWarm, Fverycold} | 2.2 | 0.37 |
| {TCool, FCool} | 1 | 0.17 | {IWarm, FCold} | 2.2 | 0.37 |
| {TCool, FWarm} | 2.8 | 0.47 | {IWarm, FCool} | 1.6 | 0.27 |
| {TCool, FHot} | 2.8 | 0.47 | {IWarm, FWarm} | 1.4 | 0.23 |
| {TWarm, THot} | 0.4 | 0.07 | {IWarm, FHot} | 1.7 | 0.28 |
| {TWarm, ICool} | 0.2 | 0.03 | {IHot, Fverycold} | 0.9 | 0.15 |
| {TWarm, IWarm} | 1.1 | 0.18 | {IHot, FCold} | 0.9 | 0.15 |
| {TWarm, IHot} | 0.4 | 0.07 | {IHot, FCool} | 0.9 | 0.15 |
| {TWarm, Fverycold} | 1.6 | 0.27 | {IHot, FWarm} | 0.6 | 0.10 |
| {TWarm, FCold} | 1.6 | 0.27 | {IHot, FHot} | 0.4 | 0.07 |
| {TWarm, FCool} | 1.6 | 0.27 | {Fverycold, FCold} | 5 | 0.83 |
| {TWarm, FWarm} | 0.6 | 0.10 | {Fverycold, FCool} | 3.2 | 0.53 |
| {TWarm, FHot} | 1.6 | 0.27 | {Fverycold, FWarm} | 4.4 | 0.73 |
| {THot, IWarm} | 0.6 | 0.10 | {Fverycold, FHot} | 5.4 | 0.90 |
| {THot, IHot} | 0.6 | 0.10 | {FCold, FCool} | 3 | 0.50 |
| {THot, Fverycold} | 0.6 | 0.10 | {FCold, FWarm} | 3.4 | 0.57 |
| {THot, FCold} | 0.6 | 0.10 | {FCold, FHot} | 4.4 | 0.73 |
| {THot, FCool} | 0.6 | 0.10 | {FCool, FWarm} | 1.8 | 0.30 |
| {THot, FWarm} | 0.6 | 0.10 | {FCool, FHot} | 2.6 | 0.43 |
| {THot, FHot} | 0.4 | 0.07 | {FWarm, FHot} | 4.2 | 0.70 |
Table 8.
Segment of data after preparation.
| Ts_Date | Month | Quarter | Change | Volume | Change30 | Change70 | Change100 |
|---|---|---|---|---|---|---|---|
| 13 September 2012 | September | 3 | 0.64 | 0.03 | −1.11 | 0.01 | −0.43 |
| 16 September 2012 | September | 3 | 0.07 | 0.02 | 2.82 | 4.50 | 3.67 |
| 17 September 2012 | September | 3 | 3.47 | 0.12 | 1.27 | 0.76 | 0.81 |
| 18 September 2012 | September | 3 | 1.38 | 0.03 | −0.08 | −0.48 | −0.43 |
| 19 September 2012 | September | 3 | −1.48 | 0.02 | 0.35 | −1.10 | −0.64 |
| 20 September 2012 | September | 3 | 0.47 | 0.05 | −1.41 | −1.64 | −1.55 |
| 23 September 2012 | September | 3 | 3.64 | 0.02 | −0.21 | 1.00 | 0.41 |
| 24 September 2012 | September | 3 | −0.47 | 0.05 | 0.27 | −0.09 | 0.03 |
| 25 September 2012 | September | 3 | −2.77 | 0.15 | 2.15 | 1.79 | 1.85 |
| 26 September 2012 | September | 3 | 1.96 | 0.04 | 0.22 | 0.96 | 0.57 |
| 27 September 2012 | September | 3 | 0.90 | 0.05 | −1.38 | −0.88 | −0.92 |
| 30 September 2012 | September | 3 | −0.14 | 0.00 | −1.11 | −0.79 | −0.75 |
| 1 October 2012 | October | 4 | −1.60 | 0.02 | −2.95 | −4.00 | −3.51 |
Table 9.
No. of resulted fuzzy rules with different min-support.
| Min-Support | 0.02 | 0.03 | 0.04 | 0.05 |
|---|---|---|---|---|
| 1-itemset | 10 | 10 | 10 | 10 |
| 2-itemset | 37 | 36 | 36 | 33 |
| 3-itemset | 55 | 29 | 15 | 10 |
| 4-itemset | 32 | 4 | 2 | 0 |
Table 10.
No. of neutrosophic rules with different min-support threshold.
| Min-Support | 0.02 | 0.03 | 0.04 | 0.05 |
|---|---|---|---|---|
| 1-itemset | 26 | 26 | 26 | 26 |
| 2-itemset | 313 | 311 | 309 | 300 |
| 3-itemset | 2293 | 2164 | 2030 | 1907 |
| 4-itemset | 11233 | 9689 | 8523 | 7768 |
Table 11.
No. of neutrosophic rules with different min-support threshold.
| Min-Support | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|---|
| 1-itemset | 11 | 9 | 9 | 6 | 5 |
| 2-itemset | 50 | 33 | 30 | 11 | 10 |
| 3-itemset | 122 | 64 | 50 | 10 | 10 |
| 4-itemset | 175 | 71 | 45 | 5 | 5 |
| 5-itemset | 151 | 45 | 21 | 1 | 1 |
| 6-itemset | 88 | 38 | 8 | 0 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Abdel-Basset, M.; Mohamed, M.; Smarandache, F.; Chang, V. Neutrosophic Association Rule Mining Algorithm for Big Data Analysis. Symmetry 2018, 10, 106. https://doi.org/10.3390/sym10040106
AMA Style
Abdel-Basset M, Mohamed M, Smarandache F, Chang V. Neutrosophic Association Rule Mining Algorithm for Big Data Analysis. Symmetry. 2018; 10(4):106. https://doi.org/10.3390/sym10040106
Chicago/Turabian StyleAbdel-Basset, Mohamed, Mai Mohamed, Florentin Smarandache, and Victor Chang. 2018. "Neutrosophic Association Rule Mining Algorithm for Big Data Analysis" Symmetry 10, no. 4: 106. https://doi.org/10.3390/sym10040106
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.