
Comparative Studies of Different Imputation Methods for Recovering Streamflow Observation


Abstract
:1. Introduction
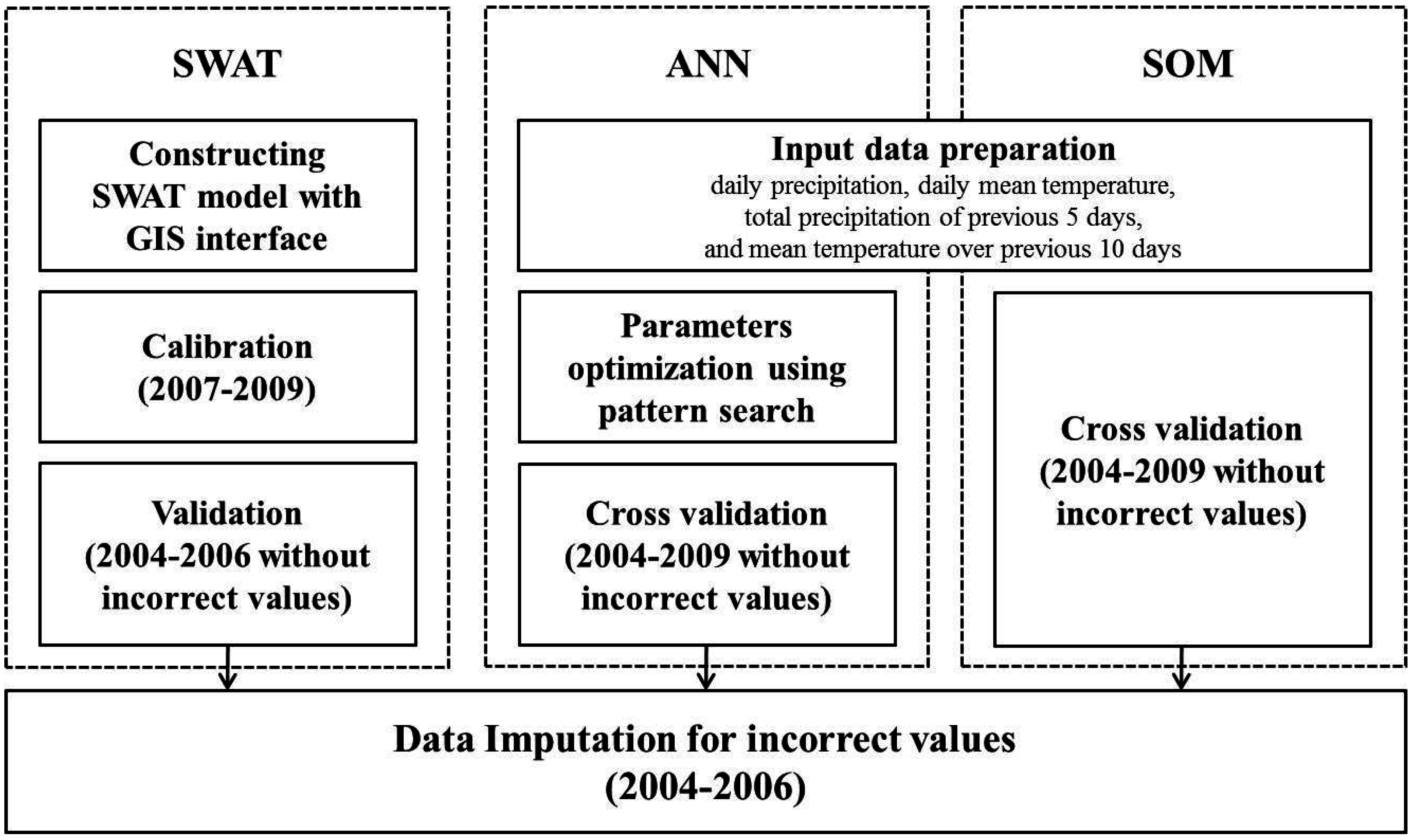
2. Methods
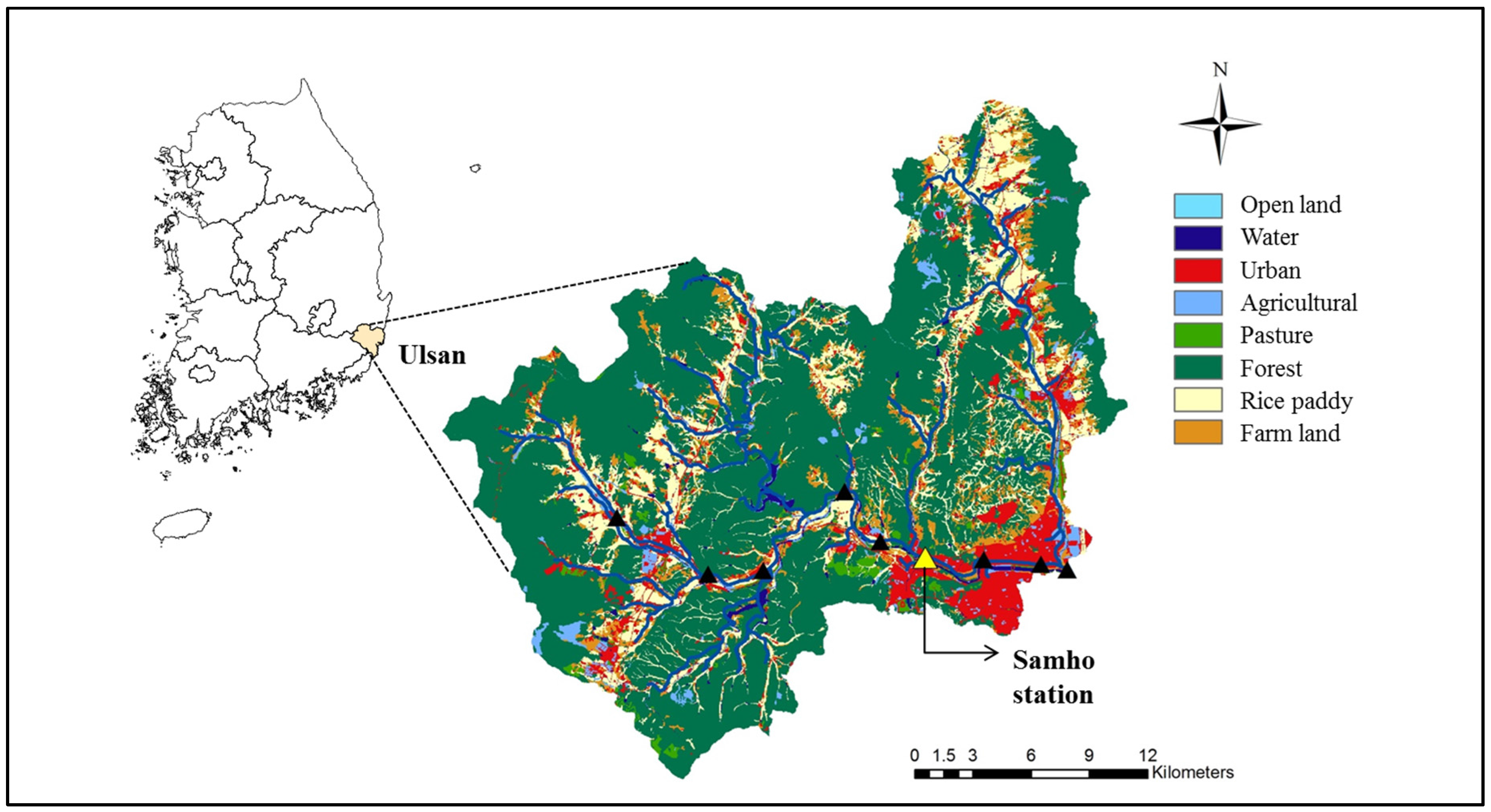
2.1. Study Area and Data Acquisition
2.2. Data Imputation Methods

2.2.1. Soil and Water Assessment Tool

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Method | Min | Max | Rank | Value | Definition |
|---|---|---|---|---|---|---|
| CH_N2.rte | Replace | 0.0001 | 0.3 | 1 | 0.0015 | Manning‘s n value for the main channel length |
| SLSUBBSN.hru | Replace | 10 | 150 | 2 | 18.39 | Slope length (m) |
| CN2.mgt | Relative | −0.2 | 0.2 | 3 | 0.035 | Moisture condition II curve number |
| SOL_K.sol | Relative | −0.8 | 0.8 | 4 | 0.19 | Saturated hydraulic conductivity (mm/h) |
| ALPHA_BF.gw | Replace | 0 | 1 | 5 | 0.61 | Base flow recession constant |
| CH_K2.rte | Replace | 0 | 150 | 6 | 77.42 | Effective hydraulic conductivity of channel (mm/h) |
| CANMX.hru | Replace | 0 | 15 | 7 | 0.49 | Maximum canopy storage (mm H2O) |
| SOL_AWC.sol | Relative | −0.5 | 0.5 | 8 | −0.32 | Available water capacity of the soil layer (mm H2O/mm soil) |
| EPCO.hru | Replace | 0 | 1 | 9 | 0.077 | Plant uptake compensation factor |
| RCHRG_DP.gw | Replace | 0 | 1 | 10 | 0.19 | Deep aquifer percolation fraction |
| ESCO.hru | Replace | 0 | 1 | 11 | 0.37 | Soil evaporation compensation factor |
| SFTMP.bsn | Replace | 0 | 5 | 12 | 2.55 | Snowfall temperature (°C) |
| SURLAG.bsn | Replace | 0.05 | 24 | 13 | 0.15 | Surface runoff lag coefficient |
| SMFMN.bsn | Replace | 0 | 10 | 14 | 4.85 | Melt factor for snow on December 21 (mm H2O/day-°C) |
| TLAPS.sub | Replace | −10 | 10 | 15 | −8.83 | Temperature lapse rate (°C/km) |
| SOL_ALB.sol | Relative | 0 | 1 | 16 | 0.58 | Moist soil albedo |
| GWQMN.gw | Replace | 0 | 50 | 17 | 25.95 | Threshold depth of water in the shallow aquifer for return flow (mm H2O) |
| GW_DELAY.gw | Replace | 0 | 100 | 18 | 94.50 | Groundwater delay time (days) |
| TIMP.bsn | Replace | 0 | 1 | 19 | 0.95 | Snow peak temperature lag factor |
| REVAPMN.gw | Replace | 0 | 500 | 20 | 324.54 | Threshold depth of water in the shallow aquifer for percolation to the deep aquifer (mm H2O) |
| SMTMP.bsn | Replace | 0 | 5 | 21 | 0.045 | Snow melt base temperature (°C) |
| BIOMIX.mgt | Replace | 0 | 1 | 22 | 0.12 | Biological mixing efficiency |
| EPCO.bsn | Replace | 0 | 1 | 23 | 0.55 | Plant uptake compensation factor |
| SMFMX.bsn | Replace | 0 | 10 | 24 | 4.91 | Melt factor for snow on June 21 (mm H2O/day-°C) |
| ESCO.bsn | Replace | 0 | 1 | 25 | 0.17 | Soil evaporation compensation factor |
2.2.2. Artificial Neural Network
2.2.3. Self-Organizing Map
2.2.4. Cross-Validation and Evaluation
3. Results and Discussion
3.1. Parameter Estimation
| Model | Model Parameters/Error | Value |
|---|---|---|
| ANN (Tansig) | Learning rate | 0.75 |
| Momentum constant | 0.5 | |
| Number of neuron | 9 | |
| SOM | Quantization error | 0.335 |
| Topographic error | 0.039 |
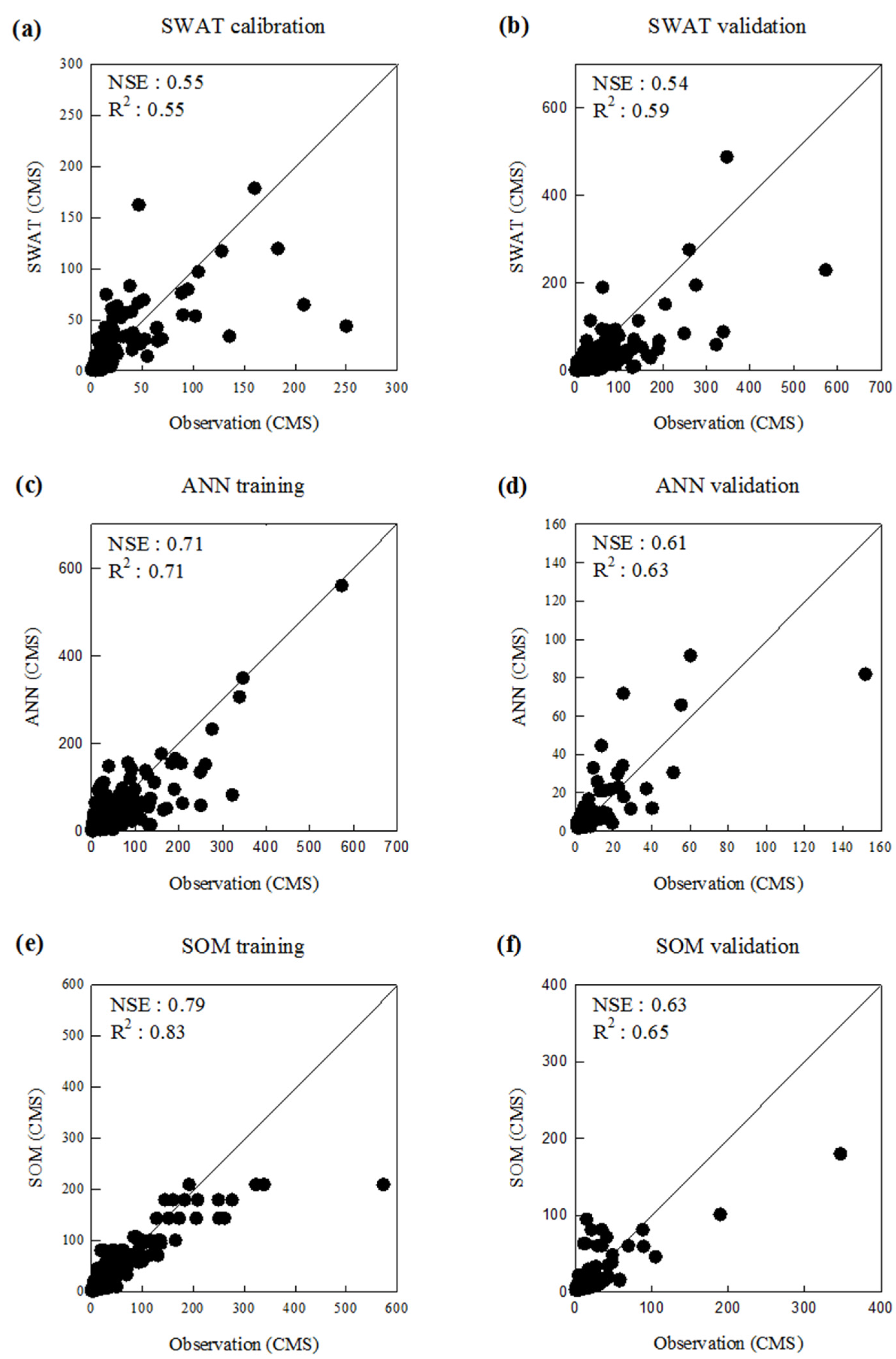
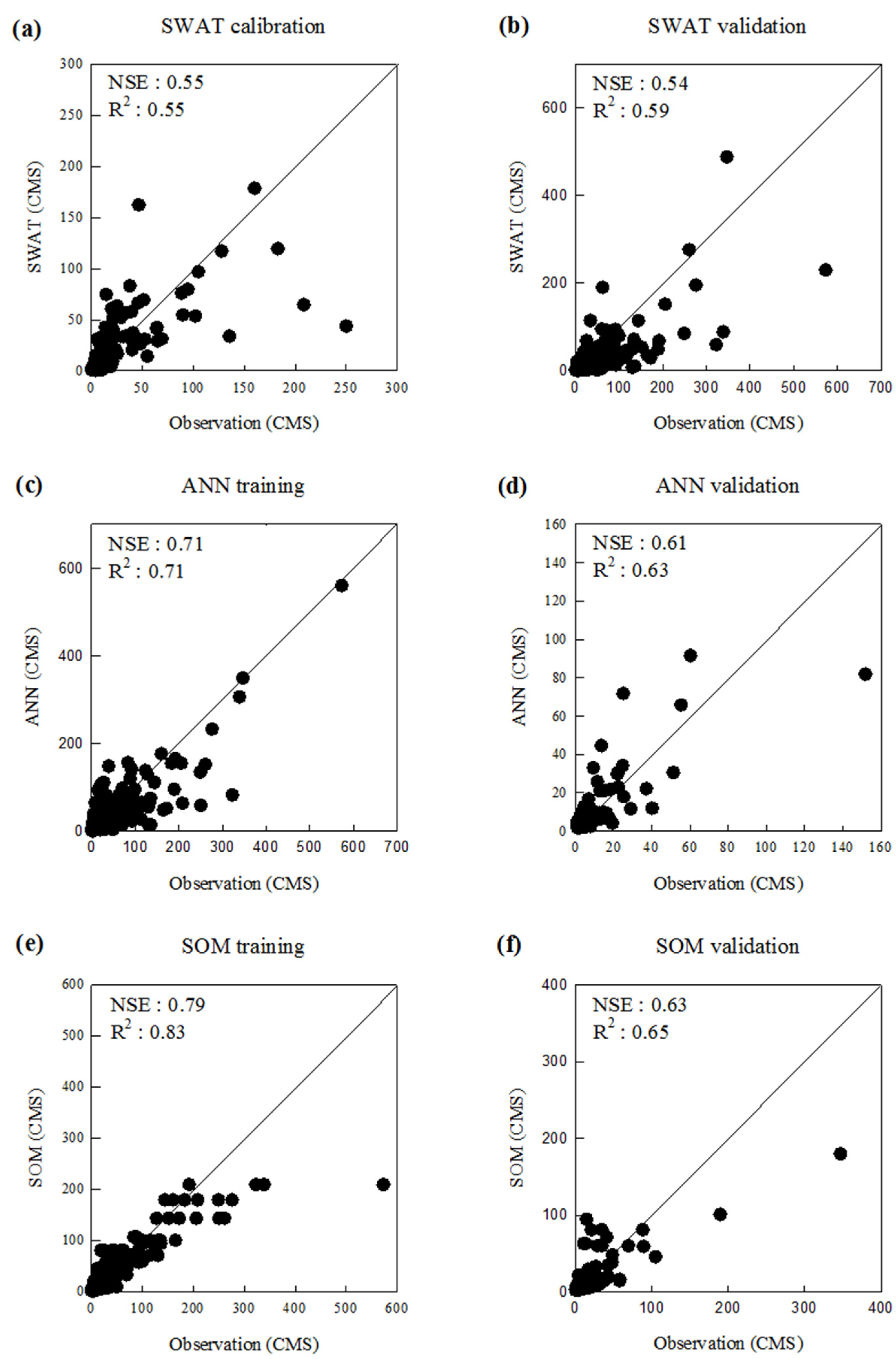
3.2. Comparison of Model Performance
| Method | NSE | R2 | ||
|---|---|---|---|---|
| Calibration | Validation | Calibration | Validation | |
| SWAT | 0.55 | 0.54 | 0.55 | 0.59 |
| ANN | 0.71 | 0.61 | 0.71 | 0.63 |
| SOM | 0.79 | 0.63 | 0.83 | 0.65 |

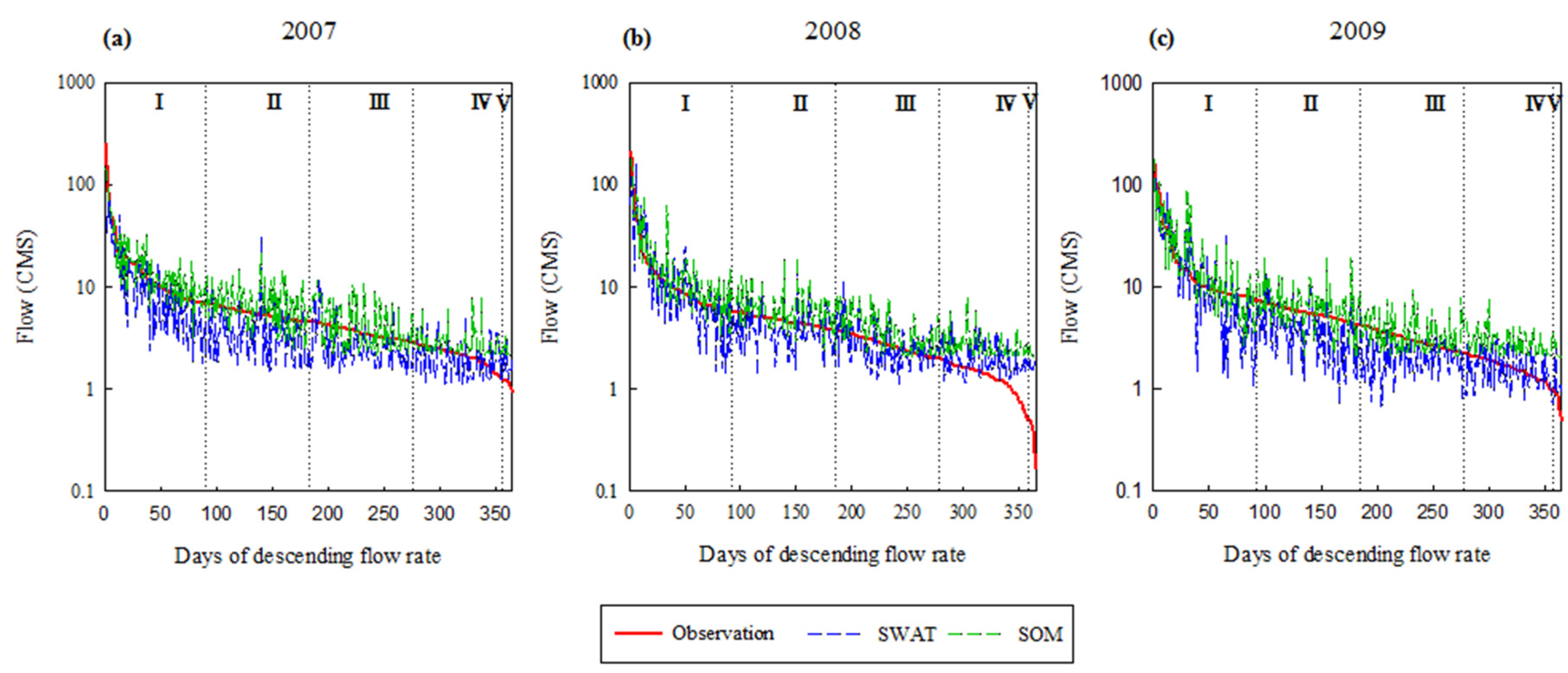
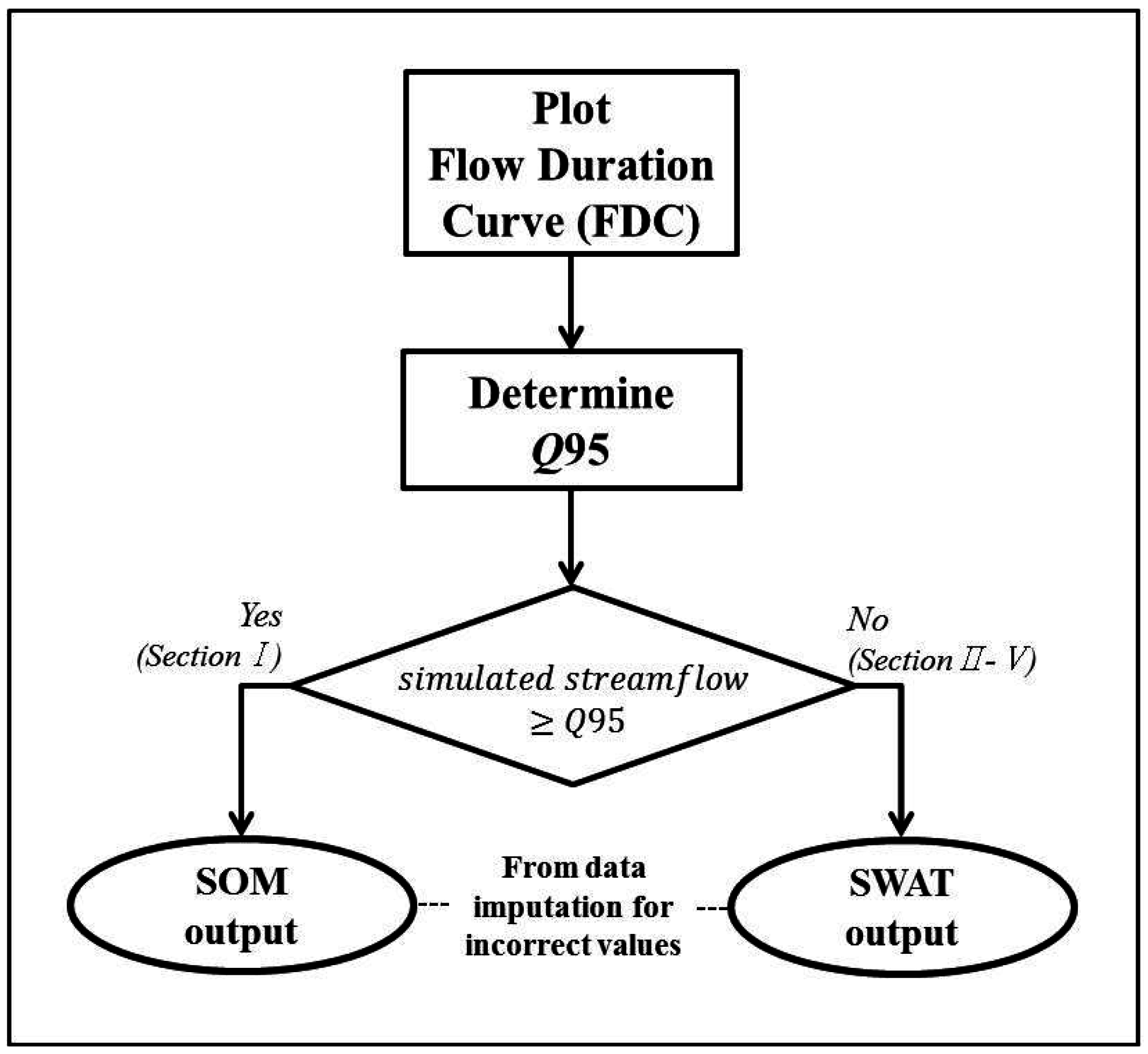
3.3. Comparison of Flow Duration Curve

| Section | 2007 | 2008 | 2009 | |||
|---|---|---|---|---|---|---|
| SWAT | SOM | SWAT | SOM | SWAT | SOM | |
| I | 24.85 | 12.86 | 22.49 | 11.48 | 3.73 | 4.03 |
| II | 3.76 | 3.81 | 2.33 | 3.38 | 1.66 | 1.91 |
| III | 1.73 | 2.56 | 1.49 | 2.04 | 1.19 | 1.31 |
| IV | 1 | 1.32 | 1.04 | 1.74 | 0.86 | 1.25 |
| V | 0.9 | 1.26 | 1.41 | 1.95 | 0.79 | 1.32 |
| Year | SWAT | SOM |
|---|---|---|
| 2007 | 0.46 | 0.86 |
| 2008 | 0.55 | 0.89 |
| 2009 | 0.78 | 0.73 |
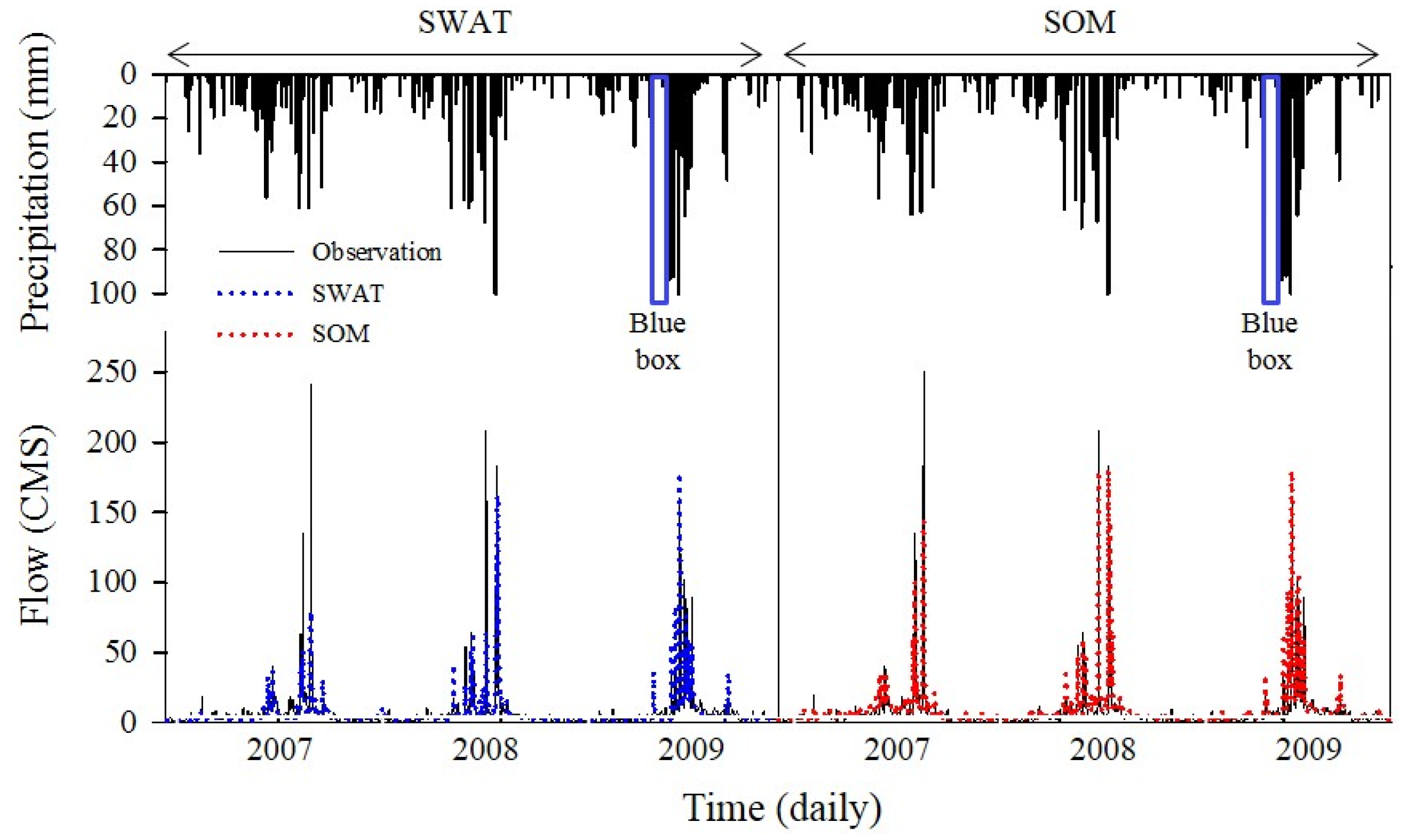
3.4. Data Imputation Result

4. Conclusions
- (1).
- Based on the statistical index, SOM was considered the best model at simulating streamflow in the TR watershed. It demonstrated that the machine learning model is usually better at capturing high flow than SWAT.
- (2).
- SWAT, however, could simulate low-flows better than SOM, although it had smaller NSE and R2 values.
- (3).
- Using an ANN or SOM model for the data imputation of high-flow events is recommended, while the SWAT model would be desirable for low-flow events.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- USGS. A New Evaluation of the Usgs Streamgaging Network; USGS: Washington, DC, USA, 1998.
- Ng, W.W.; Panu, U.S.; Lennox, W.C. Comparative studies in problems of missing extreme daily streamflow records. J. Hydrol. Eng. 2009, 14, 91–100. [Google Scholar] [CrossRef]
- United States Environmental Protection Agency. Clean Water Action Plan: Restoring and Protecting America’s Waters; EPA: Washington, DC, USA, 1998.
- Wallis, J.R.; Lettenmaier, D.P.; Wood, E.F. A daily hydroclimatological data set for the continental united-states. Water Resour. Res. 1991, 27, 1657–1663. [Google Scholar] [CrossRef]
- Gyauboakye, P.; Schultz, G.A. Filling gaps in runoff time-series in west-africa. Hydrol. Sci. J. 1994, 39, 621–636. [Google Scholar] [CrossRef]
- Hirsch, R.M. An evaluation of some record reconstruction techniques. Water Resour. Res. 1979, 15, 1781–1790. [Google Scholar] [CrossRef]
- Hirsch, R.M. A comparison of four streamflow record extension techniques. Water Resour. Res. 1982, 181, 1081–1088. [Google Scholar] [CrossRef]
- Kottegoda, N.T.; Elgy, J. Infilling Missing Data, Modeling Hydrologic Processes. In Proceedings of the Fort Collings 3rd International Hydrologic Symposium on Theoretical and Applied Hydrology, Colorado State University, Fort Collins, CO, USA, 27–29 July 1977.
- Mwale, F.D.; Adeloye, A.J.; Rustum, R. Infilling of missing rainfall and streamflow data in the shire river basin, malawi—A self organizing map approach. Phys. Chem. Earth 2012, 50, 34–43. [Google Scholar] [CrossRef]
- Khalil, M.; Panu, U.; Lennox, W. Estimating of missing streamflows: A historical perspective. In Proceedings of the Annual Conference of the Canadian Society for Civil Engineering, Halifax, NS, Canada, 10–13 June 1998.
- Rees, G. Hydrological data. In Manual on Low-Flow Estimation and Prediction; World Meteorological Organization: Geneva, Switzerland, 2008. [Google Scholar]
- Adeloye, A. The relative utility of regression and artificial neural networks models for rapidly predicting the capacity of water supply reservoirs. Environ. Modell. Softw. 2009, 24, 1233–1240. [Google Scholar] [CrossRef]
- Loke, E.A.-N.K.; Harremoes, P. Artificial Neural Networks and Grey-Box Modelling: A Comparison. In Proceedings of the Eighth International Conference: Urban Storm Drainage Proceedings, the Institution of Engineers Australisa, Sydney, Australia, 1 January 1999.
- Ilunga, M.; Stephenson, D. Infilling streamflow data using feed-forward back-propagation (BP) artificial neural networks: Application of standard bp and pseudo mac laurin power series bp techniques. Water SA 2005, 31, 171–176. [Google Scholar]
- Ogwueleka, T.C.; Ogwueleka, F. Feed-forward neural networks for precipitation and river level prediction. Adv. Natl. Appl. Sci. 2009, 3, 350–356. [Google Scholar]
- Cheng, C.T.; Niu, W.J.; Feng, Z.K.; Shen, J.J.; Chau, K.W. Daily reservoir runoff forecasting method using artificial neural network based on quantum-behaved particle swarm optimization. Water 2015, 7, 4232–4246. [Google Scholar] [CrossRef]
- Rustum, R.; Adeloye, A.J. Replacing outliers and missing values from activated sludge data using kohonen self-organizing map. J. Environ. Eng. ASCE 2007, 133, 909–916. [Google Scholar] [CrossRef]
- Kalteh, A.M.; Hjorth, P. Imputation of missing values in a precipitation-runoff process database. Hydrol. Res. 2009, 40, 420–432. [Google Scholar] [CrossRef]
- Dastorani, M.; Moghadamnia, A.; Piri, J.; Rico-Ramirez, M. Application of ann and anfis models for reconstructing missing flow data. Environ. Monit. Assess. 2010, 166, 421–434. [Google Scholar] [CrossRef] [PubMed]
- Carpenter, J. Personal Communication, Occoquan Watershed Monitoring Laboratory, Department of Civil and Environmental Engineering; Virginia Tech: Manassas, VA, USA, 1999. [Google Scholar]
- Arnold, J.G.; Srinivasan, R.; Muttiah, R.S.; Williams, J.R. Large area hydrologic modeling and assessment-part 1: Model development. J. Am. Water Resour. Assoc. 1998, 34, 73–89. [Google Scholar] [CrossRef]
- Abbaspour, K.C. User manual for swat-cup, swat calibration and uncertainty analysis programs. In Swiss Federal Institute of Aquatic Science and Technology; Eawag: Duebendorf, Switzerland, 2007. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Cho, K.H.; Sthiannopkao, S.; Pachepsky, Y.A.; Kim, K.W.; Kim, J.H. Prediction of contamination potential of groundwater arsenic in Cambodia, Laos, and Thailand using artificial neural network. Water Res. 2011, 45, 5535–5544. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Jeong, K.; Lim, J.; Jo, J.; Kim, Y.M.; Park, J.P.; Kim, J.H.; Cho, K.H. Prediction of effluent concentration in a wastewater treatment plant using machine learning models. J. Environ. Sci. 2015, 32, 90–101. [Google Scholar] [CrossRef] [PubMed]
- Govindaraju, R.S. Artificial neural networks in hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar]
- Govindaraju, R.S. Artificial neural networks in hydrology. II: Hydrologic applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar]
- Bonafe, A.; Galeati, G.; Sforna, M. Neural networks for daily mean flow forecasting. Hydraul. Eng. Softw. V 1994, 1, 131–138. [Google Scholar]
- Dawson, C.W.; Wilby, R. An artificial neural network approach to rainfall-runoff modelling. Hydrol. Sci. J. 1998, 43, 47–66. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, S.L.; Xiong, L.H.; Liu, P.; Liu, D.D. Daily runoff forecasting model based on ANN and data preprocessing techniques. Water 2015, 7, 4144–4160. [Google Scholar] [CrossRef]
- Shukla, M.B.; Kok, R.; Prasher, S.O.; Clark, G.; Lacroix, R. Use of artificial neural networks in transient drainage design. Trans. ASAE 1996, 39, 119–124. [Google Scholar] [CrossRef]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer: Berlin, Germany, 1996. [Google Scholar]
- Dawson, C.W.; Wilby, R.L. Hydrological modelling using artificial neural networks. Progress Phys. Geogr. 2001, 25, 80–108. [Google Scholar] [CrossRef]
- Kalteh, A.M.; Hiorth, P.; Bemdtsson, R. Review of the self-organizing map (SOM) approach in water resources: Analysis, modelling and application. Environ. Modell. Softw. 2008, 23, 835–845. [Google Scholar] [CrossRef]
- Vesanto, J. Neural Network Tool for Data Mining: Som Toolbox. In Proceedings of the Symposium on Tool Environments and Development Methods for Intelligent Systems (TOOLMET2000), Oulu, Finland, 13–14 April 2000.
- Huang, R.Q.; Xi, L.F.; Li, X.L.; Liu, C.R.; Qiu, H.; Lee, J. Residual life predictions for ball bearings based on self-organizing map and back propagation neural network methods. Mech. Syst. Signal Proc. 2007, 21, 193–207. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. Asabe 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Cho, K.H.; Pachepsky, Y.A.; Kim, J.H.; Kim, J.W.; Park, M.H. The modified swat model for predicting fecal coliforms in the wachusett reservoir watershed, USA. Water Res. 2012, 46, 4750–4760. [Google Scholar] [CrossRef] [PubMed]
- White, K.L.; Chaubey, I. Sensitivity analysis, calibration, and validations for a multisite and multivariable swat model. J. Am. Water Resour. Assoc. 2005, 41, 1077–1089. [Google Scholar] [CrossRef]
- Kim, J.W.; Pachepsky, Y.A.; Shelton, D.R.; Coppock, C. Effect of streambed bacteria release on E. coli concentrations: Monitoring and modeling with the modified swat. Ecol. Model. 2010, 221, 1592–1604. [Google Scholar]
- Bação, F.; Lobo, V.; Painho, M. Applications of different self-organizing map variants to geographical information science problems. In Self-Organising Maps; Wiley: Hoboken, NJ, USA, 2008; pp. 21–44. [Google Scholar]
- Lee, J.H.; Kil, J.T.; Jeong, S. Evaluation of physical fish habitat quality enhancement designs in urban streams using a 2D hydrodynamic model. Ecol. Eng. 2010, 36, 1251–1259. [Google Scholar] [CrossRef]
- Jeong, J.; Kannan, N.; Arnold, J.; Glick, R.; Gosselink, L.; Srinivasan, R. Development and integration of sub-hourly rainfall–runoff modeling capability within a watershed model. Water Resour. Manag. 2010, 24, 4505–4527. [Google Scholar] [CrossRef]
- Eckhardt, K.; Arnold, J.G. Automatic calibration of a distributed catchment model. J. Hydrol. 2001, 251, 103–109. [Google Scholar] [CrossRef]
- Borah, D.K.; Arnold, J.G.; Bera, M.; Krug, E.C.; Liang, X.Z. Storm event and continuous hydrologic modeling for comprehensive and efficient watershed simulations. J. Hydrol. Eng. 2007, 12, 605–616. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/)
Share and Cite
Kim, M.; Baek, S.; Ligaray, M.; Pyo, J.; Park, M.; Cho, K.H. Comparative Studies of Different Imputation Methods for Recovering Streamflow Observation. Water 2015, 7, 6847-6860. https://doi.org/10.3390/w7126663
Kim M, Baek S, Ligaray M, Pyo J, Park M, Cho KH. Comparative Studies of Different Imputation Methods for Recovering Streamflow Observation. Water. 2015; 7(12):6847-6860. https://doi.org/10.3390/w7126663
Chicago/Turabian StyleKim, Minjeong, Sangsoo Baek, Mayzonee Ligaray, Jongcheol Pyo, Minji Park, and Kyung Hwa Cho. 2015. "Comparative Studies of Different Imputation Methods for Recovering Streamflow Observation" Water 7, no. 12: 6847-6860. https://doi.org/10.3390/w7126663