Genome-Wide Identification of the Alba Gene Family in Plants and Stress-Responsive Expression of the Rice Alba Genes

Abstract
:1. Introduction
2. Materials and Methods
2.1. Identification and Sequence Retrieval of Alba Genes
2.2. Sequence Analysis and Structural Characterization
2.3. Phylogenetic Analysis
2.4. Subcellular Localization and Analysis of Cis-Acting Regulatory Elements in OsAlba
2.5. Prediction of miRNA Targets
2.6. Molecular Modeling of OsAlba Proteins
2.7. Plant Materials, Growth Conditions, and Stress Treatment
2.8. RNA Isolation and Quantitative Real-Time PCR Analysis
3. Results and Discussion
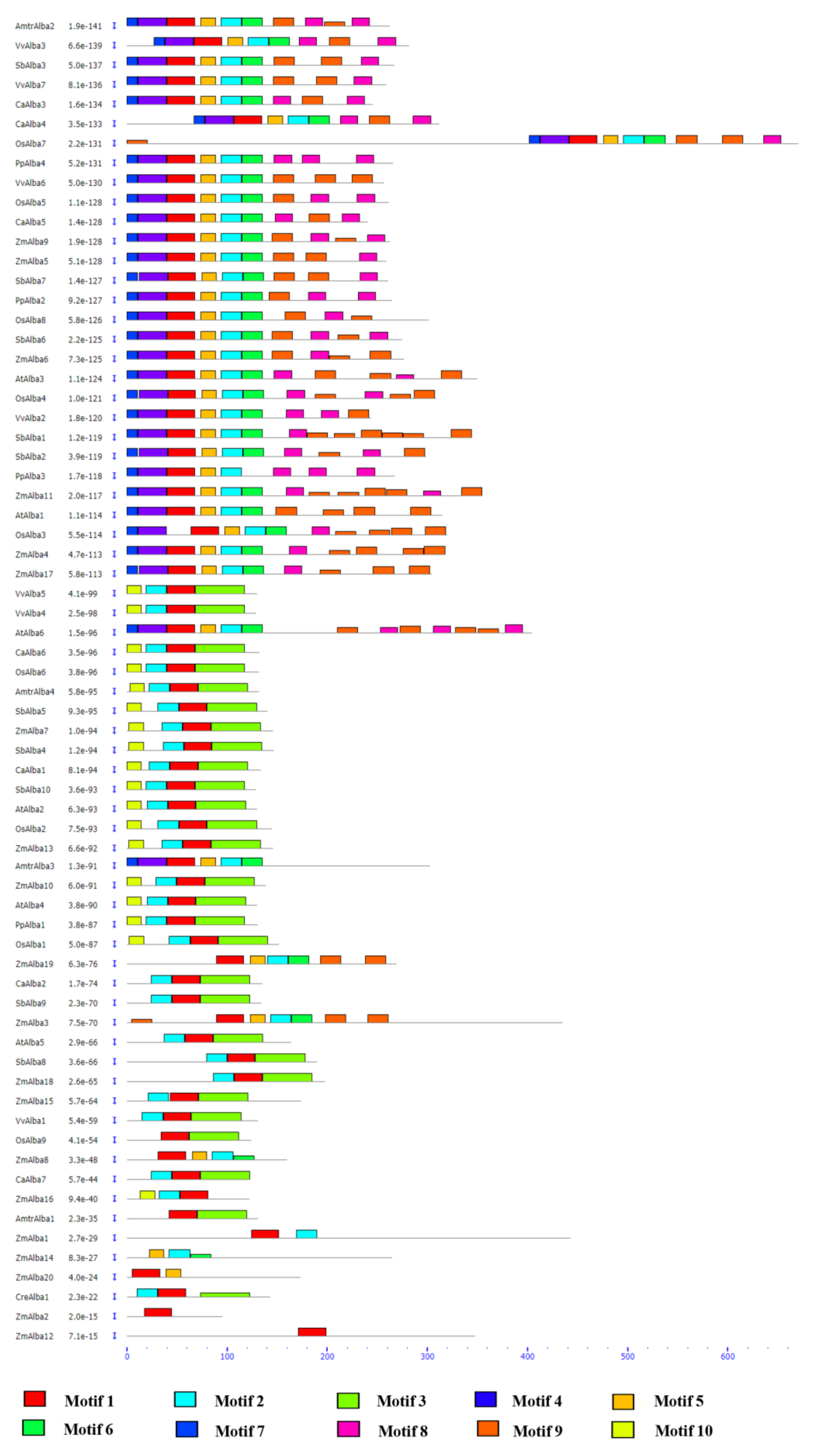
3.1. Identification of Plant-Specific Alba Proteins
3.2. Genomic Organization of Alba Genes and Their Chromosomal Distribution
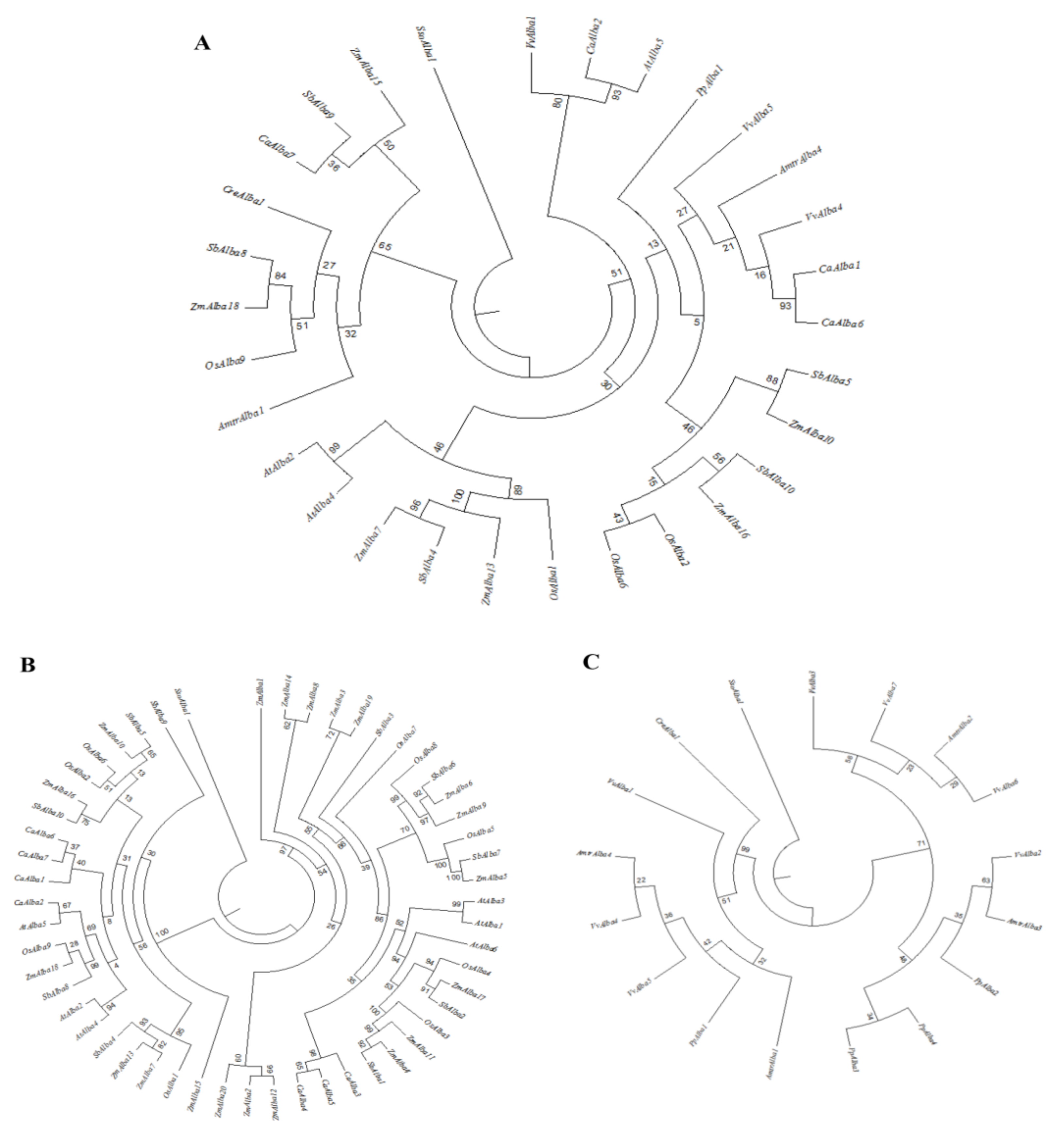
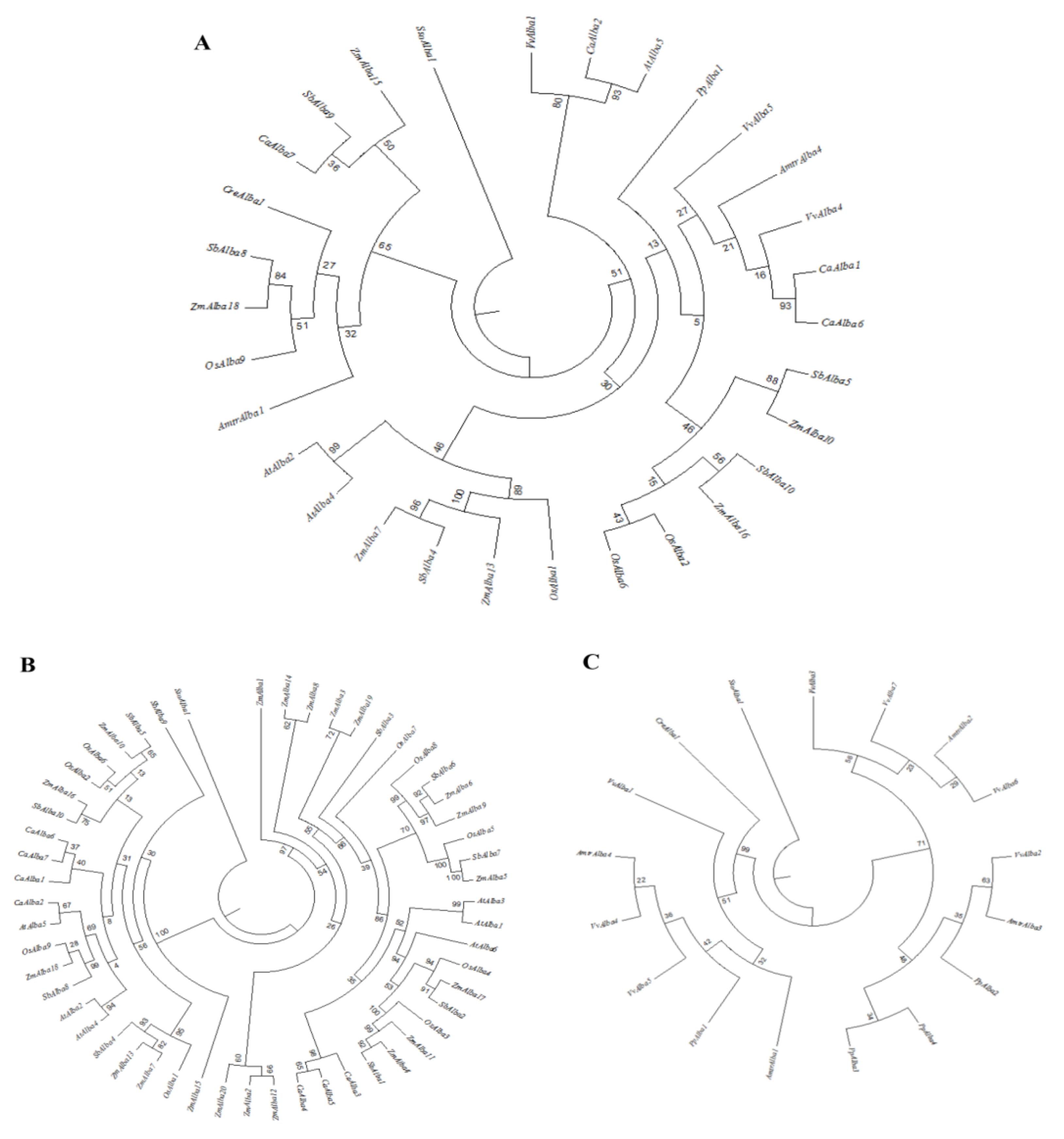
3.3. Phylogenetic Analysis of Alba Gene Families
3.4. Subcellular Localization of the Alba Family Proteins
3.5. Analysis of Upstream Regulatory Elements in Alba Genes
3.6. Prediction of miRNA Targets in Plant-Specific Alba Proteins
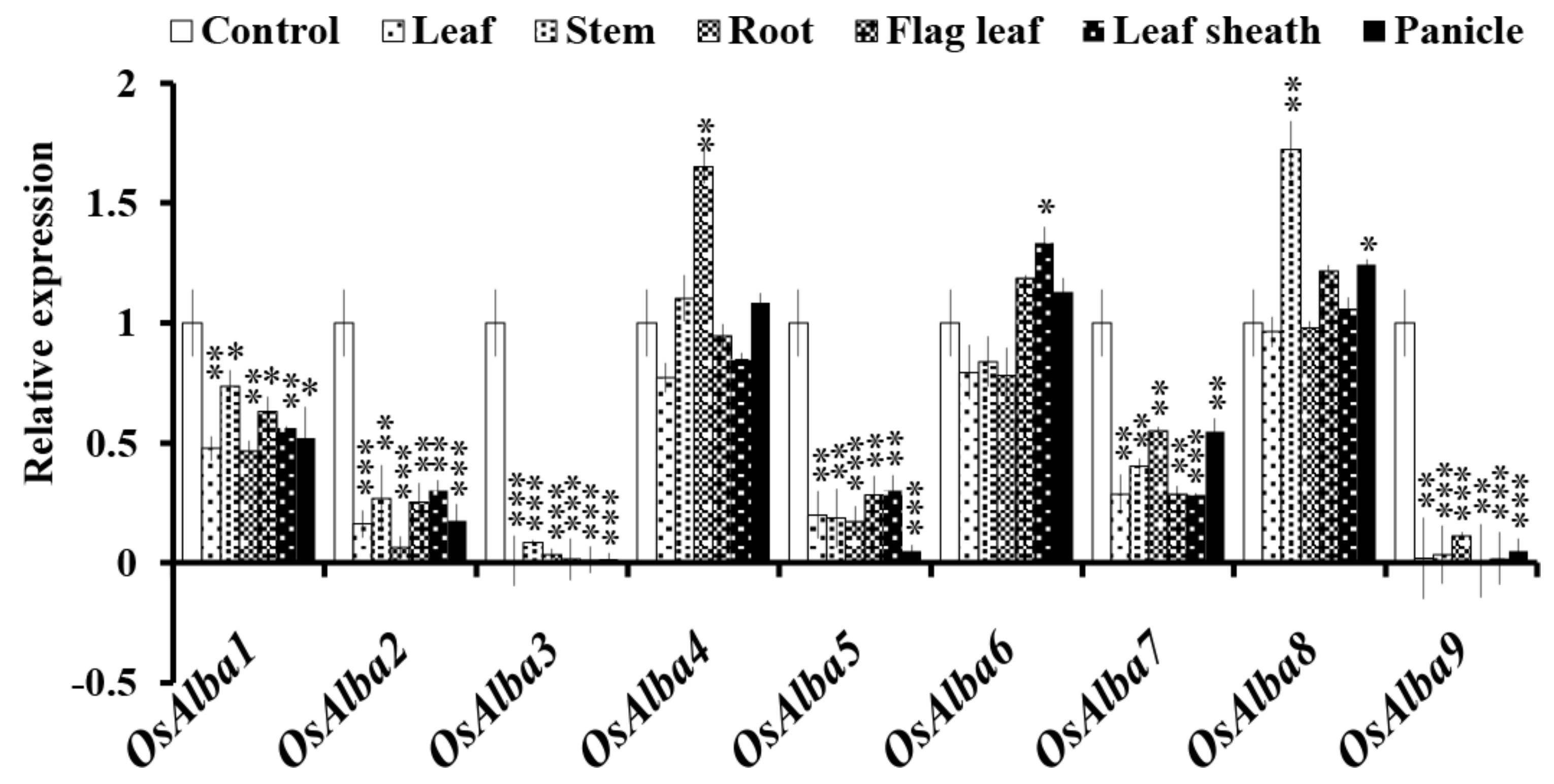
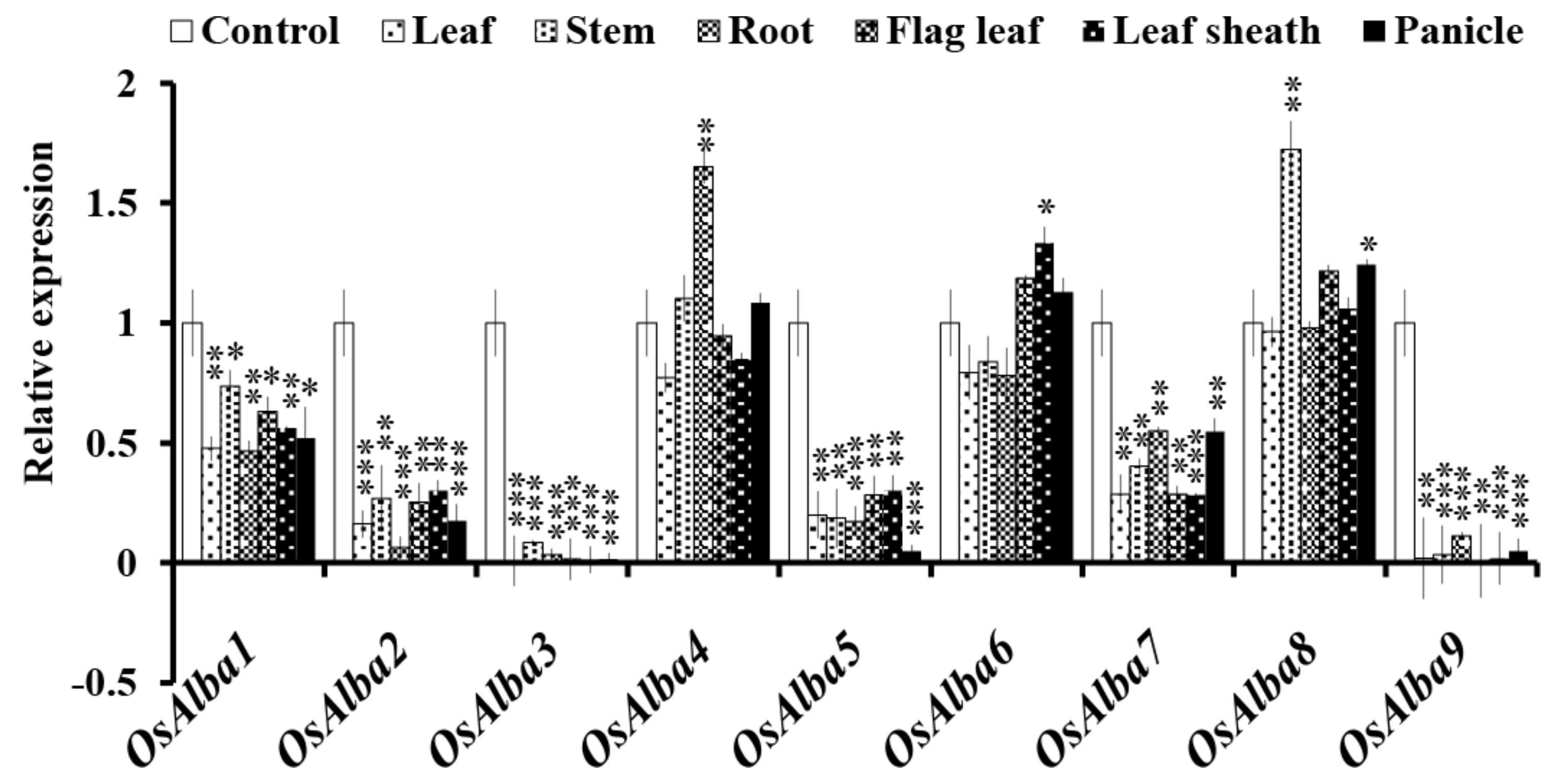
3.7. Tissue-Specific Expression Profiles of OsAlba Genes
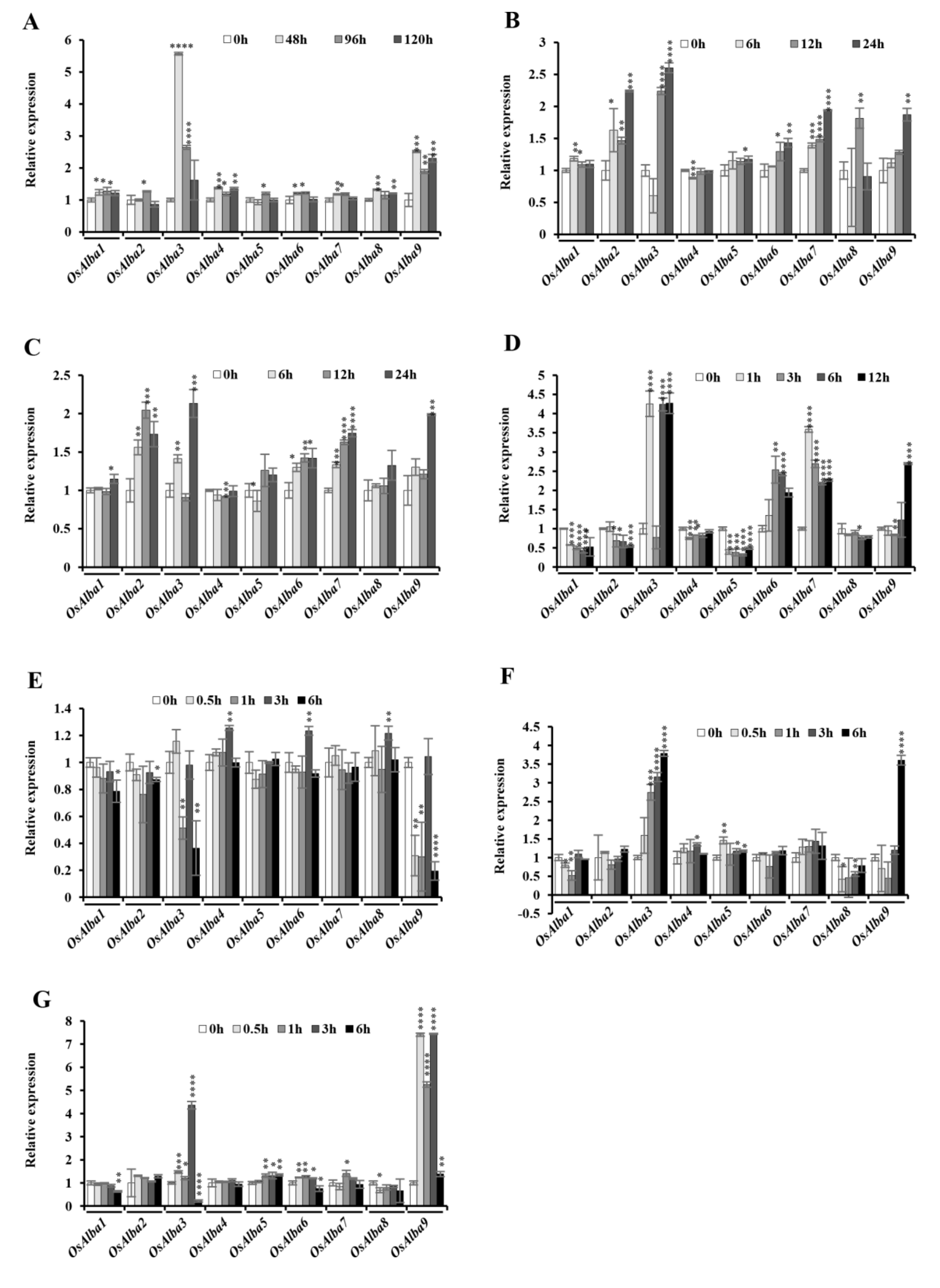
3.8. Stress-Induced Expression of OsAlba Genes
3.9. Influence of Phytohormones on the Expression of the OsAlba Genes
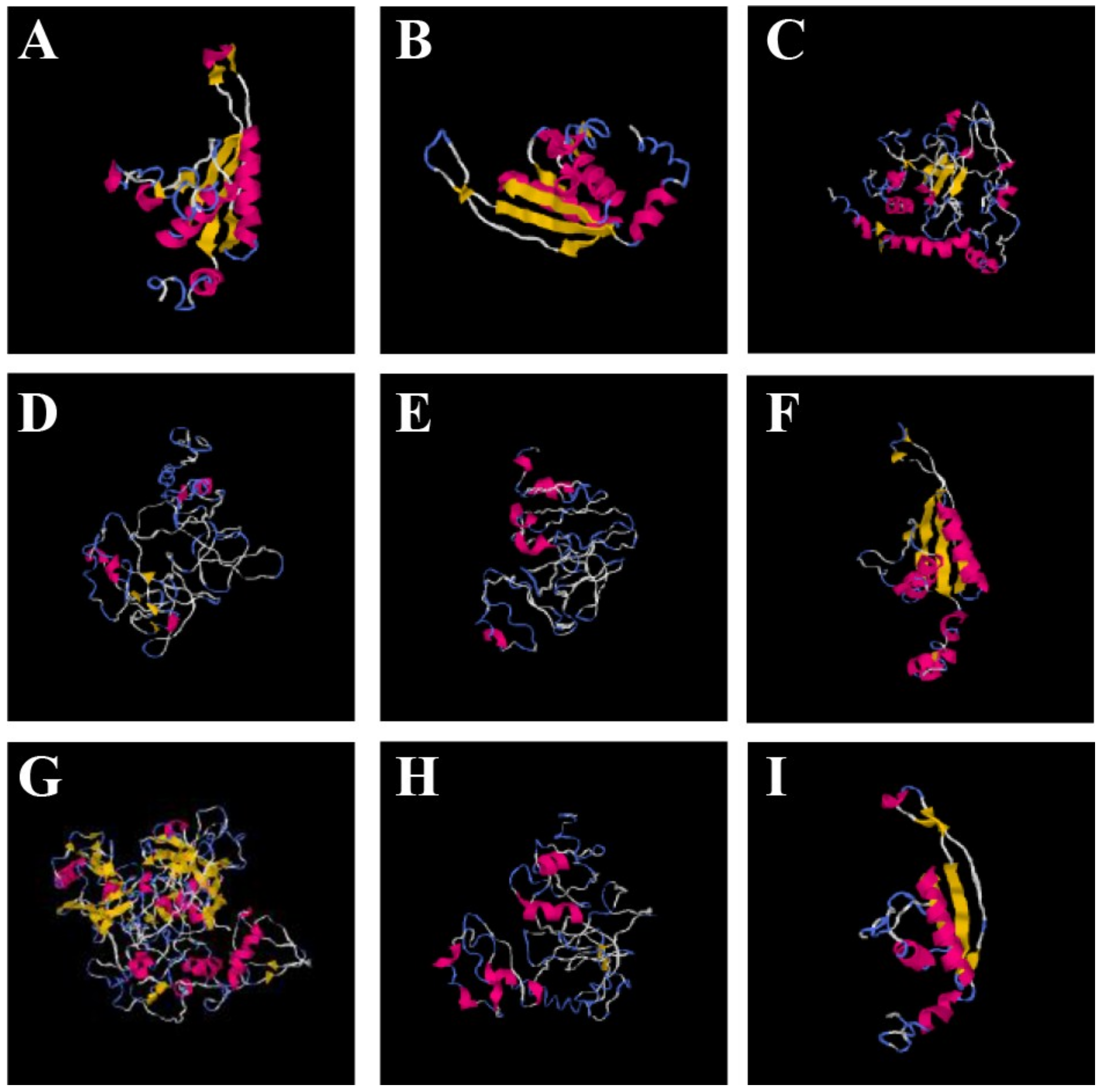
3.10. Three-Dimensional Structure Prediction and Homology Modeling
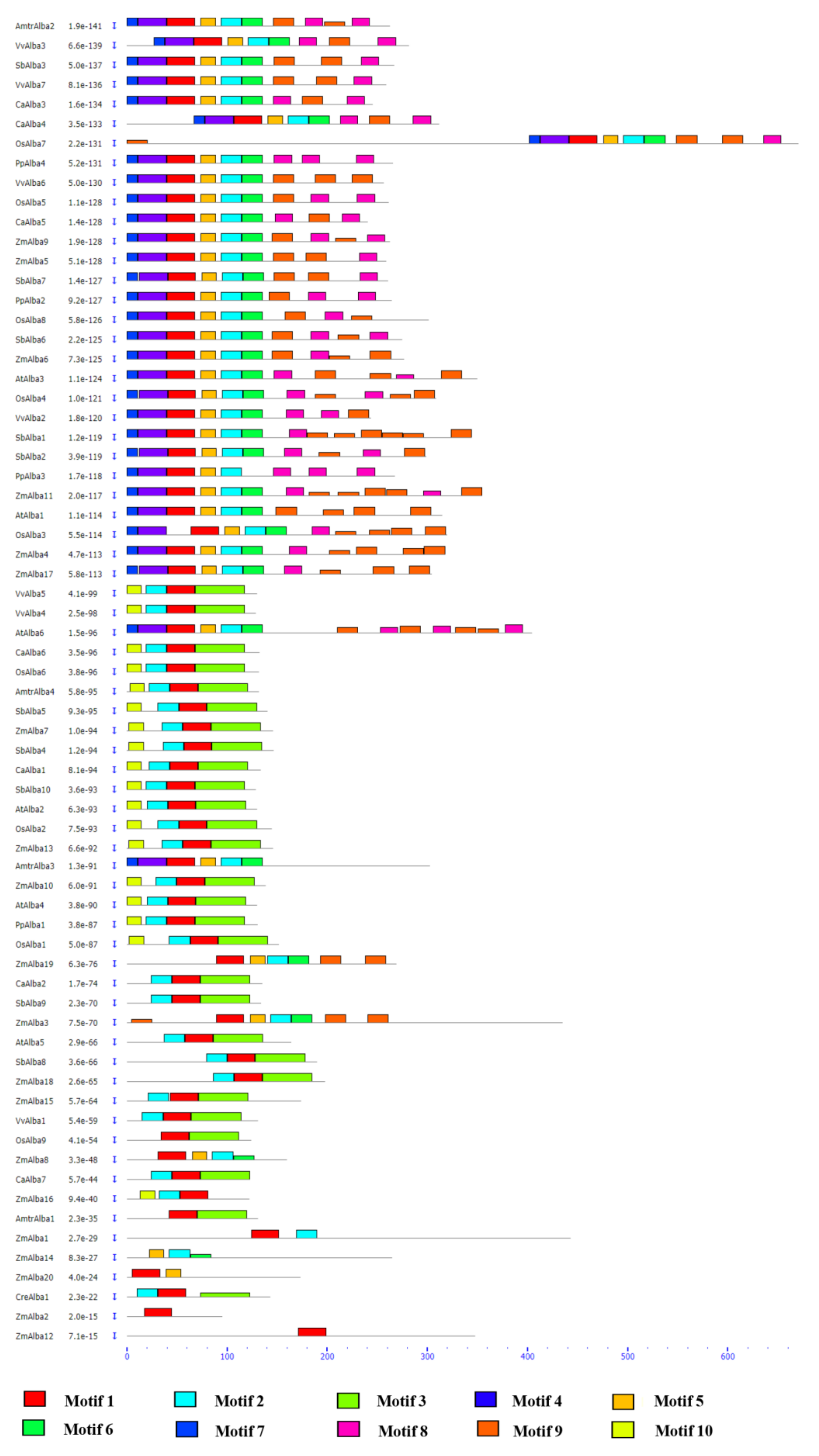
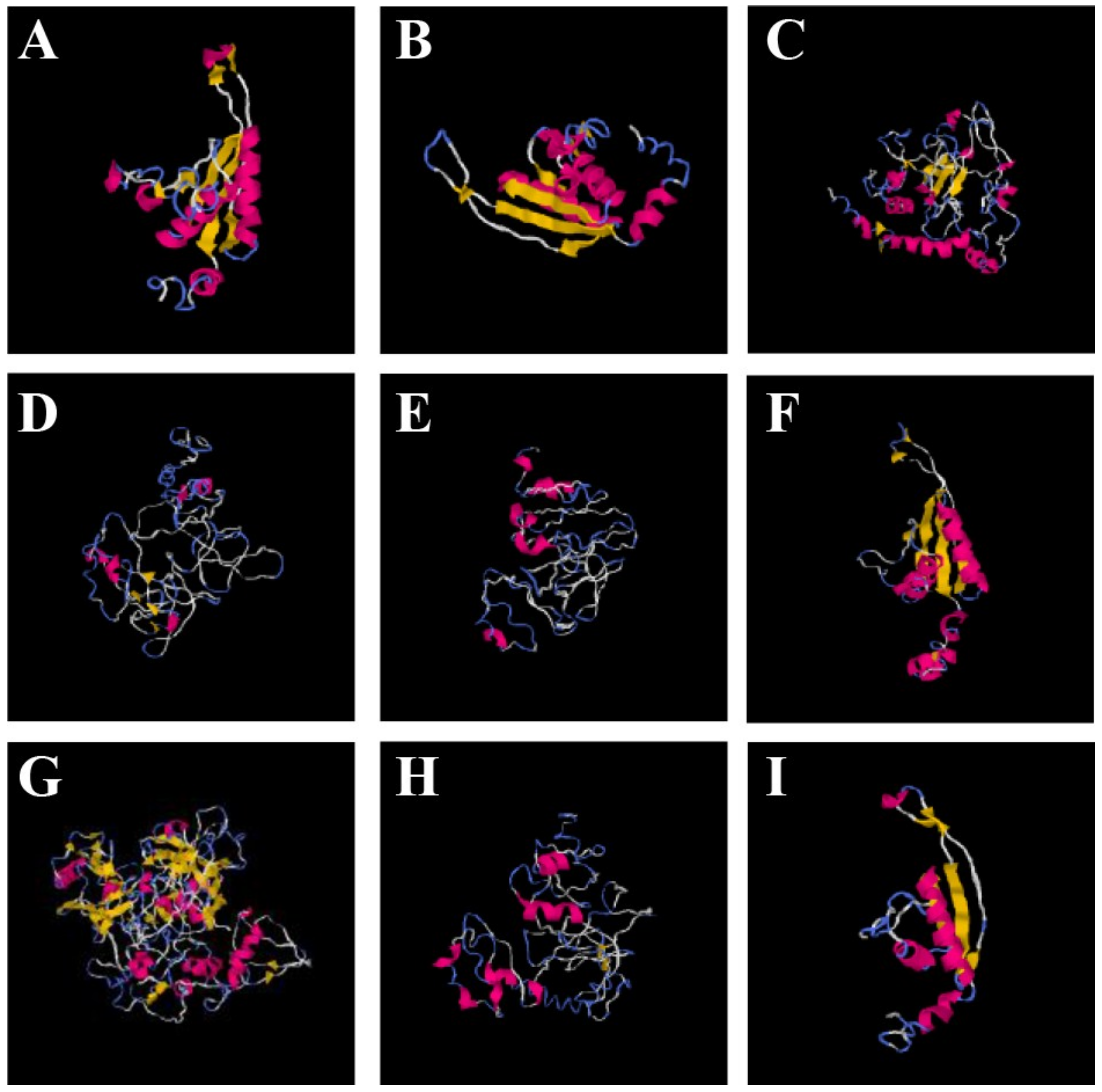
3.11. Structure–Function Relationship of OsAlba Proteins
4. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cramer, G.R.; Urano, K.; Delrot, S.; Pezzotti, M.; Shinozaki, K. Effects of abiotic stress on plants: A systems biology perspective. BMC Plant Biol. 2011, 11, 163. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, C.; Kumar, C.; Gnad, F.; Nielsen, M.L.; Rehman, M.; Walther, T.C.; Olsen, J.V.; Mann, M. Lysine acetylation targets protein complexes and co-regulates major cellular functions. Science 2009, 325, 834–840. [Google Scholar] [CrossRef] [PubMed]
- Hebbes, T.R.; Thorne, A.W.; Crane-Robinson, C. A direct link between core histone acetylation and transcriptionally active chromatin. EMBO J. 1988, 7, 1395–1402. [Google Scholar] [PubMed]
- Bell, S.D.; Botting, C.H.; Wardleworth, B.N.; Jackson, S.P.; White, M.F. The interaction of Alba, a conserved archaeal chromatin protein, with Sir2 and its regulation by acetylation. Science 2002, 296, 148–151. [Google Scholar] [CrossRef] [PubMed]
- Xue, H.; Guo, R.; Wen, Y.; Liu, D.; Huang, L. An abundant DNA binding protein from the hyperthermophilic archaeon Sulfolobus shibatae affects DNA supercoiling in a temperature-dependent fashion. J. Bacteriol. 2000, 182, 3929–3933. [Google Scholar] [CrossRef] [PubMed]
- Forterre, P.; Confalonieri, F.; Knapp, S. Identification of the gene encoding archeal-specific DNA-binding proteins of the Sac10b family. Mol. Microbiol. 1999, 32, 669–670. [Google Scholar] [CrossRef] [PubMed]
- Biyani, K.; Kahsai, M.A.; Clark, A.T.; Armstrong, T.L.; Edmondson, S.P.; Shriver, J.W. Solution Structure, Stability, and Nucleic Acid Binding of the Hyperthermophile Protein Sso10b2. Biochemistry 2005, 44, 14217–14230. [Google Scholar] [CrossRef] [PubMed]
- Hada, K.; Nakashima, T.; Osawa, T.; Shimada, H.; Kakuta, Y.; Kimura, M. Crystal structure and functional analysis of an archaeal chromatin protein Alba from the hyperthermophilic archaeon Pyrococcus horikoshii OT3. Biosci. Biotechnol. Biochem. 2008, 72, 749–758. [Google Scholar] [CrossRef] [PubMed]
- Kumarevel, T.; Sakamoto, K.; Gopinath, S.C.; Shinkai, A.; Kumar, P.K.; Yokoyama, S. Crystal structure of an archaeal specific DNA-binding protein (Ape10b2) from Aeropyrum pernix K1. Proteins 2008, 71, 1156–1162. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Guo, R.; Bartlam, M.; Yang, H.; Xue, H.; Liu, Y.; Huang, L.; Rao, Z. Crystal structure of a DNA binding protein from the hyperthermophilic euryarchaeon Methanococcus jannaschii. Protein Sci. 2003, 12, 2815–2822. [Google Scholar] [CrossRef] [PubMed]
- Xuan, J.; Feng, Y. The archaeal Sac10b protein family: Conserved proteins with divergent functions. Curr. Protein Pept. Sci. 2012, 13, 258–266. [Google Scholar] [CrossRef] [PubMed]
- Guo, R.; Xue, H.; Huang, L. Ssh10b, a conserved thermophilic archaeal protein, binds RNA in vivo. Mol. Microbiol. 2003, 50, 1605–1615. [Google Scholar] [CrossRef] [PubMed]
- She, Q.; Singh, R.K.; Confalonieri, F.; Zivanovic, Y.; Allard, G.; Awayez, M.J.; Christina, C.Y.; Clausen, I.G.; Curtis, B.A.; De Moors, A.; et al. The complete genome of the crenarchaeon Sulfolobus solfataricus P2. Proc. Natl. Acad. Sci. USA 2001, 98, 7835–7840. [Google Scholar] [CrossRef] [PubMed]
- Chêne, A.; Vembar, S.S.; Rivière, L.; Lopez-Rubio, J.J.; Claes, A.; Siegel, T.N.; Sakamoto, H.; Scheidig-Benatar, C.; Hernandez-Rivas, R.; Scherf, A. PfAlbas constitute a new eukaryotic DNA/RNA-binding protein family in malaria parasites. Nucleic Acids Res. 2012, 40, 3066–3077. [Google Scholar] [CrossRef] [PubMed]
- Goyal, M.; Alam, A.; Iqbal, M.S.; Dey, S.; Bindu, S.; Pal, C.; Banerjee, A.; Chakrabarti, S.; Bandyopadhyay, U. Identification and molecular characterization of an Alba-family protein from human malaria parasite Plasmodium falciparum. Nucleic Acids Res. 2011, 40, 1174–1190. [Google Scholar] [CrossRef] [PubMed]
- Reddy, B.N.; Shrestha, S.; Hart, K.J.; Liang, X.; Kemirembe, K.; Cui, L.; Lindner, S.E. A bioinformatic survey of RNA-binding proteins in Plasmodium. BMC Genom. 2015, 16, 890. [Google Scholar] [CrossRef] [PubMed]
- Mani, J.; Güttinger, A.; Schimanski, B.; Heller, M.; Acosta-Serrano, A.; Pescher, P.; Späth, G.; Roditi, I. Alba-domain proteins of Trypanosoma brucei are cytoplasmic RNA-binding proteins that interact with the translation machinery. PLoS ONE 2011, 6, e22463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Subota, I.; Rotureau, B.; Blisnick, T.; Ngwabyt, S.; Durand-Dubief, M.; Engstler, M.; Bastin, P. Alba proteins are stage regulated during trypanosome development in the tsetse fly and participate in differentiation. Mol. Biol. Cell 2011, 22, 4205–4219. [Google Scholar] [CrossRef] [PubMed]
- Olguin-Lamas, A.; Madec, E.; Hovasse, A.; Werkmeister, E.; Callebaut, I.; Slomianny, C.; Delhaye, S.; Mouveaux, T.; Schaeffer-Reiss, C.; Van Dorsselaer, A.; et al. A novel Toxoplasma gondii nuclear factor TgNF3 is a dynamic chromatin-associated component, modulator of nucleolar architecture and parasite virulence. PLoS Pathog. 2011, 7, e1001328. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Mistry, J.; Mitchell, A.L.; Potter, S.C.; Punta, M.; Qureshi, M.; Sangrador-Vegas, A.; et al. The Pfam protein families database: Towards a more sustainable future. Nucleic Acids Res. 2016, 44, D279–D285. [Google Scholar] [CrossRef] [PubMed]
- Aravind, L.; Iyer, L.M.; Anantharaman, V. The two faces of Alba: The evolutionary connection between proteins participating in chromatin structure and RNA metabolism. Genome Biol. 2003, 4, R64. [Google Scholar] [CrossRef] [PubMed]
- Dupé, A.; Dumas, C.; Papadopoulou, B. An Alba-domain protein contributes to the stage-regulated stability of amastin transcripts in Leishmania. Mol. Microbiol. 2014, 91, 548–561. [Google Scholar] [CrossRef] [PubMed]
- Gissot, M.; Walker, R.; Delhaye, S.; Alayi, T.D.; Huot, L.; Hot, D.; Callebaut, I.; Schaeffer-Reiss, C.; Van Dorsselaer, A.; Tomavo, S. Toxoplasma gondii Alba proteins are involved in translational control of gene expression. J. Mol. Biol. 2013, 425, 1287–1301. [Google Scholar] [CrossRef] [PubMed]
- Mair, G.R.; Lasonder, E.; Garver, L.S.; Franke-Fayard, B.M.; Carret, C.K.; Wiegant, J.C.; Dirks, R.W.; Dimopoulos, G.; Janse, C.J.; Waters, A.P. Universal features of post-transcriptional gene regulation are critical for Plasmodium zygote development. PLoS Pathog. 2010, 6, e1000767. [Google Scholar] [CrossRef] [PubMed]
- Thandapani, P.; O’Connor, T.R.; Bailey, T.L.; Richard, S. Defining the RGG/RG motif. Mol. Cell. 2013, 50, 613–623. [Google Scholar] [CrossRef] [PubMed]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2011, 40, D1178–D1186. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Bateman, A.; Clements, J.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Heger, A.; Hetherington, K.; Holm, L.; Mistry, J.; et al. Pfam: The protein families database. Nucleic Acids Res. 2014, 42, D222–D230. [Google Scholar] [CrossRef] [PubMed]
- Marchler-Bauer, A.; Bo, Y.; Han, L.; He, J.; Lanczycki, C.J.; Lu, S.; Chitsaz, F.; Derbyshire, M.K.; Geer, R.C.; Gonzales, N.R.; et al. CDD/SPARCLE: Functional classification of proteins via subfamily domain architectures. Nucleic Acids Res. 2016, 45, D200–D203. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Jin, J.; Guo, A.Y.; Zhang, H.; Luo, J.; Gao, G. GSDS 2.0: An upgraded gene feature visualization server. Bioinformatics 2015, 31, 1296–1297. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Boden, M.; Buske, F.A.; Frith, M.; Grant, C.E.; Clementi, L.; Ren, J.; Li, W.W.; Noble, W.S. MEME SUITE: Tools for motif discovery and searching. Nucleic Acids Res. 2009, 37, W202–W208. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular Evolutionary Genetics Analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [PubMed]
- Lemire, A.; Goudenège, D.; Versigny, T.; Petton, B.; Calteau, A.; Labreuche, Y.; Le Roux, F. Populations, not clones, are the unit of vibrio pathogenesis in naturally infected oysters. ISME J. 2015, 9, 1523–1531. [Google Scholar] [CrossRef] [PubMed]
- Pierleoni, A.; Martelli, P.L.; Fariselli, P.; Casadio, R. BaCelLo: A balanced subcellular localization predictor. Bioinformatics 2006, 22, e408–e416. [Google Scholar] [CrossRef] [PubMed]
- Bhasin, M.; Raghava, G.P. ESLpred: SVM-based method for subcellular localization of eukaryotic proteins using dipeptide composition and PSI-BLAST. Nucleic Acids Res. 2004, 32, W414–W419. [Google Scholar] [CrossRef] [PubMed]
- Briesemeister, S.; Rahnenführer, J.; Kohlbacher, O. YLoc—An interpretable web server for predicting subcellular localization. Nucleic Acids Res. 2010, 38, W497–W502. [Google Scholar] [CrossRef] [PubMed]
- Nakai, K.; Horton, P. PSORT: A program for detecting sorting signals in proteins and predicting their subcellular localization. Trends Biochem. Sci. 1999, 24, 34–35. [Google Scholar] [CrossRef]
- Goldberg, T.; Hecht, M.; Hamp, T.; Karl, T.; Yachdav, G.; Ahmed, N.; Altermann, U.; Angerer, P.; Ansorge, S.; Balasz, K.; et al. LocTree3 prediction of localization. Nucleic Acids Res. 2014, 42, W350–W355. [Google Scholar] [CrossRef] [PubMed]
- Horton, P.; Park, K.J.; Obayashi, T.; Fujita, N.; Harada, H.; Adams-Collier, C.J.; Nakai, K. WoLF PSORT: Protein localization predictor. Nucleic Acids Res. 2007, 35, W585–W587. [Google Scholar] [CrossRef] [PubMed]
- Chou, K.C.; Shen, H.B. Plant-mPLoc: A top-down strategy to augment the power for predicting plant protein subcellular localization. PLoS ONE 2010, 5, e11335. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.S.; Chen, Y.C.; Lu, C.H.; Hwang, J.K. Prediction of protein subcellular localization. Proteins Struct. Funct. Bioinform. 2006, 64, 643–651. [Google Scholar] [CrossRef] [PubMed]
- Lescot, M.; Déhais, P.; Thijs, G.; Marchal, K.; Moreau, Y.; Van de Peer, Y.; Rouzé, P.; Rombauts, S. PlantCARE, a database of plant cis-acting regulatory elements and a portal to tools for in silico analysis of promoter sequences. Nucleic Acids Res. 2002, 30, 325–327. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Zhao, P.X. psRNATarget: A plant small RNA target analysis server. Nucleic Acids Res. 2011, 39, W155–W159. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Yan, R.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Shen, X.; Wang, N.; Ding, X. Characterization of a novel cyclase-like gene family involved in controlling stress tolerance in rice. J. Plant Physiol. 2015, 181, 30–41. [Google Scholar] [CrossRef] [PubMed]
- Semon, M.; Wolfe, K.H. Reciprocal gene loss between Tetraodon and zebrafish after whole genome duplication in their ancestor. Trends Genet. 2007, 23, 108–112. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.H.; Tang, H.; Wang, X.; Paterson, A.H. PGDD: A database of gene and genome duplication in plants. Nucleic Acids Res. 2012, 41, D1152–D1158. [Google Scholar] [CrossRef] [PubMed]
- Schlueter, J.A.; Lin, J.Y.; Schlueter, S.D.; Vasylenko-Sanders, I.F.; Deshpande, S.; Yi, J.; O’bleness, M.; Roe, B.A.; Nelson, R.T.; Scheffler, B.E.; et al. Gene duplication and paleopolyploidy in soybean and the implications for whole genome sequencing. BMC Genom. 2007, 8, 330. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Rosenberg, H.F.; Nei, M. Positive Darwinian selection after gene duplication in primate ribonuclease genes. Proc. Natl. Acad. Sci. USA 1998, 95, 3708–3713. [Google Scholar] [CrossRef] [PubMed]
- Nowak, M.A.; Boerlijst, M.C.; Cooke, J.; Smith, J.M. Evolution of genetic redundancy. Nature 1997, 388, 167–171. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Nielsen, R. Estimating synonymous and nonsynonymous substitution rates under realistic evolutionary models. Mol. Biol. Evol. 2000, 17, 32–43. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Tate, J.; Mistry, J.; Coggill, P.C.; Sammut, S.J.; Hotz, H.R.; Ceric, G.; Forslund, K.; Eddy, S.R.; Sonnhammer, E.L.; et al. The Pfam protein families database. Nucleic Acids Res. 2008, 36, D281–D288. [Google Scholar] [CrossRef] [PubMed]
- Dupé, A.; Dumas, C.; Papadopoulou, B. Differential subcellular localization of Leishmania Alba-Domain proteins throughout the parasite development. PLoS ONE 2015, 10, e0137243. [Google Scholar] [CrossRef] [PubMed]
- Verma, J.K.; Gayali, S.; Dass, S.; Kumar, A.; Parveen, S.; Chakraborty, S.; Chakraborty, N. OsAlba1, a dehydration-responsive nuclear protein of rice (Oryza sativa L. ssp. indica), participates in stress adaptation. Phytochemistry 2014, 100, 16–25. [Google Scholar] [CrossRef]
- Wardleworth, B.N.; Russell, R.J.; Bell, S.D.; Taylor, G.L.; White, M.F. Structure of Alba: An archaeal chromatin protein modulated by acetylation. EMBO J. 2002, 21, 4654–4662. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B. MicroRNA: A new target for improving plant tolerance to abiotic stress. J. Exp. Bot. 2015, 66, 1749–1761. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Zhang, H.; Ding, Y. Identification of conserved microRNAs and their targets in the model legume Lotus japonicus. J. Biotechnol. 2013, 164, 520–524. [Google Scholar] [CrossRef] [PubMed]
- Vashisht, I.; Mishra, P.; Pal, T.; Chanumolu, S.; Singh, T.R.; Chauhan, R.S. Mining NGS transcriptomes for miRNAs and dissecting their role in regulating growth, development, and secondary metabolites production in different organs of a medicinal herb, Picrorhiza kurroa. Planta 2015, 241, 1255–1268. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Wang, Y.; Liu, X.; Lv, S.; Feng, C.; Qi, M.; Li, T. Small RNA and degradome sequencing reveals microRNAs and their targets involved in tomato pedicel abscission. Planta 2015, 242, 963–984. [Google Scholar] [CrossRef] [PubMed]
- Din, M.; Barozai, M.Y.; Baloch, I.A. Identification and functional analysis of new conserved microRNAs and their targets in potato (Solanum tuberosum L.). Turk. J. Bot. 2014, 38, 1199–1213. [Google Scholar] [CrossRef]
- Tang, Z.; Zhang, L.; Xu, C.; Yuan, S.; Zhang, F.; Zheng, Y.; Zhao, C. Uncovering small RNA-mediated responses to cold stress in a wheat thermosensitive genic male-sterile line by deep sequencing. Plant Physiol. 2012, 159, 721–738. [Google Scholar] [CrossRef] [PubMed]
- Frazier, T.P.; Sun, G.; Burklew, C.E.; Zhang, B. Salt and drought stresses induce the aberrant expression of microRNA genes in tobacco. Mol. Biotechnol. 2011, 49, 159–165. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Kong, H.; Ma, H. F-box proteins regulate ethylene signaling and more. Genes Dev. 2009, 23, 391–396. [Google Scholar] [CrossRef] [PubMed]
- Qiao, H.; Chang, K.N.; Yazaki, J.; Ecker, J.R. Interplay between ethylene, ETP1/ETP2 F-box proteins, and degradation of EIN2 triggers ethylene responses in Arabidopsis. Genes Dev. 2009, 23, 512–521. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Yang, R.; Li, M.; Xing, Z.; Yang, W.; Chen, G.; Guo, H.; Gong, X.; Du, Z.; Zhang, Z.; et al. Transcriptome phase distribution analysis reveals diurnal regulated biological processes and key pathways in rice flag leaves and seedling leaves. PLoS ONE 2011, 6, e17613. [Google Scholar] [CrossRef] [PubMed]
- Wan, A.L.; Zhong, Y.M. Studies on the relationship between the flag leaf area and the panicle weight in rice cultivars. Sci. Agric. Sin. 1981, 6, 21–28. [Google Scholar]
- Zhang, X.; Li, J.; Liu, A.; Zou, J.; Zhou, X.; Xiang, J.; Rerksiri, W.; Peng, Y.; Xiong, X.; Chen, X. Expression profile in rice panicle: Insights into heat response mechanism at reproductive stage. PLoS ONE 2012, 7, e49652. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Wang, X.; Jiao, Y.; Qin, Y.; Liu, X.; He, K.; Chen, C.; Ma, L.; Wang, J.; Xiong, L.; et al. Global genome expression analysis of rice in response to drought and high-salinity stresses in shoot, flag leaf, and panicle. Plant Mol. Biol. 2007, 63, 591–608. [Google Scholar] [CrossRef] [PubMed]
- Kreps, J.A.; Wu, Y.; Chang, H.S.; Zhu, T.; Wang, X.; Harper, J.F. Transcriptome changes for Arabidopsis in response to salt, osmotic, and cold stress. Plant Physiol. 2002, 130, 2129–2141. [Google Scholar] [CrossRef] [PubMed]
- Pastori, G.M.; Foyer, C.H. Common components, networks, and pathways of cross-tolerance to stress: The central role of ‘redox’ and abscisic acid-mediated controls. Plant Physiol. 2002, 129, 460–468. [Google Scholar] [CrossRef] [PubMed]
- Glazebrook, J. Contrasting mechanisms of defense against biotrophic and necrotrophic pathogens. Annu. Rev. Phytopathol. 2005, 43, 205–227. [Google Scholar] [CrossRef] [PubMed]
- Robert-Seilaniantz, A.; Navarro, L.; Bari, R.; Jones, J.D.G. Pathological hormone imbalances. Curr. Opin. Plant Biol. 2007, 10, 372–379. [Google Scholar] [CrossRef] [PubMed]
- Nishimura, N.; Yoshida, T.; Kitahata, N.; Asami, T.; Shinozaki, K.; Hirayama, T. Hypersensitive Germination1 encodes a protein phosphatase 2C, an essential component of abscisic acid signaling in Arabidopsis seed. Plant J. 2007, 50, 935–949. [Google Scholar] [CrossRef] [PubMed]
- Adie, B.A.; Perez-Perez, J.; Perez-Perez, M.M.; Godoy, M.; Sanchez-Serrano, J.J.; Schmelz, E.A.; Solano, R. ABA is an essential signal for plant resistance to pathogens affecting JA biosynthesis and the activation of defenses in Arabidopsis. Plant Cell 2007, 19, 1665–1681. [Google Scholar] [CrossRef] [PubMed]
- De Torres-Zabala, M.; Truman, W.; Bennett, M.H.; Lafforgue, G.; Mansfield, J.W.; Rodriguez Egea, P.; Bogre, L.; Grant, M. Pseudomonas syringae pv. tomato hijacks the Arabidopsis abscisic acid signaling pathway to cause disease. Embo J. 2007, 26, 1434–1443. [Google Scholar] [CrossRef]
- Hernandez-Blanco, C.; Feng, D.X.; Hu, J.; Sanchez-Vallet, A.; Deslandes, L.; Llorente, F.; Berrocal-Lobo, M.; Keller, H.; Barlet, X.; Sanchez-Rodriguez, C.; et al. Impairment of cellulose synthases required for Arabidopsis secondary cell wall formation enhances disease resistance. Plant Cell 2007, 19, 890–903. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Zhang, Y. LOMETS: A local meta-threading-server for protein structure prediction. Nucleic Acids Res. 2007, 35, 3375–3382. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Skolnick, J. TM-align: A protein structure alignment algorithm based on the TM-score. Nucleic Acids Res. 2005, 33, 2302–2309. [Google Scholar] [CrossRef] [PubMed]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Couch, G.S.; Greenblatt, D.M.; Meng, E.C.; Ferrin, T.E. UCSF Chimera—A visualization system for exploratory research and analysis. J. Comput. Chem. 2004, 25, 1605–1612. [Google Scholar] [CrossRef] [PubMed]
- Heinicke, I.; Müller, J.; Pittelkow, M.; Klein, A. Mutational analysis of genes encoding chromatin proteins in the archaeon Methanococcus voltae indicates their involvement in the regulation of gene expression. Mol. Genet. Genom. 2004, 272, 76–87. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plants | Name | Chromosome No. | Gene Location | Exons | Length (bp) | Number of aa | MW (kDa) | Iso Electric Point | Identity/e-Value | Accession Numbers |
|---|---|---|---|---|---|---|---|---|---|---|
| Chlamydomonas | CreAlba1 | 9 | 864278..866101 forward | 5 | 1824 | 143 | 15.12 | 5.02 | 100/5 × 10−97 | XP_001695217.1 |
| Physcomitrella moss | PpAlba1 | 12 | 13891844..13896427 reverse | 1 | 4584 | 131 | 14.7 | 5.14 | 100/1 × 10−90 | XP_001768991.1 |
| PpAlba2 | 20 | 9435522..9440461 forward | 8 | 4940 | 265 | 28.79 | 9.76 | 100/3 × 10−171 | XP_001767525.1 | |
| PpAlba3 | 23 | 6029976..6034958 reverse | 8 | 4983 | 268 | 29.2 | 10.06 | 100/0 | XP_001753647.1 | |
| PpAlba4 | 24 | 3314088..3317325 forward | 8 | 3238 | 266 | 29.07 | 10.2 | 100/0 | XP_001755565.1 | |
| Amborella | AmtrAlba1 | scaffold00002 | 8145087..8147916 forward | 5 | 2830 | 131 | 14.2 | 9.46 | 100/4 × 10−91 | XP_020520141.1 |
| AmtrAlba2 | scaffold00017 | 5252778..5262210 forward | 8 | 9433 | 263 | 28.48 | 10.06 | 100/0 | XP_006847137.1 | |
| AmtrAlba3 | scaffold00067 | 2229721..2240829 reverse | 9 | 11,109 | 303 | 33.94 | 4.89 | 100/0 | ERN18878.1 | |
| AmtrAlba4 | scaffold00104 | 1833918..1840085 reverse | 5 | 6168 | 132 | 14.69 | 5.67 | 100/4 × 10−90 | XP_006837817.1 | |
| Grape | VvAlba1 | 5 | 6754914..6756137 forward | 5 | 1224 | 131 | 14.24 | 9.6 | 100/6 × 10−89 | XP_002280347.1 |
| VvAlba2 | 7 | 9926246..9934777 forward | 8 | 8532 | 244 | 27.07 | 10.48 | 100/5 × 10−171 | XP_010652481.1 | |
| VvAlba3 | 7 | 18184062..18194607 forward | 10 | 10,546 | 282 | 31.19 | 10.24 | 100/0 | CBI21553.3 | |
| VvAlba4 | 9 | 6407205..6412879 forward | 5 | 5675 | 129 | 14.39 | 5.47 | 100/3 × 10−88 | CBI36290.3 | |
| VvAlba5 | 11 | 4382031..4385728 forward | 5 | 3698 | 130 | 14.55 | 5.28 | 100/2 × 10−89 | XP_002285115.1 | |
| VvAlba6 | 18 | 1752391..1758060 forward | 8 | 14,972 | 257 | 28.3 | 10.4 | 100/0 | CBI18930.3 | |
| VvAlba7 | 18 | 19508351..19517807 forward | 8 | 9457 | 259 | 28.34 | 10.13 | 100/0 | XP_002264932.1 | |
| Chickpea | CaAlba1 | 1 | 9204378..9202500 reverse | 5 | 1879 | 134 | 14.74 | 5.23 | 100/2 × 10−90 | XP_004486682.1 |
| CaAlba2 | 4 | 4931675..4930115 reverse | 5 | 1561 | 135 | 14.71 | 9.46 | 100/1 × 10−91 | XP_004495605.1 | |
| CaAlba3 | 5 | 46947757..46950898 forward | 8 | 3142 | 246 | 27.23 | 10.14 | 100/1 × 10−171 | XP_004502885.1 | |
| CaAlba4 | 5 | 46952324..46956941 forward | 9 | 4618 | 312 | 34.58 | 10.24 | 100/0 | XP_004502886.1 | |
| CaAlba5 | 5 | 46958526..46962753 reverse | 8 | 4228 | 241 | 26.81 | 9.82 | 100/4 × 10−169 | XP_004502888.1 | |
| CaAlba6 | 6 | 50716068..50719107 reverse | 5 | 3040 | 133 | 14.46 | 5.42 | 100/2 × 10−89 | XP_004506910.1 | |
| CaAlba7 | 8 | 786966..785427 reverse | 5 | 1540 | 123 | 13.48 | 9.35 | 100/3 × 10−81 | XP_004511396.1 | |
| Arabidopsis | AtAlba1 | 1 | 7004879..7007651 reverse | 10 | 2773 | 315 | 33.76 | 9.92 | 100/0 | NP_564108.1 |
| AtAlba2 | 1 | 10223266..10224727 reverse | 5 | 1462 | 130 | 14.57 | 5.31 | 100/5 × 10−87 | NP_564325.1 | |
| AtAlba3 | 1 | 28528077..28530790 reverse | 8 | 2714 | 350 | 37.38 | 9.78 | 100/0 | NP_565124.1 | |
| AtAlba4 | 2 | 14426203..14427383 forward | 5 | 1181 | 130 | 14.62 | 5.28 | 100/3 × 10−87 | NP_565781.1 | |
| AtAlba5 | 3 | 1255526..1256869 reverse | 5 | 1344 | 164 | 17.66 | 5.79 | 100/4 × 10−111 | NP_187113.1 | |
| AtAlba6 | 3 | 2223001..2225254 reverse | 8 | 2254 | 405 | 42.5 | 9.15 | 100/0 | NP_187359.2 | |
| Rice | OsAlba1 | 1 | 3742694..3744539 reverse | 5 | 1684 | 152 | 16.26 | 5.1 | 100/4 × 10−101 | NP_001042157.1 |
| OsAlba2 | 2 | 5740408..5742520 reverse | 5 | 2113 | 145 | 15.51 | 5.17 | 100/6 × 10−97 | BAD15498.1 | |
| OsAlba3 | 3 | 30119573..30123252 reverse | 9 | 3645 | 320 | 35.39 | 9.81 | 100/0 | EEE59881.1 | |
| OsAlba4 | 3 | 3565365..3561501 reverse | 8 | 3770 | 309 | 33.21 | 9.99 | 100/0 | NP_001049072.1 | |
| OsAlba5 | 4 | 21232538..21235466 reverse | 7 | 2922 | 262 | 28.51 | 9.06 | 100/0 | CAD41015.3 | |
| OsAlba6 | 6 | 23821372..23823339 forward | 5 | 1870 | 132 | 14.61 | 5.5 | 100/6 × 10−89 | NP_001058008.1 | |
| OsAlba7 | 9 | 21343532..21346652 reverse | 17 | 6507 | 671 | 71.68 | 8.59 | 100/0 | EEE70143.1 | |
| OsAlba8 | 11 | 3297930..3303336 forward | 8 | 5111 | 302 | 34.46 | 9.06 | 100/0 | AAX92995.1 | |
| OsAlba9 | 12 | 18351588..18353679 reverse | 4 | 2092 | 124 | 14.03 | 8.96 | 100/1 × 10−83 | EEC69301.1 | |
| Maize | ZmAlba1 | 1 | 17932570..17953959 reverse | 11 | 21,390 | 443 | 49.15 | 8.59 | 100/0 | DAA43763.1 |
| ZmAlba2 | 1 | 197014554..197016807 reverse | 5 | 2254 | 95 | 10.52 | 9.2 | 100/2 × 10−62 | DAA48353.1 | |
| ZmAlba3 | 1 | 203886863..203889397 reverse | 9 | 2535 | 435 | 47.21 | 9.53 | 100/0 | DAA48594.1 | |
| ZmAlba4 | 1 | 273633103..273636648 reverse | 8 | 3546 | 318 | 34.4 | 9.85 | 100/0 | NP_001140948.1 | |
| ZmAlba5 | 2 | 52865684..52870403 forward | 8 | 4720 | 259 | 28.5 | 9.68 | 100/2 × 10−180 | NP_001140391.1 | |
| ZmAlba6 | 2 | 138609879..138620022 reverse | 8 | 10,144 | 276 | 30.98 | 9.31 | 100/0 | NP_001146602.1 | |
| ZmAlba7 | 3 | 12031159..12039337 forward | 5 | 8179 | 146 | 15.79 | 5.06 | 100/1 × 10−98 | NP_001141319.1 | |
| ZmAlba8 | 3 | 140869717..140869074 reverse | 3 | 3345 | 160 | 18.03 | 6.94 | 100/1 × 10−112 | XP_008676084.1 | |
| ZmAlba9 | 4 | 25351731..25363303 reverse | 8 | 11,573 | 262 | 29.58 | 9.31 | 100/0 | AFW60929.1 | |
| ZmAlba10 | 4 | 232536528..232538464 forward | 5 | 1937 | 139 | 15.03 | 5.75 | 100/2 × 10−93 | NP_001143331.1 | |
| ZmAlba11 | 5 | 8422556..8425967 forward | 8 | 3412 | 355 | 38.09 | 9.77 | 100/0 | XP_008644524.1 | |
| ZmAlba12 | 7 | 100322879..100327949 reverse | 7 | 5071 | 348 | 47.42 | 10.07 | 100/1 × 10−33 | DAA51661.1 | |
| ZmAlba13 | 8 | 17424473..17428831 reverse | 5 | 4359 | 146 | 15.87 | 5.19 | 100/7 × 10−99 | ACN31274.1 | |
| ZmAlba14 | 8 | 73390426..73394062 reverse | 10 | 3637 | 265 | 30.02 | 8.47 | 100/0 | AFW81235.1 | |
| ZmAlba15 | 8 | 79903859..79905084 forward | 5 | 1226 | 174 | 18.49 | 5.7 | 100/1 × 10−120 | XP_008656129.1 | |
| ZmAlba16 | 9 | 85118424..85120875 reverse | 5 | 2452 | 122 | 13.91 | 9.22 | 100/2 × 10−81 | AFW87068.1 | |
| ZmAlba17 | 9 | 153687377..153692790 reverse | 8 | 5414 | 305 | 33.26 | 9.69 | 100/0 | NP_001132775.1 | |
| ZmAlba18 | 10 | 13160976..13162521 forward | 5 | 1546 | 198 | 21.69 | 4.74 | 100/5 × 10−133 | XP_008662548.1 | |
| ZmAlba19 | 10 | 65669734..65672121 reverse | 7 | 2388 | 269 | 28.91 | 9.86 | 100/0 | AFW57019.1 | |
| ZmAlba20 | 10 | 125226158..125230941 forward | 7 | 4784 | 173 | 19.16 | 8.57 | 100/2 × 10−124 | AFW58594.1 | |
| Sorghum | SbAlba1 | 1 | 7634252..7637528 forward | 8 | 3277 | 345 | 36.9 | 9.87 | 100/0 | XP_002463920.1 |
| SbAlba2 | 1 | 76251059..76254951 forward | 8 | 3893 | 299 | 32.42 | 9.89 | 100/0 | KXG40112.1 | |
| SbAlba3 | 2 | 66308102..66311291 reverse | 8 | 3190 | 267 | 29.82 | 9.82 | 100/0 | XP_002462756.1 | |
| SbAlba4 | 3 | 4567538..4570747 forward | 5 | 3210 | 147 | 15.76 | 5.17 | 100/5 × 10−99 | XP_002455102.1 | |
| SbAlba5 | 4 | 7088829..7090849 reverse | 5 | 2021 | 141 | 15.24 | 5.5 | 100/4 × 10−95 | XP_002453505.1 | |
| SbAlba6 | 5 | 4826765..4832055 forward | 8 | 5291 | 275 | 30.93 | 9.39 | 100/0 | XP_002449052.1 | |
| SbAlba7 | 6 | 44833619..44836936 reverse | 8 | 3318 | 261 | 28.38 | 9.57 | 100/0 | XP_002447839.1 | |
| SbAlba8 | 8 | 46970489..46972066 reverse | 5 | 1578 | 190 | 20.73 | 4.87 | 100/4 × 10−128 | XP_002443196.1 | |
| SbAlba9 | 9 | 6694750..6696439 reverse | 5 | 1690 | 134 | 14.3 | 5.43 | 100/7 × 10−90 | XP_002440693.1 | |
| SbAlba10 | 10 | 52387417..52389679 forward | 5 | 2263 | 129 | 14.39 | 5.29 | 100/1 × 10−86 | XP_002437246.1 |
| S. No. | GI Number | Type | TM-Score | RMSD |
|---|---|---|---|---|
| 1 | 115434798 | OsAlba1 | 0.49 ± 0.15 | 8.8 ± 4.6 |
| 2 | 46390081 | OsAlba2 | 0.50 ± 0.15 | 8.4 ± 4.5 |
| 3 | 62701922 | OsAlba3 | 0.34 ± 0.11 | 14.7 ± 3.6 |
| 4 | 115450943 | OsAlba4 | 0.28 ± 0.09 | 16.3 ± 3.0 |
| 5 | XP_006652291.1 | OsAlba5 | 0.29 ± 0.09 | 15.8 ± 3.2 |
| 6 | XP_015643177.1 | OsAlba6 | 0.62 ± 0.14 | 6.0 ± 3.7 |
| 7 | 222642011 | OsAlba7 | 0.34 ± 0.11 | 16.6 ± 2.9 |
| 8 | 62701922 | OsAlba8 | 0.30 ± 0.10 | 15.6 ± 3.3 |
| 9 | 218186874 | OsAlba9 | 0.57 ± 0.15 | 6.8 ± 4.1 |
| S. No. | Type | GI Number | Score | No. of Decoys | Cluster Density |
|---|---|---|---|---|---|
| 1 | OsAlba1 | 115434798 | −1.83 | 3476 | 0.0607 |
| 2 | OsAlba2 | 46390081 | −1.73 | 3848 | 0.0657 |
| 3 | OsAlba3 | 62701922 | −3.41 | 621 | 0.0170 |
| 4 | OsAlba4 | 115450943 | −4.03 | 626 | 0.0091 |
| 5 | OsAlba5 | XP_006652291.1 | −4.00 | 621 | 0.0093 |
| 6 | OsAlba6 | XP_015643177.1 | −0.72 | 7113 | 0.1765 |
| 7 | OsAlba7 | 222642011 | −3.36 | 171 | 0.0100 |
| 8 | OsAlba8 | 62701922 | −3.81 | 621 | 0.0113 |
| 9 | OsAlba9 | 218186874 | −1.18 | 6399 | 0.1204 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verma, J.K.; Wardhan, V.; Singh, D.; Chakraborty, S.; Chakraborty, N. Genome-Wide Identification of the Alba Gene Family in Plants and Stress-Responsive Expression of the Rice Alba Genes. Genes 2018, 9, 183. https://doi.org/10.3390/genes9040183
Verma JK, Wardhan V, Singh D, Chakraborty S, Chakraborty N. Genome-Wide Identification of the Alba Gene Family in Plants and Stress-Responsive Expression of the Rice Alba Genes. Genes. 2018; 9(4):183. https://doi.org/10.3390/genes9040183
Chicago/Turabian StyleVerma, Jitendra Kumar, Vijay Wardhan, Deepali Singh, Subhra Chakraborty, and Niranjan Chakraborty. 2018. "Genome-Wide Identification of the Alba Gene Family in Plants and Stress-Responsive Expression of the Rice Alba Genes" Genes 9, no. 4: 183. https://doi.org/10.3390/genes9040183