1. Introduction
A significant difference between present day electronic devices, such as von Neumann microprocessors and biological computational devices, such as the brain, is the spatial arrangement of their basic building blocks. At both the transistor, as well as the chip scale, conventional integrated circuits and electronic devices are composed of components that are arranged in inherently two dimensions (2D), although there may be several layers of processing elements and connections. In contrast, the brain consists of on the order of one hundred billion neurons that are interconnected in a truly three-dimensional (3D) architecture. As compared to a 2D architecture, a true 3D architecture leads to shorter average path lengths in the interconnect network and offers the potential for higher interconnect densities which can lead to increased circuit complexity, computational speed, and power efficiency [
1,
2,
3,
4]. A number of approaches have been developed to interconnect electronic components ranging from transistors to microchips in 3D. These include conventional approaches, such as monolithic integration and die and wafer stacking [
5,
6,
7,
8,
9,
10,
11,
12], which have advanced significantly in the industry with noted challenges associated with precise alignment of devices and throughput [
13]. It should be noted that wafer stacking is a serial process and, as a consequence, the extent of three-dimensionality that could be achieved is limited; hence, wafer stacking actually achieves a 2.5D architecture, and not a truly 3D architecture. In addition, wafer stacking comes with its own challenge: the alignment of the vias [
14,
15].
An alternative approach to top-down design is the biologically-inspired approach of self-assembly. Indeed, there has been a long-standing effort in the research community to build 3D electronic devices and reconfigurable modular robots using self-assembly [
16,
17,
18]. In self-assembly, the focus is on generating smart building blocks that can self-organize into a functional structure. Various building blocks, such as molecules or nanoparticles, have been proposed. However, these approaches have limitations, such as the relative thermal fragility and low electrical conductance of organic molecules or the inability to precisely define patterned transistors using nanoparticles. Hence, there is an urgent need for scalable and mass-producible processes that bridge the gap between existing chip manufacturing strategies and self-assembly methodologies.
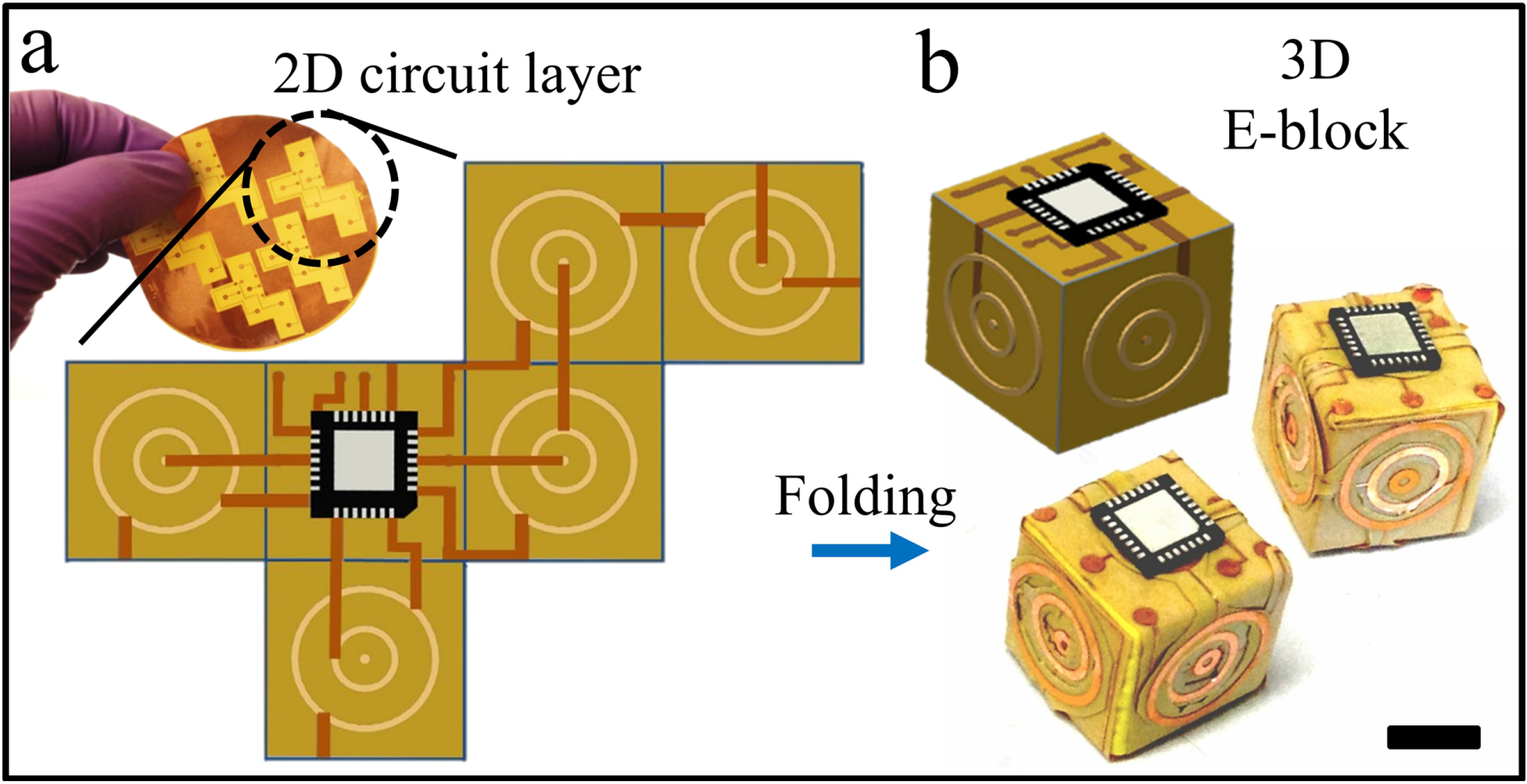
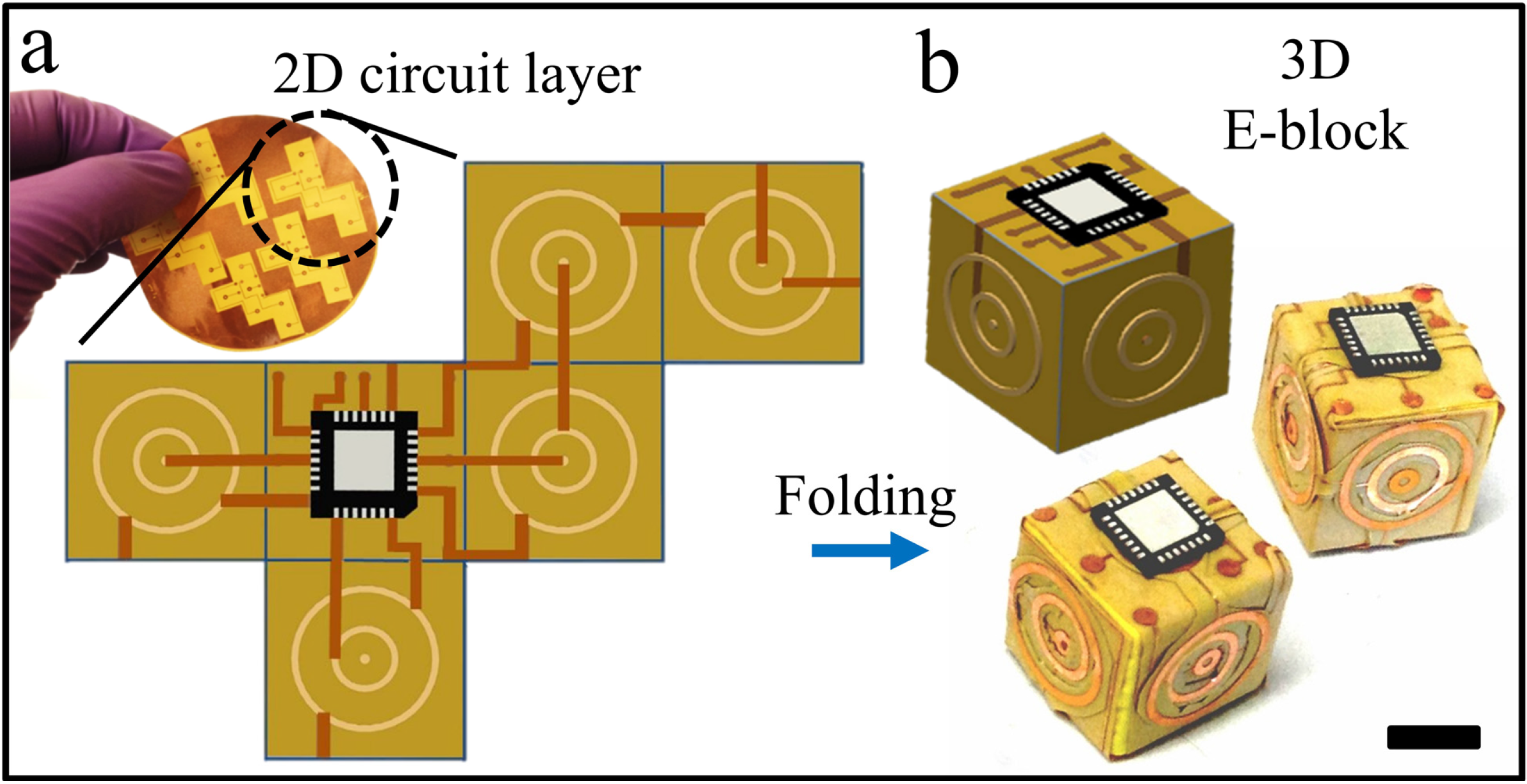
Here, we describe a new framework for the creation of 3D devices using polyhedral folded electronic blocks (E-blocks) and demonstrate proof-of-concept for the fabrication of fully functional 3D computational devices. The approach for fabricating E-blocks by folding is illustrated in
Figure 1. We describe the software and hardware foundations for implementing this concept using cellular computational chips and discuss the challenges with fabrication, interconnect routing, assembly, defect mitigation, and programming. Based on these results, and prior literature on self-folding and self-assembly of polyhedra, we argue that this approach is manufacture-ready in a high-throughput and fully self-directed manner to create truly 3D, very large scale integration of next generation computational devices. While we realize that the self-assembly of E-blocks will have technical challenges such as the generation and electrical testing of defect-free organized aggregates with appropriate wiring and pin-on-pin connectivity, work to date suggests that with the addition of the self-configurable, fault tolerant cell matrix architecture, most of the hardware related challenges can be addressed.
2. Results and Discussion
This work consists of two parts: (a) software foundations for the development of a self-configurable and fault-tolerant 3D tool chain and (b) hardware foundations for a fabrication method to manufacture folded E-blocks.
2.1. Software Foundations
Although cellular systems can be attractive for 3D computers, there are significant challenges for the software, especially in the handling of defects that arise during the hardware assembly process. Prior approaches for handling defects in cellular computational devices include increasing redundancy or implementing architecture that is inherently defect-tolerant, such as scale-free networks. Such networks can still robustly communicate data between nodes despite high failure rates [
19,
20]. The core of our approach consists in extending the cell matrix architecture from a 2D to a 3D architecture, as introduced earlier [
21,
22,
23]. In order for this approach to work, a balance must be struck. The cells need to be simple enough that they can be fully tested with a small, well-defined set of test sequences; yet they must be powerful enough to be able to autonomously interact with neighbors (thus reducing reliance on a central, external control system). Cell matrix strikes this balance by using an extremely simple atomic unit, which has been endowed with the ability to read and write neighbors’ configurations.
This mechanism supports the development of powerful circuit behaviors. For example, in testing cells for defects, a classic issue is the possibility that the testing circuitry itself may be defective. In a cell matrix, the testing circuitry can be synthesized from the same cells that are being tested. Simple test sequences (generated from an external, trusted source) are used to first test a small number of manufactured cells one at a time. Once those cells are known to be good, they can be configured into a larger, parallel test circuit. As this test circuit discovers more perfect cells, it expands into a larger, more-parallel circuit, which is able to test more cells in parallel. This approach has a four-fold advantage: (1) it requires only a small number of known-to-be-good initial cells; (2) it grows geometrically, testing
O(
n3) cells in
O(n) steps; (3) the circuit can continue to grow despite the presence of scattered defects (up to a critical defect density); and (4) it can operate with minimal need for external control/intervention [
22,
23].
The self-configurability of the matrix can also augment the physical self-assembly of E-blocks. For example, the physical orientation of assembled blocks relative to an external orientation is essentially unpredictable. However, an initial software-driven introspection process—similar to the defect-detection process described above—can be used to determine, one-by-one, the orientation of a small set of cells near the edge of the assembly. Once those blocks’ orientation is known, programming sequences can be adjusted, and the blocks can be used to build a larger orientation-detection circuit, whose testing-capability grows geometrically over time [
22,
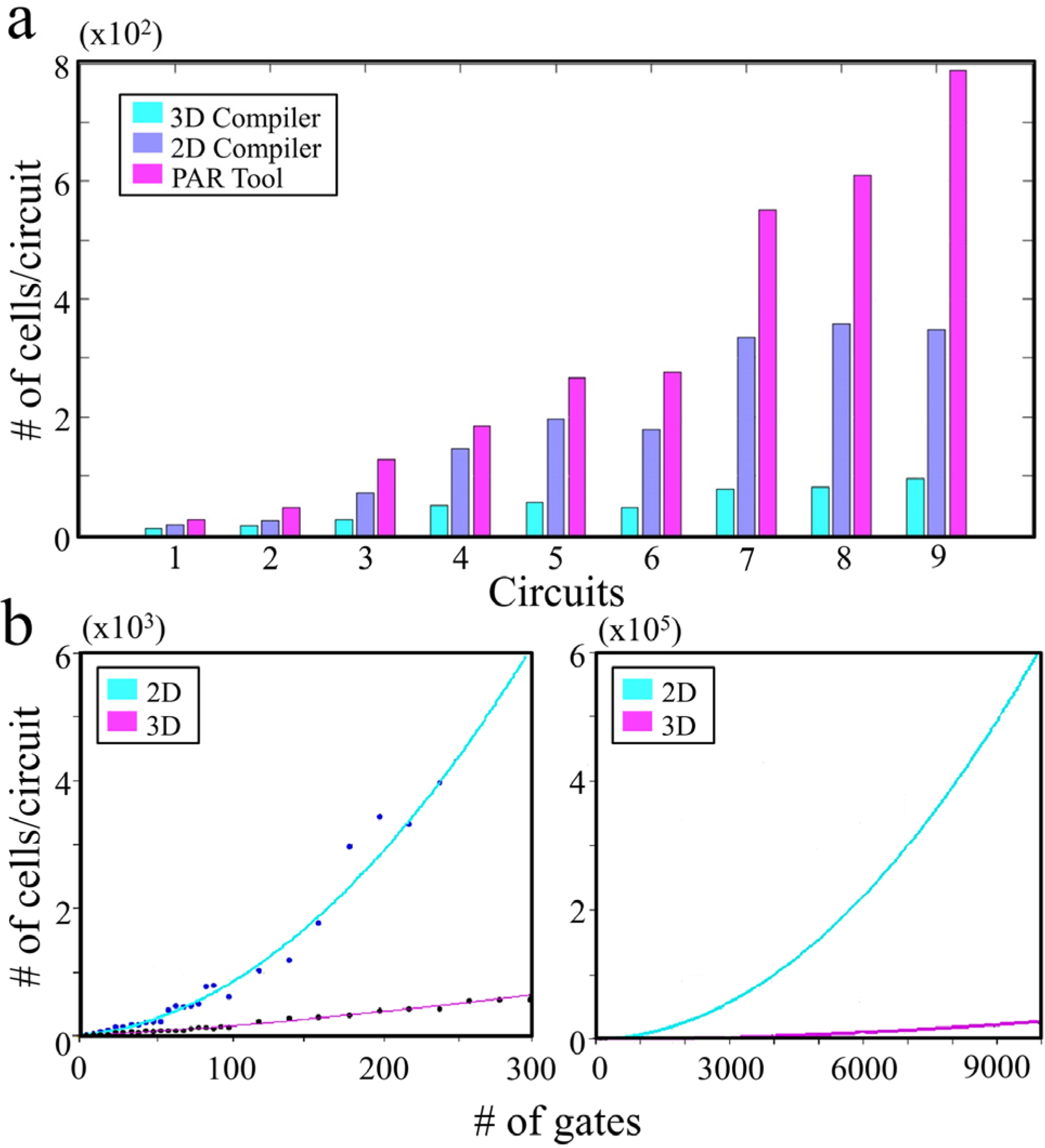
23]. With simulations, we show that a 63.2% greater compactness over a 2D integration can be achieved with our 3D architecture (
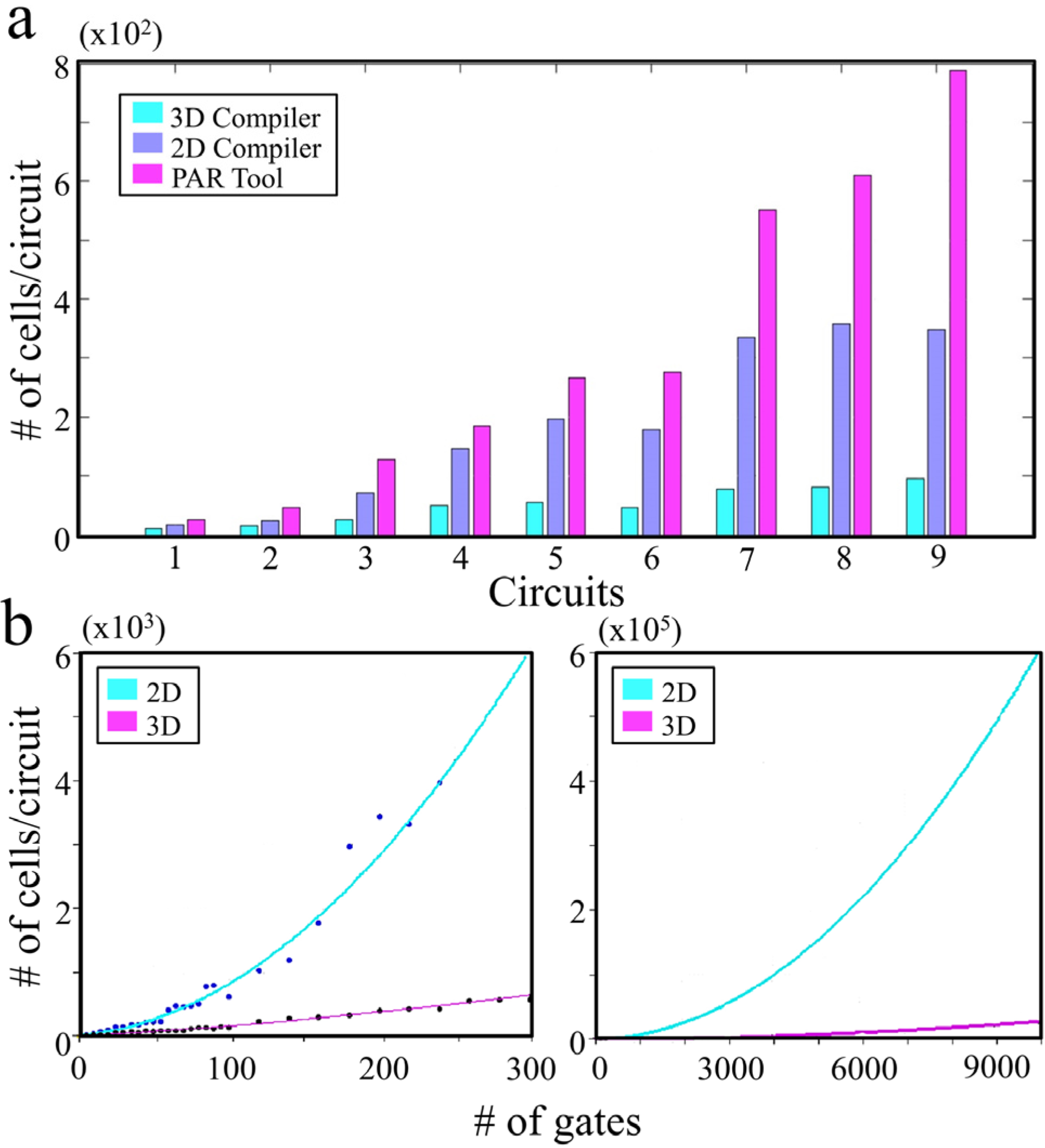
Figure 2).
2.2. Hardware Foundations
For cellular 3D computers, there are significant challenges in implementing the hardware in practice. Hardware unit cells can be composed of biological matter, such as neurons or nucleic acids, to perform computations, but these cannot be easily used for practical computational devices for higher order computations [
25,
26,
27,
28]. The highlight of our approach is the utilization of polyhedral E-blocks as computing cells with attractive characteristics, such as manufacturability, scalability, controlled assembly, density, robustness, and the ability to include porosity to circulate fluids to reduce heating of the elements. We show proof-of-concept with larger blocks mainly due to the relatively high costs of fabricating smaller Complementary Metal–Oxide–Semiconductor (CMOS) enabled units in an academic setting.
To our knowledge, the first self-folded E-block with patterned connector pads and single crystal silicon faces was demonstrated by Gracias
et al. [
29]. Since then, the creation of self-folded polyhedra using a high throughput and fully manufacturable process with metals, dielectrics, and semiconductors for sizes as small as 100 nm has been demonstrated [
30,
31,
32,
33]. Hence, the polyhedral E-block approach could be implemented at smaller scales and with high throughput fabrication approaches, albeit at a higher cost but readily achievable in an industry setting, and consequently represents a manufacture-ready process. Conceptually, a folding approach is also attractive because there already exists a vast infrastructure for patterning 2D CMOS devices. Folding can readily transform 2D patterned CMOS circuits into 3D curved and polyhedral devices in a high throughput manner [
34]. Hence, E-blocks with surfaces patterned with a variety of electronic modules ranging from transistors to chips to interconnect and solder bumps can be readily patterned in all three dimensions in a highly parallel manner. To our knowledge, such high throughput patterning of E-blocks cannot be achieved by any other approach.
Further, polyhedral E-blocks are attractive for self-assembly because the properties of polyhedra and their 3D tiling lattices have been extensively studied since the days of Plato over 2000 years ago [
35]. Polyhedral units have been previously used for forming self-assembled functional electrical connections and periodic metamaterials [
18,
36]. Due to the vast knowledge of the geometric properties of these shapes, they offer unprecedented opportunities for the assembly of electronic devices. The assembly networks of polyhedral blocks can also be made both symmetrically and asymmetrically depending on the kind of polyhedral shape. For example, the tiling of polyhedra, such as cubes or truncated octahedra, results in symmetric networks while that of rectangular parallelepipeds or square pyramids results in asymmetric ones. In addition, porous networks can be synthesized using truncated octahedra, cuboctahedra, or truncated cubes, and the porosity can enable fluidic or convective cooling of 3D electronic networks, which is important for practical operation. In this study, we focus on building and configuring cube-shaped E-blocks for illustrating models of computational devices.
2.3. Design of E-blocks and the Computer
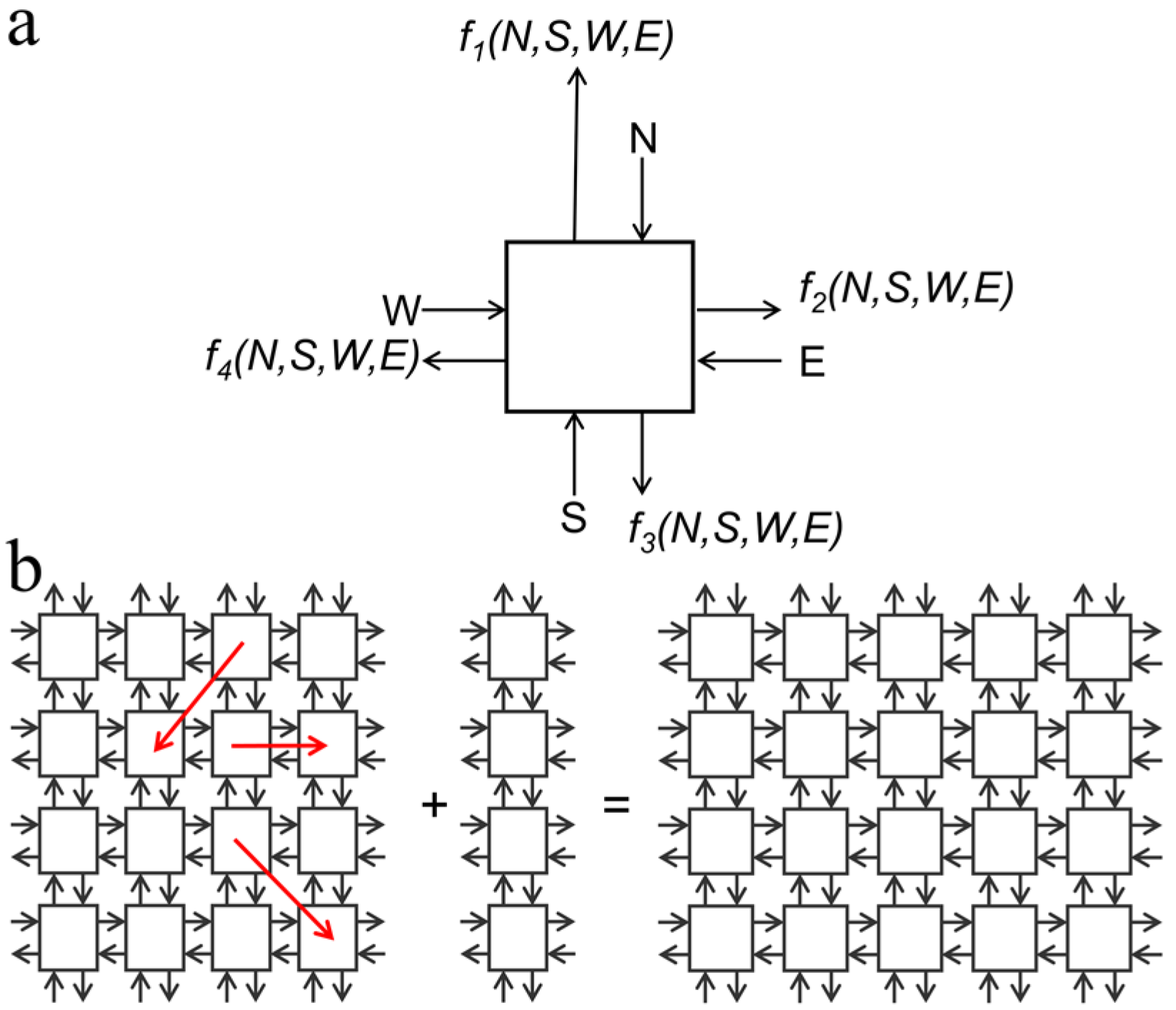
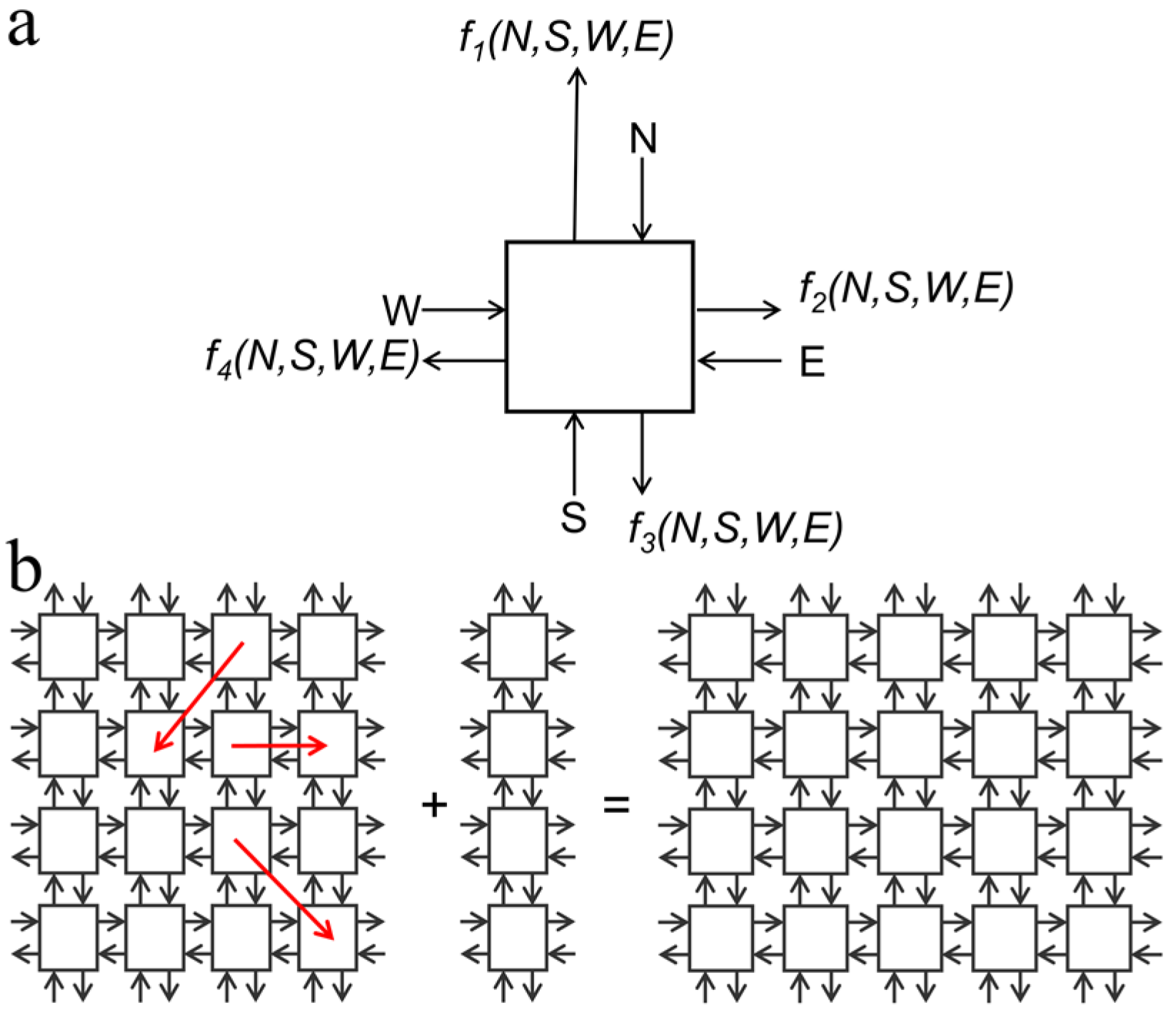
The architectural design of a 3D computer presented in this paper is based on the aforementioned self-configurable inherently defect- and fault-tolerant cell matrix. Briefly, a 2D cell is a four-sided digital element that has two inputs and outputs on each side. One set of inputs look up outputs from the internal truth table of the cell, and the other set of inputs is used to read and update the truth table of that cell. After processing the data, the cell feeds the output to its neighboring cells. Thus, each cell behaves as an independent digital circuit while processing the data, which is needed to differentiate between functional and non-functional (defective) cells in the matrix. Once functional cells are identified, defective cells are excluded and functional cells interact with one another independently and generate a self-configurable fault-tolerant circuit. In addition to defect- and fault-tolerant self-configurability, cell matrix is scalable irrespective of matrix size (
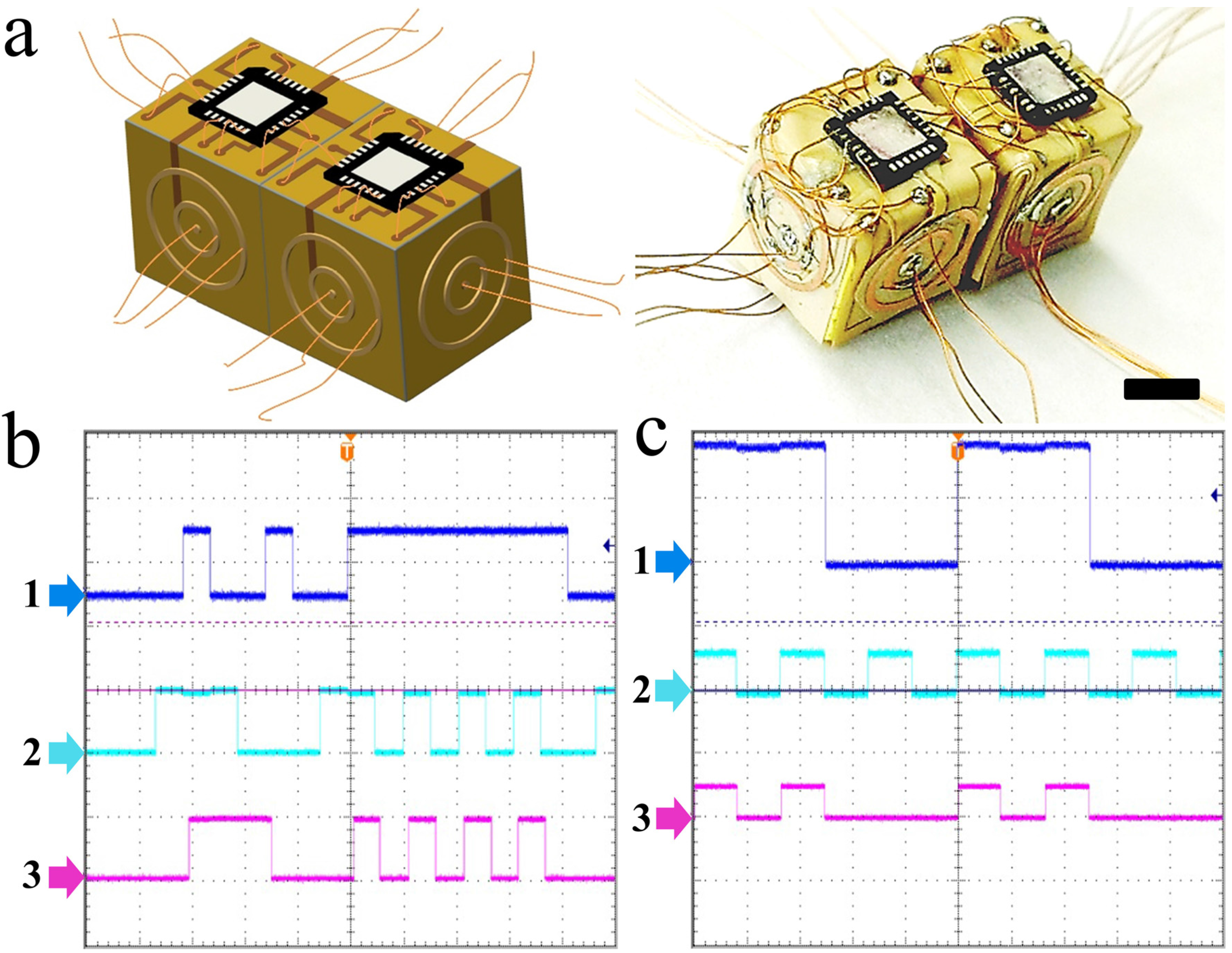
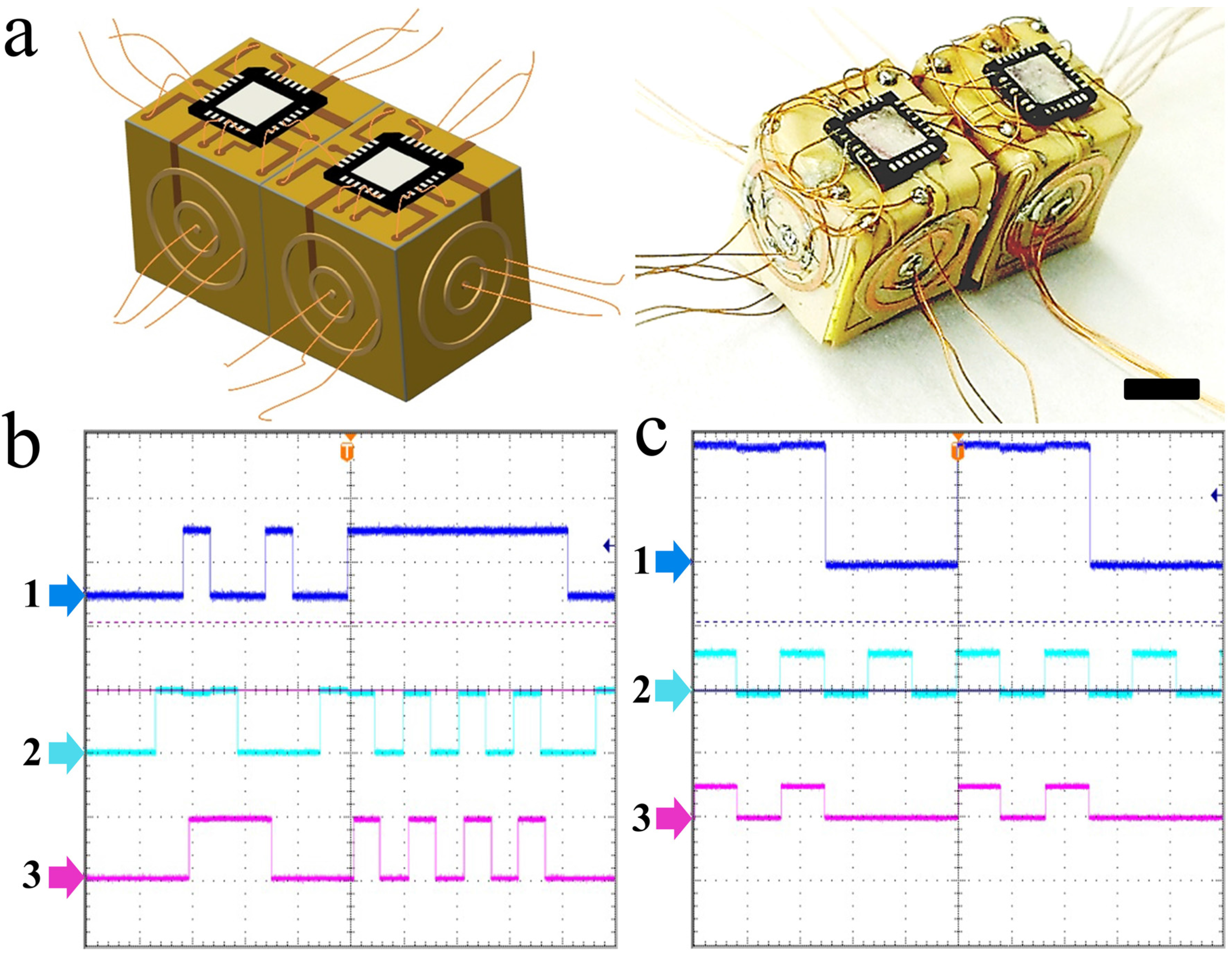
Figure 3). The design of a 3D computer using 3D cells is simply an extension of a 2D cell matrix. In a 2D cell matrix, a unit cell is a four-sided cell whereas in a 3D cell matrix, each unit which is a cubic E-block in this case is a six-faced 3D cell. In our experiments, these functional cubic cell units were assembled to create a 3D cell matrix of the dimer, tetramer, and octamer shapes (
Figure 4 and
Figure 5).
Although the eventual goal of this work is to build self-assembled 3D computers at a miniaturized scale, we made the following simplifications to illustrate proof-of-concept: (a) instead of patterning the target digital circuitry (e.g., the cell matrix architecture) onto a 2D substrate, we chose to emulate the cell matrix using a conventional microprocessor. This is an imperfect approximation, as the cell matrix’s hardware operation is parallel, whereas a software simulation on a conventional CPU is inherently sequential. Nonetheless, this allowed us to explore the configuration of a 3D cell matrix implemented via a collection of E-blocks; (b) since the only available commercial packaged microprocessor was physically large (a few mm in length and width), the E-blocks also needed to be large as well. This meant that hand-folding and assembly rather than self-folding and self-assembly was required; (c) In a 3D cell matrix comprised of six-sided cells, each cell requires seven connections (two data/two control signals, one clock signal, plus power and ground) to each neighboring cell. Since the E-blocks were manually assembled, creating seven conductors per face was not feasible. Instead, we chose to use only three conductors: power, ground, and a single shared (time-multiplexed) signal line (which carried the two data/two control signals and the clock). This is another approximation, and a departure from the inherent dataflow behavior of the cell matrix, but it presents a useful step toward the higher-level design.
One of the challenges in self-assembly is that the tiling is generated via programmed interactions of the blocks and hence patterns and the blocks themselves must encode this information. In order to facilitate high yielding self-assemblies, it is necessary to build redundancy and create funnel shaped potential interactions between blocks. While a variety of interactions such as solder based surface tension forces [
18] or magnetic connectors [
11,
16] could be utilized for self-assembly, these principles stay the same. Here, we assembled aggregates using solder based interactions and we used two concentric circular connectors on each face to enable this interaction (see layout in
Figure 1a). Our choice was based on results from prior research [
37], where we discovered that geometric patterns with large overall areas, low radii of gyration, and high angular distributions result in efficient and low-defect assembly of cubes. In contrast to wafer stacking, where via alignment is required over large areas, potentially the size of a 12 or 16 inch wafer, in E-block assembly self-alignment of only two concentric circles are needed, thus greatly minimizing the challenge of providing high-fidelity alignments over large areas. Our wiring layout was designed so that a single chip on each block would connect with another chip on another block during concentric ring-on-ring assembly.
2.4. Testing the Assembled E-Blocks
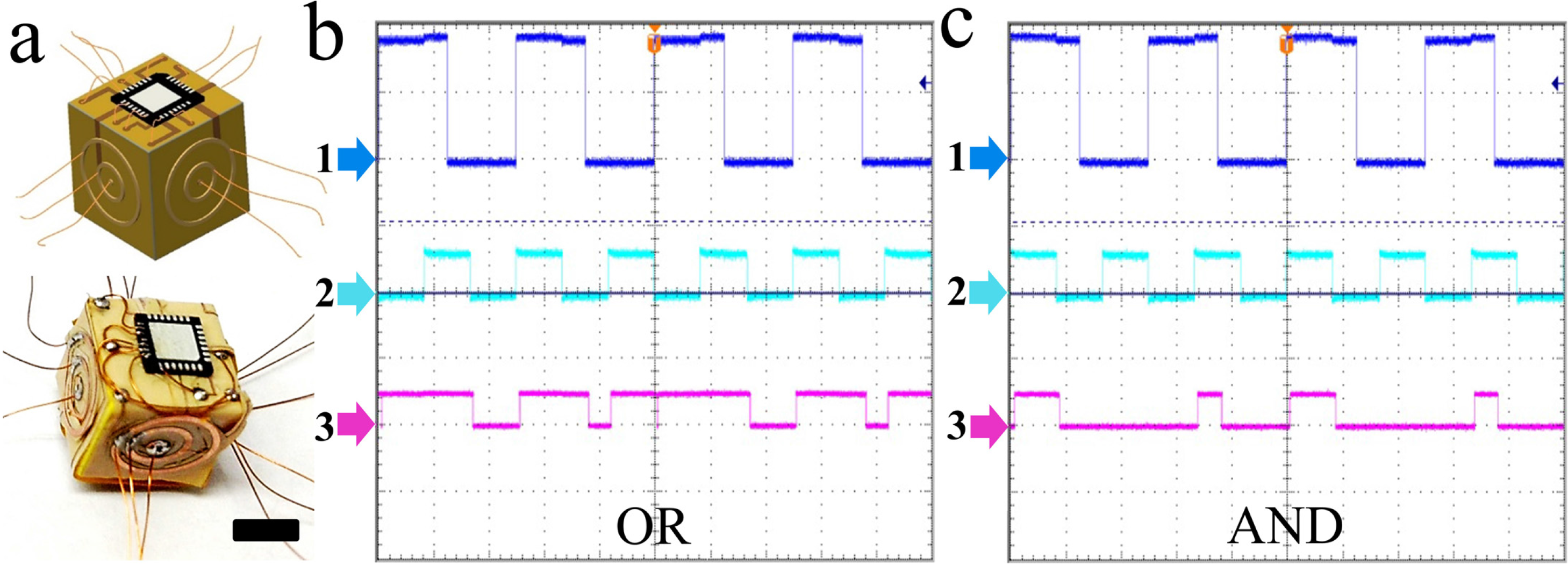
To test the E-blocks, we used a testbed driver, which performs three functions: (a) it allows a host Linux machine to send 1's and 0's to the C and D inputs of the cells being tested and for outgoing bits (generated by the cells) to be displayed on a series of Light Emitting Diodes (LEDs); (b) it also allows the driving program to be disconnected, so that external hardware can supply the 1’s and 0’s to the cells being tested: and (c) it handles the time-multiplexing of D and C inputs and outputs (and clock signals) through the single-conductor signal contact on each face of the E-blocks. Time-multiplexing was employed to reduce the number of inter-block connections. In a self-assembled system built from lithographically-patterned blocks, we anticipate multiple signal connections per face, thus avoiding the need to time-multiplex signals. The testbed set-up and configuration of the E-blocks as gates and latches are shown in
Figure S1. We note that we were successfully able to configure monomers and dimer as simple OR, XOR, AND gates, 2-bit adder, and D-latches for various inputs and confirmed that the folded E-blocks were fully functional (
Figure 6 and
Figure 7). Dimer testing showed that the circuits can be built to incorporate feedback mechanisms of functional E-blocks.
2.5. Scalability and Manufacturability
As a proof-of-concept for a 3D computer, we manufactured, assembled, and tested the millimeter-scale cube-shaped E-blocks and successfully demonstrated their functionality as an AND gate, OR gate and simple 2-bit adder. By using 3D self-assembly methodologies to create nano- and microscale complex-shape 3D structures from 2D precursors and self-assembly approaches [
28,
29,
30,
31], the E-blocks could potentially be manufactured at the nano- and microscale in a high yield parallel fabrication process. In order to mitigate defects during self-assembly, optimized patterns can be introduced on the faces of E-blocks as described above [
36].
4. Conclusions
The eventual goal of this work is to: (a) lithographically pattern micro-nanoscale 2D digital circuit patterns; (b) have these patterns self-fold (in parallel) into 3D polyhedra (E-blocks); and (c) have those polyhedra self-assemble into 3D collections of E-blocks which function as computational devices. Unfortunately, step (a) requires large up-front costs and non-recurring engineering charges, which were outside the budget of this effort. Instead, we opted for a proof-of-concept of the process, by utilizing a commercial off-the-shelf packaged 4 mm sized microprocessor which required large E-blocks and the process was implemented manually, but we note that all elements of the process such as self-folding of smaller units and pin-on-pin aggregative solder assembly have been independently verified, and hence this represents a manufacture-ready process.
Despite the presence of a complete microprocessor in each E-block, it was pre-programmed prior to mounting, and not re-programmed after assembly. Consequently, the microprocessor was only used to emulate the fixed cell matrix architecture. However, the same architecture allows the implementation and re-implementation of digital circuits using the matrix's self-configurability. This means that when E-blocks are eventually produced from micropatterned silicon that directly implements the cell matrix architecture, the system's behavior will still be modifiable via the ability to configure/re-configure/self-configure cells within the system. This is particularly important since when E-blocks self-assemble, the relative orientation of the blocks is effectively unknown. By arranging inter-block connections in a series of concentric circles, face-to-face communication is ensured regardless of orientation. While cells rely on an understanding of their orientation within the matrix (since faces are specified in terms of +/−
X, +/−
Y, +/−
Z), a collection of cells can work cooperatively to determine the orientation of cells within the collection [
23].
Given an assembled collection of 3D E-blocks, it can be configured to implement any desired digital circuit, including combinational logic, state machines, a CPU, a cluster of CPUs,
etc. This configuration can be done using very conventional design techniques (external to the 3D assembly), but, for very large collections, this may not be feasible. Instead, self-organizing principles can be employed, such as those described in [
38]. By designing a blueprint or a target circuit, the 3D assembly can be tiled with identically-configured sub-blocks ("supercells"), each containing a copy of the blueprint, plus the necessary machinery for a variety of functions, including (a) testing of regions of E-blocks for errors; (b) parallel configuration of supercells from sets of defect-free E-blocks; (c) interpreting the blueprint; (d) self-locating (determining (
X,
Y,
Z) location) within the collection of supercells; (e) mapping of communication paths from supercell to supercell; and (f) differentiation of supercells into desired functions in order to implement the target circuit.
In conclusion, the self-assembly of a 3D self-configuring cell matrix is significant in several ways—(a) the parallelism of self-folding of E-blocks means large numbers of blocks can be readily manufactured; (b) the fault-tolerance of the architecture means that even with a low yield, useful circuitry can still be built via use of introspective assembly techniques [
23]; (c) digital circuitry that fully exploits all three dimensions that remain elusive under conventional manufacturing, whereas 3D E-blocks provide a manufacture-ready path to large-scale 3D assemblies; (d) target circuits can be specified/modified post-manufacture, allowing the physical substrate to be manufactured in a fixed, pre-defined way regardless of the specific intended use; and (e) customization of the system's behavior is specified via reconfiguration of hardware (which is inherently parallel),
vs. reprogramming of software (which is primarily sequential), thus allowing potentially higher performance.
Our work is thus broadly relevant for future and emerging 3D computers that may be self-assembled from a massive number of imperfect building blocks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}