1. Introduction
Scientists currently adopt a wide array of methods to visualize the structures hidden within data. Andrews’ plots [
1] constitute one such method that enables scientists to identify structures within data, because they preserve some inherent properties of the data after transformation. In recent decades, Andrews’ plots have been applied via data transformation to fields including ecology [
2], social sciences [
3], biomedical techniques [
4], signal processing [
5], Internet user clustering [
6], and data mining [
7], but not, thus far, to satellite image classification. Of specific interest is a study by Norliza et al. [
4], which used Andrews’ plots to study X-ray data from mycobacterium tuberculosis patients, as well as to compare new patient data with existing disease data, showing that diseased and healthy patient curves can be visually separated.
Fuzzy sets [
8] and their various extensions can elucidate vagueness in mathematical theory, as well as explain real-life phenomena. Their evident flexibility stems from the adjustability of their inference procedures through IF-THEN rules [
9]. Several types of fuzzy sets have been developed to provide an attractive framework for building classifiers that closely mimic human perception [
10]. Fuzzification is a process that assigns a degree of fuzziness to a crisp input that belongs to a certain membership function. Fuzzification and fuzzy algorithms have been effectively adopted in a wide range of studies [
11,
12,
13].
The Dempster-Shafer (DS) theory of evidence [
14,
15] is a generalization of the Bayesian theory of subjective probability, which obtains degrees of belief for different hypotheses from a combination of independent lines of evidence that can be acquired from one or more sources. In contrast to traditional probability theory, multiple events can occur in a piece of evidence. The most attractive feature of this theory is that it can manage different levels of data precision, and the results can be flexibly interpreted for different purposes [
16].
DS theory and fuzzy sets or their extensions have been jointly applied to numerous fields. For example, a model for selecting a plant location and its application were proposed in [
17]. In the article, linguistic conditions were used to assign uncertainties to the model. Moreover, Dempster’s rule of combination was proved to be efficient in the decision model. Mönks et al. focused on the fuzzified balanced two-layer conflict solving (µBalYLCS) algorithm, which originates from DS theory and operates on fuzzy sets. The algorithm works well in situations with high data conflict [
18]. Furthermore, Lu et al. [
19] have confirmed the effectiveness and usefulness of fuzzy logic combined with an extension of DS theory in data fusion. In land cover classification, DS theory and fuzzy-contextual information [
20] have been used in the classification of multispectral satellite images. This method reduces classification error compared to Markov random field (MRF)-based contextual classification. Recently, Yang et al. [
21] proposed a classification approach based on DS theory and fuzzy rough sets. This approach can effectively delineate land cover types in urban fringe areas when uncertainties occur in the processing.
The main problem that might arise when dealing with relatively coarse-resolution satellite image data is the inclusion of small objects inside a pixel [
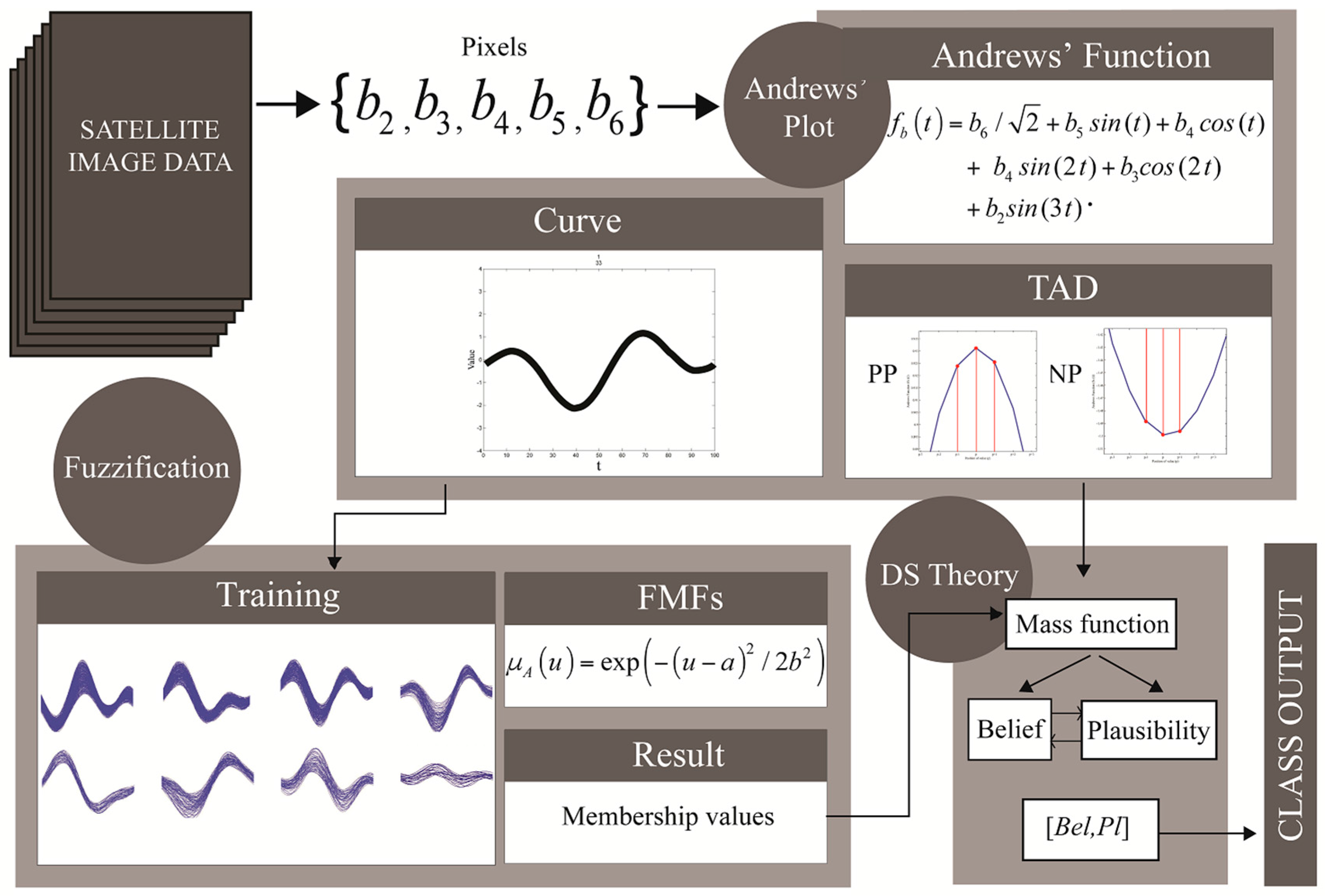
22], e.g., a farmhouse in the middle of a crop area, a small pond, or a road. Unwanted, or impure, pixels have a greater impact when they occur within training data. To visualize multivariate data, such as the different dimensions of satellite image pixels, Andrews’ curves enable the interpreter to select outlier or impurity data that can be grouped into a new category for classification. These tasks can be performed using only a single Andrews’ function combined with a visual interpreter.
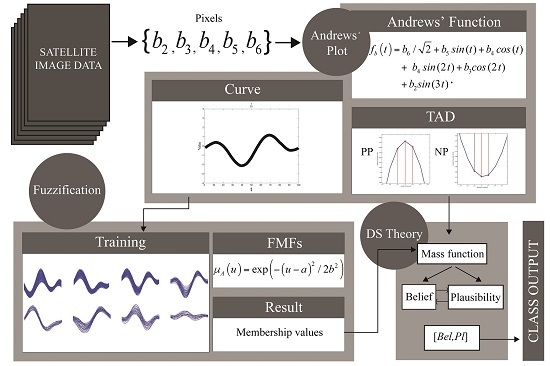
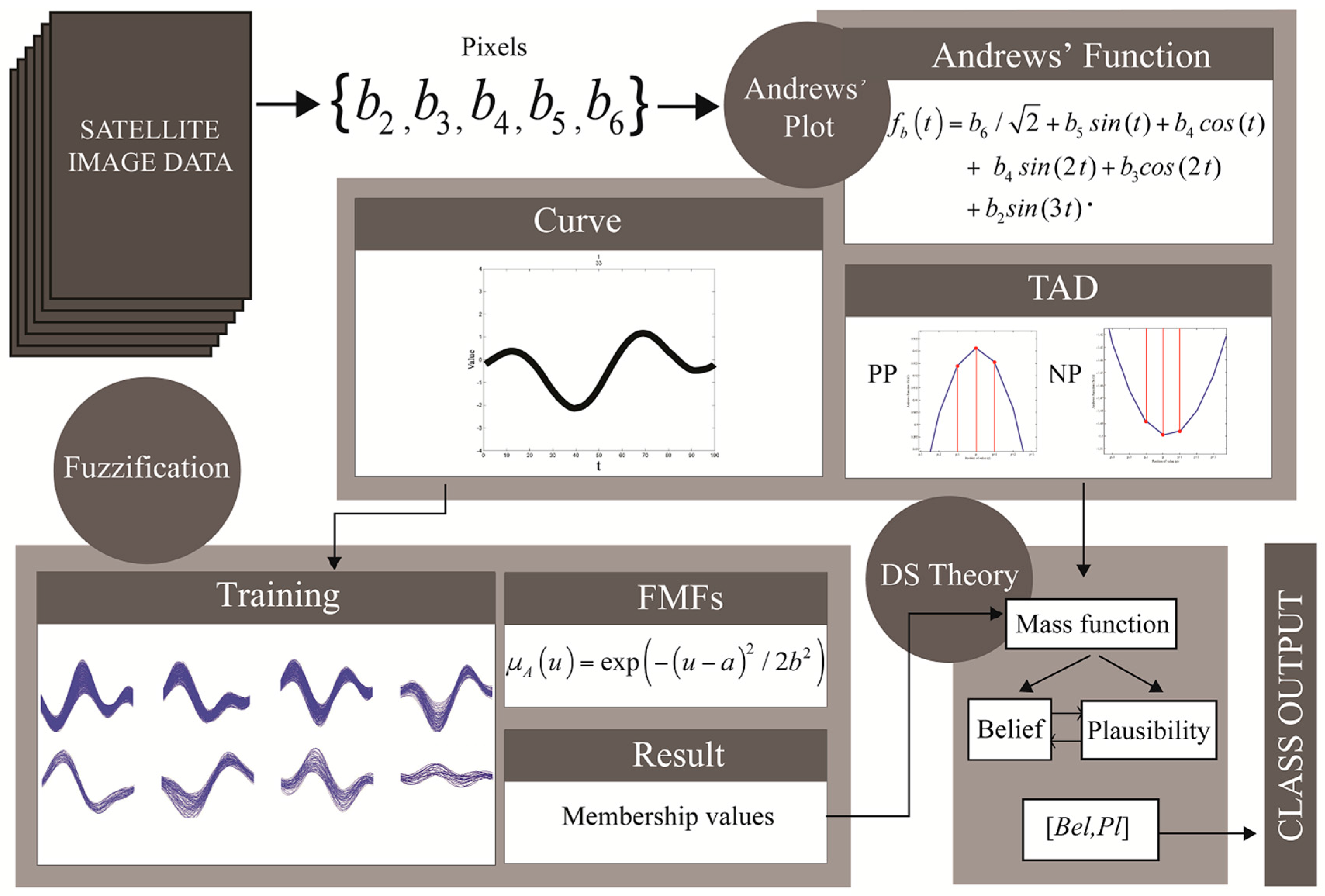
For satellite images, assigning a class to an input pixel by human action, involves transforming the input into an Andrews' curve and visually matching it with various prepared training Andrews’ curves. However, this process is time-consuming and its precision is limited by human perception, especially as the number of categories and the curve’s complexity increases, i.e., a full satellite image. To overcome these problems, this paper proposes a method for Andrews’ curve classification based on a combination of fuzzy sets and DS theory. By examining training curves, we found identical patterns in the same crop type. The learning-based classifier builds on several sets of training curves incorporating the curves’ properties. The membership value for each curve is calculated by fuzzification, and the probability of the curve’s characteristic or the type of Andrews’ curve dynamic (TAD) is obtained. DS theory is used to obtain confidence intervals, which are based on maximum belief and plausibility, to determine which curves are assigned to each category. Finally, the results obtained by the proposed method validate our hypothesis that Andrews’ plots can be applied to satellite image data. We compare this method with traditional supervised classification methods, and discuss the accuracy, precision, and robustness of our approach, as well as its additional advantages and disadvantages.
4. Results
4.1. Andrews’ Curve of Training Sets
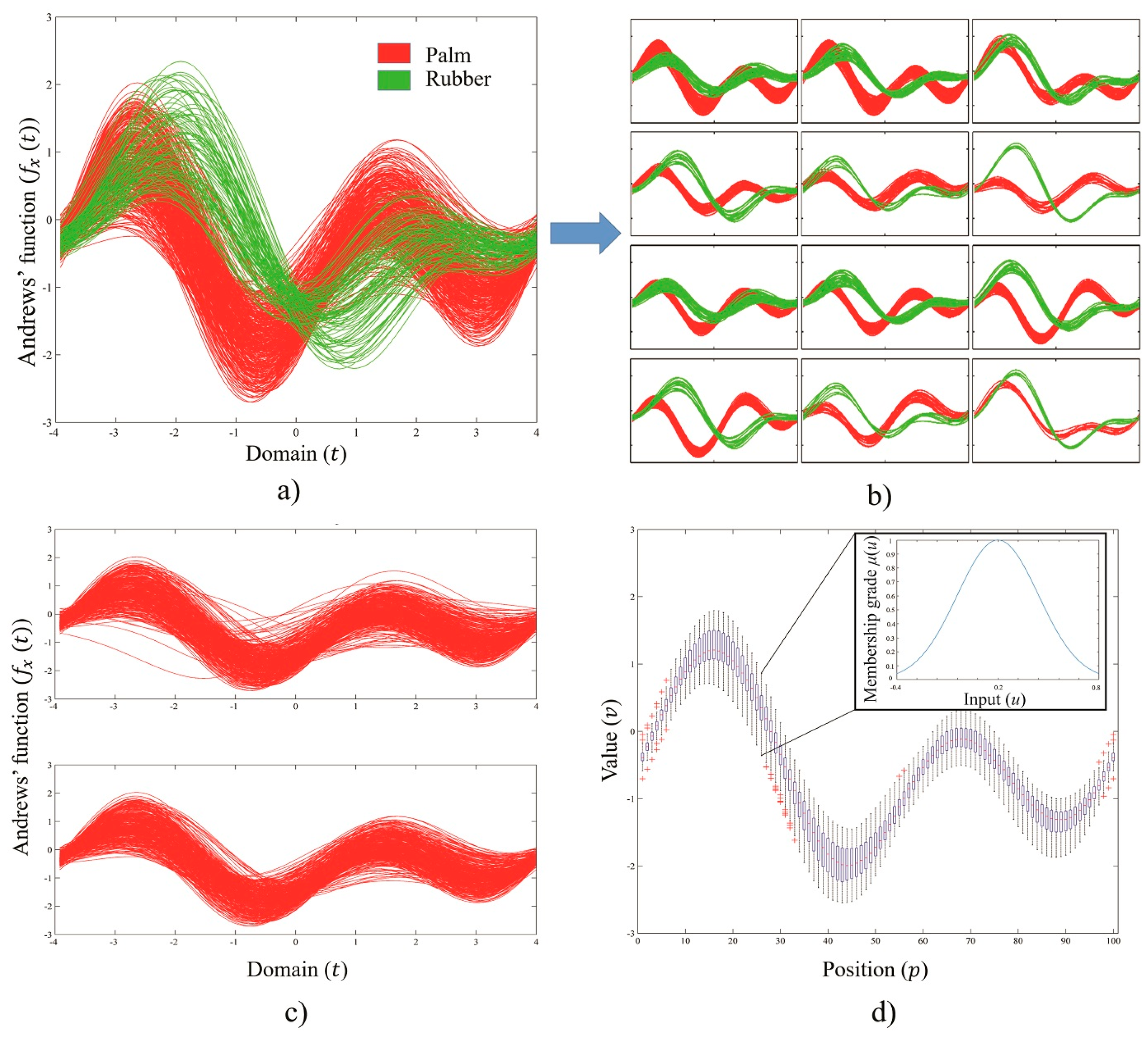
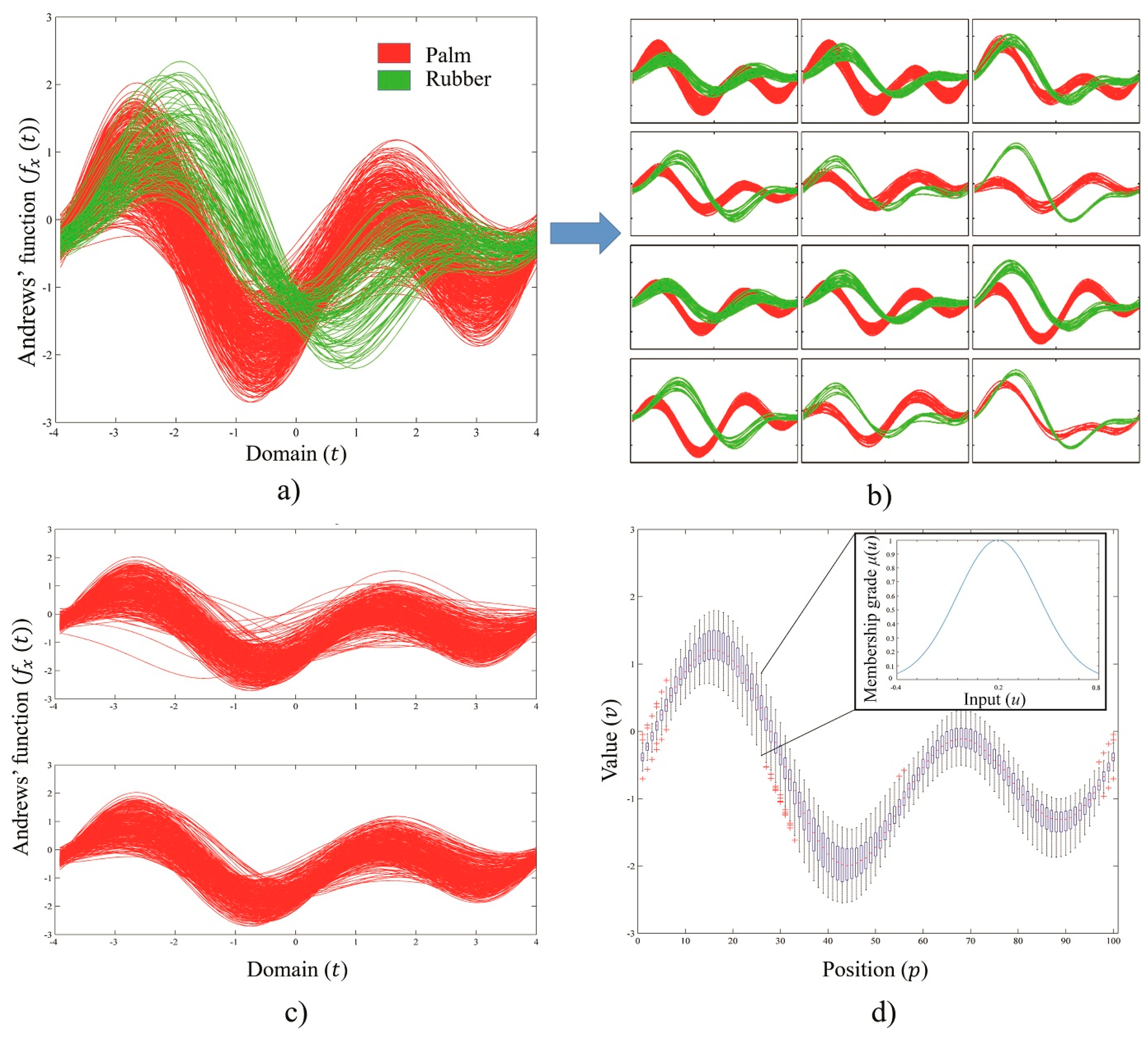
The training classes were divided into categories based on their TAD. To avoid confusion within the overlapping area, as shown in
Figure 3a, we simply subdivided the types by visual interpretation, which is the main advantage of using Andrews’ curves (see, e.g., the separation illustrated in
Figure 3b). Furthermore,
Figure 3c shows a training set of the
PM class before (top) and after (bottom) manual noise removal and subgroup extraction with visual interpretation.
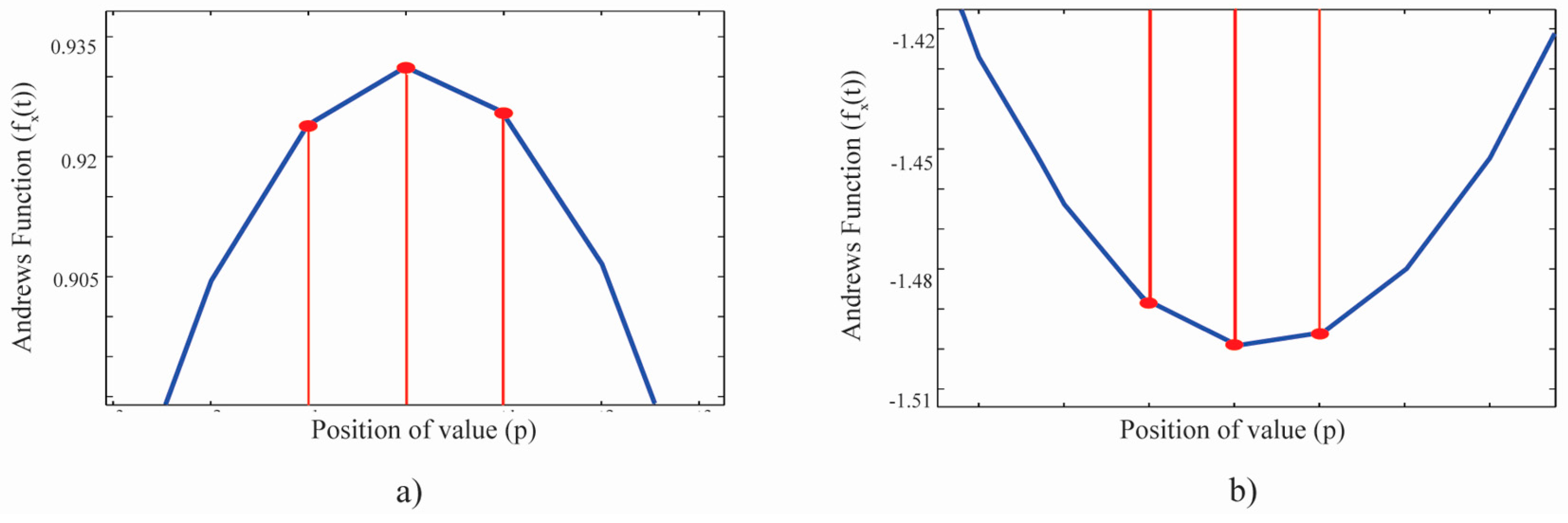
The possible TAD of all remote sensing datasets and the basic probability assignments are presented in
Table 2, where 1 and 0 denote the positive and negative peaks of the Andrews’ curves, respectively. The number patterns directly refer to the order of peak arrangement in the curve.
The result from the examined TAD of each training set shows that different classes may have different TADs, but if they have the same TAD, their Andrews’ value pattern must differ. However, this conclusion is limited by the precision of the data and the maximum ability for classifying the data type.
4.2. Example Fuzzification, Belief and Plausibility Calculation Results
To easily understand how the process works, we selected an input (labeled as PD) as a sample for illustrating the calculation. The two pieces of evidence are fuzziness and dynamic . The fuzzification believes that the input curve pattern is in BLPS with a probability of 0.1924, PD with a probability of 0.6235, or SC with a probability of 0.1841. However, we added a bias (directly multiply by 0.85) to the PD and SC fuzzification results of 15% of the original results. This caused the results of PD and SC to be reduced to 0.5300 and 0.1565, respectively, based on the assumption that the summation of the mass values in a set must be equal to 1 in Equation (6). The dynamic believes that the input is BLPS with a probability of 0.1000, PD with a probability of 0.6000, or SC with a probability of 0.3000.
Dempster’s rule of combination in Equations (12) and (13) was adopted for the distribution of the basic probability assignments, as shown in
Table 3.
There are seven null entries in
Table 3. Thus, we computed
in Equation (13) and the mass combinations in Equation (12), which gave the belief in Equation (8), and we computed the plausibility by its relationship with the belief in Equations (10) and (11) or directly from the mass combinations in Equation (9), as follows:
for the maximum belief of 0.7923 in the
PD set,
The belief interval ranges from 0.7923 to 0.8121, i.e., the two classifiers coincidentally believe that the input curve is in PD with a minimum probability of 0.7923 and a maximum probability of 0.8121. Therefore, the crisp output is from the PD class for the example input that matches with its true class from the reference.
5. Discussion
5.1. Accuracy and Data Uncertainties
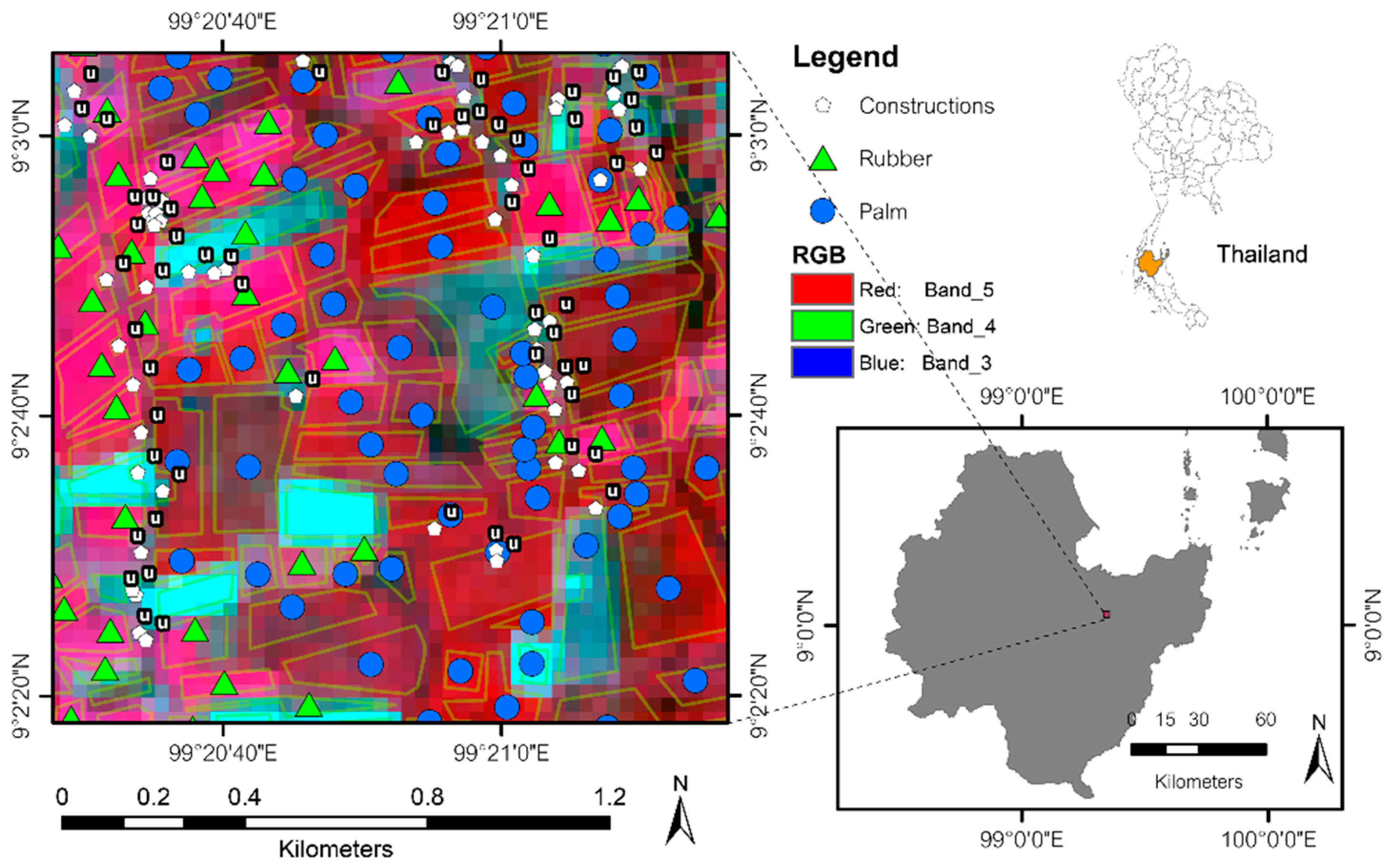
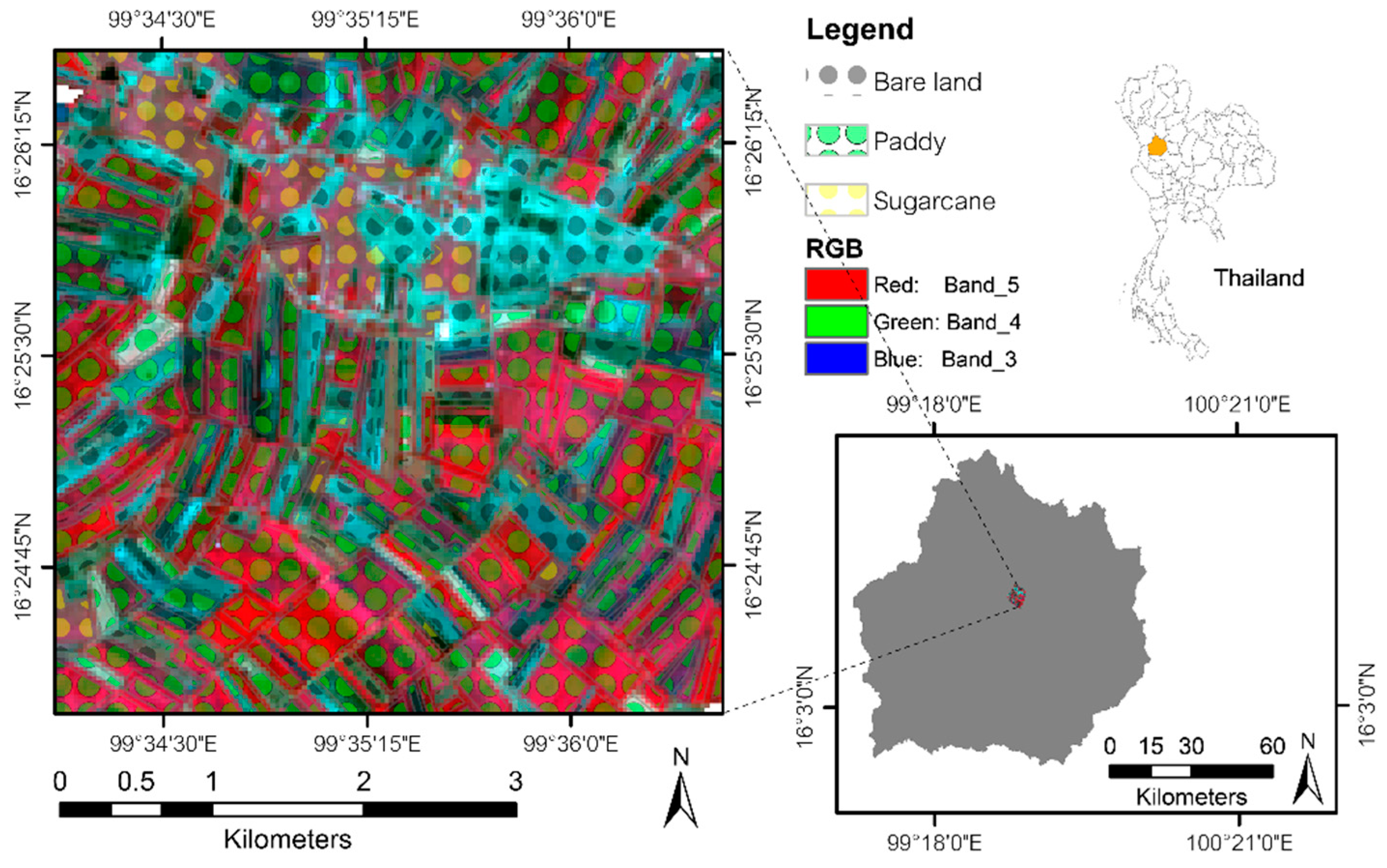
Per the fixed validation dataset (
Table 1), the overall accuracy of the
RP data was 92.06%, compared to 91.80% and 90.16% for the 24% and 11% training sets, respectively. This behavior is similar to that of the
PS data, with a slight decrease from 98.35% for the 15% training set to 98.20% and 97.92% for the 10% and 7% training sets, respectively. The
PS satellite data, collected in the sugarcane harvest season, may introduce a certain discrepancy, as the non-cut sugarcane area, already cut sugarcane area with bare land, medium-growth sugarcane, and paddy field have similar reflectance data. A similar ambiguity arises in the
RP data, wherein the satellite acquisition occurs during the shedding season of rubber, when palm is non-shed. Herein, there is ambiguity between young palm with shedding rubber, young palm or young rubber with bare land, and shed rubber with bare land, which have similar reflectance data. The confusion matrix between the reference and classified data is shown in
Table 4 and
Table 5.
5.2. Representative of Training Data
We inspected the significance of the difference in accuracy between the
RP and
PS data. As per
Table 1, the number of training samples directly influences the accuracy if it cannot represent most of the characteristics of the class. For the same training size proportion (around 10%), the number of paddy field reference curves (the majority class of the
PS dataset) is 1035, which may be sufficient to represent all possible paddy fields occurring in the area, while oil palm (the majority class of
RP dataset) has only 109 curves. However, we can assume that the training sets of
RP data may be less representative than the training sets of
PS data at the same training ratio. The training sample cannot completely represent all input data, which is the main drawback of the sampling design [
31].
5.3. Robustness
To test the performance of our method, we randomly reduced the number of training samples to different proportions. Although the training data were reduced, the test data remained at the same proportion of the population. The accuracy of the result shows that the reduction in training data leads to a slight decrease in the overall accuracy of the remote sensing data. This phenomenon is referred to as an increase in commission and emission errors (those that can be interpreted from the reduction of the user’s and producer’s accuracy, respectively). The main reason for such errors is that the random procedure of our method generates an extremely small training size in some subgroups. After examining the result of misclassified curves, e.g., we scanned the 11% training set of the RP data and found that some subgroups show a substantial change in width compared to the original training set of 35% (some subgroups left only four training curves). However, the overall accuracy is greater than 90% for all datasets.
Moreover, we compared the proposed method with two traditional classification methods, the maximum likelihood and minimum distance, for the RP data. We used the minimum training size of 11% and the same 1524 validating points. The experiment was completed using supervised classification functions in the ENVI 5.0 software and its results showed that the proposed method has a commission error rate for the PM class greater than that of the minimum distance method—about 8%—while the minimum distance method provided a poor user accuracy for the RB class. In contrast, the maximum likelihood yielded the highest user accuracy for the PM class, but seemed to include the RB and PM classes in the results of the BLRP class, more so than the other two methods. In conclusion, the proposed method has the highest overall accuracy among the methods.
The benefit of using Andrews’ plots in preparing training data is to screen outliers that may be included, as well as to subdivide the training sets to improve the accuracy. The next step is to reject low membership grade inputs by DS theory. These are the differences of the proposed method from traditional methods.
Table 6 illustrates the accuracies from the comparison experiment.
5.4. Limitations and Suggestions
Andrews’ plots can precisely visualize high-dimensional data. However, they also have a shortcoming, i.e., their shapes become completely different when the order of the variables is changed. This phenomenon was described by Andrews himself in his original paper [
1]. Note that it is expedient to subordinate the most important variables with low frequencies, as we did with the near-infrared band, whose values were mainly affected by the plants. Conversely, this shortcoming may be advantageous in other contexts. The differing shapes of Andrews’ curves illustrate different characteristics of the data source. For example, in a complicated work, one may use at least two orders to ensure that a pixel is categorized precisely into a class based on the distinguishability of the orders. If an order is insufficient to represent the pixel, it may be advantageous to draw another order based on the band characteristics.
As we noted in
Section 3.2.1, extracting the overlapping area in the training data is an optional task to optimize the training selection procedure. The main objective of this method is to reduce the overlapping area of the curves, resulting in less overlap in the shape of the membership function of each class. However, it can be avoided in many cases if details of the reference used are available.
Owing to the high flexibility provided by the core concepts of fuzzification and DS theory, users can develop their own rules and make individual decisions. The two theories are representative of vagueness and uncertainty. The major problem of any classification task is achieving maximal accuracy. These theories are usually used to handle vagueness in data that normal crisp methods cannot. However, when the data have no uncertainty, to use such theories may be inappropriate. Note that very good data may produce relatively good results, while fairly good training data may also produce equally good results from a well-prepared method that reduces time and cost requirements. Theoretically, the power of such a supervised method depends on understanding the data and the experience of the user in designing a workflow.
5.5. Future Work
We hypothesized that different subgroups may be due to stages of cultivation or the specific characteristics of the crop species, depending on the date of data acquisition. However, this assumption cannot be proven in the current paper because the ground survey reference used does not show stages of crop cultivation or areas containing a large amount of private crop land, where planting is based on individual decisions. Moreover, the proof must be pursued carefully using time series and available ground survey data.
The data used in this study were acquired using the same sensor, Landsat-8 OLI. However, the acquisition date, area elevation, weather, and so on, varied. Moreover, the crop land occurring in the areas had varied properties. For example, rubber is a deciduous crop, but oil palm is not, whereas paddy and sugarcane fields share the same reflectance at some stages of cultivation. The classifier worked well under these ambiguous conditions. Furthermore, the Andrews’ curve of the bare land class seemed to have the same shape across the two datasets and was distinct from that of pure vegetation areas. In addition, the data points that included a combination of bare land, construction areas, bodies of water, and vegetation seemed to have specific curves. Further investigation is required to ensure that different objects have at least one specific Andrews’ curve that can be used to distinguish them under the controlled conditions of Andrews’ curve plotting. Moreover, comparisons with other classification techniques must be observed.
6. Conclusions
In this study, the satellite image pixels were accurately classified using a technique based on data visualization (Andrews’ plots) and the combination of DS and fuzzy set theory (accuracy more than 97% and 90% for PS and RP data, respectively). The main advantage of using Andrews’ plots is that they make impure data more easily detectable by human interpretation. Moreover, they envision not only the structures within data, but also seem to yield signature curves for a class. Two widely used machine learning algorithms were used to handle the many transformed curves. Fuzzification was used to obtain the membership grades, which assign each curve to a given training-curve class, while the real decisions were made by DS theory with the obtained grades and a few given conditions (curve’s characteristic possibilities and assigned uncertainties). The study provided not only a crop type classification framework, but also incidentally gave a practical method for finding curve similarities. The proposed method still worked well when we changed the training sizes. At the same training size, it also produced a better result when compared to the maximum likelihood and minimum distance algorithm. However, the proposed framework also has its shortcomings, e.g., the Andrews’ function is very sensitive to the data arrangement applied. Furthermore, the process requires a relatively fast computer that supports curve visualization. Future work will focus on investigating the signature curves for commercial crops and a comparison of the proposed method with other advanced methods such as the support vector machine, neural network, pure fuzzy classification, decision tree, etc.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}