
An Improved Combination of Spectral and Spatial Features for Vegetation Classification in Hyperspectral Images

 ,
,  , and
, and
Abstract
:
1. Introduction
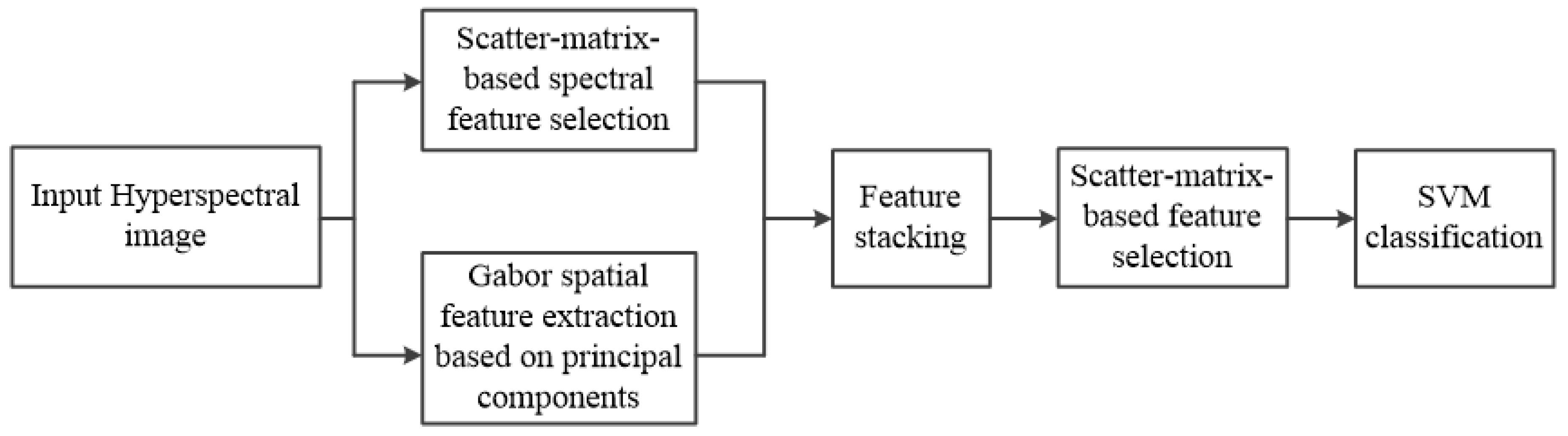
2. Methods
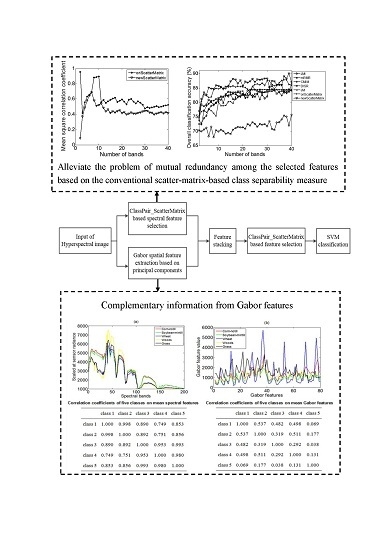
2.1. Scatter-Matrix-Based Feature Selection
2.2. GaborSpatial Features Extraction
2.3. An Integrated Scheme for Vegetation Classification
3. Experiments and Analysis
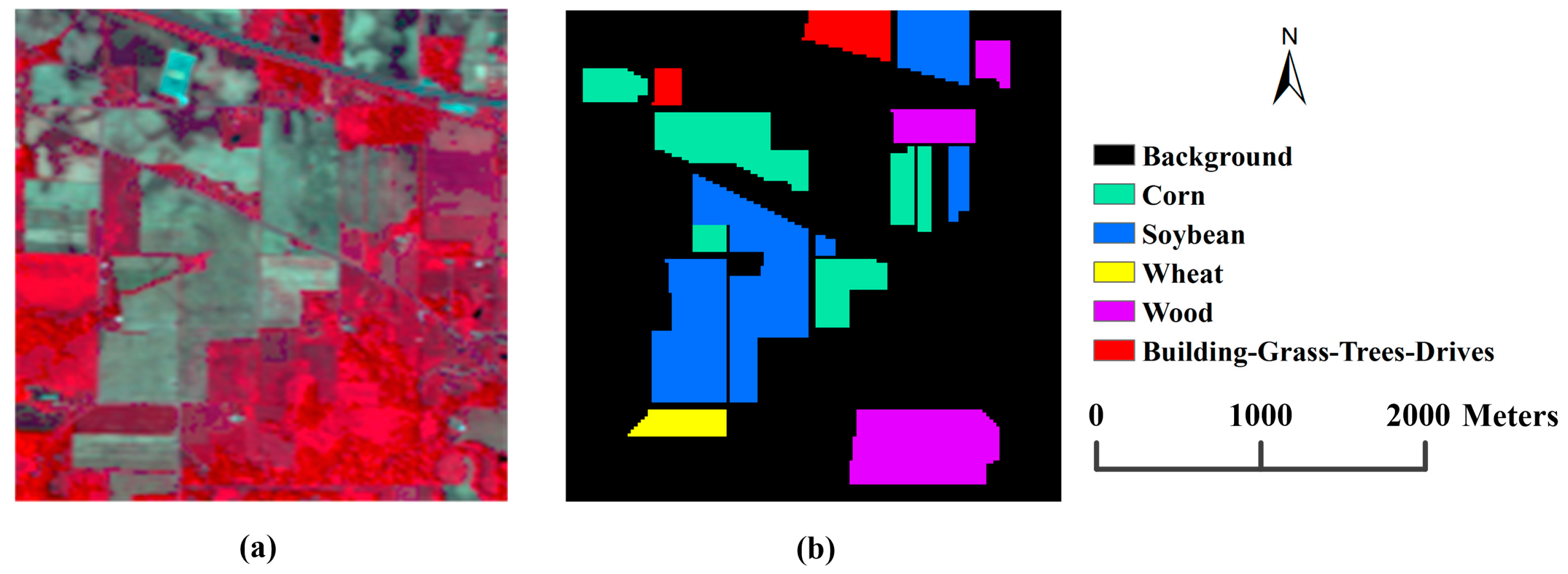
3.1. Data Set Description
3.2. Experimental Settings
3.3. Results
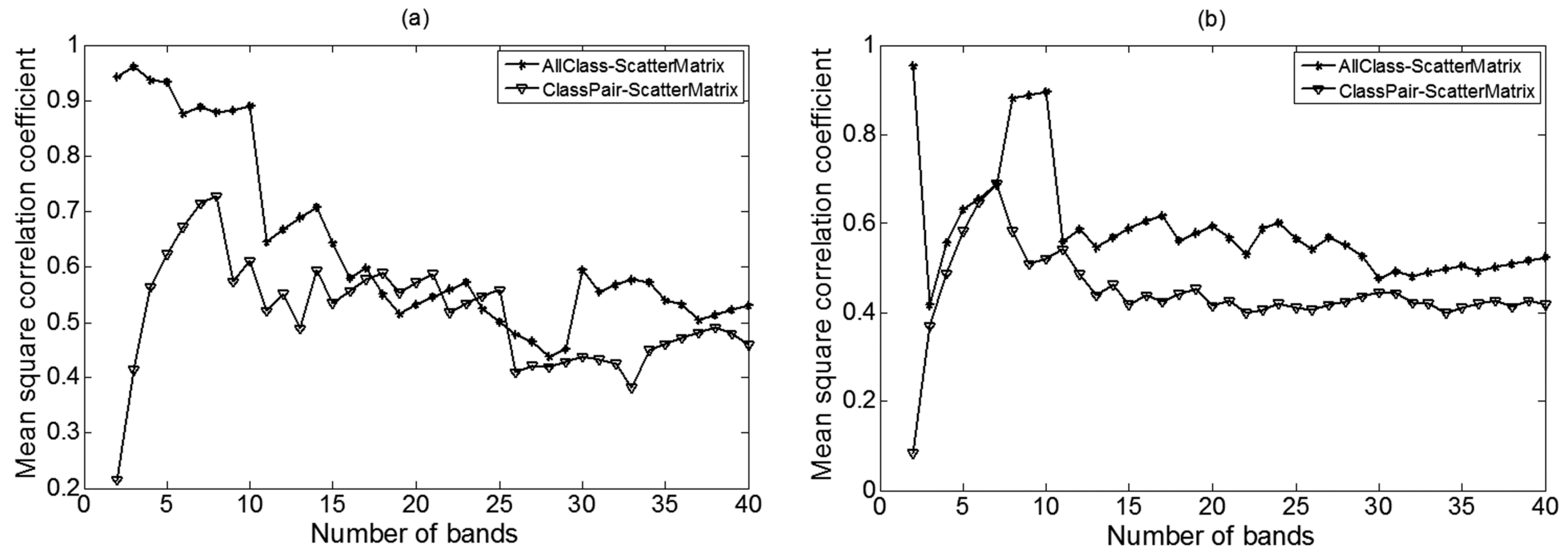
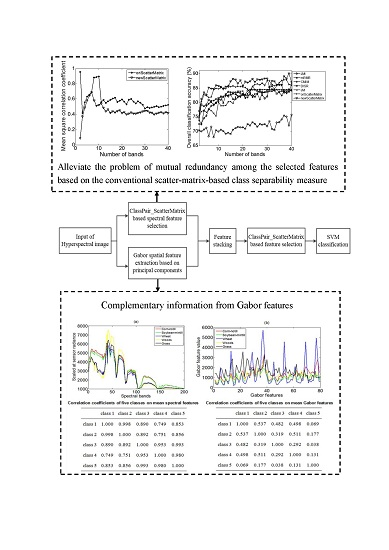
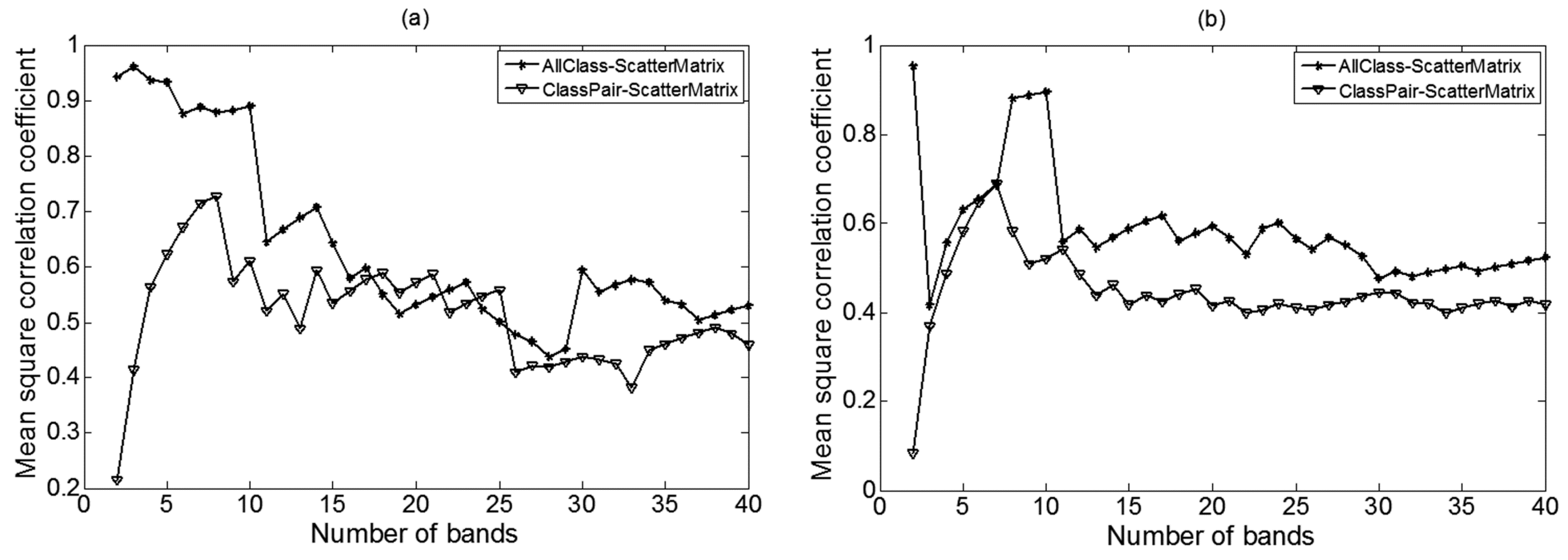
3.3.1. Performance of the Scatter-Matrix-Based Feature Selection Method
3.3.2. Complementary Information from Gabor Spatial Features
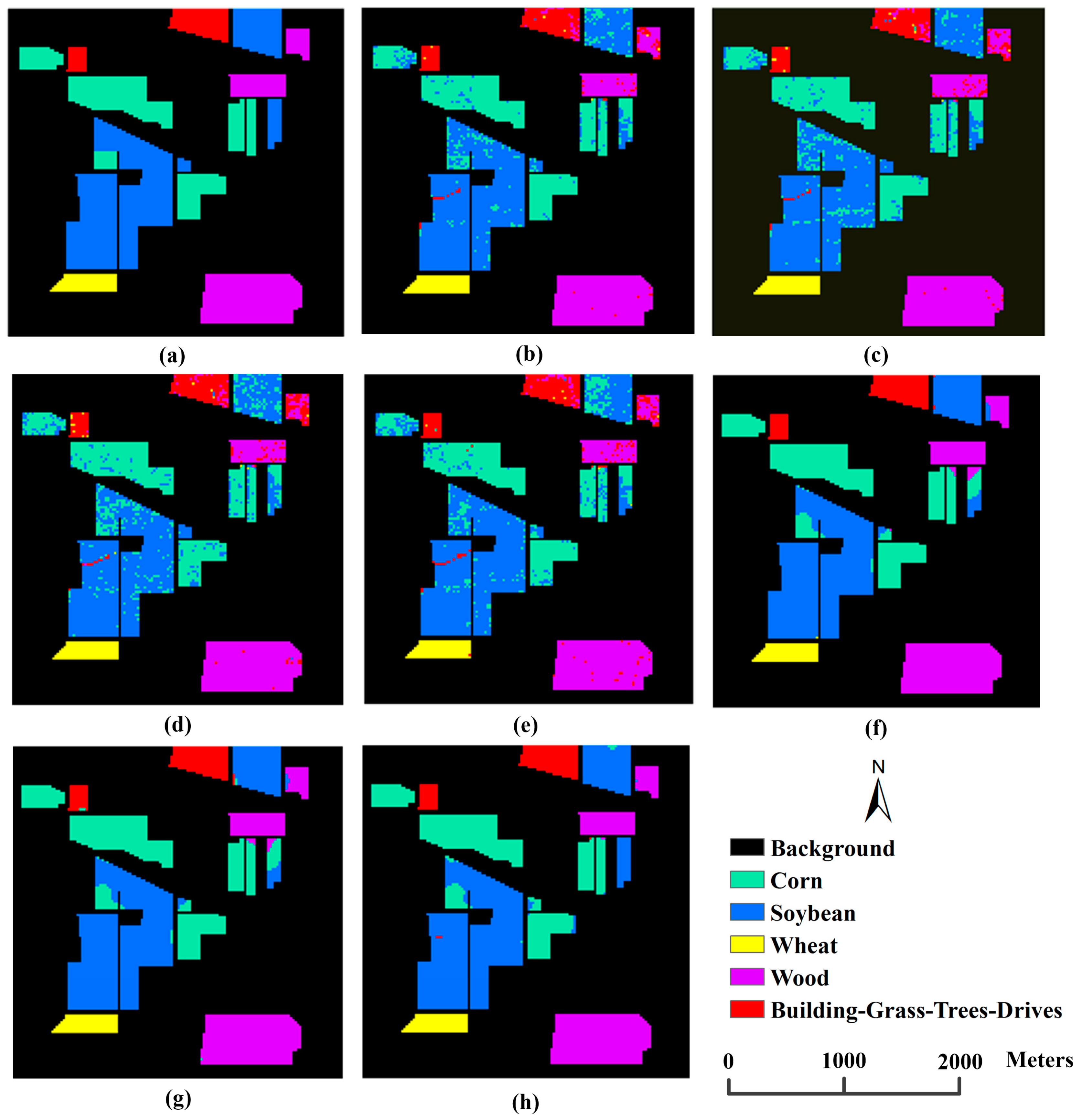
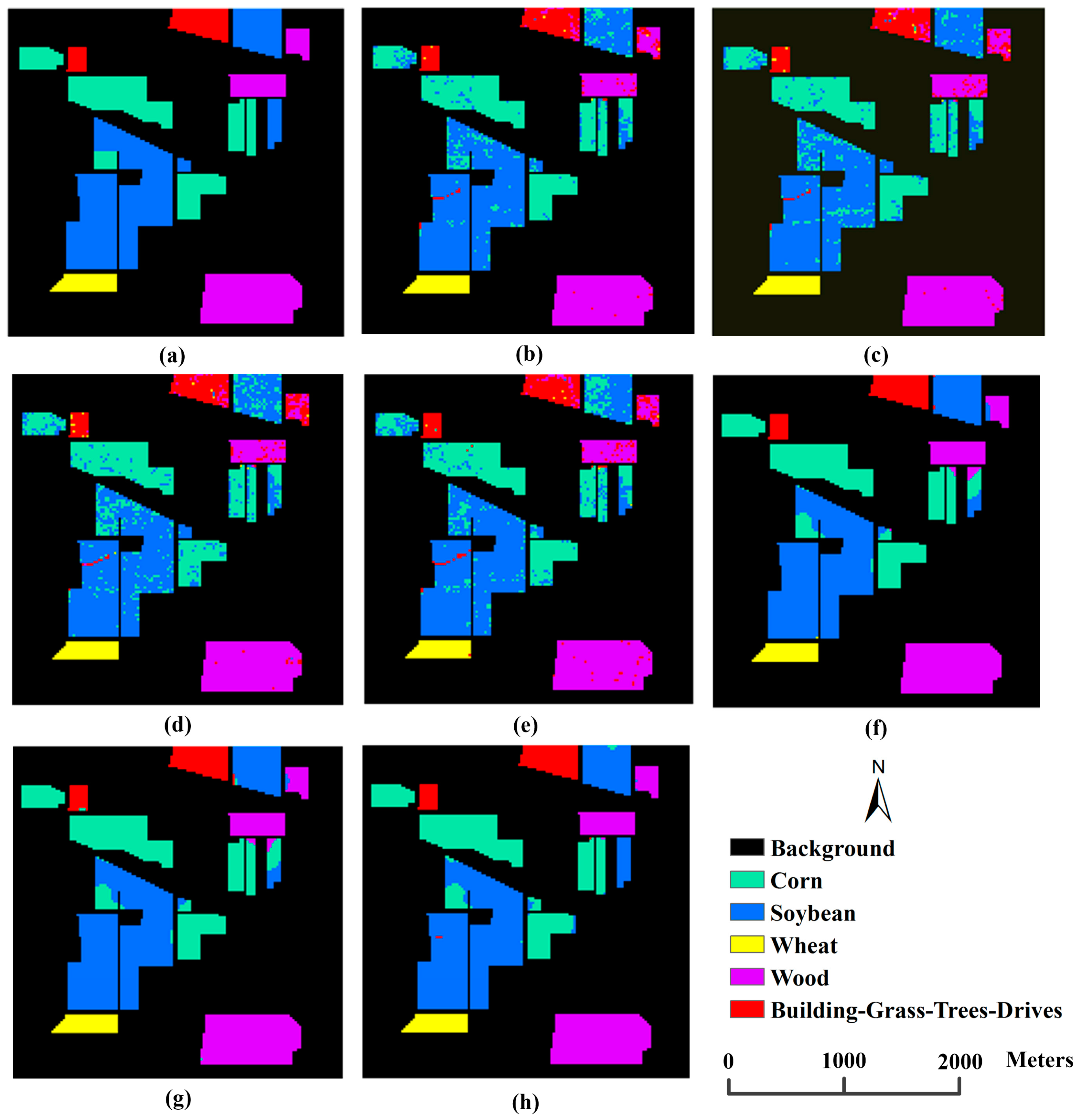
3.3.3. Performance of the Proposed Integrated Scheme
4. Discussions
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Richards, J.A.; Jia, X. Remote Sensing Digital Image Analysis, 4th ed.; Springer: Berlin, Germany, 2006. [Google Scholar]
- Lelong, C.C.; Pinet, P.C.; Poilvé, H. Hyperspectral imaging and stress mapping in agriculture: A case study on wheat in Beauce (France). Remote Sens. Environ. 1998, 66, 179–191. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Enclona, E.A.; Ashton, M.S.; Van Der Meer, B. Accuracy assessments of hyperspectral waveband performance for vegetation analysis applications. Remote Sens. Environ. 2004, 91, 354–376. [Google Scholar] [CrossRef]
- Huang, W.; Lamb, D.W.; Niu, Z.; Zhang, Y.; Liu, L.; Wang, J. Identification of yellow rust in wheat using in-situ spectral reflectance measurements and airborne hyperspectral imaging. Precis. Agric. 2007, 8, 187–197. [Google Scholar] [CrossRef]
- Mahesh, S.; Manickavasagan, A.; Jayas, D.S.; Paliwal, J.; White, N.D.G. Feasibility of near-infrared hyperspectral imaging to differentiate Canadian wheat classes. Biosyst. Eng. 2008, 101, 50–57. [Google Scholar] [CrossRef]
- Cheng, W.C.; Chang, J.C.; Chang, C.P.; Su, Y.; Tu, T.M. A fixed-threshold approach to generate high-resolution vegetation maps for IKONOS imagery. Sensors 2008, 8, 4308–4317. [Google Scholar] [CrossRef] [PubMed]
- Tu, T.M.; Lu, H.T.; Chang, Y.C.; Chang, J.C.; Chang, C.P. A new vegetation enhancement/extraction technique for IKONOS and QuickBird imagery. IEEE Geosci. Remote Sens. 2009, 6, 349–353. [Google Scholar]
- Plaza, A.; Martinez, P.; Plaza, J.; Pérez, R. Dimensionality reduction and classification of hyperspectral image data using sequences of extended morphological transformations. IEEE Trans. Geosci. Remote Sens. 2005, 43, 466–479. [Google Scholar] [CrossRef]
- De Backer, S.; Kempeneers, P.; Debruyn, W.; Scheunders, P. A band selection technique for spectral classification. IEEE Geosci. Remote Sens. 2005, 2, 319–323. [Google Scholar] [CrossRef]
- Jia, X.; Kuo, B.C.; Crawford, M.M. Feature mining for hyperspectral image classification. Proc. IEEE 2013, 101, 676–697. [Google Scholar] [CrossRef]
- Harsanyi, J.C.; Chang, C.I. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef]
- Pal, M. Multinomial logistic regression-based feature selection for hyperspectral data. Int. J. Appl. Earth Obs. Geoinform. 2012, 14, 214–220. [Google Scholar] [CrossRef]
- Hossain, M.A.; Jia, X.; Pickering, M. Subspace detection using a mutual information measure for hyperspectral image classification. IEEE Geosci. Remote Sens. 2014, 11, 424–428. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.; Pocock, A.; Zhao, M.J.; Luján, M. Conditional likelihood maximisation: A unifying framework for information theoretic feature selection. J. Mach. Learn Res. 2012, 13, 27–66. [Google Scholar]
- Fleuret, F. Fast binary feature selection with conditional mutual information. J. Mach. Learn Res. 2004, 5, 1531–1555. [Google Scholar]
- Meyer, P.E.; Schretter, C.; Bontempi, G. Information-theoretic feature selection in microarray data using variable complementarity. IEEE J. Sel. Top. Signal Process. 2008, 2, 261–274. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Wang, L. Feature selection with kernel class separability. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1534–1546. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Wang, L.; Shen, C. Feature selection with redundancy-constrained class separability. IEEE Trans. Neural Netw. 2010, 21, 853–858. [Google Scholar] [CrossRef] [PubMed]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Jiménez, L.O.; Rivera-Medina, J.L.; Rodríguez-Díaz, E.; Arzuaga-Cruz, E.; Ramírez-Vélez, M. Integration of spatial and spectral information by means of unsupervised extraction and classification for homogenous objects applied to multispectral and hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 844–851. [Google Scholar] [CrossRef]
- Kalluri, H.R.; Prasad, S.; Bruce, L.M. Decision-level fusion of spectral reflectance and derivative information for robust hyperspectral land cover classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4047–4058. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. On combining multiple features for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 879–893. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. A spatial–spectral kernel-based approach for the classification of remote-sensing images. Pattern Recognit. 2012, 45, 381–392. [Google Scholar] [CrossRef]
- Daugman, J.G. Complete discrete 2-D Gabor transforms by neural networks for image analysis and compression. IEEE Trans. Acoust. Speech. Signal Process. 1988, 36, 1169–1179. [Google Scholar] [CrossRef]
- Kumar, S.; Ghosh, J.; Crawford, M.M. Best-bases feature extraction algorithms for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1368–1379. [Google Scholar] [CrossRef]
- Maghsoudi, Y.; Valadan Zoej, M.J.; Collins, M. Using class-based feature selection for the classification of hyperspectral data. INT. J. Remote Sens. 2011, 32, 4311–4326. [Google Scholar] [CrossRef]
- Bai, J.; Xiang, S.; Shi, L.; Pan, C. Semisupervised Pair-Wise Band Selection for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2798–2813. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- D. A. Landgrebe. Available online: https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html (accessed on 20 March 2014).
- Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J. Spectral–spatial classification of hyperspectral imagery based on partitional clustering techniques. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2973–2987. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Huang, X.; Liu, X.; Zhang, L. A multichannel gray level co-occurrence matrix for multi/hyperspectral image texture representation. Remote Sens. 2014, 6, 8424–8445. [Google Scholar] [CrossRef]
- Kuo, B.C.; Landgrebe, D.A. Nonparametric weighted feature extraction for classification. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1096–1105. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Label | Class Name | Samples |
|---|---|---|
| class 1 | Corn-notill | 1428 |
| class 2 | Soybean-mintill | 2455 |
| class 3 | Wheat | 205 |
| class 4 | Wood | 1265 |
| class 5 | Building–Grass–Trees–Drives | 386 |
| Method | Num. of Bands | OA | KC | PA | ||||
|---|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | ||||
| JMI | 40 | 0.863 | 0.798 | 0.823 | 0.861 | 0.982 | 0.913 | 0.839 |
| mRMR | 40 | 0.757 | 0.644 | 0.708 | 0.732 | 0.945 | 0.883 | 0.623 |
| CMIM | 32 | 0.846 | 0.773 | 0.784 | 0.844 | 0.982 | 0.917 | 0.839 |
| DISR | 23 | 0.844 | 0.768 | 0.760 | 0.852 | 0.982 | 0.938 | 0.750 |
| JM | 24 | 0.856 | 0.788 | 0.843 | 0.843 | 1.000 | 0.899 | 0.818 |
| AllClass_ScatterMatrix | 38 | 0.879 | 0.821 | 0.854 | 0.871 | 1.000 | 0.930 | 0.822 |
| ClassPair_ScatterMatrix | 39 | 0.901 | 0.853 | 0.891 | 0.885 | 1.000 | 0.948 | 0.856 |
| All bands | 200 | 0.874 | 0.814 | 0.851 | 0.880 | 1.000 | 0.888 | 0.856 |
| Method | Num. of Fea. | OA | KC | PA | ||||
|---|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | ||||
| ClassPair_ScatterMatrix | 31 | 0.872 | 0.814 | 0.873 | 0.862 | 0.990 | 0.900 | 0.780 |
| GLCM | 8 | 0.857 | 0.798 | 0.864 | 0.803 | 1.000 | 0.915 | 0.990 |
| Gabor | 80 | 0.955 | 0.935 | 0.980 | 0.918 | 1.000 | 0.986 | 1.000 |
| Morph | 20 | 0.904 | 0.860 | 0.870 | 0.884 | 0.990 | 0.967 | 0.941 |
| SpeSpaDF | 31/80 | 0.916 | 0.879 | 0.989 | 0.823 | 0.990 | 0.997 | 0.979 |
| SpeSpaVS_NWFE | 29 | 0.964 | 0.948 | 0.972 | 0.937 | 1.000 | 0.999 | 1.000 |
| SpeSpaVS_ClassPair_ScatterMatrix | 23 | 0.976 | 0.964 | 0.977 | 0.959 | 1.000 | 0.998 | 0.990 |
| Method | Num. of Fea. | OA | KC | PA | ||||
|---|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | ||||
| ClassPair_ScatterMatrix | 39 | 0.901 | 0.853 | 0.891 | 0.885 | 1.000 | 0.948 | 0.856 |
| GLCM | 8 | 0.874 | 0.818 | 0.894 | 0.825 | 1.000 | 0.921 | 0.987 |
| Gabor | 80 | 0.967 | 0.951 | 0.984 | 0.944 | 1.000 | 0.987 | 1.000 |
| Morph | 20 | 0.926 | 0.890 | 0.871 | 0.928 | 1.000 | 0.970 | 0.987 |
| SpeSpaDF | 39/80 | 0.930 | 0.897 | 0.991 | 0.858 | 1.000 | 0.996 | 0.979 |
| SpeSpaVS_NWFE | 29 | 0.974 | 0.961 | 0.986 | 0.951 | 1.000 | 0.995 | 1.000 |
| SpeSpaVS_ClassPair_ScatterMatrix | 24 | 0.986 | 0.980 | 0.991 | 0.979 | 1.000 | 0.993 | 1.000 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Zhao, C.; Wang, J.; Jia, X.; Yang, G.; Song, X.; Feng, H. An Improved Combination of Spectral and Spatial Features for Vegetation Classification in Hyperspectral Images. Remote Sens. 2017, 9, 261. https://doi.org/10.3390/rs9030261
Fu Y, Zhao C, Wang J, Jia X, Yang G, Song X, Feng H. An Improved Combination of Spectral and Spatial Features for Vegetation Classification in Hyperspectral Images. Remote Sensing. 2017; 9(3):261. https://doi.org/10.3390/rs9030261
Chicago/Turabian StyleFu, Yuanyuan, Chunjiang Zhao, Jihua Wang, Xiuping Jia, Guijun Yang, Xiaoyu Song, and Haikuan Feng. 2017. "An Improved Combination of Spectral and Spatial Features for Vegetation Classification in Hyperspectral Images" Remote Sensing 9, no. 3: 261. https://doi.org/10.3390/rs9030261