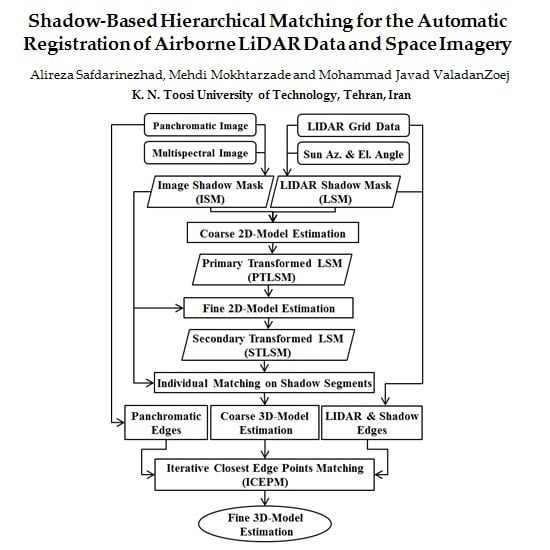
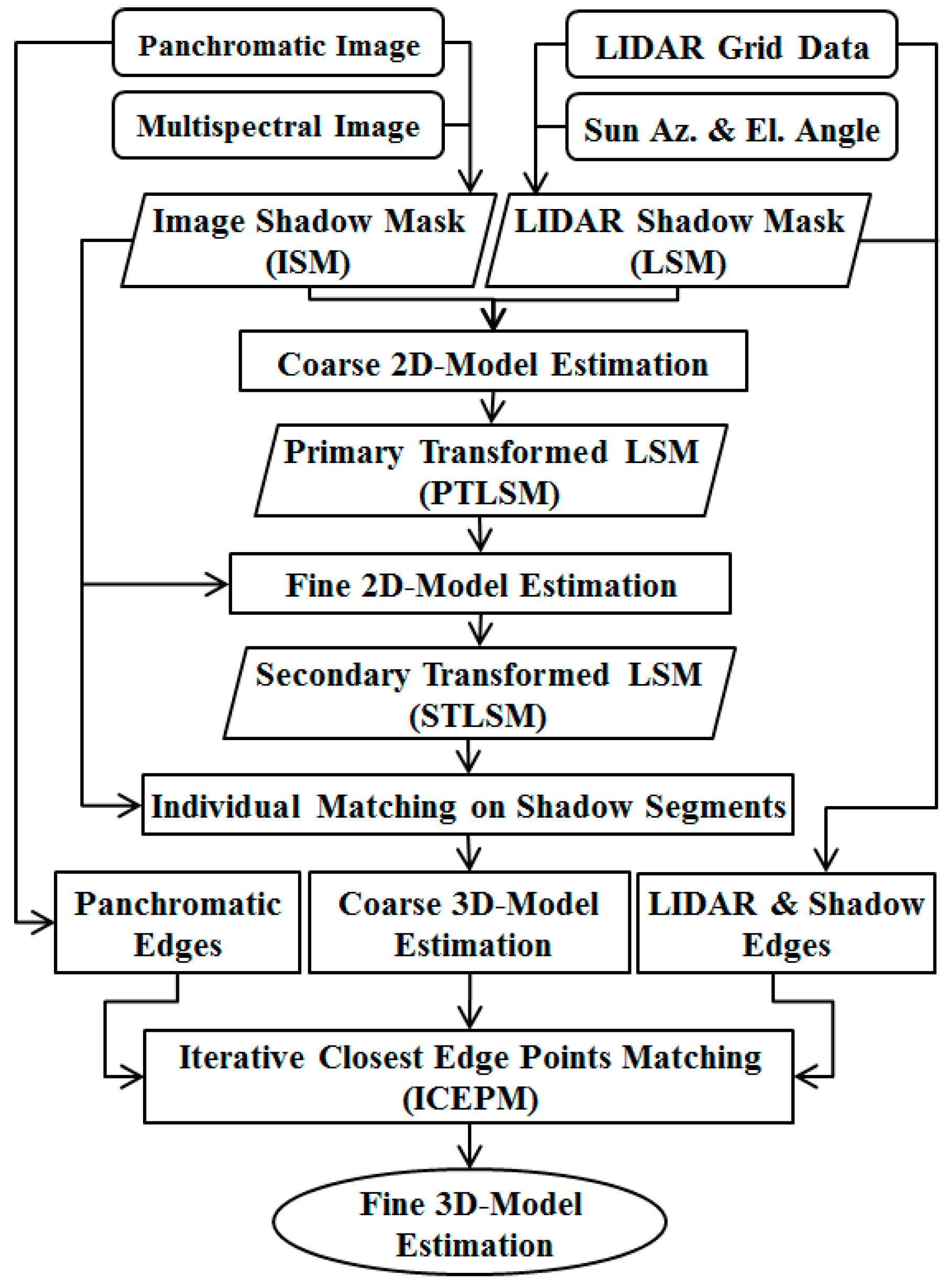
4.1.1. Automatic Shadow Extraction in HRSI
To date, several algorithms have been developed for shadow detection and segmentation from remote sensing images [
25,
26]. These methods have very diverse methodologies such as texture and morphology features [
15,
16], enhancing and thresholds [
14], color spaces and spectral characteristics [
15,
17,
18,
26,
27,
28,
29,
30,
31], region growing segmentation [
15], using complementary data such as DSM [
13] and hybrid strategies [
14,
15]. It is worth noting that the radiometric similarity of shadows and features with low reflectance (e.g., water, asphalt,
etc.) is one of the main challenges in this field.
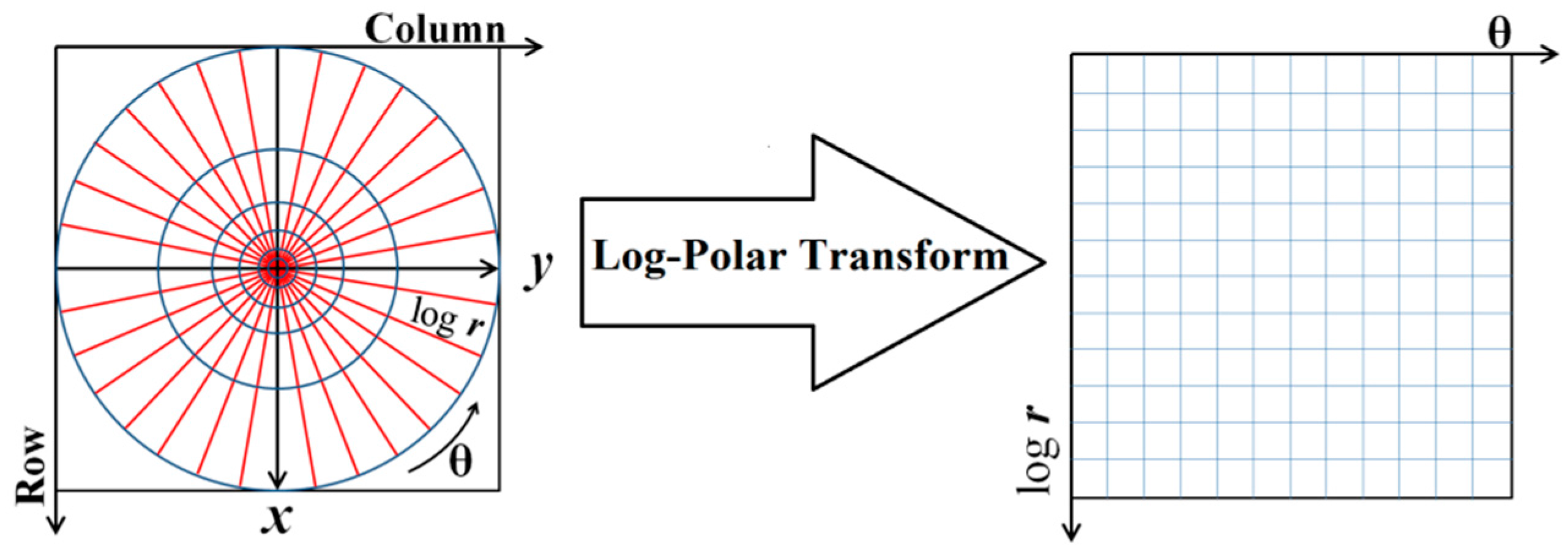
In most HRSI, spectral bands are available along with the panchromatic images. Therefore, it is preferable to exploit all of these bands for shadow detection. Accordingly, the proposed shadow detection algorithm was designed in the spectral feature space, where it was intended to be fully automatic (
i.e., needed no operator interaction) [
32].
Among the variety of proposed spectral features for shadow detection, two groups that are based on the color invariant transforms were used in this study [
29,
30,
31]. These features are introduced in Equations (2)–(8).
In the above equations, B, G, R and NIR are blue, green, red and near infrared bands respectively. Equations (5) and (8) were not proposed in the original references [
29,
30,
31] but were extended in this study due to the availability of the NIR band and its effectiveness in vegetation suppression.
These features, when normalized, were used to discriminate shadows from non-shadow regions.
Figure 5 shows these normalized features beside the panchromatic image for a subset of QB image. They are specifically designed to provide separation of shadows from other image features [
29,
30,
31]. Visual inspection of
Figure 5 demonstrates the separability of the shadows by these features.
The above mentioned features, called Normalized Color Invariant Features (NCIFs), were then applied in traditional K-Means clustering to recognize pixels in the shadow regions. The preliminary image clustering results via the NCIFs showed promising separability of shadow with other phenomena. In this respect, shadow cluster was characterized as a resistant cluster against the variations in the number of clusters.
Figure 6 shows the K-Means clustering results for different cluster numbers. In this figure, shadow cluster is shown by red.
For designing a fully automatic process, clustering initialization, setting parameters and the automatic recognition of shadow cluster are the main challenges to be addressed. A novel clustering strategy, incremental clustering, was therefore designed and is described below [
32].
Incremental clustering was conceptually designed based on a geometric and a radiometric interpretation of shadow characteristics. In the geometric interpretation of shadows, their separability with other phenomena was considered. In that respect, a shadow cluster was characterized as a resistant cluster against the variations in the number of clusters. In other words, it was expected that the cluster containing shadow pixel would have negligible changes when the clustering was repeated with different number of initial clusters. This characteristic was quantified via a Geometric Index (GI), which is described later.
In the radiometric interpretation of shadows, their homogenous and dark natures were considered. Accordingly, the shadow cluster was characterized as a cluster that contained pixels with low intensities (i.e., digital numbers, DNs) in the panchromatic image. This radiometric interpretation was also quantified via a Radiometric Index (RI), which is introduced later.
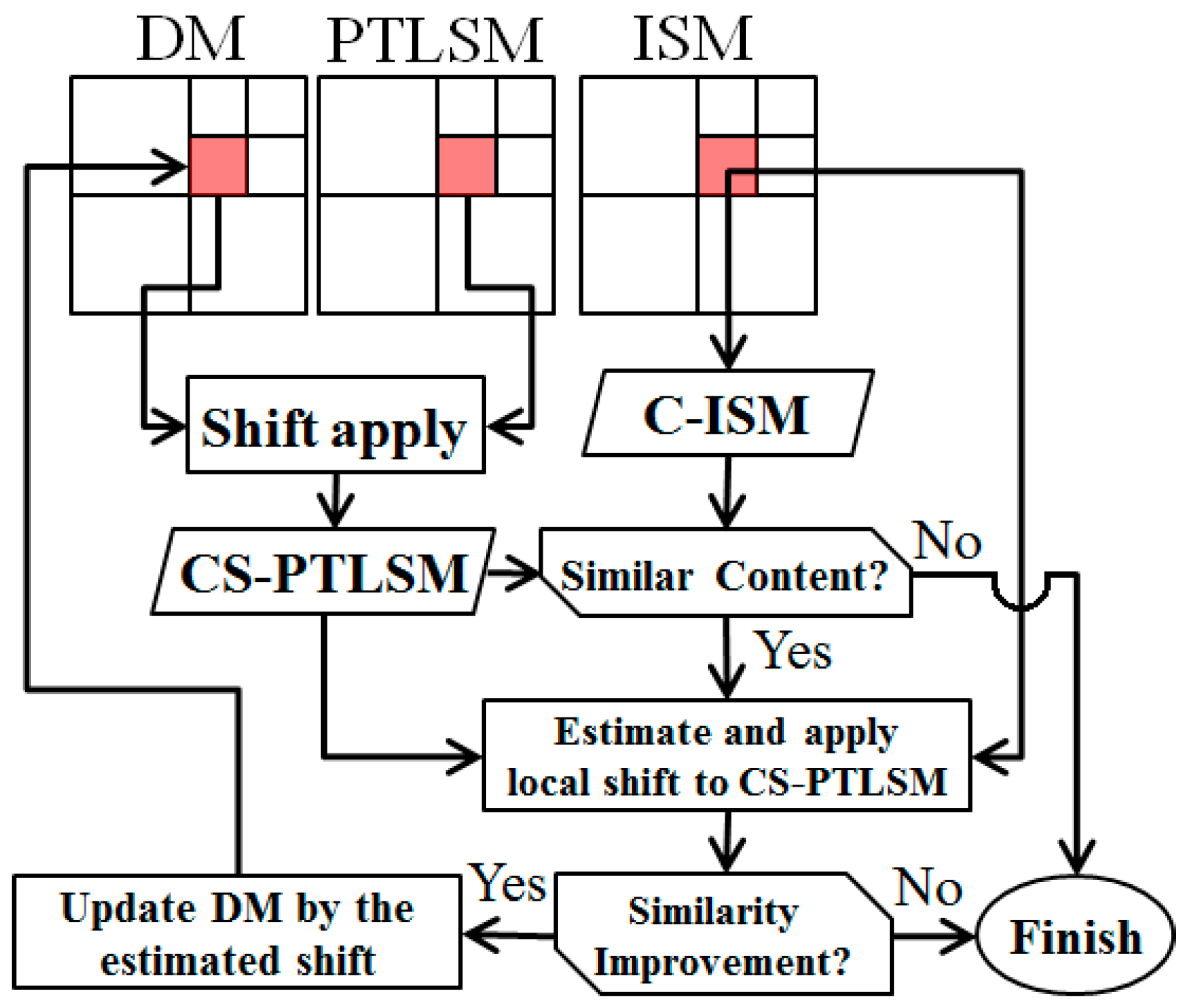
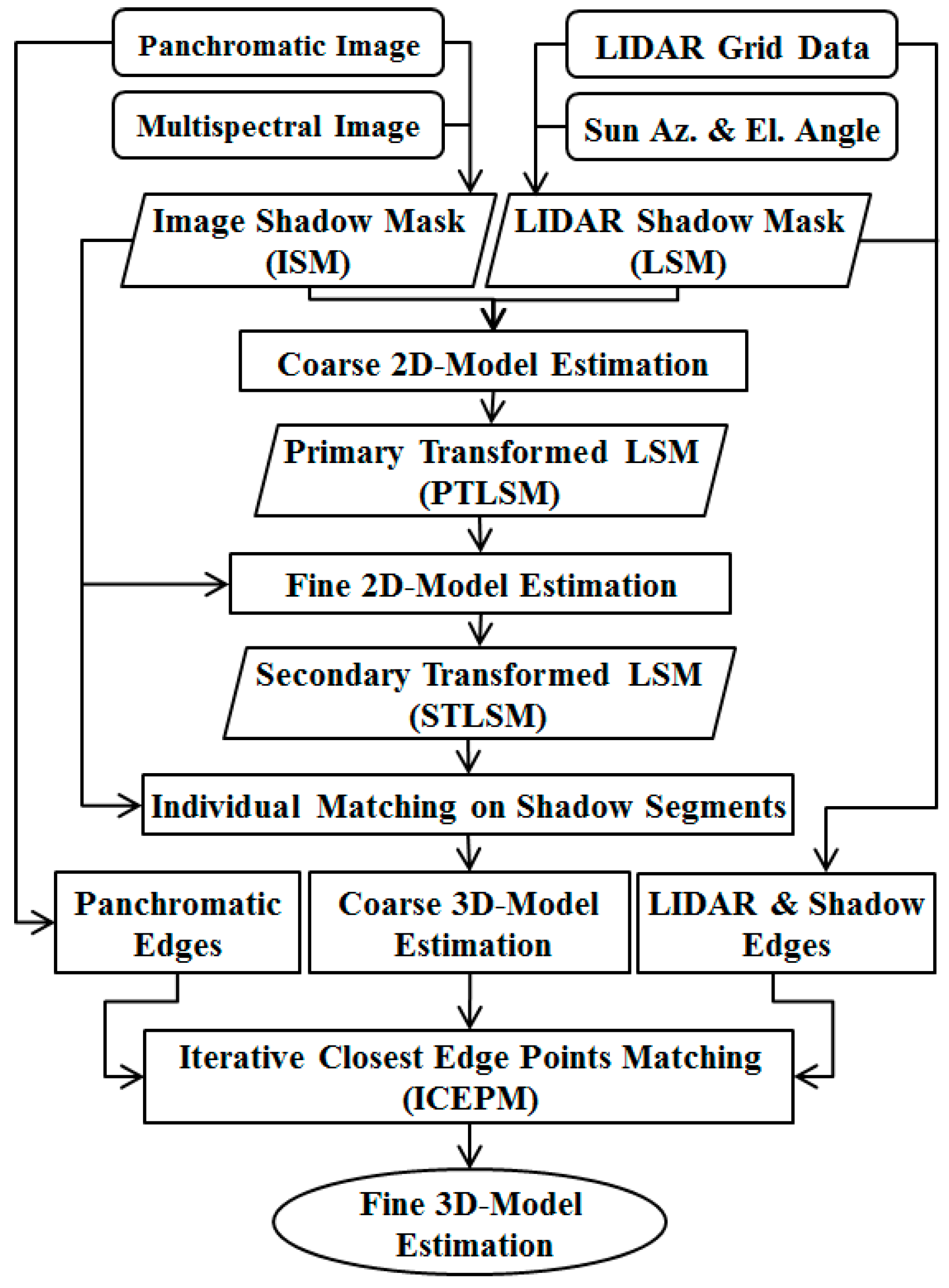
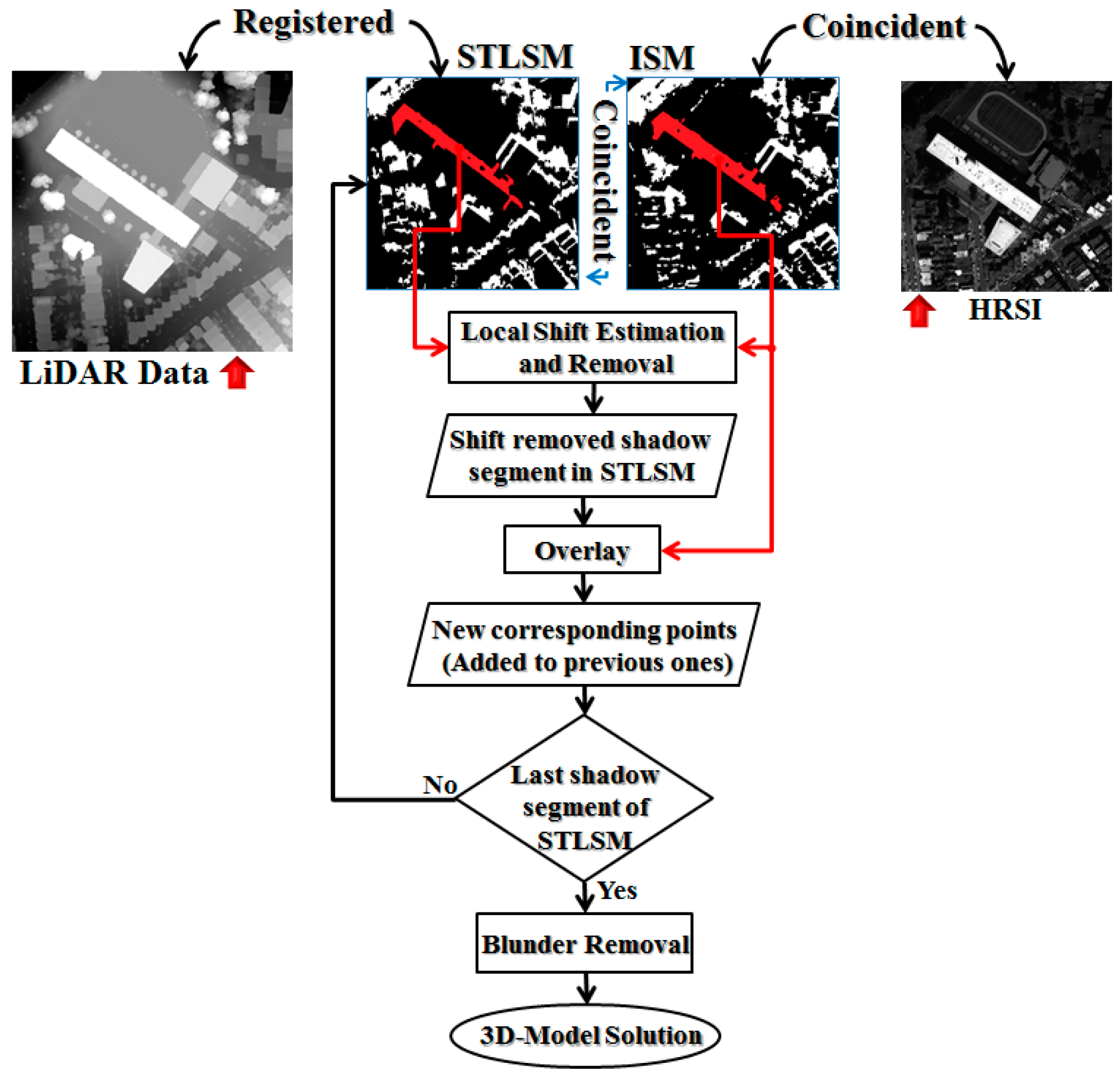
According to these two interpretations, an iterative and fully automatic shadow extraction process was designed and is described in the next page entitled as Algorithm 1.
According to the Algorithm 1, a binary mask, NI, is produced in each iteration, which is finally (i.e., after the convergence of iterations) regarded as the initial Image Shadow Mask (iISM). The iteration is repeated until NI experienced less than a 3% change in two successive iterations.
In this algorithm, clustering maps (cmj; j = 1, 2, …, n) are produced through a gradual increase in the number of clusters (Kj). A majority filter is then applied to each cluster map to improve its spatial consistency.
In line 12 and in each iteration, all possible clusters permutations (
i.e., {CP} = {CP
1, CP
2, …,
}) are generated. Each permutation is comprised of an
n-member set of C
ji binary maps. Each binary map, say C
ji, is related to one of the clusters (according to the permutation order) in the
jth clustering map, CM
j (Equation (9)).
Given that cm
1, cm
2,…, cm
n consists of K
1, K
1 + 1, …, K
n clusters, respectively, the number of all possible permutations,
mn, is shown in Equation (10).
A map intersection (MI
i) was produced from each permutations of {CP
i} as shown in Equation (11).
The Shadow Fitness of each map intersection MI
i is computed according to its geometric and radiometric indices, as shown in Equation (12).
The Geometric and Radiometric Indices, which are represented by GI
i and RI
i, respectively, are computed for each map intersection MI
i using Equations (13) and (14).
Here, Nr ( ) is a counter of the number of pixels with true values in a binary image, and PAN<MIi> represents a vector of normalized PAN digital numbers taken from the pixels assigned to MIi.
| Algorithm 1 Incremental Clustering for Shadows Detection |
Input: Normalized Panchromatic Image (PAN)
Normalized Color Invariant Features (NCIFs)
Output: Image Shadow Mask
|
1 n = 1 /* Iteration Number /
2 Kn = 3 /* minimum number of clusters /
3 cm1 ← K1-Means Clustering of the NCIFs
4 Estimate Radiometric Index (RI) for each cm1’s Cluster
5 NI ← Set the binary map correspond to the cluster with minimum RI as the New
Index /* first New Index /
6 BEGIN
7 | LI ← Set the NI as the Last Index
8 | n ← n + 1
9 | Kn ← Kn−1 + 1
10 | cmn ← Kn-Means Clustering of the NCIFs
11 | Majority filtering of the cmn /* to improve its spatial consistency /
12 | {CP} ← Generate all Clusters Permutations among {CM} = {cm1, …, cmn}
13 | {MI} ← Generate the Map of Intersection for each member of {CP} (Equation (11))
14 | {SF} ← Estimate Shadow Fitness for each member of {MI} (Equations (12)–(14))
15 | NI ← Set the MI correspond the maximum value of SF as the New Index
16 | Θ ∈ [0, 1] ← Compute the Area Consistency of NI and LI (Equation (15))
17 DO UNTIL Θ < 0.97
18 iISM ← Set the NI as the initial Image Shadow Mask
19 (μ, σ) ← mean and std of PAN<iISM>after successive blunder removals
20 PAN_Slice ← Generate the binary PAN_Slice via (Equation (16))
21 Segment PAN_Slice via N-8 neighborhood analysis
22 FOR all PAN_ Slice’s segments
23 | PAN_Slicei ← ith PAN_ Slice’s segment
24 | IF (PAN_Slicei ∩ iISM) ≠ ø THEN iISM = iISM ∪ PAN_Slicei
25 END
26 ISM ← Set the iISM as the Image Shadow Mask
|
According to Equation (13), GIi shows the spatial consistency among the binary maps of a cluster permutation (i.e., {CPi}). If the binary maps associated to {CPi} (i.e., Cji) are similar, then their map intersection MIi will be approximately the same as the Cji binary maps, which increases the GIi measure for that cluster permutation. In other words, a large value of GIi [0, 1] indicates an increased stability of the associated clusters in {CPi} against the increase in the number of clusters. As mentioned before, this index is expected to have large values for a shadow cluster due to its considerable separability with other image phenomena.
Conversely, in Equation (14), RIi is an index of the mean and variation of the intensity for the pixels associated with MIi. The lower values of RIi are expected when all of the clusters are associated to {CPi}, and thus their map intersection MIi belong to dark and homogenous objects such as shadows.
The map intersection MI
i with the highest SF value is selected as the New Index (NI) map (Line 15). The area consistency of this NI with the Last Index (LI) is then measured via Equation (15) and is used as the convergence criterion. In this equation and in rest of the paper, Nr( ) has the same meaning as in Equation (13).
The last NI, which is obtained after the convergence, is considered as the initial Image Shadow Mask (iISM). This iISM, which is the intersection of all of the shadow clusters, suffers from gaps and discontinuity and is thus refined via the panchromatic image (Lines 18–25). To do so, the mean (µ) and standard deviation (σ) of PAN<iISM> is computed and refined iteratively with a 2.5σ statistical test. The PAN< > operator is the same as that in Equation (14). A PAN_Slice binary map is then produced via Equation (16).
In the above equation, PAN (
i,
j) represents the normalized digital number of the panchromatic image in the (
i,
j) position. The PAN_Slice is then segmented via an N-8 connectivity analysis in which two true-valued pixels are connected when located in the 8 neighboring of each other. Those segments connected to the iISM are finally added to it for gap removal.
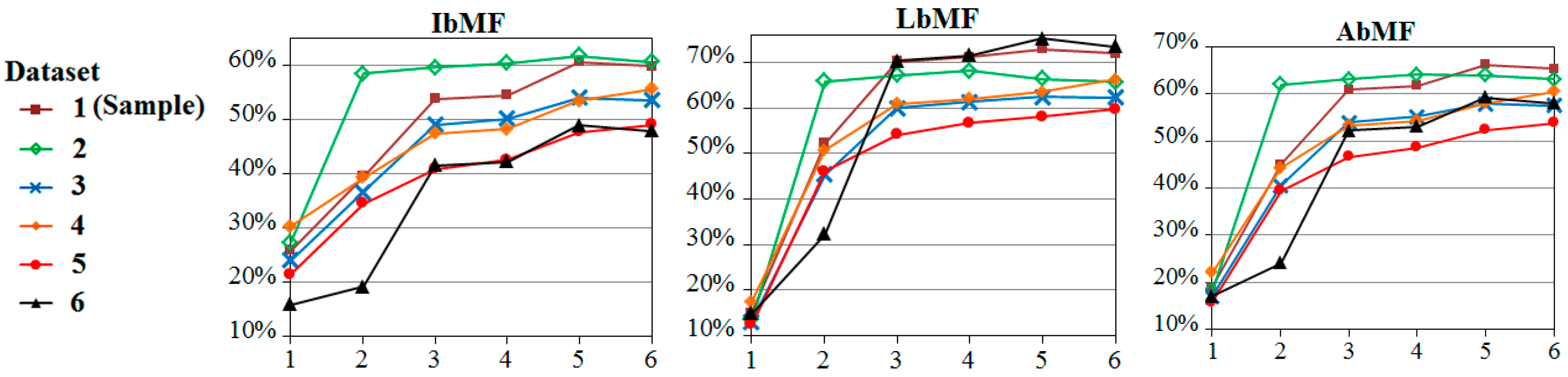
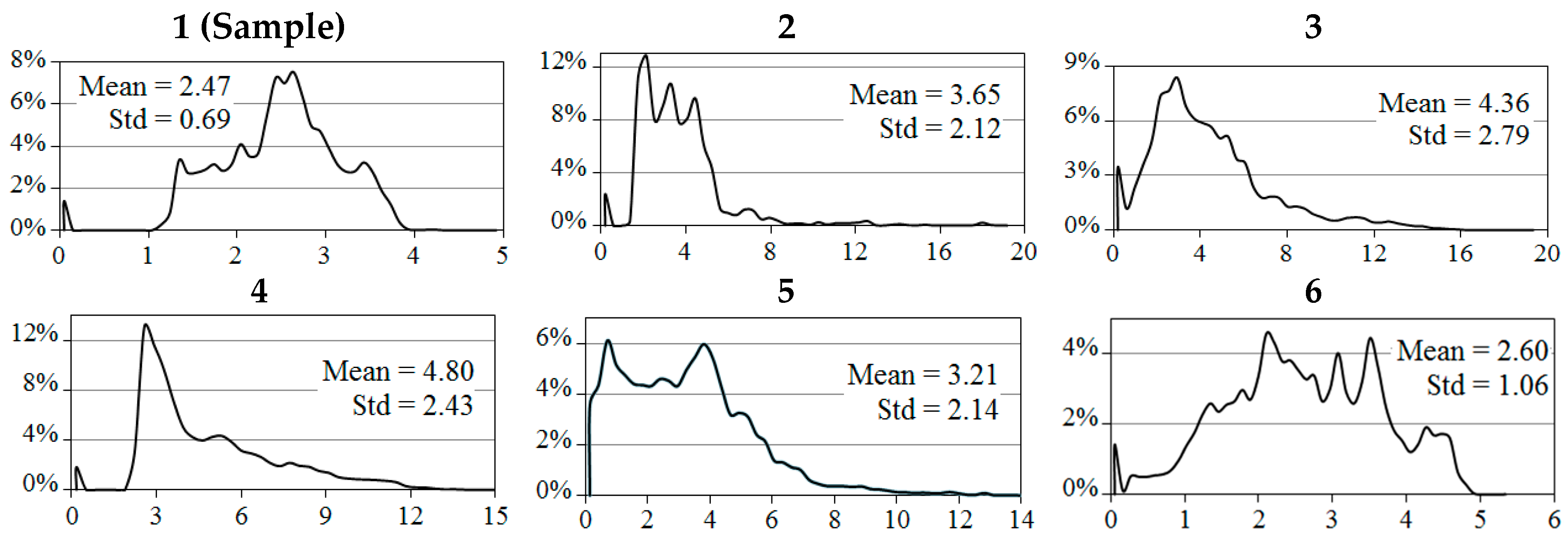
Figure 7 shows the result of the ISM generation from the sample dataset’s QB image.
Figure 7 shows the success of the proposed ISM extraction in recognizing the shadow cluster. In general, the extracted ISM and true image shadows are similar; however, there are discontinuities in the results as well as some unrecognized shadow pixels.
In order to evaluate the produced ISM, some reference shadow and non-shadow regions were manually identified to form the confusion matrix. Non-shadow regions were mainly selected from dark image objects which are more prone to be misclassified as shadow. The overall accuracy of 91% was achieved while user accuracy of shadow and non-shadow classes were 99% and 82% respectively. Although shadow detection is not the ultimate purpose of this study, the preliminary results are sufficiently satisfactory to motivate the further development of this idea in future research that will concentrate on shadow detection. The separability of shadows from other image objects is an assumption of this method that can be weakened, for example, by high sun elevation angles, the high presence of dark objects (e.g., asphalt) and vast water covered regions. Furthermore, the presence of clouds may degrade the results. These concerns can be the subject of further studies.
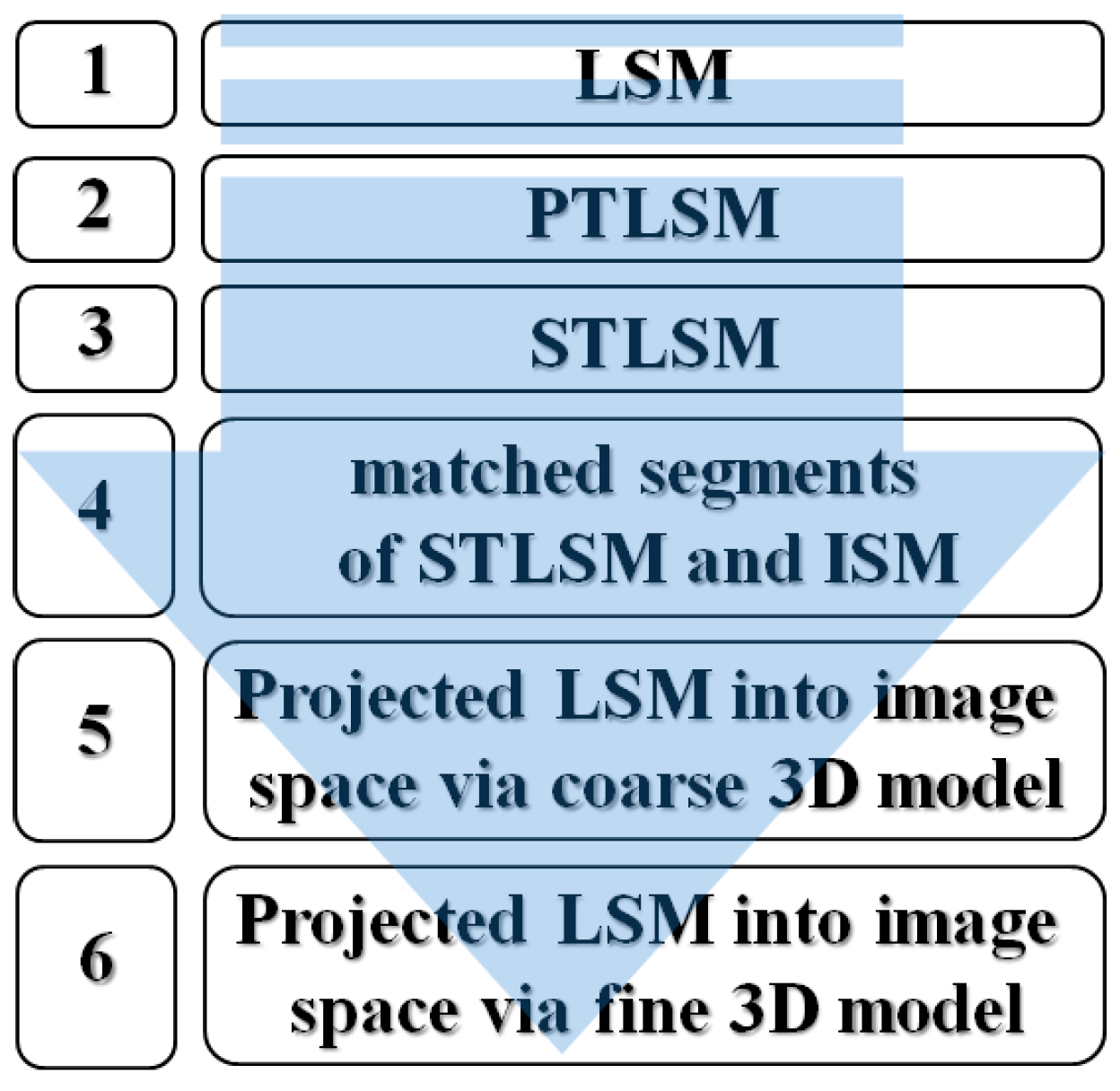
4.1.2. Automatic Shadow Extraction in LiDAR
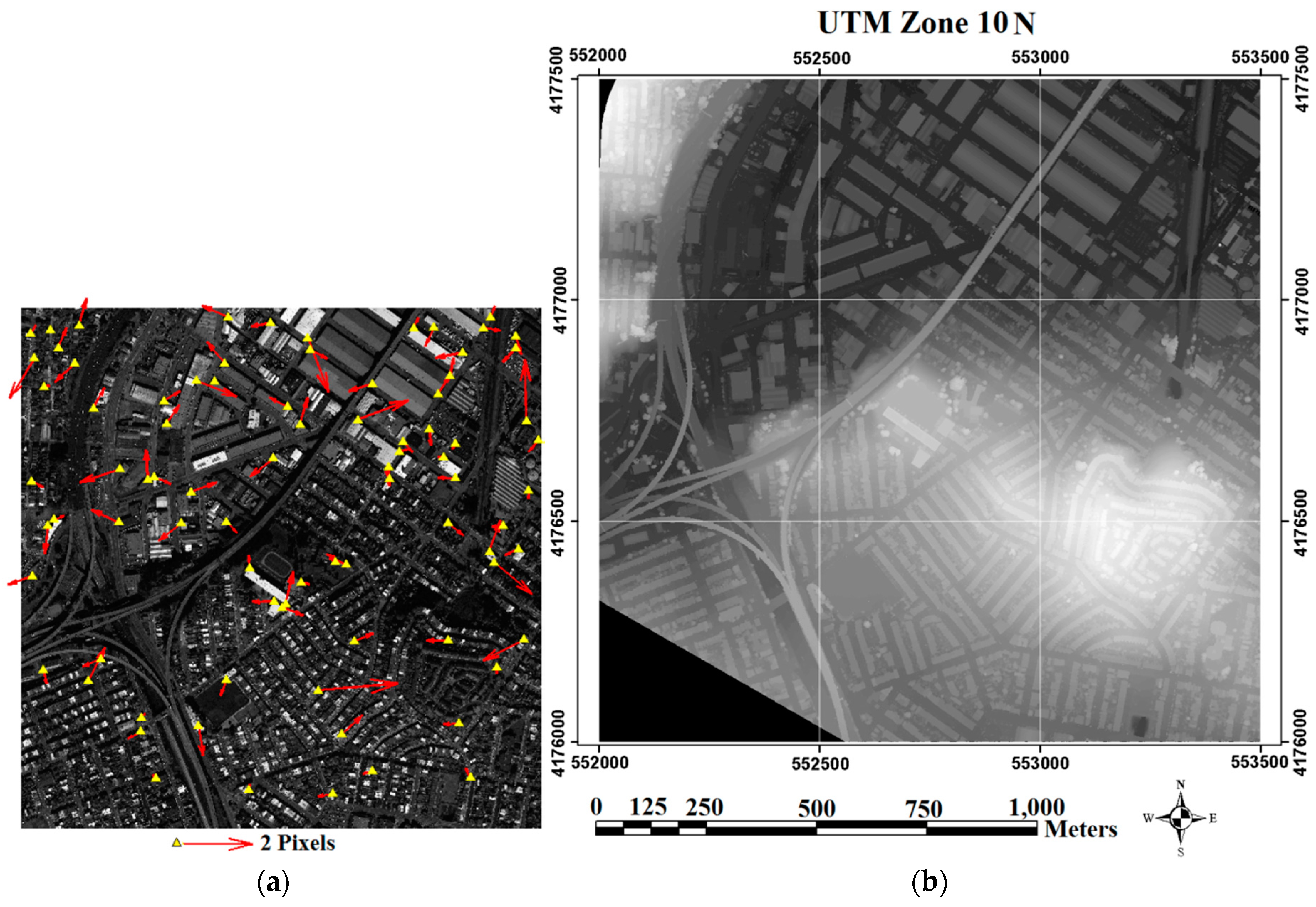
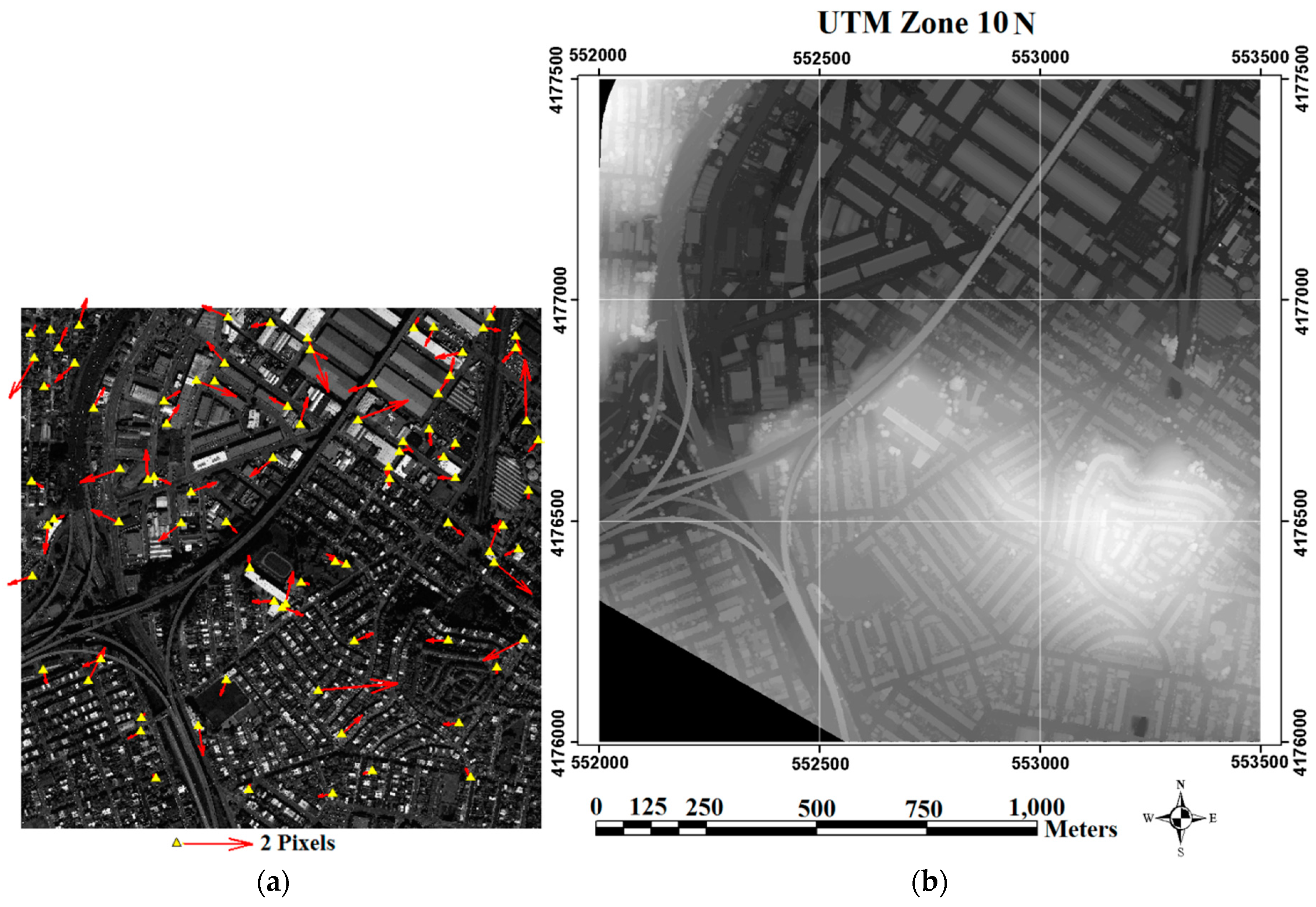
From the geometrical point of view, the LiDAR Grid data (
Figure 3b) and relevant information of the light source provide the necessary information for virtual shadow reconstruction. From an assumption of the availability of the sun azimuth (Az.) and elevation angles (Elv.), a simple algorithm was designed for the reconstruction of shadows from LiDAR data.
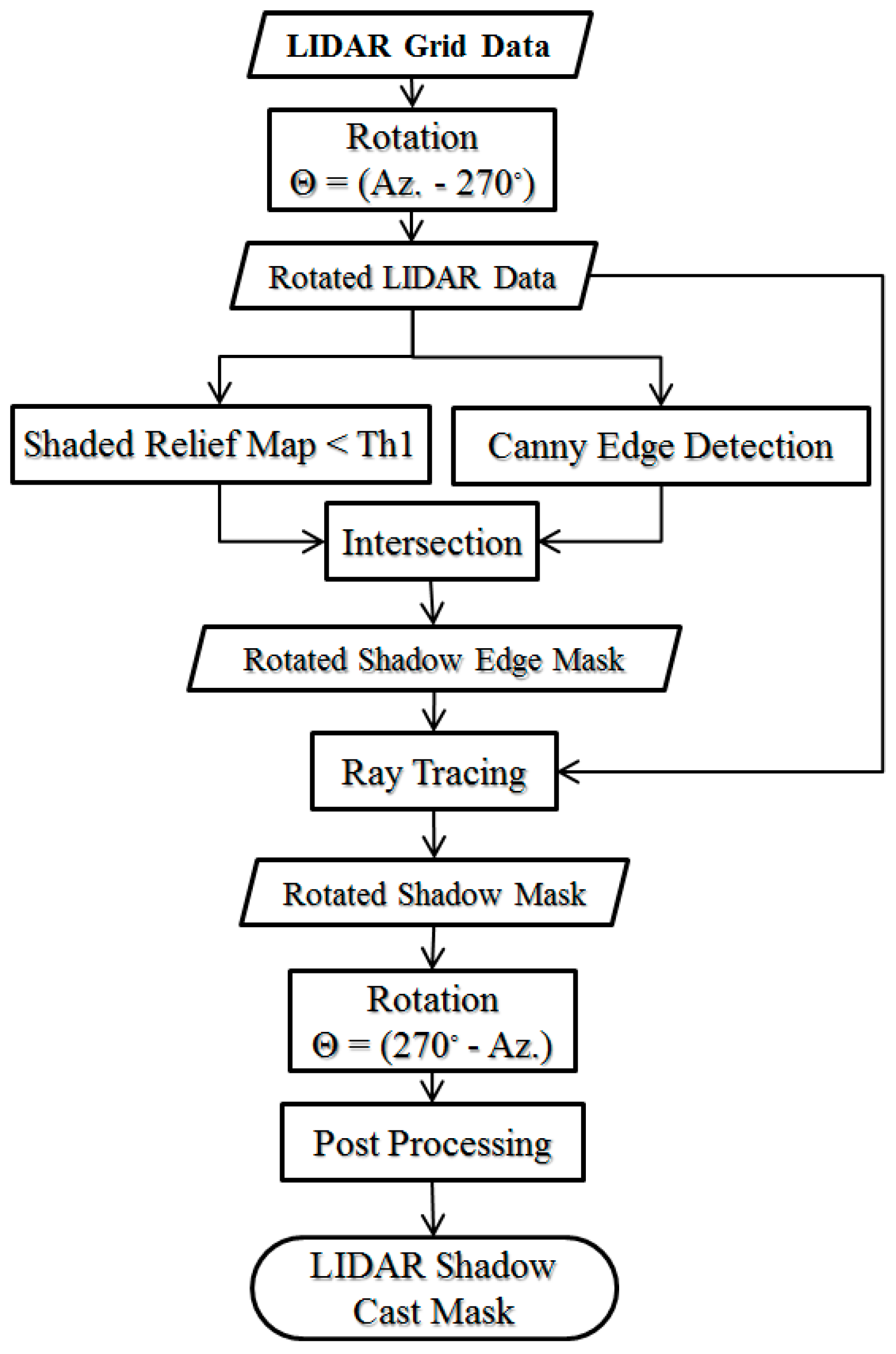
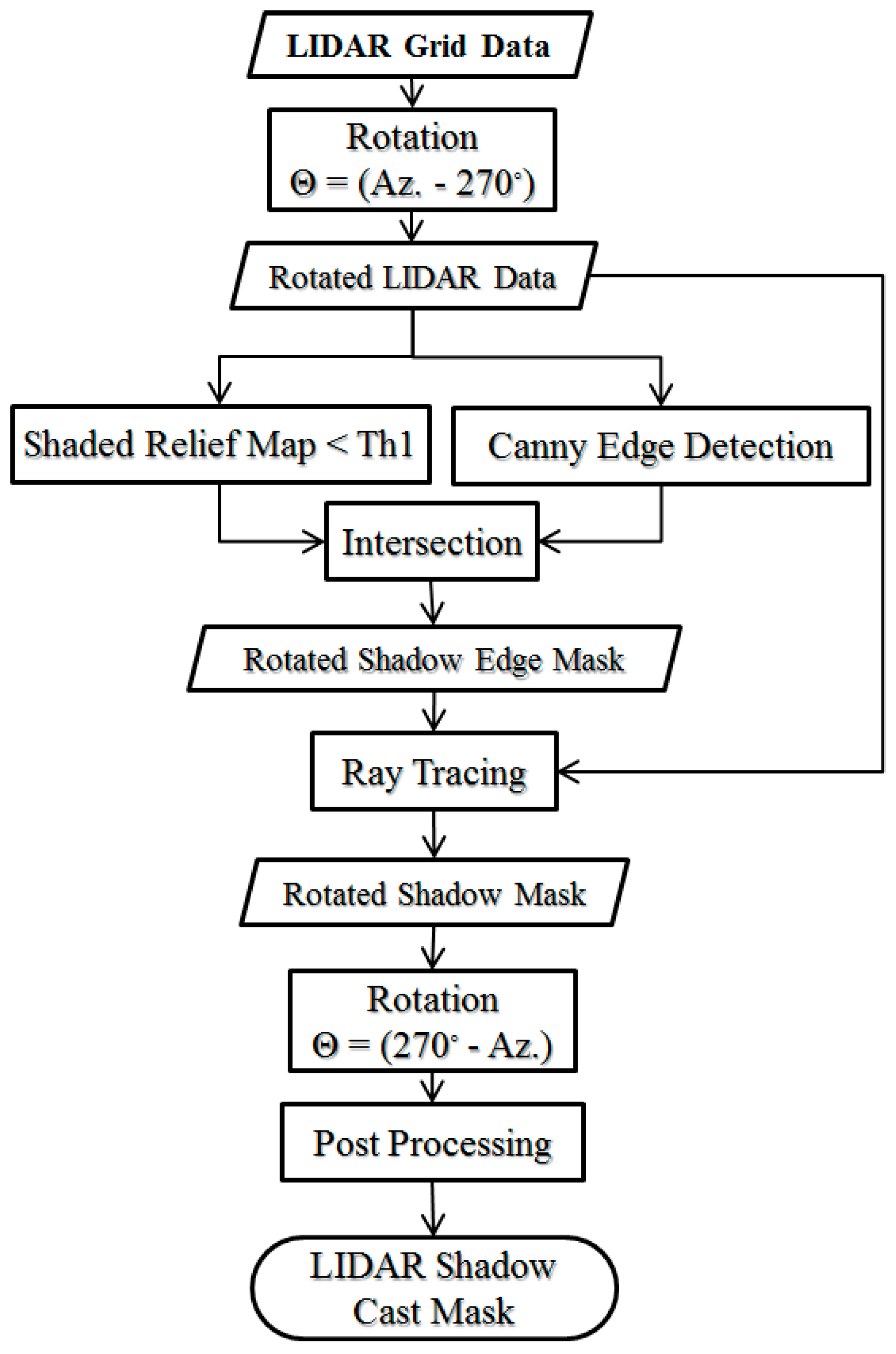
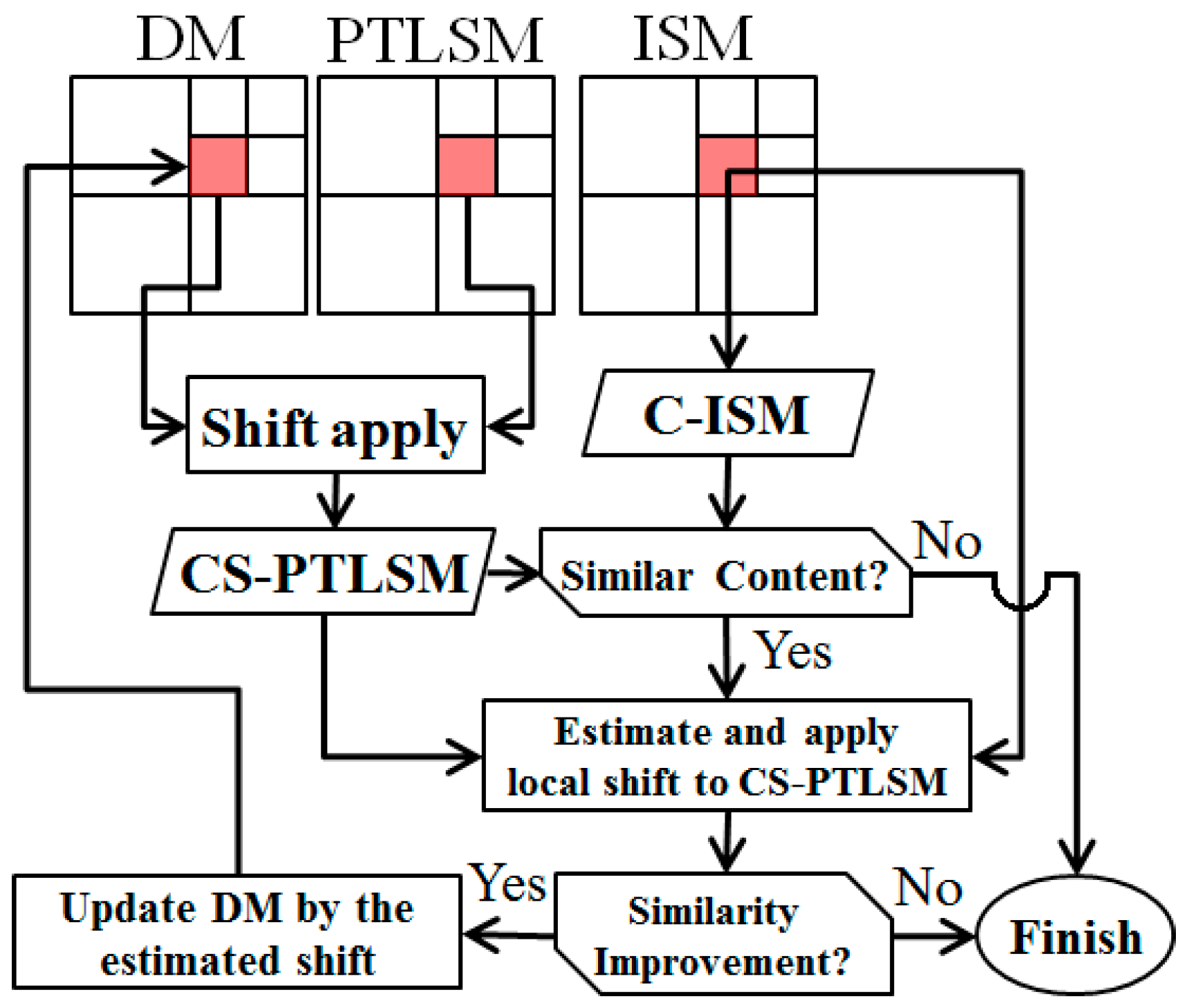
Figure 8 shows a flowchart of the proposed algorithm [
32].
With regard to the assumption of parallel sunlight, the casted shadow will be formed along the inverse sun azimuth. Accordingly, in the first step, the LiDAR data were rotated by θ = Az. − 270°. From the rotation, the layout of the rows in the raster LiDAR data (from left to right) will be in the direction of the inverse sun azimuth. In this situation, the identification of the shadow regions is reduced to a 1D independent search in each row of the rotated raster LiDAR data.
The shadow detection from the rotated raster LiDAR was performed in two main stages: 1—shadow edge detection, which is followed by 2—shadow region detection. The elevated points that caused the shadow regions were found in the first step. These points were then used to find their resultant shadow lines in their relevant row of the LiDAR raster data. In the following, the two steps are described.
• LiDAR shadow edge detection
Herein, shadow edges are regarded as locally elevated positions where shadow regions originate. Because these edges are locally evaluated, edge detection on the LiDAR raster can be used to find their initial positions. For this, the Canny edge detector is proposed [
33].
Although shadow edges are among the Canny results, the inverse in not essentially true. In other words, all of the edge pixels detected by Canny are not necessarily the requested shadow edges. Therefore, a shaded relief mask was designed to exclude non-shadow edge pixels. This process is explained in the following.
In conventional shaded relief analysis, the angle between the surface normal and the sun direction vectors (say α) is first determined. The shaded pixels are then marked as those with α > threshold. From a theoretical point of view, the threshold should be 90°; however, higher values can be used to yield more reliable results.
In this step, a shaded relief analysis is performed on all of the edges detected by Canny. Those pixels with α < 115° are excluded. The obtained binary image is considered to be the shadow edge pixels, which are exploited in the next section.
• Shadow region detection
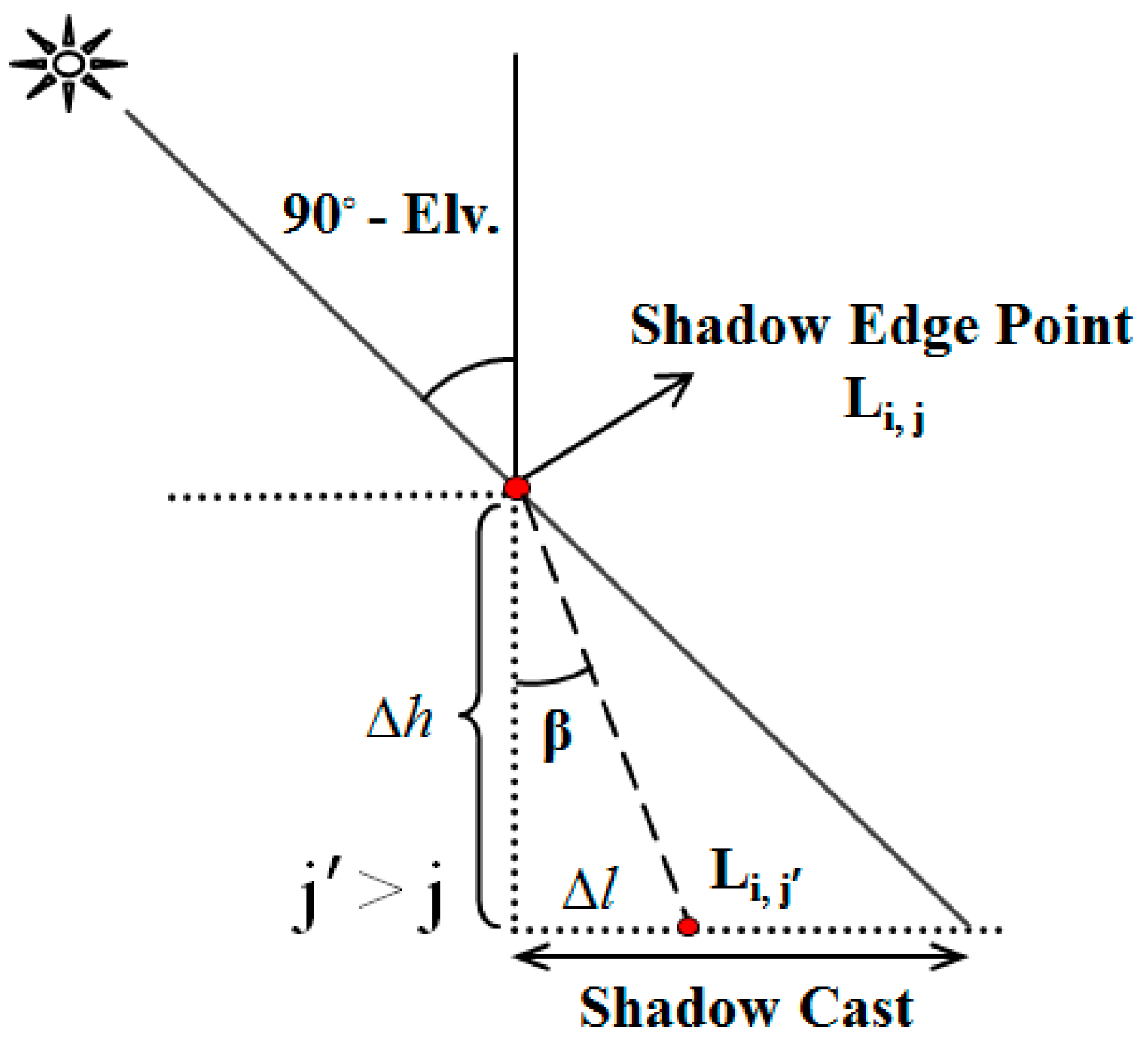
In this section, the extracted shadow edges are regarded as the barriers to detect the pixels in their shadows. For that reason, a ray tracing process was implemented.
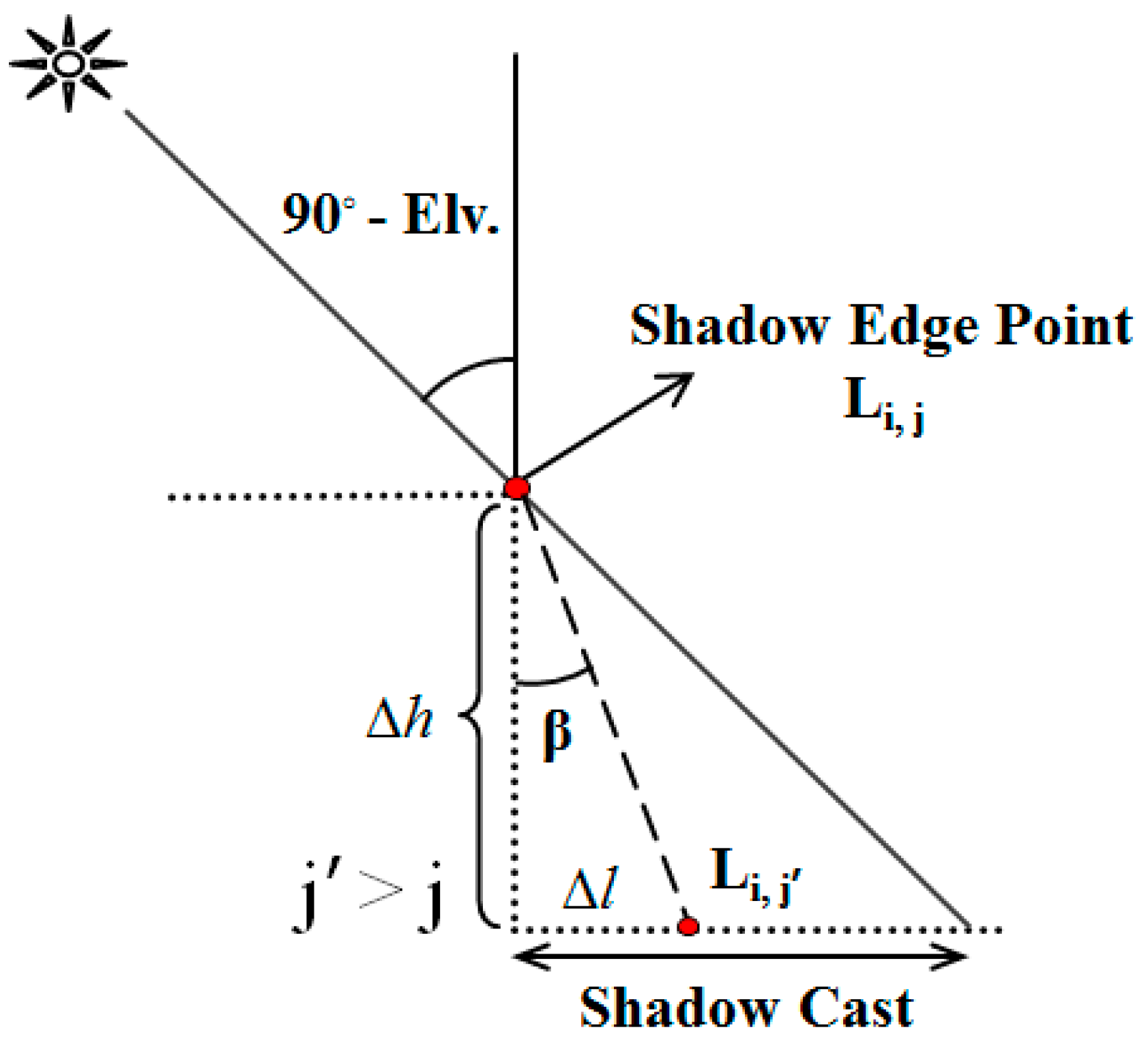
Figure 9 shows the concept applied in this step. In this figure, L
i,j is the rotated position of LiDAR shadows. For all j’ > j the value of Equation (17) is computed in which Δ
l and Δ
h represent the horizontal and vertical distances between L
i,j and L
i,j’ respectively.
Pixels with (β < 90° − Elv.) are considered to be located in the shadow cast.
Figure 9 shows the concept applied in this step.
The following pseudocode (Algorithm 2) shows the methodology implemented to detect shadow regions:
| Algorithm 2 Shadow Extraction in LiDAR |
Input: Rotated LiDAR Grid Data (θ = Az. − 270°)
Shadow Edge Pixels
Sun Azimuth and Elevation Angle
WidthTh & AreaTh
Output: LSM
|
1 BEGIN /* shadow region detection /
2 | For all shadow edge pixels (Li,j) /* found previously /
3 | BEGIN /* shadow line detection /
4 | . In a 3 × 3 window, assign the max elevation to shadow edge pixel
5 | . For {Li,j’ | j’ > j} until the next shadow edge point
6 | . BEGIN /* check whether it is in the shadow cast /
7 | . | Compute β /* Figure 9 /
8 | . | IF β < (90° − Elv.) & {Li,c | j < c < j’} ∈ shadow casts then Li,j’ to be marked as shadow
9 | . END
10 | END
11 | Rotate back LiDAR raster with θ = 270° − Az.
12 | Implement a morphology closing with a 3 × 3 structure element /* to fill the
| shadow gaps occurred by noise /
13 | Segment shadow pixels via N-8 neighborhood analysis
14 | For all shadow segments
15 | BEGIN /* shadow noise removal /
16 | . Compute the width and area
17 | . IF width <WidthTh or area <AreaTh THEN remove the shadow segment
18 | END
19 END
|
In line 5, only the pixels in the same row of the shadow edge pixels are examined due to previous θ = Az. − 270° rotation. This rotation is compensated for in line 11. Angle β in line 7 is computed using the 3D coordinates of the shadow edge pixel and the pixel under investigation. The shadow segment widths, which are applied in line 16, are considered to be the smallest eigenvalues of the covariance matrix of that segment.
The small shadow segment removal at line 17 is justifiable due to factors such as (1) the low probability of the identification of small shadows in the optical images and (2) the noisy nature of the small shadows (e.g., the noise in LiDAR systems and small features such as cars and plants). The
WidthTh threshold also prevents the formation of tall 3D-features that do not have significant thicknesses (noise and features such as lighting poles). In this paper, those thresholds were set to 100 and 10 pixels for
AreaTh and
WidthTh, respectively. The results of the LiDAR shadow extraction on the sample dataset are presented in
Figure 10.
In
Figure 7 and
Figure 10, comparable results can be observed as the obtained shadow maps in the LiDAR data and QB image. In other words, despite the different natures of the optic satellite image and LiDAR data, the same spatial topology of the occurrence of shadows was obtained.
Note that some of differences between the ISM and LSM are due to the spatial changes that occurred during the acquisition time difference between the LiDAR data and satellite imagery. This issue is more severe in the northwestern part of the sample dataset.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}