1.1. Motivation and Objective
HRS images, compared to ordinary low- and medium-resolution images, have some special properties; e.g., (1) the geometry of ground objects is more distinct; (2) the spatial layout is clearer; (3) the texture information is relatively finer; and (4) the entire image is a collection of multi-scale objects. The continuous improvement of spatial resolution poses substantial challenges to traditional pixel-based spectral and texture analysis methods. The variety observed in objects’ spectra and the multi-scale property differentiates HRS image classification from conventional natural image classification. In particular, this paper focuses on object categorization and scene classification using HRS images by analyzing the following two aspects:
(1) Multi-resolution representation of the HRS images: An HRS image is a unification of multi-scale objects, where there are substantial large-scale objects at coarse levels as well as small objects at fine levels. In addition, given the multi-scale cognitive mechanism underlying the human visual system, which operates on the level of the object to the environment and then to the background, analysis on a single scale is insufficient for extracting all semantic objects. To represent HRS images on multiple scales, three main methods are utilized: image pyramid [
6], wavelet transform [
7] and hierarchical image partitions [
8]. However, how to consider the intrinsic properties of local objects in multi-scale image representation is a key problem worth studying.
(2) The efficient combination of various features: Color, texture and structure are reported to be discriminative and widely-used features for HRS image classification [
1,
2,
3,
4,
5]. An efficient combination of the three cues can help us better understand HRS images. Conventional methods using one or two features have achieved good results in image classification and retrieval, e.g., in Bag of SIFT [
1] and Bag of colors [
9]. However, color, texture, and structure information also contribute to the understanding of the images, and image descriptors defined in different feature spaces usually help improve the performance of analyzing objects and scenes in HRS images. Thus, how to efficiently combine different features represents another key problem.
1.2. Related Works
Focusing on the two significant topics in HRS image interpretation, it is of great importance to investigate the literature on object-based image analysis, hierarchical image representation and multiple cues fusion methods.
(1) Object-based feature extraction methods for HRS images: The sematic gap is more apparent in HRS imagery, and surface objects consist of substantially richer spectral, textural and structural information. Object-based feature extraction methods enable the clustering of several homogeneous pixels and the analysis of both local and global properties; moreover, the successful development of feature extraction technologies for HRS satellite imagery has greatly increased its usefulness in many remote sensing applications [
10,
11,
12,
13,
14,
15,
16,
17,
18]. Blaschke
et al. [
10] discussed several limitations of pixel-based methods in analyzing high-resolution images and crystallized core concepts of Geographic Object Based Image Analysis. Huang and Zhang proposed an adaptive mean-shift analysis framework for object extraction and classification applied to hyperspectral imagery over urban areas, therein demonstrating the superiority of object-based methods [
11]. Mallinis and Koutsias presented a multi-scale object-based analysis method for classifying Quickbird images. The adoption of objects instead of pixels provided much more information and challenges for classification [
12]. Trias-Sanz
et al. [
14] investigated the combination of color and texture factors for segmenting high-resolution images into semantic regions, therein illustrating different transformed color spaces and texture features of object-based methods. Re-occurring compositions of visual primitives that indicate the relationships between different objects can be found in HRS images [
19]. In the framework of object based image analysis, the focus of attention is object semantics, the multi-scale property and the relationships between different objects.
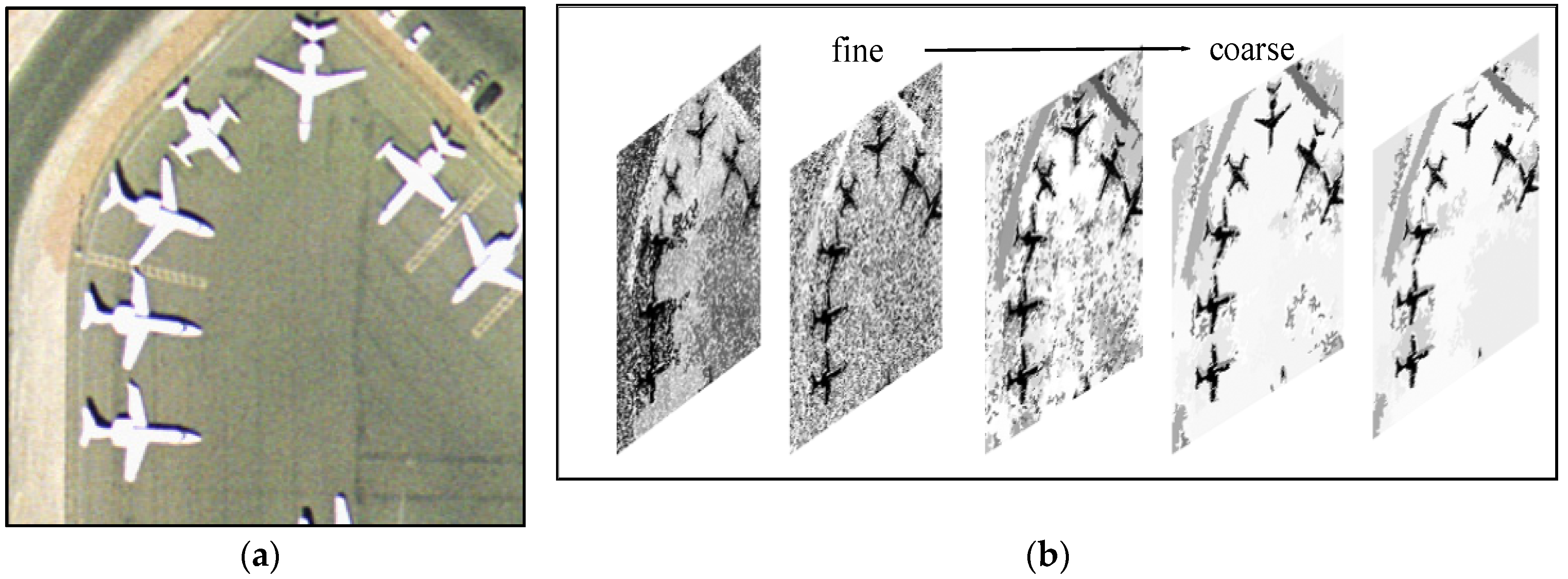
(2) Hierarchical image representation for HRS images: Because an HRS image is a unification of multi-scale objects, there are substantial large-scale objects at coarse levels, such as water, forests, farmland and urban areas, as well as small targets at fine levels, e.g., buildings, cars and trees. In addition, a satellite image at different resolutions (from low to medium and subsequently to high spatial resolutions) will present different objects. Therefore it is very important to consider the object differences at different scales. Several studies have utilized Gaussian pyramid image decomposition to build a hierarchical image representation [
6,
20]. In [
6], Binaghi
et al. analyzed a high-resolution scene through a set of concentric windows, and a Gaussian pyramidal resampling approach was used to reduce the computational burden. In [
20], Yang and Newsam proposed a spatial pyramid co-occurrence to characterize the photometric and geometric aspects of an image. The pyramid captured both the absolute and relative spatial arrangements of objects (visual words). The obvious limitations of these approaches are the fixed regular shape and choice of the analysis window size [
21]. Meanwhile, some researchers employed wavelet-based methods to address the multi-scale property. Baraldi and Bruzzone used an almost complete (near-orthogonal) basis for the Gabor wavelet transform of images at selected spatial frequencies, which appeared to be superior to the dyadic multi-scale Gaussian pyramid image decomposition [
7]. In [
22], an object’s contents were represented by the object’s wavelet coefficients, the multi-scale property was reflected by the coefficients in different bands, and finally, a tree structural representation was built. Observing that wavelet decomposition is a decimation of the original image and is a low-pass filter convolution of the image that lacks consideration of the relationships between objects. By fully considering the intrinsic properties of the object, some studies have relied on hierarchical segmentation and have produced hierarchical image partitions [
8,
23]. These methods have addressed the multi-scale properties of objects [
24]; however, they demonstrate few relationships between objects at different scales. Luo
et al. proposed to use a topographic representation of an image to generate objects, therein considering both the spatial and structural properties [
25]. However, the topographic representation is typically built on the gray-level image, which rarely concerns color difference. In [
26,
27,
28,
29,
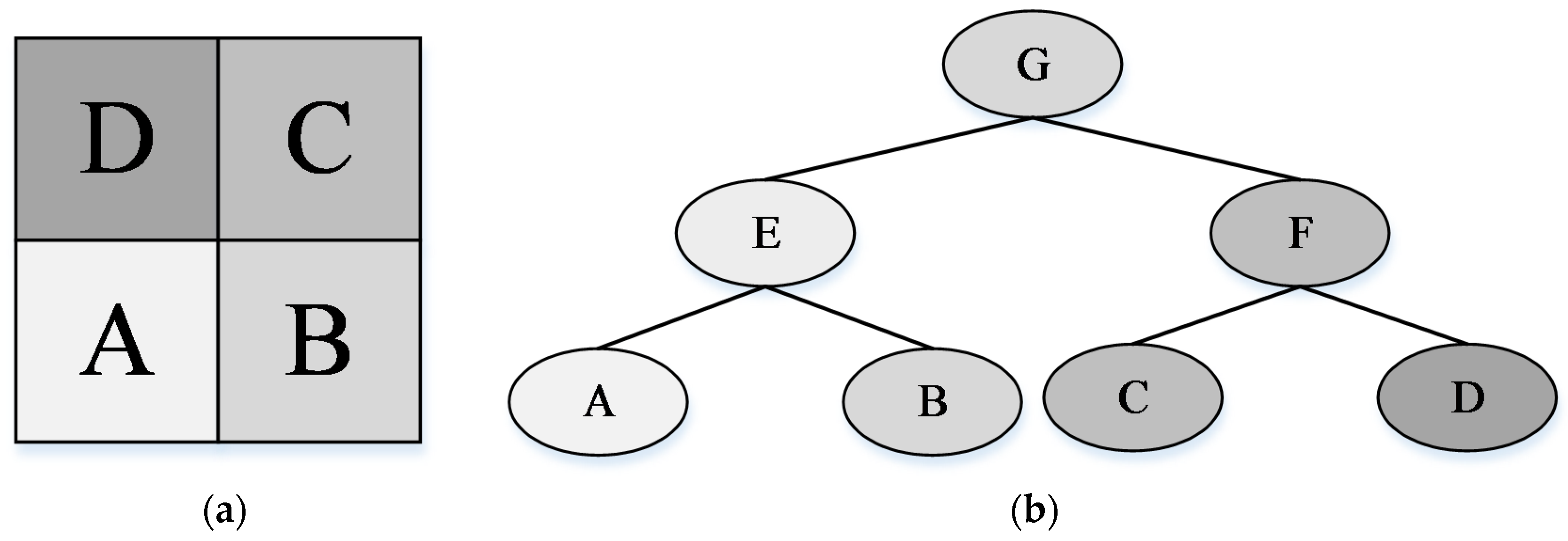
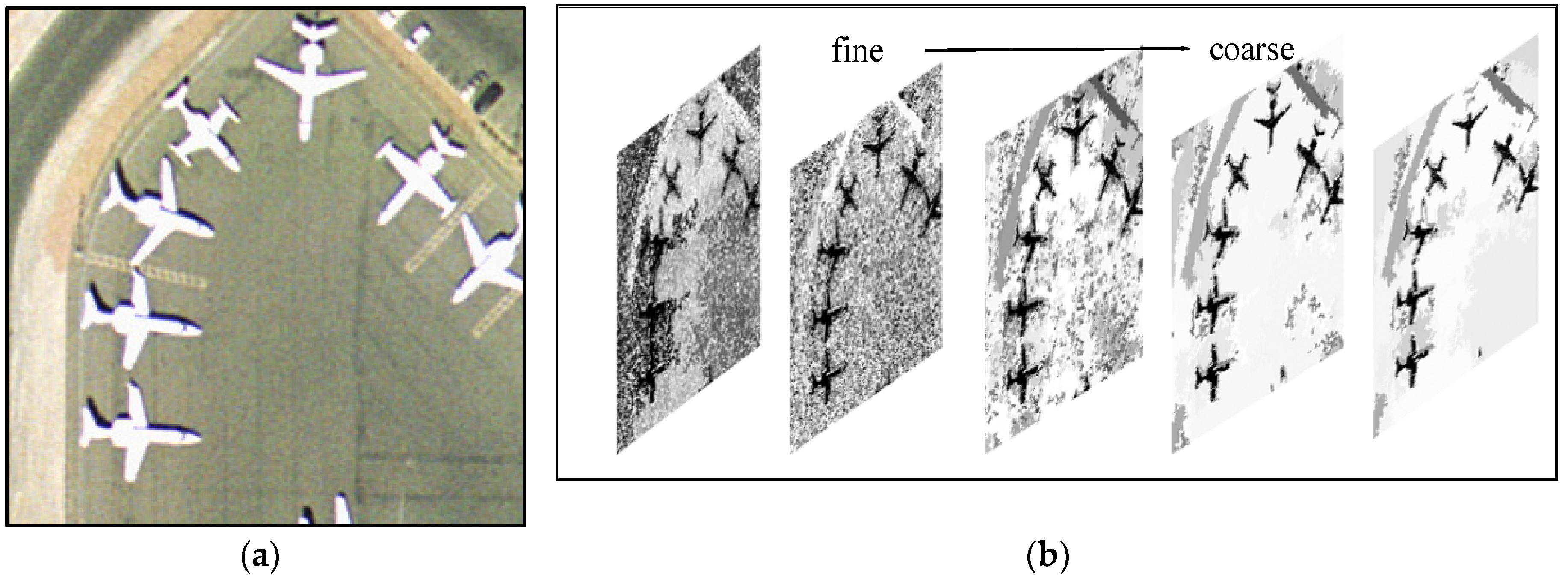
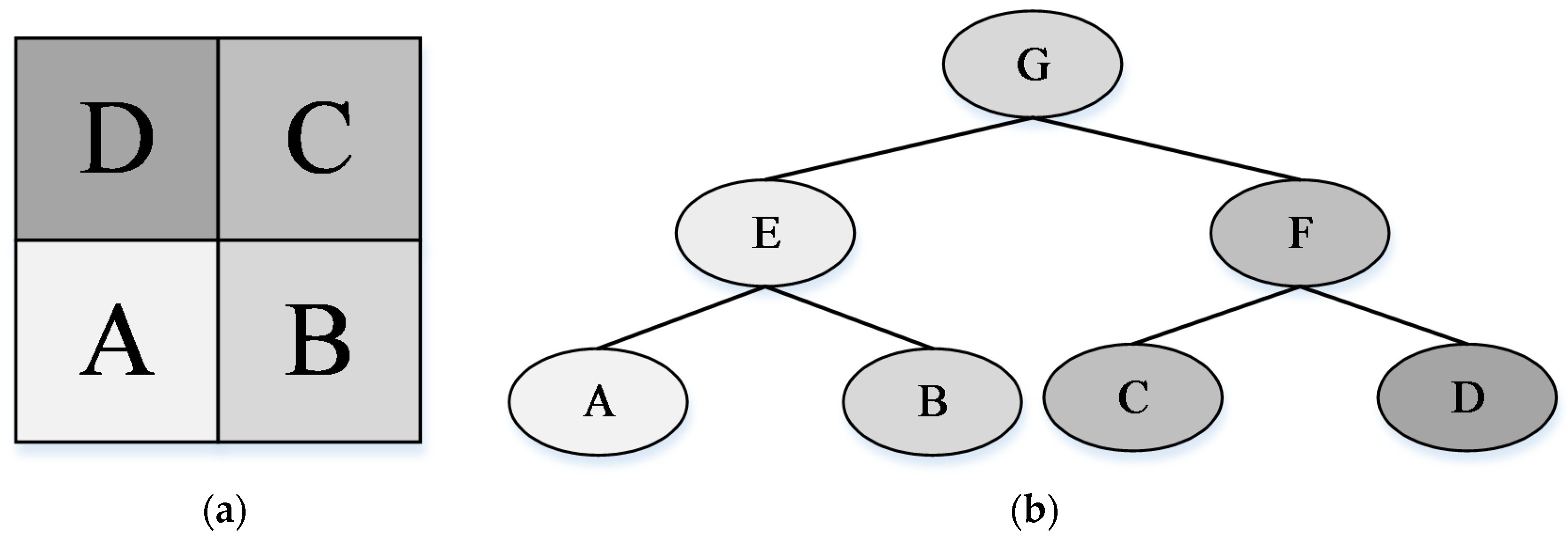
30], various types of images, e.g., natural images, hyperspectral images, and PolSAR images, were represented by a hierarchical structure, namely, Binary Partition Tree (BPT), which was constructed based on particular region models and merge criteria. BPT can represent multi-scale objects from fine to coarse levels. In addition, the topological relationships between regions are translation invariant because the tree encodes the relationships between regions. Therefore we can fully consider the multi-scale, spatial structure relationship and intrinsic properties of objects using BPT representation.
(3) Multiple-cue fusion methods: Color features describe the reflective spectral information of images, and are usually encoded with statistical measures, e.g., color distributions [
31,
32,
33,
34]. Texture features reflect a specific, spatially repetitive pattern of surfaces by repeating a particular visual pattern in different spatial positions [
35,
36,
37], e.g., coarseness, contrast and regularity. For HRS images, structure features contain the macroscopic relationships between objects [
38,
39,
40], such as adjacent relations and inclusion relations. Because structure features exist between different objects, the discussion is primarily concerned with the fusion of color and texture. There are two main fusing methods: early fusion and late fusion. Methods that combine cues prior to feature extraction are called early fusion methods [
32,
41,
42]. Methods wherein color and texture features are first separately extracted and then combined at the classifier stage are called late fusion methods [
43,
44,
45]. In [
46], the authors explained the properties of the two fusion methods and concluded that classes that exhibit color-shape dependency are better represented by early fusion, whereas classes that exhibit color-shape independency are better represented by late fusion. In HRS images, classes have both color-shape dependency and independency. For example, a dark area can be water, shadow or asphalted road; in contrast, a dark area near a building with a similar contour is most likely to be a shadow. Consequently, both early and late fusion methods can be used to classify an HRS image.
Many local features have been developed to describe color, texture and structure properties, such as Color Histogram, Gabor, SIFT and HOG (Histograms of Oriented Gradients). To further improve classification accuracy, Bag of Words (BOW) [
47] and Fisher vector (FV) coding [
48] have been proposed to achieve more discriminative feature representation. BOW strategies have achieved great success in computer vision. Under the BOW framework, there are three representative coding and pooling methods, Spatial Pyramid Matching (SPM) [
38], Spatial Pyramid Matching using Sparse Coding (ScSPM) [
49] and Locality-constrained Linear Coding (LLC) [
50]. The traditional SPM approach uses vector quantization and multi-scale spatial average pooling and thus requires nonlinear classifiers to achieve good image classification performance. ScSPM, however, uses sparse coding and the multi-scale spatial max pooling method and thus can achieve good performance with linear classifiers. LLC utilizes the locality constraints to project each descriptor into its local-coordinate system, and the projected coordinates are integrated via max pooling to generate the final representation. With the linear classifier, it performs remarkably better than traditional nonlinear SPM. An alternative to BOW is FV coding, which combines the strength of generative and discriminative approaches for image classification [
48,
51]. The main idea of FV coding is to characterize the local features with a gradient vector derived from the probability density function. FV coding uses a Gaussian Mixture Model (GMM) to approximate the distribution of low-level features. Compared to the BOW, FV is not only limited to the number of occurrences of each visual word but also encodes additional information about the distribution of the local descriptors. The dimension of FV is much larger for the same dictionary size. Hence, there is no need to project the final descriptors into higher dimensional spaces with costly kernels.
1.3. Contribution of this Work
Because BPT is a hierarchical representation that fully considers multi-scale characteristics and topological relationships between regions, we propose using BPT to represent HRS images. Based on our earlier work [
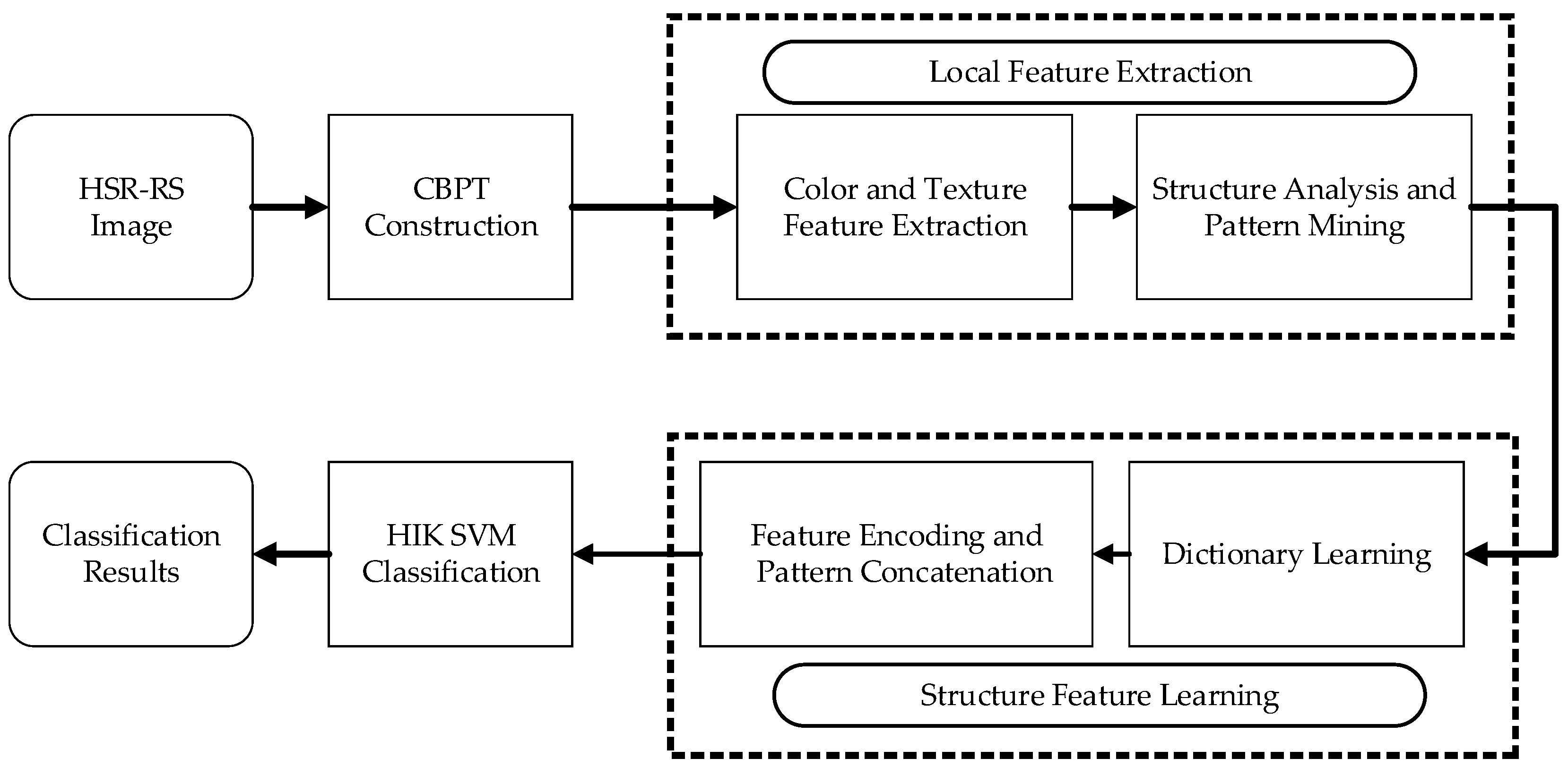
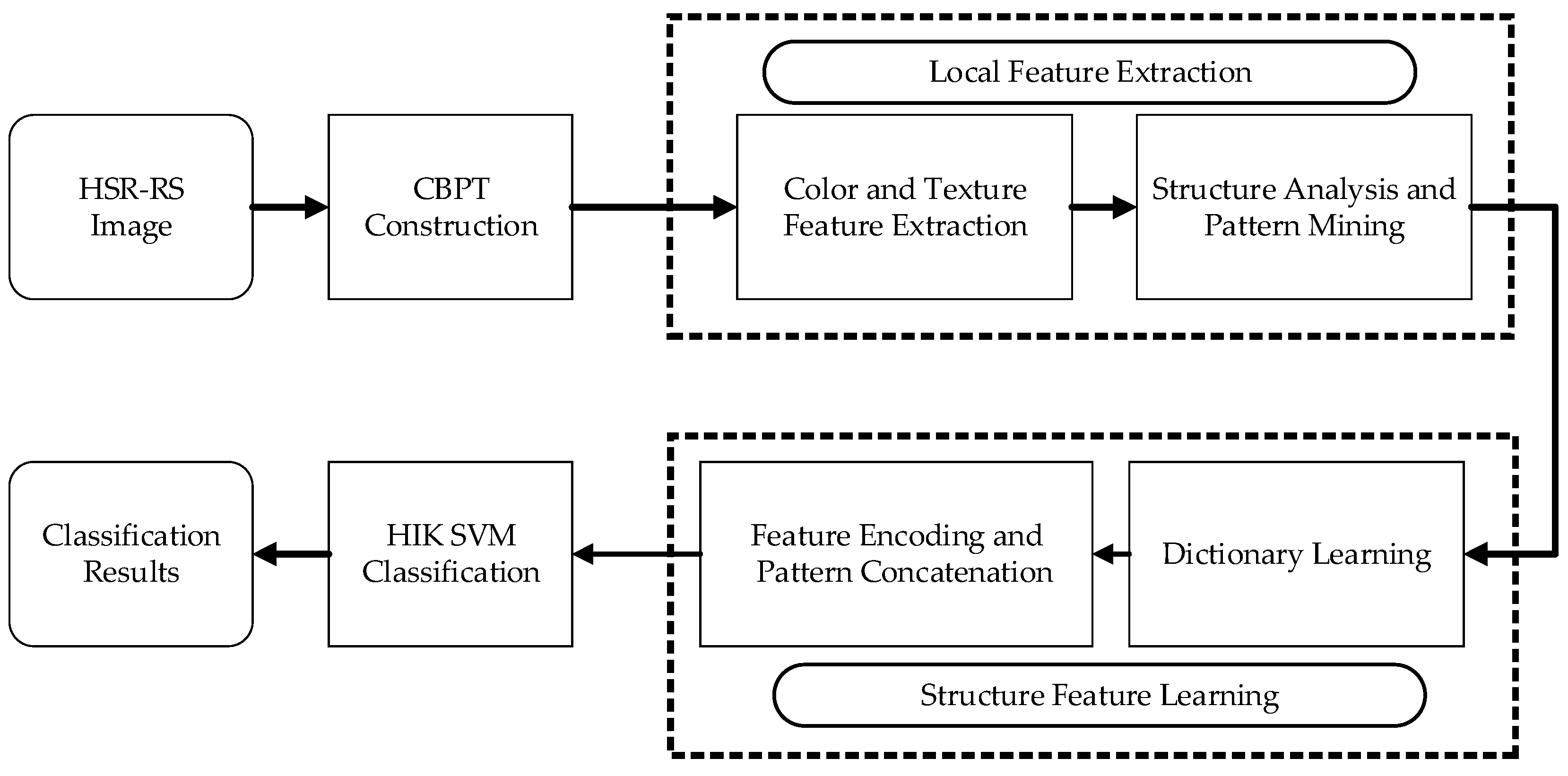
36] addressing texture analysis, we further implement an efficient combination of color, texture and structure features for object categorization and scene classification. In this paper, we propose a new color-texture-structure descriptor, referred to as the CTS descriptor, for HRS image classification based on the color binary partition tree (CBPT). The CBPT construction fully considers the spatial and color properties of HRS images, thereby producing a compact hierarchical structure. Then, we extract plentiful color features and texture features of local regions. Simultaneously, we analyze the CBPT structure and design co-occurrence patterns to describe the relationships of regions. Next, we encode these features by FV coding to build the CTS descriptor. Finally, we test the CTS descriptor as applied to HRS image classification.
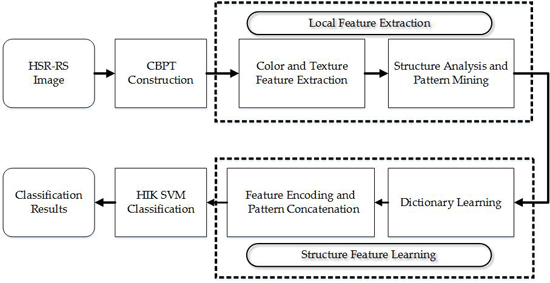
Figure 1 illustrates the flowchart of the HRS image classification process using the CTS descriptor.
Our main contribution is the description of color and texture information based on the BPT structure. By fully considering the characteristics of CBPT, we not only build region-based hierarchical structures for HRS images, but also establish the topological relationship between regions in terms of space and scale. We present an efficient combination of color and texture via CBPT and analyze the co-occurrence patterns of objects from the connective hierarchical structure, which can effectively address the multi-scale, topological relationship and intrinsic properties of HRS images. Using the CBPT representation and the combination of color, texture and structure information, we finally achieve the combination of early and late fusion. To our knowledge, this is the first time that color, texture and structure information have been analyzed based on BPT for HRS image interpretation.
The remainder of this paper is organized as follows.
Section 2 first analyzes color features and the construction of the CBPT. Texture and color feature analysis of the CBPT is presented in detail in
Section 3. Moreover, we briefly introduce the pattern design and coding method. Next, experimental results are given in
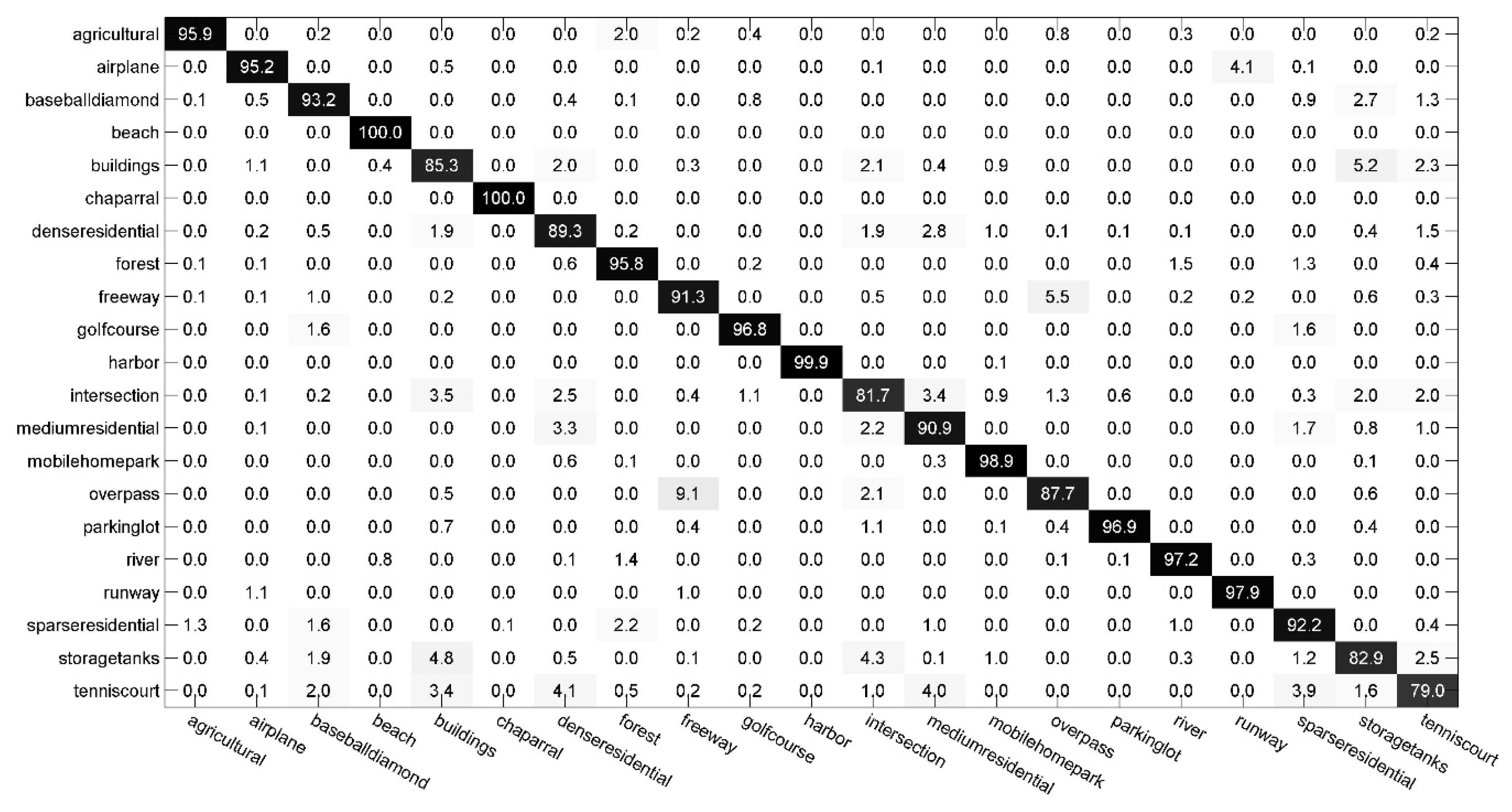
Section 4, and capabilities and limitations are discussed in
Section 5. Finally, the conclusions are presented in
Section 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



