
Image Segmentation Based on Constrained Spectral Variance Difference and Edge Penalty


Abstract
:
1. Introduction
2. Study Area and Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Platform | Size | Spatial Resolution | Position | Code |
|---|---|---|---|---|---|
| a | WorldView-2 | 872 × 896 | 0.6 m | Hanzhong | R1 |
| b | Aerial plane | 835 × 835 | 1 m | Three Gorges | R2 |
| c | RapidEye | 622 × 597 | 5 m | Miyun | R3 |
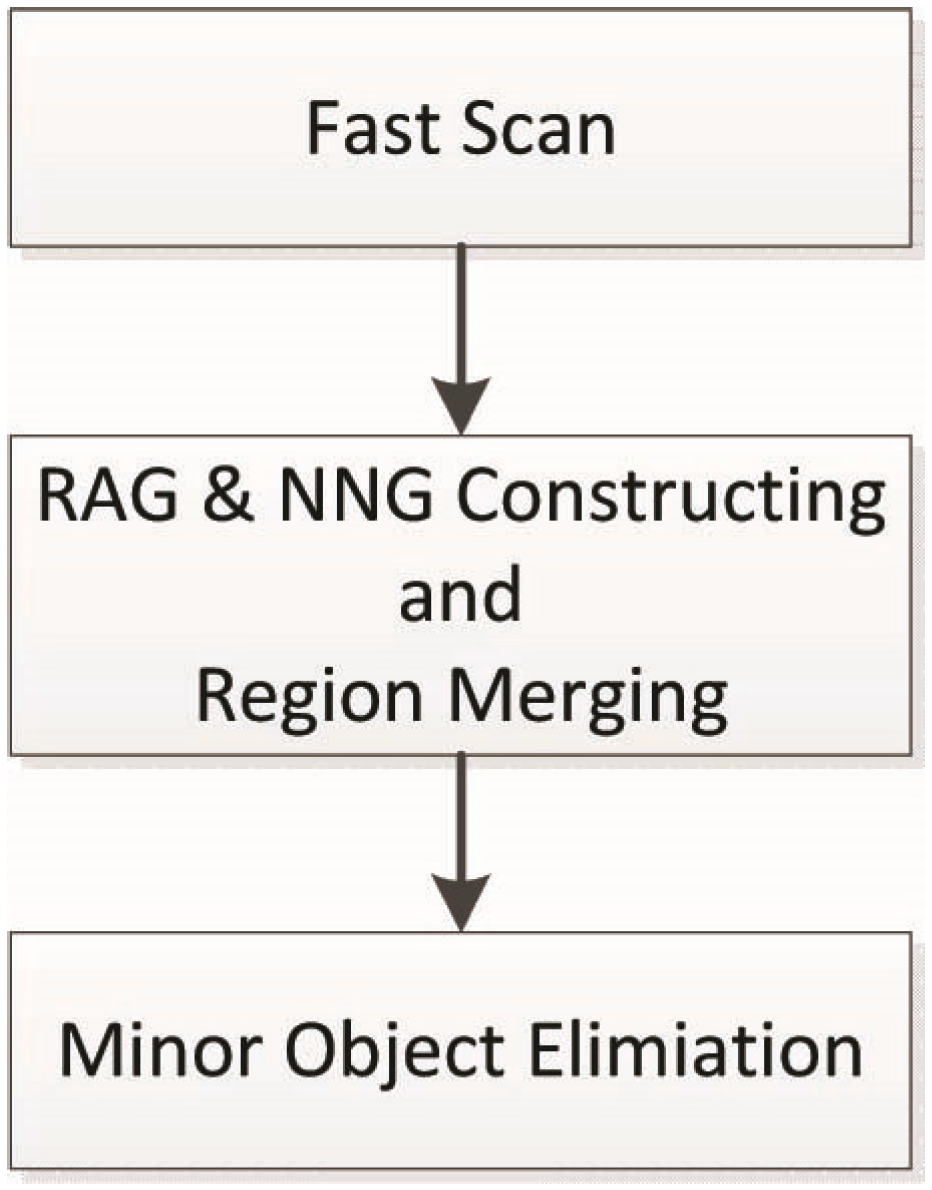
3. Methodology
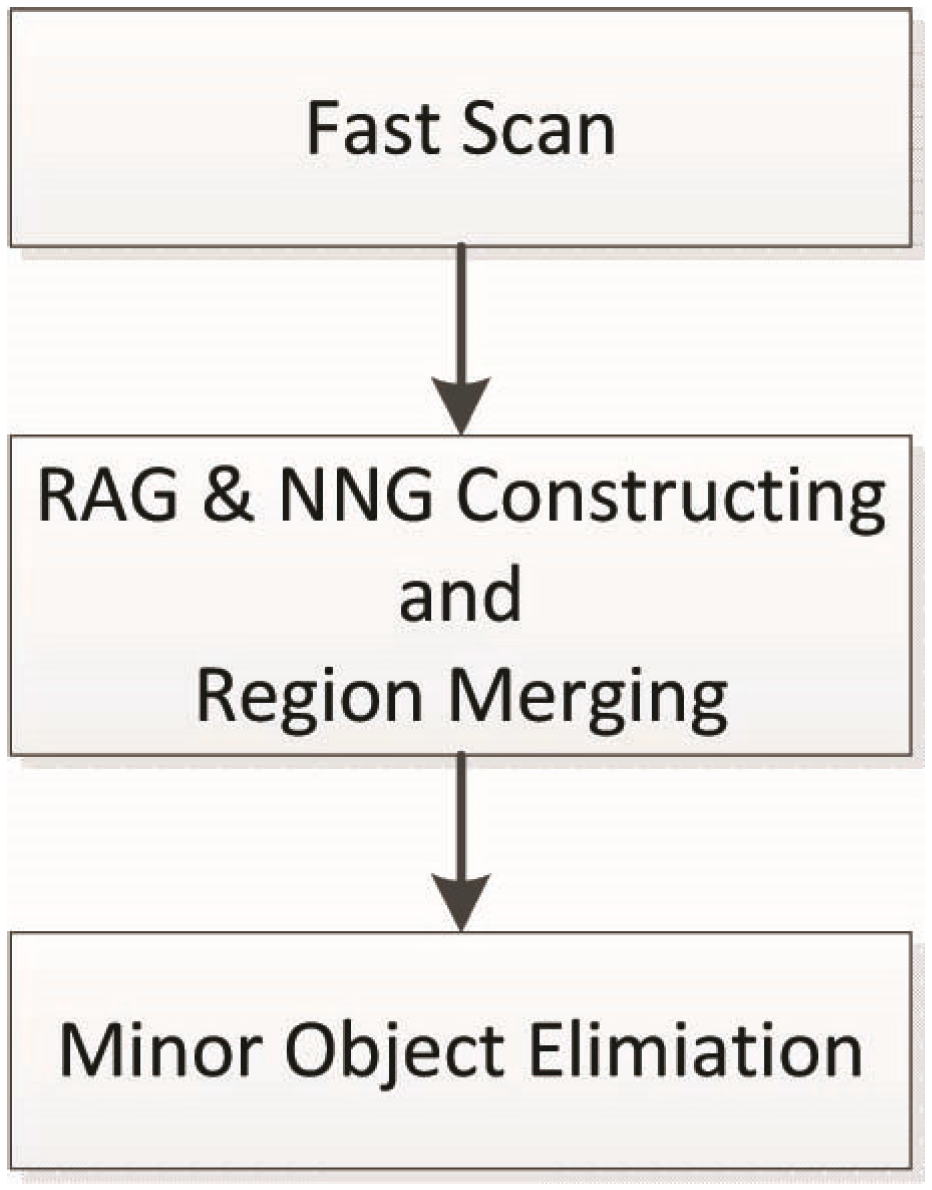
3.1. Initial Segmentation
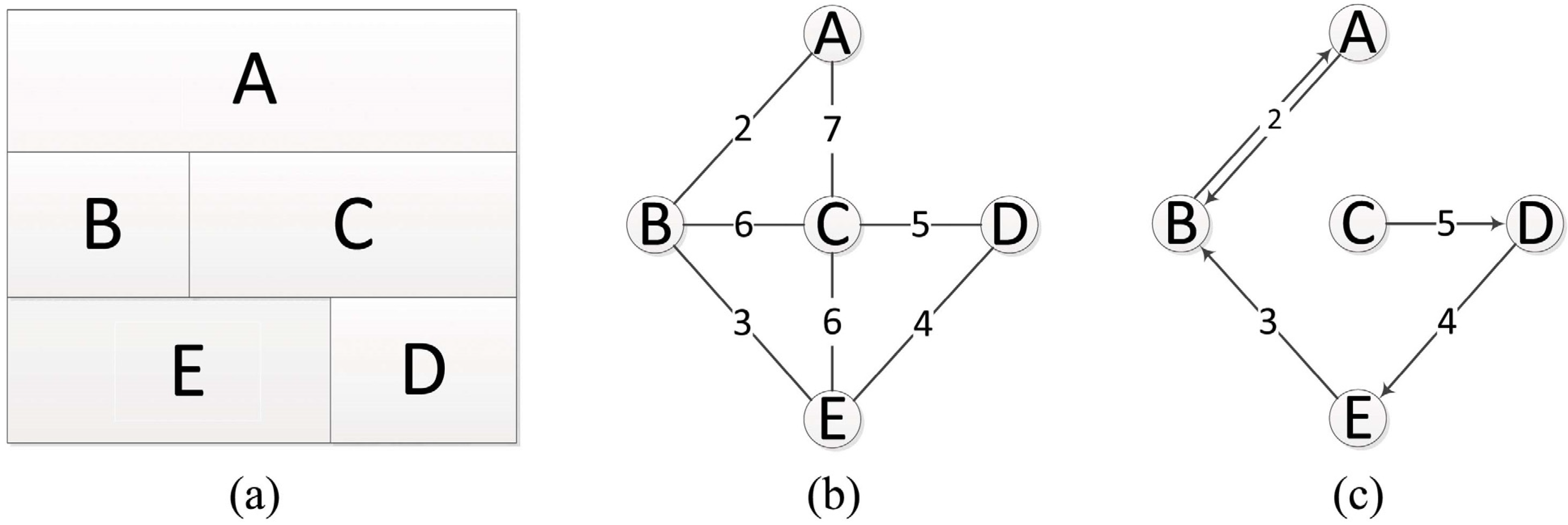
3.2. RAG and NNG Constructing and Region Merging
3.2.1. RAG and NNG Construction

3.2.2. Region Merging
Merging Criterion
Merging Strategy
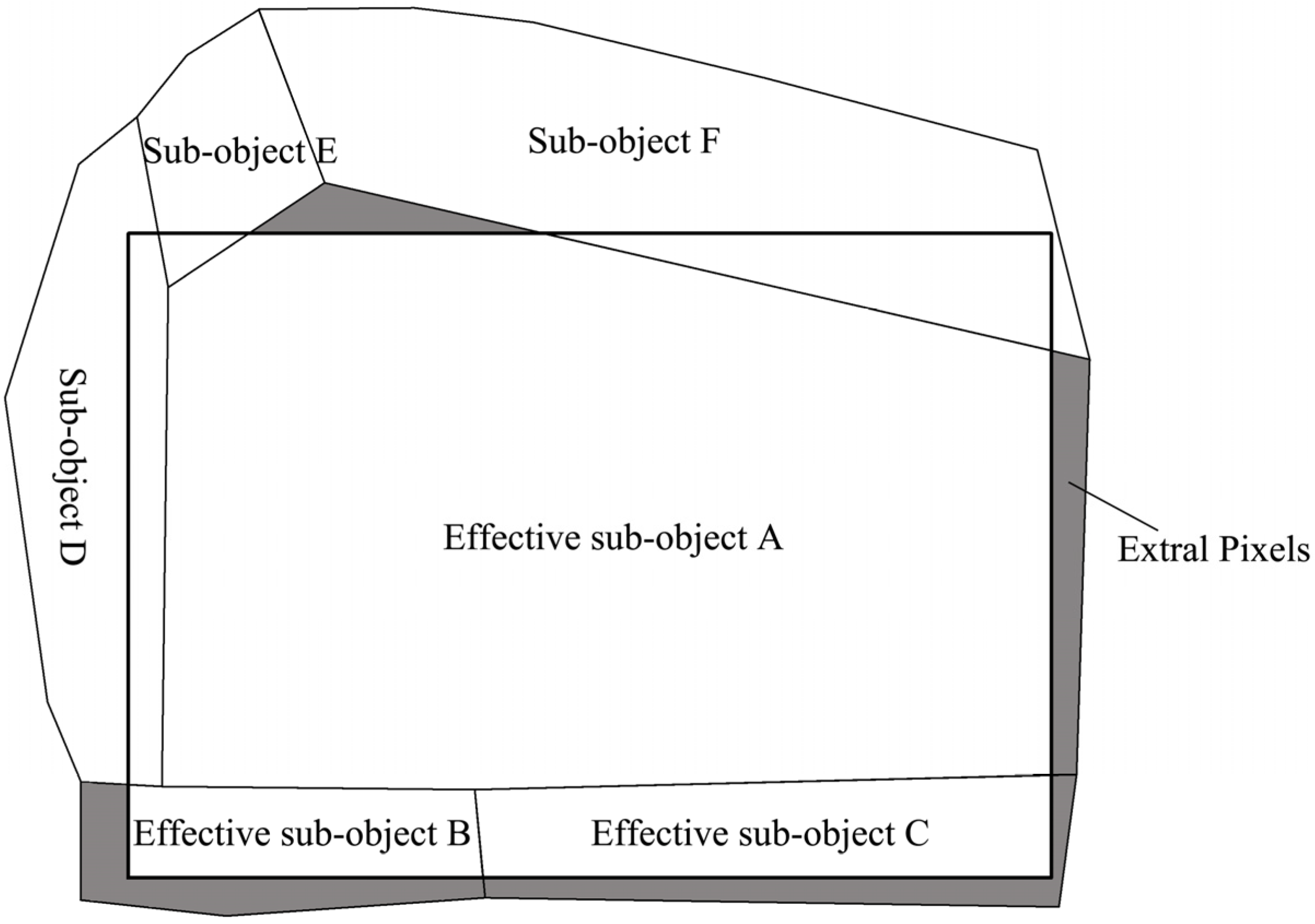
3.3. Minor Object Elimination
3.4. Quantitative Assessment Method

4. Results and Discussion
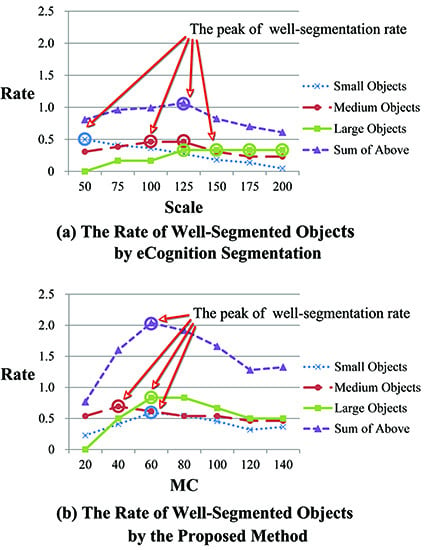
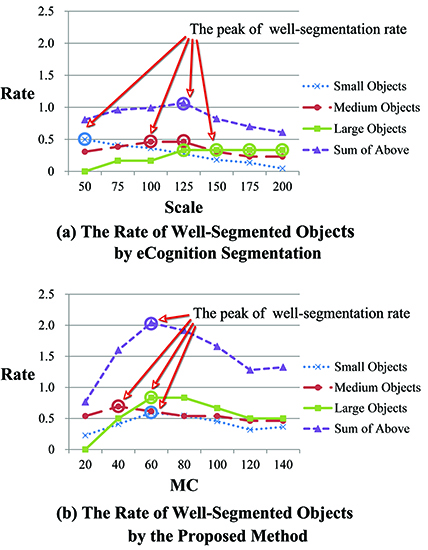
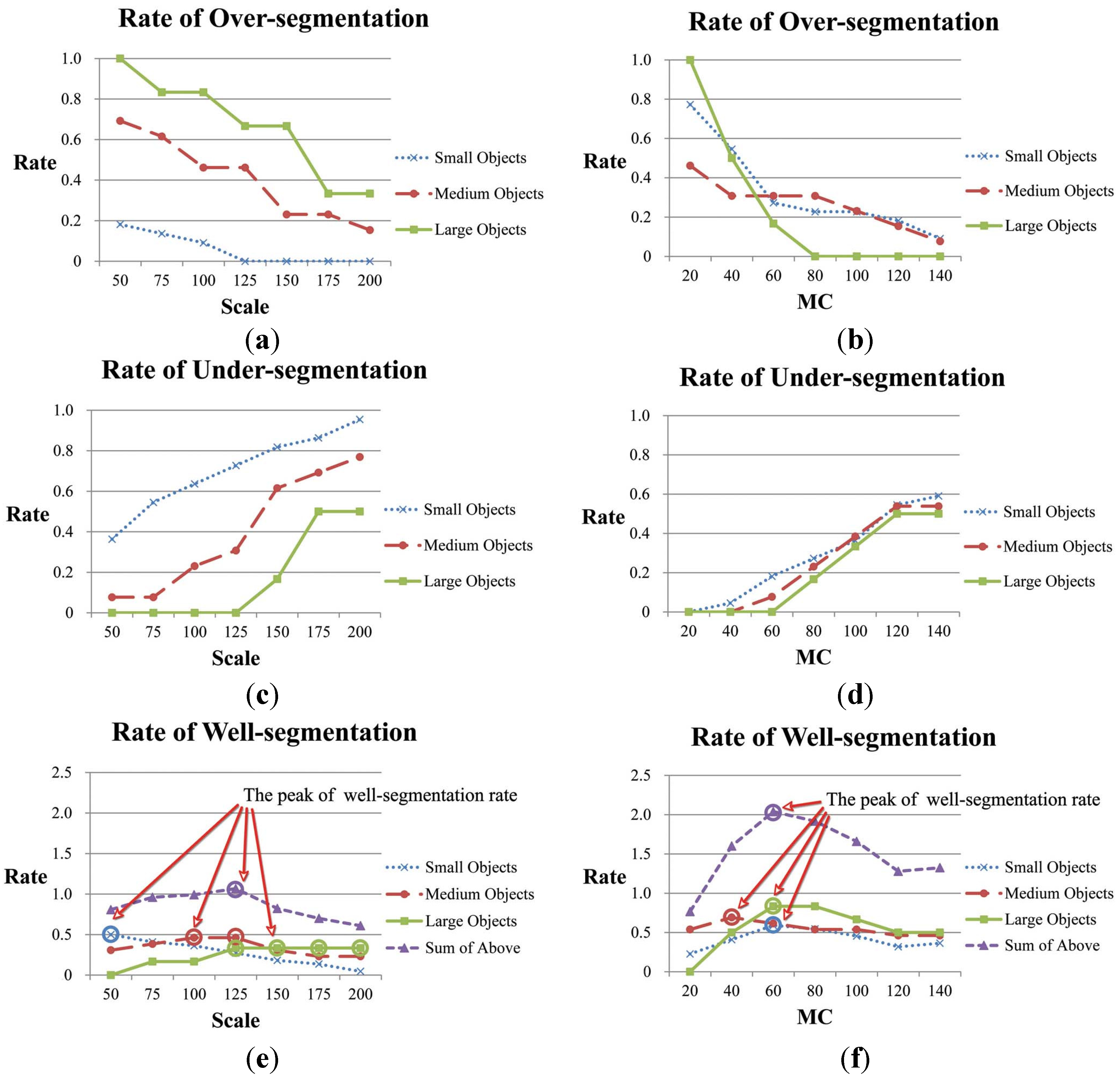
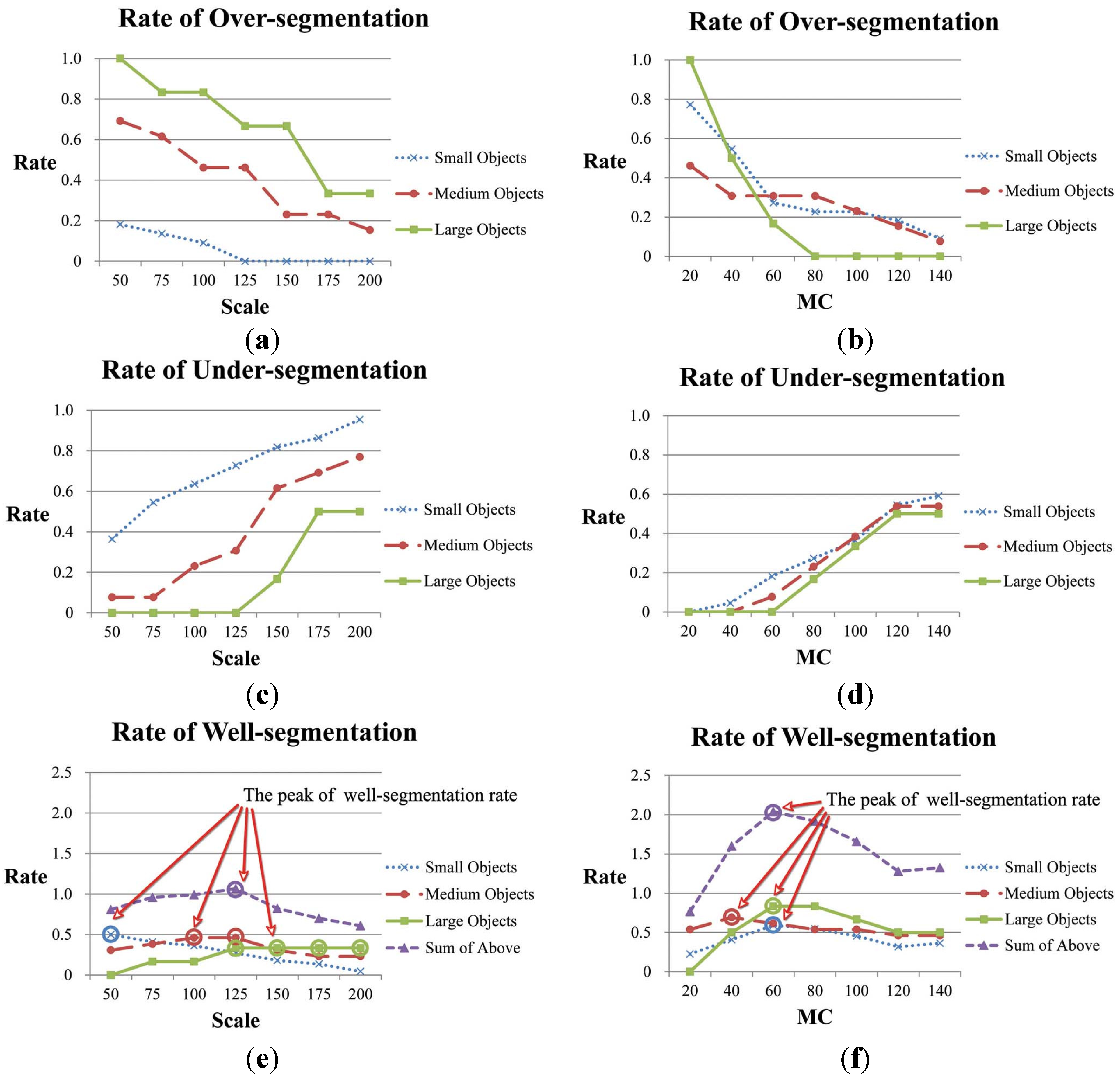
4.1. The Effect of Algorithm Parameters
4.1.1. Scale of Initial Segmentation
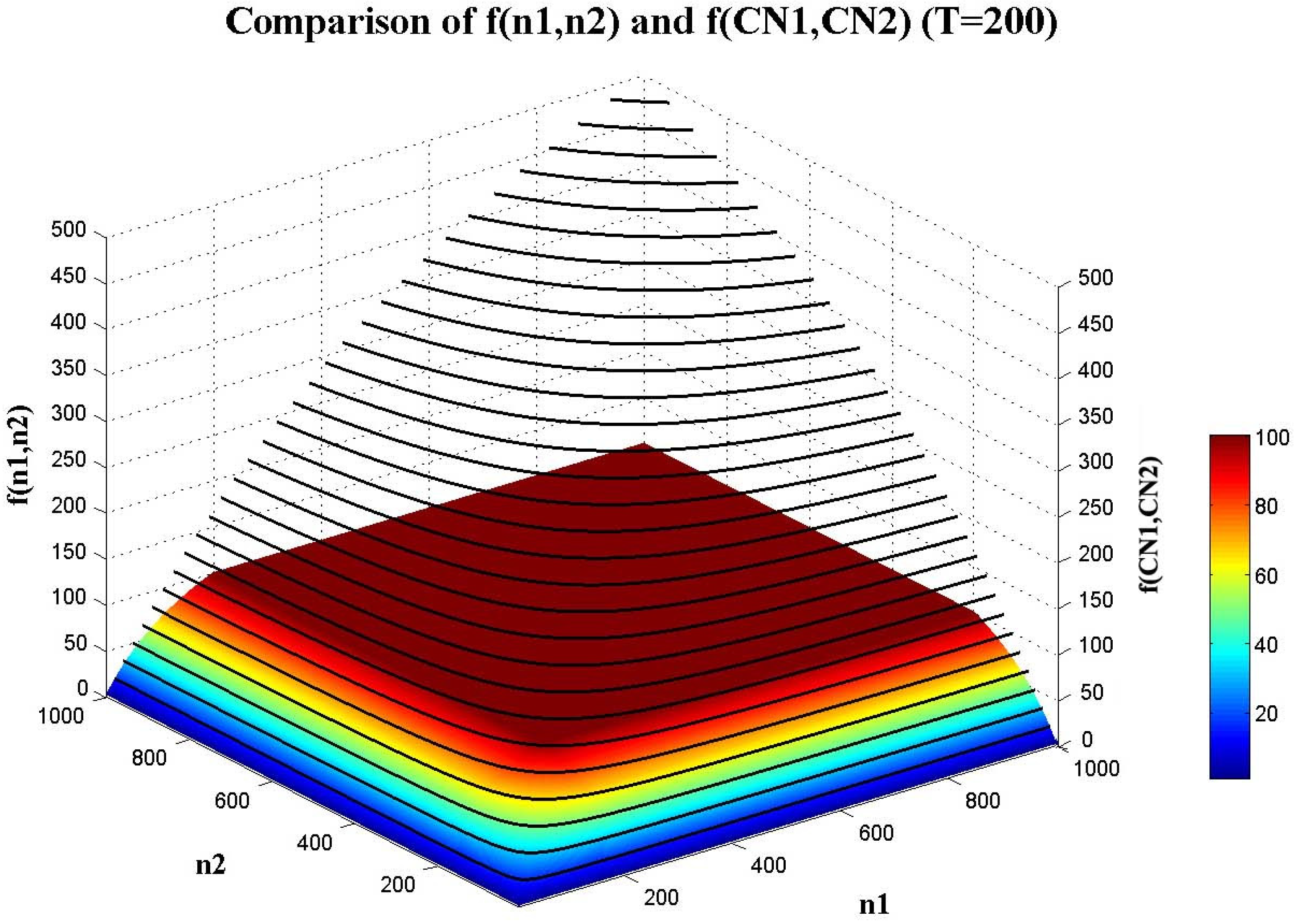
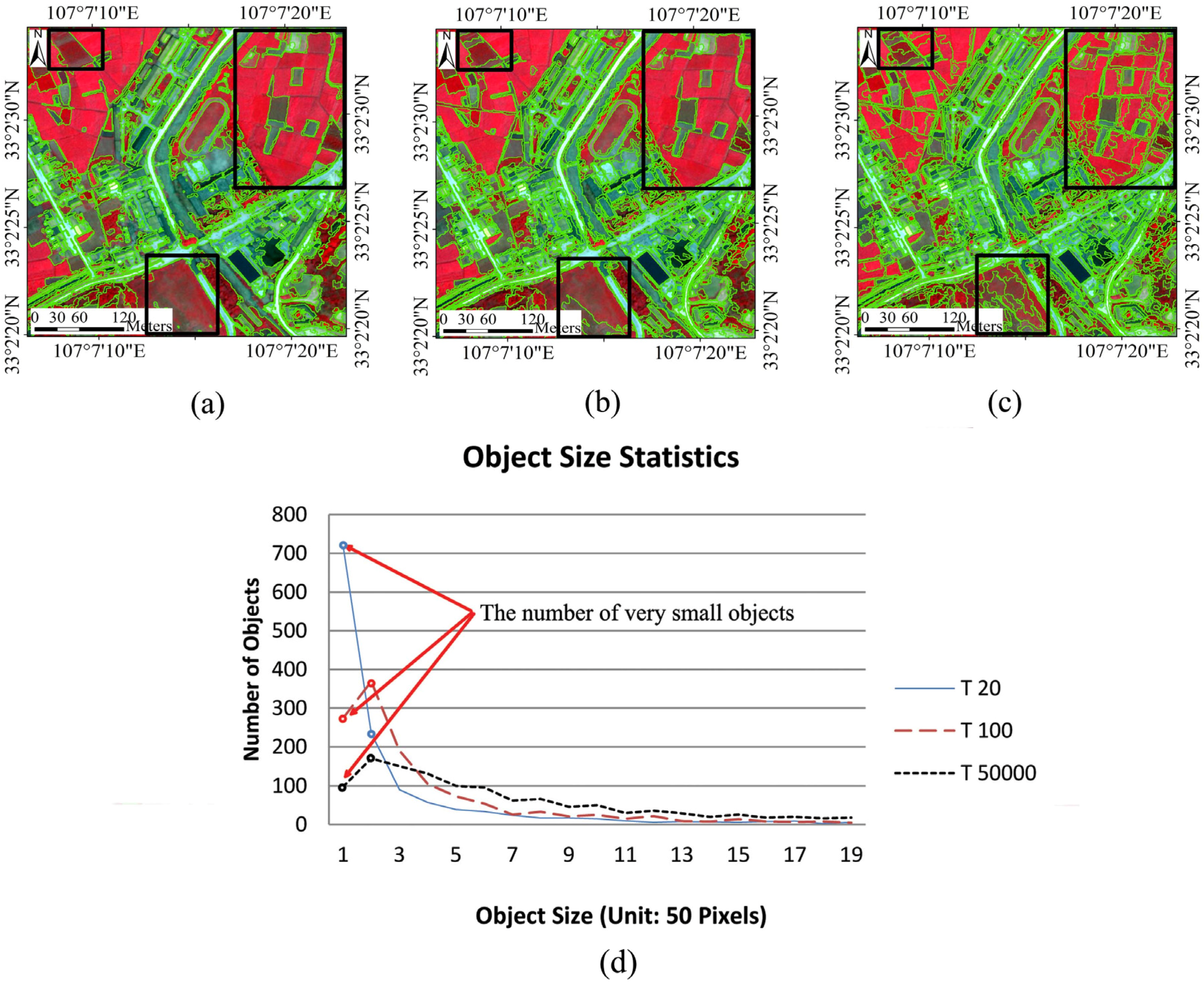
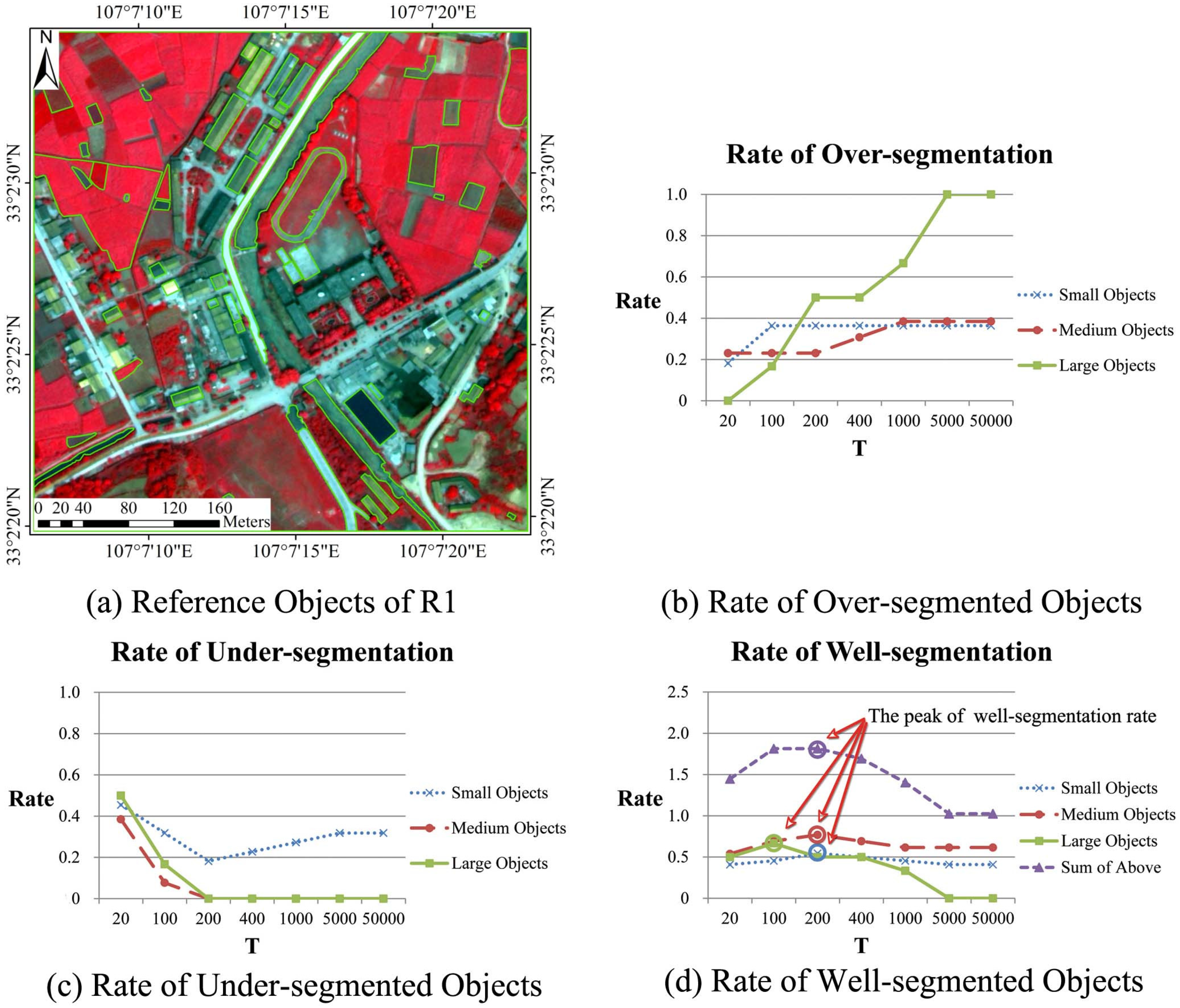
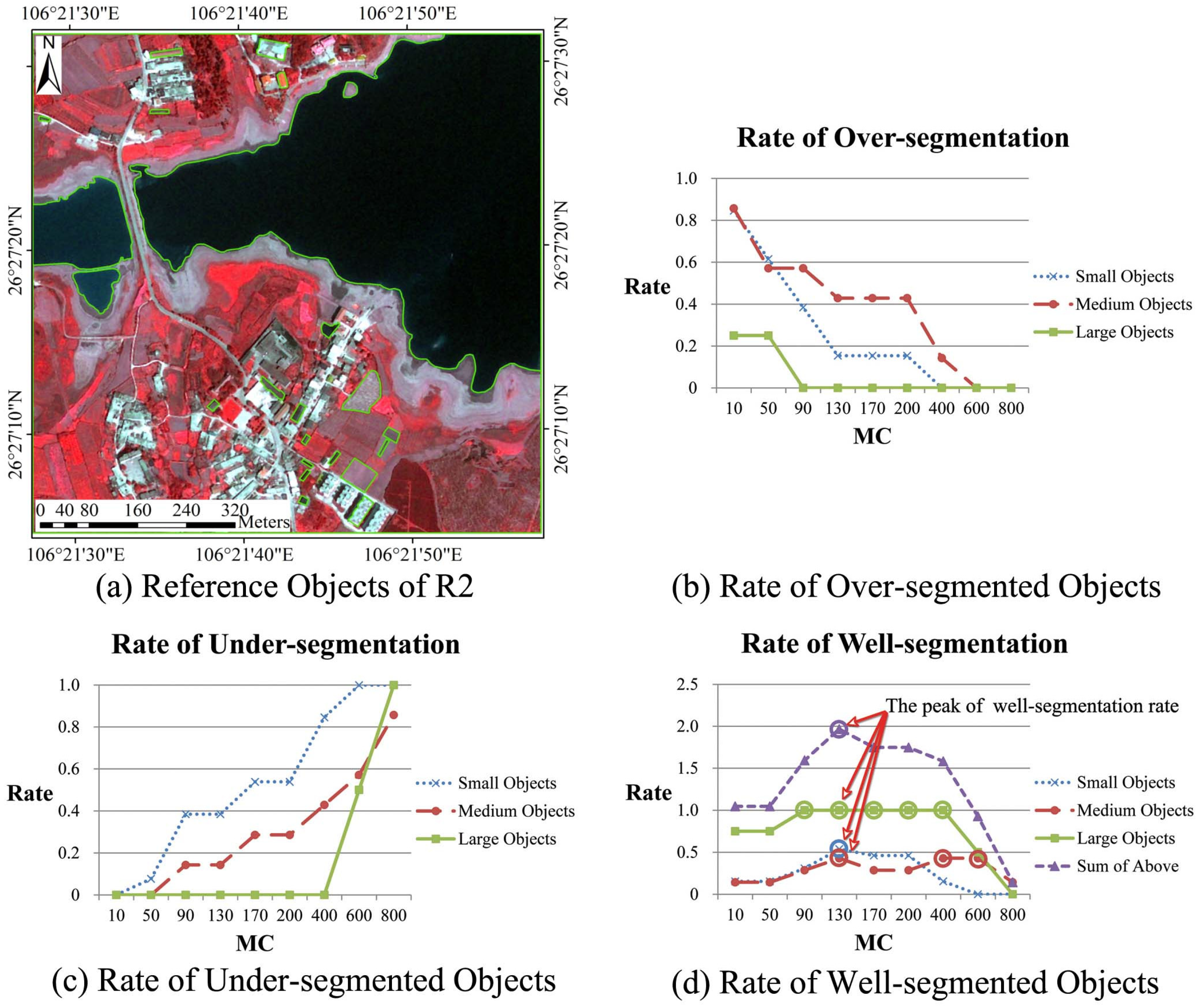
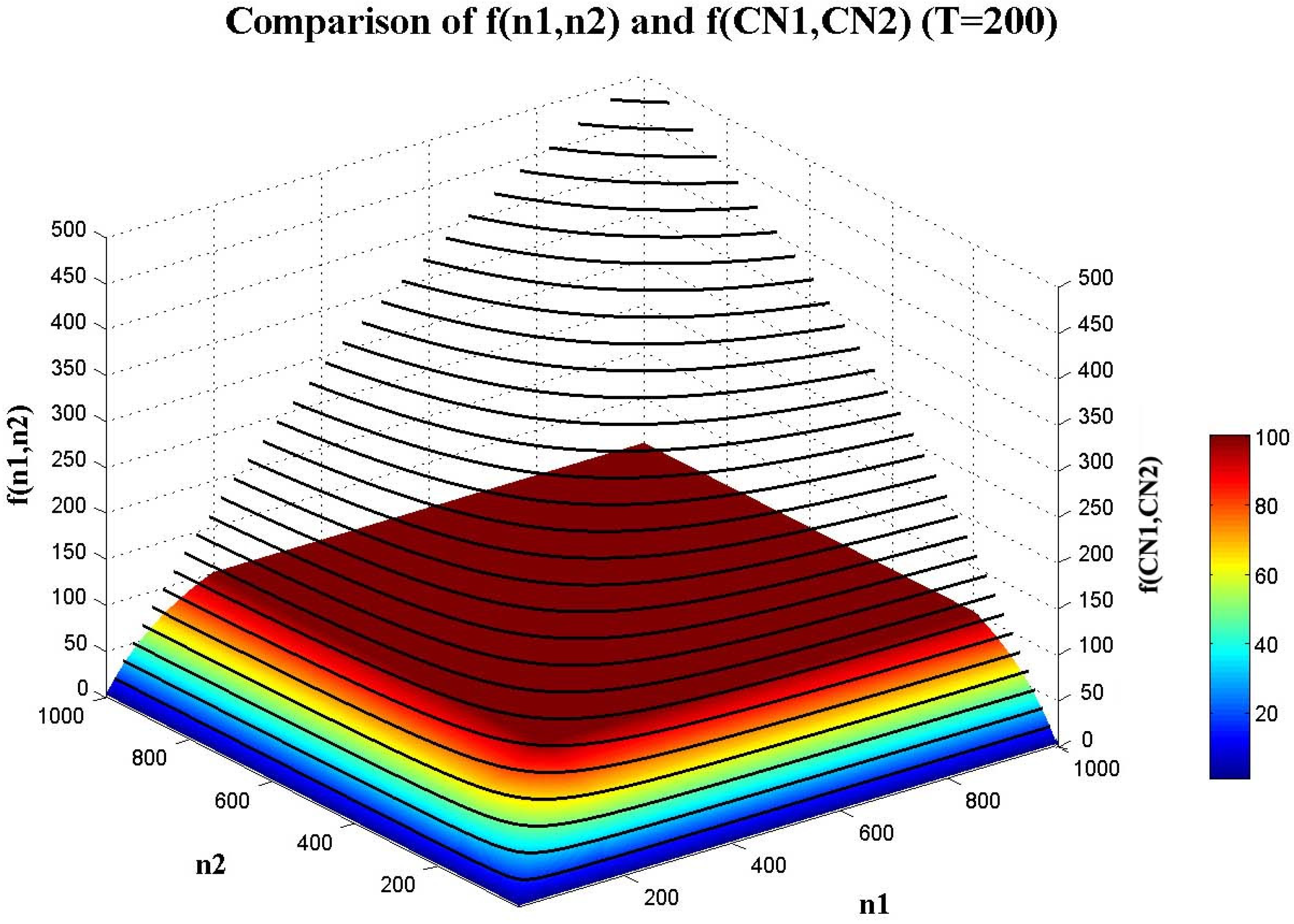
4.1.2. The Constraining Threshold for Object Size in CSVD: T
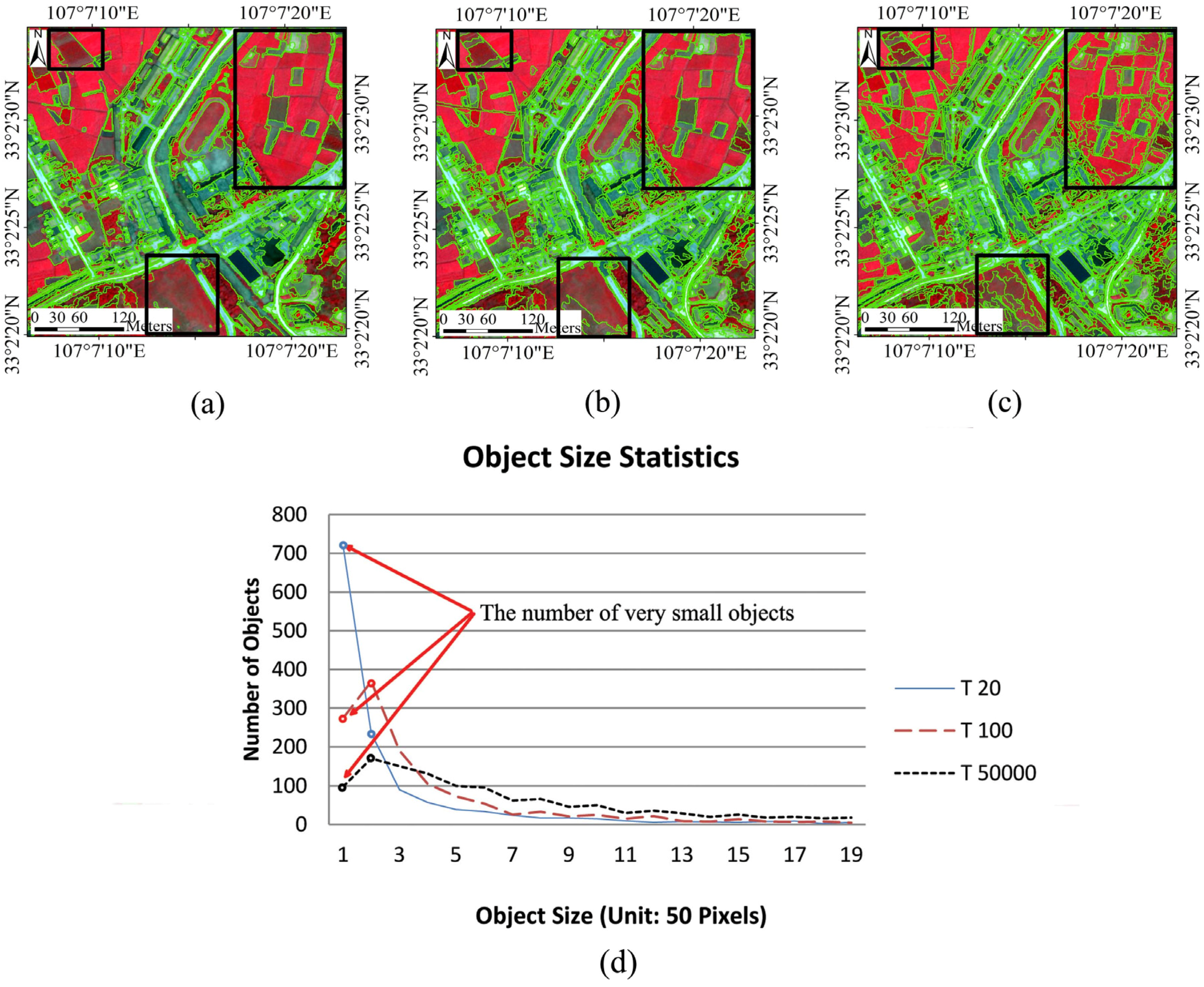
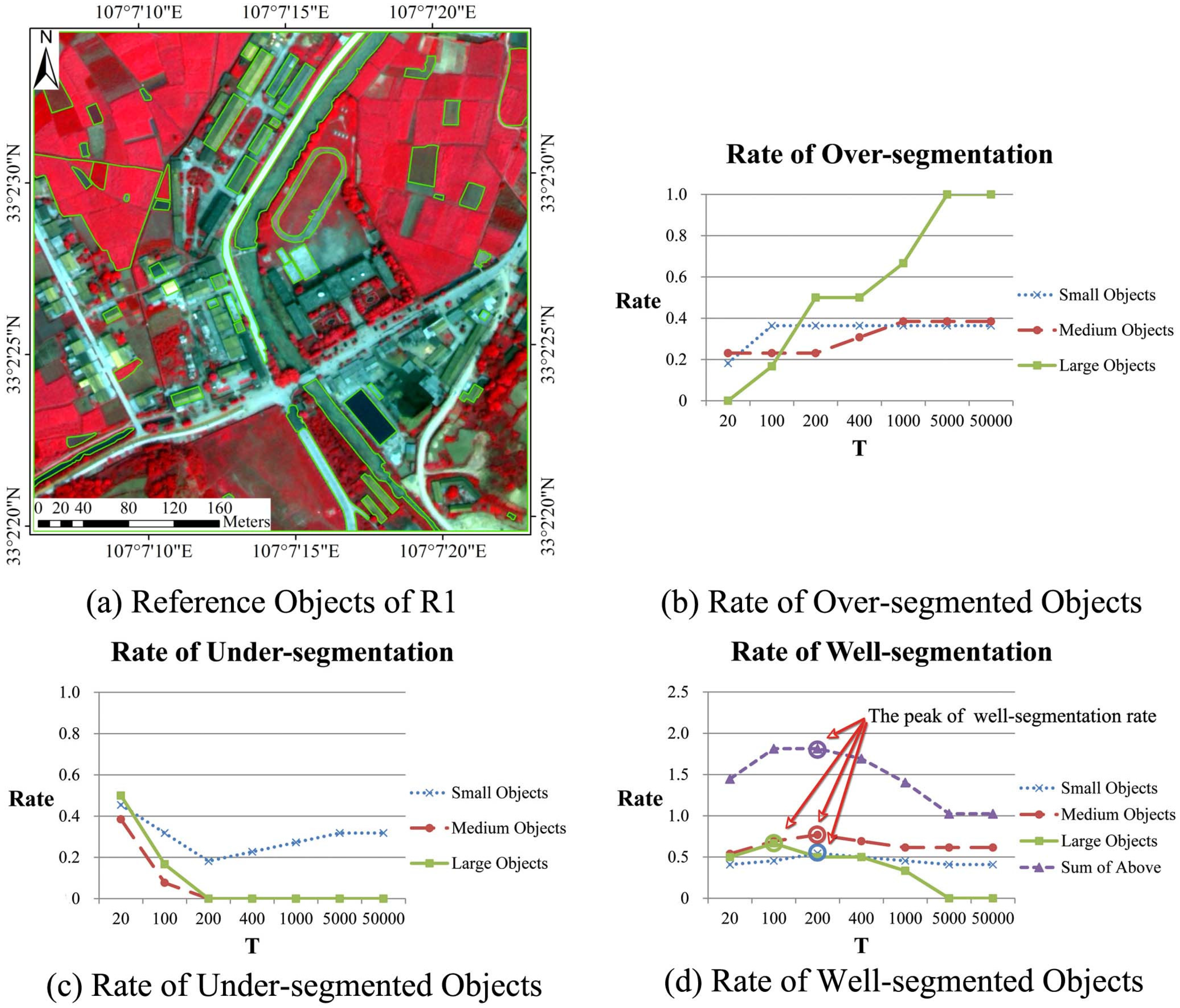
4.1.3. The Edge Penalty Control Variable ε
4.1.4. The Scale Parameter for MC
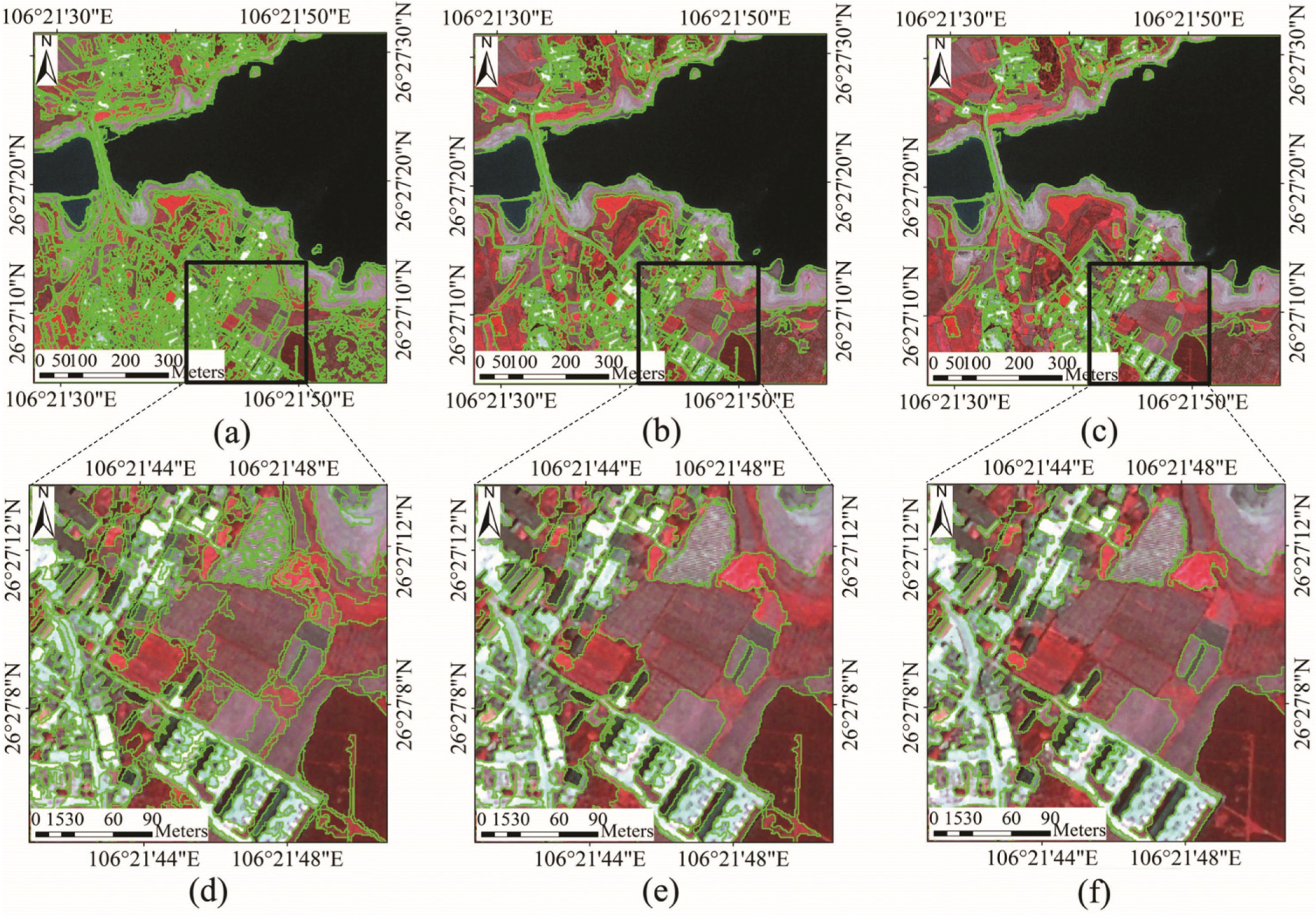

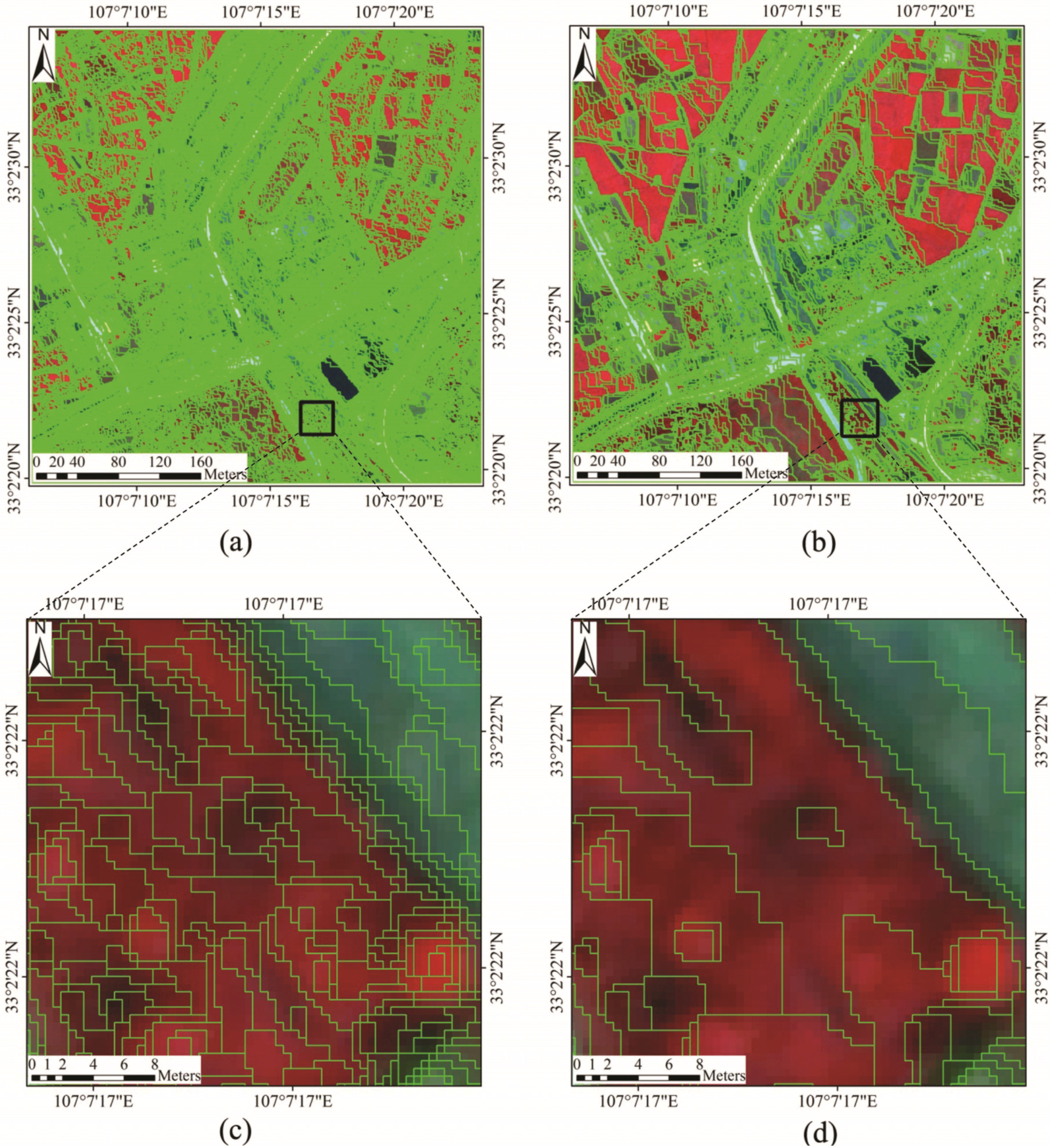
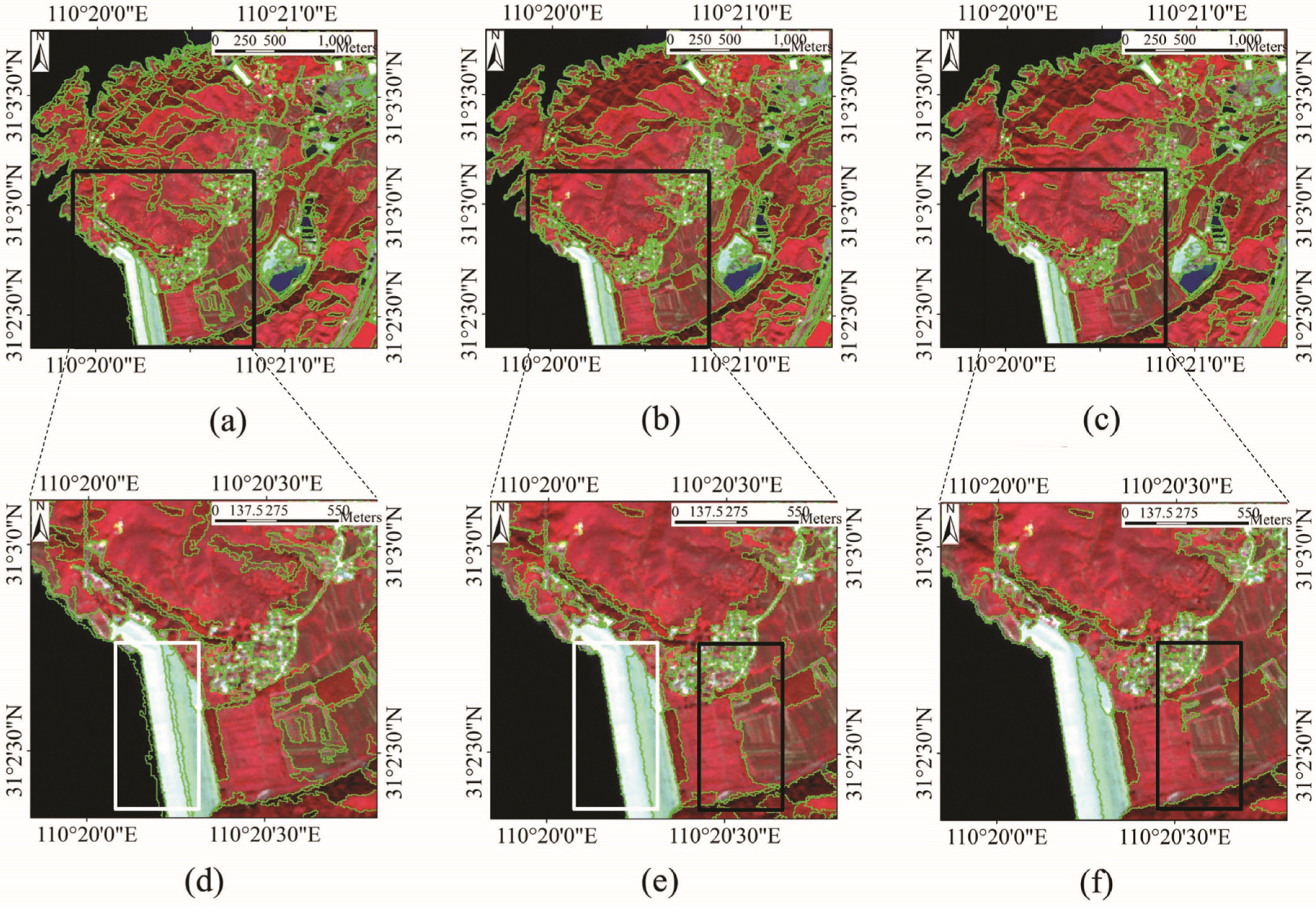
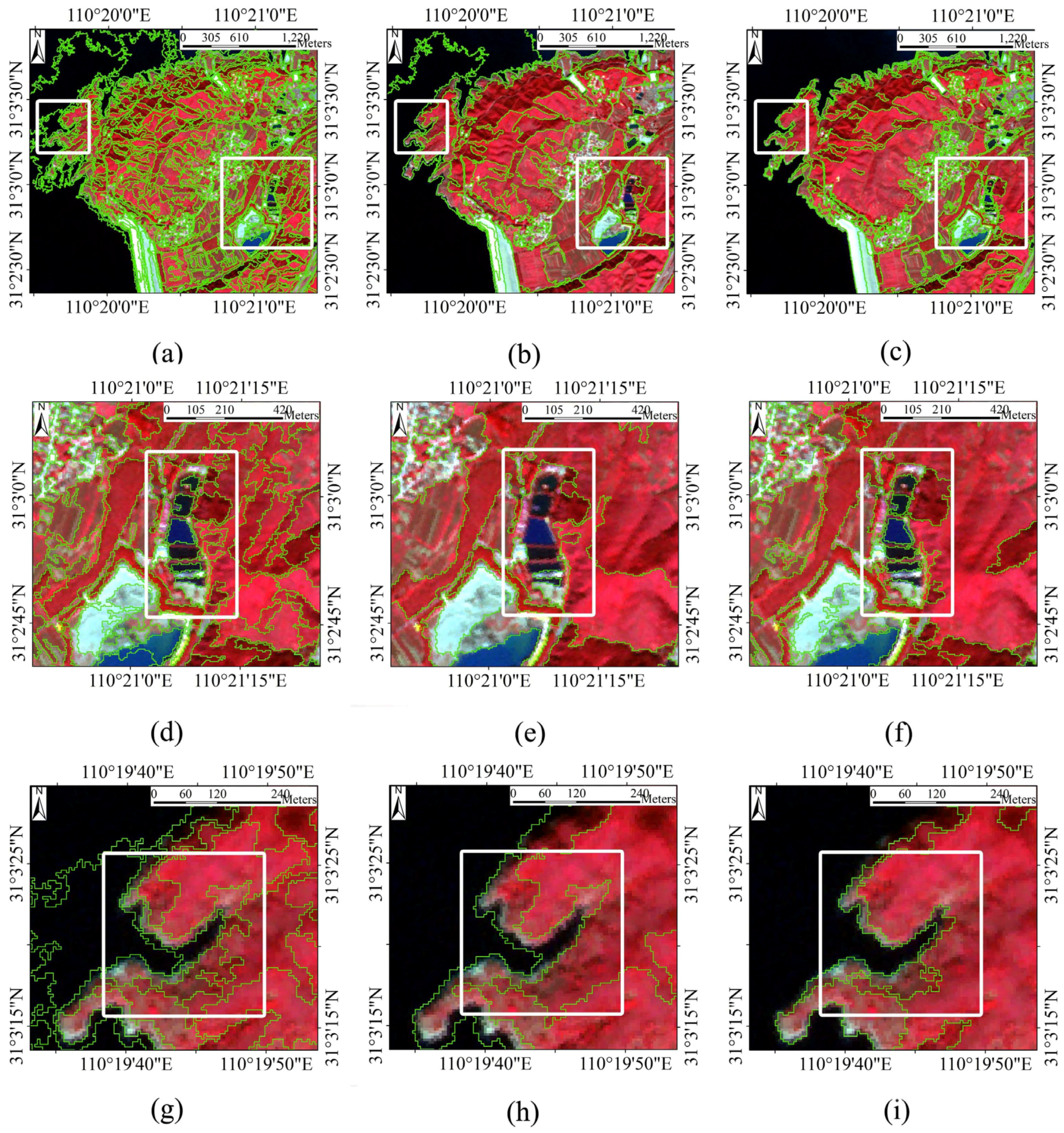
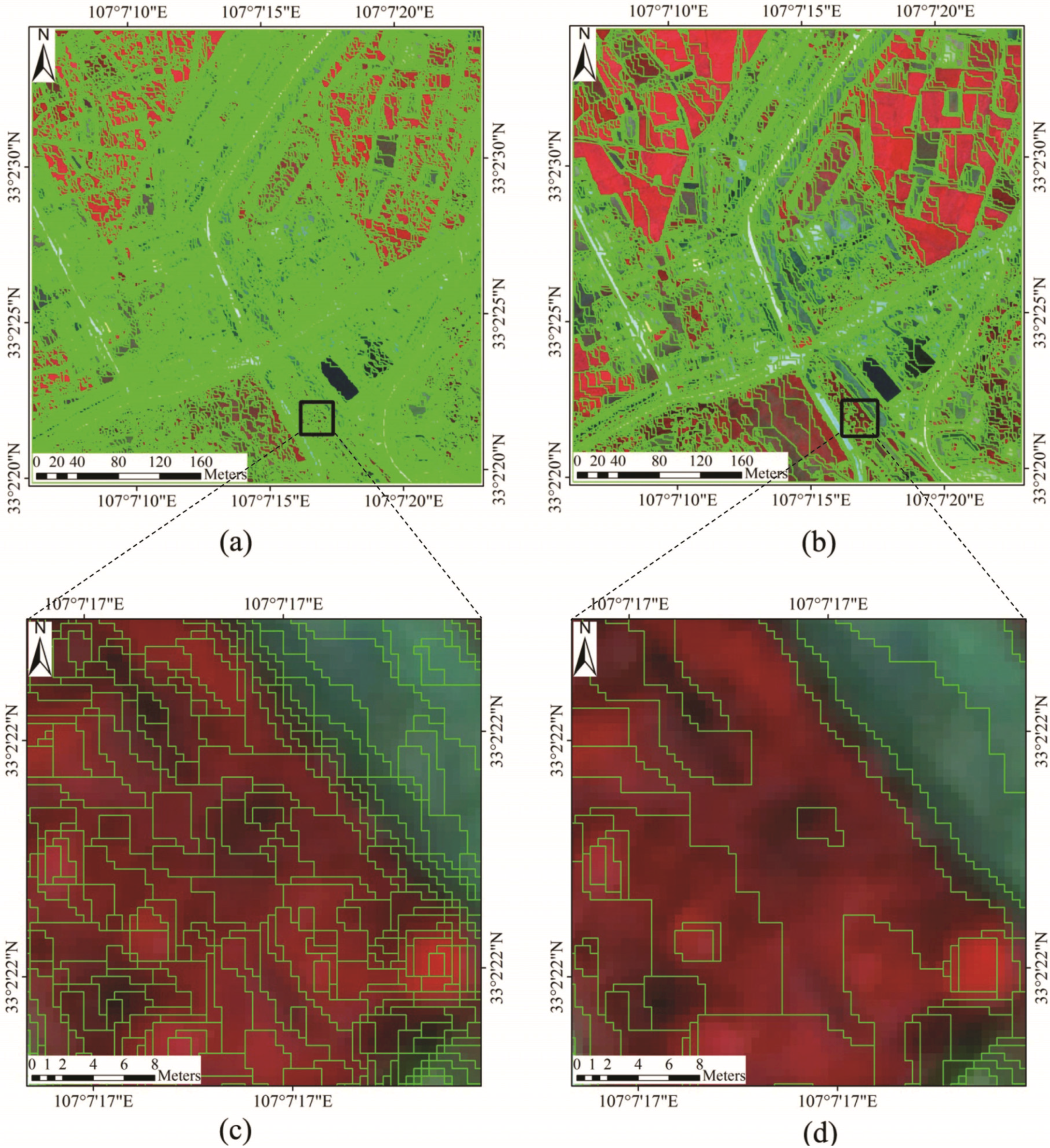
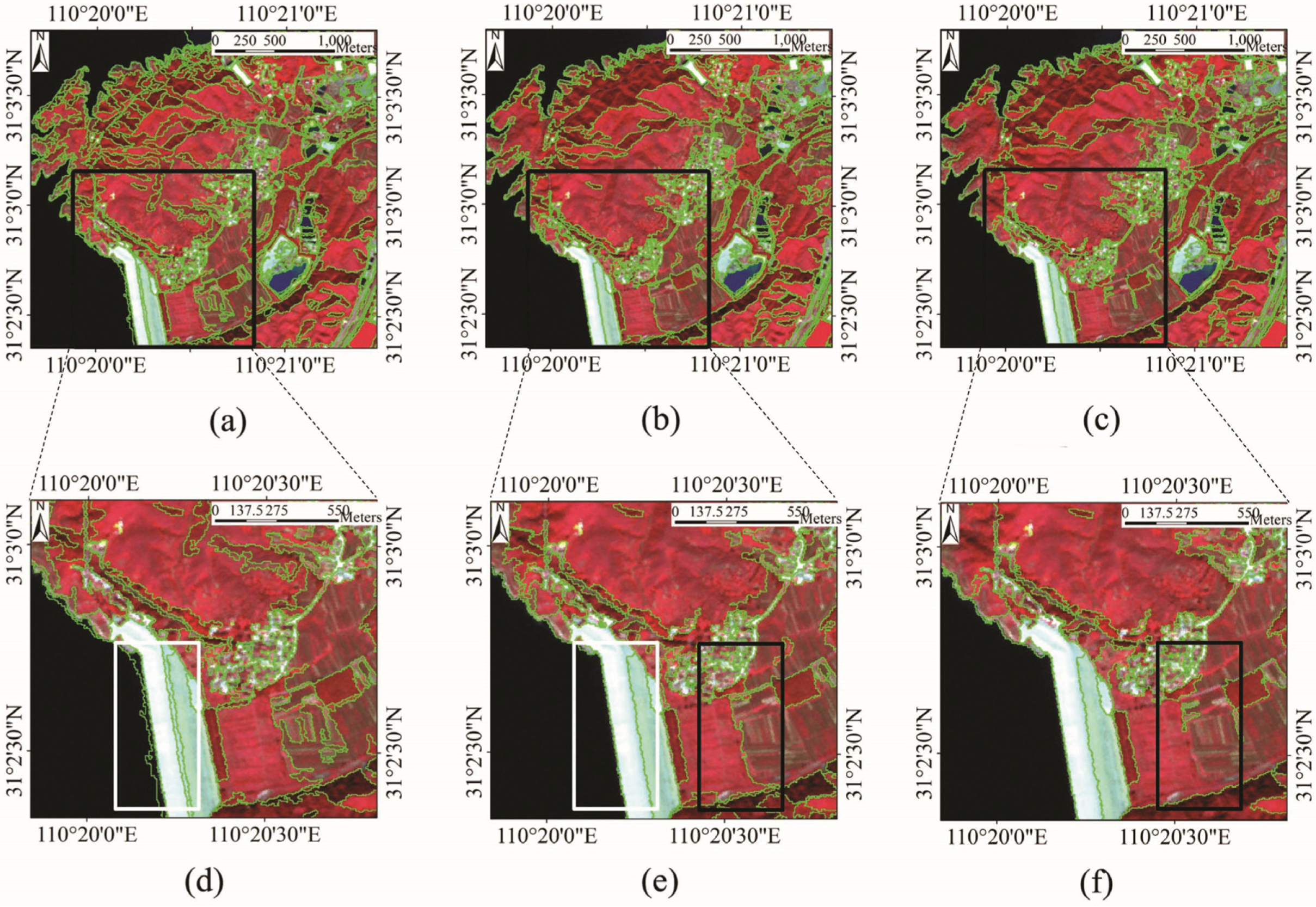
4.2. Comparison with eCognition Software Segmentation
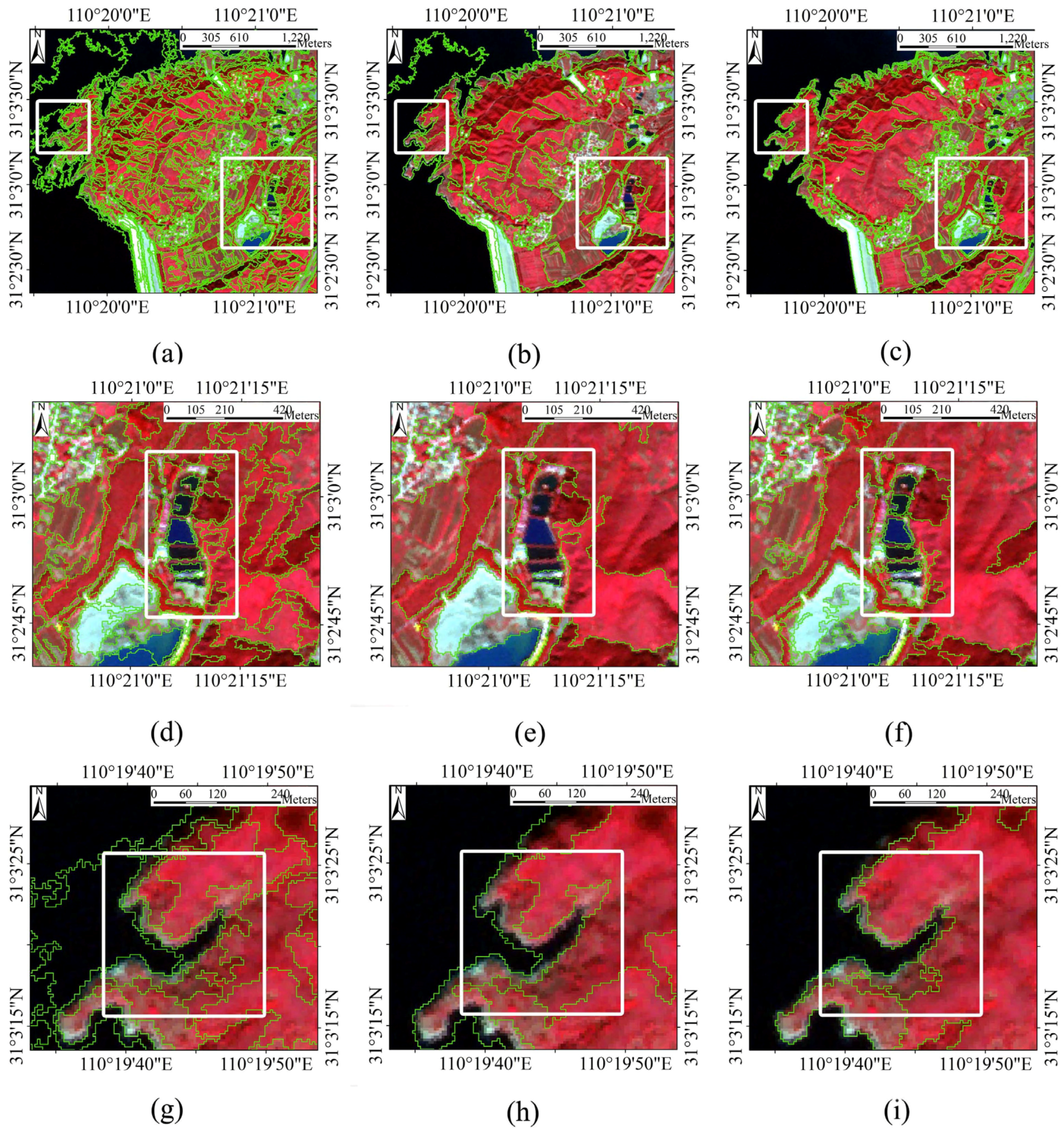
5. Conclusions
Acknowledgment
Author Contributions
Conflicts of Interest
References
- Cracknell, A.P. Synergy in remote sensing—What’s in a pixel? Int. J. Remote Sens. 1998, 19, 2025–2047. [Google Scholar]
- Blaschke, T.; Strobl, J. What’s wrong with pixels? Some recent developments interfacing remote sensing and GIS. GeoBIT/GIS 2001, 6, 12–17. [Google Scholar]
- Burnett, C.; Blaschke, T. A multi-scale segmentation/object relationship modelling methodology for landscape analysis. Ecol. Model. 2003, 168, 233–249. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; 1st ed.; Blaschke, T., Lang, S., Hay, G., Eds.; Springer: Heidelberg/Berlin, Germany; New York, NY, USA, 2008; pp. 93–112. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 63, 2–16. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shapiro, L. Survey: Image segmentation techniques. Comput. Vis. Graph. Image Process. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Pal, R.; Pal, K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Blaschke, T.; Burnett, C.; Pekkarinen, A. New contextual approaches using image segmentation for object-based classification. In Remote Sensing Image Analysis: Including the Spatial Domain, 1st ed.; de Meer, F., de Jong, S., Eds.; Kluver Academic Publishers: Dordrecht, The Netherland, 2004; Volume 5, pp. 211–236. [Google Scholar]
- Reed, T.R.; Buf, J.M.H.D. A review of recent texture segmentation and feature extraction techniques. Comput. Vis. Graph. Image Process. 1993, 57, 359–372. [Google Scholar] [CrossRef]
- Schiewe, J. Segmentation of high-resolution remotely sensed data- concepts, applications and problems. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 380–385. [Google Scholar]
- Dey, V.; Zhang, Y.; Zhong, M. A review on image segmentation techniques with remote sensing perspective. In Proceedings of the ISPRS TC VII Symposium—100 Years ISPRS, Vienna, Austria, 5–7 July 2010; Wagner, W., Székely, B., Eds.; ISPRS: Vienna, Austria, 2010. [Google Scholar]
- Gonçalves, H.; Gonçalves, J.A.; Corte-Real, L. HAIRIS: A method for automatic image registration through histogram-based image segmentation. IEEE Trans. Image Process. 2011, 20, 776–789. [Google Scholar] [CrossRef] [PubMed]
- Cocquerez, J.P.; Philipp, S. Analyse D’images: Filtrage et Segmentation; Masson: Paris, France, 1995; p. 457. [Google Scholar]
- Vincent, L.; Soille, P. Watershed in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef]
- Debeir, O. Segmentation Supervisée d’Images. Ph.D. Thesis, Faculté des Sciences Appliquées, Université Libre de Bruxelles, Brussels, Belgium, 2001. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Carleer, A.P.; Debeir, O.; Wolff, E. Assessment of very high spatial resolution satellite image segmentations. Photogramm. Eng. Remote Sens. 2005, 71, 1285–1294. [Google Scholar] [CrossRef]
- Jain, A.K. Fundamentals of Digital Image Processing; Prentice-Hall: Upper Saddle River, NJ, USA, 1989; pp. 347–356. [Google Scholar]
- Wang, D. A multiscale gradient algorithm for image segmentation using watersheds. Pattern Recognit. 1997, 30, 2043–2052. [Google Scholar] [CrossRef]
- Horowitz, S.L.; Pavlidis, T. Picture segmentation by a tree traversal algorithm. J. ACM 1976, 23, 368–388. [Google Scholar] [CrossRef]
- Adams, R.; Bischof, L. Seeded Region Growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, M. Multiresolution segmentation—An optimization approach for high quality multi-scale image segmentation. In Angewandte Geographische Informations-Verarbeitung XII, Beiträge zum AGIT-Symposium Salzbug, Salzbug, Austria; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Herbert Wichmann Verlag: Karlsruhe, Germany, 2000; pp. 12–23. [Google Scholar]
- Pavlidis, T.; Liow, Y.T. Integrating region growing and edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 225–233. [Google Scholar] [CrossRef]
- Cortez, D.; Nunes, P.; Sequeira, M.M.; Pereira, F. Image segmentation towards new image representation methods. Signal Process. 1995, 6, 485–498. [Google Scholar]
- Haris, K.; Efstratiadis, S.N.; Maglaveras, N.; Katsaggelos, A.K. Hybrid image segmentation using watersheds and fast region merging. IEEE Trans. Image Process. 1998, 7, 1684–1699. [Google Scholar] [CrossRef] [PubMed]
- Castilla, G.; Hay, G.J.; Ruiz, J.R. Size-constrained region merging (SCRM): An automated delineation tool for assisted photointerpretation. Photogramm. Eng. Remote Sens. 2008, 74, 409–419. [Google Scholar] [CrossRef]
- Yu, Q.; Clausi, D.A. IRGS: Image segmentation using edge penalties and region growing. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2126–2139. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Xiao, P.; Song, X.; She, J. Boundary-constrained multi-scale segmentation method for remote sensing images. ISPRS J. Photogramm. Remote Sens. 2013, 78, 15–25. [Google Scholar] [CrossRef]
- Zhang, X.; Xiao, P.; Feng, X. Fast hierarchical segmentation of high-resolution remote sensing image with adaptive edge penalty. Photogramm. Eng. Remote Sens. 2014, 80, 71–80. [Google Scholar] [CrossRef]
- Robinson, D.J.; Redding, N.J.; Crisp, D.J. Implementation of a fast algorithm for segmenting SAR imagery. In Scientific and Technical Report; Defense Science and Technology Organization: Canberra, Australia, 2002. [Google Scholar]
- Marpu, P.R.; Neubert, M.; Herold, H.; Niemeyer, I. Enhanced evaluation of image segmentation results. J. Spat. Sci. 2010, 55, 55–68. [Google Scholar] [CrossRef]
- Benz, U.C.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multiresolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens. 2004, 58, 239–258. [Google Scholar] [CrossRef]
- Beaulieu, J.M.; Goldberg, M. Hierarchy in picture segmentation: A stepwise optimization approach. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 150–163. [Google Scholar] [CrossRef]
- Saarinen, K. Color image segmentation by a watershed algorithm and region adjacency graph processing. In Proceedings of the IEEE International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 3, pp. 1021–1025.
- Chen, Z.; Zhao, Z.M.; Yan, D.M.; Chen, R.X. Multi-scale segmentation of the high resolution remote sensing image. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, 2005, (IGARSS’05), Seoul, South Korea, 29 July 2005; Volume 5, pp. 3682–3684.
- Tan, Y.M.; Huai, J.Z.; Tan, Z.S. Edge-guided segmentation method for multiscale and high resolution remote sensing image. J. Infrared Millim. Waves 2010, 29, 312–316. [Google Scholar]
- Deng, F.L.; Tang, P.; Liu, Y.; Yang, C.J. Automated hierarchical segmentation of high-resolution remote sensing imagery with introduced relaxation factors. J. Remote Sens. 2013, 17, 1492–1499. [Google Scholar]
- Ballard, D.; Brown, C. Computer Vision, 1st ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1982; pp. 159–164. [Google Scholar]
- Wu, X. Adaptive split-and-merge segmentation based on piecewise least-square approximation. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 808–815. [Google Scholar]
- Kanungo, T.; Dom, B.; Niblack, W.; Steele, D. A fast algorithm for MDL-based multi-band image segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 609–616.
- Luo, J.B.; Guo, C.E. Perceptual grouping of segmented regions in color images. Pattern Recognit. 2003, 36, 2781–2792. [Google Scholar] [CrossRef]
- Tupin, F.; Roux, M. Markov random field on region adjacency graph for the fusion of SAR and optical data in radar grammetric applications. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1920–1928. [Google Scholar] [CrossRef]
- Xiao, P.; Feng, X.Z.; Wang, P.; Ye, S.; Wu, G.; Wang, K.; Feng, X.L. High Resolution Remote Sensing Image Segmentation and Information Extraction, 1st ed.; Science Press: Beijing, China, 2012; pp. 167–168. [Google Scholar]
- Sarkar, A.; Biswas, M.K.; Sharma, K.M. A simple unsupervised MRF model based image segmentation approach. IEEE Trans. Image Process. 2000, 9, 801–812. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.J. A survey on evaluation methods for image segmentation. Pattern Recognit. 1996, 29, 1335–1346. [Google Scholar] [CrossRef]
- Lucieer, A. Uncertainties in Segmentation and Their Visualization. Ph.D. Thesis, Utrecht University, Utrecht, The Netherlands, 2004. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Qiu, F.; Wu, B.; Du, H. Image Segmentation Based on Constrained Spectral Variance Difference and Edge Penalty. Remote Sens. 2015, 7, 5980-6004. https://doi.org/10.3390/rs70505980
Chen B, Qiu F, Wu B, Du H. Image Segmentation Based on Constrained Spectral Variance Difference and Edge Penalty. Remote Sensing. 2015; 7(5):5980-6004. https://doi.org/10.3390/rs70505980
Chicago/Turabian StyleChen, Bo, Fang Qiu, Bingfang Wu, and Hongyue Du. 2015. "Image Segmentation Based on Constrained Spectral Variance Difference and Edge Penalty" Remote Sensing 7, no. 5: 5980-6004. https://doi.org/10.3390/rs70505980