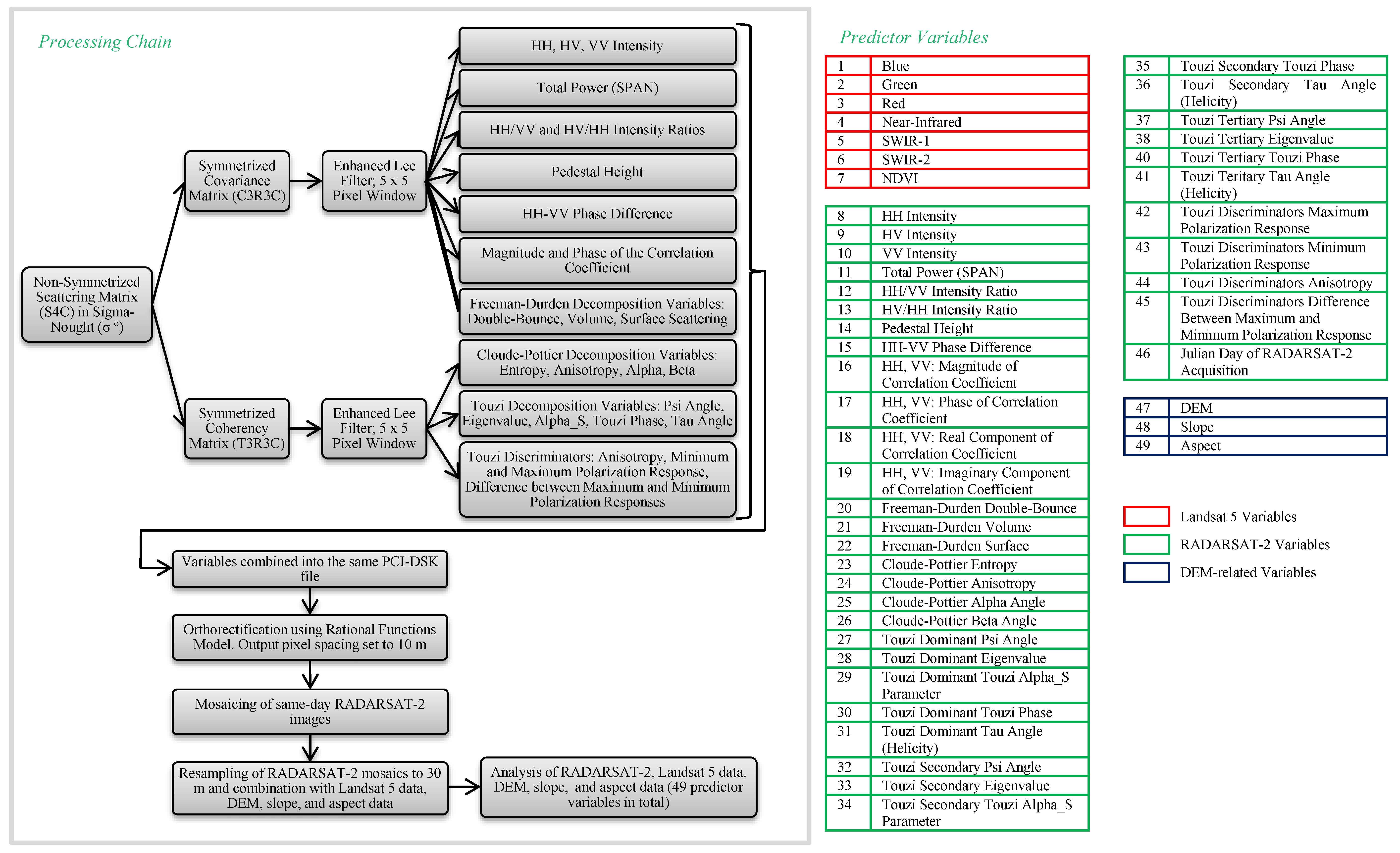
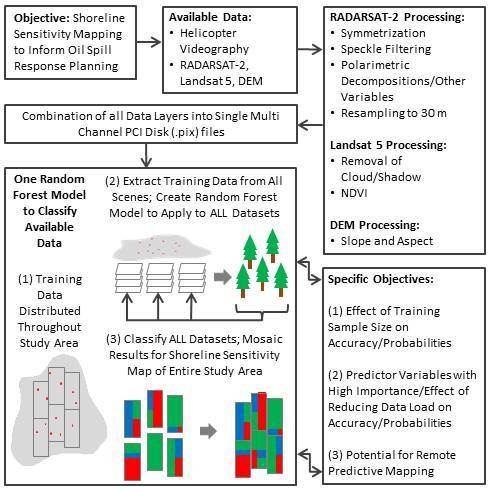
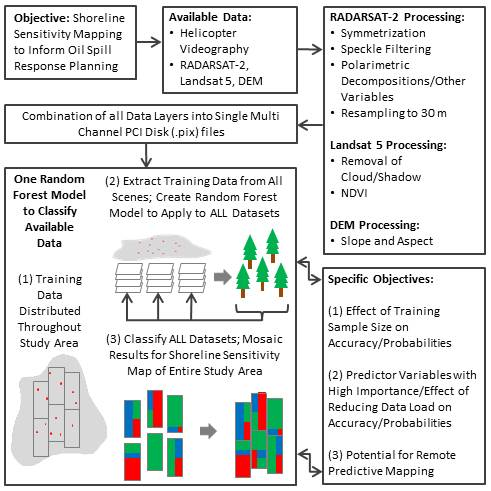
5.1. Effect of Training Sample Size on Classifier Accuracies and Probabilities
Three model iterations were deemed sufficient to represent the variability of outputs since models generated with the same training sample size tended to predict the same classes at the same locations, and tended to achieve similar accuracies, Kappa statistic values, and probabilities. For the 15 models that were generated in total: OOBAs, independent overall accuracies, Kappa statistic values, and per-class User’s and Producer’s accuracies are provided in
Table 4. Average probabilities for the winning class are provided in
Table 5.
Results indicate that acceptable accuracies for all land cover types were achieved with as few as 25 training points per-class. Models based on 13 points per-class yielded poor User’s accuracies for Mixed Sediment (65% to 69%), and though a McNemar’s test indicated there was not a significant difference between models generated with 13 or 25 points per-class, the notable increase in the User’s accuracies for Mixed Sediment (87%) indicates that the latter should be preferred (
Table 4). Training sample sizes of 25 to 167 points per-class yielded comparable results (OOBAs ranged from 88% to 91%, independent overall accuracies from 88% to 92%, Kappa statistic values from 0.88 to 0.90, and User’s and Producer’s Accuracies from 78% to 100%), indicating that under the conditions tested, model performance was not highly dependent on the training sample size. This was confirmed with the McNemar’s statistic, which indicated that differences between all models generated with 25
versus 50, and 25
versus 100 points per-class were not significant to the 95% confidence level. In some cases a significant difference was observed for models based on 25
versus 167 points per-class (nine comparisons made between the six models, five of which showed significant differences), though acceptable classification accuracies for all land cover types (
i.e., >~80%) were still achieved with either training sample size.
These results are consistent with Waske and Braun [
27], who classified multi-temporal C-band SAR data and achieved overall accuracies of 69%, 75% and 75% with training sample sizes of 15, 30, and 50 points per-class, respectively. The authors similarly noted that Random Forest showed little sensitivity to training sample size, and they also achieved acceptable accuracies with relatively few samples. Other authors have reported similar findings with different data types, including Landsat imagery and a DEM [
30], as well as hyperspectral imagery [
40]. In contrast, Millard and Richardson [
26] used LiDAR derivatives to classify wetland types, and found that both the training sample size and the proportion allocated to individual classes had a significant impact on independent accuracies. This indicates that the effect of training sample size may also depend on the individual dataset. As such, the results demonstrated here should not be expected in all cases.
Table 4.
OOBA, independent overall accuracies, Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) of Random Forest models generated with different training sample sizes. For each model all 49 image channels were included as predictor variables.
Table 4.
OOBA, independent overall accuracies, Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) of Random Forest models generated with different training sample sizes. For each model all 49 image channels were included as predictor variables.
| Proportion of Dataset Used to Train the Model | Model Iteration | OOBA (%) | Independent Overall Accuracy (%) | Kappa Statistic | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) |
|---|
| ~5% (13 points per-class) | 1 | 78 | 88 | 0.86 | 100 | 86 | 93 | 88 | 65 | 86 | 92 | 80 | 87 | 92 | 83 | 97 | 95 | 89 |
| 2 | 79 | 87 | 0.85 | 100 | 84 | 90 | 87 | 65 | 86 | 92 | 80 | 87 | 92 | 83 | 97 | 95 | 89 |
| 3 | 80 | 88 | 0.86 | 100 | 85 | 92 | 87 | 69 | 86 | 92 | 82 | 87 | 92 | 83 | 97 | 95 | 90 |
| 10% (25 points per-class) | 1 | 91 | 90 | 0.88 | 98 | 86 | 90 | 90 | 87 | 80 | 89 | 94 | 86 | 99 | 81 | 96 | 96 | 86 |
| 2 | 89 | 90 | 0.88 | 98 | 86 | 92 | 90 | 87 | 80 | 88 | 94 | 86 | 97 | 81 | 96 | 96 | 87 |
| 3 | 91 | 89 | 0.88 | 99 | 86 | 92 | 92 | 87 | 80 | 88 | 94 | 86 | 99 | 78 | 96 | 96 | 84 |
| 20% (50 points per-class) | 1 | 89 | 89 | 0.87 | 100 | 84 | 94 | 94 | 86 | 87 | 86 | 92 | 86 | 95 | 83 | 86 | 87 | 85 |
| 2 | 89 | 88 | 0.86 | 100 | 85 | 94 | 93 | 83 | 87 | 86 | 91 | 86 | 92 | 84 | 85 | 86 | 86 |
| 3 | 88 | 89 | 0.87 | 100 | 85 | 94 | 93 | 86 | 88 | 86 | 92 | 87 | 95 | 82 | 87 | 88 | 84 |
| 40% (100 points per-class) | 1 | 90 | 91 | 0.89 | 100 | 86 | 94 | 92 | 84 | 84 | 84 | 92 | 88 | 94 | 93 | 92 | 90 | 95 |
| 2 | 90 | 91 | 0.89 | 100 | 86 | 94 | 91 | 83 | 86 | 87 | 92 | 88 | 94 | 93 | 91 | 89 | 95 |
| 3 | 90 | 90 | 0.89 | 100 | 86 | 94 | 92 | 84 | 84 | 84 | 92 | 88 | 92 | 92 | 90 | 89 | 95 |
| ~67% (167 points per-class) | 1 | 90 | 91 | 0.90 | 98 | 88 | 96 | 91 | 88 | 87 | 86 | 93 | 89 | 96 | 94 | 91 | 89 | 95 |
| 2 | 90 | 92 | 0.90 | 98 | 88 | 96 | 92 | 88 | 88 | 86 | 93 | 89 | 95 | 94 | 91 | 90 | 95 |
| 3 | 90 | 91 | 0.90 | 98 | 88 | 96 | 93 | 88 | 85 | 84 | 93 | 89 | 95 | 93 | 91 | 89 | 94 |
Table 5.
Average classification probability for the winning class over all validation sites for Random Forest models generated with different training sample sizes. For each model all 49 image channels were used as predictor variables. Values for sites that were incorrectly classified were excluded from averages.
Table 5.
Average classification probability for the winning class over all validation sites for Random Forest models generated with different training sample sizes. For each model all 49 image channels were used as predictor variables. Values for sites that were incorrectly classified were excluded from averages.
| Proportion of Dataset used for Training | Model Iteration | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| ~5% (13 points per-class) | 1 | 0.92 | 0.67 | 0.48 | 0.67 | 0.61 | 0.58 | 0.61 |
| 2 | 0.92 | 0.70 | 0.49 | 0.67 | 0.60 | 0.58 | 0.61 |
| 3 | 0.92 | 0.68 | 0.49 | 0.66 | 0.61 | 0.58 | 0.61 |
| 10% (25 points per-class) | 1 | 0.96 | 0.72 | 0.57 | 0.78 | 0.66 | 0.71 | 0.70 |
| 2 | 0.96 | 0.71 | 0.58 | 0.79 | 0.64 | 0.71 | 0.70 |
| 3 | 0.95 | 0.71 | 0.58 | 0.79 | 0.65 | 0.71 | 0.69 |
| 20% (50 points per-class) | 1 | 0.93 | 0.79 | 0.60 | 0.86 | 0.72 | 0.79 | 0.78 |
| 2 | 0.93 | 0.80 | 0.61 | 0.86 | 0.72 | 0.79 | 0.78 |
| 3 | 0.93 | 0.79 | 0.60 | 0.86 | 0.72 | 0.79 | 0.78 |
| 40% (100 points per-class) | 1 | 0.97 | 0.86 | 0.68 | 0.88 | 0.82 | 0.78 | 0.79 |
| 2 | 0.97 | 0.85 | 0.68 | 0.87 | 0.82 | 0.79 | 0.80 |
| 3 | 0.97 | 0.85 | 0.68 | 0.88 | 0.82 | 0.79 | 0.80 |
| ~67% (167 points per-class) | 1 | 0.97 | 0.86 | 0.70 | 0.89 | 0.84 | 0.79 | 0.82 |
| 2 | 0.98 | 0.86 | 0.69 | 0.88 | 0.84 | 0.80 | 0.82 |
| 3 | 0.97 | 0.86 | 0.69 | 0.89 | 0.84 | 0.80 | 0.83 |
While not entirely conclusive, these findings do indicate that it may be possible to classify shore and near-shore land covers to acceptable levels (e.g., >~80%) with a relatively small amount of training data. This has important implications since collecting training data can be difficult along remote Arctic shorelines, which are costly and challenging to access, and which tend to make up only a fraction of the total image area [
11,
12,
13,
40]. The potential for accurate classification with a reduced training sample size is also relevant for mapping large areas, since reducing the training sample size also decreases memory requirements and the duration of the tree-growing process [
25,
26]. These benefits were similarly noted by Deschamps
et al. [
24] who classified crop types, albeit using a much larger dataset (25,000 to 200,000 training points). However, results from this analysis also show that under certain conditions, some classes may require additional training data to be accurately classified. We theorize that the lower User’s accuracy observed for mixed sediment in particular, could be due to the fact that the range and diversity of the SAR and spectral values were not well represented by just 13 training samples. This seems plausible since compared to other classes like sand, which were well classified with 13 training samples, values for mixed sediment were much more variable.
Despite the advantages associated with a decreased training sample size, in this analysis models built on the largest training sample sizes also had the highest overall accuracies. This suggests that the added effort associated with collecting more training data, as well as the added memory requirements and processing times may be warranted in some cases [
24]. This is further supported by the fact that classifier probabilities were also considerably higher for models generated with larger training sample sizes (
Table 5), indicating greater certainty associated with class predictions [
69]. For these reasons the largest training sample size (
i.e., 167 points per-class or ~67% of the training/validation dataset) was selected as the final, optimal dataset used to generate subsequent models. While not addressed here, it is possible that models based on fewer predictor variables would need less training data, as increasingly complex datasets (higher dimensionality) often require more training samples to achieve acceptable accuracy levels [
26,
35].
In this analysis differences observed between independent overall accuracies and OOBAs ranged from +10% to −2% (independent overall accuracy-OOBA), with independent accuracies generally being higher than OOBAs. Larger differences were also observed for models based on 13 training points per-class (8% to 10%) compared to all others (1% to 2%). While the tendency for OOBAs to underestimate true accuracies is well known [
14,
30], this analysis has shown that with a sufficient training sample size OOBA rates are similar enough to true accuracy rates to warrant the use of the former alone for model assessment. This result is also of interest for shoreline mapping applications, as users could potentially collect less ground data, as independent validation sites would not be required. However, other authors have also observed the opposite result. Millard and Richardson [
25,
26], for example, found that OOBA rates were up to 21% higher than independent accuracies (
i.e., OOBAs were overly optimistic), and so this result may not be repeatable with a different dataset.
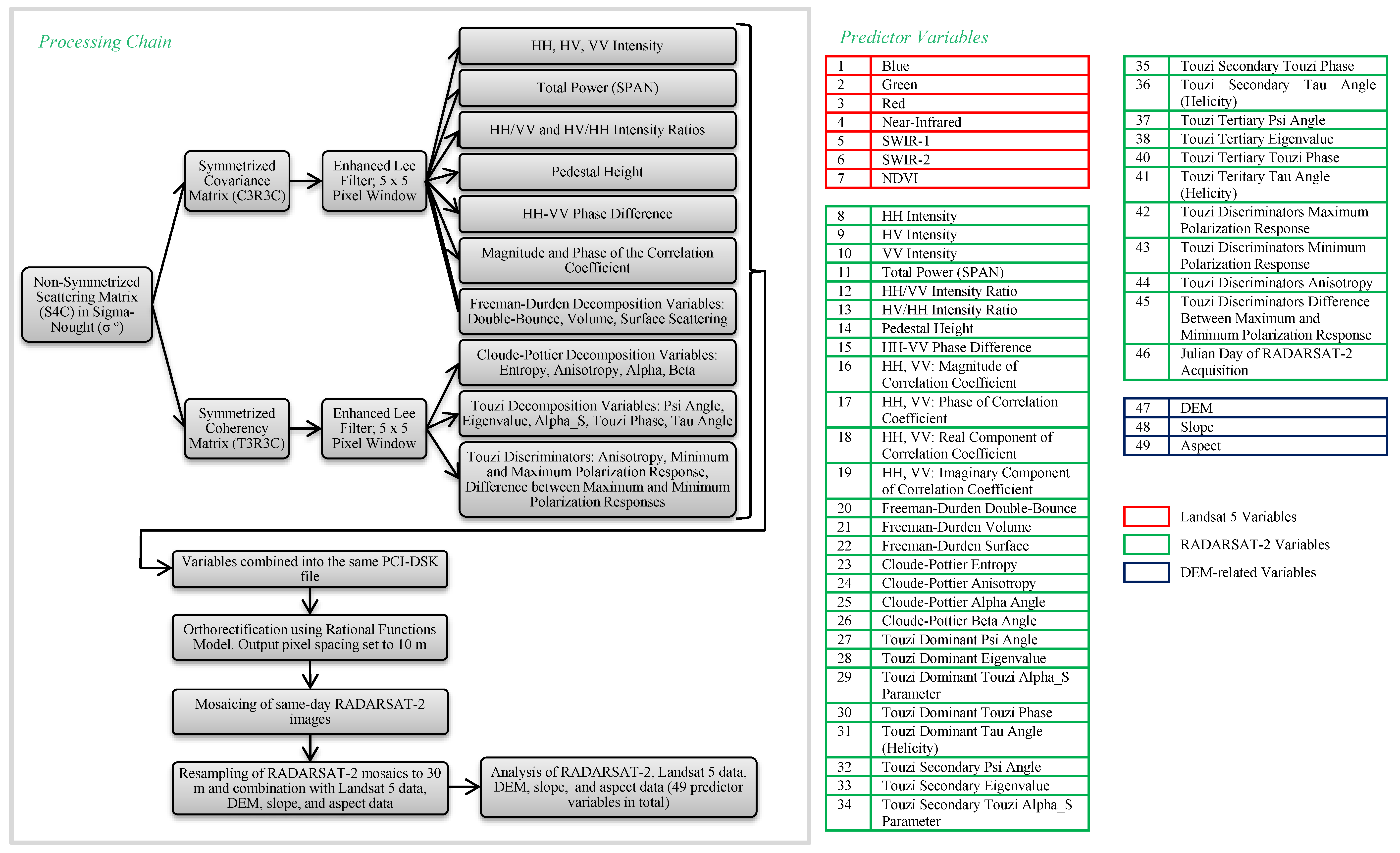
5.2. Predictor Variables Providing Relevant Information to the Model and the Effect of Reducing Data Load on Classifier Accuracies and Probabilities
The rank of variable importances differed between models generated with the same training data and predictor variables, so 10 models were required to adequately represent the variability of outputs (for the 10 sets of variables tested 100 models were generated in total). As was observed in 1., models generated with the same set of predictor variables still tended to predict the same classes at the same locations, and accuracies, Kappa statistic values, and probabilities were also similar. As such, we present results of the first three models only for each set of increasingly fewer predictor variables. Results from this test, including: OOBAs, independent overall accuracies, Kappa statistic values, and per-class User’s, Producer’s accuracies are provided in
Table 6, and classifier probabilities are provided
Table 7.
Models generated with nine or more variables achieved relatively stable results regardless of the number of inputs (OOBAs and independent overall accuracies ranged from 90% to 92%, Kappa statistic values from 0.89 to 0.90, and User’s and Producer’s accuracies from 84% to 99%). This indicates that under the conditions tested, model performance was not adversely affected by reducing the number of inputs from 49 to nine predictor variables. However, a decrease in accuracy was observed with models generated with four predictor variables, and the McNemar’s test indicated that the difference between these and models generated with nine predictor variables was significant to the 95% confidence level. Classifier probabilities tended to remain stable or increase slightly as fewer predictor variables were included as inputs, though with fewer than 14 predictor variables, probabilities for some classes also decreased substantially (e.g., for Pebble/Cobble/Boulder probabilities were ~0.92 with 14 predictor variables, and ~0.86 with nine predictor variables). Since the set of 14 predictor variables achieved both relatively high classifier accuracies and probabilities it was chosen as the final, optimized dataset used to generate subsequent models (
Table 6 and
Table 7).
The ability to achieve similar outputs from Random Forest with a reduced data load was also observed by Corcoran
et al. [
44] who classified uplands, water and wetlands using Landsat 5, PALSAR, topographic, and soils data. The authors found comparable results when generating models with all, or just the top 10 most important predictor variables (an overall accuracy of 85% and Kappa statistic of 0.73 was achieved with the former, and an overall accuracy of 81% and Kappa statistic of 0.67 was achieved with the latter). The authors found similar results while classifying more detailed wetland types. Millard and Richardson [
26] also classified wetland types using LiDAR data, though in their study the authors found that accuracies significantly improved when just the most important predictor variables were included in the model.
This finding is relevant for mapping large areas, as reducing the model data load also reduces data storage requirements, and increases computational efficiency. These results may also inform future shoreline mapping work, as a similar set predictor variables could be used to classify other areas. Then, fewer variables would need to be generated, which would decrease the time required to prepare images for classification. However, it is worth noting that a different set of predictor variables could achieve comparable results, and another user may find different predictor variables are important for classifying their particular dataset. Similarly, because both the Mean Decrease in Accuracy and Gini Index values identified different variables as having the lowest importance values another analyst may have chosen to remove other variables through the same iterative process. Since focus was to accurately classify the land covers of interest, values for the Mean Decrease in Accuracy were used more often in making final decisions regarding which variables to remove, and to some extent, expert knowledge also played a role [
44].
Table 6.
OOBAs, independent overall accuracies, and Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) for Random Forest models generated with increasingly fewer predictor variables. For each model a training sample size of 167 points per-class was used.
Table 6.
OOBAs, independent overall accuracies, and Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) for Random Forest models generated with increasingly fewer predictor variables. For each model a training sample size of 167 points per-class was used.
| Number of Variables | Model Iteration | OOBA (%) | Independent Overall Accuracy (%) | Kappa Statistic | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) |
|---|
| 49 | 1 | 91 | 90 | 0.90 | 98 | 88 | 96 | 91 | 88 | 87 | 86 | 93 | 89 | 96 | 94 | 91 | 89 | 95 |
| 2 | 92 | 90 | 0.90 | 98 | 88 | 96 | 92 | 88 | 88 | 86 | 93 | 89 | 95 | 94 | 91 | 90 | 95 |
| 3 | 91 | 90 | 0.90 | 98 | 88 | 96 | 93 | 88 | 85 | 84 | 93 | 89 | 95 | 93 | 91 | 89 | 94 |
| 44 | 1 | 90 | 91 | 0.90 | 98 | 88 | 96 | 92 | 87 | 87 | 86 | 93 | 90 | 94 | 92 | 90 | 89 | 94 |
| 2 | 90 | 91 | 0.90 | 98 | 88 | 96 | 92 | 89 | 86 | 86 | 95 | 88 | 95 | 94 | 91 | 89 | 95 |
| 3 | 90 | 91 | 0.90 | 98 | 88 | 96 | 92 | 88 | 87 | 86 | 95 | 90 | 95 | 93 | 91 | 89 | 94 |
| 39 | 1 | 91 | 91 | 0.90 | 98 | 87 | 96 | 92 | 87 | 87 | 86 | 93 | 90 | 95 | 92 | 90 | 89 | 94 |
| 2 | 90 | 91 | 0.90 | 98 | 88 | 96 | 92 | 87 | 87 | 86 | 93 | 90 | 95 | 93 | 91 | 89 | 94 |
| 3 | 91 | 91 | 0.90 | 98 | 88 | 96 | 91 | 86 | 87 | 86 | 93 | 90 | 95 | 94 | 91 | 89 | 95 |
| 34 | 1 | 91 | 91 | 0.90 | 98 | 88 | 96 | 91 | 88 | 87 | 86 | 93 | 89 | 96 | 94 | 91 | 89 | 95 |
| 2 | 90 | 92 | 0.90 | 98 | 88 | 96 | 93 | 88 | 87 | 86 | 93 | 90 | 95 | 94 | 91 | 89 | 95 |
| 3 | 90 | 91 | 0.90 | 98 | 88 | 96 | 91 | 87 | 86 | 84 | 93 | 89 | 95 | 93 | 91 | 89 | 94 |
| 29 | 1 | 90 | 91 | 0.90 | 98 | 87 | 96 | 91 | 86 | 88 | 86 | 93 | 90 | 94 | 93 | 92 | 90 | 95 |
| 2 | 90 | 91 | 0.90 | 98 | 88 | 96 | 91 | 86 | 87 | 86 | 93 | 90 | 95 | 94 | 91 | 89 | 95 |
| 3 | 91 | 92 | 0.90 | 98 | 87 | 96 | 93 | 88 | 88 | 86 | 93 | 90 | 94 | 93 | 93 | 92 | 95 |
| 24 | 1 | 90 | 92 | 0.90 | 98 | 88 | 96 | 92 | 87 | 87 | 87 | 94 | 90 | 95 | 93 | 92 | 90 | 95 |
| 2 | 91 | 92 | 0.90 | 99 | 88 | 96 | 93 | 88 | 87 | 87 | 94 | 90 | 96 | 93 | 91 | 89 | 95 |
| 3 | 91 | 91 | 0.90 | 98 | 87 | 96 | 92 | 87 | 87 | 87 | 94 | 90 | 95 | 92 | 90 | 89 | 95 |
| 19 | 1 | 90 | 92 | 0.90 | 98 | 88 | 95 | 92 | 87 | 85 | 87 | 94 | 90 | 96 | 95 | 92 | 90 | 97 |
| 2 | 91 | 92 | 0.90 | 98 | 87 | 95 | 92 | 88 | 85 | 87 | 94 | 90 | 97 | 93 | 92 | 90 | 96 |
| 3 | 90 | 91 | 0.90 | 98 | 87 | 95 | 92 | 88 | 86 | 87 | 94 | 90 | 97 | 92 | 92 | 90 | 94 |
| 14 | 1 | 90 | 91 | 0.90 | 99 | 88 | 95 | 92 | 86 | 86 | 87 | 94 | 90 | 95 | 92 | 92 | 90 | 95 |
| 2 | 90 | 91 | 0.90 | 99 | 87 | 95 | 93 | 87 | 85 | 86 | 93 | 90 | 95 | 90 | 93 | 92 | 94 |
| 3 | 90 | 91 | 0.90 | 99 | 88 | 96 | 93 | 86 | 86 | 86 | 92 | 90 | 95 | 93 | 92 | 90 | 95 |
| 9 | 1 | 91 | 91 | 0.90 | 99 | 87 | 93 | 92 | 87 | 86 | 86 | 95 | 92 | 94 | 92 | 92 | 90 | 94 |
| 2 | 91 | 91 | 0.89 | 99 | 87 | 93 | 91 | 86 | 86 | 86 | 95 | 92 | 94 | 92 | 92 | 90 | 94 |
| 3 | 91 | 91 | 0.90 | 99 | 87 | 93 | 92 | 87 | 86 | 86 | 95 | 92 | 94 | 92 | 92 | 90 | 94 |
| 4 | 1 | 86 | 88 | 0.86 | 96 | 83 | 90 | 91 | 82 | 84 | 87 | 90 | 88 | 91 | 86 | 87 | 86 | 89 |
| 2 | 87 | 87 | 0.85 | 96 | 83 | 88 | 91 | 82 | 80 | 87 | 90 | 88 | 91 | 84 | 88 | 84 | 88 |
| 3 | 86 | 87 | 0.85 | 95 | 83 | 89 | 89 | 80 | 80 | 87 | 90 | 88 | 91 | 84 | 88 | 87 | 89 |
Table 7.
Average classification probability for the winning class over all validation sites for Random Forest models generated with increasingly fewer predictor variables. Values for sites that were incorrectly classified were excluded from averages.
Table 7.
Average classification probability for the winning class over all validation sites for Random Forest models generated with increasingly fewer predictor variables. Values for sites that were incorrectly classified were excluded from averages.
| Number of Variables | Model Iteration | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| 49 | 1 | 0.97 | 0.86 | 0.70 | 0.89 | 0.84 | 0.79 | 0.82 |
| 2 | 0.98 | 0.86 | 0.69 | 0.88 | 0.84 | 0.80 | 0.82 |
| 3 | 0.97 | 0.86 | 0.69 | 0.89 | 0.84 | 0.80 | 0.83 |
| 44 | 1 | 0.97 | 0.86 | 0.70 | 0.89 | 0.84 | 0.80 | 0.82 |
| 2 | 0.97 | 0.86 | 0.70 | 0.89 | 0.85 | 0.80 | 0.82 |
| 3 | 0.97 | 0.86 | 0.70 | 0.89 | 0.84 | 0.80 | 0.83 |
| 39 | 1 | 0.98 | 0.87 | 0.71 | 0.89 | 0.85 | 0.82 | 0.84 |
| 2 | 0.97 | 0.87 | 0.72 | 0.89 | 0.85 | 0.81 | 0.84 |
| 3 | 0.98 | 0.87 | 0.72 | 0.89 | 0.85 | 0.81 | 0.83 |
| 34 | 1 | 0.98 | 0.87 | 0.72 | 0.90 | 0.86 | 0.81 | 0.84 |
| 2 | 0.97 | 0.87 | 0.71 | 0.90 | 0.86 | 0.81 | 0.84 |
| 3 | 0.98 | 0.87 | 0.72 | 0.90 | 0.86 | 0.81 | 0.84 |
| 29 | 1 | 0.97 | 0.88 | 0.73 | 0.90 | 0.87 | 0.83 | 0.84 |
| 2 | 0.98 | 0.88 | 0.73 | 0.90 | 0.87 | 0.82 | 0.85 |
| 3 | 0.98 | 0.88 | 0.73 | 0.90 | 0.87 | 0.83 | 0.84 |
| 24 | 1 | 0.98 | 0.88 | 0.73 | 0.90 | 0.87 | 0.84 | 0.85 |
| 2 | 0.97 | 0.88 | 0.73 | 0.90 | 0.87 | 0.84 | 0.85 |
| 3 | 0.98 | 0.88 | 0.73 | 0.90 | 0.87 | 0.84 | 0.85 |
| 19 | 1 | 0.98 | 0.89 | 0.77 | 0.90 | 0.90 | 0.84 | 0.86 |
| 2 | 0.98 | 0.89 | 0.76 | 0.90 | 0.90 | 0.85 | 0.86 |
| 3 | 0.98 | 0.89 | 0.76 | 0.90 | 0.90 | 0.86 | 0.86 |
| 14 | 1 | 0.98 | 0.90 | 0.77 | 0.92 | 0.91 | 0.88 | 0.86 |
| 2 | 0.98 | 0.90 | 0.77 | 0.92 | 0.91 | 0.88 | 0.85 |
| 3 | 0.98 | 0.89 | 0.78 | 0.92 | 0.91 | 0.87 | 0.86 |
| 9 | 1 | 0.99 | 0.88 | 0.75 | 0.86 | 0.91 | 0.90 | 0.87 |
| 2 | 0.98 | 0.88 | 0.75 | 0.86 | 0.91 | 0.91 | 0.87 |
| 3 | 0.98 | 0.88 | 0.75 | 0.87 | 0.91 | 0.90 | 0.87 |
| 4 | 1 | 0.91 | 0.81 | 0.77 | 0.91 | 0.94 | 0.92 | 0.88 |
| 2 | 0.91 | 0.82 | 0.77 | 0.92 | 0.94 | 0.93 | 0.89 |
| 3 | 0.91 | 0.82 | 0.78 | 0.92 | 0.94 | 0.93 | 0.88 |
Variables included in the final, optimized dataset, as well as their respective importance values (averaged for all 10 model iterations) are presented in
Table 8. Of the six spectral channels available with the Landsat 5 data, all but the blue channel were included. As was the case for all models generated in this research, the most important predictor variable was NDVI. This result is sensible since it was often difficult to distinguish between vegetated and un-vegetated classes in available SAR imagery. During the collection of field data many classes appeared to have comparable surface roughnesses (e.g., Tundra and Mixed Sediment), and moisture conditions could have also been similar or not detectable in available SAR imagery due to the acquisition of shallow
versus steep incidence angle data, which tends to be more sensitive to differences in roughness than differences moisture [
11]. This result is consistent with Demers
et al. [
13], who found that NDVI was instrumental in differentiating vegetated
versus un-vegetated shoreline types. The DEM and slope were also important variables in this analysis. Baptist [
71] found that classification of coastal features often improves with the inclusion of these data.
Table 8.
Reduced set of predictor variables for an optimal Random Forest model, and their respective importance values for the Mean Decrease in Accuracy and Gini Index (importance values are based on averages generated from all 10 model iterations).
Table 8.
Reduced set of predictor variables for an optimal Random Forest model, and their respective importance values for the Mean Decrease in Accuracy and Gini Index (importance values are based on averages generated from all 10 model iterations).
| | | Average Importance Value |
|---|
| Mean Decrease in Accuracy | Rank of Variable (Most to Least Important) | Gini Index | Rank of Variable (Most to Least Important) |
|---|
| Landsat 5 Variables | Green | 37.25 | 8 | 47.85 | 13 |
| Red | 39.75 | 6 | 73.15 | 5 |
| Near-Infrared | 39.35 | 7 | 88.91 | 3 |
| SWIR-1 | 36.79 | 10 | 82.64 | 4 |
| SWIR-2 | 40.62 | 4 | 91.89 | 2 |
| NDVI | 68.94 | 1 | 119.90 | 1 |
| RADARSAT-2 Variables | Freeman-Durden decomposition: double-bounce scattering | 56.58 | 3 | 57.47 | 12 |
| Freeman-Durden decomposition: volume scattering | 36.22 | 11 | 62.94 | 9 |
| Pedestal Height | 31.31 | 14 | 65.26 | 7 |
| Touzi Decomposition: Secondary Eigenvalue | 31.86 | 13 | 60.35 | 10 |
| Touzi Decomposition: Tertiary Eigenvalue | 33.68 | 12 | 65.97 | 6 |
| HV Intensity | 37.17 | 9 | 65.22 | 8 |
| DEM Variables | DEM | 57.82 | 2 | 60.28 | 11 |
| Slope | 40.27 | 5 | 35.28 | 14 |
Several SAR variables were found to be of high importance to the model (
Table 8). Of these, the Freeman-Durden double bounce parameter had the highest importance. Demers
et al. [
13] similarly observed that this variable was useful for detecting wetlands, and Ullmann
et al. [
17] found that double bounce intensity was related to vegetation density (low values were observed over sparser vegetation; high values were observed over denser vegetation). Banks
et al. [
12] observed that double bounce scattering was useful for differentiating wetlands from other vegetated land covers, and while double bounce values for all other classes were vastly different between their two study areas, values for wetlands at shallow angles were highly consistent. HV was the only SAR intensity channel included in the final, optimized set of 14 predictor variables (
Table 8). Banks
et al. [
11] also found that compared to HH and VV, HV achieved the highest average class separability (based on the Bhattacharyya Distance) for multiple shoreline types [
12]. Several SAR and optical variables achieved similar importance values, indicating a multi-sensor approach is optimal for this application. This is supported by the fact that Banks
et al. [
11] found low overall classification accuracies when attempting to classify shore and near-shore land cover types with SAR data alone, and found that their model required the combination of both SAR and optical data to distinguish sand from mixed-sediment beaches and flats.
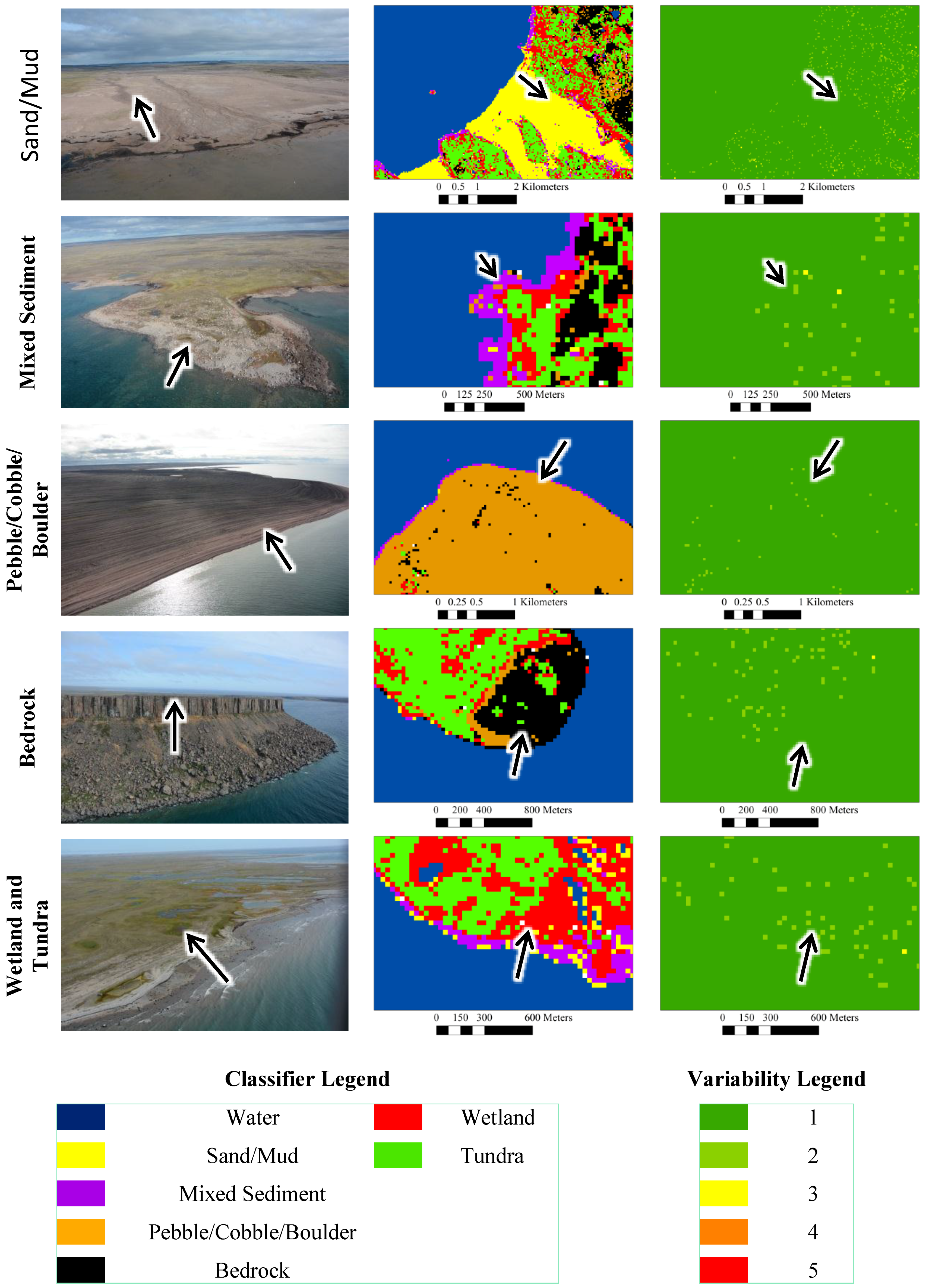
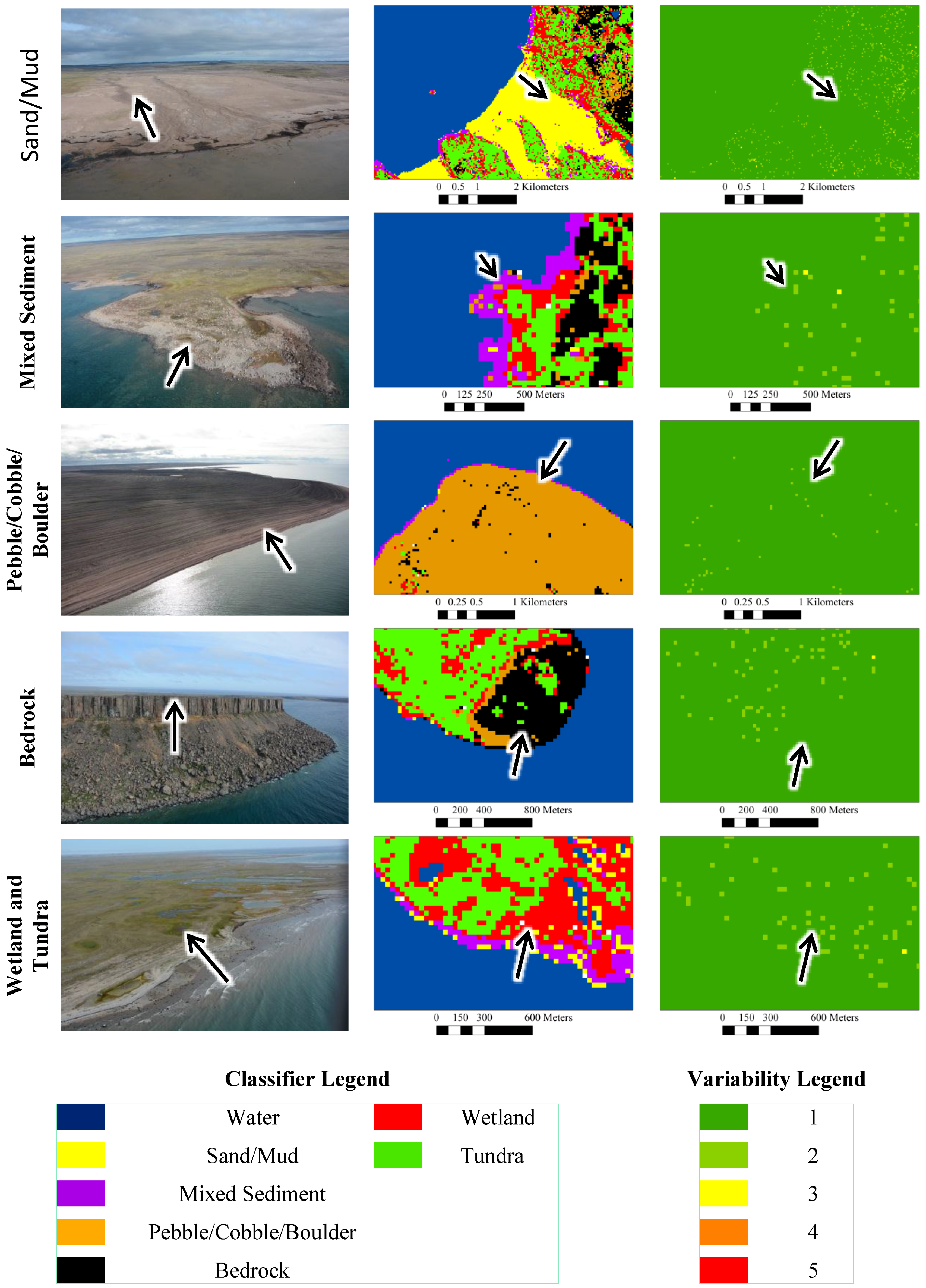
Classifier results for models generated with 14 predictor variables are presented visually in
Figure 3, including outputs for the first model as well as variability of class predictions for all 10 model runs (
i.e., the number of times a different class was predicted by one of the 10 models). Results show that while many areas are well classified, there is still potential for improvement. For example, some portions of the backshore containing pebbles and cobbles were misclassified as Bedrock (
Figure 3; example for Mixed Sediment). This could be due to an insufficient number of training sites for that particular type of material, which could be of a similar roughness and colour as the bedrock types that were sampled [
13]. This seems plausible since it was observed during the collection of field data that, in some cases, pebbles and cobbles were approximately as smooth as bedrock due to the size and arrangement or packing of materials. This is relevant with respect to the SAR data, since backscattering behaviour is affected by roughness, especially at shallow incidence angles [
11,
12].
In some cases Tundra was also misclassified as Wetland, though because wetlands are more sensitive to the effects of oiling this is not of major concern for the application of shoreline sensitivity mapping. This is because preference is always to avoid under-estimating the more sensitive class [
8,
13]. Demers
et al. [
13] also observed confusion between tundra and wetlands, which they suggested could be due to the misidentification of features during the training and or validation process, as both classes tended to transition into one another making it difficult to establish boundaries even in the field [
72]. A similar observation was made in this research during the collection of training and validation data.
Though it is possible for Random Forest outputs to vary, despite models being generated with the same training data and set of predictor variables [
25], this analysis has demonstrated potential for highly consistent results. Specifically, the last column of
Figure 3 shows that the majority of each sub-scene was classified as the same land cover type by all 10 models. Other authors have observed highly variable outputs. Millard and Richardson [
26] for example, found a high degree of variability between model iterations particularly along the edges of features. To compensate the authors ran 25 iterations of the same model and calculated probability values based on the number of times each model assigned the most commonly predicted class. As such, the degree of variability observed, may again depend on the particular dataset being tested.
OOBAs and independent accuracies were similar for all models generated in this test (differences ranged between 0% and 2%). This further demonstrates that with a sufficient training sample size it may be possible to utilize the internal accuracy assessments of Random Forest alone for model validation.
Figure 3.
Field photos (left), classifier results for the first model generated with 14 predictor variables and 167 training points per-class (middle), and inter-model variability the number of times a different class was predicted by one of the 10 models (right). Values of 1 indicate no variability (all models predicted the same class) and values of 5 indicate the highest observed variability (five models predicted different classes at that pixel location). Approximately the same area in all three images is indicated by arrows.
Figure 3.
Field photos (left), classifier results for the first model generated with 14 predictor variables and 167 training points per-class (middle), and inter-model variability the number of times a different class was predicted by one of the 10 models (right). Values of 1 indicate no variability (all models predicted the same class) and values of 5 indicate the highest observed variability (five models predicted different classes at that pixel location). Approximately the same area in all three images is indicated by arrows.
For this research, preference would have been to use training and validation data that was completely randomly distributed throughout the study area. Implementing this approach proved difficult in practice however, as analysts could not interpret the land cover types present at all locations, resulting in a large proportion of points being disregarded. As such we chose a purposeful sampling design, and while effort was still made to ensure some independence between training and validation data (e.g., each training/validation site was separated in space by a minimum of 100 m), it is still possible that the accuracies presented here are somewhat inflated as a result of optimistic bias [
67]. Further study is required to fully address the degree to which this has affected classifier performance.
5.3. Potential for Remote Predictive Mapping
As was the case for test (1), three model iterations were deemed sufficient to represent the variability of outputs as only model accuracies and probabilities were assessed in this test. For each of the 15 models that were generated in total (three models each for the five different sets of training data), OOBAs, independent accuracies, Kappa statistic values, and per-class User’s and Producer’s accuracies for each iteration are provided in
Table 9, and average probabilities for the winning class are provided in
Table 10.
Results indicate that further study is required to fully assess the potential for spatial transferability of the model to areas without training data (
Table 9). In all cases, models performed relatively well (OOBAs ranged from 89% to 92%, independent overall accuracies from 81% to 88%, Kappa statistic values from 0.77 to 0.86), though for each set of training data one or more land cover types tended to be poorly classified. The Class(es) that were poorly classified also varied between the different sets of training data. As an example, Bedrock was classified relatively well by all models except those that excluded data from survey 4 (User’s and Producer’s accuracies for the former were 71% and 74%; User’s and Producer’s accuracies for the latter were 33% and 7%). In contrast, Tundra was well classified by all models except those that excluded data from survey 3 (User’s and Producer’s accuracies for the former were 86% and 78%; User’s and Producer’s accuracies for the latter were 25% to 29% and 67%).
It is expected that the low accuracies observed in these cases are as a result of image-to-image variations in moisture conditions, differences in plant phenology, and for the substrate classes in particular (Sand/Mud, Pebble/Cobble/Boulder, and Bedrock) both differences in colour and in surface roughness. These are all likely to impact the consistency of SAR and optical image values in space and in time [
60,
61,
62,
63], which would make it more difficult to classify a given land cover type, especially if the full range of values exhibited throughout the study area are not well represented in the training dataset. This could explain why better accuracies were achieved when training data from all regions were included in the model, even if the sample size was relatively small (e.g., 13 to 25 points per-class, as was the case for test (1)).
Table 9.
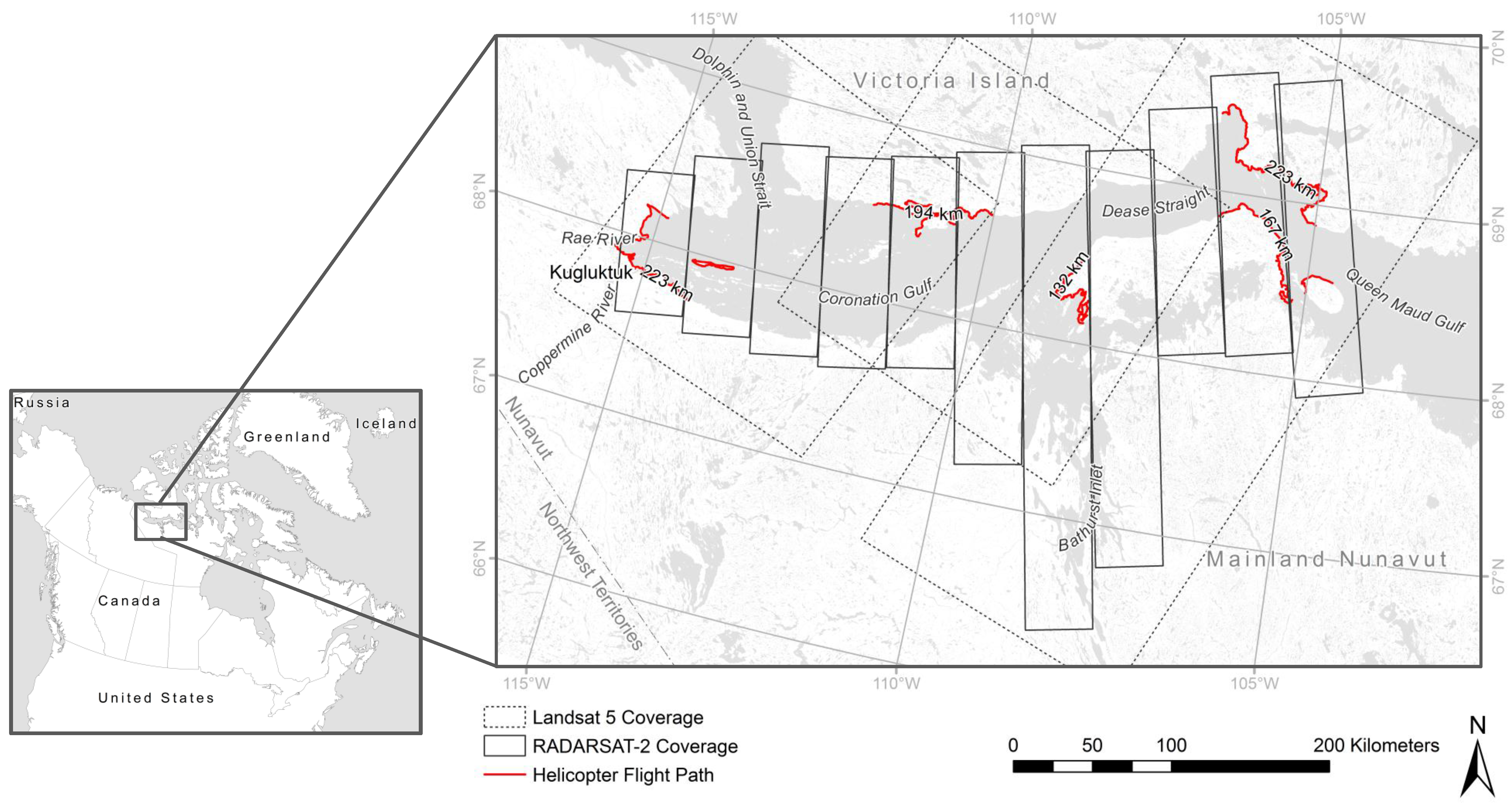
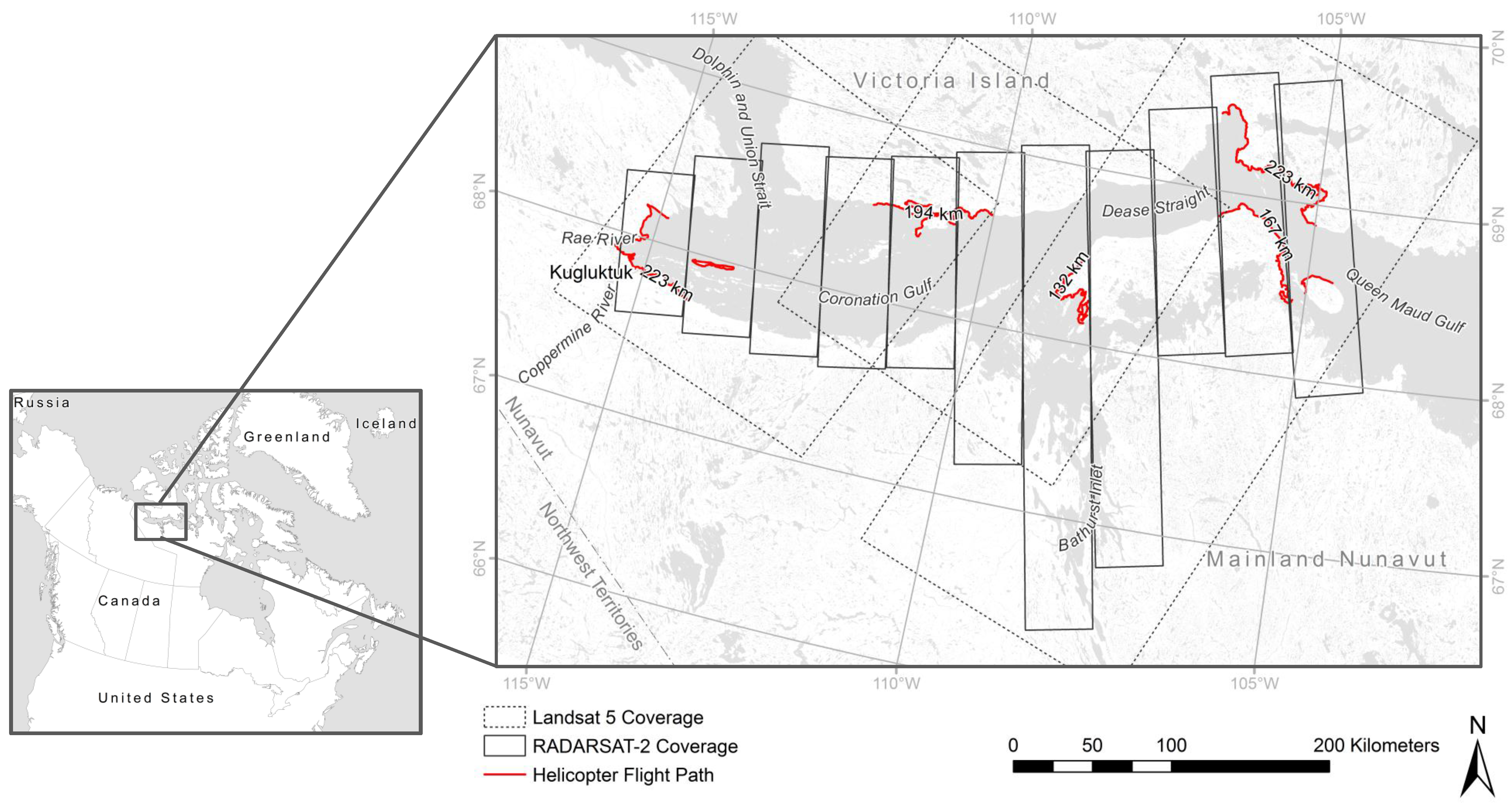
OOBAs, independent overall accuracies, and Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) for Random Forest models generated with excluded training data from one in five videography surveys (numbered from west to east (see
Figure 1)).
Table 9.
OOBAs, independent overall accuracies, and Kappa statistic values, and per-class User’s and Producer’s accuracies (UA and PA) for Random Forest models generated with excluded training data from one in five videography surveys (numbered from west to east (see Figure 1)).
| Survey Data Excluded From Model | Model Iteration | OOBA (%) | Independent Overall Accuracy (%) | Kappa Statistic | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) |
|---|
| 1 | 1 | 90 | 84 | 0.80 | 94 | 99 | 100 | 32 | 26 | 90 | 88 | 70 | 97 | 100 | 66 | 93 | 100 | 78 |
| 2 | 89 | 84 | 0.80 | 96 | 99 | 100 | 32 | 25 | 90 | 88 | 70 | 97 | 100 | 66 | 93 | 100 | 78 |
| 3 | 90 | 84 | 0.81 | 96 | 99 | 100 | 32 | 24 | 90 | 88 | 70 | 99 | 100 | 68 | 93 | 100 | 80 |
| Number of Validation Sites | 67 | 38 | 10 | 10 | 72 | 45 | 97 |
| 2 | 1 | 90 | 83 | 0.79 | 70 | 92 | 79 | 95 | 72 | 72 | 38 | 75 | 96 | 75 | 91 | 74 | 93 | 86 |
| 2 | 90 | 83 | 0.80 | 71 | 94 | 81 | 95 | 72 | 72 | 38 | 75 | 96 | 75 | 91 | 74 | 93 | 86 |
| 3 | 90 | 83 | 0.79 | 70 | 92 | 79 | 95 | 72 | 72 | 38 | 75 | 96 | 75 | 91 | 74 | 93 | 86 |
| Number of Validation Sites | 49 | 61 | 18 | 8 | 101 | 39 | 77 |
| 3 | 1 | 91 | 81 | 0.77 | 79 | 100 | 77 | 95 | 75 | 68 | 99 | 72 | 72 | 80 | 91 | 91 | 29 | 67 |
| 2 | 92 | 81 | 0.77 | 79 | 100 | 77 | 95 | 74 | 68 | 99 | 72 | 73 | 80 | 94 | 91 | 25 | 67 |
| 3 | 91 | 81 | 0.77 | 79 | 100 | 77 | 95 | 74 | 68 | 99 | 72 | 73 | 80 | 91 | 91 | 29 | 67 |
| Number of Validation Sites | 41 | 59 | 80 | 96 | 41 | 33 | 3 |
| 4 | 1 | 90 | 88 | 0.86 | 94 | 100 | 85 | 90 | 84 | 81 | 85 | 97 | 33 | 7 | 93 | 93 | 91 | 85 |
| 2 | 90 | 88 | 0.86 | 94 | 100 | 85 | 90 | 84 | 81 | 86 | 97 | 33 | 7 | 93 | 92 | 88 | 86 |
| 3 | 90 | 88 | 0.86 | 94 | 100 | 85 | 90 | 84 | 82 | 86 | 97 | 33 | 7 | 93 | 93 | 93 | 86 |
| Number of Validation Sites | 58 | 67 | 94 | 72 | 14 | 102 | 59 |
| 5 | 1 | 91 | 85 | 0.83 | 85 | 100 | 91 | 80 | 88 | 73 | 81 | 89 | 74 | 74 | 100 | 97 | 86 | 86 |
| 2 | 90 | 85 | 0.82 | 85 | 100 | 91 | 80 | 89 | 71 | 79 | 89 | 74 | 74 | 100 | 97 | 86 | 86 |
| 3 | 90 | 85 | 0.82 | 85 | 100 | 91 | 80 | 88 | 73 | 80 | 89 | 77 | 74 | 100 | 97 | 86 | 86 |
| Number of Validation Sites | 35 | 25 | 48 | 64 | 31 | 31 | 14 |
Table 10.
Average classification probability for the winning class over all validation sites for Random Forest models generated with excluded training data from one in five videography surveys (numbered from west to east (see
Figure 1)). Values for sites that were incorrectly classified were excluded from averages.
Table 10.
Average classification probability for the winning class over all validation sites for Random Forest models generated with excluded training data from one in five videography surveys (numbered from west to east (see Figure 1)). Values for sites that were incorrectly classified were excluded from averages.
| Survey Data Excluded From Model | Model Iteration | Water | Sand/Mud | Mixed Sediment | Pebble/Cobble/Boulder | Bedrock | Wetland | Tundra |
|---|
| 1 | 1 | 0.98 | 0.71 | 0.74 | 0.72 | 0.87 | 0.91 | 0.79 |
| 2 | 0.99 | 0.72 | 0.73 | 0.72 | 0.87 | 0.91 | 0.79 |
| 3 | 0.99 | 0.71 | 0.74 | 0.72 | 0.87 | 0.91 | 0.79 |
| 2 | 1 | 0.99 | 0.93 | 0.81 | 0.93 | 0.85 | 0.85 | 0.81 |
| 2 | 0.98 | 0.93 | 0.80 | 0.93 | 0.85 | 0.85 | 0.81 |
| 3 | 1.00 | 0.93 | 0.81 | 0.94 | 0.85 | 0.85 | 0.80 |
| 3 | 1 | 1.00 | 0.97 | 0.70 | 0.86 | 0.84 | 0.82 | 0.71 |
| 2 | 1.00 | 0.97 | 0.70 | 0.85 | 0.84 | 0.82 | 0.70 |
| 3 | 1.00 | 0.97 | 0.70 | 0.85 | 0.84 | 0.82 | 0.70 |
| 4 | 1 | 0.98 | 0.86 | 0.72 | 0.89 | 0.83 | 0.81 | 0.80 |
| 2 | 0.98 | 0.85 | 0.73 | 0.88 | 0.84 | 0.81 | 0.80 |
| 3 | 0.98 | 0.85 | 0.73 | 0.88 | 0.84 | 0.81 | 0.80 |
| 5 | 1 | 0.98 | 0.82 | 0.72 | 0.90 | 0.91 | 0.85 | 0.83 |
| 2 | 0.98 | 0.82 | 0.73 | 0.89 | 0.91 | 0.85 | 0.83 |
| 3 | 0.98 | 0.82 | 0.72 | 0.89 | 0.91 | 0.86 | 0.83 |
These results are comparable to those achieved by Demers
et al. [
13] who assessed the transferability of both pixel-based Maximum Likelihood and hierarchical object-based classifiers for shoreline sensitivity mapping. The authors similarly observed relatively high overall accuracies, with only one or two land cover types being poorly classified. While the focus of this analysis was not to compare Random Forest to object-based classification, it is worth noting that the latter approach has greater flexibility in terms of being able to make site-specific adjustments to the segmentation approach, as well as to the threshold values being used [
73,
74]. Demers
et al. [
13] theorized that this could improve results on a site-by-site basis, though this would require more user interference developing the model. While similar adjustments cannot be made to the Random Forest model produced in this research, it has been demonstrated that it is still possible to achieve accurate results with quality training data that better represents the full range of values for a given class.



{kind=link}
{kind=link}
{kind=link}
{kind=link}