An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery

Abstract
:
1. Introduction
2. Neural Network Classification Approaches
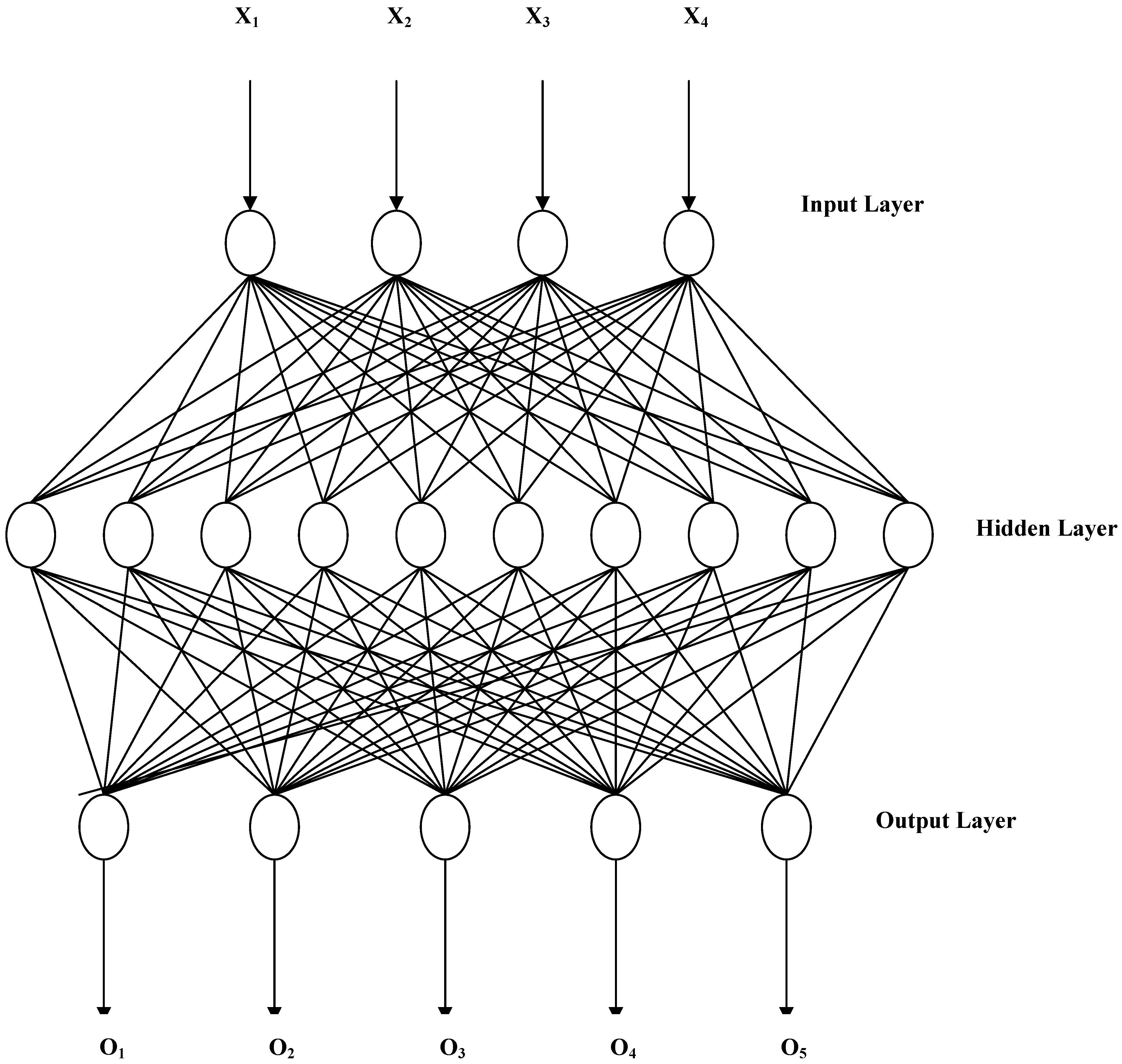
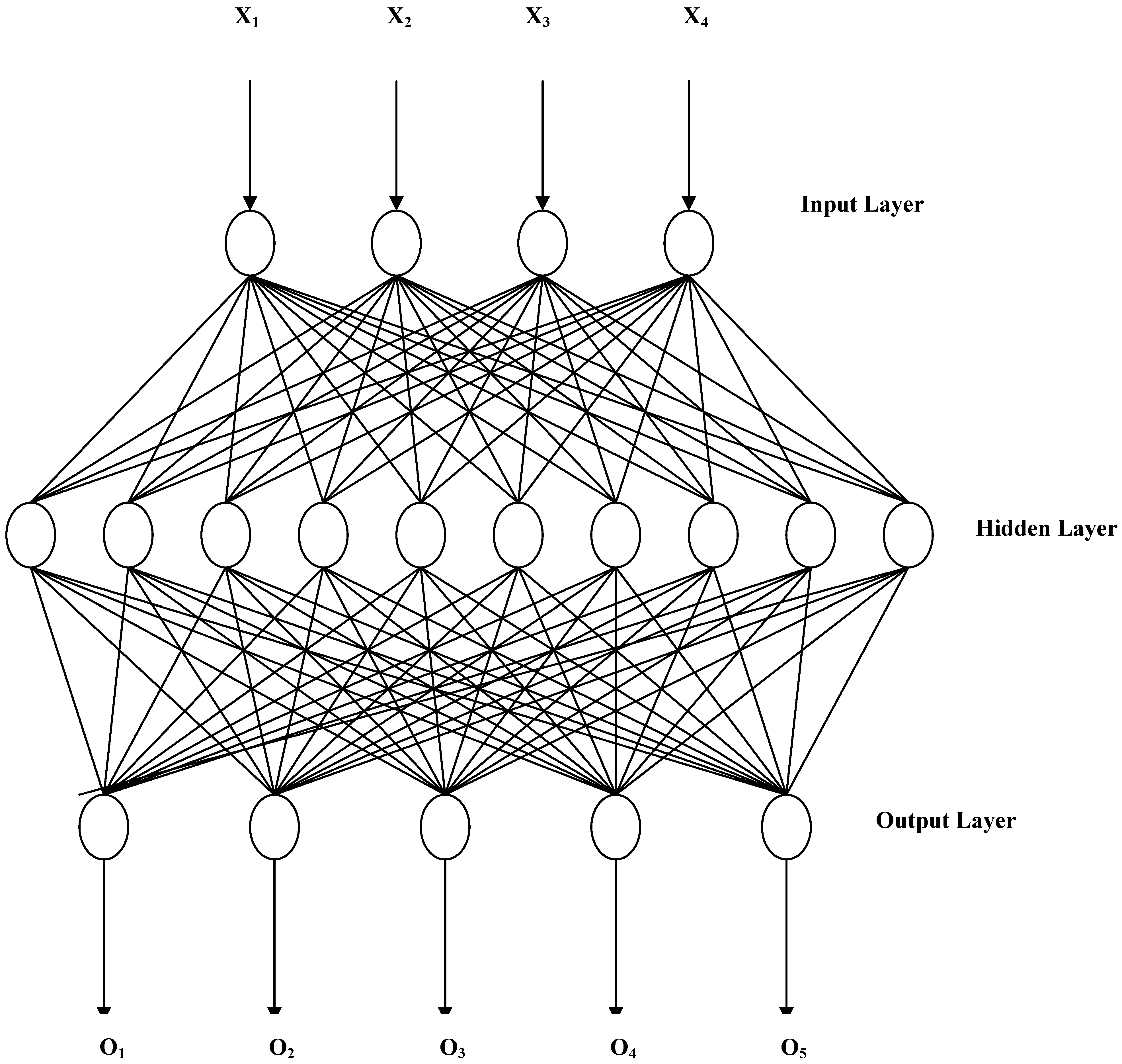
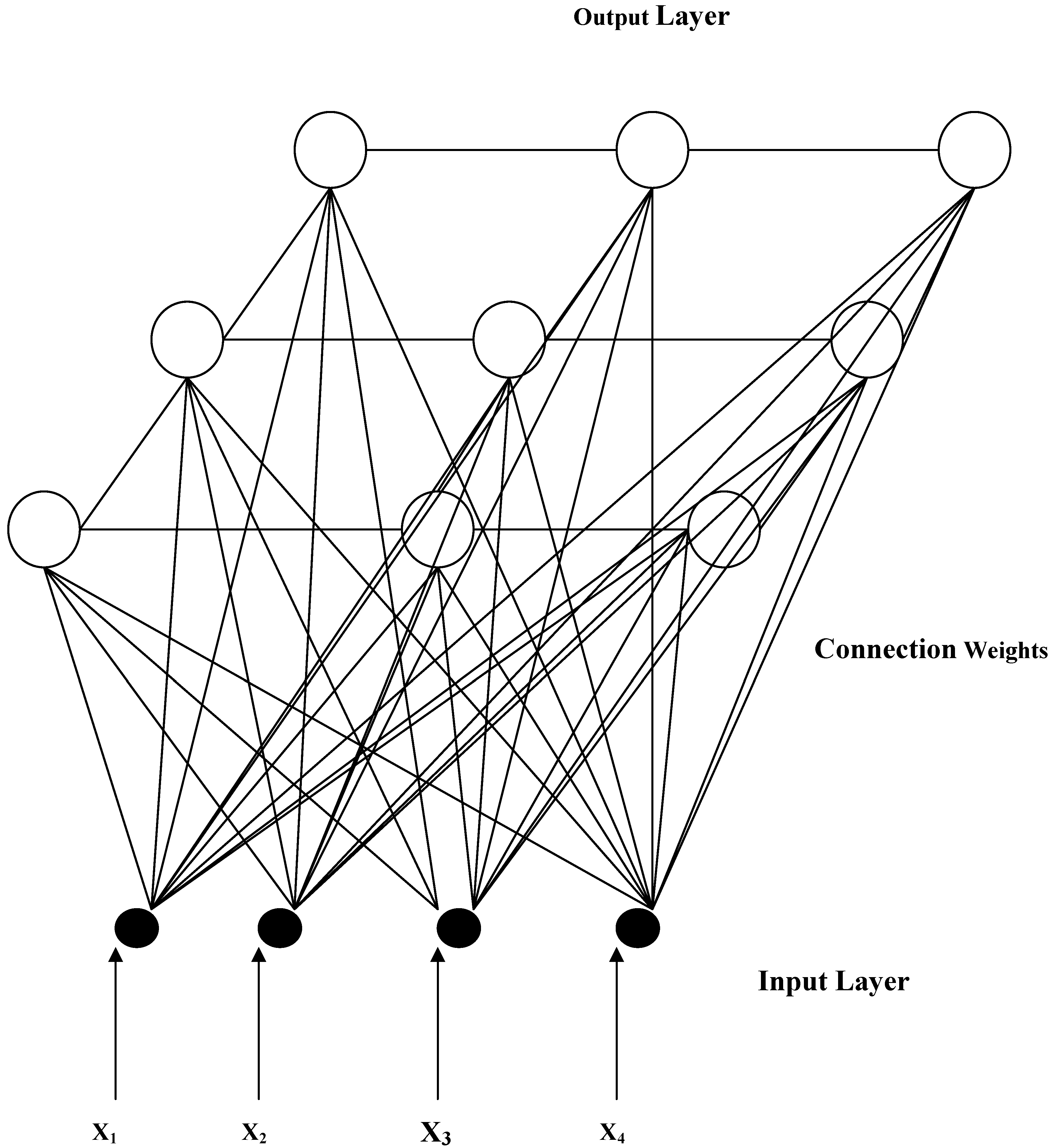
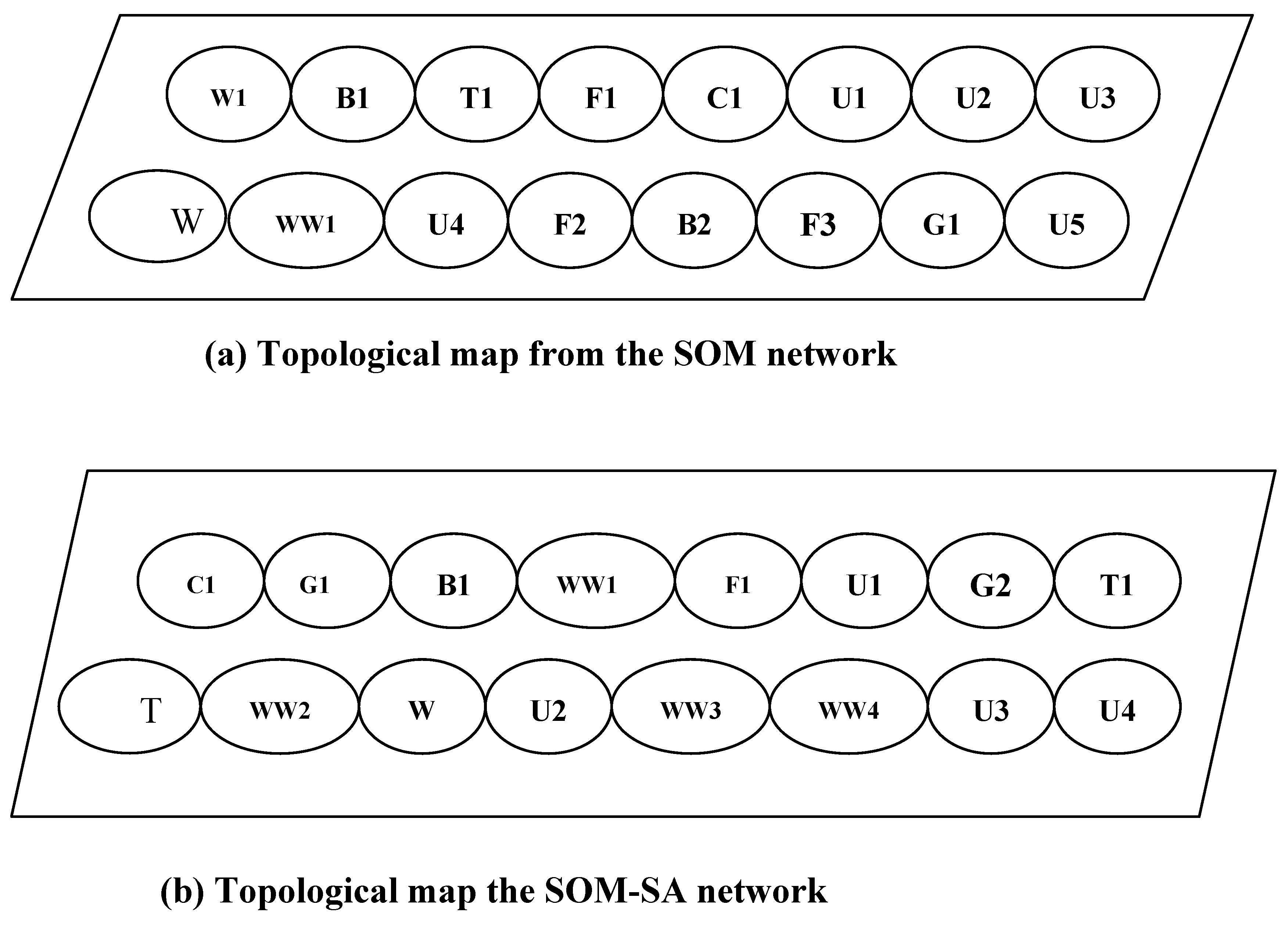
2.1. Kohonen’s Self-Organizing Mapping (SOM) Neural Network

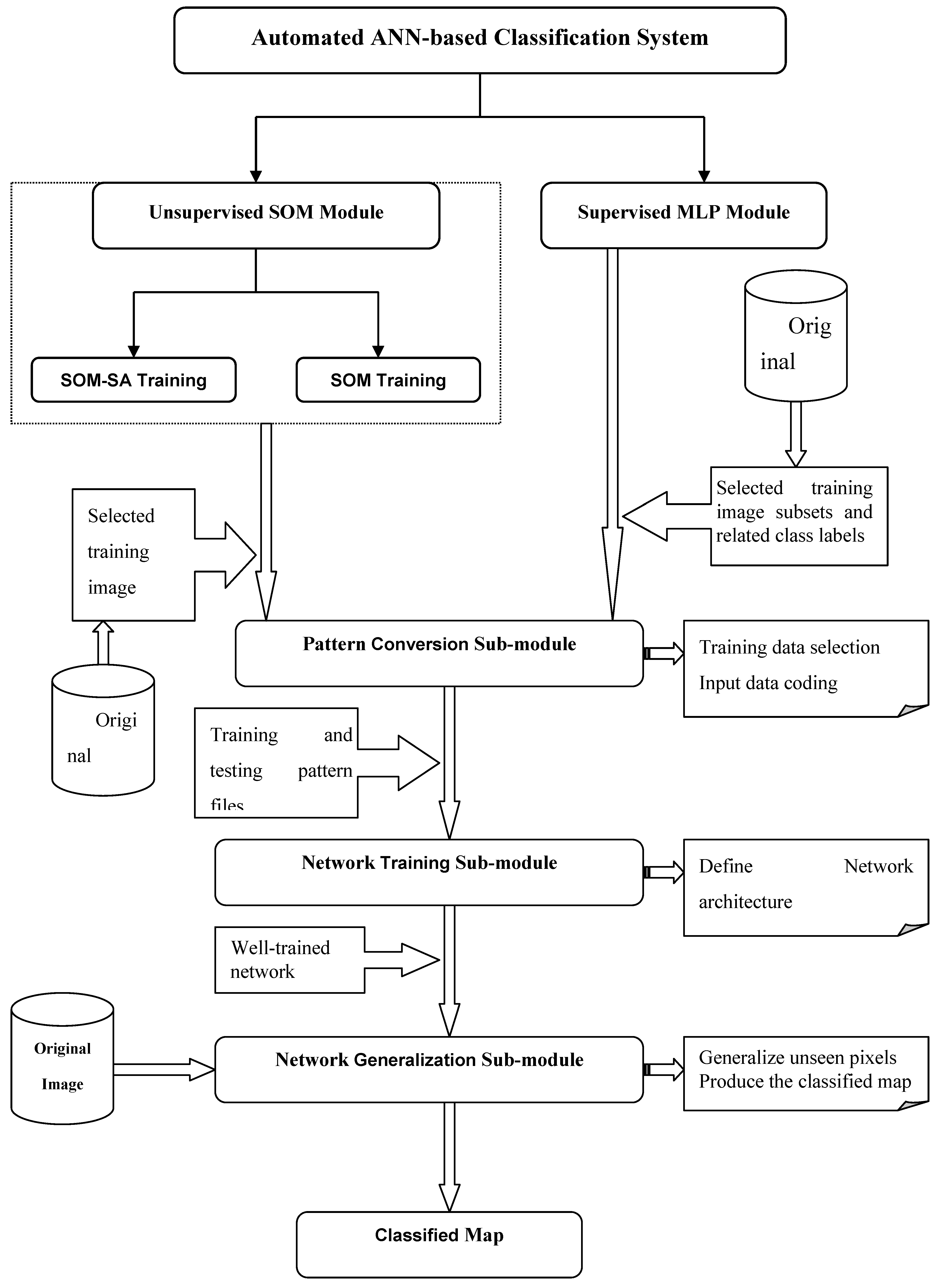
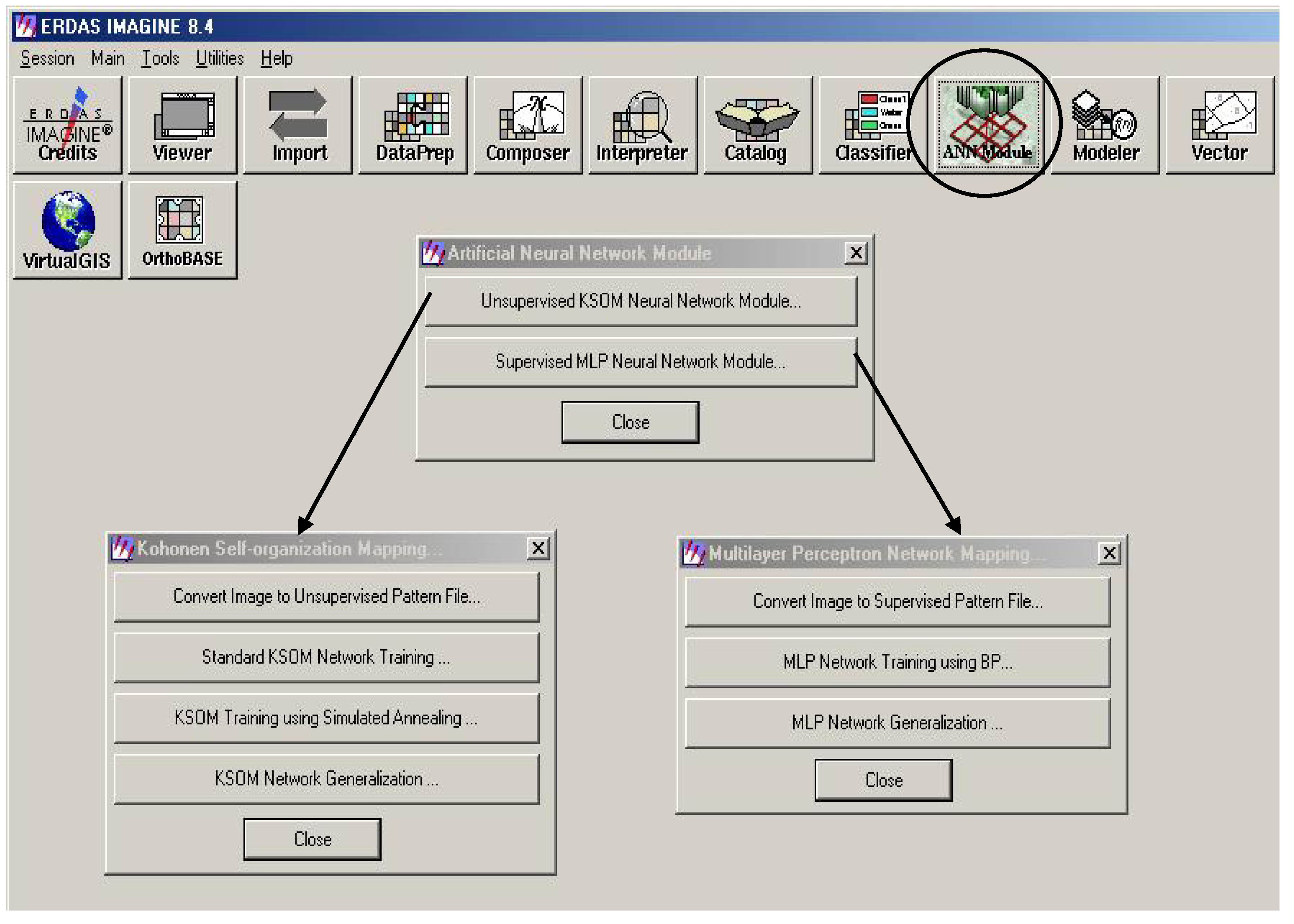
3. Development of an Automated ANN Classification System
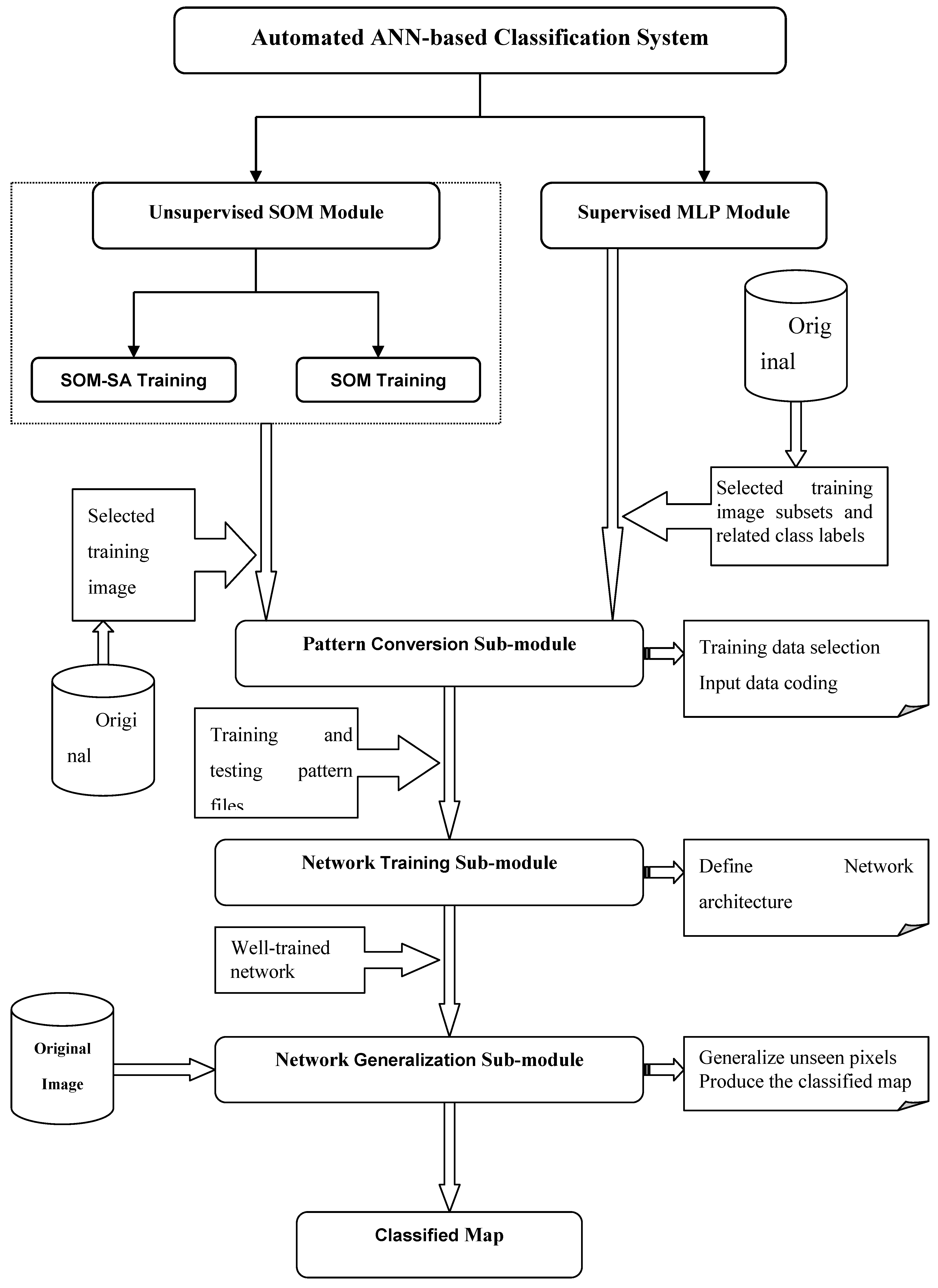
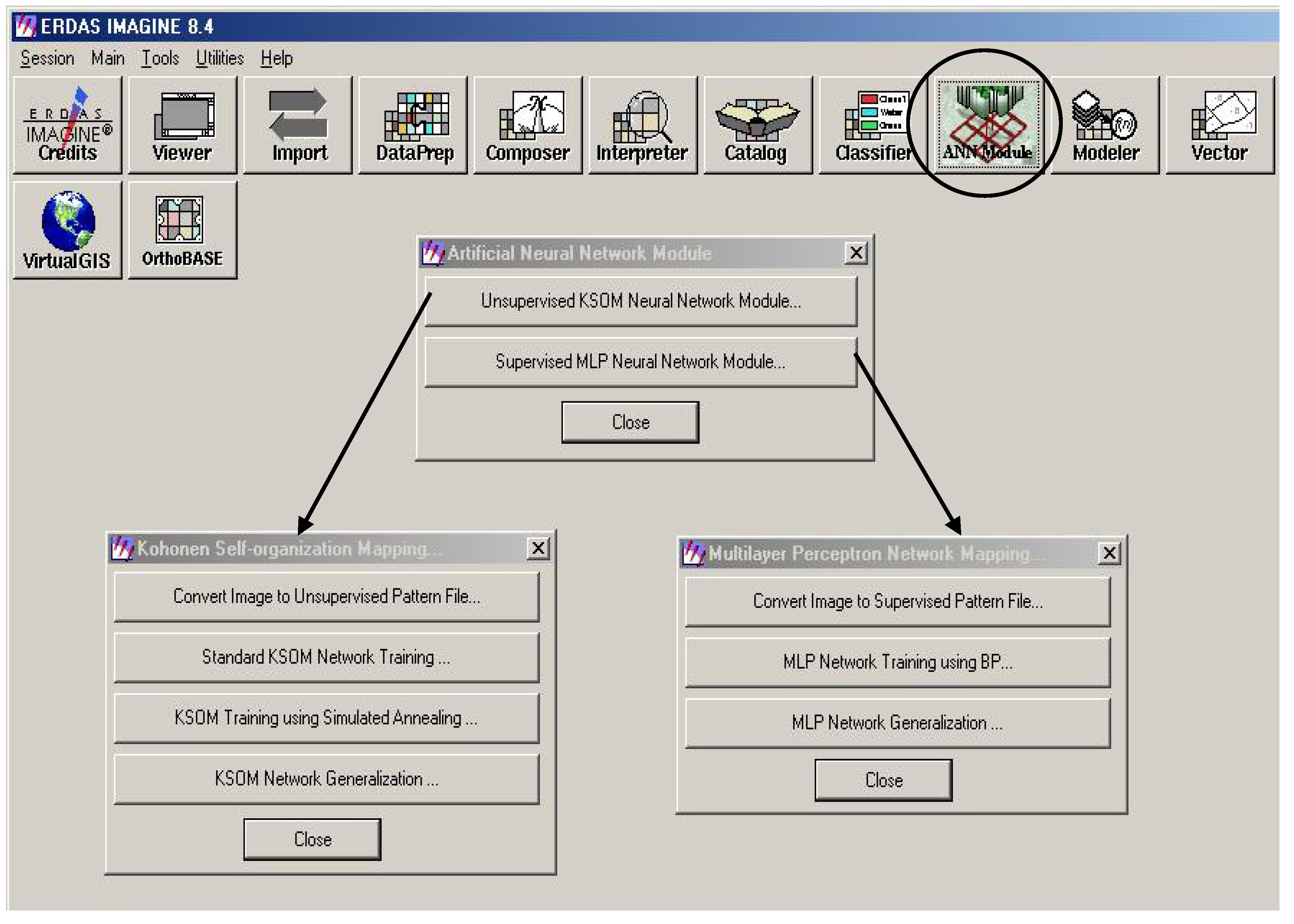
4. Case Study: Neural Network Classification
4.1. Study Area and Classification Scheme


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Number | Class Name | Class Definition |
|---|---|---|
| 1 | Urban | Commercial/Industrial/Residential/transportation |
| 2 | Forest | Natural Forested Upland including evergreen, deciduous, and mixed forests |
| 3 | Planted crop field | Planted crop fields for the production of crops |
| 4 | Grass/pasture | Vegetation planted in developed settings for recreation, erosion control, or aesthetic purposes, or hay crops or pasture |
| 5 | Bare/fallow area | Bare construction sites, rock, sand, or fallow agricultural land |
| 6 | Transitional area | Areas dynamically changing from one land cover to another |
| 7 | Woody wetland | Areas of forested or shrubland vegetation where soil or substrate is periodically saturated with or covered with water |
| 8 | Water | All areas of open water |
4.2. Operational Issues in Neural Network Classification
4.2.1. Quality and size of training data sets
4.2.2. Network architecture complexity
4.2.2.1. Network input/output coding
4.2.3. Training parameters and learning rate
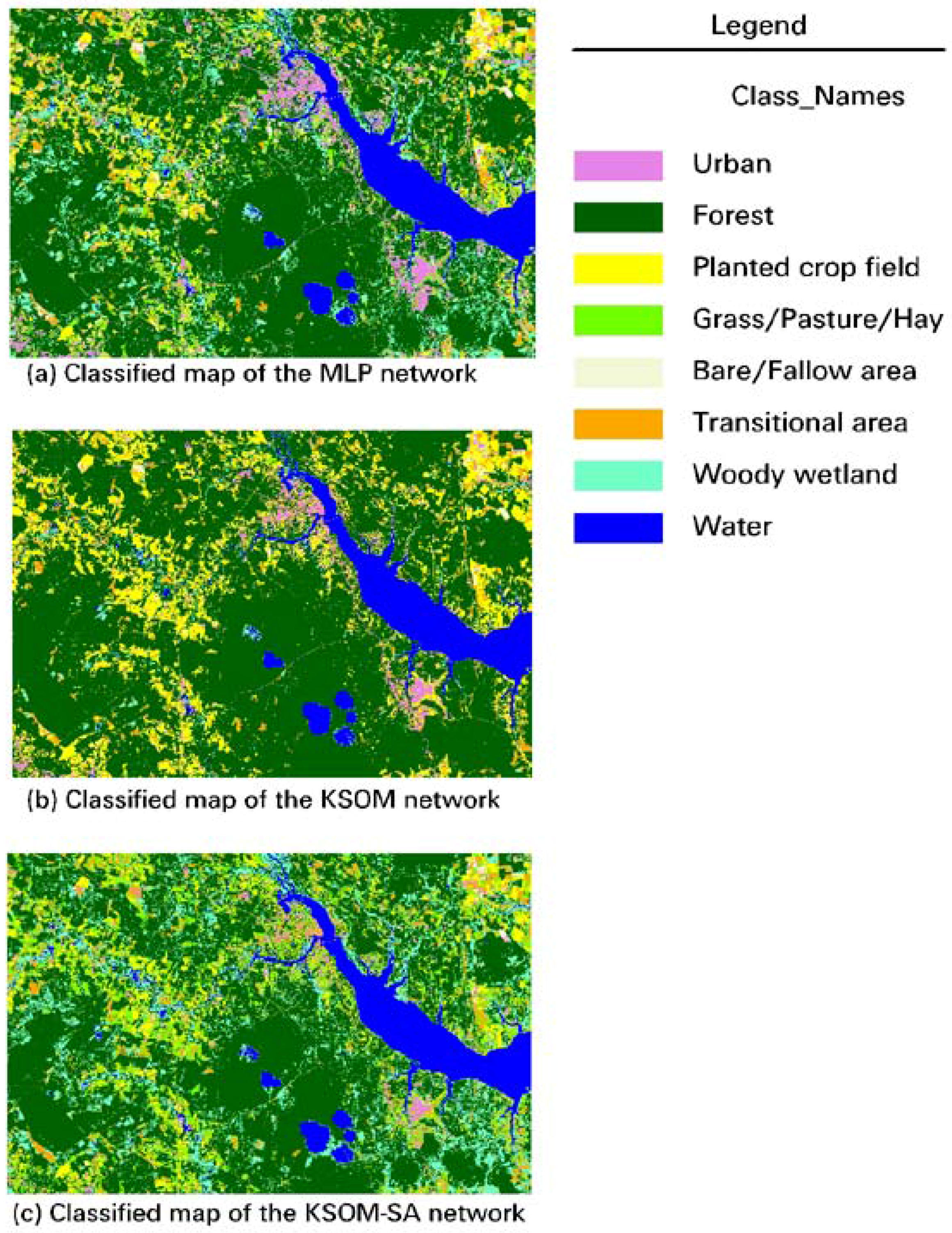
4.3. Neural Network Classification and Discussions
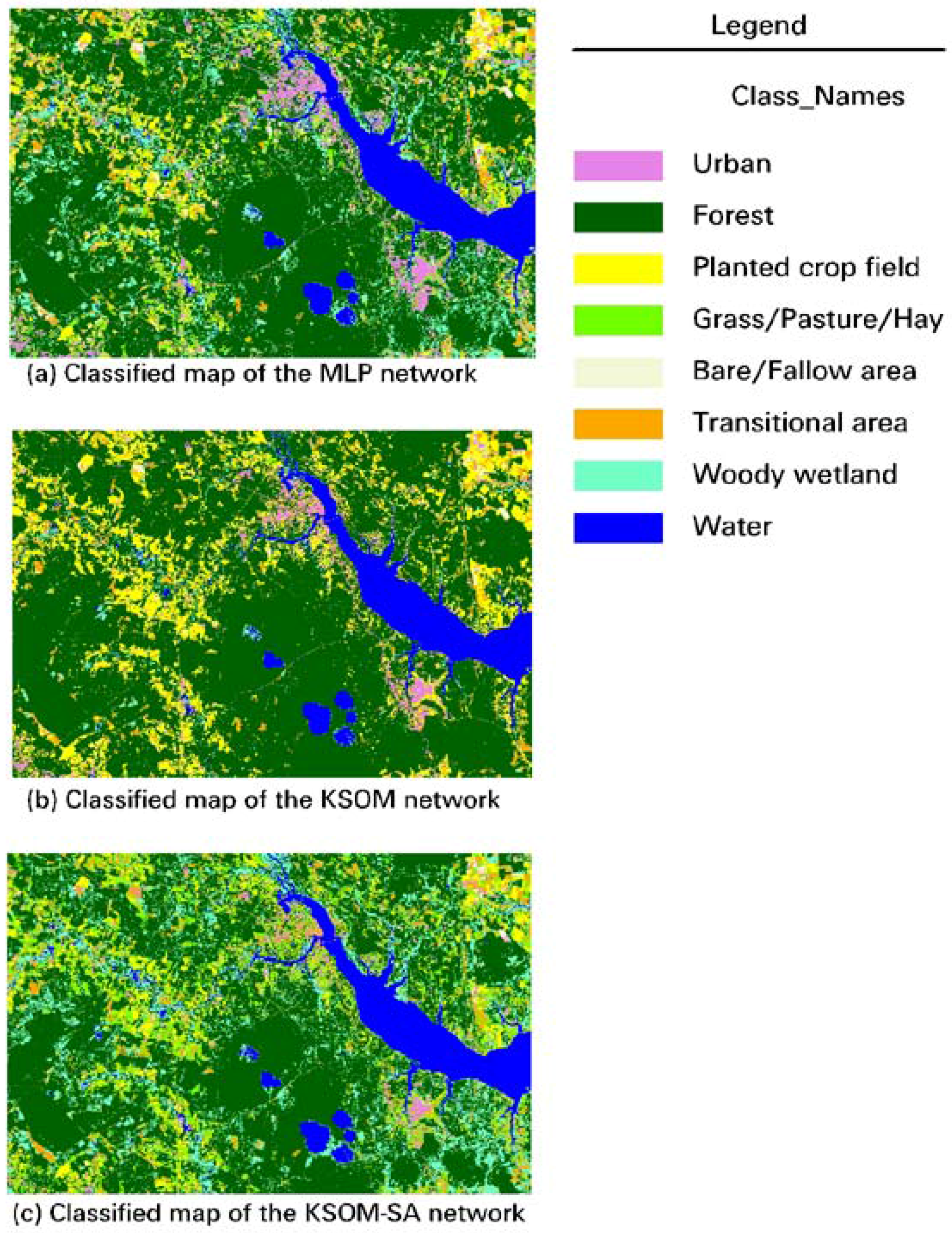

4.3.1. Accuracy assessment
| Reference Data | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classified Image | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Classified Totals | Users’ Accuracy | |
| 1 | 46 | 1 | 1 | 1 | 11 | 60 | 76.7% | ||||
| 2 | 60 | 60 | 100.0% | ||||||||
| 3 | 2 | 52 | 6 | 60 | 86.7% | ||||||
| 4 | 2 | 4 | 53 | 1 | 60 | 88.3% | |||||
| 5 | 2 | 1 | 1 | 56 | 60 | 93.3% | |||||
| 6 | 4 | 2 | 52 | 2 | 60 | 86.7% | |||||
| 7 | 12 | 3 | 44 | 1 | 60 | 73.3% | |||||
| 8 | 60 | 60 | 100.0% | ||||||||
| Reference Totals | 48 | 81 | 60 | 61 | 68 | 55 | 46 | 61 | 480 | ||
| Producers’ Accuracy | 95.8% | 74.1% | 86.7% | 86.9% | 83.4% | 94.6% | 95.7% | 98.3% | |||
| Overall Accuracy: 423/480 = 88.13% | |||||||||||
| Reference Data | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classified Image | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Classified Totals | Users’ Accuracy | |
| 1 | 22 | 1 | 10 | 33 | 66.7% | ||||||
| 2 | 8 | 75 | 1 | 1 | 13 | 30 | 128 | 58.6% | |||
| 3 | 12 | 5 | 59 | 60 | 27 | 9 | 1 | 173 | 34.1% | ||
| 4 | 1 | 4 | 5 | 0.0% | |||||||
| 5 | 19 | 19 | 100.0% | ||||||||
| 6 | 5 | 1 | 7 | 33 | 3 | 49 | 67.4% | ||||
| 7 | 12 | 1 | 13 | 92.3% | |||||||
| 8 | 60 | 60 | 100.0% | ||||||||
| Reference Totals | 48 | 81 | 60 | 61 | 68 | 55 | 46 | 61 | 480 | ||
| Producers’ Accuracy | 45.8% | 92.6% | 98.3% | 0.0% | 27.9% | 60.0% | 26.1% | 98.4% | |||
| Overall Accuracy: 280/480 = 58.33% | |||||||||||
| Reference Data | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classified Image | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Classified Totals | Users’ Accuracy | |
| 1 | 13 | 22 | 35 | 37.1% | |||||||
| 2 | 1 | 56 | 1 | 58 | 96.6% | ||||||
| 3 | 3 | 32 | 12 | 1 | 48 | 66.7% | |||||
| 4 | 14 | 5 | 27 | 48 | 15 | 5 | 1 | 115 | 41.7% | ||
| 5 | 12 | 12 | 100.0% | ||||||||
| 6 | 17 | 4 | 1 | 1 | 16 | 42 | 1 | 82 | 51.22% | ||
| 7 | 16 | 1 | 8 | 40 | 1 | 66 | 60.6% | ||||
| 8 | 4 | 60 | 64 | 93.6% | |||||||
| Reference Totals | 48 | 81 | 60 | 61 | 68 | 55 | 46 | 61 | 480 | ||
| Producers’ Accuracy | 27.1% | 69.1% | 53.3% | 78.7% | 17.7% | 76.4% | 87.0% | 98.4% | |||
| Overall Accuracy: 303/480 = 63.13% | |||||||||||
| MLP | SOM | SOM-SA | |
|---|---|---|---|
| KHAT | 0.86 | 0.52 | 0.58 |
| Kappa Variance | 0.0003 | 0.0006 | 0.0006 |
| Z-Value | 51.32 | 20.70 | 23.48 |
| MLP | SOM | SOM-SA | |
|---|---|---|---|
| MLP | 11.44 | 9.55 | |
| SOM | 1.72 | ||
| SOM-SA |
5. Conclusions and Future Work
- ▪
- An automated ANN classification system was developed within the working environment of ERDAS IMAGINE and has been shown to be suitable for land cover mapping using remotely sensed data and could be especially useful when the distribution of the input data are not normal.
- ▪
- This study provided one strong case study to verify the better classification capabilities of the automated SOM_SA over the single SOM system for land cover and land use classification applications. Based on the knowledge obtained from this case study, we recommend that in complex LU/LC mapping applications, supervised MLP networks be used to derive detailed and more accurate image classification, and unsupervised SOM networks be used to assist in analyzing the inherent spectral characteristics between and within classes. This can be highly useful in the laborious and critical task of selecting and analyzing the training data sets to be utilized for any supervised classification of complex land use and land cover.
- ▪
- Though powerful, the performance of neural network approaches is sensitive to the selection of operational parameters, including the size and quality of training data set, network architecture, and training parameters. Furthermore, the over-fitting problem was effectively avoided using a cross-validation training method.
- ▪
- The parallel computing potential and the computational efficiency of the SOM and SOM-SA classifier when combined with the ability to estimate the non-linear relationship between the input data and the desired output present advantages over the MLP classifier. Thus, for large study areas such as regional and national applications, one may consider the SOM_SA classification over the supervised classifiers for the reasons discussed in this article.
References and Notes
- Solberg, A.H.S. Multisource classification of remotely sensed data: fusion of Landsat TM and SAR images. IEEE Trans. Geosci. Remote Sens. 1994, 32, 768–778. [Google Scholar] [CrossRef]
- Khorram, S. Comparison of Landsat MSS and TM data for urban land-use classification. IEEE Trans. Geosci. Remote Sens. 1987, 25, 238–243. [Google Scholar] [CrossRef]
- Haack, B.N. Assessment of Landsat MSS and TM data for urban and near-urban landcover digital classification. Remote Sens. Environ. 1987, 21, 201–213. [Google Scholar] [CrossRef]
- Ulaby, F.T. Crop classification using airborne RADAR and Landsat data. IEEE Trans. Geosci. Remote Sens. 1982, 20, 518–528. [Google Scholar] [CrossRef]
- Ediriwickrema, J.; Khorram, S. Hierarchical maximum-likelihood classification for improved accuracies. IEEE Trans. Geosci. Remote Sens. 1997, 35, 810–816. [Google Scholar] [CrossRef]
- Schowengerdt, R.A. Techniques for image processing and classification in remote sensing; Academic Press: New York, NY, USA, 1983; pp. 129–214. [Google Scholar]
- Swain, P.H.; Davis, S.M. Remote sensing: the quantitative approach; McGraw-Hill: New York, NY, USA, 1978; pp. 136–188. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern classification and scene analysis; Wiley-Interscience: New York, NY, USA, 1973. [Google Scholar]
- Dam, H.H.; Abbass, H.A.; Lokan, C.; Yao, X. Neural-based learning classifier systems. IEEE Trans. Knowl. Data Eng. 2008, 20, 26–39. [Google Scholar] [CrossRef]
- Weller, A.F.; Harris, A.J.; Ware, J.A. Artificial neural networks as potential classification tools for dinoflagellate cyst images: A case using the self-organizing map clustering algorithm. Rev. Paleobot. Palynol. 2006, 141, 287–302. [Google Scholar] [CrossRef]
- Dai, X.L.; Khorram, S. Data fusion using artificial neural networks: a case study on multitemporal change analysis. Comput. Environ. Urban Syst. 1999, 23, 19–31. [Google Scholar] [CrossRef]
- Heermann, P.D.; Khazenie, N. Classification of multispectral remote sensing data using a back-propagation neural network. IEEE Trans. Geosci. Remote Sens. 1992, 30, 81–88. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Swain, P.H.; Ersoy, O.K. Neural network approaches versus statistical methods in classification of multi-source remote sensing data. IEEE Trans. Geosci. Remote Sens. 1990, 28, 540–551. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Sveinsson, J.R. Feature extraction for multisource data classification with artificial neural networks. Int. J. Remote Sens. 1997, 18, 727–740. [Google Scholar] [CrossRef]
- Foody, G.M. Land-cover classification by an artificial neural-network with ancillary information. Int. J. Geogr. Inf. Syst. 1995, 9, 527–542. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. An evaluation of some factors affecting the accuracy of classification by an artificial neural network. Int. J. Remote Sens. 1997, 18, 799–810. [Google Scholar] [CrossRef]
- Bischof, H.; Schneider, W.; Pinz, A.J. Multispectral classification of landsat images using neural networks. IEEE Trans. Geosci. Remote Sens. 1992, 30, 482–490. [Google Scholar] [CrossRef]
- Klein, R.W.; Dubes, R.C. Experiments in projection and clustering by annealing. Patt. Recogn. 1989, 22, 213–220. [Google Scholar] [CrossRef]
- Laarhoven, P.J.M. Theoretical and computational aspects of simulated annealing; Centre for mathematics and computer science: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Carpenter, G.A.; Gjaja, M.N.; Gopal, S.; Woodcock, C.E. ART neural networks for remote sensing: vegetation classification from Landsat TM and terrain data. IEEE Trans. Geosci. Remote Sens. 1997, 35, 308–325. [Google Scholar] [CrossRef]
- Bishop, C.M. Radial basis functions. In Neural networks for pattern recognition; Clarendon Press: Oxford:: New York, NY, USA, March 8-12 1995. [Google Scholar]
- Bezdek, J.C. Fuzzy Kohonen clustering networks. In IEEE International Conference on Fuzzy Systems, San Diego, CA, USA; 1992; pp. 1035–1043. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Babu, G.P. Self-organizing neural networks for spatial data. Patt. Recogn. Lett. 1997, 18, 133–142. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organizing formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 56–69. [Google Scholar] [CrossRef]
- Kanellopoulos, I.; Wilkinson, G.G. Strategies and best practice for neural network image classification. Int. J. Remote Sens. 1997, 18, 711–725. [Google Scholar] [CrossRef]
- Paola, J.D.; Schowengerdt, R.A. The effect of neural-network structure on a multispectral land-use/land-cover classification. Photogram. Eng. Remote Sens. 1997, 63, 535–544. [Google Scholar]
- Foody, G.M.; McCulloch, M.B.; Yates, W.B. The effect of training set size and composition on artificial neural network classification. Int. J. Remote Sens. 1995, 16, 1707–1723. [Google Scholar] [CrossRef]
- Cuiying, Z.; Liang, Z.; Xianyi, H. Classification of rocks surrounding tunnel based on improved BP network algorithm. Earth Sci. J. China Univ. Geosci. 2005, 30, 480–486. [Google Scholar]
- Principe, J.C.; Euliano, N.R.; Lefebvre, W.C. Neural and adaptive systems: fundamentals through simulations; John Wiley & Sons, Inc.: New York, NY, USA, 1999; pp. 100–222. [Google Scholar]
- Verbeke, L.P.C.; Vancoillie, F.M.B.; De Wulf, R.R. Reusing back-propagation artificial neural networks for land cover classification in tropical savannahs. Int. J. Remote Sens. 2004, 25, 2747–2771. [Google Scholar] [CrossRef]
- Lee, J. A neural network approach to cloud classification. IEEE Trans. Geosci. Remote Sens. 1990, 28, 846–855. [Google Scholar] [CrossRef]
- Lippmann, R.P. An introduction to computing with neural networks. IEEE ASSP Mag. 1987, 4, 4–22. [Google Scholar] [CrossRef]
- Chen, Z. Texture segmentation based on Wavelet and Kohonen network for remotely sensed images. In IEEE SMC’99 Conference Proceedings, Tokyo, Japan, Oct. 12-15, 1999; Vol. 6, pp. 816–821.
- Goncalves, M.L. A neural architecture for the classification of remote sensing imagery with advanced learning algorithms. In Proceedings of IEEE Signal Processing Society Workshop, Cambridge, UK, Aug. 31- Sep. 2, 1998; pp. 577–586.
- Thomson, A.G.; Fuller, R.M.; Eastwoods, J.A. Supervised versus unsupervised methods for classification of coasts and river corridors from airborne remote sensing. Int. J. Remote Sens. 1998, 18, 3423–3431. [Google Scholar] [CrossRef]
- Das, A.; Chakrabarti, B.K. Quantum annealing and related optimization methods. Lect. Notes Phys.; Springer Berlin Heidelberg: The Netherlands, 2005. [Google Scholar]
- De Vincente, J.; Lanchares, J.; Hermida, J. Placement by thermodynamic simulated annealing. Phys. Lett. A 2003, 317, 415–423. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–688. [Google Scholar] [CrossRef] [PubMed]
- Cerny, V. Thermodynamical approach to the traveling salesman problem: an efficient simulation algorithm. J. Optimiz. Theory Appl. 1985, 45, 45–51. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Patt. Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef]
- Baraldi, A.; Parmiggiani, F. A neural network for unsupervised categorization of multivalued input patterns: an application to satellite image clustering. IEEE Trans. Geosci. Remote Sens. 1995, 33, 305–316. [Google Scholar] [CrossRef]
- Bischof, H.; Leonardis, A. Finding optimal neural networks for land use classification. IEEE Trans. Geosci. Remote Sens. 1998, 36, 337–341. [Google Scholar] [CrossRef]
- Serpico, S.B.; Roli, F. Classification of multisensor remote-sensing images by structured neural networks. IEEE Trans. Geosci. Rem. Sens. 1995, 33, 562–578. [Google Scholar] [CrossRef]
- ERDAS. ERDAS field guide; ERDAS, Inc.: Atlanta, GA, USA, 2007. [Google Scholar]
- Anderson, J.R. A land use and land cover classification system for use with remotely sensed data. In U.S. Geological Survey Professional Paper 964; Washington, DC, USA, 1986; p. 28. [Google Scholar]
- Foody, G.M. The significance of border training patterns in classification by a feedforward neural network using back propagation learning. Int. J. Remote Sens. 1999, 20, 3549–3562. [Google Scholar] [CrossRef]
- Lippmann, R.P. Pattern classification using Neural Networks. IEEE Commun. Mag. 1989, 47–64. [Google Scholar] [CrossRef]
- Wang, K.; Yang, J.; Shi, G.; Wang, Q. An expanded training set based validation method to avoid overfitting for neural network classifier. In Natural Computation 2008. ICNC '08. Fourth International Conference on, Jinan, China, Oct. 10-20, 2008; Vol. 3, pp. 83–87.
- Sterlin, P. Overfitting prevention with cross-validation. Master’s thesis, University Pierre and Marie Curie (Paris VI), Paris, France, 2007. [Google Scholar]
- Bishop, Y.M.M.; Feinberg, S.E.; Holland, P.W. Discrete multivariate analysis-theory and practice; MIT Press: Cambridge, MA, USA, 1975. [Google Scholar]
- Cohen, J.A. A Coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Khorram, S.; Biging, G.S.; Chrisman, N.R.; Colby, D.R.; Congalton, R.G.; Dobson, J.E.; Ferguson, R.L.; Goodchild, M.F.; Jensen, J.R.; Mace, T.H. Accuracy assessment of remote sensing-derived change detection. In American Society for Photogrammetry and Remote Sensing, Monograph Series; 1999; ISBN 1-57083-058-4. [Google Scholar]
- Fiannaca, A.; Di Fatta, G.; Gaglio, S.; Rizzo, R.; Urso, A.M. Improved SOM learning using simulated annealing. Lect. Notes Comput. Sci. 2007, 4668, 279–288. [Google Scholar]
- Morisette, J.; Khorram, S. Exact confidence interval for proportions. Photogramm. Eng. Remote Sens. 2003, 66, 875–880. [Google Scholar]
- Yuan, H. Development and evaluation of advanced classification systems using remotely sensed data for accurate Land-Use/Land-Cover mapping. Ph.D dissertation, Center for Earth Oservation, North Carolina State University, Raleigh, NC, USA, 2002. [Google Scholar]
- Klein, R.W.; Dubes, R.C. Experiments in projection and clustering by annealing. Patt. Recogn. 1989, 22, 213–220. [Google Scholar] [CrossRef]
- Selim, S.Z.; Alsultan, K. A simulated annealing algorithm for the clustering problem. Patt. Recogn. 1991, 24, 1003–1008. [Google Scholar] [CrossRef]
- Aarts, E.H.L.; van Laarhoven, P.J.M. Simulated annealing: a pedestrian review of the theory and some applications. Patt. Recogn. Theory Appl. 1987, 179–192. [Google Scholar]
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Yuan, H.; Van Der Wiele, C.F.; Khorram, S. An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery. Remote Sens. 2009, 1, 243-265. https://doi.org/10.3390/rs1030243
Yuan H, Van Der Wiele CF, Khorram S. An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery. Remote Sensing. 2009; 1(3):243-265. https://doi.org/10.3390/rs1030243
Chicago/Turabian StyleYuan, Hui, Cynthia F. Van Der Wiele, and Siamak Khorram. 2009. "An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery" Remote Sensing 1, no. 3: 243-265. https://doi.org/10.3390/rs1030243