
Groundwater Depth Prediction Using Data-Driven Models with the Assistance of Gamma Test

Abstract
:1. Introduction
2. Data and Methodology
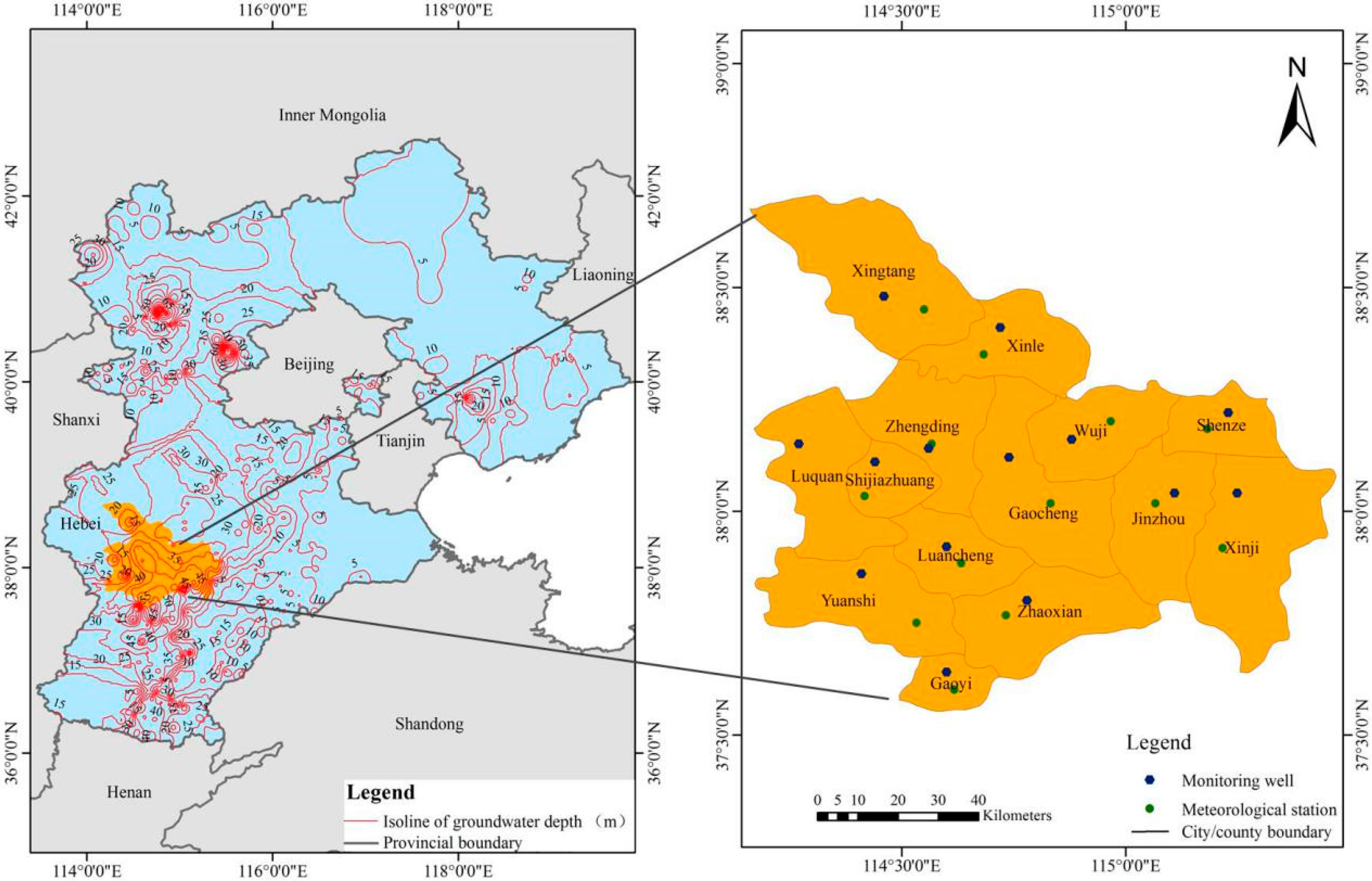
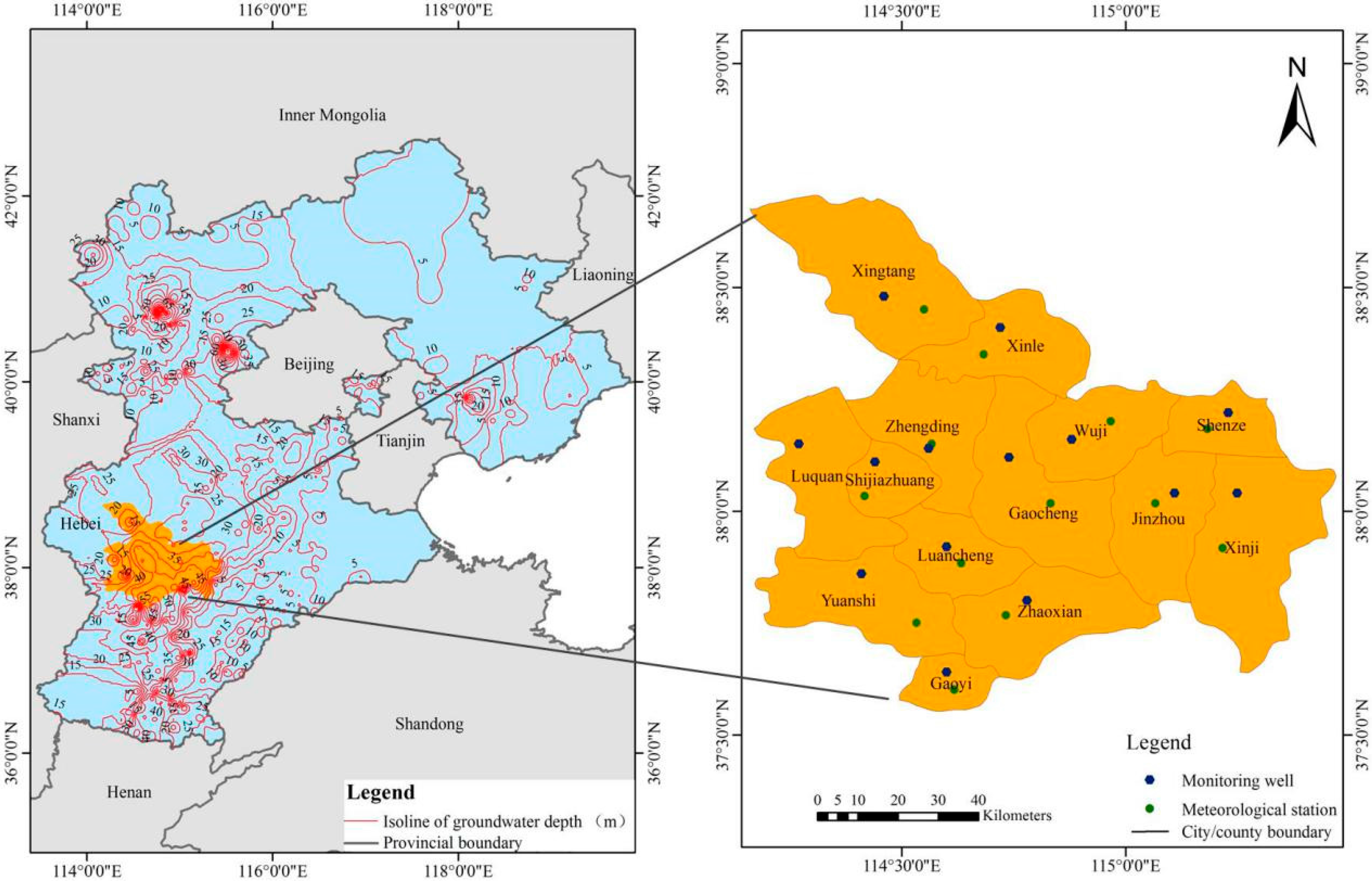
2.1. Study Area
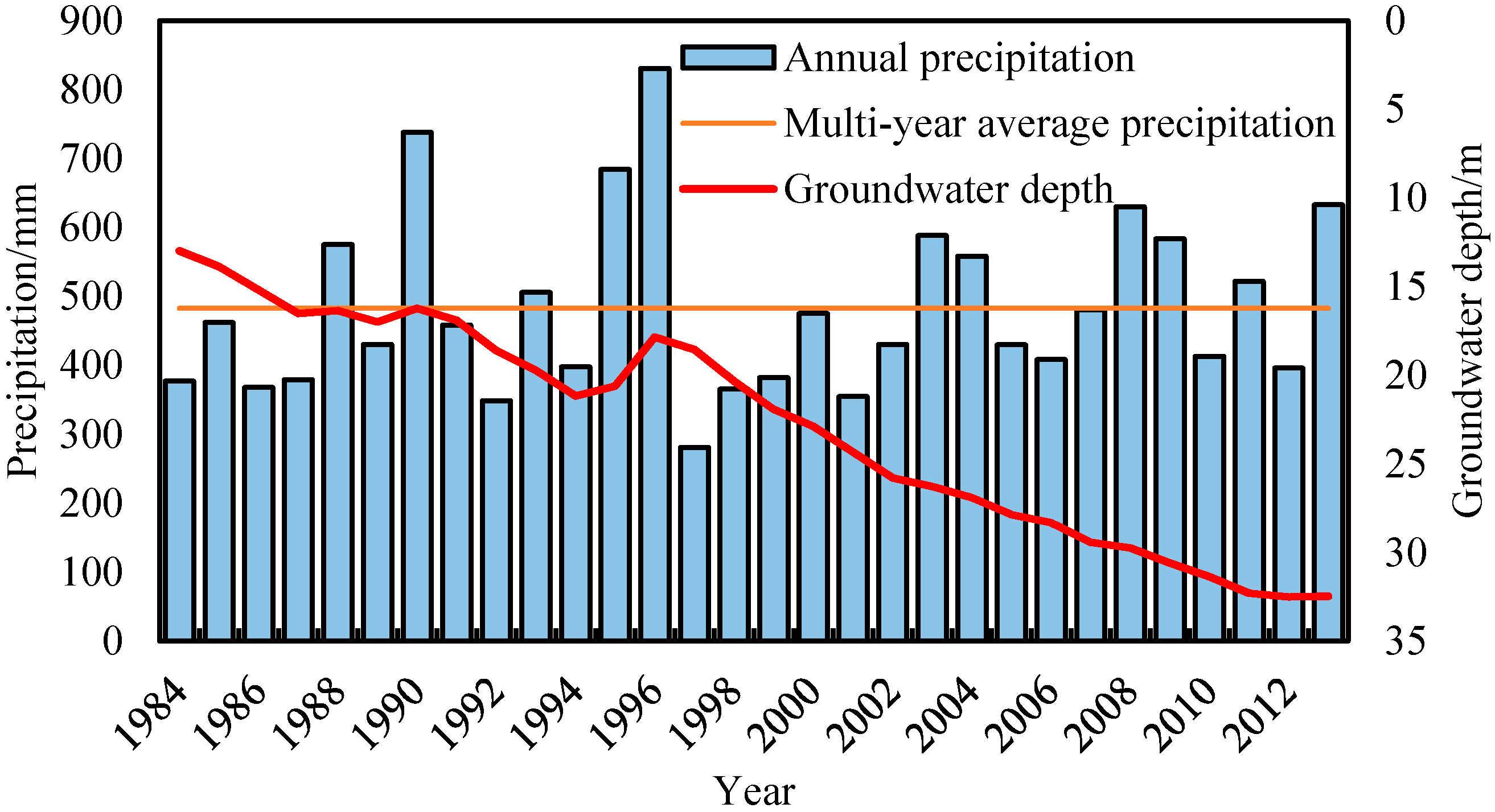
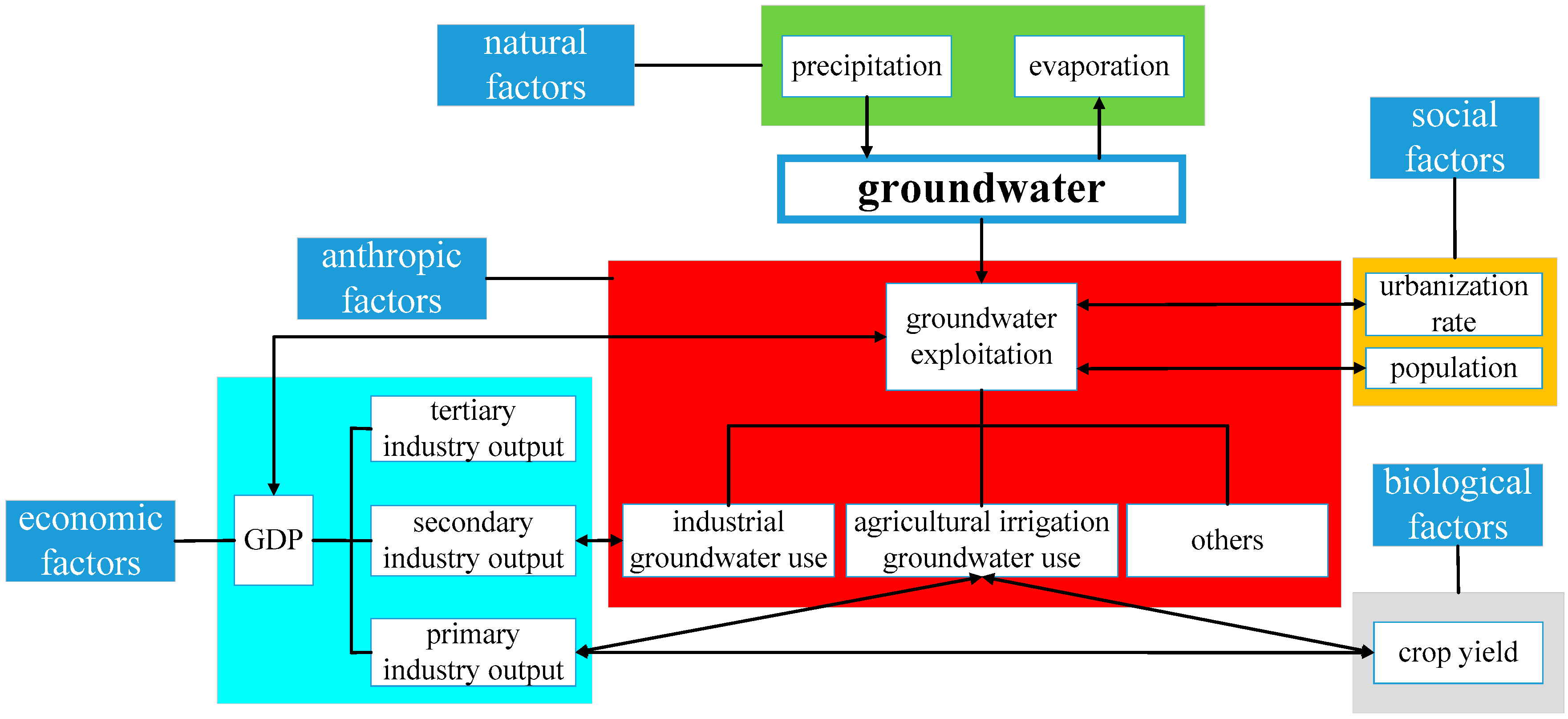
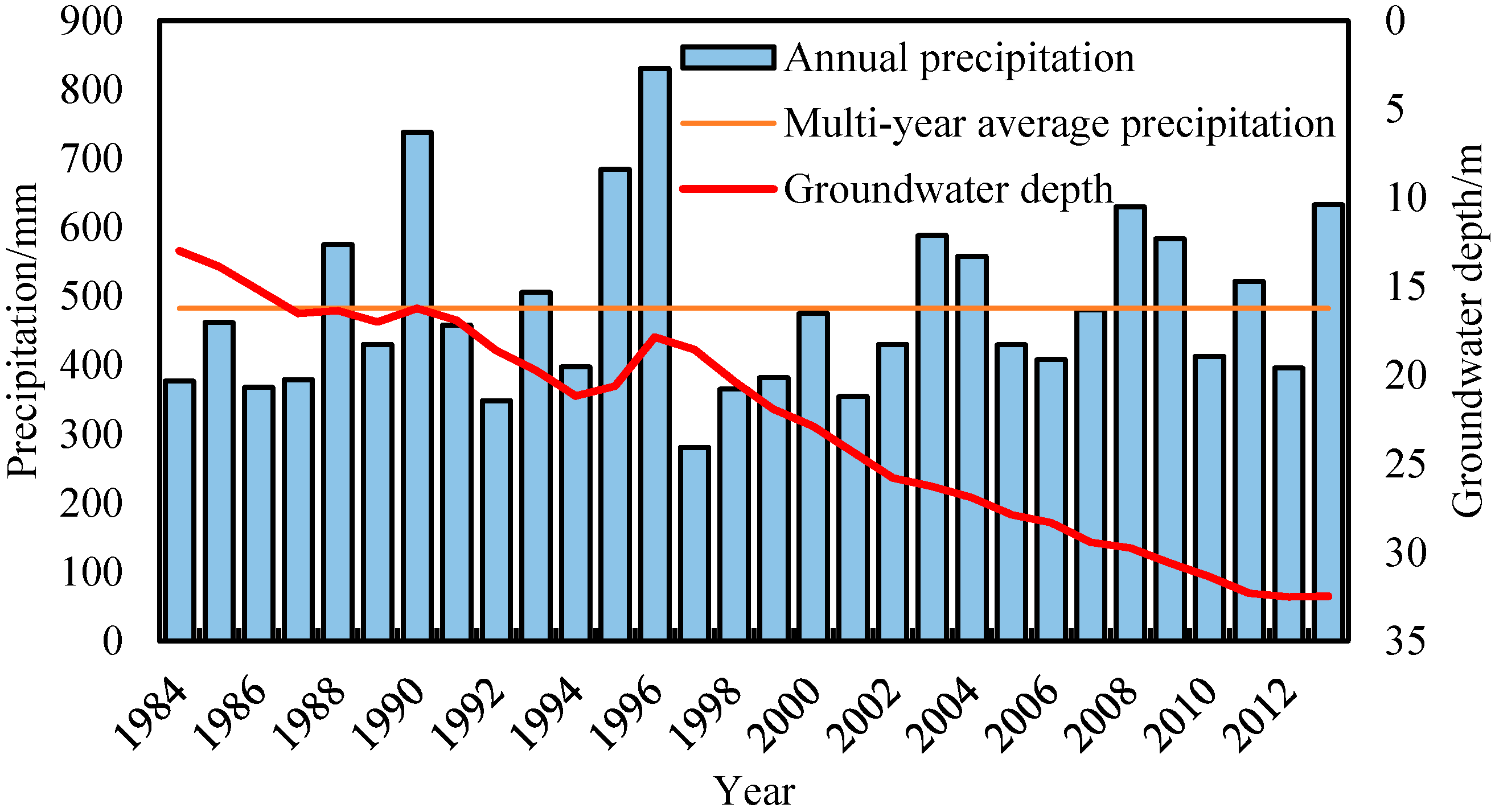
2.2. Input Indices and Data Source
2.3. Methodology
2.3.1. Gamma Test
2.3.2. Power Function Model (PFM)
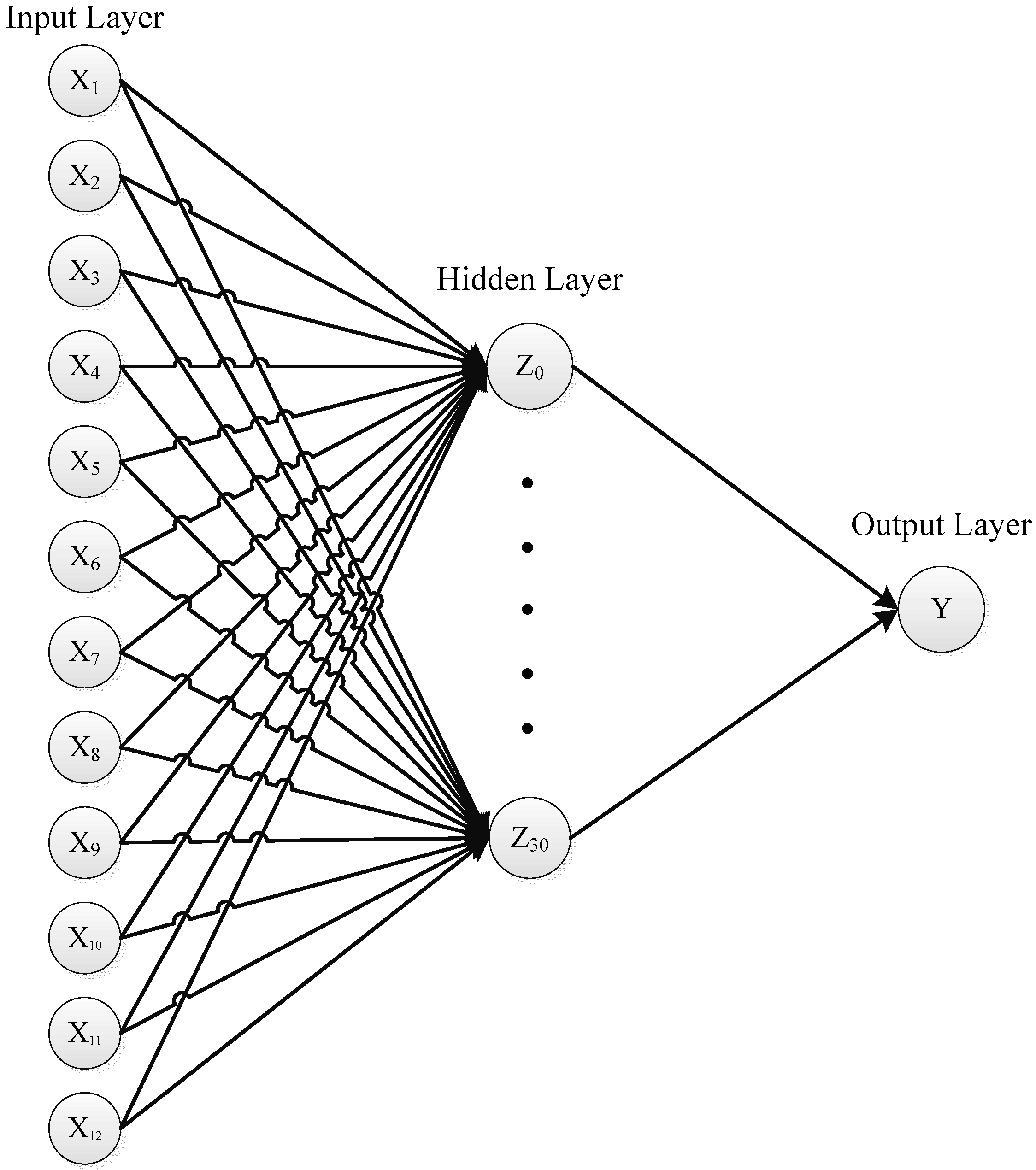
2.3.3. Back-Propagation Artificial Neural Network (BPANN)
2.3.4. Support Vector Machines (SVMs)
2.3.5. Implementation and Assessment of Three Models
3. Results
3.1. Correlation Test for 12 Inputs
3.2. Relative Importance of the Model Inputs
3.3. Model Input Selection Based on Gamma Test
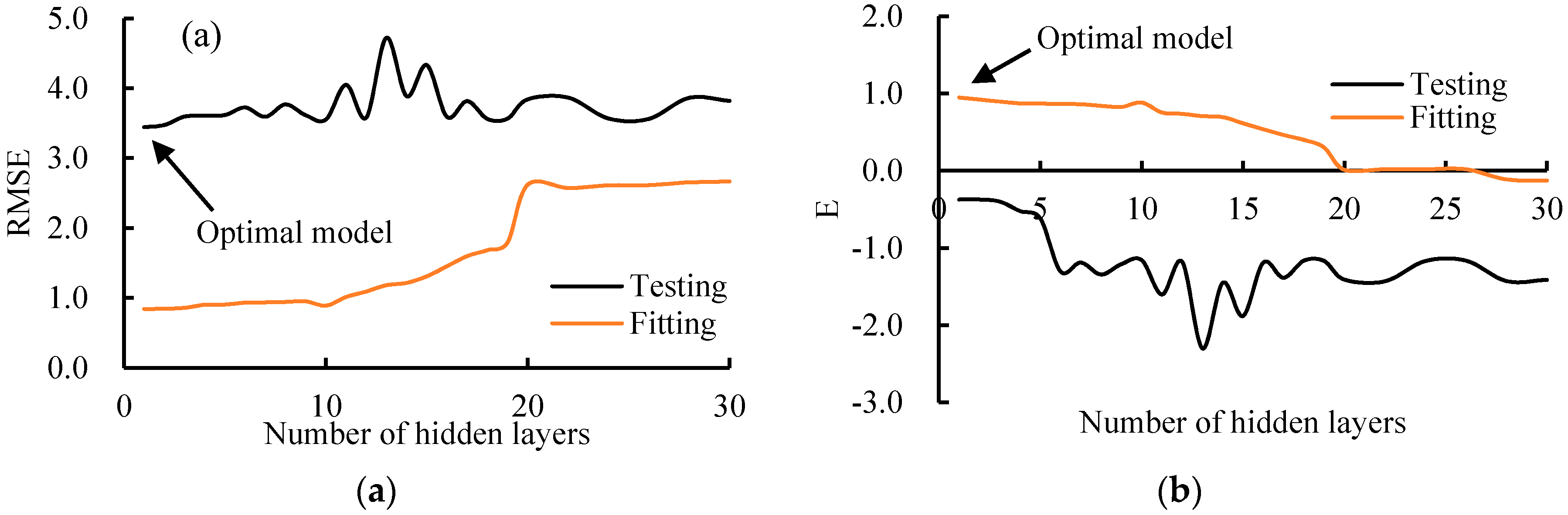
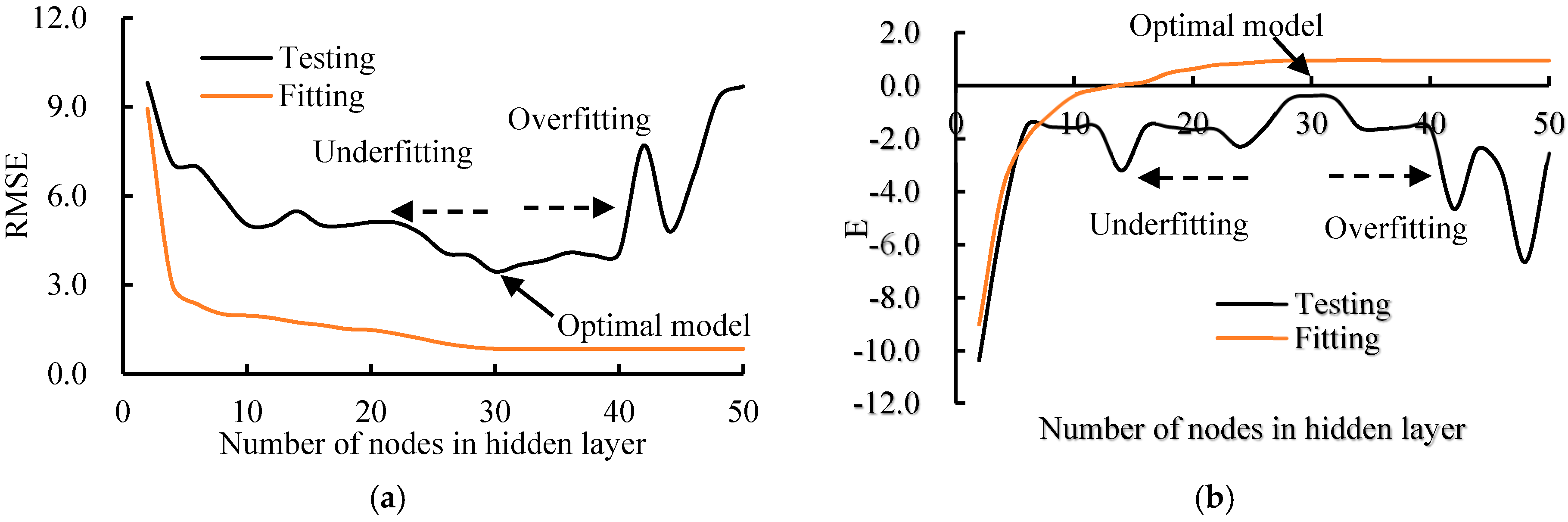
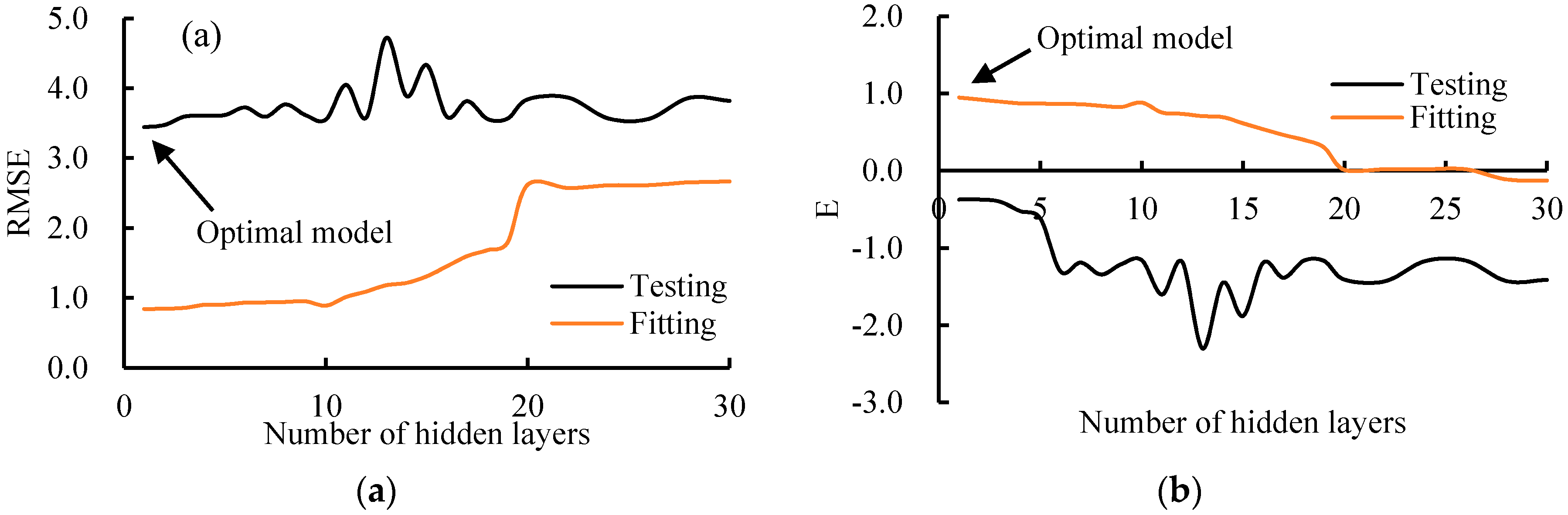
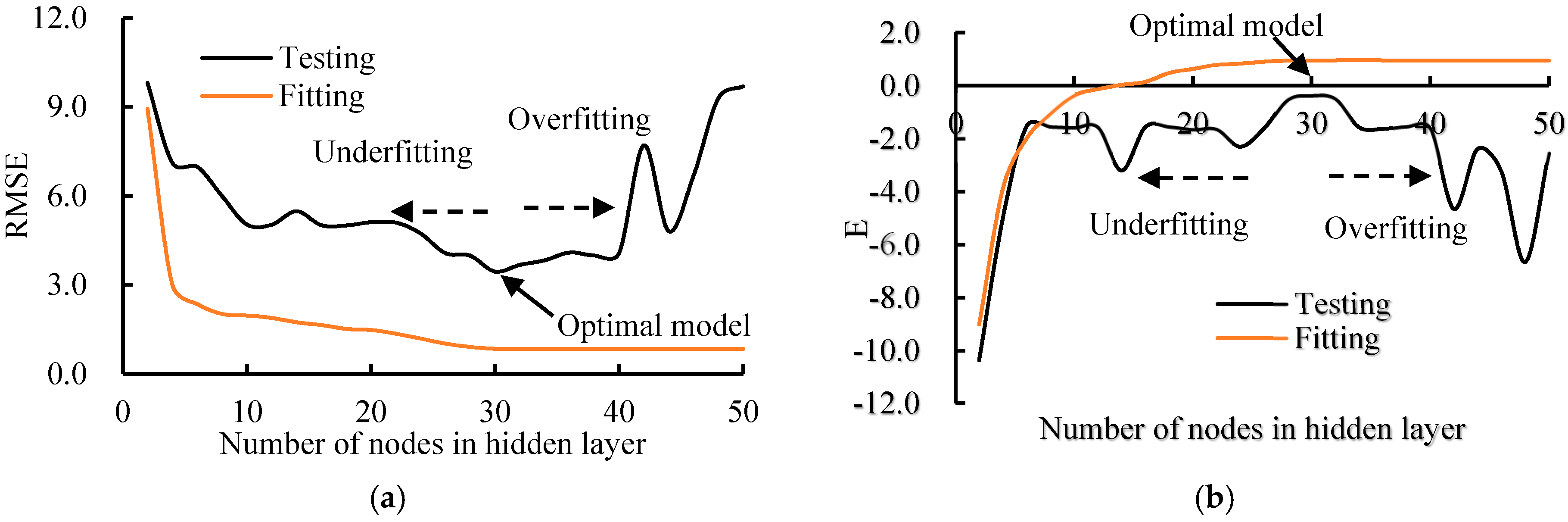
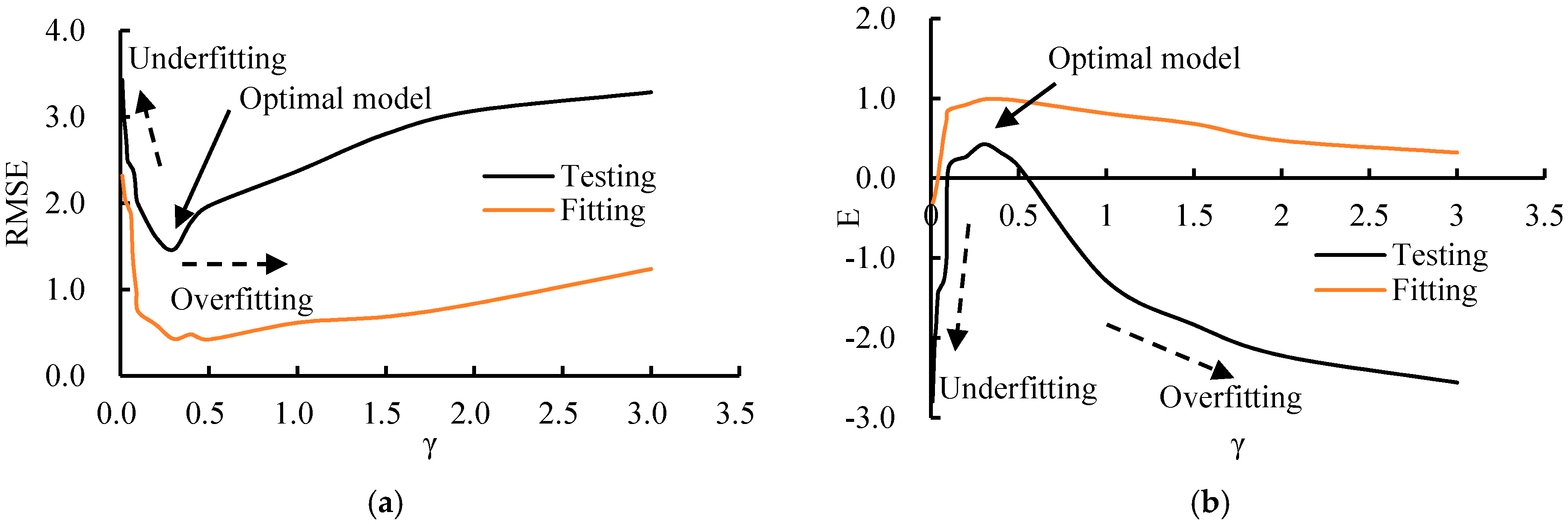
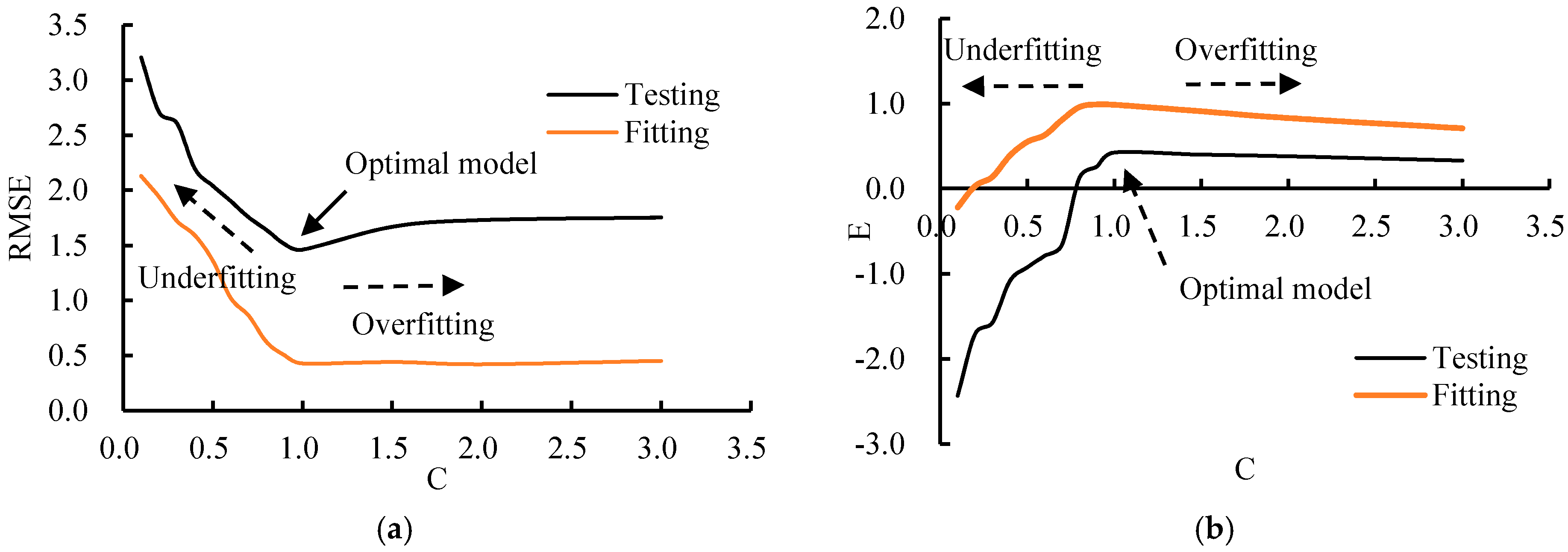
3.4. Influence of the Parameters in BPANN and SVM (RBF)
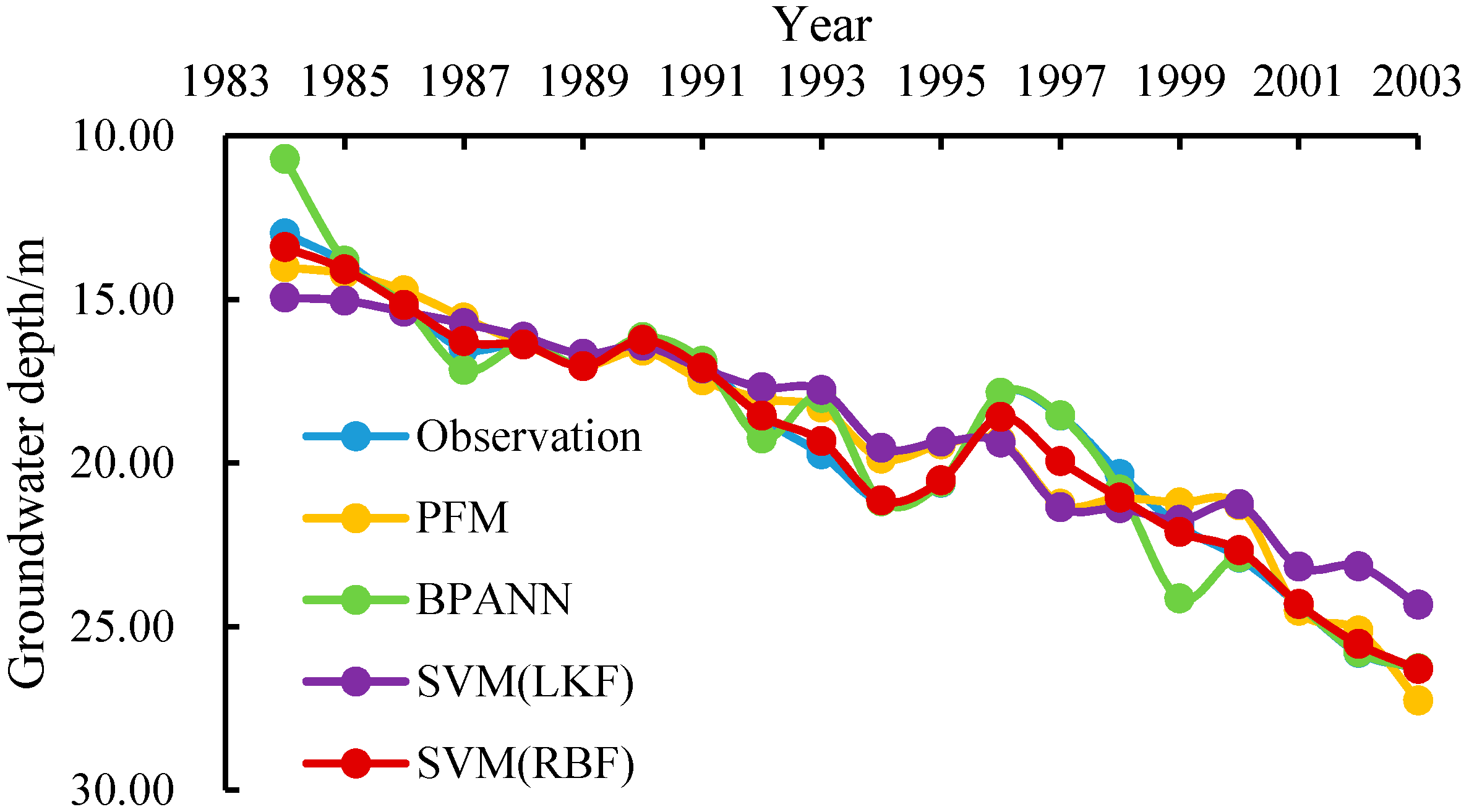
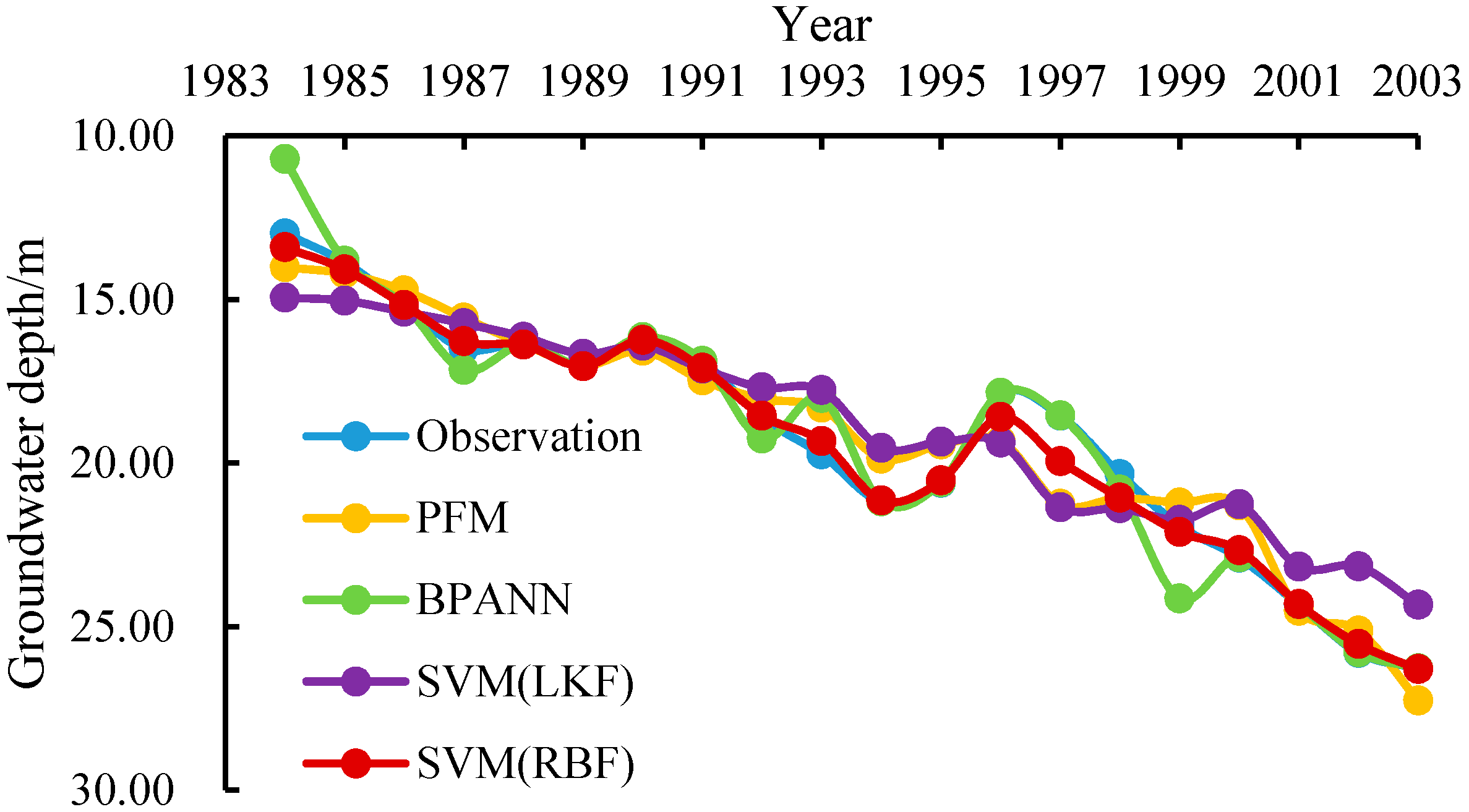
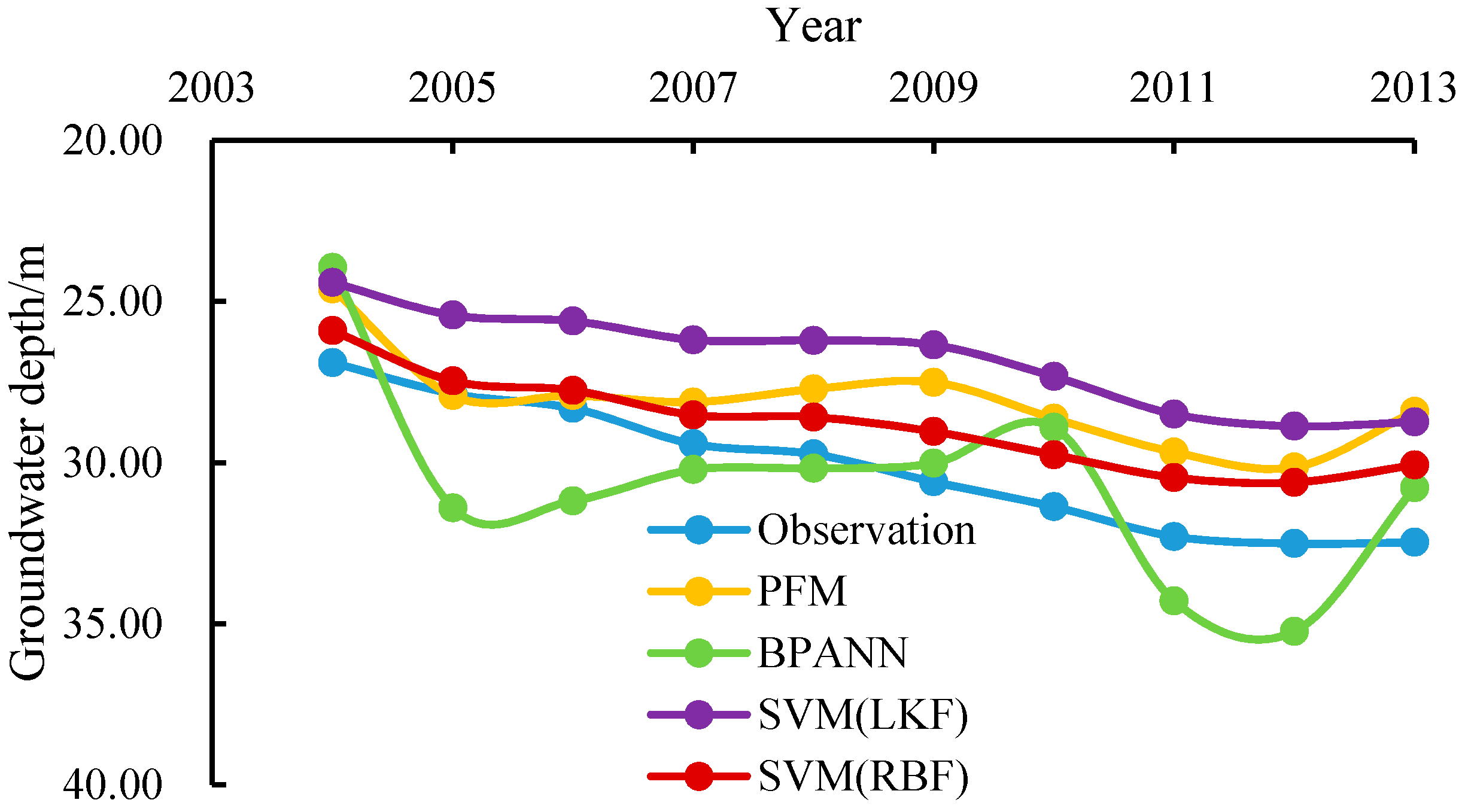
3.5. Fitting Results and Model Errors
3.6. Testing Results and Model Errors
3.7. Sensitivity Analysis of the Input Choice
4. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cao, G.; Zheng, C.; Scanlon, B.R.; Liu, J.; Li, W. Use of flow modeling to assess sustainability of groundwater resources in the North China Plain. Water Resour. Res. 2013, 49, 159–175. [Google Scholar] [CrossRef]
- Natkhin, M.; Steidl, J.; Dietrich, O.; Dannowski, R.; Lischeid, G. Differentiating between climate effects and forest growth dynamics effects on decreasing groundwater recharge in a lowland region in Northeast Germany. J. Hydrol. 2012, 448, 245–254. [Google Scholar] [CrossRef]
- Goderniaux, P.; Brouyère, S.; Wildemeersch, S.; Therrien, R.; Dassargues, A. Uncertainty of climate change impact on groundwater reserves—Application to a chalk aquifer. J. Hydrol. 2015, 528, 108–121. [Google Scholar] [CrossRef]
- Yuan, Z.; Shen, Y. Estimation of agricultural water consumption from meteorological and yield data: A case study of Hebei, North China. PLoS ONE 2013, 8, e58685–e58685. [Google Scholar] [CrossRef] [PubMed]
- Davidsen, C.; Liu, S.; Mo, X.; Rosbjerg, D.; Bauer-Gottwein, P. The cost of ending groundwater overdraft on the North China Plain. Hydrol. Earth Syst. Sci. 2015, 12, 5931–5966. [Google Scholar] [CrossRef]
- Kendy, E.; Gérard-Marchant, P.; Walter, M.T.; Zhang, Y.; Liu, C.; Tammo, S.S. A soil-water-balance approach to quantify groundwater recharge from irrigated cropland in the North China Plain. Hydrol. Process. 2003, 17, 2011–2031. [Google Scholar] [CrossRef]
- Hu, Y.; Moiwo, J.P.; Yang, Y.; Han, S.; Yang, Y. Agricultural water-saving and sustainable groundwater management in Shijiazhuang Irrigation District, North China Plain. J. Hydrol. 2010, 393, 219–232. [Google Scholar] [CrossRef]
- Knotters, M.; Bierkens, M.F.P. Physical basis of time series models for water table depths. Water Resour. Res. 2000, 36, 181–188. [Google Scholar] [CrossRef]
- Asefa, T.; Kemblowski, M.; Urroz, G.; Mckee, M. Support vector machines (SVMs) for monitoring network design. Groundwater 2005, 43, 413–422. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.F.; Valocchi, A.J.; Choi, J.; Amir, E. Use of machine learning methods to reduce predictive error of groundwater models. Groundwater 2013, 52, 448–460. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.P.; Lu, W.X.; Long, Y.Q.; Li, P. Application and comparison of two prediction models for groundwater levels: A case study in Western Jilin Province, China. J. Arid Environ. 2009, 73, 487–492. [Google Scholar] [CrossRef]
- Shirmohammadi, B.; Vafakhah, M.; Moosavi, V.; Moghaddamnia, A. Application of several data-driven techniques for predicting groundwater level. Water Resour. Manag. 2013, 27, 419–432. [Google Scholar] [CrossRef]
- Ping, J.; Qiang, Y.; Xi, M. A combination model of chaos, wavelet and support vector machine predicting groundwater levels and its evaluation using three comprehensive quantifying techniques. Inf. Technol. J. 2013, 12, 3158–3163. [Google Scholar] [CrossRef]
- Evans, D.; Jones, A.J. A proof of the Gamma test. Proc. R. Soc. Lond. A 2002, 458, 2759–2799. [Google Scholar] [CrossRef]
- Moghaddamnia, A.; Gousheh, M.G.; Piri, J.; Amin, S.; Han, D. Evaporation estimation using artificial neural networks and adaptive neuro-fuzzy inference system techniques. Adv. Water Resour. 2009, 32, 88–97. [Google Scholar] [CrossRef]
- Noori, R.; Karbassi, A.R.; Moghaddamnia, A.; Han, D.; Zokaei-Ashtiani, M.H.; Farokhnia, A.; Gousheh, M.G. Assessment of input variables determination on the SVM model performance using PCA, Gamma test, and forward selection techniques for monthly stream flow prediction. J. Hydrol. 2011, 401, 177–189. [Google Scholar] [CrossRef]
- Han, D.; Wan Jaafar, W.Z. Model structure exploration for index flood regionalization. Hydrol. Process. 2013, 27, 2903–2917. [Google Scholar] [CrossRef]
- Lu, X.; Jin, M.; Martinus, T.V.G.; Wang, B. Groundwater recharge at five representative sites in the Hebei Plain, China. Ground Water. 2011, 49, 286–294. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.M.; Yu, J.J.; Kendy, E. Groundwater exploitation and its impact on the environment in the North China Plain. Water Int. 2001, 26, 265–272. [Google Scholar]
- Cao, G.; Han, D.; Song, X. Evaluating actual evapotranspiration and impacts of groundwater storage change in the North China Plain. Hydrol. Process. 2014, 28, 1797–1808. [Google Scholar] [CrossRef]
- Shijiazhuang Bureau of Statistics. Shijiazhuang Statistical Yearbook; China Statistics Press: Beijing, China, 1984–2013.
- Cortes, C.; Vapnik, V. Support-Vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Elangovan, M.; Sugumaran, V.; Ramachandran, K.I.; Ravikumar, S. Effect of SVM kernel functions on classification of vibration signals of a single point cutting tool. Expert Syst. Appl. 2011, 38, 15202–15207. [Google Scholar] [CrossRef]
- Safavi, H.R.; Esmikhani, M. Conjunctive use of surface water and groundwater: Application of support vector machines. SVMs and genetic algorithms. Water Resour. Manag. 2013, 27, 2623–2644. [Google Scholar] [CrossRef]
- Wan Jaafar, W.Z.; Han, D. Variable Selection Using the Gamma Test Forward and Backward Selections. J. Hydrol. Eng. 2012, 17, 182–190. [Google Scholar] [CrossRef]






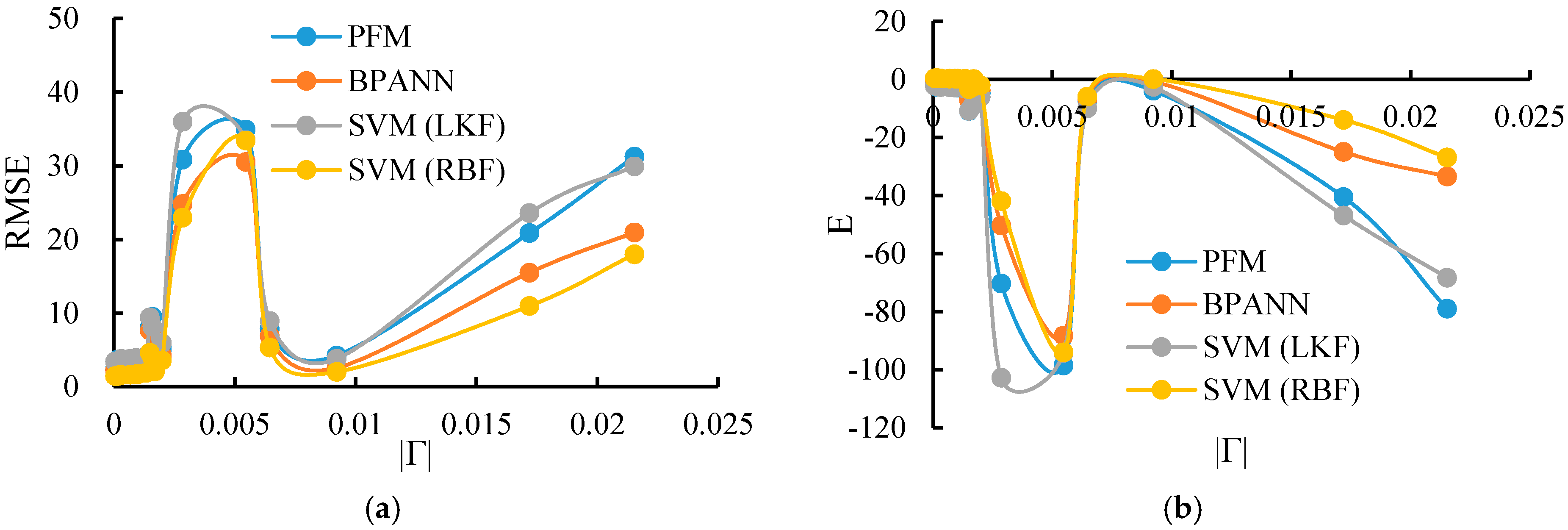

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
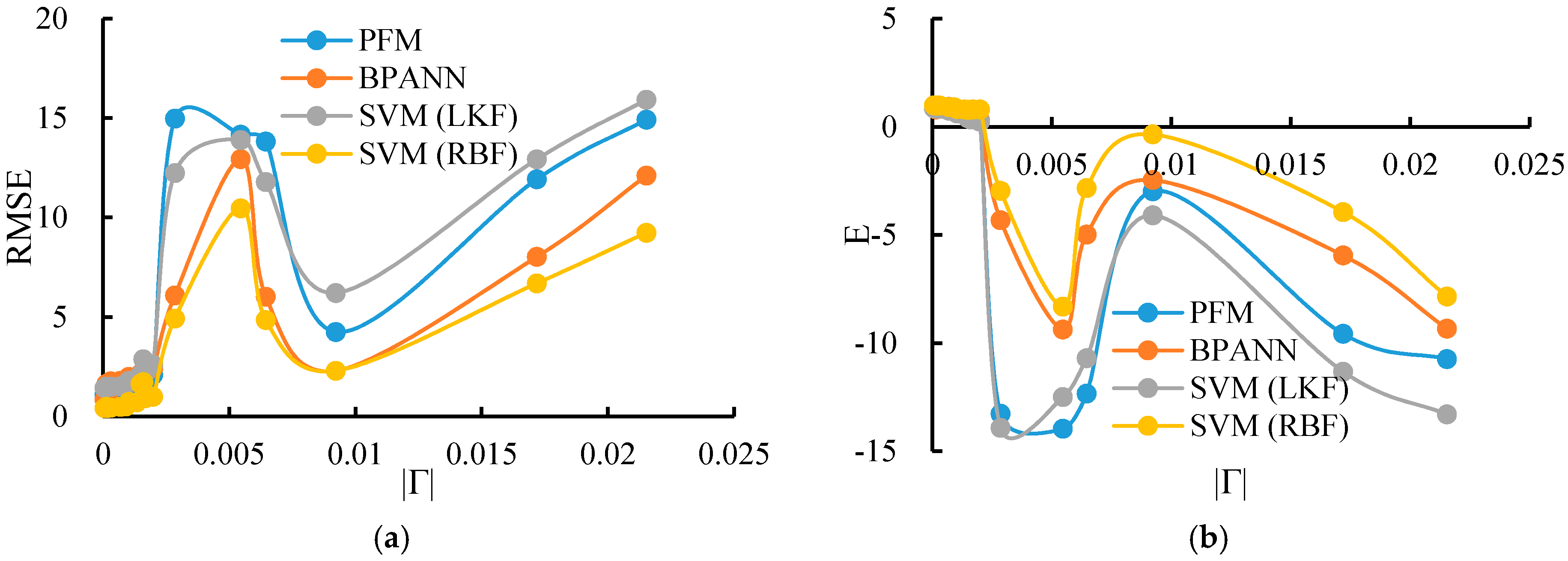{kind=link}
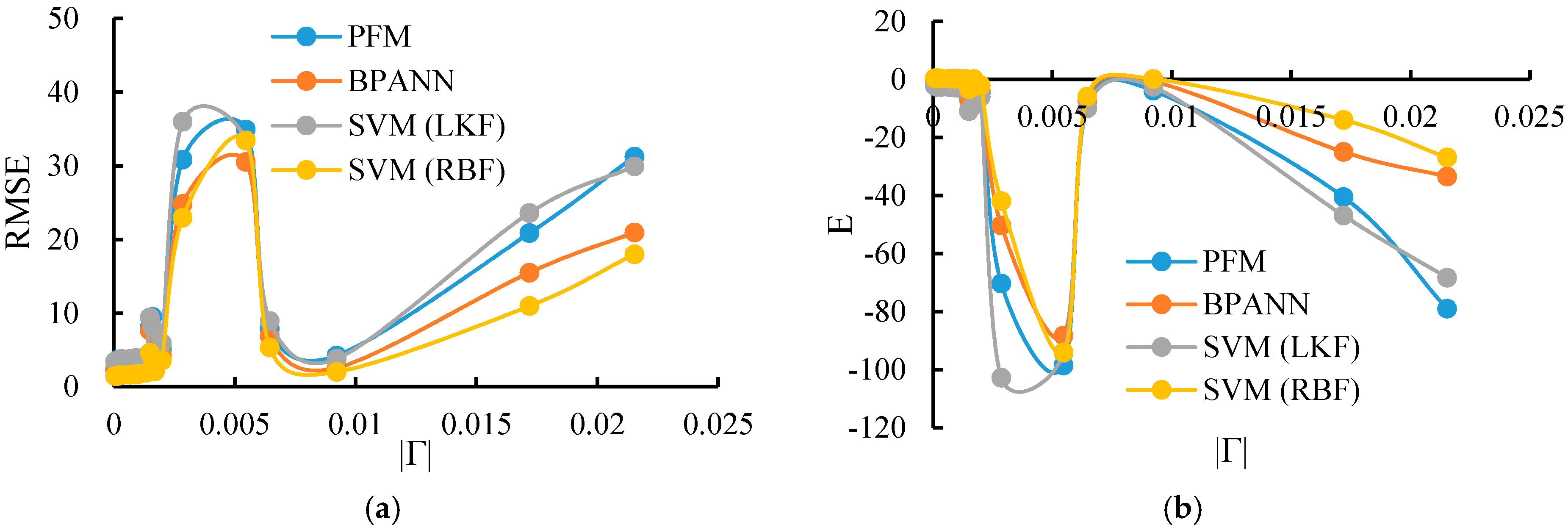{kind=link}
| Number | Indices | Number | Indices |
|---|---|---|---|
| 1 | Precipitation (mm) | 7 | GDP (million USD) |
| 2 | Evaporation (mm) | 8 | Primary industry output (million USD) |
| 3 | Groundwater exploitation (million m3) | 9 | Secondary industry output (million USD) |
| 4 | Industrial groundwater use (million m3) | 10 | Tertiary industry output (million USD) |
| 5 | Irrigation groundwater use (million m3) | 11 | Population (million) |
| 6 | Crop yield (million ton) | 12 | Urbanization rate (%) |
| Inputs Number | Correlation Coefficient (ρ) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| 1 | 1 | |||||||||||
| 2 | −0.199 | 1 | ||||||||||
| 3 | −0.360 | 0.376 | 1 | |||||||||
| 4 | −0.225 | −0.176 | −0.115 | 1 | ||||||||
| 5 | −0.355 | 0.346 | 0.352 | 0.190 | 1 | |||||||
| 6 | 0.122 | 0.357 | 0.406 | −0.234 | 0.175 | 1 | ||||||
| 7 | 0.131 | 0.211 | 0.168 | −0.410 | −0.175 | 0.309 | 1 | |||||
| 8 | 0.139 | 0.315 | 0.250 | −0.392 | −0.105 | 0.324 | 0.432 | 1 | ||||
| 9 | 0.135 | 0.217 | 0.167 | −0.387 | −0.178 | 0.309 | 0.799 * | 0.282 | 1 | |||
| 10 | 0.131 | 0.189 | 0.150 | −0.288 | −0.189 | 0.388 | 0.399 | 0.376 | 0.398 | 1 | ||
| 11 | 0.150 | 0.313 | 0.323 | −0.381 | −0.049 | 0.385 | 0.430 | 0.371 | 0.328 | 0.720 * | 1 | |
| 12 | 0.154 | 0.146 | 0.238 | −0.324 | −0.160 | 0.217 | 0.455 | 0.347 | 0.354 | 0.351 | 0.440 | 1 |
| Scheme ID | Combination of Indices | Masked Index | Gamma (Γ) | Gradient | Standard Error | Vratio |
|---|---|---|---|---|---|---|
| 1 | 1,2,3,4,5,6,7,8,9,10,11,12 | None | −0.00922 | 0.02841 | 0.01161 | −0.03687 |
| 2 | 2,3,4,5,6,7,8,9,10,11,12 | 1 | −0.00212 | 0.02529 | 0.00420 | −0.00848 |
| 3 | 1,3,4,5,6,7,8,9,10,11,12 | 2 | −0.00170 | 0.02776 | 0.00612 | −0.00679 |
| 4 | 1,2,4,5,6,7,8,9,10,11,12 | 3 | −0.00836 | 0.03004 | 0.00767 | −0.03343 |
| 5 | 1,2,3,5,6,7,8,9,10,11,12 | 4 | −0.01020 | 0.03265 | 0.00566 | −0.04082 |
| 6 | 1,2,3,4,6,7,8,9,10,11,12 | 5 | −0.00732 | 0.03007 | 0.00711 | −0.02927 |
| 7 | 1,2,3,4,5,7,8,9,10,11,12 | 6 | −0.00559 | 0.02845 | 0.00606 | −0.02235 |
| 8 | 1,2,3,4,5,6,8,9,10,11,12 | 7 | −0.00714 | 0.02955 | 0.00510 | −0.02857 |
| 9 | 1,2,3,4,5,6,7,9,10,11,12 | 8 | −0.00580 | 0.02850 | 0.00613 | −0.02320 |
| 10 | 1,2,3,4,5,6,7,8,10,11,12 | 9 | −0.00745 | 0.02944 | 0.00993 | −0.02981 |
| 11 | 1,2,3,4,5,6,7,8,9,11,12 | 10 | −0.00316 | 0.02759 | 0.00739 | −0.01264 |
| 12 | 1,2,3,4,5,6,7,8,9,10,12 | 11 | −0.00351 | 0.02842 | 0.00810 | −0.01405 |
| 13 | 1,2,3,4,5,6,7,8,9,10,11 | 12 | −0.01372 | 0.03514 | 0.00919 | −0.05487 |
| Scheme ID | Combination of Indices | Index Removed | Gamma (Γ) | Gradient | Standard Error | Vratio |
|---|---|---|---|---|---|---|
| 1 | 1,2,3,4,5,6,7,8,9,10,11,12 | None | −0.00922 | 0.02841 | 0.01161 | −0.03687 |
| 3 | 1,3,4,5,6,7,8,9,10,11,12 | 2 | −0.00170 | 0.02776 | 0.00612 | −0.00679 |
| 14 | 1,3,4,5,6,7,8,9,10,12 | 11 | 0.00103 | 0.02878 | 0.00555 | 0.00413 |
| 15 | 3,4,5,6,7,8,9,10,12 | 1 | 0.00031 | 0.03579 | 0.00625 | 0.00124 |
| 16 | 3,4,5,6,7,9,10,12 | 8 | −0.00014 | 0.03999 | 0.00916 | −0.00054 |
| 17 | 3,4,5,6,9,10,12 | 7 | 0.00021 | 0.04415 | 0.00776 | 0.00085 |
| 18 | 3,4,5,6,9,12 | 10 | 0.00091 | 0.05043 | 0.00736 | 0.00366 |
| 19 | 3,4,6,9,12 | 5 | −0.00006 | 0.06856 | 0.00886 | −0.00023 |
| 20 | 3,4,6,12 | 9 | 0.00160 | 0.08593 | 0.00660 | 0.00640 |
| 21 | 3,4,12 | 6 | 0.01719 | 0.08515 | 0.01186 | 0.06877 |
| 22 | 4,12 | 3 | 0.02153 | 0.15409 | 0.01040 | 0.08612 |
| 23 | 12 | 4 | 0.00546 | 0.71495 | 0.00361 | 0.02185 |
| Scheme ID | Combination of Indices | Index added | Gamma (Γ) | Gradient | Standard Error | Vratio |
|---|---|---|---|---|---|---|
| 23 | 12 | None | 0.00546 | 0.71495 | 0.00361 | 0.02185 |
| 24 | 10,12 | 10 | 0.00285 | 0.19576 | 0.00491 | 0.01142 |
| 25 | 7,10,12 | 7 | 0.00149 | 0.13163 | 0.00483 | 0.00597 |
| 26 | 6,7,10,12 | 6 | 0.00645 | 0.08496 | 0.00294 | 0.02579 |
| 27 | 3,6,7,10,12 | 3 | −0.00069 | 0.07638 | 0.00797 | −0.00277 |
| 28 | 3,4,6,7,10,12 | 4 | 0.00199 | 0.05354 | 0.00541 | 0.00796 |
| 29 | 3,4,5,6,7,10,12 | 5 | 0.00134 | 0.04241 | 0.00717 | 0.00539 |
| 16 | 3,4,5,6,7,9,10,12 | 9 | −0.00014 | 0.03999 | 0.00916 | −0.00054 |
| 15 | 3,4,5,6,7,8,9,10,12 | 8 | 0.00031 | 0.03579 | 0.00625 | 0.00124 |
| 14 | 1,3,4,5,6,7,8,9,10,12 | 1 | 0.00103 | 0.02878 | 0.00555 | 0.00414 |
| 3 | 1,3,4,5,6,7,8,9,10,11,12 | 11 | −0.00170 | 0.02776 | 0.00612 | −0.00679 |
| 1 | 1,2,3,4,5,6,7,8,9,10,11,12 | 2 | −0.00922 | 0.02841 | 0.01161 | −0.03687 |
| Scheme ID | PFM | BPANN | SVM (LKF) | SVM (RBF) | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | |
| 19 | 1.0638 | 0.9157 | 0.8411 | 0.9473 | 1.4345 | 0.8467 | 0.4265 | 0.9864 |
| Scheme ID | PFM | BPANN | SVM (LKF) | SVM (RBF) | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | |
| 19 | 2.3916 | −0.5409 | 2.2597 | −0.3755 | 3.4417 | −2.1910 | 1.4612 | 0.4248 |
| Scheme ID | Gamma (Γ) | PFM | BPANN | SVM (LKF) | SVM (RBF) | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | ||
| 19 | −0.00006 | 1.0638 | 0.9157 | 0.8411 | 0.9473 | 1.4345 | 0.8467 | 0.4265 | 0.9864 |
| 16 | −0.00014 | 1.1770 | 0.8968 | 1.6441 | 0.7986 | 1.4995 | 0.8351 | 0.4868 | 0.9823 |
| 17 | 0.00021 | 1.1626 | 0.8993 | 0.9923 | 0.9266 | 1.4874 | 0.8325 | 0.4279 | 0.9864 |
| 15 | 0.00031 | 1.2342 | 0.8801 | 1.7692 | 0.9359 | 1.5033 | 0.8302 | 0.4427 | 0.9821 |
| 27 | −0.00069 | 1.3094 | 0.7908 | 1.7903 | 0.9137 | 1.5232 | 0.7365 | 0.4915 | 0.9122 |
| 18 | 0.00091 | 1.2942 | 0.7882 | 1.8233 | 0.8244 | 1.6044 | 0.7086 | 0.5111 | 0.9035 |
| 14 | 0.00103 | 1.5336 | 0.6627 | 1.9917 | 0.6823 | 1.7908 | 0.6109 | 0.7293 | 0.8146 |
| 29 | 0.00134 | 1.6092 | 0.5634 | 1.9737 | 0.5605 | 1.7834 | 0.5701 | 0.7184 | 0.8003 |
| 25 | 0.00149 | 1.8864 | 0.4101 | 2.1431 | 0.4023 | 2.0937 | 0.3952 | 1.6436 | 0.7822 |
| 20 | 0.00160 | 1.6903 | 0.4629 | 2.2098 | 0.3857 | 2.8806 | 0.3328 | 1.7305 | 0.7909 |
| 3 | −0.00170 | 1.6805 | 0.4307 | 2.3105 | 0.3632 | 2.2308 | 0.3586 | 0.9236 | 0.8013 |
| 28 | 0.00199 | 2.0937 | 0.2956 | 2.4208 | 0.2924 | 2.6011 | 0.2393 | 0.9937 | 0.8028 |
| 24 | 0.00285 | 14.9721 | −13.2698 | 6.0912 | −4.3223 | 12.2426 | −13.9142 | 4.9251 | −2.9634 |
| 23 | 0.00546 | 14.1693 | −13.9601 | 12.9411 | −9.3762 | 13.9031 | −12.4881 | 10.4623 | −8.3092 |
| 26 | 0.00645 | 13.8233 | −12.3302 | 6.0265 | −4.9808 | 11.7868 | −10.6984 | 4.8521 | −2.8341 |
| 1 | −0.00922 | 4.2475 | −2.9804 | 2.2928 | −2.4636 | 6.2099 | −4.0928 | 2.2947 | −0.3525 |
| 21 | 0.01719 | 11.9236 | −9.5725 | 8.0231 | −5.9467 | 12.9325 | −11.3207 | 6.6943 | −3.9408 |
| 22 | 0.02153 | 14.9261 | −10.7363 | 12.1099 | −9.3307 | 15.9222 | −13.2903 | 9.2362 | −7.8460 |
| Scheme ID | Gamma (Γ) | PFM | BPANN | SVM (LKF) | SVM (RBF) | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | ||
| 19 | −0.00006 | 2.3916 | −0.5409 | 2.2597 | −0.3755 | 3.4417 | −2.191 | 1.4612 | 0.4248 |
| 16 | −0.00014 | 3.6501 | −2.5891 | 2.5698 | −0.7791 | 3.4791 | −2.2608 | 1.4359 | 0.4446 |
| 17 | 0.00021 | 3.1715 | −1.7097 | 2.2831 | −0.4042 | 3.4125 | −2.1371 | 1.5822 | 0.3256 |
| 15 | 0.00031 | 3.7253 | −2.5912 | 2.4672 | −0.7923 | 3.7982 | −2.6952 | 1.5901 | 0.3083 |
| 27 | −0.00069 | 3.7526 | −2.6108 | 2.5094 | −0.8155 | 3.8023 | −2.7325 | 1.6433 | 0.2596 |
| 18 | 0.00091 | 3.7802 | −2.7941 | 2.6455 | −0.9406 | 3.9246 | −2.8244 | 1.7024 | 0.2319 |
| 14 | 0.00103 | 3.8204 | −2.7992 | 2.5123 | −0.8299 | 3.4819 | −2.4953 | 1.7293 | 0.2297 |
| 29 | 0.00134 | 3.8246 | −2.8456 | 2.5297 | −0.8482 | 4.1284 | −3.2349 | 1.9039 | 0.2006 |
| 25 | 0.00149 | 8.0644 | −10.936 | 7.6436 | −7.0354 | 9.423 | −10.843 | 4.6255 | −3.4251 |
| 20 | 0.00160 | 9.5036 | −9.4213 | 7.9928 | −8.3409 | 8.1567 | −9.6242 | 3.9288 | −2.8603 |
| 3 | −0.00170 | 4.8355 | −3.2194 | 2.4093 | −0.7021 | 3.6938 | −3.0365 | 2.0934 | 0.1353 |
| 28 | 0.00199 | 5.1032 | −4.9412 | 4.2356 | −3.9236 | 5.9435 | −6.0256 | 3.5647 | −2.0425 |
| 24 | 0.00285 | 30.8291 | −70.3527 | 24.821 | −50.3423 | 35.9801 | −102.8313 | 22.9564 | −41.9327 |
| 23 | 0.00546 | 34.9115 | −98.5744 | 30.5092 | −88.3257 | 33.4883 | −94.2952 | 33.4219 | −94.0942 |
| 26 | 0.00645 | 7.9212 | −7.2205 | 6.9023 | −6.8211 | 8.9346 | −9.9438 | 5.3196 | −5.9443 |
| 1 | −0.00922 | 4.2245 | −3.9231 | 2.5646 | −0.7924 | 3.7992 | −2.5871 | 2.0293 | 0.1212 |
| 21 | 0.01719 | 20.8431 | −40.5496 | 15.4925 | −24.9825 | 23.5794 | −46.9324 | 10.9577 | −13.9548 |
| 22 | 0.02153 | 31.2469 | −79.0362 | 20.9421 | −33.4924 | 29.91207 | −68.3629 | 17.9822 | −26.9293 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, J.; Li, C.; Liu, J.; Yu, F.; Cheng, S.; Zhao, N.; Wan Jaafar, W.Z. Groundwater Depth Prediction Using Data-Driven Models with the Assistance of Gamma Test. Sustainability 2016, 8, 1076. https://doi.org/10.3390/su8111076
Tian J, Li C, Liu J, Yu F, Cheng S, Zhao N, Wan Jaafar WZ. Groundwater Depth Prediction Using Data-Driven Models with the Assistance of Gamma Test. Sustainability. 2016; 8(11):1076. https://doi.org/10.3390/su8111076
Chicago/Turabian StyleTian, Jiyang, Chuanzhe Li, Jia Liu, Fuliang Yu, Shuanghu Cheng, Nana Zhao, and Wan Zurina Wan Jaafar. 2016. "Groundwater Depth Prediction Using Data-Driven Models with the Assistance of Gamma Test" Sustainability 8, no. 11: 1076. https://doi.org/10.3390/su8111076