1. Introduction
In this generation of information technology, the amount of available information is rapidly increasing. Information both becomes available on the Internet and spreads at considerable speeds, causing information overload. No one has time to read everything, but people often make decisions based on the degree of informational importance and critical information; thus, automatic summarization technology is becoming an indispensable method of addressing this problem.
Automatic summarization enables users to rapidly digest the essential information conveyed by single or multiple documents; this is indispensable for managing the rapidly growing amount of available textual information and multimedia. Automatic summarization can be divided into two categories: text and speech summarization [
1].
Text summaries can be either query-relevant or generic summaries. A query-relevant summary presents the contents of a document that are closely related to the initial search query. Creating a query-relevant summary essentially involves retrieving the query-relevant sentences or passages from a document, which is similar to the text retrieval process. Therefore, query-relevant summarization is often achieved by extending conventional IR technologies, and numerous text summarizers described in the literature fall into this category. By contrast, a generic summary provides an overview of the document contents. An effective generic summary should contain the main topics of the document and minimize redundancy. Because no query or topic is provided during the summarization process, developing a high-quality generic summarization method is challenging and objectively evaluating such methods is difficult [
2].
Speech summarization should distil vital information and remove redundant or incorrect information caused by recognition errors from spoken documents, thereby enabling users to efficiently review spoken documents and rapidly understand the content. It could also enhance the efficiency of numerous potential applications such as retrieving and mining large volumes of spoken documents. Speech styles exhibit distinct features and implications; however, these features lack obvious advantages and disadvantages, making it difficult to determine whether a speech style is effective. Previous studies on speech summarization have focused on the broadcast news [
3], meeting [
4,
5,
6], and conference lecture [
7] domains. Because the current study explored general lecture speech, no suitable features were obtained from previous research; therefore, experiments were conducted to determine which features are applicable to general lecture speech.
To address information overload in the general lecture speech domain, a RTSSLS system was proposed based on MEAD [
8,
9,
10,
11]. Because the features influence the RTSSLS performance level, a three-phase feature selection process can facilitate the determination of suitable features in this domain. A weighted average was used to improve the performance level of the RTSSLS, because each feature of the system yields distinct implications.
The remainder of this paper is organized as follows. The research background and related work including multiple document summarization and evaluation of automatic summary are presented in
Section 2. The RTSSLS design is introduced in
Section 3 and the experiment is discussed in
Section 4. Finally, the paper is concluded in
Section 5.
2. Research Background and Related Work
The RTSSLS provide the real-time summarization of speeches for the learning of sustainability. Required research background and relevant technology for this study are (1) corpus-based text summarization approaches; (2) multiple-document summarization; (3) evaluation of automatic summarization; and (4) learning of sustainability.
2.1. Corpus-Based Text Summarization Approach
Some corpus-based text summarization approaches were proposed to consider several features and to be combined with the techniques of machine learning. Edmundson proposed some features which included cue phrase, title and heading word, and sentence location for document summarizer [
12]. Kupiec
et al. used a Naïve Bayesian classifier and considered the features of sentence length, fixed-phrase, location, thematic word, and uppercase word to determine the score of a sentence [
13]. A text summarization was built by using a Naïve Bayesian classifier with the features of cue phrase, location, sentence length, thematic word, and title [
14]. Furthermore, Radev
et al. presented a multi-document summarizer which analyzed the topic of multi-document and considered the features of centrality, sentence position, and resemblance to the title [
15]. In summary, the important features for corpus-based text summarization approach are centrality, resemblance to the title, sentence length, term frequency, thematic words, and position. Although several features were proposed and analyzed, the combined features have not been investigated. Furthermore, some features (e.g., position) were given the absolute values to evaluate the scores of sentences in previous studies. This study will consider these features and design the combined features to improve the performance of text summarization.
2.2. Multiple-Document Summarization
A popular multiple-document summarization, MEAD, was designed and implemented to analyze the topic and calculate the scores of sentences from multiple documents for summarization [
15,
16,
17,
18]. The main steps of MEAD are illustrated in follows.
- (1)
Preprocess. This step retrieves the sentences from multiple documents and segments these sentences into individual words. Each sentence of document is given an identity for calculating the score of sentence in following steps.
- (2)
Feature Selection. Several features (e.g., centrality, sentence length, term frequency, etc.) are implemented and selected in this step. The sentences in corpus are analyzed in accordance with the selected features for contributing the scores of each sentence.
- (3)
Classifier. The classifier includes calculation method and the weight of each feature in this step. The weight of each feature can be trained by using statistical methods and machine learning methods. Then the scores of sentence are mainly computed in accordance with the weight of each feature.
- (4)
Re-ranker. The classifier is only carried out in accordance with the score of sentence similarity calculation, so it makes the problem that may exist the high similarity between sentences, especially in multi-document summarization. Therefore, re-ranker mechanism is needed to re-calculate the scores of sentences with syntactic similarity for redundancy reduction.
- (5)
Summarization. Summarization can retrieve and recombine words and phrases in the original document according to the order of the sentences by Re-ranker sorting
- (6)
Evaluation. Several indices including recall, precision, F-Measure, and accuracy can be designed and implemented to measure the performance of text summarization system.
Although MEAD was a good multiple-document summarization, MEAD only considered one phase. MEAD cannot adopt the combined features to calculate the scores of sentences. Therefore, this study will propose a three-phase real-time speech summarizer system based on MEAD for learning of sustainability and adopt the practical results to evaluate the performance of the proposed system.
2.3. Evaluation of Automatic Summary
In recent years, different summarizers and features have been proposed and designed to improve the quality of multiple-document summarization. However, there is still a lack of fair and objective way to evaluate the quality of summaries. The evaluation methods can be mainly grouped into two categories: (1) subjective evaluation and (2) objective evaluation [
19,
20,
21].
For subjective evaluation methods, the summaries can be judged and evaluated by human arbitrariness. The rules of subjective evaluation method involve the following factors: (1) the summary is match for the main information of documents; (2) the summary is covered with the main information of documents; (3) the summary represents the main information of documents; (4) The summary is comprehensive and fluent.
For objective evaluation methods, several evaluators and indices are used simultaneously for the improvement of confidence and objectivity. The popular evaluators and indices include the recall, precision, F-Measure, and accuracy [
22,
23,
24] which are considered in this study for the evaluation of RTSSLS.
2.4. Learning of Sustainability
In recent years, some approaches used information techniques have been investigated for learning of sustainability. For instance, Zhan
el al. proposed and designed the Massive Open Online Courses (MOOCs) for sustainability education. The study indicated the online discussion and lecture video were more popular in the MOOCs, and 41.5% of these MOOCs had subtitles for videos in experimental environment. The experimental results illustrated the subtitles and transcription of MOOC documents were important tool for the improvement of learning efficiency [
25]. Furthermore, Knowlton
et al. proposed and designed the web-based interactions for teaching interdisciplinary sustainability science teamwork skills to graduate students. The experimental results indicated the students preferred more time to learn each other’s disciplines and developed their own interdisciplinary research questions [
26]. Therefore, a real-time speech summarizer can support to analyze the online discussion and lecture video and to generate the text summaries for user references and the improvement of learning efficiency.
3. The Design and Implementation of Real-Time Speech Summarizer System for the Learning of Sustainability
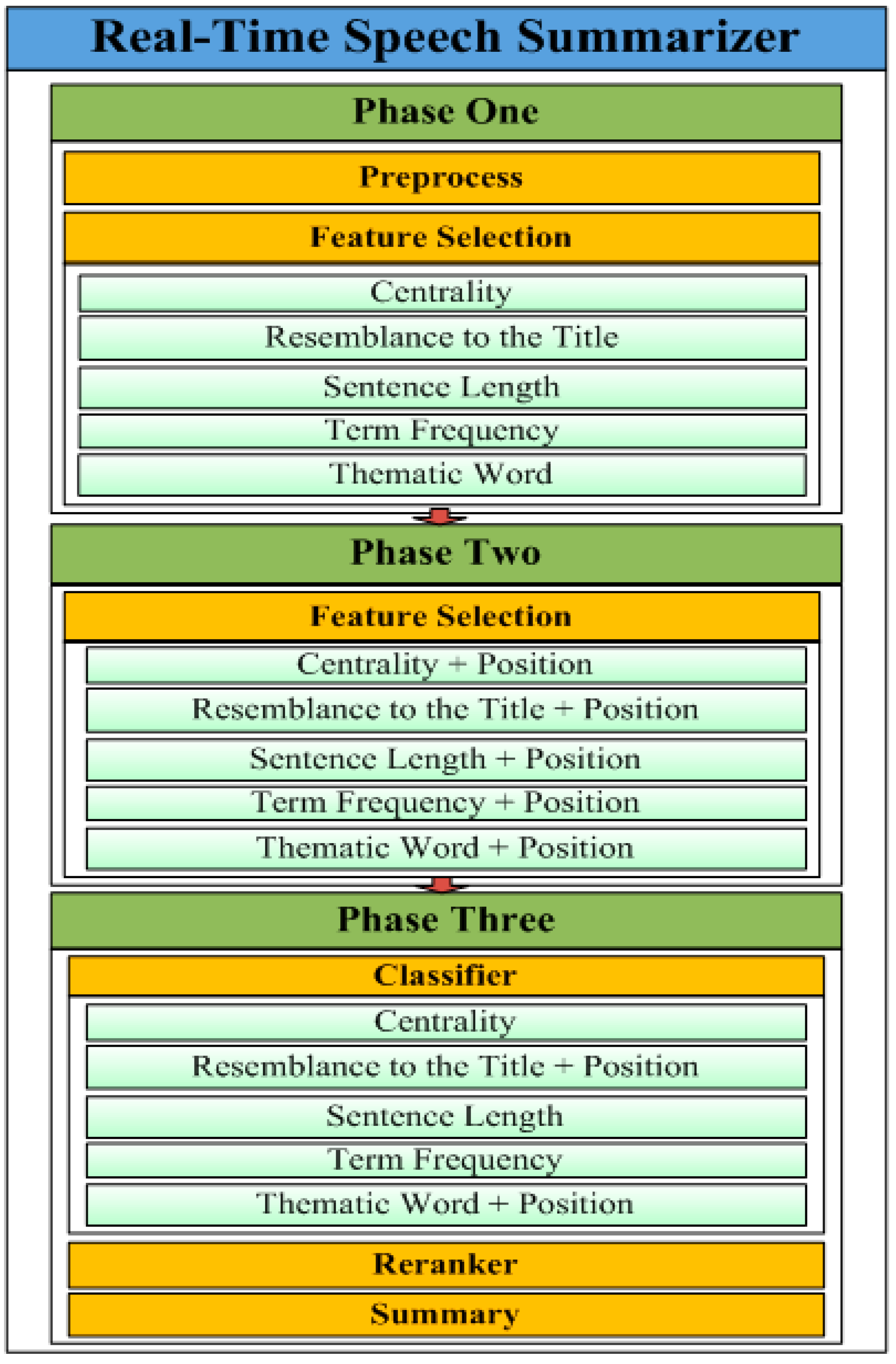
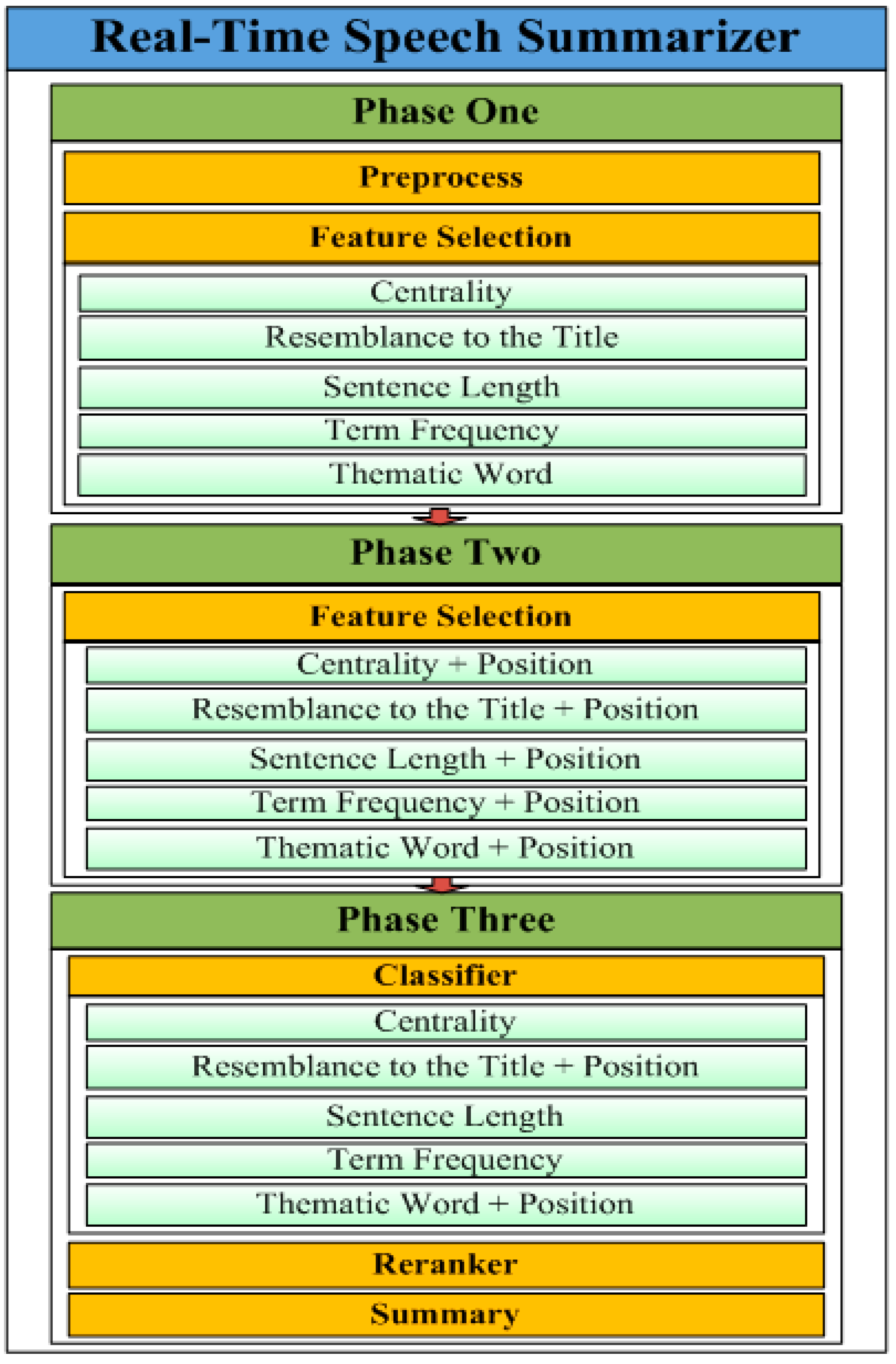
In this section, a three-phase RTSSLS is proposed, comprising preprocessing, feature selection, classification, re-ranking, and summary functions (
Figure 1). In the proposed RTSSLS, preprocessing produces the speech documents. Subsequently, in Phase One, feature selection is used to consider several independent (e.g., centrality, resemblance to the title, sentence length, term frequency, and thematic words) and dependent (
i.e., position) features; these features were combined in Phase Two. In Phase Three, the centrality, sentence length, and term frequency of the independent features and position of the dependent features were combined with the resemblance to the title, and thematic words were chosen to determine the feature scores.
Table 1 lists the parameters and descriptions of these features.
Figure 1.
The architecture of real-time speech summarizer system.
Figure 1.
The architecture of real-time speech summarizer system.
Table 1.
Parameters of Feature Description.
Table 1.
Parameters of Feature Description.
| Parameter | Description |
|---|
| D | a document |
| n | the total sentences of document D |
| the
is the i-th sentence in document D |
| the word set of sentence
in document D |
| T | the word set of the title in document D |
| the total words of the sentence
in document D |
| the j-th word of sentence
in document D |
| the frequency of
in document D |
| H | the word set of the top frequency words in document D |
| I | the total sentences in summary of document D |
3.1. Phase One
In this phase, the speech documents were preceded and the individual independent feature-scores were calculated.
3.1.1. Preprocessing
The speech documents and sentences were numbered, and common morphological words, flexional word endings, and stop words were removed.
3.1.2. Feature Selection–Independent Features
During the feature selection process, the RTSSLS was used to calculate the independent feature scores for centrality, the resemblance to the title, sentence length, term frequency, and thematic words. The detailed phases and definitions of each feature are described as follows.
(1)—Centrality
Centrality is the similarity of a sentence to other sentences in a document. The importance of a sentence depends on whether it represents the key ideas of the document. The centrality value is measured based on the degree to which the words in a sentence overlap the other words. For a sentence
, this feature-score is defined as follows.
(2)—Resemblance to the Title
The document title typically represents the primary points of a document. If a sentence is similar to the title, it is typically critical. The resemblance to the title feature is used to calculate the similarity of each sentence to the title. Therefore, the more words in a sentence that overlap those in the title, the more vital that sentence is in the document. For a sentence
, this feature-score is defined as follows:
(3)—Sentence Length
Long sentences commonly present more information than do short sentences; thus, sentence length affects the amount of information in a sentence. For a sentence
, this feature-score is defined as follows.
(4)—Term Frequency
The frequency of a word in a document, excluding stop words, often demonstrates the importance of a word in a document. This is calculated as the sum of word frequency and adjusted based on sentence length. For a sentence
, this feature-score is defined as follows.
(5)—Thematic Words
The words that most frequently occur in a document are thematic words. They are measured by comparing the number of words that overlap in a sentence to the thematic words. For a sentence
, this feature-score is defined as follows.
3.2. Phase Two
In this phase, the feature-scores were calculated for the dependent feature (position) and combined with the independent features (centrality, resemblance to the title, sentence length, term frequency, and thematic words). The traditional position was ignored because the relationships among paragraphs could not be determined; therefore, the modified position feature was considered to improve the accuracy of the proposed method.
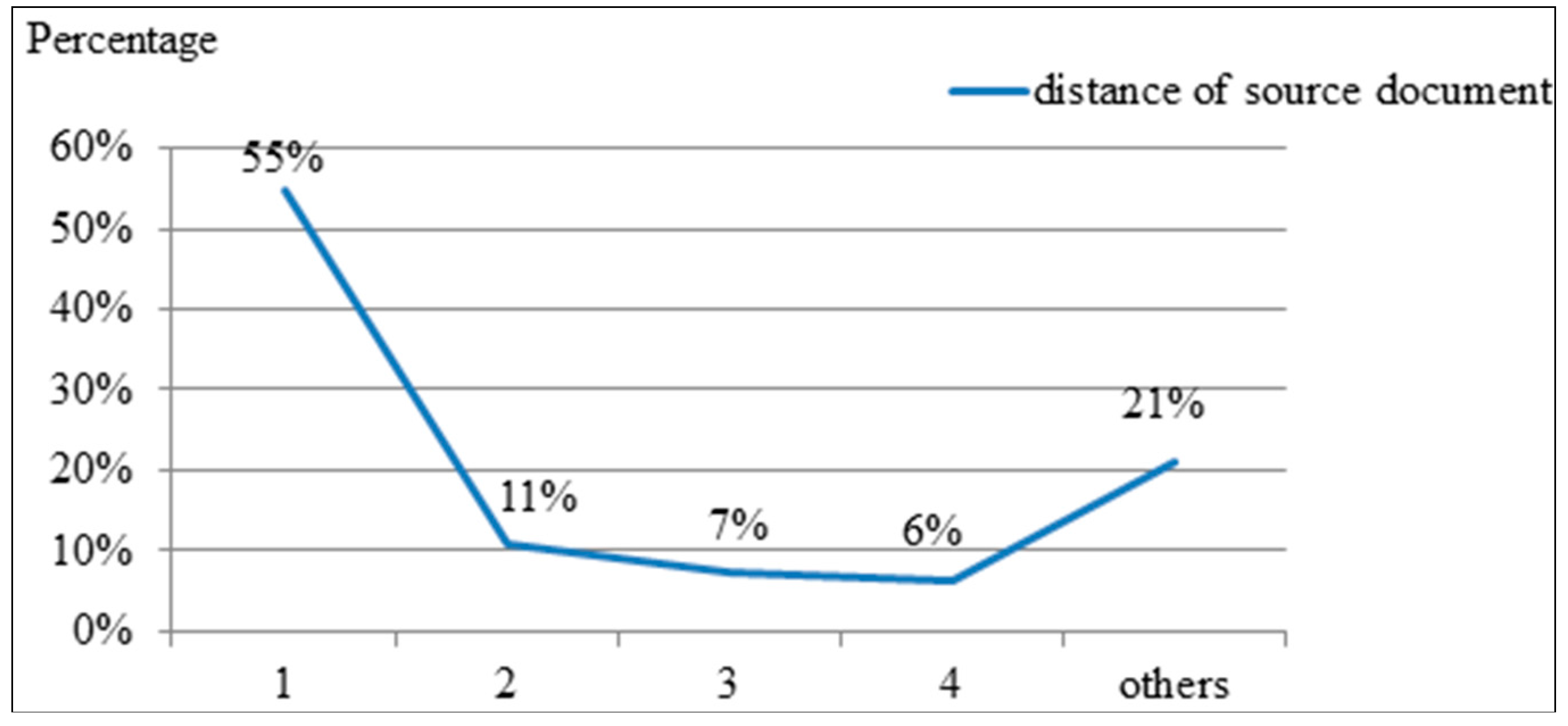
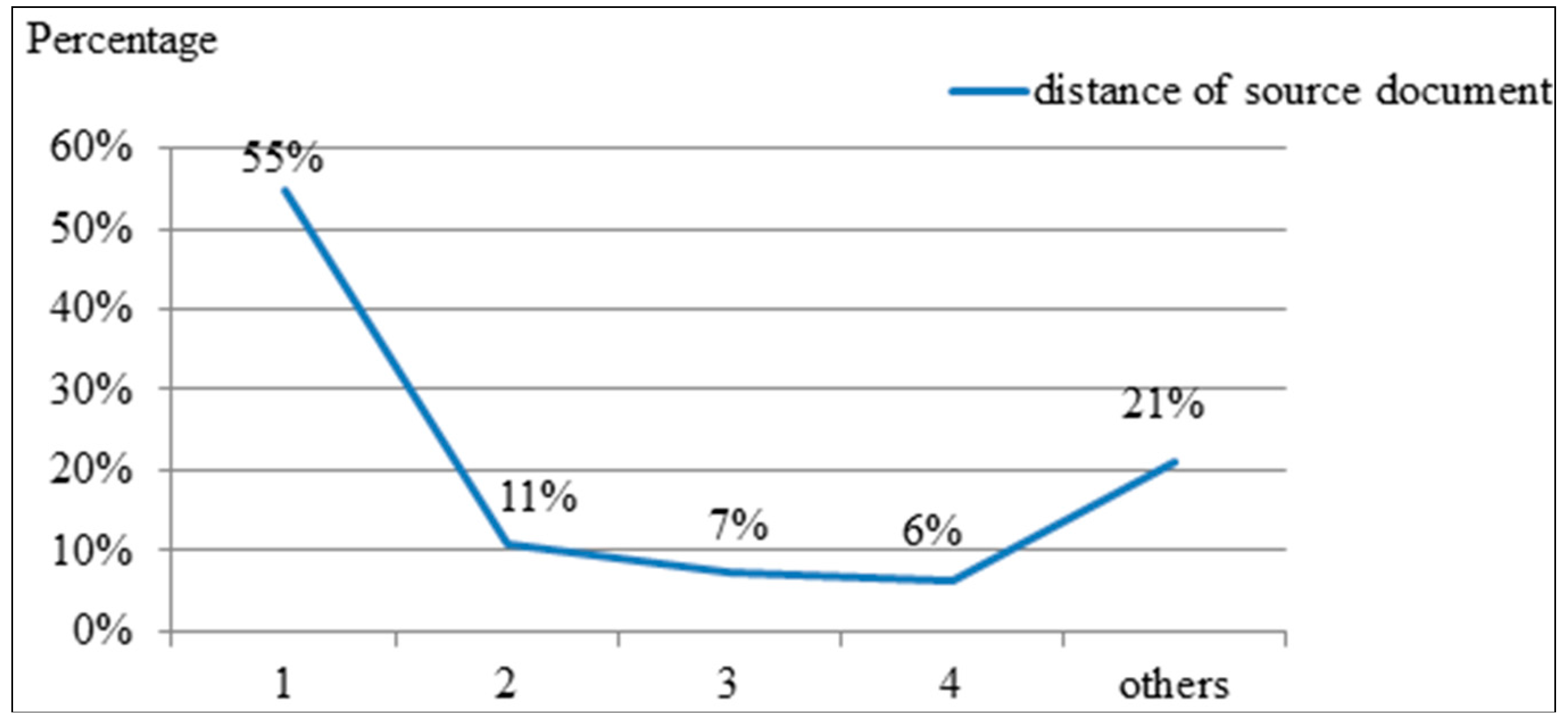
Figure 2 shows the distance of the sentences in the set of expert summaries mapping the positions of the source documents. Regarding the source documents, the x-axis represents the position distance of one summarized sentence to the subsequent summarized sentence. The y-axis represents the percentage of the sentence distance (1–4) among all sentences (
n). Position Distance 1 was 55%, indicating that the summary sentences were often sentence next to sentence in the source document. Position Distance 2 was 11%, indicating that the summary sentences were sometimes sentence spaced one sentence. Position Distance 3 was 7% and Position Distance 4 was 6%. Of the expert summary sentences, 79% were under Position Distance 4. The expert summary sentences were typically nearby sentences; thus, combining the position and aforementioned features may improve the F-Measure value. The equation for determining the position with respect to other features is defined as follows.
Figure 2.
Sentences of Experts’ Summary Mapping to the Distance of Source Documents.
Figure 2.
Sentences of Experts’ Summary Mapping to the Distance of Source Documents.
–PositionPx
An analysis indicated that more than half the sentences in the summary were nearby sentences in the source documents. The position was measured by adjusting the feature-score calculated in Phase One based on the close two summary picked sentences feature-scores. This feature must be applied in combination with other features. Only position is useful. For a sentence
, this feature-score is defined as follows:
3.3. Phase Three
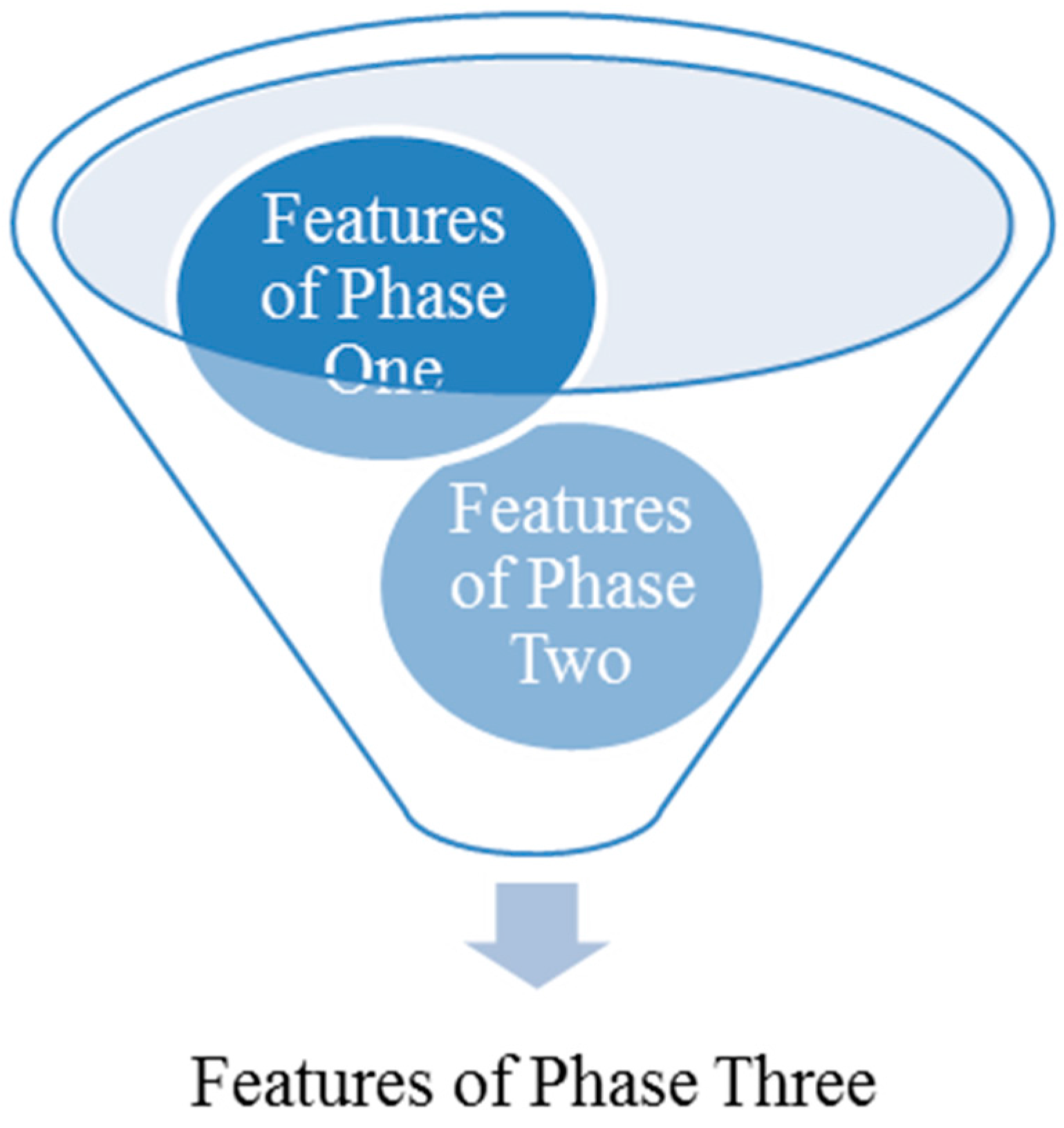
In this phase, the classification function of the RTSSLS was used to compare the five feature-scores from Phases One and Two, yielding five optimal features that exhibited differing weights to calculate the weighted average function scores. The Re-ranker function was used to pick up sentences with score-function, and Summary was used to get the picked sentences with source document order.
3.3.1. Classifier
The feature scores generated in Phases One and Two were compared (
Figure 3), the average F-Measure values of the features were applied to the present weights of the features, and the weighted-average score function yielded the score of each sentence (
Figure 4).
Figure 3.
Feature Comparison.
Figure 3.
Feature Comparison.
Figure 4.
Weight Comparison.
Figure 4.
Weight Comparison.
3.3.2. Feature Weight and Weighted Average
The importance of each feature is distinct and should be considered as such. Because the F-Measure of each feature demonstrates the feature priority, which can facilitate the determination of the weight, the average feature F-Measure was applied to determine the feature weight.
The score-function (
i.e., the feature scores for centrality, resemblance to the title with position, sentence length, term frequency, and thematic words with position) was trained to yield a suitable combination of feature weights. Each feature exhibits a distinct weight based on its importance level; thus, five features were combined with distinct weights into Equation (7) for adjustment. For a sentence
, the weighted score function in Equation (7) was defined to integrate all of the feature scores, where
indicates the weight of each feature.
3.3.3. Re-Ranker and Summary
The sentences were ranked based on the score function and extracted using a compression ratio of −15%. The compression ratio was determined based on the least percentage of experts summarize from documents in the training data. The extracted sentences were mapped, permuted, and combined with numbered sentences during preprocessing to generate a summary for users to read.
3.4. Discussions
Combining features, such as centrality, resemblance to the title with position, sentence length, term frequency, and thematic word with position, enables general lecture speeches to be summarized and is essential to maintaining an effective summarization performance level. Using an RTSSLS can enable users to acquire key speech information. RTSSLS is suitable for generating general lecture speech digests and can be used to acquire key information from lecture speech; however, the proposed system focused on general lecture speech and may not be applicable in summarizing conference speech information.
4. Experimental Results and Discussions
In this section, the experimental environment is designed and presented to evaluate the proposed RTSSLS system. The analyses of classifiers, the weight of each feature, and indices are illustrated in following subsections.
4.1. Experimental Environment
In experimental environment, 15 speeches from “Technology, Entertainment and Design (TED)” are selected as corpus, and the length of each selected speech is longer than 15 minutes. For evaluation and analyses, the leave-one-out method [
27] is applied to evaluate the performance of RTSSLS. First, the one speech of corpus is selected as the testing dataset, and the remaining 14 speeches of corpus are selected as the training dataset. Then 15 runs are designed for testing each speech. Finally, the experimental results of each run can be evaluated for the analysis indices which include recall, precision, F-Measure, and accuracy. The steps of evaluation procedure are presented as follows.
- (1)
One speech which has not yet been selected is randomly selected as testing data, and the other 14 speeches are selected as training data.
- (2)
The selected training data is adopted to train the proposed RTSSLS system in training stage, and the selected testing data is used to evaluate the proposed system after training stage.
- (3)
Each round includes Steps (1) and (2), and 15 rounds are performed in experimental environment.
4.2. Analyses of Classifiers
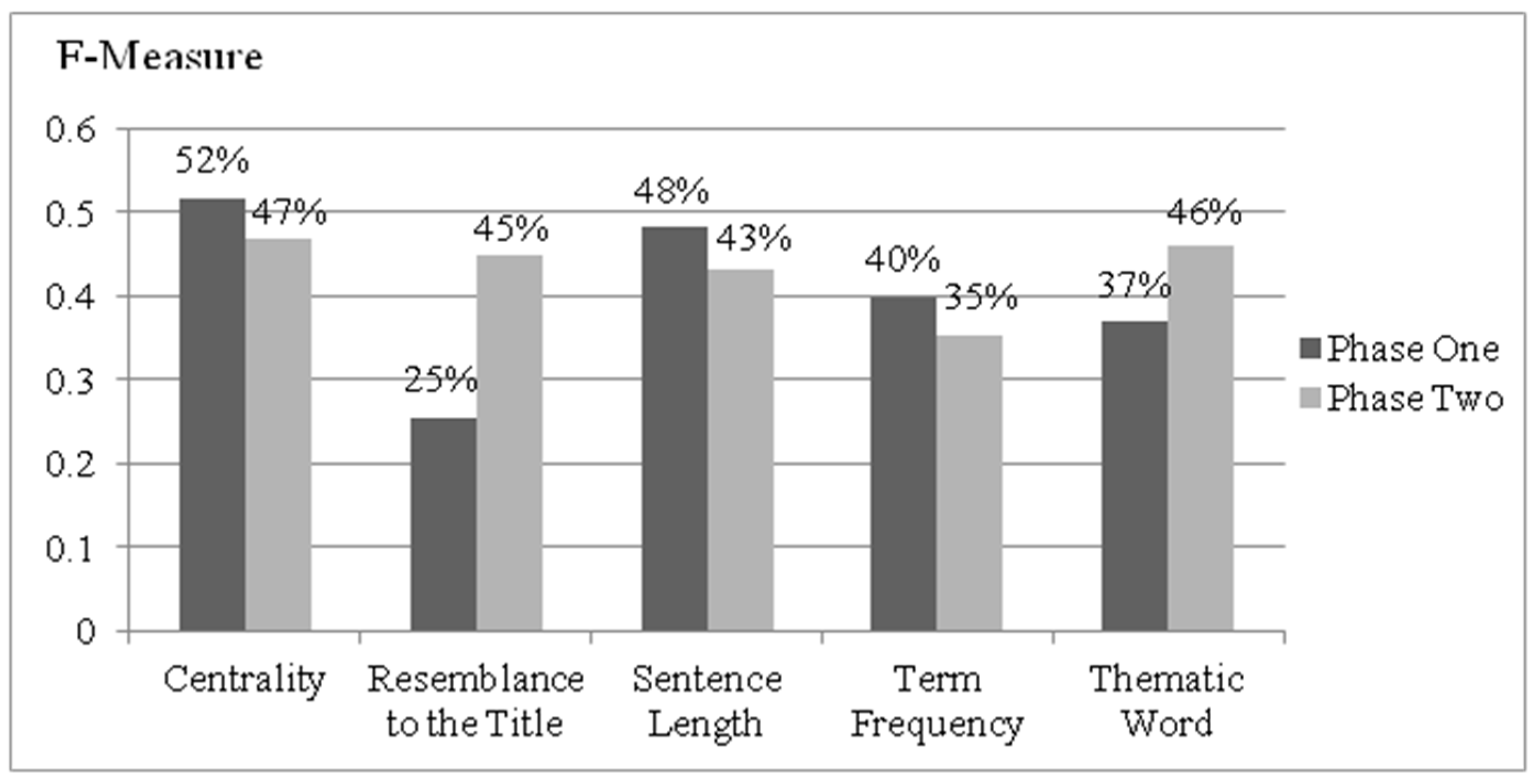
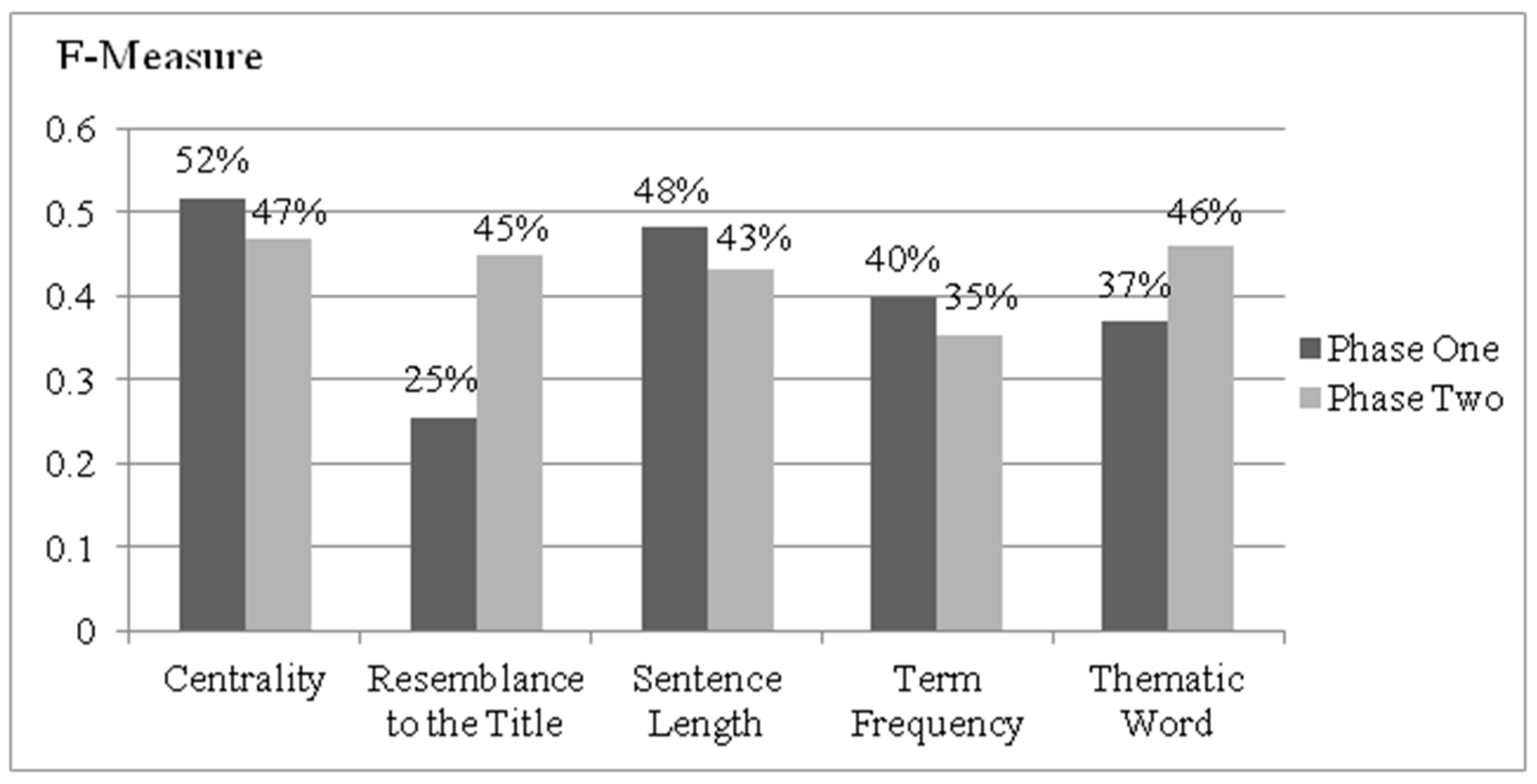
Figure 5 shows the F-Measure values of each feature in Phase 1 and Phase 2. The comparisons show that the F-Measure scores of “resemblance to the title” and “thematic word” are higher after combining with the feature of position. The F-Measure value of “resemblance to the title” with position in Phase 2 is 20% better than it in Phase 1; The F-Measure score of “thematic word” with position in Phase 2 is 9% better than it in Phase 1. Therefore, the features of “centrality”, “sentence length”, and “term frequency” are considered without the feature of “position”, and the features of “resemblance to the title” and “thematic word” are combined with the feature of “position”.
Figure 5.
Sentences of Experts’ Summary Mapping to the Distance of Source Documents.
Figure 5.
Sentences of Experts’ Summary Mapping to the Distance of Source Documents.
4.3. Analyses of Weights
In this subsection, the weight of each feature is determined by the relative mean F-Measure scores from Phase 1 and Phase 2. In accordance with the experimental results, the mean F-Measure scores of
F1,
F3, and
F4 were 52%, 48%, and 40% in Phase 1; the mean F-Measure scores of
P2 and
P5 were 45% and 46% in Phase 2, respectively. For instance, the feature of “centrality” with the highest F-Measure score was the most important feature to analyze the relationship between words and sentences and to retrieve the key sentences, so the weight of “centrality” shall be higher. Although the feature of “term frequency” can analyze the term frequency and retrieve the important words, the F-Measure score of this feature was lower. The weight of “term frequency” may be lower. Therefore, the weight of each feature can be determined by the relative mean F-Measure scores in
Table 2.
Table 2.
Weight of Each Feature.
Table 2.
Weight of Each Feature.
| Feature | | | | | |
| Weight | | | | | |
| 22.45% | 19.42% | 20.89% | 17.29% | 19.95% |
4.4. Comparisons of Simple-Average Method and Weighted-Average Method
In this subsection, the F-Measure scores of using simple-average method and using weighted-average method are evaluated and compared for the design of RTSSLS.
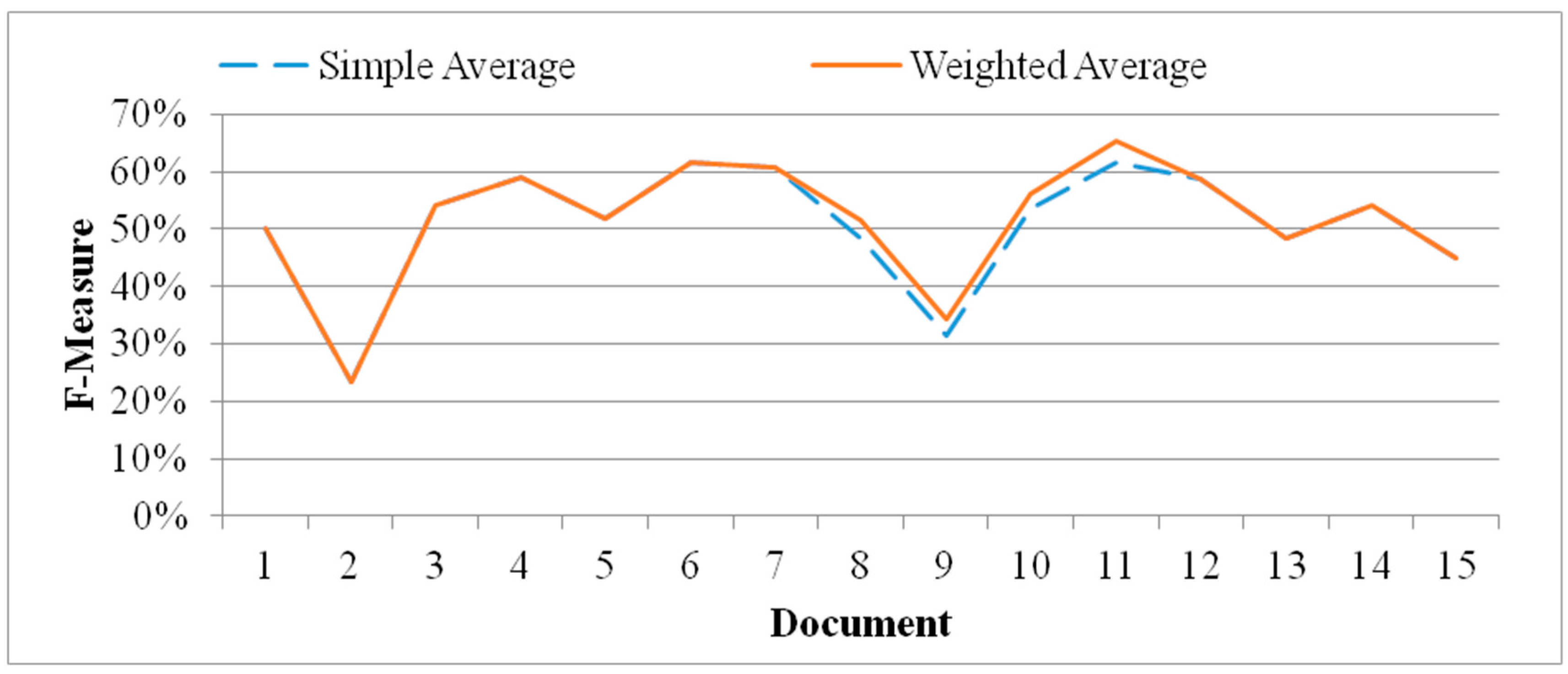
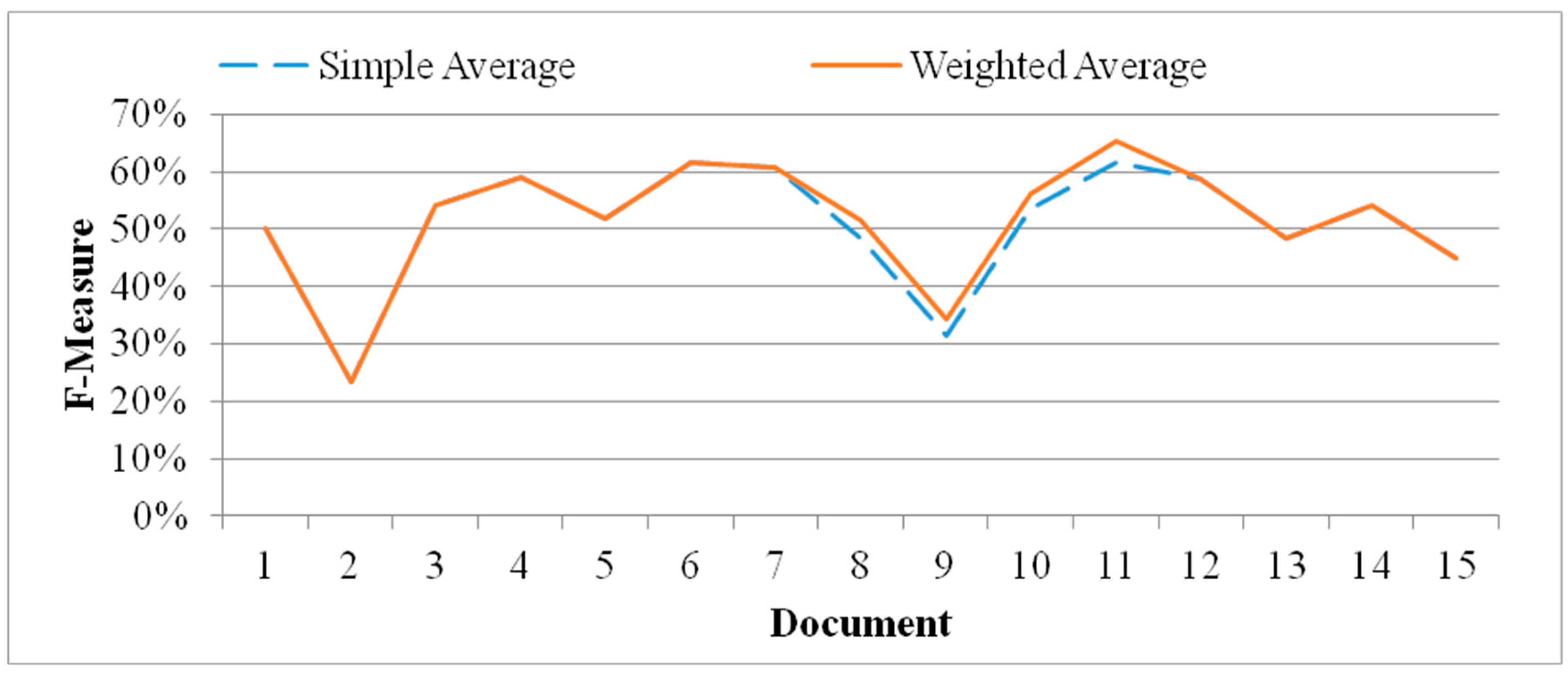
Figure 6 shows the comparison results and illustrates that the mean F-Measure scores of using simple-average method and using weighted-average method were 51% and 52%, respectively. Furthermore, weighted-average method is better than simple-average method for six documents which were enumerated from 7 to 12. Therefore, the performance of F-Measure score can be improved 1% by using weighted-average method which is suitable for RTSSLS.
Figure 6.
The Comparisons of Simple-average Method and Weighted-average Method.
Figure 6.
The Comparisons of Simple-average Method and Weighted-average Method.
4.5. Analyses of Indices
This subsection illustrates the results of each analysis index (
i.e., recall, precision, F-Measure, and accuracy).
Table 3 shows the experimental results, in which the macro-average recall rate, macro-average precision rate, and macro-average F-Measure scores are 52%. The macro-average accuracy score was 70%. Furthermore, the micro-average recall rate, micro-average precision rate, and micro-average F-Measure scores were 50%. The micro-average accuracy score was 73%. Regarding extraction, the F-Measure value plays a crucial role, ensuring a superior macro-average F-Measure score of 52%. Regarding the micro-average, the accuracy of 73% could be improved. In addition, in the training set,
used the same number as
did, yielding identical denominators for the recall and precision rates. Therefore, the recall rate, precision rate, and F-Measure values were the same.
Table 3.
Results of Experiment.
Table 3.
Results of Experiment.
| Experiment | Recall | Precision | F-Measure | Accuracy |
|---|
| Macro-average | 52% | 52% | 52% | 70% |
| Micro-average | 50% | 50% | 50% | 73% |
5. Conclusions and Future Work
Given the rapid increase in available video and audio information, speech summarization has become increasingly vital. Previous research in this domain has typically focused on broadcasts and news. Unfortunately, previous automatic summarization methods may not be applicable to other speech domains. Therefore, this study explored the lecture speech domain.
The features used in previous research were analyzed and suitable features were selected following experimentation; subsequently, a RTSSLS was proposed based on a three-phase feature selection method. Phase One involved calculating the independent feature scores; Phase Two involved combining the dependent and independent feature scores; and Phase Three involved comparing these feature scores to obtain the weighted averages of the function scores, determine the highest-scoring sentence, and provide a summary.
Regarding the experiment, the independent (i.e., centrality, resemblance to the title, sentence length, term frequency, and thematic words) and dependent (i.e., position) features were combined with the resemblance to the title, and thematic words were subsequently chosen. The weighted average based on the F-Measure facilitated the enhancement of the performance level of the RTSSLS. The accuracies of macro-average and micro-average for the RTSSLS were 70% and 73%, respectively.
Combining features, such as centrality, resemblance to the title with position, sentence length, term frequency, and thematic words with position, enables general lecture speeches to be summarized and is essential to maintaining an effective summarization performance level. Furthermore, using a RTSSLS can enable users to acquire key speech information for the learning of sustainability.
However, this study only selected 15 speeches from TED in experimental environment. In the future, more speeches from a variety of sources can be considered and analyzed to evaluate the each analysis index of real-time speech summarizer. Furthermore, more users can be invited to participate to use the proposed RTSSLS system, and empirical approach can be applied to evaluate the learning efficiency and outcome.
Acknowledgments
The research is supported by the National Science Council of Taiwan under the grant Nos. NSC 102-2622-H-009-002-CC3, NSC 102-2410-H146-002-MY2, NSC 102-2410-H-009-052-MY3, and MOST 103-2622-H-009-001-CC3.
Author Contributions
Hsiu-Wen Wang and Ding-Yuan Cheng proposed and designed the real-time speech summarizer system for the learning of sustainability. Chi-Hua Chen performed research and designed the algorithms for speech summarization. Yu-Rou Wu collected and analysed the data, and wrote the first draft. Chi-Chun Lo and Hui-Fei Lin reported research results and wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Furui, S. Recent advances in automatic speech summarization. In Proceedings of the 8th RIAO Conference on Large Scale Semantic Access to Content (Text, Image, Video, and Sound), Paris, France, 30 May–1 June 2007.
- Gong, Y.; Liu, X. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001.
- Hori, C.; Furui, S.; Malkin, R.; Yu, H.; Waibel, A. Automatic speech summarization applied to English broadcast news speech. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 22–25 September 2002.
- Liu, F.; Liu, Y. Using spoken utterance compression for meeting summarization: A pilot study. In Proceedings of the 2010 IEEE Spoken Language Technology Workshop, Berkeley, CA, USA, 12–15 December 2010.
- Yeh, J.Y.; Ke, H.R.; Yang, W.P. iSpreadRank: Ranking sentences for extraction-based summarization using feature weight propagation in the sentence similarity network. Expert Syst. Appl. 2008, 35, 1451–1462. [Google Scholar] [CrossRef]
- Lee, J.K.; Song, H.J.; Park, S.B. Two-step sentence extraction for summarization of meeting minutes. In Proceedings of the 2011 Eighth International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 11–13 April 2011.
- Zhang, J.J.; Chan, H.Y.; Fung, P. Improving lecture speech summarization using rhetorical information. In Proceedings of the IEEE Workshop on Automatic Speech Recognition & Understanding, Kyoto, Japan, 9–13 December 2007.
- Reeve, L.H.; Han, H.; Brooks, A.D. The use of domain-specific concepts in biomedical text summarization. Inf. Process. Manag. 2007, 43, 1765–1776. [Google Scholar] [CrossRef]
- Lo, C.C.; Kuo, T.H.; Kung, H.Y.; Kao, H.T.; Chen, C.H.; Wu, C.I.; Cheng, D.Y. Mobile merchandise evaluation service using novel information retrieval and image recognition technology. Comput. Commun. 2011, 34, 120–128. [Google Scholar] [CrossRef]
- Lo, C.C.; Chen, C.H.; Cheng, D.Y.; Kung, H.Y. Ubiquitous healthcare service system with context-awareness capability: Design and implementation. Expert Syst. Appl. 2011, 38, 4416–4436. [Google Scholar] [CrossRef]
- Lin, H.F.; Chen, C.H. An intelligent embedded marketing service system based on TV apps: Design and implementation through product placement in idol dramas. Expert Syst. Appl. 2013, 40, 4127–4136. [Google Scholar] [CrossRef]
- Edmundson, H.P. New methods in automatic extracting. J. ACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Kupiec, J.; Pedersen, J.; Chen, F. A trainable document summarizer. In Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 9–13 July 1995.
- Teufel, S.; Moens, M. Sentence extraction as a classification task. In Advances in Automated Text Summarization; Mani, I., Maybury, M., Eds.; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Radev, D.R.; Jing, H.; Styś, M.; Tam, D. Centroid-based summarization of multiple documents. Inf. Process. Manag. 2004, 40, 919–938. [Google Scholar] [CrossRef]
- Radev, D.; Otterbacher, J.; Winkel, M.; Blair-Goldensohn, S. NewsInEssence: Summarizing online news topics. Commun. ACM 2005, 48, 95–98. [Google Scholar] [CrossRef]
- Lam, W.; Chan, K.; Radev, D.; Saggion, H.; Teufel, S. Context-based generic cross-lingual retrieval of documents and automated summaries. J. Am. Soc. Inf. Sci. Technol. 2005, 56, 129–139. [Google Scholar] [CrossRef]
- Otterbacher, J.; Radev, D.; Kareem, O. Hierarchical summarization for delivering information to mobile devices. Inf. Process. Manag. 2008, 44, 931–947. [Google Scholar] [CrossRef]
- Furui, S.; Kikuchi, T.; Shinnaka, Y.; Hori, C. Speech-to-text and speech-to-speech summarization of spontaneous speech. IEEE Trans. Speech Audio Process. 2004, 12, 401–408. [Google Scholar] [CrossRef]
- Chen, F.; de Vleeschouwer, C.; Cavallaro, A. Resource allocation for personalized video summarization. IEEE Trans. Multimed. 2014, 16, 455–469. [Google Scholar] [CrossRef]
- Ejaz, N.; Tariq, T.B.; Baik, S.W. Adaptive key frame extraction for video summarization using an aggregation mechanism. J. Vis. Commun. Image Represent. 2012, 23, 1031–1040. [Google Scholar] [CrossRef]
- Zhong, N.; Li, Y.; Wu, S.T. Effective pattern discovery for text mining. IEEE Trans. Knowl. Data Eng. 2011, 24, 30–44. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.F.; Chen, C.H. Design and application of augmented reality query-answering system in mobile phone information navigation. Expert Syst. Appl. 2015, 42, 810–820. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. Performance evaluation methodology for historical document image binarization. IEEE Trans. Image Process. 2013, 22, 595–609. [Google Scholar] [CrossRef] [PubMed]
- Zhan, Z.; Fong, P.S.W.; Mei, H.; Chang, X.; Liang, T.; Ma, Z. Sustainability education in massive open online courses: A content analysis approach. Sustainability 2015, 7, 2274–2300. [Google Scholar] [CrossRef]
- Knowlton, J.L.; Halvorsen, K.E.; Handler, R.M.; O’Rourke, M. Teaching interdisciplinary sustainability science teamwork skills to graduate students using in-person and web-based interactions. Sustainability 2014, 3, 9428–9440. [Google Scholar] [CrossRef]
- Weber, P.; Bordbar, B.; Tino, P. A framework for the analysis of process mining algorithms. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 303–317. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}