Session-Based Recommender System for Sustainable Digital Marketing


1
Graduate School of Information, Yonsei University, 50 Yonsei-ro, Seodaemun-Gu, Seoul 03722, Korea
2
Department of Management Information Systems, KeiMyung University, 1095 Dalgubeol-daero, Dalseo-Gu, Daegu 42061, Korea
*
Author to whom correspondence should be addressed.
Sustainability 2019, 11(12), 3336; https://doi.org/10.3390/su11123336
Submission received: 10 April 2019
/
Revised: 6 June 2019
/
Accepted: 7 June 2019
/
Published: 17 June 2019
(This article belongs to the Special Issue Digital Marketing for Sustainable Growth: Business Models and Online Campaigns using Sustainable Strategies)
Abstract
:Many companies operate e-commerce websites to sell fashion products. Some customers want to buy products with intention of sustainability and therefore the companies need to suggest appropriate fashion products to those customers. Recommender systems are key applications in these sustainable digital marketing strategies and high performance is the most necessary factor. This research aims to improve recommendation systems’ performance by considering item session and attribute session information. We suggest the Item Session-Based Recommender (ISBR) and the Attribute Session-Based Recommenders (ASBRs) that use item and attribute session data independently, and then we suggest the Feature-Weighted Session-Based Recommenders (FWSBRs) that combine multiple ASBRs with various feature weighting schemes. Our experimental results show that FWSBR with chi-square feature weighting scheme outperforms ISBR, ASBRs, and Collaborative Filtering Recommender (CFR). In addition, it is notable that FWSBRs overcome the cold-start item problem, one significant limitation of CFR and ISBR, without losing performance.
1. Introduction
Modern companies are interested in sustainable marketing, where they aim to propose value to the consumer and satisfy the customer’s needs in a sustainable way [1]. Providing appropriate products and services that meet customers’ needs and wants is one of major factors that enable sustainable marketing. With digital technology, modern customers can access various product and service information on the web and usually experience difficulty in choosing right products. Many web analytics studies have been conducted to address this problem in the digital marketing context [2,3]. In this sense, recommender systems are an important web analytic application for sustainable digital marketing, because they can propose products and services in a personalized manner satisfying individual customers’ sustainability preferences [4].
Recommender systems can be applied in many areas, including various products, books, news, etc. In this research, we propose recommender systems for fashion products, which might be closely related to sustainability needs, namely sustainable fashion [5]. Fashion products are a major category of products sold in online shopping malls. According to Statista, the worldwide revenue of the e-commerce fashion industry is expected to rise from $481.2 billion in 2018 to $712.9 billion by 2022 [6]. In online shopping malls, customers express their preferences implicitly and thus we do not know which customers have sustainable preferences. It is possible to achieve goals of sustainability marketing by developing recommender systems that perform accurately.
Recommender systems are broadly classified into two categories—Attribute-Based Recommenders (ABRs) and Behavior-Based Recommenders (BBRs). ABRs, such as Content-Based Recommenders (CBR) and Knowledge-Based Recommenders (KBR), use item attributes to create recommendation models. [7,8,9,10]. In general, fashion item attributes, such as brand, color, price, season and style, are important in fashion recommendation, because they significantly affect users’ preference. Fashion item attributes can be considered individually or collectively. Fashion item attributes can be created by manual tagging or by automated tagging extracted from images. Customer preference is expressed in text or in images and customer context also constitutes a part of attribute data [9,11,12,13,14].
On the other hand, BBRs, such as various Collaborative Filtering Recommenders (CFRs) [15,16], use user–item interactions when creating recommendation models. CFRs are categorized into Item-Based CFRs (IBCFRs) and User-Based CFRs (UBCFRs). IBCFRs pre-compute an item-to-item similarity matrix from available click data, where items that are often clicked in succession by the same user are regarded as similar. UBCFRs identify a set of similar users, where users who interact with items in succession are regarded as similar, and use the items they prefer to generate recommendations. By contrast, SBRs deal with scenarios in which the sequence of recent interactions of a user is relevant in inferring their current preferences for fashion items to provide higher quality recommendations [17]. In the case of BBRs, new users that have no behavioral data with items cannot receive recommendations for items and new items that have no behavioral data with the users cannot be recommended to the users. This problem is well-known problem in BBRs and known as the cold-start problem. Many studies have been conducted to find a solution for this problem [18,19,20,21,22,23].
It is desirable to use both item attributes and user behavior data for building recommendation models. There are many studies that consider these two types of information [24,25,26]. We propose hybrid recommender systems that use both item attributes and user–item interactions by adopting session-based recommenders (SBRs) approach. While SBRs such as Association Rules Recommenders (ARRs) only consider the order of user interactions, namely sessions, when recommending items, our proposed recommender systems consider the order of item attributes.
More specifically the study addresses the following research objects: First, we suggest two types of SBRs—the interaction session-based SBR (ISBR) and the attribute session-based SBRs (ASBRs). Then we evaluate whether these SBRs outperform CFR, a conventional interaction-based recommender. Since fashion items have multiple attributes, it is possible to create multiple ASBRs by using different attribute session data. Thus, we evaluate which ASBR performs the best among ASBRs. Second, we suggest various FWSBRs that use various feature weighting schemes. We then evaluate their performance and compare the best FWSBR with other recommenders like ISBR, CFR and individual ASBRs. Finally, we evaluate how well the best FWSBR suggests recommendation with the with cold-start items. The cold-start items have no interaction history in the dataset, so ISBR as well as BBRs cannot recommend them to users. However, since FWSBR only uses attributes of items to generate recommendations, it can be used to suggest the cold-start items to users. This research evaluates how FWSBR performs with the non-cold-start items.
2. Literature Review
2.1. Recommender Systems
Recommenders are broadly classified into two categories—ABRs and BBRs. In the literature, CBRs and CFRs are the most significant ABR and BBR respectively. CBRs use user and item attributes to recommend items and can recommend items without using interaction data between users and items. However, they cannot recommend items to users if there no users and item attributes and perform poorly if item attribute data is insufficient [27].
CFRs suggest items using the user’s interaction with items, rather than the attributes of the user or item [28]. CFRs have two major classes—User-Based CFRs and Item-Based CFRs. User-Based CFRs identify groups of users who have similar preferences for items, named ‘similar users’ and then recommendations are generated for the user using items preferred by the similar users. Item-Based CFRs determine similar items using user interactions with items. Item-Based CFRs recommend similar items precomputed in advance using interaction data when a user selects an item [29].
Although CFRs are successfully used in many situations, they cannot be used with new users and new items. If a user has no interactions with items, CFRs cannot recommend any items for this user; alternatively, if an item has not been interacted with by users, CFRs cannot recommend them to any user. This problem is called the cold-start problem. Usually this limitation of CFRs is addressed by considering content and developing hybrid recommender systems [18,19,22,30,31]. In addition, CFRs do not consider the order or sequence of user interactions. Although some temporal recommender systems include a time factor when suggesting items [32,33], they do not focus on sequential patterns.
2.2. Session-Based Recommender Systems
SBRs explicitly consider the order of user interactions, namely sessions, when recommending items. The Association Rules Recommender (ARR) is a representative approach among SBRs. Originally it was developed to discover user consumption patterns within a large transaction database regardless of the order of their appearance [34,35]. Later was extended to consider sequence patterns in the transactions [36,37,38]. In the ARR, the usefulness of a sequence pattern is usually assessed using measures such as support, confidence and lift. Each measure is defined as follows:
Since the sequence pattern is regarded as significant only if the conditional probability is greater than , the lift of the sequence pattern should be larger than 1 [39,40]. The ARR is easy to understand, such that it can be easily deployed in practice. The ARR has been used to find next webpage [41,42], next book [41], next mobile application [43] and next song [44]. However, similar to CFR, ARR cannot suggests recommendation with new items and new users, because the user and the item has no interaction related to them. This research proposes SBRs that use attribute session data and item session data to suggest recommendations. While item SBRs still encounter the cold-start problem similar to the CFR, the attribute SBRs can overcome the cold-start problem, which will be discussed in Section 5 in detail.
2.3. Feature Weighting
Users generally consider multiple attributes simultaneously with different importance when they interact with fashion items, so it is natural to consider different weights when we create recommendation models by combining different ASBRs. In order to find weights that reflect attribute importance, this research adopted the following wrapper feature weighting methods to evaluate the goodness of a selected feature subset [45]: chi-square score, PCA, gain ratio, RELIEF and SVM.
2.3.1. Chi-square score
This score utilizes the test of independence to assess whether the feature is independent of the class label [46]. Given a particular feature with class different feature values, the chi-square (CHI) score of that feature can be computed as:
where is the number of examples with the feature value given feature . In addition, , where is the number of examples with the feature value given feature , denotes the number of examples in class . A higher CHI score indicates that the feature is relatively more important [47].
2.3.2. PCA score
Principal Components Analysis (PCA) is a predominant linear dimensionality reduction technique. PCA seeks to map or embed examples from a high dimensional space to a low dimensional space, while keeping all the relevant linear structure intact. During feature reduction process, PCA calculates the contribution of the feature as follows:
where denote the entry of , the eigenvectors corresponding to the first m largest eigenvalues [48]. In PCA, principal components are linear combinations of existing features, where the weights used in the linear combination can be used to show the importance of attributes [49].
2.3.3. Gain Ratio
The information gain (IG) measure is used to select the best attribute at each node of the decision tree. Gain ratio (GR) enhances IG as it offers a normalized score of a feature’s contribution to an optimal information gain based classification decision [45]. Let be the probability that an arbitrary example in dataset belongs to class , estimated by . Expected information (entropy) needed to classify an example in is defined as:
Let it be assumed that D is divided by feature , which has values. Information needed to classify is defined as:
Thus, information gain (IG), which shows information gained by branching on feature , is defined as:
Since information gain is biased towards features with a large number of values, it is better to normalize to resolve this problem. Gain ratio is defined as:
where . Gain ratio is used as one of disparity measures and a high gain ratio for a selected feature implies that the feature will be useful for classification [45].
2.3.4. RELIEF
This algorithm is considered one of the most successful ones due to its simplicity and effectiveness [50]. RELIEF iteratively estimates feature scores according to their ability to discriminate between neighboring patterns. Specifically, it tries to find a good estimate of the following probability to assign as the weight for each feature .
where and are the nearest examples of in the same class and in class , respectively. Their sizes are and , respectively. is the ratio of examples in class [47]. RELIEF cannot not deal with categorical attributes. Therefore, we convert the categorical values into numerical values using dummy coding.
2.3.5. SVM
Unlike other feature selection algorithms, Support Vector Machines (SVM) is a wrapper feature selection method which uses the classifiers as a black box and the classifier performance as the objective function to evaluate the feature subset. We choose SVM as a representative wrapper feature selection method because it helps to avoid estimating the statistical distributions of different classes in hyper-dimensional feature space based on a margin maximization principle [51].
2.4. Sustainable Marketing and Recommenders for Fashion Products
Sustainable marketing aims to implement the concept of sustainability in marketing. Digital marketing is regarded as a key factor that can fill the gap between the behavior and beliefs of society and market regarding sustainability [52]. Recommender systems are major applications that support digital marketing via recommending products reflecting user preference. Recommenders for fashion products have been sought after to improve customer satisfaction [9,10,11,15,16,53,54,55,56,57,58]. The fashion product recommenders usually use interaction logs between users and products and visual features [8,15,16]. In relation to visual features, an interesting characteristic of fashion recommenders is that systems consider fashion coordination between multiple products whether it is based on interaction logs or visual features [7,8,9,15,59,60,61]. When choosing clothes, people consider various aesthetic factors such as color, type, material, style and season [60]. Shen et al. [10] suggest a scenario-oriented recommender that suggests recommendations by mapping users’ daily scenarios to fashion product attributes.
The collaborative filtering approach has been used for exploiting interaction logs [15,16,62]. However, most studies consider visual features of fashion products. Hu et al. [15] suggested a collaborative filtering recommendation that suggests multiple fashion items together, which implies that their system considers fashion coordination. He and McAuley [58] suggested a one-class collaborative filtering fashion recommender that combines images and user interaction to capture temporal drifts of fashion and personal preferences.
Recent studies in fashion recommendation employed deep learning techniques such as convolutional neural networks (CNN) in order to enhance feature processing. Yu et al. [60] introduced Brain-inspired Deep Networks (BDN), a deep CNN structure consisting of several parallel pathways and high level synthesis networks. They used this to extract the aesthetic features of clothing from images. Gu et al. [8] suggested a deep learning modeling algorithm, called Autoencoder, which differs from CNN and used it to extract features from fashion product images. He and McAuley [58] also used CNN for extracting visual features as well as temporal dynamics.
Most studies gave attention to the visual aspect of fashion products and coordination of fashion products. This research aims to develop SBRs to address the fashion product recommendation problem by reflecting users’ sequential behavior on websites. When developing the SBRs, we will focus on not only item sequences but also item attribute sequences because the attributes of fashion items are important decision factors for users, and the cold-start problem can be resolved by using attribute SBRs.
3. Method
We propose various SBRs using interaction session and attribute session data. First, we constructed interaction and attribute session datasets from the user interaction data. With these data we then constructed an ISBR with interaction session dataset and ASBRs with attribute session datasets. Then we integrated the multiple ASBRs into a single recommender by using attribute weights by using various feature weighting algorithms.
3.1. Definitions and Notations
3.1.1. Item
The term item refers to fashion product/s listed on the online shopping mall. A collection of items is denoted by .
3.1.2. Attribute
The term attribute refers to values that describe an item. An item is described by attributes , where represents the attribute.
3.1.3. User
The term user refers to the customer/s who use the online shopping mall. A user is denoted by and all users are denoted by . In this research, the user has no attribute except a unique user identifier.
3.1.4. Interaction
The term interaction refers to a user’s click on one of the items listed on the online shopping mall website. Implicitly an interaction presents a user’s preference for a specific item. An interaction between user () and item () is denoted by , where timestamp, , shows when the interaction occurs.
3.1.5. Session
The term session refers to sequential items or attributes selected by a user within a specific minimum and maximum time interval. An item session is denoted by , where comes before in the interactions of . Similarly an attribute session is denoted by , where comes before in the interactions of .
3.1.6. Conversion Probability
For a given item session, the item conversion probability between and , denoted by , is obtained by dividing the number of sessions between and with the number of sessions from . Similarly the attribute conversion probability between and , denoted by , is obtained by dividing the number of sessions between and with the number of sessions from .
3.2. Construct Session Data
We generated an item session dataset and attribute session dataset from an interaction dataset collected from the online shopping mall. There were two constraints: First, maximum and minimum interval time were set by analyzing historical data as discussed in Section 4. Second, the sessions that had the same precedent item and attribute were not included in the session data.
3.3. Session-Based Recommenders
Item conversion probability and attribute conversion probability of five attributes were calculated according to the definition in Section 3.1. We assumed that items are recommended to the user when they click an item in the online shopping mall. For each item, top-N items were selected based on item and attribute conversion probability. If multiple items had the same conversion probability, the item that had been clicked most recently was recommended to the user.
3.4. Feature-Weighted Session-Based Recommenders
Since users usually select items considering different attributes of a fashion item at once, it is logical to integrate individual ASBRs. For this purpose, we consider the aggregation of individual attribute conversion probabilities with different weights to reflect different importance of attributes. This research uses the recommendation results of the item session recommender to obtain aggregation weights of individual attribute conversion probabilities. The recommendation of ISBR can be represented as follows:
where is an item in test, is a recommended item and is a recommendation result (success or fail). Based on attributes of and , we can derive attribute conversion probability data as follows:
where is attribute conversion probability between attribute of and attribute of . Since the problem is binary classification, various weighting algorithms, such as gain ratio, PCA, chi-square score, were used to obtain normalize attribute importance weights. Finally, the aggregated attribute conversion probability was defined as:
where is the weight of attribute derived from a feature weighting algorithm and is the conversion probability between a value of attribute of and a value of attribute of . Note that it is possible to calculate the integrated attribute conversion probability for attribute pairs, including new items which appeared in the testing. Recommendation worked as follows: for each item in the testing dataset, top-N items were selected based on the integrated attribute conversion probability. Similar to the item conversion probability recommender and individual attribute recommenders, we used the recency criterion to determine what items to display when items with the same conversion probability exist.
4. Experimental Design
4.1. Baseline Recommender
In this experiment, the Item-Based CF recommender (Item-Based CFR) was employed as a baseline recommender and its performance was compared with the proposed SRSs. Item-Based CFR finds similar k-nearest items by calculating similarities between items. The top-N recommendations were generated by using a weighted average of the user’s ratings of these similar items. In our experiment, the user’s rating is a binary value—0 or 1. We use Item-Based CFR as a baseline recommender because it is conventional and used as baseline in previous recommendation studies [28,63].
4.2. Data Sets
Data used in this research was collected from the online shopping mall website of a leading fashion company in Korea, henceforth referred to as Company K. Data consisted of interactions between users of the website and fashion items listed on the website. A total of 51,079 unique customers were users and a total 117,791 unique fashion items were listed on the website. While items had an item identifier and brand, color, style, season and price attributes, no information was recorded about users aside from their user identifier. A total of 3,980,457 interactions were collected over one year from August 2015 to August 2016. Each entry of click data consisted of a user identifier, an item identifier, and creation date time.
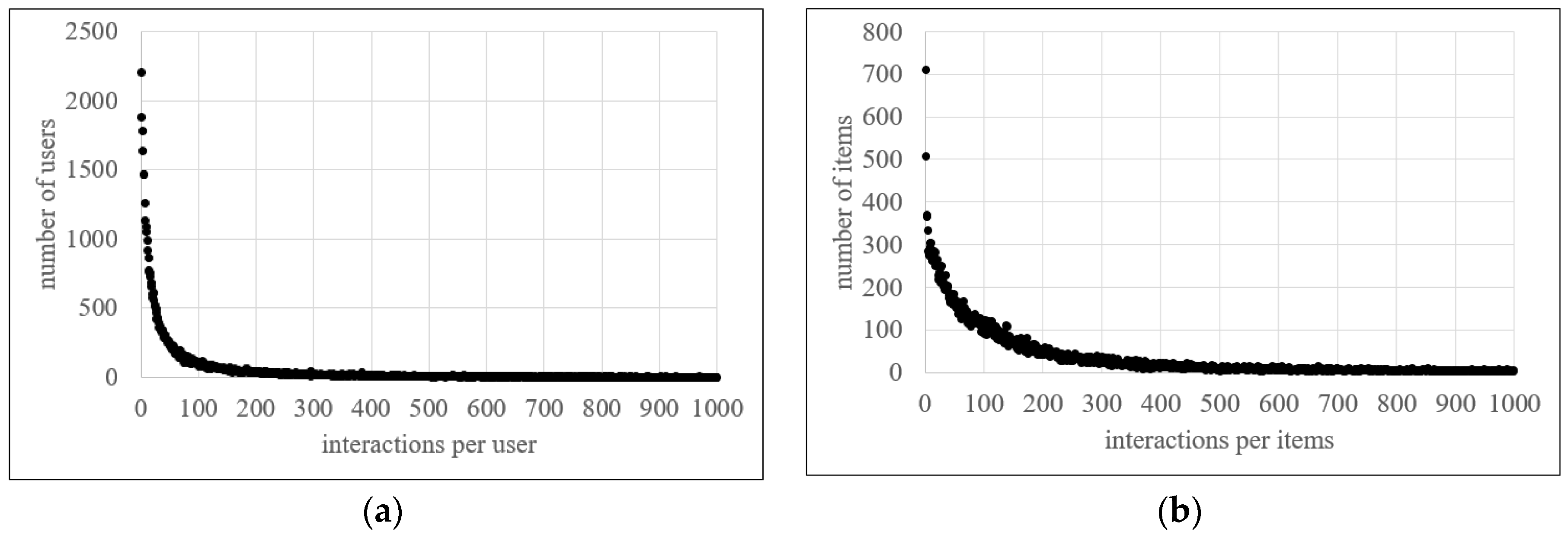
Figure 1 illustrates distribution of clicks per user and clicks per item. Average clicks per user was 77.9, median click per user was 26 and the standard deviation was 127.5. Average clicks per item was 113.7, median click per item was 64 and standard deviation was 137.7. Users who only clicked once and items clicked only once by the user could not be used for this research evaluation.
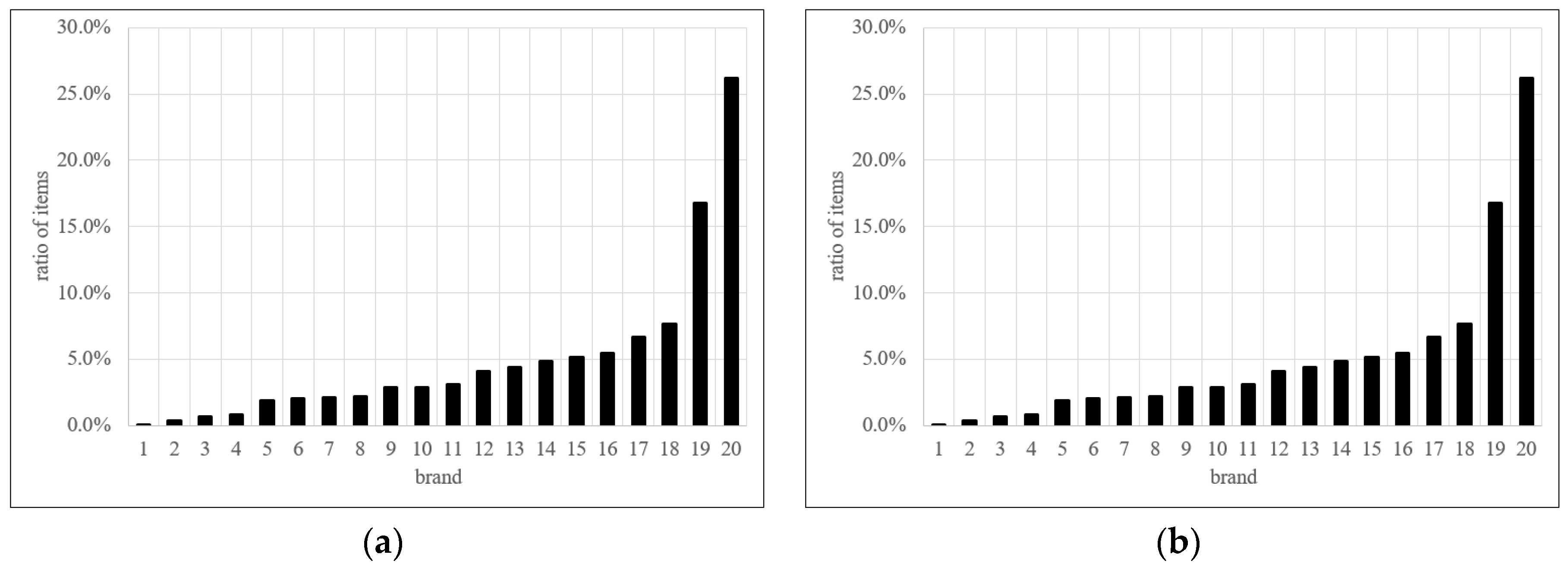
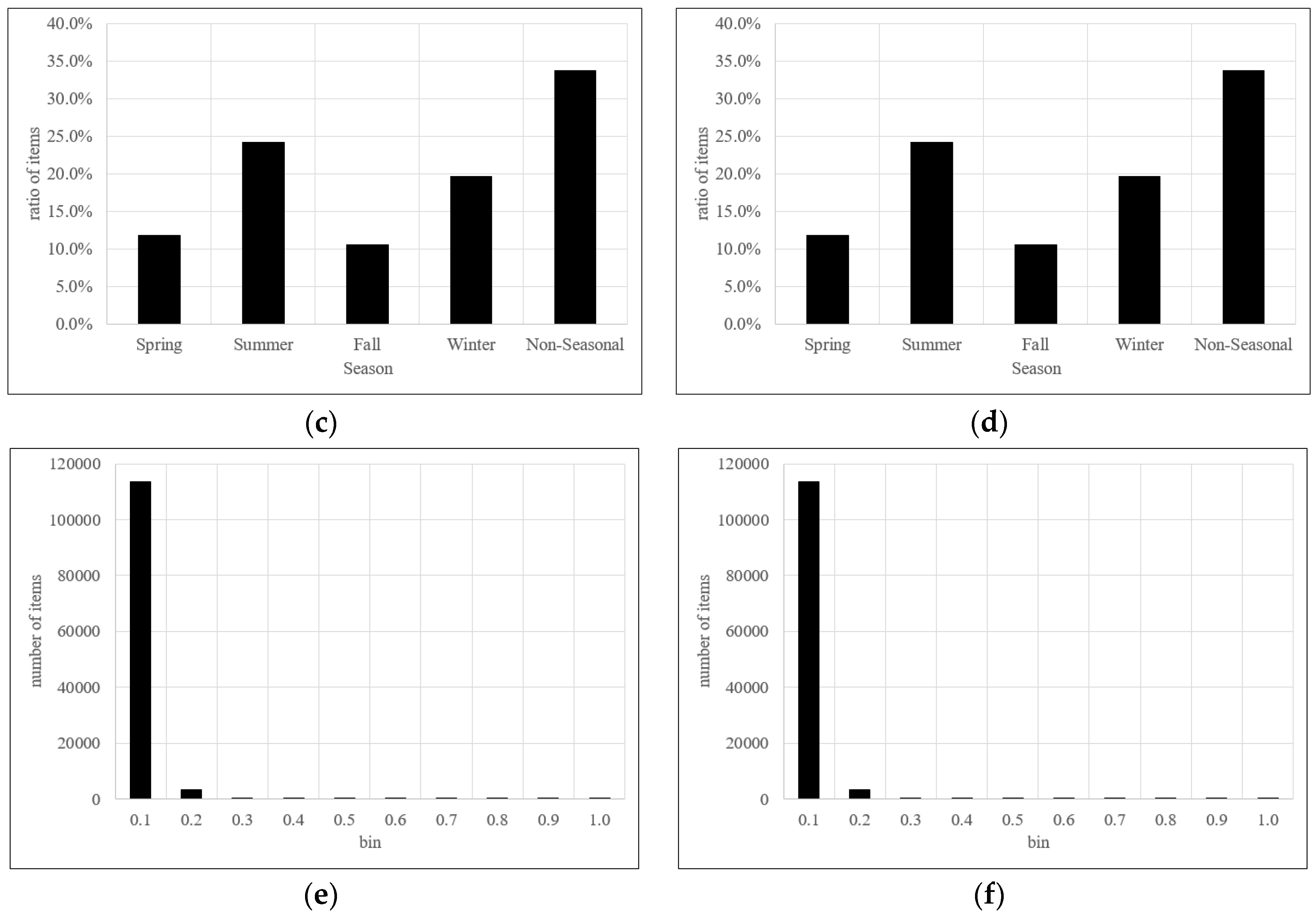
Each fashion product has five attributes—brand, style, color, season and price. A total of twenty brands supply fashion items to Company K. Items from two major brands (19 and 20) accounted for a large proportion of all fashion items listed on the online shopping mall website (see Figure 2a). There were 192 style type classification for all fashion items listed on the website. However, the product classification was skewed because the top 20 products accounted for 71% of all items (see Figure 2b). There were 448 color classifications for fashion items, but similar to style type classification, the top 20 colors accounted for majority of all items (81.1%) (see Figure 2c). There were five classifications for season—spring, summer, fall, winter and non-seasonal. Non-seasonal products accounted for the largest proportion of all items (33.7%), followed by summer (24.3%) and winter (19.7%) (see Figure 2d). Fashion item prices are continuous values and had a large range. We normalized the price by using min-max normalization. Figure 2e illustrates the normalized price distribution when applying equal-width discretization. In this case, most items belong to bin 1. Figure 2f illustrates normalized price distribution when applying equal-frequency discretization. Since the latter approach shows a reasonable distribution, we used it as the discretization for the fashion product prices.
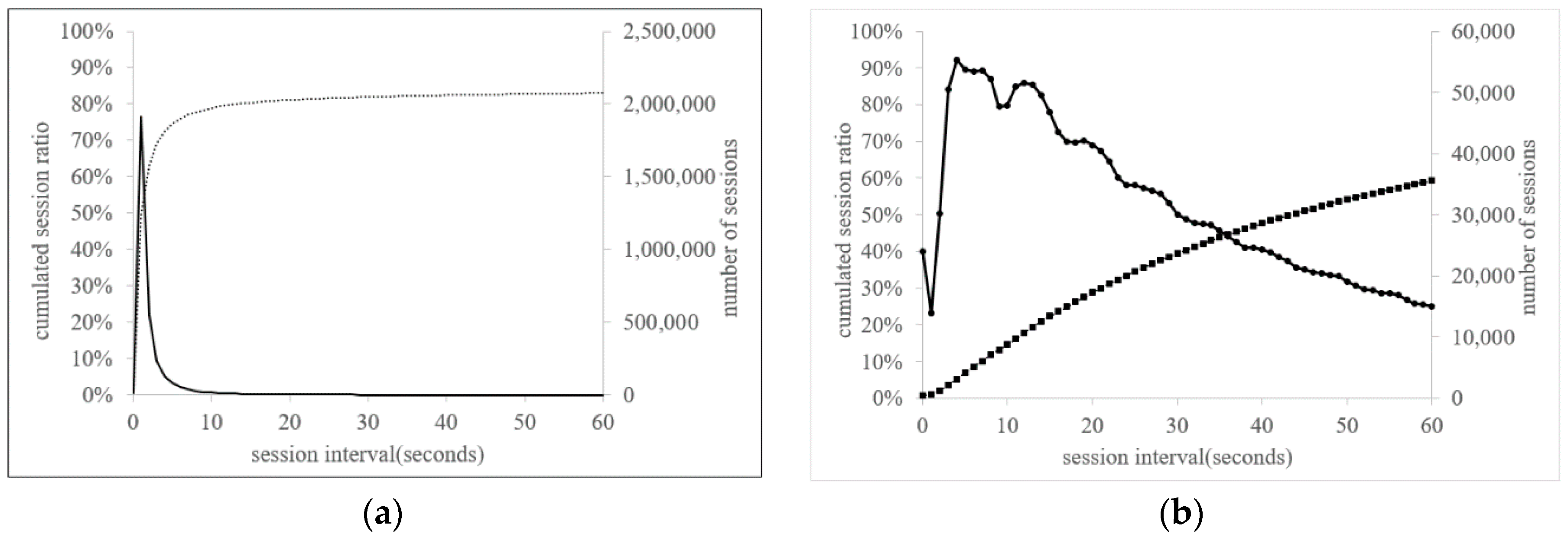
Based on the interaction data, we derived session data, which represents the sequence of interaction data. We considered the following two constraints: if the interval time between two sequential interactions is too large, the session is not regarded as a true session. If the interval time between two sequential interactions is too short (e.g., less than one second), the session cannot be human activity; it must be a crawler. Sessions belonging to these two type of sessions were removed from the session data. In order to set the minimum and maximum interval thresholds, we used the following heuristics: First, we set 60 min as the maximum threshold because we viewed that if the interval is greater than one hour, it cannot not be seen as a sequential behavior. Figure 3a illustrates the distribution of sessions and cumulated session ratio by session interval. Sessions within 60 min accounts for 83.1% of all sessions, but most sessions occur within 10 min (78.9% of all sessions). Secondly, we set 2 s (≤2 s) as the minimum interval because that is too short to be regarded as true expression of the user’s preferences. Of all session data, 2.0% was removed by setting this minimum threshold (see Figure 3b).
Since timestamps for data were available, we collected training and testing datasets for our evaluation from the full dataset reflecting temporal order. The training dataset (Table 1) was collected for six weeks from 03-JAN-16 to 13-FEB-16 and the test dataset was collected for one week from 14-FEB-16 to 20-FEB-16.
Note that some items in the test period did not exist in the training period. We call these items ‘cold-start items’ in the following discussion. We generated session data, consisting of a precedent item and a subsequent item. There were 433,515 sessions created by 17,364 users in the training period and 72,104 sessions created by 5821 users in the test period. Note that there were precedent cold-start items (1307) and subsequent cold-start items (1297).
4.3. Procedures for Performance Evaluation
The performance evaluation was conducted using the following steps:
- (1)
- Construct session data for training and testing;
- (2)
- Calculate the item conversion probability, attribute conversion probability and integrated conversion probability using the training dataset;
- (3)
- Suggest top-N recommendation items for each precedent item in the test dataset. N was varied from five to 25 in increments of five in this study;
- (4)
- Check whether the top-N recommendation is successful. If a precedent item’s subsequent is in the recommendation, the recommendation is regarded as a ‘success’; otherwise, ‘fail’ [64].
In Step 3, the top-N list includes the items of the first N highest preference levels. Then, the performance of the proposed recommender system was evaluated by determining how effective the top-N list was in finding the hidden items. A similar evaluation procedure was used in previous studies (e.g., Sarwar et al. [65]).
4.4. Evaluation Metrics
Recall, precision and f1 measures are used to evaluate the performance of a recommender system [64,65]. They are respectively defined as:
where is the number of test data and is the number of recommended products for each product. In addition to these two measures, we also used the F1 measure, which combines recall and precision, because these two measures are inversely related. For instance, as N increases, recall also increases but precision generally decreases. F1 is defined as the harmonic mean of recall and precision as follows [65].
5. Results
5.1. ISBR and ASBRs
Table 2 summarizes top-N recommendation results by the item k-NN CFR as well as ISBR and ASBRs. For each top-N recommendation, ISBR and ASBRs exhibited significantly better performance compared to Item-Based CFR in all performance measures. ISBR showed higher recall compared to ASBRs when top-5 and top-10 items are recommended. However, ASBRs achieved comparable recalls with ISBR when top-15, top-20 and top-25 items are recommended. In particular, ASBR of ‘style’ attribute outperformed ISBR in these recommendations (see Table 2a).
Precisions were also similar to recalls. When small number of items were suggested (top-5 and top-10), ISBR outperformed ASBRs. However, when a large number of items were recommended (e.g., top-15, top-20, and top-25), ASBRs outperformed ISBR (see Table 2b). As ISBR showed better performance in recall and precision when suggesting small numbers of items (e.g., top-5 and top-10), its f1-measure was also better than ASBRs. The ASBR of ‘style’ attribute showed better performance compared to the item SRS and other attribute SRSs (see Table 2c).
5.2. Feature-Weighted Session-Based Recommenders
Table 3 summarizes attribute importance weights derived by feature weight algorithms. The results show that the importance weights were significantly different amongst algorithms. GR suggested ‘style’ was the most important, followed by ‘color’ and ‘brand’, and ‘season’ was the least important. PCA suggested ‘brand’ was the most important but other than that, weight differences were not significant compared to other algorithms. PCA suggested ‘color’ was the least important. CHI showed ‘style’ was the most important but ‘color’ was the least important. Interestingly RELIEF regarded ‘price’ as the most important, while ‘style’ was the least important. Finally SVM suggested ‘brand’ was the most important while ‘Price’ was the least important. Since there were significant differences in the weights, it was expected that the recommender systems that used different weights would produce different performance levels.
FWSBRs achieved significant performance improvements when using attribute importance weights to combine ASBRs. In recall, all FWSBRs outperformed ASBRs. In particular, FWSBR with CHI outperformed ISBR as well as other FWSBRs (see Table 4a). Similarly, in precision, all FWSBRs outperformed any individual ASBR, and FWSBR with CHI outperformed ISBR as well as other FWSBRs (see Table 4b). Finally, F1-measures of FWSBRs with CHI exhibited the best performance among all recommender systems (see Table 4c).
5.3. FWSBRs with Cold-Start Items
The performance of FWSBRs with cold-start items was significantly better than FWSBRs without cold-start items. Recalls of FWSBR with chi-square scores exhibited higher performance compared to other recommender systems (see Table 5a). However, unlike FWSBRs without the cold-start items, the precision of FWSBR with PCA exhibited higher performance compared to other recommender systems, except FWSBR with GR. Finally, FWSBR with PCA exhibited the highest performance in the F1-measure.
6. Discussion
This paper examines various fashion item recommendation methods that assist customers’ selection of fashion items in an e-commerce website. Recommender systems are regarded as one of the major types of web analytics systems in sustainable digital marketing, because they help the customers who have specific personal preferences, including needs for sustainability.
Sustainable fashion has diverse definitions and may cause confusion among writers. Lundblad and Davies [66] define sustainable fashion as “clothing that incorporate fair trade principles with sweatshop-free labor conditions; that does not harm the environment or workers by using biodegradable and organic cotton, and designed for a longer lifetime use; that is produced in an ethical production system, perhaps even locally; that which causes little or no environmental impact and makes use of eco-labeled or recycled materials”.
In e-commerce, customers usually express their preference for sustainable fashion but consumers do not have a real choice since large quantities of such fashion products doesn’t appear in the market [67]. In this context, the recommenders are essential in promoting consumption of sustainable fashion products [4]. In order to achieve this goal, the recommenders should promote consumption of sustainable fashion products according to the customers’ preference. This implies that the recommender should work with high level performance.
This research suggested various SBRs in order to improve recommenders’ performance. There are existing studies that focus on session information [34,35,36,37,38]. Our proposed SBR methods are unique compared to previous research because we consider item sessions as well as attribute sessions. In addition, we suggest SBRs that combine item and attribute sessions by using various feature-weighting schemes. Our experimental demonstrates that the item and session combined SBRs perform better than baseline CFR as well as ISBR. The cold-start problem is a significant problem in the interaction-based recommenders, including various CFRs [18], Matrix Factorization recommender [19,68] and ISBR. Our proposed FWSBRs successfully suggest the cold-start items to the customers with significant performance improvement.
7. Conclusions
This research proposes new fashion product recommendation methods for the sustainable digital marketing using item and attribute session data. Our research suggests theoretical contributions, detailed as follows. Recommender systems have been researched to resolve information overflow problems. Content-based recommender systems and collaborative-based recommender systems have been extensively researched in academia as well as in commercial areas and have exhibited significant success in practice. These recommender systems are based on timeless information, such as item/user content and user behaviors with items. User activities and preferences depend on time factors and the recommender systems should include them when creating recommendation models. Recent temporal or time sensitive recommender systems such as [32,69,70] consider time factor and gained substantial improvement in recommendation performance. However, these studies do not consider sequential patterns when they consider temporal factors. Our major theoretical contribution is that time factor is explicitly considered when creating recommendation models. Our proposed methods also include not only sequential behavioral patterns but also sequential attribute patterns when creating session-based recommenders. In addition, we combined various ASBRs with feature weighted schemes, resulting in superior performance over pure ISBR and conventional CFR. This allows the recommenders of cold-start items to users without a loss of performance.
In addition to theoretical contributions, our research has practical implications, detailed as follows. Recently, sustainable digital marketing has gained interest from many industries. The meanings of sustainable digital marketing are two-fold. One the one hand, marketing efforts have a sustained impact on a company’s results. On the other hand, the system and processes allow continuous improvement by maximizing existing assets. In this sense, recommender systems are an appropriate technical medium for sustainable digital marketing because they allow the company to provide accurate information regarding what the users want to see. Sustainability of recommender systems largely depends on their performance. Since our proposed methods achieved higher performance compared to conventional recommenders, we believe that our recommenders can have a positive impact on sustainable digital marketing results for the fashion products.
Although this research shows that various SBRs can suggest recommendation successfully, there are several limitations. First, this research uses session information, which is a special type of sequence pattern that consider only one step further from the current status to the next status. Since a series of sequence can show users’ preference more completely, it is better to consider multiple sequences together [17]. Second, our proposed method uses conversion probability, but there are better ways to consider sequence conversion, for example deep learning approaches. Therefore, our further research will consider these alternative approaches.
Author Contributions
Conceptualization, Y.K.; Data curation, H.H.; Formal analysis, Y.K.; Funding acquisition, Y.K.; Investigation, Y.K.; Methodology, Y.K.; Project administration, H.H.; Resources, H.H.; Software, Y.K.; Supervision, H.H.; Validation, H.H.; Visualization, Y.K.; Writing—original draft, Y.K.; Writing—review & editing, H.H.
Funding
This research was supported by the Bisa Scholar Research Grant of Keimyung University in 2019 (No. 20180731).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jones, P.; Clarke-Hill, C.; Comfort, D.; Hillier, D. Marketing and sustainability. Mark. Intell. Plan. 2008, 26, 123–130. [Google Scholar] [CrossRef]
- Saura, J.R.; Palos-Sánchez, P.; Cerdá Suárez, L.M. Understanding the digital marketing environment with KPIs and web analytics. Future Internet 2017, 9, 76. [Google Scholar] [CrossRef]
- Minton, E.; Lee, C.; Orth, U.; Kim, C.-H.; Kahle, L. Sustainable marketing and social media: A cross-country analysis of motives for sustainable behaviors. J. Advert. 2012, 41, 69–84. [Google Scholar] [CrossRef]
- Tomkins, S.; Isley, S.; London, B.; Getoor, L. Sustainability at Scale: Towards Bridging the Intention-Behavior Gap with Sustainable Recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 214–218. [Google Scholar]
- Shen, B.; Zheng, J.-H.; Chow, P.-S.; Chow, K.-Y. Perception of fashion sustainability in online community. J. Text. Inst. 2014, 105, 971–979. [Google Scholar] [CrossRef]
- Orendorff, A. The State of the Ecommerce Fashion Industry: Statistics, Trends & Strategy. Available online: https://www.shopify.com/enterprise/ecommerce-fashion-industry (accessed on 9 June 2018).
- Fukuda, M.; Nakatani, Y. Clothes Recommend Themselves: A New Approach to a Fashion Coordinate Support System. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 19–21 October 2011; pp. 19–21. [Google Scholar]
- Gu, S.; Liu, X.; Cai, L.; Shen, J. Fashion coordinates recommendation based on user behavior and visual clothing style. In Proceedings of the 3rd International Conference on Communication and Information Processing, Tokyo, Japan, 24–26 November 2017; pp. 185–189. [Google Scholar]
- Iwata, T.; Wanatabe, S.; Sawada, H. Fashion Coordinates Recommender System Using Photographs from Fashion Magazines. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; p. 2. [Google Scholar]
- Shen, E.; Lieberman, H.; Lam, F. What am I gonna wear?: Scenario-oriented recommendation. In Proceedings of the 12th international conference on Intelligent user interfaces, Honolulu, HI, USA, 28–31 January 2007; pp. 365–368. [Google Scholar]
- Yonezawa, Y.; Nakatani, Y. Fashion support from clothes with characteristics. In Symposium on Human Interface; Springer: Berlin/Heidelberg, Germany, 2009; pp. 323–330. [Google Scholar]
- Guo, Y.; Yin, C.; Li, M.; Ren, X.; Liu, P. Mobile e-Commerce Recommendation System Based on Multi-Source Information Fusion for Sustainable e-Business. Sustainability 2018, 10, 147. [Google Scholar] [CrossRef]
- Fu, X.; Han, G. Trust-Embedded Information Sharing among One Agent and Two Retailers in an Order Recommendation System. Sustainability 2017, 9, 710. [Google Scholar] [CrossRef]
- Hu, Y.; Yi, X.; Davis, L.S. Collaborative Fashion Recommendation: A Functional Tensor Factorization Approach. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 129–138. [Google Scholar]
- Quanping, H. Analysis of Collaborative Filtering Algorithm fused with Fashion Attributes. Int. J. U- E-Serv. Sci. Technol. 2015, 8, 159–168. [Google Scholar] [CrossRef]
- Quadrana, M.; Cremonesi, P.; Jannach, D. Sequence-Aware Recommender Systems. arXiv 2018, arXiv:1802.08452. [Google Scholar]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41 Pt 2, 2065–2073. [Google Scholar] [CrossRef]
- Ocepek, U.; Rugelj, J.; Bosnić, Z. Improving matrix factorization recommendations for examples in cold start. Expert Syst. Appl. 2015, 42, 6784–6794. [Google Scholar] [CrossRef]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual international ACM SIGIR conference on research and development in information retrieval (SIGIR ‘02), Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Victor, P.; Cornelis, C.; Teredesai, A.M.; Cock, M.D. Whom should I trust?: The impact of key figures on cold start recommendations. In Proceedings of the 2008 ACM symposium on Applied computing, Fortaleza, Ceara, Brazil, 16–20 March 2008; pp. 2014–2018. [Google Scholar]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef]
- Sun, G.; Cui, T.; Beydoun, G.; Chen, S.; Dong, F.; Xu, D.; Shen, J. Towards Massive Data and Sparse Data in Adaptive Micro Open Educational Resource Recommendation: A Study on Semantic Knowledge Base Construction and Cold Start Problem. Sustainability 2017, 9, 898. [Google Scholar] [CrossRef]
- Lucas, J.P.; Luz, N.; Moreno, M.N.; Anacleto, R.; Figueiredo, A.A.; Martins, C. A hybrid recommendation approach for a tourism system. Expert Syst. Appl. 2013, 40, 3532–3550. [Google Scholar] [CrossRef] [Green Version]
- Lekakos, G.; Caravelas, P. A hybrid approach for movie recommendation. Multimed. Tools Appl. 2008, 36, 55–70. [Google Scholar] [CrossRef]
- Wetzker, R.; Umbrath, W.; Said, A. A hybrid approach to item recommendation in folksonomies. In Proceedings of the WSDM’09 Workshop on Exploiting Semantic Annotations in Information Retrieval, Barcelona, Spain, 9–11 February 2009; pp. 25–29. [Google Scholar]
- Cacheda, F.; Carneiro, V.; Fernández, D.; Formoso, V. Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems. ACM Trans. Web TWEB 2011, 5, 2. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, M.; Hanjalic, A. Collaborative Filtering beyond the User-Item Matrix: A Survey of the State of the Art and Future Challenges. ACM Comput. Surv. 2014, 47, 3. [Google Scholar] [CrossRef]
- Deshpande, M.; Karypis, G. Item-based top-N recommendation algorithms. ACM Trans. Inf. Syst. TOIS 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Zhao, Z.-L.; Wang, C.-D.; Wan, Y.-Y.; Lai, J.-H. Recommendation in feature space sphere. Electron. Commer. Res. Appl. 2017, 26, 109–118. [Google Scholar] [CrossRef]
- Wei, S.; Zheng, X.; Chen, D.; Chen, C. A hybrid approach for movie recommendation via tags and ratings. Electron. Commer. Res. Appl. 2016, 18, 83–94. [Google Scholar] [CrossRef]
- Hong, W.; Li, L.; Li, T. Product recommendation with temporal dynamics. Expert Syst. Appl. 2012, 39, 12398–12406. [Google Scholar] [CrossRef]
- Campos, P.G.; Díez, F.; Cantador, I. Time-aware recommender systems: A comprehensive survey and analysis of existing evaluation protocols. User Model. User-Adapt. Interact. 2013, 24, 67–119. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 487–499. [Google Scholar]
- Aryabarzan, N.; Minaei-Bidgoli, B.; Teshnehlab, M. negFIN: An efficient algorithm for fast mining frequent itemsets. Expert Syst. Appl. 2018, 105, 129–143. [Google Scholar] [CrossRef]
- Kieu, T.; Vo, B.; Le, T.; Deng, Z.-H.; Le, B. Mining top-k co-occurrence items with sequential pattern. Expert Syst. Appl. 2017, 85, 123–133. [Google Scholar] [CrossRef]
- Srikant, R.; Agrawal, R. Mining Sequential Patterns: Generalizations and Performance Improvements; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Soysal, Ö.M. Association rule mining with mostly associated sequential patterns. Expert Syst. Appl. 2015, 42, 2582–2592. [Google Scholar] [CrossRef]
- Gupta, S.; Rawat, M. Recommendations through click stream: Tracking the need, current work and future directions. In Proceedings of the 2nd International Conference on Contemporary Computing and Informatics (IC3I), Noida, India, 14–17 December 2016; pp. 736–740. [Google Scholar]
- Kim, Y.S.; Yum, B.-J. Recommender system based on click stream data using association rule mining. Expert Syst. Appl. 2011, 38, 13320–13327. [Google Scholar] [CrossRef]
- Yap, G.-E.; Li, X.-L.; Philip, S.Y. Effective next-items recommendation via personalized sequential pattern mining. In Proceedings of the International Conference on Database Systems for Advanced Applications, Busan, Korea, 15–19 April 2012; pp. 48–64. [Google Scholar]
- Jiang, F.; Leung, C.; Pazdor, A.G.M. Web Page Recommendation Based on Bitwise Frequent Pattern Mining. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016; pp. 632–635. [Google Scholar]
- Lu, E.H.-C.; Lin, Y.-W.; Ciou, J.-B. Mining mobile application sequential patterns for usage prediction. In Proceedings of the 2014 IEEE International Conference on Granular Computing (GrC), Noboribetsu, Japan, 22–24 October 2014; pp. 185–190. [Google Scholar]
- Zheleva, E.; Guiver, J.; Mendes Rodrigues, E.; Milić-Frayling, N. Statistical models of music-listening sessions in social media. In Proceedings of the 19th international conference on World wide web, Raleigh, NC, USA, 26–30 April 2010; pp. 1019–1028. [Google Scholar]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Huan, L.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the 7th IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 5–8 November 1995; pp. 388–391. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2017, 50, 94. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature Selection Using Principal Component Analysis. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Yichang, China, 12–14 November 2010; pp. 27–30. [Google Scholar]
- Tosun, A.; Turhan, B.; Bener, A.B. Feature weighting heuristics for analogy-based effort estimation models. Expert Syst. Appl. 2009, 36, 10325–10333. [Google Scholar] [CrossRef]
- Sun, Y. Iterative RELIEF for Feature Weighting: Algorithms, Theories, and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1035–1051. [Google Scholar] [CrossRef]
- Ghamisi, P.; Couceiro, M.S.; Benediktsson, J.A. A Novel Feature Selection Approach Based on FODPSO and SVM. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2935–2947. [Google Scholar] [CrossRef]
- Diez-Martin, F.; Blanco-Gonzalez, A.; Prado-Roman, C. Research Challenges in Digital Marketing: Sustainability. Sustainability 2019, 11, 2839. [Google Scholar] [CrossRef]
- Chao, X.; Huiskes, M.J.; Gritti, T.; Ciuhu, C. A framework for robust feature selection for real-time fashion style recommendation. In Proceedings of the 1st international workshop on Interactive multimedia for consumer electronics, Beijing, China, 19–24 October 2009; pp. 35–42. [Google Scholar]
- Tu, Q.; Dong, L. An Intelligent Personalized Fashion Recommendation System. In Proceedings of the 2010 International Conference on Communications, Circuits and Systems (ICCCAS), Chengdu, China, 28–30 July 2010; pp. 479–485. [Google Scholar]
- Chen, Y.; Wu, C.; Xie, M.; Guo, X. Solving the sparsity problem in recommender systems using association retrieval. J. Comput. 2011, 6, 1896–1902. [Google Scholar] [CrossRef]
- Hwangbo, H.; Kim, Y. An empirical study on the effect of data sparsity and data overlap on cross domain collaborative filtering performance. Expert Syst. Appl. 2017, 89, 254–265. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Almenningen, T.; Havig, M.; Schistad, H.; Kofod-Petersen, A.; Langseth, H.; Ramampiaro, H. Learning to rank for personalised fashion recommender systems via implicit feedback. In Mining Intelligence and Knowledge Exploration; Springer: Basel, Switzerland, 2014; pp. 51–61. [Google Scholar]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- Sato, A.; Watanabe, K.; Yasumura, M.; Rekimoto, J. In suGATALOG: Fashion coordination system that supports users to choose everyday fashion with clothed pictures. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2013; pp. 112–121. [Google Scholar]
- Yu, W.; Zhang, H.; He, X.; Chen, X.; Xiong, L.; Qin, Z. Aesthetic-based Clothing Recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 649–658. [Google Scholar]
- Jagadeesh, V.; Piramuthu, R.; Bhardwaj, A.; Di, W.; Sundaresan, N. Large scale visual recommendations from street fashion images. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA, 24–27 April 2014; pp. 1925–1934. [Google Scholar]
- Hwangbo, H.; Kim, Y.S.; Cha, K.J. Recommendation system development for fashion retail e-commerce. Electron. Commer. Res. Appl. 2018, 28, 94–101. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web (WWW ‘01), Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Cremonesi, P.; Koren, Y.; Turrin, R. Performance of recommender algorithms on top-n recommendation tasks. In Proceedings of the fourth ACM conference on Recommender systems, Barcelona, Spain, 26–30 September 2010; pp. 39–46. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for e-commerce. In Proceedings of the 2nd ACM conference on electronic commerce, Minneapolis, MN, USA, 17–20 October 2000; pp. 158–167. [Google Scholar]
- Lundblad, L.; Davies, I.A. The values and motivations behind sustainable fashion consumption. J. Consum. Behav. 2016, 15, 149–162. [Google Scholar] [CrossRef]
- Joergens, C. Ethical fashion: Myth or future trend? J. Fash. Mark. Manag. Int. J. 2006, 10, 360–371. [Google Scholar] [CrossRef]
- Nguyen, A.-T.; Denos, N.; Berrut, C. Improving new user recommendations with rule-based induction on cold user data. In Proceedings of the 2007 ACM conference on Recommender systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 121–128. [Google Scholar]
- Du, N.; Wang, Y.; He, N.; Sun, J.; Song, L. Time-Sensitive Recommendation From Recurrent User Activities. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 3474–3482. [Google Scholar]
- Vaz, P.C.; Ribeiro, R.; Matos, D.M. Understanding temporal dynamics of ratings in the book recommendation scenario. In Proceedings of the 2013 International Conference on Information Systems and Design of Communication, Lisboa, Portugal, 11–12 July 2013; pp. 11–15. [Google Scholar]
- Devooght, R.; Bersini, H. Long and Short-Term Recommendations with Recurrent Neural Networks. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 13–21. [Google Scholar]
Figure 1.
Clicks per user and clicks per item. (a) Interactions per user; (b) interactions per item.
Figure 1.
Clicks per user and clicks per item. (a) Interactions per user; (b) interactions per item.

Figure 2.
Product distribution by brand, style, color and season. (a) Item distribution by brand, (b) item distribution by style, (c) item distribution by color, (d) item distribution by season, (e) item distribution by price (equal-width discretization) and (f) item distribution by price (equal-frequency discretization).
Figure 2.
Product distribution by brand, style, color and season. (a) Item distribution by brand, (b) item distribution by style, (c) item distribution by color, (d) item distribution by season, (e) item distribution by price (equal-width discretization) and (f) item distribution by price (equal-frequency discretization).


Figure 3.
Transition ratio by minute. (a) Session interval (≤60 min), (b) session interval (≤60 s).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Dataset for evaluation.
| Dataset | Number of Sessions | Number of Users | Number of Precedent Items | Number of Precedent Cold-Start Items | Number of Subsequent Items | Number of Subsequent Cold-Start Items |
|---|---|---|---|---|---|---|
| Training | 433,515 | 17,364 | 16,583 | 16,647 | ||
| Test | 72,104 | 5821 | 12,350 | 1307 | 12,474 | 1297 |
Table 2.
Individual attribute session recommendation results.
(a) Recall of top-N recommendations.
| Top-N | Item-Based CFR | ISBR | Brand ASBR | Color ASBR | Style ASBR | Season ASBR | Price ASBR |
|---|---|---|---|---|---|---|---|
| 5 | 5.9% | 22.1% | 16.1% | 9.8% | 19.1% | 15.1% | 18.3% |
| 10 | 7.7% | 26.8% | 23.2% | 15.6% | 26.0% | 22.0% | 24.0% |
| 15 | 8.9% | 29.4% | 27.0% | 20.4% | 29.7% | 26.0% | 27.3% |
| 20 | 9.9% | 31.0% | 29.4% | 23.8% | 31.6% | 28.6% | 29.4% |
| 25 | 10.6% | 32.0% | 31.2% | 26.5% | 32.8% | 30.3% | 31.0% |
(b) Precision of top-N recommendations.
| Top-N | Item-Based CFR | ISBR | Brand ASBR | Color ASBR | Style ASBR | Season ASBR | Price ASBR |
|---|---|---|---|---|---|---|---|
| 5 | 1.2% | 4.5% | 3.3% | 2.0% | 3.9% | 3.1% | 3.8% |
| 10 | 0.8% | 2.9% | 2.5% | 1.7% | 2.8% | 2.4% | 2.6% |
| 15 | 0.6% | 2.2% | 2.0% | 1.5% | 2.2% | 2.0% | 2.1% |
| 20 | 0.5% | 1.8% | 1.8% | 1.4% | 1.9% | 1.7% | 1.8% |
| 25 | 0.4% | 1.6% | 1.6% | 1.3% | 1.7% | 1.5% | 1.6% |
(c) F1-Measure of top-N recommendations.
| Top-N | Item-Based CFR | ISBR | Brand ASBR | Color ASBR | Style ASBR | Season ASBR | Price ASBR |
|---|---|---|---|---|---|---|---|
| 5 | 2.0% | 7.5% | 5.5% | 3.4% | 6.5% | 5.2% | 6.2% |
| 10 | 1.4% | 5.2% | 4.5% | 3.0% | 5.1% | 4.3% | 4.7% |
| 15 | 1.1% | 4.1% | 3.8% | 2.9% | 4.2% | 3.7% | 3.8% |
| 20 | 0.9% | 3.5% | 3.3% | 2.7% | 3.6% | 3.2% | 3.3% |
| 25 | 0.8% | 3.1% | 3.0% | 2.6% | 3.2% | 2.9% | 3.0% |
Table 3.
Attribute importance weights.
| Attribute | GR | PCA | CHI | RELIEF | SVM |
|---|---|---|---|---|---|
| Color | 0.648 | 0.031 | 0.000 | 0.156 | 0.304 |
| Season | 0.000 | 0.446 | 0.318 | 0.270 | 0.985 |
| Price | 0.278 | 0.226 | 0.714 | 1.000 | 0.000 |
| Brand | 0.537 | 0.681 | 0.495 | 0.211 | 1.000 |
| Style | 1.000 | 0.533 | 1.000 | 0.000 | 0.467 |
Table 4.
Recommendation results of FWSBRs.
(a) Recall of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 22.1% | 24.3% | 22.5% | 21.0% | 20.2% | 19.0% |
| 10 | 26.8% | 31.2% | 30.4% | 29.7% | 28.3% | 28.0% |
| 15 | 29.4% | 34.7% | 34.3% | 34.0% | 32.3% | 32.7% |
| 20 | 31.0% | 36.7% | 36.5% | 36.4% | 34.9% | 35.3% |
| 25 | 32.0% | 38.1% | 37.9% | 37.9% | 36.6% | 37.1% |
(b) Precision of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 4.5% | 5.0% | 4.6% | 4.3% | 4.1% | 3.9% |
| 10 | 2.9% | 3.3% | 3.3% | 3.2% | 3.0% | 3.0% |
| 15 | 2.2% | 2.6% | 2.6% | 2.6% | 2.4% | 2.5% |
| 20 | 1.8% | 2.2% | 2.2% | 2.2% | 2.1% | 2.1% |
| 25 | 1.6% | 1.9% | 1.9% | 1.9% | 1.8% | 1.9% |
(c) F1-Measure of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 7.5% | 8.3% | 7.7% | 7.1% | 6.9% | 6.5% |
| 10 | 5.2% | 6.0% | 5.9% | 5.7% | 5.5% | 5.4% |
| 15 | 4.1% | 4.8% | 4.8% | 4.7% | 4.5% | 4.6% |
| 20 | 3.5% | 4.1% | 4.1% | 4.1% | 3.9% | 4.0% |
| 25 | 3.1% | 3.6% | 3.6% | 3.6% | 3.5% | 3.5% |
Table 5.
Recommendation results of FWSBR with cold-tart items.
(a) Recall of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 22.1% | 34.6% | 30.1% | 28.9% | 28.1% | 28.0% |
| 10 | 26.8% | 38.8% | 36.9% | 36.3% | 35.0% | 35.1% |
| 15 | 29.4% | 41.4% | 40.4% | 40.2% | 38.6% | 39.2% |
| 20 | 31.0% | 43.1% | 42.5% | 42.5% | 41.0% | 41.6% |
| 25 | 32.0% | 44.2% | 43.9% | 43.9% | 42.7% | 43.1% |
(b) Precision of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 4.4% | 4.4% | 5.1% | 4.8% | 4.6% | 4.4% |
| 10 | 2.8% | 3.3% | 3.6% | 3.5% | 3.3% | 3.3% |
| 15 | 2.1% | 2.7% | 2.8% | 2.8% | 2.7% | 2.7% |
| 20 | 1.8% | 2.3% | 2.4% | 2.3% | 2.3% | 2.3% |
| 25 | 1.6% | 2.1% | 2.1% | 2.1% | 2.0% | 2.0% |
(c) F1-Measure of top-N recommendations.
| Top-N | ISBR | FWSBR CHI | FWSBR PCA | FWSBR GR | FWSBR RELIEF | FWSBR SVM |
|---|---|---|---|---|---|---|
| 5 | 7.3% | 7.8% | 8.7% | 8.2% | 8.0% | 7.6% |
| 10 | 5.1% | 6.2% | 6.5% | 6.3% | 6.1% | 6.0% |
| 15 | 4.0% | 5.1% | 5.2% | 5.2% | 5.0% | 5.0% |
| 20 | 3.4% | 4.4% | 4.5% | 4.5% | 4.3% | 4.3% |
| 25 | 3.0% | 3.9% | 4.0% | 4.0% | 3.8% | 3.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hwangbo, H.; Kim, Y. Session-Based Recommender System for Sustainable Digital Marketing. Sustainability 2019, 11, 3336. https://doi.org/10.3390/su11123336
AMA Style
Hwangbo H, Kim Y. Session-Based Recommender System for Sustainable Digital Marketing. Sustainability. 2019; 11(12):3336. https://doi.org/10.3390/su11123336
Chicago/Turabian StyleHwangbo, Hyunwoo, and Yangsok Kim. 2019. "Session-Based Recommender System for Sustainable Digital Marketing" Sustainability 11, no. 12: 3336. https://doi.org/10.3390/su11123336
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.