Semantic Legal Policies for Data Exchange and Protection across Super-Peer Domains in the Cloud

Abstract
:1. Introduction

1.1. Semantic Policy Infrastructure
1.2. Principles of Data Protection Laws
- The registration principle: the location of service provider registration, which enables data collection services;
- The nationality principle: the nationality of the data owner whose data are being used;
- The territoriality principle: the data center location where the actual data processing occurs.
1.3. Research Issues and Contributions
1.3.1. Research Issues
1.3.2. Contributions
1.3.3. Outline
2. Background
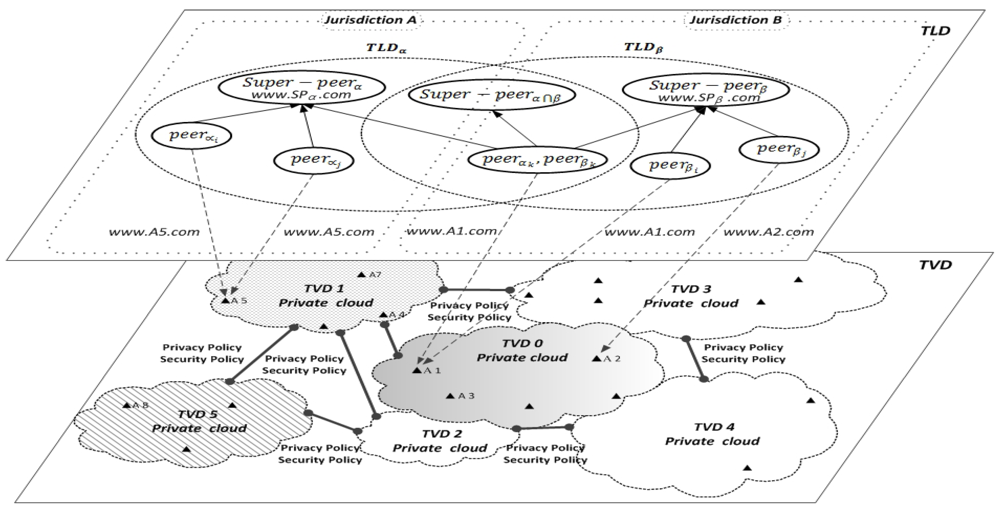
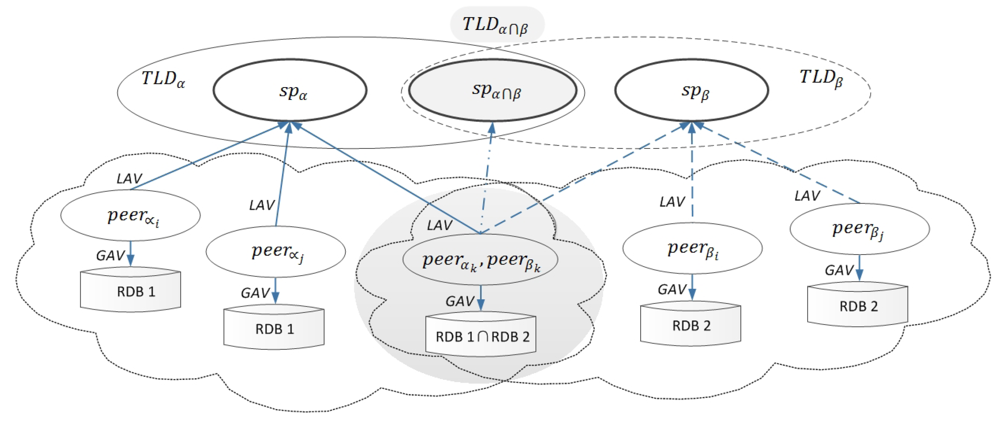
2.1. A Super-Peer Domain Model
2.2. Queries as Views

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Full spelling | Acronym | Full spelling |
|---|---|---|---|
| TLD | Trusted Legal Domain | TVD | Trusted Virtual Domain |
| SPD | Super-Peer Domain | sp | super-peer |
| GAV | Global-As-View | XaaS | Everything-as-a-Service |
| GLAV | Global-Local-As-View | LAV | Local-As-View |
| CQ | Conjunctive Query | VMs | Virtual Machines |
2.3. Stratified Datalog¬ for Non-Monotonic Reasoning
2.4. Conjunctive Query Programs (CQ-Programs)
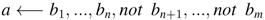
2.5. Prioritized Default Theory
 is sufficient to model our exceptions, where φ is prerequisite, ψ is justifications, and ψ the consequent of δ in D. We apply the novel transformation Ω of default theories into cq-programs, which is based on the select-default-and-check principle. The evaluating extensions principle in default theories is: “If the prerequisites can be derived, and the justifications can be consistently assumed, then the conclusion can be concluded [23]”.
is sufficient to model our exceptions, where φ is prerequisite, ψ is justifications, and ψ the consequent of δ in D. We apply the novel transformation Ω of default theories into cq-programs, which is based on the select-default-and-check principle. The evaluating extensions principle in default theories is: “If the prerequisites can be derived, and the justifications can be consistently assumed, then the conclusion can be concluded [23]”. 3. Law-Aware Semantic Cloud
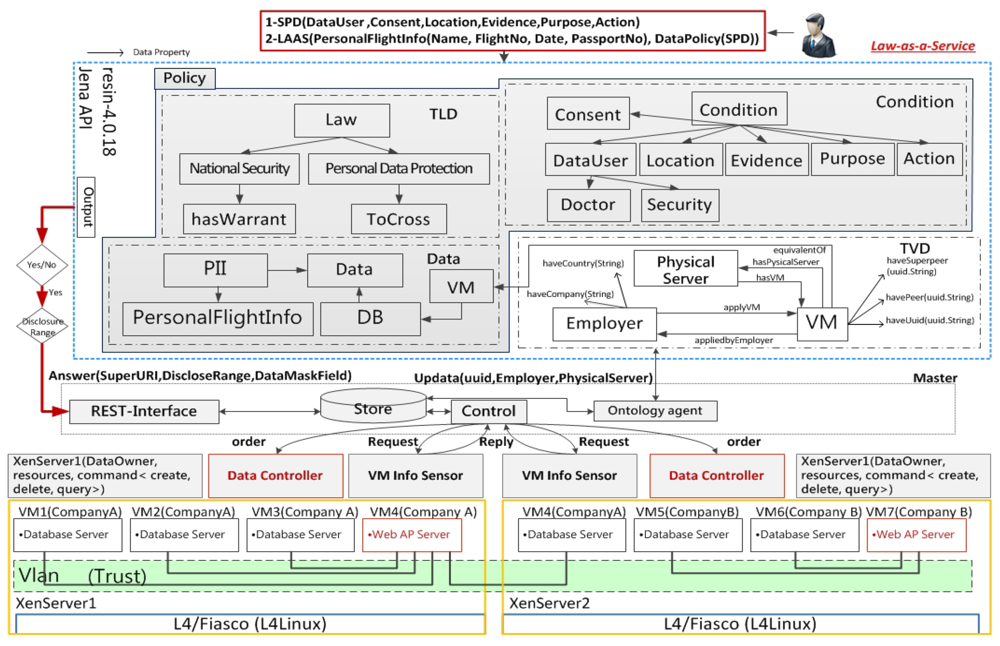
- The semantic data cloud offers LaaS for CSPs while integrating semantic data modeled as ontologies from multiple data sources. The law-aware semantic cloud services help CSPs spot and track infractions when they plan to deploy their resources and services. LaaS also provides CSPs with transparent updating semantic policies that are compliant with the most up-to-date laws.
- Ontologies and stratified Datalog rules with negation are used for representing semantic legal policies to enable query services for real cloud end-users. Semantic legal policies are manually unified but automatically enforced by the systems because metadata extracted from the semantic data cloud are used in deciding whether the integrated data satisfy the relevant legal policy’s preconditions. If the data usage context satisfies the preconditions, data are disclosed. Otherwise, they are hidden (or ¬disclosed).
3.1. A Pandemic Investigation Scenario
4. Semantic Super-Peer Data Cloud

4.1. Semantics of a TLD
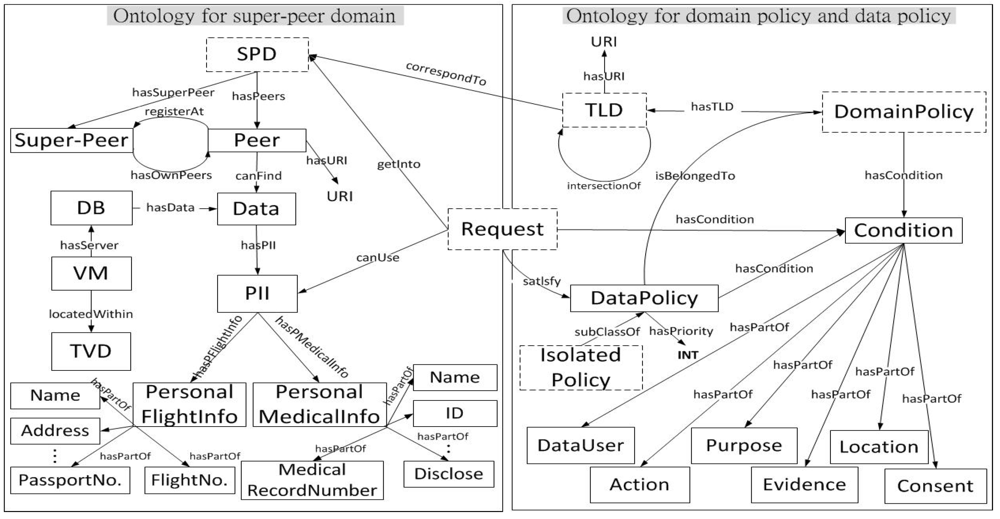
- An spα ∈ SPDα is the only node in an SPD πα, which allows an agentα to enforce semantic legal policies. This enforcement empowers agentα in an spα to facilitate information collection through a conjunctive query CQπα (spα) posed to the global schema GSα.A CQπα (spα) can be defined as a subset of the Datalog program, i.e.,a CQ containment problem, for querying the relational database [32].
- Through local LAV mapping assertions, a global schema GSα provides an integrated view for a set of peers from Pα in πα. We propose that every LAV assertion has the form VLSpeeri ⇝ CQπα (spα), where VLSpeeri provides the views of the CQπα (spα) over the global schema GSα at an spα for peeri.
- A set of peers from Pα are mediators. Peeri ∈ Pα maps its local ontology schema, LSpeeri, to a set of fragmented relational data sources, dsi, from DSα in πα. Therefore, a query uses unfolding GAV mapping assertions VLSpeeri ⇝ CQπα (DSα), where VLSpeeri is the vocabulary of an ontology local schema of peeri that maps to the SQL of CQπα (DSα) over a set of fragmented data sources, dsi, from DSα.
- A set of local mapping assertions, Mα, created from a mapping language, ML, are used to semantically link between spα and a set of peers from Pα in πα. The semantics of a set of global mapping assertions created from a Datalog rule language among super-peers are addressed in Section 4.2.
- A set of local data sources, dsi, from DSα, are fragmented relational structured data that store the materialized instances.
4.2. Semantics of Multiple TLDs
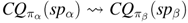
4.3. Semantic Data Exchange Between SPs


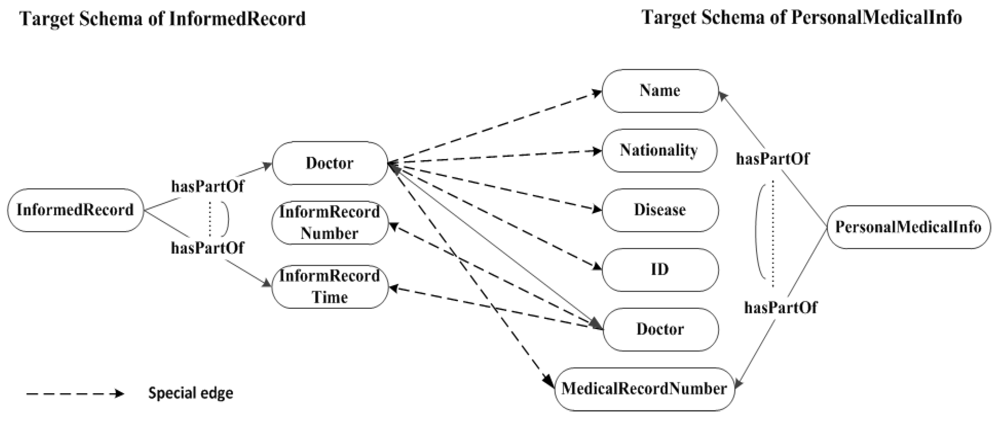
5. Semantic Legal Policies
5.1. Legal Policy Representation
5.2. Legal Policy Compliance
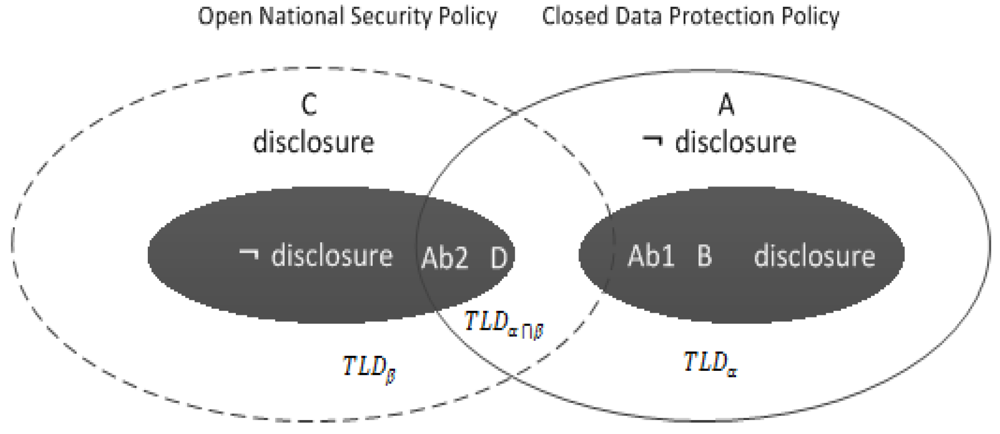
6. Unifying Semantic Legal Policies
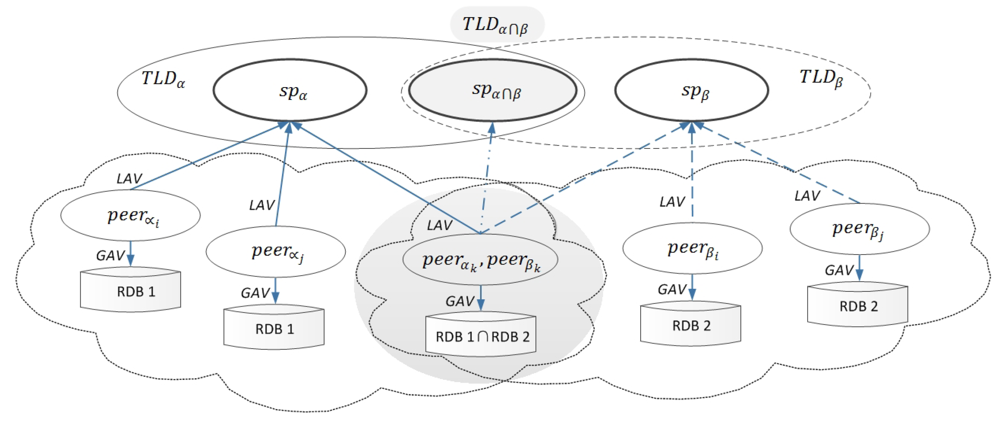
6.1. A Peer Registers at a TLD
6.2. Query at the TLDα∩β for Data Exchange
7. Semantic Legal Policy Enforcement
7.1. Semantic Data Outsourcing in an SPD

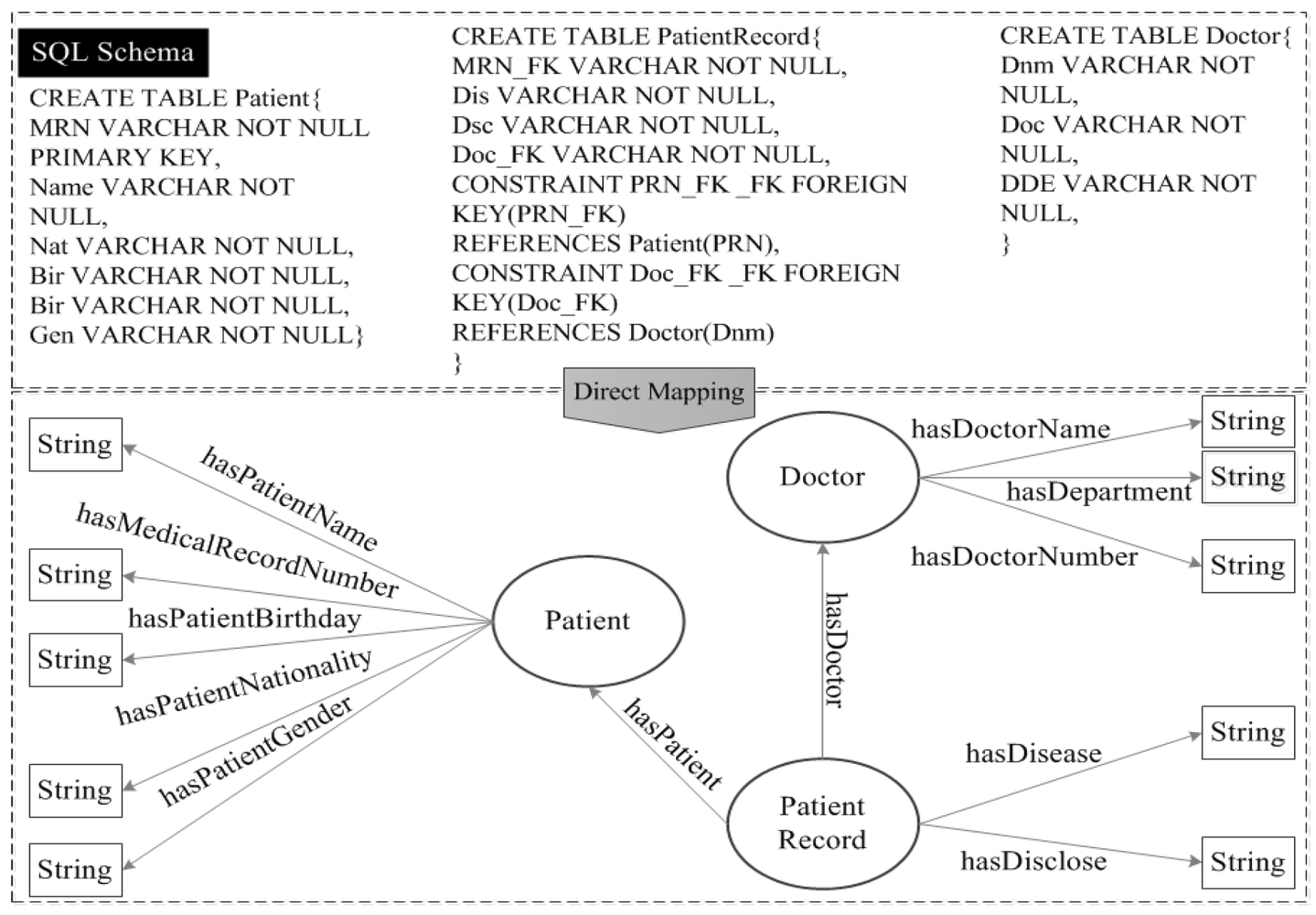

7.2. Legal Reasoning in SPDα
- hasTLD.DomainPolicy(dmp),
- hasTLD−.TLD(tld).
- hasCondition.DomainPolicy(dmp),
- hasCondition− .Condition(dmc).
- hasPartOf.Condition(dmc),
- hasPartOf− .Purpose(checkIn),
- hasPartOf− .DataUser(airlineStaff),
- hasPartOf− .Action(read).
- hasPartOf− .Location(TW),
- hasPartOf− .Consent(T).
- 1 hasSuperPeer− .Super − Peer(sp),
- hasPeers.Peer(p),
- registerAt.Peer(p),
- registerAt− .Super − Peer(sp).


- satisfy.Request(r),
- satisfy−.DataPolicy(dap).
- canFind.Peer(p),
- canFind−.PII(pii).
- isBelongedTo.DataPolicy(dap),
- isBelongedTo−.DomainPolicy(dmp).
- hasPII.Data(da),
- hasPII−.PII(pii),
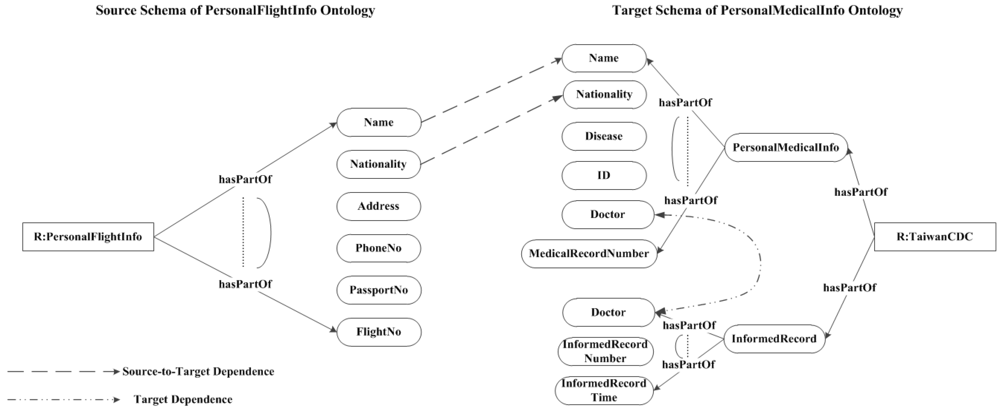
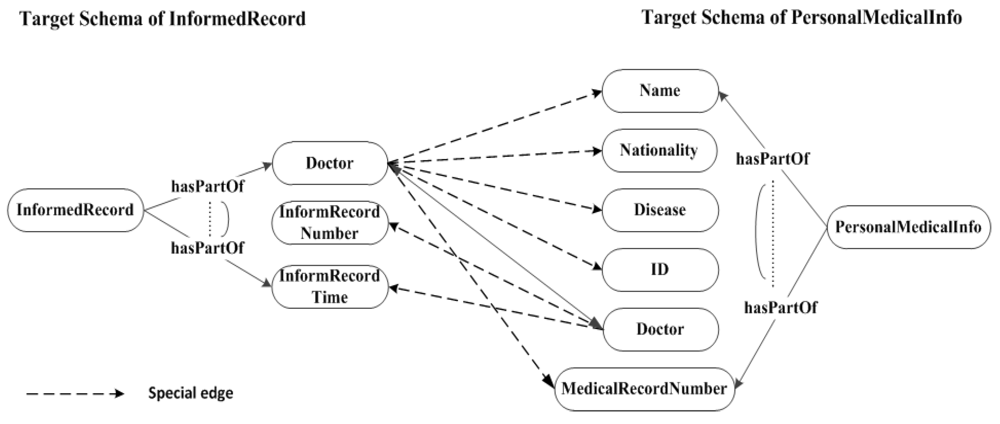
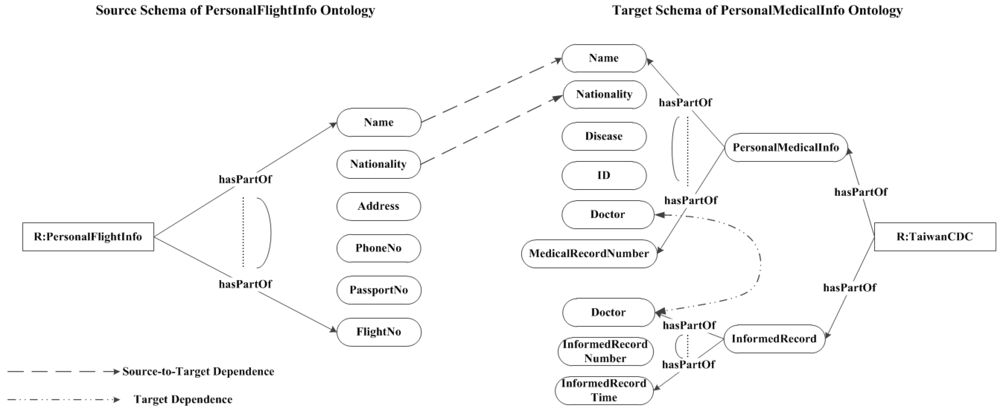
- hasPFlightInfo.PII(pii),
- hasPFlightInfo−.PersonalFlightInfo(fInfo).
- hasPartOf.PersonalFlightInfo(finfo),
- hasPartOf−.Name(name),
- hasPartOf−.PassportNo.(pano),
- hasPartOf−.Nationality(citizenship),
- hasPartOf−.FlightNo.(fno),
- hasPartOf−.Date(date).
- hasPartOf−.Address(addr).
- hasPartOf−.PhoneNo.(pono).


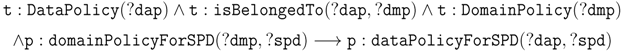

7.3. Policy Exceptions Handling
7.4. Non-Monotonic Reasoning in SPDα∩β


 inPIIdisclosure is the update list of form PII¬disclosure in Tα, where ⊎ (resp., ) increases PII¬disclosure (resp., PIIdisclosure). The answer set is Iωα = {inPII¬disclosure(Alice)}
inPIIdisclosure is the update list of form PII¬disclosure in Tα, where ⊎ (resp., ) increases PII¬disclosure (resp., PIIdisclosure). The answer set is Iωα = {inPII¬disclosure(Alice)}
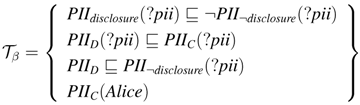
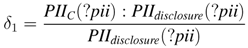
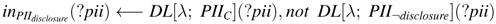 inPII¬disclosure is the update lists of form PIIdisclosure in Tβ, where ⊎ (resp., ) increases PIIdisclosure (resp., PII¬disclosure). The answer set Iωβ = {inPII¬disclosure(Alice)}
inPII¬disclosure is the update lists of form PIIdisclosure in Tβ, where ⊎ (resp., ) increases PIIdisclosure (resp., PII¬disclosure). The answer set Iωβ = {inPII¬disclosure(Alice)}
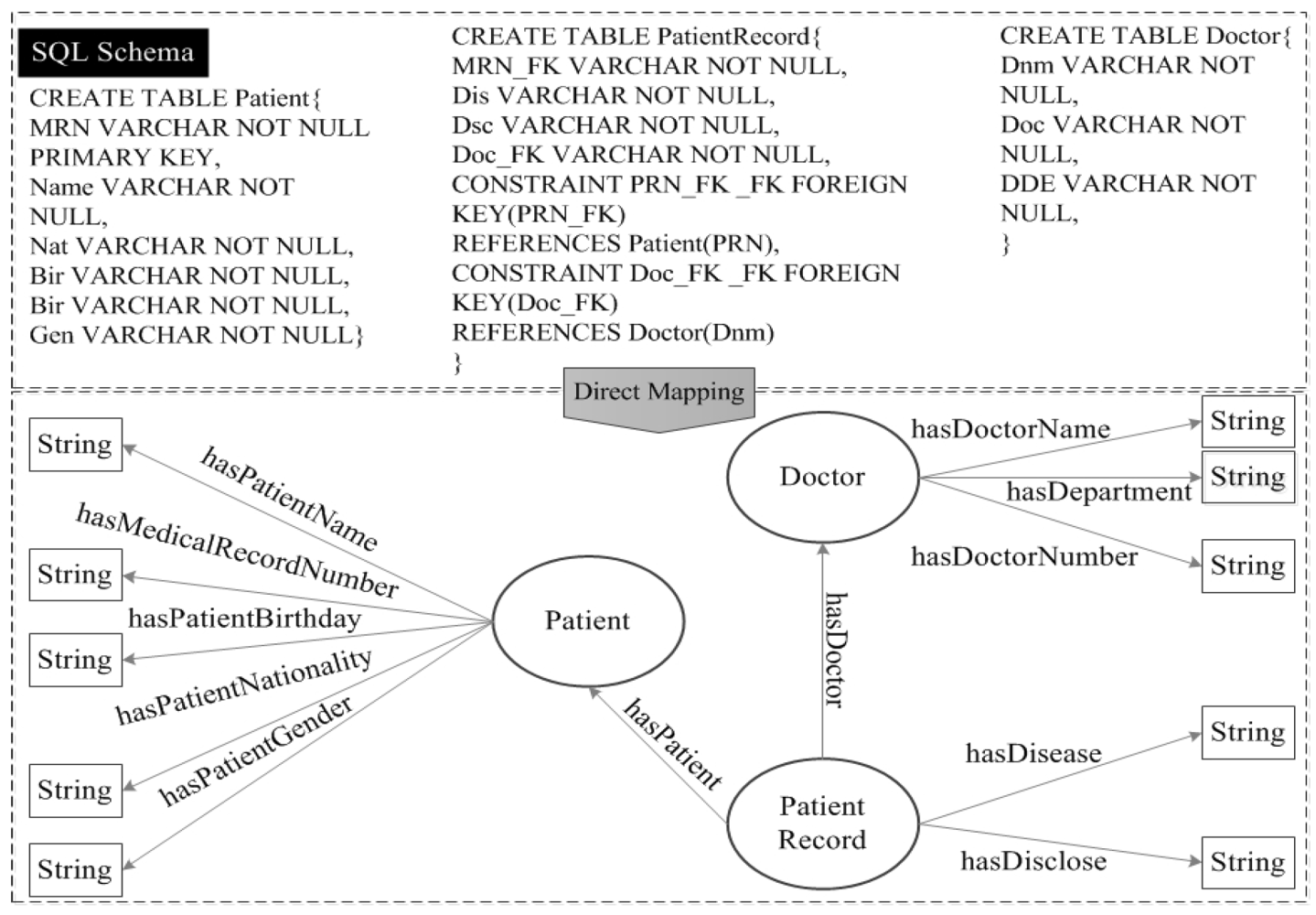
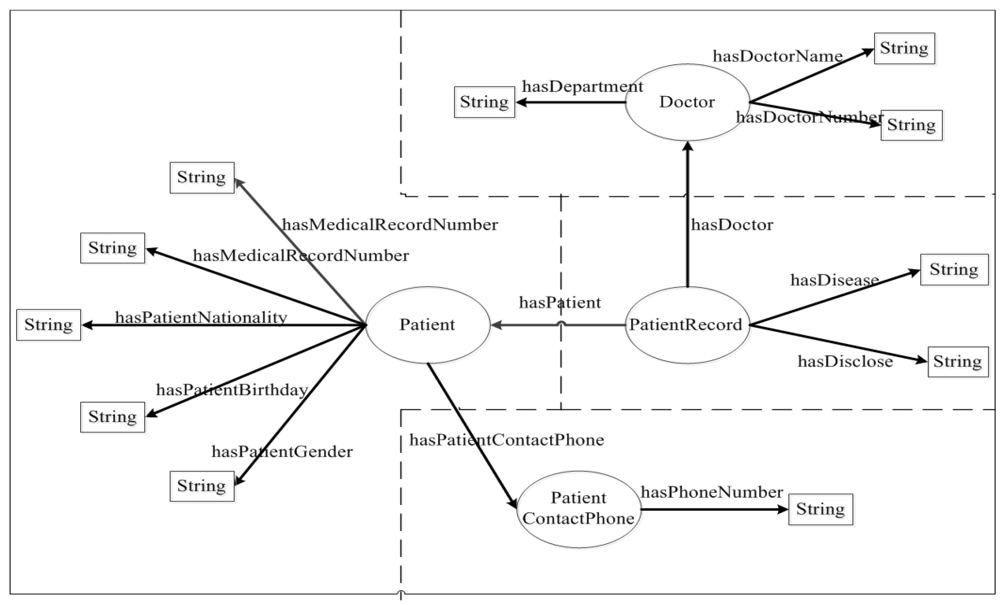
7.5. LaaS Implementation
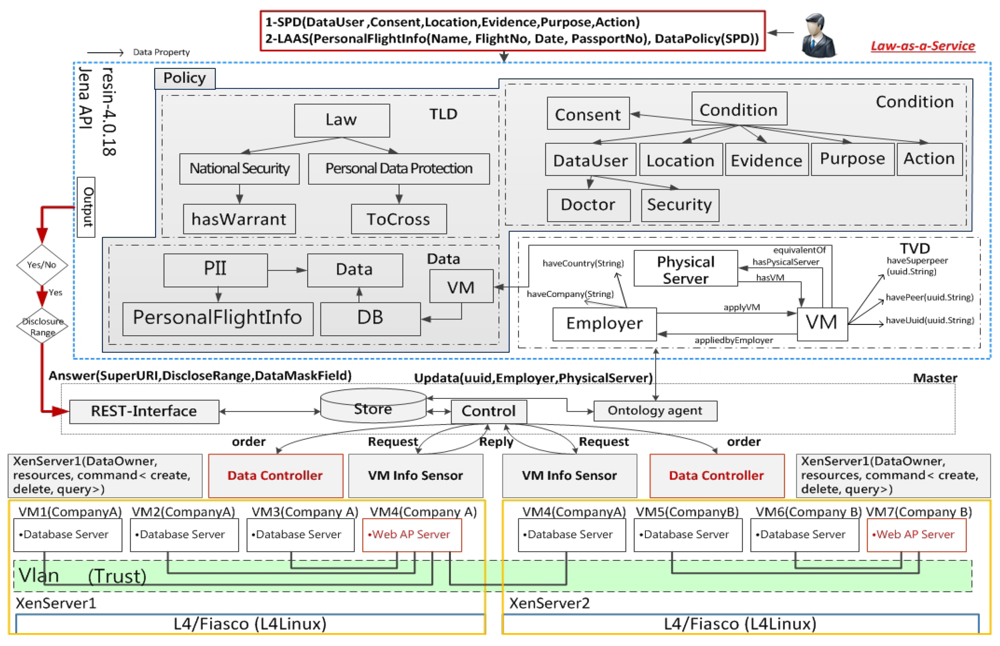
8. Related Work
9. Conclusions and Future Work
Acknowledgements
References
- Eberhart, A.; Haase, P.; Oberle, D.; Zacharias, V. Semantic technologies and cloud computing. In Foundations for the Web of Information and Services; Fensel, D., Ed.; Springer: Berlin, Germany, 2011; pp. 239–251. [Google Scholar]
- Abbadi, M.I. Self-managed services conceptual model in trustworthy clouds’ infrastructure. In Proceedings of Workshop on Cryptography and Security in Clouds, Zurich, Switzerland, 15–16 March 2011.
- Cabuk, S.; Dalton, C.I.; Eriksson, K.; Kuhlmann, D.; Ramasamy, H.V.; Ramunno, G.; Sadeghi, A.R.; Schunter, M.; St¨uble, C. Towards automated security policy enforcement in multi-tenant virtual data centers. J. Comput. Secur. 2010, 18, 89–121. [Google Scholar]
- Calvanese, D.; de Giacomo, D.; Lenzerini, M.; Rosati, R. View-based query answering over description logic ontologies. In Proceedings of Eleventh International Conference on Principles of Knowledge Representation and Reasoning, Sydney, Australia, 16–19 September 2008.
- Bonatti, A.P. Datalog for security, privacy and trust. Datalog Reloaded 2011, 6702, 21–36. [Google Scholar]
- Hu, Y.J.; Wu, W.N.; Yang, J.J. Semantics-enabled policies for information sharing and protection in the cloud. Lect. Notes Comput. Sci. 2011, 6984, 198–211. [Google Scholar]
- Hu, Y.J.; Wu, W.N.; Cheng, D.R. Towards law-aware semantic cloud policies with exceptions for data integration and protection. In Proceedings of International Conference on Web Intelligence, Mining and Semantics (WIMS12), Craiova, Romania, 13–15 June 2012.
- Popp, R.; Poindexter, J. Countering terrorism through information and privacy protection technologies. IEEE Secur. Priv. 2006, 4, 24–33. [Google Scholar]
- Peter Fleischer’s Blog: Which Privacy Laws Should Apply on the Global Internet? Available online: http://peterfleischer.blogspot.com (accessed on 19 October 2012).
- Pollock, L.J. Defeasible reasoning. In Reasoning: Studies of Human Inference and Its Foundations; Adler, J., Rips, L., Eds.; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Drabent, W.; Eiter, T.; Ianni, G.; Krennwallner, T.; Lukasiewicz, T.; Mauszynski, J. Hybrid reasoning with rules and ontologies. Semant. Tech. Web 2009, 5500, 1–49. [Google Scholar]
- Calvanese, D.; de Giacomo, G.; Lembo, D.; Lenzerini, M.; Rosati, R. Data Management in Peer-to-Peer Data Integration Systems; IOS Press: Amsterdam, The Netherlands, 2006; pp. 177–201. [Google Scholar]
- Halevy, A.; Ives, Z.G.; Madhavan, J.; Mork, P.; Suciu, D.; Tatarinov, I. The Piazza Peer data management system. IEEE Trans. Knowled. Data Eng. 2004, 16, 787–798. [Google Scholar] [CrossRef]
- Madhavan, J.; Jeffery, S.R.; Cohen, S.; Dong, X.; Ko, D.; Yu, C.; Halevy, A. Web-scale data integration: You can only afford to pay as you go. In Proceedings of Third Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 7–10 January 2007.
- Halevy, Y.A. Answering queries using views: A survey. VLDB J. 2001, 10, 270–294. [Google Scholar] [CrossRef]
- Lenzerini, M. Data integration: A theoretical perspective. In Proceedings of the ACM Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002.
- Friedman, M.; Levy, A.; Millstein, T. Navigational plans for data integration. In Proceedings of the 16th National Conference on Artificial Intelligence, Orlando, Fl ,USA, 19–22 July 1999.
- Faigin, R.; Kolaitis, P.G.; Miller, R.J.; Popa, L. Data exchange: Semantics and query answering. Theor. Comput. Sci. 2005, 336, 89–124. [Google Scholar] [CrossRef]
- Clifton, C.; Kantarcioğlu, M.; Doan, A.; Schadow, G.; Vaidya, J.; Elmagarmid, A.; Suciu, D. Privacy-preserving data integration and sharing. In Proceedings of 9th ACM SIGMOD workshop on Research issues in data mining and knowledge discovery, Paris, France, 13 June 2004.
- Nash, A.; Deutsch, A. Privacy in GLAV Information integration. Lect. Notes Comput. Sci. 2006, 4353, 89–103. [Google Scholar]
- Ceri, S.; Gottlob, G.; Tanca, L. What you always wanted to know about Datalog (and never dared to ask). IEEE Trans. Knowl. Data Eng. 1989, 1, 146–166. [Google Scholar] [CrossRef]
- Meditskos, G.; Bassilliades, N. Rule-based OWL ontology reasoning systems: Implementations, strength, and weakness. In Handbook of Research on Emerging Rule-Based Languages and Technologies: Open Solutions and Approaches; IGI Global: Hershey, PA, USA, 2009; pp. 124–148. [Google Scholar]
- Dao-Tran, M.; Eiter, T.; Krennwallner, T. Realizing default logic over description logic knowledge bases. Lect. Notes Comput. Sci. 2009, 5590, 602–613. [Google Scholar]
- Antoniou, G. Nonmontonic Reasoning; The MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Brewka, G. Reasoning about priorities in default logic. In Proceedings of 12th National Conference on Artificial Intelligence, Seattle, WA, USA, 31 July–4 August 2012.
- Weitzner, J.D.; Hendler, J. Creating a policy-aware web: Discretionary, rule-based access for the World Wide Web. In Web and Information Security; Ferrari, E., Thuraisingham, B., Eds.; IGI Global: Hershey, PA, USA, 2006; pp. 1–31. [Google Scholar]
- Halevy, A.; Ives, Z.G.; Suciu, D.; Tatarinov, I. Schema mediation in peer data management systems. In Proceedings of 19th International Conference on Data Engineering (ICDE), Bangalore, India, 5–8 March 2003; pp. 505–516.
- Beneventano, D.; Bergamaschi, S.; Guerra, F.; Vincini, M. Querying a super-peer in a schema-based super-peer network. Lect. Notes Comput. Sci. 2007, 4125, 13–25. [Google Scholar]
- Euzenat, J.; Shvaiko, P. Ontology Matching; Springer: Berlin, Germany, 2007. [Google Scholar]
- Hu, Y.J.; Yang, J.J. A semantic privacy-preserving model for data sharing and integration. In Proceedings of International Conference on Web Intelligence, Mining and Semantics, Sogndal, Norway, 25–27 May 2011.
- Foresti, S. Preserving Privacy in Data Outsourcing; Springer: Berlin, Germany, 2011. [Google Scholar]
- Goasdoue, F.; Rousset, M.C. Answering queries using views: A KRDB perspective for the semantic web. ACM Trans. on Internet Technol. 2004, 4, 255–288. [Google Scholar] [CrossRef]
- Di Vimercati, S.C.; Foresti, S.; Jajodia, S.; Samarati, P. Access control policies and languages in open environments. Adv. Inf. Secur. 2007, 33, 21–58. [Google Scholar] [CrossRef]
- Perry, J.W. Protecting Individual Privacy in the Struggle Against Terrorists: A Framework for Program Assessment; The National Academies Press: Washington, DC, USA, 2008. [Google Scholar]
- Deyrup, I.; Matthew, S. Cloud Computing and National Security Laws; Technical report; The Harvard Law National Security Research Group: Cambridge, MA, USA, 2010. [Google Scholar]
- Sequeda, F.J.; Tirmizi, S.H.; Corcho, O.; Miranker, D.P. Survey of directly mapping SQL databases to the Semantic Web. Knowl. Eng. Rev. 2011, 26, 445–486. [Google Scholar] [CrossRef]
- Haase, P.; Matha, T.; Schmidt, M.; Eberhart, A.; Walther, U. Semantic technologies for enterprise cloud management. Lect. Notes Comput. Sci. 6497, 98–113. [Google Scholar]
- Boer, A. Legal Theory: Sources of Law and the Semantic Web; IOS Press: Amsterdam, The Netherlands, 2009. [Google Scholar]
- Horrocks, I.; Patel-Schneider, P.F.; Boley, H.; Tabet, S.; Grosof, B.; Dean, M. SWRL: A semantic web rule language combing OWL and RuleML. World Wide Web. 2004. Available online: http://www.w3.org/Submission/SWRL/ (accessed on 19 October 2012).
- Hu, Y.J.; Boley, H. SemPIF: A semantic meta-policy interchange format for multiple web policies. In Proceedings of Web Intelligence and Intelligent Agent Technology (WI-IAT), Toronto, Canada, 31 August–3 September 2010; pp. 302–307.
- Barth, A.; Datta, A.; Mitchell, J.C.; Nissenbaum, H. Privacy and contextual integrity: Framework and applications. In Proceedings of IEEE Symposium on Security and Privacy, Oakland, CA, USA, 21–24 May 2006.
- Datta, A.; Blocki, J.; Christin, N.; DeYoung, H.; Garg, D.; Jia, L.; Kaynar, D.; Sinha, A. Understanding and protecting privacy: Formal semantics and principled audit mechanisms. Lect. Notes Comput. Sci. 2011, 7093, 1–27. [Google Scholar]
- Cali, A.; Gottlob, G.; Lukasiewicz, T.; Marnette, B.; Pieris, A. Datalog+−: A family of logical knowledge representation and query languages for new applications: Keynote lecture. In Proceedings of 25th annual IEEE Symposium on Logic in Computer Science, Edinburgh, UK, 11–14 July 2010.
- Gordon, F.T. The Legal Knowledge Interchange Format (LKIF); Technical report, Deliverable D4.1.; The European project for Standardized Transparent Representations in order to Extend Legal Accessibility (ESTRELLA): Amsterdam, The Netherlands, 2008. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Hu, Y.-J.; Wu, W.-N.; Cheng, K.-P.; Huang, Y.-L. Semantic Legal Policies for Data Exchange and Protection across Super-Peer Domains in the Cloud. Future Internet 2012, 4, 929-954. https://doi.org/10.3390/fi4040929
Hu Y-J, Wu W-N, Cheng K-P, Huang Y-L. Semantic Legal Policies for Data Exchange and Protection across Super-Peer Domains in the Cloud. Future Internet. 2012; 4(4):929-954. https://doi.org/10.3390/fi4040929
Chicago/Turabian StyleHu, Yuh-Jong, Win-Nan Wu, Kua-Ping Cheng, and Ya-Ling Huang. 2012. "Semantic Legal Policies for Data Exchange and Protection across Super-Peer Domains in the Cloud" Future Internet 4, no. 4: 929-954. https://doi.org/10.3390/fi4040929