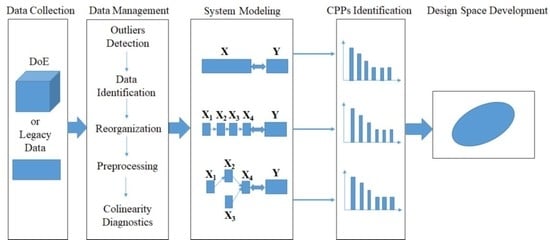
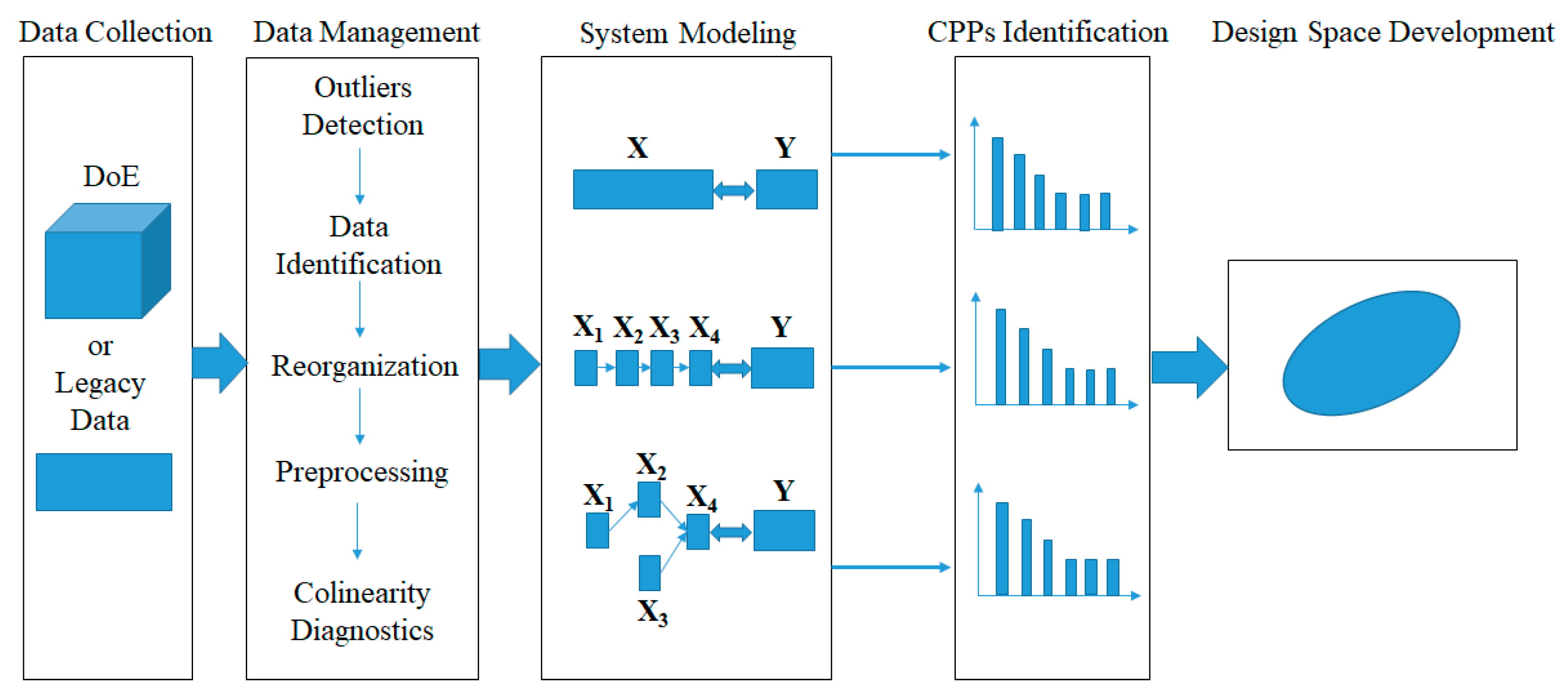
2.1.1. A Novel Framework to Develop the Design Space across Multi-Unit Operation Pharmaceutical Processes
As displayed in
Figure 2, a systematic procedure to establish a design space that spans multi-unit operation processes in a line includes the following activities: (1) data collection; (2) data preprocessing; (3) system modeling; (4) CPPs identification; and (5) design space development.
(1) Data Collection
The first step of the proposed framework is data collection. Generally, DoE is considered one of the most useful tools for the development of design space. Besides, a massive amount of data is generated and collected during the lifecycle of pharmaceutical products. Pharmaceutical companies can also benefit from better management of legacy data, from which useful information can be extracted for process understanding, process monitoring and process control.
(2) Data Management
Data management is crucial for the entire procedure despite its time-consuming nature. The objective of this step is to arrange the available data into different blocks that match the process flow-sheet as closely as possible. The main operations include outlier detection, identifying inputs and outputs of each unit operation, reorganizing the available data into different blocks, data preprocessing, and collinearity diagnostics.
Before analysis, outliers should be detected and eliminated from the data set as they may affect the performance of the process model in the subsequent analysis. Generally, the input variables of unit operation are material properties and manipulated process parameters whereas the output variables always represent the intermediate and final product properties and process measurements. After identification of the input and output variables, different data blocks are divided according to the unit operation or the variable types. Due to the dimensional differences in the collected variables and unhelpful information in the available data, it is essential to conduct data pretreatment before performing the subsequent analysis. Mean centering and unit variance are common preprocessing methods for the material and process data, while multiplicative scatter correction (MSC) and other smoothing methods [
43] are usually used for spectral data. In addition, the collinearity among the variables should be evaluated to determine a suitable modeling algorithm to deal with this problem.
(3) System Modeling and CPPs Identification
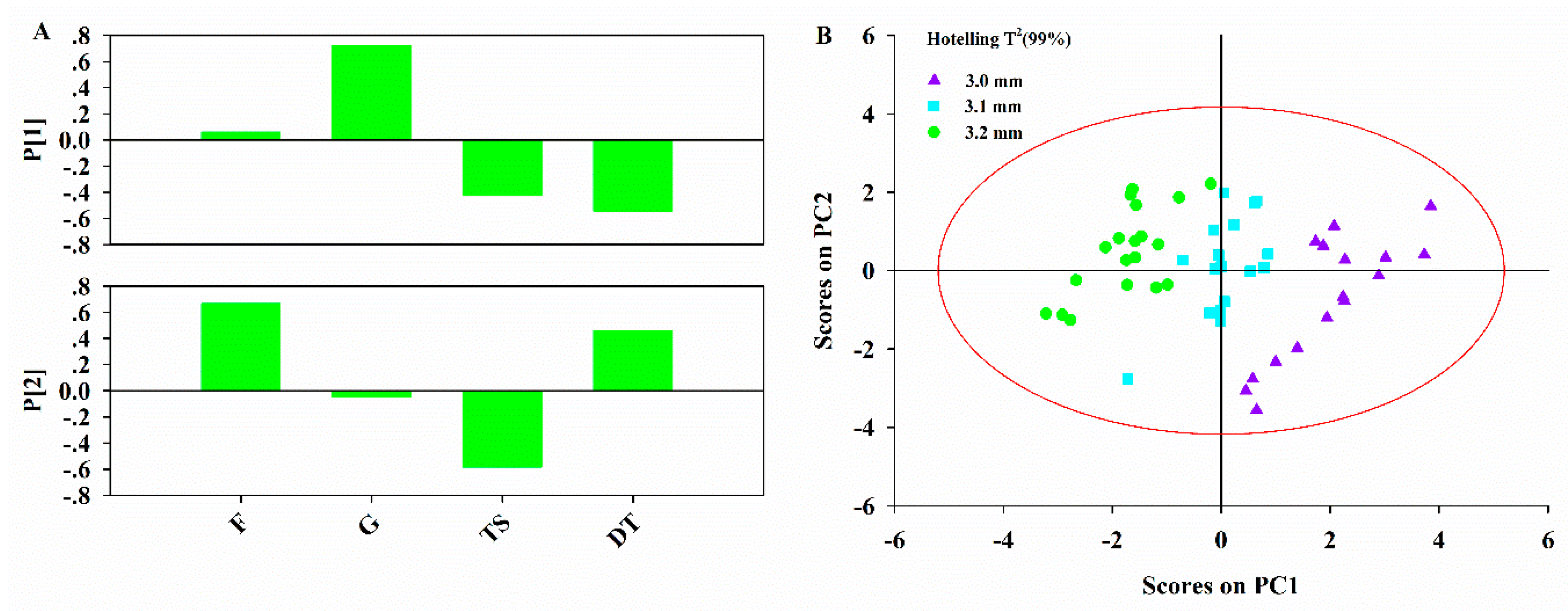
The third step of the proposed framework is to model the pharmaceutical manufacturing process system to obtain a comprehensive understanding of the process. Under the QbD principle, the process is generally considered to be well understood when (1) all critical sources of variability are identified and explained; (2) variability is managed by the process; and (3) product quality attributes can be accurately and reliably predicted [
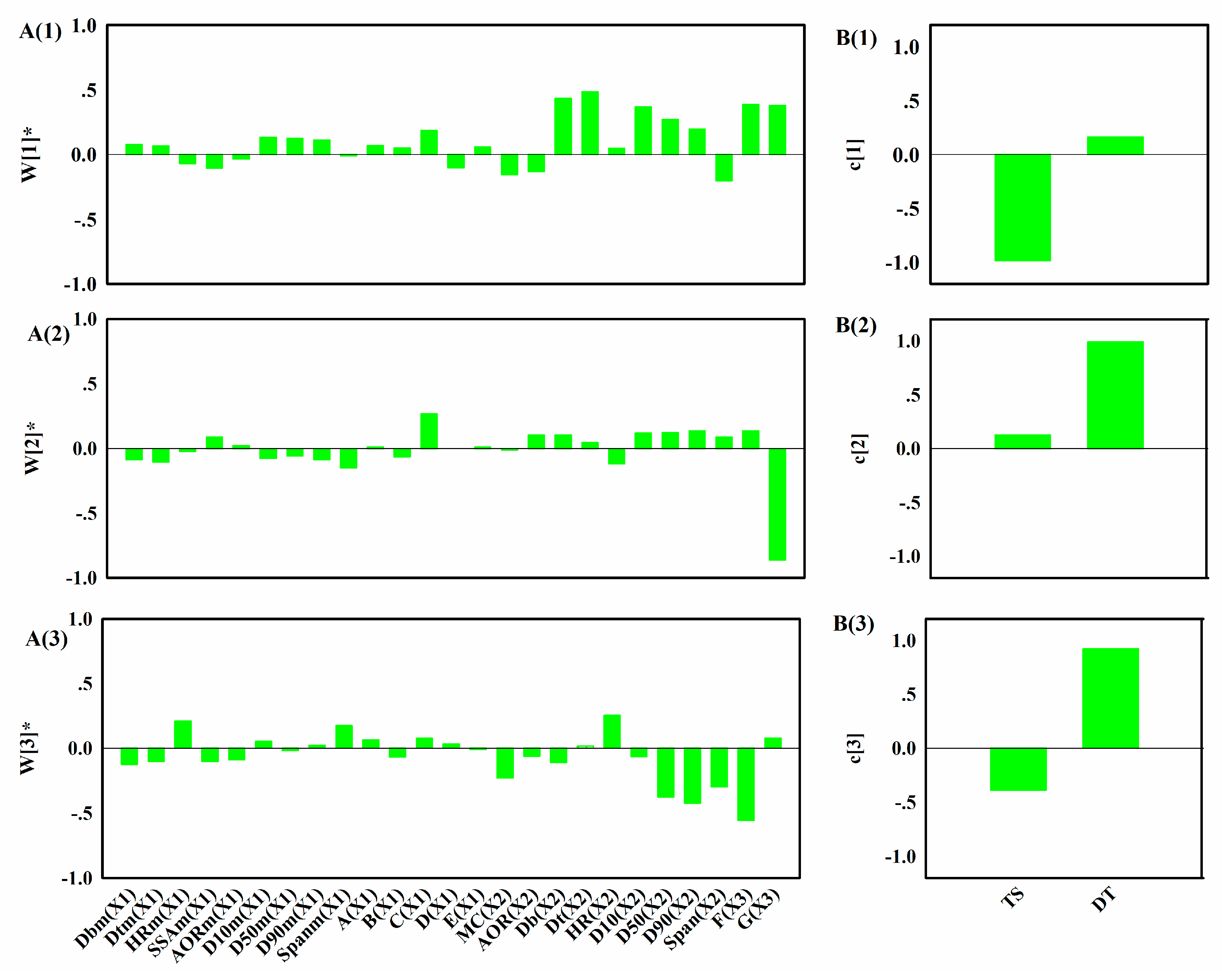
44]. Therefore, the main aim of this step is to study how the variables in different units are related and interact, in order to illustrate how the downstream units or intermediate and final product properties are affected by the raw materials properties or process parameters in the upstream units. Hence, it is helpful to perform an exploratory analysis on each data block to understand the driving forces acting on each unit operation. Principal component analysis (PCA) is an effective tool to this end. Then the critical process units (CPUs) in the manufacturing line, as well as the CMAs or the CPPs in each unit can be determined through the process system model. The target can be realized through multi-block analysis such as multi-block principal component analysis (MBPCA) or MBPLS. Interpretation of the parameters in the system model can help to identify correlations among the variables of different blocks. Loadings of the model indicate which process parameters and attributes affect product quality and estimate their contribution to quality [
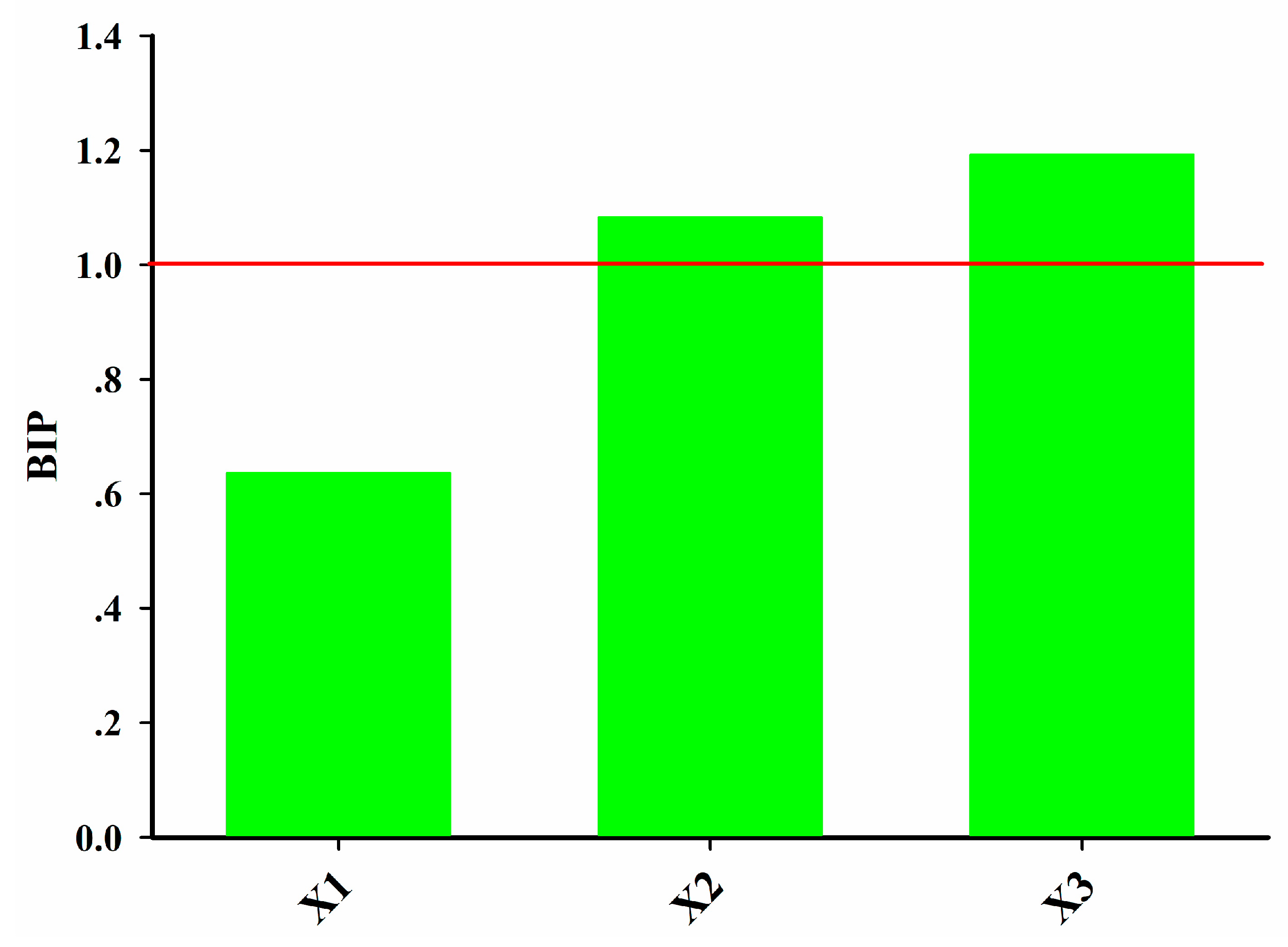
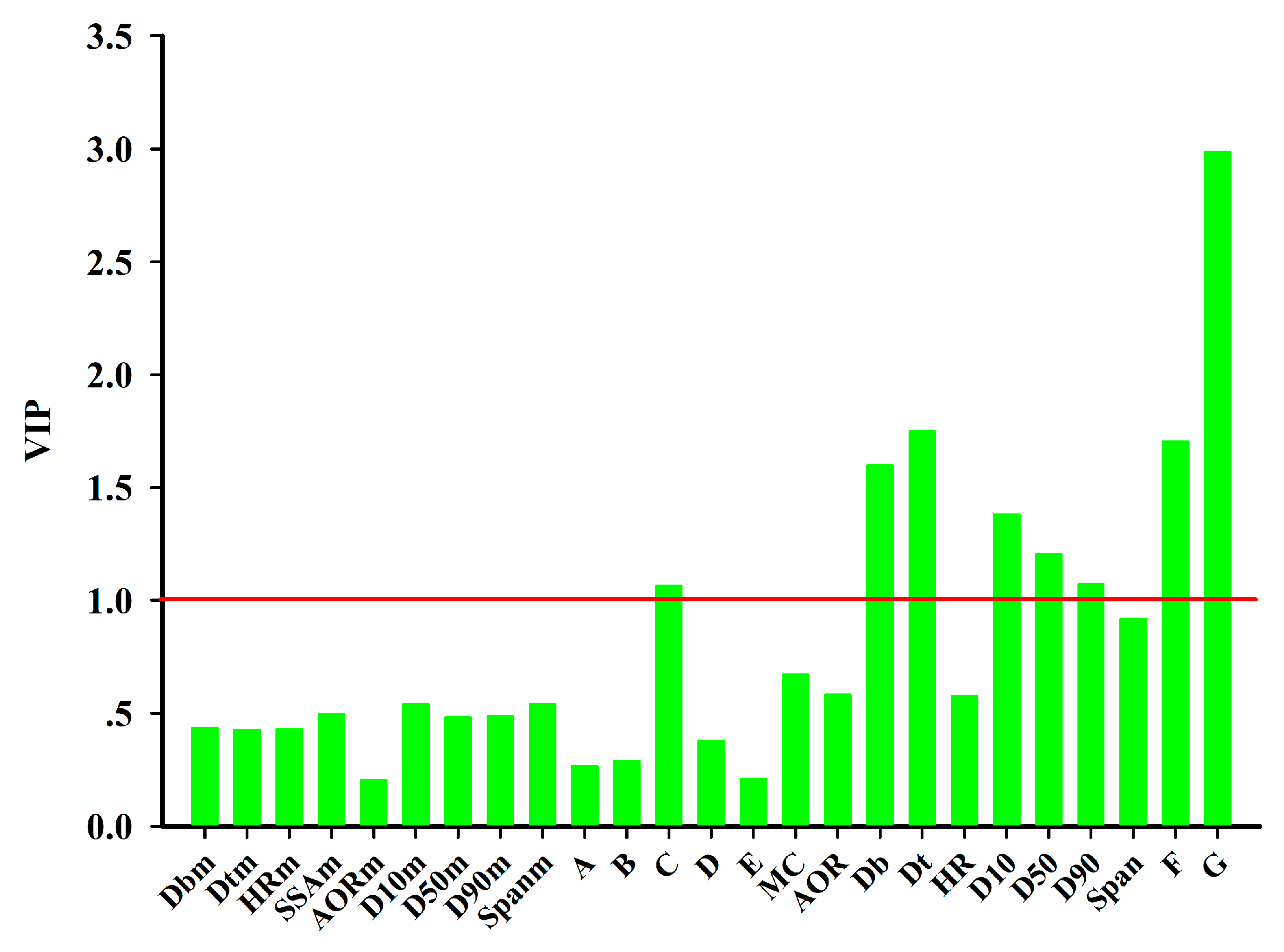
45]. The variable importance in the projection (VIP) [
46] helps identify the CPPs that contribute most to the product quality.
(4) Design Space Development
The final step of the framework is to develop a design space that spans the multi-unit operation process. An independent design space can be established for one or more-unit operations, and a single design space covering a series of successive unit operations is also acceptable. While a separate design space for each unit operation is easier to develop, an integrated design space that spans the entire process offers more operational flexibility because the type and location of the control action can be decided based on knowledge of the interactions of parameters between unit operations. Problems at the later stage can be anticipated and corrected at an early stage of the process.
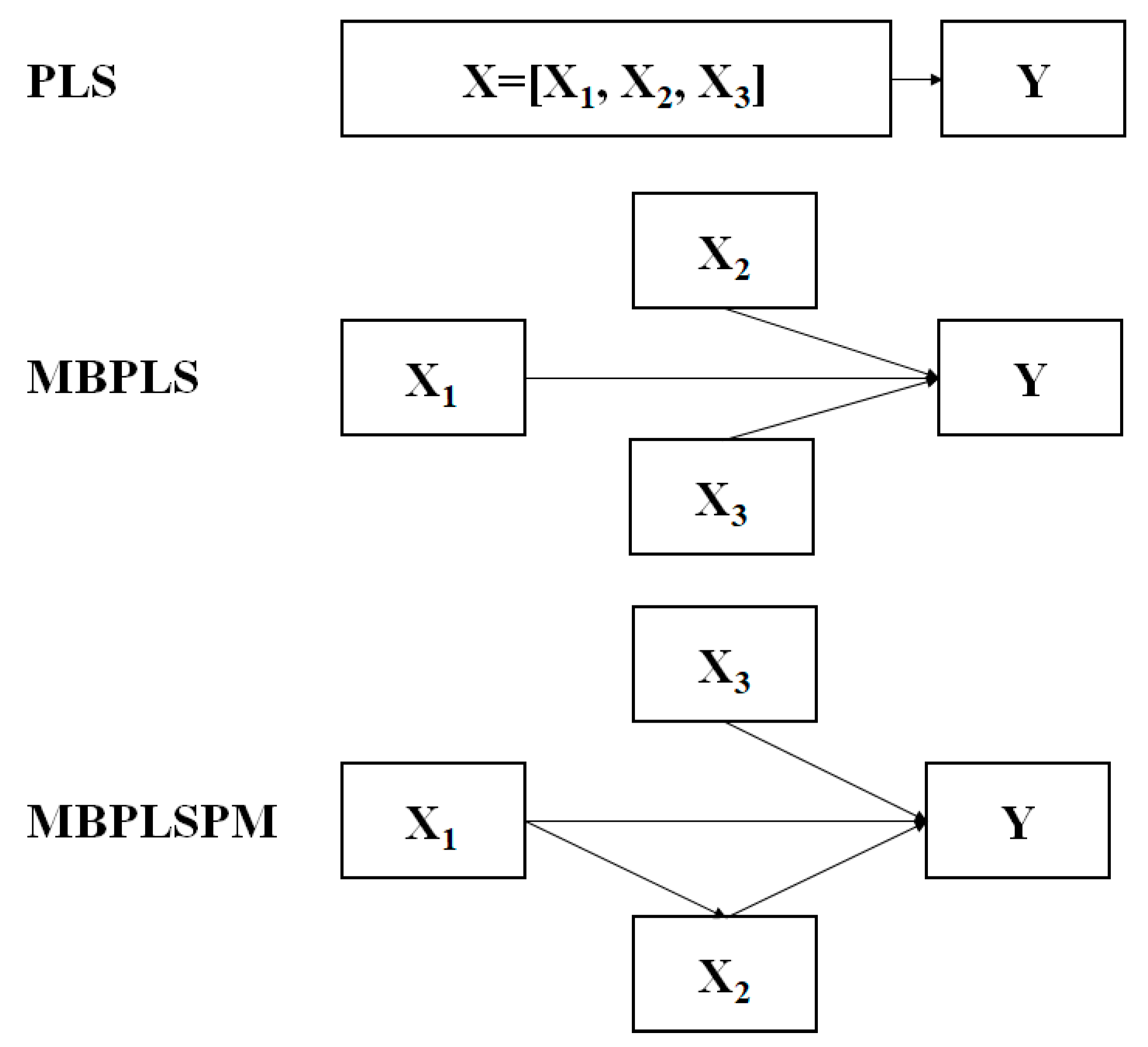
2.1.3. Multi-Block Partial Least Squares (MBPLS)
MBPLS is an extension of PLS to analyze the complex multivariate relationships among a set of data blocks [
47]. Wold et al. originally developed and presented the main features of the MBPLS algorithm [
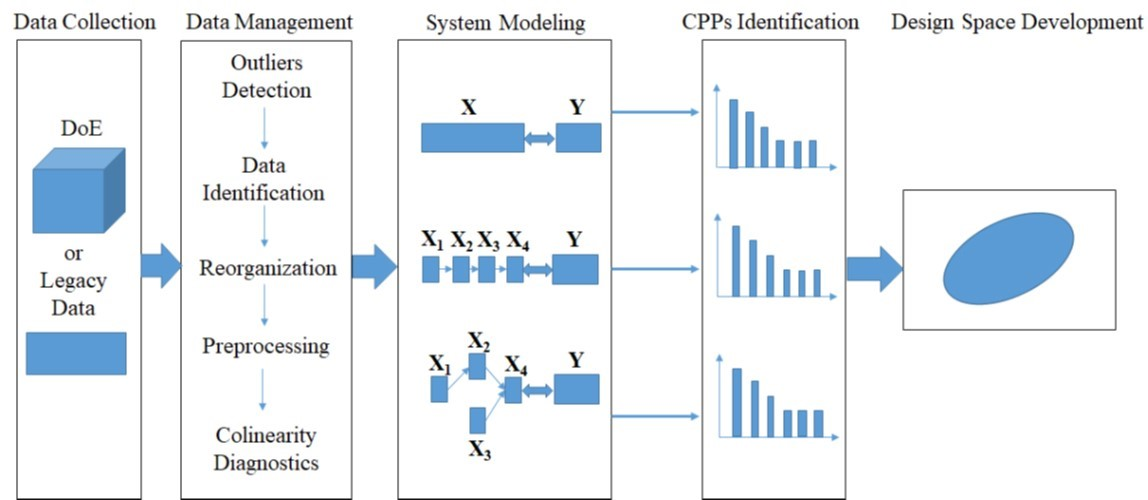
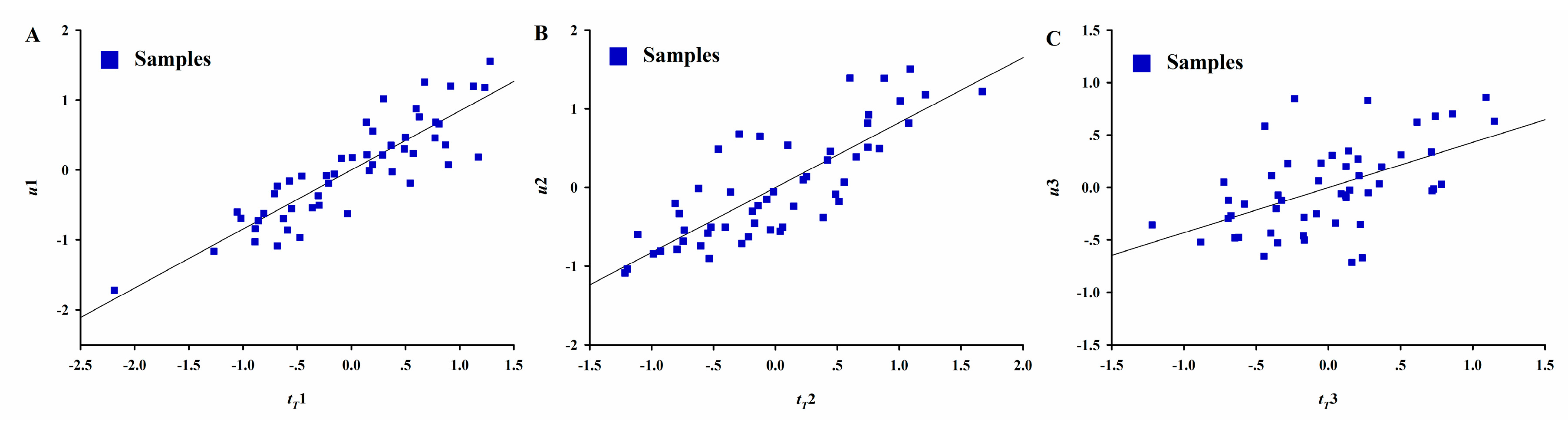
48]. Later, two varieties of the MBPLS algorithm were reported. One used the block scores to calculate the loadings and residuals, while the other used the super scores. In this study, four data blocks (
X1,
X2,
X3, and
Y) were used to construct the MBPLS model (
Figure 3) based on the later version. The MBPLS model is illustrated as follows:
In Equations (4)–(7), Ts refers to the super scores; P1, P2, and P3 refer to the loadings of matrix X1, X2, and X3, respectively; E1, E2, and E3 refer to the residuals of matrix X1, X2, and X3, respectively; Q refers to the loadings of matrix Y; F refers to the residuals of matrix Y.
2.1.4. Multi-Block Partial Least Squares Path Model (MBPLSPM)
The MBPLSPM algorithm is a general form of the MBPLS algorithm. It was first proposed by Wangen and Kowalski [
49]. This algorithm can be able to handle most types of relationships between different blocks and constitutes a significant advancement in the modeling of complex process systems [
49]. The details of this algorithm were introduced in [
49]. In this study, four data blocks (
X1,
X2,
X3, and
Y) were used to realize the MPLSPM. The pathway between different data blocks is shown in
Figure 3. The MBPLSPM is assumed to be logically specified from left to right, where the left end blocks, namely, predictor blocks (e.g.,
X1 and
X3), only predict and the right end blocks (e.g.,
Y), namely, predictee blocks, are only predicted. The blocks in the middle, namely, interior blocks (e.g.,
X2), are both predictor blocks and predictee blocks.
The calculation procedure to construct the MBPLSPM is divided into a backward phase, where predictor vectors are calculated, and a forward phase for predictee vectors. The phase alternates until the predictee vector converges. The first step is to scale each block. Then, initialization of t and u vectors for X1, X2, and X3 are selected.
In the backward phase, the scores of
X1,
X2 and
X3 are calculated. Since
X2 and
X3 only predict
Y, the
tX2 and
tX3 can be calculated as Equations (8)–(11):
where
wX2 and
wX3 are weights of
X2 and
X3.
X1 predicts both
X3 and
Y. To calculate
tX1, which predicts both blocks
X3 and
Y, a superblock
U that contains
uX3 and
uY is defined.
tX1 is calculated as follows:
In Equations (12)–(16), cU is the weight of U, uU is the score of U, wX1 is the weight of X1.
In the forward phase, the scores of
X3 and
Y are determined.
X3 is only predicted by
X1, so
uX3 can be directly calculated as follows:
In Equations (17)–(18), cX3 is the weights of X3.
Y is predicted by X1, X2, and X3. A superblock T is defined which consists of tX1, tX2, and tX3.
Assuming
wT and
cY are the weights of
T and
Y,
uY can be calculated.
After completing one cycle of the backward and forward phase, uY is tested for convergence within a desired precision (e.g., 10−8).
The loadings for predictor blocks (
p) and predictee blocks (
q) are calculated. As block scores
tX1,
tX2 and
tX3 are combined to calculate the super score
tT, there are two methods, namely, the block score update method and the super score update method, to calculate the loadings. In this case, the former is used for calculating loadings of block
X1, while the latter is used for block
X2 and
X3.
The regression coefficients (
b) are calculated for each block in the prediction.
In Equations (28) and (29), bX1→U and bT→Y are used to predict U and Y, respectively.
For interior block
X3, the regression coefficient used to determine the predictor and predictee part of
X3 is calculated in Equations (30) and (31).
Finally, assuming that
EX1,
EX2,
EX3, and
EY are residuals of
X1,
X2,
X3, and
Y, respectively, the residuals are calculated for each block.
In Equation (35), rX3 = bX1→X32/(bX1→X32 + bX3→Y2), sX32 = 1 − rX32, uX3 = bX1→X3 tX1.
In the next cycle for calculating the following scores and loadings, X1, X2, X3, and Y are replaced by EX1, EX2, EX3, and EY, respectively.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}