A Review of Statistical Failure Time Models with Application of a Discrete Hazard Based Model to 1Cr1Mo-0.25V Steel for Turbine Rotors and Shafts


College of Engineering, Swansea University, Fabian Way, Crymlyn Burrows, Wales SA1 8EN, UK
Materials 2017, 10(10), 1190; https://doi.org/10.3390/ma10101190
Submission received: 20 August 2017
/
Revised: 28 September 2017
/
Accepted: 12 October 2017
/
Published: 17 October 2017
(This article belongs to the Special Issue The Life of Materials at High Temperatures)
Abstract
:Producing predictions of the probabilistic risks of operating materials for given lengths of time at stated operating conditions requires the assimilation of existing deterministic creep life prediction models (that only predict the average failure time) with statistical models that capture the random component of creep. To date, these approaches have rarely been combined to achieve this objective. The first half of this paper therefore provides a summary review of some statistical models to help bridge the gap between these two approaches. The second half of the paper illustrates one possible assimilation using 1Cr1Mo-0.25V steel. The Wilshire equation for creep life prediction is integrated into a discrete hazard based statistical model—the former being chosen because of its novelty and proven capability in accurately predicting average failure times and the latter being chosen because of its flexibility in modelling the failure time distribution. Using this model it was found that, for example, if this material had been in operation for around 15 years at 823 K and 130 MPa, the chances of failure in the next year is around 35%. However, if this material had been in operation for around 25 years, the chance of failure in the next year rises dramatically to around 80%.
1. Introduction
The prediction of long-term creep properties from short timescale experiments is rated as the most important challenge to the UK Energy Sector in a recent UK Energy Materials Review [1]. Creep strain (ε) is a function not only of stress (τ) and absolute temperature (T), but also of time (t)
ε = f1(τ, T, t)
After an initial strain on loading, a decaying creep rate () during the primary stage of creep is followed by an accelerating strain during the tertiary stage. A minimum creep rate () occurs at the boundary of these two stages. As such, Equation (1a) is often represented in differential form
When it comes to extrapolating from short term accelerated test data, three very broad approaches can be identified. Whole creep curve methods work by relating the whole creep curve to the test conditions under which that creep curve was obtained. A single creep curve at steady uniaxial stress τ and absolute temperature T can be modelled using a general functional form
where η is some non-linear function and the Ψj are numerical parameters. At any one test condition, the Ψj parameters are constant, but they do vary systematically with the test conditions. It is this fact that enables creep curve predictions to be made
where gj are non-linear functions, and bj,k are additional numerical parameters that can be estimated using a suitable estimation technique. However, the form of the η and gj functions are not known and consequently the literature contains many representations of these including, for example, the Theta methodology proposed by Evans and Wilshire [2]
with
Whilst Evans [3] derived Equation (3a) from creep deformation mechanism theory, the all important extrapolation function given by Equation (3b) is mainly empirical in nature. There are many other approaches in the literature including those by McVetty [4], Garofalo [5], Ion et al. [6], Prager [7], Othman and Hayhurst [8], Kachanov [9] and Rabotnov [10].
Secondly, parametric techniques work by relating a measured point on the creep curve to the test conditions under which that measurement was made. This point is typically the minimum creep rate or the time to rupture. Around the minimum creep rate there remains a considerable period of time where remains more or less constant, so that Equation (1b) reduces to
with, following Monkman and Grant [11],
where here t represent the time at which failure occur. Because the functional form of f3 is not known the literature again contains many different representations of Equations (4a) and (4b). For example, Dorn [12] and Larson and Miller [13], both assumed that at a constant stress
where Qc is the activation energy in J/mol. These two approaches then diverge with the incorporation of stress with Dorn suggesting the parameter C0 varies with stress, whilst the Larson and Miller model has Qc varying with stress—but in both cases the form of the stress function was empirically specified (typically involving the use of polynomials in stress or the log of stress).
The literature contains many other variations including Manson and Haferd [14], Manson and Muraldihan [15], Manson and Brown [16] and Trunin et al. [17]. Unfortunately, all these parametric models suffer from parameter instability with respect to stress and temperature making reliable long term life predictions from accelerated short term testing impossible—as empirically illustrated by Abdallah et al. [18]. These empirical models are now quite old and, despite their known short comings, are still extensively used for safe life estimation. The hyperbolic tangent method [19] and the Wilshire Equation [20] can be seen as the most recent types of parametric model, with the later having the form
where R is the universal gas constant, τ* = ln(−ln(τ/τTS)) with τTS being the tensile strength. Unlike the above models, a raft of recent publications [21,22,23,24,25,26] on a wide range of high temperature materials have demonstrated the parameters of this model (b0, b1, and Qc) are stable and so reliable long term predictions have been made from this model using short term data of no more than 5000 h duration.
Finally, there are computational/numerical approaches that often incorporate detailed deformation mechanism into finite element code to obtain creep property predictions. Many of these numerical models are based on remaining life assessment with abridged accelerated testing. In some of these approaches, for example [27,28], uniaxial test specimens are cut from removed components that have been in service for over a long time (typically over 100,000 h) and re-tested under laboratory conditions for short times until failure occurs by accelerating the temperatures (but using the in service stress). Such testing yields the remaining life or useable residual life (around 60% of remaining life). The above parametric models are then used to predict/extrapolate these residual lives to operating temperatures. Often numerical models are used to extrapolate such abridged short-term testing. An alternative to this destructive approach is the non-destructive disc test, where small discs are taken from in service components without destroying their integrity. Again numerical models can be built for this disc test, e.g., Evans [29] or parametric procedures can be used for extrapolative purposes.
What all the above studies have in common however is that they are all deterministic in nature. As the level of stress increases the time to failure diminishes and the primary component of the creep curve becomes less pronounced. These variations in creep properties are governed by (as yet not fully understood) physical laws that can be used to determine creep properties at any test condition. These physical laws are embedded into the above mechanistic models that can then be used to explain variations in creep properties as a function of test conditions alone.
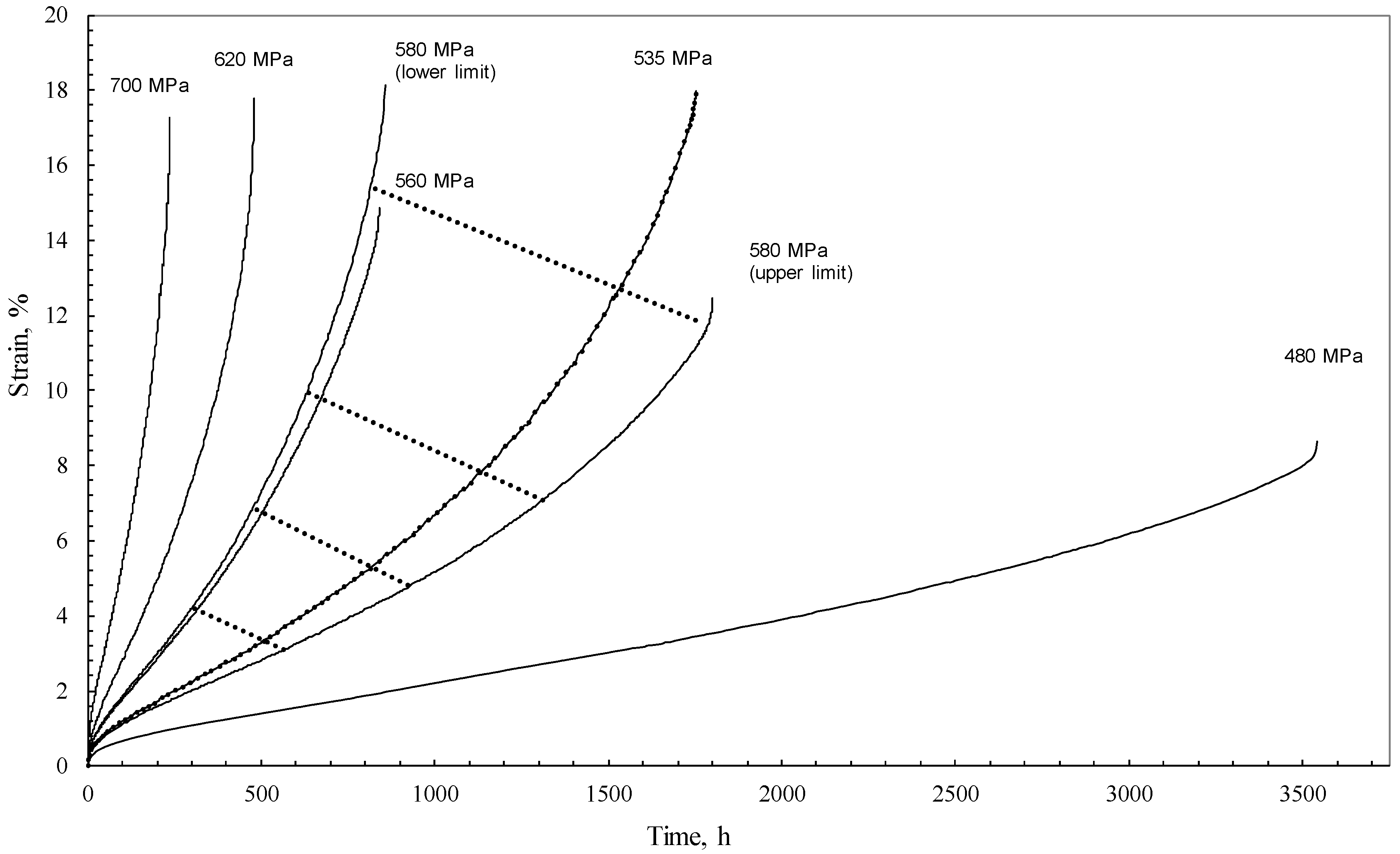
However, creep is not just a deterministic process that is predetermined by physical laws. It is also a random process. If the time function, f1, could be quantified, it could then be used to predict the strain at any time. Unfortunately, the nature of creep is such that this function could not then be used to predict the strain for another specimen tested under exactly the same conditions. This random component of creep is in turn very large. For example, in the NIMS [30] 1Cr-1Mo-0.25V steel database used in this paper, the time to failure at 773 K and 373 MPa varies between the limits of 125 h and 1360 h depending on the batch. A lot of the random variation seen in creep databases of this nature are down to variations in chemical composition and heat treatments experienced by the different batches of the test material. However, even when such factors are removed, failure times are still highly stochastic in nature. This was illustrated by Evans [31], who tested 15 specimens of Ti-6.2.4.6 at different temperatures and stresses. These test specimens were all cut from the same batch and tested within the same laboratory on the same make of calibrated uniaxial test apparatus. The results are reproduced in Figure 1 where it can be seen that the random variation is great enough to encompass variations induced by changes in stress.
This random component of creep is not just important because it is large in size, but also because if predictions are to be made for more than just the average time at failure, then this random component must be modelled with the same degree of vigour as displayed by all the above deterministic models. However, they are not. We can summarise the above as stating creep life has both a deterministic and a random component
where u is the random component and f4 is some function that describes how the random component is distributed.
The first aim of this paper is to address this shortcoming by providing a detailed, although by no means complete (as this is a very large subject area), review of statistical failure time models that describe different ways that f4(u) can be specified, so as to provide materials scientists with a framework for further developing their deterministic creep models, such as the Wilshire Equation, so that they become cable of providing predictions that have levels of confidence attached to them. It should be noted that these statistical models say nothing about the deterministic models reviewed above and do not imply that one model is any better at prediction than another. However, when a model of the random component is combined with the above deterministic components, they become more capable of predicting both the systematic variation with test conditions and the observed random variation at each test condition. Without this, the deterministic models can do no more than accurately predict the average safe life and not the safe life corresponding to say a 1% chance of failure. This review is provided in Section 3 of this paper and where appropriate illustrated using data on 1Cr-1Mo-0.25V steel.
The second aim of this paper is to illustrate one of the many ways that these deterministic and random component models can be combined. It is impossible in one paper to do an illustration for all of the above deterministic models reviewed above, and so the Wilshire model is selected for this purpose. This approach is selected because it has been shown to outperform the others in terms of accurately predicting the average time to failure beyond 100,000 h using very short term data (less than 5000 h). The Wilshire equation is combined with a discrete hazard based model for the random component. A hazard based model was chosen because it offers extra flexibility on distributional shape and form compared to other approaches as discussed in the review section below. Further, a discrete version of the hazard function is used because it helps empirically quantify the form of the hazard function (and because it has never been used within the context of creep failure before—whereas other approaches have [32]).
2. The Data
This present study features forged 1Cr-1Mo-0.25V steel for turbine rotors and shafts. For multiple batches of this bainitic product, both the creep and creep fracture properties have been documented comprehensively by the National Institute for Materials Science (NIMS), Japan [30]. NIMS creep data sheet No. 9B includes information on nine batches of as tempered 1Cr-1Mo-0.25V steel. Each batch of material had both a different chemical composition and a different thermal and processing history—details of which can be found in creep data sheet No. 9B. Specimens for the tensile and creep rupture tests were taken radially from the ring shaped samples which were removed from the turbine rotors. Each test specimen had a diameter of 10 mm with a gauge length of 50 mm. These specimens were tested at constant load over a wide range of conditions: 47–333 MPa and 723–923 K. In addition to failure time (t) measurements, values of the 0.2% proof stress (τY) and the ultimate tensile strength (τTS) determined from high strain rate (~10−3 s−1) tensile tests carried out at the creep temperatures for each batch of steel investigated were also reported.
3. Illustrated Review of Approaches to Modelling the Stochastic Nature of Creep Failure
3.1. A Statistical Description of Continuous Failure at Fixed Test Conditions
Due to batch to batch variations in chemistry and heat treatment and within batch variations in microstructure, creep failure times for a high temperature material (or indeed any given material), even under fixed test conditions, are stochastic in nature. Therefor such failure times need to be described through a random variable T. In reality, T can take on a large and continuous number of different values at a given test condition, t1, t2, …, tn, with 0 ≤ t1 ≤ t2 ≤ … ≤ tn. As such it cannot be known with certainty when failure will occur and so failure must be expressed using the survivor function which gives the probability of surviving beyond a certain length of time, S(t)
The probability of failing at or before a given length of time is then given by F(t) = 1 − S(t). The probability of failure in a very small increment of time, ∆t, is then f(t) = ∆F(t)/∆t. F(t) is often referred to as the cumulative distribution function (cdf) and its derivative, f(t), the probability density function (pdf).
The probability of failure can also be expressed through the hazard function. This function gives the rate of failure at time t, given the specimen survives up to time t
where |T ≥ t reads given that T is greater than or equal to t. As such, the hazard rate is a conditional probability of failure. A conditional probability is defined as P(A|B) = P(A and B)/P(B), where in terms of the hazard rate event B is the probability of surviving a length of time t and so equals S(t). Event A and B would then be the probability of failing in the small increment of time ∆t beyond t, which is the pdf at time t. Thus
If follows from these definitions that the hazard function can also be found from the survivor function using
and the cumulative (or integral) hazard function is given by
Approaches to estimating the survivor function generally fall under three headings: parametric, non-parametric and semi-parametric. The assumption behind the parametric approach is that the form of the survivor function can be captured through a small number of parameters. For example, if failure times at a fixed test condition are normally distributed, then the survivor function is fully defined through two parameters—the mean and the standard deviation. In contrast, the non-parametric approach is model (parameter) free and as such makes no assumptions about how failure times are distributed. The semi-parametric approach combines these two approaches, for example, by specifying a base line hazard function at a particular test condition non-parametrically and then using a few parameters to model how this baseline function changes with the test conditions.
3.1.1. Non-Parametric Estimation
The starting point for many non-parametric techniques is to partition time into j = 1 to k equal intervals, with k being as large as practically possible. If n equals the number of specimens placed on test at the same test condition and dj the number of specimens failing during the kth interval, then Kaplan and Meier [33] proposed the following estimator of the survivor function (for uncensored data) that has as its basis the binomial distribution
where dj is the number of failures in time interval j. This estimator is also referred to as the product-limit estimator as originally these authors justified this estimator based on its properties when k tended to infinity or as the time interval tended to zero.
Nelson [34] and Aalen [35] proposed the following non-parametric estimator of the cumulative hazard function
where rj is the total number of specimens at risk (or not yet failed) just prior to time ti. The Fleming-Harrington [36] estimator of the survivor function is, from Equations (7e) and (8b),
The above are of course estimates (designated by the hat symbol) of the survivor function computed in the above ways, but from a population or very large sample. The standard deviation of the above estimators provides a way to quantify the possible size of the difference between the true or population survivor function—S(t)—and that calculated from a small sample or a randomly selected sub set of the population. The standard deviation of these estimators are in turn estimated by
In large samples, these estimates are unbiased and the Nelson Aalen estimator is then also approximately normally distributed.
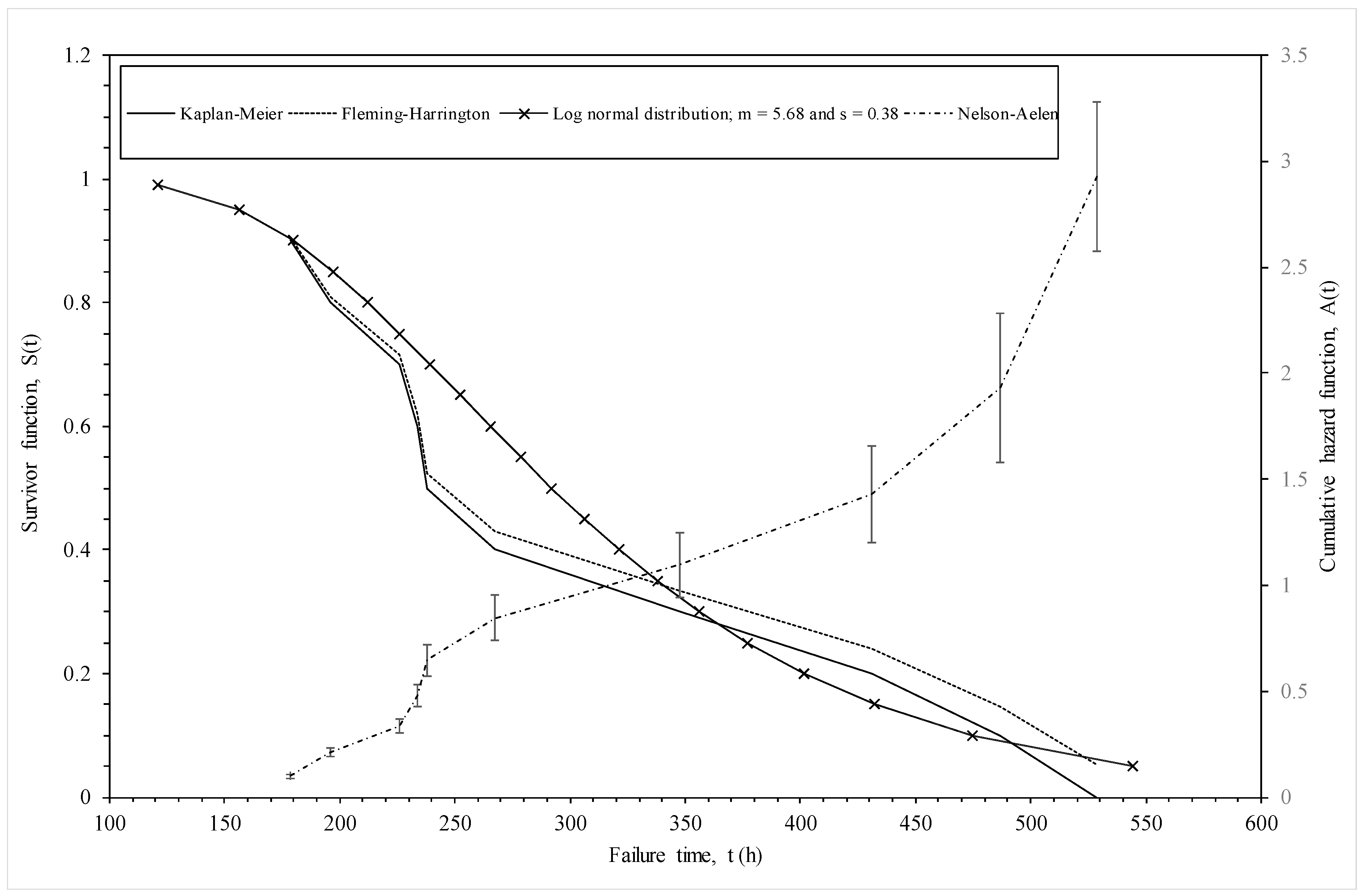
As an illustration, Figure 2 compares these non-parametric estimators of the survivor function for the 1Cr-1Mo-0.25V specimens in the NIMS dataset tested at 823 K and 294 MPa. At low times to failure the above two estimators provide very similar values for the survivor function, but these estimators start to diverge at around 250 h—with the Fleming-Harrington estimator exceeding the Kaplan-Meier estimator. The Nelson-Aalen estimator of the cumulative hazard function is shown on the right hand side vertical axis. The errors bars associated with the estimated cumulative hazard function, which are made equal to one standard deviation, are also shown. As can be seen, the standard error increases quite dramatically with the time to failure, making the estimates at high survival probabilities quite unreliable in a sample this small.
3.1.2. Parametric Estimation
Any distribution defined for t ∈ (0, ∞) can be used to specify parametric survivor and hazard rate functions. A good transformation for visualising many commonly used parametric distributions is the log transformation of failure time, Y = ln(T), with y ∈ (−∞, ∞). Then, a whole family of distributions for Y opens up by introducing location (via parameter μ) and scale (via parameter b) changes of the form
where, like T and Y, Z is a random (but standardised) variable, z ∈ (−∞, ∞). To prevent the occurrence of a degenerate distribution for large values of k1 and/or k2, the following re-parameterisation is used
where , σ = b/δ and where W is therefore another standardised random variable defined as W = δZ.
ln(T) = Y = μ + bZ
ln(T) = Y = μ + (b/δ)W = μ + σW
By specifying a very general distribution for Z, it is possible to identify many of the familiar failure time distributions used in failure time analysis. Prentice [37] and Kalbfleisch and Prentice [38] for example defined the probability density function for Z as
where Z is said to be distributed as the logarithm of an F random variable with 2k1 and 2k2 degrees of freedom. T is described as following a four parameter generalised F distribution, T ~ GENF(μ, σ, k1, k2). Г(k) is the gamma function at k. The Appendix A to this paper also shows that the pdf of this generalised gamma distribution can be re-parameterised as a function of time
where λ = exp(−μ) and β = 1/(δσ) = 1/b. Except, under some restricted values for k1 and k2, there is no closed form expression for the survivor and hazard functions, but they are related to the incomplete beta function and Appendix A shows how this can be computed using percentiles from the F distribution. Equation (9d) is however degenerate when k1 = k2 = ∞ and then a different specification of the pdf must be used (see Appendix A).
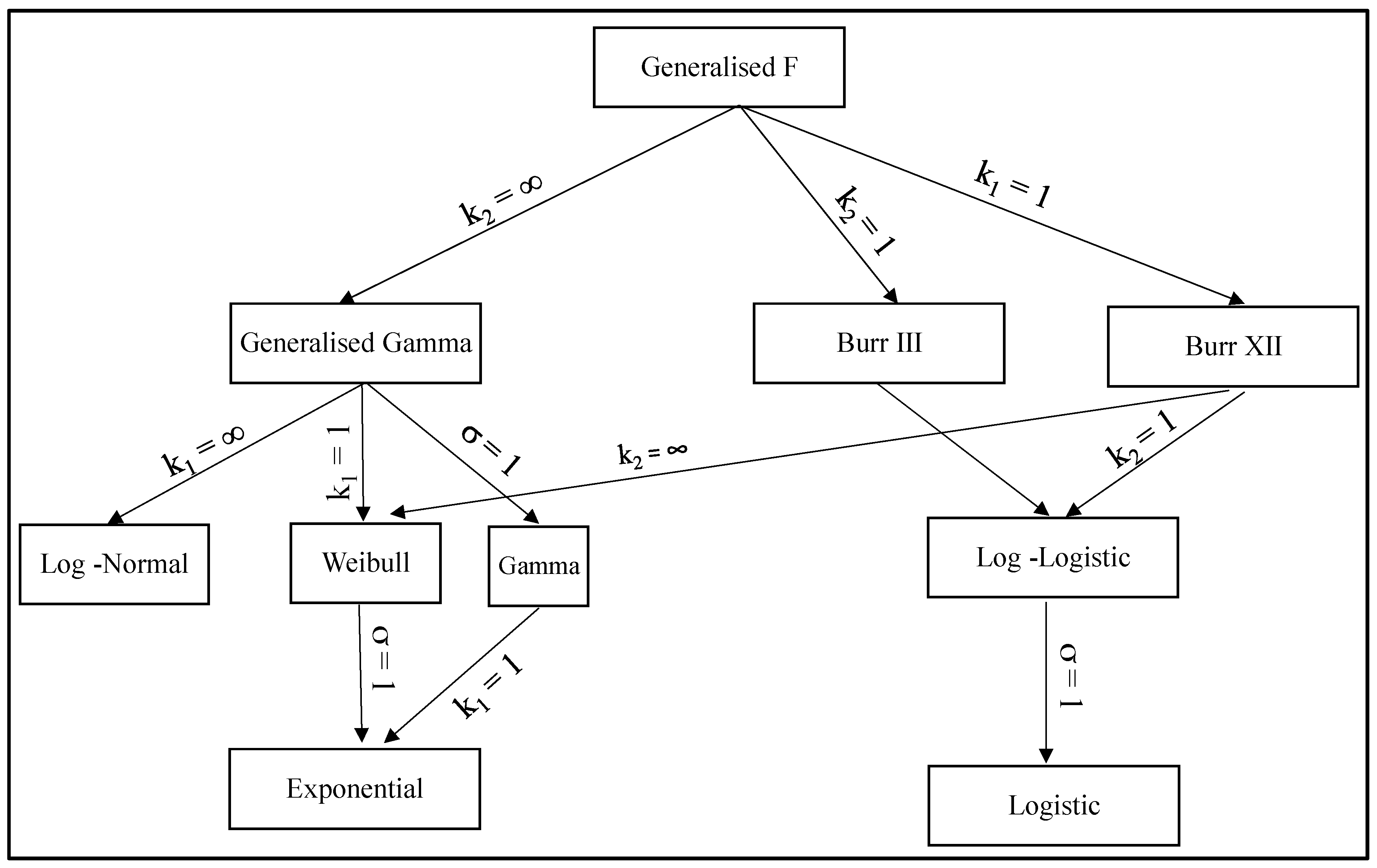
Particular values for these parameters define important sub families within the GENF family and these sub families are summarised in Figure 3. It can be seen that some of these distributions are commonly used within engineering. When k2 = ∞, failure times have a Generalised Gamma distribution, T ~ GENG(μ, σ, k1). There are then three well known two parameter distributions within this Generalised Gamma family. T is gamma distributed, T ~ GAM(μ, σ, k1), when k2 = ∞ and σ = 1. T is log normally distributed, T ~ LOGNOR(μ, σ), when k2 = k1 = ∞; and T is Weibull distributed, T ~ WEIB(μ, σ), when k2 = ∞ and k1 = 1. In turn, the Weibull distribution collapses to the exponential distribution when k2 = ∞, k1 = 1 and σ = 1. The family, T ~ BURR(μ, σ, k1), is obtained when either k1 = 1 (Burr III) or k2 = 1 (Burr XII). Then when k2 = k1 = 1, T has a log-logistic distribution, T ~ LOGLOGIS(μ, σ), and when k2 = k1 = 1 = σ the log-logistic distribution collapses to the logistic distribution, T ~ LOGIS(μ). The form and characteristics of all these special cases are further described in the Appendix A.
Evans [32] has shown how the parameters of these distributions can be estimated using maximum likelihood procedures. An alternative semi-parametric approach is to use the least-square procedure in conjunction with a probability plot. The procedure here is to linearise a plot of t against S(t) by finding suitable transformations of S(t) and possibly t. A least squares best fit line to the data on such a plot then yields estimates of the parameters μ (given by the intercept of the best fit line) and σ (the slope of the best fit line). However, as seen in Figure 1, the non-parametric estimate is a step function increasing by an amount 1/n at each recoded failure time. Plotting at the bottom (top) of the steps would lead to the best fit line being above (below) the plotted points and so lead to a bias in the resulting parameter estimates. A reasonable compromise plotting position is the mid-point of the jump
where i indexes the ordered failure times (i = 1 for the smallest failure time, i = 2 for the next smallest all the way up to n for the largest failure time), with t1 being the smallest failure time up to tn the largest failure time. From the Appendix A to this paper, the log of the pth percentile for t is given by
where wk1,k2,p is the pth quantile of an F distribution with (2k1, 2k2) degrees of freedom. Percentiles of the F distribution are tabulated at the back of many well know engineering statistical text books (it can also be found in Excel using the FINV function). Using in Equation (4a) for p in Equation (10b) allows values for wk1,k2,p to be computed. Thus, when is plotted against the ordered values for ln(t), ln(ti), the data points will reveal scatter around a linear line provided the data have a generalised F distribution with given values for k1 and k2.
ln(tp) = μ + (b/δ){wk1,k2,p} = μ + σ{wk1,k2,p}
The generality of Equation (10b) is clearly seen by considering the special case of k2 = ∞ and k1 = 1, which is the Weibull distribution, whose survivor function is shown in the Appendix A of this paper to be
This can be linearised as
Then, replacing S(t) with the parametric estimator and t by its ordered value ti gives
Equations (11c) and (10b) imply that wk1,k2,p collapses to ln{−ln[S(t)]} when k2 = ∞ and k1 = 1.
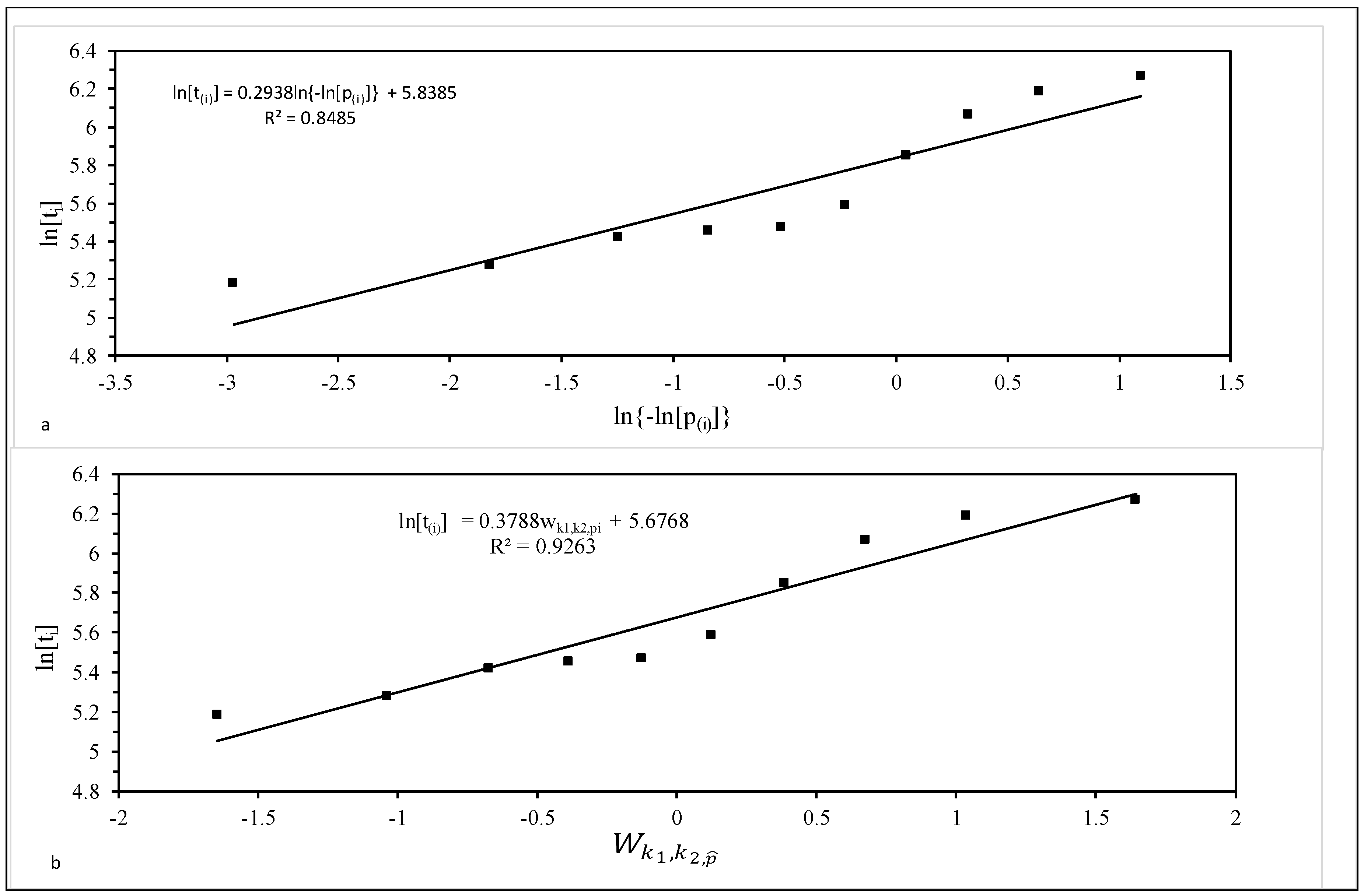
As an illustration, Figure 4a is a plot for the ten 1Cr-1Mo-0.25V specimens tested at 823 K and 294 MPa. The best fit line obtained using the least squares technique is also shown. The slope of this best fit line is σ = 0.2938, with intercept μ = 5.8385. This implies β = 1/σ = 3.4 and λ = exp(−5.8385) = 0.0029. However, with a coefficient of determination (R2) of just 85%, the Weibull distribution is unlikely to be the best description of this sample of failure times.
This R2 value was computed over the range p = 0 to 2 and q = 0 to 1 (both in increments of 0.1), where
As such, this range covered all the distributions shown in Figure 3. It was found that R2 was maximised when p = q = 0, i.e., when k1 = k2 = ∞. It therefore appears that, within the generalised F distribution family, it is the log normal distribution that best describes the specimens tested at 823 K and 294 MPa. This is consistent with the findings by Evans [32].
Figure 4b plots ln(ti) against when k1 = k2 = ∞, so that the variable on the horizontal axis is essentially a standard normal variate. The R2 value is 93% and so much higher than the Weibull case. The slope of this best fit line is σ = 0.3788 and can be interpreted as an estimate of the standard deviation in log times to failure. The intercept is μ = 5.6768 and can be interpreted as an estimate for the mean of the log times to failure at the stated test conditions. The survivor function associated with his normal distribution (using these parameter estimate) is shown in Figure 2. It tends to be lie above the parametric estimators at intermediate failure times, but below it as the higher failure times.
3.2. A Statistical Description of Continuous Failure Times at Varying Test Conditions
There are a number of approaches to extending the above concepts to the case of varying test conditions.
3.2.1. Accelerated Failure Time Models (AFT)
In this type of model, μ in Equation (9b) is made a function of the test conditions
with
where x1 to xm are separate variables describing the test condition (for example, x1 may be stress, x2 temperature etc.) and r is an un-specified function (its form being best suggested by creep theory). x is a 1 by m matrix containing the m test variables that describe the test conditions for each of the N specimen placed on test. A commonly used specification for r(x) is
where b1 to bm are parameters that require estimation. As the name suggests, this approach has an accelerated life interpretation. In this formulation, the error term σW is seen as a base or reference distribution that applies when x1 = x2 = … = xm = 0. This base distribution can be translated to a time scale by defining T0 = exp{σW}. The probability that a test specimen will survive time t, S0(t), is then
ln[T] = Y = μ + σW = r(x) + σW
r(x) = r(x1 + x2 +…. + xm)
r(x) = b1x1 + b2x2 + … + bmxm
S0(t) = Pr{T0 > t} = Pr{W > ln(t)/σ}
In this accelerated model, T is distributed as
and so the test conditions act multiplicatively on survival times. Therefore, the probability that a test specimen with test conditions x will be survive time t is
T0exp(b1x1 + b2x2 + … + bmxm)
S(t,x) = Pr{T > t|x} = Pr{T0er(x) > t} = Pr{T0 > ter(x)} = S0(teb1x1+…+bmxm)
Thus, the probability that a specimen with test conditions x will survive time t is the same as the probability that a base test specimen will be alive at time texp{r(x)}. This can be interpreted as time passing more rapidly by a factor exp{r(x)}—for example, twice as fast or half as fast. (A good analogy here is the use by humans of pet years to describe the age of their pets in relation to their life). Consider for example a multiplier of two for a specimen with test condition x. In terms of survival, this means that the probability that the specimen would be alive at any given time is the same as the probability that a base specimen would be alive at twice the length of time. In terms of risk, this model implies that an engineering component is exposed at any service life to double the risk of a base component that has been in service for twice as long.
The importance of Equation (12c) for this paper is that Evans [32] has shown, when using an AFT model, that whilst a generalised F distribution explained the shape of the failure time distribution at most test conditions for 1Cr-1Mo-0.25V steel, none of the distributions contained as special cases within the generalised F distribution adequately explained the shape of the actual failure time distributions at the remaining test conditions. This failure is explained by Equation (6c) as it shows that the survivor function should have the same form at all test conditions (namely that form identified for specimens tested at the base conditions)—unless time is stretched too much. However, in hazard based models, to be discussed below, the survivor function at a particular test conditions can differ markedly from that identified at the base test conditions and so offers extra flexibility over AFT models.
3.2.2. Proportional Odds Models
Another approach assumes that the effect of the test conditions is to increase or decrease the odds of failure by a given duration by a proportionate amount:
where S0(t,x) is a baseline survivor function, taken from a suitable distribution, and exp{b1x1 + … + bmxm} is a multiplier reflecting the proportionate increase in the odds associated with test condition values x. Taking natural logs, gives
so the test conditions effects are linear in the logit scale. A somewhat more general version of the proportional odds model is known as the relational logit model. The idea is to allow the log-odds of failing in a given population to be a linear function of the log-odds in a reference or baseline population, so that
logit(1 − S(t,x)) = logit(1 − S0(t)) + b1x1 + … + bmxm
logit(1 − S(t)) = α + θlogit(1 − S0(t))
The proportional odds model is the special case where θ = 1 (and where the constant α depends on the test conditions).
As an example, consider a proportional odds model with a log-logistic baseline. The corresponding survival function and the odds of failure are
Multiplying the odds by exp(b1x1 + … + bmxm) yields another log-logistic model. However, this is not true of other distributions: if the baseline survivor function is Weibull then this baseline multiplied by the odds of failing is not a Weibull survivor function.
3.2.3. Proportional Hazard Models (PH)
The PH model of Cox [39] has a baseline hazard function h0(t) that shows how the hazard rate increases with time when this linear combination of test conditions equals unity
The log hazard function is then additive
Obviously, the cumulative hazards would follow the same relationship, as can be seen by integrating both sides of the previous equation. Exponentiating minus the integrated hazard, we find the survivor functions to be
so the survivor function for test conditions x is the baseline survivor raised to a power that is dependent upon the test condition. If a test specimen is exposed to twice the risk of a reference specimen at every point in time, then the probability that the specimen will be alive at any given time is the square of the probability that the reference or base specimen would be alive at the same time. In this PH model, a simple relationship in terms of hazards translates into a more complex relationship in terms of survival functions. Choosing a different parametric form for the baseline hazard, leads to a different model in the proportional hazards family. Apart from when the baseline hazard function corresponds to that of the Weibull hazard function, the hazard function at all other test conditions will be different in form from the baseline hazard function.
S(t,x) = S0(t)exp(b1x1+b2x2+…+bmxm)
A possible limitation of the PH model is seen in Equation (14a), which implies that hazard functions associated with different test conditions are always constant multiples of one another—hence the name “proportional” hazards. One way to relax this proportionality assumption is to allow the test variables to interact with time or equivalently to allow b1, b2 etc. to be time dependent. Then, Equation (12b) becomes
b1(tx1) + b2(tx2) + … + bp(txp)
If, for example, the base line hazard function corresponds to the log normal distribution (so under test conditions r(x) = 1 the underlying failure time distribution is log normal), the underlying failure time distribution will not be log normal at any other test condition (i.e., when r(x) ≠ 1). This is a major advantage of building a failure time model around the hazard function rather than around the pdf or f(t).
3.3. Modelling Discrete Failure Times at Varying Test Conditions
Another major issue with hazard based models is to do with the identification of the baseline hazard function, ho(t). Without having many repeat tests carried out at a single test condition, it is difficult to accurately identify its functional form. One solution to this problem is to create a discrete failure time dataset from the original continuous one, i.e., split the continuous failure time data up into small but equally sized time spans. By doing so, it is possible to calculate a piecewise hazard function for each interval of time, which over all time intervals allows the shape of the base line hazard function to be identified. Springer and Willett [40] provide a good review of this approach. This is the approach taken in Section 4.
3.3.1. Creating Discrete Data from Continuous Data
The first step required in building a discrete hazard function is to create the specimen-specimens dataset from the continuous failure time database. Here time is partitioned into k equal intervals Ij = (aj−1 to aj), j = 1 to k and with k being as large as practically possible and a being a point in time. As an illustration of how this is done, consider batch VaA of the NIMS database, where i = 1, N = 43 specimens are tested, with each specimen receiving a different stress-temperature test combination. If x1 in Equation (12a) represent stress, then in batch VaA of NIMS this was varied from 412 MPa to 47 MPa and if x2 represents temperature this varied over the range 723 K to 948 K. The smallest recorded failure time was 338,760 s and the largest was 407,844,720 s. Many creep prediction models work with the log time to failure and so in natural log units these failure time limits corresponded to 12.73 and 19.83. The researcher then needs to decide upon how many discretised time intervals to work with. For example, the NIMS data could discretised into 15 equal (log) time intervals, respectively giving (log) time intervals of width 0.5. In this example, k = 15 and aj−1 − aj = 0.5 with a0 = 12.5 and ak = 20). The first interval this NIMS dataset is therefore 12.5–13.0 and corresponds to j = 1, the second is 13.0–13.5 and corresponding to j = 2 all the way up to the interval 19.5–20 and corresponding to j = 15. The specimens-specimen data are then generated by creating a binary variable, v, for each time interval. Thus, the binary variable equals 0 in time interval It if the specimen does not fail in that interval and 1 if it does. This binary variable is created for each specimen in the test matrix.
Table 1 illustrates the start of the creation of this specimens-specimen format by considering just the firsts two NIMS specimen in batch VaA using aj−1 − aj = 0.5. The first specimen was tested at x1 = 412 MPa and x2 = 723 K. It failed at 16.36 log seconds. The second was tested at x1 = 373 MPa and x2 = 723 K and it failed at 17.84 log seconds. Continuing the process shown in Table 2, creates M values for v, where M = kN = 358 for this NIMS batch.
3.3.2. Re-Specification of the Continuous Hazard Based Models
Equation (14b) can be re-specified as
where .
In Equation (14b), x is a Nk by 2 matrix where each column contains the i different stress and temperature combinations that each specimen was tested at and xi is the ith first row of the matrix x. However, when the data are discretised in this way, h(ij|x) in Equation (14a) is not directly observable. Instead, there is the binary variable vij that equals zero when the specimen is un-failed in time interval aj−1 − aj or 1 if it fails in that time interval. Therefore, what is required is a non-linear function that maps between vij = 0 and vij = 1 to give the hazard rate between 0 and 1 for each specimen in each time interval. Two commonly used functions that achieve this are the logistic
and the log-log
functions. These are in turn special cases of a more general S shaped curve given by
so Equation (16d) collapses to Equation (16b) when α = 1 and tends to Equation (16c) as α tends to ∞.
Plotting estimated values of b0,j against time allows the shape of the baseline hazard function to be observed, which in turn could lead to a simplification of Equation (16d). For example, if such a plot reveals a straight line, the k bo,jDj terms can be replaced by a + b0j
Non-proportionality can then be accommodated by allowing the x variables to interact with time t in the following way
3.3.3. Estimation
These discrete hazard models are essentially binary response regression models and so the unknown parameters can be estimated by maximising the log likelihood function given by
where the binary response variable vij and h(t|x) is given by Equation (16d), Equation (16e) or Equation (16f). Hence, Equation (17) will be maximised yielding some given set of values for the unknown parameters on the right hand side of Equation (16d), Equation (16e) or Equation (16f). This function can be maximised for various values of α, with the chosen value for α corresponding to the largest of these maximised log likelihoods. Direct maximisation can be carried out using standard non-linear optimisation algorithms [41], or alternatively Equation (17) can be maximised indirectly by using the iteratively reweighted least squares algorithm of McCullagh and Nelder [42].
3.3.4. Assessing Model Adequacy
There are a number of ways to assess the adequacy of these discrete hazard based models. The discrete hazard models given by either Equation (16d), Equation (16e) or Equation (16f) produce a predicted hazard rate or probability of failure within the time intervals at−1 to at, rather than a specific time at which failure occurs. This makes it a little more complicated to assess whether the model is capable of accurately predicting the observed failure times. To obtain predicted times to failure (more specifically the time interval in which failure is predicted to occur), a cut-off point c is needed, such that if the predicted hazard rate exceeds c in time interval at−1 to at then failure is predicted to have occurred in that time zone. Otherwise, the prediction is that the specimen will not fail in that time interval. The usual value for c is 0.5, and once chosen a simple classification table, such as that in Table 2, can be constructed.
In Table 2, there are M2 time intervals where a specimen failed. The model correctly predicted correctly m4 of these, but incorrectly predicted m3 of these intervals, that is m3 specimens failed in times zones different from those the model predicted them to fail in (where M2 = m3 + m4). Similarly, there are M1 time zones where vij actually equalled zero (M1 time zones not containing failed specimens) and of these, the model predicted correctly m1 of these time zones, but incorrectly predicted m2 of these zones (i.e., there were m2 times zones where a specimen survived, but the model predicted failures to occur). M can be found from summing either M1 and M2 or M3 and M4.
The models success rate in predicting the time zones where specimens will not fail is given by m1/M1. This can be taken to be the probability of the model correctly detecting a false signal and is called the models specificity. The models success rate in predicting the time zones where specimens will fail is given by m4/M2. This can be taken to be the probability of the model correctly detecting a true signal and is called the models sensitivity. The models over-all rate of correct classification is then given by (m1 + m4)/M.
Given the way in which a specimens-specimen dataset is constructed, there are many more values of vij = 0 compared to vij = 1, it is common to observe sensitivity values well below specificity values. Thus a well specified model will have high values for both sensitivity and specificity. However, the sensitivity and specificity depend in part on the chosen value for the cut-off point c and c = 0.5 may not be the optimal value as far as failure time prediction is concerned. One solution to this is to construct a classification table for a range of cut-off points to see how the discrete hazard model works as a classifier of when failure will occur. However, a neater way of doing this is given by the area under the receiver operating characteristic (ROC) curve. The ROC emerges on a graph that plots the sensitivity against (1-specificity) associated with all possible values for c (c = 0 to 1). The resulting area under the ROC curve lies between zero and unity and measures the ability of the hazard model to discriminate between time zones where a specimen will fail and zones where it will not. Hosmer and Lemenshow [43] suggest the following benchmarks for this area: An ROC of 0.5 provides no discrimination implying the model performance no better than tossing a coin to decide if a specimen fails in a given time interval. An ROC between 0.7 and 0.8 gives acceptable discrimination, whilst a ROC between 0.8 and 0.9 gives excellent discrimination. Finally, a ROC above 0.9 gives outstanding discrimination.
One way to determine an optimal value for c is to choose that value that yields the best failure time predictions. For example, if c inserted for v in say Equation (16e), then the variable t on the right hand side of the equation becomes the predicted time zone at which a specimen fails,
This can be solved for
Thus, is a prediction of the time interval where a specimen fails. For example, if = 2.5, failure is predicted to occur in the time interval I2 = a2 − a1, and the actual predicted time is then equal to (a2 + a1)/2 (or another example, actual failure time = 0.25a2 + 0.75a1 if = 2.75). Notice the j = 2 time interval is, from Table 1, the 12.5–13 logged seconds and its mid point is therefore 12.75 logged seconds (or 96 h).
A plot can then be made of actual failure time against this predicted time. If a best fit line is put through the data on such a plot, the optimal value for c can be taken to be the one that produces a best fit line closest to the 45° line on such a plot. As an alternative, c can be chosen to minimise the mean squared error defined as
Using c = 0.5 in Equation (18b) can also be interpreted as yielding a median predicted time to failure, whilst using c = 0.05 produces a time interval prediction such that there is only a 5% chance of failure occurring in that or an early time interval. Likewise using c = 0.95 produces a time interval prediction such that there is a 95% chance of failure occurring in that or an early time interval. These then come together to define a 90% confidence interval for the time interval where failure will occur.
4. Application of Discrete Hazard Function to Batch VaA of 1Cr-1Mo-0.25V
4.1. Incorporating Wilshire Variables into a Discrete Hazard Model
The intention of this paper is to keep within the discrete hazard model as many features of the Wilshire methodology as possible—purely to illustrate the assimilation of that creep model with this statistical model for the random component of creep and not because one implies the other. In its simplest form, the Wilshire Equation is given by Equation (5b). However, the hazard function describes a failure rate or conditional probability of failure and not the failure time itself. There are a number of ways to incorporate this Wilshire equation into a discrete hazard based model and the following describes some of the possibilities. The starting point is to map Equation (5b) onto Equation (16d–f) by replacing ln[t] = y with the log hazard rate ln[h(t|x)]. This gives, based on Equation (16d),
where x1 = τ* and x2 = 1000/RT.
However, h(ij|x) is not observable. Instead there is the binary variable vij that equals zero when the specimen is un-failed in time interval aj−1 − aj or 1 if it fails in that time interval. Therefore, what is required is a non-linear function that maps between vij = 0 and vij = 1 to give the hazard rate between 0 and 1 for each specimen in each time interval. Section 3.3.2 outlined a general form of such a function allowing Equation (19a) to be written as
If the b0,j parameters trace out a linear time trend, then Equation (19b) can be written as
As will be seen below, this plausibility of such a simplification can be assessed by plotting out the estimated b0j values. Non-proportionality can then be accommodated by allowing τ and 1000/RT to interact with time in the following way
In addition, it is known (see Wilshire [21] and Evans [32]) that for this material the relationship between t and τ* changes at some critical value for τ* (i.e., b1 changes value at this point) and that the activation energy changes at around 823 K (i.e., b2 changes value at this point). Thus, Equation (19b) can be written as
where B1 = 0 when τ* ≤ τcrit and unity otherwise. Similarly, B2 = 0 when T ≤ 823 and unity otherwise. The reason for doing this is that it allows stress and temperature to have a different effect on the hazard rate either side if 823 K and τcrit. The explanation provided by Wilshire is that as τcrit is close in value to the yield stress, dislocation movement is confined to grain boundaries below the yield stress so that the activation energy falls below that for self diffusion through the crystal—so causing the value for b2 to change. Thus, when τ* ≤ τcrit, B2 = 0, and so the effect of temperature on the hazard rate is determined by the value for b2. However, when τ* > τcrit, B2 = 1, and so the effect of temperature on the hazard rate is determined by the value for b2 + b4. The role of stress is also different either side of τcrit (changing from b2 to b2 + b3).
Often, the values for b0,j reveal a linear trend or some well defined non-linear trend such as a polynomial, exponential or power law trend. For example, if a linear trend is revealed by a plot of the b0,t values against t, then Equation (19e) takes the form
In Equation (19e,f), the effect of changing test conditions is to shift in a parallel fashion the log baseline hazard function, but it is also possible to allow the slope of the baseline hazard function to depend on x1 and/or x2. For example, if b0 depends on x1 then Equation (19f) becomes
4.2. Results
4.2.1. Model Given by Equation (19e)
A specimens-specimen dataset was created for batch VaA using k = 15 and Ij = aj−1 − aj = 0.5 with a0 = 12.5 and ak = 20. This dataset consisted of M = 358 observations on v. Using these data, the parameters of Equation (19e) were estimated for a range of values for α and τcrit. The values for α and τcrit that produced the highest ROC were α = 1 and τcrit = 0.1. This α value suggests the logistic discrete hazard model is preferable to the log-log discrete hazard model, whilst the τcrit value is a little higher than that identified by Evans [32] and Wilshire [21] but is broadly similar in value. Table 3 shows the results of applying the McCullagh and Nelder algorithm to this data. The values for x1 and x2 were normalised to be zero at 823 K and 294 MPa so that the resulting estimated value for b0,t give the baseline log hazard rates that corresponds to this test condition.
The student t-values associated with x1 and x2 in Table 3 reveals that both τ* and the reciprocal of temperature are statistically significant variables so yielding support for the Wilshire methodology, whilst the last two rows show a discontinuity in the Wilshire model at τ* = 0.1 and at a temperature of 823 K. These estimates are not comparable in value to those in Equation (5b) because the latter show the impact of τ* and T on failure times directly, rather than the log hazard rate as is so in the former case. Reading across row one of Table 3, the estimated log hazard rate for time interval j = 1 (12.5–13.0 log seconds) when temperature is 823 K and stress is 294 MPa is −4.7526, implying a hazard rate of exp(−4.7526) = 0.0086. This hazard rate corresponds to the log time interval of 12.5 to 13.0, which in turn corresponds to a time interval in hours of 75 to 123. Associating this hazard rate with the mid point of this time interval gives a hazard rate of 0.0086 at time 100 h. Proceeding in the same way for this next two rows of Table 3 gives a cumulative hazard rate of 0.189 at 163 h and 0.795 at 268 h. Recall that Figure 2 show the non-parametric estimate of the cumulative hazard rate associated with the test conditions of this estimated baseline hazard rate. Reading of this graph at 270 h shows the non-parametric estimate of the cumulative hazard rate is 0.85, showing this model is consistent with this non-parametric estimator.
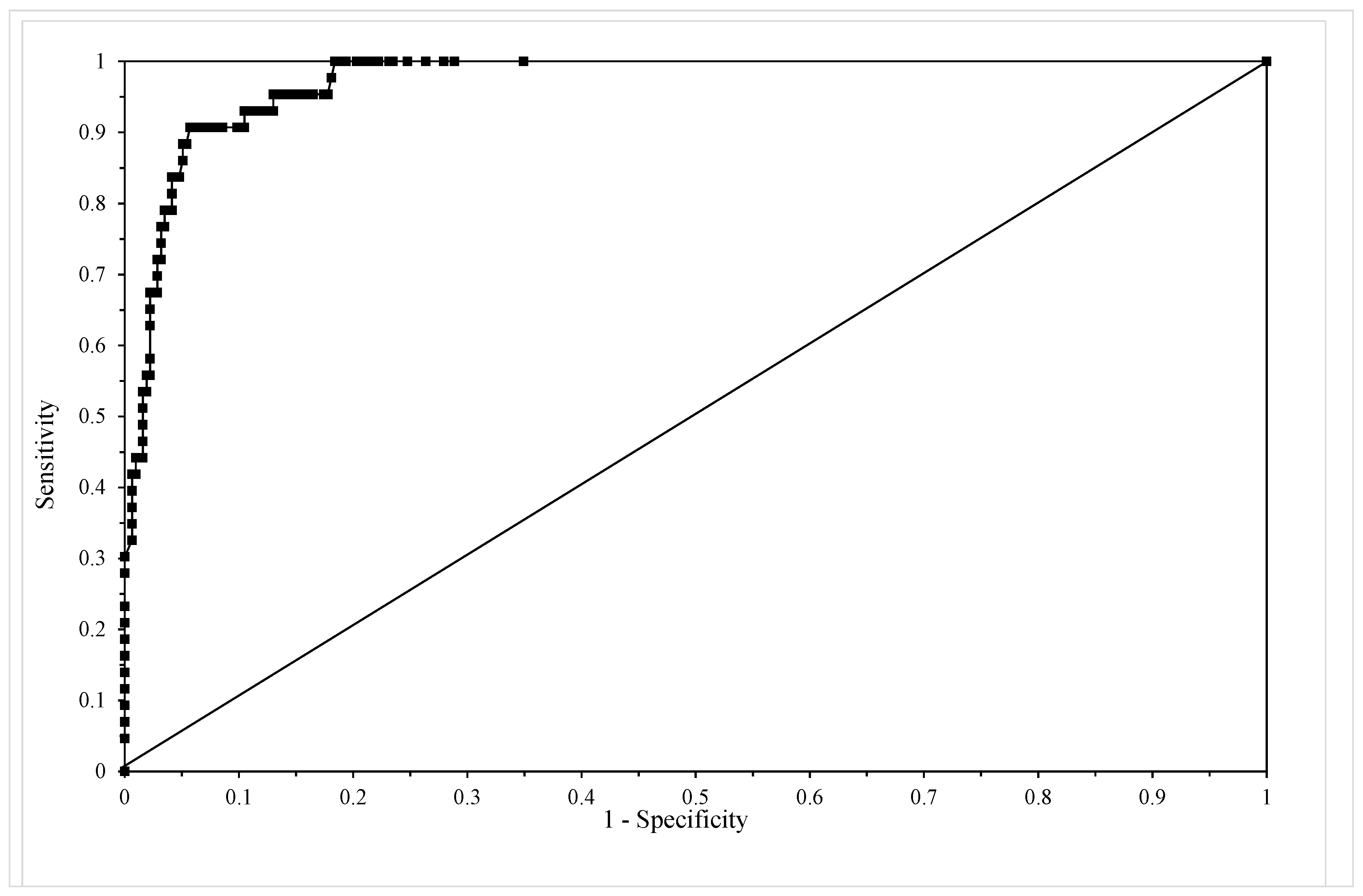
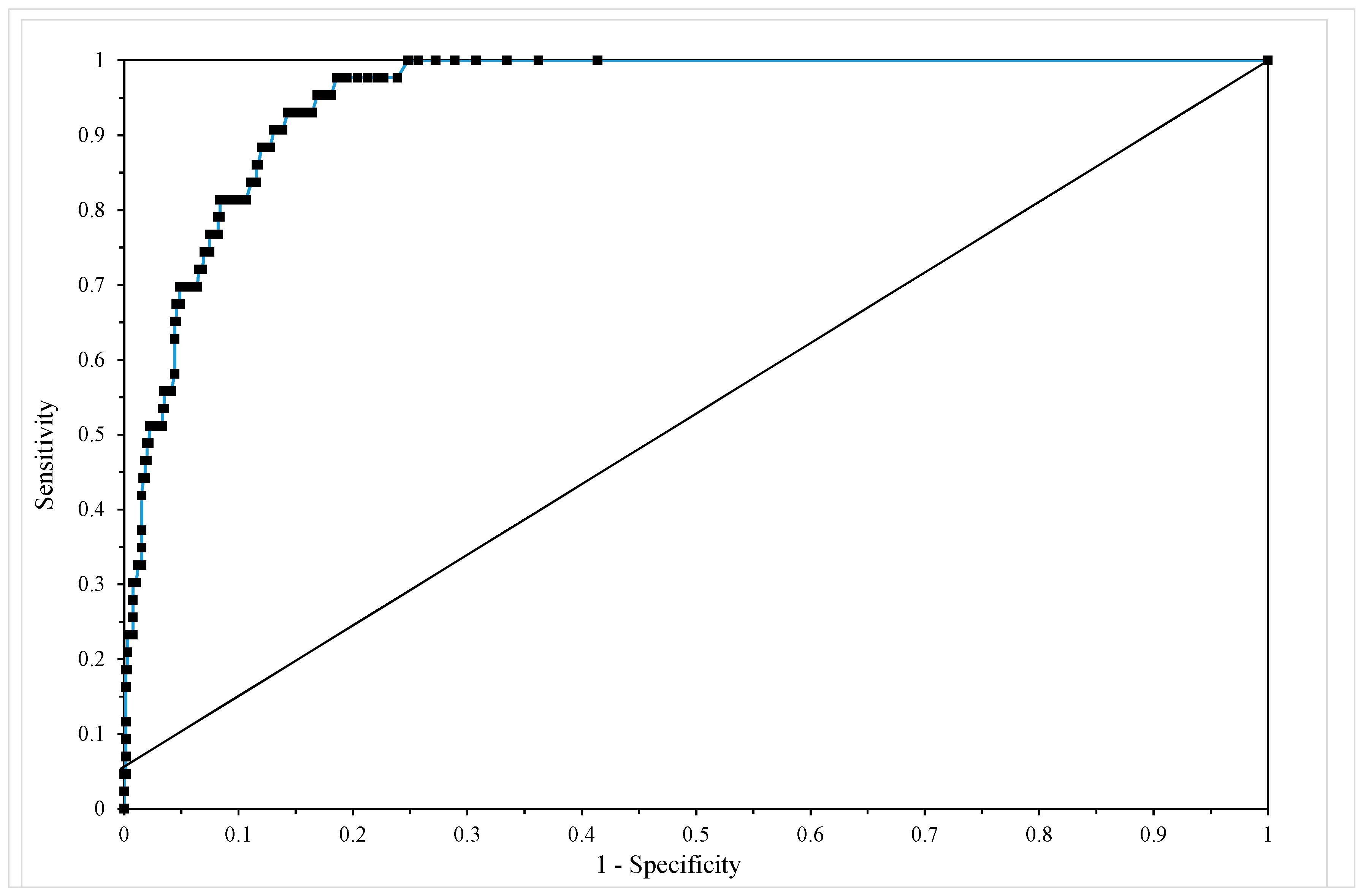
Table 4 shows the classification table for this model using c = 0.5 revealing that sensitivity equals 68% and specificity equals 98% with an overall correct failure time zone prediction rate of 94%. Figure 5 shows the ROC for this model and the area under this curve is 0.972, which according to Hosmer and Lemenshow, makes this model outstanding in its ability to discriminate between failure and non-failure in the 15 time zones.
The MSE is minimised at c = 0.53 with a value of 0.0526. Figure 6 then plots the actual times to failure (hours) for specimens in batch VaA, together with the failure time zones predicted by the model using c = 0.53. The error bars shown around the predictions reflect the fact that this model predicts the time interval in which failure occurs and the width of this time interval is 0.5 log hours. The models predictions are taken to be the mid points of these error bars. With only a few exceptions (for example, at 773 K with 373 MPa and 823 K with 157 MPa), the model predicts the time interval at which failure actually occurs correctly. The worst prediction comes at 873 K and 47 MPa—but this point was also poorly predicted in the original Wilshire [21] paper as well.
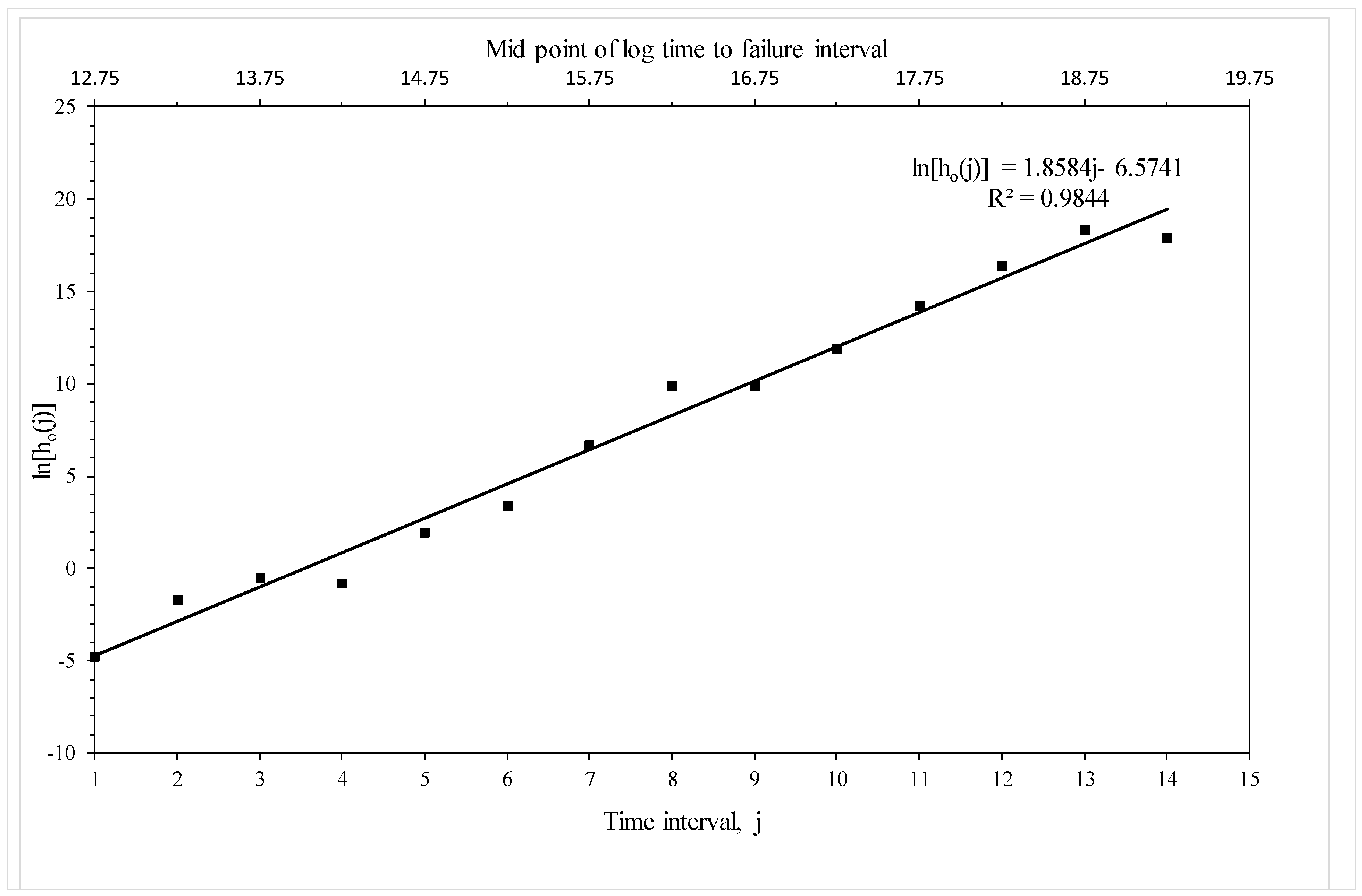
Figure 7 plots the piece-wise log hazard rates associated with each time zone (the b0t in Table 3) against the numbered time zone and this plot reveals a well-defined linear trend. The trend is very strong with an R2 value of 98.4% with no obvious deviation from linearity. This suggests that it should be possible to create a more parsimonious version of Equation (19e), without affecting the predictive ability of the simpler model, by replacing the fifteen b0t parameters with a linear trend containing just two parameters—a and b0. Figure 7 implies that a = 6.57 and b0 = 1.86. This parsimonious version is estimated in the following subsection.
4.2.2. Model Given by Equation (19f)
When Equation (19g) was estimated, the t value associated with parameter b5 suggested that b5 was insignificantly different from zero at the 1% significance level so that the data were not supportive of the slope of the log base hard function estimated in the previous sub section changing at some critical value for the normalised stress. Table 5 shows the estimated parameters of Equation (19f) obtained using the McCullagh and Nelder algorithm (again the values for α and τcrit that produced the highest ROC were α = 1 and τcrit = 0.1).
The estimated values for b1 to b4 in Table 5 are consistent with those shown in Table 3 and, again, the student t-values associated with these parameters reveal they are significantly different from zero at either the 1% or 5% significance level. Further, the values for a and b0 are not that dissimilar from the values sown in Figure 6. These parameter estimates can be used to calculate the hazard rate at the base or reference test conditions of temperature = 823 K and stress = 294 MPa. For example, in time zone j = 1 (corresponding to the log time interval of 12.5 to 13 or 75 to 123 h) the hazard rate is predicted to be exp(−5.8351 + 2.0736 × 1) = 0.0232.
Table 6 shows the classification table for this model when c = 0.5 revealing that sensitivity equals 69.8% and (1-specificity) equals 96.8% with an overall correct failure time zone prediction rate of 95%. Figure 8 shows the ROC for this model and the area under this curve is 0.951, which according to Hosmer and Lemenshow, makes this model outstanding in its ability to discriminate between failure and non-failure in the 15 time zones. Further, this value is only slightly below that from the previous model, showing that the use of a simple linear time trend instead of a piece-wise hazard function has not resulted in a significant reduction in predictive ability.
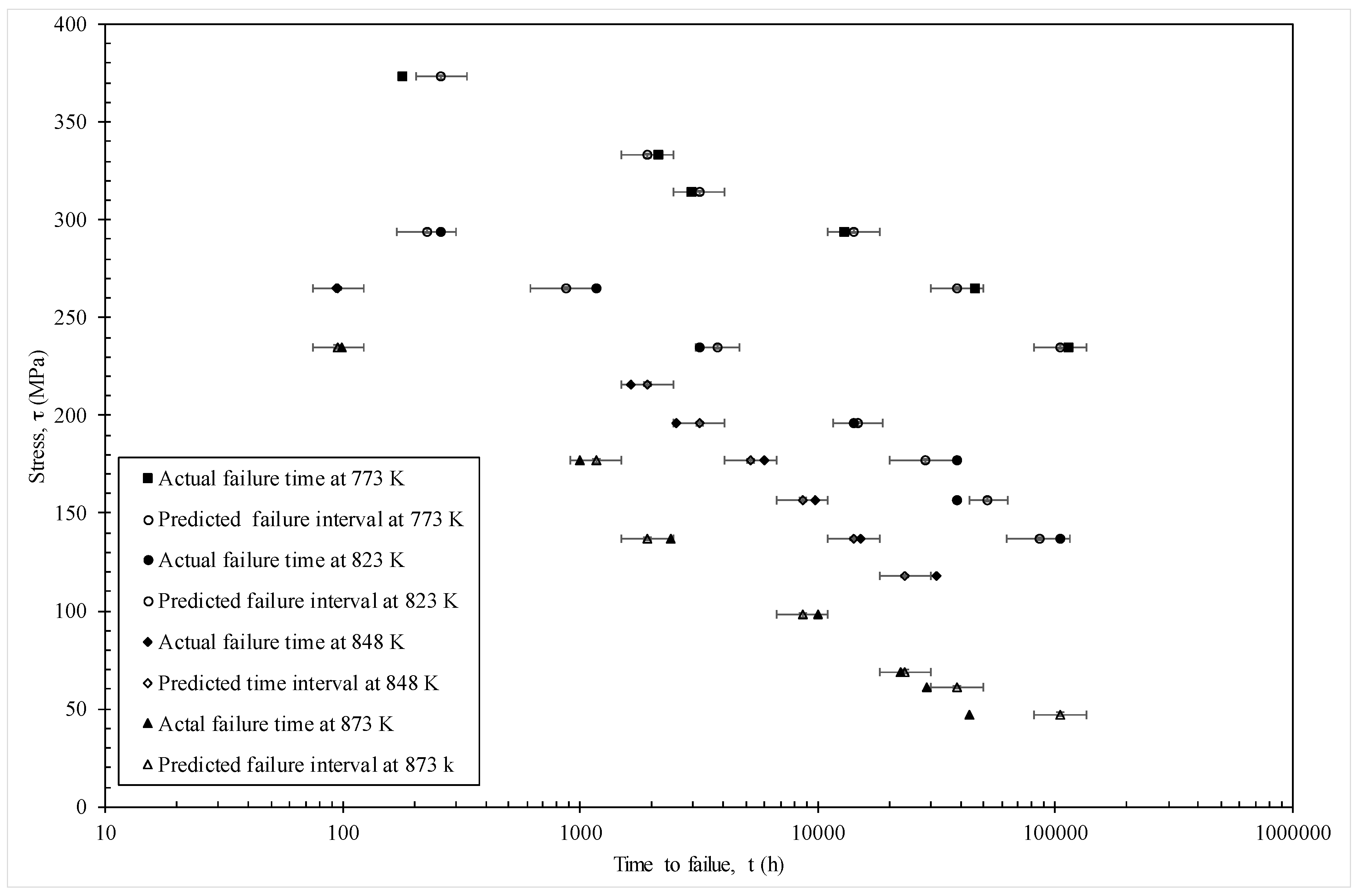
The MSE is minimised at c = 0.53 and Figure 9 then plots the actual times to failure for specimens in batch VaA against the failure time predicted by the model using c = 0.53. As a continuous base hazard function is now used instead of the piece-wise hazard function, an actual failure time, rather than an interval time, prediction can be made. Figure 9 plots the actual failure times against the predicted failure times (n natural logs). The best fit line on this plot is very close to the ideal outcome associated with the 45 degree line—corresponding to a situation where the model predicts each failure time perfectly. Hence, the bias in prediction remains small in this more parsimonious model.
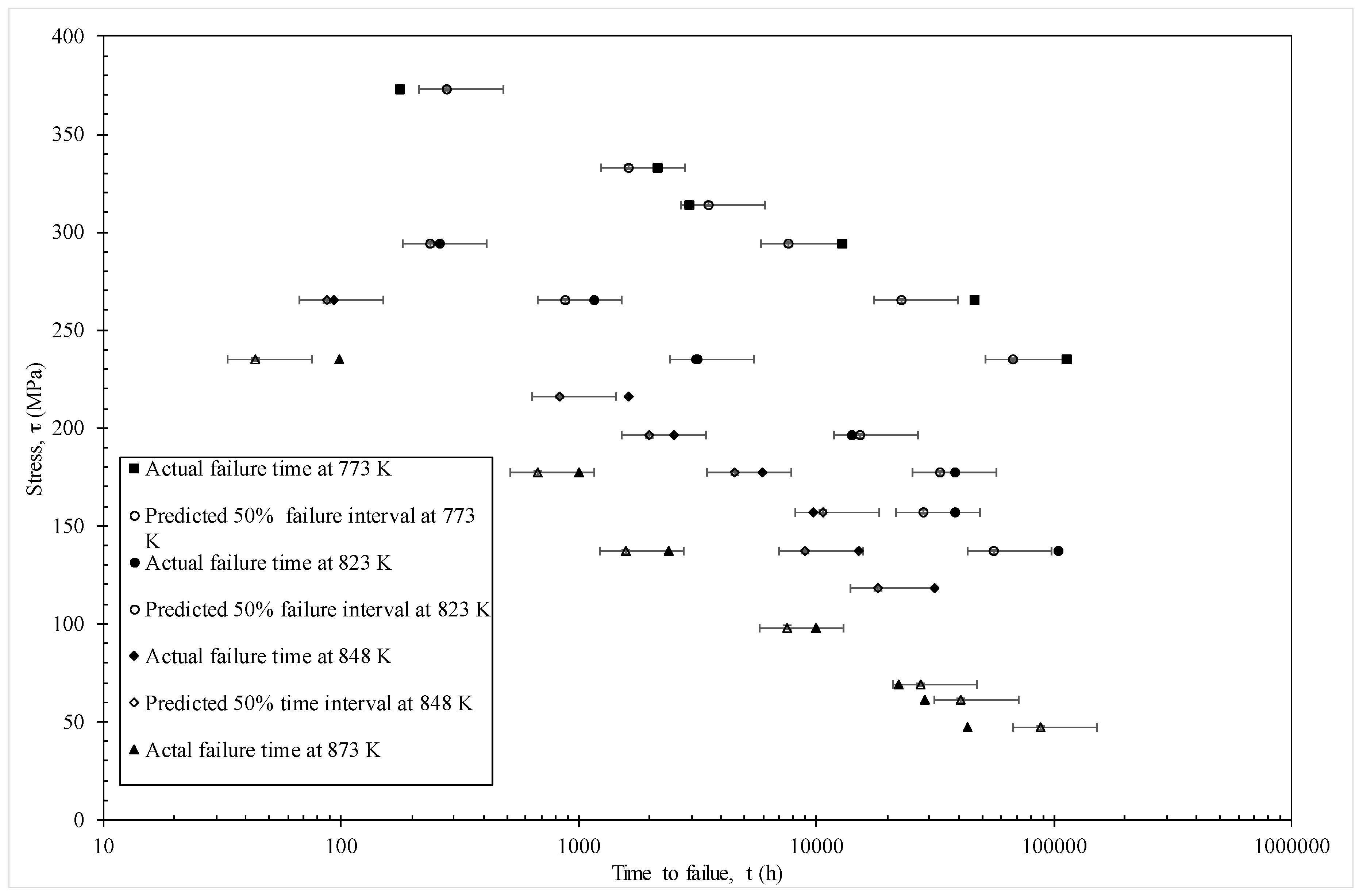
Figure 10 shows a different representation of these predictions—where stress is shown on the vertical axis and times to failure on the horizontal. This time the error bars show a 50% prediction band based on using c = 0.25 and c = 0.75 in Equation (18b). Again, and with only a few exceptions, the actual failure times fall within the models 50% prediction bands.
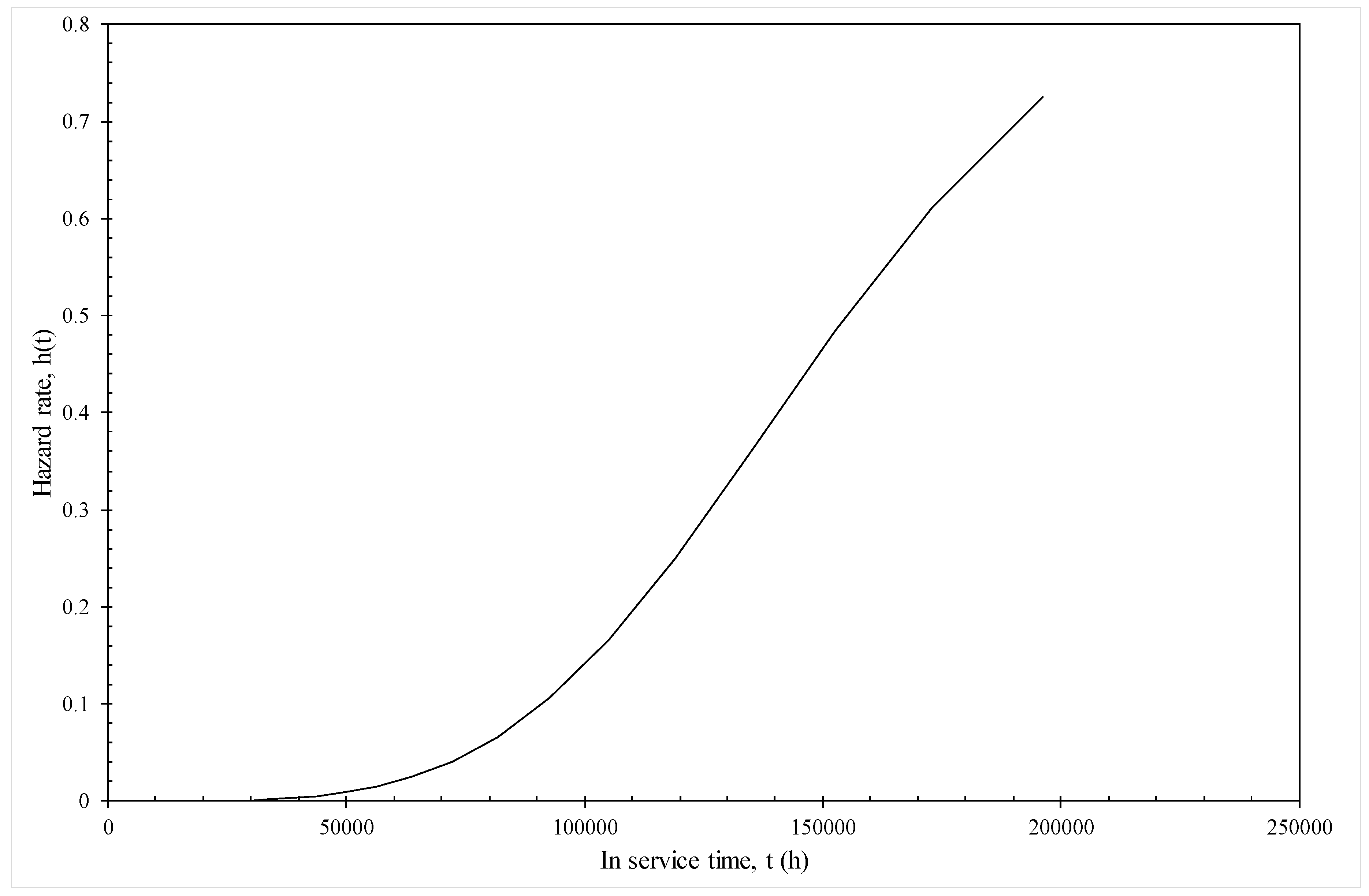
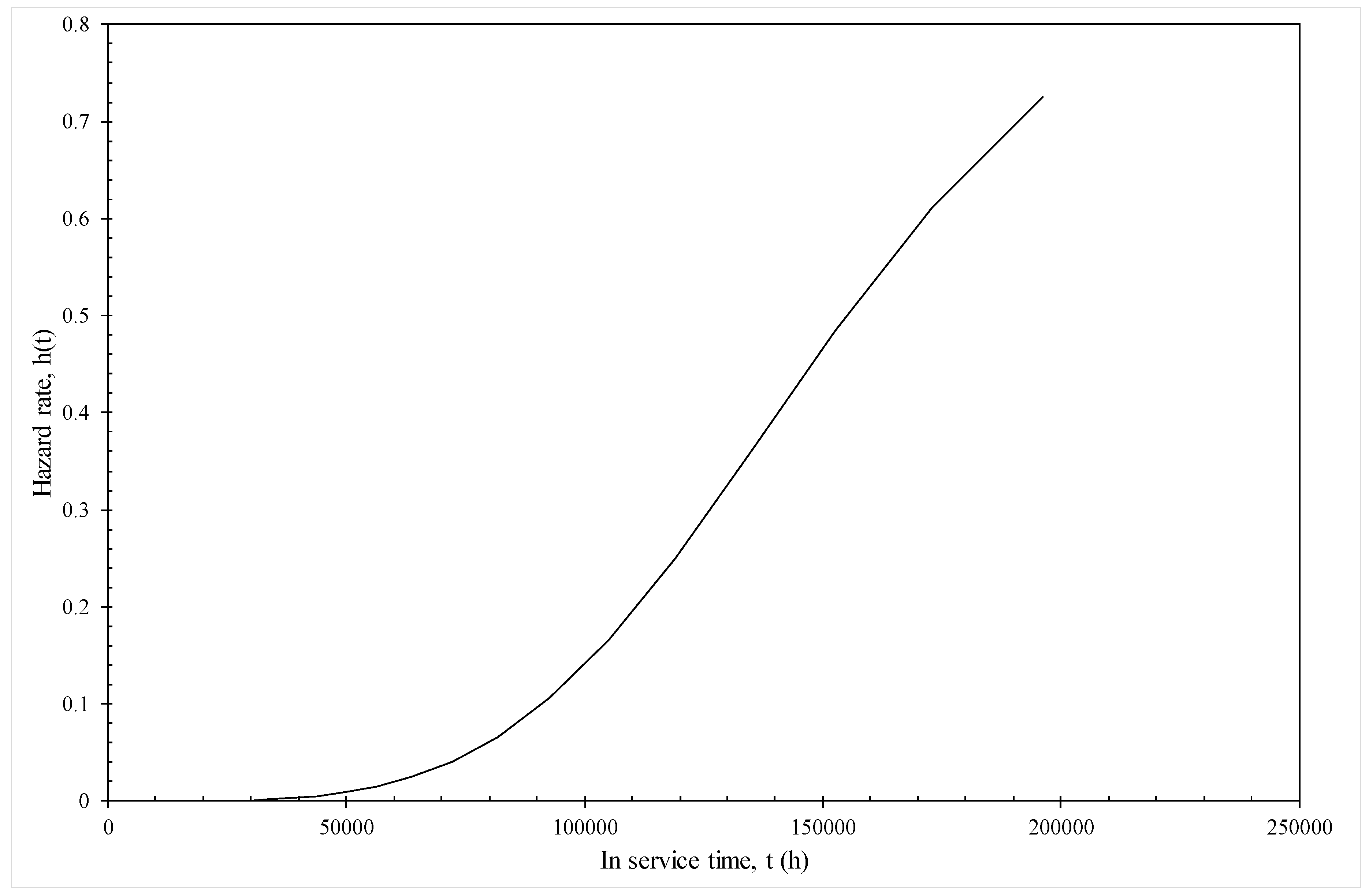
Figure 11 illustrates how this model can be used to predict the hazard rates associated with in service life under various conditions—in this illustration operating at 130 MPa and 823 K. It can be seen that the hazard rate remains very close to zero up to 50,000 h or about 8 years of in service use. The risk of failure then starts to rise quite dramatically. For example, if this material had been in operation for around 15 years, the chances of it failing in the next year is around 35%, but, if this material had been in operation for around 25 years, the chances of it failing in the next three years rises dramatically to around 80%.
5. Conclusions
This paper has provided a summary review of some statistical failure time models with the aim of aiding the assimilation of such models with existing predictive models for creep life. This will enable an enrichment of prediction to be achieved with a move away from predicting failure times on the average towards predicting the safe life associated with a minimum chance of failure This was followed by an illustration of one possible assimilation, namely—the deterministic Wilshire equation and the statistical discrete hazard model. This statistical model was chosen because it provided the capability of estimating failure probabilities in future time intervals for materials that have already been in service for various lengths of time.
Estimation of this model revealed that at a fixed test condition, the log of the probability of failure in the next time interval (given survival up to then) is a linear function of time. This log base line hazard function then shifted in a parallel fashion with the well-known Wilshire variables of τ* and the reciprocal of temperature. Like in the original Wilshire methodology, this shifting nature of the base hazard function was different above and below 823 K and τ* = 0.1. The model was shown to produce outstanding discrimination with respect to which time interval a specimen would fail in. Finally, and as an illustration of the output this model was capable of producing, it was found that if this material had been in operation for around 15 years at 823 K and 130 MPa, the chances of it failing in the next year is around 35%. However, if this material had been in operation for around 25 years under this condition, the chances of it failing in the next year rose dramatically to around 80%.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. The Generalised F Family of Failure Time Distributions
Using the change of variables technique, and substituting Z = (Y − μ)/b into the pdf of Equation (9c) in Section 3.1.2 yields
Using β = 1/b, λ = exp(−μ) and T = exp(Y), it follows that
Substituting Equation (A2) into Equation (A1) and using the change of variable technique then gives the pdf for T
This equation is not valid when k1 = k2 = ∞, which corresponds to the log normal distribution. Abramowitz and Stegun [44] show that the gamma function can be approximated by
and based on this approximation, it follows that Г (k + 1) = kГ(k) and Г(1) = 1. As mentioned in the main text, Z is a standardised variable, and its mean (or expected value E) and its variance are given by
where Var(Z) reads the variance of Z and the di (Ψ) and tri (Ψ/) gamma functions are the first and second derivatives respectively of the log gamma function with respect to k and so
E[Z] = Ψ(k1) − Ψ(k2) + ln(k2) − ln(k1)
Var[Z] = Ψ/(k1) + Ψ/(k2)
The distribution of Z is degenerate in that as either k1 or k2 tends to infinity, Ψ/(k) tends to zero and so the variance of Z tends also to zero, i.e., the pdf for Z collapses to a single point. However, from the rules behind computing expected values, it follows that Var(W) = δ2Var(Z).
For example, as k2 → ∞, δ2 → k1, Ψ/(k2) → 0 and Ψ/(k1) → 1/k1 and so Var[W] → 1. Thus, W has a non-degenerate distribution.
It follows from Equations (A7) and (A8) and the rules of expected values that:
and
where Var(Y) is the variance of Y. Meeker and Escobar [45] have shown that, when k2 > 1/β the mean and variance for T are given by
and
E[Y] = μ + bE[Z]
Var(Y) = b2Var(Z)
There is no closed form expression for the survivor function, but the pth percentile for T is given by
where wk1,k2,p is the pth quantile of an F distribution with (2k1, 2k2) degrees of freedom. tp can thus be computed for various values of p and a plot of 1 − p against tp defines the survivor function for T.
tp = exp(μ)(wk1,k2,p)(b/δ)
Appendix A.1. The Generalized Logistic Family
Appendix A.1.1. The Burr XII [46] Distribution (k1 = 1)
Setting k1 = 1 into Equation (A3) gives
Further when k1 = 1, Г(1 + k2) = k2 Г(k2) and so Г(k2)/Г(1 + k2) = 1/k2 and Equation (A13) becomes
The survivor function is therefore given by
Substituting k1 = 1 into Equation (A11) leads to the following expressions for the mean and variance of T
and
Appendix A.1.2. The Burr III Distribution (k2 = 1)
Setting k2 = 1 into Equation (A3) gives
Appendix A.1.3. The Log-Logistic [47] Distribution (k1 = k2 = 1)
Setting k1 = k2 = 1 into Equation (A3) gives
The survivor function can easily be found by substituting k2 = 1 into Equation (A13)
Substituting k1 = k2 = 1 into Equation (A11) leads to the following expressions for the mean and variance of T
and
Appendix A.1.4. The Logistic Distribution (k1 = k2 = σ = 1)
σ = 1 implies β = 1, Setting k1 = k2 = 1 into Equation (A3) gives
The survivor function can easily be found by substituting β = 1 into Equation (A17)
Appendix A.2. The Generalised Gamma Family
Appendix A.2.1. The Generalised Gamma Distribution (k2 = ∞)
Prentice [37] has shown that, when k2 = ∞, Equation (9c) in Section 3.1.2 reduces to
with and thus . Using the change of variable technique, it follows that
Again, using β = 1/b, λ = exp(−μ) and T = exp(Y), and the change of variable technique
Appendix A.2.2. The Weibull (k1 = 1) [49] and Exponential Distributions (k1 = 1 = σ)
Inserting k1 = 1 into Equation (A22) yields the well-known Weibull distribution
Closed form expressions exist for the survivor and hazard function of the Weibull
As k2 tends to infinity it can be shown that
and substituting this expression and k1 = 1 into Equation (A11) gives the formulas for the mean and variance of T when this variable is Weibull distributed
If σ also equals 1, then β = 1 and the Weibull distribution collapses to the exponential distribution
Substituting β = 1 into the survivor and hazard functions of the Weibull distribution then gives these functions for the exponential distribution
Given Г(2) = Г(1) = 1 and, Г(3) = 2,
Appendix A.2.3. The Gamma [50] Distribution (σ = 1).
σ = 1 implies β = and so
Appendix A.2.4. The Log Normal Distribution (k1 = k2 = ∞)
Lawless [51] has shown that the distribution for W when k2 = ∞
tends to
as k1 → ∞. This is the equation for a standard normal distribution, so W is a standard normal variate with mean zero and standard deviation of 1. This then implies Y is normally distributed and therefore T is log normally distributed with pdf
References
- Allen, D.; Garwood, S. Energy Materials-Strategic Research Agenda. Q2. Materials Energy Review; IoMMh: London, UK, 2007. [Google Scholar]
- Evans, R.W.; Wilshire, B. Creep of Metals and Alloys; The Institute of Metals: London, UK, 1985. [Google Scholar]
- Evans, R.W. A Constitutive Model for the High Temperature Creep of Particle-hardened Alloys on the Θ Projection Method. Proc. R. Soc. 1996, A456, 835–868. [Google Scholar] [CrossRef]
- McVetty, P.G. Creep of Metals at Elevated Temperatures—The Hyperbolic Sine Relation between Stress and Creep Rate. Trans. ASME 1943, 65, 761–769. [Google Scholar]
- Garofalo, F. Fundamentals of Creep Rupture in Metals; Macmillan: New York, NY, USA, 1965. [Google Scholar]
- Ion, J.C.; Barbosa, A.; Ashby, M.F.; Dyson, B.F.; McLean, M. The Modelling of Creep for Engineering Design. I; NPL Report DMA A115; National Physical Laboratory: London, UK, April 1986. [Google Scholar]
- Prager, M. The Omega Method- An Engineering Approach to Life Assessment. J. Press. Vessel. Technol. 2000, 22, 273–280. [Google Scholar] [CrossRef]
- Othman, A.M.; Hayhurst, D.R. Multi-Axial Creep Rupture of a Model Structure using a Two Parameter Material Model. Int. J. Mech. Sci. 1990, 32, 35–48. [Google Scholar] [CrossRef]
- Kachanov, L.M. The Theory of Creep; Kennedy, A.J., Ed.; National Lending Library: Boston, UK, 1967. [Google Scholar]
- Rabotnov, Y.N. Creep Problems in Structural Members; North-Holland: Amsterdam, The Netherlands, 1969. [Google Scholar]
- Monkman, F.C.; Grant, N.J. An Empirical Relationship between Rupture Life and Minimum Creep Rate. In Deformation and Fracture at Elevated Temperature; Grant, N.J., Mullendore, A.W., Eds.; MIT Press: Boston, MA, USA, 1963. [Google Scholar]
- Dorn, J.E.; Shepherd, L.A. What We Need to Know About Creep. In Proceedings of the STP 165 Symposium on The Effect of Cyclical Heating and Stressing on Metals at Elevated Temperatures, Chicago, IL, USA, 17 June 1954. [Google Scholar]
- Larson, F.R.; Miller, J. A Time Temperature Relationship for Rupture and Creep Stresses. Trans. ASME 1952, 174, 5. [Google Scholar]
- Manson, S.S.; Haferd, A.M. A Linear Time-Temperature Relation for Extrapolation of Creep and Stress-Rupture Data; NACA Technical Note 2890; National Advisory Committee for Aeronautics: Cleveland, OH, USA, 1953.
- Manson, S.S.; Muraldihan, U. Analysis of Creep Rupture Data in Five Multi Heat Alloys by Minimum Commitment Method Using Double Heat Term Centring Techniques; Progress in Analysis of Fatigue and Stress Rupture MPC-23; ASME: New York, NY, USA, 1983; pp. 1–46. [Google Scholar]
- Manson, S.S.; Brown, W.F.J. Time-Temperature-Stress Relations for the Correlation and Extrapolation of Stress Rupture Data. Proc. ASTM 1953, 53, 693–719. [Google Scholar]
- Trunin, I.I.; Golobova, N.G.; Loginov, E.A. New Methods of Extrapolation of Creep Test and Long Time Strength Results. In Proceedings of the 4th International Symposium on Heat Resistant Metallic Materials, Mala Fatra, Czechoslovakia, 1971. [Google Scholar]
- Abdallah, Z.; Perkins, K.; Whittaker, M. A Critical Analysis of the Conventionally Employed Creep Lifing Methods. Materials 2014, 7, 3371–3398. [Google Scholar] [CrossRef] [PubMed]
- Williams, S.J. An Automatic Technique for the Analysis of Stress Rupture Data; Report MFR30017; Rolls-Royce Plc: Derby, UK, 1993. [Google Scholar]
- Wilshire, B.; Battenbough, A.J. Creep and Creep Fracture of Polycrystalline Copper. Mater. Sci. Eng. A 2007, 443, 156–166. [Google Scholar] [CrossRef]
- Wilshire, B.; Scharning, P.J. Prediction of Long Term Creep Data for Forged 1Cr-1Mo-0.25V Steel. Mater. Sci. Technol. 2008, 24, 1–9. [Google Scholar] [CrossRef]
- Wilshire, B.; Whittaker, M. Long Term Creep Life Prediction for Grade 22 (2·25Cr-1Mo) Steels. Mater. Sci. Technol. 2011, 27, 642–647. [Google Scholar]
- Wilshire, B.; Scharning, P.J. A New Methodology for Analysis of Creep and Creep Fracture Data for 9–12% Chromium Steels. Int. Mater. Rev. 2008, 53, 91–104. [Google Scholar] [CrossRef]
- Abdallah, A.; Perkins, K.; Williams, S. Advances in the Wilshire Extrapolation Technique—Full Creep Curve Representation for the Aerospace Alloy Titanium 834. Mater. Sci. Eng. A 2012, 550, 176–182. [Google Scholar] [CrossRef]
- Whittaker, M.T.; Evans, M.; Wilshire, B. Long-Term Creep Data Prediction for Type 316H Stainless Steel. Mater. Sci. Eng. A 2012, 552, 145–150. [Google Scholar] [CrossRef]
- Evans, M. Incorporating specific batch characteristics such as chemistry, heat treatment, hardness and grain size into the Wilshire equations for safe life prediction in high temperature applications: An application to 12Cr stainless steel bars for turbine blades. Appl. Math. Model. 2016, 40, 10342–10359. [Google Scholar] [CrossRef]
- Zieliński, A.; Golański, G.; Sroka, M. Comparing the Methods in Determining Residual Life on the Basis of Creep Tests of Low-Alloy Cr-Mo-V Cast Steels Operated Beyond the Design Service Life. Int. J. Press. Vess. Pip. 2017, 152, 1–6. [Google Scholar]
- Sroka, M.; Zieliński, A.; Dziuba-Kałuża, M.; Kremzer, M.; Macek, M.; Jasiński, A. Assessment of the Residual Life of Steam Pipeline Material beyond the Computational Working Time. Metals 2017, 7, 82. [Google Scholar] [CrossRef]
- Evans, R.W.; Evans, M. Numerical Modelling the Small Disc Creep Test. J. Mater. Sci. Technol. 2006, 22, 1155–1162. [Google Scholar] [CrossRef]
- NIMS Creep Data Sheet No. 9b, 1990. Available online: http://smds.nims.go.jp/MSDS/en/sheet/Creep.html (accessed on 1 April 2017).
- Evans, M. A stochastic Lifing Method for Materials Operating under Long Service Conditions: With Application to the Creep Life of a Commercial Titanium Alloy. J. Mater. Sci. 2001, 36, 4927–4941. [Google Scholar] [CrossRef]
- Evans, M. A Re-evaluation of the Causes of Deformation in 1Cr1Mo-0.25V Steel for Turbine Rotors and Shafts based on iso-Thermal Plots of the Wilshire Equation and the Modelling of Batch to Batch Variation. Materials 2017, 10, 575. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, E.L.; Meier, P. Nonparametric Estimation from Incomplete Observations. J. Am. Stat. Assoc. 1958, 53, 457–481. [Google Scholar] [CrossRef]
- Nelson, W. Theory and Applications of Hazard Plotting for Censored Failure Data. Technometrics 1972, 14, 945–965. [Google Scholar] [CrossRef]
- Aalen, O.O. Nonparametric Inference for a Family of Counting Processes. Ann. Stat. 1978, 6, 701–726. [Google Scholar] [CrossRef]
- Fleming, T.R.; Harrington, D.P. Counting Processes and Survival Analysis; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Prentice, R.L. Discrimination amongst Some Parametric Models. Biometrika 1975, 62, 607–614. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data, 2nd ed.; Wiley: New York, NJ, USA, 2002; Chapter 3. [Google Scholar]
- Cox, D.R. Regression Models and Life-Tables. J. R. Stat. Soc. Ser. B 1972, 34, 187–220. [Google Scholar]
- Singer, J.D.; Willett, J.B. Applied Longitudinal Data Analysis: Modelling Change and Event Occurrence; Oxford University Press: New York, NY, USA, 2003. [Google Scholar]
- Berndt, B.; Hall, B.; Hall, R.; Hausman, J. Estimation and Inference in Nonlinear Structural Models. Ann. Econ. Soc. Meas. 1974, 3, 653–665. [Google Scholar]
- McCullagh, P.; Nelder, J. Generalized Linear Models, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 1989; Chapter 2. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; Dover Publications: New York, NY, USA, 1964. [Google Scholar]
- William, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; John Wiley & Sons: New York, NY, USA, 1998; Chapters 4 and 5. [Google Scholar]
- Burr, I.W. Cumulative Frequency Functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Bennett, S. Log-Logistic Regression Models for Survival Data. J. R. Stat. Soc. Ser. C 1983, 32, 165–171. [Google Scholar] [CrossRef]
- Gumbel, E.J. The Return Period of Flood Flows. Ann. Math. Stat. 1941, 12, 163–190. [Google Scholar] [CrossRef]
- Weibull, W. A Statistical Distribution Function of wide Applicability. J. Appl. Mech. Trans. ASME 1951, 18, 293–297. [Google Scholar]
- Choi, S.C.; Wette, R. Maximum Likelihood Estimation of the Parameters of the Gamma Distribution and Their Bias. Technometrics 1969, 11, 683–690. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley: Hoboken, NJ, USA, 2003; Chapter 1. [Google Scholar]
Figure 1.
Uniaxial creep curves at 773 K for Ti-6.2.4.6 (including the band of creep curves obtained at a repeat stress of 580 MPa bounded by the maximum and minimum rupture times).
Figure 1.
Uniaxial creep curves at 773 K for Ti-6.2.4.6 (including the band of creep curves obtained at a repeat stress of 580 MPa bounded by the maximum and minimum rupture times).
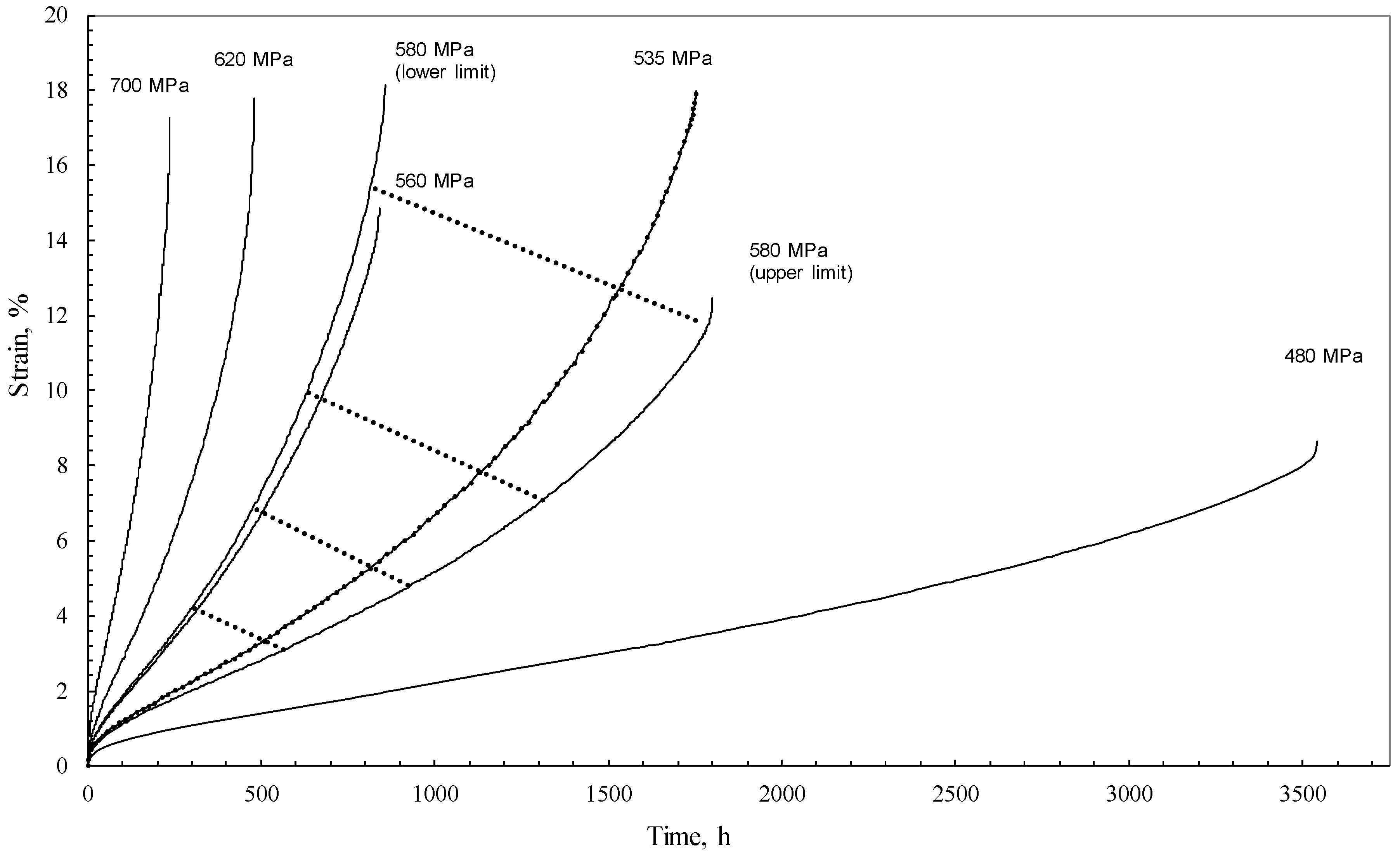
Figure 2.
Various non-parametric and parametric estimates of the survivor and hazard functions for batches of 1Cr-1Mo-0.25V steel tested at 823 K and 294 MPa.
Figure 2.
Various non-parametric and parametric estimates of the survivor and hazard functions for batches of 1Cr-1Mo-0.25V steel tested at 823 K and 294 MPa.
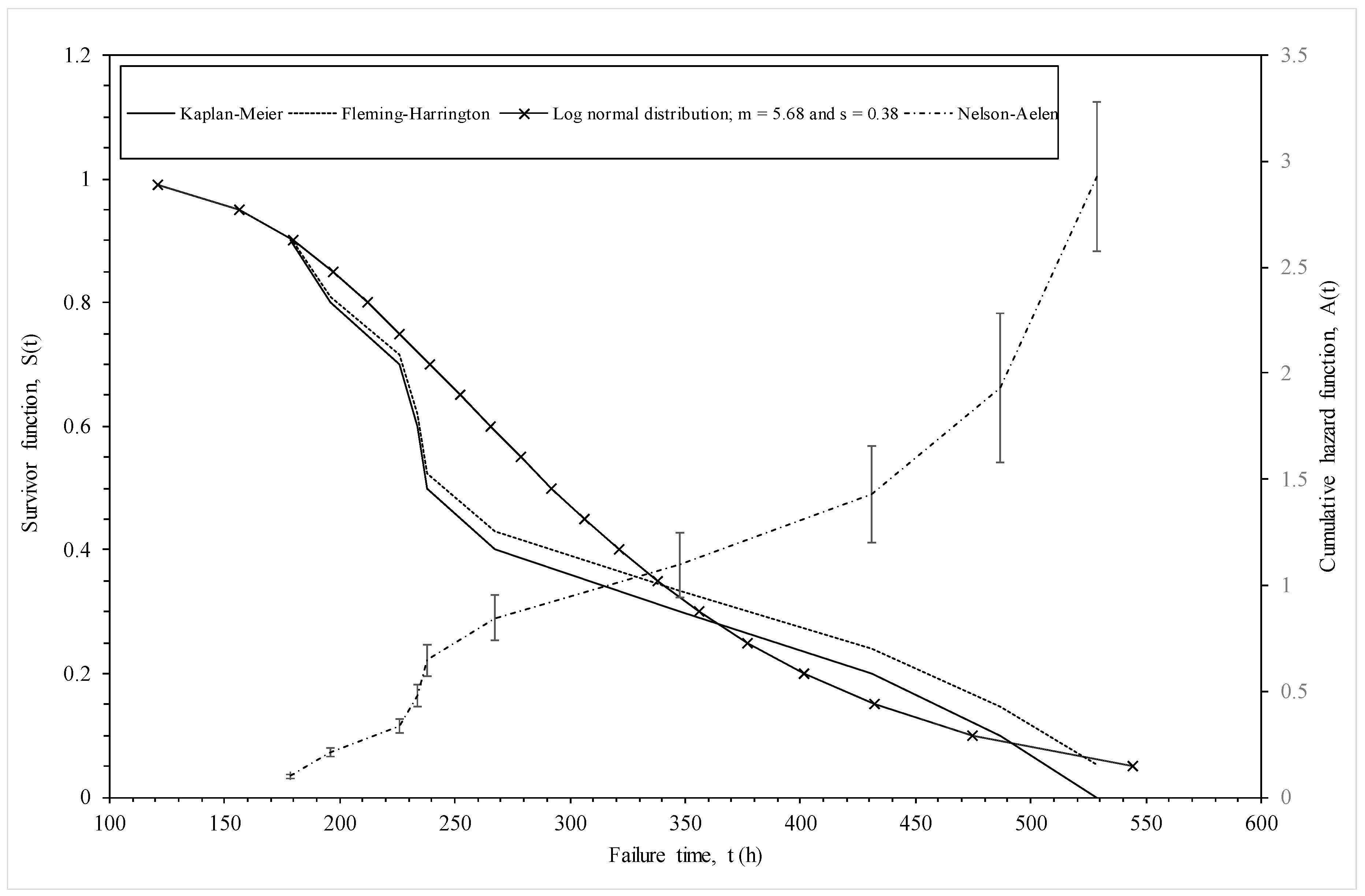
Figure 3.
Members of the Generalised F distribution.
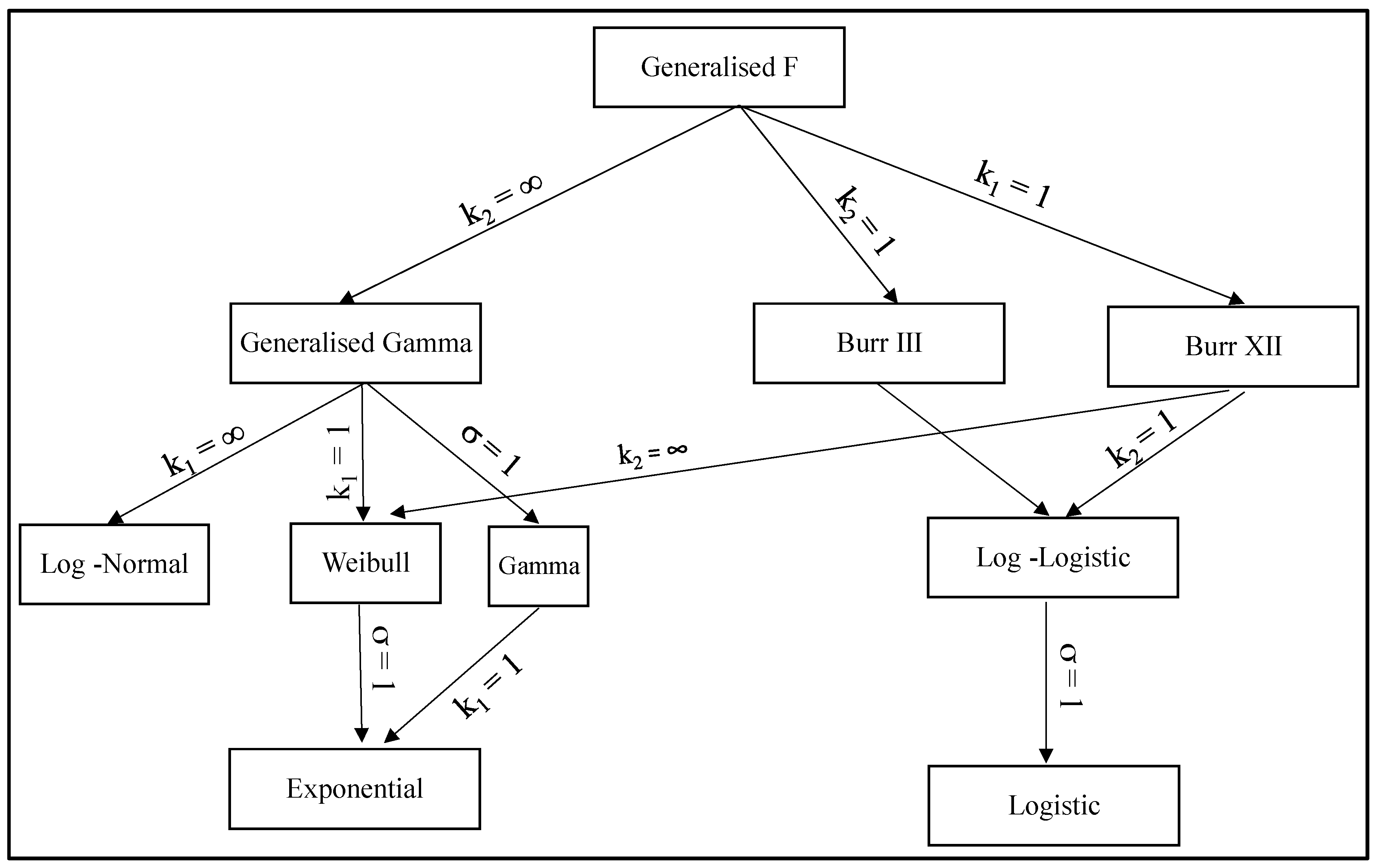
Figure 4.
Probability plots for 10 batches of 1Cr-1Mo-0.25V tested at 823 K and 294 MPa: (a) the Weibull distribution; and (b) the log normal distribution.
Figure 4.
Probability plots for 10 batches of 1Cr-1Mo-0.25V tested at 823 K and 294 MPa: (a) the Weibull distribution; and (b) the log normal distribution.
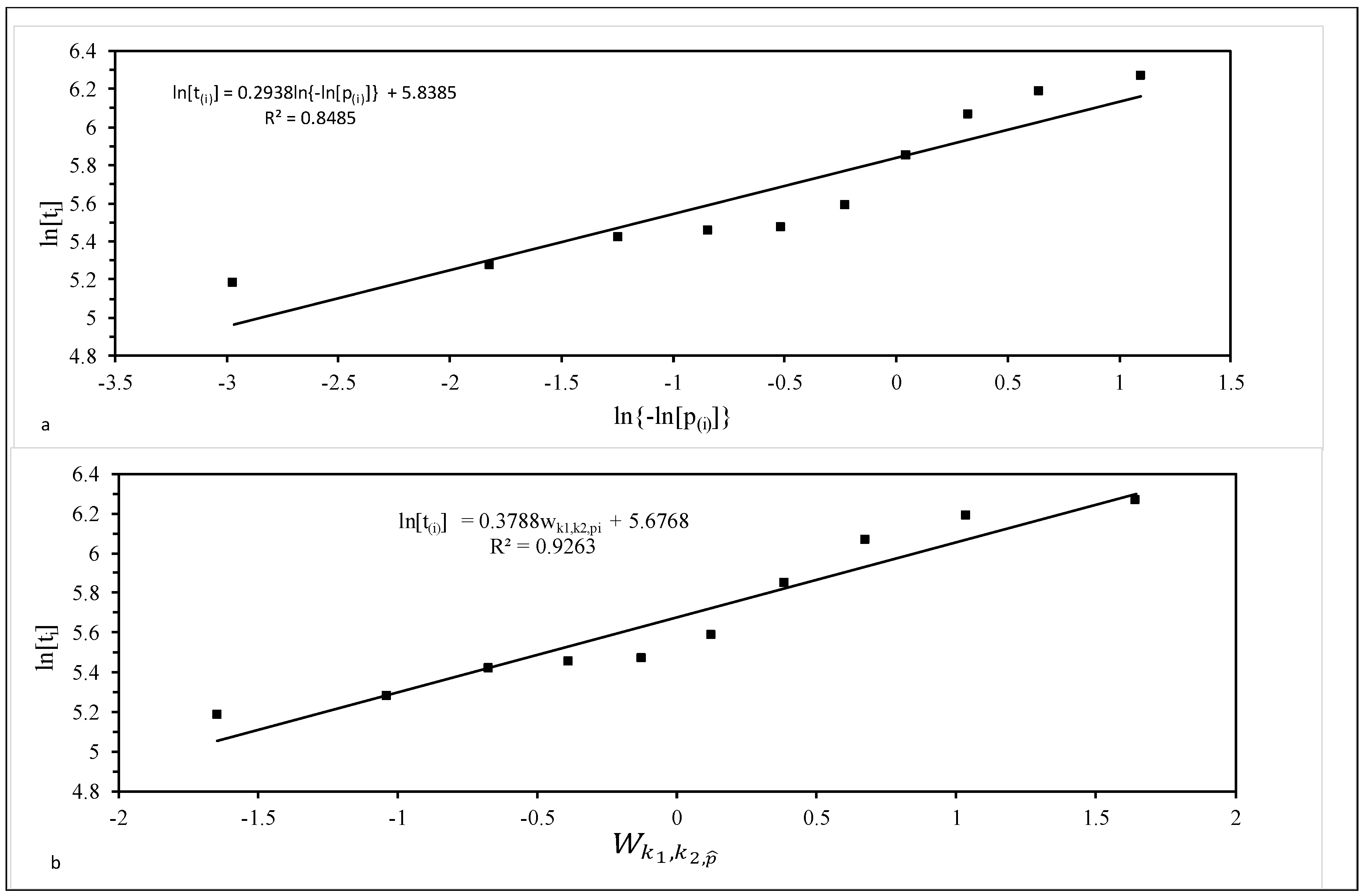
Figure 5.
The receiver operating characteristic (ROC) from model given by Equation (13e).
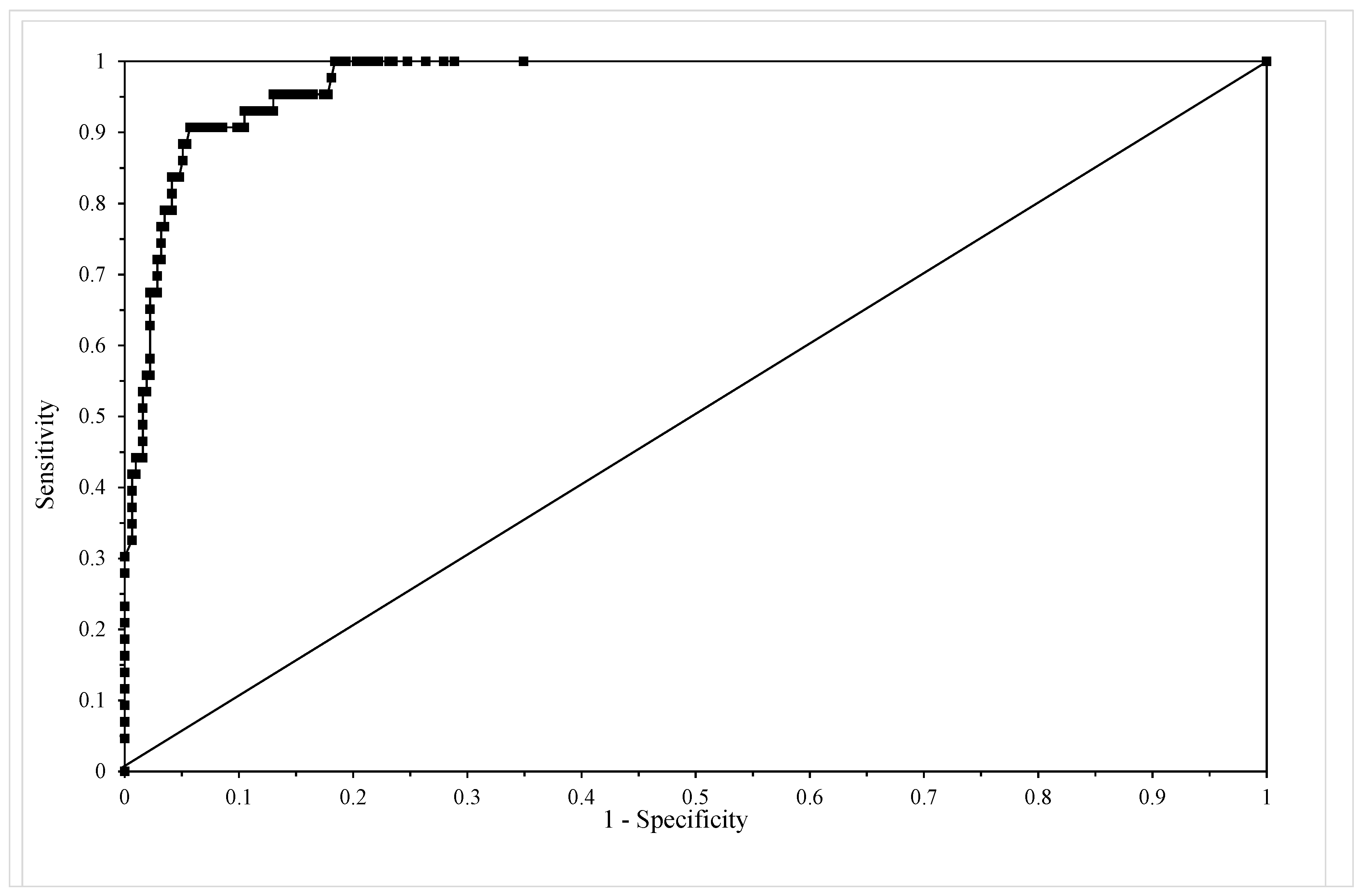
Figure 6.
Actual failure times and predicted times interval obtained from the model given by Equation (19e).
Figure 6.
Actual failure times and predicted times interval obtained from the model given by Equation (19e).
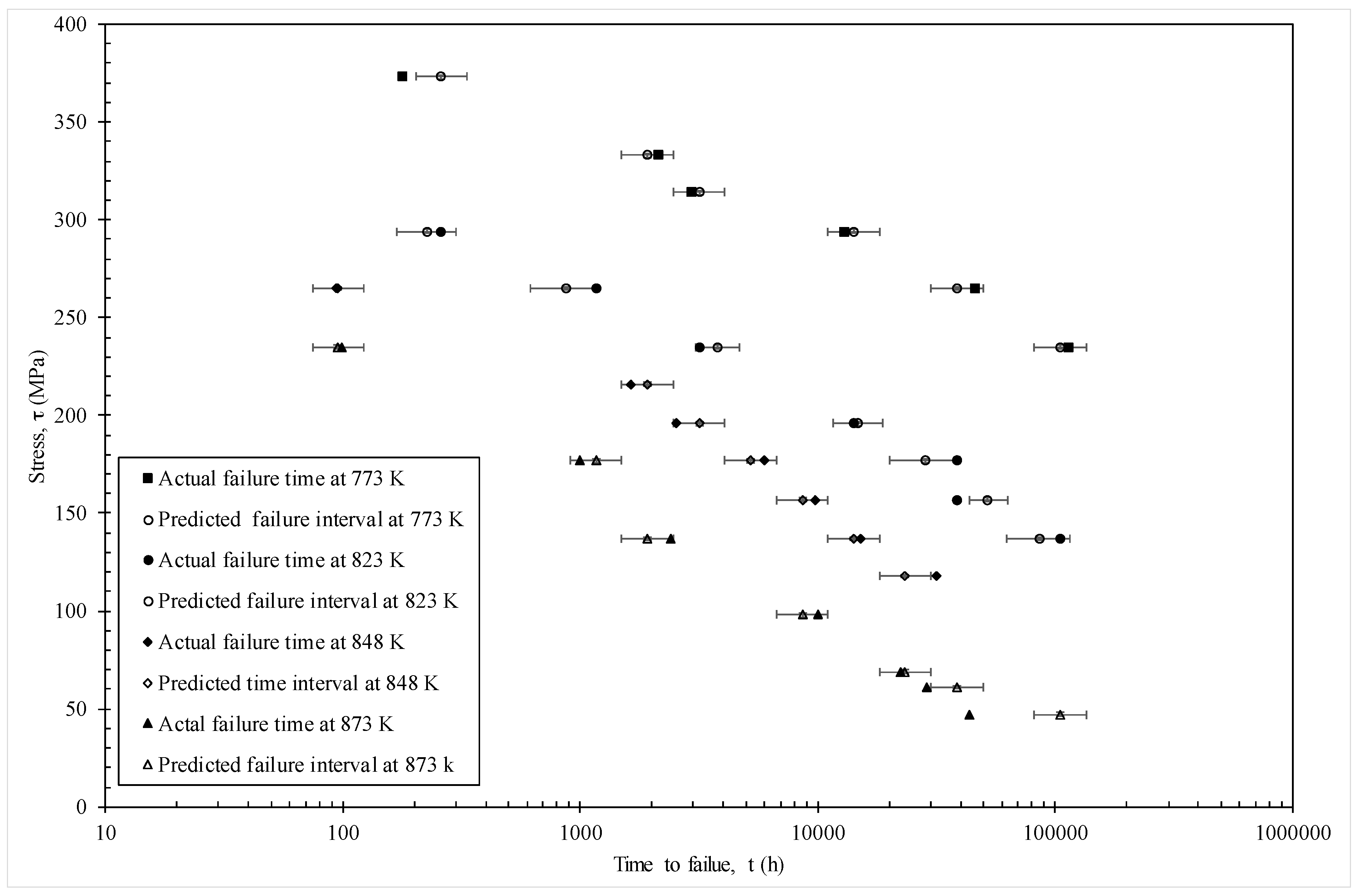
Figure 7.
Estimated baseline (i.e., corresponding to 823 K and 294 MPa) piece-wise log hazard function based on Equation (19e).
Figure 7.
Estimated baseline (i.e., corresponding to 823 K and 294 MPa) piece-wise log hazard function based on Equation (19e).
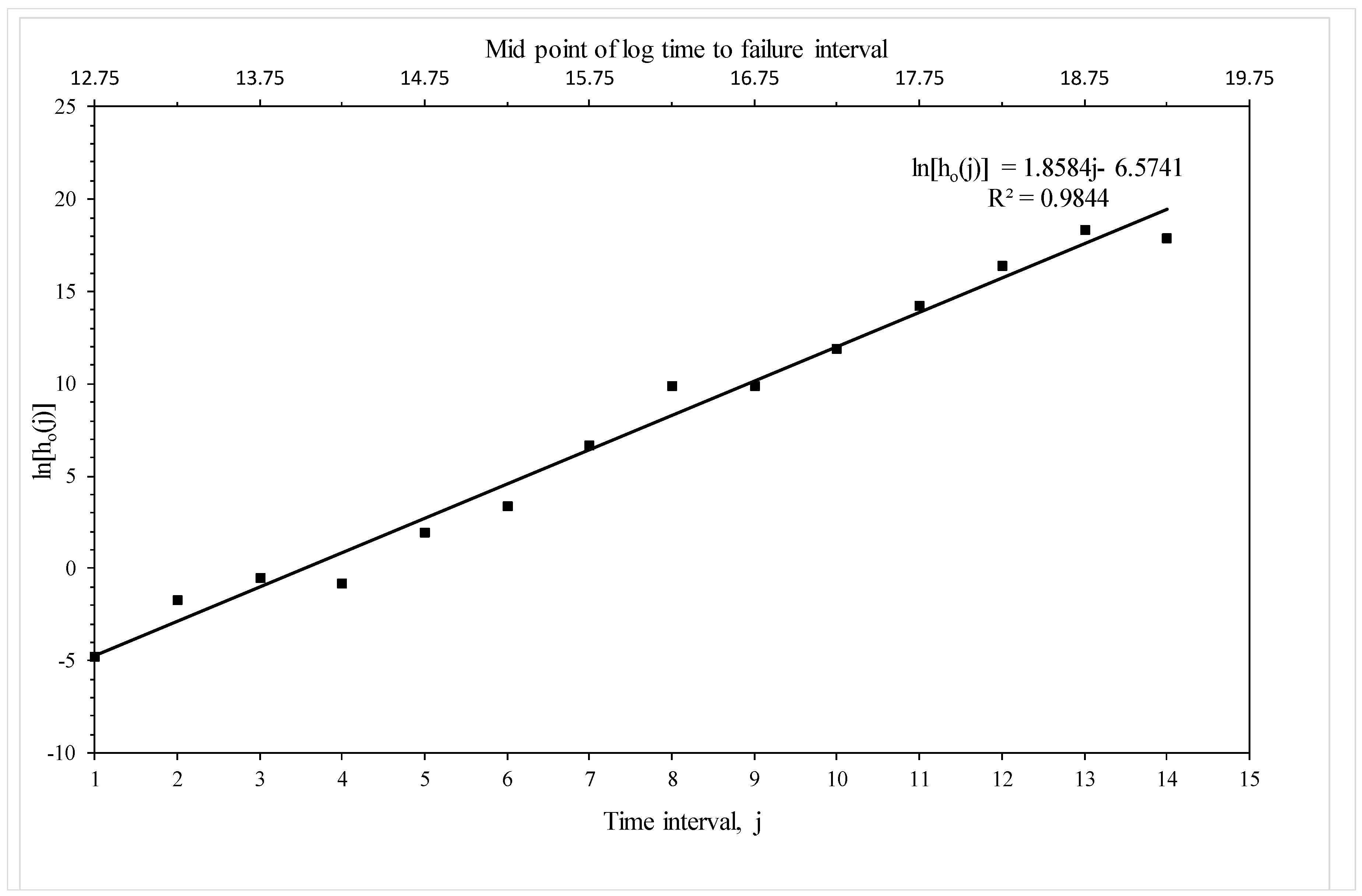
Figure 8.
The receiver operating characteristic (ROC) from model given by Equation (19f).

Figure 9.
Actual log failure times plotted against predicted log failure times obtained from the model given by Equation (19f).
Figure 9.
Actual log failure times plotted against predicted log failure times obtained from the model given by Equation (19f).
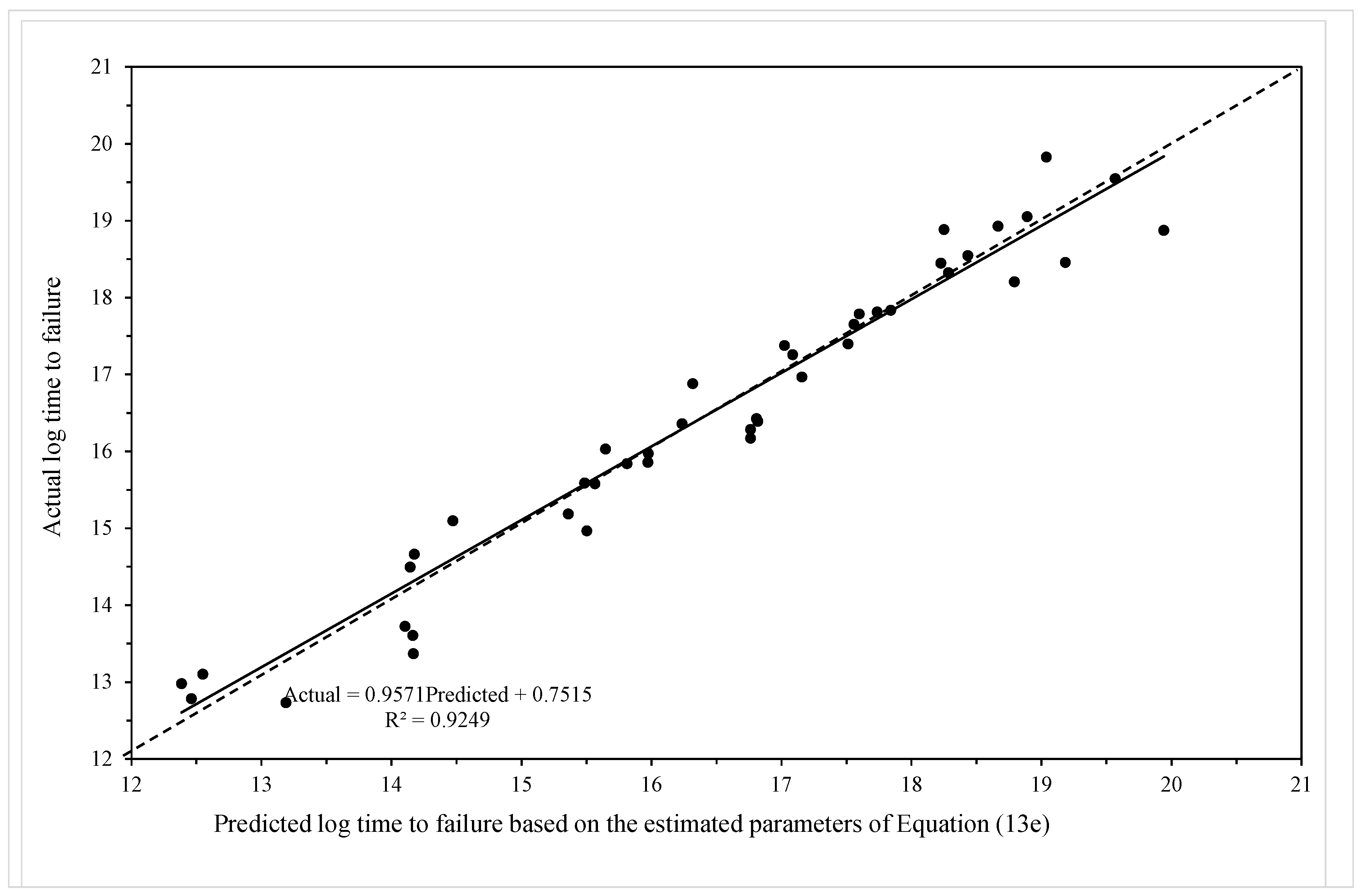
Figure 10.
Actual failure times and predicted failure times obtained from the model given by Equation (19f).
Figure 10.
Actual failure times and predicted failure times obtained from the model given by Equation (19f).
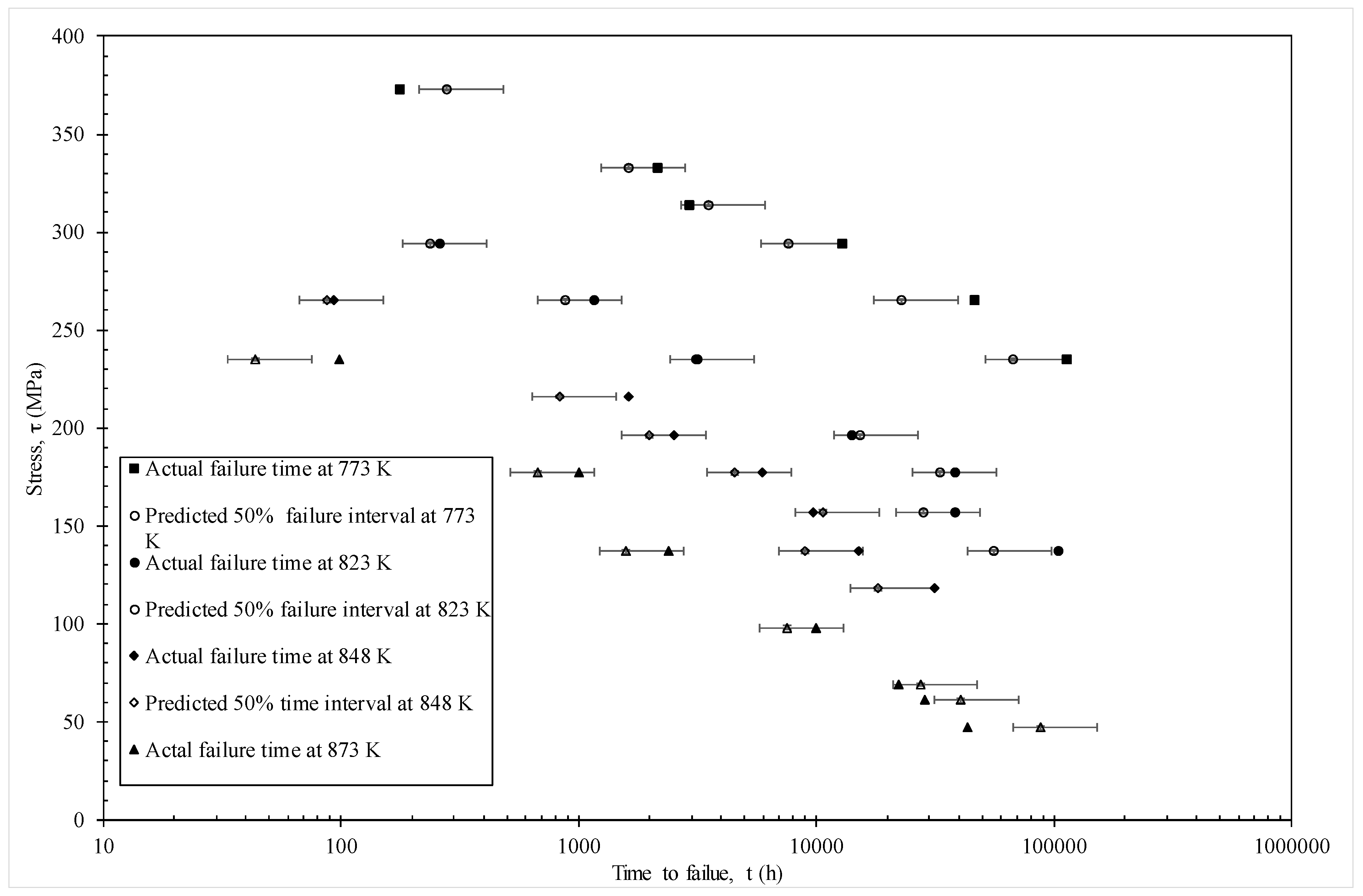
Figure 11.
Predicted hazard rates at various times in operation at 823 K and 130 MPa from the model given by Equation (19f).
Figure 11.
Predicted hazard rates at various times in operation at 823 K and 130 MPa from the model given by Equation (19f).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Illustration of the creation of a specimens-specimen dataset.
| Time Interval Ij = aj−1 − aj (Log Seconds) | Specimen Number, i | Stress, x1 (MPa) | Temperature, x2 (K) | vij |
|---|---|---|---|---|
| 12.5–13.0 | 1 | 412 | 723 | 0 |
| 13.0–13.5 | 1 | 412 | 723 | 0 |
| 13.5–14.0 | 1 | 412 | 723 | 0 |
| 14.0–14.5 | 1 | 412 | 723 | 0 |
| 14.5–15.0 | 1 | 412 | 723 | 0 |
| 15.0–15.5 | 1 | 412 | 723 | 0 |
| 15.5–16.0 | 1 | 412 | 723 | 0 |
| 16.0–16.5 | 1 | 412 | 723 | 1 |
| 12.5–13.0 | 2 | 373 | 723 | 0 |
| 13.0–13.5 | 2 | 373 | 723 | 0 |
| 13.5–14.0 | 2 | 373 | 723 | 0 |
| 14.0–14.5 | 2 | 373 | 723 | 0 |
| 14.5–15.0 | 2 | 373 | 723 | 0 |
| 15.0– 15.5 | 2 | 373 | 723 | 0 |
| 15.5–16.0 | 2 | 373 | 723 | 0 |
| 16.0–16.5 | 2 | 373 | 723 | 0 |
| 16.5–17.0 | 2 | 373 | 723 | 0 |
| 17.0–17.5 | 2 | 373 | 723 | 0 |
| 17.5–18.0 | 2 | 373 | 723 | 1 |
Table 2.
Classification table for a discrete hazard model.
| Predicted vij | Observed vij | Total | |
|---|---|---|---|
| Survived: vij = 0 | Failed: vij = 1 | ||
| Survived: vij = 0 | m1 | m3 | M3 |
| Failed: vij = 1 | m2 | m4 | M4 |
| Total | M1 | M2 | M |
Table 3.
Estimation of the parameters in Equation (19e).
| Parameter | Variable | Estimate | Student t-value |
|---|---|---|---|
| b0,1 | ln[ho(j = 1)] for 12.5–13.0 | −4.7526 | −2.81 ** |
| b0,2 | ln[ho(j = 2)] for 13.0–13.5 | −1.7111 | −1.43 |
| b0,3 | ln[ho(j = 3)] for 13.5–14.0 | −0.5019 | −0.48 |
| b0,4 | ln[ho(j = 4)] for 14.0–14.5 | −0.7838 | −0.53 |
| b0,5 | ln[ho(j = 5)] for 14.5–15.0 | 1.9713 | 1.26 |
| b0,6 | ln[ho(j = 6)] for 15.0–15.5 | 3.4266 | 2.16 ** |
| b0,7 | ln[ho(j = 7)] for 15.5–16.0 | 6.7247 | 4.24 *** |
| b0,8 | ln[ho(j = 8)] for 16.0–16.5 | 9.8840 | 4.81 *** |
| b0,9 | ln[ho(j = 9)] for 16.5–17.0 | 9.9378 | 4.31 *** |
| b0,10 | ln[ho(j = 10)] for 17.0–17.5 | 11.9647 | 4.85 *** |
| b0,11 | ln[ho(j = 11)] for 17.5–18.0 | 14.2367 | 5.11 *** |
| b0,12 | ln[ho(j = 12)] for 18.0–18.5 | 16.4289 | 5.27 *** |
| b0,13 | ln[ho(j = 13)] for 18.5–19.0 | 18.3696 | 5.39 *** |
| b0,14 | ln[ho(j = 14)] for 19.0–19.5 | 17.9018 | 5.04 *** |
| b0,15 | ln[ho(j = 15)] for 19.5–20.0 | 19.2411 | 0.38 |
| b1 | x1 | −28.554 | −5.13 *** |
| b2 | x2 | −1363.8818 | −5.62 *** |
| b3 | x3 | 5.4672 | 2.37 ** |
| b4 | x4 | 642.0808 | −4.43 *** |
Parameters estimates using the iteratively reweighted least squares technique of McCullagh and Nelder [42]. Student t-values test the null hypothesis that the true parameter values equal zero. ** identifies statistically significant variables at the 5% significance level, and *** identifies statistically significant variables at the 1% significance level. These levels of significance are based on the student t-statistic that has a student t distribution.
Table 4.
Classification table for a discrete hazard model of Equation (13e) with c = 0.5.
| Predicted vij | Observed vij | Total | |
|---|---|---|---|
| Survived: vij = 0 | Failed: vij = 1 | ||
| Survived: vij = 0 | 306 | 14 | 320 |
| Failed: vij = 1 | 9 | 29 | 38 |
| Total | 315 | 43 | 358 |
Table 5.
Estimation of the parameters in Equation (19f).
| Parameter | Variable | Estimate | Student t-value |
|---|---|---|---|
| a | Constant | −5.8351 | −4.91 *** |
| b0 | Time trend, j | 2.0736 | 6.02 *** |
| b1 | x1 | −30.8703 | −5.85 *** |
| b2 | x2 | −1451.7496 | −5.93 *** |
| b3 | x3 | 5.1666 | 3.84 *** |
| b4 | x4 | 596.9284 | 4.48 *** |
Parameters estimates using the iteratively reweighted least squares technique of McCullagh and Nelder [42]. Student t-values test the null hypothesis that the true parameter values equal zero. *** identifies statistically significant variables at the 1% significance level. These levels of significance are based on the student t-statistic that has a student t distribution.
Table 6.
Classification table for a discrete hazard model of Equation (19f) with c = 0.5.
| Predicted vij | Observed vij | Total | |
|---|---|---|---|
| Survived: vij = 0 | Failed: vij = 1 | ||
| Survived: vij = 0 | 305 | 13 | 318 |
| Failed: vij = 1 | 10 | 30 | 40 |
| Total | 315 | 43 | 358 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Evans, M. A Review of Statistical Failure Time Models with Application of a Discrete Hazard Based Model to 1Cr1Mo-0.25V Steel for Turbine Rotors and Shafts. Materials 2017, 10, 1190. https://doi.org/10.3390/ma10101190
AMA Style
Evans M. A Review of Statistical Failure Time Models with Application of a Discrete Hazard Based Model to 1Cr1Mo-0.25V Steel for Turbine Rotors and Shafts. Materials. 2017; 10(10):1190. https://doi.org/10.3390/ma10101190
Chicago/Turabian StyleEvans, Mark. 2017. "A Review of Statistical Failure Time Models with Application of a Discrete Hazard Based Model to 1Cr1Mo-0.25V Steel for Turbine Rotors and Shafts" Materials 10, no. 10: 1190. https://doi.org/10.3390/ma10101190
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.