1. Introduction
The unique characteristic of electricity is that it cannot be stored. In order to achieve frequency stability energy production must be equal to the instantaneously consumed production. Considering also the physical constraints that impose limitations (congestion) on the power transferred in transmission lines we can realize why competitive pricing is not easy to implement in real-time markets.
Today energy markets’ products are defined in terms of delivering a predetermined amount of power over a specified period of time. These markets are usually called spot markets where the prices (spots) are determined within one hour or half an hour time periods (e.g., Australia). Spot prices emerge either from auctions which take place in the so-called market pool, where retailers and generators’ representatives make offers and bids or from trading on an exchange platform either in the day-ahead or in the real-time market [
1,
2,
3]. The market clearing price is therefore determined by the most expensive unit dispatched in the abovementioned mechanisms over the respective trading period. The key factors that influence spot prices are mainly the demand or load as well as the ability to respond to this demand by the available generating units. Therefore, possible errors in load forecasting could have significant cost implications for the market participants. More specifically an underestimated predicted load could lead to unavailability the required reserve margin which in turn could lead to high costs from peak units. On the other hand, load overestimations would cause the problem of excess supply management pushing spot prices downwards.
Load prediction is a complex procedure because of the nature of the influencing factors—weather factors, seasonal factors and social-economic factors [
4]. Weather factors include temperature, relative humidity, wind speed, dew point, etc. Seasonal factors include climate variation during a year while social-economic factors are depicted through periodicities inside the time-series of the load as well as trends through years.
An electricity utility also can use forecasts in making important decisions related to purchasing and generating electric power, load switching and investing in infrastructure development. Also, energy suppliers, financial institutions and other “players” in the electric energy generation and distribution markets can benefit from reliable load forecasting.
Load is a variable that is affected by a large number of factors whose influences are “imprinted” in its dynamic evolution. Its historical past values, weather data, the clustering of customers according to their consumption profiles, the number of types of electric appliances in a given region as well as consumer age, economic and demographic data and their evolution in the future, are some of the crucial factors taken into account in medium and long-term load forecasting.
Also, the time of the year, the day of the week and the hour of the day are time factors that must be included in load forecasting. The consumption of electricity for example in Mondays, Fridays, or holidays etc. is different. Load is also strongly influenced by weather conditions. In a survey performed in 2001 bu Hippert et al. [
5], in out of 22 research papers, 13 only considered temperature, indicating the significance of this meteorological parameter in load forecasting. In this work, we have included the average temperature in the country, as a predictor, in the seasonal Auto-Regressive Integrated Moving Average (ARIMA) model for load forecasting.
Load forecasting is also a necessary tool for Transmission System Operators (TSOs) since it is used for different purposes and on different time scales. Short-term forecasts (one hour–one week) are useful for dispatchers to schedule short-term maintenance, unit commitment, fuel allocation, and cross-border trade, but also to operation engineers for network feature analysis such as optimal power flow, etc. Medium term forecasts (one week–one month) are used by TSOs for planning and operation of the power system while long-term forecasts (one month–years) are required for capacity planning and maintenance scheduling.
In this sense, load forecasting is of crucial importance for the operation and management of power systems and thus has been a major field of research in energy markets. There exist many statistical methods which are implemented to predict the behavior of electricity loads, with varying success under different market conditions [
6]. In this approach, the load pattern is treated as a time series signal, where various time series techniques are applied. The most common approach is the Box-Jenkins’ Auto-Regressive Integrated Moving Average (ARIMA) [
7] model and its generalized form Seasonal ARIMA with eXogenous parameters (SARIMAX) [
8,
9]. Models utilized in electricity load forecasting also include reg-ARIMA, a regressive ARIMA model, Principal Component Analysis and Holt-Winters exponential smoothing [
10,
11,
12]. All of the abovementioned methods are structured in such a way in order to deal with the double seasonality (intraday and intraweek cycles) inherent in load data.
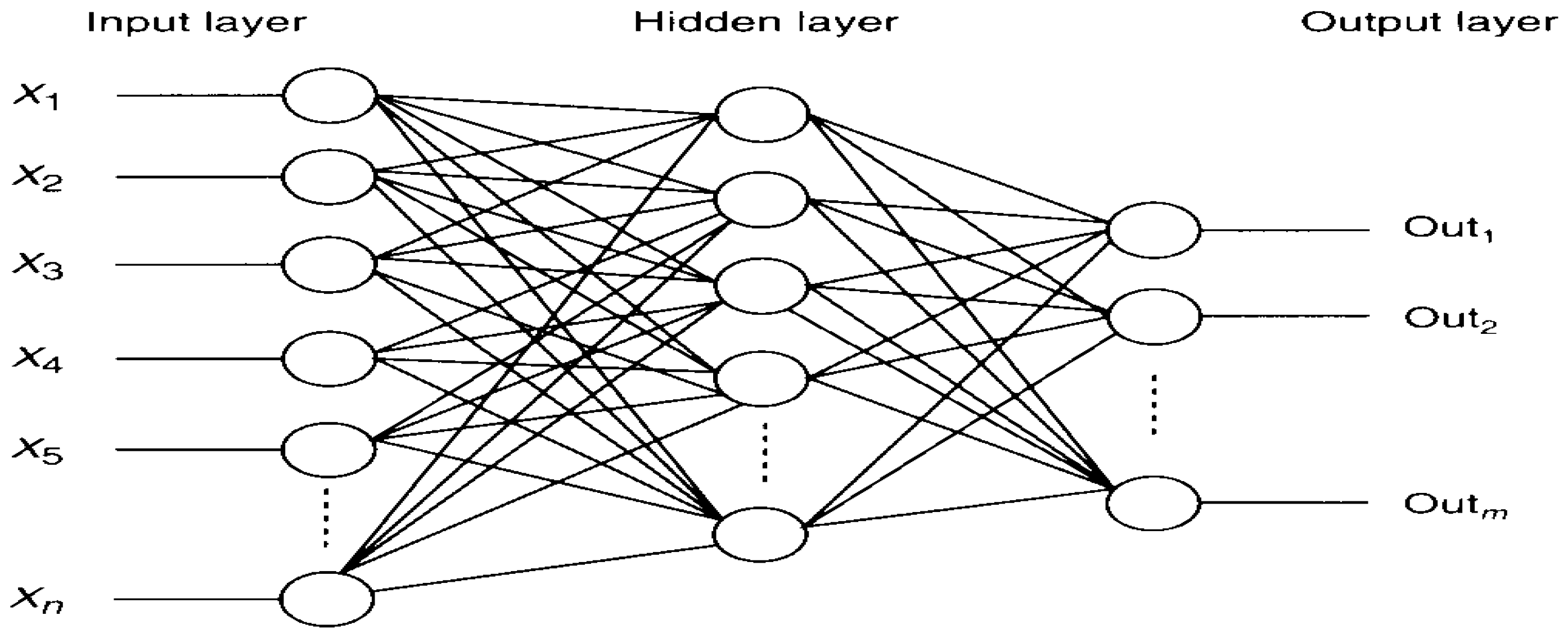
Neural Networks (NNs) and Artificial Neural Networks (ANNs) [
13,
14] are considered to be other more advanced forecasting methods. ANNs are useful for multivariate modeling but have not been reported to be so effective in univariate short-term prediction. However, the complexity of the latter and their questionable performance has relegated NNs and ANNs to being perhaps considered the last resort solution to any forecasting problem [
15]. State space and Kalman filtering technologies have thus far proved to be one of the most complex, yet reliable methods in time series forecasting [
16,
17]. A number of different load forecasting methods have been developed over the last few decades, as described below.
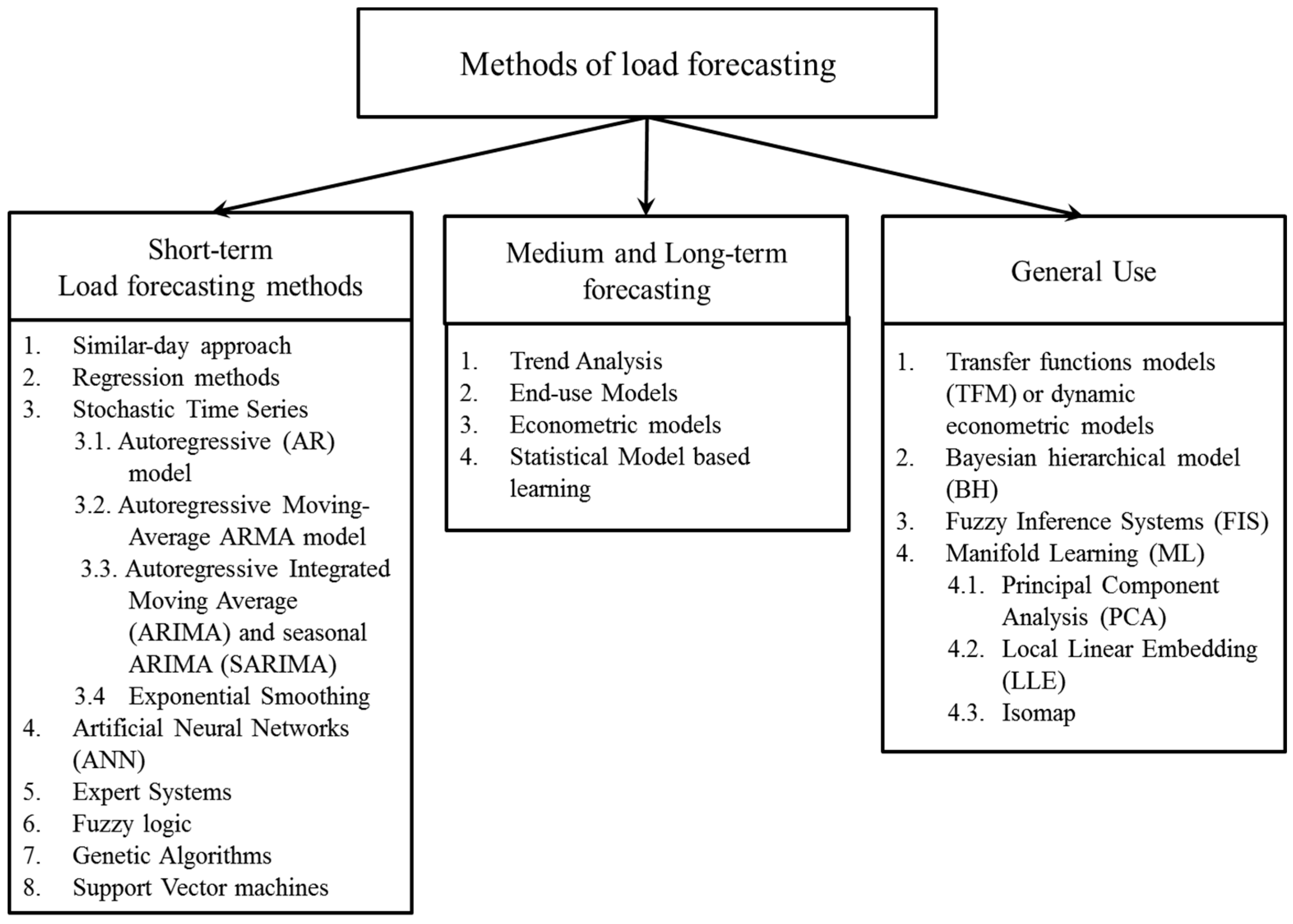
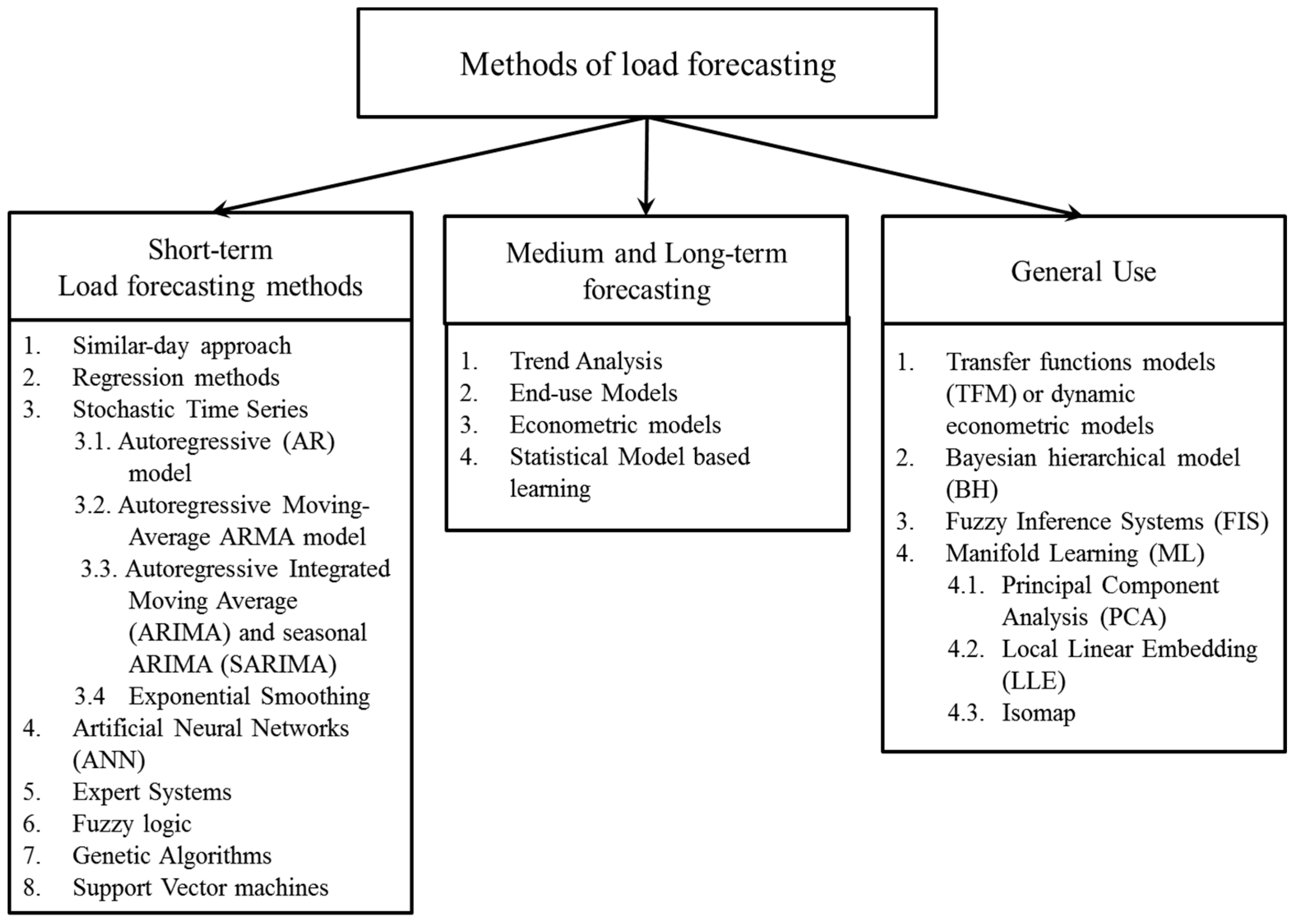
Figure 1 shows the spectrum of all methods categorized according to their short-term and medium to long-term usage, based on a literature review by the authors of this work. Other authors categorize the methods in two groups:
classical mathematical statistical and
artificial intelligence.
In order for this work to be as self-contained as possible with respect to the references we have decided to provide a short description of the most widely used methods in
Figure 1. Further survey and review papers are provided for example in Heiko et al. [
18], Kyriakides and Polycarpou) [
19], Feinberg and Genethliou [
20], Tzafestas and Tzafesta [
21] and Hippert et al. [
5] and a very recent one by Martinez-Alvarez et al. [
22]. The group of models on the right part of
Figure 1 contains new forecasting approaches that cannot be classified into any of the other two groups [
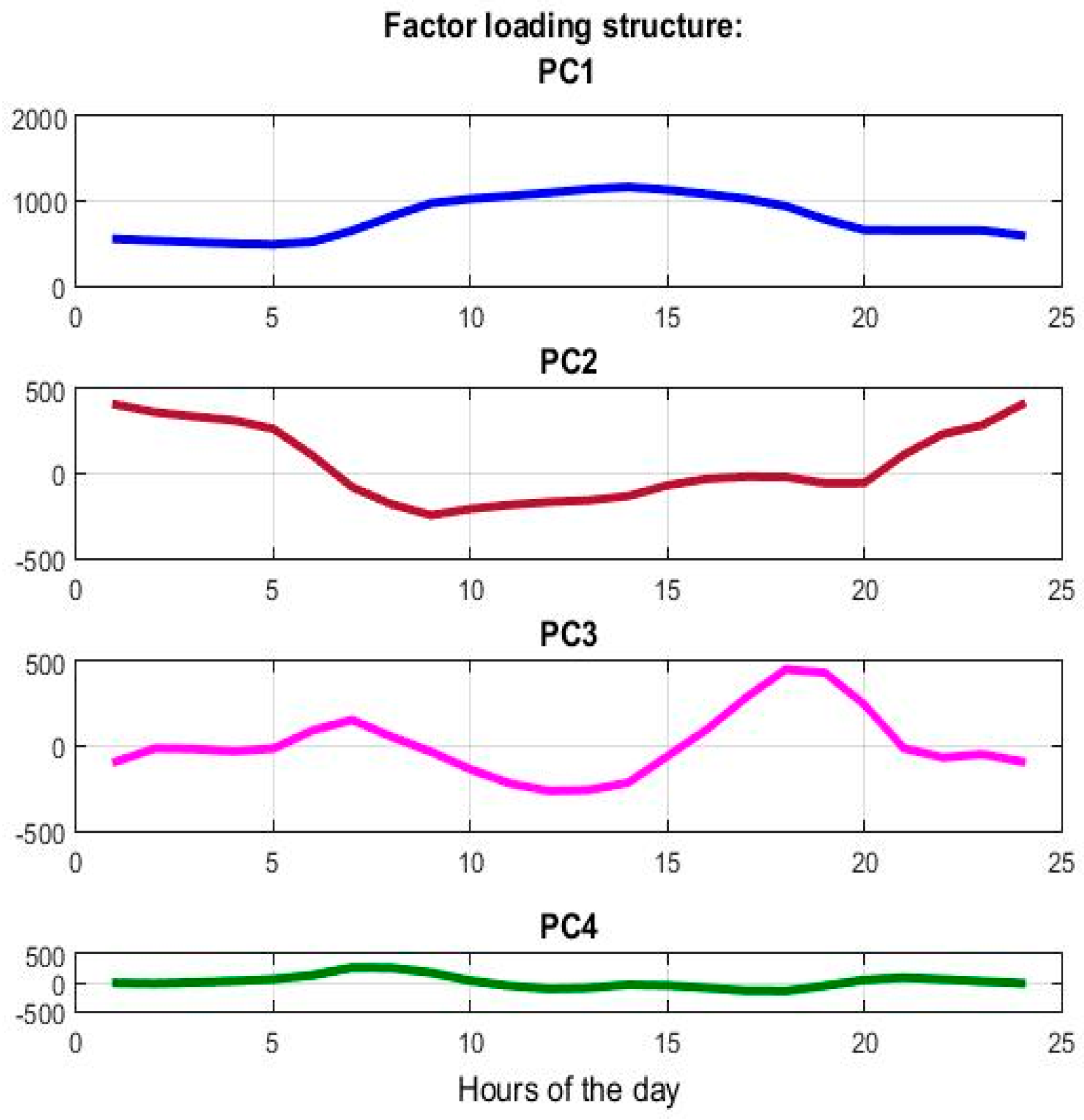
22]. A description of manifold learning Principal Component Analysis (PCA) technique is given in
Section 4.3 and
Section 5.2 below. Basic definitions of statistical tests and a short description of ETS models are given in Appendices A and B respectively while in
Appendix C methods for Support Vector Machine (SVM) and ANN are also described.
Trend analysis uses historical values of electricity load and projects them into the future. The advantage of this method is that it generates only one result, future load, but provides no information on why the load evolves the way it does. The
end-use method estimates electricity load, directly, by using records on end use and end users, like appliances, the customer usage profile, their age, type and sizes of buildings, etc. Therefore, end-use models explain electricity load as a function of how many appliances are in the market (Gellings [
23]).
Combining economic theory and statistical analysis, the
econometric models have become very important tools in forecasting load, by regressing various factors that influence consumption on load (the response variable). They provide detailed information on future levels of load, explain why future load increases and how electricity load is influenced by all the factors. The works of Genethliou and Feinberg [
20], Fu Nguyen [
24], and Li Yingying.; Niu Dongxiao [
25], describe in depth both their theoretical structure and how they are applied in various markets. Feinberg et al., [
26,
27] developed
statistical models that learn the load model parameters by using past data values. The models simplify the work in medium-term forecasting, enhance the accuracy of predictions and use a number of variables like the actual load, day of the week, hour of the day, weather data (temperature, humidity), etc.
The similar-day approach is based on searching historical data for days within one, two or three years with features that are similar to the day we want to forecast. The load of a similar day is taken as a forecast and we can also take into consideration similar characteristics of weather, day of the week and the date.
The technique that is the most widely used is
regression analysis modeling and forecasting. We regress load on a number of factors like weather, day type, category of customers etc. Holidays, stochastic effects as average loads as well as exogenous variables as weather, are incorporated in this type of models. The works of Hyde et al. [
28], Haida et al. [
29], Ruzic et al. [
30] and Charytoniuk et al. [
31], provide various applications of this kind of models to load prediction. Engle et al. [
32,
33] applied a number of regression models for forecasting the next day peak value of load.
Stochastic time series load forecasting methods detect and explore internal structure in load series like autocorrelation, trend or seasonal variation. If someone assumes that the load is a linear combination of previous loads, then the
autoregressive (AR) model can be fitted to load data. If the current value of the time series is expressed linearly in terms of its values at previous periods and in terms of previous values of white noise, then the ARMA model results. This model as well as the multiplicative or seasonal Autoregressive Integrated Moving Average (ARIMA, for non-stationary series), are the models that we will use in this work and are described in
Section 4. Chen et al. [
34] have applied an adaptive ARMA model for load prediction, where the resulting available prediction errors are used to update the model. This adaptive model outperformed typical ARMA models. Now, in case that the series is non-stationary, then a transformation is needed to make time series stationary. Differentiating the series is an appropriate form of transformation. If we just need to differentiate the data once, i.e., the series is integrated of order 1, the general form of ARIMA (p,1,q) where p and q are the number or AR and MA parameters in the model (see
Section 4 for more details). Juberias et al. [
35] have created a real time load forecasting ARIMA model, incorporating meteorological variables as predictors or explanatory variables.
References [
36,
37,
38,
39,
40] refer to application of hybrid wavelet and ANN [
36], or wavelet and Kalman filter [
37] models to short-term load forecasting STLF, and a Kalman filter with a moving window weather and load model, for load forecasting is presented by Al-Hamadi et al. [
38]. In the Greek electricity market Pappas et al. [
39] applied an ARMA model to forecast electricity demand, while an ARIMA combined with a lifting scheme for STLF was used in [
40].
Artificial Neural Networks (ANN) have been used widely in electricity load forecasting since 1990 (Peng et al. [
41]). They are, in essence, non-linear models that have excellent non-linear curve fitting capabilities. For a survey of ANN models and their application in electricity load forecasting, see the works of Martinez-Alvarez et al. [
22], Metaxiotis [
42] and Czernichow et al. [
43]. Bakirtzis et al. [
44] developed an ANN based on short-term load forecasting model for the Public Power Corporation of Greece. They used a fully connected three-layer feed forward ANN and back propagation algorithm for training. Historical hourly load data, temperature and the day of the week, were the input variables. The model can forecast load profiles from one to seven days. Papalexopoulos et al. [
45] developed and applied a multi-layered feed forward ANN for short-term system load forecasting. Season related inputs, weather related inputs and historical loads are the inputs to ANN. Advances in the field of artificial intelligence have resulted in the new technique of
expert systems, a computer algorithm having the ability to “think”, “explain” and update its knowledge as new information comes in (e.g., new information extracted from an expert in load forecasting). Expert systems are frequently combined with other methods to form hybrid models (Dash et al. [
46,
47], Kim et al. [
48], Mohamad et al. [
49]).
References [
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69,
70] cover the period 2000–2015 in which the work of Maier et al. [
50] is one of the first ones related to ANN application in forecasting water resources, while during the same period we note also the creation of hybrid methods combining the strengths of various techniques that still remain popular until today. A combination of ANN and fuzzy logic approaches to predict electricity prices is presented in [
51,
52]. Similarly, Amjady [
53] applied a feed-forward structure and three layers in the NN and a fuzzy logic model to the Spanish electricity price, outperforming an ARIMA model. Taylor [
54] tested six models of various combinations (ARIMA, Exponential Smoothing, ANN, PCA and typical regression) for forecasting the demand in England and Wales. Typical applications of ANN on STLF are also presented in [
55,
56,
57,
58]. The book of Zurada [
59] also serves as a good introduction to ANN. A wrapper method for feature selection in ANN was introduced by Xiao et al. [
60] and Neupane et al. [
61], a method also adopted by Kang et al. [
62]. A Gray model ANN and a correlation based feature selection with ANN are given in [
63,
64]. The Extreme Learning Machine (ELM), a feed-forward NN was used in the works [
65,
66] and a genetic algorithm, GA, and improved BP-ANN was used in [
67]. Cecati et al. [
68] developed a “super-hybrid” model, consisting of Support Vector Regression (SVR), ELM, decay Radial Basis function RBF-NN, and second order and error correction, to forecast the load in New England (USA). A wavelet transform combined with and artificial bee colony algorithm and ELM approach was also used by Li et al. [
69] for load prediction in New England. Jin et al. [
70] applied Self Organizing Maps (SOM), a method used initially in discovering patterns in data to group the data in an initial stage, and then used ANN with an improved forecasting performance. One of the most recent and powerful methods is
SVM, originated in Vapnik’s (Vane [
71]) statistical learning theory (see also Cortes and Vapnik [
72], and Vapnik [
73,
74]). SVM perform a nonlinear (kernel functions) mapping of the time series into a high dimensional (feature) space (a process which is the opposite of the ANN process). Chen et al. [
75] provides an updated list of SVM and its extensions applied to load forecasting. SVM use some linear functions to create linear decision boundaries in the new space. SVM have been applied in load forecasting in different ways as in Mohandas [
76], and Li and Fang [
77], who blend wavelet and SVM methods.
References [
76,
77,
78,
79,
80,
81,
82,
83,
84,
85,
86,
87,
88,
89,
90,
91,
92,
93,
94] on SVM and its various variations-extensions for performance improvement cover the period 2003–2016. Traditional SVM has some shortcomings, for example SVM cannot determine the input variables effectively and reasonably and it is characterized by slow convergence speed and poor forecasting results. Suykens and Vandewalle [
78] proposed the least square support vector machine (LSSVM), as an improved SVM model. Hong [
79] analyzed the suitability of SVM to forecast the electric load for the Taiwanese market, as Guo et al. [
80] did for the Chinese market. To capture better the spikes in prices, Zhao et al. [
81] adopted a data mining framework based on both SVM and probability classifiers. In order to improve the forecasting quality and reduce the convergence time, Wang et al. [
82] combined rough sets techniques (RS) on the data and then used a hybrid model formed by SVM and simulated annealing algorithms (SAA). A combination of Particle Swarm Optimization (PSO) and data mining methods in a SVM was used by Qiu [
83] with improved forecasting results. In general, various optimization algorithms are extensively used in LSSVM to improve its searching performance, such as Fruit Fly Optimization (FFO) [
85,
88], Particle Swarm Optimization (PSO) [
93], and Global Harmony Search Algorithm [
75].
The most recent developments on load forecasting are reviewed by Hong and Fan [
95]. An interesting big data approach on load forecasting is examined by Wang [
96], while Weron’s recent work is mostly focused on improving load forecast accuracy combining sister forecasts [
97]. New methods on machine learning are covered in [
98,
99]. A regional case study is performed by Saraereh [
100] using spatial techniques. Kim and Kim examine the error measurements for intermittent forecasts [
101].
The structure of this paper is as follows:
Section 2 includes a short description of the Greek electricity market with emphasis on the dynamic evolution of load during the 2004–2014 period. In
Section 3 we quote the load series data performing all tests which are required for further processing by our models (stationarity tests, unit-root tests, etc.).
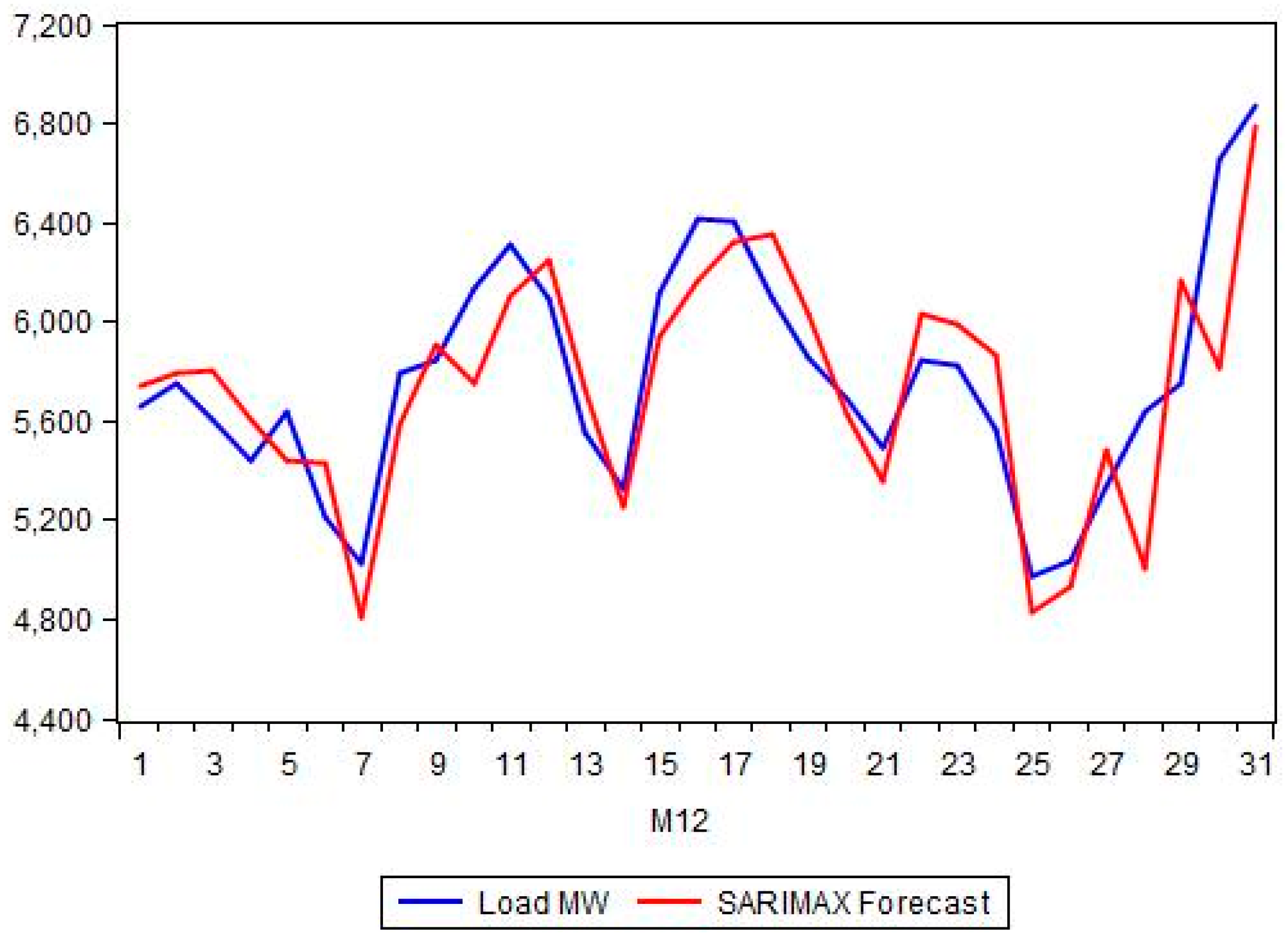
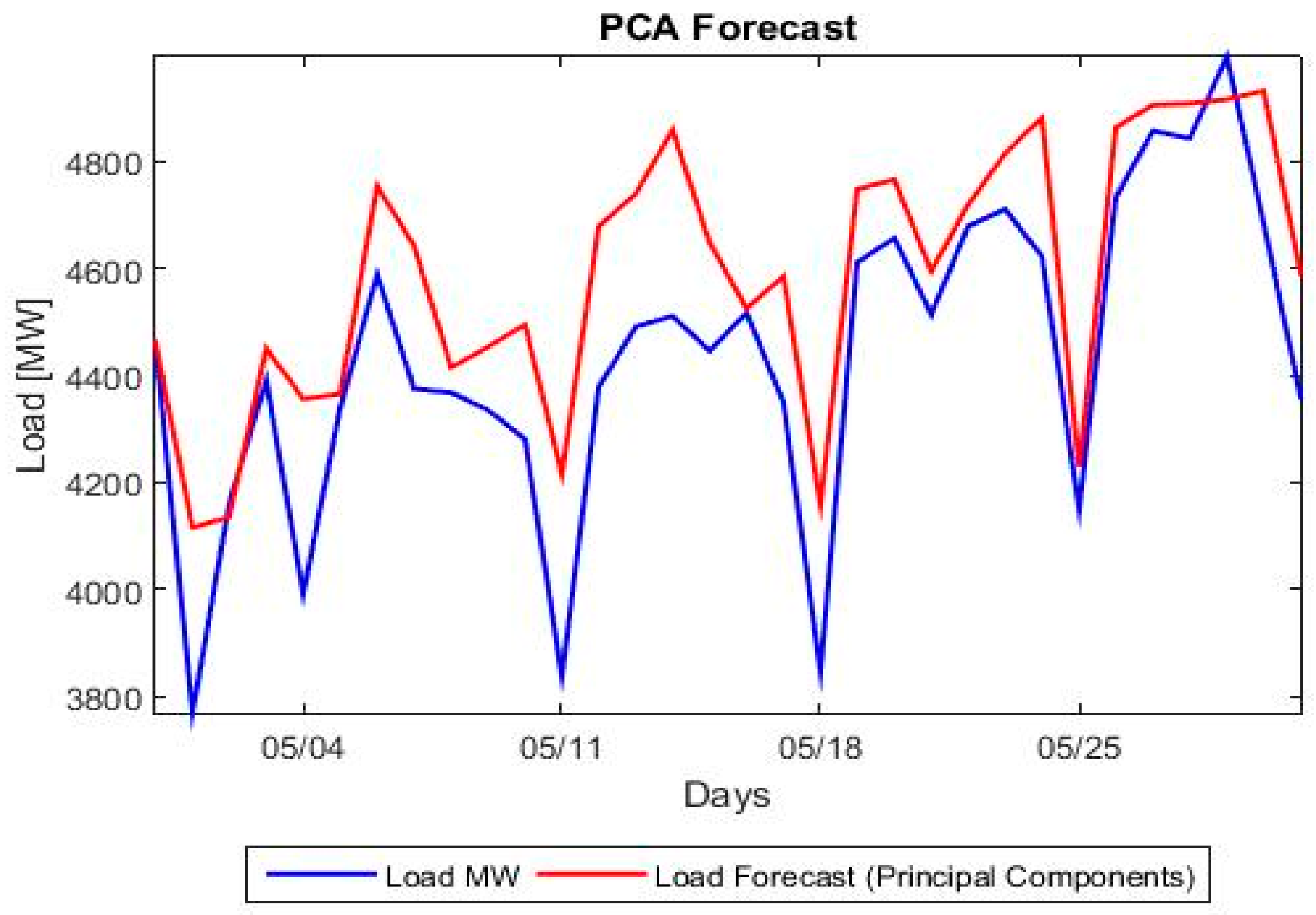
Section 4 is the suggested methodology; it encompasses the mathematical formulation of the proposed models (SARIMAX, Exponential Smoothing and PC Regression analysis).
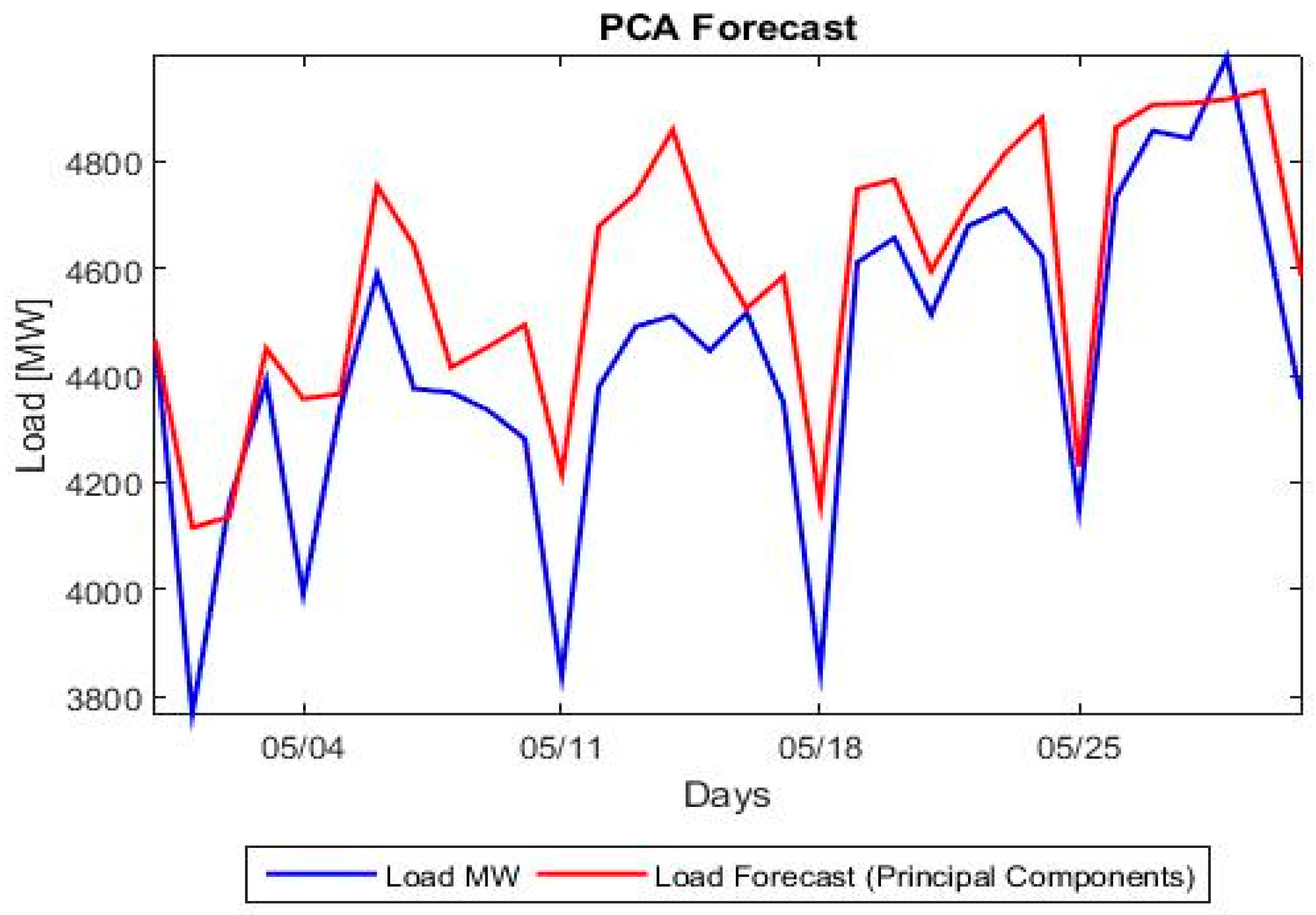
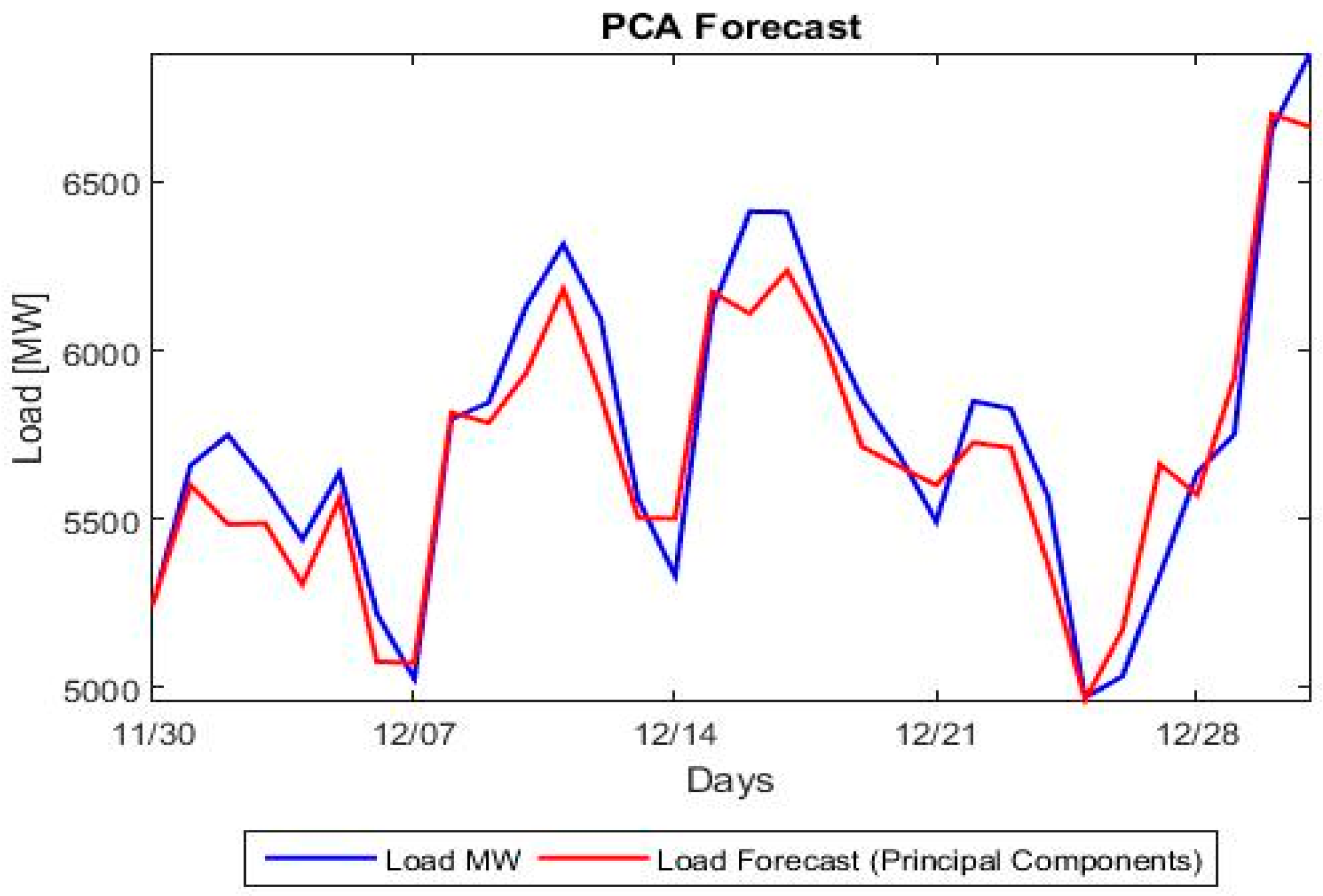
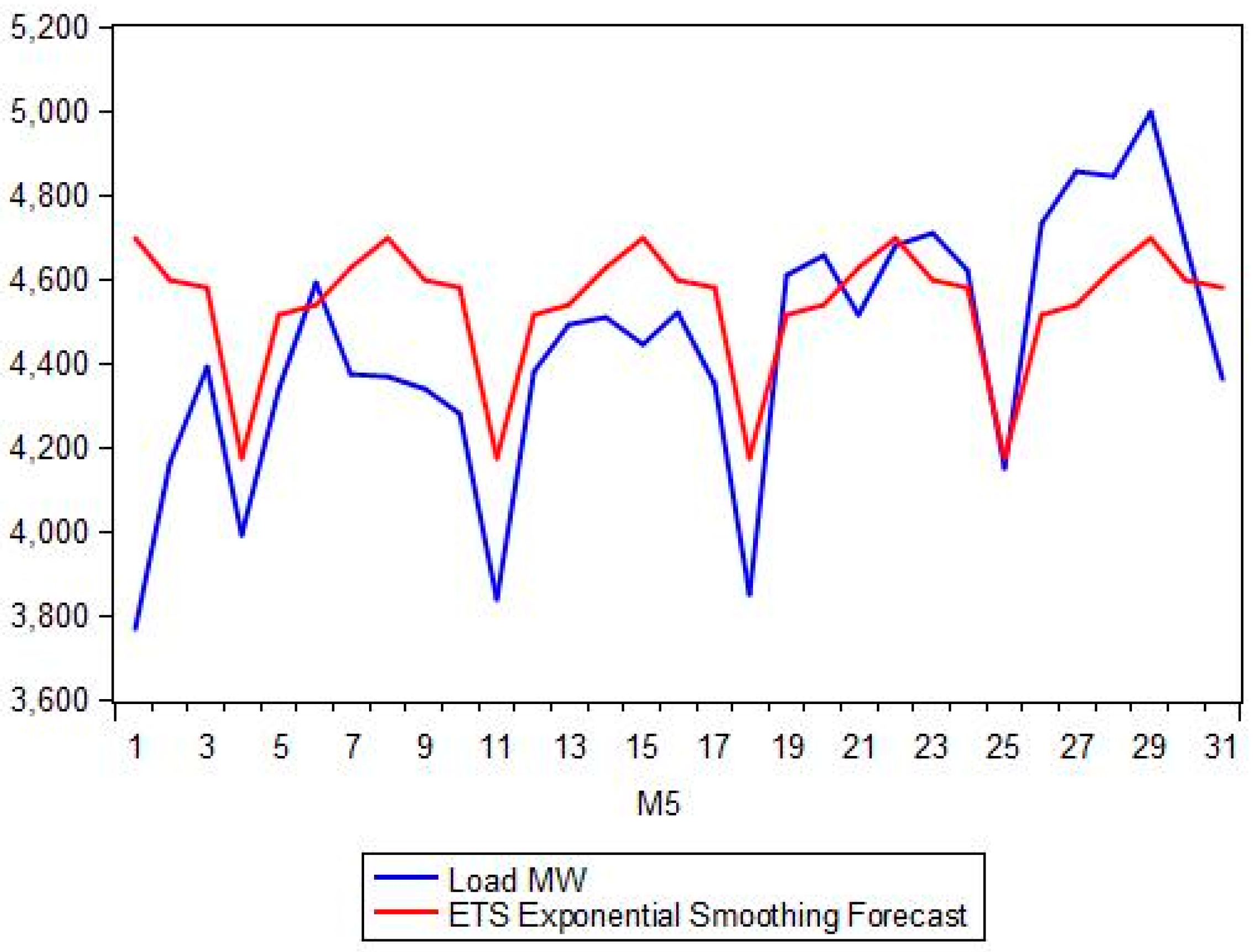
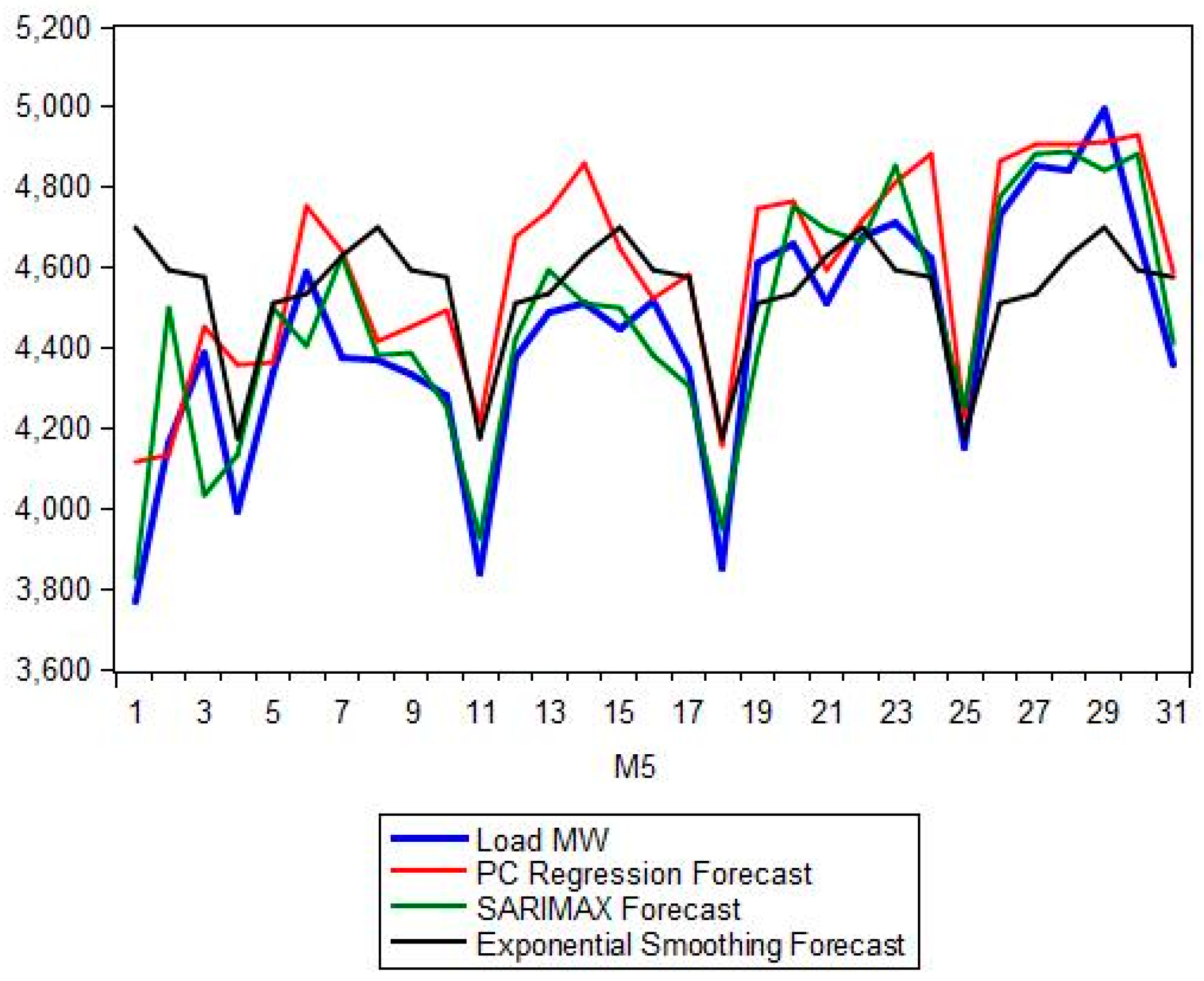
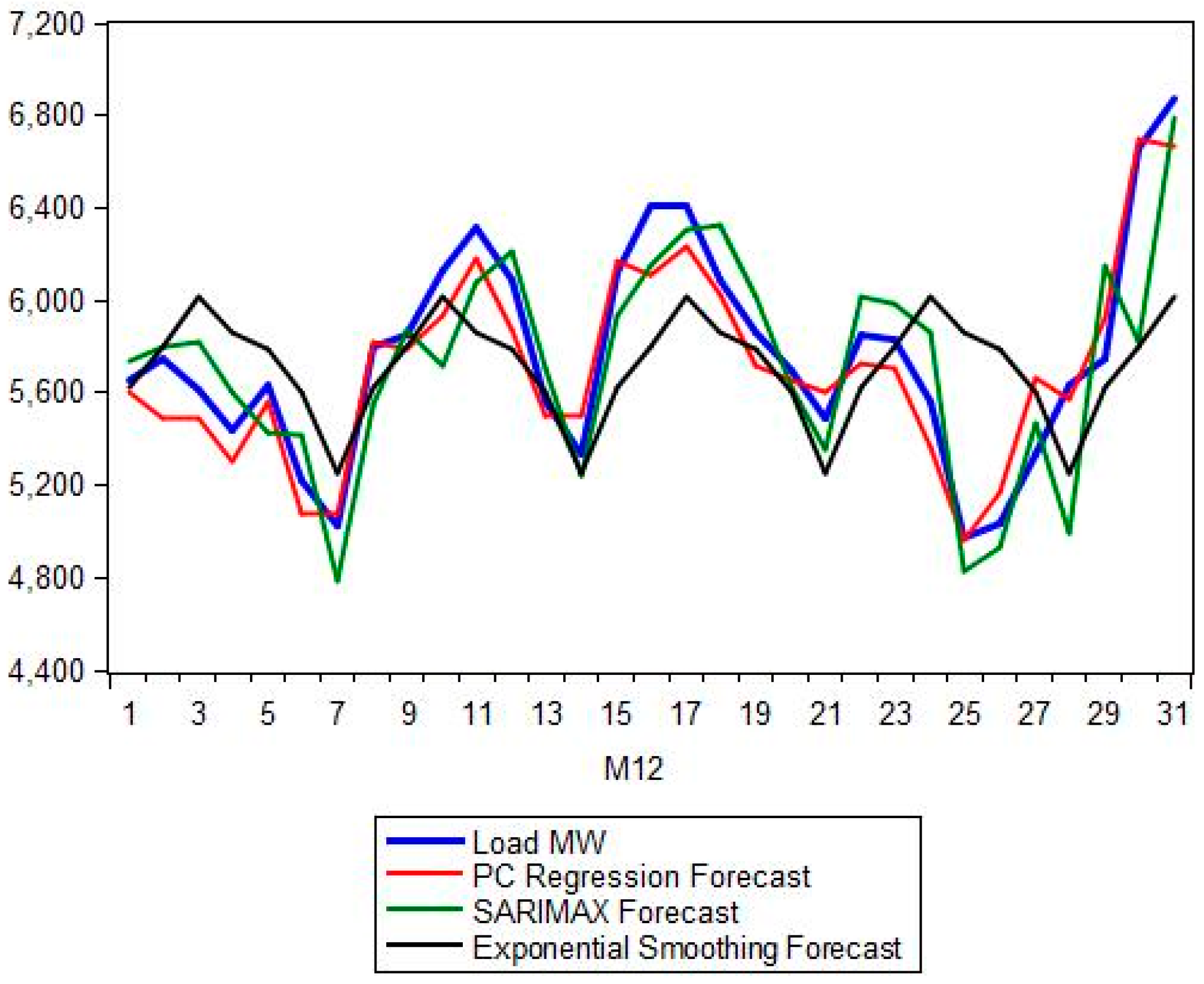
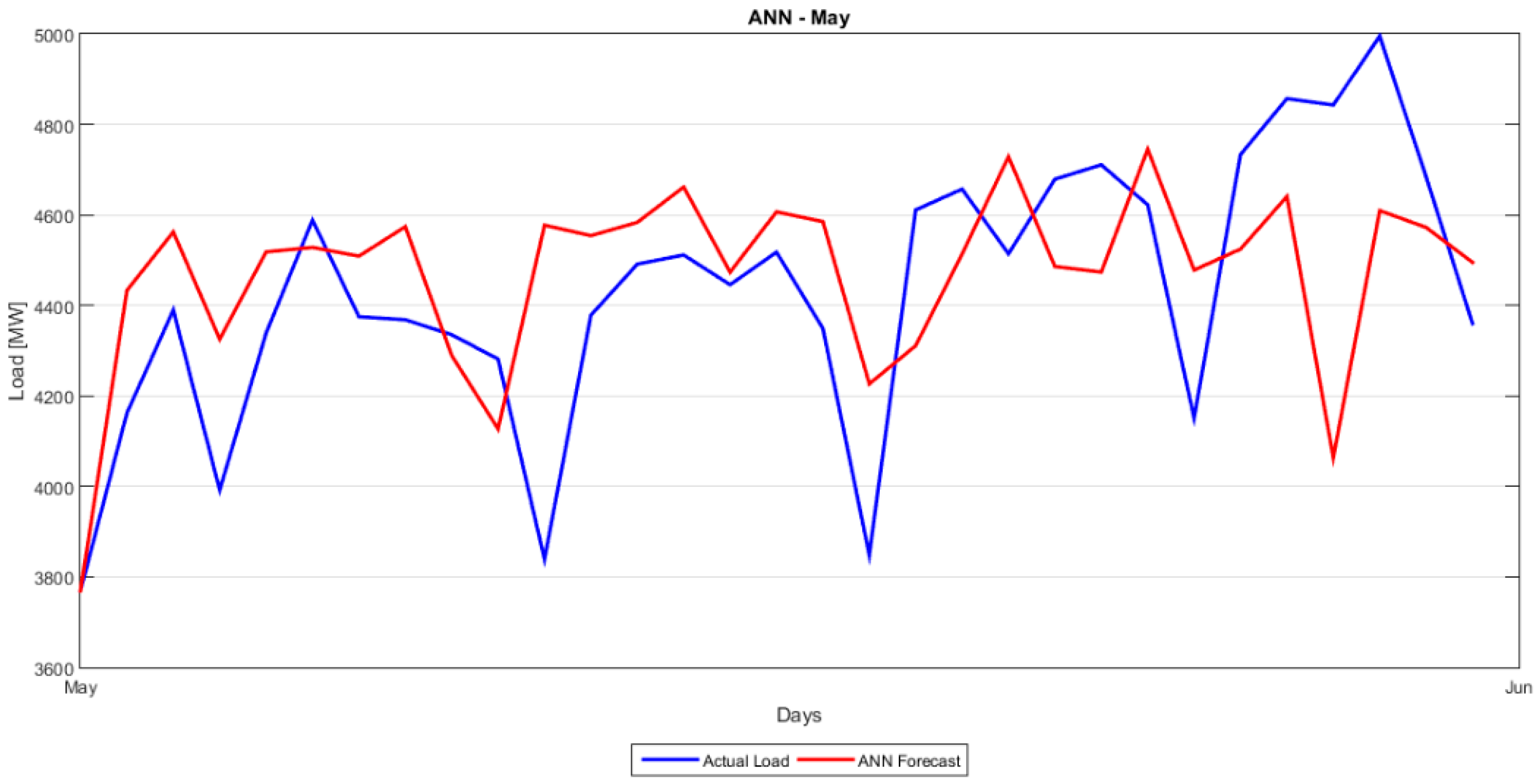
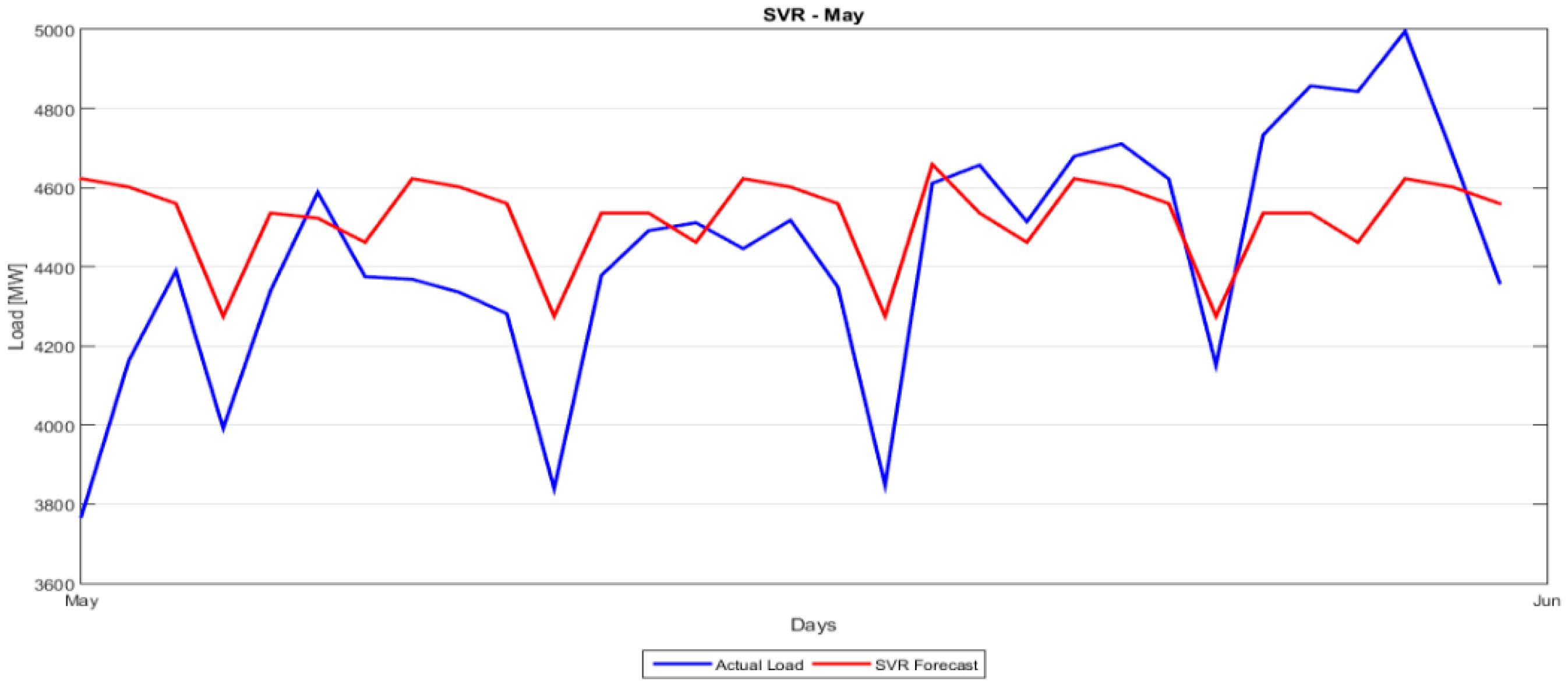
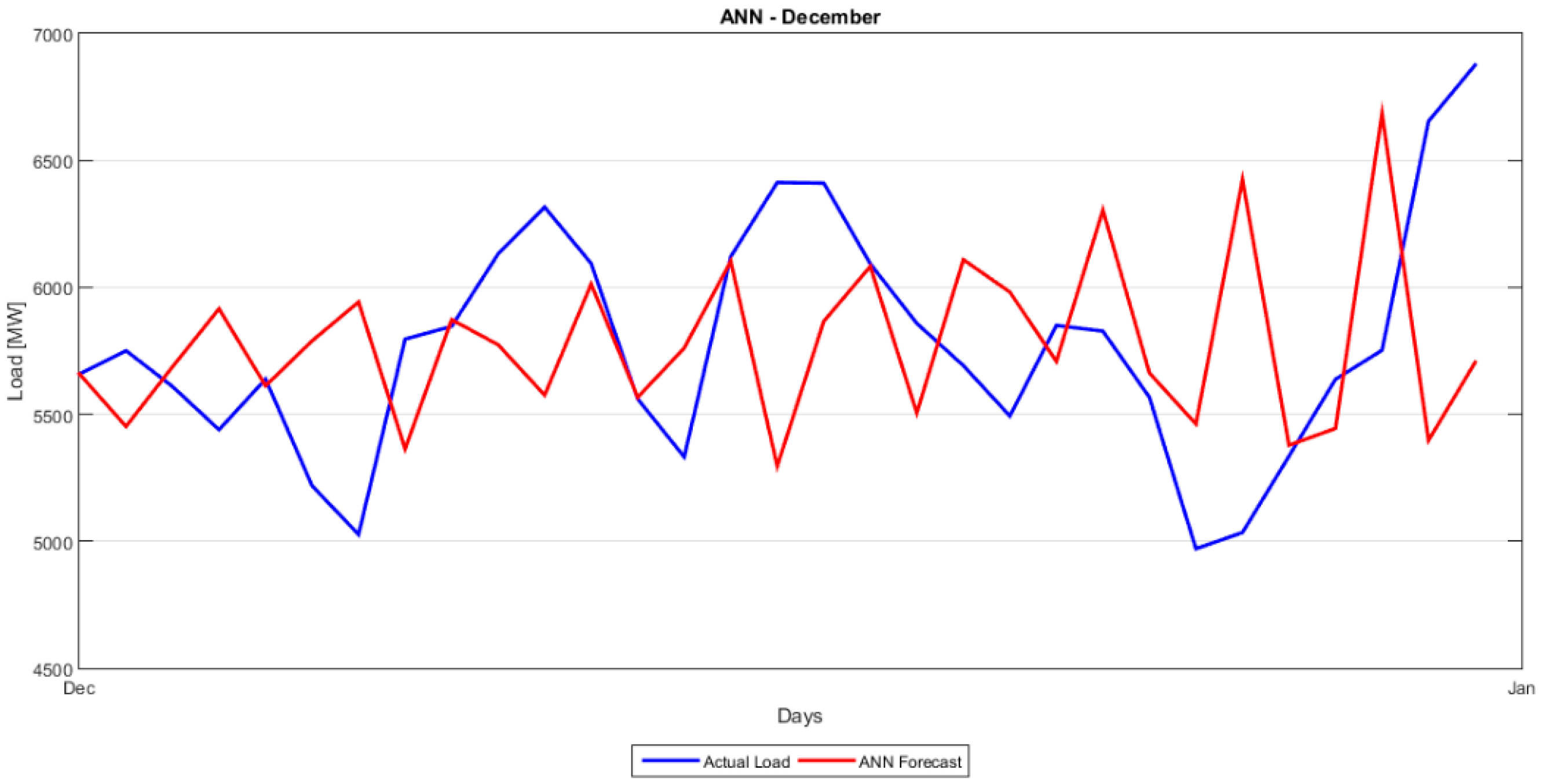
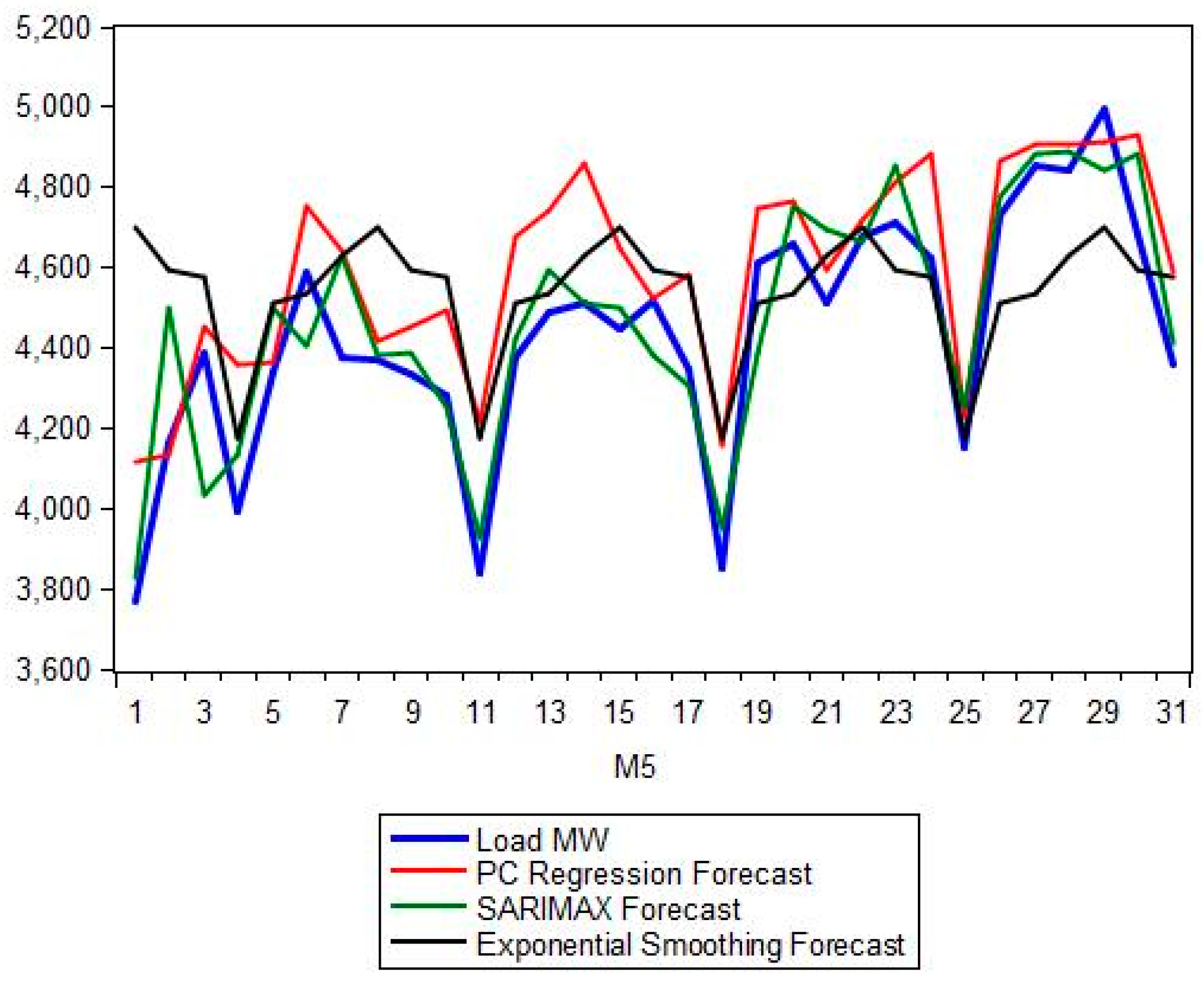
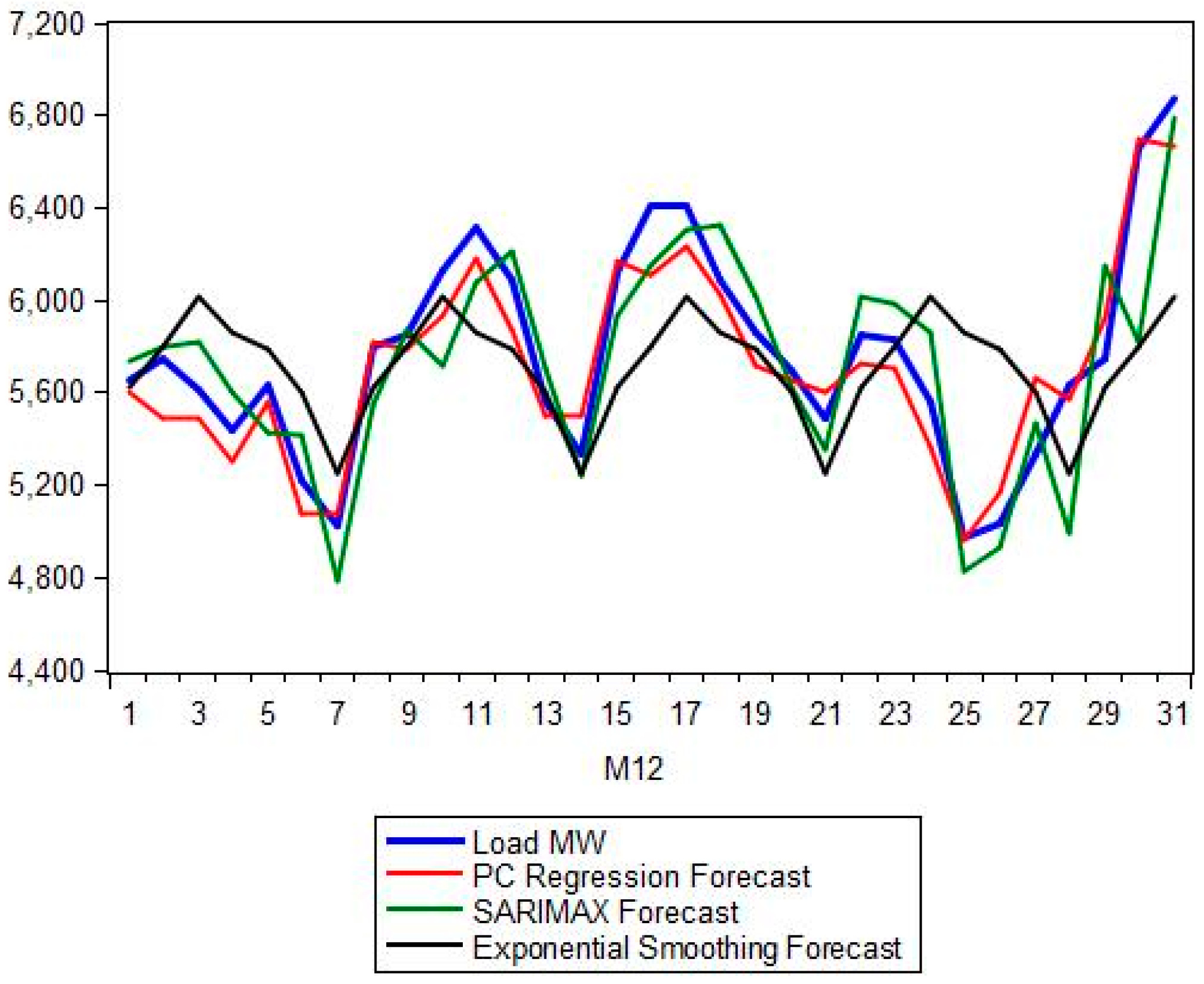
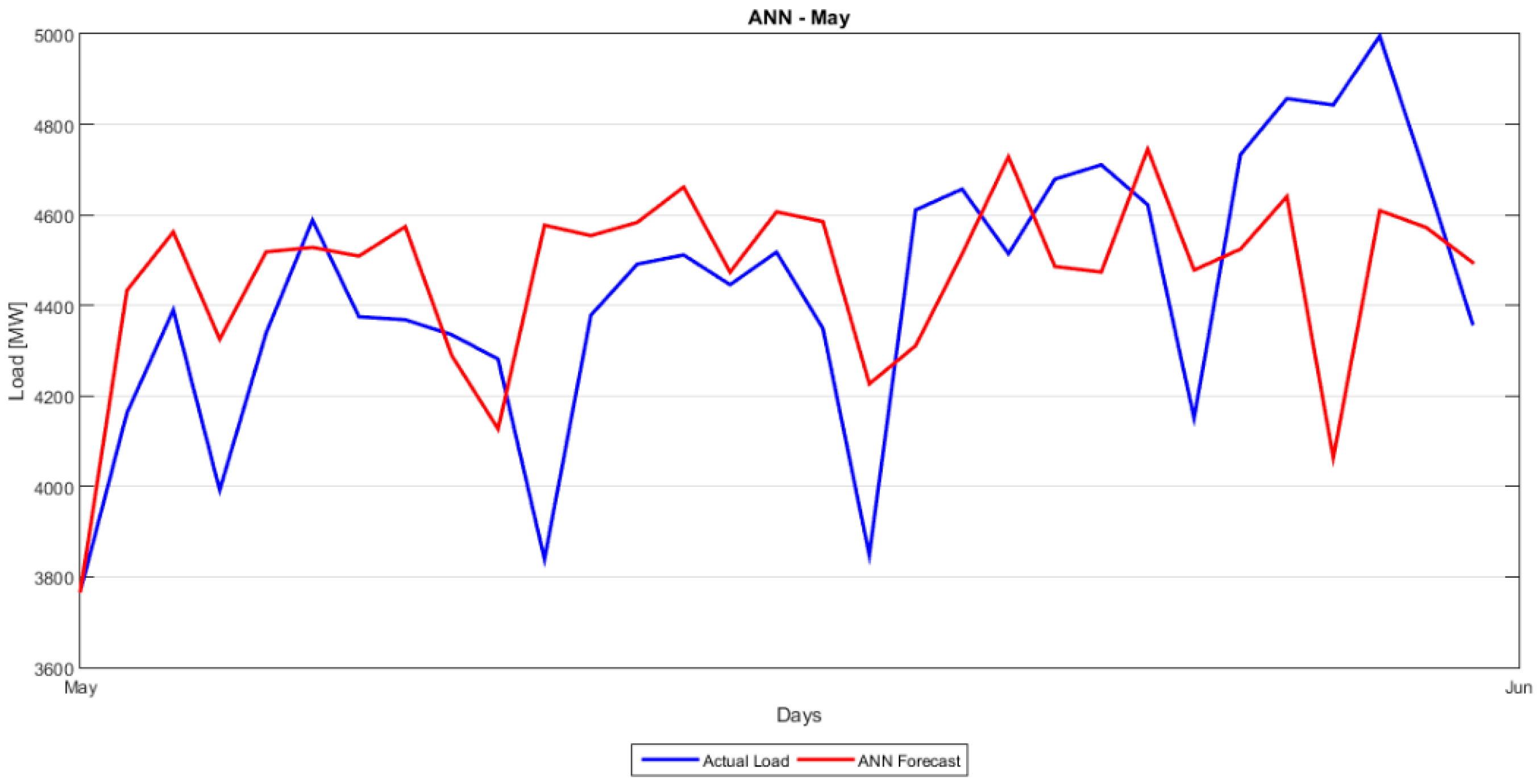
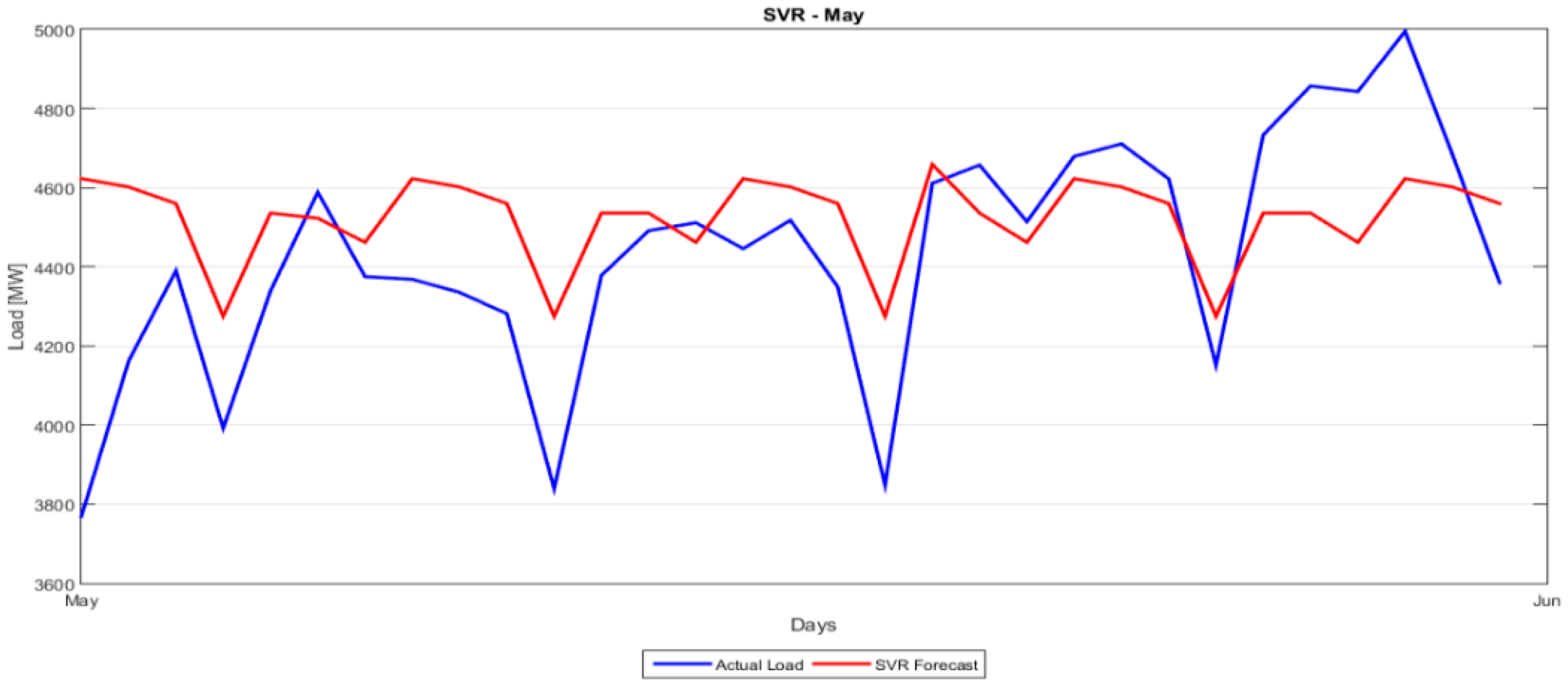
Section 5 presents the comparison between the proposed hybrid model and the classical forecasting methods as well as the more recent ANN and SVM approaches. A number of forecasting quality measures Mean Absolute Percentage Error (MAPE), Root Mean Squared Error (RMSE), etc. are evaluated and strengths and weaknesses of each model are noted.
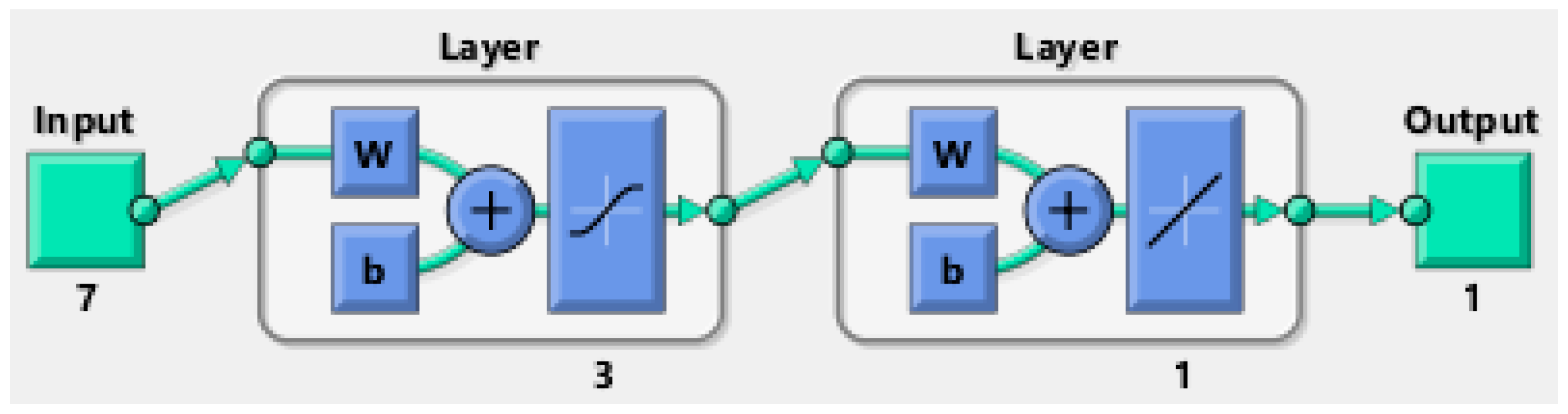
Section 6 (Conclusions) summarizes and proposes the next steps. A short description of the ANN and SVM methods is given in
Appendix C.
3. Data Description and Preparation
This section is devoted to the description and preprocessing of the data available. The main time series we focus on is the system load demand in the Greek electricity market. This is defined as the system’s net load; more specifically the system’s net load is calculated as the sum demanded by the system (total generation including all types of generation units, plus system losses, plus the net difference of imports & exports, minus the internal consumption of the generating units). In this article we use the terms system load and load interchangeably.
The raw data are provided by Independent Power Transmission Operator (IPTO or ADMIE) (
http://www.admie.gr) and include the hourly and daily average load, for the 10 year period from 1 January 2004 to 31 December 2014, as well as average external temperature in Greece, for the same time period.
In this work, we aim to capture the effect of seasonal events on the evolution of the load demand [
4,
103]. For this reason and as bibliography suggests, we also include as exogenous variables three indicator vectors that use Boolean logic notation to point states like working days, weekend and holidays. The study is conducted on the Greek electricity market, therefore we consider the Greek holidays (Christmas, Orthodox Easter, Greek national holidays). The abovementioned vectors and the temperature are imported as exogenous variables to the SARIMA model for building our final SARIMAX model (see
Section 4).
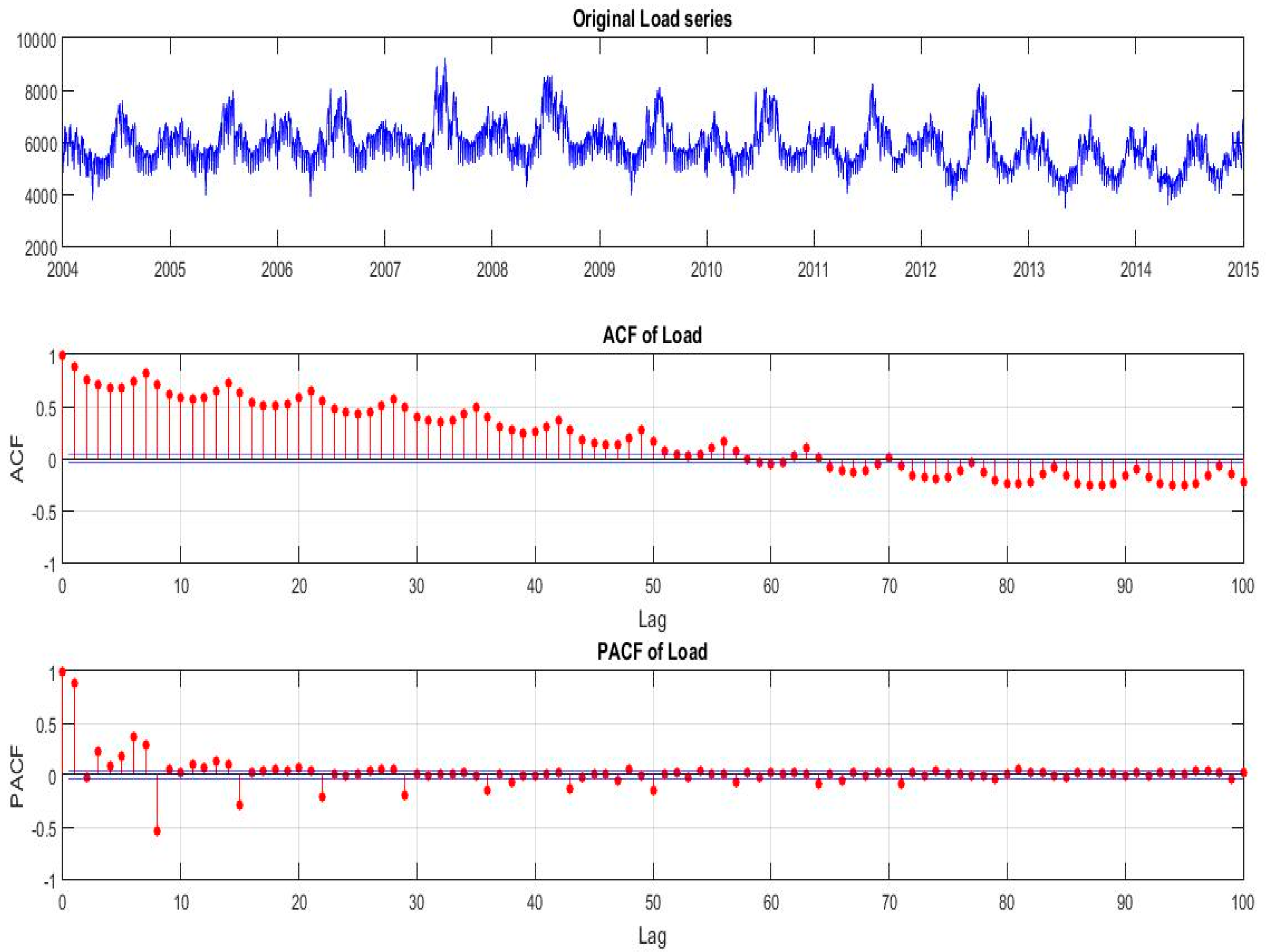
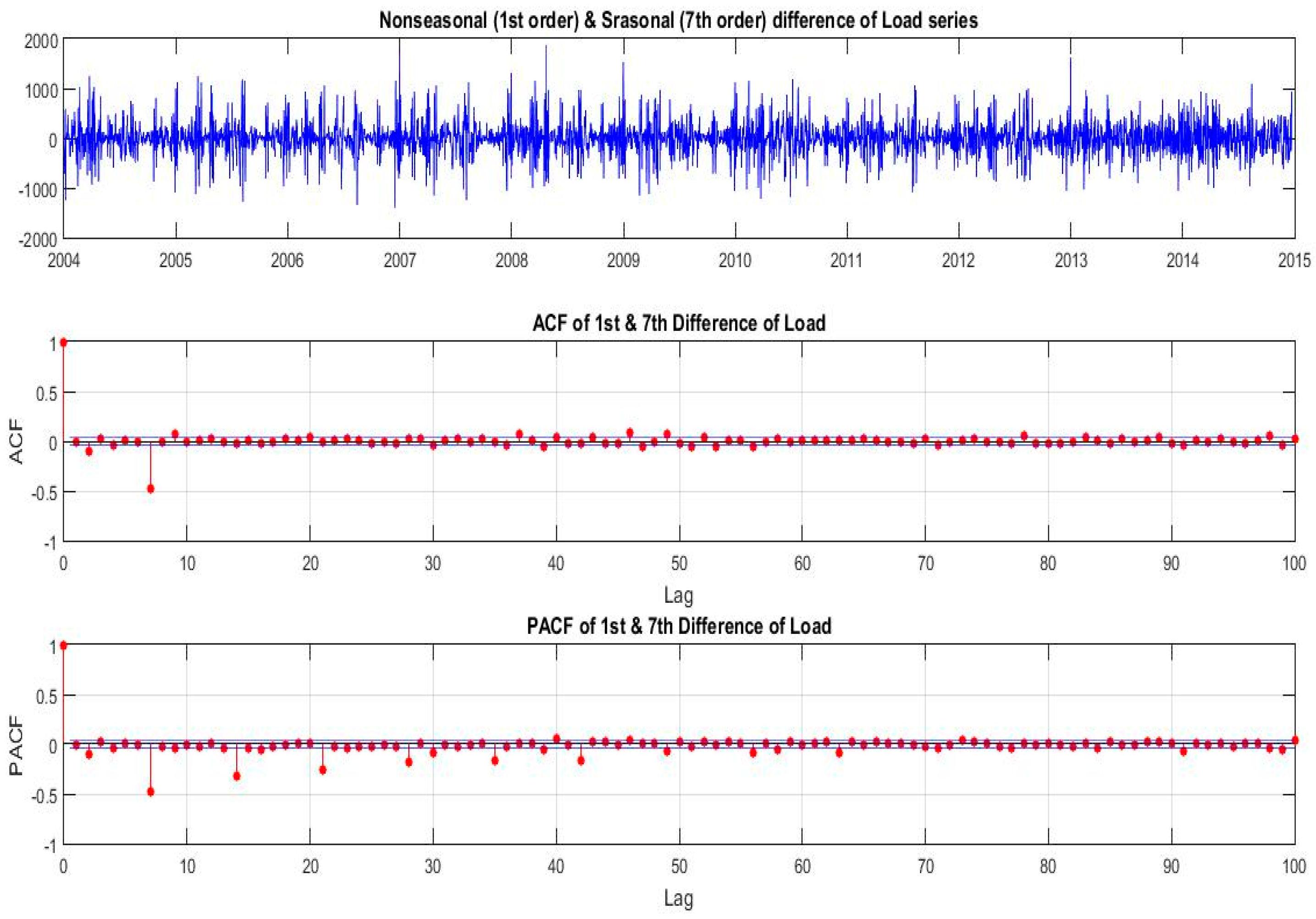
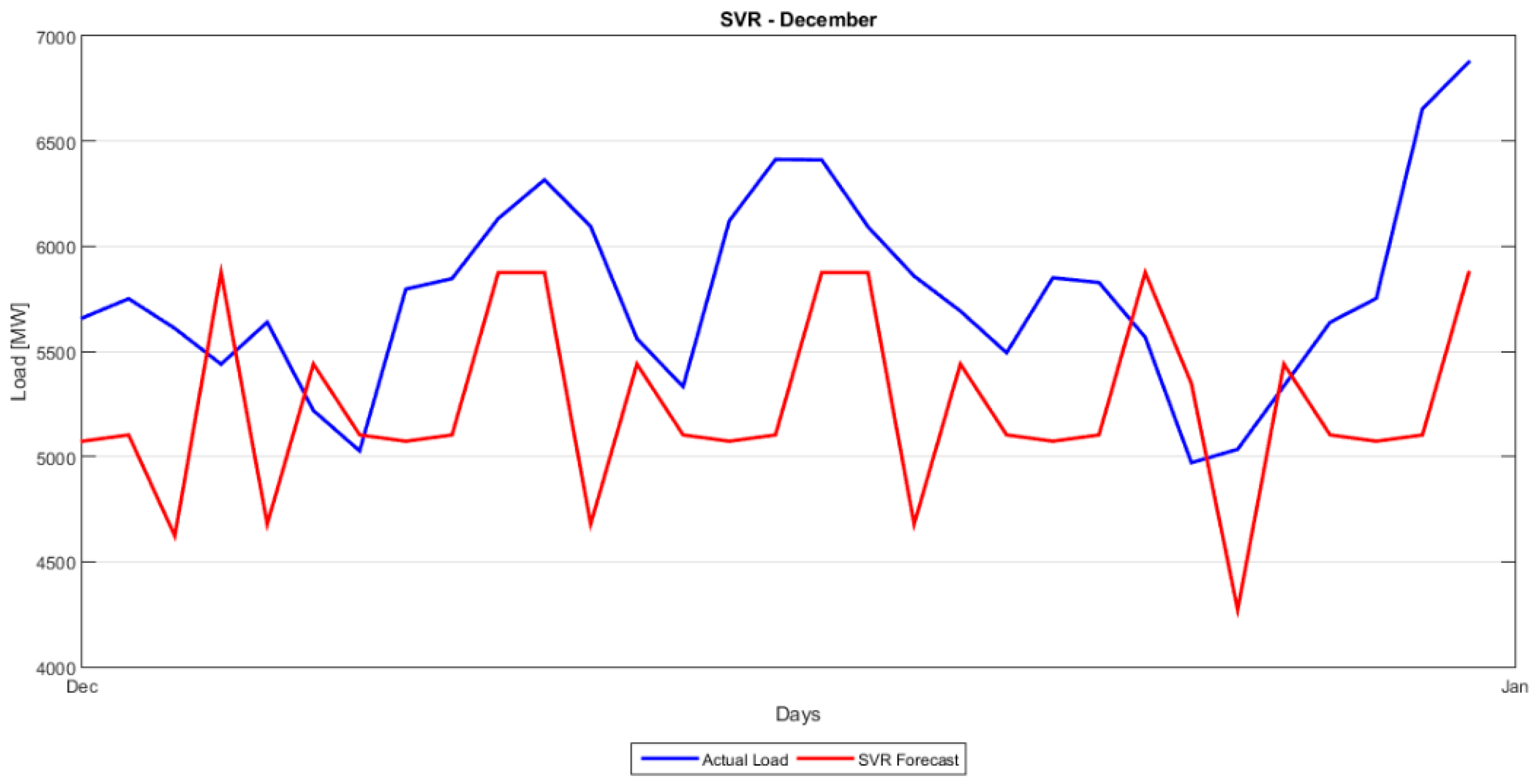
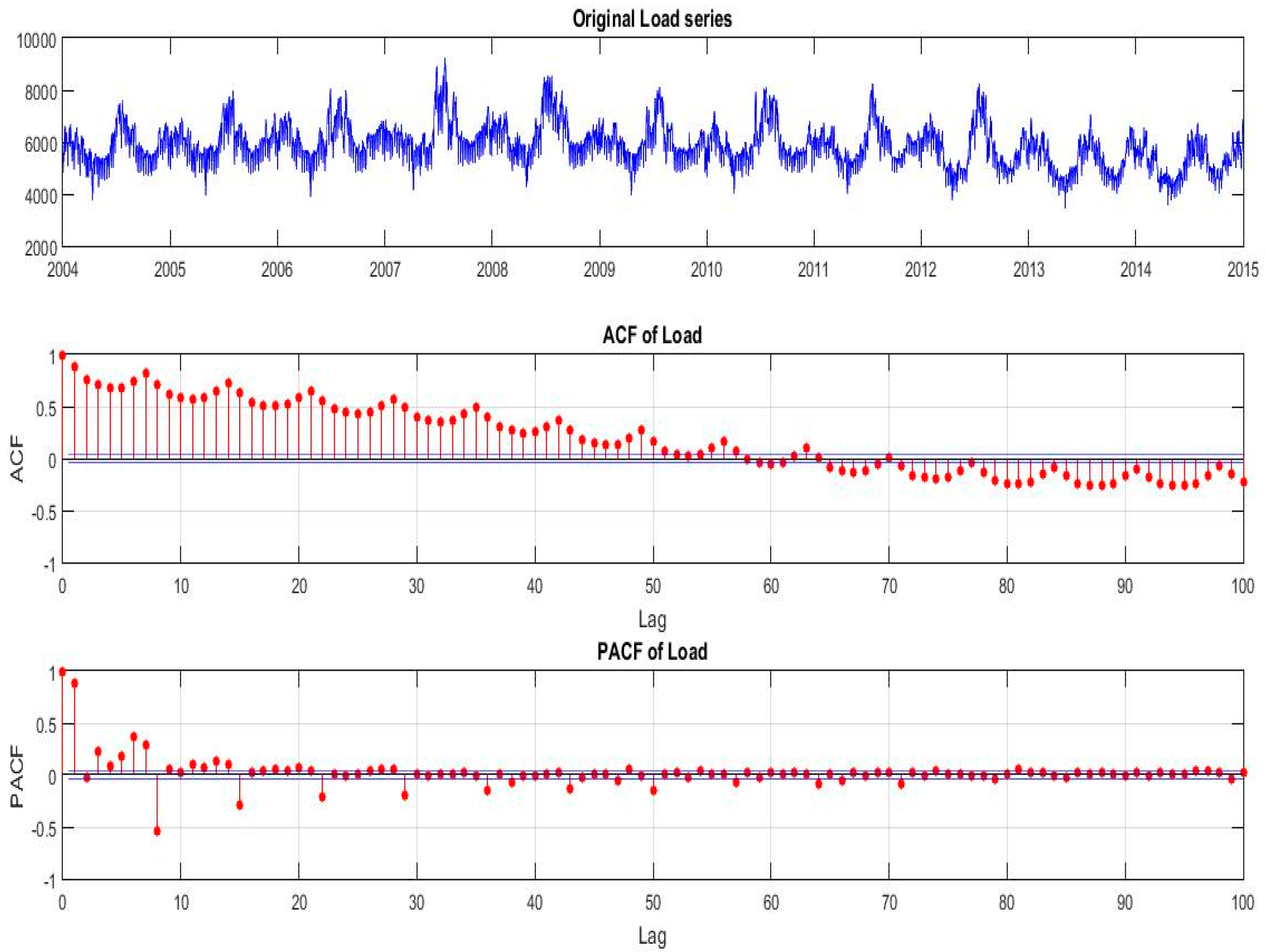
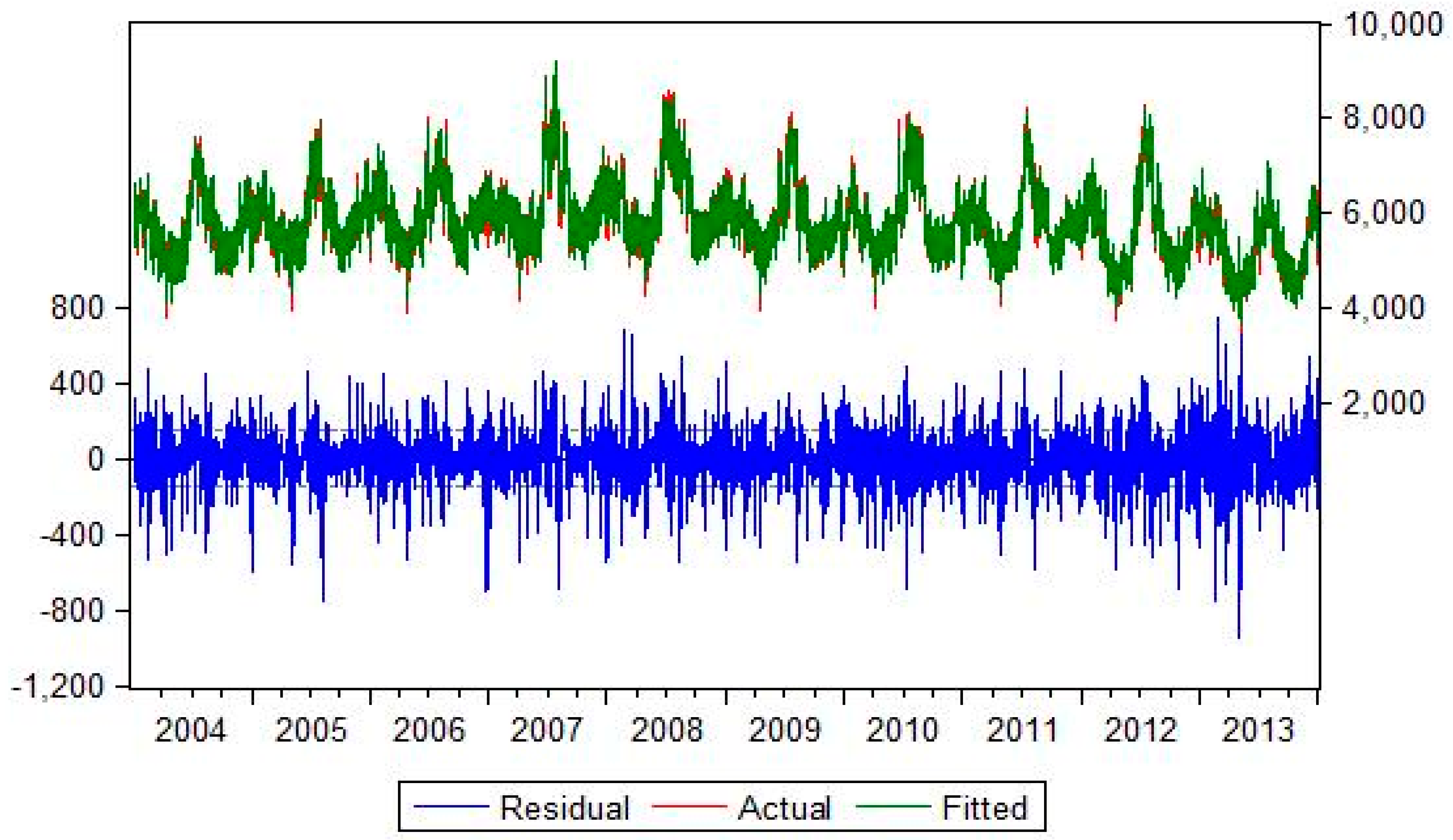
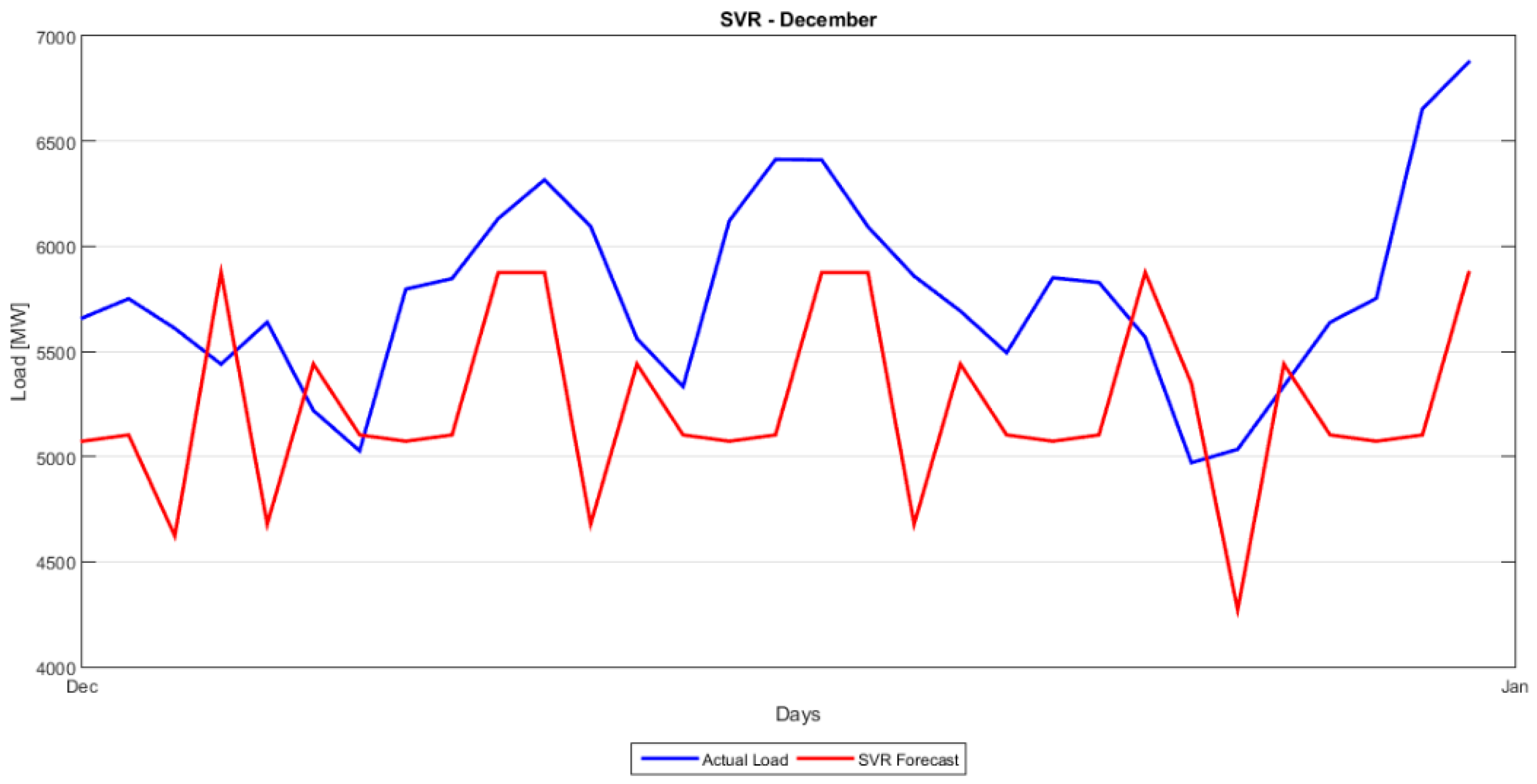
Figure 2 shows the evolution of load demand in Greece for the time period 2004–2014. We also plot the Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) of the load for the period 2004–2014. From this plot we observe strong, persistent 7-day dependence and that both the ACF and PACF decay slowly, indicating a strong autocorrelated or serially correlated time series. This is a strong indication of seasonality in our load series and also an implication of non-stationarity. The PACF also shows the seasonality with spikes at lags 8, 15, 22 and so on.
Table 1 provides the summary or descriptive statistics of the load and temperature time series.
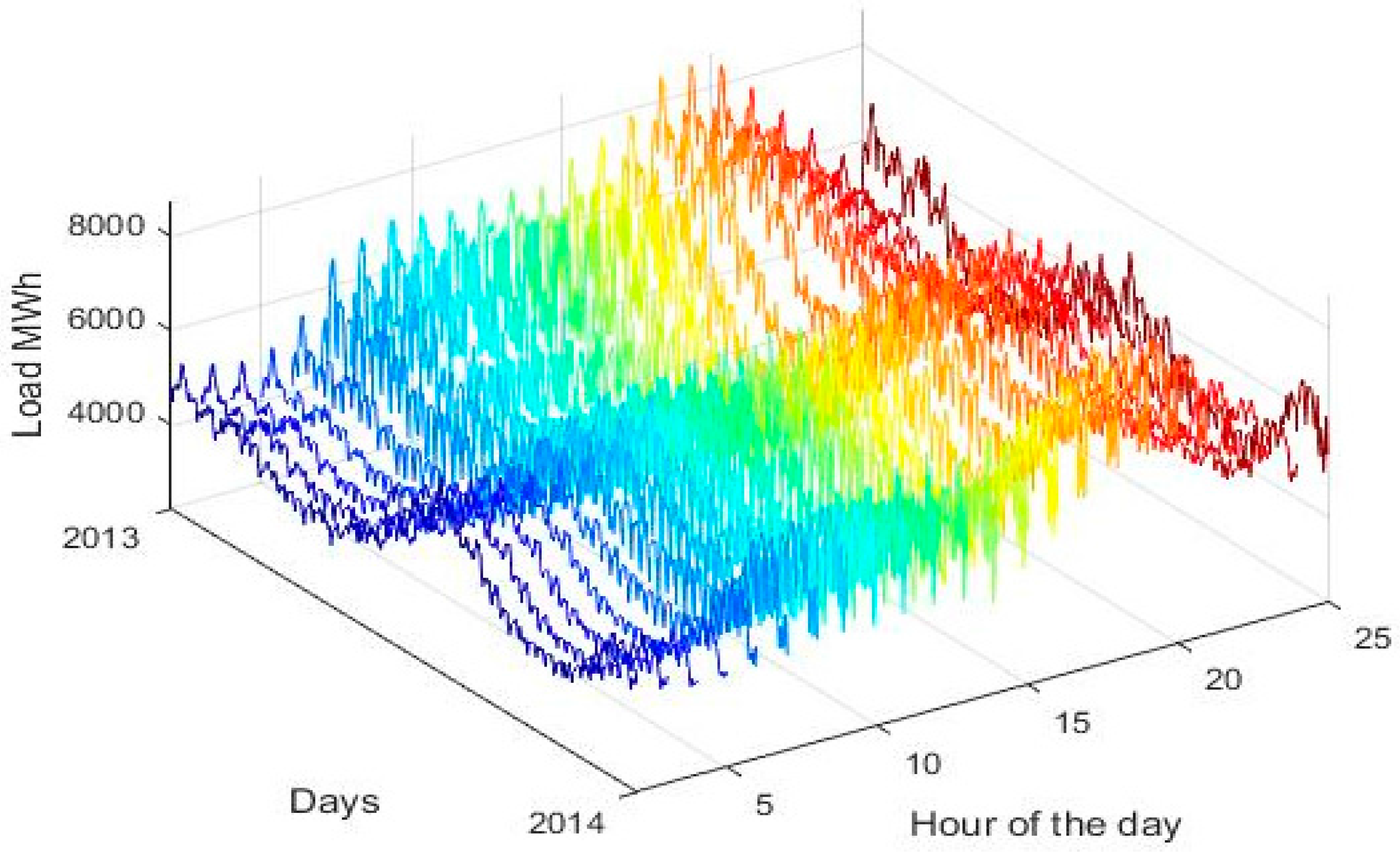
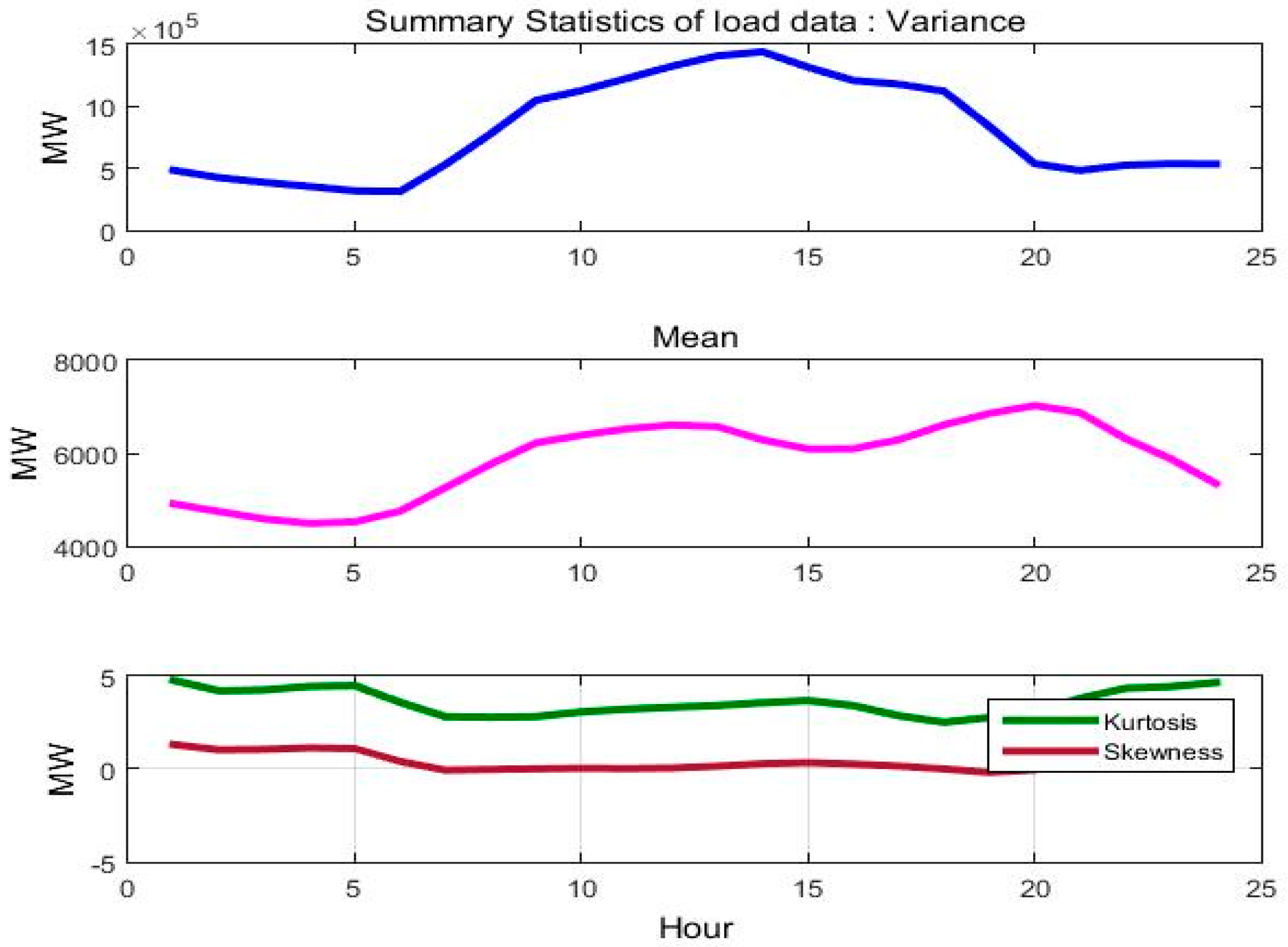
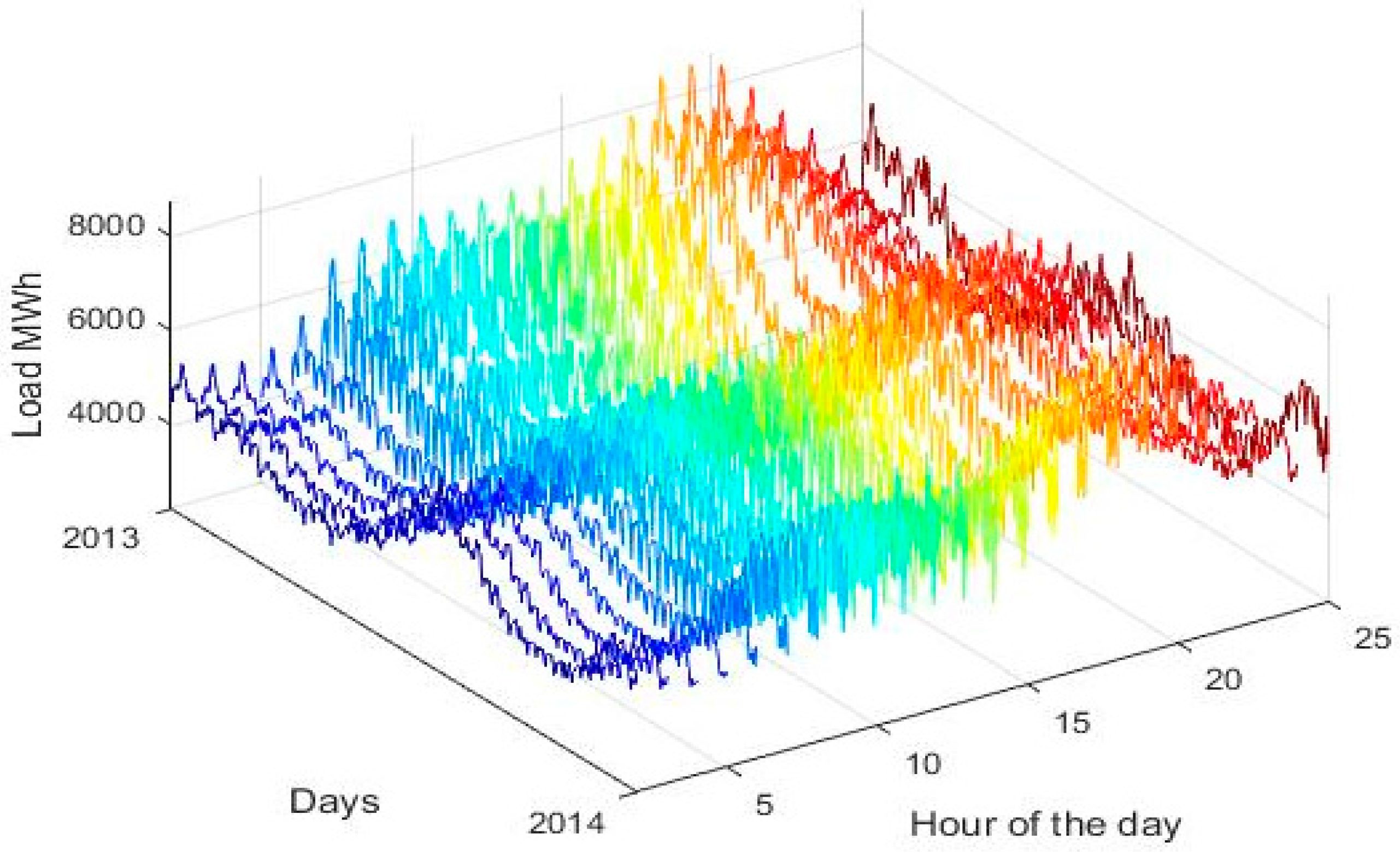
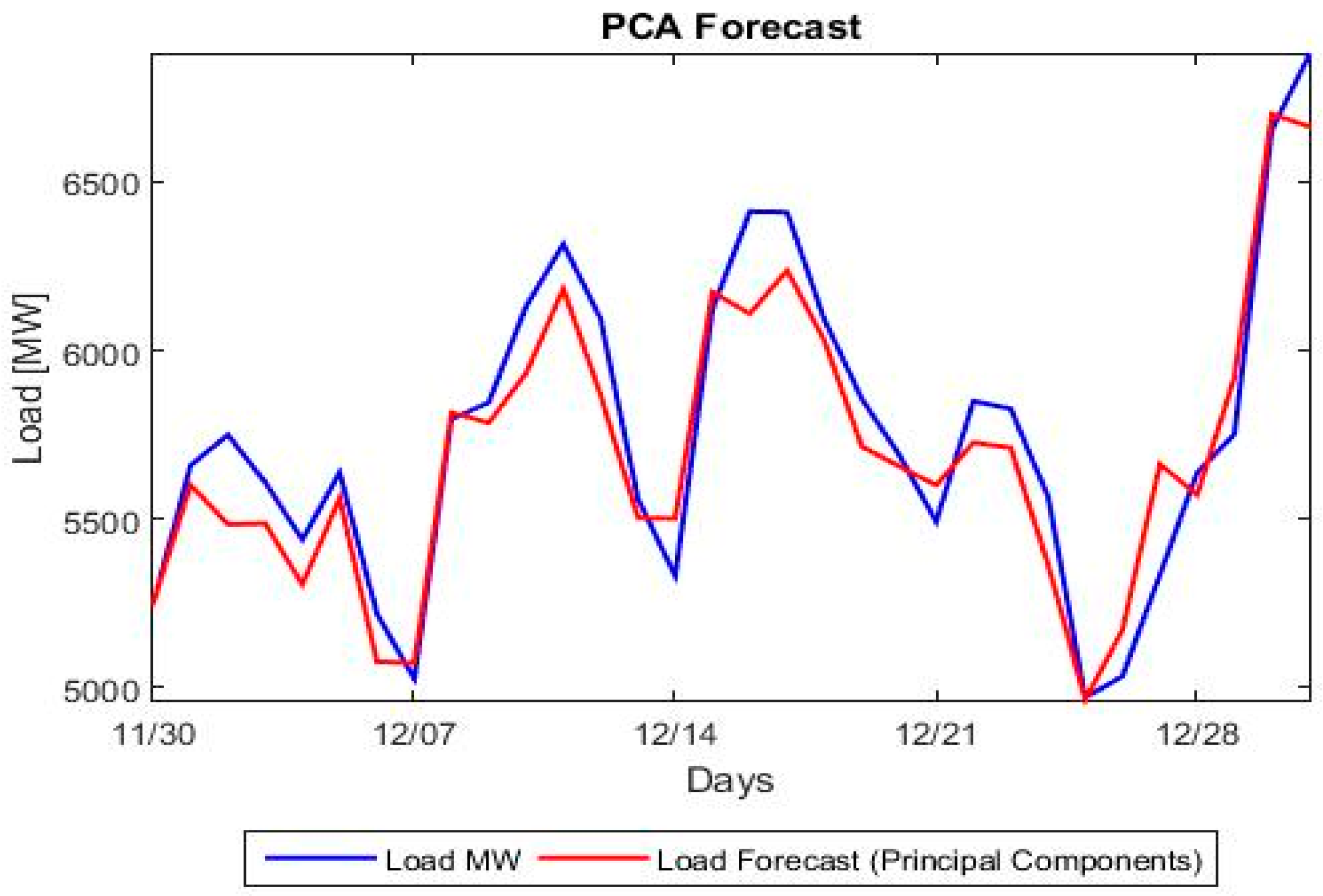
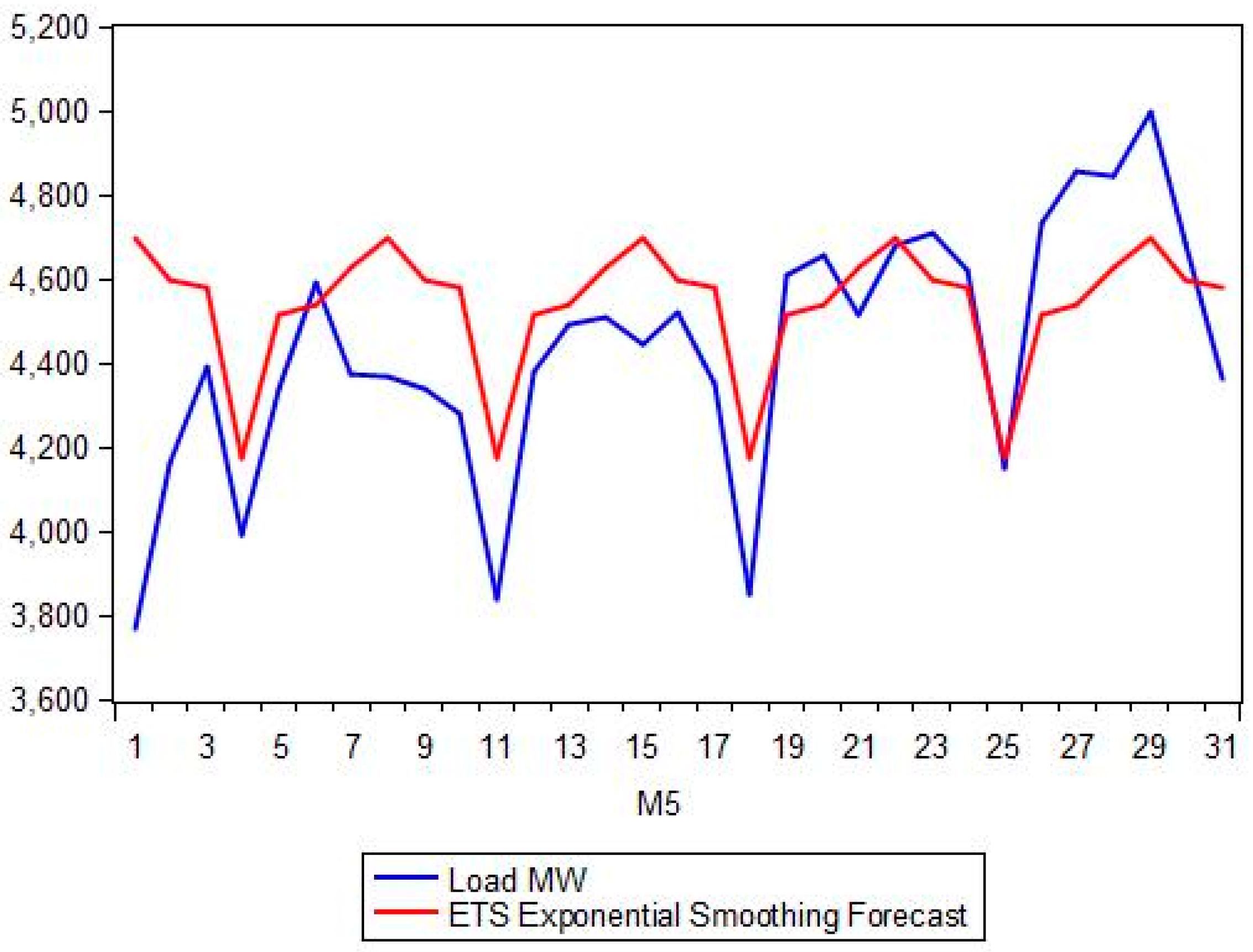
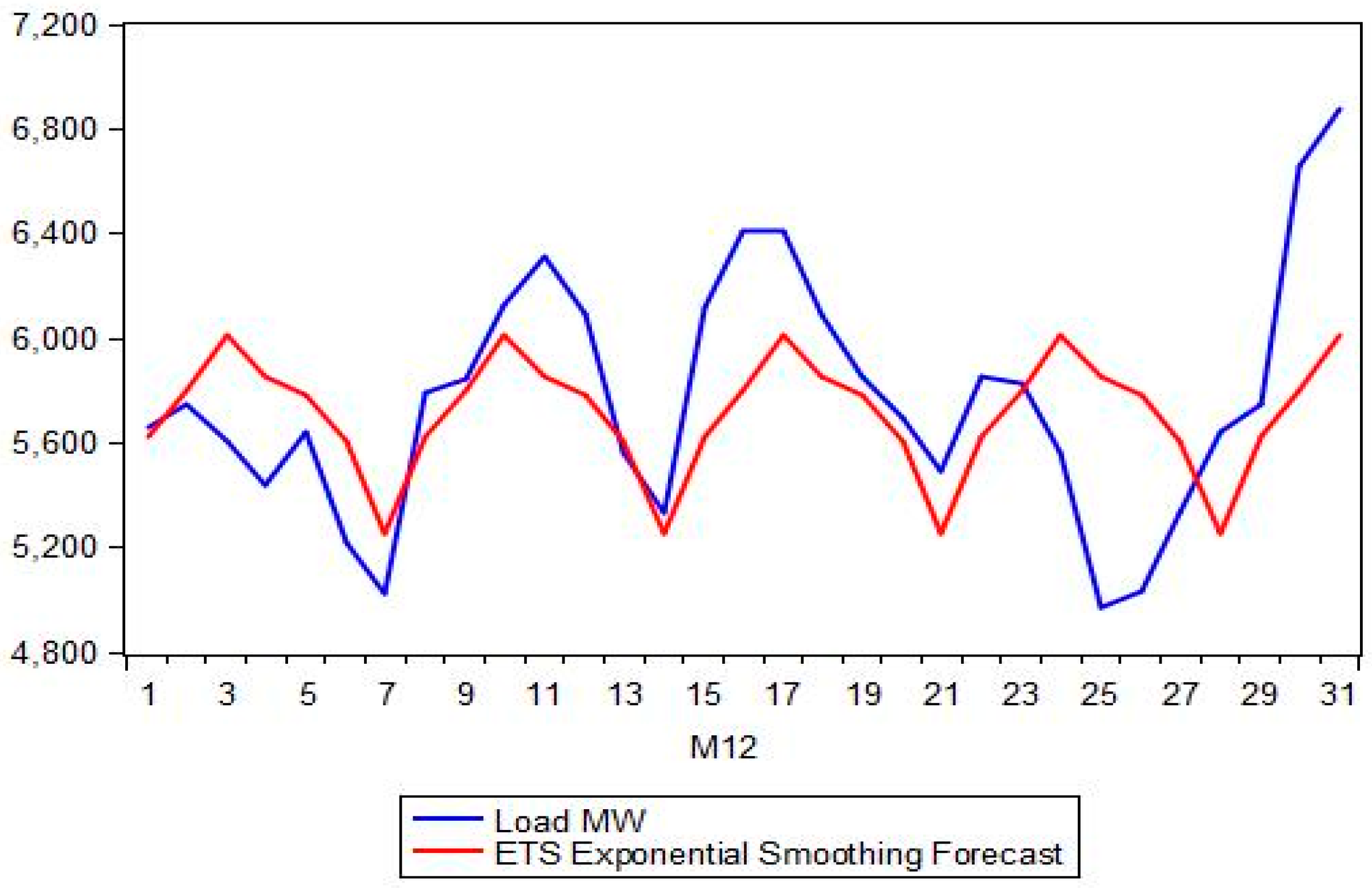
Figure 3 depicts the evolution of load for each hour of the day for the year 2013, while in
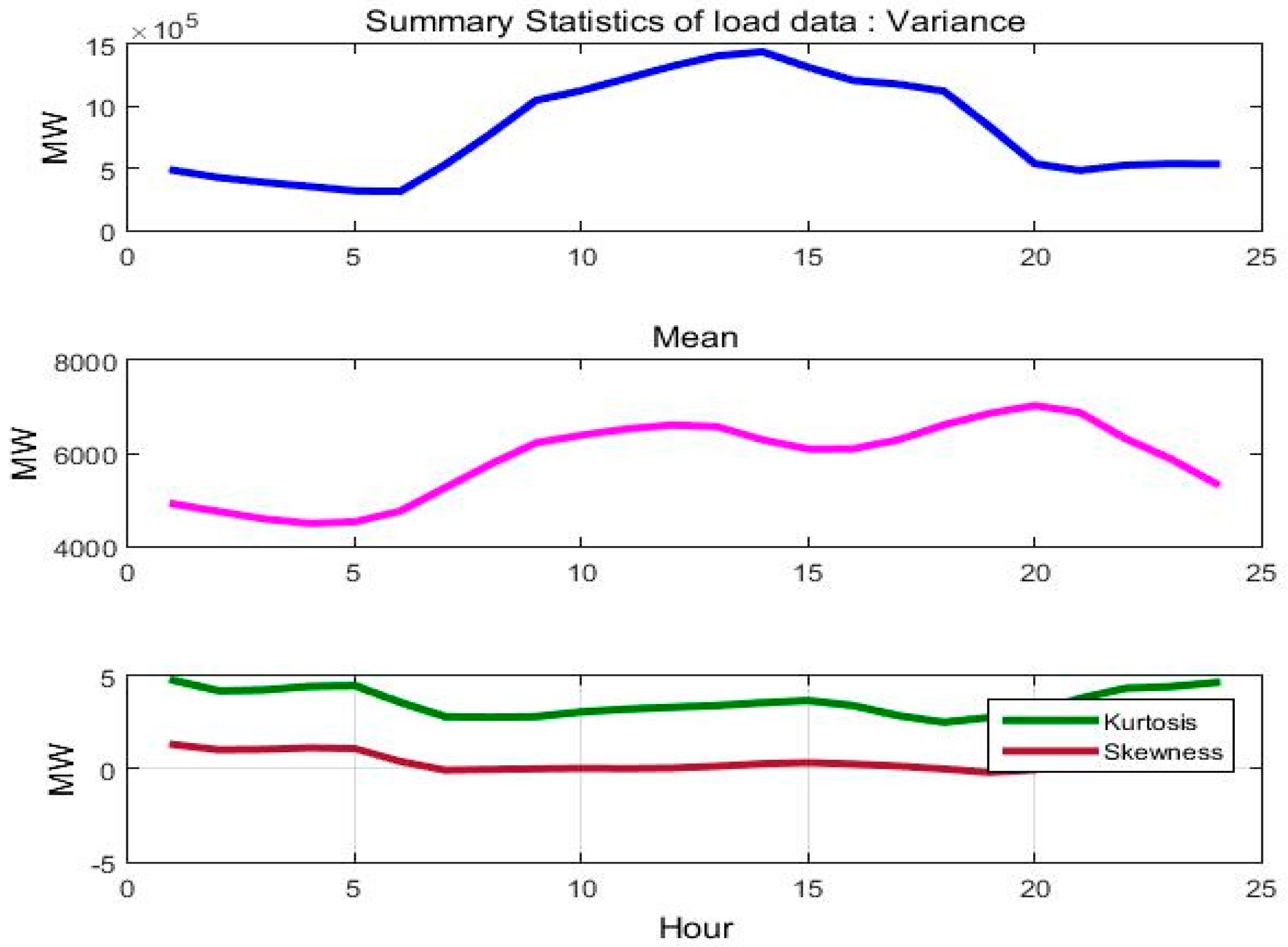
Figure 4 we show the fluctuation of the mean, variance, kyrtosis and skewness of load for each hour of the day and for the period 2004–2014.
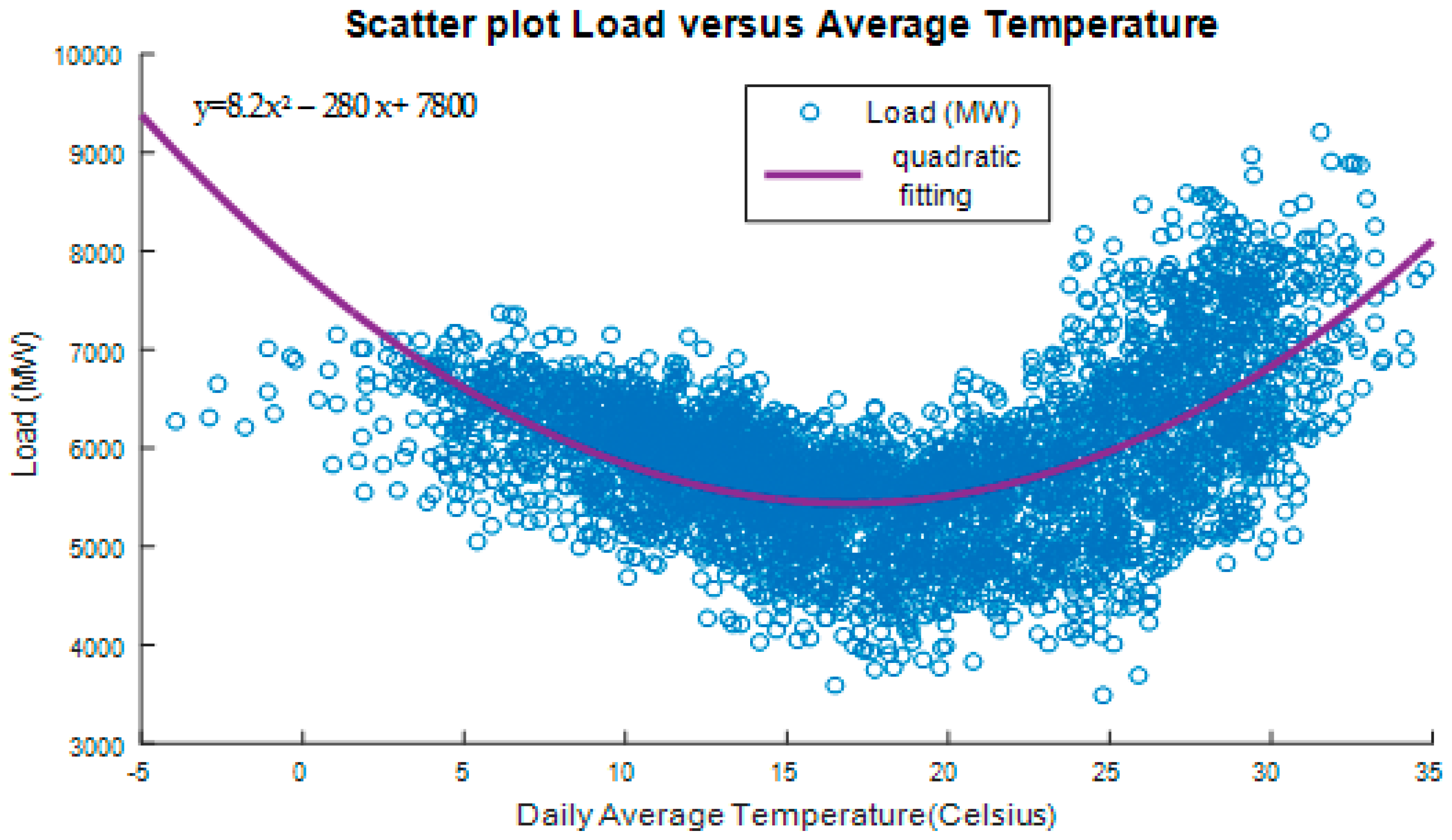
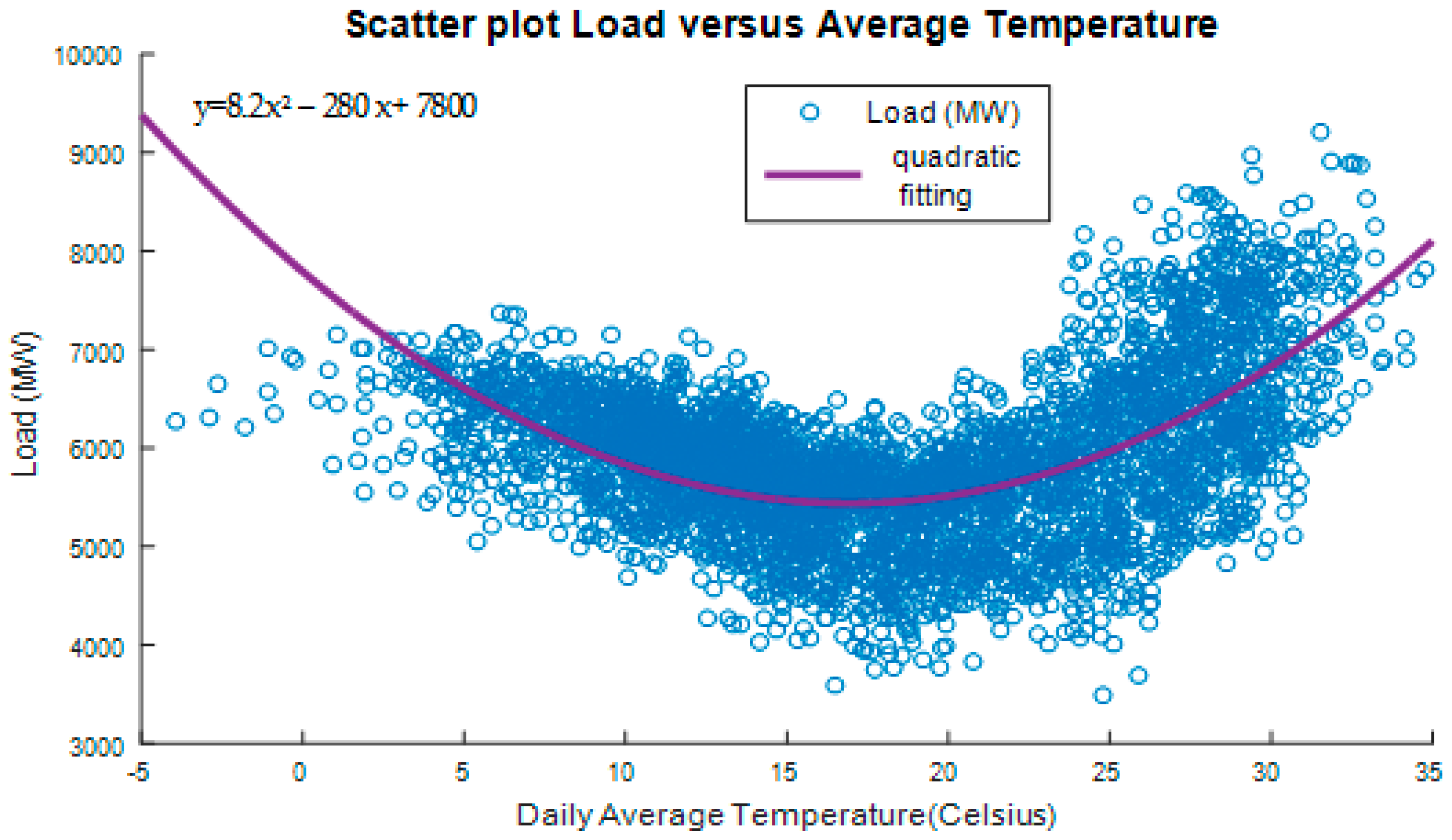
The variation of load with average daily temperature is depicted in
Figure 5.
The graph shows a parabolic shape indicating increased consumption at high and low temperatures [
33]. It suggests also that forecasting future load (demand), requires the knowledge of load growth profile, relative to a certain reference i.e., the current year. The polynomial function of load versus temperature shown on the graph seems a reasonable approximation for load forecasting. Due to quadratic and strong correlation between temperature and load, we have included temperature as an exogenous—explanatory variable in the modeling in order to enhance model’s predictive power. More specifically, we have considered the temperature deviation from comfortable living conditions temperature in Athens, for the current and previous day
respectively (Tsekouras [
104]):
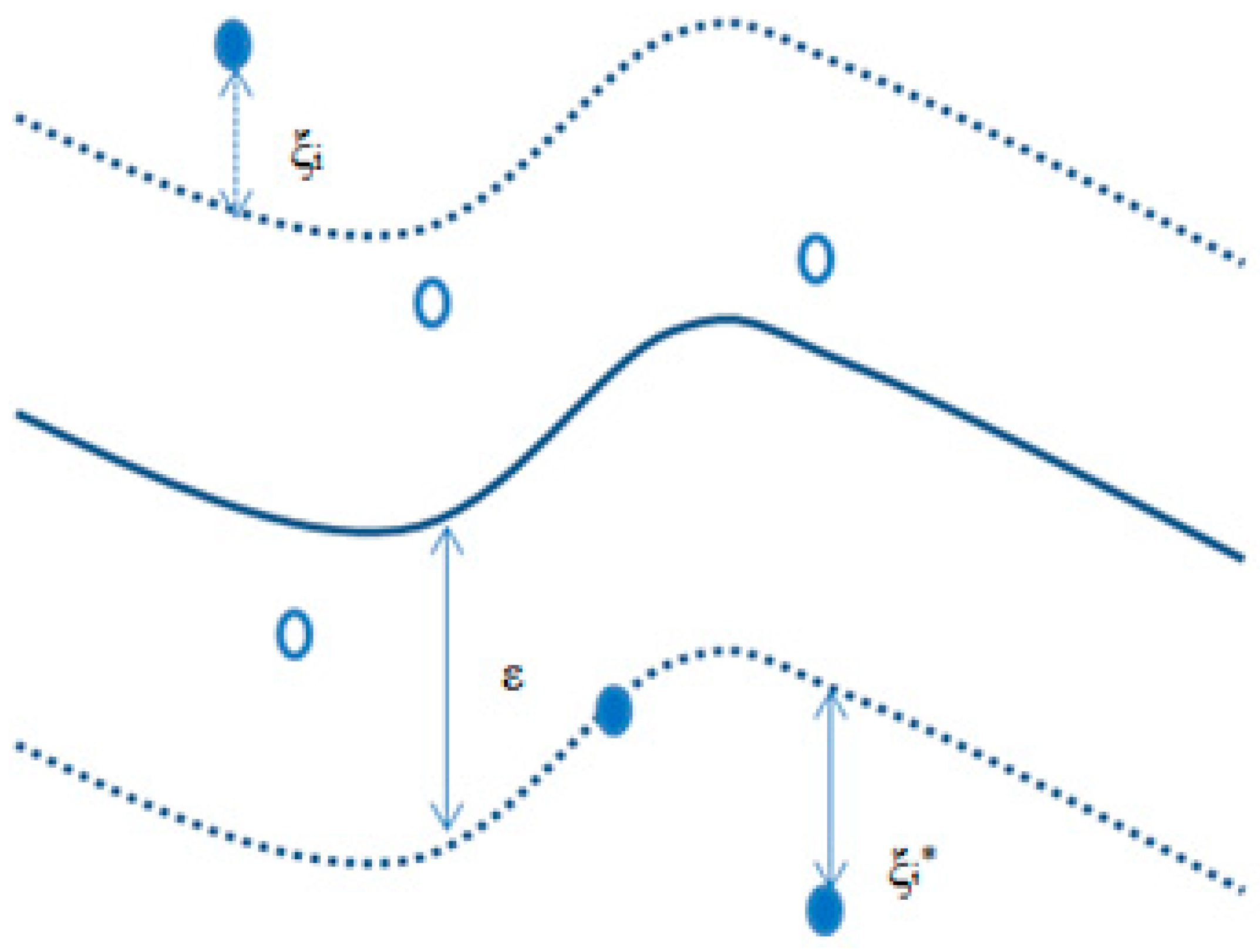
where
Tc = 18 °C,
Th = 25 °C. This expression for
capture the nonlinear (parabolic) relation of temperature and system load shown in
Figure 5.
The same plot is expected if instead of the daily average temperature we use daily maximum or minimum temperature.
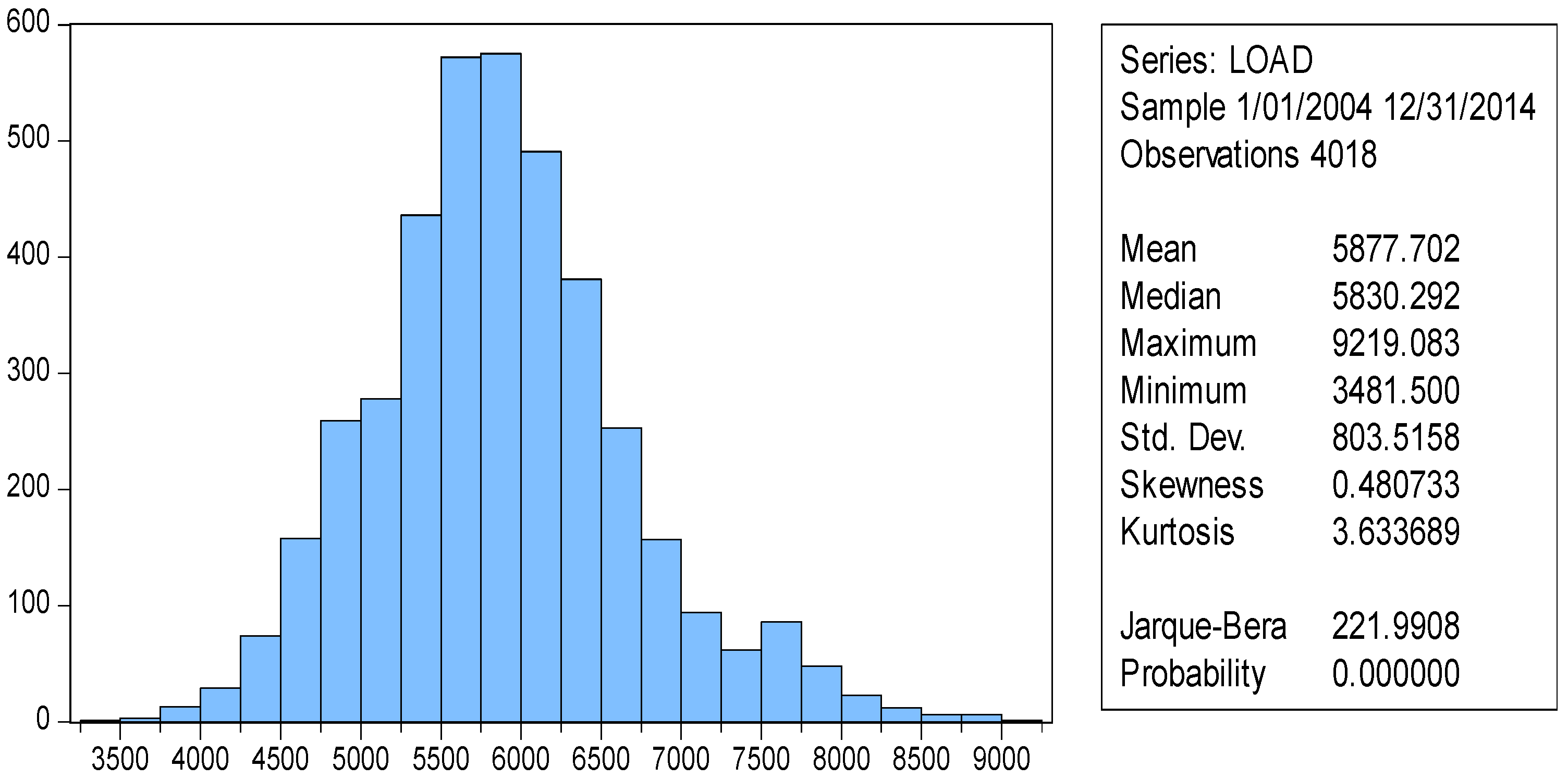
Figure 6 gives the histogram of the load as well as its summary statistics.
Before proceeding to formulate a model, we apply various statistical tests in order to examine some core properties of our data, namely stationarity, normality, serial correlation, etc. The Jarque and Bera (JB) algorithm [
105] assumes the null hypothesis that the sample load series has a normal distribution. The test as we see rejected the null hypothesis at the 1% significance level, as it is shown in the analysis (
p = 0.000, JB Stat significant). From the descriptive statistics of the above figure the positive skewness and kurtosis indicate that load distribution has an asymmetric distribution with a longer tail on the right side, fat right tail. Thus load distribution is clearly non-normally distributed as it is indicated by its skewness (different but still close to zero), and excess kurtosis (>3) since normal distribution has kurtosis almost equal to three (3). That means that our data need to be transformed in such way in order to have a distribution as close to normal as possible.
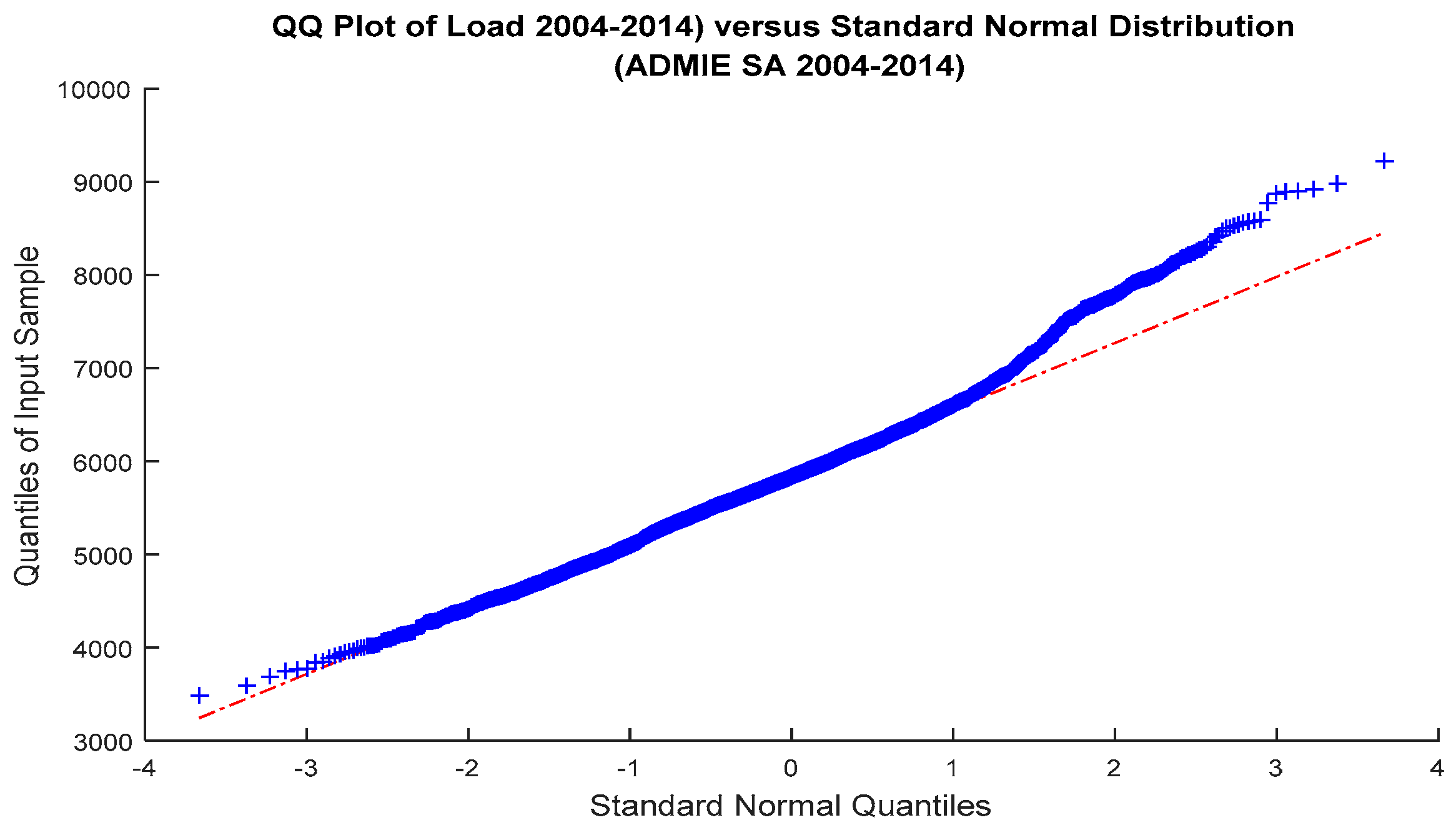
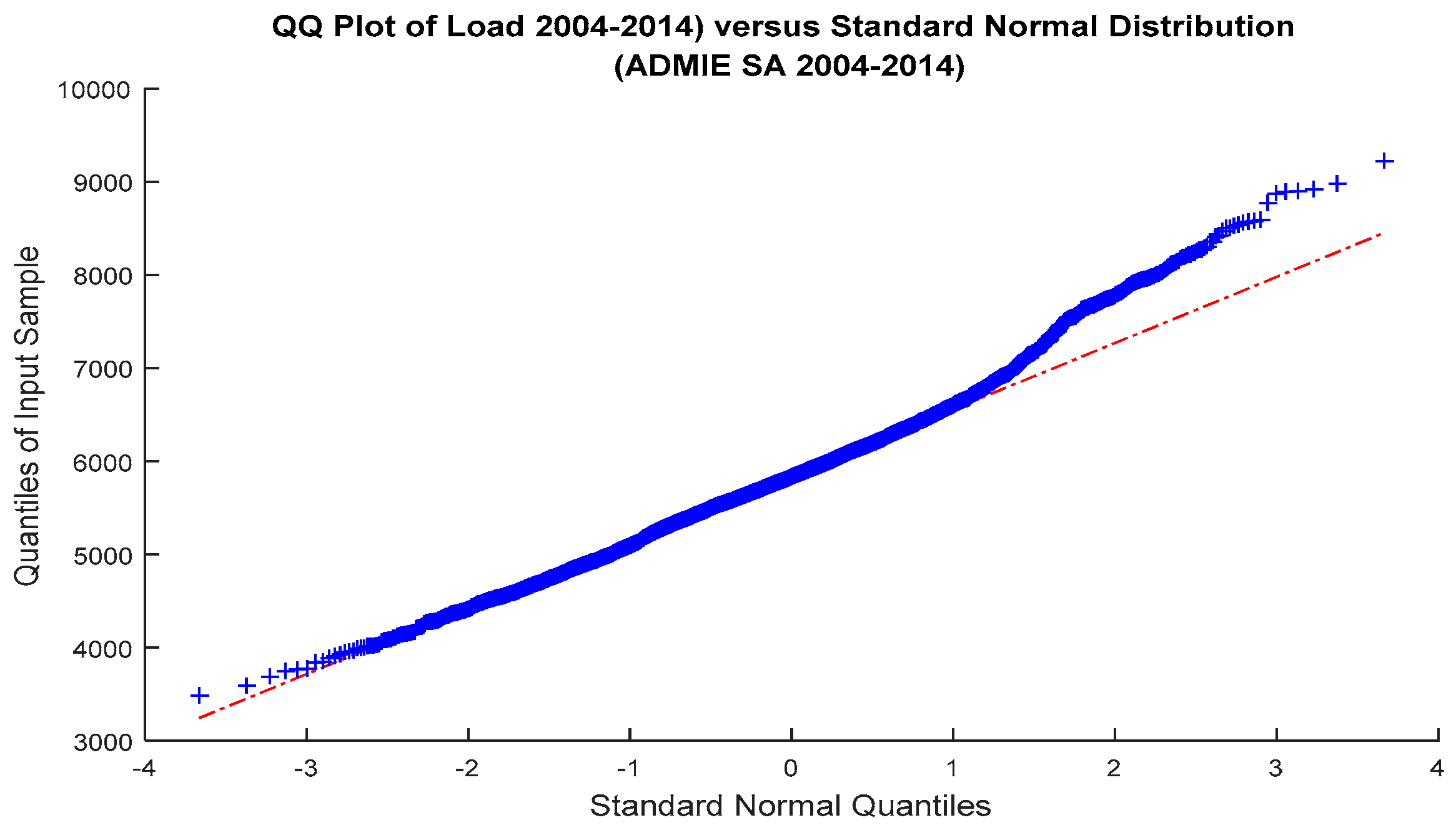
The deviation of load distribution from normality is also apparent in the Q-Q plot,
Figure 7. We see that the empirical quantiles (blue curve) versus the quantiles of the normal distribution (red line) do not coincide, even slightly and exhibit extreme right tails:
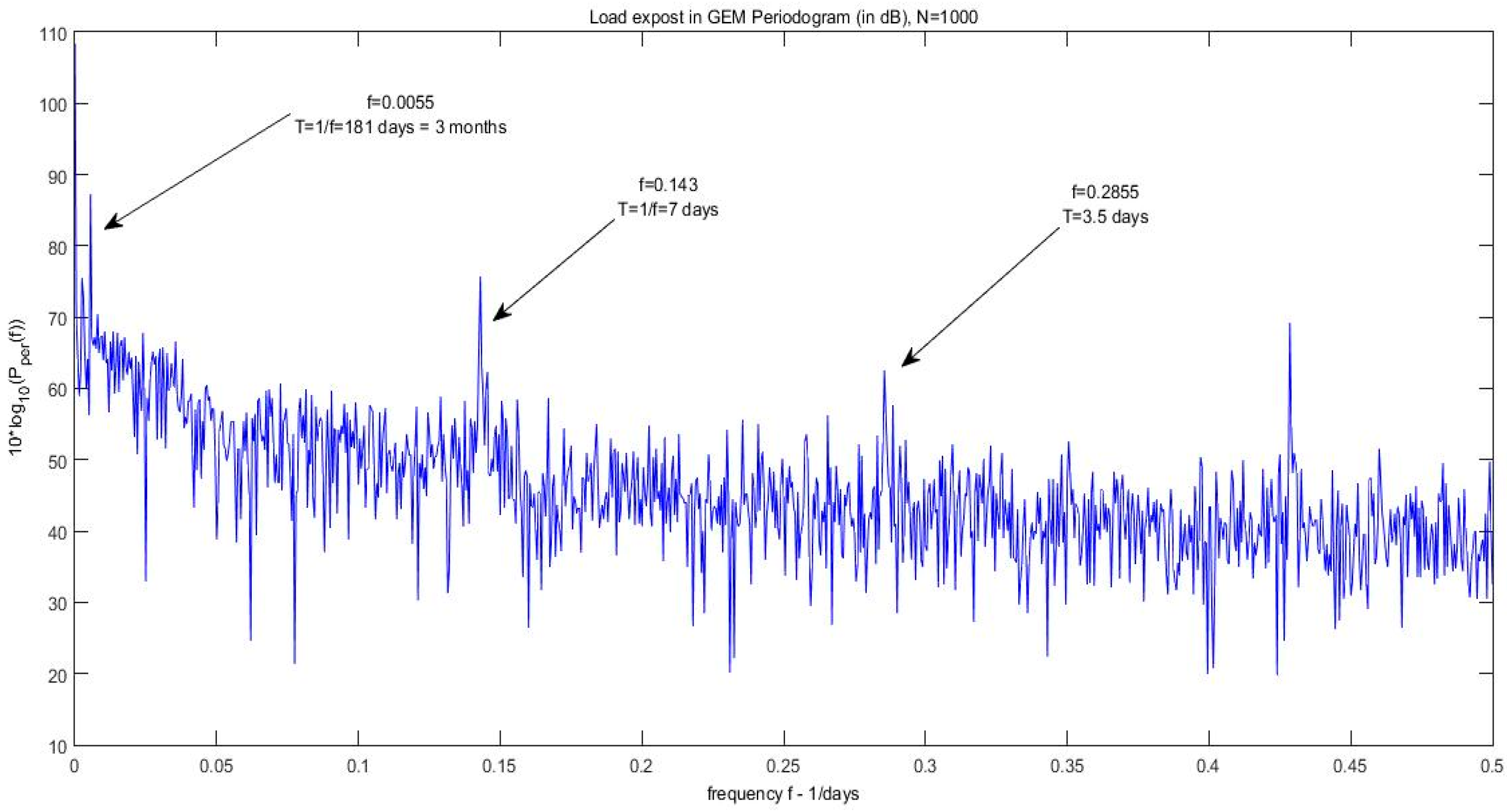
In this section we also identify the cyclical patterns of load for the period 2004 to 2014. This can be done by decomposing our signals which contain cyclical components in its sinusoidal functions, expressed in terms of frequency i.e., cycles per unit time, symbolized by ω. The period, as we know, is the reciprocal of ω i.e., T = 1/ω. Since our signal is expressed in daily terms, a weekly cycle is obviously 1/0.4128 = 7 days or 1/52.14 = 0.0192 years expressed annually. A typical tool for revealing the harmonics or spectral components is the periodogram. Let our set of signal measurements or the load time series is {x
i, i = 1,…n}, then the periodogram is given as follows:
where
are the Fourier frequencies, given in radians per unit time. In
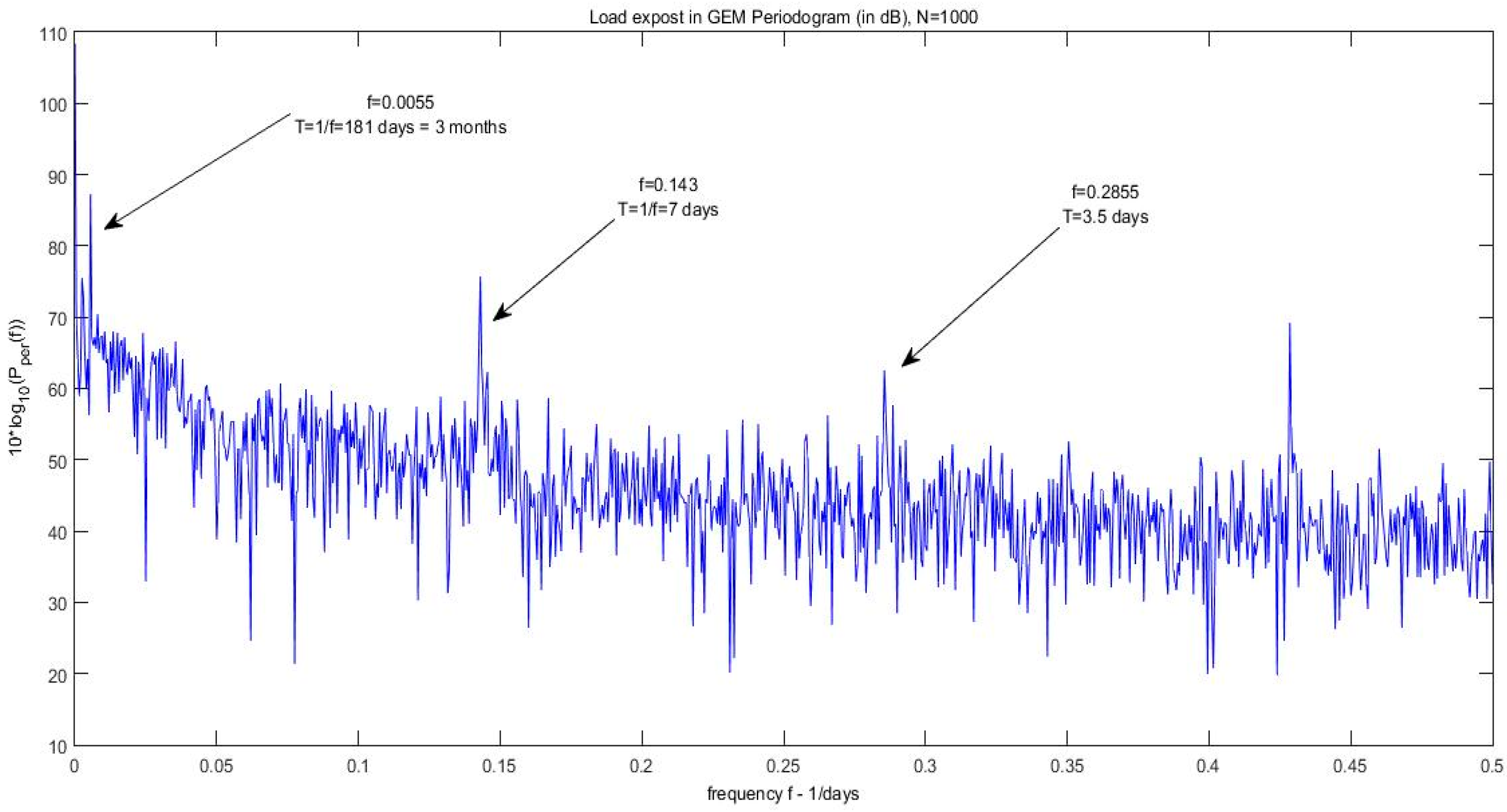
Figure 8 the periodogram of daily average system load is shown, for the same period as before. Obviously the signal exhibits the same periods and its harmonics as described above. The periodic harmonics identified in this graph correspond to 7-day period (peak), 3.5-day and 2.33-day (bottom part) which in turn correspond to frequencies ω
k = 0.1428, 0.285 and 0.428 respectively (upper part of the figure). The existence of harmonics i.e., multiples of the 7-day periodic frequency reveal that the data is not purely sinusoidal.
We treat load as a stochastic process and before proceeding further in our analysis, it is necessary to ensure that conditions of stability and stationarity are satisfied. For this purpose, we will utilize the necessary tests proposed by bibliography [
106], Augmented-Dickey-Fuller (ADF) [
107] test for examination of the unit-root hypothesis and Kwiatkowski-Phillips-Schmidt-Shin (KPSS) [
108] test for stationarity. Applying the ADF test we acquire the information that the series is stable; therefore null hypothesis is rejected. Additionally performing the KPSS test to the load series, we also obtain that the null hypothesis is rejected hence our time series is non-stationary. Even after applying 1st difference, although this forces the time series to become stationary, as the KPSS test applied on the 1st difference also confirms, the ACF and PACF still suggest that a seasonality pattern is present, at every 7 lags. Therefore, we will proceed and filter our data through with a 1st and 7th order differencing filter. The above tests ensure that the stability and stationarity requirements are met [
8]. The aforementioned preliminary tests, as shown in
Table 2, indicate that our time series has to be differenced before we fit it in a regressive model.
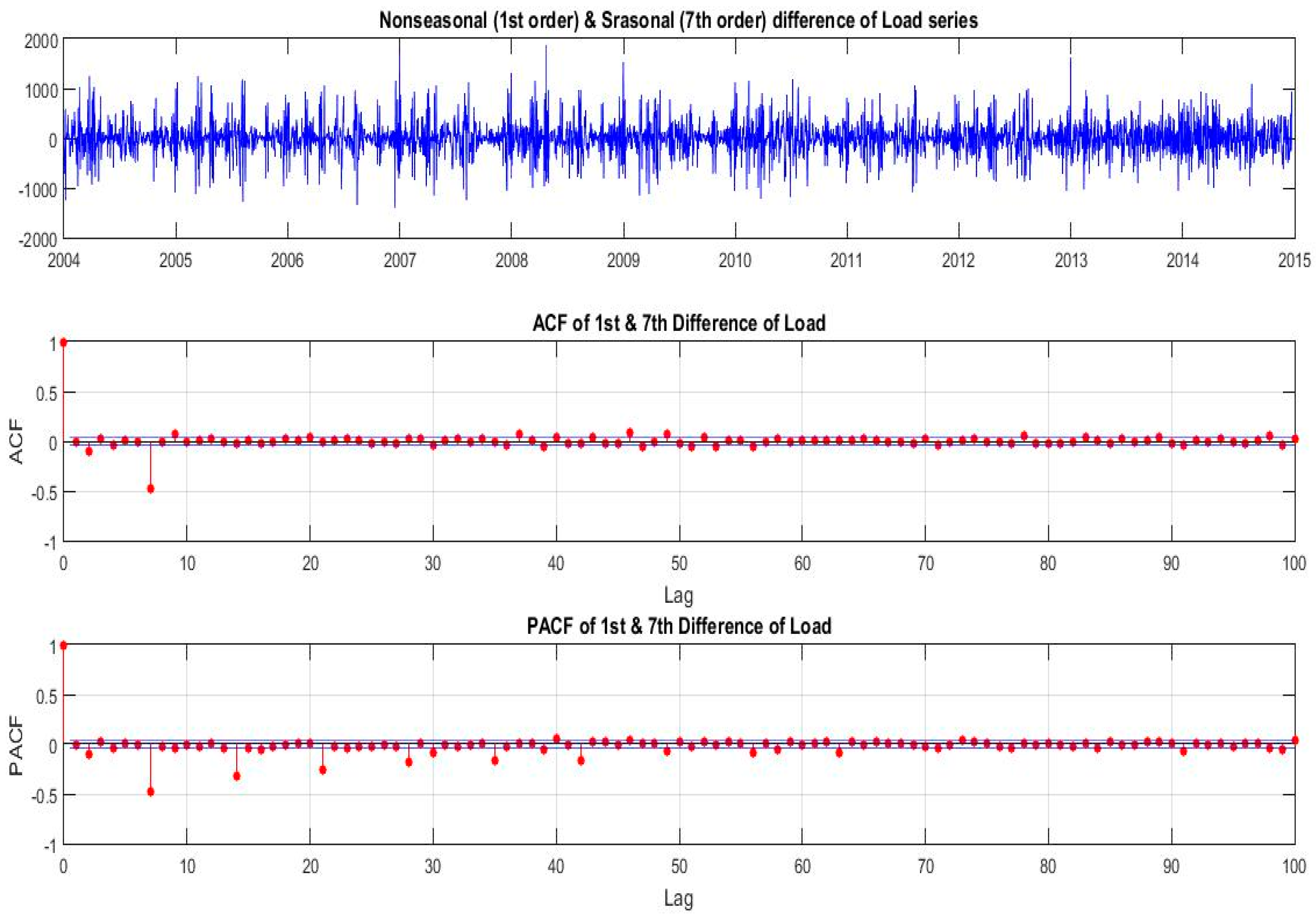
The slowly decaying positive ACF in
Figure 2, after 1st differencing, becomes a slowly decaying but still an oscillatory behavior with 7 lags period, a fact suggesting the need to fit a seasonal (multiplicative) ARMA model to our data. The damping of this oscillation is faster as the ACF value is away for the value of 1. Therefore, in order to capture the 7 lags-period seasonality in load time series, we must also apply, in addition to 1st difference operator (1−B), the operator (1−B
7), on
(load). The needed transformed series is given by:
i.e., the nonseasonal first difference times the seasonal (of period 7 days) difference times Load, where
, the lag operator. In
Figure 9 we show the ACF and PACF of the transformed series.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}