
Using Trajectory Clusters to Define the Most Relevant Features for Transient Stability Prediction Based on Machine Learning Method


Abstract
:1. Introduction
2. Methodology
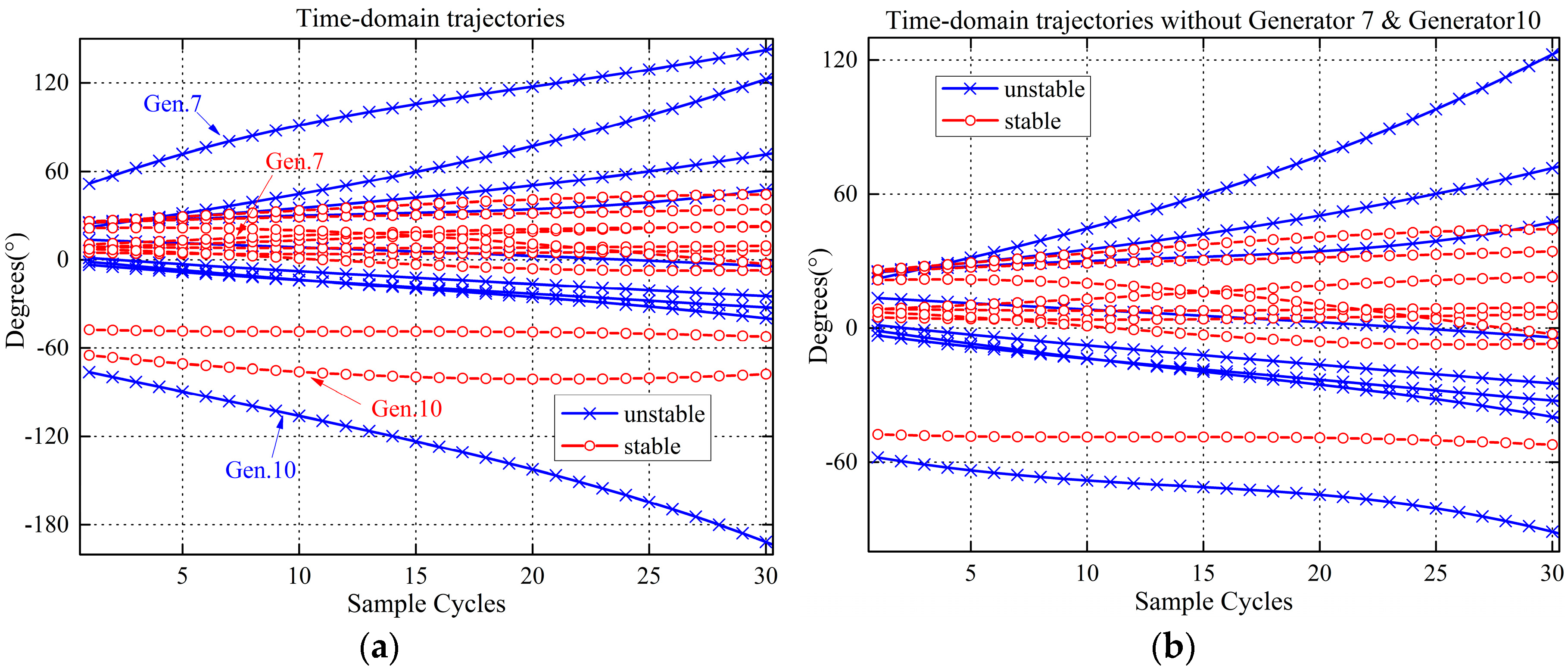
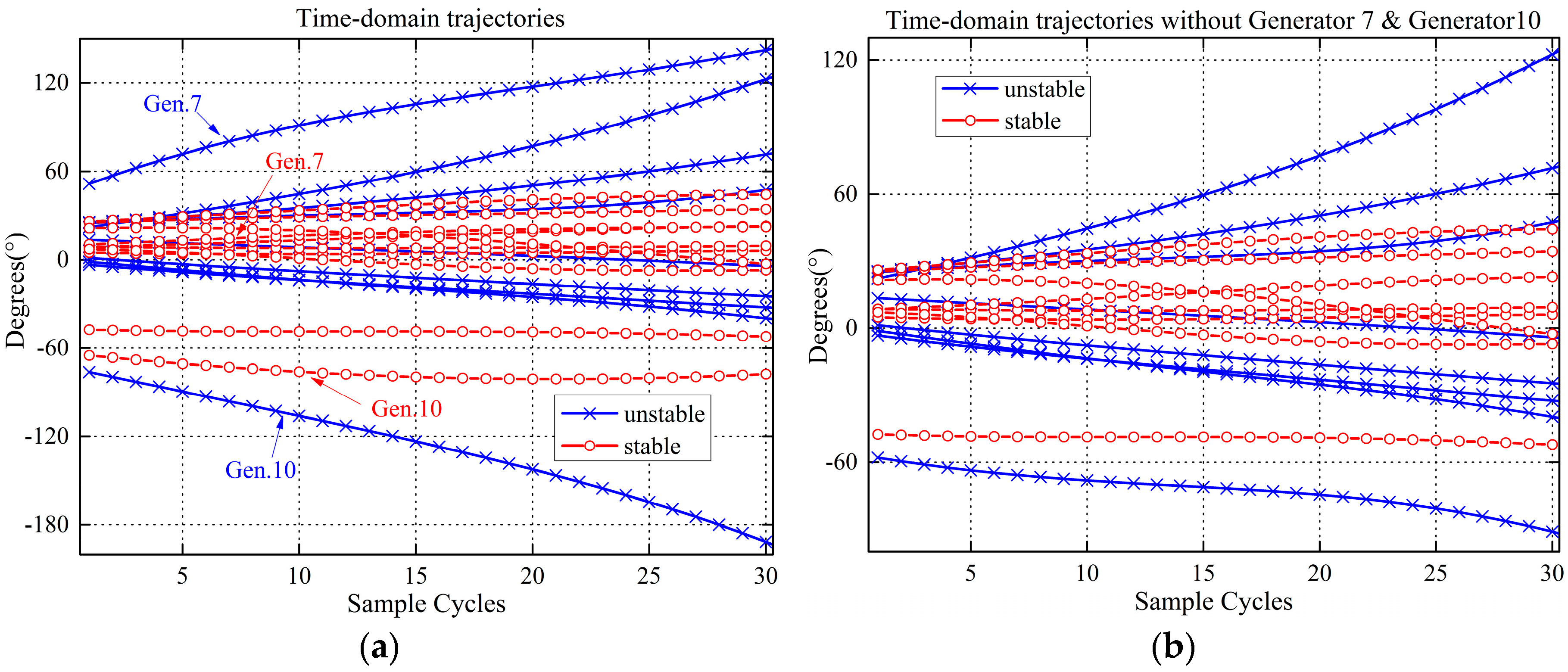
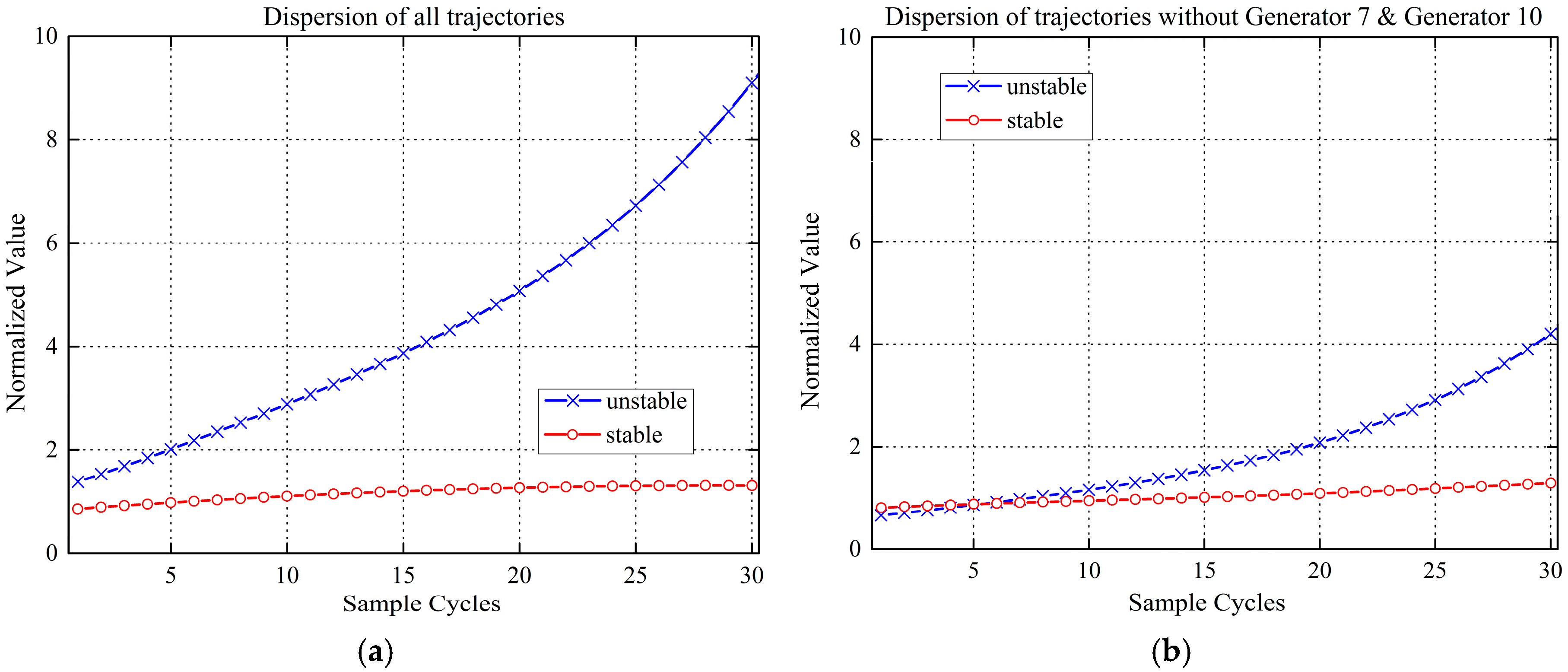
2.1. Observations on Post-Fault Trajectories
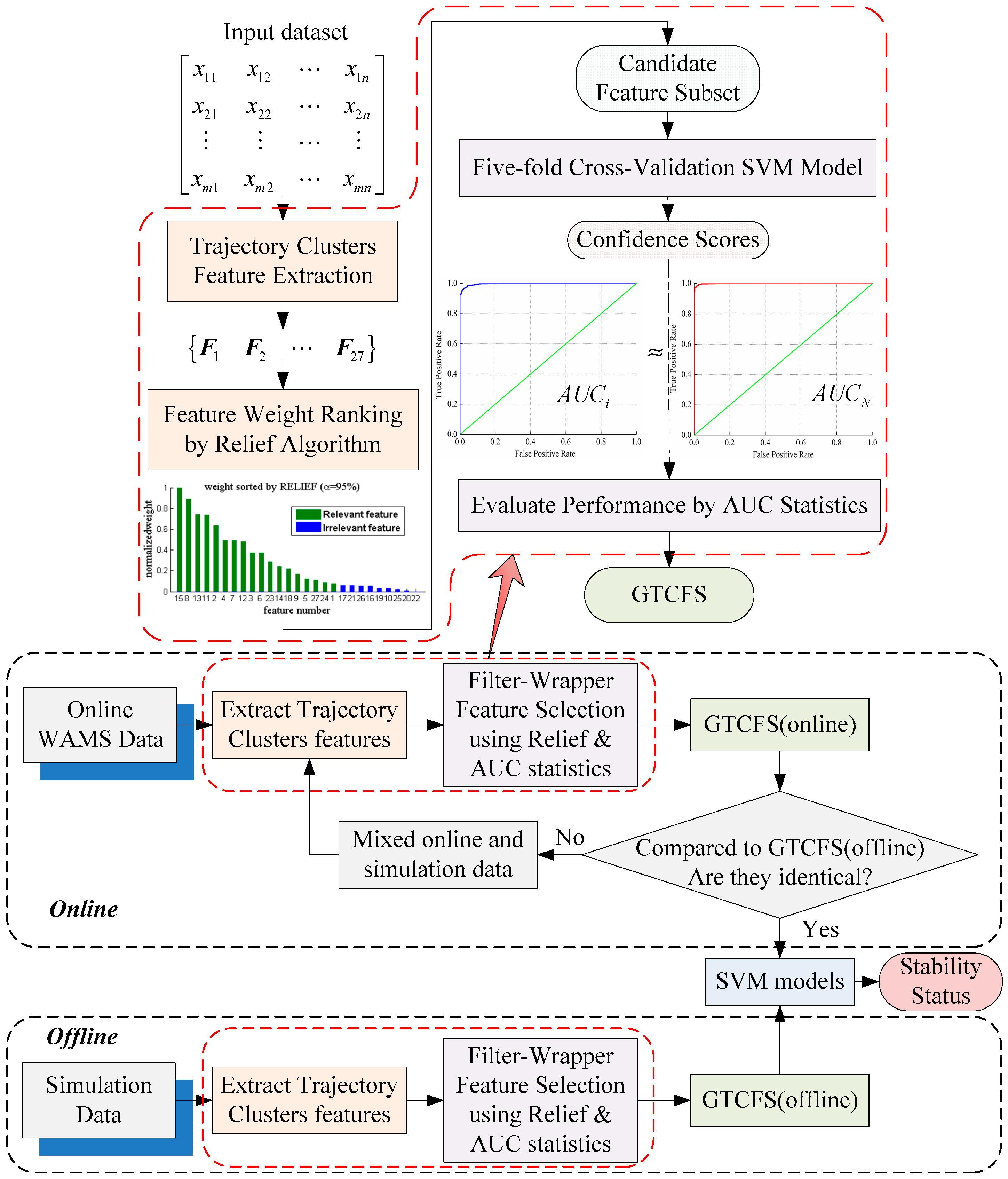
2.2. Trajectory Clusters Feature Extraction
2.3. Feature Selection: RELIEF Algorithm
| Algorithm 1. Pseudo-code of the RELIEF algorithm. |
| Input: for each training instance, a vector of attribute values and the class value |
| Output: the vector W of estimations of the qualities of attributes |
| 1. set all weights W[A] = 0; |
| 2. for i = 1 to m do begin |
| 3. randomly select an instance ; |
| 4. find nearest hit H and nearest miss M; |
| 5. for A = 1 to a do |
| 6. ; |
| 7. end; |
| 8. end; |
| 9. The selected feature set is , where is a threshold. |
2.4. SVM Classifier
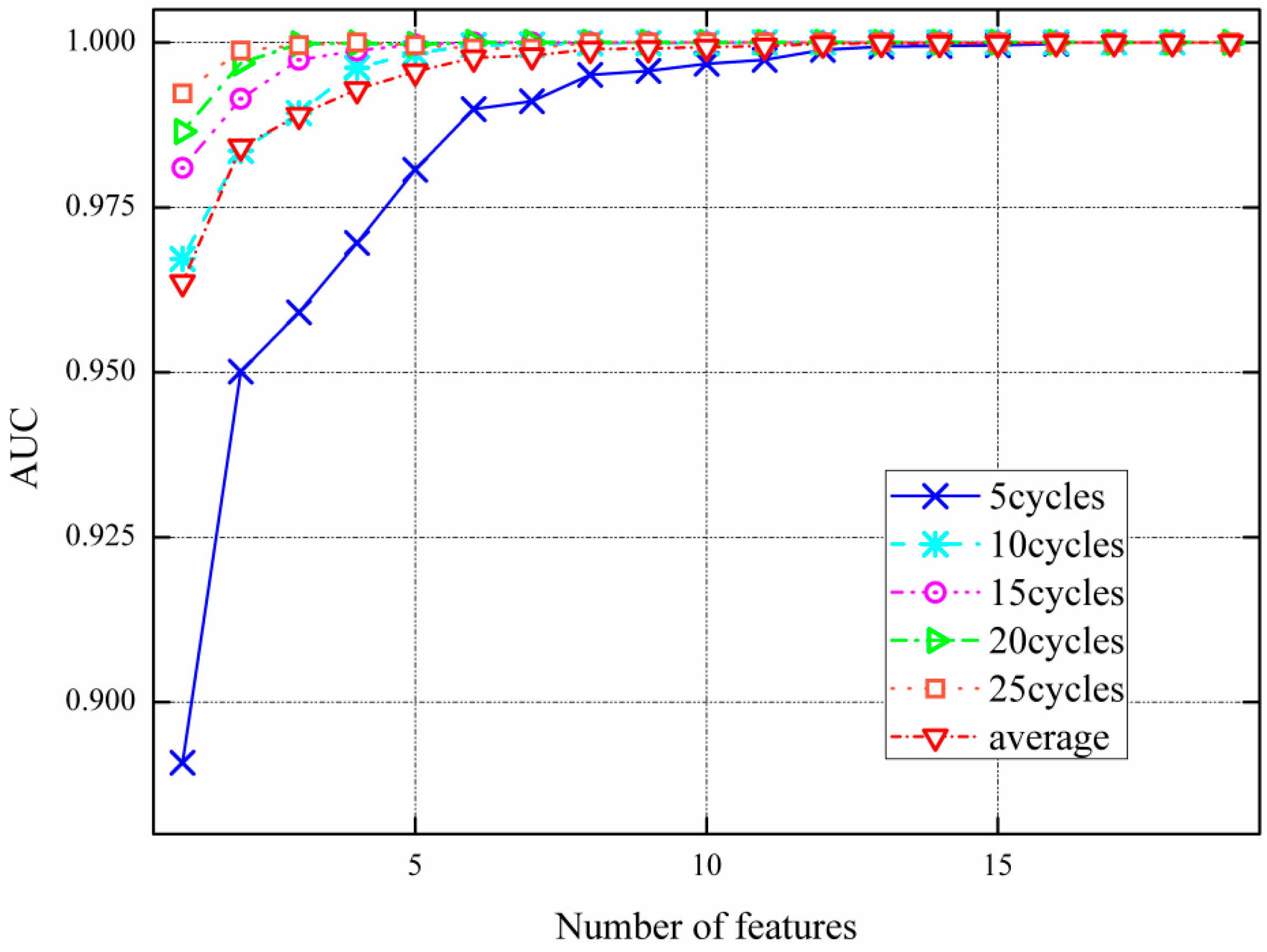
2.5. AUC Based Global Trajectory Clusters Feature Subset (GTCFS) Method
2.6. Overall Transient Stability Prediction Strategy
3. Results and Discussion
3.1. Database Generation
3.2. Training and Testing Datasets
3.3. Feature Extraction, Selection and Test Results
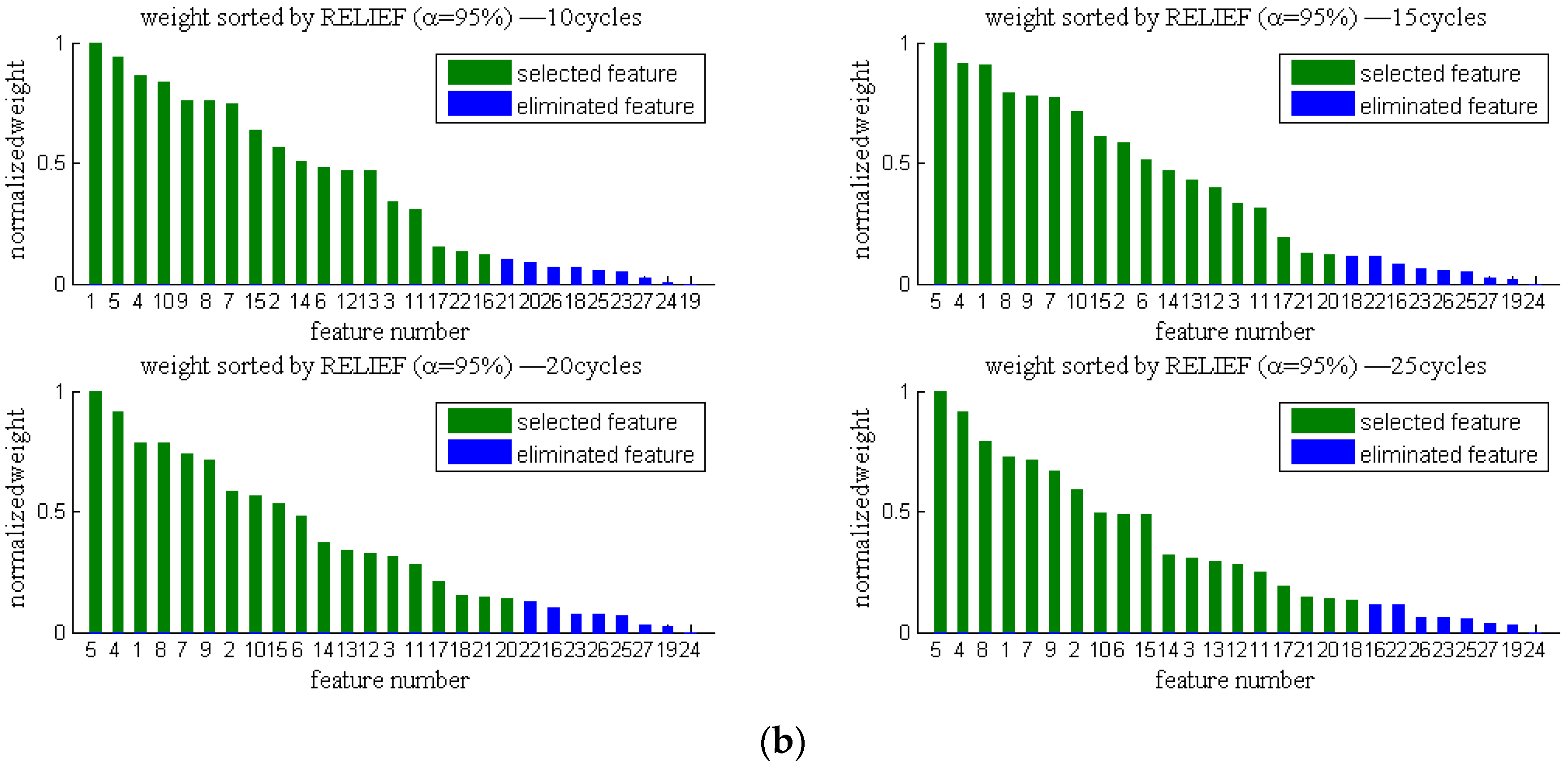
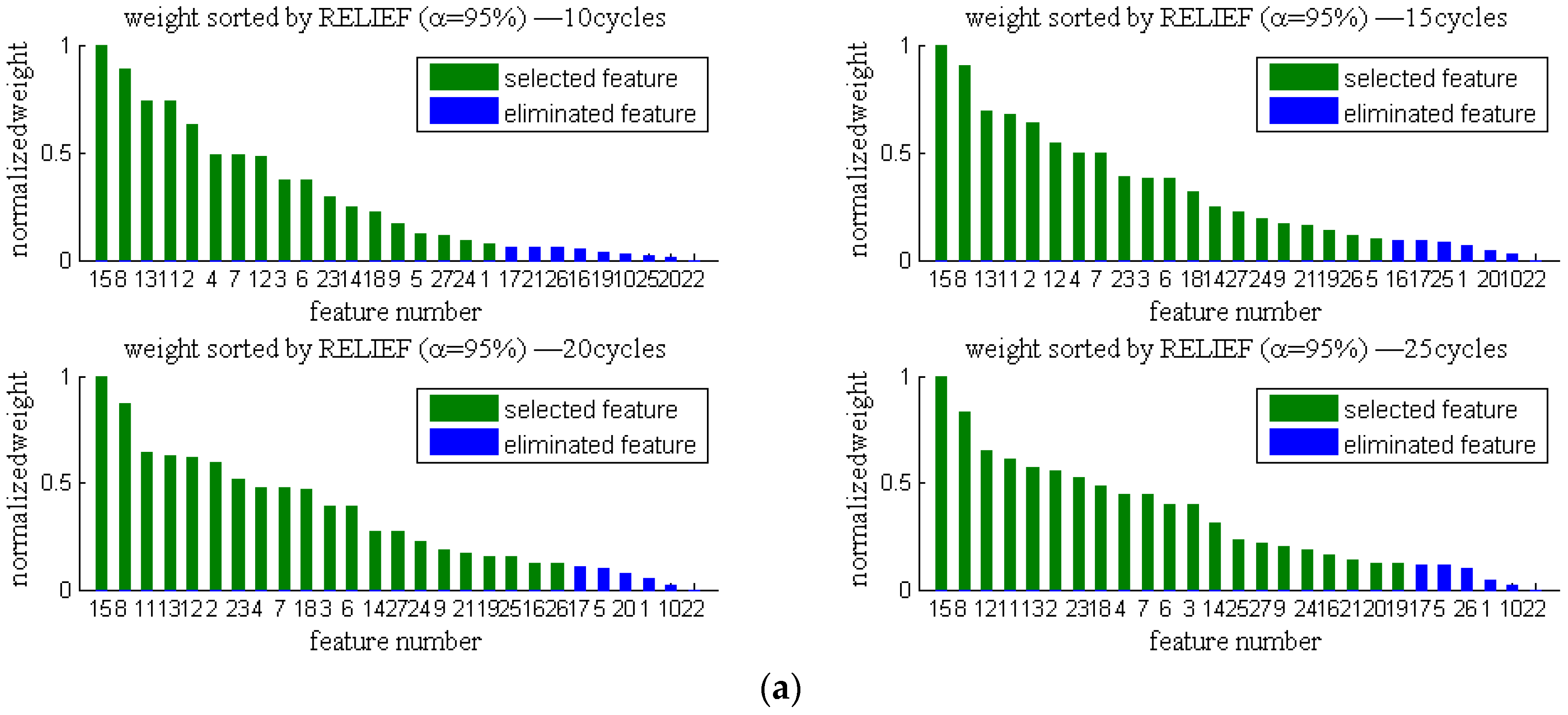
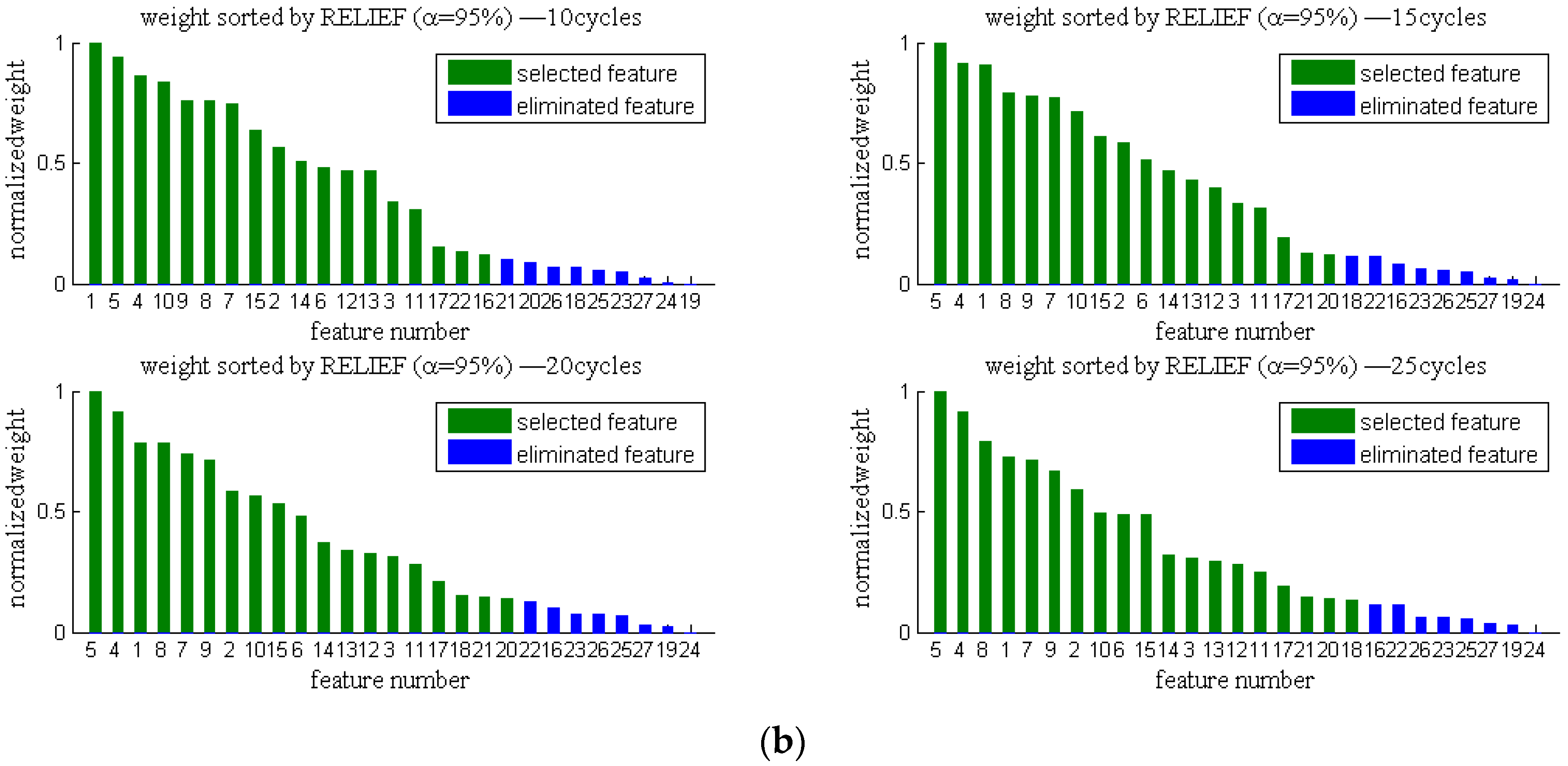
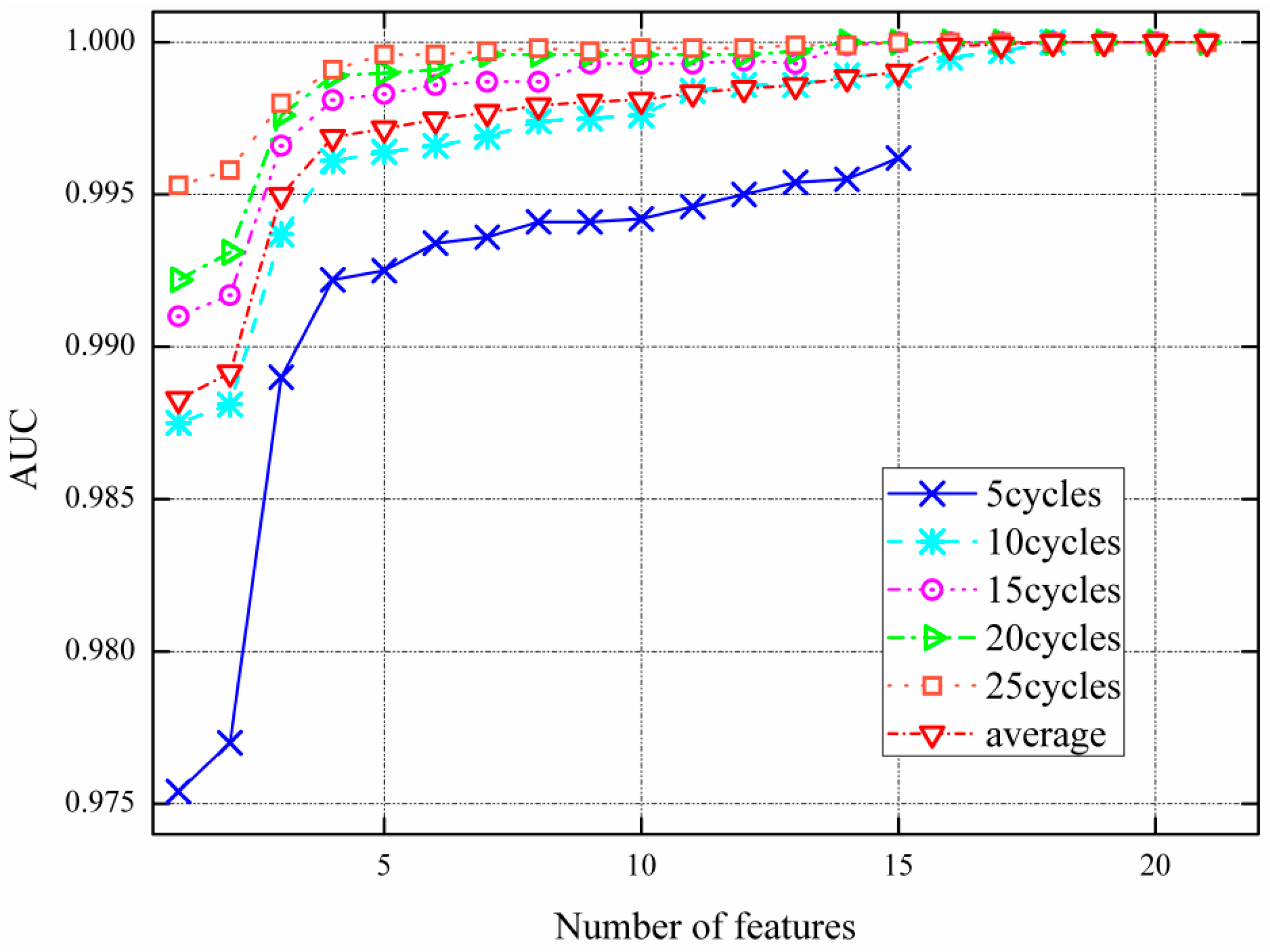
3.3.1. Filter Feature Selection Procedure
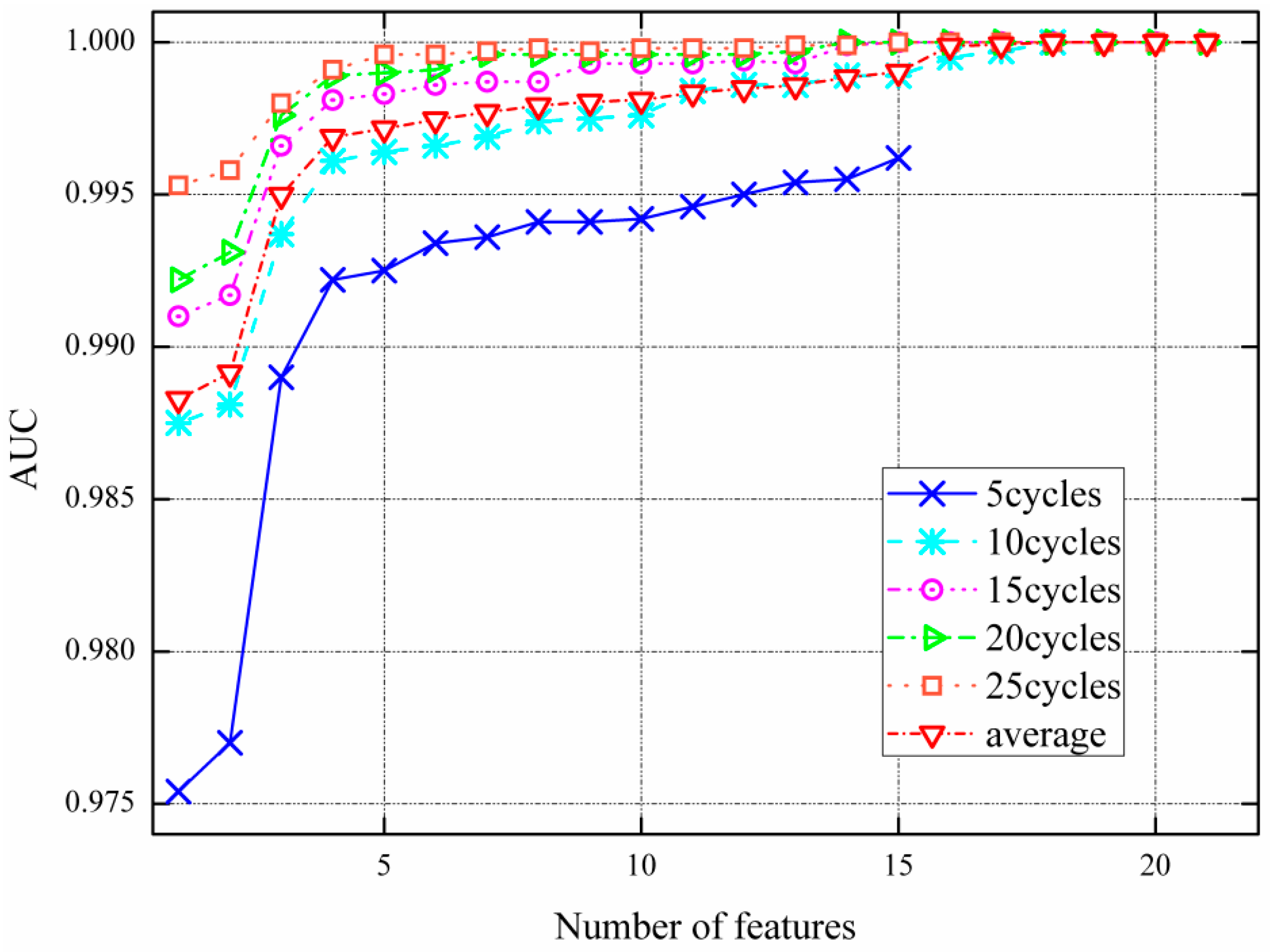
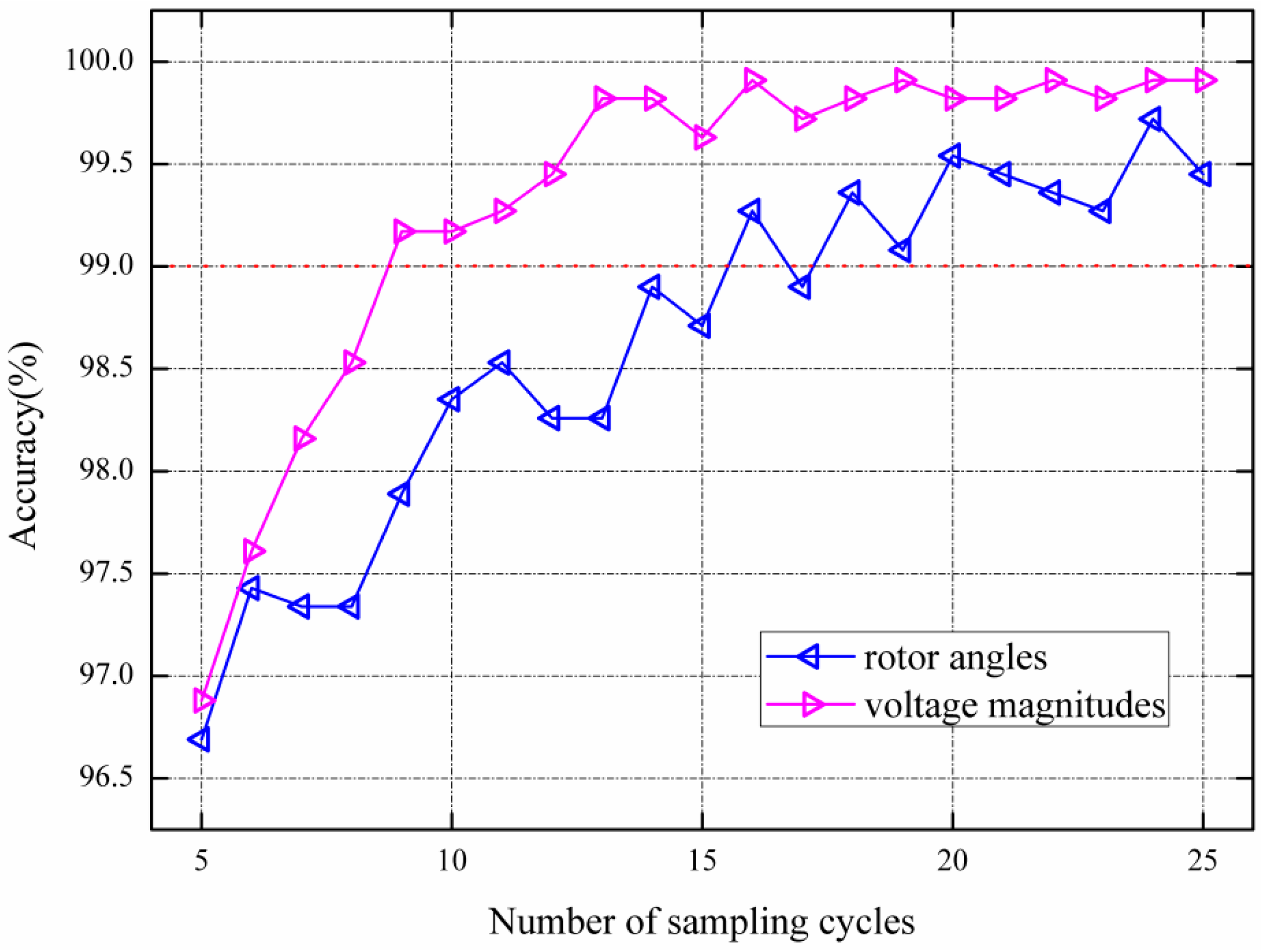
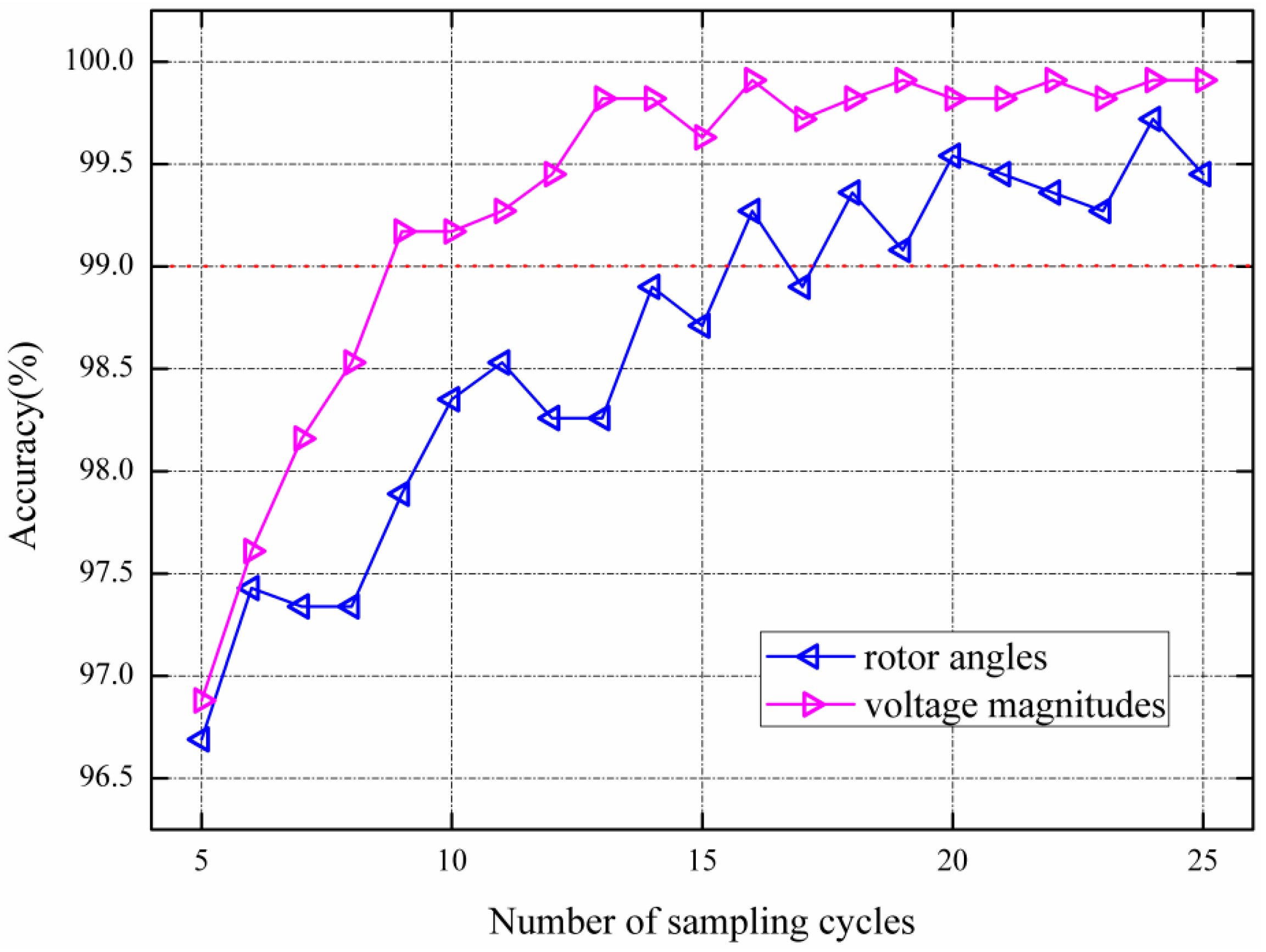
3.3.2. Wrapper Feature Selection Procedure
3.4. Model Generalization Performance
3.4.1. Impact of Topology Changes
3.4.2. Impact of Load Level Changes
3.4.3. Prediction Based on Incomplete WAMS Information
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pai, M.A. Energy Function Analysis for Power System Stability; Kluwer: Boston, MA, USA, 1989. [Google Scholar]
- Xue, Y.; Wehenkel, L.; Belhomme, R.; Rousseaux, P.; Pavella, M.; Euxibie, E. Extended equal area criterion revisited. IEEE Trans. Power Syst. 1992, 7, 1012–1022. [Google Scholar] [CrossRef]
- Wahab, N.I.A.; Mohamed, A.; Hussain, A. Fast transient stability assessment of large power system using probabilistic neural network with feature reduction techniques. Expert Syst. Appl. 2011, 38, 11112–11119. [Google Scholar] [CrossRef]
- Sharifian, A.; Sharifian, S. A new power system transient stability assessment method based on Type-2 fuzzy neural network estimation. Electr. Power Energy Syst. 2015, 64, 71–87. [Google Scholar] [CrossRef]
- Verma, K.; Niazi, K.R. Rotor Trajectory Index for Transient Security Assessment using Radial Basis Function Neural Network. In Proceedings of the IEEE PES Meeting, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5.
- Haidar, A.M.A.; Mustafa, M.W.; Ibrahim, F.A.F.; Ibrahim, A.A. Transient stability evaluation of electrical power system using generalized regression neural networks. Appl. Soft Comput. 2011, 11, 3558–3570. [Google Scholar] [CrossRef]
- Rovnyak, S.M.; Taylor, C.W.; Sheng, Y. Decision trees using apparent resistance to detect impending loss of synchronism. IEEE Trans. Power Deliv. 2000, 15, 1157–1162. [Google Scholar] [CrossRef]
- Gao, Q.; Rovnyak, S.M. Decision trees using synchronized phasor measurements for wide-area response-based control. IEEE Trans. Power Syst. 2011, 26, 855–861. [Google Scholar] [CrossRef]
- Dong, Z.Y.; Xu, Y.; Zhang, P.; Wong, K.P. Using IS to Assess an Electric Power System’s Real-Time Stability. IEEE Intell. Syst. 2013, 28, 60–66. [Google Scholar] [CrossRef]
- Bahbah, A.G.; Girgis, A.A. New method for generators’ angles and angular velocities prediction for transient stability assessment of multimachine power systems using recurrent artificial neural network. IEEE Trans. Power Syst. 2004, 19, 1015–1022. [Google Scholar] [CrossRef]
- Karami, A.; Esmaili, S.Z. Transient stability assessment of power systems described with detailed models using neural network. Int. J. Electr. Power Energy Syst. 2013, 45, 279–292. [Google Scholar] [CrossRef]
- Sulistiawati, I.B.; Priyadi, A.; Qudsi, O.A.; Soeprijanto, A.; Yorino, N. Critical Clearing Time prediction within various loads for transient stability assessment by means of the Extreme Learning Machine method. Int. J. Electr. Power Energy Syst. 2016, 77, 345–352. [Google Scholar] [CrossRef]
- Li, Y.; Li, G.Q.; Wang, Z.H. A Multifeature Fusion Approach for Power System Transient Stability Assessment Using PMU Data. Math. Probl. Eng. 2015, 6, 1–10. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Tsoa, S.K.; Gu, X.P. Feature selection by separability assessment of input spaces for transient stability classification based on neural networks. Int. J. Electr. Power Energy Syst. 2004, 26, 153–162. [Google Scholar] [CrossRef]
- Sawhney, H.; Jeyasurya, B. A feed-forward artificial neural network with enhanced feature selection for power system transient stability assessment. Electr. Power Syst. Res. 2006, 76, 1047–1054. [Google Scholar] [CrossRef]
- Rajapakse, A.D.; Gomez, F.R.; Nanayakkara, K.; Crossley, P.A.; Terzija, V.T. Rotor angle instability prediction using post-disturbance voltage trajectories. IEEE Trans. Power Syst. 2010, 25, 947–956. [Google Scholar] [CrossRef]
- Gomez, F.R.; Rajapakse, A.D.; Annakkage, U.; Fernando, I. Support vector machine-based algorithm for post-fault transient stability status prediction using synchronized measurements. IEEE Trans. Power Syst. 2011, 26, 1474–1483. [Google Scholar] [CrossRef]
- Guo, T.Y.; Milanović, J.V. Online Identification of Power System Dynamic Signature Using PMU Measurements and Data Mining. IEEE Trans. Power Syst. 2016, 31, 1760–1768. [Google Scholar] [CrossRef]
- Gomez, F.R.; Rajapakse, A.D.; Annakkage, U. Transient stability prediction algorithm based on post-fault recovery voltage measurements. In Proceedings of the 2009 IEEE Electrical Power & Energy Conference (EPEC), Montreal, QC, Canada, 22–23 October 2009; pp. 1–6.
- Zhao, J.Q.; Li, J.; Wu, X.C.; Men, K.; Hong, C.; Liu, Y.J. A novel real-time transient stability prediction method based on post-disturbance voltage trajectories. In Proceedings of the International Conference on Advanced Power System Automation and Protection (APAP), Beijing, China, 16–20 October 2011; pp. 730–736.
- Gu, X.P.; Li, Y.; Jia, J.H. Feature selection for transient stability assessment based on kernelized fuzzy rough sets and memetic algorithm. Int. J. Electr. Power Energy Syst. 2015, 64, 664–670. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Proceedings of the Ninth International Workshop on Machine Learning, San Jose, CA, USA, 12–16 July 1992; Morgan Kaufmann Publishers Inc.: Aberdeen, Scotland, UK, 1992; pp. 249–256. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Block, P.; Paern, J.; Hüllermeier, E.; Sanschagrin, P.; Sotriffer, C.A. Physicochemical descriptors to discriminate protein–protein interactions in permanent and transient complexes selected by means of machine learning algorithms. Proteins Struct. Funct. Bioinform. 2006, 65, 607–622. [Google Scholar] [CrossRef] [PubMed]
- Mizianty, M.; Kurgan, L. Modular prediction of protein structural classes from sequences of twilight-zone identity with predicting sequences. BMC Bioinform. 2009, 10, 414. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support Vector Networks. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.15.9362&rank=3 (accessed on 8 October 2016).
- Herrera, L.; Pomares, H.; Rojas, I.; Guillén, A.; Prieto, A.; Valenzuela, O. Recursive prediction for long term time series forecasting using advanced models. Neurocomputing 2007, 70, 2870–2880. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. 2001. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 8 October 2016).
- Suykens, J.A.K.; Gestel, T.V.; Brabanter, J.D.; Moor, B.D.; Vandewalle, J. Least Squares Support Vector Machines; World Scientific Publishing Company: Singapore, 2003. [Google Scholar]
- Wu, T.; Lin, C.; Weng, R.C. Probability estimates for multi-class classification by pairwise coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Zhang, T. Statistical behaviour and consistency of classification methods based on convex risk minimization. Ann. Stat. 2004, 32, 56–134. [Google Scholar] [CrossRef]
- Chen, X.W.; Wasikowski, M. FAST: A roc-based feature selection metric for small samples and imbalanced data classification problems. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2008; pp. 124–132.
- Alshawabkeh, M.; Aslam, J.A.; Dy, J.; Kaeli, D. Feature Selection Metric Using AUC Margin for Small Samples and Imbalanced Data Classification Problems. IEEE Comput. Soc. 2011, 1, 145–150. [Google Scholar]
- Krawczyk, B.; Woźniak, M.; Herrera, F. Weighted one-class classification for different types of minority class examples in imbalanced data. In Proceedings of the 2014 IEEE Computational Intelligence and Data Mining (CIDM), Orlando, FL, USA, 9–12 December 2014; pp. 337–344.
- Wu, Z.X.; Zhou, X.X. Power system analysis software package (PSASP)—An integrated power system analysis tool. In Proceedings of the 1998 International Conference POWERCON, Beijing, China, 18–21 August 1998; pp. 7–11.


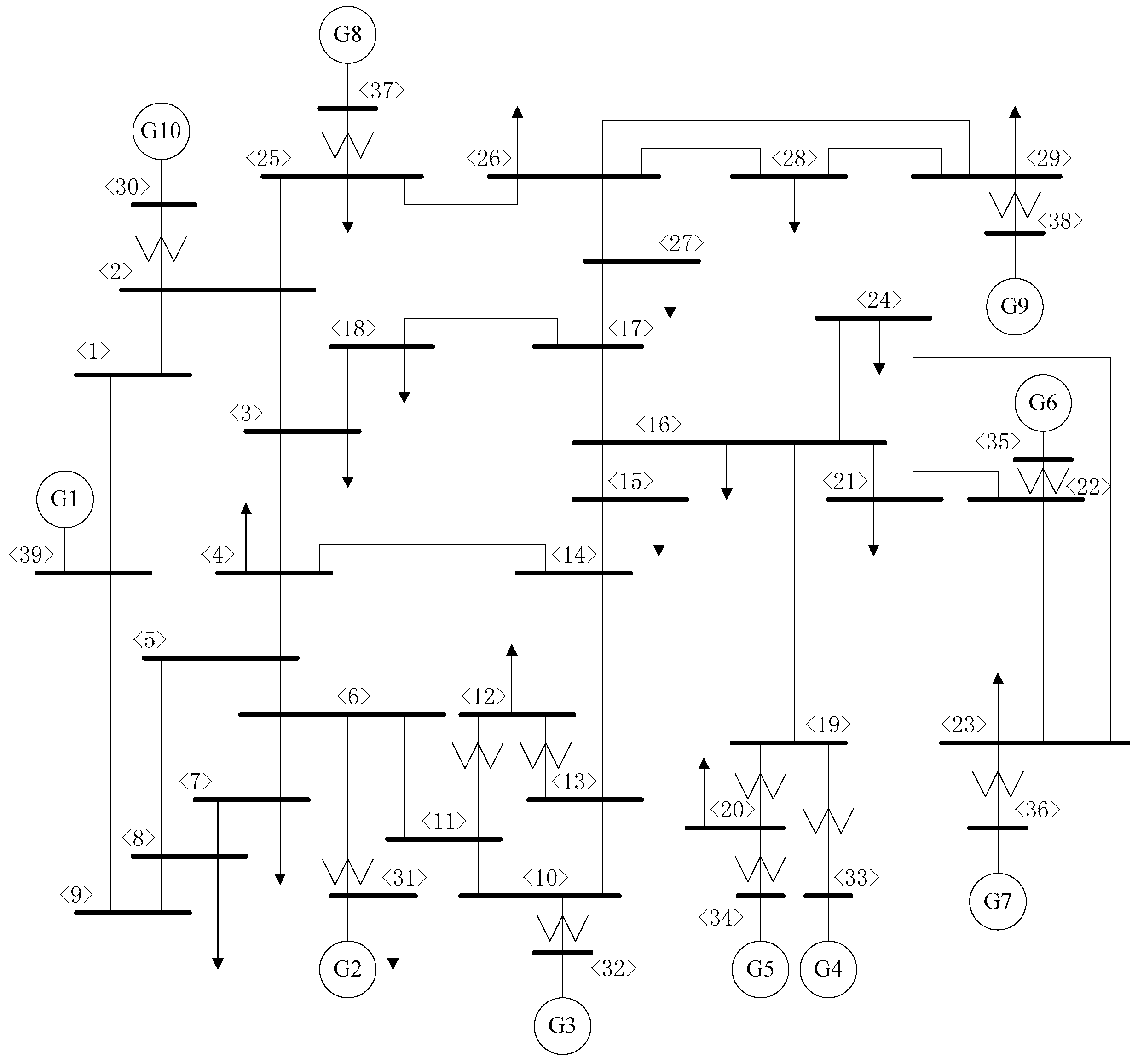



{kind=link}
{kind=link}
{kind=link}
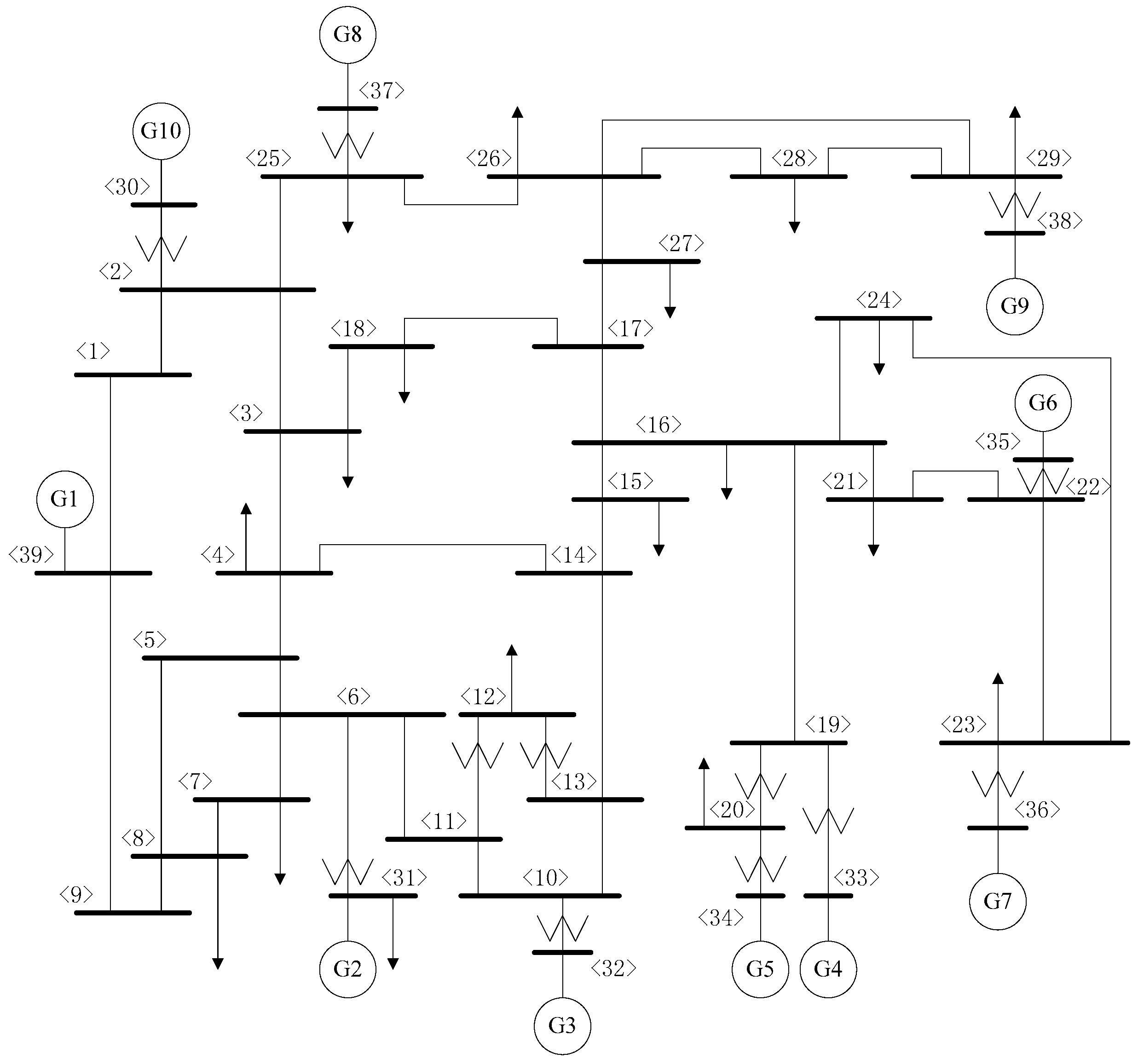{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Description | No. | Description |
|---|---|---|---|
| F1 | Arithmetic mean | F15 | Gradient of the envelope height |
| F2 | Degree of dispersion | F16 | Trajectory curvature |
| F3 | Upper envelope | F17 | Curvature of the arithmetic mean |
| F4 | Lower envelope | F18 | Curvature of dispersion |
| F5 | Mid-range | F19 | Curvature of the upper envelope |
| F6 | Difference between the upper envelope and arithmetic mean | F20 | Curvature of the lower envelope |
| F7 | Difference between the lower envelope and arithmetic mean | F21 | Curvature of the mid-range |
| F8 | Envelope height | F22 | Arithmetic mean variation acceleration |
| F9 | Difference between the arithmetic mean and mid-range | F23 | Dispersion variation acceleration |
| F10 | Gradient of the arithmetic mean | F24 | Upper envelope acceleration |
| F11 | Gradient of dispersion | F25 | Lower envelope acceleration |
| F12 | Gradient of the upper envelope | F26 | Mid-range variation acceleration |
| F13 | Gradient of the lower envelope | F27 | Envelope height variation acceleration |
| F14 | Gradient of the arithmetic mean | - | - |
| Training and Test Group | Rotor Angles | Voltage Magnitudes | ||||||
|---|---|---|---|---|---|---|---|---|
| GTCFS Set | Total Feature Set | GTCFS Set | Total Feature Set | |||||
| Acc 1(%) | AUC | Acc (%) | AUC | Acc (%) | AUC | Acc (%) | AUC | |
| 1st | 98.35 | 0.999 | 100 | 1 | 99.08 | 0.9998 | 100 | 1 |
| 2nd | 98.44 | 0.9989 | 99.36 | 0.9997 | ||||
| 3rd | 98.71 | 0.999 | 98.99 | 0.9997 | ||||
| 4th | 98.26 | 0.9992 | 98.90 | 0.9996 | ||||
| Mean | 98.44 | 0.999 | 99.08 | 0.9997 | ||||
| Training and Test Group | Rotor Angles | Voltage Magnitudes | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | T4 | Sum | T1 | T2 | T3 | T4 | Sum | |
| 1st | 0.05 | 5.93 | - | 28.07 | 34.05 | 0.04 | 5.97 | - | 80.83 | 86.85 |
| 2nd | 0.05 | 6.25 | - | 26.95 | 33.24 | 0.05 | 5.88 | - | 80.27 | 86.20 |
| 3rd | 0.05 | 6.03 | - | 28.00 | 34.08 | 0.05 | 6.18 | - | 79.19 | 85.42 |
| 4th | 0.05 | 6.09 | - | 29.24 | 35.38 | 0.04 | 6.07 | - | 80.40 | 86.51 |
| Mean | 0.05 | 6.08 | - | 28.07 | 34.19 | 0.05 | 6.03 | - | 80.17 | 86.24 |
| Training and Test Group | Rotor Angles | Voltage Magnitudes | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | T4 | Sum | T1 | T2 | T3 | T4 | Sum | |
| 1st | 0.05 | 4.57 | 21.33 | 3.54 | 29.48 | 0.04 | 3.18 | 15.50 | 5.11 | 23.83 |
| 2nd | 0.05 | 4.56 | 20.51 | 3.35 | 28.46 | 0.04 | 3.36 | 15.77 | 5.17 | 24.34 |
| 3rd | 0.04 | 4.54 | 24.30 | 3.74 | 32.63 | 0.04 | 3.31 | 15.77 | 5.16 | 24.28 |
| 4th | 0.04 | 4.47 | 23.70 | 3.30 | 31.51 | 0.04 | 3.38 | 14.68 | 5.16 | 23.26 |
| Mean | 0.05 | 4.54 | 22.46 | 3.48 | 30.52 | 0.04 | 3.31 | 15.43 | 5.15 | 23.93 |
| Scenarios | Stable Case Number | Unstable Case Number | Prediction Accuracy (%) | AUC | ||
|---|---|---|---|---|---|---|
| Actual | Predicted | Actual | Predicted | |||
| Scenario 1 | 141 | 141 | 24 | 22 | 98.79 | 0.9994 |
| Scenario 2 | 127 | 126 | 38 | 32 | 95.76 | 0.9758 |
| Scenario 3 | 127 | 127 | 38 | 32 | 96.36 | 0.9816 |
| Load Level | Prediction Accuracy (%) | AUC |
|---|---|---|
| 80% | 93.52 | 0.9999 |
| 90% | 99.07 | 0.9997 |
| 110% | 90.74 | 0.9978 |
| 120% | 81.01 | 0.9901 |
| Missing Number of Generators | Stable Case Number | Unstable Case Number | Prediction Accuracy (%) | AUC | ||
|---|---|---|---|---|---|---|
| Actual | Predicted | Actual | Predicted | |||
| 0 | 828 | 825 | 261 | 249 | 98.62 | 0.9961 |
| 1 | 828 | 825 | 261 | 247 | 98.43 | 0.9948 |
| 2 | 828 | 823 | 261 | 243 | 97.89 | 0.9943 |
| 3 | 828 | 820 | 261 | 245 | 97.78 | 0.9942 |
| 4 | 828 | 821 | 261 | 245 | 97.89 | 0.9955 |
| 5 | 828 | 819 | 261 | 242 | 97.43 | 0.9931 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, L.; Wu, J.; Zhou, Y.; Hao, L. Using Trajectory Clusters to Define the Most Relevant Features for Transient Stability Prediction Based on Machine Learning Method. Energies 2016, 9, 898. https://doi.org/10.3390/en9110898
Ji L, Wu J, Zhou Y, Hao L. Using Trajectory Clusters to Define the Most Relevant Features for Transient Stability Prediction Based on Machine Learning Method. Energies. 2016; 9(11):898. https://doi.org/10.3390/en9110898
Chicago/Turabian StyleJi, Luyu, Junyong Wu, Yanzhen Zhou, and Liangliang Hao. 2016. "Using Trajectory Clusters to Define the Most Relevant Features for Transient Stability Prediction Based on Machine Learning Method" Energies 9, no. 11: 898. https://doi.org/10.3390/en9110898