3.1. CO2 Emissions Data Sources
This section describes how to apply the QHS algorithm to searching for the optimal β values for the DMSFE method and then establish the QHS-based optimization DMSFE combination forecast model. To examine the applicability and efficiency of the proposed method, the proposed method is applied to the top-5 CO2 emitters.
British Petroleum (BP) provides high-quality, objective and globally consistent data on World energy markets, covering data on petroleum, coal, natural gas, nuclear and power. The data of CO
2 emissions from fossil fuel consumption were adopted from the
BP Statistical Review of World Energy (Excel data, 2011) [
30]. BP presents in detail main 68 countries for the period from 1965 until 2010. In 2010, China, the United States, the Russian Federation, India and Japan, the largest five emitters, produced together 57.8% of the World’s CO
2 emissions, with the shares of China and the United States far surpassing those of all others. Combined, these two countries alone produced 14.48 Gt CO
2, about 43.6% of World CO
2 emissions. China has experienced an approximate 10 percent average annual GDP growth over the last two decades and caused a large amount of resource and energy consumption and associated emissions creating serious environmental problems [
31]. China, now the World’s largest emitter of CO
2 emissions from fuel combustion, generated 8.33 Gt CO
2, which accounts 25.1% of the World total. Due to the energy-intensive industrial production, large coal reserves exist and with intensified use of coal, the CO
2 emissions would increase substantially for a certain period. The United States alone generated 18.5% of World CO
2 emissions, despite a population of less than 5% of the global total. In the United States, the large share of global emissions is associated with a commensurate share of economic output. The Russian Federation and India are the two BRICS countries representing over one-fourth of World GDP, 30% of global energy use and 33% of CO
2 emissions from fuel combustion. With their ongoing strong economic performance, the share of global emissions for the Russian Federation and India are likely to rise further in coming years. India now emits over 5% of global CO
2 emissions, and emissions will continue to grow. The World Energy Outlook projects that CO
2 emissions in India will more than double between 2007 and 2030. Japan, one of the world’s leading industrial economies, is the fifth emitter, with 1.31 Gt CO
2 in 2010, contributing a significant share of global CO
2 emissions (3.9%).
In this study, the annual CO
2 emissions data of the top-5 countries for the period from 2000 to 2010 were collected.
Table 1 shows the data for CO
2 emissions from fossil fuel consumption from 2000 to 2010 and
Table 2 shows the share of the World total amount for these countries in 2010.
Table 1.
CO2 emissions data from 2000 to 2010 for top-5 countries (Mtonnes).
Table 1.
CO2 emissions data from 2000 to 2010 for top-5 countries (Mtonnes).
| Country | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 |
| China | 3659.3483 | 3736.9794 | 3969.8231 | 4613.9200 | 5357.1651 | 5931.9713 |
| USA | 6377.0493 | 6248.3608 | 6296.2248 | 6343.4769 | 6472.4463 | 6493.7341 |
| Russia | 1562.9791 | 1574.4929 | 1583.9895 | 1624.7682 | 1628.0350 | 1618.0046 |
| India | 952.7665 | 959.1636 | 1001.2000 | 1030.4714 | 1118.3646 | 1172.8631 |
| Japan | 1327.1324 | 1324.4486 | 1322.9523 | 1376.2507 | 1380.7913 | 1397.7016 |
| Country | 2006 | 2007 | 2008 | 2009 | 2010 | |
| China | 6519.5965 | 6979.4653 | 7184.8542 | 7546.6829 | 8332.5158 | |
| USA | 6411.9503 | 6523.7987 | 6332.6004 | 5904.0382 | 6144.8510 | |
| Russia | 1663.3323 | 1678.7276 | 1711.0866 | 1602.5212 | 1700.1992 | |
| India | 1222.4088 | 1327.0771 | 1442.1529 | 1563.9172 | 1707.4594 | |
| Japan | 1379.2997 | 1392.1297 | 1389.3573 | 1225.4810 | 1308.3958 | |
Table 2.
Share of the World total in 2010.
Table 2.
Share of the World total in 2010.
| Rank | Country | CO2 emission | Total (%) |
|---|
| 1 | China | 8332.5 | 25.1% |
| 2 | US | 6144.9 | 18.5% |
| 3 | Russian Federation | 1700.2 | 5.1% |
| 4 | India | 1707.5 | 5.1% |
| 5 | Japan | 1308.4 | 3.9% |
3.2. Experimental Simulation
(1) The combination forecasting procedures
Since the CO2 emission curves of different industries have different characteristics and the future trend is full of uncertainties, it is more risky to select a certain forecasting model. To establish a combination model for CO2 emissions becomes a better solution.
Firstly, choose individual forecasting model and calculate individual forecasting results. Linear regression model [
7], time series model [
32], Grey (1,1) forecasting model [
33] and Grey Verhulst model [
34] are selected to generate the individual forecasting results. The reason why we choose these models is that they have been widely and successfully used in forecasting CO
2 emissions. Considering the time series method may lead to the loss of data, more original data were chosen in order for the consistent comparison period. The participating model forecasting results are shown in
Appendix from
Table A1,
Table A2,
Table A3,
Table A4,
Table A5.
Secondly, establish DMSFE combination forecasting model. According to Equation (3), the DMSFE combination forecasting model could be established based on the individual forecasting model.
Thirdly, determine the optimal βit values for every separate forecasting model and period by using QHS algorithm. The β matrix is 4 × 11 in this simulation since four individual models and 11 periods are adopted. In other words, there are 44 parameters to be optimized. It is a relatively high dimension problem. Finally, achieve the combination forecasting results according to Equation (8).
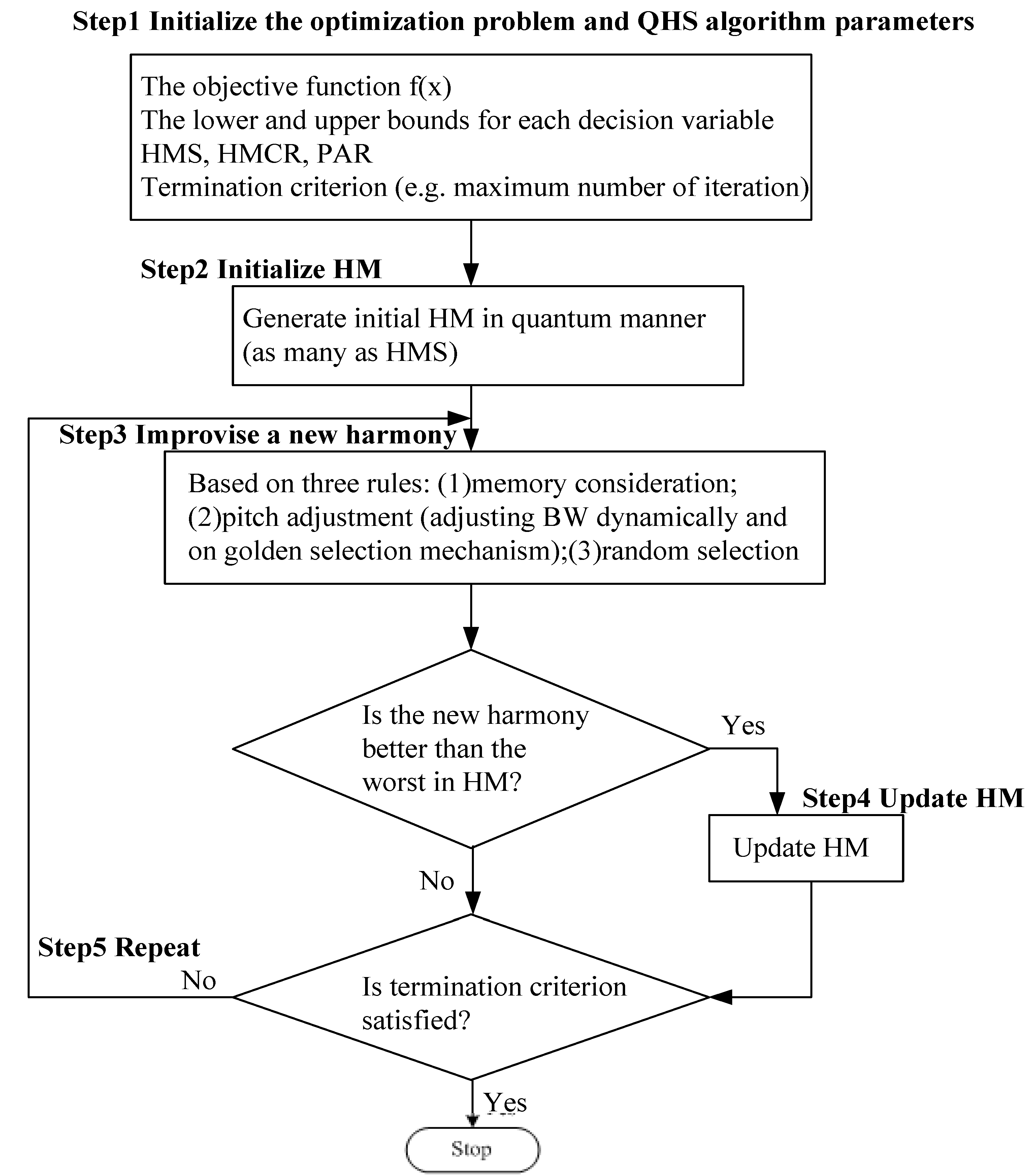
(2) The β optimization process based on the QHS algorithm
The optimization objective function
f(
x) of QHS algorithm is specified as the Mean Absolute Percentage Error (MAPE) in this proposed investigation. The MAPE is the measure of accuracy in a fitted time series value in statistics, specifically trending. It usually expresses accuracy as a percentage, eliminating the interaction between negative and positive values by taking absolute operation [
10], shown in Equation (9):
Minimize:
The QHS optimization DMSFE approach has been employed to determine optimal β
it values for the top-5 CO
2 emitting countries. The QHS algorithm parameters are selected by uniform design [
35] as follows: HMS = 35, HMCR = 0.99, PAR = 0.6, lb = 0, ub = 1, where lb is the lower bound for decision variable β
it, ub is the upper bound for decision variable β
it.
All the programs were run on a 2.27 GHz Intel Core Duo CPU with 1 GB of random access memory. In each case study, 30 independent runs were made for the QHS optimization procedure in MATLAB 7.6.0 (R2008a) on Windows 7 with 32-bit operating systems. Then, the best key was assigned as the optimal β
it values for the corresponding individual model and period shown as follows:
where
is the optimal β matrix for China,
for US,
for Russia,
for India and
for Japan. It could be found that the optimal β
it values vary quite a lot from each other even for the same county. The data differ from each other heavily in the case of China. The situations of Russia and Japan are similar to it of China. In the first column of matrix, all data, with uniform magnitude, are very close or equal to 1.0000 except one in the case of USA. The situation of India is similar to that of the USA. From the final optimal β values, we can draw two conclusions: (1) the best β values may be different for different counties; (2) the best β values may be different for different individual models and forecasting periods, even in the same country, since β ranges from 0 to 1, therefore, the arbitrary selection of β may not result in the best combination forecast effect,
i.e., not the minimal MAPE. Taking the same β for all individual models and forecasting period may bring the same drawback as the one above. It is vital to select suitable β values for the combination model. Through an optimization process, the best β values could be found with the minimal MAPE for combination forecast based on QHS algorithm. With these optimal β values the forecasting results and evaluating indexes could be obtained and presented in next sections.
(3) The forecasting results
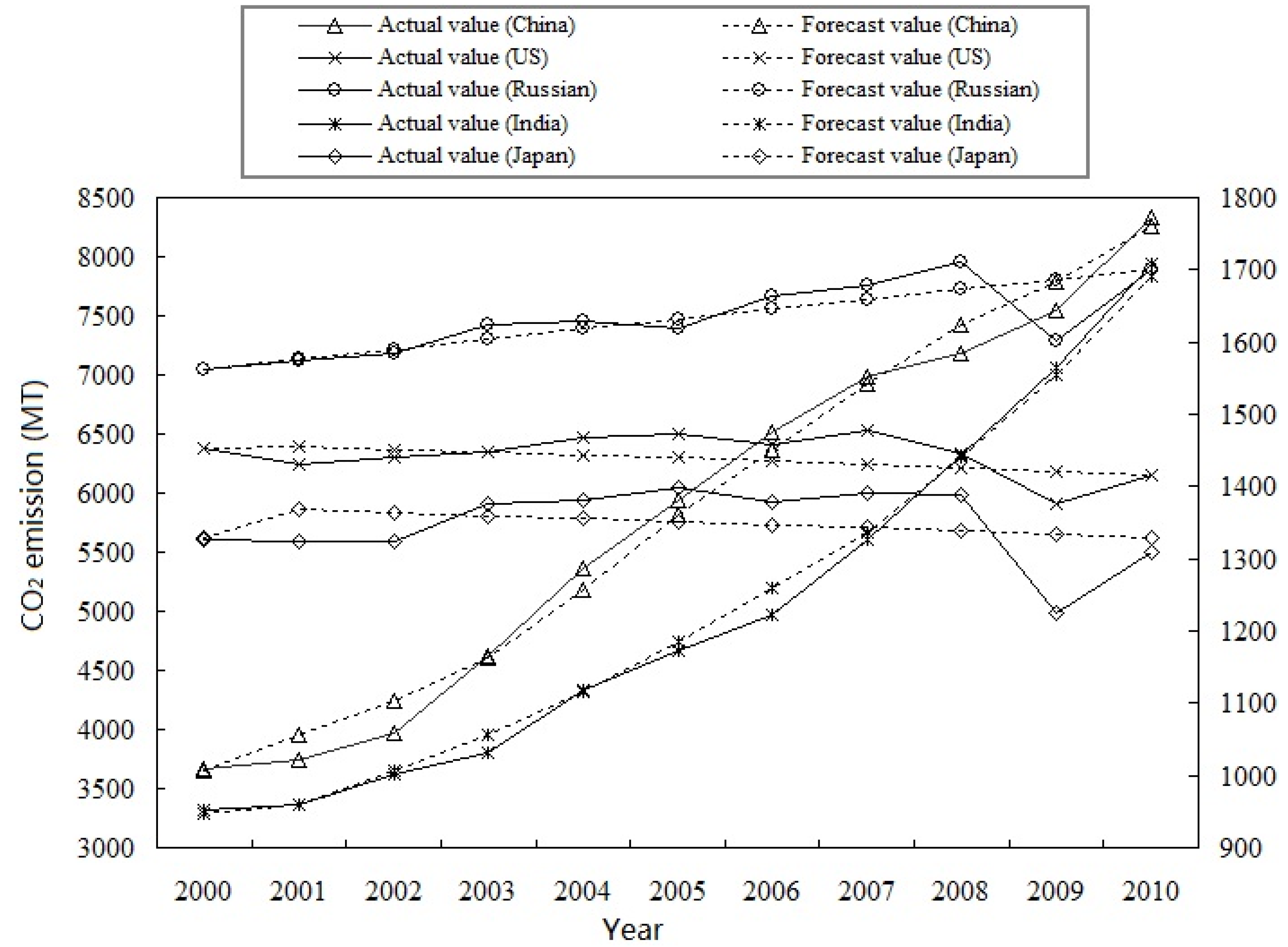
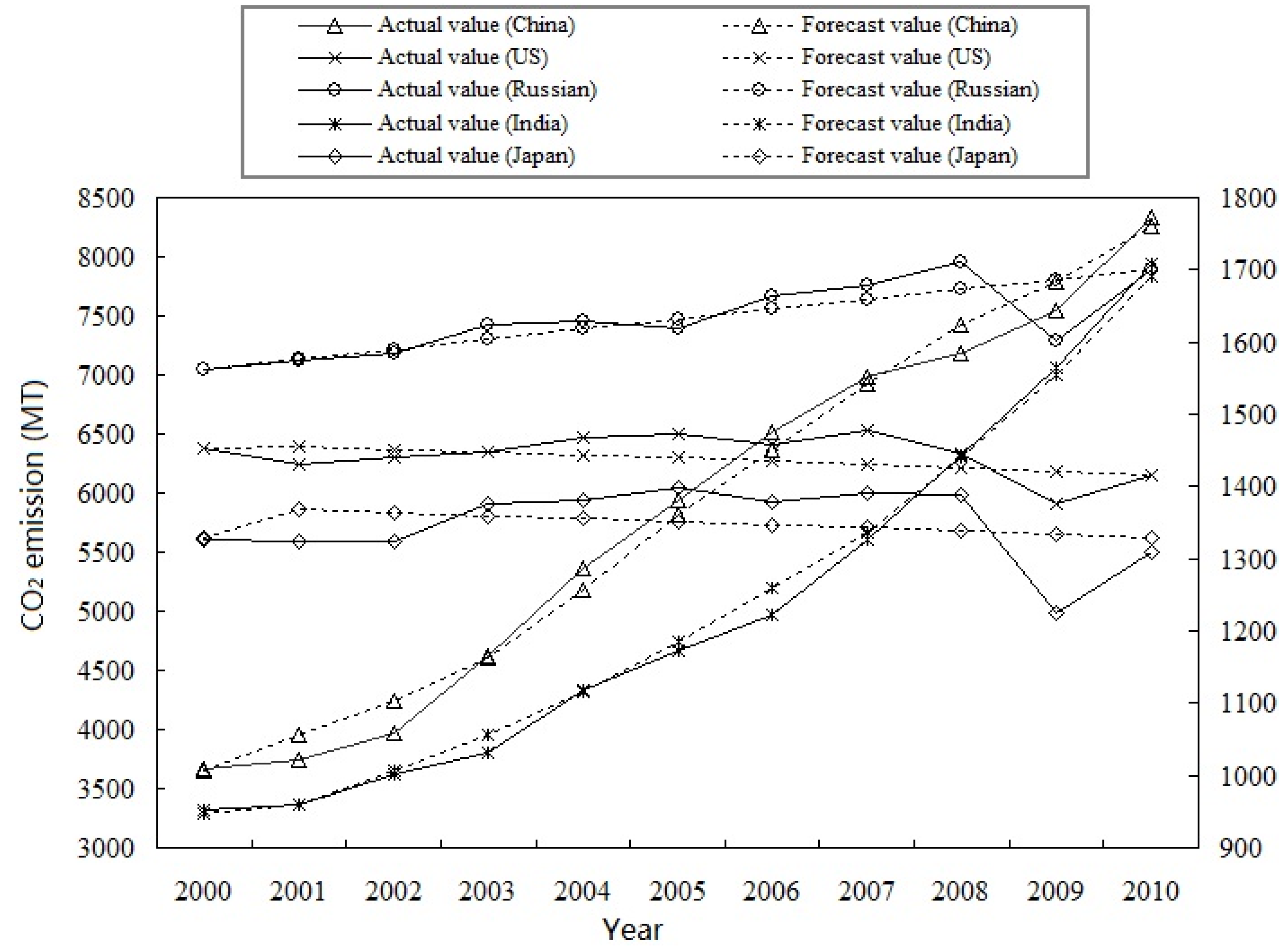
Figure 2 shows the curves of actual data and forecasting results achieved by the presented approach for the top-5 emitters from 2000 to 2010 respectively. Dual coordinates are employed in
Figure 2: the curves of actual data and forecasting results for China and US correspond to the left y-axis coordinate; the curves of actual data and forecasting results for the other three countries correspond to the right y-axis coordinate. These five counties could be divided into two kinds according to the growth direction: (1) ascending cases such as China, India and Russia; (2) fluctuating cases such as the US and Japan. From
Figure 2 we find that the forecasting results of China, Russia, India and US are relatively close to the original values at every point. For Japan, the proposed approach behaves well at some points and relatively poor at others. But, analyzing the MAPE in next section, the forecasting errors are acceptable, even in those poor situations. There is a sudden drop in the actual values of Russia, US and Japan between 2008 and 2010 because an abrupt economy crisis broke out around the World and resulted in lowered CO
2 emissions in these countries. The forecasting results are relatively inaccurate in those years because of the abruptness. It is natural since there is no one method works well for all situations. Every method has its own application circumstance. The presented method forecasting results are satisfied for different growth pattern that means the flexibility of the QHS algorithm based DMFSE combination model is excellent.
Figure 2.
Actual and forecast values for the World top-5 emitters.
Figure 2.
Actual and forecast values for the World top-5 emitters.
3.3. Case Comparison
In order to testify the validity of the QHS algorithm-based DMFSE combination forecasting method, five cases were considered in this section: Case 1, β = 0.1; Case 2, β = 0.5; Case 3, β = 1; Case 4, β* (adopting the same optimal β value for all individual models and all forecasting periods obtained by QHS algorithm shown in
Table 3; the parameters of QHS algorithm achieved by uniform design); Case 5, Dβ* (adopting the different optimal β values for different individual model and period obtained by QHS algorithm). We selected three cases near the beginning, middle and end of β span as examples since β varies from 0 to 1.
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 show the combination forecasting results of different cases for China, US, Russian Federation, India and Japan respectively. From these tables we could find that the forecasting results obtained by the presented approach are the best in most situations for all the five counties.
Furthermore, the fitting effect is evaluated through some common evaluating indicators
i.e., MAPE, RMSE and MAE shown in Equations (9), (11) and (12). The evaluating results are exhibited in
Table 9,
Table 10 and
Table 11:
Table 3.
The optimal β values in case 4 for top-5 countries.
Table 3.
The optimal β values in case 4 for top-5 countries.
| China | United States | Russian Federation | India | Japan |
|---|
| β* | 1.0000 | 2.2195 × 10−5 | 2.9628 × 10−5 | 2.7599 × 10−5 | 1.0000 |
Table 4.
Forecasting values with different cases for China (Mtonnes).
Table 4.
Forecasting values with different cases for China (Mtonnes).
| Year | t | Original data | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| 2000 | 1 | 3659.3483 | 3530.3572 | 3558.3733 | 3606.6073 | 3606.6073 | 3658.8771 |
| 2001 | 2 | 3736.9794 | 3932.1966 | 3942.4741 | 3959.6479 | 3959.6479 | 3959.8116 |
| 2002 | 3 | 3969.8231 | 4332.1111 | 4320.5721 | 4302.4815 | 4302.4815 | 4243.2317 |
| 2003 | 4 | 4613.9200 | 4761.4967 | 4734.9856 | 4693.8221 | 4693.8221 | 4599.3799 |
| 2004 | 5 | 5357.1651 | 5267.1257 | 5247.2098 | 5222.9176 | 5222.9176 | 5186.9109 |
| 2005 | 6 | 5931.9713 | 5795.6774 | 5787.7327 | 5788.9735 | 5788.9735 | 5825.7973 |
| 2006 | 7 | 6519.5965 | 6303.2887 | 6299.5006 | 6309.3182 | 6309.3182 | 6368.3617 |
| 2007 | 8 | 6979.4653 | 6823.7005 | 6827.1577 | 6848.8813 | 6848.8813 | 6930.0485 |
| 2008 | 9 | 7184.8542 | 7807.4174 | 7339.7023 | 7808.0081 | 7362.8626 | 7430.7278 |
| 2009 | 10 | 7546.6829 | 8316.2067 | 7807.1845 | 8316.1072 | 7808.0081 | 7793.0080 |
| 2010 | 11 | 8332.5158 | 8348.3939 | 8320.2893 | 8348. 5952 | 8316.1072 | 8251.4506 |
Table 5.
Forecasting values with different cases for the United States (Mtonnes).
Table 5.
Forecasting values with different cases for the United States (Mtonnes).
| Year | t | Original data | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| 2000 | 1 | 6377.0493 | 6381.0250 | 6373.7812 | 6380.1481 | 6386.2180 | 6377.5702 |
| 2001 | 2 | 6248.3608 | 6375.7827 | 6368.4882 | 6378.6697 | 6385.2835 | 6388.6531 |
| 2002 | 3 | 6296.2248 | 6353.7094 | 6345.6626 | 6356.3869 | 6363.6782 | 6366.5027 |
| 2003 | 4 | 6343.4769 | 6330.7889 | 6322.1567 | 6333.6167 | 6341.3799 | 6343.6542 |
| 2004 | 5 | 6472.4463 | 6306.9531 | 6297.9141 | 6310.3176 | 6318.3324 | 6320.0496 |
| 2005 | 6 | 6493.7341 | 6282.1296 | 6272.8750 | 6286.4460 | 6294.4762 | 6295.6276 |
| 2006 | 7 | 6411.9503 | 6256.2428 | 6246.9770 | 6261.9561 | 6269.7488 | 6270.3240 |
| 2007 | 8 | 6523.7987 | 6229.2130 | 6220.1543 | 6236.7998 | 6244.0848 | 6244.0715 |
| 2008 | 9 | 6332.6004 | 6200.9574 | 6192.3385 | 6210.9268 | 6217.4158 | 6216.7998 |
| 2009 | 10 | 5904.0382 | 6171.3898 | 6163.4585 | 6184.2853 | 6189.6709 | 6188.4359 |
| 2010 | 11 | 6144.8510 | 6140.4217 | 6133.4411 | 6156.8215 | 6160.7771 | 6158.9047 |
Table 6.
Forecasting values with different cases for the Russian Federation (Mtonnes).
Table 6.
Forecasting values with different cases for the Russian Federation (Mtonnes).
| Year | t | Original data | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| 2000 | 1 | 1562.9791 | 1567.4618 | 1570.7326 | 1570.5784 | 1563.0058 | 1563.1559 |
| 2001 | 2 | 1574.4929 | 1583. 8675 | 1586.3849 | 1586.1943 | 1576.6864 | 1576.8574 |
| 2002 | 3 | 1583.9895 | 1595.8494 | 1597.7964 | 1597.6500 | 1590.3556 | 1590.4870 |
| 2003 | 4 | 1624.7682 | 1607.7865 | 1609.0065 | 1608.9094 | 1604.0405 | 1604.1273 |
| 2004 | 5 | 1628.0350 | 1619.6925 | 1620.0589 | 1620.0154 | 1617.7395 | 1617.7777 |
| 2005 | 6 | 1618.0046 | 1631.5788 | 1630.9891 | 1631.0024 | 1631.4507 | 1631.4374 |
| 2006 | 7 | 1663.3323 | 1643.4545 | 1641.8253 | 1641.8980 | 1645.1725 | 1645.1050 |
| 2007 | 8 | 1678.7276 | 1655.3266 | 1652.5904 | 1652.7245 | 1658.9030 | 1658.7795 |
| 2008 | 9 | 1711.0866 | 1667.2010 | 1663.3029 | 1663.4998 | 1672.6407 | 1672.4596 |
| 2009 | 10 | 1602.5212 | 1679.0820 | 1673.9774 | 1674.2383 | 1686.3835 | 1686.1438 |
| 2010 | 11 | 1700.1992 | 1690.9734 | 1684.6257 | 1684. 9515 | 1700.1300 | 1699.8306 |
Table 7.
Forecasting values with different cases for India (Mtonnes).
Table 7.
Forecasting values with different cases for India (Mtonnes).
| Year | t | Original data | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| 2000 | 1 | 952.7665 | 942.7369 | 942.0609 | 940.7183 | 942.7948 | 946.7714 |
| 2001 | 2 | 959.1636 | 946.7968 | 944.4024 | 945.9440 | 947.4891 | 959.1655 |
| 2002 | 3 | 1001.2000 | 999.7583 | 998.5021 | 998.9527 | 1000.1231 | 1005.5160 |
| 2003 | 4 | 1030.4714 | 1056.8241 | 1056.7104 | 1055.8411 | 1056.8488 | 1055.8330 |
| 2004 | 5 | 1118.3646 | 1120.3921 | 1121.0592 | 1119.4426 | 1120.1885 | 1114.9742 |
| 2005 | 6 | 1172.8631 | 1191.5319 | 1192.5314 | 1190.8567 | 1191.2380 | 1184.5290 |
| 2006 | 7 | 1222.4088 | 1269.0237 | 1270.2957 | 1268.2112 | 1268.6389 | 1260.5112 |
| 2007 | 8 | 1327.0771 | 1351.2171 | 1353.3176 | 1348.9823 | 1350.5562 | 1337.5920 |
| 2008 | 9 | 1442.1529 | 1449.8665 | 1451.0315 | 1447.4499 | 1449.4336 | 1441.1711 |
| 2009 | 10 | 1563.9172 | 1558.7055 | 1559.0465 | 1554.8412 | 1558.4475 | 1553.8716 |
| 2010 | 11 | 1707.4594 | 1685.9968 | 1684.4426 | 1680.3683 | 1686.2154 | 1690.9122 |
Table 8.
Forecasting values with different cases for Japan (Mtonnes).
Table 8.
Forecasting values with different cases for Japan (Mtonnes).
| Year | t | Original data | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| 2000 | 1 | 1327.1324 | 1335.7870 | 1337.9497 | 1340.2127 | 1340.2127 | 1328.2275 |
| 2001 | 2 | 1324.4486 | 1345.3518 | 1348.5590 | 1352.5496 | 1352.5496 | 1368.1131 |
| 2002 | 3 | 1322.9523 | 1342.5741 | 1346.1892 | 1350.6658 | 1350.6658 | 1363.8899 |
| 2003 | 4 | 1376.2507 | 1339.5890 | 1343.5568 | 1348.4494 | 1348.4494 | 1359.6458 |
| 2004 | 5 | 1380.7913 | 1336.4605 | 1340.7632 | 1346.0493 | 1346.0493 | 1355.3961 |
| 2005 | 6 | 1397.7016 | 1333.2195 | 1337.8593 | 1343.5409 | 1343.5409 | 1351.1491 |
| 2006 | 7 | 1379.2997 | 1329.8798 | 1334. 8695 | 1340.9617 | 1340.9617 | 1346.9085 |
| 2007 | 8 | 1392.1297 | 1326.4468 | 1331.8050 | 1338.3305 | 1338.3305 | 1342.6762 |
| 2008 | 9 | 1389.3573 | 1322.9214 | 1328.6703 | 1335.6560 | 1335.6560 | 1338.4531 |
| 2009 | 10 | 1225.4810 | 1319.3021 | 1325.4661 | 1332.9418 | 1332.9418 | 1334.2398 |
| 2010 | 11 | 1308.3958 | 1315.5861 | 1322.1915 | 1330.1890 | 1330.1891 | 1330.0362 |
Table 9.
MAPE values with different case for top-5 countries (%).
Table 9.
MAPE values with different case for top-5 countries (%).
| Country | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| China | 3.3011 | 3.2285 | 3.0601 | 3.0601 | 2.6211 |
| United States | 2.0594 | 2.1104 | 2.0494 | 2.0282 | 2.0135 |
| Russian Federation | 1.3183 | 1.4003 | 1.3959 | 1.1854 | 1.1894 |
| India | 1.3249 | 1.4144 | 1.3537 | 1.3010 | 0.9462 |
| Japan | 3.2263 | 3.1894 | 3.1415 | 3.1415 | 2.9949 |
Table 10.
MAE values with different case for top-5 countries (Mtonnes).
Table 10.
MAE values with different case for top-5 countries (Mtonnes).
| Country | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| China | 1.6886 × 102 | 1.6659 × 102 | 1.6017 × 102 | 1.6017 × 102 | 1.4196 × 102 |
| United States | 1.3022 × 102 | 1.3357 × 102 | 1.2943 × 102 | 1.2797 × 102 | 1.2703 × 102 |
| Russian Federation | 2.1597 × 10 | 2.2967 × 10 | 2.2893 × 10 | 1.9402 × 10 | 1.9469 × 10 |
| India | 1.6003 × 10 | 1.7051 × 10 | 1.6466 × 10 | 1.5728 × 10 | 1.1539 × 10 |
| Japan | 4.3382 × 10 | 4.2723 × 10 | 4.1881 × 10 | 4.1881 × 10 | 3.9763 × 10 |
Table 9 shows the MAPE values of different β values for these five countries. The MAE values for all situations for all the five countries are shown in
Table 10. The MAPE and MAE values of Dβ* are the least in five situations for China, USA, India and Japan. The MAPE and MAE values of Dβ* are better than those of βs obtained arbitrarily, but worse a little than β* for Russia. Actually, they are very close to those of β* for Russia. Comparing the MAPE and MAE results of β* and Dβ* with those of the other three βs shown in
Table 9 and
Table 10 it could be found: (1) the MAPE and MAE values of the first three βs are close to each other; (2) the MAPE and MAE values of β* increase to a certain extent for USA and India; (3) the MAPE and MAE values of β* are the same as those of β = 1 and better than those of β = 0.1 and β = 0.5 for China and Japan; (4) the MAPE and MAE values of β* are the best among the five cases for Russia; (5) the MAPE and MAE values of Dβ* are improved relatively remarkably for all five countries, especially in the case of India compared with those of βs obtained arbitrarily; (6) the MAPE and MAE values of Dβ* are the best among all five cases for all countries except Russia; (7) the MAPE and MAE values of Dβ* are better than those of βs obtained arbitrarily and close to those of β* for Russia. The results of β* for China and Japan are the same as those of β = 1 because the optimal β values found are 1. The results of β* show that adopting an optimization method to choose an optimal β value is better than the method of assigning β values arbitrarily. The results of Dβ* indicate that considering different individual models and periods is better than applying one β value to all separate models and periods. The empirical results suggest that QHS algorithm-based combination forecasting method enhances the MAPE and MAE to a certain degree for every country, especially for India. Namely, the proposed method outperforms all the other methods concerned. For India, the MAPE increases from over 1.3249% to 0.9462% and the MAE increases from over 16.003 Mtonnes to 11.539 Mtonnes. It means over 28% performance enhancement compared with the original method. It enhances over 14% in the case of China. For Russian it improves by over 10%. It increases relatively indistinctively only in the case of Japan and US, near 5% and 2%, respectively.
The RMSE values of all situations for five countries are shown in
Table 11. The results of Dβ* are the best among all five situations for all countries, except Russia. The RMSE results for Russia presents an opposite situation compared with the status when considering the MAPE values
viz. the results of β* and Dβ* are worse than those of β = 0.1, β = 0.5 and β = 1. The RMSE value of Dβ* is better than that of β* for Russia. The RMSE value for India of Dβ* is improved over 22.3% compared with the original method. It increases over 6.7% for China, 1.5% for USA and 1.7% for Japan. The RMSE values of β* for USA and India are enhanced too compared with those of β = 0.1, β = 0.5 and β = 1. China and Japan share the same RMSE value of β = 1 and β* for the reason mentioned last paragraph. And the values of β* are better than those of β = 0.1, β = 0.5. All these again show that adopting the optimization method to choose an optimal β value is better than the method of assigning β value arbitrarily. The method taking different individual models and periods into consideration is the best among all the methods. The conclusion is the same as the one drawn when discussing the MAPE index.
Table 11.
RMSE values with different case for top-5 countries (Mtonnes).
Table 11.
RMSE values with different case for top-5 countries (Mtonnes).
| Country | β = 0.1 | β = 0.5 | β = 1 | β* | Dβ* |
|---|
| China | 1.8966 × 102 | 1.8748 × 102 | 1.8325 × 102 | 1.8325 × 102 | 1.7000 × 102 |
| United States | 1.6285 × 102 | 1.6600 × 102 | 1.6190 × 102 | 1.5966 × 102 | 1.5951 × 102 |
| Russian Federation | 2.9552 × 10 | 2.9619 × 10 | 2.9606 × 10 | 3.0144 × 10 | 3.0113 × 10 |
| India | 2.0462 × 10 | 2.1386 × 10 | 2.0705 × 10 | 2.0218 × 10 | 1.5907 × 10 |
| Japan | 5.0801 × 10 | 4.9519 × 10 | 4.8536 × 10 | 4.8536 × 10 | 4.7725 × 10 |
According to the discussions above, the presented method shows the best MAPE, RMSE and MAE performance among the five situations for all countries, except Russia. For Russia the proposed method shows a better RMSE performance than the method of applying the same optimal β value for all individual models and forecasting periods. A better MAPE and MAE performance are obtained by the presented method compared with those of the original method. All in all the presented approach could provide a relatively better forecasting performance in comparison with the methods of choosing β values arbitrarily and assigning the same optimal β value to all individual models synthesizing the MAPE, RMSE and MAE indexes discussed above. The analysis based on MAPE, RMSE and MAE indicates that the proposed method has a good robustness to the choice of index for forecasting accuracy.




{kind=link}
{kind=link}