Forecasting Carbon Emissions Related to Energy Consumption in Beijing-Tianjin-Hebei Region Based on Grey Prediction Theory and Extreme Learning Machine Optimized by Support Vector Machine Algorithm

Abstract
:1. Introduction
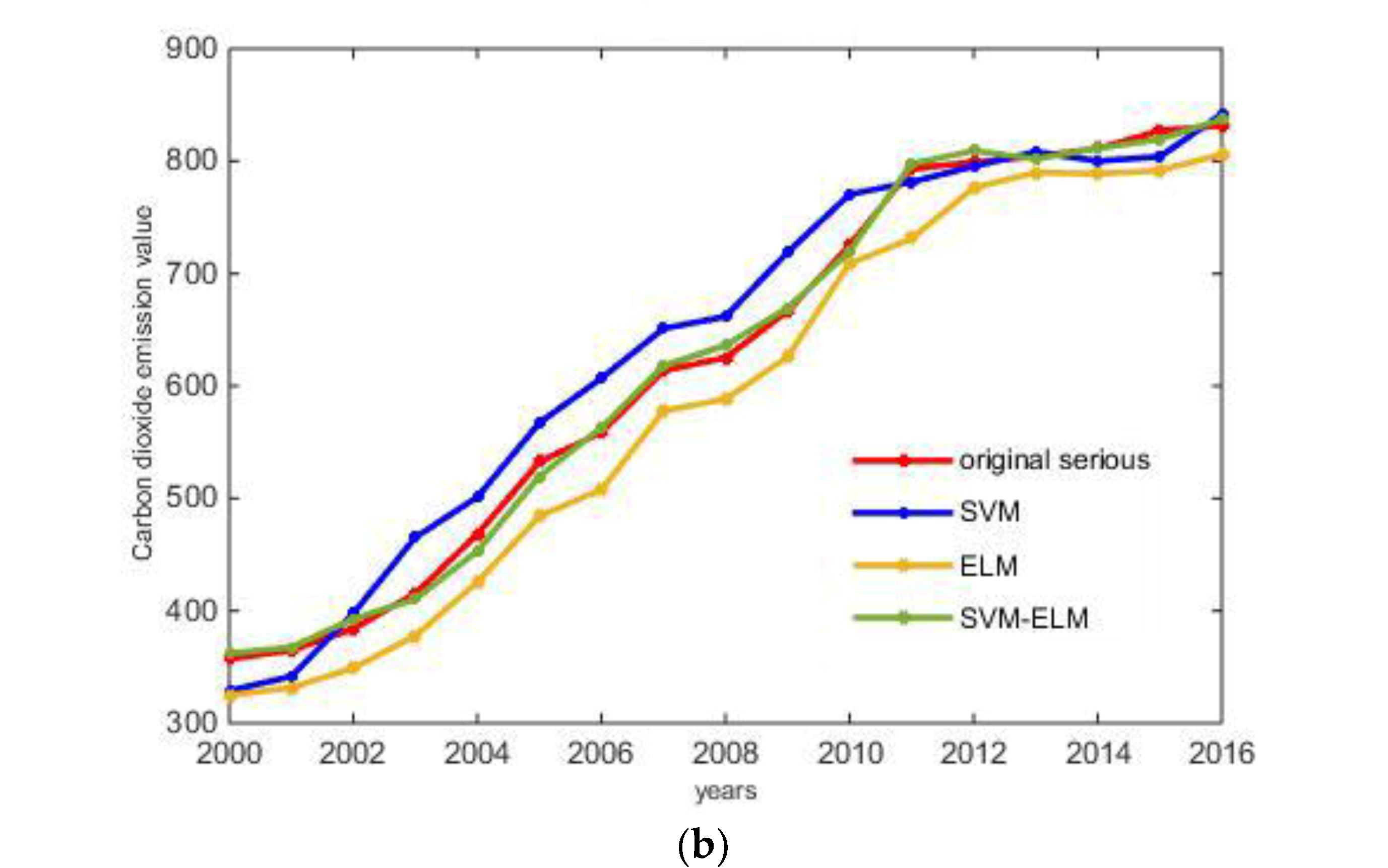
- A new forecasting model based on the extreme learning machine algorithm optimized by grey prediction theory and support vector machine is proposed. Firstly, the grey prediction theory was used to predict the amount of energy consumption in the Beijing-Tianjin-Hebei region from 2017 to 2030. Then, we used the forecasting result of the energy consumption from 2017 to 2030 as the input of the learning machine algorithm model optimized by the support vector machine to obtain the carbon emissions forecasting result in the region from 2017 to 2030. Finally, it was proven that SVM-ELM model has higher prediction accuracy than SVM model and ELM model through the analysis of empirical research.
- Because the accuracy of carbon emissions prediction is not only affected by the superiority of the algorithm, but also affected by data collection of the influencing factors, while the energy consumption is the main factor affecting carbon emissions in the Beijing-Tianjin-Hebei region, this study focused on energy consumption to forecast carbon emissions, which may not only improve accuracy but also help studying energy consumption structure and its upgradation methods.
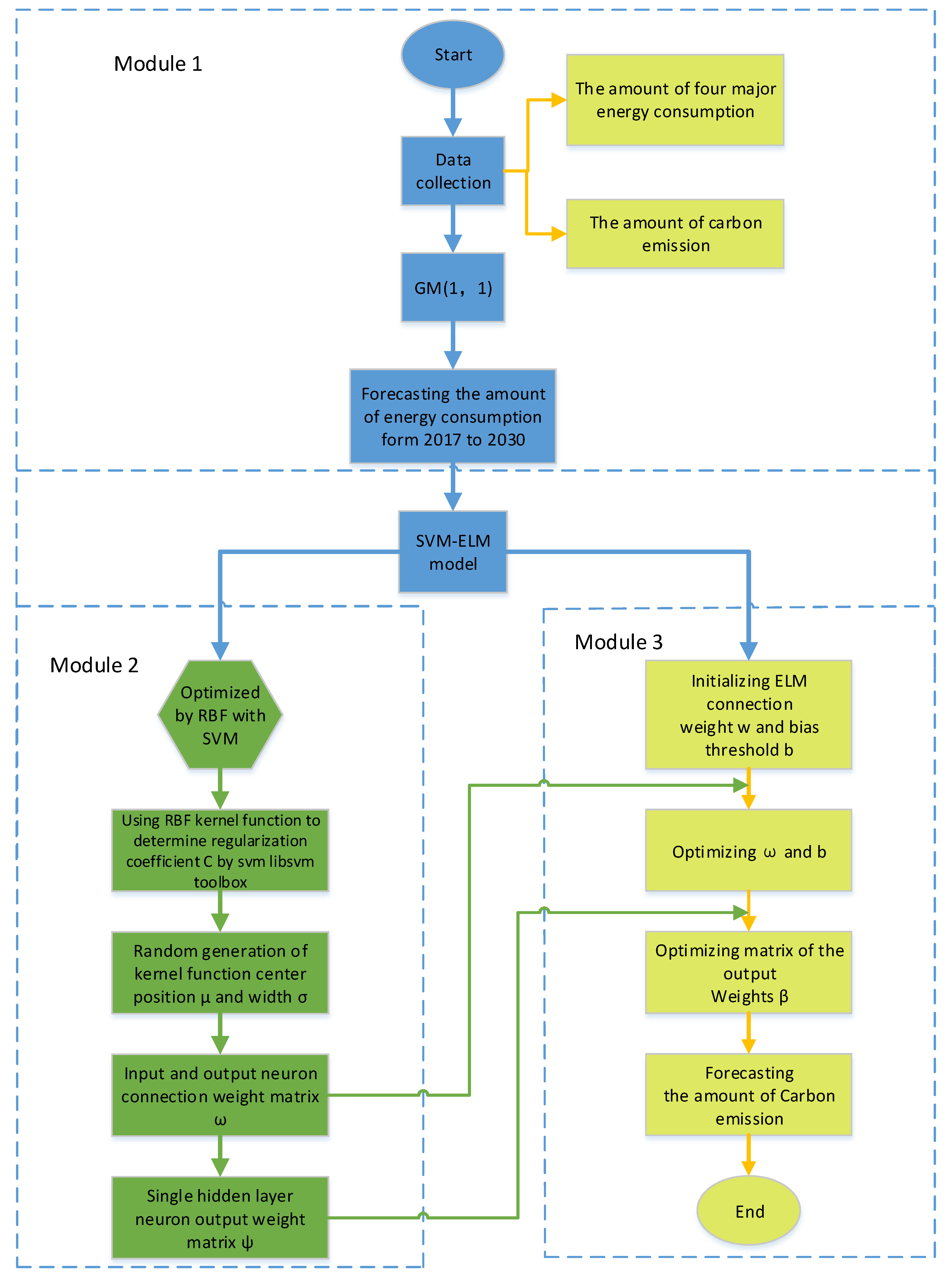
2. Materials and Methods
2.1. GM (1, 1) Forecasting Model
2.2. Basic Methodology of Extreme learning Machine Algorithm
2.3. Basic Methodology of Support Vector Machines
2.4. Primary Principal of the SVM-ELM Model for Carbon Emissions Forecasting
2.5. The Forecasting Model Based on Grey Prediction Theory and ELM Optimized by SVM Algorithm
- (1)
- Data collection and preprocessing.
- (2)
- Predicting the main types of energy consumption from 2017 to 2030 in the Beijing-Tianjin-Hebei region based on the grey prediction theory.
- (3)
- Forecasting carbon emissions related to energy consumption in the Beijing-Tianjin-Hebei region based on SVM-ELM Model.
3. Empirical Simulation and Data Analysis
3.1. Coefficients of Carbon Emissions Related to Energy Consumption
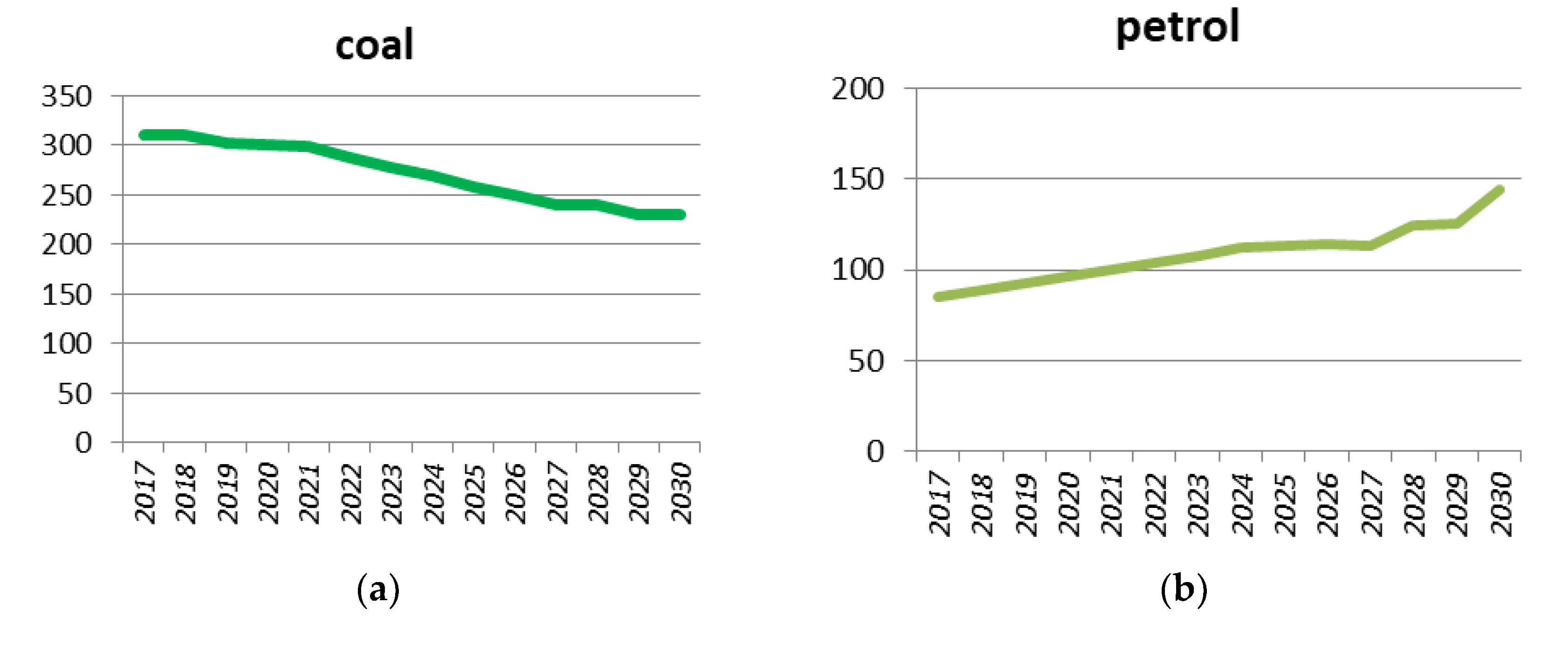
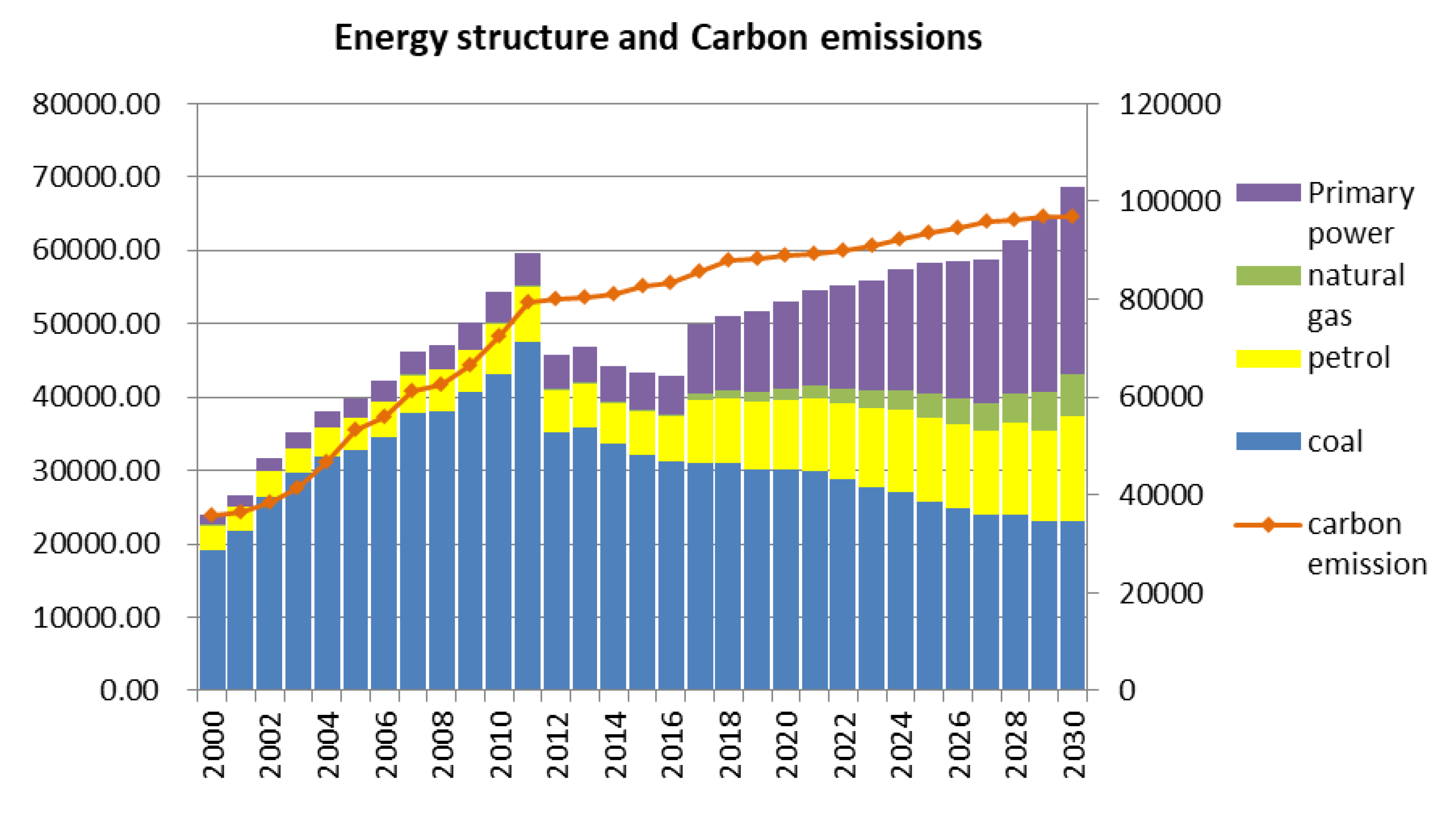
3.2. Forecasting Energy Consumption Based on GM (1, 1)
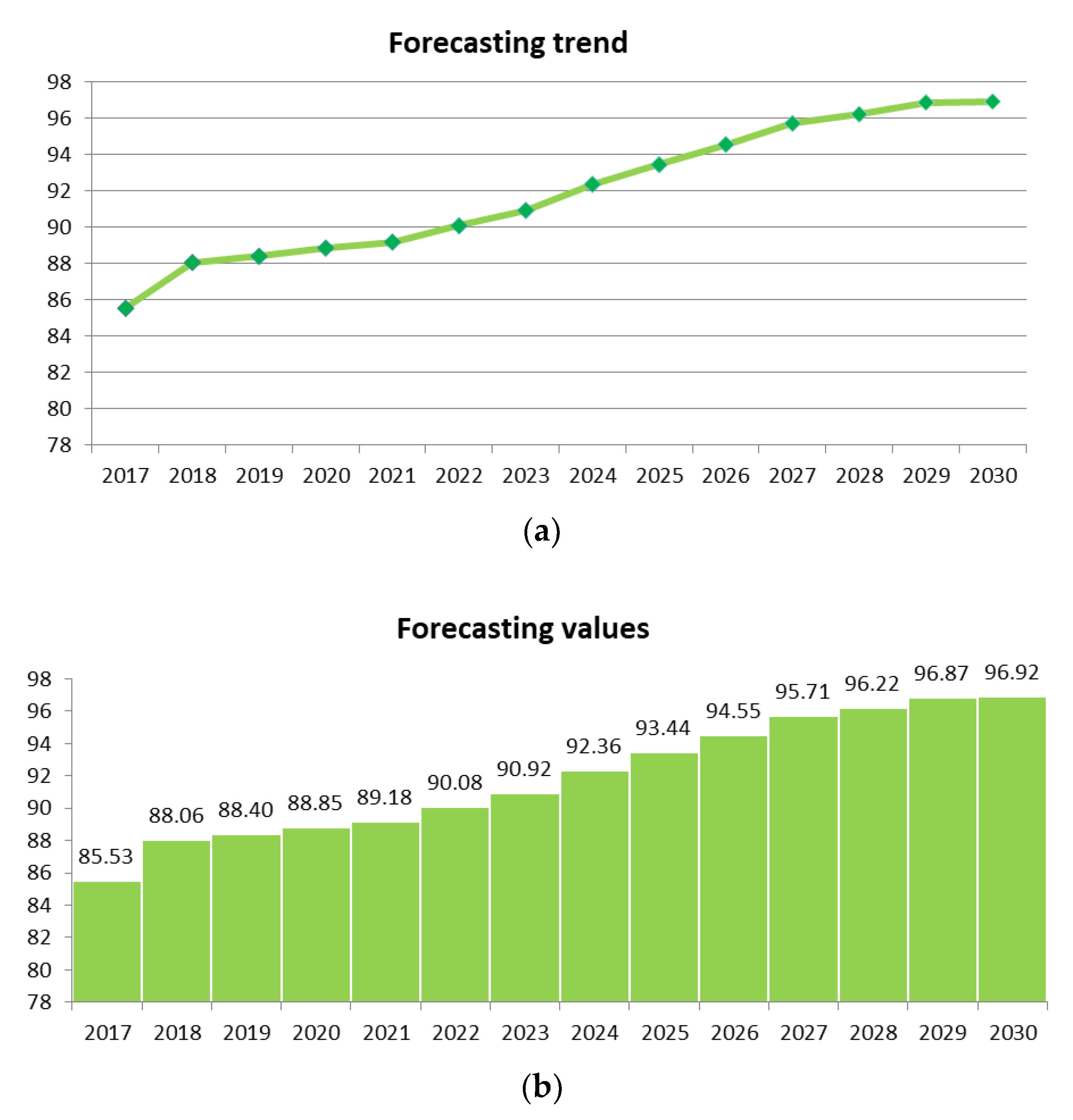
3.3. Forecasting Carbon Emissions Based on SVM-ELM Model
4. Conclusions
- (1)
- First, we must accelerate the upgradation of industrial structure. The secondary industry including steel, electricity, building materials and chemical industry are key industries for energy conservation and emission reduction. Therefore, it is necessary to speed up the elimination of industries with high energy consumption and backward production capacity.
- (2)
- The government must develop the tertiary industry vigorously, especially the energy service industry. Since the Beijing-Tianjin-Hebei region is dominated by coal consumption, it is necessary to expand the supply of natural gas and replace coal with gas.
- (3)
- It is time China strengthens the use of renewable energy such as wind energy and solar energy. The government should increase subsidies for clean energy power generation and promote the trading mechanism in carbon market right now. For instance, “green certificates” can be applied to reduce the coal-fired rate of power plant, and photovoltaic technology can be actively applied in rural areas of the Beijing-Tianjin-Hebei region.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Thirteenth Five-Year Plan-Integrated Work Program. Available online: http://www.sh.xinhuanet.com/2016-03/18/c_135200400_2.htm (accessed on 9 June 2018).
- China Statistical Yearbook. Available online: http://tongji.cnki.net/kns55/Navi/YearBook.aspx?id=N2017030066&floor=1 (accessed on 6 June 2018).
- 2017–2023 China Beijing-Tianjin-Hebei Air Pollution Control Market Research and Development Trend Research Report. Available online: http://m.chyxx.com/view/533619.html (accessed on 12 June 2018).
- China Low Carbon Development Report in 2017. Available online: http://mini.eastday.com/mobile /180118141508633.html (accessed on 30 June 2018).
- Cohen, S.M.; Rochelle, G.T.; Webber, M.E. Optimizing post-combustion CO2, capture in response to volatile electricity prices. Int. J. Greenh. Gas Control 2012, 8, 180–195. [Google Scholar] [CrossRef]
- Safdarnejad, S.M.; Hedengren, J.D.; Baxter, L.L. Plant-level dynamic optimization of Cryogenic Carbon Capture with conventional and renewable power sources. Appl. Energy 2015, 149, 354–366. [Google Scholar] [CrossRef]
- Inglesi-Lotz, R.; Dogan, E. The role of renewable versus non-renewable energy to the level of CO2 emissions a panel analysis of sub-Saharan Africa’s Big 10 electricity generators. Renew. Energy 2018, 123, 36–43. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, B.B.; Huang, G.H. GHG-mitigation oriented and coal-consumption constrained inexact robust model for regional energy structure adjustment A case study for Jiangsu Province, China. Renew. Energy 2018, 123, 549–562. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Zheng, W. Decomposition Analysis of Energy-Related CO2 Emissions and Decoupling Status in China’s Logistics Industry. Sustainability 2018, 10, 1340. [Google Scholar] [CrossRef]
- Bo, Z.; Meng, Z.; Jun, Z. Forecasting the Energy Consumption of China’s Manufacturing Using a Homologous Grey Prediction Model. Sustainability 2017, 9, 1975. [Google Scholar] [Green Version]
- Chen, Y.H.; Zhang, C.; He, K.J. Trend Prediction and Decomposed Driving Factors of Carbon Emissions in Jiangsu Province during 2015–2020. Sustainability 2016, 8, 1018. [Google Scholar] [Green Version]
- Zhao, Z.D.; Hu, C.Z. Grey prediction models for the standard limit of vehicle noise. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2018, 232, 973–979. [Google Scholar] [CrossRef]
- Yang, J.W.; Xiao, X.P.; Mao, S.H.; Rao, C.J. Grey couple prediction model for traffic flow with panel data characteristics. Entropy. 2016, 18, 454. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, H.; Wang, X.F.; He, Y.F. A novel servo control method based on feedforward control-fuzzy-grey prediction controller for stabilized and tracking platform system. J. Vibroeng. 2016, 18, 5266–5280. [Google Scholar]
- Gerami, M.H.; Rabbaniha, M. Forecasting the Anchovy Kilka Fishery in the Caspian Sea Using a Time Series Approach. Turk. J. Fish. Aquat. Sci. 2018, 18, 1288–1292. [Google Scholar] [CrossRef]
- Cheng, C.H.; Yang, J.H. Fuzzy time-series model based on rough set rule induction for forecasting stock price. Neurocomputing 2018, 302, 33–45. [Google Scholar] [CrossRef]
- Qi, R.H.; Li, D.J.; Zhang, L.Z. Performance investigation on polymeric electrolyte membrane-based electrochemical air dehumidification system. Appl. Energy 2017, 208, 1174–1183. [Google Scholar] [CrossRef]
- Afshari, A.; Friedrich, L.A. Inverse modeling of the urban energy system using hourly electricity demand and weather measurements, Part 1: Black-box model. Energy Build. 2017, 157, 126–138. [Google Scholar] [CrossRef]
- Matjafri, M.Z.; Lim, H.S. Prediction models for CO2 emission in Malaysia using best subsets regression and multi-linear regression. Proc. SPIE Int. Soc. Opt. Eng. 2015, 9638, 12. [Google Scholar]
- Wang, C.C. Modelling of the compressive strength development of cement mortar with furnace slag and desulfurization slag from the early strength. Constr. Build. Mater. 2016, 128, 108–117. [Google Scholar] [CrossRef]
- Takahashi, T.; Thornton, B.; Sato, T. Temperature based segmentation for spectral data of laser-induced plasmas for quantitative compositional analysis of brass alloys submerged in water. Spectrochim. Acta Part B At. Spectrosc. 2016, 124, 87–93. [Google Scholar] [CrossRef]
- Zhong, Q. Prediction of energy consumption and CO2 emission by system dynamics approach. Chin. J. Eco-Agric. 2008, 16, 1043–1047. [Google Scholar]
- Zhao, H.N.; Yu, W.Y. Research on Influence Factors of Carbon Emissions and Forecast in Hebei Province. Environ. Prot. Resour. Exploit. 2012, 807–809, 790–794. [Google Scholar] [CrossRef]
- Fang, D.B.; Zhang, X.L.; Yu, Q. A novel method for carbon dioxide emission forecasting based on improved Gaussian processes regression. J. Clean. Prod. 2018, 173, 143–150. [Google Scholar] [CrossRef]
- Zhao, X.; Han, M.; Ding, L.L. Forecasting carbon dioxide emissions based on a hybrid of mixed data sampling regression model and back propagation neural network in the USA. Environ. Sci. Pollut. Res. 2018, 25, 2899–2910. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Ma, Z.Y.; Li, Y. An investigation and forecast on CO2 emission of China: Case studies of Beijing and Tianjin. Environ. Eng. Res. 2017, 22, 407–416. [Google Scholar] [CrossRef]
- Chang, H.; Sun, W.; Gu, X.S. Forecasting Energy CO2 Emissions Using a Quantum Harmony Search Algorithm-Based DMSFE Combination Model. Energies 2013, 6, 1456–1477. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J.Y. Prediction of carbon dioxide emissions based on principal component analysis with regularized extreme learning machine: The case of China. Environ. Eng. Res. 2017, 22, 302–311. [Google Scholar] [CrossRef]
- Zhao, H.R.; Huang, G.; Yan, N. Forecasting Energy-Related CO2 Emissions Employing a Novel SSA-LSSVM Model: Considering Structural Factors in China. Energies 2018, 11, 781. [Google Scholar] [CrossRef]
- Zhou, J.G.; Zhang, X.G. Projections about Chinese CO2 emissions based on rough sets and gray support vector machine. Chin. Environ. Sci. 2013, 33, 2157–2163. [Google Scholar]
- Sun, W.; Wang, C.F.; Zhang, C.C. Factor analysis and forecasting of CO2 emissions in Hebei, using extreme learning machine based on particle swarm optimization. J. Clean. Prod. 2017, 162, 1095–1101. [Google Scholar] [CrossRef]
- Chon, A.T.; Kim, Y.-S. Design of Fuzzy Pattern Classifier based on Extreme Learning Machine. J. Korean Inst. Intell. Syst. 2015, 25, 509–514. [Google Scholar] [Green Version]
- Liu, H.; Mi, X.W.; Li, Y.F. An experimental investigation of three new hybrid wind speed forecasting models using multi-decomposing strategy and ELM algorithm. Renew. Energy 2018, 123, 694–705. [Google Scholar] [CrossRef]
- Huang, G.B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local respective fields based extreme learning machine. IEEE Comput. Intell. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Guo, B.X.; Li, J. Kernel extreme learning machine for indoor positioning in location finger printing. Comput. Eng. Appl. 2016, 52, 78–83. [Google Scholar]
- Wu, J.J. Short-Term Wind Power Prediction Research Based on Extreme Learning Machine. Master’s Thesis, North China Electric Power University, Beijing, China, 2017. [Google Scholar]
- 2006 IPCC Guidelines for National Greenhouse Gas Inventories. Available online: https://www.ipcc-nggip.iges.or.jp/public/2006gl/ (accessed on 23 June 2018).
- Dai, S.; Niu, D.; Li, Y. Forecasting of Energy Consumption in China Based on Ensemble Empirical Mode Decomposition and Least Squares Support Vector Machine Optimized by Improved Shuffled Frog Leaping Algorithm. Appl. Sci. 2018, 8, 678. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
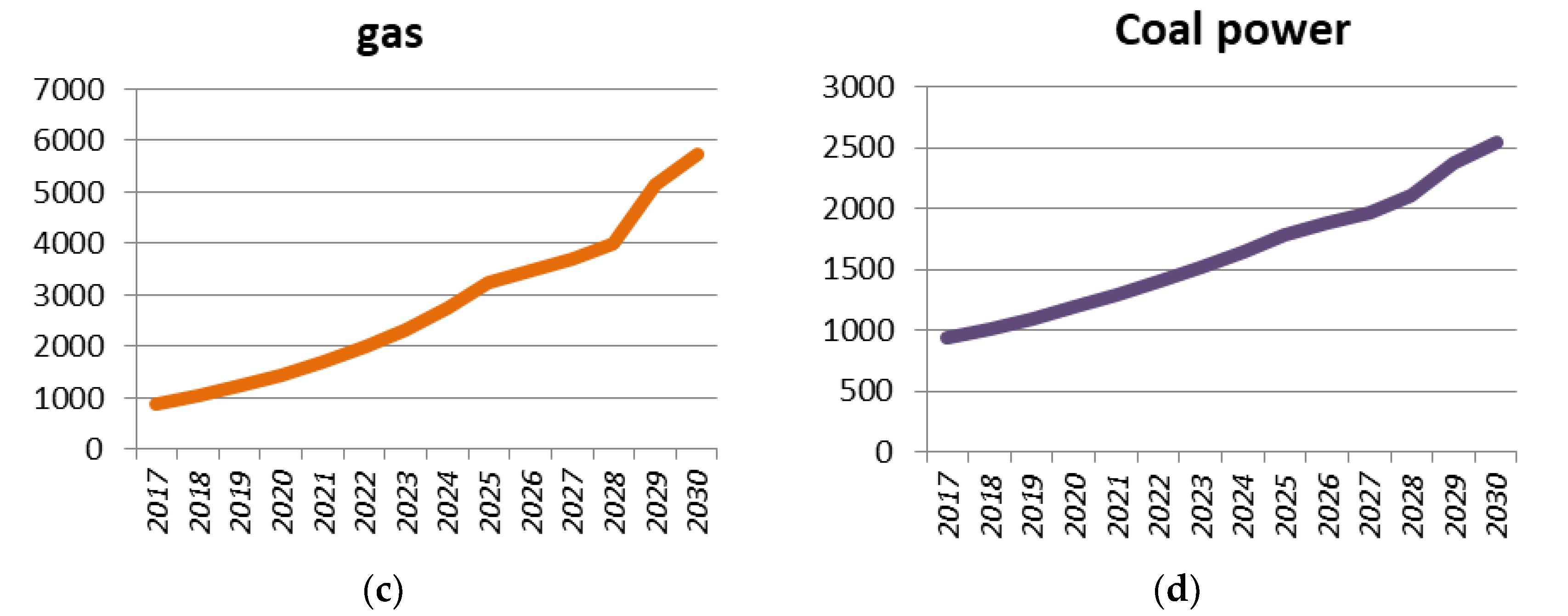{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Discounted Coal Standard (kg/kg, kg/cm3) | CEC (Tons/Trillion Joules) | NCV (100 million J/t) | COF (%) |
|---|---|---|---|---|
| raw coal | 0.7143 | 26.8 | 209.08 | 99.8 |
| clean coal | 0.9 | 25.8 | 263.44 | 99.3 |
| liquefied petroleum gas | 1.7143 | 17.2 | 501.78 | 99.2 |
| refinery dry gas | 1.5714 | 18.2 | 460.55 | 99.2 |
| natural gas | 1.33 | 15.3 | 389.31 | 99.4 |
| crude | 1.4286 | 20.0 | 418.16 | 99.4 |
| petrol | 1.4714 | 18.9 | 430.7 | 99.5 |
| kerosene | 1.4714 | 19.5 | 430.7 | 99.4 |
| diesel | 1.4571 | 20.2 | 426.52 | 99.3 |
| fuel oil | 1.4286 | 21.1 | 418.16 | 99.2 |
| coke | 0.9714 | 29.2 | 284.55 | 99.1 |
| coke oven gas | 0.5714 | 12.1 | 173.53 | 99.7 |
| electricity | 1.229 | 10,069 (t/GWh) | 35.96 (kwh/t) | 100 |
| heat | 0.03412 | 9.46 |
| Parameter | Value |
|---|---|
| regularization coefficient C | 17 |
| RBF kernel parameter | 0.1 |
| number of node in hidden layer | 100 |
| Year | Actual Value | Forecasting Result | RE of SVM-ELM | RE of SVM | RE of ELM |
|---|---|---|---|---|---|
| 2000 | 35,726.78 | 42,207.87 | 1.346569 | 7.935378 | 9.090909 |
| 2001 | 36,471.51 | 41,747.78 | 0.757491 | 6.354631 | 9.090909 |
| 2002 | 38,402.42 | 40,287.36 | 2.304398 | 3.551576 | 9.092880 |
| 2003 | 41,530.01 | 40,029.32 | −1.20561 | 12.01801 | 9.092880 |
| 2004 | 46,828.24 | 45,316.87 | −3.22747 | 7.035180 | 9.090909 |
| 2005 | 53,241.51 | 51,959.19 | −2.40849 | 6.545364 | 9.090909 |
| 2006 | 55,868.82 | 56,310.56 | 0.79067 | 8.637444 | 9.090909 |
| 2007 | 61,360.13 | 63,480.21 | 0.68461 | 6.115011 | 5.835405 |
| 2008 | 62,511.46 | 63,623.06 | 1.77823 | 5.856977 | 5.891496 |
| 2009 | 66,640.81 | 69,829.08 | 0.43257 | 7.879682 | 6.089745 |
| 2010 | 72,472.94 | 71,993.97 | −0.66090 | 6.311114 | 2.191782 |
| 2011 | 79,335.39 | 78,763.13 | 0.53915 | 1.487073 | 7.838322 |
| 2012 | 79,890.07 | 80,919.62 | 1.28871 | 0.438569 | 2.828369 |
| 2013 | 80,404.42 | 81,197.71 | −0.25709 | 0.528436 | 1.765441 |
| 2014 | 81,132.76 | 82,741.96 | 0.01134 | 1.379333 | 2.800976 |
| 2015 | 82,694.21 | 80,743.88 | −0.90735 | 2.781821 | 4.253811 |
| 2016 | 83,173.62 | 84,732.31 | 0.67171 | 1.21454 | 3.079388 |
| Model | RMSE (100%) | MRE | |
|---|---|---|---|
| ELM | 45.2721 | 99.5906 | 7.364145 |
| SVM | 40.5655 | 97.9671 | 6.049756 |
| ELM-SVM | 12.3356 | 99.7780 | 1.623347 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Wang, W.; De, G.; Ji, X.; Tan, Z. Forecasting Carbon Emissions Related to Energy Consumption in Beijing-Tianjin-Hebei Region Based on Grey Prediction Theory and Extreme Learning Machine Optimized by Support Vector Machine Algorithm. Energies 2018, 11, 2475. https://doi.org/10.3390/en11092475
Li M, Wang W, De G, Ji X, Tan Z. Forecasting Carbon Emissions Related to Energy Consumption in Beijing-Tianjin-Hebei Region Based on Grey Prediction Theory and Extreme Learning Machine Optimized by Support Vector Machine Algorithm. Energies. 2018; 11(9):2475. https://doi.org/10.3390/en11092475
Chicago/Turabian StyleLi, Menglu, Wei Wang, Gejirifu De, Xionghua Ji, and Zhongfu Tan. 2018. "Forecasting Carbon Emissions Related to Energy Consumption in Beijing-Tianjin-Hebei Region Based on Grey Prediction Theory and Extreme Learning Machine Optimized by Support Vector Machine Algorithm" Energies 11, no. 9: 2475. https://doi.org/10.3390/en11092475