1. Introduction
Transmission line icing has a significant impact on the safe operation of power systems. In severe cases, it can even cause trips, disconnections, tower collapses, insulator ice flashovers, communication interruptions and other problems, which bring about great economic losses [
1]. For example, a large cold wave area occurred in southeastern Canada and the northeastern United States in 1998, resulting in the collapse of more than 1000 power transmission towers, 4.7 million people couldn’t use electricity properly and the direct economic losses reached
$5.4 billion [
2]. In 2008, severe line icing accidents happened in South China, and caused forced-outages of 7541 10 KV lines and the power shortfall reached 14.82 GW [
3]. The construction of a reasonable and scientific transmission line icing prediction model would be helpful for the power sector to deal with icing accidents in advance so as to effectively reduce the potential accident losses. Therefore, the study of icing prediction is of great practical significance and value.
In recent years, many scholars have been carrying out research on transmission line icing prediction. Some experts have developed sensor systems for direct measurement of icing events on transmission lines and they obtained real-time and intuitive icing thickness monitoring information [
4,
5,
6]. However, the prediction accuracy of this method is poor, and this method is more suitable for collection equipment as raw data for it often needs icing model algorithms to predict the future icing trends. As a result, it is necessary to study model algorithms to predict icing thickness. Generally, the icing forecasting models can be divided into two categories, which include traditional models and modern intelligent models. Traditional models are further divided into two methods: physical models and statistical models. The physical prediction models are based on heat transmission science and fluid mechanics and other physics theories to analyze the icing thickness, such as Imai model [
7], Goodwin model [
8], Lenhard model [
9], and hydrodynamic model [
10]. However, icing is caused by many factors with too many uncertainties, which leads to the fact that the final forecasts provided by physical prediction models cannot live up to expectations. The statistical prediction models use the notion of mathematical statistics to predict the icing thickness based on icing records and extreme value theory. They include the time series model [
11], extreme value model [
12] and so on. However the application of statistical forecasting models needs to meet a variety of statistical assumptions, and they cannot consider the factors that influence icing thickness, which greatly limits the scope of application of the statistical models and improvement of the forecasting accuracy.
Therefore, it is more important to adopt the modern intelligent prediction models to predict transmission line icing with the development of big data, further research on artificial intelligence and constantly emerging optimization algorithms. Modern intelligent prediction models can handle nonlinear and uncertain problems scientifically and efficiently with computer technology and mathematical tools to improve prediction accuracy and speed. The back propagation neural network model and the support vector machine model are commonly-used intelligent models in the field of transmission line icing prediction. Li et al. [
13] proposed a model based on BP neural networks for forecasting the ice thickness and the forecasting results showed that this model had good accuracy of prediction whether in the same icing process or in a different one. Wang et al. [
14] put forward a prediction model of icing thickness and weight based on a BP neural network. The orthogonal least squares (OLS) method was used for the number of network hidden layer units and center vector so that the forecasting error could be controlled in a smaller range. However, the BP algorithm has a very slow convergence speed and it falls into local minima easily, so some scholars use the genetic algorithm and the particle swarm optimization to optimize the BP neural network. Zheng and Liu [
15] proposed a forecast model based on genetic algorithm (GA) and BP, and the predication results proved that the GA-BP model was more effective than BP to forecast transmission line icing. Wang [
16] structured a prediction model which used improved particle swarm optimization algorithm to optimize a normalized radial basis function (NRBF) neural network, and the training speed of the network was improved. In addition, some scholars used SVM to avoid the selection of neural network structure and local optimization problems, [
17] and [
18] built the icing prediction model based on a SVM algorithm with better accuracy, but the SVM algorithm is hard to implement for large-scale training samples, and there are difficulties in solving multiple classification problems, so some scholars have addressed these defects of SVM using the ant colony (ACO) [
19], particle swarm (PSO) [
19], fireworks algorithm (FA) [
20] and quantum fireworks algorithm (QFA) [
21]. Xu et al. [
19] introduced a weighted support vector machine regression model that was optimized by the particle swarm and ant colony algorithms, and the proposed method obtained a higher forecasting accuracy. Ma and Niu [
20] combined a weighted least squares support vector machine (W-LSSVM) with a fireworks algorithm to forecast icing thickness, which improved the prediction accuracy and robustness. Ma et al. [
21] proposed a combination model based on the wavelet support vector machine (w-SVM) and the quantum fireworks algorithm (QFA) for icing forecasting.
GA, PSO, ACO and other algorithms are applied to advance the performance of BP neural networks and SVM, but these algorithms require a large initial population to solve large-scale optimization problems, and the solving efficiency and the ability to solve local optimization problems are still relatively general. Both the mind evolutionary computation (MEC) [
22] and the bat algorithm (BA) [
23] have high solving efficiency and strong competence in global optimization. Two new operators are added to MEC on the basis of genetic algorithm: convergence and dissimilation. They are responsible for local and global optimization, respectively, which greatly enhances the overall search efficiency and global optimization algorithm ability. The BA algorithm is a meta-heuristic algorithm proposed by Yang in 2010. Many scholars at home and abroad have studied the proposed algorithm, indicating that this algorithm takes into account both local and global aspects of solving a problem compared with other algorithms. In the search process, both of them can be interconverted into each other so that they can avoid falling into local optimal solutions and achieve better convergence.
As a new feed forward neural network, ELM can overcome the shortcomings of the traditional BP neural network and SVM. The algorithm not only reduces the risk of falling into a local optimum but also greatly improves the learning speed and generalization ability of the network. It has been applied in several prediction fields and obtained relatively accurate prediction results [
24,
25,
26]. However, its prediction robustness is relatively poor due to the random initialization of the input weights and hidden layer bias characteristics, so Huang [
27] proposed the kernel extreme learning machine algorithm (KELM) and thus overcame the weakness of poor stability and improved the algorithm precision.
The different forecasting methods reflect the change tendency of the object and its influencing factors from different aspects, respectively, and provide different information because of the respective principles, so any single forecasting method confronts the obstacle that the information is not comprehensive and the fluctuation of prediction accuracy is larger. Based on this, Bates and Granger [
28] put forward the combination forecasting method for the first time in 1969 and it has achieved good results in many fields. For example, Liang et al. [
29] proposed the optimal combination forecasting model combined the extreme learning machine and the multiple regression forecasting model to predict the power demand. The result indicated that this method effectively combined the advantages of the single forecasting models, thus its global instability was reduced and the prediction precision was satisfactory. Reference [
30] introduced a combination model that included five single prediction models for probabilistic short-term wind speed forecasting and the proposed combination model generated a more reliable and accurate forecast. Few scholars have applied combination prediction methods in the field of the transmission line icing forecasting, so in this paper, we decided to adopt the combination forecasting method to predict line icing thickness. How to determine the weighted average coefficients of individual methods is the key problem. Compared to the arithmetic mean method [
31] and induced ordered weighted averaging (IOWA) [
32], the biggest advantage of the variance-covariance combined method [
33] is that it can improve the robustness of prediction, which is more suitable for forecasting icing thickness.
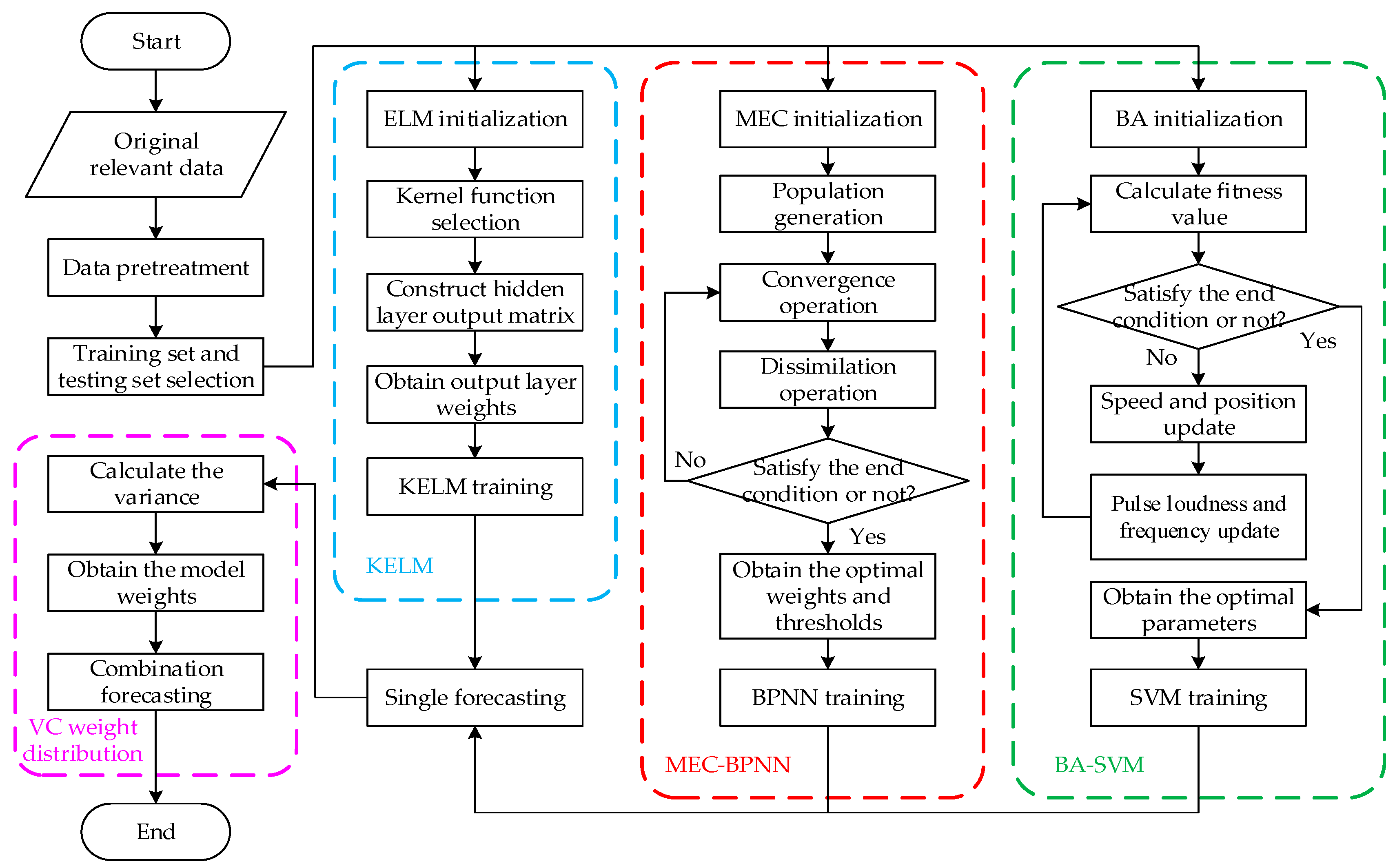
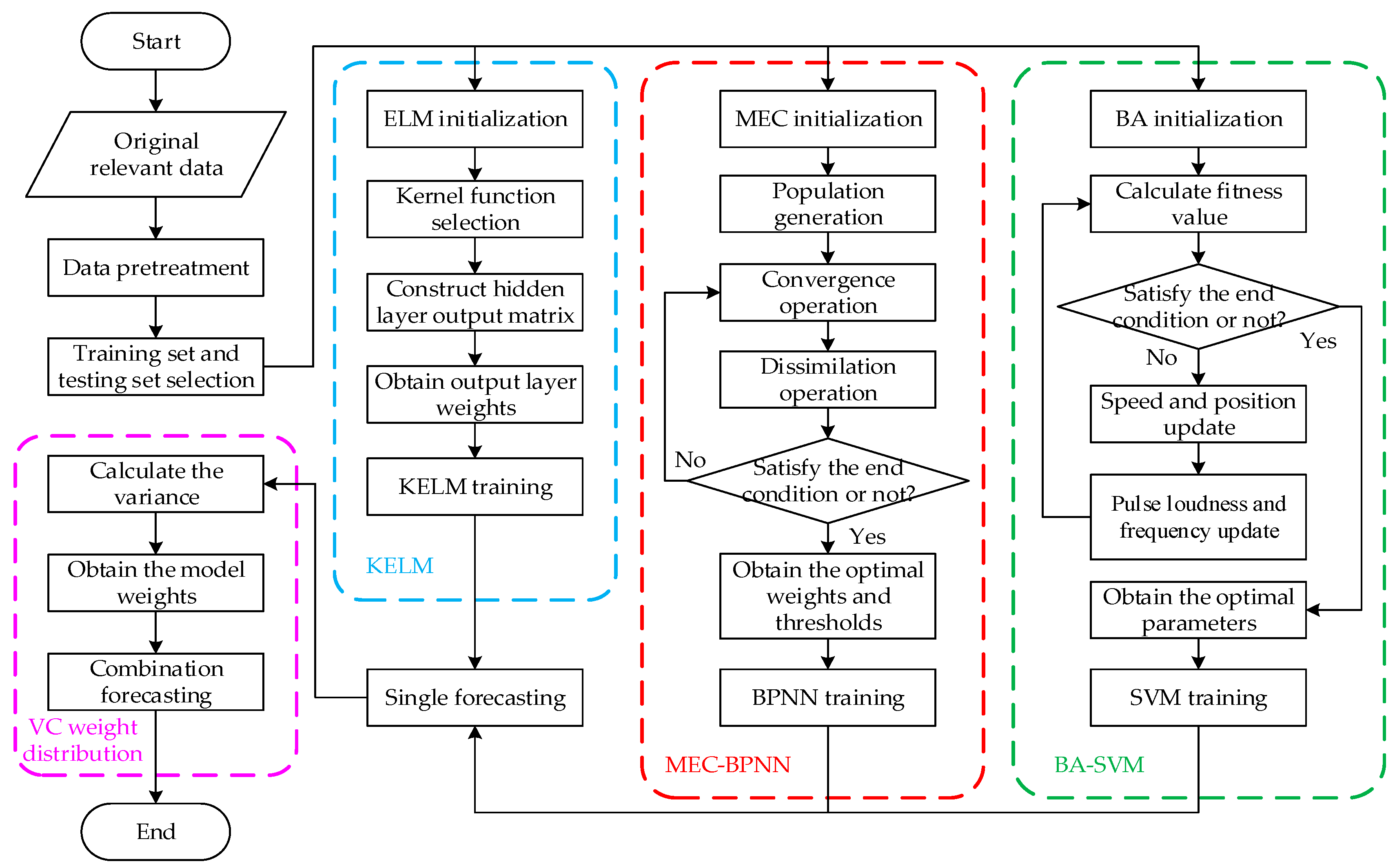
In summary, this paper adopts three models, including the BPNN optimized by the mind evolutionary algorithm (MEC-BPNN), the SVM optimized by the bat algorithm (BA-SVM) and the extreme learning machine with kernel based on single-hidden layer feed-forward neural network, to predict icing thickness using the historical icing thickness data and related meteorological data. The weighted average coefficients of individual forecasting methods are determined by a variance-covariance combined method to solve the problem of dynamic weight distribution. Then a modified BP-SVM-KELM combination forecasting model based on the VC combined method solving the problem of dynamic weight distribution method is constructed. The reason why we combine the three modified models is that their individual robustness is still poor, especially the BA-SVM and KELM. Furthermore, MEC-BPNN and KELM have the defects of underfitting and overfitting, respectively, and BA-SVM has difficulties dealing with large-scale training samples. Therefore, the combination model can give full play to the advantages of various prediction models, complement each other, and offer better robustness, stronger adaptability and higher prediction accuracy.
The rest of this paper is organized as follows: in
Section 2, the MEC-BP, BA-SVM, KELM and VC combined method are presented in detail. Also, in this section, the integrated prediction framework is built. In
Section 3, several real-world cases are selected to verify the robustness and accuracy of this model. In
Section 4, another case is used to test the prediction performance of the proposed model.
Section 5 concludes this paper.
3. Case Study and Results Analysis
3.1 Data Selection
There are many factors affecting the transmission line icing thickness. According to [
38], the temperature, relative air humidity, wind speed and wind direction are the major factors. The temperature must be less than or equal to 0 °C. If the relative air humidity is above 85%, it is easier for icing to occur on transmission lines. When the icing temperature and vapor conditions are present the wind plays an important role in the icing of the wires. It can deposit large amounts of supercooled water droplets continuously onto the lines, and then collide with the wire and gradually increase these deposits to cause icing phenomens. It is observed that icing first grows on the windward side of the line, and the wire is twisted due to gravity when the windward side reaches a certain icing thickness, so a new windward surface appears. In this way, the icing gradually increases by constantly twisting, and eventually circular or elliptical icing is formed, so the wind speed should exceed 1 m/s in the process. In addition, the wind direction also affects the lines’ icing. The angle of wind direction is measured by taking the direction of the wire as the benchmark, i.e., the direction of the wire is set to be horizontal 0°. When the wind rotates counterclockwise around the wire, if the angle between the wind and the wire is in the range of [0°, 180°), the closer the angle is to 0° or 180°, the lighter the icing degree is, and the closer the angle is to 90°, the more serious the degree of icing is, or the closer the angle is to 180° or 360°, the lighter the icing degree is, and the closer the angle is to 270°, the more serious the degree of icing.
Affected by the abnormal atmospheric circulation and La Niña weather patterns, cold air entered Hunan in 11 January 2008 making the area cool rapidly. The strength of the frontal inversion formed by the confluence of cold and warm air was great. What’s more, the terrain in Hunan is lower in the north and higher in the south, which made the strength of the frontal inversion greater. The stronger the strength of the frontal inversion, the stronger the strength of the rain and snow, so a continuous glaze was formed with the continuous supplement of warm wet air, and Hunan power grid suffered a record disaster accompanied by a large area of rain and snow, freezing rain incidents and large scale icing of transmission lines and substations. During the freezing disaster, the number of collapsed transmission towers reached 2242 and the number of deformed transmission towers reached 692, causing serious damage to the power grid. Therefore, we selected the "Dong-Chao line" of Hunan, which was the hardest-hit area during the Chinese icing incident in 2008 as a case study to verify the effectiveness of the proposed model. The example chooses some data including the transmission lines icing thickness, regional temperature, relative air humidity, wind speed and wind direction from 0:00 12 January 2008 to 24:00 6 February 2008. Here we take 2 h as the data collection frequency, and each indicator collects 312 sets of data where the first 192 are used as the training samples and the latter 120 are test samples in Case 1.
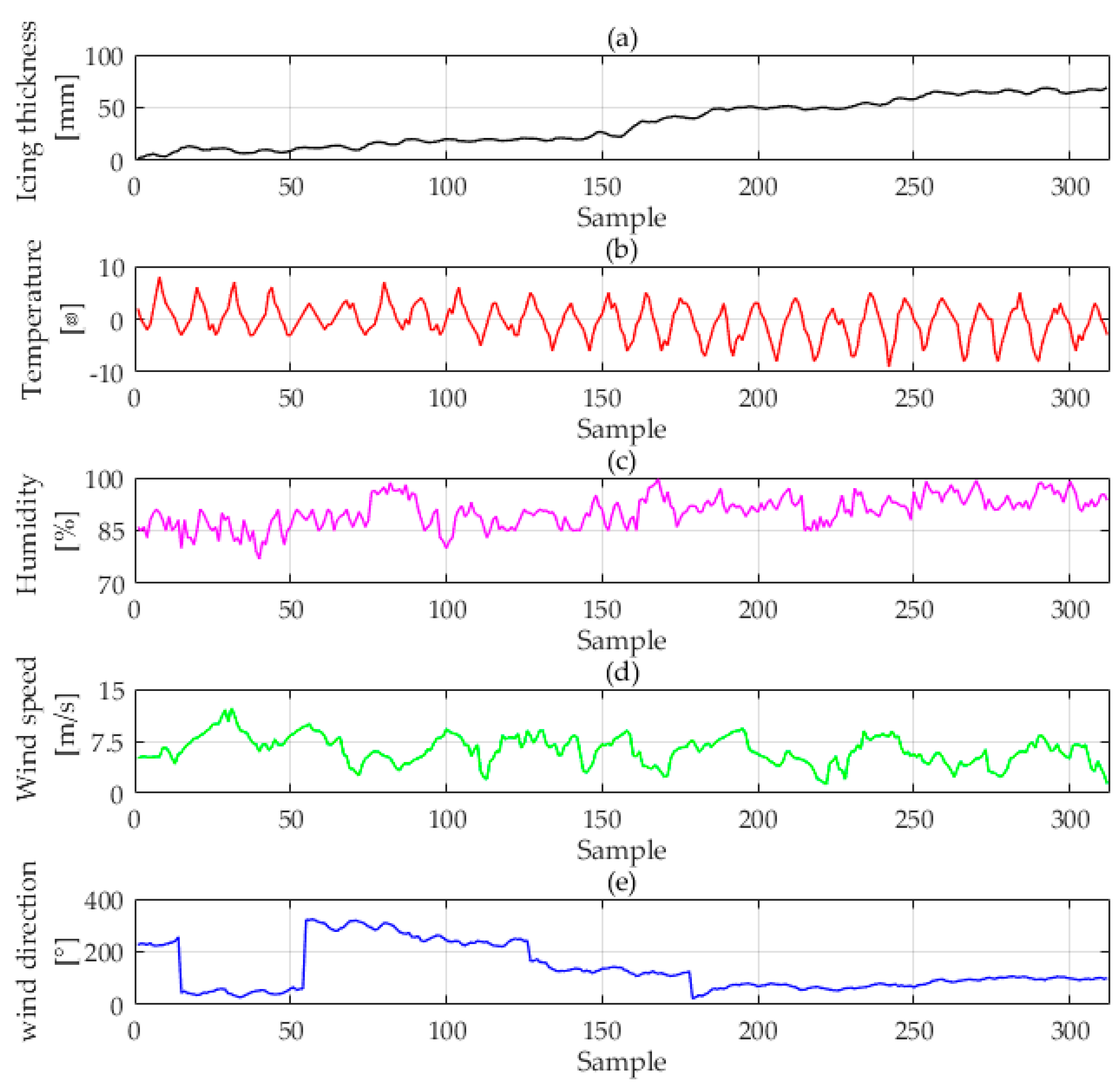
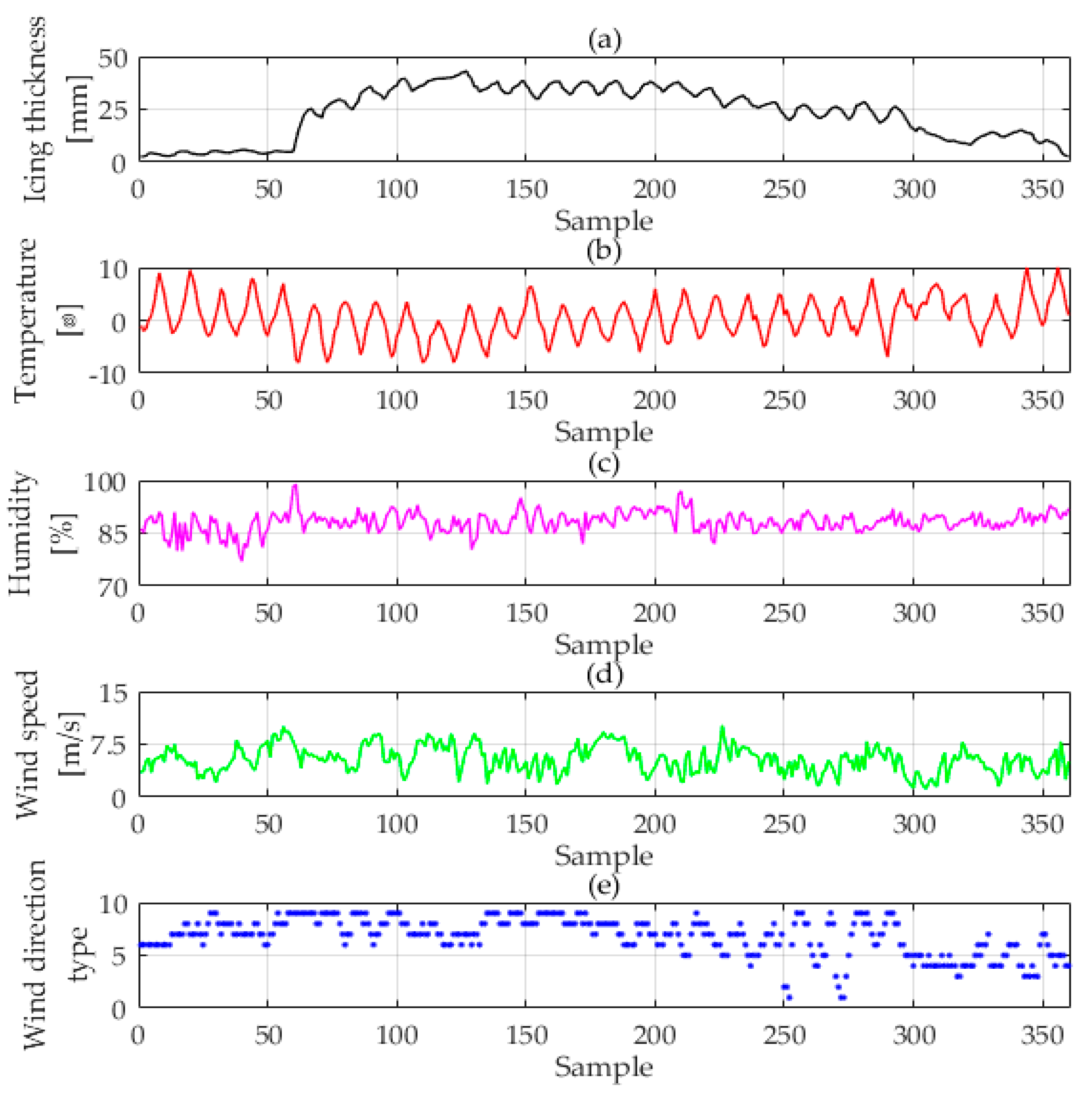
The original data is shown in
Figure 2. All of the data were provided by Key Laboratory of Disaster Prevention and Mitigation of Power Transmission and Transformation Equipment (Changsha, Hunan Province, China), where all the data are collected by professional instruments and can reflect the state changes during the icing process. As we can see from
Figure 2, the temperature and wind speed data present a cyclical downward trend, while the relative air humidity data present a cyclical upward trend. In addition, there is no exceptional data or missing data. Hence these data can be used directly as data sources.
In addition to the icing thickness, the data of temperature, relative air humidity, wind speed and wind direction at the forecast point T was selected as input data. However, ice accretion phenomenon is a continuous process and the prior T-z’s icing thickness can influence the transmission lines icing thickness at the forecast point T. When selecting the different prior T-z’s icing thickness as input data, the forecasting effectiveness is different. Hence this paper selects different prior T-z’s icing thicknesses as input data. For example, when z equals 3, the input icing thickness data includes the icing thickness at T-1, T-2, and T-3. After selecting the input data, the proposed model is applied to check the exact input icing thickness by using the training samples, whose experimental results are shown in
Table 1.
From
Table 1, it can be found that the proposed model obtains different error values when the icing thickness values are selected at different time points. However when z equals 4, the RMSE of proposed model reaches the minimum value, thus the input icing thickness data includes the icing thickness at T-1, T-2, T-3 and T-4, while the other input data includes the temperature, relative air humidity, wind speed and wind direction at the forecast point T.
3.2. Data Pretreatment
The data preprocessing steps are as follows:
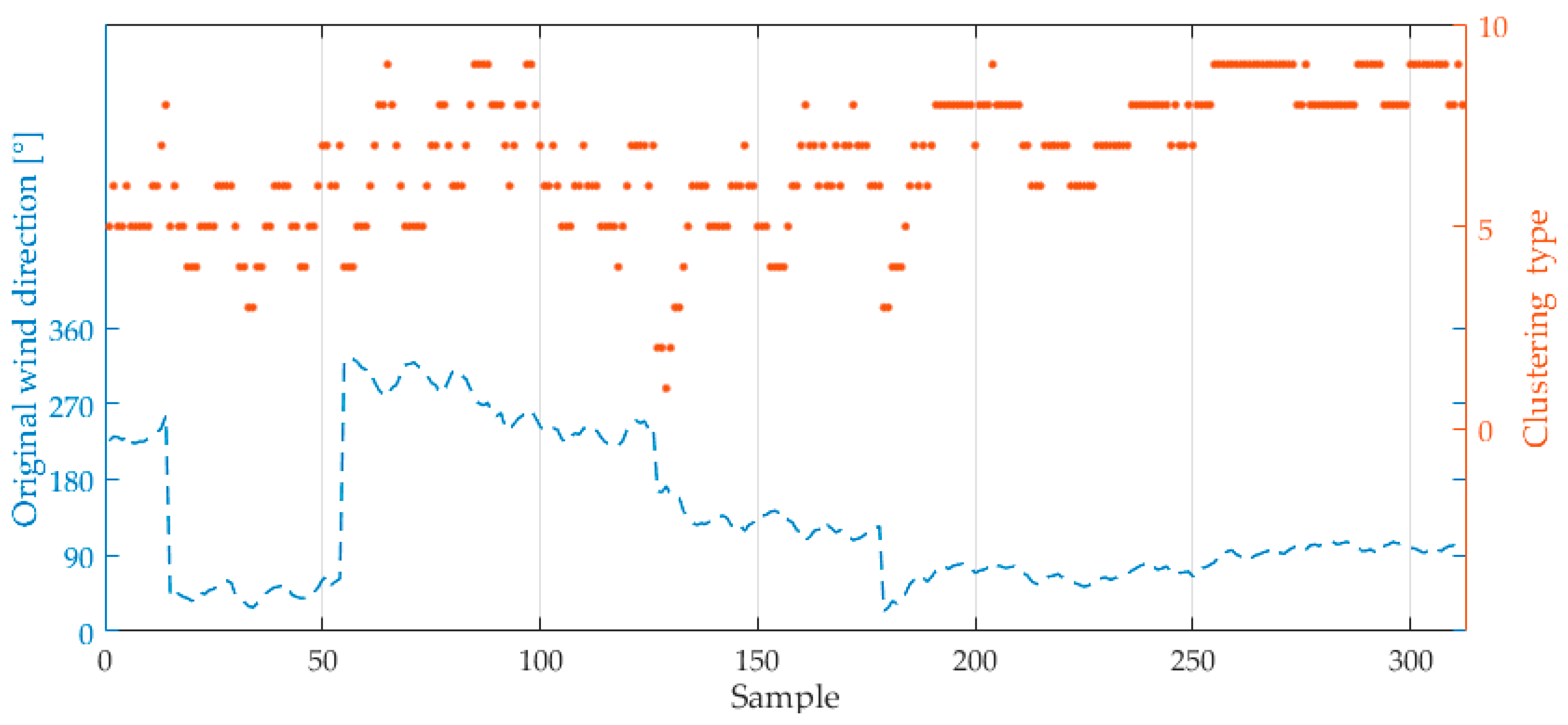
(1) Wind direction data clustering processing
The large fluctuation range of wind direction data will reduce the accuracy of prediction results, and the clustering of wind direction data can make the fluctuation smaller which can improve the prediction accuracy. Thus, the paper uses clustering to process wind direction data according to the degree of influence of wind direction on icing thickness; which formula is as follows:
where
J is the result value of clustering process for wind direction;
θ is the angle between the wind and the wire when the wind rotates counterclockwise around the wire, i.e., the direction of the transmission line is set to be horizontal 0°; Ceil is the bracket function. The wind direction processing data for "Dong-Chao line" is shown in
Figure 3.
(2) Standardized processing of all data
Due to the different nature of each evaluation index, and they usually have different dimensions and orders of magnitude. In order to ensure the accuracy of the prediction results, it is necessary to standardize the original index data. The data are processed by the following equation:
where
xi is actual value and the actual value of wind direction data is the result of clustering;
xmin and
xmax are the minimum and maximum values of the sample data.
3.3. Performance Evaluation Index
The evaluation index of the icing prediction result used in this paper are:
- (1)
- (2)
Root-mean-square error (RMSE):
- (3)
Mean Absolute Percentage Error (MAPE):
- (4)
Average absolute error (AAE):
where
is the actual value of the icing thickness;
is the forecasting value;
is groups of data. The smaller the above index value is, the higher the prediction accuracy is.
3.4. Modified BPNN-SVM-KELM for Icing Forecasting
The paper’s experiment and modeling platform is Matlab R2014a, and the operating environment is an Intel Core i5-6300U CPU with 4G memory and a 500 G hard disk. The topology structure of BPNN in MEC-BPNN is 9-7-1. The transfer function of the hidden layer uses the expression which is a tansig function. The output layer transfer function takes the form which is a purelin function. The maximum training time is 100, the training target minimum error is 0.0001, and the training speed is 0.1. In addition, the population size of MEC is 200, the sub-population is 20, the dominant sub-population’s number is 5, the quantity of the temporary population is 5, the number of iterations is 10. The parameters of the BA algorithm in the BA-SVM prediction are set as follows: the dimension of search space is 7; the size of the bat population is 30; the pulse frequency Ri of bats is 0.5; loudness Ai is 0.25; the acoustic frequency range is [0, 2]; the termination condition of the algorithm is when the calculation reaches the maximum number of iterations (300). In SVM, the penalty parameter that needs to be optimized is C whose range of variation is [0.01, 100]; the range of kernel parameter g is [0.01, 100]; the range of the ε loss function parameter p is set as [0.01, 100]. The SVM optimal penalty parameter c is 1.971, the kernel parameter g is 0.010 and the ε loss function parameter p is 0.01 by BA optimization. The kernel function of KELM algorithm uses RBF kernel function whose input and output data processing interval is [−1, 1].
In order to show whether the forecasting results of the three modified models were a local optimal or global optimal location and whether these models can be generalized to other unseen data, a K-CV test is conducted here. According to the K-CV method described in
Section 2.2, the data set is substituted into the model for testing and analysis. The 312 sets of data are randomly divided into 12 datasets, each of which has 26 groups of data and do not intersect each other. After 12 operations, each sub-data set is tested and the RMSE of the sample is obtained, which can be seen in the
Table 2.
From
Table 2, it can be known that the average RMSE values of MEC-BPNN, BA-SVM and KELM are 0.0121, 0.0142 and 0.0139, respectively. The RMSE standard deviations of MEC-BPNN, BA-SVM and KELM are 0.00129, 0.00219 and 0.00087, respectively. It is indicated that the validation error of the each modified model proposed in this paper can obtain its global minimum.
After the prediction of the three individual improved models, the VC combined method to solve the problem of dynamic weight distribution is adopted to combine these models. The result of the combination is that the corresponding weights are adjusted dynamically according to the different training results whose adaptability is better. The combination weights of three individual models of MEC-BPNN, BA-SVM and KELM are 0.42, 0.34 and 0.24, respectively.
The paper uses the mature BP neural network model and SVM model to do a comparative experiment based on the sample data mentioned in
Section 3.1 in order to verify the performance of the proposed combination forecasting model. The initial weights and thresholds of a single BPNN model are obtained by their own training, and other parameter settings are consistent with the MEC-BPNN. Besides, in the single SVM model, the penalty parameter c is 9.063, the kernel function parameter g is 0.256, and the ε loss function parameter p is 3.185.
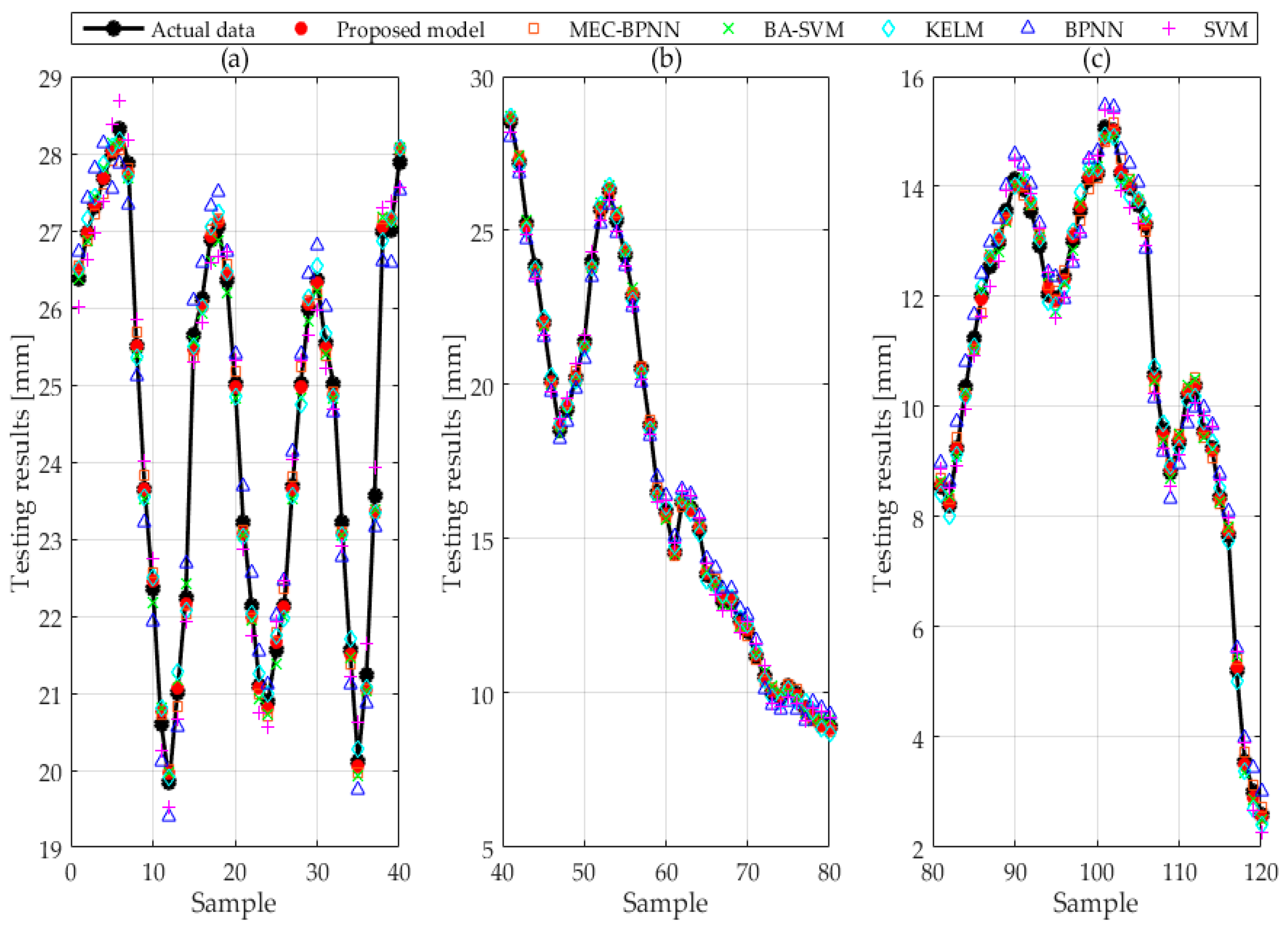
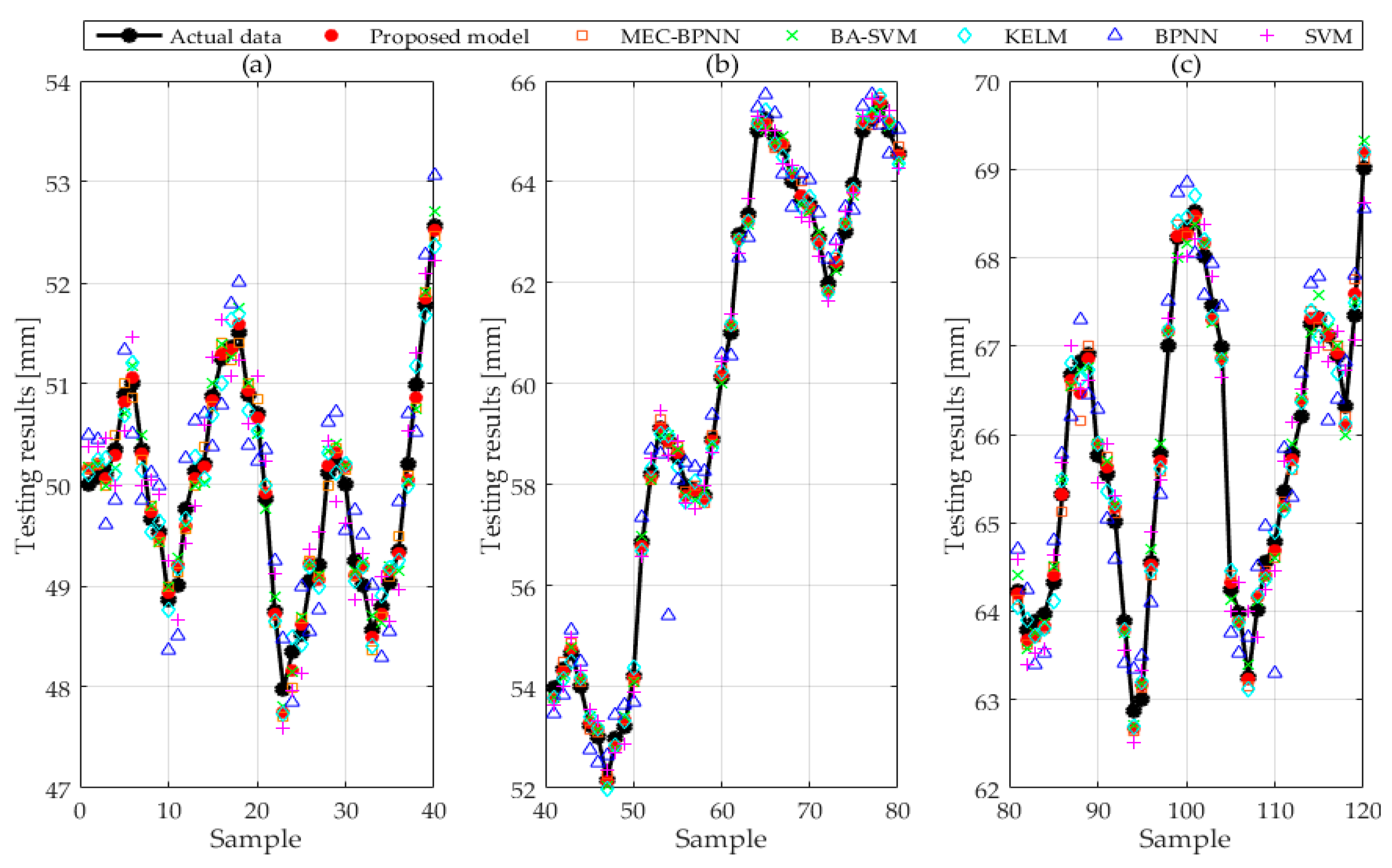
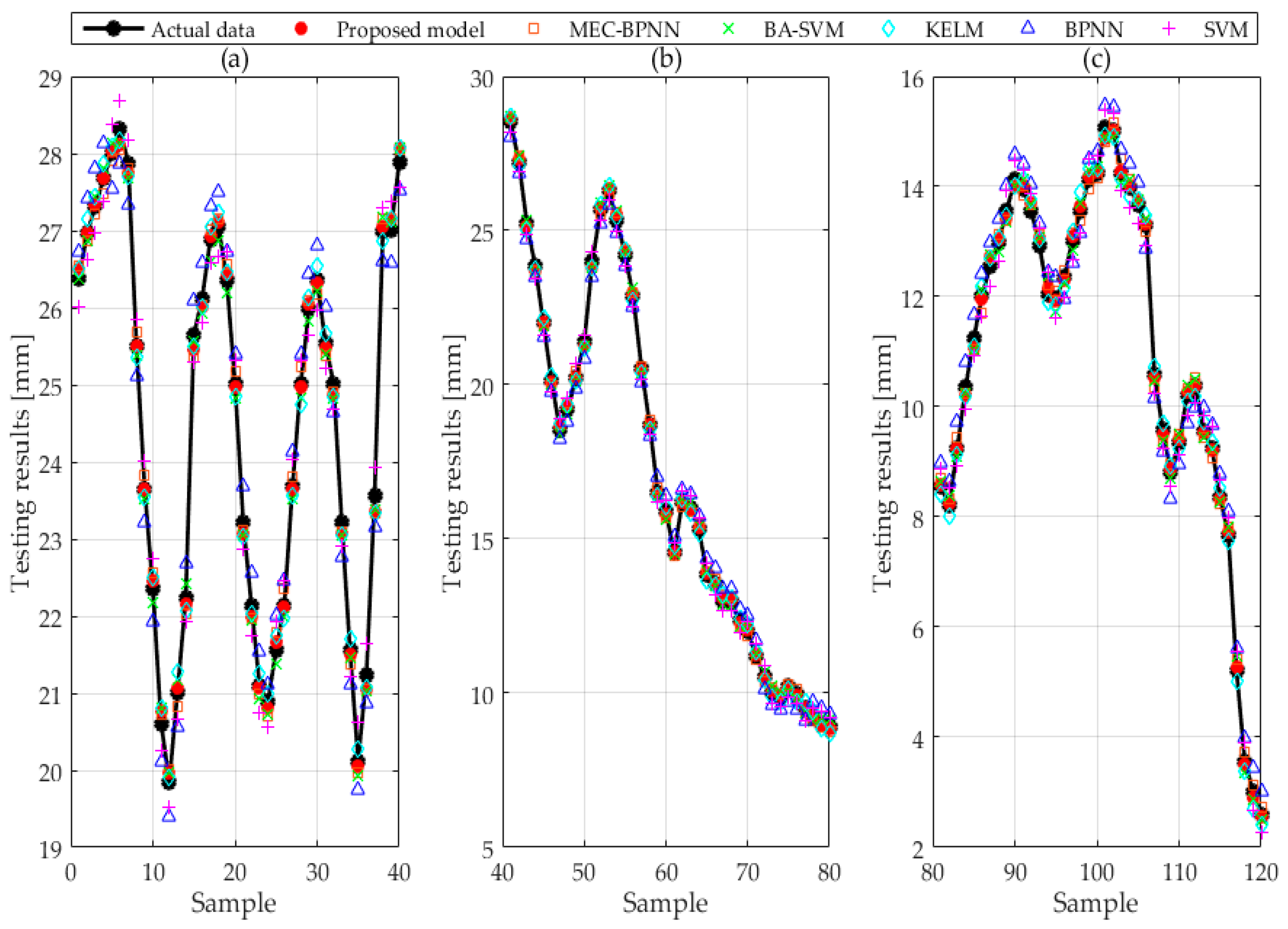
The forecasting values and original values of BPNN, SVM, MEC-BPNN, BA-SVM, KELM, and improved BP-SVM-KELM based on VC, part of which are given in
Table 3, are shown in
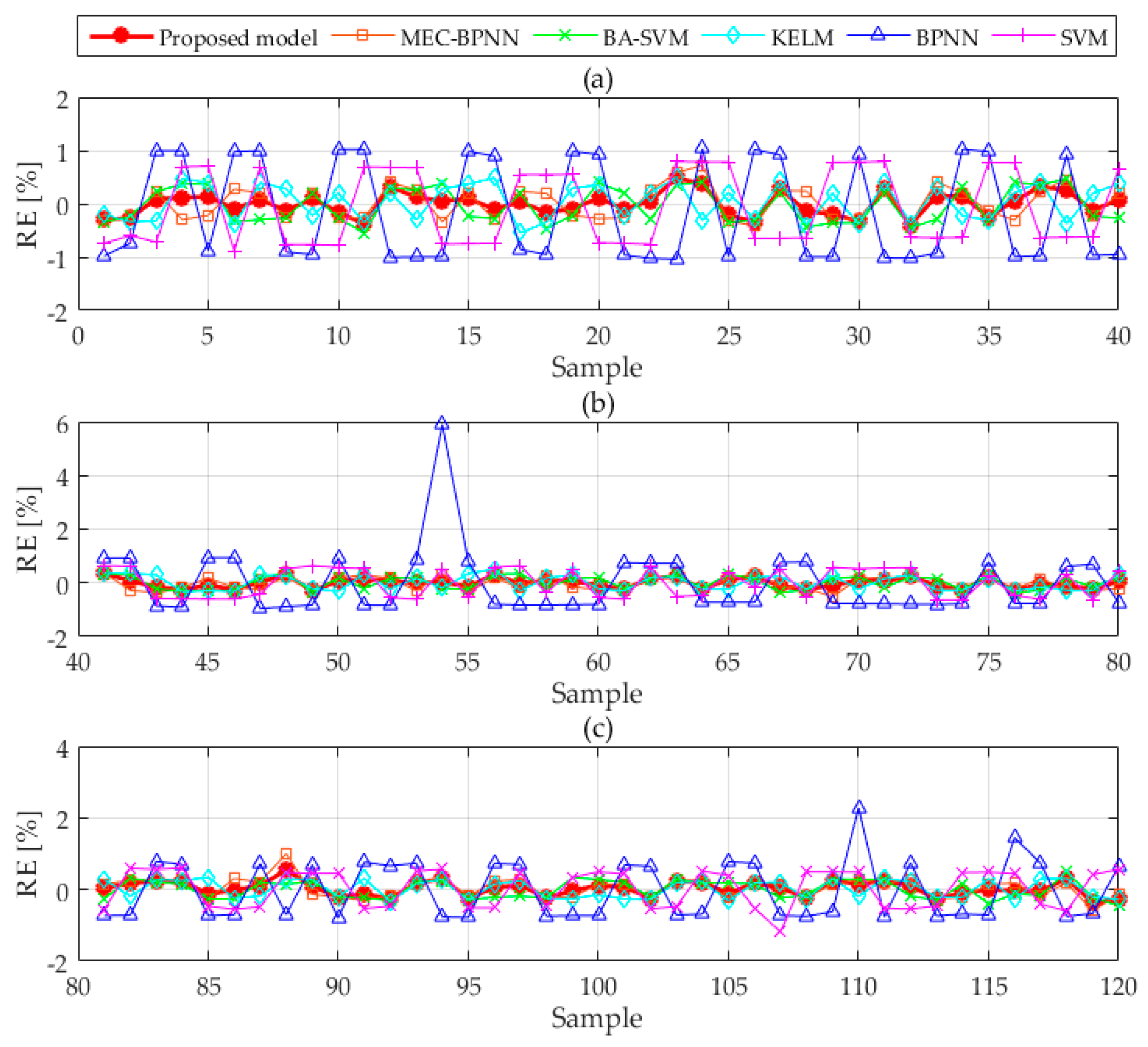
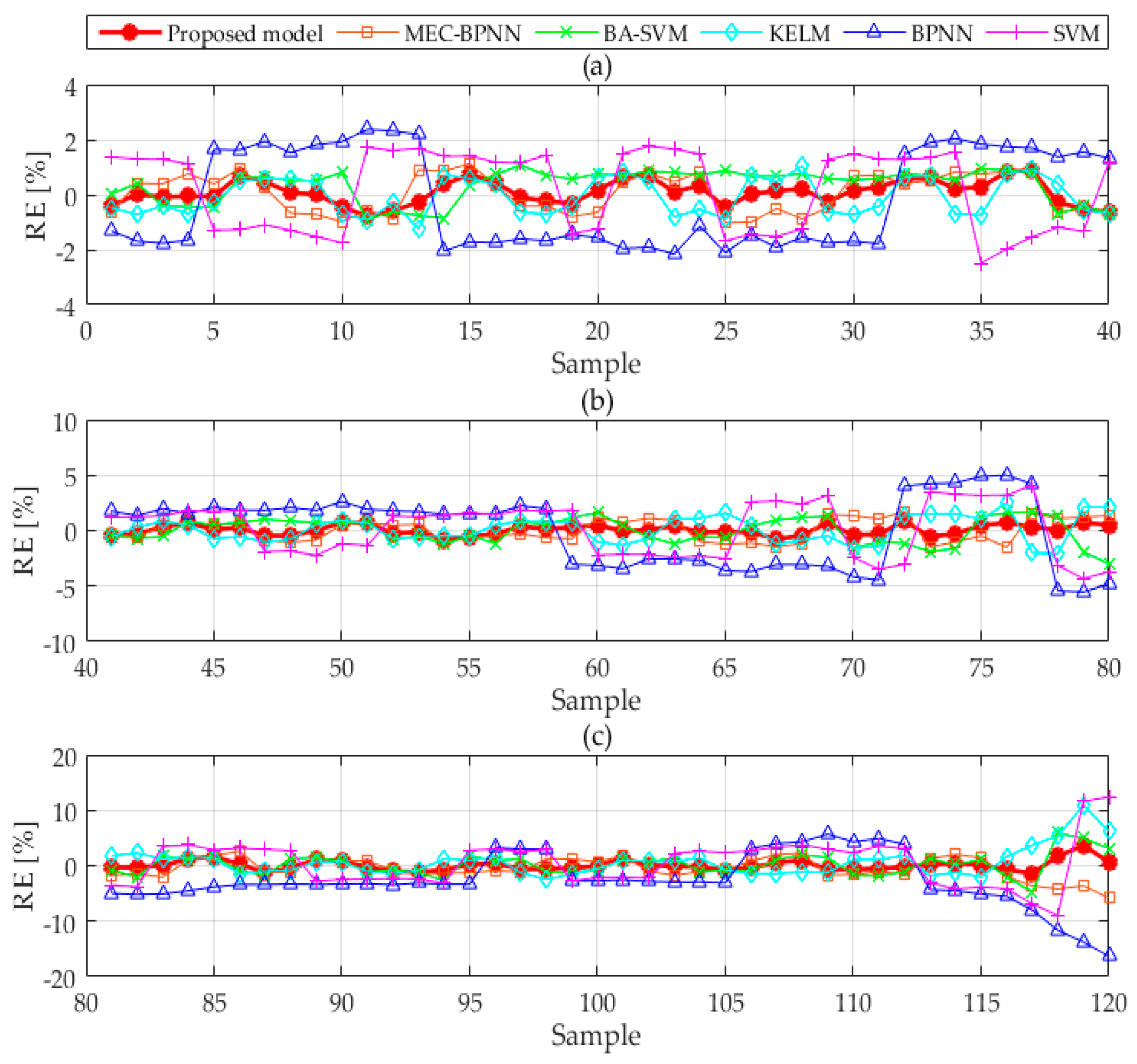
Figure 4. The relative forecasting error of each model is revealed in
Figure 5. This paper divides the test set samples into four groups to show the forecasting effect of each model owing to the large model quantities and sample points.
Figure 4 and
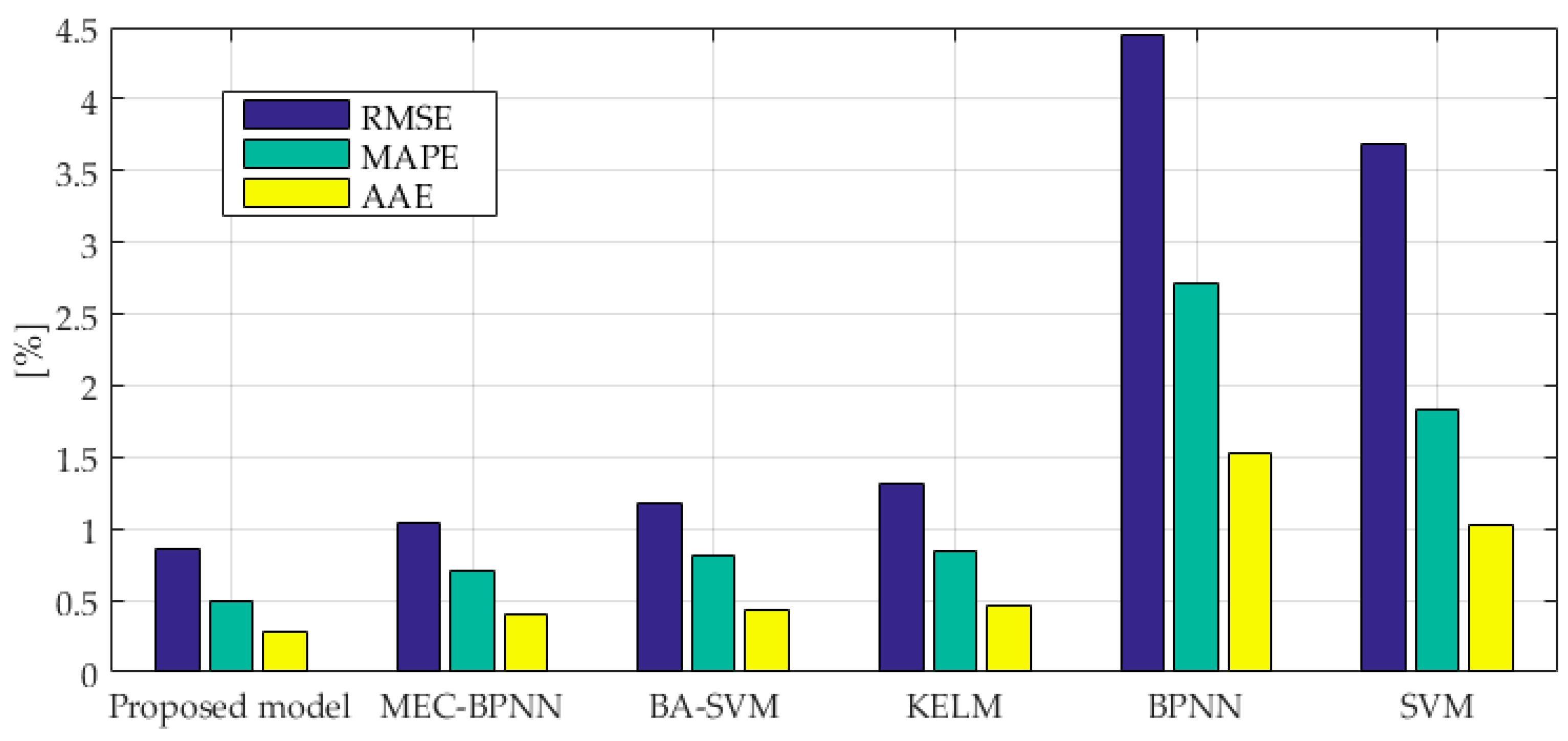
Figure 5 therefore consist of three sub-graphs, respectively. The RMSE, MAPE and AAE of models are demonstrated in
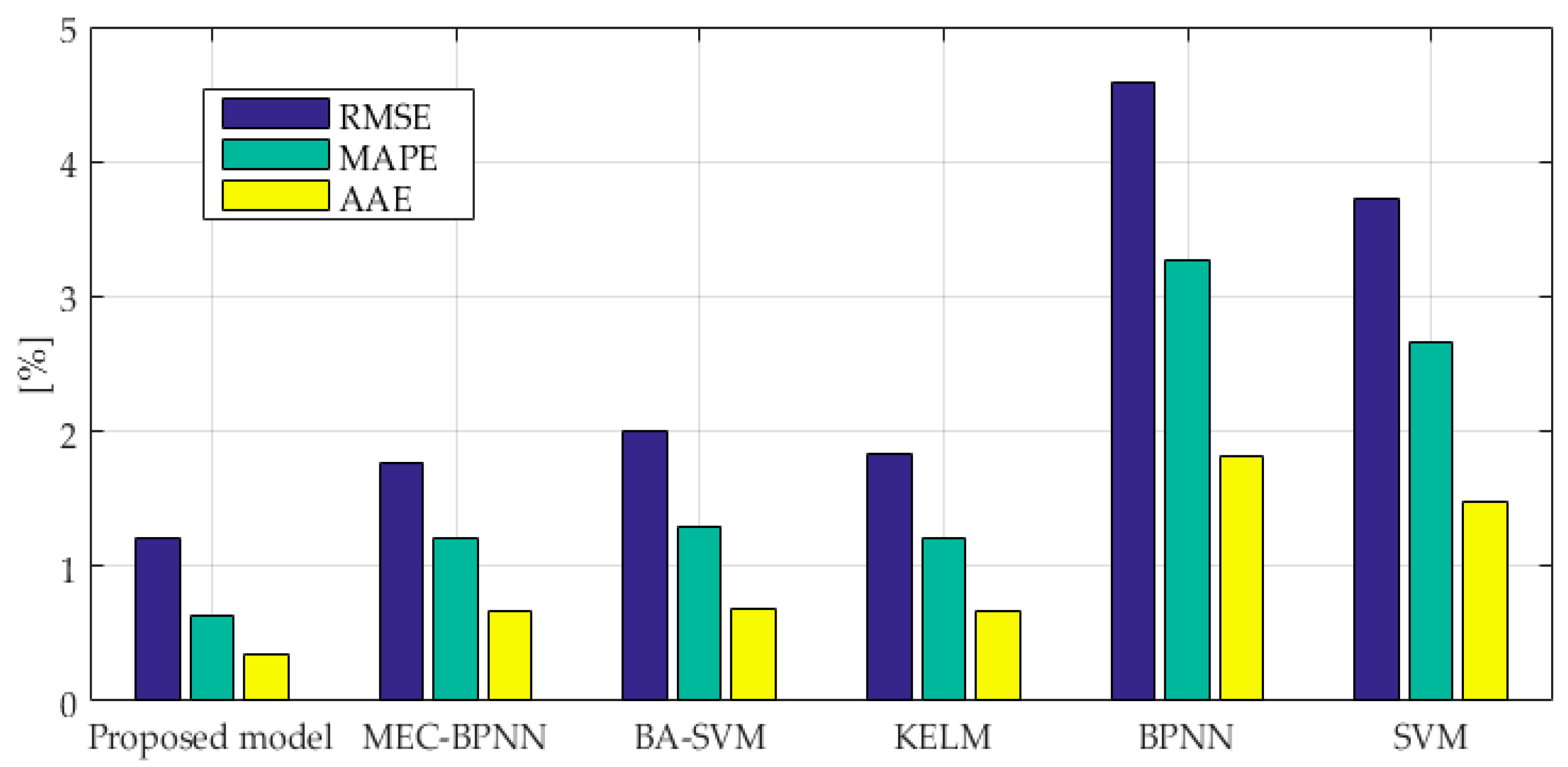
Figure 6.
The deviation between the icing thickness forecasting value and the original value of BPNN and SVM is large by contrasting the results of the six forecasting methods in
Figure 4. In addition, the curves of forecasting value and original value are suddenly far or suddenly near, indicating that the forecasting accuracy and robustness of these two methods are poor. Besides, the deviations of MEC-BPNN, BA-SVM and KELM are smaller than the above two models so that the precision is improved, but the curves are still like those with poor stability. However, the deviation which is obtained from improved BP-SVM-KELM based on VC is smaller and it is between the most accurate and the most inaccurate single improvement model. The value is the closest to the most precise model which indicates the accuracy of the combined forecasting model is guaranteed. Then the curves distance between the forecasting value and the actual value of the composite model is basically distributed near the actual value curve, indicating that the combination forecasting model has the strongest robustness.
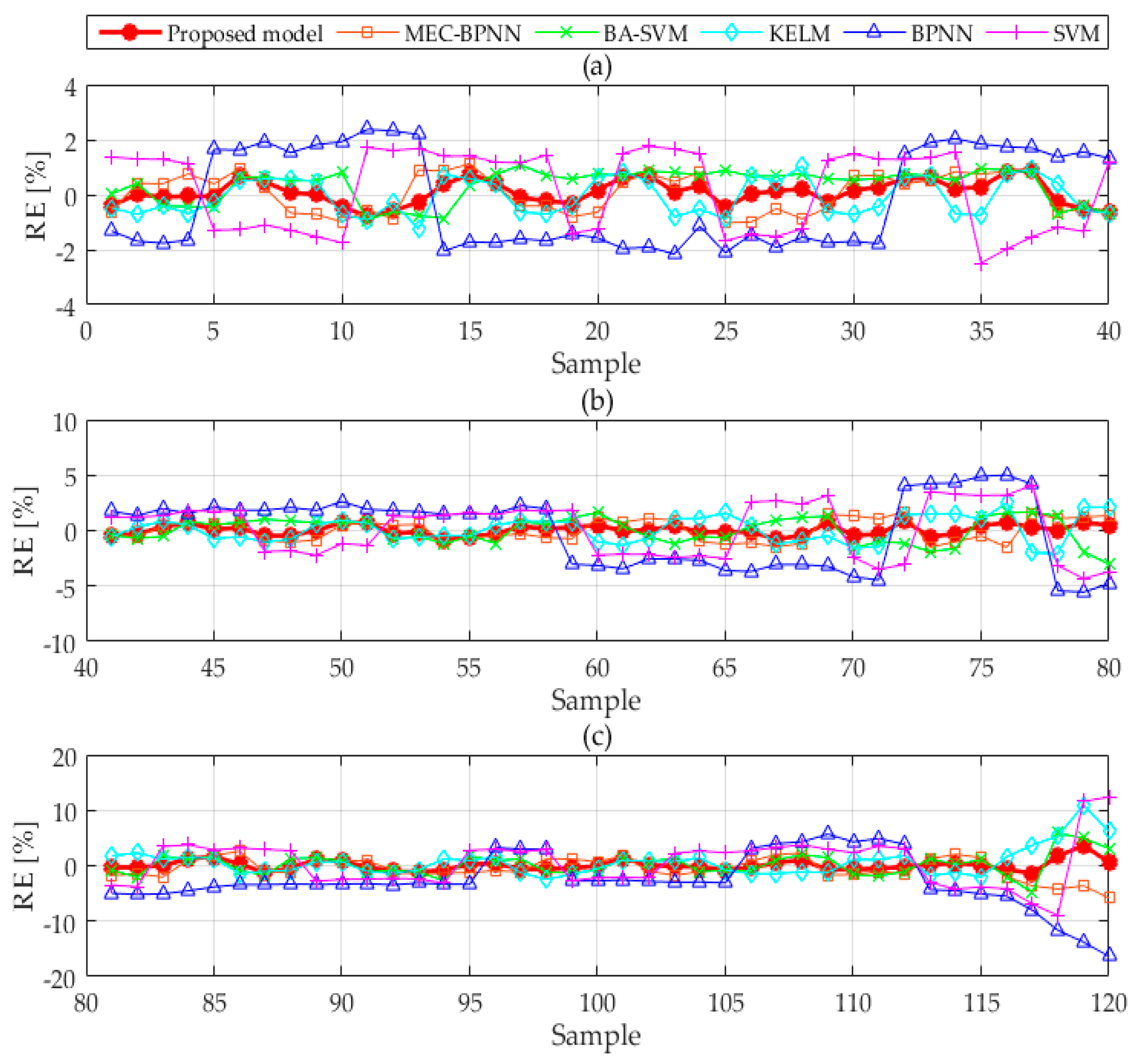
Figure 5 compares the relative errors of the six forecasting methods. By counting the maximum and minimum relative errors, it can be found that the maximum relative errors of BPNN, SVM, MEC-BPNN, BA-SVM, KELM and the combined forecasting model are 5.910%, 1.186%, 1.003%, 0.551%, 0.545% and 0.543%, the minimum values are 0.611%, 0.170%, 0.135%, 0.119% and 0.002%. The maximum and minimum values in the three improved models are less than the two basic models, which shows that the prediction accuracy is better than the BPNN model and the SVM model. The maximum and minimum values in combined forecasting model are less than the three individual improved models, indicating that its prediction value is the nearest to optimal single improved model. The fluctuation ranges of the RE curves of the two basic models are the largest showing their stabilities are the poorest, and the stabilities of the three improved models have improved with a relatively small range of fluctuation. However, compared with the combination forecasting model, the fluctuation range is still large, which shows that the combination forecasting model plays a role in avoiding the weaknesses and improves the stability of prediction under the premise of ensuring the accuracy.
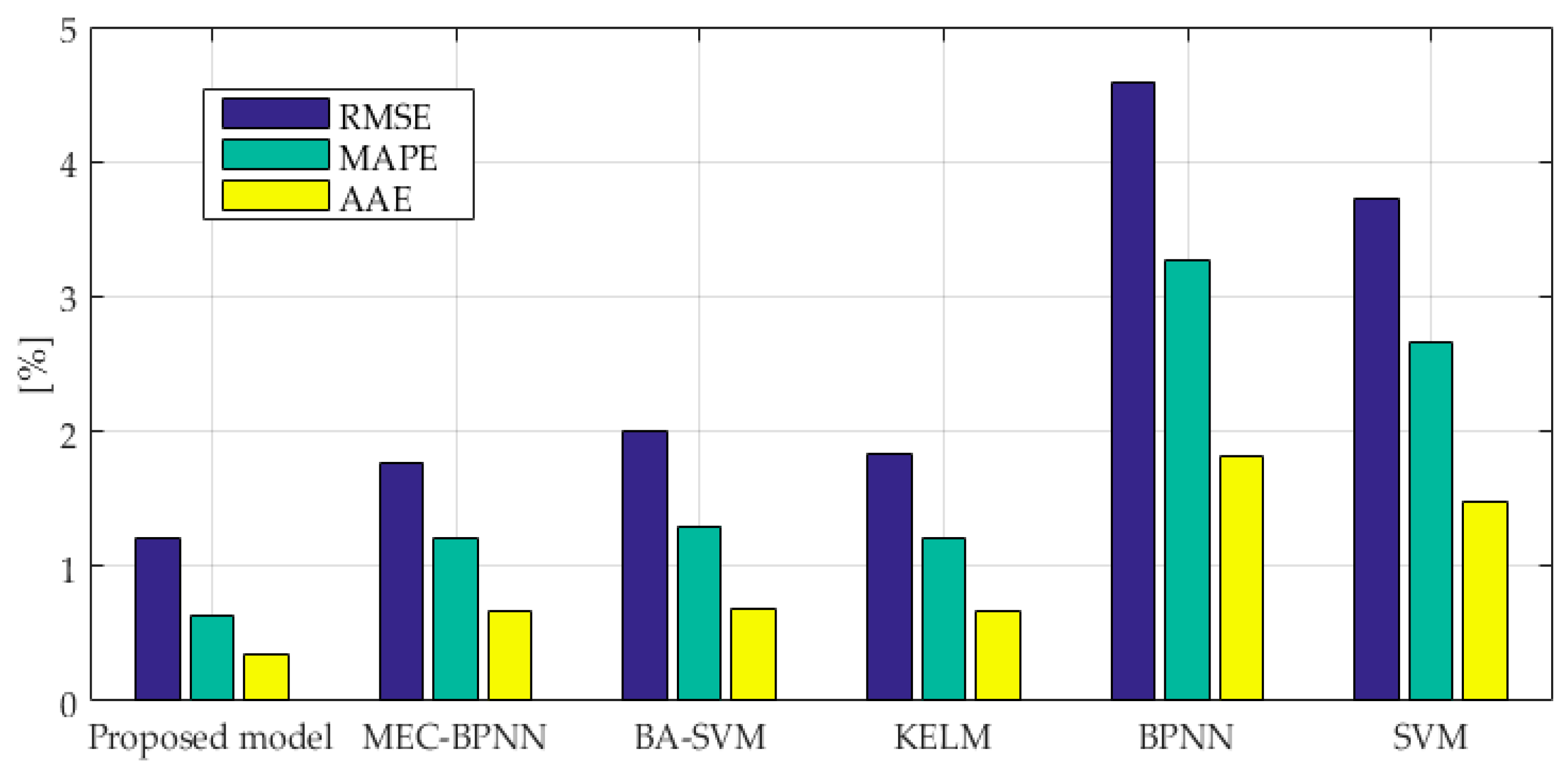
As we can see from
Figure 6, the RMSE value of the combination forecasting model is 0.86%, and the RMSE values of the BPNN, SVM, MEC-BPNN, BA-SVM and KELM models are 4.44%, 3.68%, 1.04% and 1.32%, respectively. The proposed combination forecasting model has a lower error and a higher accuracy than the other models which makes the accuracy of single points be higher than the worst though the VC combined method solved the problem of dynamic weight distribution. The value is infinitely close to the most accurate single model at this point, so its stability and accuracy can be fully guaranteed. The prediction results of the three improved models are better than SVM and BPNN models indicating that their prediction performance has been improved by intelligent algorithms. The MAPE values of the BPNN, SVM, MEC-BPNN, BA-SVM, KELM and the combination forecasting models are 2.71%, 1.83%, 0.70%, 0.81%,0.84% and 0.50%. The evaluation index also shows that the combination forecasting method has the best overall prediction effect, the three improved models are second, and the two basic models have the worst prediction performance. The AAE value of the combination forecasting method is the smallest which enough shows the overall prediction performance of the proposed model is the best.
In conclusion, the prediction accuracy of the three improved models is advanced through the improvement of the basic model, but the robustness is still poor. The combination prediction model is not the most accurate at each point, but it is the closest to the most accurate predictions because the weights tend to the model with the highest accuracy according to the weight distribution. In the unknown prediction, the combination method can make best use of the advantages and bypass the disadvantages, so the flexibility, adaptability and accuracy are guaranteed.
4. Further Simulation
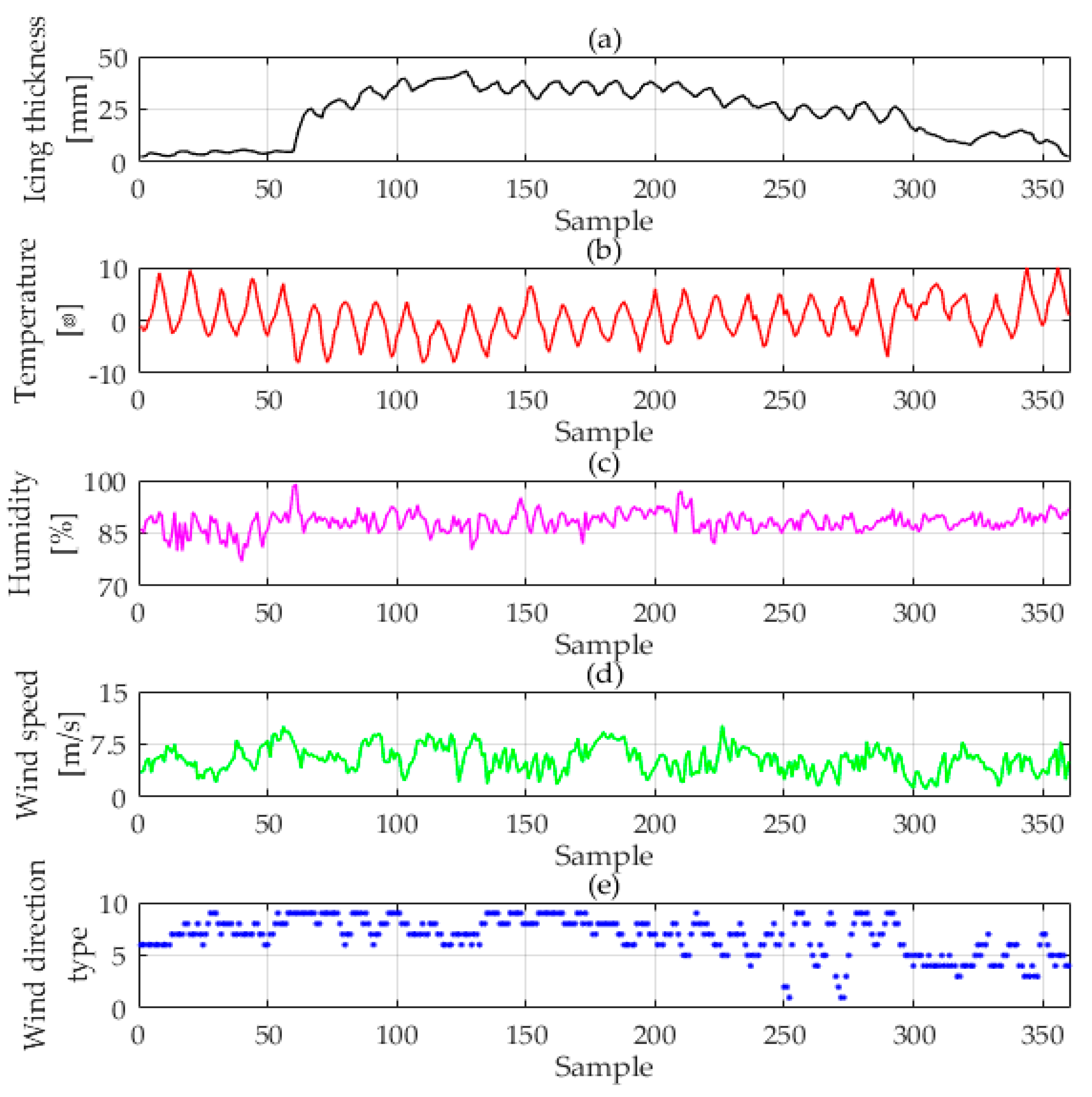
This paper now selects another line in Hunan, the "Tianshang line", as a case to further verify the performance of the proposed model. The data of “Tianshang line” are from 17 January 2008 to 15 February 2008, and have a total of 360 data groups. The first 240 are training samples and the latter 120 are test samples. All data of icing thickness, temperature, humidity, wind speed and wind direction clustering are shown in
Figure 7. Like Case 1, all of the data were provided by the Key Laboratory of Disaster Prevention and Mitigation of Power Transmission and Transformation Equipment (Changsha, China), where all the data are collected by professional instruments and can reflect the state changes in the icing process. As we can see from
Figure 7, the temperature data first decreases periodically, then rises periodically. The data of relative air humidity and wind speed present a cyclical upward trend. What’s more, there is no exception data or missing data. Hence these data can be used directly as data sources.
BPNN, SVM, MEC-BPNN, BA-SVM, KELM and thw improved BP-SVM-KELM combination model based on VC are utilized to compare and analyze in this section. The parameter setting of BPNN, MEC-BPNN, and KELM are consistent with the previous case. In the single SVM model, the penalty parameter c is 10.307, the kernel function parameter g is 0.328, and the ε loss function parameter p is 2.261. For the same case, the SVM optimal penalty parameter c is 2.083, the kernel parameter g is 0.012 and the ε loss function parameter p is 0.011 by BA optimization. The combination weights of the three individual models of MEC-BPNN, BA-SVM and KELM are 0.40, 0.25 and 0.35, respectively, through the VC combined method that solved the problem of dynamic weight distribution.
The results of the k-fold cross validation for the three modified models proposed in this paper are described in
Table 4. A part of the forecasting values and relative errors of each model is listed in
Table 5. The forecasting results of each model are described in
Figure 8, and the relative errors are shown in
Figure 9. The RMSE, MAPE and AAE are shown in
Figure 10.
As is shown in
Table 4, the average RMSE values of MEC-BPNN, BA-SVM and KELM are 0.0181, 0.0202 and 0.0186, respectively. In addition, the RMSE standard deviations of MEC-BPNN, BA-SVM and KELM are 0.00130, 0.00136 and 0.00083, respectively. These data illustrate the fact again that the generalization performance of the three modified models has been improved.
As we see from
Figure 8 and
Table 5, compared with the BPNN and SVM models, the forecasting values of the three improved models are closer to the original values, which shows that the prediction accuracy of the modified model is better. The forecasting value of combination model is between the forecasting values of the three modified models. Although the proposed model is not the most accurate, the change range of the distance between the prediction and the actual value curves is the smallest. Besides, the result of the combination forecast model is closer to the most accurate single model predictive value which further shows that the combination forecasting model greatly improves the stability of prediction under the premise of ensuring accurate prediction.
The relative errors of the BPNN model and the SVM model are at a high level and the fluctuation range is large by observing
Figure 9, where the relative forecasting error of the six models are displayed, indicating that the two models’ accuracy and robustness are poor. As we can see from
Figure 9 and
Table 5, the relative errors of MEC-BPNN, BA-SVM and KELM are lower than those of the two basic models with greater volatility, and the value at some points is still large, which shows that its accuracy has been improved while the stability is still not guaranteed. It can be found that the relative errors of the three modified models constantly change their ranking at various points, which can be classified into three cases. For instance, in the first case, the relative errors of MEC-BPNN, BA-SVM and KELM are 1.13%, 1.64% and −1.01%, respectively, at the 60th sample point, where the forecasting accuracy of KELM is the highest. In the second case, the relative errors of MEC-BPNN, BA-SVM and KELM are 1.35%, −3.04% and 2.14%, respectively, at the 80th sample point, where the forecasting accuracy of MEC-BPNN is the highest. In the third case, the relative errors of MEC-BPNN, BA-SVM and KELM are −5.81%, 3.10% and 6.20%, respectively, at the 120th sample point, where the forecasting accuracy of BA-SVM is the highest. However, the relative error curve of the proposed combination model is among the three curves of MEC-BPNN, BA-SVM and KELM and it is close to the most accurate prediction in almost every sample point. In addition, its fluctuation range is also narrower. This indicates that the combination model can obtain both accurate and stable forecasting results.
As is shown in
Figure 10, the RMSE, MAPE and AAE of the proposed combination forecasting model are the minimum at 1.20%, 0.63% and 0.34%. This indicates that its whole predictive performance is optimal. By observing these values of the three improved model, it can be found that the whole prediction accuracy of MEC-BPNN is better than KELM’s, and KELM’s is superior to BA-SVM’s. When adopting the VC combined method to solve the problem of dynamic weight distribution to assign weights, MEC-BPNN’s weight is the highest, KELM’s is the second and BA-SVM’s is the minimum. It shows that weight assignation of the proposed combination forecasting method leans toward the most precise model, which enhances the robustness of prediction and also guarantees the accuracy.
By comparing the case with the previous one, it is clear that the weights of the three individual improvement models differ from those of the previous case. The prediction accuracy of BA-SVM is better than that of KELM and its weight is higher than KELM’s in the Case 1 according to the calculation results of performance evaluation index. However, the Case 2 is just the opposite. The difference indicates that the VC combined method solved the problem of dynamic weight distribution can adjust the weights according to the prediction accuracy of each individual model. It is so flexible that the overall accuracy of the prediction is improved.
In summary, the paper introduces the MEC-BP model, the BA-SVM model and the KELM model to improve the prediction performance of the individual models. The VC combined method solved the problem of dynamic weight distribution combines these models’ advantages, and the weights are flexibly assigned, so the overall instability of the model is reduced and satisfactory prediction results are obtained.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}