
Spatial Distribution Characteristics of Healthcare Facilities in Nanjing: Network Point Pattern Analysis and Correlation Analysis


Abstract
:1. Introduction
2. Study Area and Data Sources
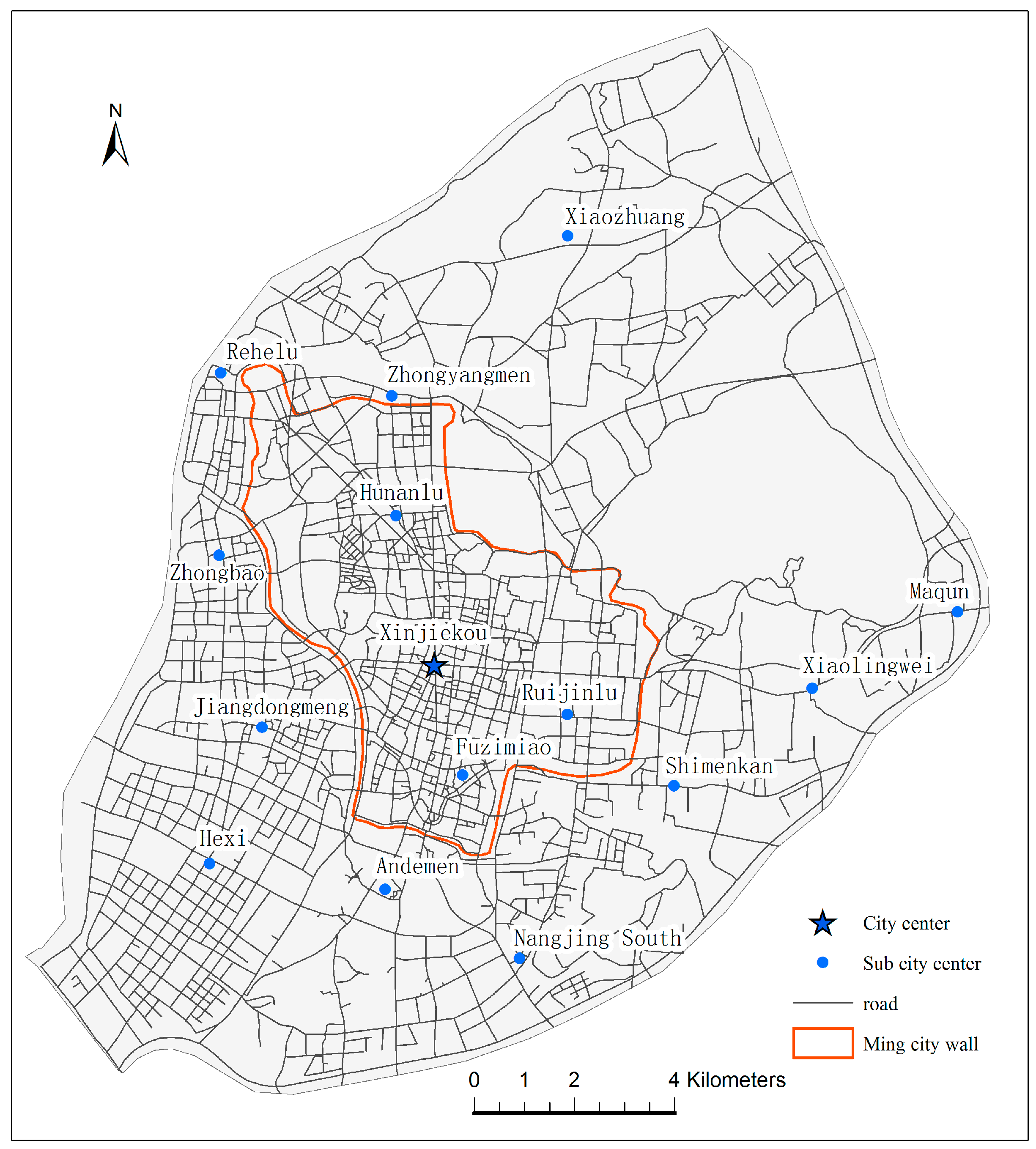
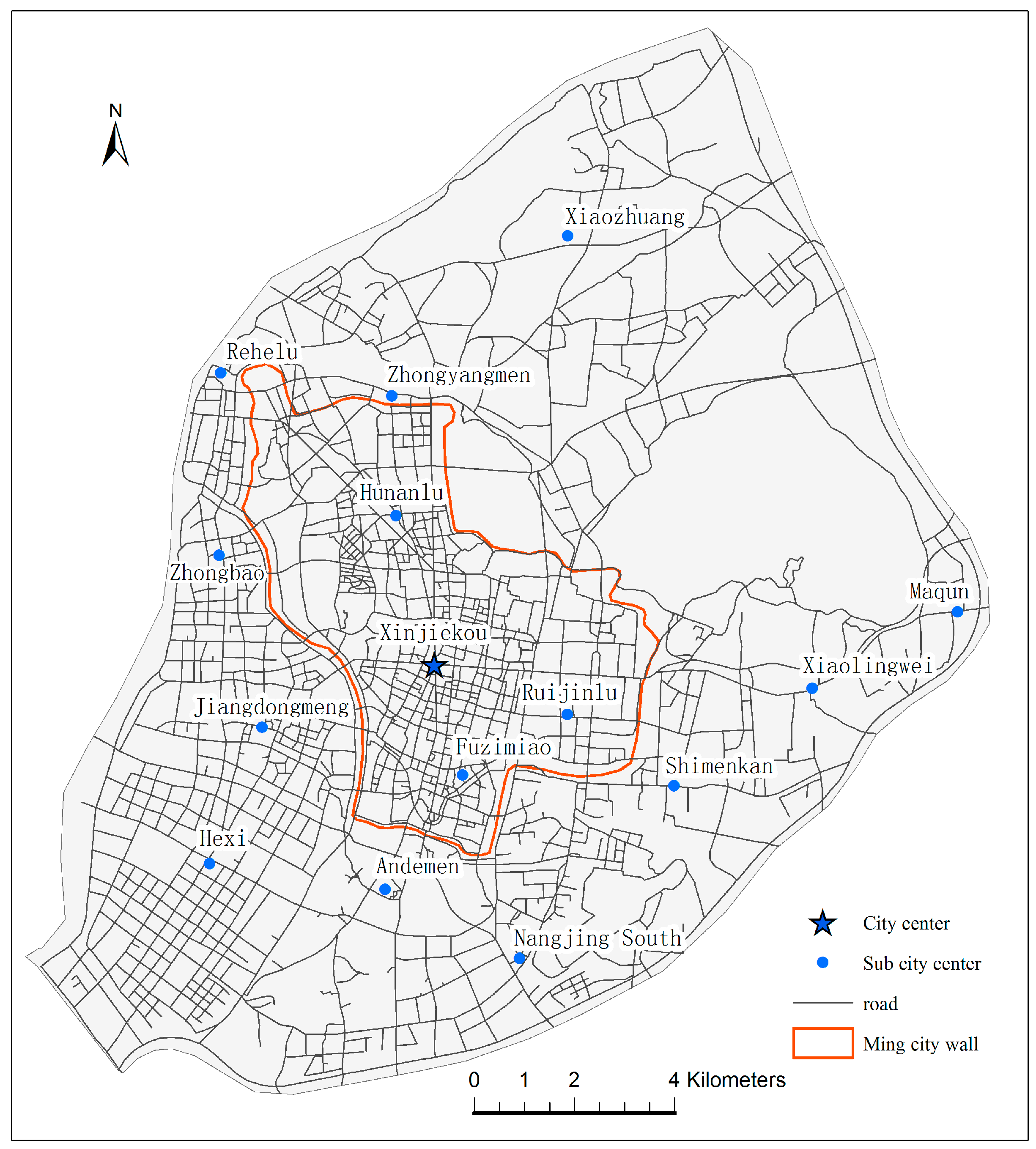
2.1. Study Area
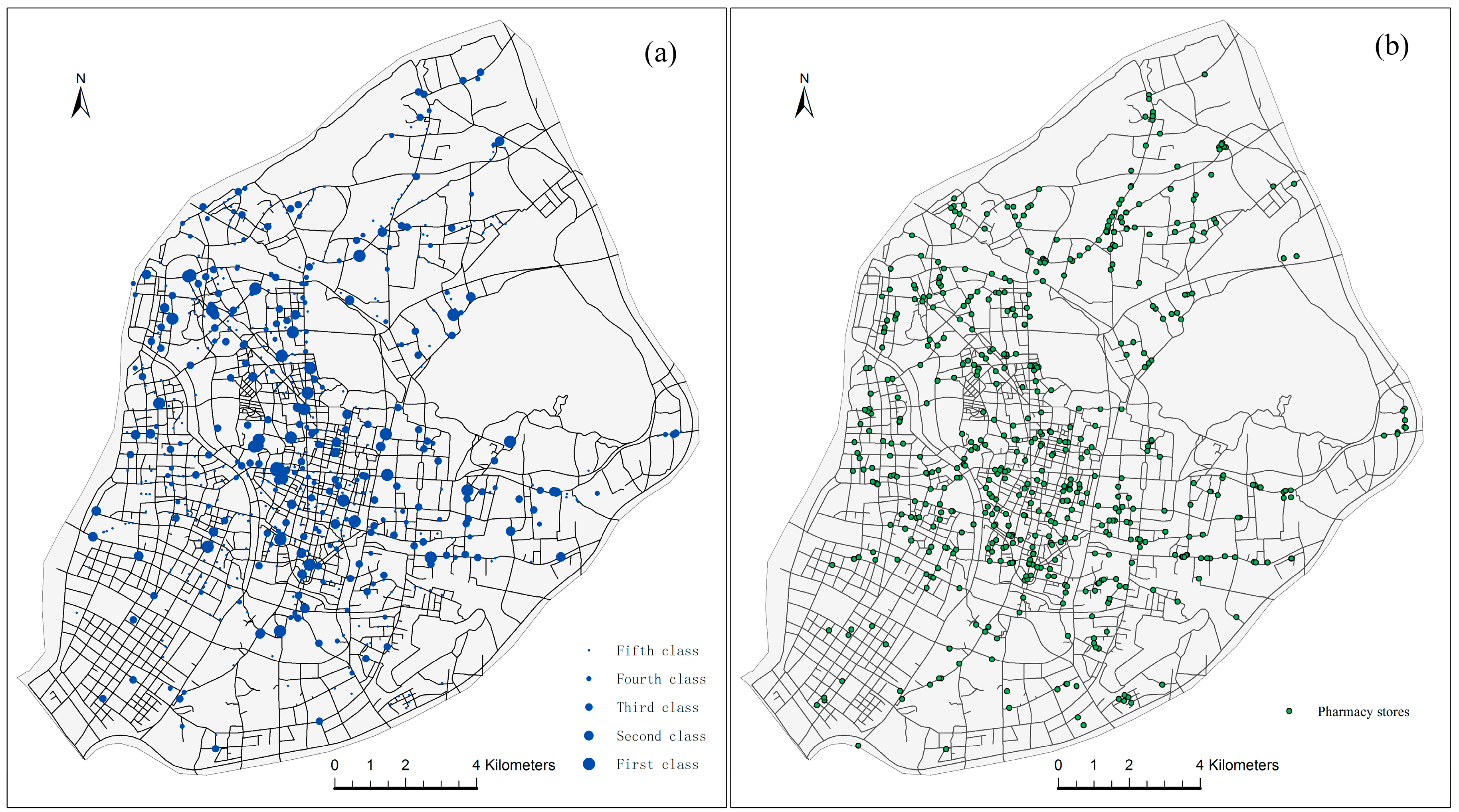
2.2. Data Sources
3. Methods
3.1. Network Kernel Density Estimation
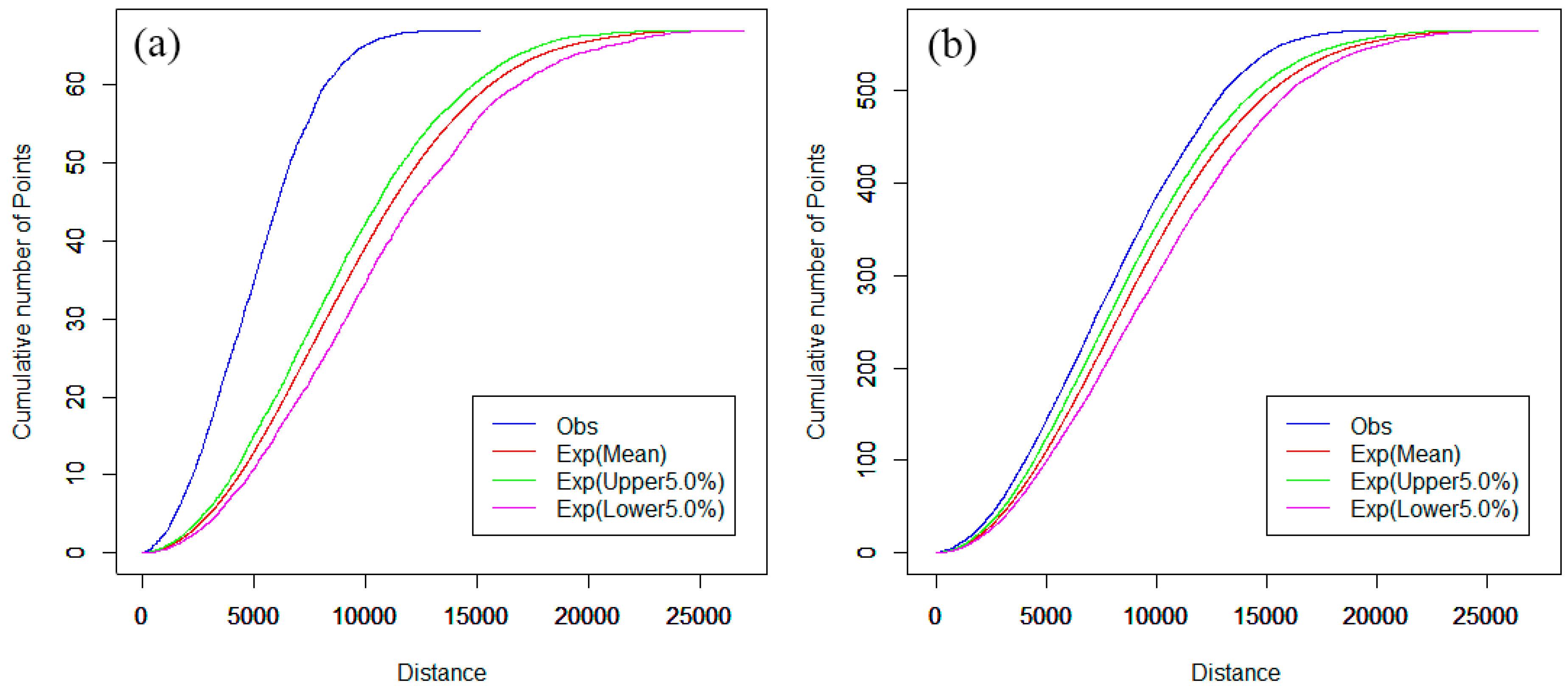
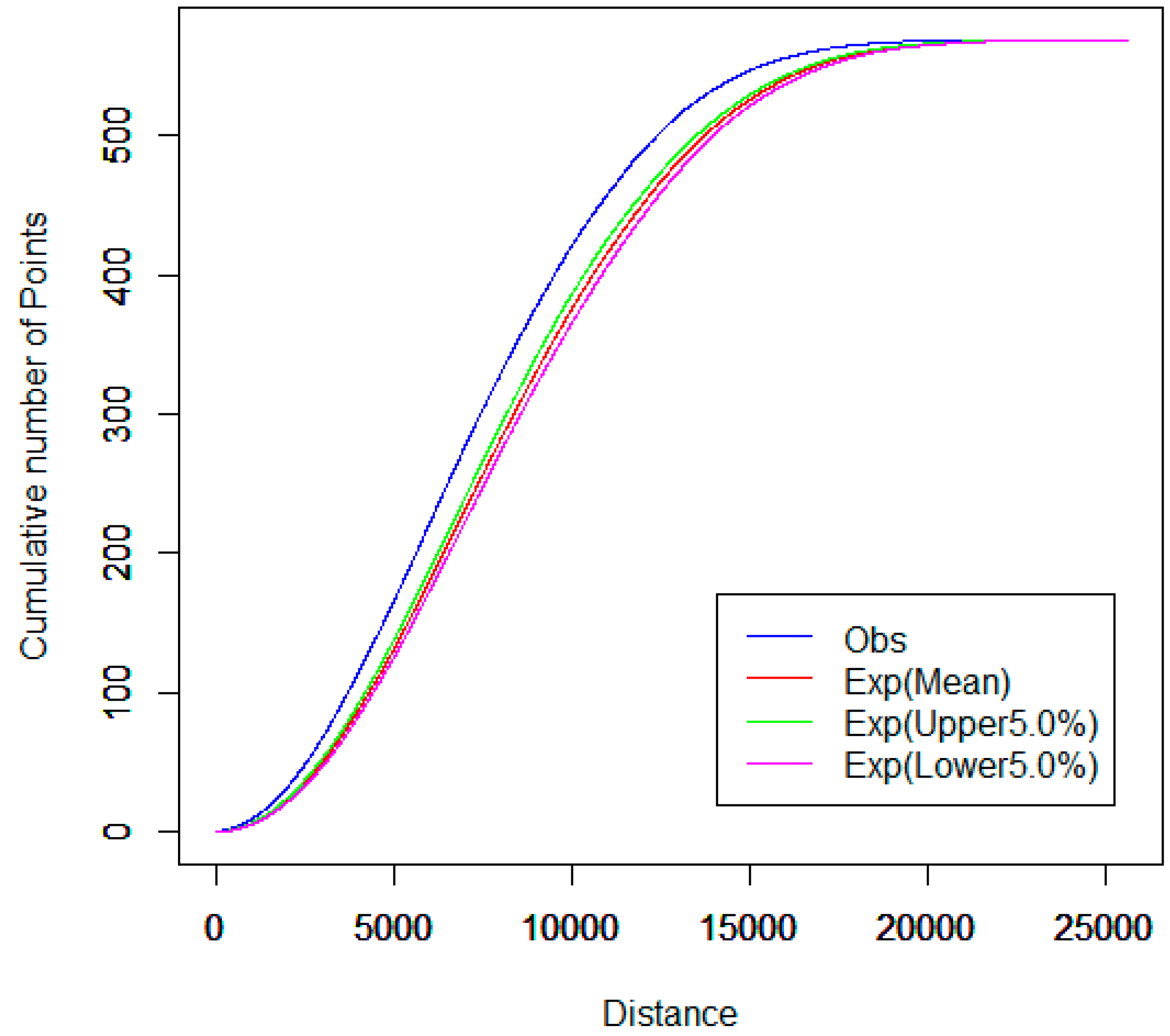
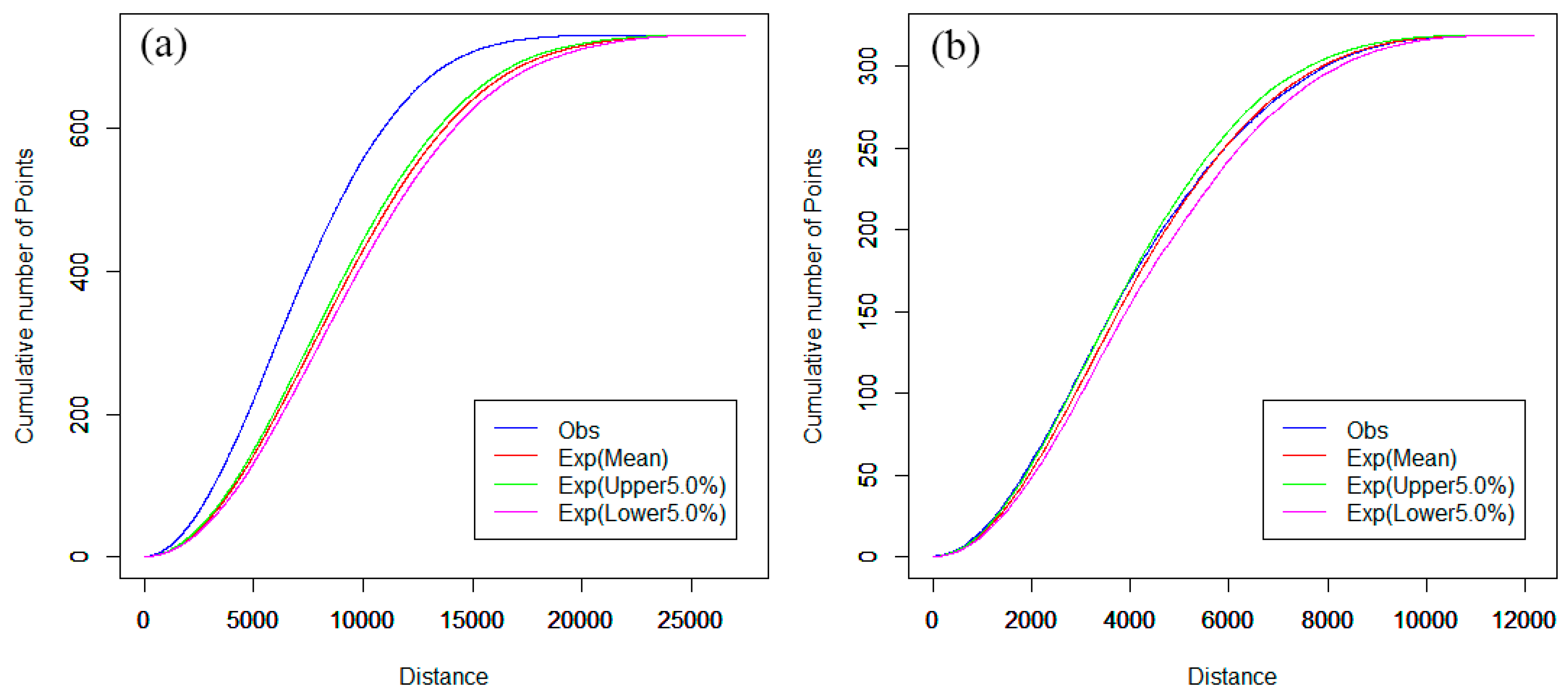
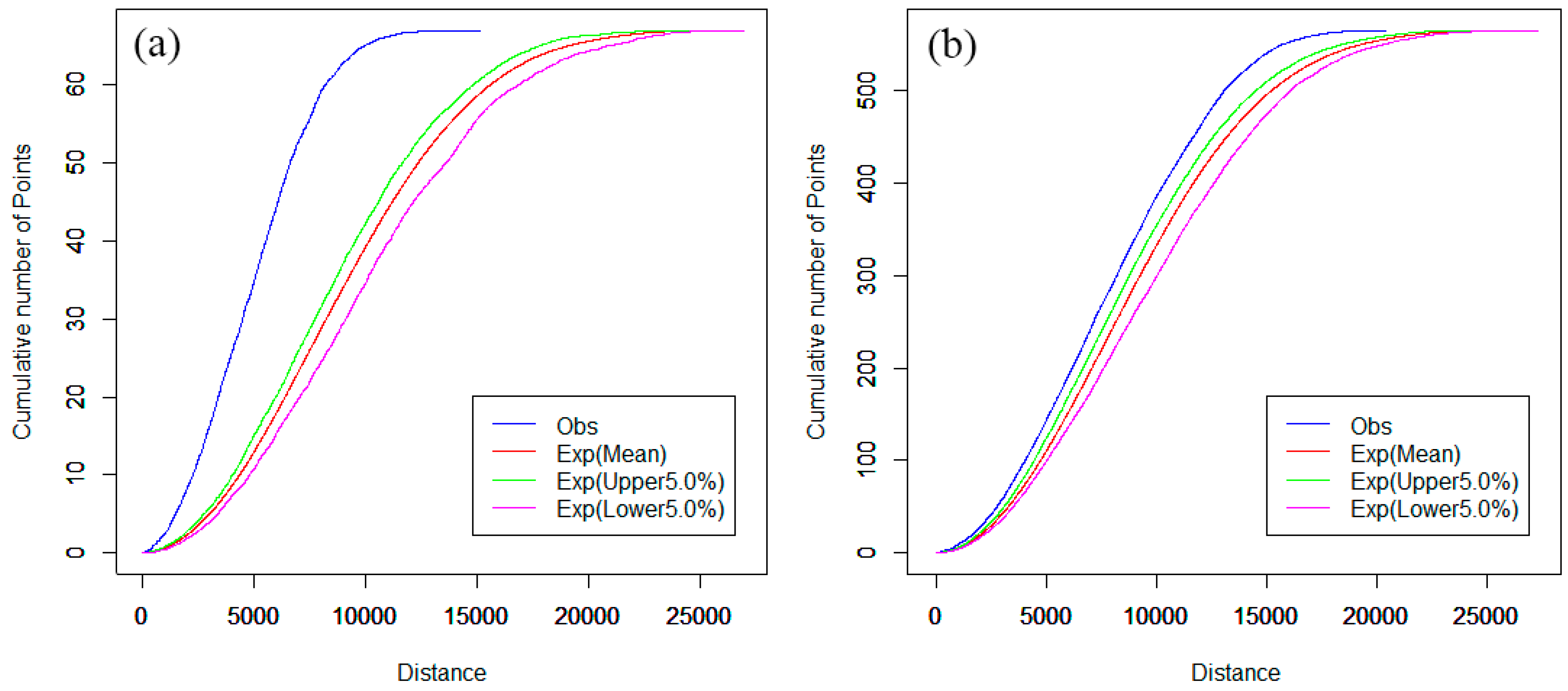
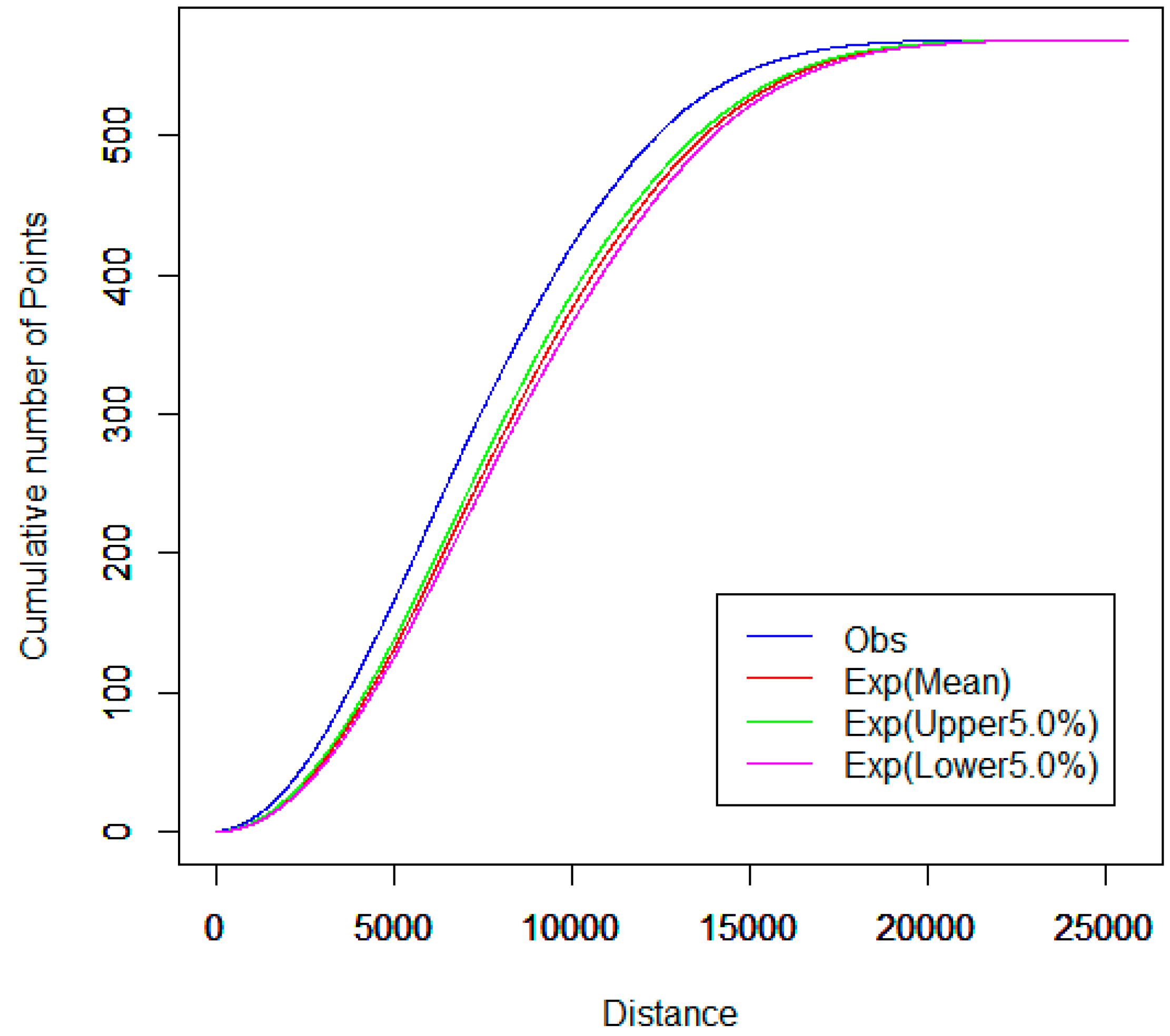
3.2. Network K-Function
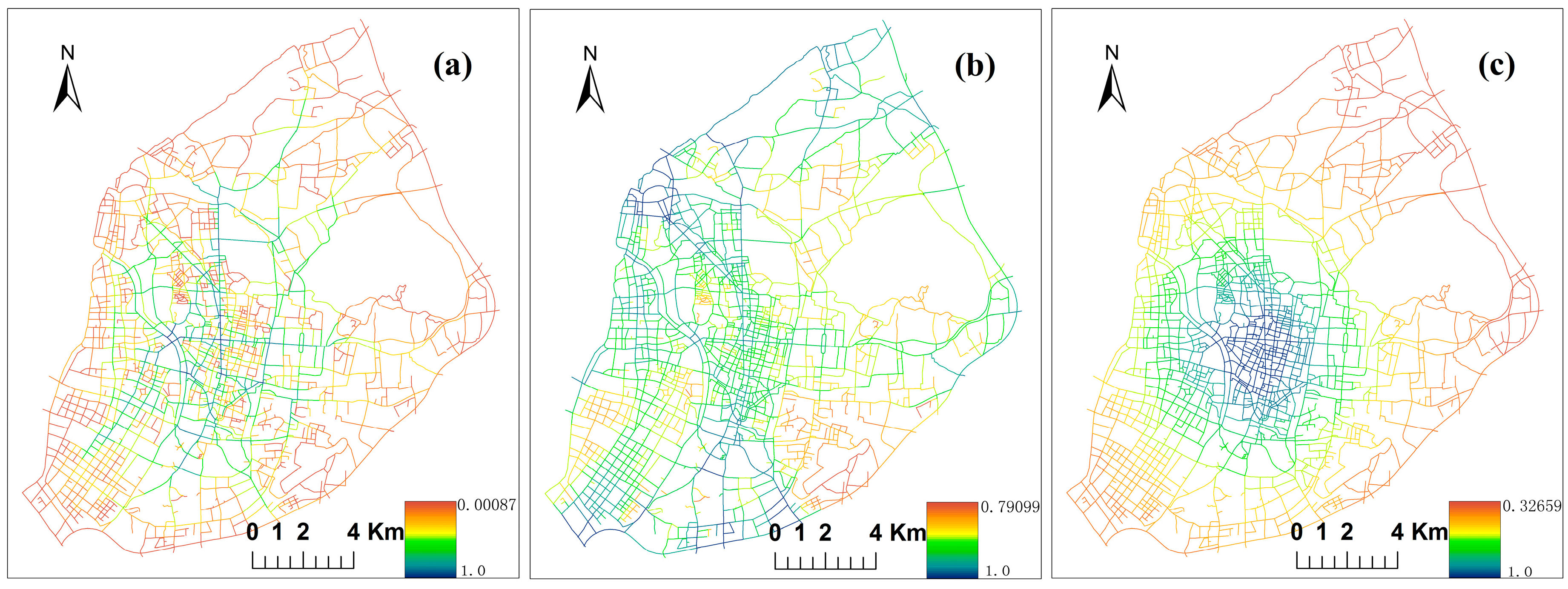
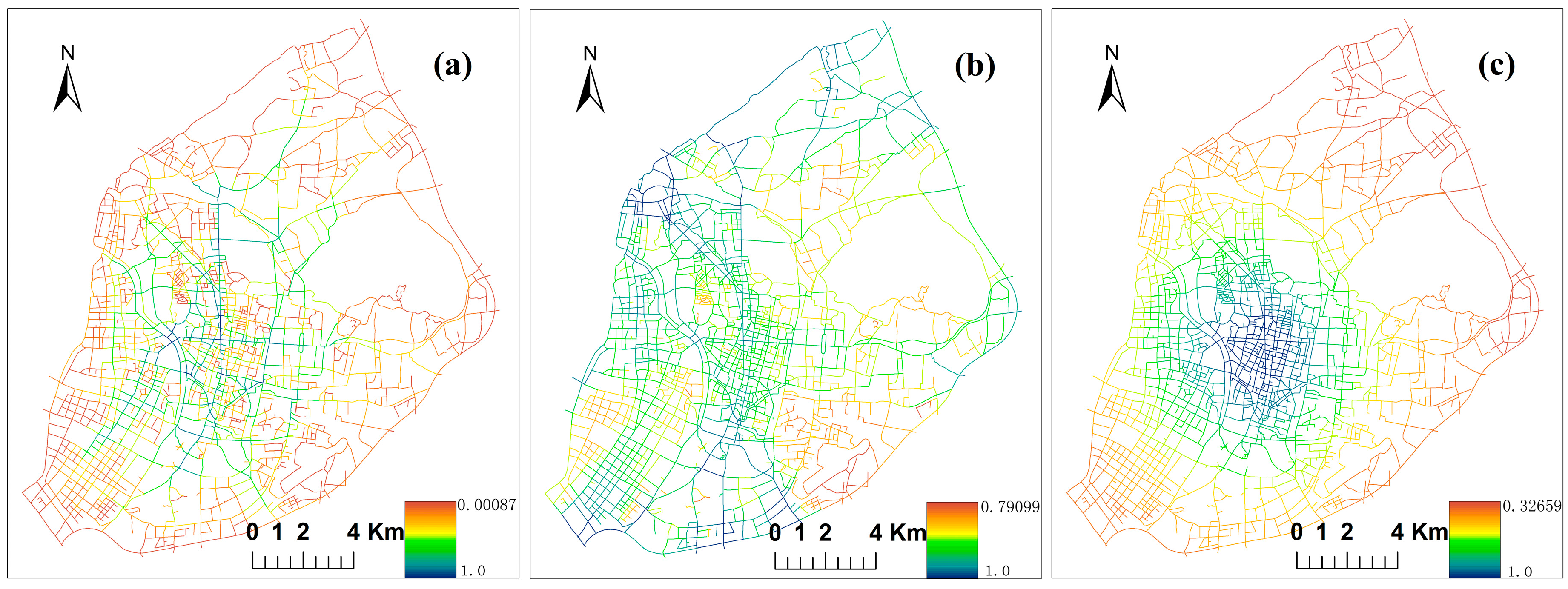
3.3. Multiple Centrality Assessment Model and Correlation Coefficient
4. Results
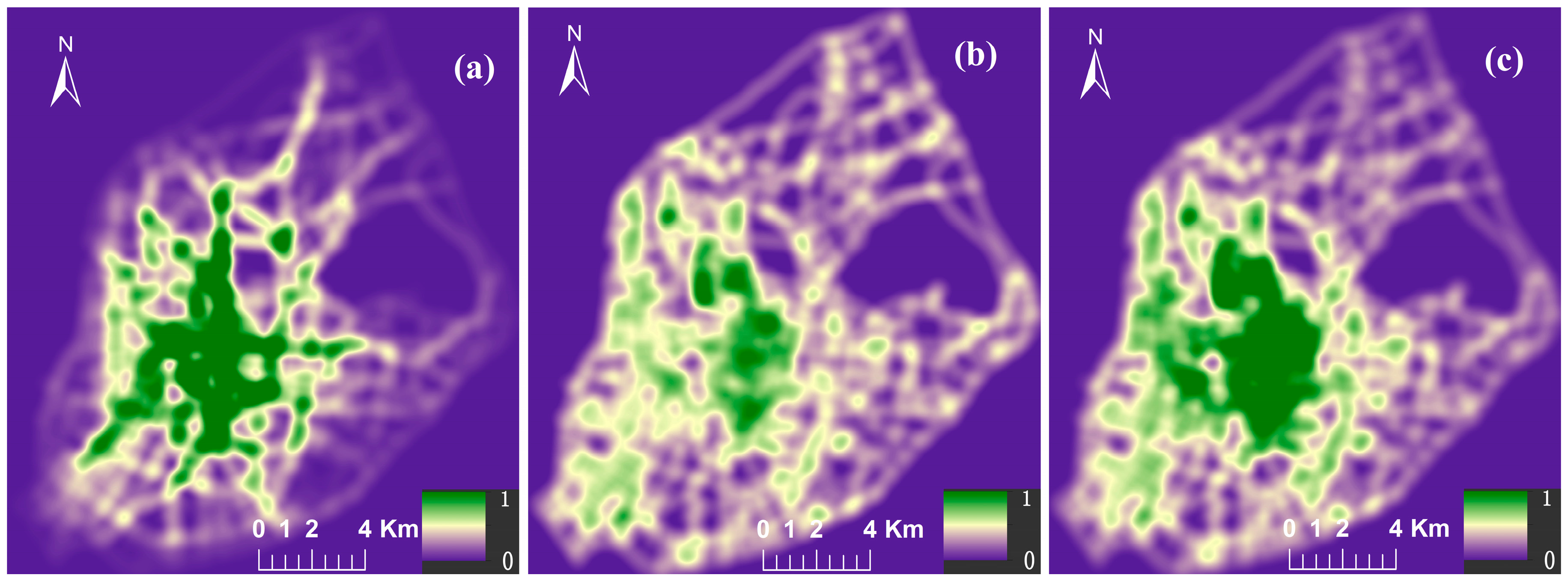
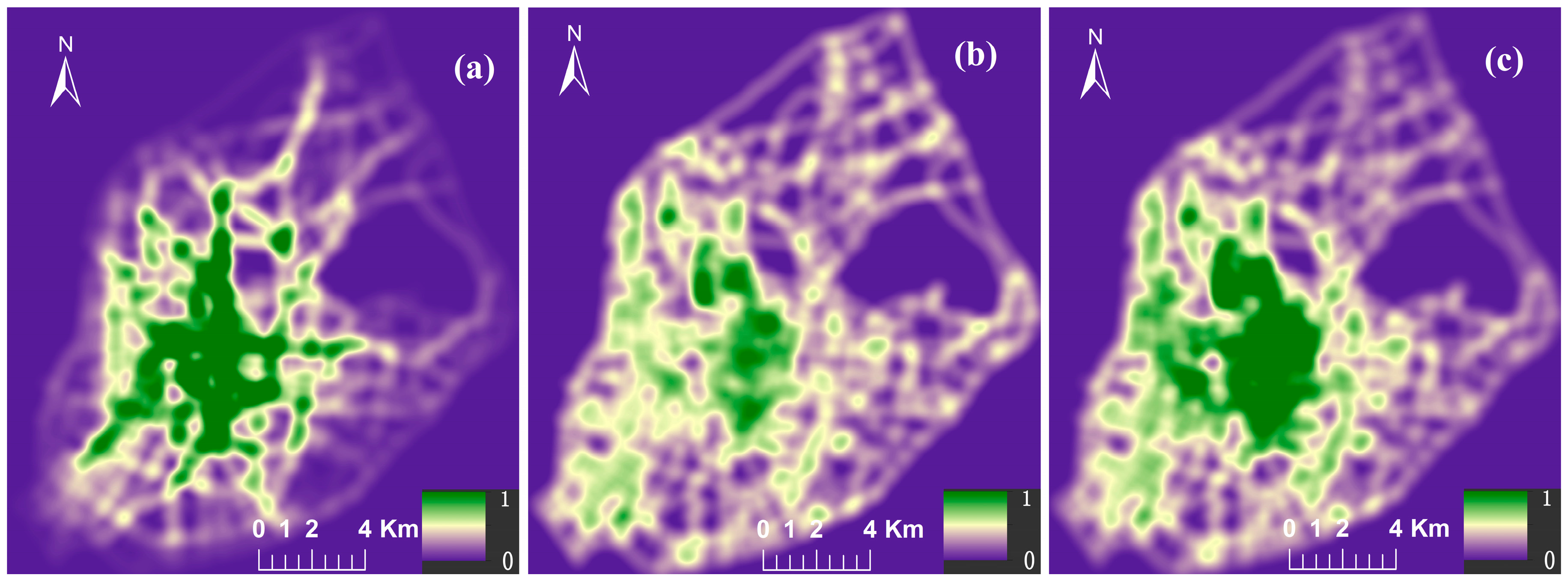
4.1. Weighted NetKDE Analysis for Detecting Hot Spots
4.2. Spatial Cluster Pattern Analysis
4.3. Street Centrality Indexes and Correlation Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- China Health Statistics Yearbook, 2013. Available online: http://www.nhfpc.gov.cn/htmlfiles/zwgkzt/ptjnj/year2013/index2013.html (accessed on 1 January 2016).
- Lee, L. The current state of public health in China. Annu. Rev. Public Health 2004, 25, 327–339. [Google Scholar] [CrossRef]
- Health and Family Planning Statistics. Available online: http://www.nhfpc.gov.cn/zwgkzt/pwstj/list.shtml (accessed on 1 January 2016).
- Wang, E. Understanding the “retail revolution” in urban China: A survey of retail formats in Beijing. Serv. Ind. J. 2011, 31, 169–194. [Google Scholar] [CrossRef]
- Bailey, T.C.; Gatrell, A.C. Interactive Spatial Data Analysis; Longman Scientific & Technical: London, UK, 1995. [Google Scholar]
- O’Sullivan, D.; Unwin, D. Geographic Information Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]
- Delmelle, E.; Thill, J.-C. Urban bicyclists: Spatial analysis of adult and youth traffic hazard intensity. Transp. Res. Rec. 2008, 2074, 31–39. [Google Scholar] [CrossRef]
- Erdogan, S.; Yilmaz, I.; Baybura, T.; Gullu, M. Geographical information systems aided traffic accident analysis system case study: City of Afyonkarahisar. Accid. Anal. Prev. 2008, 40, 174–181. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.K. Kernel density estimation and K-means clustering to profile road accident hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef] [PubMed]
- Yamada, I.; Thill, J.-C. Local indicators of network-constrained clusters in spatial point patterns. Geogr. Anal. 2007, 39, 268–292. [Google Scholar] [CrossRef]
- Borruso, G. Network density estimation: analysis of point patterns over a network. In Proceedings of the International Conference on Computational Science and Its Applications—ICCSA 2005, Suntec City, Singapore, 9–12 May 2005; Gervasi, O., Gavrilova, M.L., Kumar, V., Laganà, A., Lee, H.P., Mun, Y., Taniar, D., Tan, C.J.K., Eds.; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- Borruso, G. Network density estimation: A GIS approach for analysing point patterns in a network space. Trans. GIS 2008, 12, 377–402. [Google Scholar] [CrossRef]
- Xie, Z.; Yan, J. Kernel density estimation of traffic accidents in a network space. Comput. Environ. Urban Syst. 2008, 32, 396–406. [Google Scholar] [CrossRef]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: An integrated approach. J. Transp. Geogr. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Okabe, A.; Satoh, T.; Sugihara, K. A kernel density estimation method for networks, its computational method and a GIS-based tool. Int. J. Geogr. Inf. Sci. 2009, 23, 7–32. [Google Scholar] [CrossRef]
- Okabe, A.; Yamada, I. The K-function method on a network and its computational implementation. Geogr. Anal. 2001, 33, 271–290. [Google Scholar] [CrossRef]
- Yamada, I.; Thill, J.-C. Comparison of planar and network K-functions in traffic accident analysis. J. Transp. Geogr. 2004, 12, 149–158. [Google Scholar]
- Porta, S.; Strano, E.; Iacoviello, V.; Messora, R.; Latora, V.; Cardillo, A.; Wang, F.; Scellato, S. Street Centrality and Densities of Retail and Services in Bologna, Italy. Environ. Plan. B 2009, 36, 450–465. [Google Scholar] [CrossRef]
- Porta, S.; Latora, V.; Wang, F.; Rueda, S.; Strano, E.; Scellato, S.; Cardillo, A.; Belli, E.; Càrdenas, F.; Cormenzana, B.; et al. Street centrality and the location of economic activities in Barcelona. Urban Stud. 2012, 49, 1471–1488. [Google Scholar] [CrossRef]
- Wang, F.; Antipova, A.; Porta, S. Street centrality and land use intensity in Baton Rouge, Louisiana. J. Transp. Geogr. 2011, 19, 285–293. [Google Scholar] [CrossRef] [Green Version]
- Rui, Y.; Ban, Y. Exploring the relationship between street centrality and land use in Stockholm. Int. J. Geogr. Inf. Sci. 2014, 28, 1425–1438. [Google Scholar] [CrossRef]
- Rui, Y.; Yang, Z.; Qian, T.; Khalid, S.; Xia, N.; Wang, J. Network-constrained and category-based point pattern analysis for Suguo retail stores in Nanjing, China. Int. J. Geogr. Inf. Sci. 2016, 30, 186–199. [Google Scholar] [CrossRef]
- The 2014 Annual Nanjing Statistical Yearbook. Available online: http://221.226.86.104/file/nj2004/2014/renkou/3–1.htm (accessed on 1 January 2016).
- Query of the Province’s Medical Institutions. Available online: http://www.jswst.gov.cn:8083/wstcx/ylwsedit.action (accessed on 1 January 2016).
- Chinese Hospital Level Inquiry System. Available online: http://www.hqms.org.cn/usp/roster/index.jsp (accessed on 1 January 2016).
- Levine, N. CrimeStat III: A Spatial Statistics Program for the Analysis of Crime Incident Locations; Version 3.0; Ned Levine & Associates: Houston, TX, USA, 2004. [Google Scholar]
- Gibin, M.; Longley, P.; Atkinson, P. Kernel Density Estimation and Percent Volume Contours in General Practice Catchment Area Analysis in Urban Areas. In Proceedings of the GIScience Research UK Conference GISRUK, Maynooth, Ireland, 11–13 April 2007; Citeseer: Princeton, NJ, USA, 2007. [Google Scholar]
- Porta, S.; Crucitti, P.; Latora, V. The network analysis of urban streets: A primal approach. Environ. Plan. B 2006, 33, 705–725. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Hauke, J.; Kossowski, T. Comparison of values of Pearson’s and Spearman’s correlation coefficients on the same sets of data. Quaest. Geogr. 2011, 30, 87–93. [Google Scholar] [CrossRef]
- Mao, L.; Nekorchuk, D. Measuring spatial accessibility to healthcare for populations with multiple transportation modes. Health Place 2013, 24, 115–122. [Google Scholar] [CrossRef] [PubMed]
- Delamater, P.L. Spatial accessibility in suboptimally configured health care systems: A modified two-step floating catchment area (M2SFCA) metric. Health Place 2013, 24, 30–43. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Wang, J.; Rosenberg, M.W. Spatial access to residential care resources in Beijing, China. Int. J. Health Geogr. 2012, 11, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Epanechnikov, V.A. Non-parametric estimation of a multivariate probability density. Theory Probab. Appl. 1969, 14, 153–158. [Google Scholar] [CrossRef]
- Porter, M.D.; Reich, B.J. Evaluating temporally weighted kernel density methods for predicting the next event location in a series. Ann. GIS 2012, 18, 225–240. [Google Scholar] [CrossRef]
- Okabe, A.; Sugihara, K. Spatial Analysis along Networks: Statistical and Computational Methods; John Wiley & Sons: Hoboken, TX, USA, 2012. [Google Scholar]
- Urban Network Analysis Toolbox for ArcGIS. Available online: http://cityform.mit.edu/projects/urban-network-analysis.html (accessed on 1 January 2016).
- Ni, J.; Wang, J.; Rui, Y.; Qian, T.; Wang, J. An enhanced variable two-step floating catchment area method for measuring spatial accessibility to residential care facilities in Nanjing. Int. J. Environ. Res. Public Health 2015, 12, 14490–14504. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comprehensive Strength | Numbers | Ownership | Numbers |
|---|---|---|---|
| First class | 33 | Private | 376 |
| Second class | 38 | Public | 356 |
| Third class | 152 | ||
| Fourth class | 135 | ||
| Fifth class | 374 | ||
| Total number | 732 | 732 |
| Categories | CS | CC | CB |
|---|---|---|---|
| First class | 0.493 | 0.523 | 0.529 |
| Second class | 0.509 | 0.526 | 0.527 |
| Third class | 0.729 | 0.748 | 0.748 |
| Fourth class | 0.657 | 0.679 | 0.698 |
| Fifth class | 0.786 | 0.813 | 0.824 |
| Public | 0.777 | 0.799 | 0.812 |
| Private | 0.811 | 0.832 | 0.840 |
| All hospitals | 0.846 | 0.866 | 0.870 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Qian, T.; Xi, C.; Rui, Y.; Wang, J. Spatial Distribution Characteristics of Healthcare Facilities in Nanjing: Network Point Pattern Analysis and Correlation Analysis. Int. J. Environ. Res. Public Health 2016, 13, 833. https://doi.org/10.3390/ijerph13080833
Ni J, Qian T, Xi C, Rui Y, Wang J. Spatial Distribution Characteristics of Healthcare Facilities in Nanjing: Network Point Pattern Analysis and Correlation Analysis. International Journal of Environmental Research and Public Health. 2016; 13(8):833. https://doi.org/10.3390/ijerph13080833
Chicago/Turabian StyleNi, Jianhua, Tianlu Qian, Changbai Xi, Yikang Rui, and Jiechen Wang. 2016. "Spatial Distribution Characteristics of Healthcare Facilities in Nanjing: Network Point Pattern Analysis and Correlation Analysis" International Journal of Environmental Research and Public Health 13, no. 8: 833. https://doi.org/10.3390/ijerph13080833